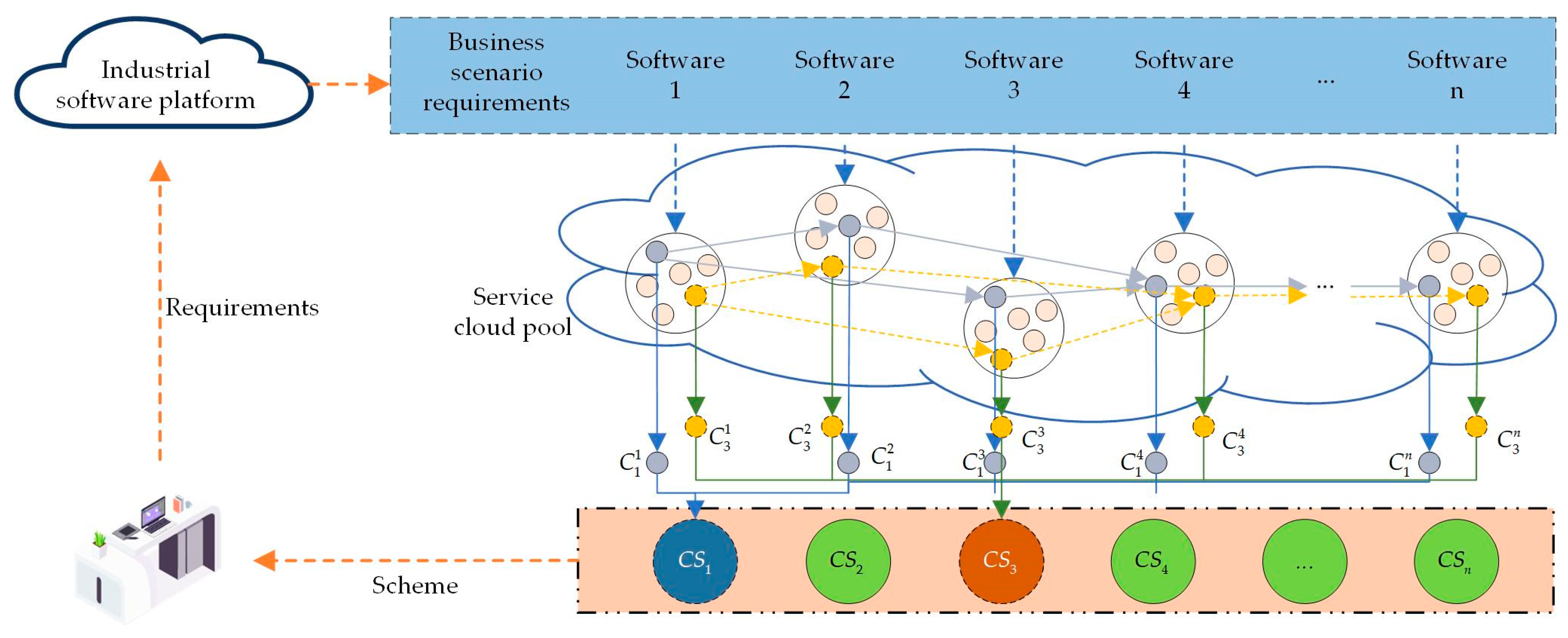
This section evaluates the performance of the proposed HEMOGWO through two sets of experiments. The first set aims to assess the algorithm’s effectiveness in solving multi-objective optimization problems. HEMOGWO is compared against several representative multi-objective optimization algorithms, including SMOGWO, MOGWO, MOEAD_DE, MOPSO, and NSGA-III. All algorithms are tested on 17 widely recognized benchmark functions to provide a comprehensive evaluation of the optimization performance and improvement capability of HEMOGWO. The second set of experiments focuses on evaluating the adaptability and robustness of HEMOGWO in solving combinatorial optimization problems of varying scales. Tests are conducted on a series of real-world service composition models to further verify the algorithm’s generality and practical applicability. All experiments are conducted under the following hardware and software environment: Windows 10 operating system, Intel Core i5-12400F processor (2.5 GHz) (Intel, Santa Clara, CA, USA), 16 GB RAM, and MATLAB R2020b as the development and execution platform.
The GD metric quantifies the average distance between the obtained approximation set (PF
know) and the true Pareto front (PF
true), and is calculated using Equation (25).
where
v represents the total number of Pareto solutions obtained, and
dvi denotes the Euclidean distance between the
i-th obtained PF
know and the closest PF
true. A smaller GD value indicates better convergence performance of the algorithm.
