1. Introduction
Research on convolutional neural network (CNN)-based image classification and object detection models has advanced significantly in recent years. Notably, the development of object detection models, such as You Only Look Once (YOLO) [
1,
2], has progressed rapidly, continuously releasing new versions. However, recent trends in computer vision research indicate a decline in studies focused on CNN-based object detection [
3,
4], while the popularity of image models like transformers and generative models is increasing. This shift suggests that the exploration of new CNN-based approaches has plateaued, given the substantial improvements and high accuracy already achieved in object detection and classification models [
5], which are key components of unstructured big-data analysis pipelines.
While promising models such as YOLOv8 and EfficientDet have emerged [
6], challenges remain in detecting small objects in images. Although these models have made significant strides in detecting smaller objects compared to earlier versions, they still struggle with detecting distant or tiny objects [
7,
8,
9].
The detection of small objects presents unique challenges compared to larger objects. These objects are more vulnerable to low resolution and are prone to background noise, occlusion, and other disturbances. Due to their limited size, small objects often lose crucial details during feature extraction [
10,
11]. This issue is exacerbated in deep convolutional layers of object detection models, making accurate detection even more challenging. Furthermore, overlapping object boundaries and complex environments complicate the detection of small objects [
12,
13].
Traditional methods for small object detection, such as increasing the input size or utilizing data augmentation, do not effectively address these challenges. Deep learning-based approaches, including two-stage detectors, like Faster Region-based Convolutional Neural Network (Faster R-CNN) [
14] features, and single-stage detectors, like single-shot multi-box detectors (SSD) [
15] and YOLO, offer higher accuracy and efficiency but still have limitations when it comes to detecting small objects. Consequently, research continues to explore innovative solutions, such as high-resolution processing and multi-scale feature extraction, to improve performance.
One fundamental approach to tackling this issue is using higher-resolution inputs during inference [
16,
17,
18,
19]. For example, YOLOv8 typically uses an input image resolution of 640 × 640 pixels, but it can be increased to 1280 × 1280 pixels to improve small object detection. However, such methods are limited by the increased computational cost.
Recent progress can be broadly divided into two independent strands. The first revisits tentative detections by repeating inference in a cascaded manner, thereby refining localization accuracy [
20,
21,
22]. The second strand replaces conventional up-sampling operators with content-aware modules—such as Content-Aware ReAssemble of FEatures (CARAFE) or deformable convolutions—to reinforce multi-scale feature fusion [
22,
23]. However, prior studies have pursued either re-detection strategies or neck-level feature reconstruction in isolation. While several studies have examined these two directions separately, the potential benefits of uniting confidence-guided re-detection with content-aware feature reconstruction within a single YOLOv8 framework have yet to be systematically investigated.
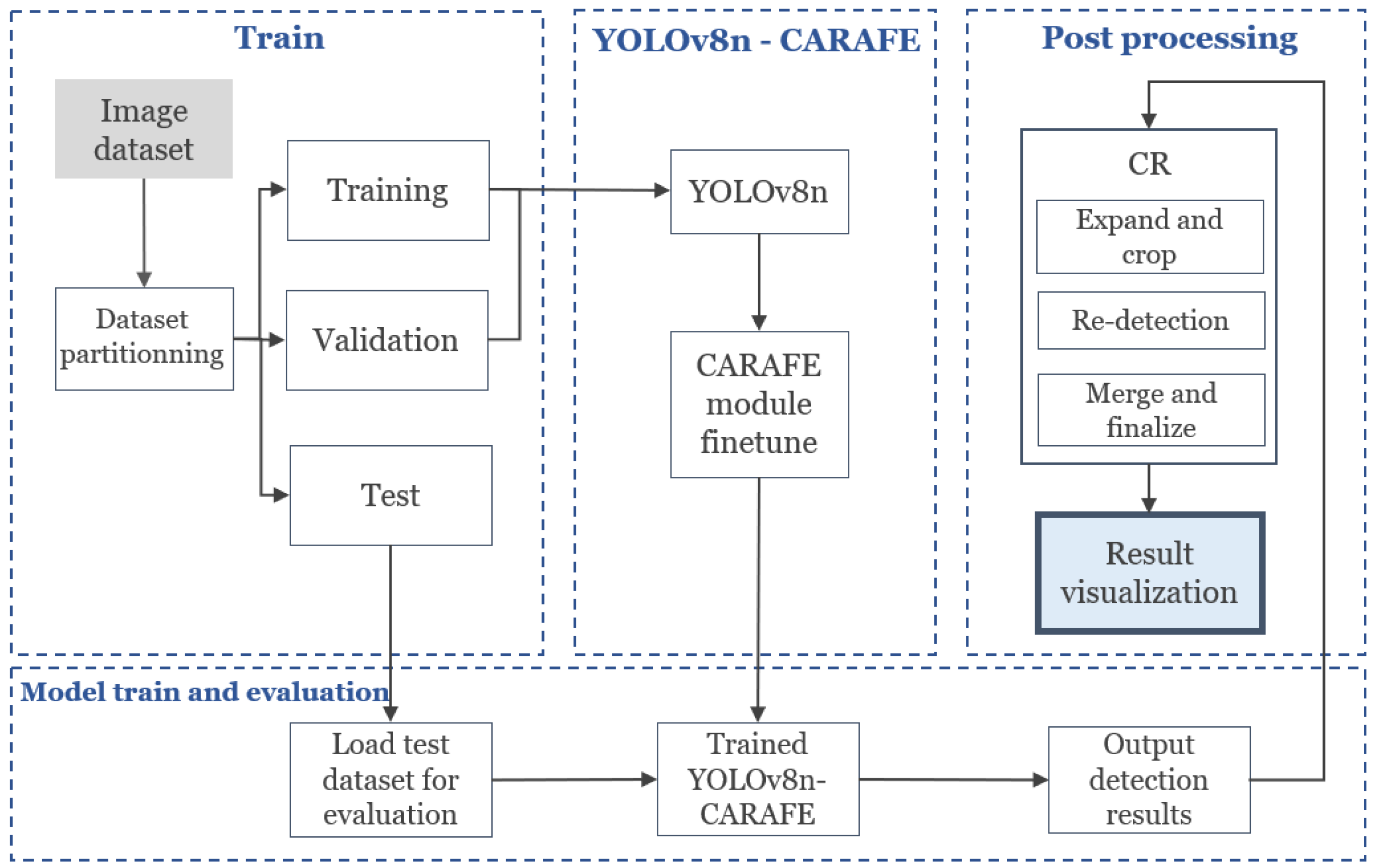
This paper proposes the pipeline depicted in
Figure 1, which integrates an additional image post-processing step with an enhanced YOLOv8n model—a lightweight YOLO family variant—to address existing methods’ computational cost issues and produce more effective results. The key idea is as follows: Object detection models’ confidence score threshold for reliable bounding box detection is typically 50%. However, as object size decreases, the model’s reliability diminishes due to feature loss and reduced Intersection over Union (IoU) values. This study introduces a confidence-based re-detection (CR) process to mitigate this. The CR process involves cropping bounding boxes with a confidence score between 10% and 49% from the original image, focusing on small objects, and performing re-detection using the YOLOv8n model. Bounding boxes with a confidence score above 50% after re-detection are integrated with the initial detection results and output as the final result.
Additionally, the YOLOv8n model uses a modified parameter, integrating a CARAFE module into the neck rather than using the basic model [
22]. The CARAFE module offers a significant advantage by replacing the upsampling module typically used in the neck and adapting the upsampling kernels according to the content of the input feature map. This enables more effective aggregation of contextual information. As a result, feature reconstruction is more precise, minimizing information loss during upsampling and significantly improving small object detection performance.
