1. Introduction
In modern agriculture, multiple challenges are observed, generally related to ensuring quality agricultural products for an ever-growing global population and for which resources become limited [
1]. A relevant research topic in modern agriculture development is technological innovation to increase the efficiency and sustainability of agricultural practices.
With the advancement of computer vision and artificial intelligence, image-based pest detection systems have gained attention as a practical and scalable solution for real-time monitoring [
2,
3]. Deep learning (DL) models, especially convolutional neural networks (CNNs), have shown strong potential in visual recognition tasks, such as object detection and classification, including applications in agricultural pest identification. However, CNNs often face limitations in capturing long-range dependencies and contextual relationships within images, particularly in complex and cluttered agricultural scenes. Recent developments in transformer-based architectures, such as vision transformers (ViTs), have demonstrated superior performance in visual tasks by modeling global feature relationships across image patches [
4,
5].
Compared to conventional CNN architectures, such as ResNet or EfficientNet, which rely on local receptive fields, vision transformers (ViTs) offer the advantage of modeling long-range spatial dependencies via self-attention mechanisms. This capability enables ViTs to better capture subtle and globally distributed features, which is particularly beneficial in insect pest classification, where fine-grained distinctions between species are required.
Using these techniques and developing systems for automatic identification and continuous monitoring can allow rapid and targeted interventions, especially for the effectiveness of treatments and the minimization of pesticide application, as well as the strengths of ecological and sustainable agriculture that ensure the quality of cultivated products [
6]. Due to the high performance on identification, speed, and accurate detection, systems integrating CNNs can reduce the risk of mass infestations. Ultimately, improved yield can be seen due to these integrations, and modern agricultural areas can have a significant ecological footprint [
7].
CNN architecture ensembles represent new trends in digital image processing and analysis for classification, segmentation, or object detection operations. Over the years, various studies in this field have been concerned with increasing the performance and robustness of these DL models [
8,
9,
10]. ViT demonstrates remarkable, competitive performance, outperforming state-of-the-art CNN models. This is complemented by ViT’s performance when trained on massive, extensive datasets.
The main contributions of this study are as follows:
We develop a novel ensemble system composed exclusively of five vision transformer (ViT) architectures—ViT Base, DeiT, MaxViT, FasterViT, and XCIT—which are independently trained and evaluated on benchmark insect datasets.
We propose a new logit-level fusion strategy in which class-wise F1 scores are used to compute a weight matrix that determines the contribution of each base model to each class prediction.
We employ logistic regression as a meta-classifier trained on scaled and weighted logits, offering a more expressive and fine-grained fusion compared to classical SoftMax averaging or majority voting methods.
These contributions provide an effective and scalable solution for insect pest classification in real-world agricultural settings, offering both accuracy and robustness. Considering these characteristics, the present paper applies ViT models to insect pest detection, highlighting their flexibility and potential to create innovative solutions for the varied contexts of modern agriculture [
11]. This work presents modern ViT architectures to combine them as an ensemble-type decision system to increase performance in the classification task. The proposed system, built by a new fusion method, considers decision-making based on the associated weights for each component network, and each predicted class outperforms the lower-level components represented by the individual models.
Apart from the introduction, the paper consists of the following sections.
Section 2 presents related works in the addressed field, following a series of challenges and limitations for the present task.
Section 3 contains the materials and methods of the study, with emphasis on datasets, CNN architecture used, hardware and software areas, and implementation of the proposed system.
Section 4 notes the experimental results. Some discussions, highlighting the strengths and analyzing the proposed methodology from various perspectives, are presented in
Section 5. Finally,
Section 6 concludes the paper.
2. Related Works
Recent papers note CNNs’ success in identifying pest insects in agriculture. Researchers have developed and implemented various architectures to distinguish between different insect pests affecting crops, based on intelligent systems and data from real scenarios. Digital images illustrating scenarios taken from the field are input data for training DL architectures [
12,
13]. The larger and better oriented the dataset is (providing a higher quality of input data), the higher the performance obtained, and the more accurately it can identify the pests in the targeted areas.
The authors of [
1] focused on crop pest identification using CNNs and a custom digital image dataset from real agricultural environments. The proposed architecture is enhanced by a parallel attention mechanism to address the challenges of effective detection in real scenarios. A proposed model, ResNet50-PCSA, integrates a channel and spatial attention module to correctly extract relevant features of insects, highlighting them against a complex background. The experiments showed that the model proposed by the authors achieved a remarkable accuracy of over 98%, being trained and evaluated using a dataset that included images taken from agricultural areas.
To automatically monitor important insect pest populations, the authors of [
14] implemented a YOLOv5-based architecture to identify two fly species affecting Mediterranean crops. An overall accuracy of 93% underlined the significant advantages of DL models over traditional methods, which are often expensive and subject to various human errors. At the same time, the researchers noted a potential extension of the proposed system’s applicability to other insect species, providing a scalable solution for modern IPM methodologies.
A recent study [
15] showed that classification architectures based on residual networks achieved remarkable results in the identification process of insect pests. However, complications occurred because of the pests’ complicated behavior and appearance changes throughout their lifecycle. To address these issues, the author proposed a multi-task learning system based on a discriminative attention multi-network (DAM-Net) module, whose job is to extract key features from digital images to help and improve the identification process of insects. For enriching texture details and global contextual information, a ResNet50 architecture was used. It was observed that these techniques were useful in understanding the data from the images that make up the datasets. In this case, the method demonstrated remarkable results with an accuracy of 99.7% on the D0 dataset and 74.1% on the IP102 dataset. The proposed DL techniques can create architectures to improve the system’s performance and robustness in different agricultural contexts.
The authors of [
16] proposed an innovative method called k-nearest neighbors distance entropy (KNN-DE) as an effective method to evaluate informative data, applied to agricultural pests’ identification. This research noted the importance of data quality instead of data quantity for accurate pest recognition. The authors noted that using high-quality data and learning based on few-shot learning can greatly reduce the resources needed to train CNN models, and such an approach can have a major impact on precision agriculture practices by applying smart and sustainable technologies.
Pursuing the maximization of performance metrics for these applications, new trends are represented by the CNN combination models. Major advantages of such an approach are increasing accuracy and improving robustness by implementing a global system, based on the decision of several architectures [
17,
18]. By using an ensemble of models, one can explore the strengths of each model while also noting specific vulnerabilities [
19]. In this case, one model may be more effective at detecting insect-specific features, and another model may excel at identifying insects depicted in complex scenarios, under different lighting conditions, and in various poses. Also, combining models can reduce the risk of identification errors and improve the system’s robustness. This improvement is crucial in agricultural environments where conditions are dynamic and variable. In a recent study, the authors [
20] discussed the development of an agricultural pest image classifier using a ResNet-based matching network and an NT-Xent loss function. The article addressed a major limitation of classical methods by proposing the detection of new classes of pests without retraining the network. This is because the features learned previously can be applied to new classes. Removing fully connected layers of the network did not require fine retraining when a new class appeared. The results demonstrated a classification accuracy of 84.29% for the D0 dataset.
