
Cross-Lingual Summarization for Low-Resource Languages Using Multilingual Retrieval-Based In-Context Learning

Abstract
1. Introduction
- We demonstrate significant performance improvements across twelve language pairs, with particularly strong gains in X→English summarization.
- We identify a notable directional asymmetry where retrieval-based selection benefits high-resource target languages substantially more than low-resource targets.
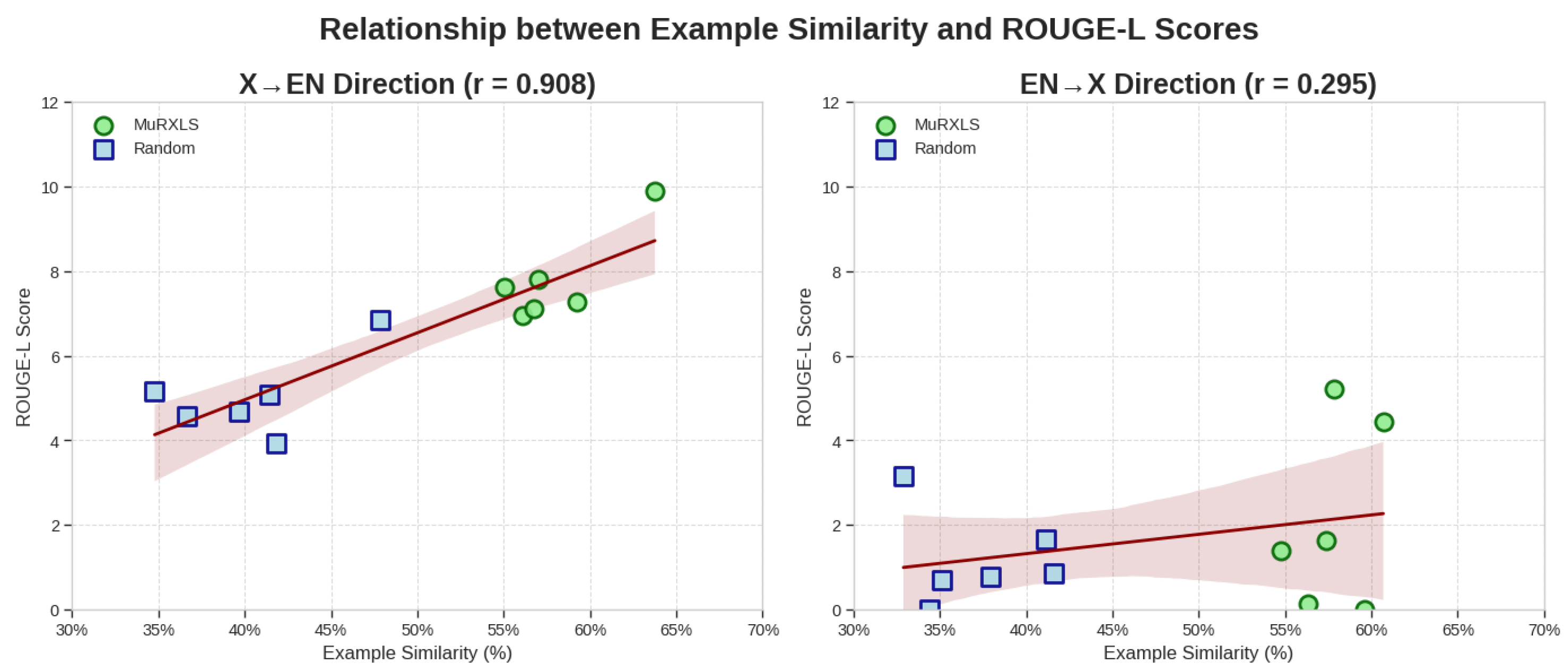
- We establish a strong correlation between example similarity and summarization quality, providing statistical evidence for the efficacy of our approach.
- We verify the effectiveness of method across multiple LLMs of varying sizes and capabilities.
