Cascaded Dual-Inpainting Network for Scene Text

Abstract
1. Introduction
2. Related Work
2.1. Image Inpainting
2.2. Scene Text Inpainting
2.3. Scene Text Recognition
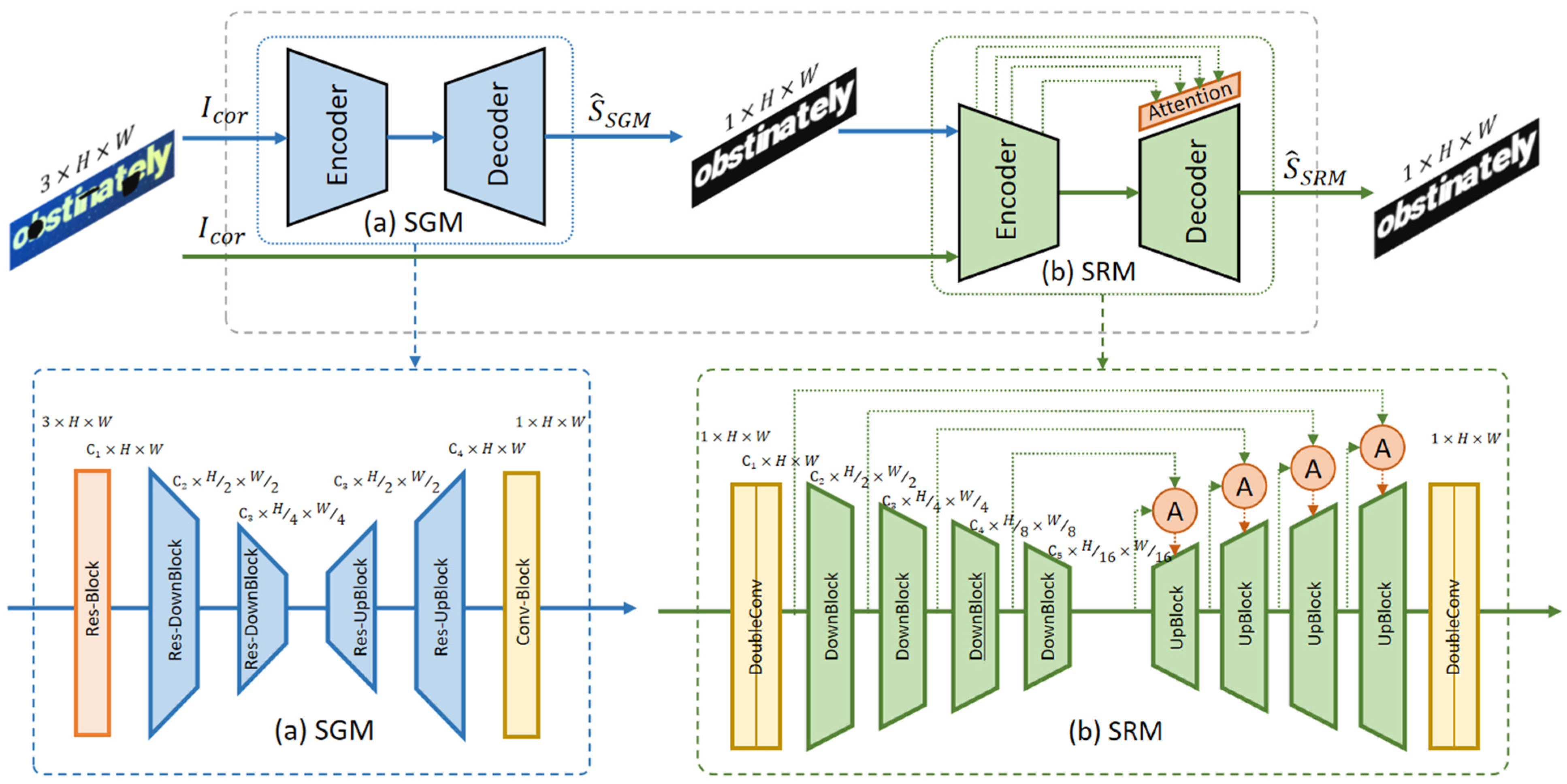
3. Methodology
3.1. Structure Generation Module (SGM)
3.2. Structure Reconstruction Module (SRM)
3.3. Training and Inference Procedure
4. Experiments and Discussion
4.1. Datasets and Evaluation Metrics
4.2. Comparison with State-of-the-Art Approaches
4.3. Ablation Experiments
4.4. Experiments on Real-World Scene Text Images
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Liu, H.; Jiang, B.; Xiao, Y.; Yang, C. Coherent semantic attention for image inpainting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4170–4179. [Google Scholar]
- Guo, Z.; Chen, Z.; Yu, T.; Chen, J.; Liu, S. Progressive image inpainting with full-resolution residual network. In Proceedings of the 27th Acm International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2496–2504. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Yan, Z.; Li, X.; Li, M.; Zuo, W.; Shan, S. Shift-net: Image inpainting via deep feature rearrangement. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 1–17. [Google Scholar]
- Liu, G.; Reda, F.A.; Shih, K.J.; Wang, T.C.; Tao, A.; Catanzaro, B. Image inpainting for irregular holes using partial convolutions. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 85–100. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Free-form image inpainting with gated convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4471–4480. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial nets. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and locally consistent image completion. ACM Trans. Graph. (ToG) 2017, 36, 1–14. [Google Scholar] [CrossRef]
- Zeng, Y.; Lin, Z.; Lu, H.; Patel, V.M. Cr-fill: Generative image inpainting with auxiliary contextual reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 14164–14173. [Google Scholar]
- Yu, Y.; Zhan, F.; Lu, S.; Pan, J.; Ma, F.; Xie, X.; Miao, C. Wavefill: A wavelet-based generation network for image inpainting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 14114–14123. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. In Proceedings of the International Conference on Machine Learning, New York City, NY, USA, 19–24 June 2016; pp. 1060–1069. [Google Scholar]
- Zhang, L.; Chen, Q.; Hu, B.; Jiang, S. Text-guided neural image inpainting. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1302–1310. [Google Scholar]
- Wu, X.; Xie, Y.; Zeng, J.; Yang, Z.; Yu, Y.; Li, Q.; Liu, W. Adversarial learning with mask reconstruction for text-guided image inpainting. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 3464–3472. [Google Scholar]
- Li, A.; Zhao, L.; Zuo, Z.; Wang, Z.; Xing, W.; Lu, D. MIGT: Multi-modal image inpainting guided with text. Neurocomputing 2023, 520, 376–385. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Nichol, A.Q.; Dhariwal, P. Improved denoising diffusion probabilistic models. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 18–24 July2021; pp. 8162–8171. [Google Scholar]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.L.; Ghasemipour, K.; Lopes, R.G.; Ayan, B.K.; Salimans, T.; et al. Photorealistic text-to-image diffusion models with deep language understanding. Adv. Neural Inf. Process. Syst. 2022, 35, 36479–36494. [Google Scholar]
