1. Introduction
Infectious diseases are major threats to global health, and TB is the world’s top infectious killer and also the major cause of death among people with HIV/AIDS. It is caused by the Mycobacterium tuberculosis bacterium that attacks the lungs. TB spreads when a person, with active TB, coughs, sneezes, or otherwise expels the bacteria. In its 2019 TB report, the WHO estimated that 10 million people were ill with TB (5.7 million males, 3.2 million females, and 1.1 million children) in 2018. Even though it is preventable and curable, it claimed 1.5 million deaths in 2018 [
1] and kills over 4000 people each day. TB occurs all over the world, whereas over 95% of cases and deaths are in middle- and low-income countries. The WHO reported that geographically high TB burden countries are in the Southeast Asian region, with 44% of new cases, followed by the African region, with 24% of new cases, and the Western Pacific with 18%, in 2018. People with HIV have a 15–22% higher risk of contracting tuberculosis than those without HIV. Undernourished people are also at high risk because their immune systems are impaired. Thus, developing countries, with widespread poverty and undernutrition, are the most TB-prevalent regions. A rising number of multi-drug-resistant bacteria has exacerbated the TB burden. Thus, TB remains a key factor in public health and a health security threat [
1]. Despite increases in notifications, there are still many undiagnosed cases because people with TB are not being checked. Early diagnosis and prompt treatment are crucial to reducing TB-related deaths and curtailing their onward transmission, allowing us to end TB epidemics.
With rapid molecular analysis and bacteria culture methods, TB detection is now very accurate [
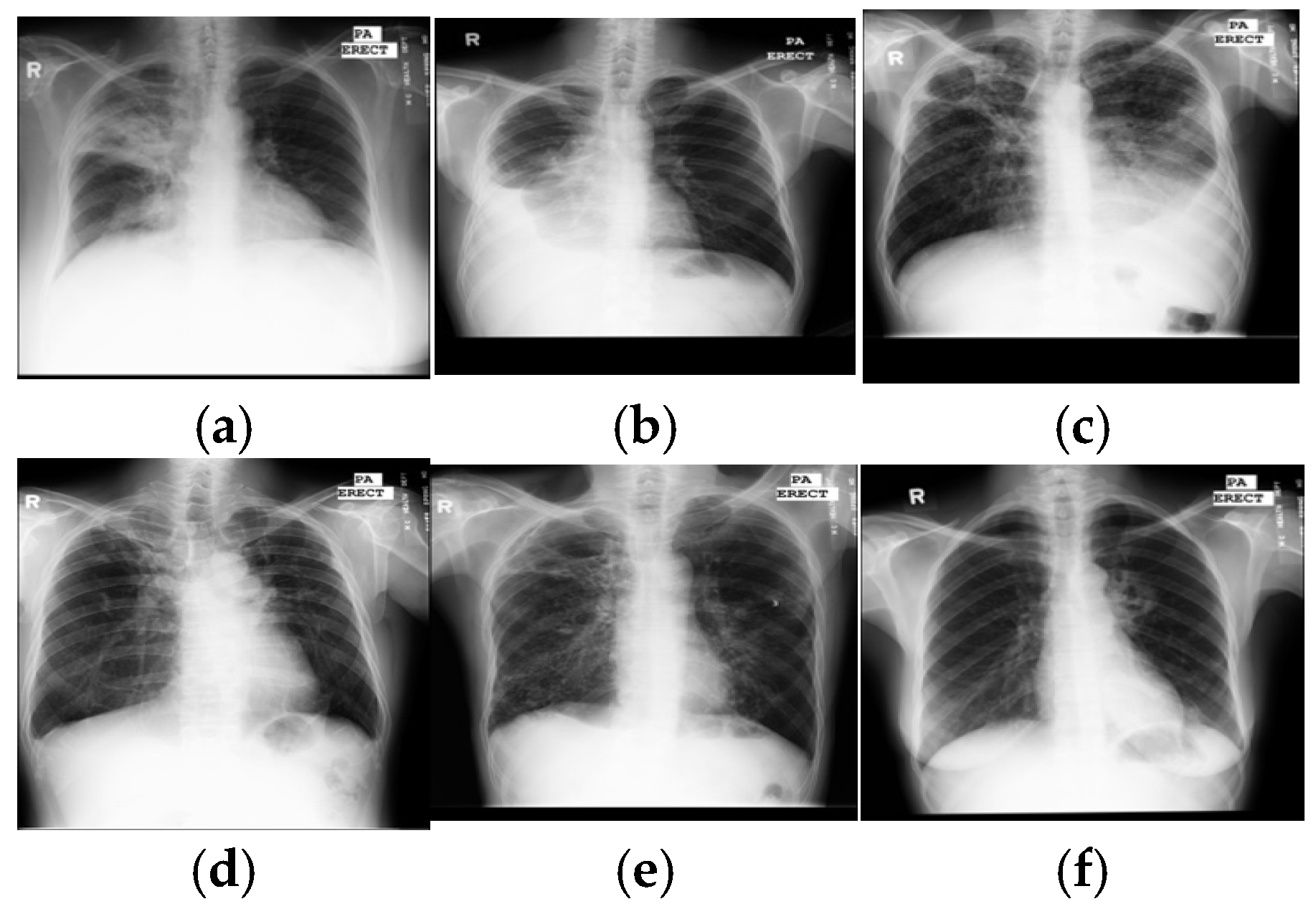
2]. However, their limited availability and expense restrict widespread use in under-resourced countries with a high TB burden. Because they are not expensive and easily accessed, chest X-rays are mandatory for every evaluation of TB and become a critical screening, diagnostic, and triaging tool for TB and other lung diseases, including lung cancer, pneumonia, etc. A chest X-ray covers all thorax anatomical structures and is a high-yield test at a low cost from a single source. Common manifestations of TB, in X-ray images, are infiltrations, cavitations, consolidations, pleural effusion and thickening, opacities, miliary pattern, and nodules. Some typical TB lesions are shown in