2. Methods
2.1. Dataset and Language Selection
2.1.1. Dataset Selection Rationale
2.1.2. Language Selection
2.2. BGE-M3 Multilingual Embedding
2.2.1. Model Architecture and Technical Specifications
2.2.2. Embedding Computation
2.2.3. Similarity Computation
2.3. Evaluation Metrics
2.3.1. Primary Evaluation Metric: ROUGE-L
2.3.2. Secondary Evaluation: BERTScore
2.3.3. Language Adherence Evaluation: Correct Language Rate (CLR)
2.3.4. Statistical Analysis
2.4. Experimental Configuration
Large Language Model Selection
2.5. Token Count Analysis
Token Calculation Protocol
3. Results
3.1. MuRXLS Framework Implementation
3.1.1. System Architecture Overview
3.1.2. Multilingual Datastore Construction and Retrieval Process
| Algorithm 1 Multilingual Retrieval-based Cross-lingual Summarization (MuRXLS) |
|
3.1.3. Dynamic Example Selection and Prompt Construction
3.2. Comprehensive Performance Evaluation
3.2.1. Overall Performance Analysis
3.2.2. Direction-Specific Performance Patterns
3.2.3. Performance Among Models
3.2.4. Performance Among Language Pairs
- Burmese→English shows the largest improvements across all models, with gains of up to +4.20 ROUGE-L points. This suggests that for languages with significant structural differences from English, contextually relevant examples provide crucial guidance for the summarization process.
- Pashto→English consistently benefits from retrieval-based examples, with substantial improvements across all models and shot settings. This further supports the observation that linguistically distant language pairs benefit more from retrieval augmentation.
- Thai→English and Gujarati→English show moderate but consistent improvements, indicating that even for language pairs where baseline performance is already reasonable, retrieval-based selection still provides meaningful benefits.
3.2.5. Performance Among the Number of Examples
3.2.6. Semantic Quality Assessment with BERTScore
- MuRXLS consistently outperforms random sampling. Table 4 presents BERTScore results across all language pairs, comparing our retrieval-based example selection (MuRXLS) against random sampling for both GPT-4o and Llama-3-70B models. Our analysis shows that MuRXLS consistently outperforms random sampling across nearly all language pairs and models. The average improvement in BERTScore F1 ranges from +0.02 to +0.07 depending on the model and direction. This confirms that retrieval-based examples enhance both lexical overlap and semantic similarity, providing summaries that better preserve the meaning of source articles.
- Two-shot settings generally outperform one-shot configurations for MuRXLS. Two-shot settings generally outperform one-shot configurations for MuRXLS, aligning with our ROUGE findings. Interestingly, random sampling does not consistently benefit from additional examples, particularly in the EN→X direction.
- Directional asymmetry remains evident in both ROUGE and BERTScore. The directional asymmetry observed in ROUGE evaluation is also evident in BERTScore results, with X→EN generally achieving higher semantic similarity than EN→X across both models and methods. This persistent pattern suggests fundamental challenges in generating content in low-resource languages that retrieval-based methods help mitigate but cannot fully overcome.
- BERTScore highlights moderate semantic similarity for English-Pashto despite low lexical overlap. Particularly notable is the case of English-Pashto. While ROUGE scores for this language pair were consistently near zero in the EN→X direction, our BERTScore analysis reveals moderate semantic similarity (around 0.73 for GPT-4o with MuRXLS), indicating that generated summaries maintain semantic correspondence with references despite lacking direct lexical matches. This highlights BERTScore’s ability to detect meaning preservation even when vocabulary choices differ substantially.
- Three-shot configurations significantly increase computational costs without commensurate gains. Regarding experiment settings, as stated in Table 5, our analysis found that three-shot configurations significantly increase computational costs without corresponding performance gains. The average context length for three-shot plus query across all language pairs is over 4000 tokens, representing a consistent 50% increase in token consumption compared to two-shot settings.
- Minimal performance improvements from three-shot usage justify focusing on up to two-shot settings. Our preliminary experiments demonstrated that this increased token usage rarely translated to performance improvements. For GPT-4o, three-shot settings only improved performance for 3 out of 12 language pairs with marginal gains. Meanwhile, GPT-3.5-turbo consistently underperformed in 10 out of 12 language pairs when using three examples. The performance impact was directionally asymmetric, with X→EN language pairs showing slightly better resilience to the three-shot format compared to EN→X pairs. Based on these findings, we focused our main experiments on zero-shot through two-shot settings, which provide the optimal balance between performance and computational efficiency.
3.2.7. Comparison with Fine-Tuned Models
3.2.8. Impact of Retrieval-Based Examples on Language Adherence
- X→EN Direction Performance: Both approaches achieve excellent language adherence when generating English summaries, with near-perfect CLR scores across all settings. Zero-shot approaches already achieve 100% CLR for both models in this direction, indicating the inherent strength of LLMs in generating content in English regardless of the input language. MuRXLS provides slight improvements over random sampling in specific language pairs, particularly for Marathi→English and Pashto→English where improvements of +0.87 percentage points are observed.
