
An Adapter and Segmentation Network-Based Approach for Automated Atmospheric Front Detection

 , ,
, ,
Abstract
1. Introduction
- Input Feature Compatibility: direct input of raw meteorological data without adaptive feature fusion leads to suboptimal model performance due to feature conflicts.
- Intelligent Adapter Module: This module performs adaptive feature fusion by dynamically weighting and combining multi-source meteorological inputs (e.g., temperature, wind fields, humidity). It resolves feature conflicts through a normalization–weighting–fusion pipeline, enhancing the synergy of input features while suppressing noise. The adapter’s design is inspired by recent work in feature fusion [17,20], which demonstrated the effectiveness of adaptive weighting in meteorological applications.
- Enhanced Instance Segmentation Network: Based on Mask R-CNN, this network extends traditional semantic segmentation by simultaneously classifying frontal types (cold/warm/stationary/occluded), localizing spatial boundaries, and identifying distinct frontal systems. The integration of feature pyramid networks (FPNs) and ROI Align ensures precise multi-scale feature extraction, as validated in [20,21].
2. Data and Method
2.1. Data
- Temperature (T), U-wind (U), V-wind (V), and specific humidity (q) at 850 hPa;
- Dew point temperature (Td) at 2 m;
- Mean sea level pressure (Pmsl).
- Test set: 2009.
- Training set: 2010–2017.
- Validation set: 2018.
2.2. Method
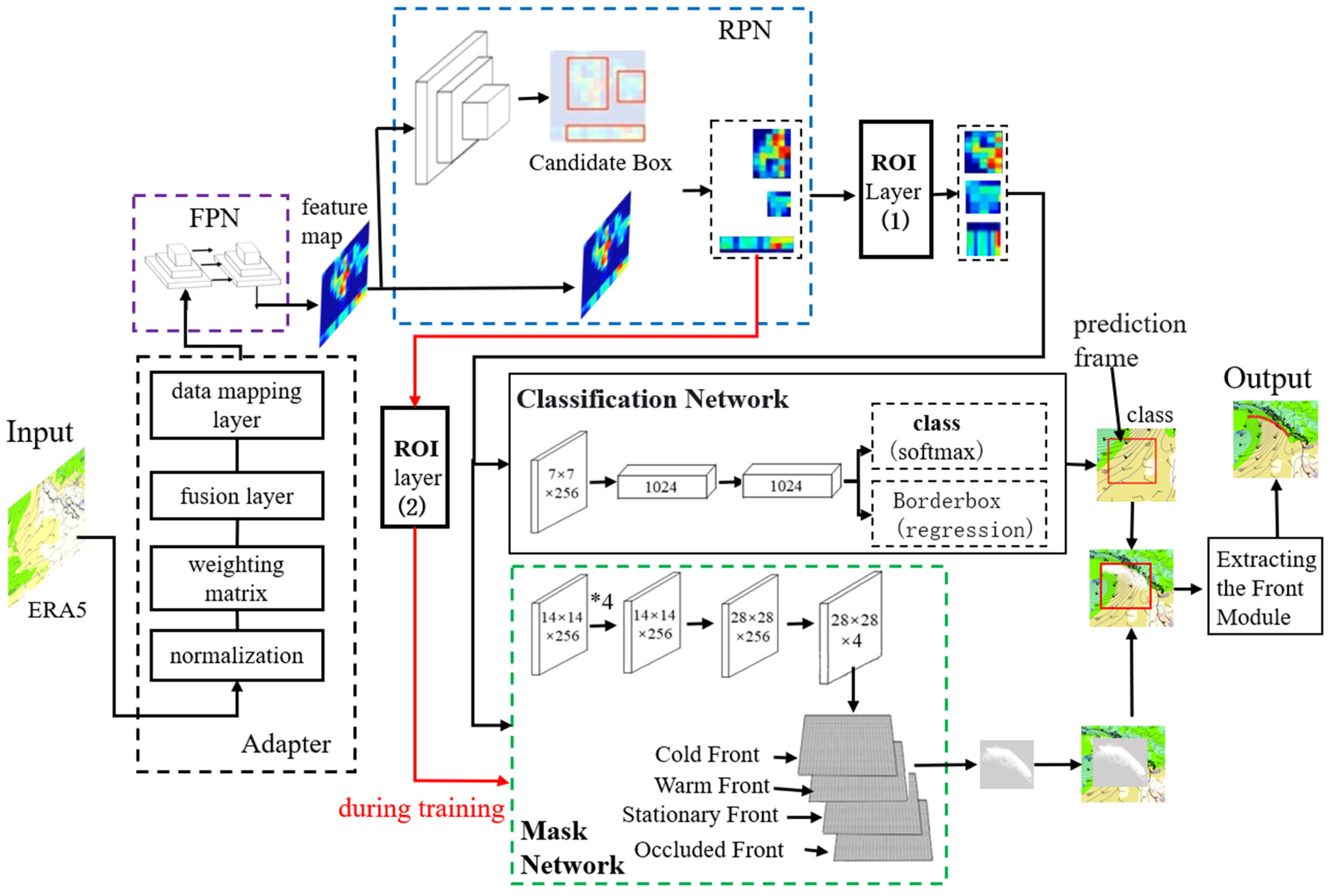
2.2.1. Adapter for Adaptive Fusion of Multiple Meteorological Elements
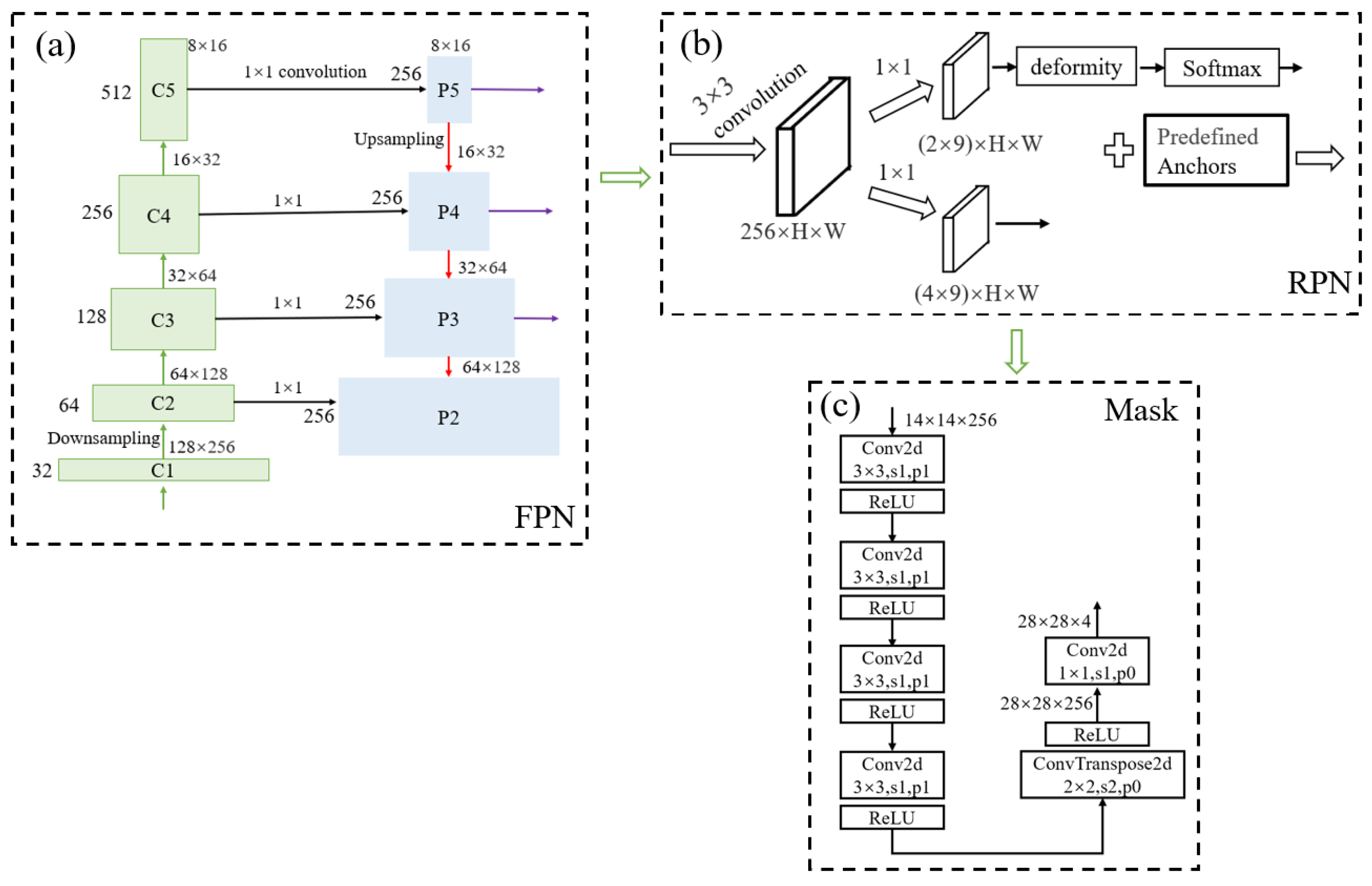