The potential of DL techniques based on a CNN ensemble for improving pest detection was emphasized in [
21]. The study introduced notable ensemble techniques based on NMS, SoftNMS, weighted box fusion (WBF), and non-maximum weighted (NMW) in this regard. The results showed that the WBF approach was valuable and improved the mAP by 20%. In addition, the study used a dataset constructed from images taken from real conditions, finally noting the relevance and applicability of such methods for advanced detection systems in real agricultural scenarios.
Another modern combining strategy was proposed as an effective pest classification method by combining multiple CNN models based on improved transformer architectures [
22]. The proposed DenseNet vision transformer system efficiently combined the local and global features of the chosen models by using an ensemble voting algorithm. The authors’ experiments were performed on the public datasets D0 and IP102 and demonstrated remarkable accuracy in both cases of 99.89% and 74.2%, respectively. The article highlighted a promising method for accurately identifying numerous insect pests, outperforming other state-of-the-art methods.
The power of combining EfficientNet CNNs to improve large-scale pest image classification was highlighted in [
15]. The combination model was based on fine-tuning and SVM techniques, proposing an approach that replaces the traditional SoftMax function with a PM-SVM one, while focusing on reducing margin-based loss instead of cross-entropy loss. The experimental results showed remarkable accuracy for the considered datasets D0 and IP102 of 99% and 72.31%, respectively. These obtained metrics underline the effectiveness of the proposed method, providing a high-performance solution for applications in smart agriculture and pest monitoring. The authors of [
23] presented an innovative approach for pest classification in agricultural areas using a weighted ensemble of CNNs, optimized with genetic algorithms. In this study, seven pretrained models were targeted, trained, and optimized using transfer learning strategies on the D0 dataset. The best models were selected (MobileNet, Xception, and InceptionV3) and combined using a weighted voting method based on genetic algorithms. The experimental results reached a classification accuracy of 98.81%, demonstrating the effectiveness of the proposed method in terms of performance and robustness. It has been observed that the implementation of a weighted ensemble of CNNs provides a valuable, efficient, and adaptable solution for accurate pest identification under various agricultural conditions.
A novel learning assistance method that enhances CNN-based models for insect pest classification using a two-step training strategy is proposed in [
24]. The “Deep” step focuses on improving feature discrimination using triplet margin loss, while the “Wide” step enhances generalization with Mixup augmentation. This approach is on IP102 and D0 datasets and improved efficiency and adaptability. The new study [
25] introduced a hybrid deep learning architecture combining CNNs and Transformers, integrating two key modules: a Feature Fusion Module for multi-scale fine-grained feature extraction and a Mixed Attention Module for modeling long-range dependencies. The model achieves state-of-the-art performance on IP102 and D0 datasets, offering robust performance in complex agricultural environments. The authors in [
26] proposed a pest recognition method based on Swin Transformers and residual attention mechanisms. The architecture enhances local and global features while mitigating background interference. It achieves strong classification results on the IP102 dataset, proving its suitability for real-world agricultural applications. Generally, diverse sets of classifiers can help maximize performance on different datasets [
27]. The paper highlighted the importance of careful parameter tuning and benchmarking on large datasets for reliable results. It also demonstrated the effectiveness of ensemble methods in different architectures, highlighting their potential to improve performance in image classification tasks.
Existing works in insect pest classification have primarily relied on convolutional neural networks, often using single-model architectures or basic ensemble strategies, such as majority voting. While some recent studies have explored hybrid or attention-based CNNs, the full potential of VIT architectures remains an important research topic in this domain. On the other hand, most ensemble methods lack adaptive mechanisms to weigh model contributions at a class level, limiting their ability to handle imbalanced datasets and fine-grained distinctions between insect species. To address these gaps, our study proposes a novel ensemble framework composed entirely of ViT-based models, incorporating a class-specific F1 score weighting strategy and a logistic regression meta-classifier trained on weighted logits. This approach offers enhanced robustness, adaptability, and superior classification performance, as validated on two challenging datasets: D0 and IP102.
3. Materials and Methods
This section presents details on the datasets, the ViT architecture, the hardware and software used, and the overall system implementation. Details on the ViT configuration and optimization for digital image classification are presented. The method that combines the predictions of the ViT models demonstrates the advantages and efficiency of exclusively using ViT models in combination with a global decision for visual recognition tasks.
3.1. Dataset Used
The datasets used included public D0 [
28] and IP102 [
29], each providing images with categories essential for the training and evaluation processes of the models used. Each has a variety of labeled images necessary for model training and validation.
The first dataset used, D0, represents a valuable resource for identifying pest insects and comprises different digital images, illustrating a range of representative insect classes. D0 has approximately 4500 images and covers 40 common pest species, from crops such as corn, soybean, wheat, and canola. Images were taken in natural field environments, ensuring variability based on illumination, background, pose, and scale, using several cameras and mobile devices. Images were normalized for uniform illumination and rescaled to a size of 200 × 200 pixels for computational efficiency. Images were collected from actual experimental fields, making them more representative of field conditions than lab-based datasets. Sample images from the D0 dataset are presented in
Figure 1a.
The second dataset, IP102, represents one of the most comprehensive and diverse datasets for insect pest detection and classification using DL techniques. IP102 has 75,222 images representing 102 different species of insect pests. The images are captured to simulate real scenarios in agricultural areas, featuring various lighting conditions, angles, and backgrounds (
https://github.com/xpwu95/IP102; accessed on 10 May 2025). Examples of images from the IP102 dataset are shown in
Figure 1b. It offers opportunities to address fine-grained classification, robust object identification in practical situations, and imbalanced learning.
The dataset included various growth stages of pests (e.g., egg, larva, and adult), emphasizing intra-class diversity. Compared to other datasets, IP102 provides significantly more categories, samples, and diversity, addressing prior limitations in scale and applicability.
For this study, all available samples from the D0 and IP102 datasets were used. Each dataset was split into 70% training, 20% validation, and 10% testing. For the D0 dataset, this corresponded to approximately 3150 training images, 900 validation images, and 450 testing images. For the IP102 dataset, the splits resulted in approximately 52,655 training images, 15,044 validation images, and 7523 testing images.
The D0 dataset is relatively balanced, with an approximately uniform number of samples per class. However, the IP102 dataset is significantly imbalanced, with a large variance in the number of images per class. In this research, no explicit balancing techniques, such as resampling or class weighting, were applied. Instead, the proposed ensemble architecture, which includes model-level decision fusion and a meta-classifier, was designed to mitigate the effects of class imbalance by enhancing generalization and robustness.
It is also important to note that the two datasets were treated independently. The ensemble models were trained and evaluated separately on D0 and IP102, without any form of cross-dataset data fusion. This ensured that the specific characteristics and complexity of each dataset were respected during model development and evaluation.
3.2. Vision Transformer Models Used
Five vision-transformer-based neural networks were analyzed to implement the ensemble system. The first model used, the ViT Base (Vision Transformer Base) [
30], is a DL model that brings the transformer architecture, well-known in natural language processing, to the field of computer vision. Unlike traditional CNNs, ViT Base processes images by dividing them into patches (smaller pieces) and treating each patch as a “word” in a sequence, applying self-awareness mechanisms to learn the relationships between these patches. This approach permits the model to capture long-term spatial relationships and handle higher image resolutions.