- EN→X Direction Performance: In this more challenging direction, MuRXLS demonstrates significant improvements over random sampling for most language pairs:
- -
- Mistral-7B shows substantial CLR gains with MuRXLS for Thai (+0.46 to +0.99), Gujarati (+1.16 to +0.96), Marathi (+3.34 to +3.45), Pashto (+4.63 to +1.10), and especially Burmese, where the improvement reaches +7.24 percentage points in the two-shot setting.
- -
- GPT-3.5 demonstrates strong improvements with MuRXLS for Gujarati (+2.04 in one-shot, +0.70 in two-shot), Marathi (+0.84 in one-shot, +0.76 in two-shot), and Pashto (+0.68 in one-shot, +1.53 in two-shot).
- -
- Slight declines are observed for Sinhala with both models, suggesting potential language-specific challenges.
- Zero-shot vs. Few-shot Comparison: Zero-shot performance reveals significant directional asymmetry, with perfect X→EN performance but highly variable EN→X performance. Particularly challenging cases include Mistral-7B’s performance for Marathi (38.70%), Pashto (27.50%), and Burmese (71.07%). This highlights the value of in-context learning approaches for improving language adherence in these challenging directions.
- Shot Setting Impact: Two-shot configurations generally outperform one-shot settings for most language pairs, particularly with MuRXLS. The improvements for Mistral-7B with Burmese (+7.24 in two-shot vs. +2.90 in one-shot) exemplify how multiple semantically relevant examples provide complementary benefits. Similarly, GPT-3.5 shows stronger two-shot performance across many language pairs.
- Language-Specific Patterns: Languages with lower baseline CLR (e.g., Marathi for Mistral-7B at 38.70% in zero-shot) show larger improvements with MuRXLS, while languages with already high CLR occasionally show slight declines. This suggests that retrieval-based selection is particularly valuable for the most challenging language pairs.
3.2.9. Correlation Between Example Similarity and Summarization Performance
4. Discussion
4.1. Directional Asymmetry in Cross-Lingual Transfer
4.2. Language Selection Limitations and Their Impact
4.3. Language-Specific Effectiveness Patterns
4.4. Comparison with Traditional Fine-Tuning Approaches
4.5. Example Quality vs. Quantity
4.6. Implications for Low-Resource Languages
4.7. Study Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Parnell, J.; Unanue, I.J.; Piccardi, M. Sumtra: A differentiable pipeline for few-shot cross-lingual summarization. arXiv 2024, arXiv:2403.13240. [Google Scholar]
- Wan, X.; Luo, F.; Sun, X.; Huang, S.; Yao, J.-G. Cross-language document summarization via extraction and ranking of multiple summaries. Knowl. Inf. Syst. 2019, 58, 481–499. [Google Scholar] [CrossRef]
- Ladhak, F.; Durmus, E.; Cardie, C.; McKeown, K. WikiLingua: A new benchmark dataset for cross-lingual abstractive summarization. arXiv 2020, arXiv:2010.03093. [Google Scholar]
- Zhang, R.; Ouni, J.; Eger, S. Cross-lingual Cross-temporal Summarization: Dataset, Models, Evaluation. Comput. Linguist. 2024, 50, 1001–1047. [Google Scholar] [CrossRef]
