
PSHNet: Hybrid Supervision and Feature Enhancement for Accurate Infrared Small-Target Detection

Abstract
1. Introduction
- (1)
- PSHNet addresses the lack of pixel-level guidance under sparse box-level supervision by generating a position heatmap, where each target center is encoded as a Gaussian distribution to supply dense localization cues. A dedicated offset branch then regresses sub-pixel shifts to refine the coarse heatmap peaks, while a size branch directly predicts each target’s width and height, yielding precise position–scale estimates.
- (2)
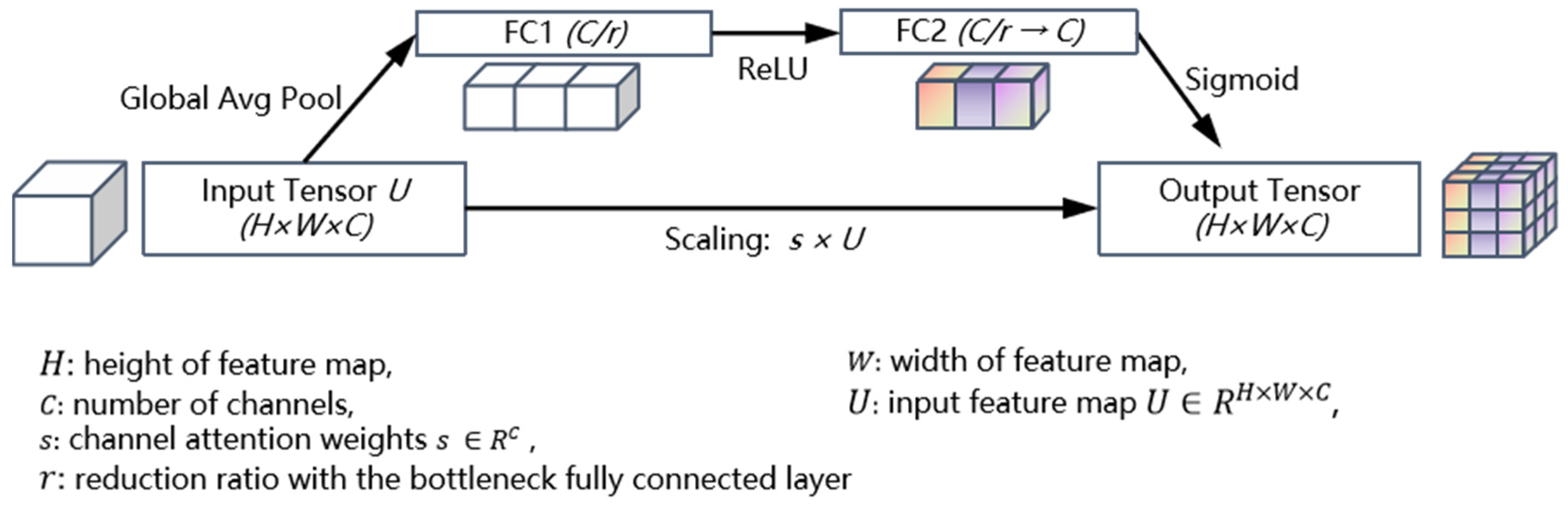
- To counteract the loss of fine details caused by deep-layer downsampling, we incorporate an Enhanced Low-level Feature Module (ELFM) immediately after the first encoder block. ELFM applies multi-scale dilated convolutions to capture contextual information across varying receptive fields and employs channel-wise attention to emphasize channels most relevant to small targets, thus preserving and amplifying critical shallow-layer spatial features.
- (3)
- To compensate for the limited global context of heatmap-plus-regression alone, we introduce a CIoU regularization term on the reconstructed bounding boxes. This auxiliary loss enforces consistency in location, scale, and aspect ratio without overriding the dense supervision signals, ensuring that detections remain both spatially sensitive and geometrically aligned.