Another implemented model, DeiT (Data-efficient Image Transformer) [
31], is a DL model developed to improve the efficiency of ViT networks using less training data. It introduces an innovative training method called “attention distillation”, where a student model (DeiT) is trained using a teacher model, another neural network model, or a traditional image classifier. DeiT achieves competitive performance with classical CNNs. The model uses a standard transformer architecture but benefits from regularization and optimization techniques that reduce computational requirements and improve generalization.
The next model used, MaxViT (Maximizing Vision Transformer) [
32], is a DL one that combines innovations in transformer architecture with the efficiency and power of CNN. MaxViT introduces a hybrid design that integrates transformers and convolution blocks, allowing the model to benefit from both the ability to capture global spatial relationships of transformers and the efficiency and locality characteristic of convolutional networks. In addition, MaxViT uses a hierarchical attention structure, where attention is calculated at multiple scales, enhancing the model’s ability to capture fine details and complex structures in images.
Faster ViT [
33] is a DL model designed to improve the efficiency and speed of ViT networks in image processing. Faster ViT uses innovative techniques to reduce computational complexity and improve performance, including optimizations. To this end, multiple attentions are handled, and efficient visual data pre- and post-processing modules are introduced. These improvements allow the model to process images at higher resolutions and with reduced inference time, making it ideal for real-time applications and resource-constrained devices.
XCIT (Cross-Covariance Image Transformer) [
34] is an innovative DL model designed to address the limitations of traditional transformer architectures in computer vision. XCIT introduces a unique cross-covariance-based attention computation method that reduces computational complexity and improves learning efficiency. Instead of using the standard self-attention mechanism that operates on the entire feature space, XCIT calculates attention based on the covariance between channels, thus allowing the relationships between feature channels to be captured directly and efficiently. This approach significantly reduces memory and computational requirements and improves the model’s ability to learn more robust and generalizable representations.
The five selected ViT models, ViT Base, DeiT, MaxViT, FasterViT, and XCIT, were chosen to represent a diverse set of attention mechanisms and design philosophies within the vision transformer family. ViT Base and DeiT served as foundational models, while MaxViT and XCIT introduced hierarchical and cross-covariance attention structures, respectively. FasterViT was included for its inference efficiency and deployment potential. These models were also readily available in the same PyTorch/TIMM ecosystem, enabling standardized training and evaluation. While other high-performing models, such as Swin Transformer, BEiT, ConvNeXt, or hybrid CNN-ViT approaches, exist, they were not included due to differences in tokenization, pretraining setup, or increased computational cost.
3.3. Hardware and Software Used
The hardware and software configuration used for the research experiments was oriented around a custom system for image classification using DL. The hardware part is described as a robust platform to handle the computationally intensive demands of the experiments. The system integrates an Intel Core i9-11900K CPU and massive support for neural network training provided by an ASUS NVIDIA RTX 2080Ti GPU equipped with 11 GB of dedicated GDDR6 memory and CUDA compatibility. The system memory is 126 GB RAM. All hardware components run on a stable Ubuntu v22 operating system. These systems handle deep learning, multitasking, and parallel processing efficiently. This is important for dataset management and complex neural network architectures. On the software side, experiments of the present study were done using the Python v3.9 programming language, popular for machine learning development due to the wide support for libraries and frameworks effective in analyzing and manipulating data, digital images, and developing DL models. The PyTorch v2.0 library was used for specific deep-learning tasks, a modern and flexible tool for implementing neural network architectures. PyTorch’s CUDA compatibility leverages GPU acceleration capabilities for fast optimization and training of deep learning models.
3.4. Global System Implementation
Improving neural network architectures for insect pest identification can go beyond traditional adjustments of existing models, exploring new paradigms and technologies. The exploration and implementation of these methods could lead to significant advances in the accurate and efficient detection of insect pests, thus contributing to more sustainable and efficient agricultural pest management [
35].
A stacking-based ensemble system with a meta-classifier was implemented to classify insect species from IP102 and D0 datasets. This approach combined the predictions of some base classifiers (weak learners), leveraging their diverse strengths to improve overall classification performance. By integrating the outputs of the base models, the meta-classifier learned how to effectively weigh and combine their predictions, resulting in a more robust and accurate ensemble model. The base models can be of any type and provide various perspectives on the data [
19,
36]. The presented ViT-type architectures were used as base models. The meta-classifier (global system) learned how to combine these perspectives to improve overall prediction accuracy.
The process started with training the basic ViT models on the training set. Each model learned to generate predictions independently. The second step was global model predictions. For an attached dataset (validation set), predictions were generated from each proposed base model. The role of these predictions was to obtain a new dataset, where features were the predictions resulting from the basic models. The base models’ predictions became the meta-classifier (ensemble system) features. Given N base ViT models and M samples, an M × N feature matrix will be generated, where each column represents the predictions from one base model. The next step was to train the meta-classifier using the new feature set (predictions of base models) as input and the true labels as the target. The meta-classifier learned how to combine the base models’ predictions to make the final prediction. For new data, predictions from each base model were generated. Then, the trained meta-classifier was used to make the final prediction based on these base model predictions. The key point behind stacking and using a meta-classifier is that different models might capture different patterns in the data. The meta-classifier can leverage these diverse patterns and potentially correct individual model weaknesses, leading to a more robust and accurate prediction. The mathematical formulas that describe this process are presented below. Implementing the formulas for the global system represents the key contribution of this study.
Each ViT model
i (where
i = 1, 2, …,
N) was trained to minimize the loss function. This was done for each model using the training dataset. After initial training, logits and F1 scores will be generated for each class and each model. After training, each model
i generates the associated
(1), represented by raw scores for each class
c and instance (image)
x, where
represents the probability that
x belongs to
c:
The
logit represents a raw, unscaled score resulting from the last layer of the neural architecture for classification, before applying the activation function (SoftMax), given the multi-class classification task [
37]. Because these values were not transformed, they were more sensitive to differences between dataset classes. The lack of transformation means that logits can highlight subtle differences between classes in a dataset. For example, if two classes have logits that are very close in value, applying an activation function, like SoftMax, can still map these logits into probability values that are extremely close to each other.
This happens even if one
logit is marginally larger than the other, as the transformation is sensitive to the relative differences between logits. This sensitivity is particularly significant when dealing with imbalanced datasets or overlapping features, as logits inherently capture the raw model confidence for each class. However, interpreting logits directly is challenging because they are not normalized or interpretable as probabilities. Instead, transforming logits into probabilities enables better understanding and practical use, such as ranking class likelihoods or making probabilistic predictions [
38]. On the other hand, raw logits preserve this small difference, which is valuable for a meta-classifier. Using logits allows flexible and adaptable combinations of basic models and avoids information compression problems. As part of a meta-classifier, it produces more accurate final predictions [
39]. It is important to note that the method ultimately allows models that perform better in certain classes to have a greater influence on the final prediction.
Thus, the
F1 score was calculated using the validation dataset for each model
i and class
c (
). The formula for the
F1 score (2) contained precision (3) and recall (4).
,
, and
represent true positives, false positives, and false negatives, respectively, for class
c and neural network
i [
35]:
The next step was to generate the weight matrix
W for the meta-classifier.