4.1. Case 1: The Performance of HEMOGWO on Benchmark Functions
This section performs a performance evaluation of the proposed HEMOGWO algorithm using 17 widely used benchmark functions in multi-objective optimization research. The benchmark functions include UF1–UF7, ZDT1–ZDT3, and CF1–CF7. The relevant experimental parameters are listed in
Table 4. All parameter values are based on the original literature of each algorithm or their commonly used configurations in the field of multi-objective optimization, unless otherwise specified, with no special tuning applied.
To comprehensively assess the algorithm’s performance, two commonly used metrics, GD and IGD, are selected. A comparison is made between the HEMOGWO, SMOGWO, MOGWO, MOEAD_DE, MOPSO, and NSGA-III algorithms. The computational results of these algorithms on the GD and IGD metrics are presented in
Table 5 and
Table 6, where each result is obtained from 30 independent runs. The best result for each metric is highlighted in bold, and “Mean/Std” represents the mean and standard deviation of the results, which are used to evaluate the stability and convergence performance of the algorithms.
Based on the statistical results presented in the table, HEMOGWO achieved the best GD values on all benchmark functions except UF1, UF5, CF1, and CF6, demonstrating its significant advantage in solving most test problems, particularly those in the ZDT series. SMOGWO also performed well on several functions, especially obtaining the best results on UF5 and CF5. MOGWO showed the most outstanding performance on CF6, while MOEAD_DE, though only achieving optimal performance on CF1, exhibited excellent results on that function. In contrast, MOPSO and NSGA-III did not achieve the best GD values on any of the tested functions. Regarding the IGD metric, HEMOGWO again exhibited strong performance, achieving the best IGD values on 13 out of the 17 benchmark functions, except for UF3, UF5, CF2, and CF5. SMOGWO outperformed others on these four functions and showed comparable performance to HEMOGWO on the remaining benchmarks, indicating strong competitiveness. However, MOGWO, MOEAD_DE, MOPSO, and NSGA-III performed poorly overall in terms of IGD, failing to achieve the best result on any function, and showed limitations in both convergence and solution set distribution. Although HEMOGWO did not consistently attain the smallest standard deviation across all functions, it outperformed other algorithms in terms of average performance and result stability on most test functions. These findings verify the effectiveness of the proposed strategies in enhancing global search capability, improving solution quality, and increasing robustness.
To further evaluate the significance of performance differences between HEMOGWO and other algorithms in terms of the GD and IGD metrics, the Wilcoxon Signed-Rank Test (WSRT) [
29] was employed for statistical comparison. The WSRT results are summarized in the last row of
Table 5 and
Table 6, respectively. In these tables, “+” indicates that HEMOGWO performs significantly better than the compared algorithm, “≈” denotes no statistically significant difference, and “−” indicates inferior performance. In terms of the GD metric, the comparison between HEMOGWO and SMOGWO yielded a result of 11/4/2, indicating that although SMOGWO demonstrates some competitiveness on a few functions, HEMOGWO still outperforms it on the majority of test cases. When compared with MOGWO, HEMOGWO shows superior performance in most instances, with a notable margin of improvement. Against MOEAD_DE, HEMOGWO achieved a result of 16/0/1, reflecting its higher convergence accuracy on nearly all test functions compared to this classic differential evolution-based multi-objective algorithm. Furthermore, HEMOGWO consistently outperformed NSGA-III and MOPSO across all 17 test functions, establishing an overwhelming and absolute advantage. Regarding the IGD metric, while HEMOGWO and SMOGWO exhibited comparable performance on some functions, HEMOGWO demonstrated overall superiority in terms of solution distribution and stability. Compared with MOGWO, HEMOGWO’s advantage became more pronounced, further validating the effectiveness of the proposed improvements in search depth and diversity control over the original MOGWO. Notably, HEMOGWO achieved complete dominance when compared with NSGA-III, MOPSO, and MOEAD_DE, which strongly supports its significant advantages in achieving balanced and representative solution sets.
