1. Introduction
It is common for artists to be influenced by the greats of their time, and imitate their work and style in their early years. After all, as Oscar Wilde said, “imitation is the sincerest form of flattery” [
1]. However, when imitation is of a certain form or reaches a certain level, it may become copyright infringement and plagiarism. In recent years, music generated by generative artificial intelligence (AI) models gained much attention, with a swirl of excitement, suspicion, and fear. There are ongoing efforts to develop a copyright and AI framework that rewards human creativity (e.g., [
2]).
Existing technical methods for detecting similarity patterns in music can broadly be categorized into two groups:
context-based and
content-based. Context-based methods use contextual metadata, an umbrella term for musical information such as user ratings, radio and user playlists that the songs are a part of, and the lyrics and collaborative tags made by users on music websites [
3]. Meanwhile, content-based methods extract music features from audio files, such as melodic structure, among many others.
Contextual methods perform well in music recommendation systems and music clustering based on similarity. For example, Schedl et al. [
4] investigated the similarity between a wide array of artist’s music and developed a recommendation strategy using text-based metadata. Karydis et al. [
5] compared user-assigned tags and features extracted from audio signal and showed that the former was outperformed by the latter in classifying the genre of musical pieces. Spärck Jones [
6] proposed a weighting system for moderating the association between tags and songs in retrieval, which was utilized in the term frequency-inverse document frequency (TFIDF) metric. According to Beel et al. [
7], 83% of text-based recommendation systems currently implement TFIDF.
Content-based methods exploit stored music pieces (audio or MIDI) in various ways, using
text-based and
audio-based approaches. Text-based approaches focus on textual representations where each music piece is an array of symbols encoding the relative locations of musical notes chronologically. With textual representations, some researchers have applied commonly used similarity metrics, such as cosine similarity or Euclidean distance, in the literature (e.g., [
8,
9]). Others developed their own music similarity metrics, e.g., fuzzy vectorial-based similarity [
9]. Text-based methods have been used to detect melodic plagiarism. However, an unsettled question is whether melodic similarity is the only factor of music plagiarism.
Audio-based approaches rely on features extracted from music files and analyze music pieces in their feature vectors. Typically, music signals contained in audio files are processed via variations of Fourier and wavelet transforms. Li and Ogihara [
10] used spectral features to find similar songs and detect emotion in music. Nguyen et al. [
11] used melodies extracted from MIDI files to cluster similar songs, in conjunction with the K-nearest neighbors (kNN) and support vector machine (SVM) methods. In essence, this is similar to a text-based approach. Nair [
12] evaluated the performance of several machine learning (ML) techniques for detecting music plagiarism, including logistic regression, naive Bayes, and random forest, among others. Karydis et al. [
5] applied neural networks to spectral features. As there are numerous ways for specifying a feature in music, many features, which may be known or unknown currently, may potentially be used to characterize music plagiarism. It will be a long-term endeavor for researchers to find the most effective feature specifications (in a vast feature space) for detecting music plagiarism.
While there is a need to improve the legal definition as to how musical plagiarism is defined for a specific type and level of musical similarity, it is desirable for us to make technical progress that can provide analytical tools to assist in legal processes. While there is little doubt that we need to develop advanced AI technology for detecting music plagiarism, it is necessary for us to address a number of technical challenges, including the following:
- C1.
As mentioned above, apart from melodic features, there is a vast feature space for us to explore in order to identify other features or combinations of features that can help detect music plagiarism.
- C2.
There is an insufficient amount of legally verified data on music plagiarism for training ML models to detect music plagiarism or to identify or formulate useful feature specifications in detecting music plagiarism.
- C3.
Music plagiarism is a serious allegation, and any ML model designed for suggesting such an allegation has to be treated with caution. How to interpret and explain ML predictions is a generally challenging topic commonly referred to as explainable AI.
In this paper, we present a study on developing ML models to detect music similarity patterns. We addressed the first challenge, C1, by analyzing and visualizing different features in terms of their similarity and dissimilarity in a number of known cases where the level of music similarity is relatively certain. This allowed us to focus our data collection and model development efforts on these indicative features. Meanwhile, we developed different sub-models for different features and trained an ensemble model to integrate these sub-models to make decisions collectively, avoiding over-reliance on a single feature.
To address the second challenge, C2, we created a dataset for the training and validation of ML models, while keeping the data of known cases for independent testing outside the development workflow. Inspired by feature-based analysis and visualization in addressing C1, we proposed a novel method for training ML models to detecting music similarity based on comparative imagery. Information-theoretical analysis indicates that the space of such comparative imagery has much lower entropy than the space of the original music signal data for creating the imagery, suggesting that training ML models requires less data in the former than the latter.
Data visualization has played an indispensable role in explainable AI, the comparative imagery used for testing an ML model provided an effective means for humans to scrutinize and interpret the judgment of the ML model, hence enhancing the explainability of the ML model. In particular, when we applied the trained ML model to a collection of AI-generated music, we were often not sure about the correctness of the similarity patterns detected by the model. By visualizing the comparative images for individual features, we were able to reason how the model made its decision.
In summary, the contributions of this work include the following:
A broad analysis of the relationship between music feature similarity and music similarity in the context of copyright infringement and plagiarism [addressing C1].
A novel method for using comparative imagery as intermediate data to train ML models to detect music similarity, while improving the interpretability of model predictions [addressing C2 and C3].
An ensemble approach to develop an ML model for music similarity detection, which enables a long-term modular approach for results analysis, performance monitoring, and improvement of sub-models [addressing C2].
A set of experiments where the ensemble model is applied to different testing data, including independent data differing significantly from the training data, known plagiarism data, and a collection of AI-generated music, demonstrating the feasibility and merits of the proposed method [addressing C1, C2, and C3].