W has size
L × N, where
L is the number of classes and
N is the number of models. Each element of the matrix
was calculated using the expression (5), where
is the weight of the model
associated with class
c, and
is the
F1 score for model
i and class
c:
The weight matrix
W can be completed as in (6), where each column corresponds to a model, and each row corresponds to a class:
Weighting the
logit using the weight matrix is another important step in system implementation. Using the matrix, the
logit generated by each model for each class was weighted. The weighted logit for a sample
x and class
c is (7):
The weighted
logit was scaled before being entered into the logistic regression area (8):
where
represents the weighted and scaled logit for a sample
x, and
Scaler is a scaling operation of type Standard
Scaler (taken for the present case from the sklearn preprocessing library) that transforms the data to have a standard deviation of 1 and a mean of 0.
Further, logistic regression was used as a meta-classifier. Logistic regression will predict the probability (9) that a given sample
x belongs to class
c using the previously mentioned weighted and scaled
logit:
where
are the coefficients for class c as part of logistic regression, and
, in this case, describes the probability that sample
x belongs to class
c.
The final class that was predicted for a given example
x was (10) the one with the maximum likelihood value, where
y(
x) is the predicted class for the example
x:
In the evaluation part of the meta-classifier, the
F1 score (11) can be calculated to note its performance on the given test set:
where
and
are the general metrics for meta-classifier predictions.
In the present context, the weight matrix W represented an essential component. As part of the presented process, it adjusted the contribution of each model to the class prediction based on the performance of the individual, underlying models, as measured by the F1 score. The weighting performed, followed by the logit combination using logistic regression, described an improvement in overall performance, better fitting the defining characteristics of the classes in the dataset.
This approach can help to weigh the base model predictions more effectively based on their performance, particularly in a multi-class classification scenario where the
F1 score is an important metric. After training the base models,
F1 scores for each basic model were calculated and weight predictions were generated. In this step, the
F1 scores were used to weigh the predictions from each base model. Higher
F1 scores can be given more weight. Finally, the meta-classifier was trained using the weight predictions as features.
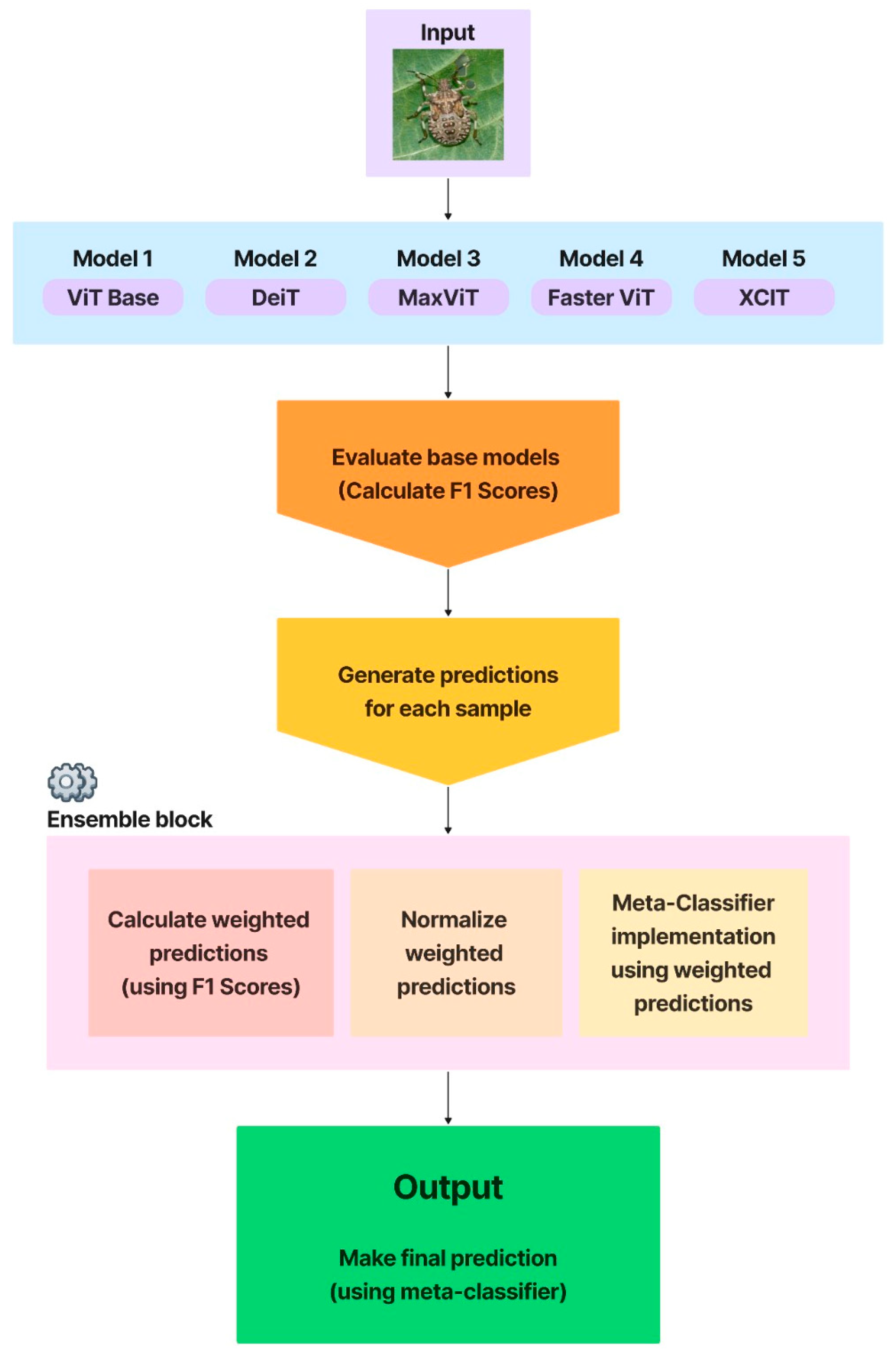
Figure 2 shows the diagram illustrating the process of training and evaluating base models, computing weighted predictions, and meta-classifier implementation.
The meta-classifier works at a higher level of classification. The individual classifiers form the first level. The meta-classifier operates at the second level, taking the predictions of the lower-level classifiers as input. In the present context, the area represented by the meta-classifier was responsible for learning the complex relationships between the base classifiers and weighting the contribution of each to obtain a better final prediction. This was based on a common learning model represented by logistic regression. To note the ensemble deep learning part, the usage example was one of the stacking types (stacked generalization). Each first-level classifier generated predictions that became the input features of the meta-classifier [
19]. The meta-model is, in this way, a useful winner-takes-all strategy. These procedures work together to integrate the capabilities of different models, resulting in improved prediction performance.
The meta-classifier used in this study was a multinomial logistic regression model, implemented via the LogisticRegression class from Scikit-learn (sklearn.linear_model). The model was trained on class-wise weighted and standardized logits from the five ViT base models. Standardization was performed using StandardScaler to zero-mean and unit-variance the features. The logistic regression model was configured with the following parameters: solver = ‘lbfgs’, multi_class = ‘multinomial’, max_iter = 1000, and the default regularization strength C = 1.0. This setup ensured stable convergence and probabilistic predictions across multiple insect classes. The model output the predicted class with the highest probability, based on SoftMax-transformed logits.