2.2.2. FPN Network Module for Extracting Multi-Meteorological-Element Fusion Features
2.2.3. The RPN (Region Proposal Network) Module for Obtaining Frontal Candidate Bounding Boxes
- Anchor Generator—Generates initial anchor boxes based on feature scales and aspect ratios. The scales are set to 8, 16, and 32, while the aspect ratios are 0.5, 1, and 2, resulting in a total of 9 anchor boxes.
- Anchor Target Generator—Determines which anchor boxes are positive samples (fronts) and which are negative samples (non-fronts) by computing the IoU (Intersection over Union) between anchors and ground truth.
- RPN Loss—Computes the classification and regression losses during training.
- Proposal Generator—Produces refined candidate regions through post-processing steps, such as clipping out-of-bound boxes and removing excessively small boxes, to obtain high-confidence ROI proposals.
- The upper branch classifies anchors into positive/negative samples using a softmax function.
- The lower branch predicts bounding box regression offsets to adjust anchor positions for better localization.
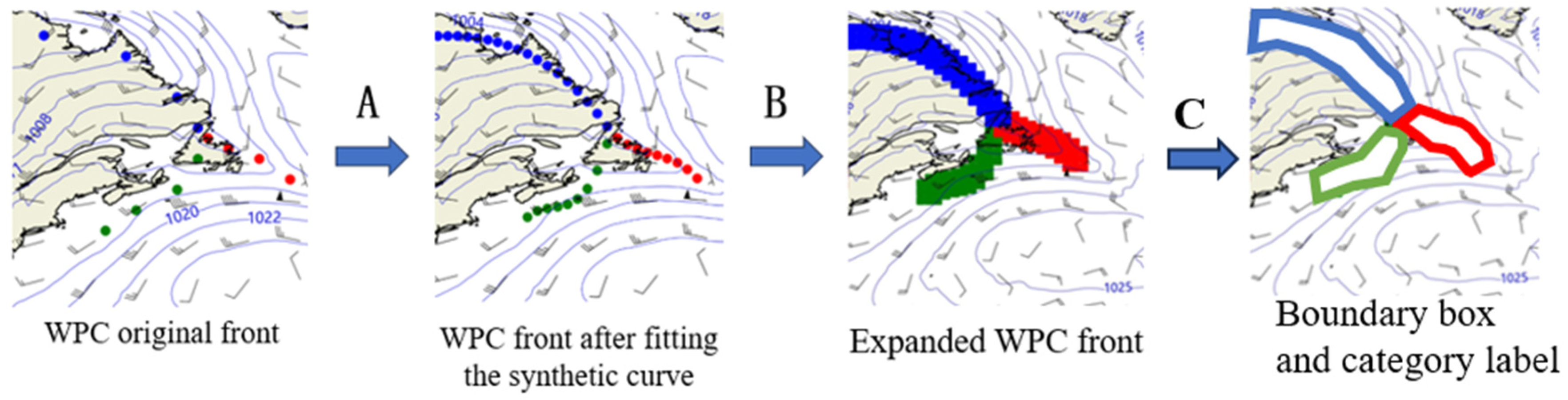
2.2.4. RoI Align Layer for Handling Frontal Candidate Regions
2.2.5. The MASK Network Module for Obtaining Binary Masks
2.3. The Training of the Network
2.3.1. The Loss of the Network
2.3.2. The Parameter Settings Related to Training the Network
2.4. Model Prediction
3. Results and Discussion
3.1. Evaluation Metrics
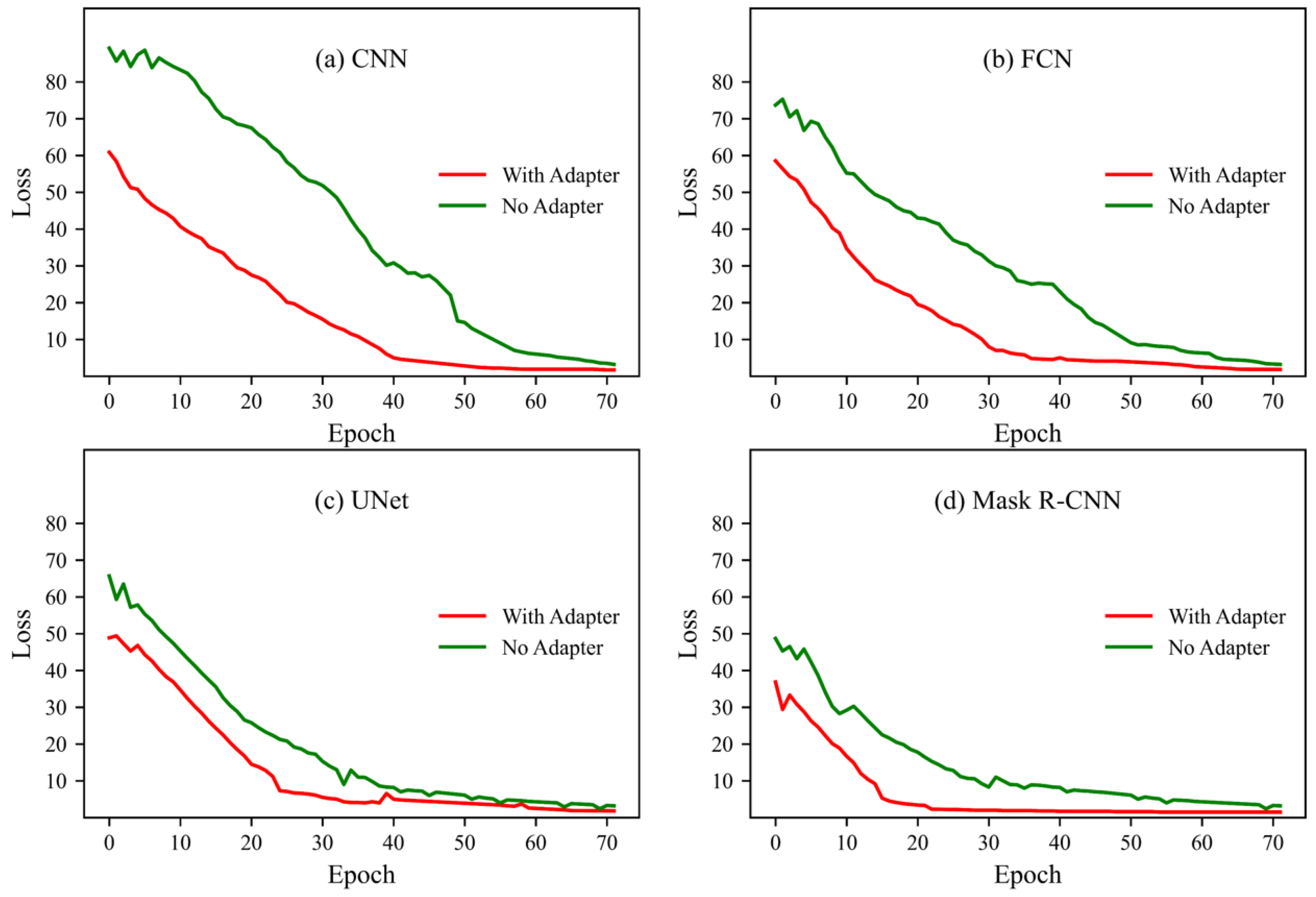
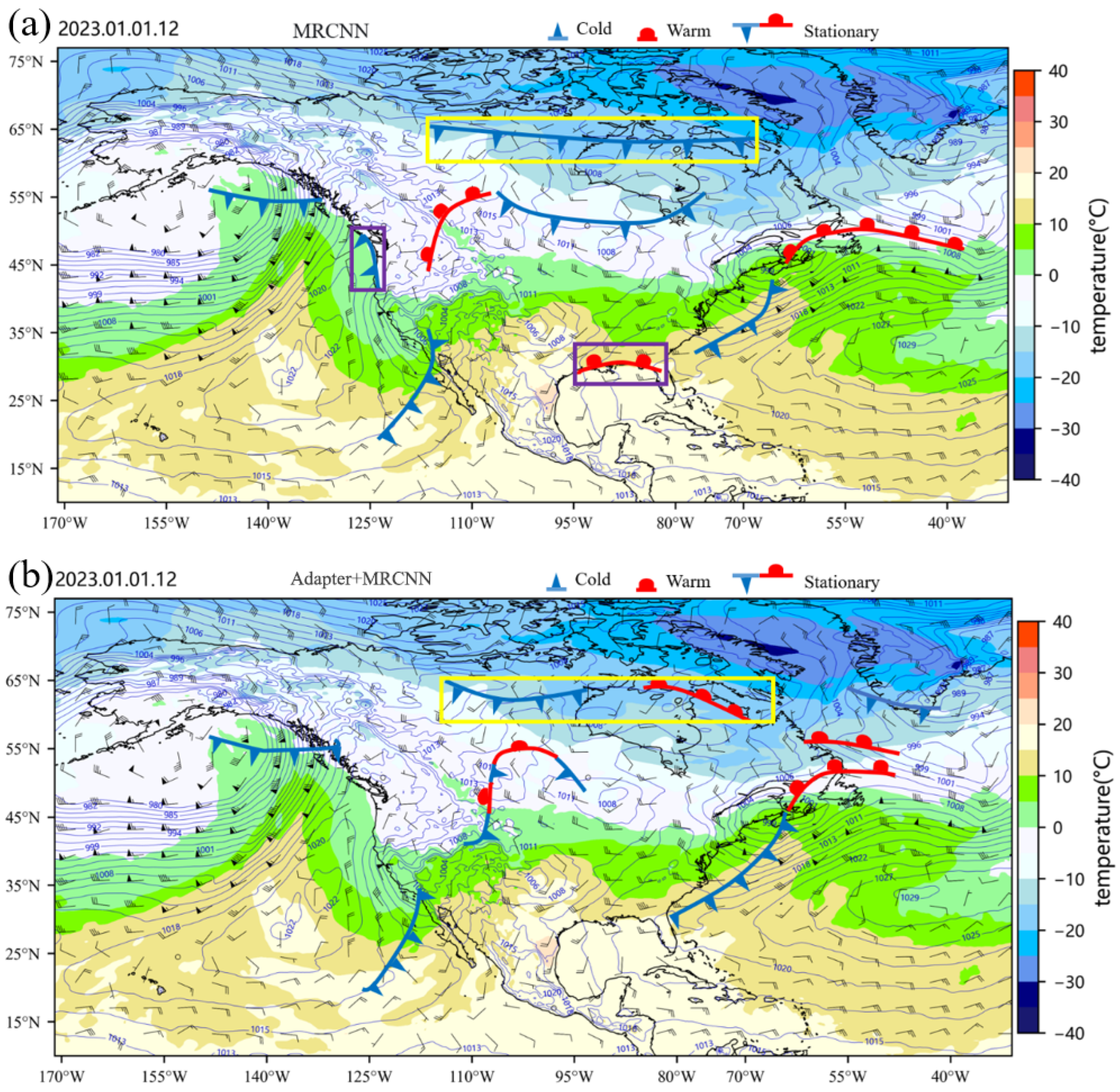
3.2. Experiment on the Effectiveness of Adapter
- The application of adapter modules in deep learning and their optimization effects on network training have been extensively studied. The literature [21,22] demonstrates the role of adapters in resolving feature conflicts and facilitating feature fusion. The weight layers within the adapter module filter out feature conflicts among multiple meteorological elements while suppressing strong non-frontal features and enhancing weak frontal features. This enables the network to efficiently and accurately learn the multi-element characteristics of fronts. Such feature conflicts primarily arise under specific weather conditions or geographical locations, where certain meteorological elements may exhibit abnormally strong non-frontal features (while others remain normally weak) or exceptionally weak frontal features (while others appear strongly frontal).
