
A Framework for User Traffic Prediction and Resource Allocation in 5G Networks

 , , , ,
, , , ,  and
and 
Abstract
1. Introduction
2. Related Work
Data-Driven User Resource Allocation and Traffic Prediction in 5G Networks
3. Datasets and Data Preprocessing
3.1. 5G Traffic Dataset
3.2. DeepMIMO Dataset
4. Methodology
4.1. User Traffic Prediction Module
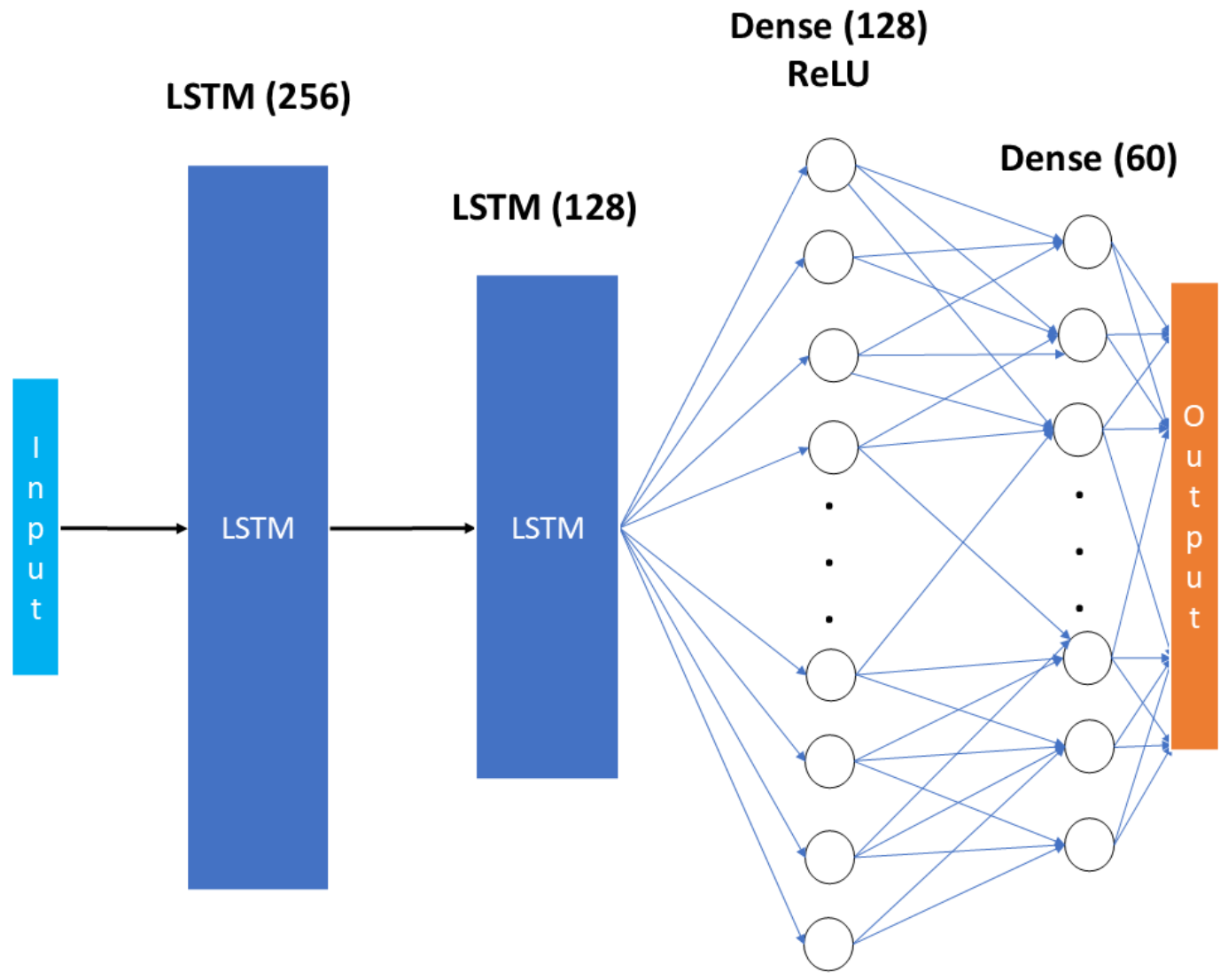
4.1.1. Long Short-Term Memory Variant
4.1.2. Transformer and Temporal Convolutional Network Variant
4.2. User Allocation Module
5. Results
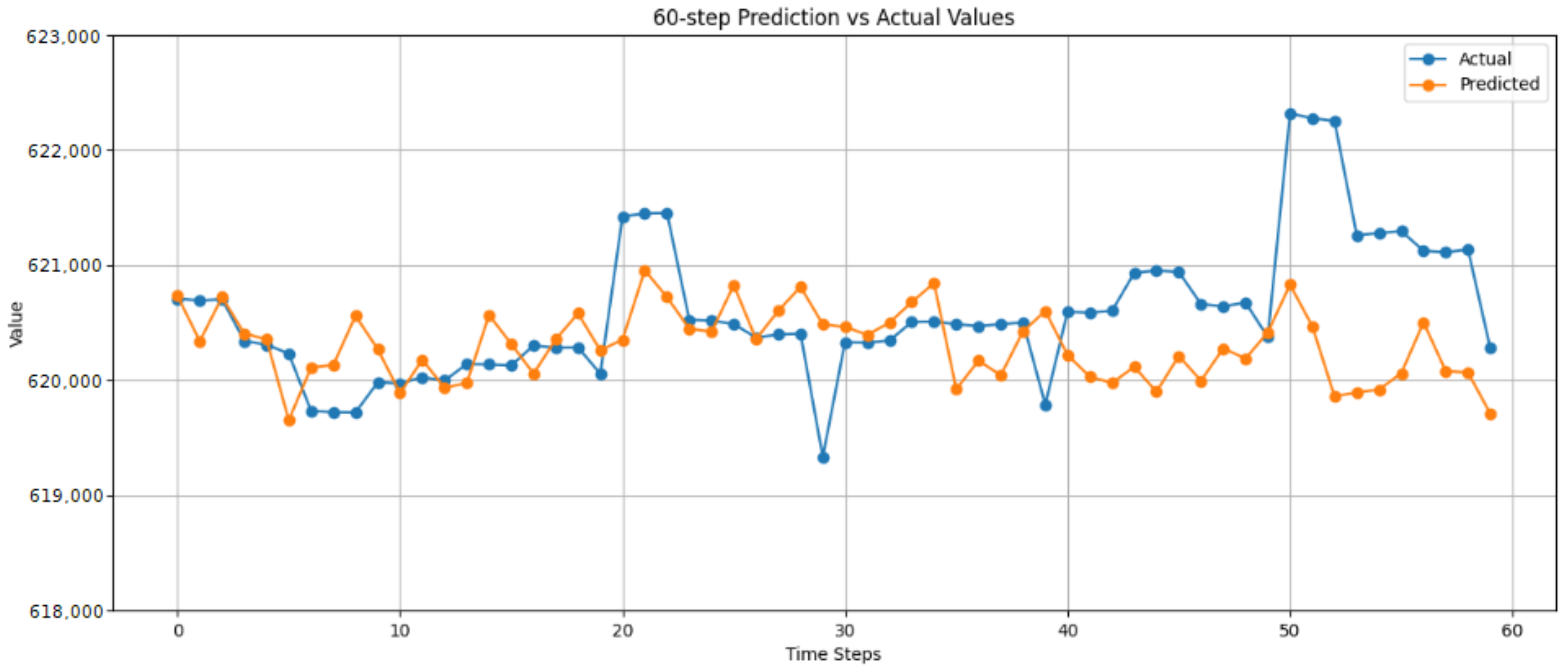
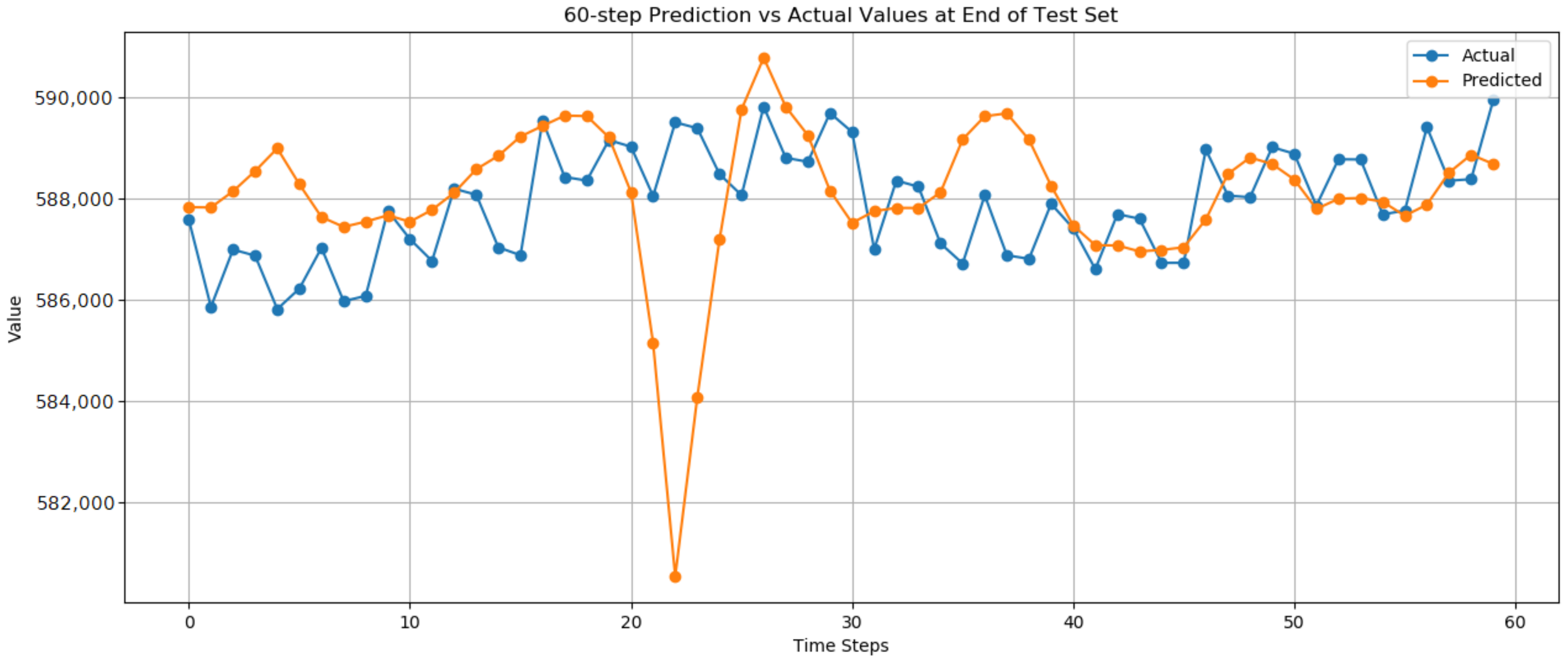
5.1. User Traffic Prediction Module Results
5.1.1. Long Short-Term Memory Results
5.1.2. Transformer and Temporal Convolutional Network Results
5.1.3. Ablations
5.2. User Allocation Module Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 5G | Fifth-Generation |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| DRL | Deep Reinforcement Learning |
| GNN | Graph Neural Network |
| IP | Internet Protocol |
| LSTM | Long Short-Term Memory Network |
| MAE | Mean Absolute Error |
| MIMO | Multiple-Input Multiple-Output |
| ML | Machine Learning |
| NOMA | Non-Orthogonal Multiple Access |
| QoS | Quality of Service |
| ReLU | Rectified Linear Unit |
| RNN | Recurrent Neural Networks |
| TCN | Temporal Convolutional Network |
References