Figure 1. More examples of TB manifestations can be found in Daley et al.’s primer [
3].
Diagnosis of TB in X-rays is still limited in under-resourced countries where sufficient trained experts to interpret every radiograph are not available. Moreover, TB manifestations are complex and diverse, so manual detection is difficult, even for radiologists. Further, TB lesions that overlap with other disease lesions can imitate many other lung diseases. These discrepancies cause significant observer variation in TB detection. Fortunately, with the advent of digital X-rays and advanced computer vision techniques, computer-aided diagnosis has become an alternative to the expert reading of radiographs. It is hoped that an inexpensive and accurate TB detection algorithm can make the widespread screening of TB a reality in large populations with limited medical resources and alleviate human observer errors.
Reported methods for automatic interpretation of TB range from conventional machine learning methods [
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14] to deep learning methods [
15,
16,
17,
18,
19,
20]. Intuitively, interpretation pipelines have two steps: segmentation of the lung region and prediction of TB manifestations. Lung regions were mostly segmented by a lung atlas-driven method, and then the TB was predicted based on hand-crafted features, followed by a supervised classifier or deep learning method, or a hybrid of both. Typical hand-crafted features were shapes and textural features. Ginneken et al. [
4] used multi-scale feature banks for feature extraction, followed by a weighted nearest-neighbor classifier; they achieved an area under the receiver operating characteristic curve (AUC) of 98.6% and 82% on two private datasets. Hogeweg et al. [
5] proposed an algorithm to detect the textural abnormality at the pixel level for TB diagnosis. The algorithm provided AUCs between 67% and 86%. Tan et al. [
6] segmented lung regions using a user-guided snake algorithm, used first-order statistical features, and a decision tree classifier to classify between normal and X-rays showing TB. On a small custom dataset, their highest accuracy was 94.9%. Unfortunately, those studies were hampered by a lack of publicly accessible datasets for comparison.