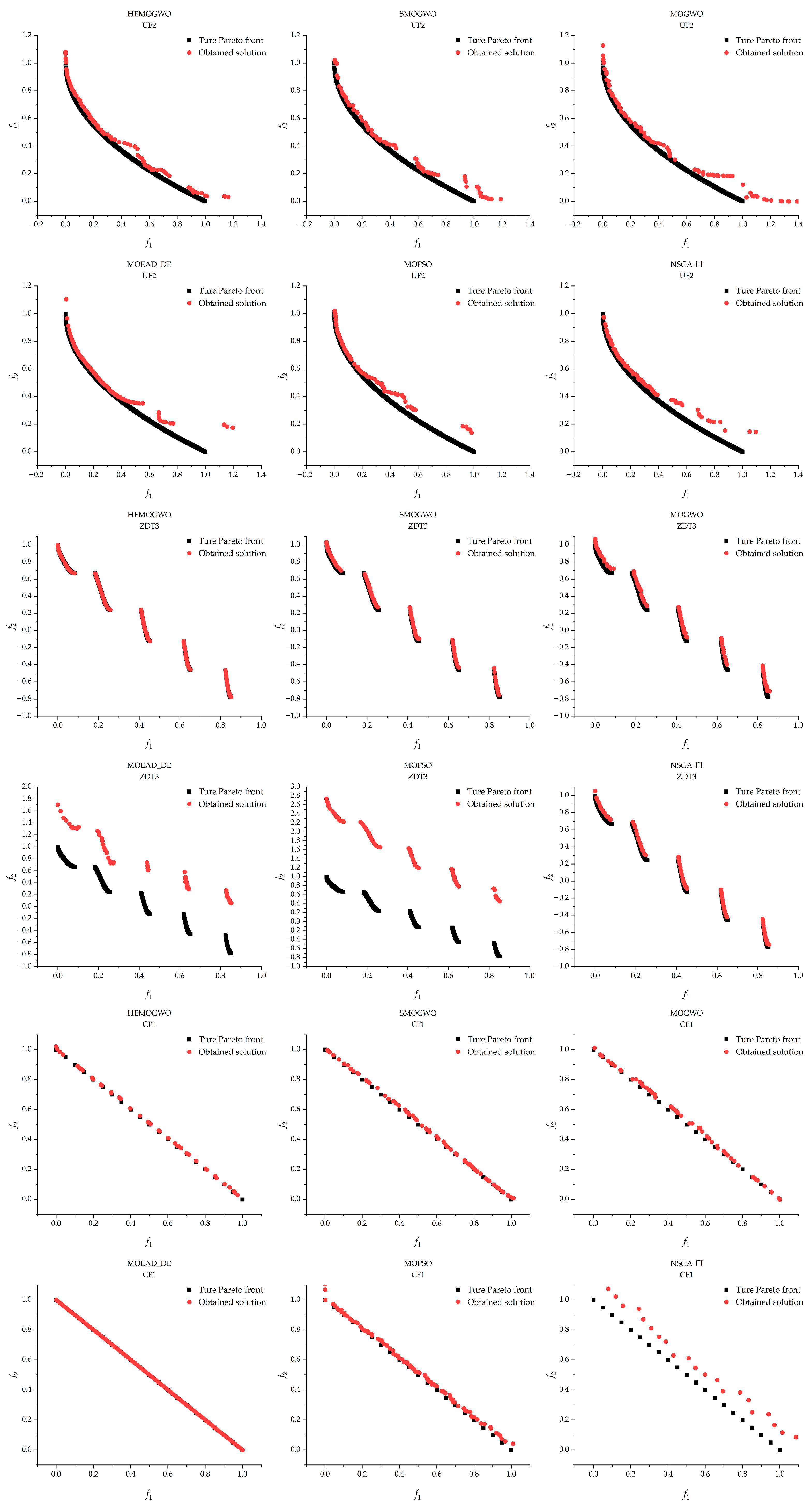
To provide a more intuitive comparison of the solution quality obtained by different algorithms,
Figure 2 illustrates the optimal solution distributions of six algorithms on three representative benchmark functions: UF2, ZDT3, and CF1. In the plots, black solid squares represent the PF
ture, while red solid circles denote the sets of optimal solutions obtained by each algorithm. The visual analysis reveals that, on the UF2 function, HEMOGWO demonstrates superior convergence and solution set coverage compared to SMOGWO and MOGWO. This is particularly evident in the latter portion of the Pareto front, where the solution distribution of HEMOGWO aligns more closely with the true Pareto-optimal front. In contrast, SMOGWO and MOGWO exhibit noticeable deviations in certain regions, and their overall solution distributions are less uniform, indicating limitations in maintaining population diversity. For the ZDT3 function, HEMOGWO achieves full coverage of the PF
true, showcasing strong global search capability and distribution control, especially when dealing with the discontinuous PF structure. While SMOGWO, MOGWO, and NSGA-III follow the general trend, they still exhibit localized deviations. In comparison, the solution sets obtained by MOEAD_DE and MOPSO significantly diverge from PF
true, reflecting poor convergence and inconsistent distribution. On the CF1 function, MOEAD_DE performs the best, with its solutions closely matching PF
true and exhibiting the most uniform distribution among all compared algorithms.
