This section discusses the implementation details and evaluates the pose estimation performance of our proposed DK-SLAM on two widely adopted public datasets: the KITTI dataset, representing the car-driving scenario, and the EuRoC dataset, representing drone navigation. Moreover, we conducted an extensive ablation study to validate the effectiveness of our proposed key modules, including learned feature extraction, coarse-to-fine matching strategy, and online learning-based Bag-of-Words (BoW).
4.2. Pose Evaluation in the Car-Driving Scenario
To evaluate the effectiveness of our SLAM system in the car-driving scenario, we conducted experiments using the KITTI dataset and employed the official evaluation metrics, computing root-mean-square error (RMSE) for both translation and rotation vectors. This evaluation spanned sequences ranging from 100 m to 800 m, providing an overall metric for pose accuracy. We conducted a comprehensive assessment of our SLAM system’s tracking and loop closure capabilities in complex environments, focusing on Sequences 00, 02, 03, 04, 05, 06, 07, 08, 09, and 10 from the KITTI dataset. We excluded Sequence 01 from our evaluation due to its unique challenges for monocular SLAM systems, as a highway scene with few distinctive feature points, especially near the horizon, led to significant scale degradation in monocular SLAM performance.
We benchmarked our DK-SLAM against several leading SLAM systems: LDSO [
52], ORB-SLAM3 [
4], VISO-M [
53], and LIFT-SLAM [
11]. The comparison of trajectories generated by the proposed SLAM and benchmarks is shown in
Figure 4. Among these, VISO-M exhibited the least accuracy, particularly struggling in low-light conditions where its corner detection algorithms were unstable. LDSO, which includes a loop closure module, managed to reduce accumulated errors effectively in challenging scenarios. ORB-SLAM3, a sophisticated keypoint-based SLAM system that uses FAST corner detection and BRIEF descriptors, performed exceptionally well across most sequences, as shown in
Table 1. However, it showed a noticeable drop in performance on Sequence 10, primarily due to a scarcity of reliable corner points, which resulted in unstable tracking and adversely affected overall pose estimation accuracy. The reliance on BRIEF, which describes local photometric information around corners, made ORB-SLAM3 particularly sensitive to lighting changes, thereby impacting feature tracking performance. In environments with significant lighting variations, the inability to track reliable feature points at the front-end increased positioning errors. Although the back-end loop closure could correct some accumulated errors, it struggled to improve overall accuracy. In contrast, LIFT-SLAM, which depends on learning-based local features, generally underperformed across most sequences. This outcome suggests that while learning-based features have potential, they do not consistently outperform traditional feature-based methods. ORB-SLAM3’s attention to scale, direction, and a traditional SLAM system for achieving an even keypoint distribution gave it a competitive advantage, helping to filter out mismatched features at the front-end.
Our DK-SLAM system demonstrated exceptional performance across most KITTI sequences. Specifically, DK-SLAM shows a substantial improvement over traditional monocular ORB-SLAM3, achieving approximately 17.7% better translation accuracy and 24.2% higher rotation accuracy on the KITTI dataset. When compared with LIFT-SLAM, a leading SLAM system based on learned features, DK-SLAM surpasses it by nearly 2.7 times in translation accuracy and 9 times in rotation accuracy. This significant enhancement in performance is attributed to DK-SLAM’s use of meta-learning-based feature extraction and a coarse-to-fine matching strategy, which focuses on keypoint-surrounding patches and optimizes pose estimation through precise 3D–2D matching relationships. Additionally, our system’s online training capability builds a learning-based Bag-of-Words (BoW) model using previously acquired data, efficiently constraining the BoW’s feature description space and improving loop scene detection. This approach enables the loop closure module to accurately correct cumulative errors. Moreover, as illustrated in
Figure 5, DK-SLAM excels in mapping performance, providing detailed geometric insights. The incorporation of MAML-based feature training enhances the generalization capability of the feature extractor, allowing it to capture more comprehensive scene details. This combination of strategies ensures that DK-SLAM offers robust and accurate performance in varied and complex environments.