2. Related Work
2.1. Traditional Infrared Small-Target Detection Methods
2.2. Deep Learning-Based Infrared Small-Target Detection Methods
- (1)
- Detection-Based Frameworks (Box-Level Supervision):
- (2)
- Segmentation-Style Networks (Pixel-Level Supervision):
- (3)
- Transformer-Based Models:
- (4)
- Specialized Training Mechanisms:
- (5)
- Multimodal and Data-Augmented Techniques:
2.3. Limitations of Existing Methods
3. Proposed Method
3.1. Overall Architecture
- A heatmap head, which produces a dense spatial probability map indicating likely target center locations using a Gaussian encoding.
- An offset head, which refines the coarse grid-aligned center predictions by regressing sub-pixel shifts.
- A size head, which predicts the width and height of each target.
3.2. Enhanced Low-Level Feature Module (ELFM)
3.3. Position–Scale Heatmap Supervision with CIoU Regularization
- is the squared center distance;
- is the squared diagonal length of the smallest enclosing box of and ;
- measures aspect ratio inconsistency;
- is a dynamically adjusted weight defined by the original CIoU formulation.
4. Experiment
4.1. Experimental Setup and Evaluation Metrics
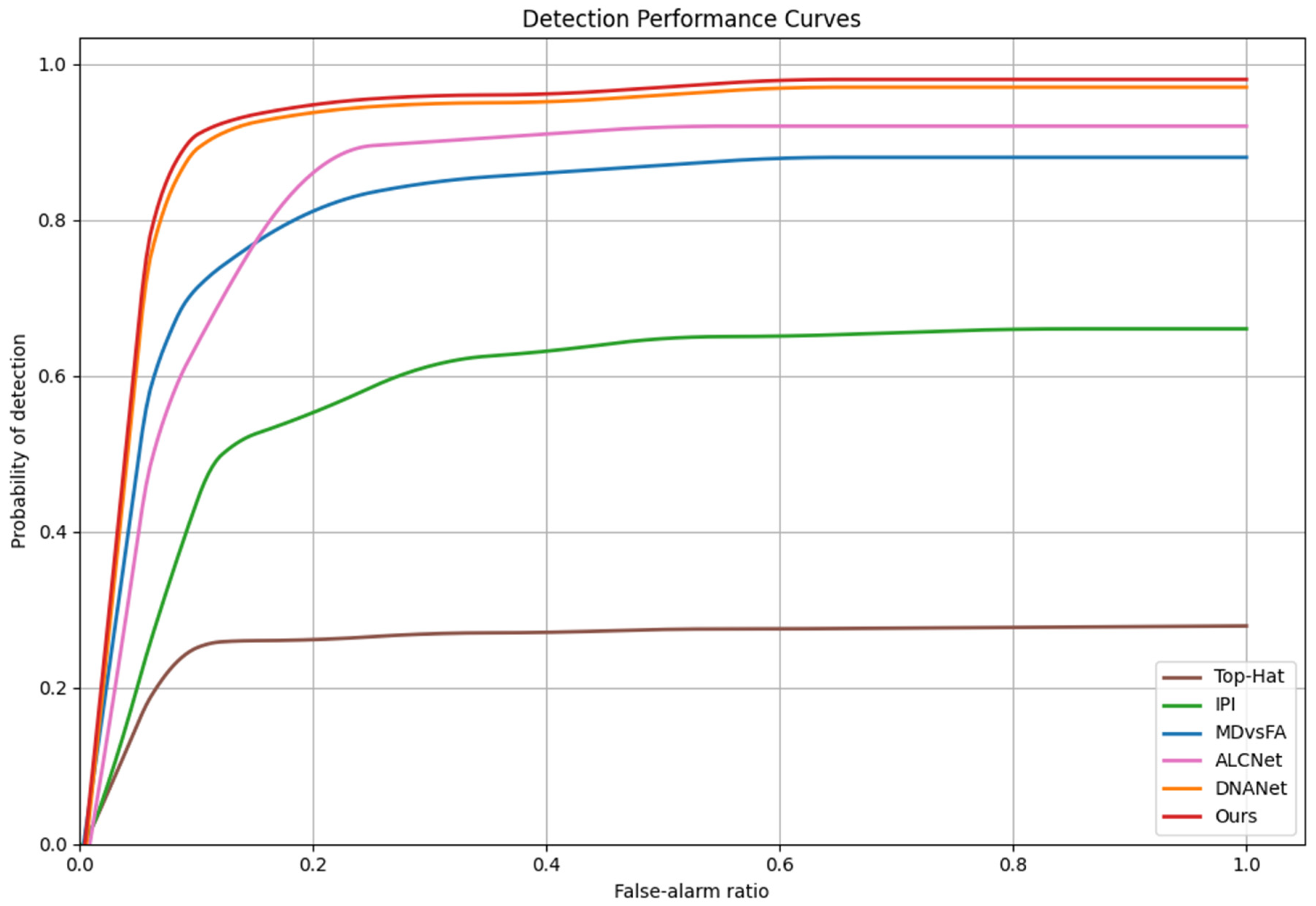
4.2. Comparison with State-of-the-Art Methods
4.3. Internal Module Evaluation (Ablation Study)
- Baseline: U-Net encoder–decoder architecture with only the heatmap branch and modified focal loss supervision.
- Baseline + ELFM: Baseline augmented with the Enhanced Low-level Feature Module to strengthen spatial details.
- Baseline + Offset/Size Heads: Baseline enhanced with offset and size regression heads supervised by L1 loss.
- Baseline + CIoU Regularization: Baseline incorporating CIoU loss to regularize geometric consistency of predictions.
- Full Model (Proposed PSHNet): Complete integration of ELFM, offset/size heads, and CIoU regularization.
5. Conclusions and Discussion
- Semi-supervised or weakly supervised learning, to reduce dependency on dense labels;
- Model compression, such as replacing deeper convolutional blocks with ghost feature modules [24], to support deployment on low-power platforms;
- Lightweight attention mechanisms [25], to better capture subtle thermal features with minimal computational cost;
- Temporal modeling or multimodal fusion, such as visible-infrared integration, to improve robustness under motion blur or complex scenes.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bai, X.; Zhou, F.; Jin, T. Enhancement of dim small target through modified top-hat transformation under the condition of heavy clutter. Signal Process. 2010, 90, 1643–1654. [Google Scholar] [CrossRef]
