1. Introduction
Above-ground biomass (AGB) is a critical indicator for evaluating crop growth status. It not only reflects the health and productive potential of crops but also correlates closely with final crop yield [
1,
2,
3]. Accurate prediction of above-ground biomass provides valuable information for growers and researchers, enabling the optimization of crop management strategies. By scientifically adjusting the application rates of fertilizers, pesticides, and irrigation water, it is possible to enhance both the yield and quality of agricultural products [
4].
Moreover, predicting above-ground biomass is crucial for adjusting the operational parameters of harvesting machinery. This biomass directly influences the intake rate of harvesting equipment, and inappropriate intake levels can adversely affect the efficiency and performance of these machines [
5,
6].
Traditional methods for monitoring above-ground biomass face numerous limitations and drawbacks, often involving destructive processes [
7,
8]. With advancements in computing and the increasing maturity of deep learning algorithms, such as deep regression networks (DRNs) [
9], non-destructive methods for predicting above-ground biomass have been increasingly adopted. Compared to conventional monitoring techniques, deep learning-based approaches offer significant advantages [
10,
11].
In deep learning, regression tasks typically encompass several research areas, including deep imbalanced regression, ordinal regression, general continuous-value regression, and contrastive regression. These areas are not mutually exclusive, as overlaps exist between different research directions. Yang investigated the issue of data imbalance in deep learning regression tasks, defining deep imbalanced regression (DIR) [
12]. Wang proposed a probabilistic deep learning model called Variational Imbalanced Regression (VIR) [
13], designed to handle imbalanced regression problems while naturally providing uncertainty estimation.
Shi introduced a novel rank-consistent ordinal regression method, CORN, which addresses the limitations of weight-sharing constraints in existing approaches [
14]. Wang studied CRGA [
15], a method that leverages contrastive learning for unsupervised gaze estimation generalization in the target domain. Zha proposed Rank-N-Contrast (RNC) [
16], which incorporates contrastive learning to rank contrastive samples in the target space, ensuring that learned representations align with the target order. Keramati introduced ConR [
17], a contrastive regularization method for addressing imbalanced regression problems in deep learning. By simulating global and local label similarities in the feature space, ConR effectively tackles the challenges of imbalanced regression. The Momentum Contrast (MoCo) method by He et al. introduced a momentum encoder for updating encoder parameters [
18]. Additionally, methods like Deep Infomax (DIM) and Contrastive Predictive Coding (CPC) have played pivotal roles in advancing self-supervised learning [
19,
20].
With the rapid development of 3D acquisition technologies, 3D sensors have become increasingly widespread. These sensors capture rich geometric, shape, and scale information. Three-dimensional data can be represented in various formats, such as depth images, point clouds, and meshes, with point clouds being the preferred format in many scenarios [
21]. Methods that use LiDAR (Light Detection and Ranging) sensors to acquire point cloud data have found extensive applications in agriculture and forestry [
22,
23,
24].
For instance, Revenga utilized drones equipped with LiDAR sensors to monitor two agricultural fields in Denmark, collecting point cloud data. They employed an extremely randomized trees regressor to predict biomass [
25]. Song developed a tree-level biomass estimation model based on LiDAR point cloud data, extracting features, such as tree height and trunk diameter, and using a Gaussian process regressor to associate these features with tree biomass [
26]. Colaco assessed spatial variability in crop biomass in a 64-hectare wheat field using LiDAR technology [
27]. Similarly, Ma extracted 56 features using LiDAR technology to estimate forest above-ground biomass (AGB) and its components. They ranked and optimized these features using variable importance projection values derived from partial least squares regression [
28].
Seely compared direct and additive models for estimating tree biomass components using point cloud data, employing dynamic graph convolutional neural networks and octree convolutional networks [
29]. Pan proposed BioNet, a point cloud processing network for wheat biomass prediction, which incorporated attention-based fusion blocks for final biomass predictions [
30]. Oehmcke developed a deep learning system to predict tree volume, AGB, and above-ground carbon stocks directly from LiDAR point cloud data, showing that an improved Minkowski convolutional neural network achieved the best regression performance [
31]. Lei introduced BioPM, an end-to-end prediction network that leveraged the upward growth characteristics of crops in wheat fields. Experimental results on public datasets demonstrated that BioPM outperformed both state-of-the-art non-deep learning methods and other deep learning approaches [
32]. Oehmcke et al. proposed a point cloud regression method based on Minkowski convolutional neural networks, which significantly improved the accuracy of forest biomass prediction [
33].
However, the existing methods for processing point cloud data often rely on basic geometric features, overlooking higher-order structures and multi-scale characteristics. This leads to a feature space that struggles to accurately reflect the mapping relationship between biomass and point cloud structures. Furthermore, biomass data inherently exhibits imbalance, and current deep learning methods have yet to effectively address the issue of features from minority samples being overlooked.