- Zhang, Y.; Gao, S.; Huang, Y.; Tan, K.; Yu, Z. A Cross-Lingual Summarization method based on cross-lingual Fact-relationship Graph Generation. Pattern Recognit. 2024, 146, 109952. [Google Scholar] [CrossRef]
- Zhu, J.; Wang, Q.; Wang, Y.; Zhou, Y.; Zhang, J.; Wang, S.; Zong, C. NCLS: Neural Cross-Lingual Summarization. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3054–3064. [Google Scholar]
- Cao, Y.; Liu, H.; Wan, X. Jointly Learning to Align and Summarize for Neural Cross-Lingual Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 6220–6231. [Google Scholar]
- Wang, J.; Liang, Y.; Meng, F.; Zou, B.; Li, Z.; Qu, J.; Zhou, J. Zero-Shot Cross-Lingual Summarization via Large Language Models. arXiv 2023, arXiv:2302.14229. [Google Scholar]
- Wang, J.; Meng, F.; Zheng, D.; Liang, Y.; Li, Z.; Qu, J.; Zhou, J. A survey on cross-lingual summarization. Trans. Assoc. Comput. Linguist. 2022, 10, 1304–1323. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Lin, X.V.; Mihaylov, T.; Artetxe, M.; Wang, T.; Chen, S.; Simig, D.; Ott, M.; Goyal, N.; Bhosale, S.; Du, J.; et al. Few-shot Learning with Multilingual Generative Language Models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, UAE, 7–11 December 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 9019–9052. [Google Scholar]
- Asai, A.; Kudugunta, S.; Yu, X.; Blevins, T.; Gonen, H.; Reid, M.; Tsvetkov, Y.; Ruder, S.; Hajishirzi, H. BUFFET: Benchmarking Large Language Models for Few-shot Cross-lingual Transfer. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Mexico City, Mexico, 16–21 June 2024; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 1771–1800. [Google Scholar]
- Jiang, A.Q.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D.S.; de las Casas, D.; Bressand, F.; Lengyel, G.; Lample, G.; Saulnier, L.; et al. Mistral 7B. arXiv 2023, arXiv:2310.06825. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Grattafiori, A.; Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Vaughan, A.; et al. The Llama 3 Herd of Models. arXiv 2024, arXiv:2407.21783. [Google Scholar]
- Zhang, P.; Shao, N.; Liu, Z.; Xiao, S.; Qian, H.; Ye, Q.; Dou, Z. Extending Llama-3’s Context Ten-Fold Overnight. arXiv 2024, arXiv:2404.19553. [Google Scholar]
- Li, P.; Zhang, Z.; Wang, J.; Li, L.; Jatowt, A.; Yang, Z. ACROSS: An Alignment-based Framework for Low-Resource Many-to-One Cross-Lingual Summarization. In Findings of the Association for Computational Linguistics: ACL 2023; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 2458–2472. [Google Scholar]
- Ram, O.; Levine, Y.; Dalmedigos, I.; Muhlgay, D.; Shashua, A.; Leyton-Brown, K.; Shoham, Y. In-Context Retrieval-Augmented Language Models. arXiv 2023, arXiv:2302.00083. [Google Scholar] [CrossRef]
- Zhang, Y.; Feng, S.; Tan, C. Active Example Selection for In-Context Learning. arXiv 2022, arXiv:2211.04486. [Google Scholar]
- Min, S.; Lyu, X.; Holtzman, A.; Artetxe, M.; Lewis, M.; Hajishirzi, H.; Zettlemoyer, L. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? arXiv 2022, arXiv:2202.12837. [Google Scholar]