In 2014, Jaeger et al. made two datasets publicly available—SZ with 662 images and MC with 138 images [
21]. These datasets led to an increased focus on automated TB detection in X-ray images. Jaeger et al. first segmented the lung region, using optimized graph cut methods, then extracted two sets of different features: object detection-inspired features and content retrieval ones. Finally, those extracted features were fed to the support vector machine (SVM) classifier to classify either negative or positive TB and obtained AUCs of 86.9% for MC and 90% for SZ datasets [
7]. Vajda et al. [
8] sequentially combined the atlas-driven lung segmentation, the extraction of the multi-level features of shape, curvature and eigenvalues of the Hessian matrix, the wrapper feature selection, and a multi-layer perceptron (MLP) network and obtained promising results with AUCs of 87% for MC and 99% for SZ. A combination of shape and texture features was studied by Karargyris et al. [
9], who used an atlas-based method for lung segmentation and SVM as a classifier. The authors obtained an AUC of 93.4% for the SZ dataset. Jemal [
10] used another texture feature-based method; after segmenting the lung region by thresholding, he extracted the textural features and, finally, differentiated between positive and negative using SVM and achieved AUCs of 71% for MC and 91% for SZ. Santosh and Antani [
11] used multi-scale features of shape, edge, and texture, and a combination of a Bayes network, MLP, and random forest to discriminate between negative and positive, yielding AUCs of 90% for MC and 96% for SZ. The multiple instance learning methods [
12] used moments of pixel intensities as features and SVM as a classifier and led to AUCs between 86% and 91% for three private datasets. In addition, the prediction scores were used to indicate the diseased regions using heat maps.
Recently, DCNNs were used for TB detection. They were based on the networks trained on ImageNet. Hwang et al. [
13] first used the pre-trained AlexNet for the detection of TB and achieved AUCs of 88.4% for MC and 92.6% for SZ datasets. A variant of AlexNet architecture, with a depth of five convolutional blocks and additional skip connections, was presented by Pasa et al. [
14] to obtain AUCs of 81.1% (MC) and 90% (SZ). They also generated the saliency maps and Grad-CAM to visualize the disease regions. Lopes et al. [