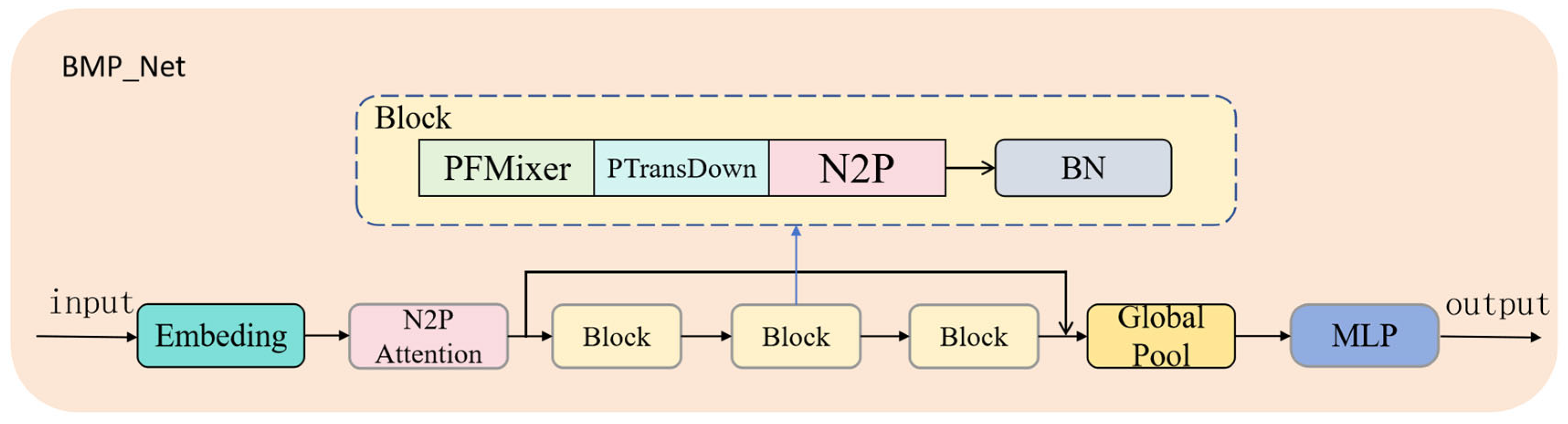
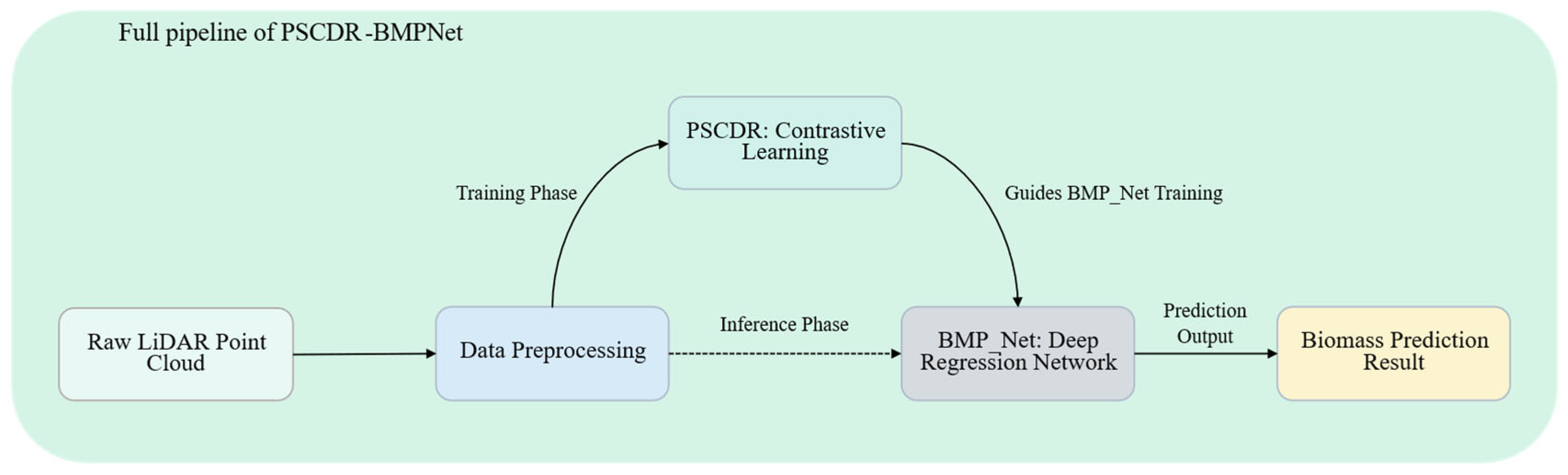
To address the aforementioned challenges, this study proposed a point cloud-based deep contrastive regression method, Point Supervised Contrastive Deep Regression (PSCDR), which leverages the Chamfer distance metric to measure similarity between point clouds, fully utilizing their geometric properties. Additionally, a deep regression network, BMP_Net (BioMixerPoint_Net), incorporating neighbor point attention, was developed to enhance the capability of processing crop structural information. The objective is to provide a reference for rapid and accurate estimation of above-ground biomass and to enable dynamic monitoring.