- Nie, E.; Liang, S.; Schmid, H.; Schütze, H. Cross-Lingual Retrieval Augmented Prompt for Low-Resource Languages. In Findings of the Association for Computational Linguistics: ACL 2023; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 8320–8340. [Google Scholar]
- Bhattacharjee, A.; Hasan, T.; Ahmad, W.U.; Li, Y.-F.; Kang, Y.-B.; Shahriyar, R. CrossSum: Beyond English-Centric Cross-Lingual Summarization for 1500+ Language Pairs. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 2541–2564. [Google Scholar]
- Chen, J.; Xiao, S.; Zhang, P.; Luo, K.; Lian, D.; Liu, Z. BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. arXiv 2024, arXiv:2402.03216. [Google Scholar]
- Lin, C.-Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; pp. 74–81. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating Text Generation with BERT. arXiv 2020, arXiv:1904.09675. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 8440–8451. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Douze, M.; Jégou, H.; Mikolov, T. FastText.zip: Compressing text classification models. arXiv 2016, arXiv:1612.03651. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Zhang, J.; Zhang, R.; Xu, L.; Lu, X.; Yu, Y.; Xu, M.; Zhao, H. FasterSal: Robust and Real-Time Single-Stream Architecture for RGB-D Salient Object Detection. IEEE Trans. Multimed. 2025, 27, 2477–2488. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Pipeline Methods | End-to-End Neural | Random ICL Methods | MuRXLS (Ours) | |
|---|---|---|---|---|
| Semantic Example Selection | × | × | × | ✔ |
| Cross-lingual Retrieval | × | × | × | ✔ |
| No Task-specific Training | × | × | ✔ | ✔ |
| Directional Analysis | × | × | × | ✔ |
| Low-resource Effectiveness | Low | Low | Medium | High |
| Computational Efficiency | Low | High | High | High |
| Component | Content |
|---|---|
| Instruction | Please summarize the following text in [TARGET_LANGUAGE] |
| Example 1 | Text: [RETRIEVED_Article_1] |
| Translated summary: [RETRIEVED_SUMMARY_1] | |
| ⋮ | ⋮ |
| Example k | Text: [RETRIEVED_Article_k] |
| Translated summary: [RETRIEVED_SUMMARY_k] | |
| Query | Text: [TEST_Article] |
| Translated summary: |
| Direction | Model | Method | Language Pair | Avg. | |||||
|---|---|---|---|---|---|---|---|---|---|
| Th-En | Gu-En | Mr-En | Pa-En | Bu-En | Si-En | ||||
| X→EN | mT5-Base | Fine-tuned | 22.63 | 19.12 | 20.14 | 24.78 | 22.07 | 22.53 | 21.88 |
| Mistral-7B | Zero-shot | 6.97 | 5.94 | 6.25 | 6.64 | 6.82 | 6.61 | 6.54 | |
| Random (1-shot) | 7.61 | 6.88 | 6.55 | 6.13 | 7.99 | 6.80 | 6.99 | ||
| Random (2-shot) | 7.85 | 6.56 | 6.69 | 5.92 | 8.84 | 7.09 | 7.16 | ||
| MuRXLS (1-shot) | 7.92 (+0.31) | 6.88 (+0.00) | 6.67 (+0.12) | 7.20 (+1.07) | 8.55 (+0.56) | 7.42 (+0.62) | 7.44 (+0.45) | ||
| MuRXLS (2-shot) | 8.01 (+0.16) | 6.94 (+0.38) | 7.12 (+0.43) | 7.28 (+1.36) | 9.88 (+1.04) | 7.62 (+0.53) | 7.81 (+0.65) | ||
| Llama-3-70B | Zero-shot | 8.70 | 8.91 | 8.38 | 9.47 | 10.63 | 9.85 | 9.32 | |