In the remainder of this paper, we first describe the technical methods used in different parts of this work in
Section 2. This is followed by
Section 3, where we report the analytical results of different features in terms of their potential relevance to music plagiarism, and
Section 4, where we report our development of ML models and our experimental results. In
Section 5, we provide our concluding remarks and suggestions for future work.
2. Methods
In this section, we first describe the theoretical reasoning behind our approach, then present the four main methods used in this work, and finally outline our system architecture for enabling the development of machine learning (ML) models for music similarity detection and the deployment of these models in an ensemble manner.
2.1. Information-Theoretical Reasoning
In information theory, a function or a process is referred to as a transformation, which we denote as
P here. The set of all possible data that
P can receive is referred to as an input alphabet and the set of all possible data that
P can produce is an output alphabet. As illustrated in
Figure 1a, the two alphabets are denoted as
and
, respectively. When a machine learning (ML) model is used to determine whether two pieces of music are similar,
P is the model,
consists of all possible pairs of music to be compared, and
consists of all possible decisions that the model may produce. Typically, a model may return a similarity judgment in two or a few levels. Hence, the entropy of the output alphabet,
, is no more than 3 bits for eight or fewer levels. Meanwhile, the informative space for all possible pairs of music is huge, and the entropy of the input alphabet,
, is very high. Hence,
and the model incurs a huge entropy loss. As Chen and Golan observed, such entropy loss is ubiquitous in most (if not all) decision workflows [
13]. If the entropy reduction (measured as alphabet compression) is too much and too fast by an unreliable transformation, decision errors are more likely (measured as potential distortion) [
13].
In practice, a common approach to address the high level of decision errors is to decompose a complex transformation
P into a series of less complex transformations,
, where entropy is reduced gradually as illustrated in
Figure 1b. For some intermediate transformations, humans can inject more knowledge in developing better algorithms, models, software, etc. For some intermediate alphabets, humans can visualize and interpret intermediate data, gaining confidence about the workflow. In essence, explainable AI is facilitated by such workflow decomposition.
Figure 1a can also represent an ML workflow, where
consists of all possible models that may be learned using the training and testing process
P. The initial search space for the optimal model in
is huge (i.e., it has very high initial entropy), but the process
P uses the input data (or its statistics) as constraints to narrow down the search space iteratively, and in effect, change its probability of each model in the space so as to be found as the optimal model. The change in the probabilities in the search space reduces the entropy of
. When the input data are scarce,
P does not have reliable statistics or invoke a sufficient number of iterations to change the probability of each model in the space appropriately, resulting in an unreliable model being found at the end of the process.
As discussed in
Section 1, for music similarity detection, data scarcity is a major challenge. Therefore, instead of training a complex model that detects similarity directly from music signals, we adopted the common approach to reduce entropy gradually by decomposing both the model development and model deployment workflows as shown in
Figure 1c. For example, transforming music pieces into fixed-length segments facilitates entropy reduction for both new music and known music, i.e.,
Meanwhile, human knowledge can help address data scarcity in ML workflows [
14]. Tam et al. [
15] estimated the amount of extra information provided by ML developers in two case studies. In this work, we make use of feature extraction algorithms as a form of human knowledge, and these algorithms are essentially transformations facilitating entropy reduction from inputs to outputs. We also employ similarity visualization to enable the involvement of humans in interpreting the predictions made by ML models. This is a way of using human knowledge to reduce uncertainty during model development as well as deployment. In the following four subsections, we will describe four methods used in the workflow as shown in
Figure 1c to show how they facilitate entropy reduction further.
2.2. Method 1: Feature-Based Analysis
Feature-based analysis has been widely used in signal processing in general and music analysis in particular. Transforming signal representations of music segments to their feature representations facilitates entropy reduction, and in the context of
Figure 1c, we have
There are numerous feature specifications for music in the literature. Many specifications have different variants controlled by parameters. It is not difficult to anticipate that some features are more relevant to music similarity detection than others. For example, one may reasonably assume that similarity detection should not influenced by a feature representing the loudness of the notes or a feature indicating the instrument used in playing a musical piece. Nevertheless, for many features, there is no previous report about whether they are relevant to music similarity detection.
Therefore, it is necessary to conduct experiments to discover such relevance. For the experimentation in this work, we selected a total of 33 features, including 7
melodic features, 8
pitch statistics features, 7
chord and vertical interval features, 7
rhythm- and beat-related features, and 4
texture features. The descriptions of these features are given in
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5. They were implemented using the jSymbolic 2.2 API. In
Section 3, we present and analyze the results of our experimentation on these features.
2.3. Method 2: Similarity Visualization
Data visualization has been used in text similarity detection (e.g., [
17]) as well as in developing ML models for music applications (e.g., [
18]). Data visualization played three roles in this work. Firstly, visualization allowed us to observe how much a feature may be relevant to music similarity detection and prioritize computational resources for harvesting training and testing data for developing ML models. In
Section 3, we present and analyze the results of our experimentation on features with the aid of such visualization.
Secondly, the comparative imagery used to depict feature similarity was used for training and testing ML models. We will describe this in detail in the next subsection.
Thirdly, whenever an ML model or an ensemble decision process produced a decision, we found it useful to use visualization to help interpret the decision. In some cases, visualization helped us to identify possible causes of erroneous decisions, and in many cases, visualization enabled us to explain why the decision was reached, gaining confidence about the validity of the workflow.