- The fusion layer in the adapter integrates features from multiple meteorological elements. By leveraging the systematic nature of fronts, it helps the network better approximate the complex patterns between frontal systems and multi-element composite features. This not only facilitates network training but also enhances the accuracy of front identification.
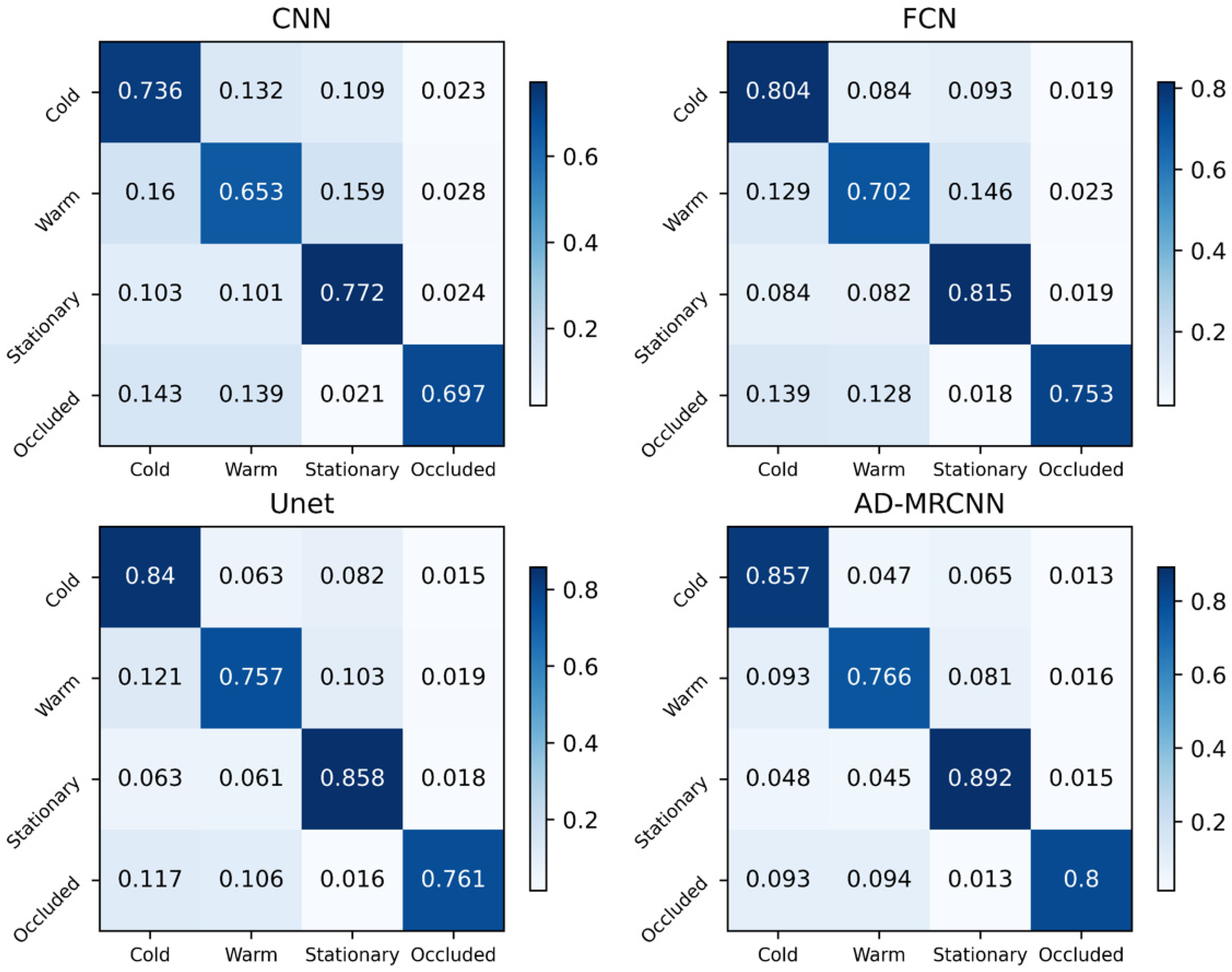
3.3. Multi-Method Comparative Experiment
- Among traditional numerical frontal analysis methods, as the number of diagnostic factors increases from one to two and the diagnostic functions become more complex, the scores across all evaluation metrics show continuous improvement.