| Random (1-shot) | 9.29 | 10.49 | 7.81 | 9.20 | 9.12 | 9.42 | 9.22 | ||
| Random (2-shot) | 8.22 | 10.85 | 7.58 | 8.19 | 8.43 | 9.37 | 8.77 | ||
| MuRXLS (1-shot) | 9.42 (+0.13) | 11.71 (+1.22) | 8.41 (+0.60) | 10.36 (+1.16) | 13.32 (+4.20) | 11.28 (+1.86) | 10.75 (+1.53) | ||
| MuRXLS (2-shot) | 9.21 (+0.99) | 11.42 (+0.57) | 8.63 (+1.05) | 9.21 (+1.02) | 11.39 (+2.96) | 11.71 (+2.34) | 10.26 (+1.49) | ||
| GPT-4o | Zero-shot | 8.70 | 8.81 | 8.87 | 9.26 | 10.37 | 10.14 | 9.36 | |
| Random (1-shot) | 9.99 | 9.52 | 9.50 | 9.84 | 11.38 | 11.30 | 10.26 | ||
| Random (2-shot) | 10.28 | 10.25 | 10.56 | 10.75 | 12.05 | 11.82 | 10.95 | ||
| MuRXLS (1-shot) | 10.21 (+0.22) | 9.72 (+0.20) | 9.90 (+0.40) | 10.19 (+0.35) | 11.64 (+0.26) | 11.48 (+0.18) | 10.52 (+0.27) | ||
| MuRXLS (2-shot) | 10.56 (+0.28) | 10.54 (+0.29) | 10.61 (+0.05) | 11.03 (+0.28) | 12.27 (+0.22) | 12.26 (+0.44) | 11.21 (+0.26) | ||
| GPT-3.5 | Zero-shot | 10.32 | 9.20 | 9.96 | 10.94 | 10.19 | 9.91 | 10.09 | |
| Random (1-shot) | 10.99 | 9.25 | 10.79 | 10.80 | 11.91 | 10.11 | 10.64 | ||
| Random (2-shot) | 11.60 | 10.57 | 11.96 | 11.06 | 12.39 | 9.81 | 11.23 | ||
| MuRXLS (1-shot) | 11.83 (+0.84) | 9.45 (+0.20) | 10.97 (+0.18) | 12.20 (+1.40) | 11.97 (+0.06) | 10.20 (+0.09) | 11.10 (+0.46) | ||
| MuRXLS (2-shot) | 11.92 (+0.32) | 11.32 (+0.75) | 12.24 (+0.28) | 12.89 (+1.83) | 12.62 (+0.23) | 10.42 (+0.61) | 11.90 (+0.67) | ||
| EN→X | mT5-Base | Fine-tuned | 4.40 | 9.37 | 8.94 | 17.55 | 4.72 | 5.13 | 8.35 |
| Mistral-7B | Zero-shot | 5.81 | 0.32 | 0.22 | 0.00 | 2.03 | 0.06 | 1.41 | |
| Random (1-shot) | 5.26 | 0.65 | 1.52 | 0.00 | 3.38 | 0.88 | 1.95 | ||
| Random (2-shot) | 5.16 | 0.77 | 1.69 | 0.00 | 2.66 | 0.86 | 1.86 | ||
| MuRXLS (1-shot) | 5.87 (+0.61) | 0.72 (+0.07) | 1.02 (−0.50) | 0.00 (+0.00) | 4.78 (+1.40) | 0.89 (+0.01) | 2.21 (+0.26) | ||
| MuRXLS (2-shot) | 5.21 (+0.05) | 0.12 (−0.65) | 1.63(−0.06) | 0.00 (+0.00) | 4.44 (+1.78) | 1.38 (+0.52) | 2.13 (+0.27) | ||
| Llama-3-70B | Zero-shot | 4.95 | 0.77 | 0.15 | 0.00 | 2.68 | 3.85 | 2.07 | |
| Random (1-shot) | 7.11 | 0.48 | 0.41 | 0.00 | 1.45 | 3.74 | 2.20 | ||
| Random (2-shot) | 7.21 | 1.09 | 0.11 | 0.00 | 0.79 | 1.64 | 1.81 | ||
| MuRXLS (1-shot) | 7.06 (−0.05) | 1.12 (+0.64) | 0.25 (−0.16) | 0.00 (+0.00) | 3.16 (+1.71) | 3.70(−0.04) | 2.55 (+0.35) | ||
| MuRXLS (2-shot) | 7.36 (+0.15) | 0.82 (−0.27) | 0.91 (+0.80) | 0.00 (+0.00) | 1.47 (+0.68) | 1.85 (+0.21) | 2.07 (+0.26) | ||
| GPT-4o | Zero-shot | 6.43 | 2.10 | 2.29 | 0.00 | 3.83 | 4.25 | 3.15 | |
| Random (1-shot) | 7.04 | 1.71 | 3.65 | 0.00 | 5.28 | 4.95 | 3.77 | ||
| Random (2-shot) | 9.12 | 1.03 | 3.56 | 0.00 | 3.86 | 5.80 | 3.90 | ||
| MuRXLS (1-shot) | 7.91 (+0.87) | 2.55 (+0.84) | 3.62 (−0.03) | 0.00 (+0.00) | 5.67 (+0.39) | 4.86 (−0.09) | 4.01 (+0.31) | ||
| MuRXLS (2-shot) | 8.85(−0.27) | 0.93 (−0.10) | 3.28 (−0.28) | 0.00 (+0.00) | 5.31 (+1.45) | 5.99 (+0.19) | 4.06 (+0.17) | ||
| GPT-3.5 | Zero-shot | 4.53 | 1.40 | 2.05 | 0.00 | 1.70 | 1.22 | 1.82 | |
| Random (1-shot) | 4.45 | 1.60 | 1.02 | 0.00 | 1.55 | 1.72 | 1.72 | ||