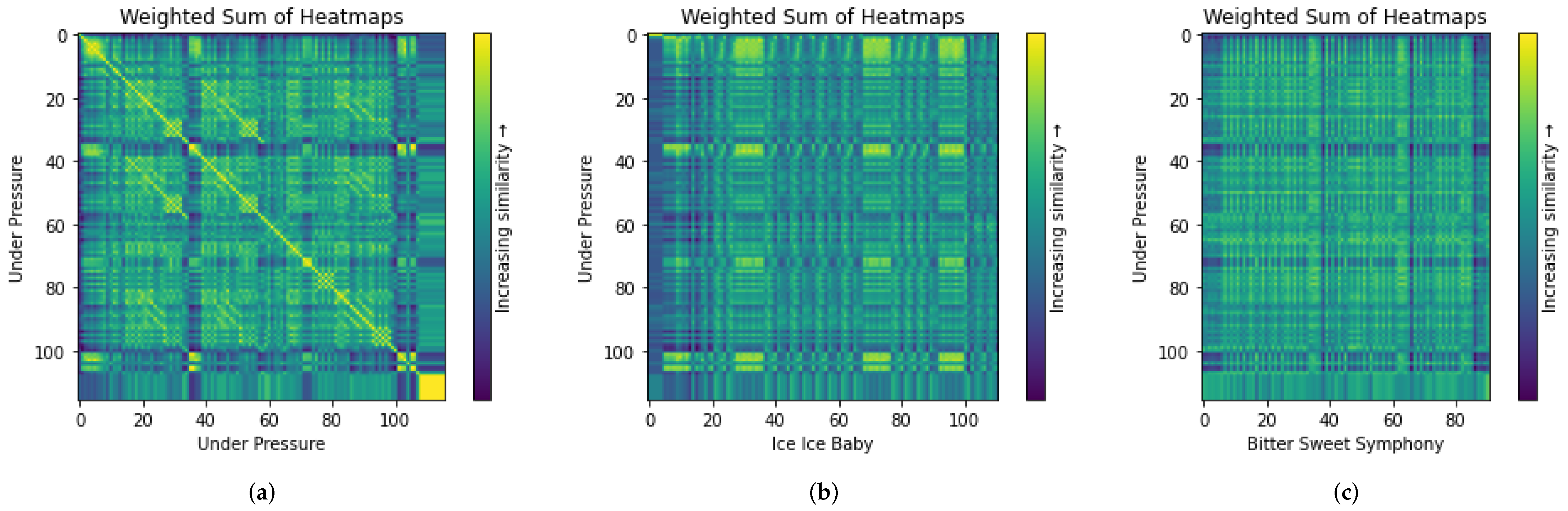
Figure 2 shows three heatmap visualizations, where the
x and
y axes correspond to the temporal sequences of two songs, respectively. In this work, we compare two music pieces in the unit of a bar. The three songs have 116 (Under Pressure), 113 (Ice Ice Baby), and 91 (Bitter Sweet Symphony) bars, respectively. The color of each cell indicates the level of similarity between the
x-th bar of one song and the
y-th bar of the other. The computed similarity level is in the range of [0, 1], and it is encoded using a continuous colormap, with a bright yellow color (RGB: 253, 231, 37) for 1 and dark purple (RGB: 68, 1, 84) for 0. The in-between colors are linearly interpolated. As shown in the legend on the right, bright yellow or green colors indicate high similarity while dark purple or blue indicate dissimilarity. In
Figure 2a, we can easily observe the strong self-similarity along the diagonal line when the song “Under Pressure ⯈” by Queen and David Bowie (
https://github.com/asaner7/imagery-music-similarity/blob/main/songs-in-paper/UnderPressure_mp3.mp3, accessed on 30 May 2025) is compared with itself. Meanwhile, we can also observe smaller similarity patterns in other temporal regions.
These heatmaps were produced in the ensemble decision process (see
Section 2.5). The individual feature heatmaps were combined based on their ensemble weights.
2.4. Method 3: Image-Based Machine Learning
Following our experimentation on the 33 features (see
Section 3), we selected a subset of
K features and prioritized our data collection and model development effort for these features. Currently, there are
features in this subset, which can easily be extended in the future.
Dataset Creation. As described in
Section 2.3, the data visualization method inspired us to develop ML models that can perform similarity detection tasks through “viewing” such heatmap images created for individual features. Note that it is not necessary for ML models to view the blue–yellow color-coded images as shown in
Section 2.3. Although heatmaps are shown as color-coded images in this paper, in the context of ML models, they are stored as numerical matrices (32-bit float per cell) without any color information.
Because of the shortage of music similarity data that are legally validated, we intentionally kept such treasured authentic data out of the dataset for training and validation, and used them for independent testing only. As part of this work, we created a training and validation dataset using traditional songs that are copyright-free. Furthermore, we selected those songs, for which it was feasible to create their variants with available expertise and resources, and the similarity labeling was fairly certain when comparing songs and variants in the collection. For the work reported in this paper, , and we are adding more songs into the corpus for future work. The six songs are Bella Ciao, Twinkle Twinkle Little Star, Row Row Row Your Boat, Ode to Joy, Happy Birthday, and Jingle Bells, which are considered to be dissimilar.
For every song in the corpus, we created some variations by using methods such as
transpose,
ornaments added,
chord altered, and
swing genre. With these variations, we expanded the song corpus from six to
music pieces. Each original song and its variations forms a song group, and any comparison between any two music pieces in the group is considered to be
similar, while any comparison between two music pieces selected from two different song groups is considered to be
dissimilar. These six songs and their variants are part of the dataset available on GitHub (
https://github.com/asaner7/imagery-music-similarity, accessed on 30 May 2025).
For each feature
f, we use the feature-based analysis and visualization methods described in
Section 2.2 and
Section 2.3 to compare every pair of music pieces in the corpus, yielding
heatmaps. Note that these heatmaps include self-comparison heatmaps as well as both orderings of every pair of music pieces (i.e., A-B and B-A). The former feature essential patterns that an ML model is expected to recognize. The latter feature diagonally mirrored patterns that an ML model can benefit from being trained and validation-tested with both.
