In this section, we introduce the dataset employed in our experiment, detail the experimental environment, and elucidate the training procedures. Furthermore, we present the evaluation metrics and demonstrate the superiority of our approach through a multitude of experimental comparisons. Additionally, ablation studies are conducted on various branches, modules, and loss functions to thoroughly assess their individual contributions.
4.1. Dataset
We trained our model on the LOLv1 dataset [
23] and a self-built low-light hydraulic concrete image dataset (LLHCID). The LOLv1 dataset, which is frequently utilized for low-light image enhancement methods, comprises 500 pairs of low-light and normal-light images, with 485 pairs designated for training purposes and the remaining 15 pairs for testing.
In our research, we found that there is currently no publicly available dataset specifically designed for low-light hydraulic concrete image enhancement. To address this gap and rigorously validate the effectiveness of our proposed method, we constructed a low-light hydraulic concrete image dataset (LLHCID) through a combination of on-site image acquisition and post-processing techniques. The dataset consists of 2000 image pairs, each containing a low-light image and a corresponding bright-light image. Among them, 1600 pairs were used for training, 200 pairs were used for validation, and 200 pairs were used for testing. All images were resized to 600 × 400 pixels using high-quality interpolation with Python V3.10’s Pillow library and saved in JPEG format to balance detail preservation and input consistency for the model.
All images in the LLHCID were of real-world hydraulic concrete structures located in Southwest China. The image acquisition was conducted using a Huawei Mate60 Pro smartphone—purchased from the official website of Huawei Technologies Co., Ltd. (Shenzhen, China)—mounted on a fixed tripod, with the aperture consistently set to f/2.0. The bright-light images were captured under controlled conditions, with ISO sensitivity ranging from 100 to 2000 and shutter speeds ranging from 1/125 to 1/60 s. The corresponding low-light images were captured at the same sites, using ISO sensitivity ranging from 50 to 80 and shutter speeds between 1/250 and 1/125 s, resulting in brightness levels that were approximately 20–60% of their bright-light counterparts. This acquisition protocol ensures significant luminance contrast while maintaining spatial alignment. Importantly, a large portion of the collected images contain visible surface defects, including cracks, spalling, and corrosion, making the dataset highly relevant for defect-aware enhancement and detection tasks.
To ensure the reliability and diversity of the dataset, all image pairs were manually reviewed and aligned.
Figure 8 presents representative samples from the LLHCID, showcasing a variety of paired low-light and bright-light hydraulic concrete images captured under different illumination conditions. The samples include diverse surface states, such as those free of defects and those with cracks, spalling, efflorescence, exposed aggregate, and erosion.
We further analyzed the histogram distribution of low-light images in the YCbCr color space. The Y channel effectively reflects the overall luminance levels, while the Cb and Cr channels exhibit more concentrated pixel distributions in background regions. In contrast, defect regions tend to show distinguishable deviations in chrominance, allowing subtle defect textures to be better preserved and distinguished through chrominance restoration.
We plan to publicly release part of the dataset in future work to support broader research in low-light enhancement and structural inspection of concrete surfaces.
We used the Peak Signal-to-Noise Ratio (PSNR) and the Structural Similarity Index Measure (SSIM) as two indicators to quantitatively evaluate the performance of the model.
4.3. Results and Evaluation
We trained the DBLCANet-HCIE model on the LOLV1 dataset and compared it with 12 other low-light image enhancement methods: CLAHE [
9], LIME [
52], KinD++ [
53], URetinex-Net [
54], HVI [
55], LYT-NET [
38], PPformer [
36], Retinexformer [
35], RetinexMamba [
56], SALLIE [
57], LCDBNet [
1], and LLFormer [
34].
Table 1 presents the quantitative performance of these diverse enhancement methods on the LOLv1 dataset. It is evident that our proposed method demonstrated superior performance compared to the majority of these methods in both the PSNR and SSIM indicators. Notably, our method achieved the best results in the SSIM category and the second-highest score in the PSNR metric, with a marginal difference of only 0.12 dB from the leading method, HVI.