3. Results
3.1. The Experimental Setup and Evaluation Metrics
The experiment was conducted using Ubuntu 20.04.4 LTS 64-bit as the operating system, with an Intel Xeon Silver 4214 processor (Intel Corporation, Santa Clara, CA, USA) running at CPU@2.20 GHz and 32 GB of RAM. The GPUs used were two NVIDIA Tesla T4 (NVIDIA Corporation, Santa Clara, CA, USA), with a total of 32 GB of video memory. The software environment was built based on the Python 3.8.19 programming language, using the PyTorch 1.13.1 deep learning framework with CUDA 11.7 acceleration. Key dependency libraries included OpenCV 4.10.0 and TorchVision 0.14.1 for computer vision processing, Torch-Pruning 1.5.2 for model compression, NumPy 1.24.3 and SciPy 1.10.1 for scientific computing, as well as Pandas 1.5.3 for data manipulation. The GPU acceleration environment was implemented via CUDA Toolkit 11.7 and cuDNN 8.5.0, with versions strictly compatible with the PyTorch framework to ensure computational stability. The Adam optimizer was employed, with 80 training epochs, and cosine annealing decay was used for the learning rate. Other hyperparameters were set according to those published in the SGCBP paper. The performance of the proposed methods and models was evaluated using three metrics: RMSE, MAE, and MAPE (Mean Absolute Percentage Error). RMSE, MAE, and MAPE were chosen as they are standard and comprehensive metrics for evaluating the accuracy of regression models, reflecting different aspects of prediction error.
3.2. Comparative Experiments
In addition to the models from the SGCBP paper, this study also included PointMixer [
35], Point Transformer [
36], and PointNeXt [
37] as comparison models. It is important to note that in the SGCBP paper, the authors did not use the MAPE metric; therefore, the data presented in
Table 1 from the SGCBP paper do not include MAPE values. PointMamba [
38] was not included in the comparison because it focuses on classification rather than regression. While classical machine learning regressors (e.g., Random Forest, Support Vector Regression with hand-crafted features) represent an alternative approach, the scope of this study was to benchmark against contemporary deep learning methods specifically designed for or adapted to point cloud data, which have generally demonstrated superior performance in capturing complex 3D spatial patterns for tasks like biomass estimation in the recent literature [
9,
10,
11,
29,
30,
31,
32,
33]. Future comparative studies could incorporate such classical baselines for a broader perspective.
As shown in
Table 1, except for BMP_Net and BioNet, the PointMixer network performs the best among all the unimproved networks. Its RMSE, MAE, and MAPE were 113.41, 93.26, and 0.194, respectively. PointMixer excels in the biomass prediction task using point cloud data, primarily because of its universal and efficient structure, as well as its parameter efficiency and hierarchical response propagation advantages. Its versatility makes it suitable for various types of point cloud data, and the channel-mixing MLP effectively promotes feature aggregation. Additionally, its concise and efficient design improves the efficiency of processing large-scale data. The use of a symmetric encoder–decoder block with a hierarchical response propagation mechanism helps capture complex relationships within the point cloud data, thereby enhancing prediction performance. This result also validated our design choices for BMP_Net, which adapted and improved upon concepts from the PointMixer [
35] architecture.
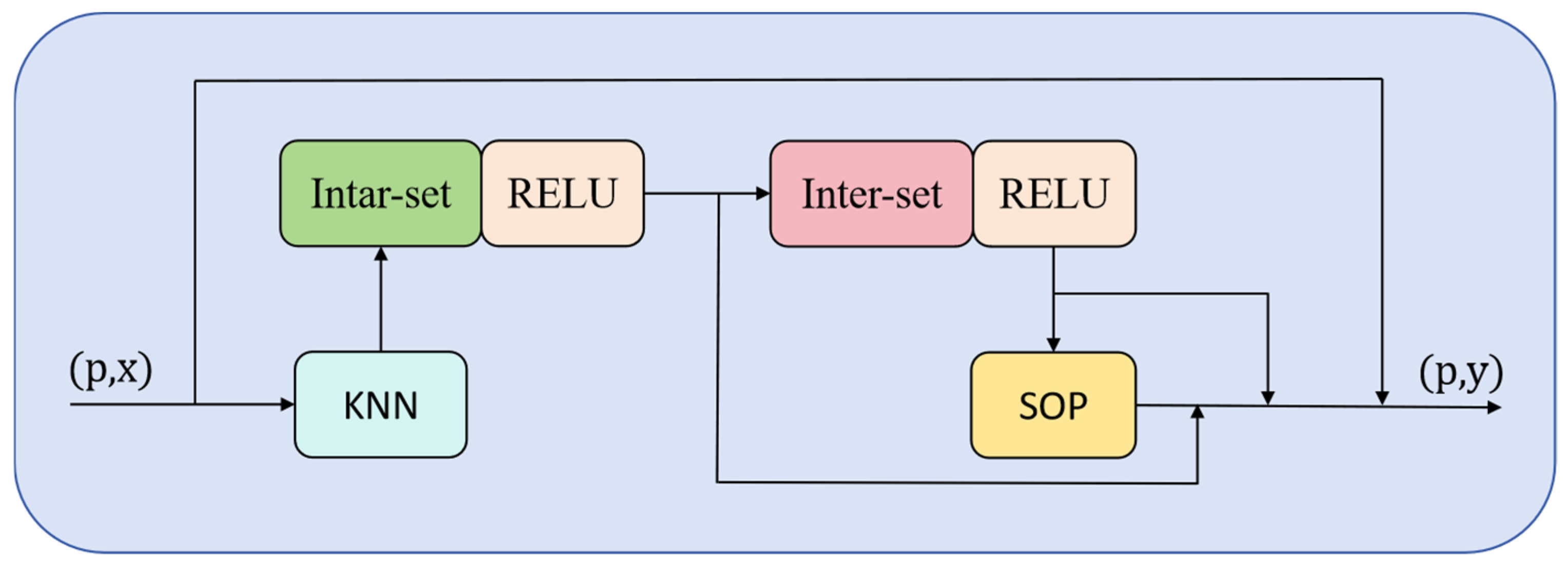
The BMP_Net model proposed in this paper outperforms the BioNet model introduced in the SGCBP paper, showing better performance in RMSE, MAE, and MAPE, with values of 84.8, 67.31, and 0.131, respectively. BMP_Net effectively extracts and utilizes the relevant information from point cloud data by leveraging key components such as the Embedding layer, N2P Attention, PFMixer module, and point cloud downsampling. This significantly improves the accuracy and performance of biomass prediction tasks. The Embedding layer transforms high-dimensional point cloud data into a more manageable vector form, N2P Attention captures local features, the PFMixer module performs deep feature extraction and data compression, and point cloud downsampling reduces noise and redundant information. These components work together to provide a more robust decision-making foundation for biomass prediction tasks.