These heatmaps are split into training and validation datasets at a ratio of 80%:20%. In order to balance the positively and negatively labeled data objects, we used a weighted random sampler with weights inversely proportional to the probabilities of class labels.
Training and Validation. With the comparative imagery as input data, we utilized convolutional neural networks (CNNs) [
19] as the technical method for training music similarity detection models. The overall model structure is an ensemble of
K CNN sub-models, each of which was trained to specialize on one of the
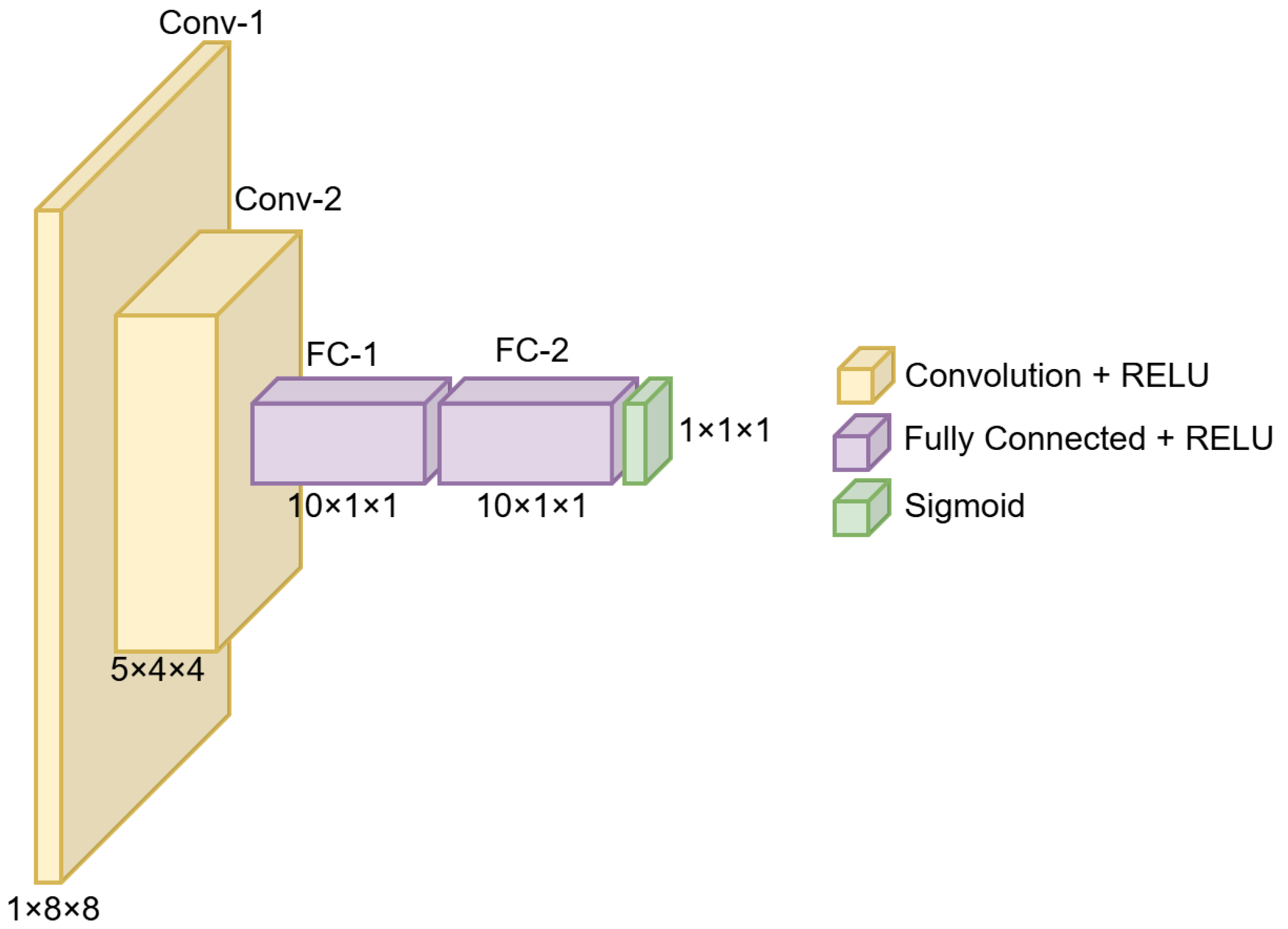
K selected features. These CNN sub-models shared the same structure as illustrated in
Figure 3. All layers including the fully connected layers were implemented as convolutional layers. For every layer, the ReLU activation [
20] function was utilized. After using the CNN, the output was passed through a sigmoid function to convert the result into a probability of similarity. Although the network was trained with heatmaps of size
, it can be used to process heatmaps of size greater than
by acting as a sliding window over a larger heatmap.
Each CNN sub-model was trained independently in order to achieve the best performance for each feature. The hyperparameters considered in the training and validation were learning rate (LR), epochs, and distance metric. To find the optimal values for these parameters and to choose the appropriate distance metric among the ones given in
Table 6, we conducted experiments, where each distance metric was tested with a range of suitable values for different parameters. For the training, BCE (binary cross entropy) loss was used with a momentum of 0.9 and a learning rate scheduler with an exponential decay of 0.9 per each epoch. In
Section 4, we report our experimental results in relation to hyperparameters and distance metrics.