4.3. Pose Evaluation in the UAV Scenario
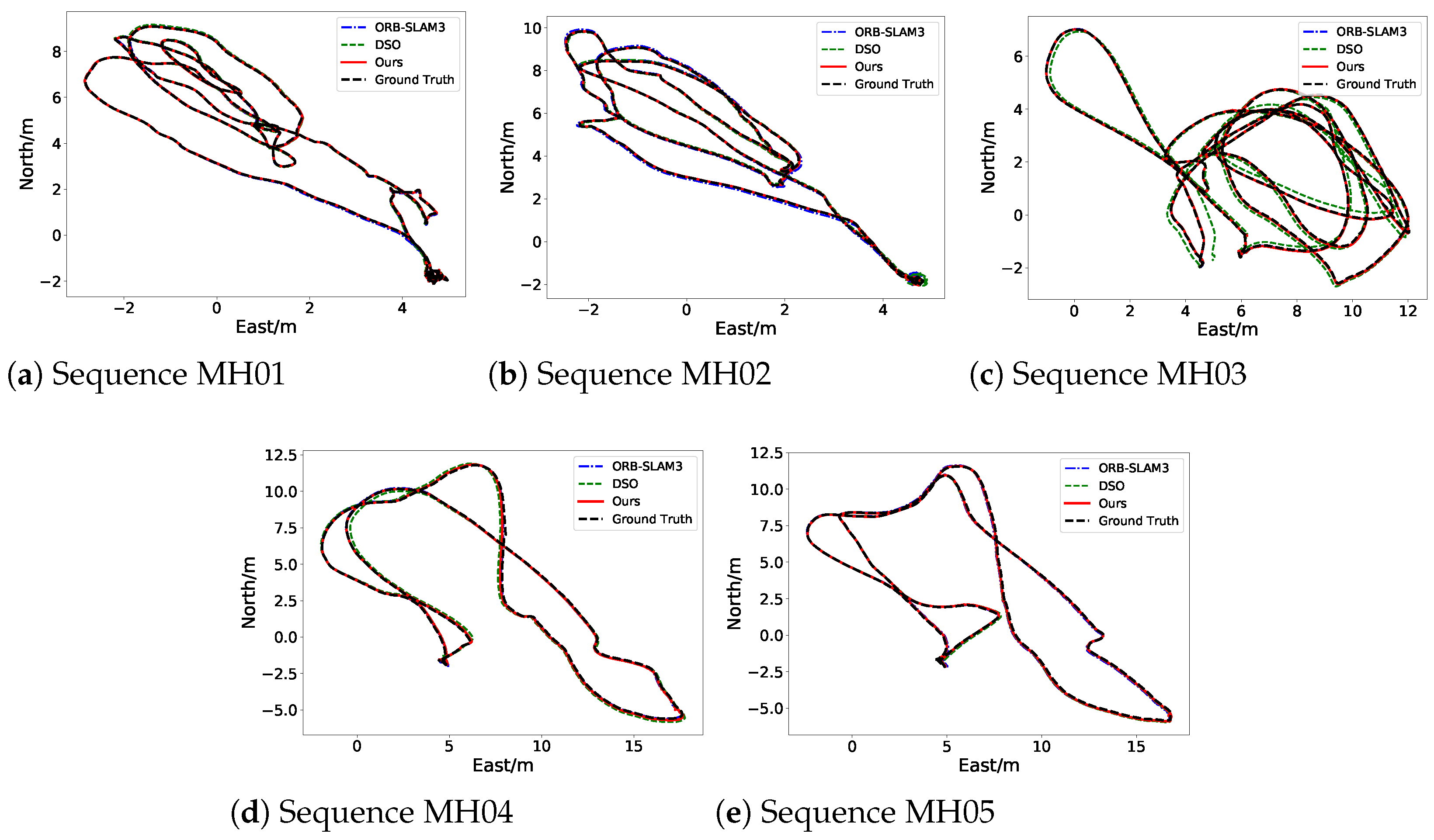
As shown in
Table 2 and
Figure 6, we come to validate our proposed DK-SLAM on the EuRoC dataset. Following the previous research, we address the scale ambiguity with Umeyama alignment [
54] for monocular vision methods. Comparisons include ORB-SLAM3 [
4], DSO [
1], DSM [
55], SVO [
2], and LIFE-SLAM [
11]. Results are derived from [
56] for ORB-SLAM3, DSO, DSM, and SVO and [
11] for LIFE-SLAM. We utilize the absolute translation error as the evaluation metric.
The evaluation results reveal that the learned feature-based SLAM, i.e., LIFE-SLAM, often fails in drone scenarios, as it relies on LIFT as a binary feature extractor and uses the Hamming distance between keypoints in consecutive frames for matching. In addition, LIFE-SLAM does not consider the structural relationships between keypoints, leading to a significant number of mismatches and subsequent feature tracking failures. ORB-SLAM3 [
4] employs an offline-trained Bag-of-Words (DBow3) for loop closure. Due to the sensitivity of its handcrafted descriptors to lighting variations, ORB-SLAM3 struggles with lower loop detection accuracy in complex lighting conditions, which diminishes the overall performance of the system.
In contrast, our DK-SLAM demonstrates outstanding localization performance. It uses a two-stage tracking strategy that precisely locates feature points and minimizes incorrect matches. The learned features in DK-SLAM are robust, performing well even in low-light conditions and supporting stable feature tracking. Moreover, the online learning-based deep Bag-of-Words model excels in loop detection. This is particularly evident in the MH02 sequence, where DK-SLAM surpasses ORB-SLAM3. This superior performance is due to the use of learned features for constructing the Bag-of-Words model, which provides detailed scene differentiation, and the online training capability, which allows for rapid adaptation to changing environments.
4.4. Ablation Study
Table 3 summarizes the results of the ablation study into the key modules within the DK-SLAM system, assessing the impact of our MAML-based deep keypoint meta-learning and coarse-to-fine keypoint tracking. For a fair comparison, “Ours1”, “Ours2”, and “Ours3” all use a keypoint search radius of 7.