15] analyzed three ways to use the pre-trained networks as the feature extractor. Features from GoogleNet, ResNet, and VGGNet were analyzed along with an SVM classifier—the highest AUC was 92.6% for both MC and SZ datasets.
However, an individual DCNN sometimes produces unsatisfactory results due to limited hypothesis space or descent into local minima. Ensembles of DCNN models have been reported to provide better accuracy than individual DCNNs. Islam et al. [
16] combined Alexnet, VGG16, VGG19, ResNet18, ResNet50, and ResNet152 CNN models and achieved a 94% AUC for the SZ dataset. Similarly, AlexNet and GoogLeNet were combined by Lakhani and Sundaram [
17], evaluated on four different datasets with 1007 images, and they achieved an AUC of 99%. Rajaraman et al. [
18] first segmented the lung region using the atlas-based method, then built a stacked model of hand-crafted features and deep DCNNs; they reported AUCs for four datasets: MC 98.6% and SZ 99.4% and two additional datasets that they built—Kenya 82.9% and India 99.5%.
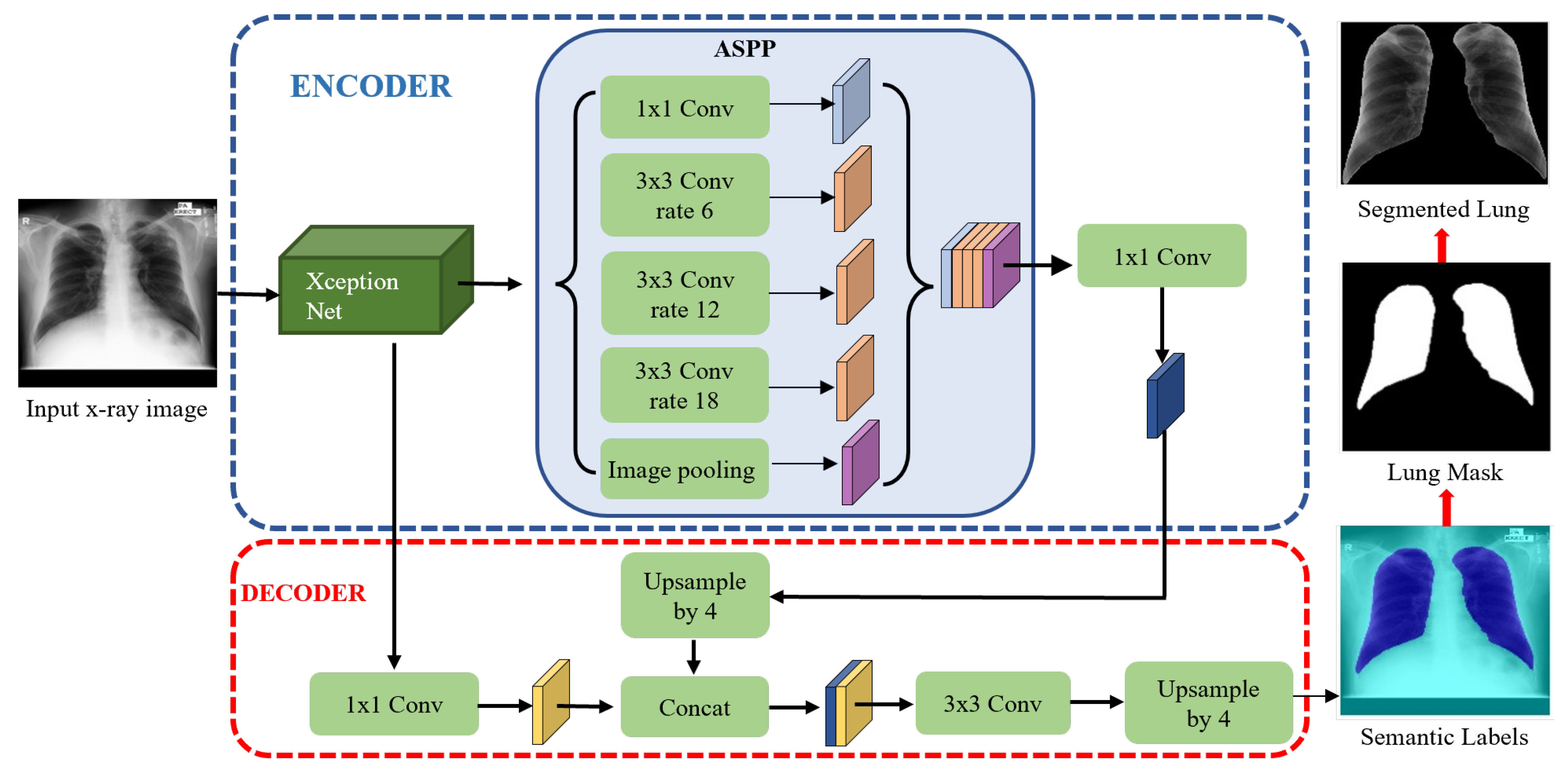
To date, lung segmentation in TB detection has mainly been based on the lung atlas-driven method and thresholding. Despite the superior performance of deep semantic segmentation in medical image segmentation [
19,
20,
22], these methods have not been applied to lung segmentation in the TB detection framework. To fill this gap, we studied and evaluated a set of deep semantic models for lung segmentation and compared their performance. For TB prediction, a few machine learning-based methods [
8,
11] performed on par with DCNNs. However, their composite frameworks are more complex than that of an end-to-end DCNN and require more development work. Previous studies showed that ensembles of DCNNs were more efficient than individual ones [
16,
17,
18] and attained state-of-the-art results [
18]. Although those ensemble methods achieved promising results, their ensembles only included a limited number of DCNN architectures and did not explore other potential models. Therefore, we herein present an alternative ensemble method of DCNNs, where several DCNN models were used as candidate learners. We noted that, currently, (a) combining all DCNNs can lead to excessive computation times, and (b) a poor choice of DCNN models for fusion can result in poor performance; thus, different combinations of twelve DCNNs were established and evaluated for accuracy, based on several trial runs. After the trial runs, the combination providing the maximum accuracy was selected as a final ensemble classifier.