2.5. Method 4: Ensemble Decision Process
Our early experimentation of the
sub-models indicated that they have different strengths and weaknesses. This naturally led to the ensemble approach to enable these sub-models to make similarity decisions collectively. Instead of simple voting or averaging, a Bayesian interpretation was adopted by viewing ensembling as marginalization over sub-models, giving the ensemble prediction
where
c is a prediction (i.e., one of the two class labels “similar” and “dissimilar”),
d is a data object in a dataset
D,
is the probability for a data object
d to result in a prediction
c,
is a sub-model for feature
f, and
is the probability for a sub-model
to make a prediction
c based on input data object
d. The probability
is moderated by
, that is, a prior distribution over all feature-based sub-models. Arguably, the most appropriate distribution over models is the posterior with respect to the training data [
22]. We can thus obtain
as ensemble weights inductively through the training process:
where each sub-model
is assigned a weight according to its likelihood to make a correct prediction in relation to the other sub-models. The weight
can be derived from the training loss. The fraction on the right expresses the relation between a sub-model
and other sub-models. The log-likelihood function,
is typically moderated by a factor
. We applied a heuristic (strongly related to shrinkage) to encourage shrinkage towards uniform weights to maximize the ensemble benefit and prevent a single model from dominating the resulting heatmap. Through our experimentation, we determined
empirically. We will report the training results about the weights further in
Section 4.
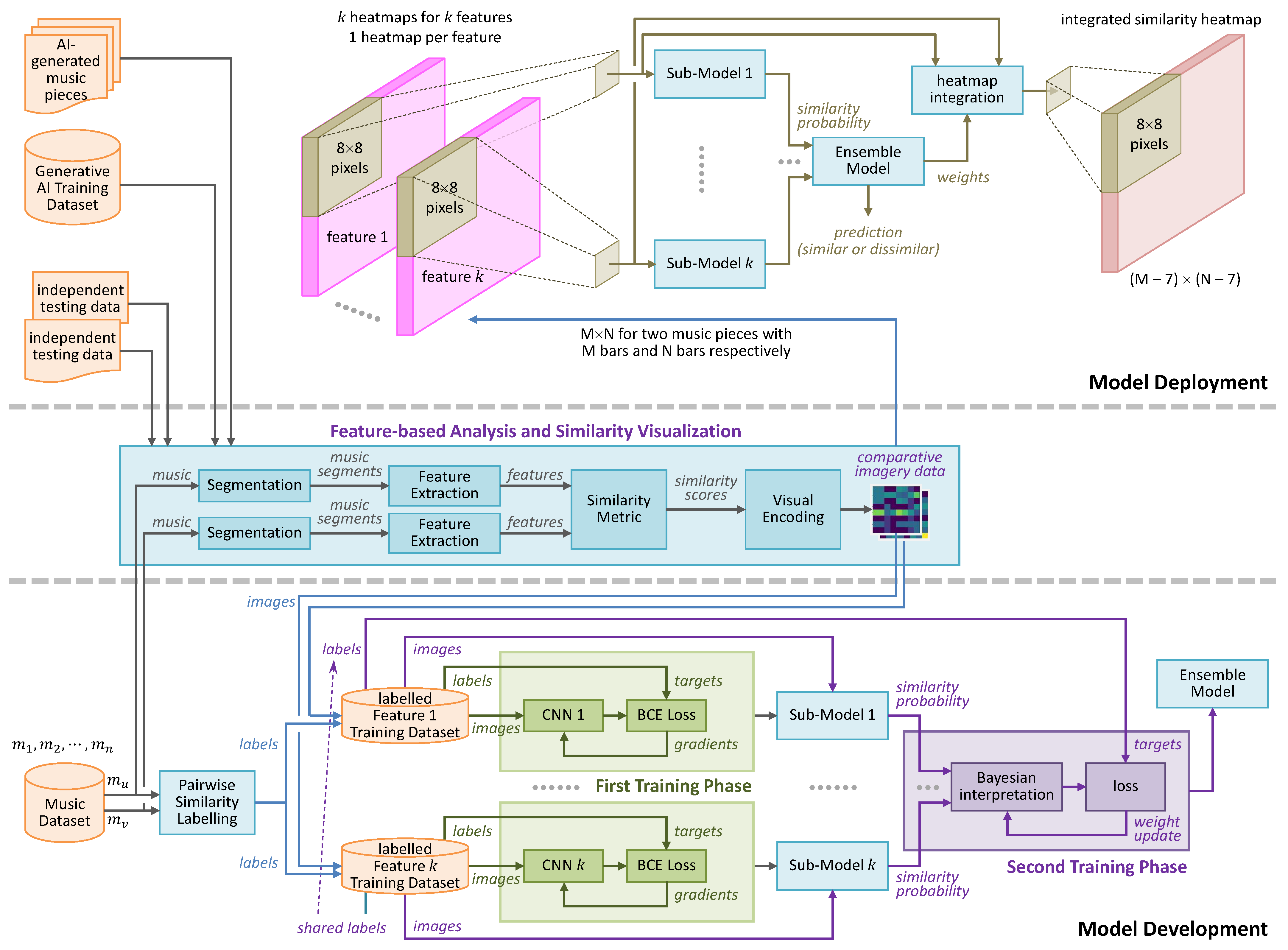
2.6. System Architecture
Figure 4 outlines the overall architecture of the technical environment that was used to conduct this research. In particular, the lower part of the figure shows the part of the environment for the training and validation of feature-based sub-models and the ensemble model. The upper part of the figure shows the part of the environment designed for deploying the trained model to test AI-generated music pieces, which were not used in the development phase. In
Section 4, we report the results of testing these AI-generated music pieces, confirming that the ensemble model trained in the development phase can positively detect similarity in AI music pieces.
The middle part of the figure shows the technical components for feature-based analysis and heatmap generation, which support both the model development and deployment phases while allowing humans to visualize intermediate results.