(1) The analysis of keypoint meta-learning module: The module’s effectiveness is evident when comparing “Ours2” and “Ours3.” “Ours2,” which employs the original SuperPoint strategy without our keypoint meta-learning approach, performs slightly worse than “Ours3,” which integrates MAML-based keypoint meta-learning. In “Ours3,” MAML is applied to train the local feature extractor by iteratively enhancing generalization on support and query sets, resulting in a robust and adaptable detector. The batch size of “Ours2” and “Ours3” is set as 8. Both models were trained for 150K iterations. In “Ours3”, we split every training batch to 4 mini-batch support sets and 4 mini-batch query sets. As mentioned in Algorithm 1, the number of update iterations in inner loop is 4.
Table 4 presents the average number of matching points for ORB-SLAM3, Ours2, and Ours3 on Sequences 00, 05, 09, and 10 of the KITTI dataset. Setting the total number of keypoints to 3000 and the pyramid level to 3, MAML-based training significantly improves the feature detection performance of SuperPoints, allowing them to acquire more robust features and enhancing SLAM accuracy.
The enhanced SLAM performance attributed to the proposed keypoint meta-learning can also be observed in feature matching results, as depicted in
Figure 7. Using SuperPoint for matching increases the number of matches, addressing ORB-SLAM3’s limitations in texture-less areas. ORB-SLAM3’s descriptors, describing lighting changes around corners, are susceptible to environmental variations. In contrast, the original learning-based local feature methods such as SuperPoint capture robust deep features unaffected by lighting changes, ensuring stable tracking across consecutive frames. Furthermore, compared with original Superpoint, MAML-based keypoint is better at capturing inter-frame matching features.
(2) The analysis of coarse-to-fine tracking module: In “Ours1”, lacking a coarse-to-fine tracking strategy, reliance on a constant velocity motion model for keypoint matching leads to errors, resulting in inaccurate correspondence and tracking failure.
Figure 8 shows a failure case for “Ours1” in accurate feature matching due to uniform motion model challenges. In contrast, “Ours3” uses a two-stage strategy for stable tracking, combining a semi-direct method for coarse pose estimation and refined feature matching.
(3) The analysis of loop-closing module: We further perform ablation studies on the proposed loop closure method to assess its performance. Precision–recall metrics on KITTI 00, 05, and 06 sequences are illustrated in
Figure 9, with additional evaluation at 100% precision. The quantitative results, presented in
Table 5, reveal our deep BoW’s superior recall rate compared with traditional BoWs. Notably, in the KITTI 06 sequence, our BoW achieves a recall rate that is remarkably close to 100%. In contrast, the recall rate of the iBoW, belonging to the traditional BoW category, is significantly lower, suggesting that handcrafted descriptors might struggle to accurately identify loop nodes in a sequence. The learned local descriptor captures high-level information, enhancing robustness across diverse environments. This feature stability, unaffected by lighting changes, results in superior loop detection performance.
(4) The analysis of SLAM efficiency: We conduct an ablation study on the computational efficiency of DK-SLAM, analyzing the time consumption of different modules. We conduct the ablation study on KITTI data. Additionally, we calculate median and mean feature tracking times for each SLAM module. Based on the results, as shown in
Table 6, MAML indicates the MAML-based local feature, Two-Stage indicates the coarse-to-fine feature tracking, and Online BoW indicates the online learning for binary BoW. The first row of results corresponds to the official ORB-SLAM2 pipeline without any proposed modules. The results indicate that adding MAML-based features significantly increases the feature tracking time. This is because the learned features are inferred on the GPU, while image processing, feature tracking, back-end optimization, and loop closure are all processed on the CPU. Transferring the inferred features from the GPU to subsequent CPU threads involves data transmission, leading to increased time cost. The coarse-to-fine feature tracking also increases the time consumption, but not significantly. This is because we employ local photometric constraints rather than global constraints, limiting the rise in computational cost. The online BoW increases additional time as well. However, by binarizing the floating-point descriptors to a compressed binary vector, we reduce the computational cost, mitigating the impact of the online BoW on processing time.
Additionally, we conduct a comparative analysis of feature tracking time consumption against other typical monocular VSLAMs. As illustrated in
Figure 10, handcrafted feature-based ORB-SLAM3 and learned feature-based SuperPoint-SLAM [
60] were selected for comparison. Notably, the proposed DK-SLAM demonstrates significantly higher efficiency than SuperPoint-SLAM. This performance advantage stems from fundamental architectural differences: SuperPoint-SLAM is developed using libtorch [
61], which transfers images to the GPU individually for processing. In contrast, our method leverages TensorRT’s C++ implementation. TensorRT provides hardware acceleration capabilities that pre-cache images in memory and enable parallel processing, thereby achieving efficiency gains over the libtorch-based approach. Nevertheless, DK-SLAM still exhibits an efficiency gap compared with ORB-SLAM3. This discrepancy is primarily attributable to the data transfer between GPU and CPU. Additionally, the proposed DK-SLAM requires about 1 GB GPU memory to operate.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}