To comprehensively evaluate the overall performance of each algorithm and establish a ranking, the GD and IGD results from
Table 5 and
Table 6 were subjected to the Friedman non-parametric test [
30]. The test outcomes for both performance metrics are summarized in
Table 7. As shown, the
p-values for both GD and IGD are significantly lower than the predefined significance level of α = 0.05, indicating that the differences in performance among the five algorithms are statistically significant for both indicators. Furthermore, the rankings of the algorithms are consistent across the GD and IGD metrics, with HEMOGWO securing the first place in both cases. This demonstrates that HEMOGWO outperforms the other algorithms in terms of both convergence accuracy and solution distribution. These statistical findings are in strong agreement with the numerical results reported in
Table 5 and
Table 6.
The experimental results show that the HEMOGWO algorithm has better convergence and diversity in solving multi-objective problems, which proves the effectiveness of the improved strategy.
4.2. Case 2: The Performance of HEMOGWO on SCOS Problems
This section focuses on evaluating the performance of the proposed HEMOGWO algorithm in solving SCOS of varying scales. A real-world case from a printing equipment manufacturer in Shaanxi Province, China, serves as the application background. To advance its digital transformation, the enterprise aims to integrate five categories of core industrial software: ERP, MES, WMS, DCS, and PLM. Upon receiving the integration request, the platform decomposes it into five sub-tasks and performs service matching and composition. Assuming each sub-task has 20 candidate services, this scenario can be abstracted as a SCOS instance of scale “5-20”. Prior to computing the aggregated QoS metric, the weights for the four attributes—execution time, cost, reputation, and service quality—are uniformly set to 0.25. Parameter settings for all comparison algorithms are configured according to
Table 4.
As the number of sub-tasks n and candidate services m increases, the solution space grows exponentially, imposing significant challenges on the algorithm’s global search capability and Pareto dominance handling. To further assess the generalizability and scalability of HEMOGWO, nine SCOS problem settings of different sizes are constructed: n ∈ {5, 10, 15} and m ∈ {20, 50, 100}, forming combinations such as 5-20, 5-50, 5-100, 10-20, 10-50, 10-100, 15-20, 15-50, and 15-100.
Given that no PF
true exists for real-world industrial composition optimization problems, this study adopts a widely used heuristic approximation method from existing research. Specifically, all algorithms are independently executed 30 times on each test instance, and the resulting solution sets are combined. A global non-dominated sorting is then applied to extract the set of globally optimal solutions, which is treated as the approximate PF
true. This approach maximizes coverage of the potential solution space and is extensively applied in multi-objective optimization research [
8,
9], effectively supporting fair performance evaluation across algorithms. To further validate the quality of the constructed PF
true, the distribution of solutions in the objective space is manually examined. Additionally, the consistency of GD and IGD metrics across algorithms confirms that the approximate PFtrue is both representative and reliable for comparative analysis.
The GD and IGD metrics are again used to evaluate convergence and distribution performance. To mitigate the influence of stochastic variations, each algorithm is independently executed 30 times. The mean and standard deviation of GD and IGD values are reported in
Table 8 and
Table 9, respectively. For clarity, the best-performing values in each metric are highlighted in bold. According to the statistical results, HEMOGWO consistently outperforms the competing algorithms across various problem scales. The specific analysis is as follows.