- Deshpande, S.D.; Er, M.H.; Venkateswarlu, R.; Venkateswarlu, R.; Chan, P. Max-mean and max-median filters for detection of small targets. SPIE 1999, 3809, 74–83. [Google Scholar]
- Zhou, D.; Wang, X. Robust infrared small target detection using a novel four-leaf model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 1462–1469. [Google Scholar] [CrossRef]
- Guan, X.; Peng, Z.; Huang, S.; Chen, Y. Gaussian scale-space enhanced local contrast measure for small infrared target detection. IEEE Geosci. Remote Sens. Lett. 2019, 17, 327–331. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, P.; Xie, J.; Li, M. Infrared small target detection based on Gaussian curvature filtering and partial sum of singular values. SPIE 2022, 12506, 928–934. [Google Scholar]
- Kou, R.; Wang, C.; Peng, Z.; Zhao, Z.; Chen, Y.; Han, J.; Huang, F.; Yu, Y.; Fu, Q. Infrared small target segmentation networks: A survey. Pattern Recognit. 2023, 143, 109788. [Google Scholar] [CrossRef]
- Hou, X.; Zhang, L. Saliency detection: A spectral residual approach. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Yan, Z.; Xin, Y.; Su, R.; Liang, X.; Wang, H. Multi-Scale Infrared Small Target Detection Method via Precise Feature Matching and Scale Selection Strategy. IEEE Access 2020, 8, 48660–48672. [Google Scholar] [CrossRef]
- Wang, K.; Du, S.; Liu, C.; Cao, Z. Interior attention-aware network for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Ciocarlan, A.; Le Hegarat-Mascle, S.; Lefebvre, S.; Woiselle, A.; Barbanson, C. A Contrario Paradigm for Yolo-Based Infrared Small Target Detection. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 5630–5634. [Google Scholar]
- Hao, X.; Luo, S.; Chen, M.; He, C.; Wang, T.; Wu, H. Infrared small target detection with super-resolution and YOLO. Opt. Laser Technol. 2024, 177, 111221. [Google Scholar] [CrossRef]
- Li, N.; Huang, S.; Wei, D. Infrared Small Target Detection Algorithm Based on ISTD-CenterNet. Comput. Mater. Contin. 2023, 77, 3511–3531. [Google Scholar] [CrossRef]
- Wang, H.; Zhou, L.; Wang, L. Miss detection vs. false alarm: Adversarial learning for small object segmentation in infrared images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8509–8518. [Google Scholar]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Attentional local contrast networks for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9813–9824. [Google Scholar] [CrossRef]