3. Experimental Results: Validating the Framework
In this section, we report the results obtained from applying feature-based analysis and visualization methods to a number of songs in order to gain an understanding as to the relationship between music feature similarity and music similarity in the context of copyright infringement and plagiarism. It is not difficult to postulate that some features are more indicative than others. However, to the best of our knowledge, there a systematic experiment has yet to be reported in the literature. We thereby designed and conducted a systematic experiment on the 33 features in
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5 in conjunction with several songs.
Given a particular piece of music, one can apply some changes to the music to generate its variations. For example, consider the traditional song “Happy Birthday” ⯈ (
https://github.com/asaner7/imagery-music-similarity/blob/main/songs-in-paper/HappyBirthday_mp3.mp3, accessed on 30 May 2025). We created its variations on MuseScore 4.2.1 [
23], characteristically representing different forms of modification. Nevertheless, the modification was not sufficient enough to make any of these variations to be considered to be a different song. The variations created for “Happy Birthday” include the following: transpose ⯈ (
https://github.com/asaner7/imagery-music-similarity/blob/main/songs-in-paper/HappyBirthday_Transpose.mp3, accessed on 30 May 2025), chord-change ⯈ (
https://github.com/asaner7/imagery-music-similarity/blob/main/songs-in-paper/HappyBirthday_Chord.mp3, accessed on 30 May 2025), genre change (specifically swing in this case) ⯈ (
https://github.com/asaner7/imagery-music-similarity/blob/main/songs-in-paper/HappyBirthday_Swing.mp3, accessed on 30 May 2025), grace notes and other embellishments ⯈ (
https://github.com/asaner7/imagery-music-similarity/blob/main/songs-in-paper/HappyBirthday_Ornamental.mp3, accessed on 30 May 2025), and a combination ⯈ of several of these changes (
https://github.com/asaner7/imagery-music-similarity/blob/main/songs-in-paper/HappyBirthday_Combo.mp3, accessed on 30 May 2025).
We intentionally avoided any preconception or biases by treating all 33 features consistently in our feature-based analysis and visualization. Each feature is defined upon a segment of 1 bar long. The MIDI file of each variation is limited to 8 bars, resulting in 8 feature values for 8 segments. The heatmaps for comparing any two songs or variations are all of
resolution. Different distance metrics were experimented (
Table 6). The figures in this section show only the results of the negative L1 norm (Manhattan distance). The pixels were all color-coded using the same color-coding scheme, with bright yellow for higher similarity and dark blue for higher dissimilarity. All of the heatmaps associated with the same feature have the same color-mapping function. All seven histogram-based features in
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5 were scaled between [−2,0] where all other features were scaled between [−3,0] to ensure maximum contrast for visual inspection. As mentioned in
Section 2.4, the color-coding does not affect the machine learning processes as only the original numerical matrices (before visualization) were used in training, validation, and testing.
3.1. Melodic Features
In the literature, melodic features have been used to detect similarity. Our experiments confirmed, largely, the usefulness of the melodic feature.
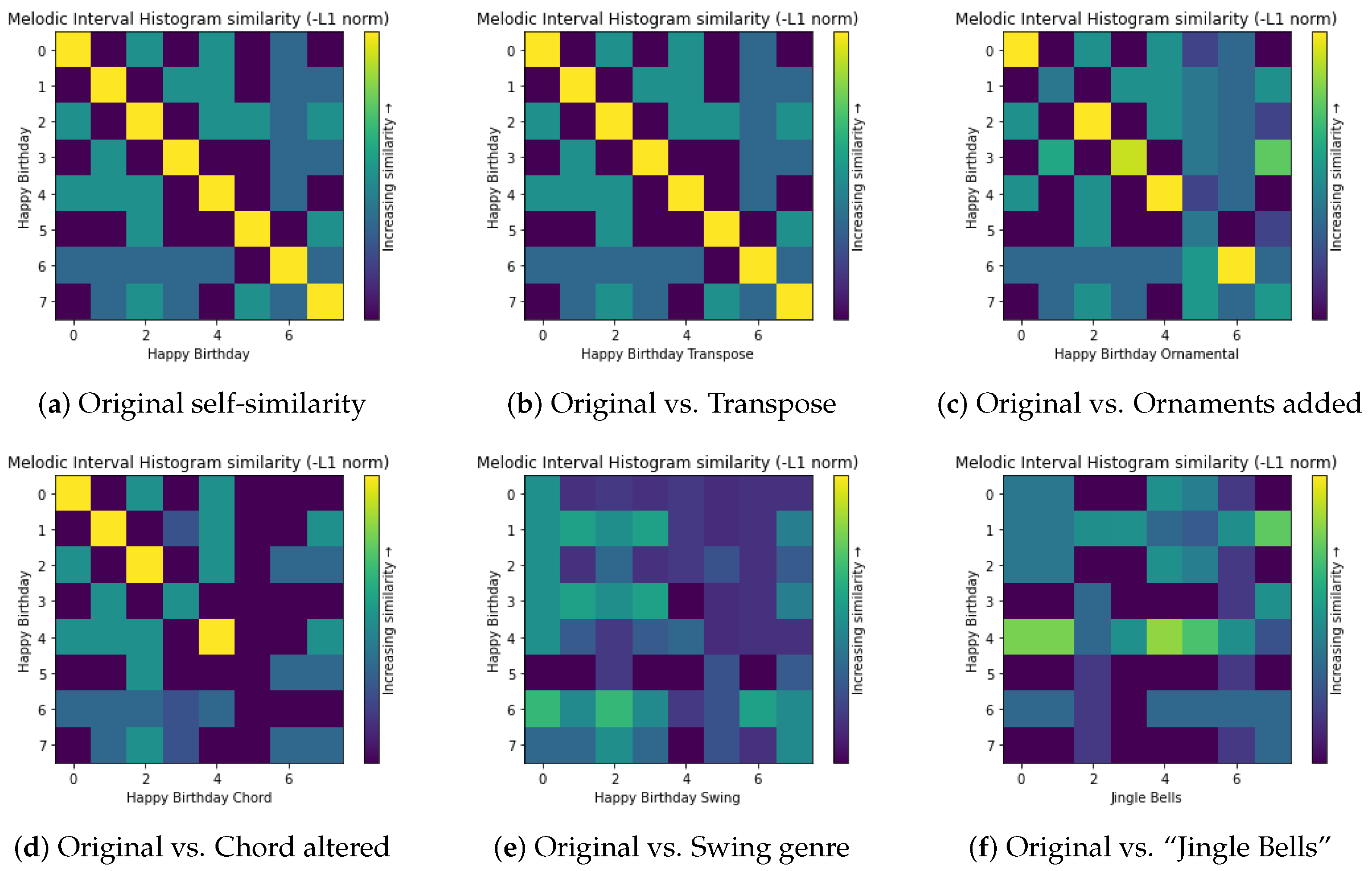
Figure 5 shows six heatmaps illustrating the use of the
melodic interval histogram to compare “Happy Birthday” with itself (a), four variations (b, c, d, e), and “Jingle Bells” ⯈ (
https://github.com/asaner7/imagery-music-similarity/blob/main/songs-in-paper/JingleBells.mp3, accessed on 30 May 2025) (f). There were also comparisons with other types of variations and many other songs, and these six heatmaps are examples demonstrating the indicative power of the melodic feature.