- Umar, A.; Khalid, Z.; Ali, M.; Abazeed, M.; Alqahtani, A.; Ullah, R.; Safdar, H. A Review on Congestion Mitigation Techniques in Ultra-Dense Wireless Sensor Networks: State-of-the-Art Future Emerging Artificial Intelligence-Based Solutions. Appl. Sci. 2023, 13, 12384. [Google Scholar] [CrossRef]
- Fowdur, T.P.; Doorgakant, B. A review of machine learning techniques for enhanced energy efficient 5G and 6G communications. Eng. Appl. Artif. Intell. 2023, 122, 106032. [Google Scholar] [CrossRef]
- López-Pérez, D.; Domenico, A.D.; Piovesan, N.; Bao, H.; Xinli, G.; Qitao, S.; Debbah, M. A Survey on 5G Radio Access Network Energy Efficiency: Massive MIMO, Lean Carrier Design, Sleep Modes, and Machine Learning. IEEE Commun. Surv. Tutor. 2021, 24, 653–697. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, S.; Lim, H. Reinforcement Learning Based Resource Management for Network Slicing. Appl. Sci. 2019, 9, 2361. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiong, L.; Yu, J. Deep learning based user association in heterogeneous wireless networks. IEEE Access 2020, 8, 197439–197447. [Google Scholar] [CrossRef]
- Yu, P.; Zhou, F.; Zhang, X.; Qiu, X.; Kadoch, M.; Cheriet, M. Deep learning-based resource allocation for 5G broadband TV service. IEEE Trans. Broadcast. 2020, 66, 800–813. [Google Scholar] [CrossRef]
- Kumaresan, S.P.; Tan, C.K.; Ng, Y.H. Deep neural network (DNN) for efficient user clustering and power allocation in downlink non-orthogonal multiple access (NOMA) 5G networks. Symmetry 2021, 13, 1507. [Google Scholar] [CrossRef]