4. Experimental Results
The main steps that define the structure and the approaches for the experimental results are represented by the analysis and the experiments performed on the individual models, choosing the right architectures for the decision fusion system, and experimental results with the decision fusion system, the meta-classifier approach.
The transfer learning technique involved pretrained models on a vast dataset (such as ImageNet) and their adaptation to a new specific task, insect pest classification. Using PyTorch, the models were implemented with the TIMM library (
https://huggingface.co/docs/timm/index; accessed on 10 May 2025). The pretrained ViT models were used, and fine-tuning techniques were applied to adjust the model parameters on the chosen datasets—D0 and IP102. The fine-tuning part involved additional training of chosen models on a new dataset. In the same framework, a lower learning rate was adopted to avoid the problem of overlearning, but also to use the prior knowledge of the model.
The initial step was to train and evaluate the base models. This step aimed to score the performance of individual models and perform rigorous training and validation sessions. For the present study, conducting these training and evaluation sessions had several essential roles: the objective evaluation of the basic models, the optimization of parameters and performances, and the prevention of unwanted cases of overfitting/underfitting were considered. Therefore, this step represents strong points for improving the robustness and effective development of the ensemble decision system.
Models trained on the defined 100 epochs featured a regular performance check to prevent overlearning. For fine-tuning all ViT-based models, the following hyperparameters were used consistently: The batch size was set to 32, and the Adam optimizer was employed with an initial learning rate of 0.001. A cosine annealing scheduler was used to gradually reduce the learning rate over the 100 training epochs. A dropout rate of 0.5 was applied to the fully connected layers of each model to mitigate overfitting. L2 regularization (weight decay) was set to 1 × 10−4, applied through the optimizer. These settings were empirically chosen based on stability across datasets and alignment with best practices in ViT-based transfer learning.
To evaluate the practical viability of our ensemble architecture, we recorded both the training and inference times for each model. Individual ViT models required, on average, between 3.4 and 4.8 h for full training (100 epochs) on the D0 dataset and up to 6.5 h on IP102. Inference time per image (averaged across all classes) was approximately ViT Base: 15.2 ms, DeiT: 13.8 ms, MaxViT: 21.1 ms, FasterViT: 11.9 ms, and XCiT: 16.6 ms. The meta-classifier training phase, based on the logit-weighted features, required under 5 min, and its inference time per image was negligible. The overall ensemble inference time, including all base models and the meta-classifier, was approximately 78 ms per image, demonstrating feasibility for near-real-time deployment in field monitoring systems. This tuning strategy helped balance training efficiency with model generalization and stability across datasets.
These techniques reduced the risk of overlearning and increased the robustness of the model concerning the datasets used. They were effective when working with many features. For the D0 dataset, for each proposed architecture, the results obtained are shown in
Table 1.
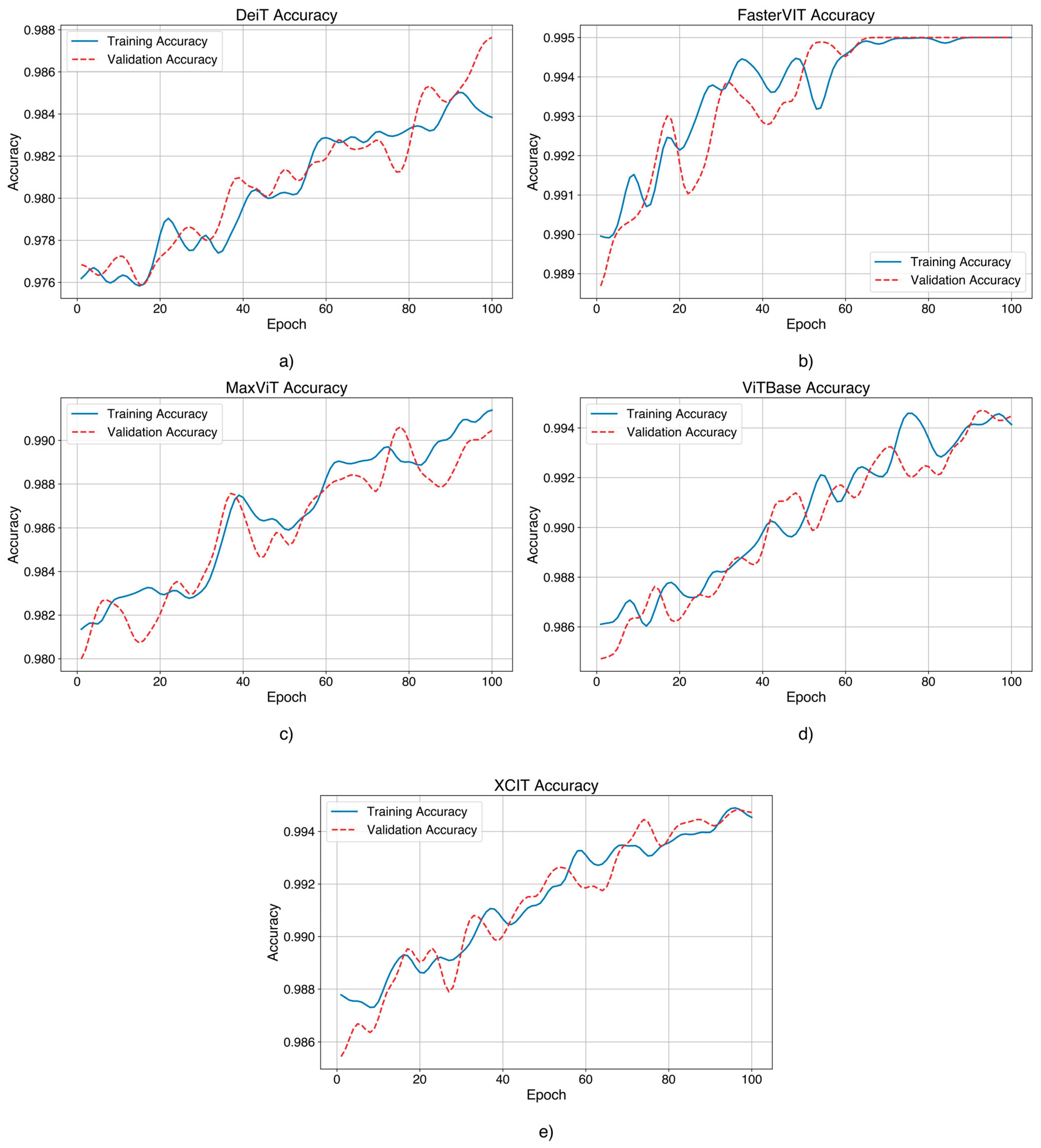
The evolution of the accuracy function after training and validating the chosen models is presented in
Figure 3.
For each graph, the horizontal axis represents the number of training epochs. The vertical axis shows the accuracy values.