As shown in
Figure 5a, a self-similarity heatmap of this feature usually has a diagonal line of bright pixels, which serves as a baseline reference for observing dissimilar patterns in other heatmaps. The transpose manipulation maintains such a pattern as shown in
Figure 5b; hence, this type of variation will be considered as similar to the feature of the melodic interval histogram.
From
Figure 5c, we can see that the addition of ornaments to each bar of the song did not change the heatmap drastically, and substantial similarity is still obvious. In
Figure 5d, it is clear that the addition of chords to each bar affected the heatmap more in comparison with
Figure 5c; the overall melodic similarity has still been captured, but the changes in the bars at the end were not detected, which suggests some weakness of the feature.
Figure 5e indicates a major weakness of the feature of the melodic interval histogram in detecting genre changes, as there are no bright patterns at all. This suggests that genre changes might fool an ML model that relies too heavily on this feature. However, this observation may be biased by visual inspection. An ML model can still potentially learn to recognize other subtle patterns. Nevertheless, the risk should not be dismissed.
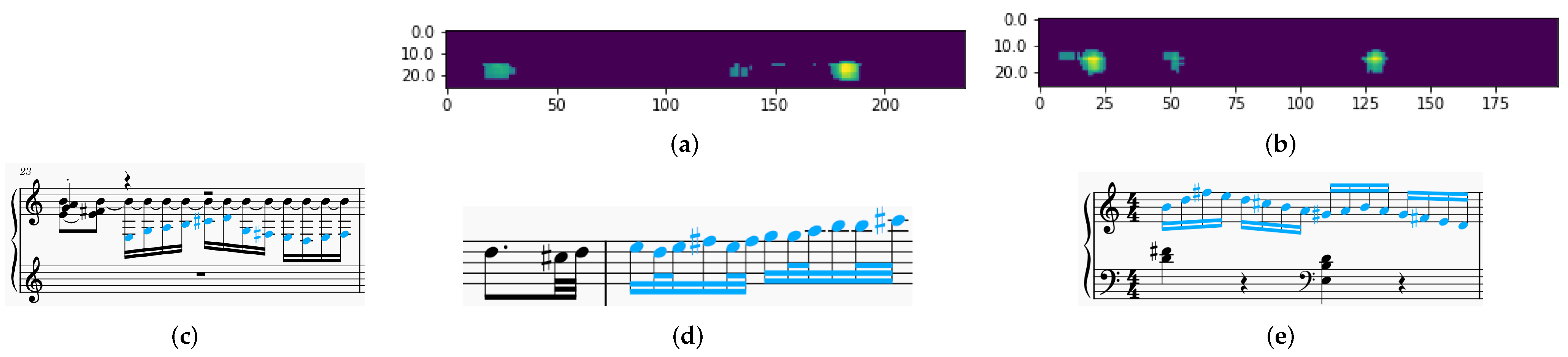
In
Figure 5f, we can observe some bright pixels, suggesting melodic similarity in the bars concerned. These bright patterns appear in different regions of the heatmap and do not form a diagonal line or a block of pixels. This suggests that the similarity is either in an isolated location (e.g., location [
]) or related to a single bar (e.g., [y = 4]).
The other melodic features in
Table 1 did not result in heatmaps as effective as the melodic interval histogram. The resultant heatmaps were either completely bright or there was almost no difference between similar cases (i.e., variations of “Happy Birthday” ) and dissimilar cases (i.e., “Jingle Bells” and some other songs). We therefore prioritize the melodic interval histogram for our data collection and ML development effort.
3.2. Pitch Statistics Features
Among the eight features in
Table 2, only the
folded fifths pitch class histogram showed some promising results. This feature is expected to be a complementary feature in the similarity detection model, since having similar pitch properties between two music pieces is not compelling enough to claim plagiarism. However, it is possible that alongside the melodic interval histogram, it may provide more evidence for an alleged plagiarism.
Figure 6 shows the performance of this feature on the swing version of “Happy Birthday”, where the visual patterns depicted are more interesting than
Figure 5e. This suggests that the feature of folded fifths pitch class histogram may potentially aid in the detection of similarity for this challenging type of variation.