- Huang, D.; Gao, Y.; Li, Y.; Hou, M.; Tang, W.; Cheng, S.; Li, X.; Sun, Y. Deep learning based cooperative resource allocation in 5G wireless networks. Mob. Netw. Appl. 2022, 27, 1131–1138. [Google Scholar] [CrossRef]
- Pamba, R.; Bhandari, R.; Asha, A.; Bist, A. An Optimal Resource Allocation in 5G Environment Using Novel Deep Learning Approach. J. Mob. Multimed. 2023, 19, 1331–1356. [Google Scholar] [CrossRef]
- Zhao, S. Energy efficient resource allocation method for 5G access network based on reinforcement learning algorithm. Sustain. Energy Technol. Assess. 2023, 56, 103020. [Google Scholar] [CrossRef]
- Bouras, C.; Caragiannis, I.; Gkamas, A.; Protopapas, N.; Sardelis, T.; Sgarbas, K. State of the Art Analysis of Resource Allocation Techniques in 5G MIMO Networks. In Proceedings of the 2023 International Conference on Information Networking (ICOIN), Bangkok, Thailand, 11–14 January 2023; pp. 632–637. [Google Scholar] [CrossRef]
- Bouras, C.; Diasakos, D.; Gkamas, A.; Kokkinos, V.; Pouyioutas, P.; Prodromos, N. Evaluation of User Allocation Techniques in Massive MIMO 5G Networks. In Proceedings of the 2023 10th International Conference on Wireless Networks and Mobile Communications (WINCOM), Istanbul, Turkiye, 26–28 October 2023; pp. 1–6. [Google Scholar]
- Liu, J.S.; Lin, C.H.R.; Hu, Y.C. Joint resource allocation, user association, and power control for 5G LTE-based heterogeneous networks. IEEE Access 2020, 8, 122654–122672. [Google Scholar] [CrossRef]