For the D0 dataset, MaxViT demonstrated a gradual and steady increase in accuracy in training and validation, reaching values close to 99%. The loss decreased gradually, indicating efficient model convergence without obvious signs of overfitting. DeiT performed similarly to MaxViT, with accuracy steadily increasing toward 98%. The loss gradually decreased, confirming the stability of the model during training. Validation performance was slightly more variable, but still very good, showing robust generalization ability. XCIT showed excellent performance, with accuracy steadily increasing to 99%. The loss decreased gradually, suggesting efficient learning of relevant features from the data. The model demonstrated excellent generalizability with consistent performance across training and validation sets. ViTBase achieved good performance, with accuracy steadily increasing toward 99%. The loss gradually decreased, indicating efficient convergence and robust generalization ability. The model showed excellent stability during training. FasterViT performed well, with accuracy steadily increasing to 99.1%. The loss decreased gradually, indicating efficient convergence and great generalization ability. The model demonstrated stable performance in training and validation, making it suitable for deployments on resource-constrained devices.
As per the previously attached results, the evolutions of the loss and accuracy functions for the IP102 dataset and the table of performance indicator values are presented. For the IP102 dataset, for each proposed architecture, the obtained results are shown in
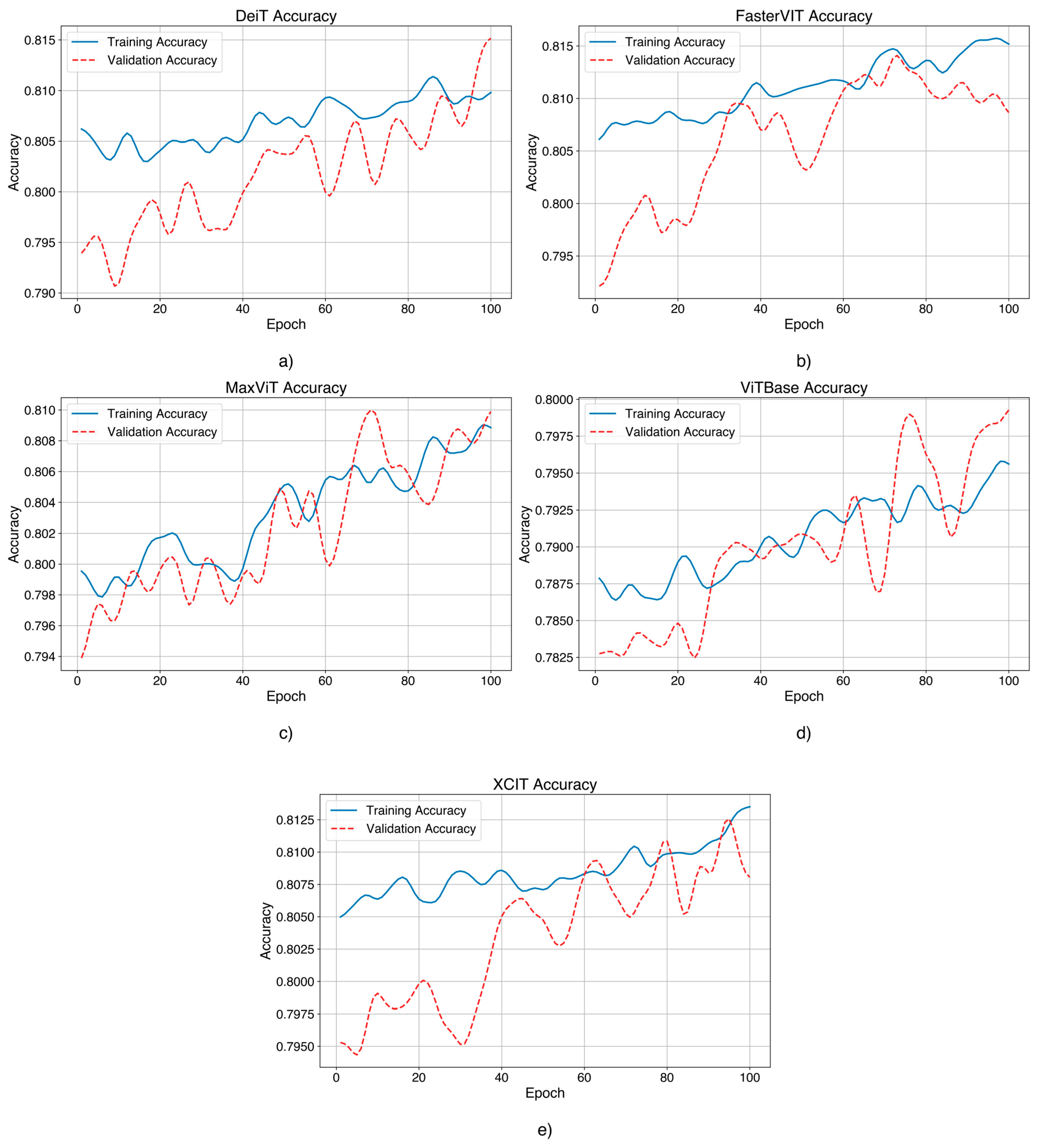
Table 2, and the performance evolution is shown in
Figure 4.
As with the D0 dataset, the ViT architecture also showed notable performance on the IP102 dataset, underscoring the power of these architectures to extract features relevant to the classification process, given a larger and multi-class insect pest dataset. By comparing the models, the FasterViT architecture demonstrated the best performance concerning the insect pest dataset, with an F1 score of 0.8145. These can be seen in the balanced metrics and stable curves on the training and validation sides. A model like this architecture is XCIT, which had good values for accuracy (0.8119), recall (0.829), and F1 score (0.8018), but slightly higher validation losses compared to FasterViT.
MaxViT, DeiT, and ViTBase had performance but showed slight instabilities and fluctuations on the training and validation side compared to the previously mentioned top models.
For the testing part, the characteristics of the proposed method were considered. The final operational scheme for classifying an image started with sending an image to each base model and preprocessing it to match the base model’s input.