After applying the PSCDR method, BMP_Net showed a reduction in RMSE, MAE, and MAPE, with decreases of 8.56, 4.12, and 0.016, respectively. This indicates that the PSCDR method plays a significant role in predicting biomass and other regression tasks with point cloud data. The combination of BMP_Net and PSCDR yields the best performance. PSCDR enhances the prediction process by introducing Chamfer distance to calculate the similarity in point cloud data in three-dimensional space while considering the similarity between features. This approach provides strong support for label comparison and label value prediction, contributing to the improved performance of deep regression tasks.
3.3. Effectiveness Analysis of the PSCDR Method
Table 2 shows the performance of common regression loss functions and the proposed PSCDR method on a range of well-known point cloud models, as well as the proposed BMP_Net. In many models, when the loss function is replaced with the proposed total loss function
, the performance of most models improves on the SGCBP dataset. This result is expected because, in regression tasks, the core objective is to predict target values from input data. Regardless of the data modality, the data is encoded into feature vectors by the encoder in the network. By considering the differences between label values and feature values, and adopting a regression-like approach, it is possible to achieve some level of clustering and relative positioning of positive and negative samples in the feature space.
While PSCDR considers these factors, it also takes advantage of the unique characteristics of point cloud data by using Chamfer distance to measure the similarity between two point cloud samples. The information contained in the feature vectors produced by the encoding process is determined by the model’s point cloud encoder. When using common regression loss functions, both PointMixer and the proposed BMP_Net also perform well.
However, the performance improvement of the PSCDR method on the DGCNN model is not significant. This may be because the DGCNN model utilizes graph convolution operations based on local connections, which primarily focus on capturing local structural information of the point cloud data. This local connectivity approach may limit the model’s ability to capture global features of the point cloud data. Although the PSCDR method considers the similarity between global features, the local connectivity nature of the DGCNN model might not fully leverage the global feature similarity loss in the PSCDR method, thus restricting the performance improvement of PSCDR on this model.
3.4. Ablation Experiments of BMP_Net
3.4.1. Ablation Experiments on the Modules of BMP_Net
To investigate the impact of key structures and modules in BMP_Net on overall performance, a series of ablation experiments was conducted. These experiments involved replacing or removing key modules, and the tests were carried out under identical conditions to validate the importance of each designed module. The results of the ablation study are shown in
Table 3. Three design components or modules were ablated, including the PFMixer module, the Point Cloud Transition Downsampling module, and the N2P Attention (Neighbor Point Attention) module. We tested five different scenarios: 1. The model with only the main structure, where the PFMixer module was removed (replaced by the MixerBlock from the PointMixer network), the Point Cloud Transition Downsampling module was substituted by a regular downsampling layer, and the N2P Attention module was excluded. 2. The model with the PFMixer module removed only. 3. The model with the Point Cloud Transition Downsampling module removed only. 4. The model with the N2P Attention module removed only. 5. The full BMP_Net model proposed in this study.
From the table, it can be observed that in Case 1, where all three key modules were removed, the model performance was the worst, which aligns with our expectations. After removing these three critical modules, the model’s ability to extract and process the point cloud structure and features significantly declined. Without the PFMixer module, which performs deep feature extraction and data compression, and given the abundance of redundant information in the data, the model’s performance dropped sharply.
In Case 4, the evaluation metrics outperformed those of Case 2 and Case 3, indicating that the PFMixer module and Point Cloud Transition Downsampling module make significant contributions to the network’s performance. The improvement in performance due to these two modules is not simply a linear addition, suggesting that careful consideration was given to the synergy between the two modules during network design, achieving a result where “one plus one is greater than two.” In both Case 2 and Case 3, where only the PFMixer module or the Point Cloud Transition Downsampling module was removed, the performance dropped significantly compared to Case 5 (the full BMP_Net model). Additionally, Case 4 demonstrated that the N2P Attention module effectively captured the surrounding information of each point, aiding in learning local features and enhancing the overall performance of point cloud data processing. This highlights the importance of N2P Attention in improving the model’s ability to focus on relevant neighborhood information, which contributes to better performance in handling complex point cloud data.