- Bouras, C.; Kalogeropoulos, R. User Allocation in 5G Networks Using Machine Learning Methods for Clustering. In Proceedings of the Advanced Information Networking and Applications, Barcelona, Spain, 9–11 April 2025; Barolli, L., Woungang, I., Enokido, T., Eds.; Springer: Cham, Switzerland, 2021; pp. 13–24. [Google Scholar]
- Yan, D.; Ng, B.K.; Ke, W.; Lam, C.T. Deep reinforcement learning based resource allocation for network slicing with massive MIMO. IEEE Access 2023, 11, 75899–75911. [Google Scholar] [CrossRef]
- Saleh, Z.Z.; Abbod, M.F.; Nilavalan, R. Intelligent Resource Allocation via Hybrid Reinforcement Learning in 5G Network Slicing. IEEE Access 2025, 13, 47440–47458. [Google Scholar] [CrossRef]
- Selvamanju, E.; Shalini, V.B. Machine learning based mobile data traffic prediction in 5G cellular networks. In Proceedings of the 2021 5th International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 2–4 December 2021; pp. 1318–1324. [Google Scholar]
- Gao, Z. 5G traffic prediction based on deep learning. Comput. Intell. Neurosci. 2022, 2022, 3174530. [Google Scholar] [CrossRef]
- Kavehmadavani, F.; Nguyen, V.D.; Vu, T.X.; Chatzinotas, S. Intelligent traffic steering in beyond 5G open RAN based on LSTM traffic prediction. IEEE Trans. Wirel. Commun. 2023, 22, 7727–7742. [Google Scholar] [CrossRef]
- Shrestha, A.; Sharma, V.; Hussein, L.; Aishwarya, M.; Satyanarayana, A.; Saimanohar, T. User Mobility Prediction in 5G Networks Using Recurrent Neural Networks. In Proceedings of the 2024 IEEE International Conference on Communication, Computing and Signal Processing (IICCCS), Asansol, India, 19–20 September 2024; pp. 1–6. [Google Scholar]