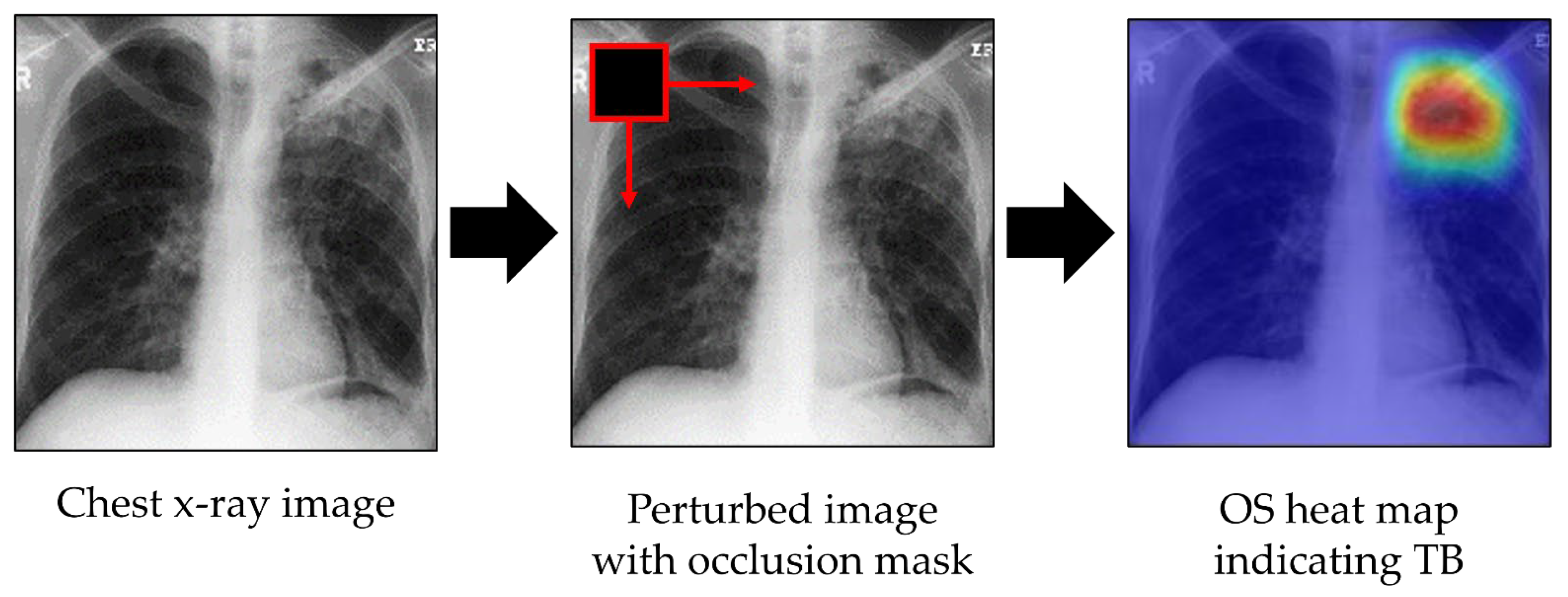
Moreover, although DCNN-based models have achieved promising results in TB diagnosis, there are few studies on the visualization and interpretation of CNNs. The success of DCNNs, coupled with a lack of interpretable decision-making, raises an issue of trust. Especially in medical diagnosis, lack of interpretability is not acceptable, since a poorly interpreted model’s behavior could adversely affect decision-making. Recently, research has shown that DCNNs are able to locate objects to highlight the indicative features to support decision-making and allow visualization in the form of heat maps. Many techniques were introduced to visualize, interpret, and explain the learning process of DCNNs [
23,
24,
25,
26]. Here, we visualized DCNN decision-making (i) to identify the indicative features and regions in images for TB prediction and (ii) to localize the lesions using occlusion sensitivity [
25] and Grad-CAM heat maps [
26].