- Machine learning methods achieve significantly higher overall scores across multiple evaluation metrics compared to traditional numerical frontal analysis methods. This is because current machine learning approaches for automatic frontal identification take multiple meteorological elements as input, capturing the systematic and comprehensive characteristics of fronts by integrating diverse meteorological features. In contrast, traditional numerical methods rely on relatively singular meteorological elements, simpler functions, and face challenges in determining appropriate thresholds. The performance differences between traditional numerical methods and machine learning methods in meteorological front identification have been supported by research [23].
- Among machine learning methods, semantic segmentation-based approaches score lower than instance segmentation-based methods. This is primarily because instance segmentation networks, in addition to providing category and location information like semantic segmentation networks, also identify which specific frontal system each grid point belongs to, offering more detailed objective frontal information.
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Garner, J. A study of synoptic-scale tornado regimes. E-J. Sev. Storms Meteorol. 2013, 8, 1–25. [Google Scholar] [CrossRef]
- Catto, J.L.; Pfahl, S. The importance of fronts for extreme precipitation. Geophys. Res. Atmos. 2013, 118, 10-791–10-801. [Google Scholar] [CrossRef]
- Renard, R.; Clarke, L. Experiments in numerical objective frontal analysis. Mon. Wea. Rev. 1965, 93, 547–556. [Google Scholar] [CrossRef]
- Dowdy, A.; Catto, J. Extreme weather caused by concurrent cyclone, front and thunderstorm occurrences. Sci. Rep. 2017, 7, 40359. [Google Scholar] [CrossRef] [PubMed]
- Clarke, L.; Renard, R. The U.S. Navy numerical frontal analysis scheme: Further development and a limited evaluation. Appl. Meteorol. 1966, 5, 764–777. [Google Scholar] [CrossRef]
- Hewson, T.D.; Titley, H.A. Objective identification, typing and tracking of the complete life-cycles of cyclonic features at high spatial resolution. Meteorol. Appl. 2010, 17, 355–381. [Google Scholar] [CrossRef]
- Simmonds, I.; Keay, K.; Bye, J. Identification and climatology of Southern Hemisphere mobile fronts in a modern reanalysis. Climate 2012, 25, 1945–1962. [Google Scholar] [CrossRef]
- Petterssen, S. Contribution to the theory of frontogenesis. Geofys. Publ. 1936, 11, 1–27. [Google Scholar]
- Parfitt, R.; Czaja, A.; Seo, H. A simple diagnostic for the detection of atmospheric fronts. Geophys. Res. Lett. 2017, 44, 4351–4358. [Google Scholar] [CrossRef]
- Thomas, C.M.; Schultz, D.M. What are the best thermodynamic quantity and function to define a front in gridded model output? Bull. Am. Meteorol. Soc. 2018, 100, 873–895. [Google Scholar] [CrossRef]
- Lagerquist, R.; Allen, J.T.; McGovern, A. Climatology and variability of warm and cold fronts over North America from 1979 to 2018. J. Clim. 2020, 33, 6531–6554. [Google Scholar] [CrossRef]
- Schemm, S.; Rudeva, I.; Simmonds, I. Extratropical fronts in the lower troposphere—Global perspectives obtained from two automated methods. Q. J. R. Meteorol. Soc. 2015, 141, 1686–1698. [Google Scholar] [CrossRef]
- Laura, M.; Annette, R.; Peter, N. Identifying atmospheric fronts based on diabatic processes using the dynamic state index (DSI). arXiv 2022, arXiv:2208.11438. [Google Scholar]
- Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef]
- Fukushima, K.; Miyake, S. Neocognitron: A new algorithm for pattern recognition tolerant of deformations and shifts in position. Pattern Recognit. 1982, 15, 455–469. [Google Scholar] [CrossRef]
- Stefan, N.; Annette, M.; Bertil, S.; Peter, S. Automated detection and classification of synoptic-scale fronts from atmospheric data grids. Weather. Clim. Dyn. 2022, 3, 113–137. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar] [CrossRef]