3.4.2. PSCDR Algorithm Parameter Ablation Experiments
To investigate the impact of various parameters on the experimental results, multiple sets of parameter ablation experiments were conducted on the SGCBP dataset.
Table 4 presents the ablation experiment results for the weight coefficients used in the similarity computation of Equation (3). In these experiments, four different values of
were selected: 0.01, 0.05, 0.1, and 0.5. The value of
ranged from 0.001 to 0.009, with a step size of 0.002.
The first weight coefficient
corresponds to the coefficient of the reciprocal of the cosine similarity plus two, while
represents the weight coefficient for the Chamfer distance between point clouds. Due to the significant variability among negative point cloud samples, the computed Chamfer distance tends to be large and exhibits a wide range of values. Therefore, the range of
was constrained based on preliminary experiments to ensure the overall value of Equation (3) did not become excessively large, and the optimal values reported in
Table 4 were identified through these systematic ablation experiments.
Through multiple experiments, it was observed that under different values of , when is greater than or equal to 0.01, all evaluation metrics result in NaN values, indicating that the value of should not be too large. As shown in the experimental results in the table, the best performance is achieved when and . Among the four sets of values, as increases, the overall evaluation metric values increase to varying degrees. This experimental result aligns with the hypothesis: when the value of is large, multiplying it with the computed Chamfer distance yields a significantly large value, which, when incorporated into the PSCDR method, may lead to numerical overflow and result in NaN values. Additionally, a larger value also contributes to an increase in the evaluation metric values.
To investigate the impact of the temperature coefficient τ on the PSCDR algorithm, temperature coefficient ablation experiments were conducted, with the results summarized in
Table 5. As shown in the table, the PSCDR algorithm achieves optimal performance when τ = 0.5. This value was determined through the systematic ablation experiments summarized in
Table 5, which explored a range of values to balance model discriminative ability against numerical stability. Compared to image data, point cloud data typically exhibits higher dimensionality and complexity, necessitating a larger temperature parameter to ensure that the contrastive learning algorithm can effectively explore its data space. A larger temperature parameter smooths the overall output of
, thereby enhancing the model’s performance on point cloud data.
However, for the PSCDR algorithm, both excessively high and excessively low temperature parameters can have detrimental effects. An overly high temperature parameter causes the output distribution of to become excessively smooth, which blurs the differences between samples, diminishes the model’s discriminative ability, and may lead to overfitting. Conversely, the ablation experiments revealed that when ≤ 0.01, the values of all three evaluation metrics become NaN. This indicates that an excessively low temperature parameter results in an overly sharp output distribution of , increasing numerical instability in computations. Such instability may cause numerical overflow or underflow in the loss function, potentially rendering optimization infeasible. Therefore, selecting an appropriate temperature parameter is crucial for the performance of the PSCDR algorithm. While τ = 0.5 was optimal in our experiments on the SGCBP dataset, this parameter generally acts as a hyperparameter that may require tuning (e.g., via a validation set) when applying PSCDR to new datasets or different model architectures, typically by exploring values within a range such as [0.05, 1.0].