| Random (2-shot) | 5.20 | 0.55 | 0.88 | 0.00 | 1.55 | 1.63 | 1.63 | ||
| MuRXLS (1-shot) | 4.37 (−0.08) | 1.49 (−0.11) | 1.02 (+0.00) | 0.00 (+0.00) | 3.26 (+1.71) | 2.01 (+0.29) | 2.03 (+0.31) | ||
| MuRXLS (2-shot) | 6.96 (+1.76) | 0.63 (+0.08) | 0.66 (−0.22) | 0.00 (+0.00) | 1.24 (−0.31) | 1.86 (+0.23) | 1.89 (+0.26) | ||
| Direction | Lang. Pair | GPT-4o | Llama-3-70B | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Random | MuRXLS | Random | MuRXLS | ||||||
| 1-Shot | 2-Shot | 1-Shot | 2-Shot | 1-Shot | 2-Shot | 1-Shot | 2-Shot | ||
| Th-En | 0.75 | 0.77 | 0.79 (+0.04) | 0.81 (+0.04) | 0.73 | 0.72 | 0.77 (+0.04) | 0.79 (+0.07) | |
| Gu-En | 0.74 | 0.76 | 0.78 (+0.04) | 0.80 (+0.04) | 0.74 | 0.75 | 0.79 (+0.05) | 0.80 (+0.05) | |
| Ma-En | 0.74 | 0.77 | 0.79 (+0.05) | 0.80 (+0.03) | 0.72 | 0.72 | 0.77 (+0.05) | 0.78 (+0.06) | |
| Pa-En | 0.76 | 0.78 | 0.79 (+0.03) | 0.81 (+0.03) | 0.72 | 0.72 | 0.78 (+0.06) | 0.78 (+0.06) | |
| Bu-En | 0.77 | 0.78 | 0.81 (+0.04) | 0.82 (+0.04) | 0.72 | 0.72 | 0.80 (+0.08) | 0.80 (+0.08) | |
| Si-En | 0.76 | 0.78 | 0.80 (+0.04) | 0.83 (+0.05) | 0.72 | 0.73 | 0.79 (+0.07) | 0.82 (+0.09) | |
| Average | 0.75 | 0.77 | 0.79 (+0.04) | 0.81 (+0.04) | 0.73 | 0.73 | 0.78 (+0.06) | 0.80 (+0.07) | |
| En-Th | 0.75 | 0.76 | 0.77 (+0.02) | 0.79 (+0.03) | 0.73 | 0.74 | 0.74 (+0.01) | 0.76 (+0.02) | |
| En-Gu | 0.71 | 0.71 | 0.75 (+0.04) | 0.76 (+0.05) | 0.67 | 0.72 | 0.74 (+0.07) | 0.76 (+0.04) | |
| En-Ma | 0.74 | 0.73 | 0.77 (+0.03) | 0.79 (+0.06) | 0.71 | 0.70 | 0.73 (+0.02) | 0.77 (+0.07) | |
| En-Pa | 0.70 | 0.60 | 0.71 (+0.01) | 0.73 (+0.13) | 0.66 | 0.68 | 0.70 (+0.04) | 0.75 (+0.07) | |
| En-Bu | 0.71 | 0.71 | 0.74 (+0.03) | 0.78 (+0.07) | 0.67 | 0.68 | 0.72 (+0.05) | 0.75 (+0.07) | |
| En-Si | 0.74 | 0.75 | 0.76 (+0.02) | 0.81 (+0.06) | 0.72 | 0.71 | 0.75 (+0.03) | 0.76 (+0.05) | |
| Average | 0.75 | 0.76 | 0.77 (+0.03) | 0.79 (+0.07) | 0.69 | 0.70 | 0.73 (+0.04) | 0.76 (+0.05) | |
| Direction | Language Pair | Token Count | Token Increase | Performance (ROUGE-L) | ||
|---|---|---|---|---|---|---|
| (3-Shot + Query) | vs. 2-Shot | Two-Shot | Three-Shot | Change | ||
| X→EN | Th-En | 5163.65 | +1726.80 (+50.2%) | 10.56 | 10.52 | −0.04 |
| Gu-En | 4733.10 | +1581.85 (+50.2%) | 10.54 | 10.47 | −0.07 | |
| Ma-En | 4883.25 | +1632.10 (+50.2%) | 10.68 | 10.78 | +0.10 | |
| Pa-En | 3244.90 | +1084.20 (+50.1%) | 11.03 | 11.32 | +0.29 | |
| Bu-En | 6302.40 | +2106.25 (+50.2%) | 12.27 | 12.21 | −0.06 | |
| Si-En | 5579.40 | +1865.45 (+50.2%) | 12.26 | 12.15 | −0.11 | |
| EN→X | En-Th | 3295.60 | +1101.47 (+50.1%) | 8.85 | 8.44 | −0.41 |
| En-Gu | 3289.00 | +1099.33 (+50.1%) | 0.93 | 1.76 | +0.83 | |
| En-Ma | 3121.05 | +1043.02 (+50.1%) | 3.28 | 2.89 | −0.39 | |
| En-Pa | 2647.95 | +885.12 (+50.1%) | 0.00 | 0.00 | 0.00 | |
| En-Bu | 3769.25 | +1260.05 (+50.1%) | 5.31 | 5.31 | 0.00 | |
| En-Si | 2830.45 | +945.85 (+50.1%) | 5.80 | 5.32 | −0.48 | |
| GPT-4o Average (X→EN) | 4984.45 | +1666.11 (+50.2%) | 11.22 | 11.24 | +0.02 | |