- Wang, Z.; Hu, J.; Min, G.; Zhao, Z.; Chang, Z.; Wang, Z. Spatial-temporal cellular traffic prediction for 5G and beyond: A graph neural networks-based approach. IEEE Trans. Ind. Inform. 2022, 19, 5722–5731. [Google Scholar] [CrossRef]
- Jamshidiha, S.; Pourahmadi, V.; Mohammadi, A. A Traffic-Aware Graph Neural Network for User Association in Cellular Networks. IEEE Trans. Mob. Comput. 2025, 24, 6858–6869. [Google Scholar] [CrossRef]
- Teng, W.; Sheng, M.; Chu, X.; Guo, K.; Wen, J.; Qiu, Z. Joint Optimization of Base Station Activation and User Association in Ultra Dense Networks Under Traffic Uncertainty. IEEE Trans. Commun. 2021, 69, 6079–6092. [Google Scholar] [CrossRef]
- Matoussi, S.; Fajjari, I.; Aitsaadi, N.; Langar, R. Deep Learning based User Slice Allocation in 5G Radio Access Networks. In Proceedings of the 2020 IEEE 45th Conference on Local Computer Networks (LCN), Sydney, NSW, Australia, 16–19 November 2020; pp. 286–296. [Google Scholar] [CrossRef]
- Thantharate, A.; Beard, C. ADAPTIVE6G: Adaptive resource management for network slicing architectures in current 5G and future 6G systems. J. Netw. Syst. Manag. 2023, 31, 9. [Google Scholar] [CrossRef]
- Choi, Y.H.; Kim, D.; Ko, M.; Cheon, K.y.; Park, S.; Kim, Y.; Yoon, H. Ml-based 5g traffic generation for practical simulations using open datasets. IEEE Commun. Mag. 2023, 61, 130–136. [Google Scholar] [CrossRef]
- DeepMIMO. Available online: https://www.deepmimo.net/ (accessed on 30 March 2025).