3.4.3. Ablation Experiments on the Number of Point Cloud Sampling Points
To determine the optimal number of sampling points for the proposed BMP_Net model, ablation experiments on the number of point cloud sampling points were conducted. The results of these ablation experiments are presented in
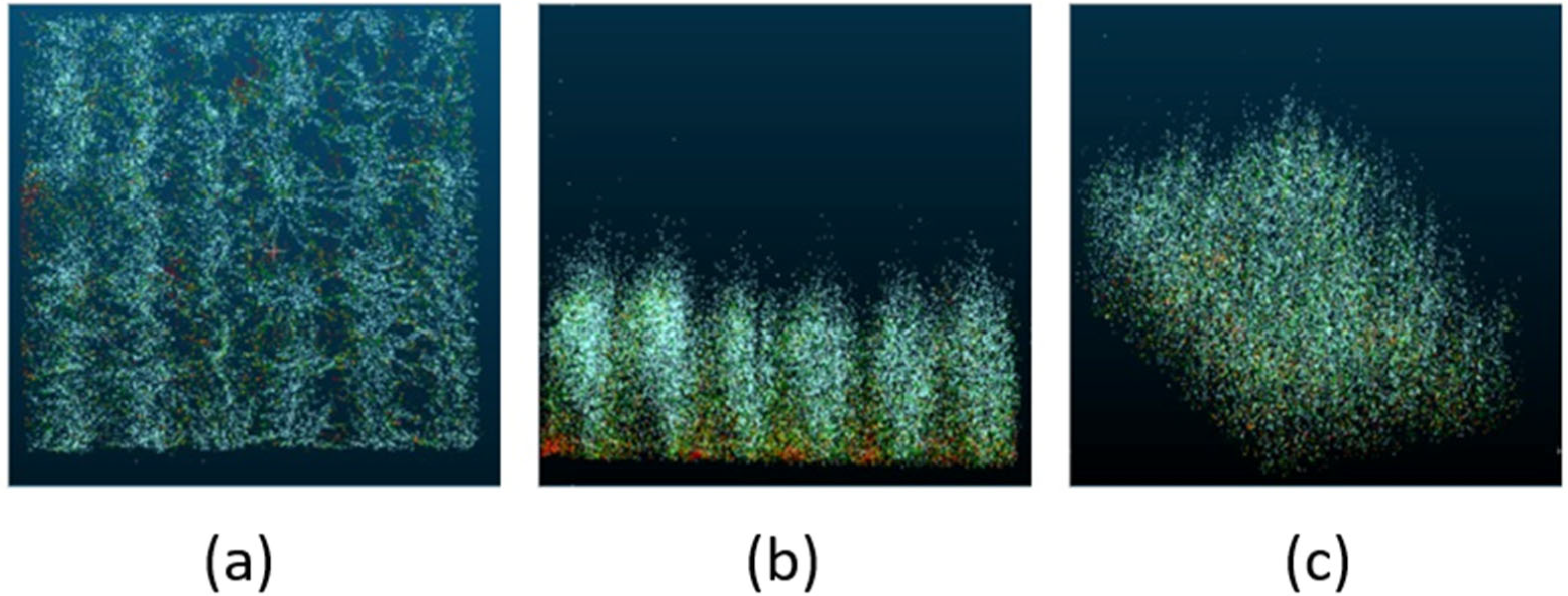
Table 6. In the original PCD files, the number of points in the point clouds varies significantly and is often excessively large, making it impractical to directly input all data points into a point cloud network for training. Therefore, the original point cloud data must undergo a sampling process, with the sampled point cloud data serving as the input to the point cloud network. This process is analogous to resizing image data in convolutional neural networks. The FPS (Farthest Point Sampling) algorithm was employed as the sampling method, with the number of sampling points set to powers of 2. According to the experimental results, the performance of the three evaluation metrics reaches its optimum when the number of sampling points is 4096. However, when the number of sampling points is either too small (e.g., num_points = 1024) or too large (e.g., num_points = 16,384), the experimental results exhibit relatively mediocre performance. An insufficient number of sampling points leads to information loss, which prevents the full representation of critical features in the point cloud—such as wheat fruit density information highly correlated with biomass—thereby limiting the model’s ability to learn the relationship between point cloud data and biomass from limited information. Conversely, an excessively large number of sampling points increases the computational burden, resulting in prolonged training times and reduced model inference efficiency. Additionally, excessive point cloud data introduces more redundant information and noise, which may cause the model to overfit the training data, consequently degrading its performance. These ablation studies demonstrate the process of parameter selection and provide insights into model sensitivity, thereby contributing to the justification of our final model configuration.
4. Discussion
The biomass prediction network, BMP_Net, proposed in this study, which is based on point cloud deep contrastive regression, along with the integrated PSCDR (Point Supervised Contrastive Learning for Deep Regression) method, has achieved significant progress in the task of above-ground biomass prediction. This section provides an in-depth discussion of the research findings by integrating prior studies and research hypotheses, focusing on technical contributions, result interpretation, practical applications, limitations, and future research directions, to comprehensively elucidate the scientific significance and potential impact of this study.
4.1. Technical Contributions and Result Interpretation
To address the limitations of traditional point cloud networks in biomass prediction tasks, particularly their insufficient handling of crop structural information and the challenge of uncovering the relationship between point cloud characteristics and biomass, this study proposes the innovative PSCDR method and the BMP_Net network. Revenga et al. [
25] employed extremely randomized tree regression, relying solely on statistical features of point cloud height while overlooking the nonlinear impact of crop canopy structure on biomass. Unlike general contrastive learning methods, such as MoCo by He et al. [
18] and ConR [
17], PSCDR introduces the Chamfer distance metric into the contrastive loss function for the first time, directly quantifying the three-dimensional spatial similarity of point clouds. The incorporation of Chamfer distance significantly enhances the model’s robustness to point cloud deformations. Specifically, PSCDR reduces the RMSE of the PointMixer from 113.41 to 102.11, outperforming ConR [
17], which relies solely on label similarity.