Table 8 and
Table 9 present the GD and IGD results of all algorithms, respectively, for evaluating their overall distribution performance. The statistical results indicate that the HEMOGWO algorithm achieves the best performance in terms of the GD metric across the majority of tested problem scales. However, in certain small- to medium-scale scenarios—such as 10-20, 10-50, and 15-50—its GD mean values are higher than those of competing algorithms, and its standard deviations are also relatively larger. This suggests that, in these specific cases, HEMOGWO does not exhibit superior convergence accuracy or stability. As the problem scale increases, particularly in medium-to-large configurations like 10-100 and 15-100, HEMOGWO once again demonstrates a clear advantage, producing solution sets that more closely approximate the true Pareto front and exhibit greater consistency. In contrast, SMOGWO, MOGWO, and NSGA-III display competitive performance only under limited scales, with less consistent results overall. Regarding the IGD metric, HEMOGWO maintains a dominant position. Except for three problem scales (5-100, 10-100, and 15-50), it achieves the lowest IGD mean values in all other test scenarios. Notably, in small-scale problems such as 5-20 and 10-20, HEMOGWO significantly outperforms all baseline algorithms, highlighting its superior ability in maintaining balanced solution set distributions. Moreover, the standard deviation analysis shows that HEMOGWO generally exhibits lower variability across most problem scales, further validating its robustness and algorithmic stability. In comparison, MOPSO performs worst in terms of IGD. It frequently suffers from poor convergence and solution sets that deviate from the Pareto front, likely due to its tendency to become trapped in local optima and its limited capacity to maintain population diversity.
The WSRT results based on GD and IGD metrics indicate that HEMOGWO achieved a complete win against MOEAD_DE and MOPSO in terms of GD, demonstrating a significant advantage in the accuracy of approximating the true Pareto front. When compared with NSGA-III, HEMOGWO attained a favorable result of 8/0/1, showing only a marginal performance gap in one test scenario. Although a few ties and isolated losses were observed in comparisons with SMOGWO and MOGWO, HEMOGWO still secured six wins in both cases, indicating superior overall performance. Regarding the IGD metric, HEMOGWO also exhibited strong distribution capability. Except for one loss and two ties against SMOGWO, it achieves a decisive victory in all comparisons with MOGWO, MOEAD_DE, MOPSO, and NSGA-III, particularly securing a perfect record in the comparisons with MOEAD_DE and MOPSO.