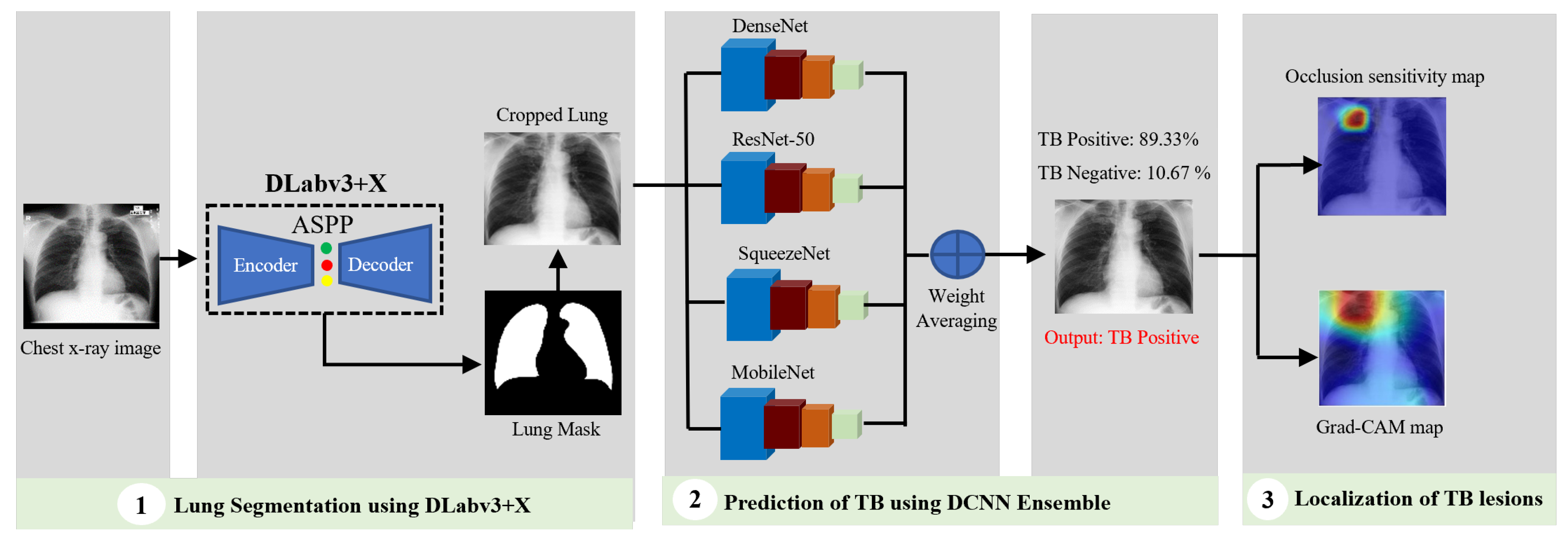
In summary, we present an algorithm for TB detection and localization of its manifestations in images by cascading the DLabv3+X semantic segmentation algorithm and the ensemble of DCNNs, followed by visualization and localization. There are three main contributions:
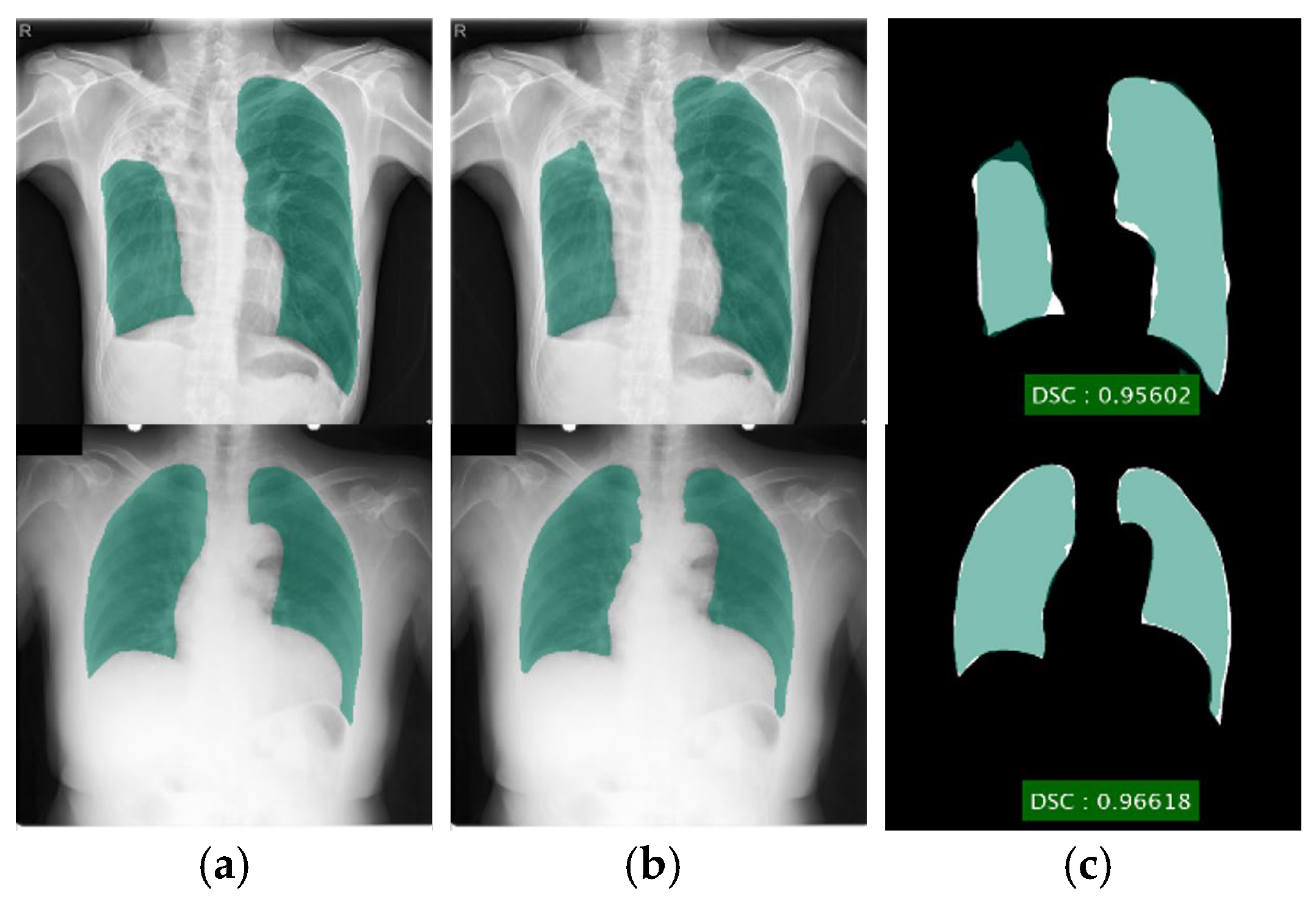
A novel lung segmentation algorithm using DLabv3+X and comparing it with other deep learning-based methods. Although semantic segmentation algorithms have been applied in lung segmentation, most of them were evaluated using datasets with no TB manifestations. Therefore, we provide a comprehensive comparison of deep semantic algorithms for lung segmentation in the presence of TB lesions.
Finding the best combination of DCNN models to build the ensemble classifier.
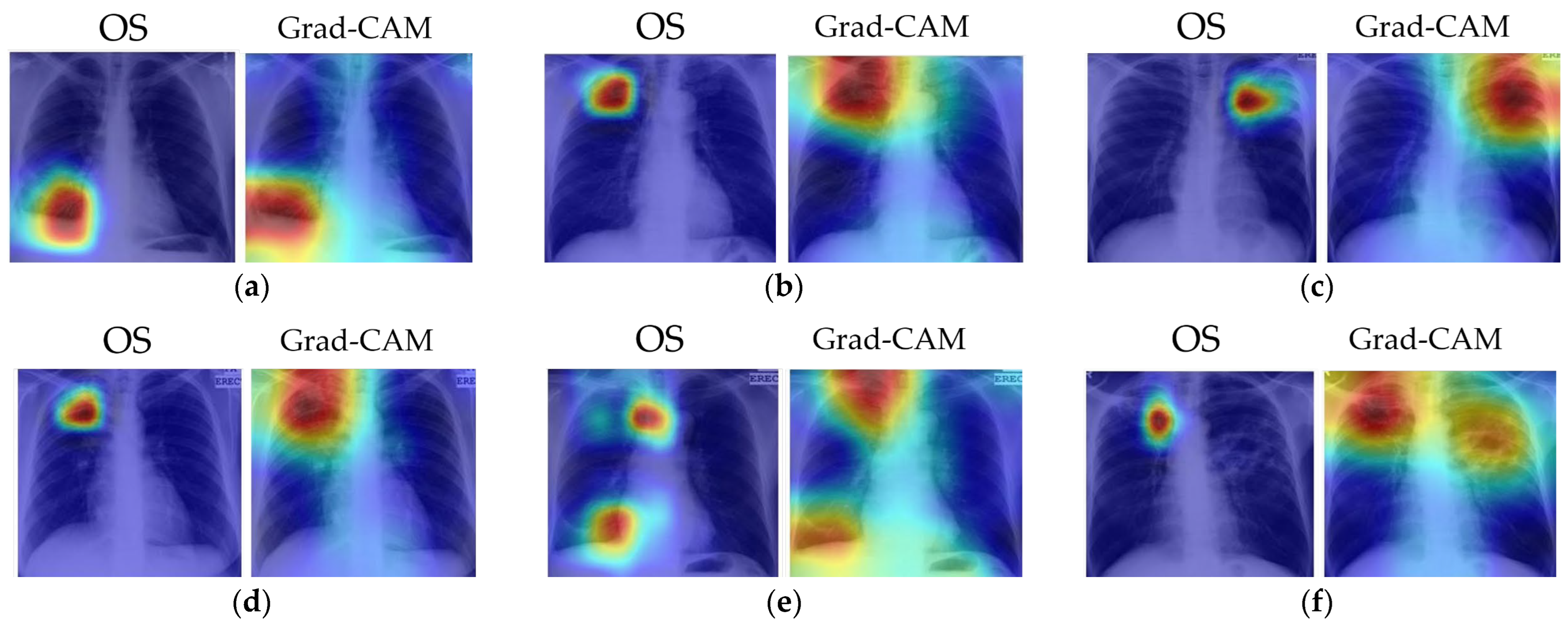
Identifying features and regions that indicate the presence of TB and localizing the lesions using OS and Grad-CAM.
In the following sections,
Section 2 presents the datasets used in the experiments, and
Section 3 describes our methodology. The results and discussion of them follow in
Section 4. The limitations and future directions are described in
Section 5. We conclude in
Section 6.
5. Limitations and Future Works
Although our cascade algorithm achieved excellent performance in detecting TB, there are still some limitations in this work and the field in general. The fundamental limitations arise from the datasets, which may limit their clinical applicability or performance in a real-world clinical practice. First, Raoof et al. [