- McGovern, A.; Lagerquist, R.; John Gagne, D.; Jergensen, G.E.; Elmore, K.L.; Homeyer, C.R.; Smith, T. Making the black box more transparent: Understanding the physical implications of machine learning. Bull. Am. Meteorol. Soc. 2019, 100, 2175–2199. [Google Scholar] [CrossRef]
- Biard, J.C.; Kunkel, K.E. Automated detection of weather fronts using a deep learning neural network. Advances in Statistical Climatology. Meteorol. Oceanogr. 2019, 5, 147–160. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; De Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-Efficient Transfer Learning for NLP. In International Conference on Machine Learning; PMLR: Cambridge, MA, USA, 2019. [Google Scholar]
- Rebuffi, S.A.; Bilen, H.; Vedaldi, A. Learning multiple visual domains with residual adapters. arXiv 2017. [Google Scholar] [CrossRef]
- Hewson, T.D. Objective fronts. Meteorol. Appl. 1998, 5, 37–65. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); IEEE: Piscataway, NJ, USA, 2017. [Google Scholar] [CrossRef]
- Tang, Y.; Bai, W.; Li, G.; Liu, X.; Zhang, Y. CROLoss: Towards a Customizable Loss for Retrieval Models in Recommender Systems. In Proceedings of the CIKM ‘22: The 31st ACM International Conference on Information and Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; Volume 25, pp. 1916–1924. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV); IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Li, M.; Zhang, T.; Chen, Y.; Smola, A.J. Efficient minibatch training for stochastic optimization. In Proceedings of the KDD ‘14: The 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 661–670. [Google Scholar] [CrossRef]
- Smith, L.N. Cyclical learning rates for training neural networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 464–472. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. Int. J. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV); IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2021, 17, 168–192. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Coverage | 37° to 165° W | |
| 10° to 74° N | ||
| Resolution ratio | 0.25° × 0.25° | |
| Interval time | 3 h | |
| Meteorological elements | 2 m above ground | Dewpoint Temperature (Td2m) |
| 850 hPa | Temperature (T850hpa) | |
| specific humidity(q) | ||
| U, Vwind | ||
| Pressure () | ||
| Data set classification | Training Set (2010–2017) | |
| Validation Set (2018) | ||
| Test set (2009) | ||
| Network Category | ACC | R | F1 | mIoU |
|---|---|---|---|---|
| CNN | 73.0% | 65.0% | 66.4% | 47% |
| Adapter + CNN | 76.7% | 70.2% | 69.7% | 52.3% |
| FCN | 75.1% | 74.5% | 74.9% | 56% |
| Adapter + FCN | 78.5% | 79.7% | 82.0% | 60.1% |
| UNet | 77.3% | 83.3% | 83.3% | 63% |
| Adapter + UNet | 80.9% | 85.9% | 85.8% | 68% |
| MRCNN | 79.2% | 84.1% | 81.6% | 72% |
| AD-MRCNN | 83.5% | 86.8% | 85.1% | 77% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, X.; Peng, X.; Xue, Y.; Zhang, L.; Wang, T.; Zhang, Y. An Adapter and Segmentation Network-Based Approach for Automated Atmospheric Front Detection. Appl. Sci. 2025, 15, 7855. https://doi.org/10.3390/app15147855
Ding X, Peng X, Xue Y, Zhang L, Wang T, Zhang Y. An Adapter and Segmentation Network-Based Approach for Automated Atmospheric Front Detection. Applied Sciences. 2025; 15(14):7855. https://doi.org/10.3390/app15147855
Chicago/Turabian StyleDing, Xinya, Xuan Peng, Yanguang Xue, Liang Zhang, Tianying Wang, and Yunpeng Zhang. 2025. "An Adapter and Segmentation Network-Based Approach for Automated Atmospheric Front Detection" Applied Sciences 15, no. 14: 7855. https://doi.org/10.3390/app15147855
APA StyleDing, X., Peng, X., Xue, Y., Zhang, L., Wang, T., & Zhang, Y. (2025). An Adapter and Segmentation Network-Based Approach for Automated Atmospheric Front Detection. Applied Sciences, 15(14), 7855. https://doi.org/10.3390/app15147855