Figure 9 illustrates the results of qualitative comparisons between our proposed method and the existing approaches. The CLAHE method exhibited limited enhancement effects, while LIME improved the luminance but introduced severe distortion artifacts. Although KinD++ and LYT-Net achieved luminance enhancement, they simultaneously developed color over-saturation issues. Compared with the other enhancement methods illustrated in the images, our approach demonstrated better performance in terms of chromatic consistency, detail clarity, and luminance optimization.
As presented in
Table 2, the PSNR and SSIM values of the seven models trained on the LOLv1 dataset showed a significant decrease when tested on our self-constructed LLHCID. Nonetheless, our method also achieved the highest scores in terms of the PSNR and SSIM. This indicates that the actual enhancement effects are far from satisfactory, which is further illustrated in
Figure 10. The luminance enhancement is insufficient, and the detailed features are severely distorted.
To ensure a fair and unbiased comparison, we retrained and evaluated all seven models on our self-constructed LLHCID under consistent experimental conditions. Specifically, the training data, preprocessing procedures, and key hyperparameter settings, such as learning rate, batch size, optimizer, and number of epochs, were maintained across all models. For the baseline models, we adopted their publicly available official implementations and retained their default hyperparameter settings, which were established by the original authors.
The results of the quantitative comparison of the LLHCID test set are shown in
Table 3, where our proposed method exhibits excellent performance in terms of the PSNR metric, achieving 28.61 dB. Our method outperforms the second-best approach, Retinexformer [
35], by 1.48 dB in PSNR. Compared to the other competing methods, including LYT-Net [
38], RetinexMamba [
56], SNR-Aware [
57], HVI [
55], and LCDBNet [
1], our approach achieves improvements of 4.96 dB, 1.87 dB, 3.81 dB, 1.98 dB, and 2.05 dB, respectively. In terms of SSIM, which reflects structural similarity and perceptual fidelity, our method achieves the highest score of 0.9574, outperforming LYT-Net by 0.1022 and showing improvements of 0.0361, 0.0473, 0.0498, 0.0298, and 0.0215 over Retinexformer, RetinexMamba, SNR-Aware, HVI, and LCDBNet, respectively. These results clearly demonstrate the superior ability of our DBLCANet-HCIE to enhance low-light hydraulic concrete images while effectively preserving structural and texture details.
To comprehensively evaluate the computational efficiency and complexity of the proposed model, we compared seven low-light image enhancement methods in terms of floating-point operations (FLOPs), number of parameters, and average inference time per image. To ensure fairness and comparability, all models were evaluated in the same hardware environment, with input tensors uniformly set to a size of 3 × 400 × 600, consistent with the training dataset. For inference time evaluation, each model was run multiple times, and the average value was recorded to reduce the impact of random fluctuations. As shown in
Table 3, DBLCANet-HCIE contains 2.13 million parameters and requires 63.90 GFLOPs, achieving the best performance among all compared approaches while maintaining a moderate level of model complexity.
Figure 11 presents a visual comparison of the results after training on the LLHCID, clearly illustrating that the images enhanced using our proposed method most closely resembled the ground-truth images. The HVI, LYT-Net, and Retinexformer methods exhibited certain distortions in color representation, while the RetinexMamba, LCDBNet, and SNR-Aware methods showed less than ideal performance in terms of detail preservation. The DBLCANet-HCIE method exhibited the best performance among the seven methods in terms of its luminance enhancement and detailed feature preservation. The defect edge details were also well preserved.
Comparisons of the enlarged defect regions in the visual results reveal that RetinexMamba, LCDBNet, and SNR-Aware introduce noticeable noise and artifacts around defect areas, which significantly compromise visual quality. Although LYT-Net, HVI, and Retinexformer show improved performance in suppressing such artifacts, they still suffer from detail loss and substantial color distortion in defect regions. In contrast, the proposed method not only enhances overall luminance effectively but also preserves fine-grained defect textures and removes noise, producing visual results that are visually closer to the reference bright-light images.