The PFMixer module in BMP_Net enhances local feature interactions through intra-set mixing and captures cross-regional correlations via inter-set mixing. Our ablation studies demonstrate that removing the PFMixer module increases the RMSE from 75.92 to 160.76, underscoring its critical role in noise suppression and feature fusion. This design surpasses the attention fusion block in BioNet [
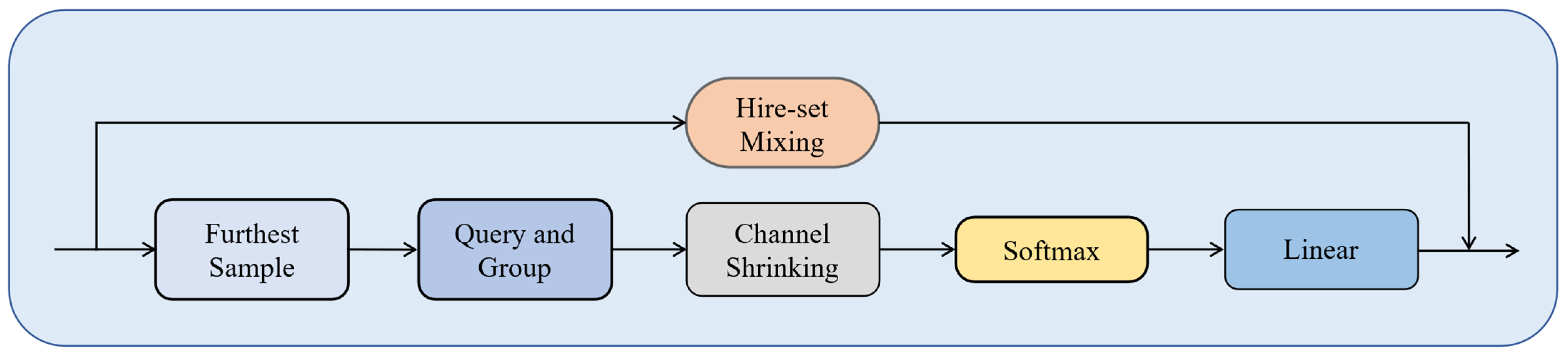
30], which depends solely on global attention, as PFMixer preserves multi-scale information through residual connections.
Traditional downsampling methods often lead to the loss of key biomass-related features. For instance, BioNet by Pan et al. [
30] suffers from excessive dilution of wheat ear point clouds due to a fixed sampling rate. In contrast, the PTransDown module in BMP_Net prioritizes the retention of dense regions, such as stems and ears, through channel contraction and Softmax normalization. Our ablation experiments reveal that removing this module increases the MAE from 63.19 to 151.04, confirming its importance in preserving critical structural information.
The N2P Attention mechanism enhances sensitivity to fine structures in point clouds by capturing information from the neighbors of each point and applying neighborhood attention weights, enabling the identification of spatial distribution patterns of wheat tillering nodes. With the introduction of N2P Attention, the network more effectively leverages the correlations within point cloud data, allowing for more accurate biomass prediction while maintaining efficiency and flexibility when handling large-scale, complex point cloud datasets.
At the technical level, this study overcomes the modality adaptation bottleneck of point cloud data in regression tasks by developing a high-precision prediction framework through contrastive learning and structured module design. Compared to BioNet by Pan et al. [
30], which relies on attention fusion blocks, and BioPM by Lei et al. [
32], which focuses on crop growth characteristics, the proposed PSCDR method and BMP_Net architecture achieve deep exploration of point cloud geometric features through modality-adapted contrastive loss and structured module design. This work establishes a methodological foundation for point cloud-based biomass prediction. The reduction in RMSE from 84.48 to 75.92 with the incorporation of PSCDR represents a relative improvement of approximately 10.1%. This level of enhancement in prediction accuracy can be significant in practical agricultural scenarios, for instance, by enabling more precise variable-rate fertilization or more reliable yield estimations.
4.2. Practical Applications
The findings of this study hold significant application value in the field of precision agriculture. Accurate biomass prediction provides data support for crop management, such as optimizing fertilization, irrigation, and pest control strategies, thereby enhancing agricultural production efficiency. Pan et al. [
39] proposed NeFF-BioNet, which integrates point clouds and UAV images to predict crop biomass, demonstrating the potential of multimodal approaches. In contrast, the BMP_Net model proposed in this study focuses on LiDAR point clouds, offering an efficient unimodal solution.
Moreover, above-ground biomass is closely related to the feed rate of harvesting machinery [
5]. The high-precision predictions of BMP_Net can serve as a basis for adjusting machinery parameters, reducing efficiency losses during equipment operation. On the SGCBP dataset, the combination of BMP_Net and PSCDR achieves a MAPE of only 0.115, significantly outperforming PointMixer’s MAPE of 0.194. This enables reliable technical support for the dynamic monitoring of small grain cereals such as wheat and barley. Compared to traditional manual sampling methods [
7,
8], this non-destructive prediction approach offers clear advantages in terms of efficiency and sustainability, laying a foundation for the modernization and intelligent development of agriculture. For instance, on a large-scale wheat farm, high-precision biomass maps generated by PSCDR-BMPNet could guide variable-rate nitrogen application by drones, optimizing fertilizer use efficiency for different growth zones and minimizing environmental runoff. Similarly, in barley cultivation, understanding biomass variability can inform decisions on differential harvesting strategies to maximize yield quality.
The incorporation of the PSCDR method with BMP_Net yielded significant performance gains, as evidenced by the reduction in RMSE from 84.48 to 75.92, MAE from 67.31 to 63.19, and MAPE from 0.131 to 0.115 when compared to BMP_Net alone on the SGCBP dataset. These represent relative improvements of approximately 10.13% in RMSE, 6.12% in MAE, and 12.21% in MAPE. Such enhancements in prediction accuracy are of considerable practical importance in precision agriculture. For instance, a reduction of 8.56 g/m2 in RMSE translates to a more precise estimation of available plant material per unit area. This increased accuracy can directly inform more efficient N-fertilizer management strategies, potentially leading to optimized fertilizer application rates, reduced input costs, and minimized environmental leaching. Furthermore, more accurate biomass predictions throughout the growing season can contribute to more reliable yield forecasting, aiding farmers and stakeholders in better logistical planning and market engagement. While the definition of “sufficient” accuracy can be application-dependent, these quantitative improvements demonstrate a meaningful step towards more robust and actionable biomass monitoring tools.