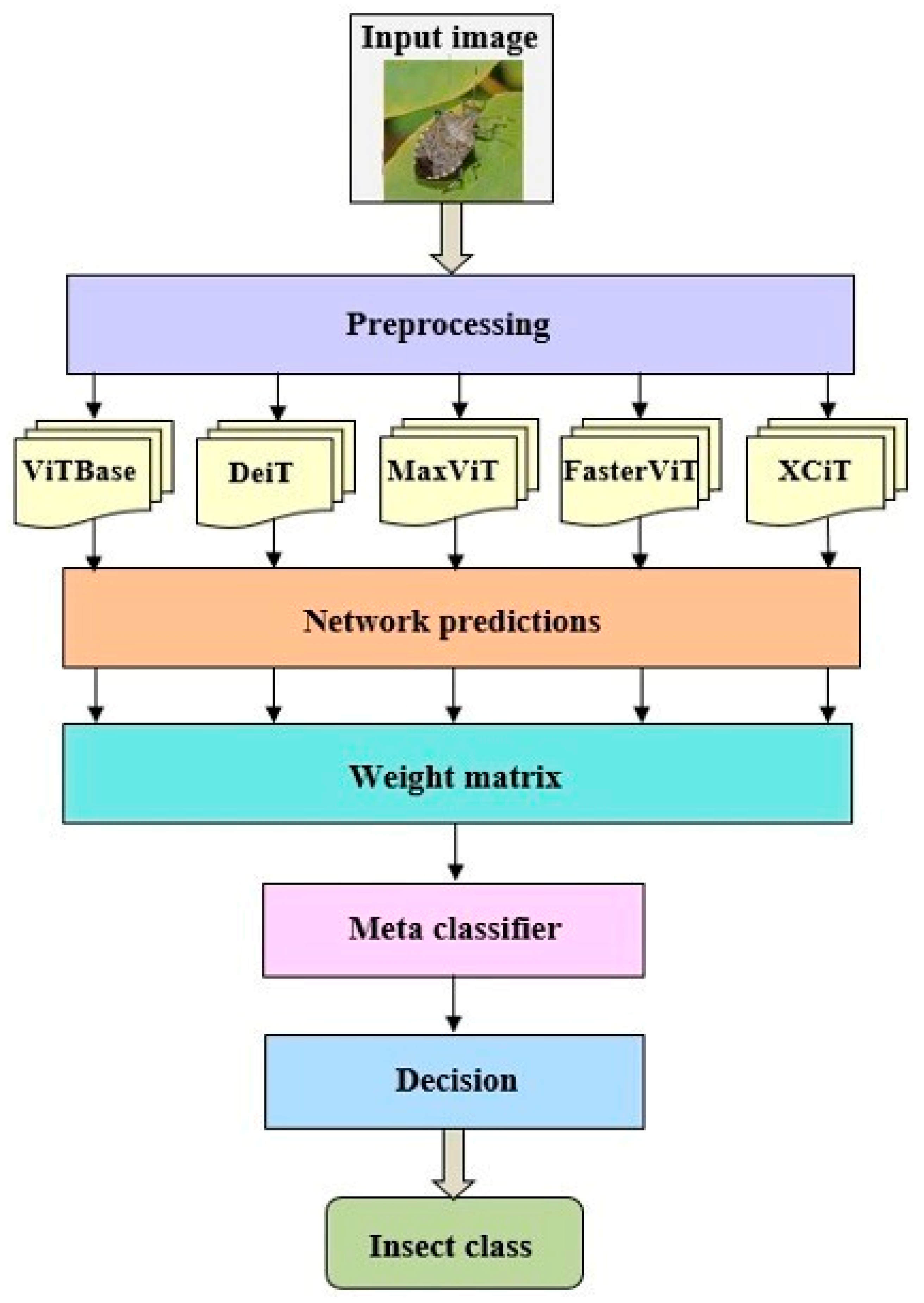
The architecture of the proposed ensemble fusion system is detailed in
Figure 5. The diagram outlines the prediction flow, starting from input preprocessing through base model inference, class-specific weighting, and final meta-classification.
After preprocessing, each base model (VitBase, DeiT, MaxViT, FasterViT, and XCIT) generated logit as the prediction for each class, which was then weighted with a coefficient from the weight matrix. The weighted logits were scaled and fed into the chosen meta-classifier, which calculated probabilities for each class. The meta-classifier thus combined the information from all the base models, following the better-performing models for certain classes. The final predicted class had the highest probability, providing a more robust and accurate prediction. The summary of this process involved processing the image by several models, combining and weighting predictions, and using an ensemble model to generate the final prediction.
The ensemble’s performance exceeded that of the individual models. This denotes that each architecture, with good metrics for the chosen datasets, had a significant decision factor, overcoming the limitations of the individual models.
Table 3 shows the metrics obtained for the ensemble architecture. It can be observed that the performances were better for the D0 dataset than IP102.
It is important to clarify that the high
F1 score of 99.82% corresponded to the ensemble model evaluated on the D0 dataset, as presented in
Table 3. This dataset was well-balanced and less complex than IP102, which facilitated better generalization. In contrast,
Figure 4 illustrates the performance on the IP102 dataset, where the larger number of classes and unbalanced distribution made overfitting more likely. The ensemble approach, based on logit-level weighting and logistic regression, played an important role in reducing overfitting and enhancing robustness, particularly in the case of the D0 dataset.
The reported metrics were computed on a single fixed split of 70% training, 20% validation, and 10% test data for each dataset. This split was randomly generated but held constant across all models to ensure comparability. Due to the size and diversity of the datasets, especially IP102, this split provided meaningful evaluation. However, no cross-validation or repeated random sampling was applied, which could provide more insight into model variance and stability.
5. Discussion
ViT architecture using transfer learning with fine-tuning provided significant insights into the performance and applicability for insect pest classification. Several challenges and limitations in the methodologies used are noted. First, using singular models for pest detection can reveal limitations that bring to the fore the need for massive optimization of architecture and the use of dedicated hardware with enormous resources to maximize performance. This comes at the cost of performance, as such systems cannot be easily integrated to create continuous monitoring systems, as computing and processing require significant hardware resources. However, there is research on such architecture development and optimization for low-resource mobile systems.
By optimization techniques, such as lower learning rates, dropout, and regularization strategies, it was observed that the risks of overfitting can be avoided while maintaining the benefits of the pretrained weights of the chosen models. This approach allowed the ViT models to be efficiently adapted to new tasks, achieving high performance and good generalization across the datasets.
The distribution of insects from the D0 dataset provided relevant training and evaluation data that resulted in maximum values for the proposed architecture in this study, with the ensemble model and individual models achieving good metrics and high generalization ability. In the case of the IP102 dataset, the insect classes represented were in greater numbers, but their distribution was not equal for each class, so there was no significant balance. It was observed that the proposed models tended to misclassify images due to the limitations present in the dataset. It can be noted that the analyzed IP102 dataset needs to present careful preprocessing and balancing modules of the presented instances to provide improved performance. By combining multiple ViT models and using a meta-classifier, the ensemble architecture can reduce overfitting, achieving better generalizations on new datasets, a powerful technique to refine the predictions of multiple individual ViT models to maximize the accuracy and robustness of an ensemble model.
The evaluation of individual models, including VitBase, DeiT, MaxViT, FasterViT, and XCIT, provided a detailed understanding of the strengths and limitations of each architecture. For the D0 dataset, all models achieved high performance, with FasterViT achieving the highest performance values. On the second dataset, IP102, which was more challenging due to its complexity and multi-class structure, FasterViT also achieved good performance, closely followed by XCiT. These details highlighted the ability of the ViT models in pest identification under various conditions and scenarios. The decision fusion system improved the classification performance by combining the results of multiple base models using a meta-classifier. This ensemble system leveraged the complementary strengths of the chosen individual models, assigning weights based on their performance, as described by F1 scores. The results demonstrated that the ensemble outperformed the individual models, highlighting the effectiveness of decision fusion in addressing the limitations of independent architecture.
In analyzing the training dynamics, moderate fluctuations were observed in the validation performance of certain models, notably DeiT and ViT Base, especially when trained on the more complex and imbalanced IP102 dataset. These fluctuations may stem from the smaller representational depth of these models compared to newer ViT variants, as well as their sensitivity to minority classes during learning. The class imbalance in IP102 likely exacerbated these effects, leading to unstable gradient updates and less consistent validation performance. In contrast, models such as FasterViT and XCIT demonstrated more stable convergence, suggesting that architectural enhancements (e.g., hierarchical attention and cross-covariance mechanisms) helped mitigate noise and imbalance. Future research should explore mitigation techniques, such as focal loss, class-aware batch construction, adaptive weight regularization, and self-distillation, to enhance training robustness and reduce performance oscillations, particularly for ViT variants applied to imbalanced or fine-grained datasets.