- Wang, S.; Saharia, C.; Montgomery, C.; Pont-Tuset, J.; Noy, S.; Pellegrini, S.; Chan, W. Imagen editor and editbench: Advancing and evaluating text-guided image inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 18359–18369. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Manukyan, H.; Sargsyan, A.; Atanyan, B.; Wang, Z.; Navasardyan, S.; Shi, H. HD-Painter: High-resolution and prompt-faithful text-guided image inpainting with diffusion models. arXiv 2023, arXiv:2312.14091. [Google Scholar]
- Xie, S.; Zhang, Z.; Lin, Z.; Hinz, T.; Zhang, K. Smartbrush: Text and shape guided object inpainting with diffusion model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 22428–22437. [Google Scholar]
- Lugmayr, A.; Danelljan, M.; Romero, A.; Yu, F.; Timofte, R.; Van Gool, L. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11461–11471. [Google Scholar]
- Mokady, R.; Hertz, A.; Aberman, K.; Pritch, Y.; Cohen-Or, D. Null-text inversion for editing real images using guided diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 6038–6047. [Google Scholar]
- Ko, K.; Kim, C.S. Continuously masked transformer for image inpainting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 13169–13178. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Jeevan, P.; Kumar, D.S.; Sethi, A. WavePaint: Resource-Efficient Token-Mixer for Self-Supervised Inpainting. arXiv 2023, arXiv:2307.00407. [Google Scholar]
- Xue, F.; Zhang, J.; Sun, J.; Yin, J.; Zou, L.; Li, J. INIT: Inpainting Network for Incomplete Text. In Proceedings of the 2022 IEEE International Symposium on Circuits and Systems (ISCAS2022), Austin, TX, USA, 27 May–1 June 2022. [Google Scholar]
- Sun, J.; Xue, F.; Li, J.; Zhu, L.; Zhang, H.; Zhang, J. TSINIT: A Two-stage Inpainting Network for Incomplete Network. IEEE Trans. Multim. 2023, 25, 5166–5177. [Google Scholar] [CrossRef]
- Zhu, S.; Fang, P.; Zhu, C.; Zhao, Z.; Xu, Q.; Xue, H. Text image inpainting via global structure-guided diffusion models. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 7775–7783. [Google Scholar]
- Chen, S.-X.; Zhu, S.-Y.; Xiong, H.-L.; Zhao, F.-J.; Wang, D.-W.; Liu, Y. A Method of Inpainting Ancient Yi Characters Based on Dual Discriminator Generative Adversarial Networks. Acta Autom. 2022, 48, 12. [Google Scholar]
- Fang, S.; Xie, H.; Wang, Y.; Mao, Z.; Zhang, Y. Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 7094–7103. [Google Scholar]
- Shi, B.; Yang, M.; Wang, X.; Lyu, P.; Yao, C.; Bai, X. Aster: An attentional scene text recognizer with flexible rectification. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2035–2048. [Google Scholar] [CrossRef] [PubMed]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed]
- Yue, X.; Kuang, Z.; Lin, C.; Sun, H.; Zhang, W. RobustScanner: Dynamically Enhancing Positional Clues for Robust Text Recognition. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Li, H.; Wang, P.; Shen, C.; Zhang, G. Show, Attend and Read: A simple and strong baseline for irregular text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8610–8617. [Google Scholar]