- Pascanu, R.; Gulcehre, C.; Cho, K.; Bengio, Y. How to Construct Deep Recurrent Neural Networks. arXiv 2014. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2023. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018. [Google Scholar] [CrossRef]
- Konstantoulas, I.; Loi, I.; Sgarbas, K.; Gkamas, A.; Bouras, C. A Deep Learning Approach to User Allocation in a 5th Generation Network. In Proceedings of the PCI ’24: 28th Pan-Hellenic Conference on Progress in Computing and Informatics, Athens, Greece, 13–15 December 2024; Association for Computing Machinery: New York, NY, USA, 2025; pp. 478–482. [Google Scholar] [CrossRef]
- Mao, A.; Mohri, M.; Zhong, Y. Cross-Entropy Loss Functions: Theoretical Analysis and Applications. arXiv 2023. [Google Scholar] [CrossRef]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling Laws for Neural Language Models. arXiv 2020. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.; Franklin, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Math. Intell. 2004, 27, 83–85. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. Proc. AAAI Conf. Artif. Intell. 2021, 35, 11106–11115. [Google Scholar] [CrossRef]
- Lim, B.; Arık, S.Ö.; Loeff, N.; Pfister, T. Temporal fusion transformers for interpretable multi-horizon time series forecasting. Int. J. Forecast. 2021, 37, 1748–1764. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Feature | Value |
|---|---|
| Second_Derivative | −0.000301 ± 0.000045 |
| First_Derivative | −0.000205 ± 0.000027 |
| Original_Values | −0.000045 ± 0.000003 |
| Rolling_Mean | −0.000003 ± 0.000001 |
| Rolling_Std | −0.000002 ± 0.000001 |
| 1 LSTM Layer | 2 LSTM Layers | 3 LSTM Layers | |||
|---|---|---|---|---|---|
| AbsError | Percent | AbsError | Percent | AbsError | Percent |
| 3225 ± 153 | 0.52% ± 0.06 | 1059 ± 47 | 0.17% ± 0.02 | 1592 ± 70 | 0.25% ± 0.03 |
| Transformer-TCN | |
|---|---|
| AbsError | Percent |
| 1215 ± 55 | 0.19% ± 0.02 |
| Loss Configuration | Trend Direction | Volatile |
|---|---|---|
| MSE_Only | - | - |
| MSE_Direction | ✓ | - |
| MSE_Volatile | - | ✓ |
| MSE_Dir_Vol | ✓ | ✓ |
| RMSE | |||
|---|---|---|---|
| Loss Configuration | Beginning | Middle | End |
| MSE_Only | 3500.426 | 2963.618 | 1300.578 |
| MSE_Direction | 2820.053 | 2543.905 | 1040.686 |
| MSE_Volatile | 3274.975 | 2359.294 | 1344.490 |
| MSE_Dir_Vol | 3311.516 | 2395.418 | 1298.337 |
| Without UserTrafficPred | With UserTrafficPred | ||
|---|---|---|---|
| Loss | Accuracy | Loss | Accuracy |
| 0.37 ± 0.02 | 0.80 ± 0.01 | 0.32 ± 0.02 | 0.84 ± 0.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Konstantoulas, I.; Loi, I.; Tsimas, D.; Sgarbas, K.; Gkamas, A.; Bouras, C. A Framework for User Traffic Prediction and Resource Allocation in 5G Networks. Appl. Sci. 2025, 15, 7603. https://doi.org/10.3390/app15137603
Konstantoulas I, Loi I, Tsimas D, Sgarbas K, Gkamas A, Bouras C. A Framework for User Traffic Prediction and Resource Allocation in 5G Networks. Applied Sciences. 2025; 15(13):7603. https://doi.org/10.3390/app15137603
Chicago/Turabian StyleKonstantoulas, Ioannis, Iliana Loi, Dimosthenis Tsimas, Kyriakos Sgarbas, Apostolos Gkamas, and Christos Bouras. 2025. "A Framework for User Traffic Prediction and Resource Allocation in 5G Networks" Applied Sciences 15, no. 13: 7603. https://doi.org/10.3390/app15137603
APA StyleKonstantoulas, I., Loi, I., Tsimas, D., Sgarbas, K., Gkamas, A., & Bouras, C. (2025). A Framework for User Traffic Prediction and Resource Allocation in 5G Networks. Applied Sciences, 15(13), 7603. https://doi.org/10.3390/app15137603