4.4. Ablation Study
To rigorously ascertain the efficacy of the DBLCANet-HCIE approach, a series of ablation studies were meticulously designed, focusing on the discrete impacts of individual modules, branching architectures, and sub-loss functions. These studies were uniformly executed within an identical training framework and environmental conditions, leveraging the LLHCID to ensure comprehensive and unbiased evaluations.
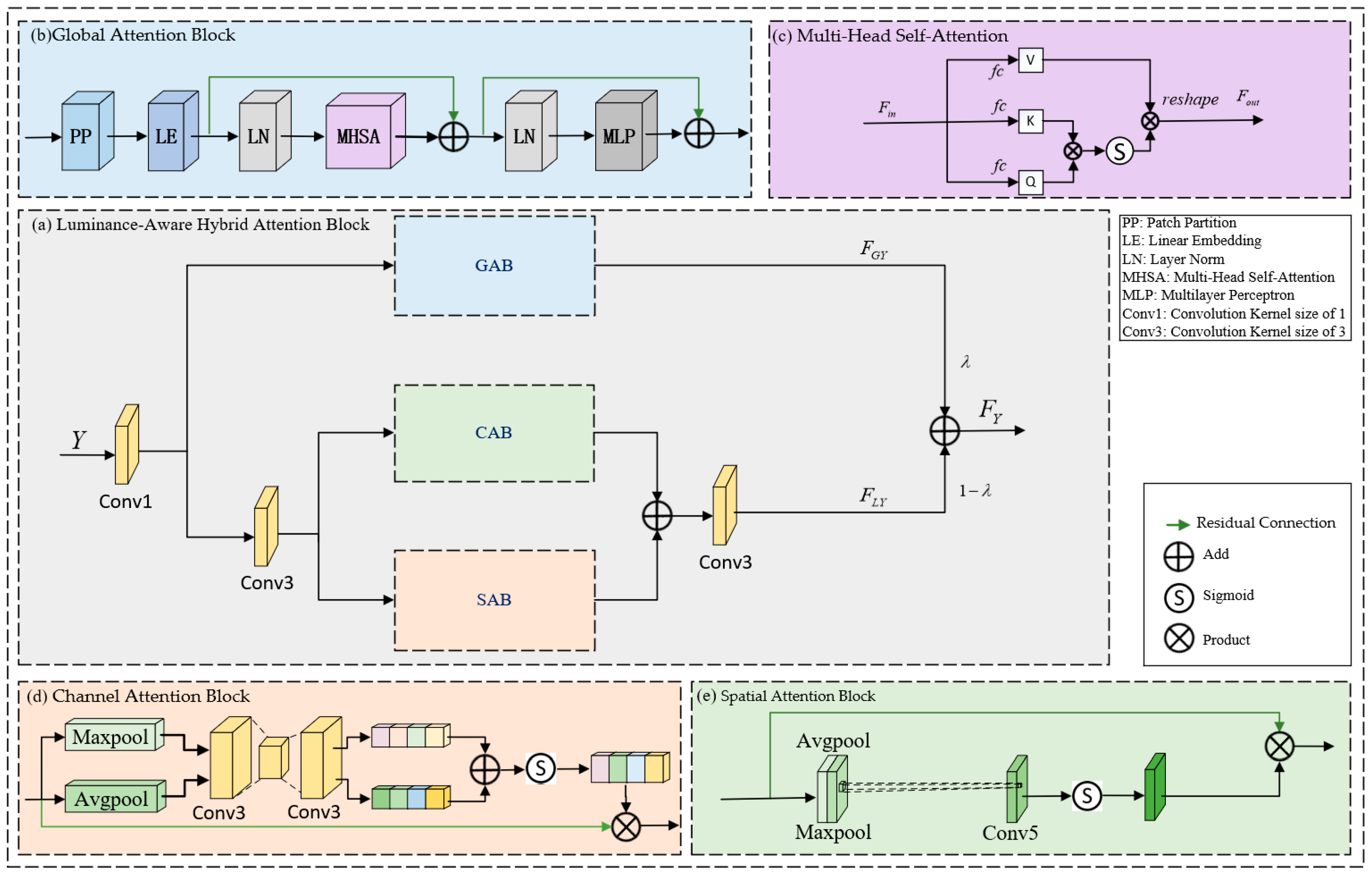
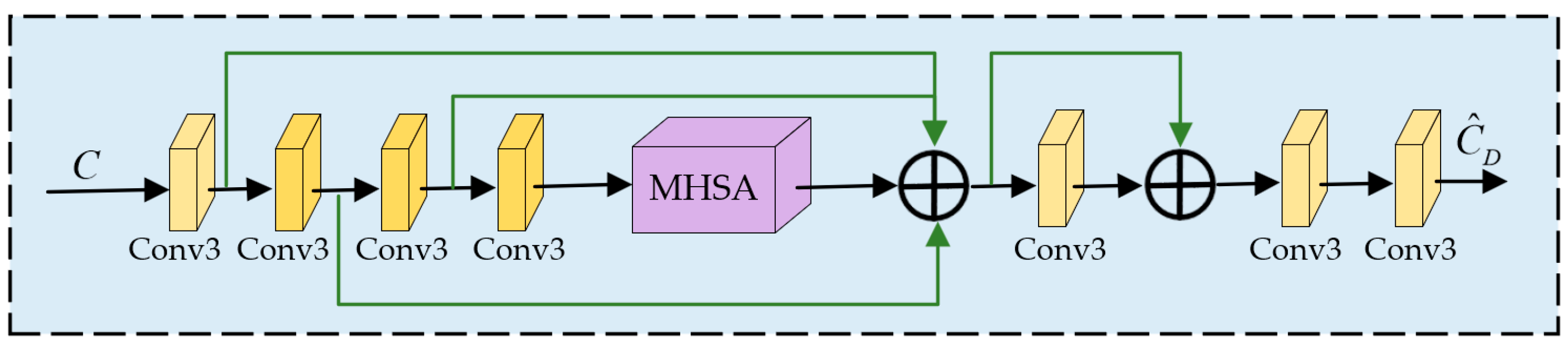
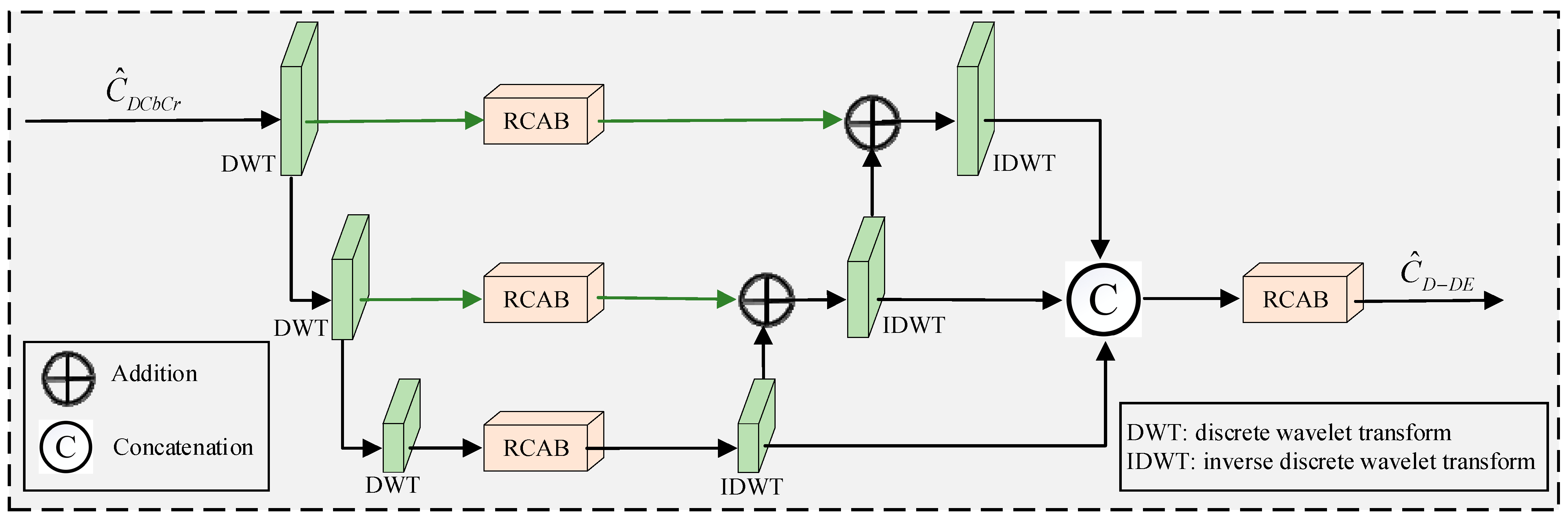
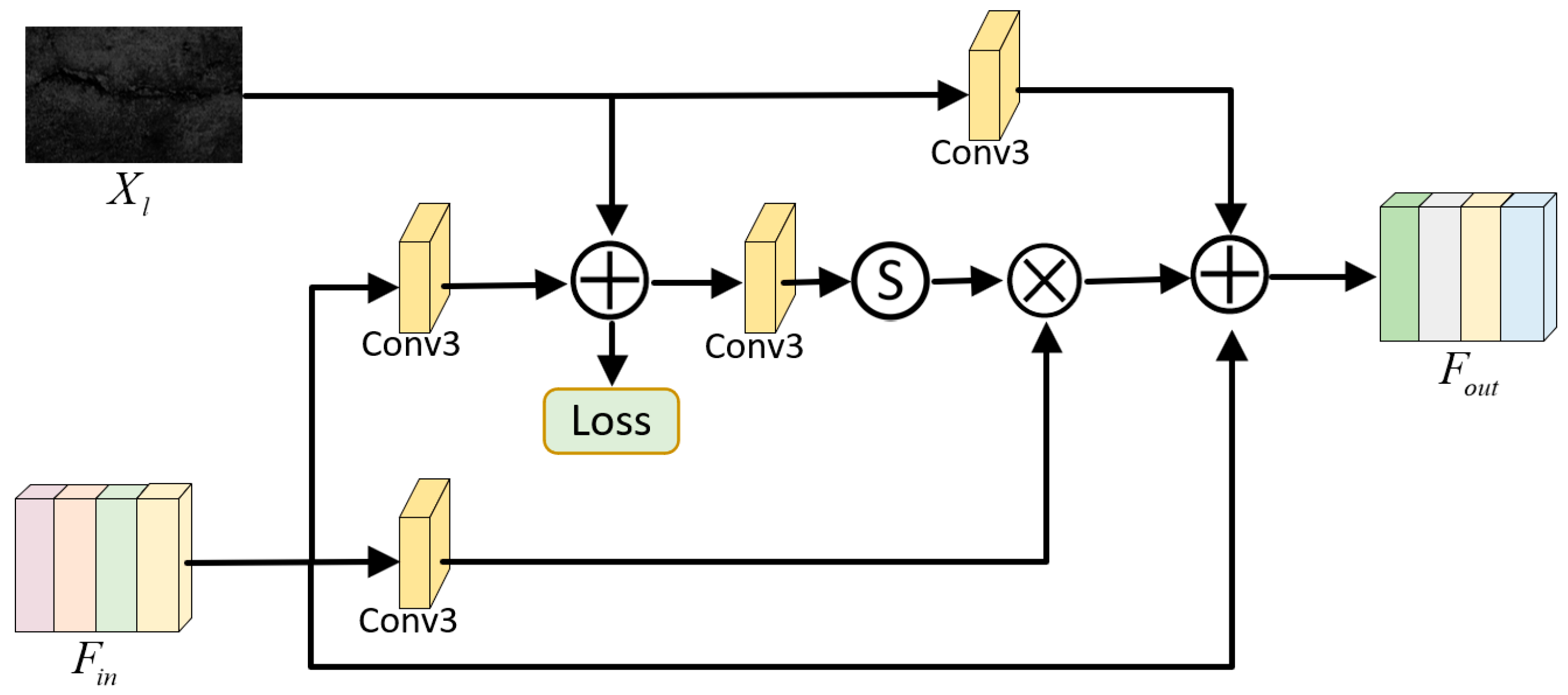
We performed ablation experiments by sequentially excluding the LAB, CRM, CDB, and FDDEB from the comprehensive model architecture. The results of the ablation studies on sub-blocks and sub-branches are shown in
Table 4. The exclusion of the LAB reduced the model’s PSNR by 5.09 dB and its SSIM by 0.114. The absence of the CRB resulted in decreases of 2.96 dB and 0.0961 in the model’s PSNR and SSIM, respectively. These results