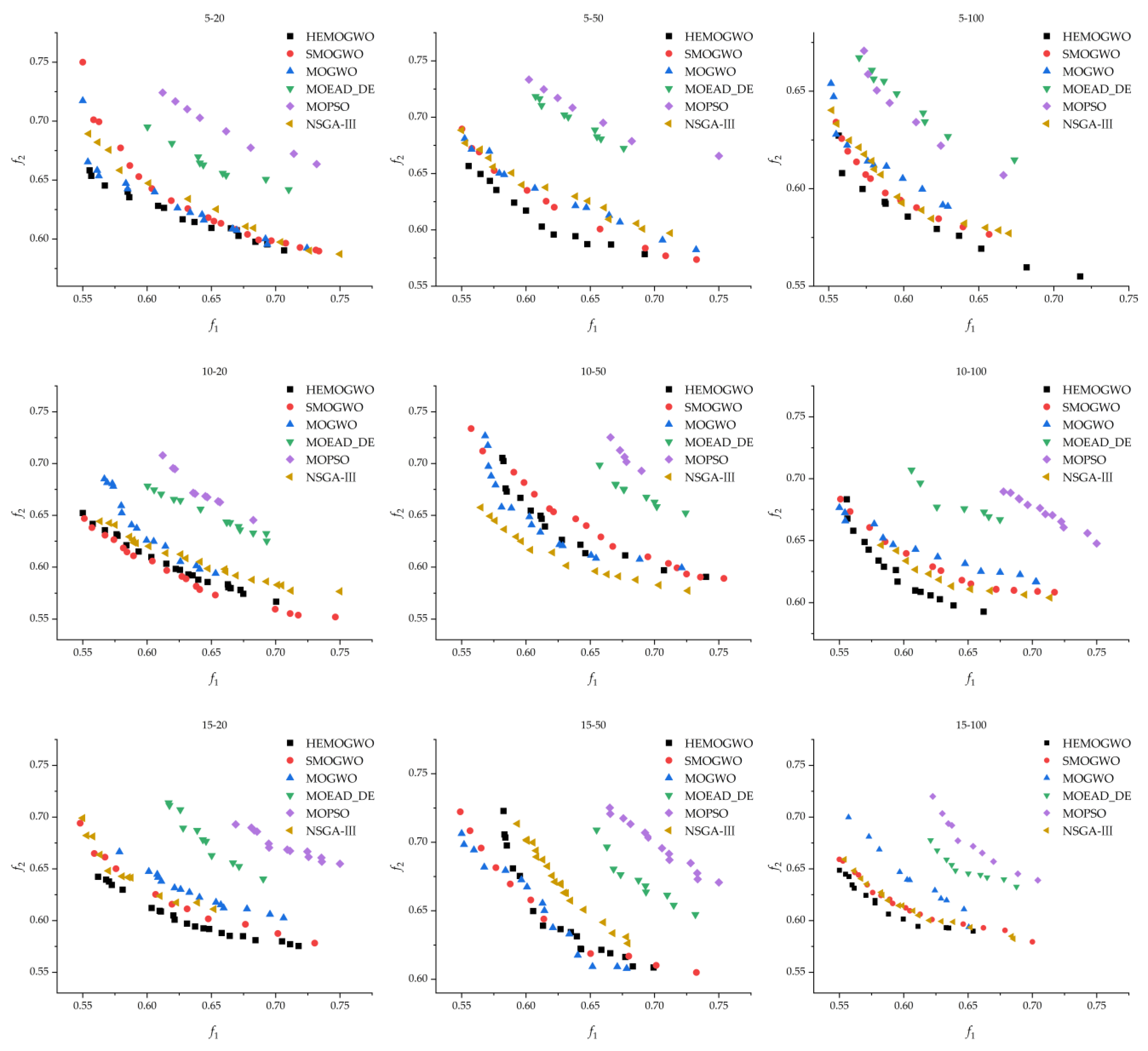
To provide an intuitive comparison of the optimization performance of each algorithm on SCOS problems,
Figure 3 shows the distribution of Pareto-optimal solutions under different problem scales after normalization. From the distribution patterns, it is evident that the optimal solutions obtained by the HEMOGWO algorithm are mainly concentrated along the outer boundary of the true Pareto front. This suggests its significant advantage in convergence, demonstrating its ability to effectively approximate the global optimal front. The results confirm HEMOGWO’s strong capability to balance solution diversity with proximity to the true Pareto front. SMOGWO and NSGA-III exhibit a nondominated solution set with a distribution pattern similar to that of HEMOGWO. The uniformity and coverage of their solutions further highlight the algorithm’s adaptability and effectiveness in solving complex SCOS scenarios. In contrast, the solution sets generated by MOPSO and MOEAD_DE show clear deviations from the true Pareto front, with this divergence becoming more pronounced as the problem scale increases.
Table 10 presents the Friedman test rankings of the compared algorithms based on the GD and IGD performance indicators. The results indicate that the HEMOGWO algorithm achieved the highest rank on both metrics, significantly outperforming the other compared algorithms. This strongly supports its superior overall performance in solving multi-objective optimization problems. SMOGWO ranked second in both GD and IGD, demonstrating its strong competitiveness in handling complex multi-objective tasks, particularly in balancing convergence and solution distribution. MOGWO ranked fourth, suggesting that while it inherits strengths from the original gray wolf optimizer, it is slightly inferior to HEMOGWO and SMOGWO in terms of convergence accuracy and solution diversity. In contrast, MOEAD_DE and MOPSO ranked fifth and sixth, respectively, reflecting clear limitations in convergence speed, solution uniformity, and proximity to the true Pareto front. Notably, the rankings across GD and IGD were highly consistent for all algorithms, further confirming the complementarity and reliability of these two metrics in evaluating multi-objective optimization performance. Finally, all
p-values from the tests were well below the 0.05 threshold, providing strong evidence of statistically significant performance differences among the algorithms.