4.3. Limitations Analysis and Future Research Directions
Despite the significant progress achieved in this study, several limitations remain:
Limited Dataset Coverage and Applicability: A primary limitation of the current study is its reliance on the SGCBP dataset. Consequently, the presented PSCDR-BMPNet method was specifically validated for the agricultural crops included in this dataset, namely, wheat and barley, and within the geographical and environmental context of New South Wales, Australia, where the data was collected. While the proposed methodological innovations in contrastive learning and network architecture are designed to be generalizable, the direct applicability and performance of the trained model on other crop types (e.g., maize, rice, soybean) or in different agro-ecological regions require further dedicated validation and potential fine-tuning. Future research efforts should prioritize expanding the evaluation to more diverse datasets to ascertain the broader applicability and robustness of the PSCDR-BMPNet.
Computational Efficiency Challenges: BMP_Net exhibits high computational complexity when processing large-scale point cloud data, making it challenging to deploy on edge devices such as drones or field robots.
Need for Improved Multimodal Data Fusion and Noise Robustness: The model relies solely on LiDAR point cloud data and does not incorporate multimodal information such as RGB images, soil moisture, or meteorological data. Additionally, its ability to filter point cloud noise in extreme environmental conditions (e.g., rain, fog, or varying lighting) is limited.
Based on the above analysis, future research can explore the following directions:
Dataset Expansion and Diversity: Expanding the dataset scale to include a broader range of crop types (e.g., maize, rice) and diverse ecological conditions would enhance the model’s robustness and generalization ability.
Model Optimization and Lightweight Design: Bornand et al. [
40] utilized deep learning to complete sparse point clouds, addressing occlusion issues in forests. In the future, such methods could be integrated to further enhance the robustness of BMP_Net in complex environments. Optimizing the network architecture to reduce computational costs or employing knowledge distillation to transfer BMP_Net’s knowledge to a lightweight framework could maintain accuracy while lowering computational complexity.
Multisource Data Fusion: Integrating multispectral and thermal infrared remote sensing data could improve the model’s perception of crop physiological states, further enhancing prediction accuracy.
4.4. Model Interpretability Considerations
Understanding how the PSCDR-BMPNet model arrives at its biomass predictions is crucial for building user trust and facilitating practical adoption in precision agriculture. While the current study primarily focused on predictive accuracy, future iterations should incorporate model interpretability techniques. For instance, methods like SHAP (SHapley Additive exPlanations) or LIME (Local Interpretable Model-agnostic Explanations) could be adapted to identify which points or learned features contribute most significantly to the biomass estimates. Given the use of the N2P Attention module, visualizing attention weights could also offer insights into the spatial regions of the point cloud that the model deems most important. Such analyses would not only demystify the “black box” nature of the deep learning model but also potentially guide further model refinement or data acquisition strategies.
5. Conclusions
This paper focused on the task of biomass prediction using point cloud data. Compared to image data, point cloud data offers more comprehensive and detailed spatial information and structural features. To better extract the spatial feature information from point cloud data, we propose a contrastive learning-based method called PSCDR, which introduces Chamfer distance as a new feature metric. Additionally, we propose a deep regression network, BMP_Net, for point cloud biomass prediction tasks. BMP_Net integrates the PFMixer module and Point Cloud Transition Downsampling module, utilizing multiple cross-level residual connections for information exchange to fully explore the relationship between point cloud structure, point cloud density, and the corresponding biomass. On this foundation, the N2P Attention mechanism is introduced to capture and fuse the neighboring point information within the point cloud.
Experiments on the SGCBP public dataset showed that BMP_Net alone achieved RMSE, MAE, and MAPE values of 84.48, 67.31, and 0.131, respectively, outperforming BioNet. After incorporating the PSCDR method, these three key performance metrics are optimized to RMSE = 75.92, MAE = 63.19, and MAPE = 0.115, demonstrating that the method significantly improves prediction accuracy. Furthermore, in experiments with different point cloud networks, adding the PSCDR method leads to performance improvements across all cases, further validating the general applicability and effectiveness of the PSCDR approach. The improved BMP_Net model achieves high recognition accuracy, making it suitable for precise above-ground biomass detection, thus providing strong technical support for research in related fields.
However, this study has certain limitations. The dataset used lacks sufficient diversity in crop types, geographic regions, and growing conditions, which could help enhance the model’s generalization capabilities. Additionally, there is room for improvement in the model’s robustness in complex environments and its computational efficiency. Future research will focus on optimizing the model structure and algorithms, expanding the dataset’s size and diversity, exploring more effective feature extraction and fusion strategies, and strengthening research on model interpretability. These efforts aim to promote the broader application of point cloud data in biomass prediction, providing more accurate and reliable technical support for precision agriculture and ecosystem research. While the improved BMP_Net model achieves high recognition accuracy on the SGCBP dataset, making it suitable for precise biomass detection of wheat and barley under similar conditions, its broader applicability to other crops and regions remains a key area for future investigation.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}