64] noted that up to 15% of accurate diagnoses using chest X-rays needed a side or lateral view. Radiologists often use X-rays acquired in both frontal and lateral projections, which aids both disease classification and localization. In this study, we only had available frontal projections, and the lack of lateral views may hinder the detection of some TB manifestations. Future work should use both frontal and lateral chest X-rays, when available, for diagnosis and automated system development. Secondly, clinical information is often necessary for a radiologist to render a specific diagnosis, or at least provide a reasonable differential diagnosis. Due to the lack of sufficient clinical information and pathological findings, our algorithm could not include patient history and other clinical information, which has been shown to improve diagnosis accuracy [
65]. Therefore, new datasets, with both frontal and lateral images, clinical reports, and annotated lesions, are urgently needed.
For lung segmentation, images with severe TB manifestations, for instance, severe pleural effusion, resulted in poor segmentation, because pleural effusion regions resemble the background. For these images, our DLabv3+X segmentation method did not generate the correct lung shape, which indicates that the segmentation alone did not capture sufficient intrinsic information about the lung shape for plausible structures. The incorporation of additional shape priors may lead to more correct segmentations. Although potentially beneficial, this will be our future work.
Although an ensemble DCNN outperformed an individual DCNN, the ensemble classifier had a higher computational cost and a longer training time than a single primary classifier. Therefore, a trade-off between prediction accuracy and computational complexity should be taken into account. In addition, the proposed ensemble algorithm is a heterogeneous method, where diverse DCNNs on the same training dataset are combined via probability averaging. When a larger dataset is available in the future, we plan to build a homogeneous ensemble classifier that combines the same-type classification model on different settings of training data and learning parameters using bagging or boosting strategies.
The combination of the prediction decision with the decision locations in the heat maps is more useful than the prediction alone. Unfortunately, mild pathologies are missed, especially when an image presents multiple TB lesions. Some images generated ‘false’ localizations because they did not focus on the right location for TB lesions. Some incorrect areas surrounded the lung area. This error is indeed a limitation of DCNN because it is difficult to explain why it activates at the wrong site. Since DCNN learned the features that were most predictive, it might use the features or regions that are insignificant to or ignored by humans. Further research, along with a radiologist, is required to investigate why the models used the wrong areas. The MC dataset is rather small, and it may simply be that more input cases are needed.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}