- Li, B.; Xiao, C.; Wang, L.; Wang, Y.; Lin, Z.; Li, M.; An, W.; Guo, Y. Dense nested attention network for infrared small target detection. IEEE Trans. Image Process. 2022, 32, 1745–1758. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Liu, R.; Zheng, B.; Wang, H.; Fu, Y. Infrared small target detection with scale and location sensitivity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 17490–17499. [Google Scholar]
- Zhang, M.; Zhang, R.; Yang, Y.; Bai, H.; Zhang, J.; Guo, J. ISNet: Shape matters for infrared small target detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 877–886. [Google Scholar]
- Qi, M.; Liu, L.; Zhuang, S.; Liu, Y.; Li, K.; Yang, Y.; Li, X. FTC-Net: Fusion of transformer and CNN features for infrared small target detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8613–8623. [Google Scholar] [CrossRef]
- Chen, T.; Tan, Z.; Chu, Q.; Wu, Y.; Liu, B.; Yu, N. Tci-former: Thermal conduction-inspired transformer for infrared small target detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; Volume 38, pp. 1201–1209. [Google Scholar]
- Ciocarlan, A.; Hégarat-Mascle, S.L.; Lefebvre, S.; Woiselle, A. Robust infrared small target detection using self-supervised and a contrario paradigms. arXiv 2024, arXiv:2410.07437. [Google Scholar]
- Ni, R.; Wu, J.; Qiu, Z.; Chen, L.; Luo, C.; Huang, F.; Liu, Q.; Wang, B.; Li, Y.; Li, Y. Point-to-Point Regression: Accurate Infrared Small Target Detection With Single-Point Annotation. IEEE Trans. Geosci. Remote. Sens. 2025, 63, 1–19. [Google Scholar] [CrossRef]
- Zhang, Q.; Qiu, L.; Zhou, L.; An, J. ESM-YOLO: Enhanced Small Target Detection Based on Visible and Infrared Multi-modal Fusion. In Proceedings of the Asian Conference on Computer Vision, Hanoi, Vietnam, 8–12 December 2024; pp. 1454–1469. [Google Scholar]
- Liu, Q.; Li, X.; Yuan, D.; Yang, C.; Chang, X.; He, Z. LSOTB-TIR: A large-scale high-diversity thermal infrared single object tracking benchmark. IEEE Trans. Neural Networks Learn. Syst. 2023, 35, 9844–9857. [Google Scholar] [CrossRef] [PubMed]
- Hayat, M.; Aramvith, S.; Bhattacharjee, S.; Ahmad, N. Attention ghostunet++: Enhanced segmentation of adipose tissue and liver in ct images. arXiv 2025, arXiv:2504.11491. [Google Scholar]
- Hayat, M.; Gupta, M.; Suanpang, P.; Nanthaamornphong, A. Super-Resolution Methods for Endoscopic Imaging: A Review. In Proceedings of the 2024 12th International Conference on Internet of Everything, Microwave, Embedded, Communication and Networks (IEMECON), Jaipur, India, 24–26 October 2024; pp. 1–6. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Dataset | IoU (%) ↑ | Pd (%) ↑ | Fa (×10−6) ↓ |