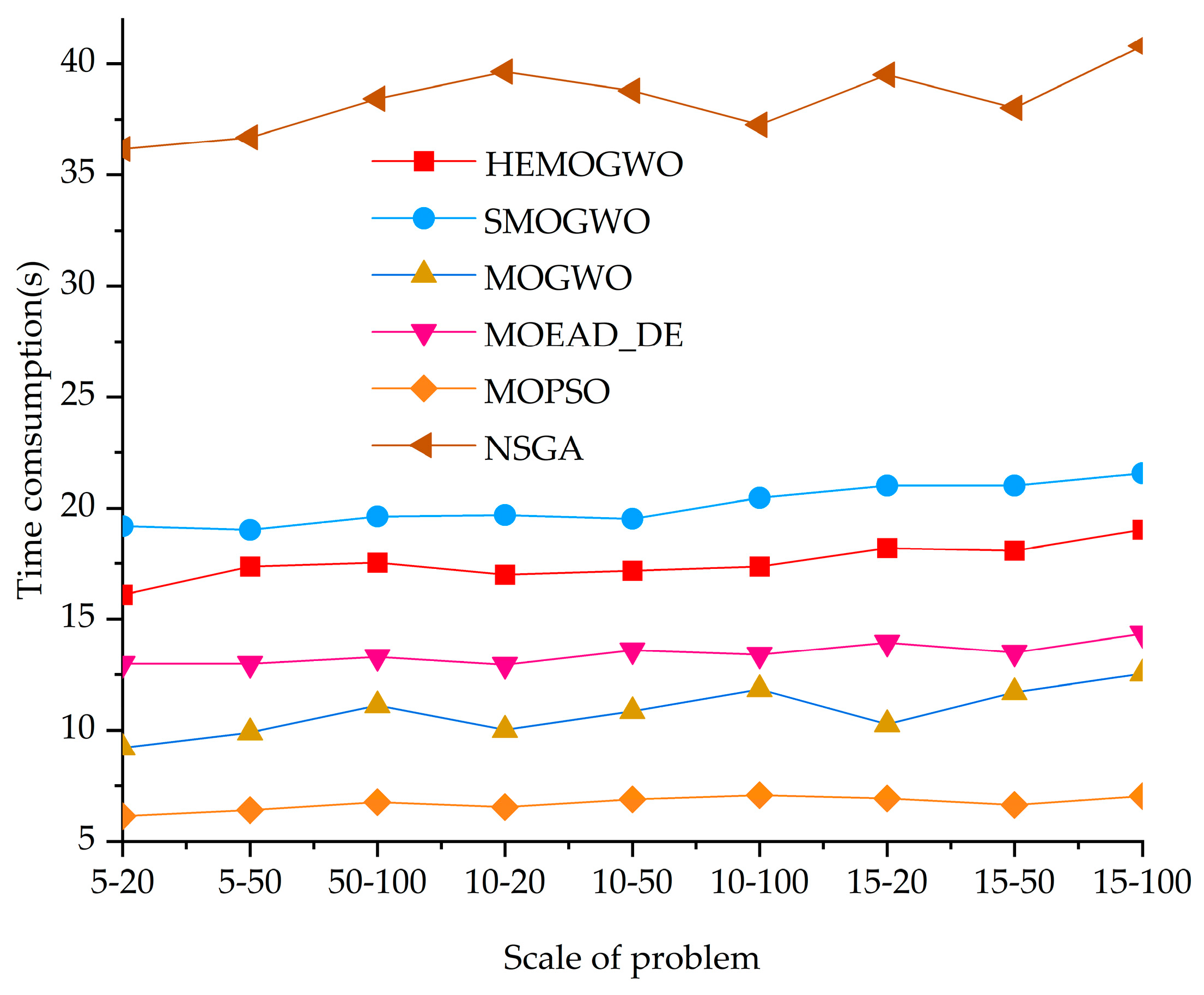
Finally, to quantitatively assess the computational cost of each algorithm across varying scales of SCOS problems, this study presents a statistical analysis of their runtime, as illustrated in
Figure 4. The experimental results show that MOPSO consistently exhibits the highest computational efficiency across all test scales, with runtimes significantly lower than those of the other algorithms. This efficiency is primarily attributed to its simple and effective particle update mechanism. MOGWO and MOEAD_DE also demonstrate slightly lower runtimes compared to HEMOGWO, indicating relatively lower computational complexity. In contrast, the HEMOGWO algorithm, due to the incorporation of a hybrid differential evolution strategy enhanced by chaotic mapping and Lévy flight mechanisms, involves a more sophisticated search process, resulting in relatively higher computational costs. However, when considered alongside the GD and IGD performance metrics, HEMOGWO clearly outperforms the other algorithms in terms of solution accuracy and stability. Although its runtime exceeds that of MOGWO, MOEAD_DE, and MOPSO, the additional computational cost remains within a reasonable and acceptable range for practical applications that demand high-quality solutions. Notably, although SMOGWO and NSGA-III exhibit performance levels close to that of HEMOGWO, their execution times are significantly longer. In particular, the average computational cost of NSGA-III is approximately three times that of HEMOGWO, which limits its applicability in resource-constrained environments.




{kind=link}
{kind=link}
{kind=link}
{kind=link}