demonstrate the effectiveness of the luminance adjustment and chrominance restoration sub-branches. The ablation results of the CDB and FDDEB modules demonstrate their distinct contributions to chrominance restoration. Specifically, the CDB effectively suppresses chromatic noise in the Cb and Cr channels, while the FDDEB enhances fine-grained detail features, enabling more accurate and perceptually consistent chrominance reconstruction.
As evidenced in
Table 5, the outcomes of the ablation studies substantiate the efficacy of the proposed joint loss function. Initial experiments employing solely the
loss yielded a PSNR of 26.21 dB and an SSIM of 0.8827. Subsequent individual integration of the
and
losses improved these metrics to 28.14 dB/0.9253 and 27.86 dB/0.9168, respectively. The synergistic combination of all three losses (
) achieved optimal performance, attaining a peak PSNR of 28.61 dB and SSIM of 0.9674. These experimental findings substantiate the efficacy of integrating holistic and branch-specific losses, thereby validating the necessity of employing a joint loss function for hydraulic concrete image enhancement.
4.5. Evaluation in Different Color Spaces
To evaluate the influence of color space selection on the enhancement of hydraulic concrete images, we conducted experiments using three widely adopted color spaces: RGB, HSV, and YCbCr. The same network structure and training configuration were used in all cases to ensure a fair comparison.
Table 6 shows the quantitative results of the LLHCID across different color spaces. The results indicate that the YCbCr color space significantly outperforms the RGB and HSV color spaces in both the PSNR and SSIM metrics when applied to low-light hydraulic concrete images. This improvement is largely due to the explicit separation of luminance (Y) and chrominance (Cb/Cr) in the YCbCr space, which aligns well with the characteristics of our dual-branch architecture. In contrast, the RGB and HSV color spaces entangle brightness and color information, which makes it more difficult to isolate and enhance subtle surface features such as fine cracks, erosion marks, efflorescence, and aggregate exposure, often resulting in color distortion or detail loss during enhancement.
Figure 12 presents the qualitative comparison results, indicating that the proposed model performs suboptimally in enhancing low-light underwater concrete images in the RGB and HSV color spaces, exhibiting color distortion and loss of detail. Attempts to use the LAB space resulted in non-convergence, likely due to its strong nonlinearity and incompatibility with the current architecture. In contrast, qualitative evaluations further demonstrate that images processed in the YCbCr color space achieve more natural color balance, clearer defect textures, and improved structural consistency. These results highlight the suitability of YCbCr for defect-aware enhancement and support its use as the preferred color space in our proposed framework.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}