- Du, Y.; Chen, Z.; Jia, C.; Yin, X.; Zheng, T.; Li, C.; Du, Y.; Jiang, Y.-G. SVTR: Scene Text Recognition with a Single Visual Model. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence(IJCAI-22), Vienna, Austria, 23–29 July 2022; pp. 884–890. [Google Scholar]
- Oktay, O.; Schlemper, J.; Le Folgoc, L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Wang, Y.; Chen, Y.; Tao, X.; Jia, J. VCNet: A Robust Approach to Blind Image Inpainting. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 752–768. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A neural algorithm of artistic style. J. Vis. 2016, 16, 326. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | GT Structure | CorImg | TSINIT | GSDM-SPM | CDINST |
|---|---|---|---|---|---|
| CRNN [34] | 95.83 | 5.74 | 45.84 | 49.14 | 62.12 |
| ASTER [33] | 96.98 | 10.18 | 62.12 | 62.12 | 65.40 |
| ABINET [32] | 97.23 | 21.40 | 61.20 | 63.89 | 71.73 |
| Robust-Scanner [35] | 97.77 | 16.13 | 50.05 | 53.62 | 64.62 |
| SAR [36] | 97.83 | 15.57 | 49.96 | 53.25 | 64.34 |
| SVTR [37] | 98.16 | 23.39 | 55.29 | 60.26 | 67.74 |
| PSNR | - | - | 14.14 | 18.75 | 16.52 |
| SSIM | - | - | 0.7294 | 0.8086 | 0.8432 |
| Metrics | GT Structure | CorImg | TSINIT | GSDM-SPM | CDINST |
|---|---|---|---|---|---|
| CRNN [34] | 99.43 | 60.30 | 84.58 | 86.31 | 90.59 |
| ASTER [33] | 99.44 | 56.46 | 83.64 | 85.90 | 90.57 |
| ABINET [32] | 99.56 | 73.10 | 88.63 | 89.77 | 92.40 |
| Robust-Scanner [35] | 99.64 | 68.07 | 84.06 | 86.10 | 90.72 |
| SAR [36] | 99.68 | 65.95 | 83.03 | 85.20 | 90.45 |
| SVTR [37] | 99.75 | 73.88 | 88.25 | 90.43 | 91.95 |
| Metrics | GT Structure | CorImg | TSINIT | GSDM-SPM | CDINST |
|---|---|---|---|---|---|
| CRNN [34] | 99.46 | 41.99 | 86.31 | 85.00 | 90.52 |
| ASTER [33] | 99.32 | 42.41 | 85.90 | 85.46 | 90.73 |
| ABINET [32] | 99.49 | 55.64 | 88.68 | 87.83 | 91.95 |
| Robust-Scanner [35] | 99.52 | 57.26 | 86.10 | 85.66 | 90.60 |
| SAR [36] | 99.54 | 55.74 | 85.20 | 85.22 | 90.42 |
| SVTR [37] | 99.61 | 58.08 | 90.43 | 87.93 | 91.66 |
| + | Accuracy | PSNR | SSIM | ||
|---|---|---|---|---|---|
| ✓ | 61.00 | 16.28 | 0.8393 | ||
| ✓ | ✓ | 60.80 | 16.01 | 0.8289 | |
| ✓ | ✓ | 59.56 | 16.43 | 0.8414 | |
| ✓ | ✓ | ✓ | 62.12 | 16.52 | 0.8432 |
| Model | Accuracy | PSNR | SSIM |
|---|---|---|---|
| SGM | 43.31 | 12.74 | 0.6650 |
| SRM | 60.66 | 16.39 | 0.8388 |
| CDINST | 62.12 | 16.52 | 0.8432 |
| Model | Parameter Count | GFLOPs | Inference Time |
|---|---|---|---|
| SGM | 1.85 M | 15.06 GFlops | 0.001 s |
| SRM | 15.14 M | 16.25 GFlops | 0.004 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C. Cascaded Dual-Inpainting Network for Scene Text. Appl. Sci. 2025, 15, 7742. https://doi.org/10.3390/app15147742
Liu C. Cascaded Dual-Inpainting Network for Scene Text. Applied Sciences. 2025; 15(14):7742. https://doi.org/10.3390/app15147742
Chicago/Turabian StyleLiu, Chunmei. 2025. "Cascaded Dual-Inpainting Network for Scene Text" Applied Sciences 15, no. 14: 7742. https://doi.org/10.3390/app15147742
APA StyleLiu, C. (2025). Cascaded Dual-Inpainting Network for Scene Text. Applied Sciences, 15(14), 7742. https://doi.org/10.3390/app15147742