A comparison of the method proposed in this study with specialized works oriented toward the same topic is presented in
Table 4.
Table 4 compares the performance of our proposed method with previously published works on the D0 and IP102 datasets. Most of the referenced approaches rely on CNN-based architectures, such as ResNet, EfficientNet, or hybrid models combining convolutional layers with attention mechanisms. For example, Reference [
23] employed a genetic-algorithm-optimized weighted ensemble of MobileNet, Xception, and InceptionV3. Reference [
22] proposed a hybrid DenseNet-ViT ensemble using voting-based fusion. More recent methods, like that in [
48], used attention-refined ResNeXt ensembles, while Reference [
49] focused on lightweight transformer-CNN fusions suitable for mobile inference. In contrast, our work leveraged an ensemble composed entirely of ViT-based architectures, guided by class-specific F1 score weighting and a logistic regression meta-classifier, leading to consistent performance gains across both datasets. This positioned our method as a ViT-native, model-agnostic ensemble framework that outperformed both traditional CNN ensembles and recent hybrid strategies.
While the proposed ensemble model demonstrated strong global performance metrics, we acknowledge that a detailed species-level analysis, such as per-class F1 scores or confusion matrix evaluation, was not included in this study. Given the imbalance and diversity in the IP102 dataset, such an analysis would provide valuable insight into model behavior across different pest species. We consider this a promising direction for future work, where we aim to evaluate and interpret class-wise performance more comprehensively, including visualizations of prediction distributions and error patterns per insect category.
The strong class imbalance in the IP102 dataset may affect training dynamics, particularly for underrepresented species. Although our ensemble design helped reduce overfitting by combining diverse models, the lack of explicit class-balancing strategies could still introduce performance bias toward dominant classes.
While the proposed ensemble model of vision transformers demonstrated strong classification performance on benchmark datasets, several limitations should be acknowledged:
- -
Lack of species-level analysis: The present study reported global performance metrics but did not include a detailed evaluation per insect class. Such analysis would provide additional insights into model strengths and weaknesses across pest species, especially for underrepresented categories.
- -
Dataset scope: Only two publicly available datasets (D0 and IP102) were used for training and evaluation. Although these are well-known and diverse, additional datasets from different agroclimatic regions, or a dedicated collection (custom dataset), would enhance the model’s generalizability.
- -
No evaluation on edge devices: While architectures like FasterViT are suitable for deployment on low-resource systems, the current study did not include inference benchmarks on embedded or mobile devices. This limited conclusions about real-time performance and deployment readiness.
- -
Static ensemble composition: The ensemble structure was fixed per dataset and not adapted dynamically. Future work could explore adaptive model selection or context-aware ensembles to further improve scalability and robustness.
Another limitation is the lack of repeated runs or k-fold cross-validation. While a large and diverse test set was used for each dataset, multiple random splits or cross-validation would help assess model variance and generalization more rigorously, especially given the class imbalance in IP102. We plan to include such evaluations in future work to further validate the ensemble system’s robustness.
These limitations serve as a basis for future developments aimed at expanding the practical impact and interpretability of the proposed insect classification system.
In future work, we aim to expand the simulation framework by incorporating additional fusion strategies, such as soft-voting ensembles, dynamic expert selection, and gating-based adaptive ensembling. These approaches may further improve robustness in variable agricultural conditions. Additionally, while the current study used accuracy, precision, recall, and F1 score as evaluation metrics—aligned with existing literature—future evaluations may include more nuanced metrics, such as ROC-AUC, to provide deeper insight into classification performance across unbalanced classes.
The current study employed logistic regression as the meta-classifier due to its interpretability, low computational cost, and strong performance when working with well-structured inputs, such as weighted logits. Its simplicity helped reduce the risk of overfitting, particularly given the relatively low dimensionality of the meta-feature space. However, we acknowledge that more complex classifiers, such as multilayer perceptron, random forests, or gradient-boosted trees, may capture higher-order interactions between model predictions. Exploring these options represents a valuable future direction to potentially improve ensemble performance, especially under more challenging data distributions.
It is important to acknowledge potential sources of bias in the present methodology. The architectural selection was based on model diversity and training feasibility but did not include certain high-performing alternatives, such as Swin Transformer or BEiT, which could influence comparative outcomes. Dataset bias is also present, as both D0 and IP102 are geographically constrained and may not fully represent pest species or environmental conditions from other regions. To mitigate overfitting, several regularization strategies were employed, including dropout (rate = 0.5), L2 weight regularization, early stopping, and basic data augmentation (e.g., flips and brightness adjustment). While these methods helped stabilize training, the fixed training/validation/test split limited the scope for performance generalization. Furthermore, no domain adaptation techniques were applied to test transferability. In future work, we plan to incorporate datasets from diverse agroclimatic zones and evaluate the ensemble system’s robustness in cross-region pest classification scenarios. This will help validate its generalizability and identify region-specific adaptation needs.
Another practical consideration is the deployment of the ensemble model in hardware-constrained environments, such as edge computing devices used for real-time pest monitoring in agricultural fields. Although architectures like FasterViT are inherently optimized for speed, the overall ensemble system may still be computationally intensive. To address this, several model compression and acceleration techniques can be applied:
Model pruning to remove redundant parameters without significant accuracy loss.
Quantization to reduce weight precision (e.g., from 32-bit float to 8-bit integer) and improve inference speed.
Knowledge distillation to train a smaller model that mimics the ensemble’s output.
Lightweight ViT variants, such as MobileViT, TinyViT, or EdgeFormer, for resource-efficient inference.
Inference optimization frameworks, like ONNX Runtime, TensorRT, or TFLite, for deployment on embedded devices.
Integrating these strategies would help bridge the gap between high-performing ViT ensembles and real-time pest detection systems suitable for use in farms, drones, or mobile platforms. Future work could explore these directions for sustainable deployment.
6. Conclusions
This study demonstrated the efficacy of an ensemble system in enhancing insect pest classification performance. The proposed approach improved the classification performances by leveraging the complementary strengths of diverse individual architectures. D0 and IP102 adoption, with a wide variety of insect details, provided robust training resources and enabled reliable performance benchmarking against public datasets. Notably, the ViT models emerged as highly effective for the chosen classification task and integrated their capabilities within an ensemble framework, guided by F1 scores as a decision factor—further optimizing the system’s performance.
The ensemble model achieved a test accuracy of 99.87% and a test F1 score of 99.82% on the D0 dataset. On the IP102 dataset, the system achieved a test accuracy of 83.71% and a test F1 score of 84.25%.
These results underline the potential of the ensemble approach to advance digital image-based pest classification, offering a robust tool for agricultural applications. Future research will focus on enhancing generalization and applicability through several extensions. The incorporation of semi-supervised learning techniques could enable the use of unlabeled agricultural data to improve robustness in underrepresented classes. Evaluating the ensemble across multiple, geographically diverse insect datasets would also test its adaptability to new domains. In terms of deployment, optimizing the system for real-time applications using model compression strategies, such as pruning, quantization, or distillation, and running inference on embedded or edge devices, like drones or mobile platforms, represents a practical next step. These directions aim to close the gap between high-accuracy experimental models and scalable, field-ready pest monitoring solutions.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}