| GPT-3.5 Average (X→EN) | 4984.45 | +1666.11 (+50.2%) | 11.74 | 10.68 | −1.06 | |
| GPT-4o Average (EN→X) | 3158.88 | +1055.81 (+50.1%) | 4.03 | 3.95 | −0.08 | |
| GPT-3.5 Average (EN→X) | 3158.88 | +1055.81 (+50.1%) | 1.82 | 1.71 | −0.11 | |
| Model | Method/Direction | Thai | Gujarati | Marathi | Pashto | Burmese | Sinhala |
|---|---|---|---|---|---|---|---|
| Mistral-7B | Zero-shot X→EN | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Random (1-shot) X→EN | 100.00 | 99.21 | 100.00 | 99.21 | 99.12 | 100.00 | |
| Random (2-shot) X→EN | 100.00 | 99.04 | 99.13 | 99.13 | 100.00 | 100.00 | |
| MuRXLS (1-shot) X→EN | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| MuRXLS (2-shot) X→EN | 100.00 | 100.00 | 100.00 (+0.87) | 100.00 (+0.87) | 100.00 | 100.00 | |
| Zero-shot EN→X | 98.02 | 88.46 | 38.70 | 27.50 | 71.07 | 87.93 | |
| Random (1-shot) EN→X | 99.54 | 98.84 | 45.53 | 78.15 | 91.30 | 98.28 | |
| Random (2-shot) EN→X | 99.01 | 99.04 | 51.22 | 86.75 | 86.96 | 99.01 | |
| MuRXLS (1-shot) EN→X | 100.00 (+0.46) | 100.00 (+1.16) | 48.87 (+3.34) | 82.78 (+4.63) | 94.20 (+2.90) | 98.02 (−0.26) | |
| MuRXLS (2-shot) EN→X | 100.00 (+0.99) | 100.00 (+0.96) | 54.67 (+3.45) | 87.85 (+1.10) | 94.20 (+7.24) | 98.84 (−0.17) | |
| GPT-3.5 | Zero-shot X→EN | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Random (1-shot) X→EN | 99.47 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| Random (2-shot) X→EN | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| MuRXLS (1-shot) X→EN | 100.00 (+0.53) | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| MuRXLS (2-shot) X→EN | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| Zero-shot EN→X | 96.04 | 94.30 | 95.12 | 91.39 | 96.46 | 95.30 | |
| Random (1-shot) EN→X | 99.32 | 97.00 | 99.00 | 99.32 | 99.50 | 98.90 | |
| Random (2-shot) EN→X | 99.32 | 99.30 | 99.24 | 98.47 | 98.92 | 99.37 | |
| MuRXLS (1-shot) EN→X | 100.00 (+0.68) | 99.04 (+2.04) | 99.84 (+0.84) | 100.00 (+0.68) | 98.80 (+0.30) | 98.15 (−0.75) | |
| MuRXLS (2-shot) EN→X | 100.00 (+0.68) | 100.00 (+0.70) | 100.00 (+0.76) | 100.00 (+1.53) | 99.03 (+0.11) | 98.57 (−0.80) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, G.; Park, J.; Lee, H. Cross-Lingual Summarization for Low-Resource Languages Using Multilingual Retrieval-Based In-Context Learning. Appl. Sci. 2025, 15, 7800. https://doi.org/10.3390/app15147800
Park G, Park J, Lee H. Cross-Lingual Summarization for Low-Resource Languages Using Multilingual Retrieval-Based In-Context Learning. Applied Sciences. 2025; 15(14):7800. https://doi.org/10.3390/app15147800
Chicago/Turabian StylePark, Gyutae, Jeonghyun Park, and Hwanhee Lee. 2025. "Cross-Lingual Summarization for Low-Resource Languages Using Multilingual Retrieval-Based In-Context Learning" Applied Sciences 15, no. 14: 7800. https://doi.org/10.3390/app15147800
APA StylePark, G., Park, J., & Lee, H. (2025). Cross-Lingual Summarization for Low-Resource Languages Using Multilingual Retrieval-Based In-Context Learning. Applied Sciences, 15(14), 7800. https://doi.org/10.3390/app15147800