|---|---|---|---|---|
| Top-Hat | IRSTD-1k | 12.56 | 68.94 | 188.78 |
| IPI | 26.01 | 70.39 | 36.69 | |
| MDvsFA | 52.88 | 86.90 | 31.32 | |
| ALCNet | 48.02 | 93.30 | 29.87 | |
| DNANet | 63.01 | 97.70 | 9.72 | |
| Ours | 66.47 | 98.01 | 6.83 | |
| Top-Hat | NUDT-SIRST | 22.34 | 70.54 | 95.37 |
| IPI | 18.67 | 67.87 | 45.78 | |
| MDvsFA | 52.84 | 82.34 | 50.55 | |
| ALCNet | 78.45 | 96.34 | 35.99 | |
| DNANet | 82.17 | 98.93 | 23.65 | |
| Ours | 83.02 | 98.94 | 14.08 |
| Method | Parameters (M) | GFLOPS | Latency (RTX 3090, ms) | Latency (Orin Nano, ms) |
|---|---|---|---|---|
| ALCNet | 1.50 | 4.2 | 6.63 | 17.8 |
| MDvsFA | 3.13 | 7.5 | 9.66 | 22.4 |
| DNANet | 4.69 | 10.8 | 24.05 | 35.6 |
| Ours | 5.7 | 12.3 | 13.4 | 28.7 |
| Method | Target Size | IoU (%) ↑ | Pd (%) ↑ | Fa (×10−6) ↓ |
|---|---|---|---|---|
| ALCNet | (0, 10] (small) | 47.26 | 91.27 | 22.53 |
| DNANet | 49.51 | 95.24 | 20.68 | |
| Ours | 52.08 | 96.12 | 17.42 | |
| ALCNet | (10, 40] (medium) | 63.14 | 91.85 | 13.25 |
| DNANet | 64.79 | 91.85 | 8.03 | |
| Ours | 66.37 | 93.16 | 6.51 | |
| ALCNet | (40, ∞) (large) | 78.46 | 93.94 | 6.78 |
| DNANet | 79.20 | 96.97 | 11.02 | |
| Ours | 80.91 | 97.34 | 9.06 |
| Configuration | IoU (%) ↑ | Pd (%) ↑ | Fa (×10−6) ↓ |
|---|---|---|---|
| Baseline | 78.16 | 96.85 | 27.14 |
| Baseline + ELFM | 80.43 | 97.32 | 20.67 |
| Baseline + Offset/Size Heads | 80.91 | 97.84 | 18.53 |
| Baseline + CIoU Regularization | 81.47 | 98.02 | 17.21 |
| Full Model (Proposed PSHNet) | 83.02 | 98.94 | 14.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, W.; Zhang, C.; Liu, Y. PSHNet: Hybrid Supervision and Feature Enhancement for Accurate Infrared Small-Target Detection. Appl. Sci. 2025, 15, 7629. https://doi.org/10.3390/app15147629
Chen W, Zhang C, Liu Y. PSHNet: Hybrid Supervision and Feature Enhancement for Accurate Infrared Small-Target Detection. Applied Sciences. 2025; 15(14):7629. https://doi.org/10.3390/app15147629
Chicago/Turabian StyleChen, Weicong, Chenghong Zhang, and Yuan Liu. 2025. "PSHNet: Hybrid Supervision and Feature Enhancement for Accurate Infrared Small-Target Detection" Applied Sciences 15, no. 14: 7629. https://doi.org/10.3390/app15147629
APA StyleChen, W., Zhang, C., & Liu, Y. (2025). PSHNet: Hybrid Supervision and Feature Enhancement for Accurate Infrared Small-Target Detection. Applied Sciences, 15(14), 7629. https://doi.org/10.3390/app15147629