3.3. Chords and Vertical Interval Features
Harmony may potentially be a useful aspect of music in similarity detection. Our experiments provided strong evidence in supporting this hypothesis. In particular, the features
wrapped vertical interval histogram and
distance between two most common vertical intervals performed well. Particularly, the distance between two most common vertical intervals performed well with the swing variation. The harmony, similar to pitch statistics, can provide supplementary evidence for similarity detection.
Figure 7 shows some of the results obtained with the feature of distance between two most common vertical intervals. We can easily observe that
Figure 7e shows a very strong indication of similarity.
3.4. Rhythm and Beat Features
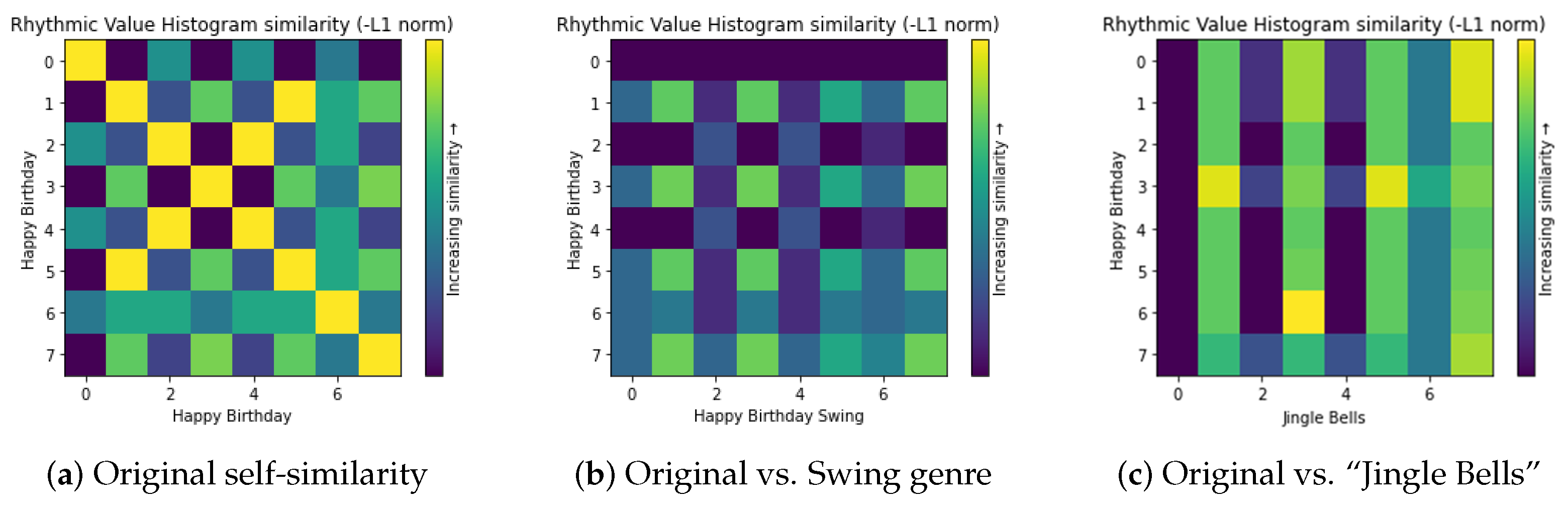
Through experimentation, we found that the seven rhythm and beat features in
Table 4 did not adequately support similarity detection. This is understandable, since two different songs could potentially have the same rhythm, which would not be considered as plagiarism. There could also be cases where a variation of a song could have a different rhythm while still being the same song, e.g., the swing variation of “Happy Birthday”. As an example,
Figure 8 shows three comparative heatmaps, indicating that the feature of
rhythmic value histogram cannot distinguish between (b) being similar and (c) being dissimilar. Therefore, we did not prioritize any feature in
Table 4 for data collection and model development in this work.
3.5. Texture Features
Our experiments showed that the four texture features in
Table 5 were not indicative in similarity detection. It is understandable as the motion of voices present in a music piece is not a characteristic that is normally used to distinguish similar pieces from dissimilar ones. For example,
Figure 9 shows three heatmaps with most pixels in bright yellow and some in bright green regardless of the songs being compared. Therefore, we did not prioritize any feature in
Table 5 for data collection and model development in this work.
3.6. Findings from the Experimental Results
In addition to “Happy Birthday” and “Jingle Bells”, we also experimented with other songs. The overall experimental results of the feature-based analysis and visualization have shed light on which features may have strong association with similarity detection in the context of copyright infringement and plagiarism. Among the thirty-three features studied, most do not have such strong association, e.g., the seven rhythm and beat features in
Table 4 and four texture features in
Table 5. For these two groups of features, the findings are consistent with the general understanding as to what may contribute to the judgment of music plagiarism.
We have identified four features that have stronger indicative power than others. They are (i) melodic interval histogram, (ii) folded fifths pitch class histogram, (iii) wrapped vertical interval histogram, and (iv) distance between two most common vertical intervals. These features are all transpose-invariant and can detect similarity to an adequate extent where different chords and embellishments are added to create variations of a music piece. Moreover, when a combination of these alterations were applied to the original version of a music piece, the performance of these features did not deteriorate.
The type of swing-genre variations has been found to be a challenge for identifying similarity visually. Nevertheless, this provided us with stronger motivation to train ML models and to investigate whether the patterns resulting from such variations could indeed be detected by ML models even though they are not too obvious to the human eye. These experiments also inspired us to use comparative imagery as input data to train ML models for similarity detection. Since humans cannot visually assess thousands of heatmaps in order to compare one piece of music with many songs in a data repository, a good-quality ML model would be significantly more cost-effective. Meanwhile, as the judgment of plagiarism is a highly sensitive matter, it is necessary for humans to be able to scrutinize and interpret the judgment of any ML model for similarity detection. Hence, being able to visualize the feature-based comparative imagery allows explainable AI to support such scrutiny and interpretation.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}