Notably, the CARAFE module does not rely solely on local pixel-based information. Instead, it utilized a broader contextual area to provide richer feature representations, enhancing model performance for small object detection and complex background environments. The YOLOv8n-CARAFE architecture used in this study aims to achieve higher accuracy and stability than the standard YOLOv8n model. Incorporating this architecture minimizes the loss of detailed information during the re-detection of small object candidate areas while maintaining computational efficiency.
2. Related Works
Recent studies have explored various upsampling methods to enhance the performance of object detection models. Among these, the CARAFE module has emerged as a highly effective enhancement to the upsampling process in the YOLOv8n model. Unlike traditional fixed-kernel upsampling techniques, CARAFE generates adaptive upsampling kernels based on the content of the input feature map, enabling more precise feature map restoration [
22].
The primary advantage of CARAFE is its ability to aggregate contextual information through a large receptive field, minimizing information loss during the upsampling process. This enhancement significantly improves the model’s performance in detecting small objects and handling complex backgrounds. For instance, a study integrating CARAFE into the neck of the YOLOv8n model demonstrated superior detection performance compared to conventional upsampling methods, with notable improvements in small object detection accuracy.
Additionally, CARAFE offers high computational efficiency and a lightweight structure, making it ideal for real-time detection tasks. By replacing the original upsampling module in the YOLOv8n model with CARAFE, performance improvements were observed in detecting small and multi-scale objects, enhancing the overall detection accuracy and consistency.
These findings underscore CARAFE’s potential to minimize information loss during upsampling while effectively detecting objects across varying scales. Building on this existing research, the current study aims to further enhance object detection performance by integrating the CARAFE module into both the image processing pipeline and the neck of the YOLOv8n model.
Another approach to improving object detection involves dividing the input image into smaller segments (slices), performing model inference on each slice individually, and then merging the results into a single image prediction. The slicing-aided hyperinference (SAHI) algorithm exemplifies this technique. SAHI divides the image into slices, applies an object detection algorithm to each segment, and combines the results to generate a final prediction [
20].
A key feature of SAHI is its compatibility with the existing object detection models, enabling integration without requiring separate retraining. Furthermore, it enhances small object detection by increasing the relative pixel size of small objects through image segmentation. Experimental results show that applying SAHI improves average precision (AP) by up to 6.8% across several models, including fully convolutional one-stage object detection (FCOS), VarifocalNet (VFNet), and task-aligned one-stage object detection (TOOD). Further improvements, up to 14.5%, were achieved by incorporating patch overlap and additional fine-tuning.
However, SAHI has some limitations. The computation time increases linearly during image segmentation and detection, and while memory requirements are constant, handling high-resolution images still demands significant computational resources. Additionally, with patch-based detection, challenges remain at the inter-patch boundaries, and performance degradation occurs when detecting large objects, necessitating further investigation.
3. Proposed Methodology
3.1. Improvement Using CARAFE Module
Detecting small objects in images with low-resolution or complex backgrounds presents a significant challenge. In such cases, small objects often lack sufficient pixel information in the feature map, leading to a substantial degradation in detection accuracy due to unclear or vague features. This issue is exacerbated by information loss and feature blurring during upsampling.
Traditional upsampling methods, such as Bilinear Interpolation and Deconvolution [
24], primarily rely on local information around individual pixels. However, these methods are limited in capturing contextual information and global features, which are crucial for detecting small objects effectively. This study employs the YOLO architecture with the CARAFE module to address these challenges [
25].
The CARAFE module creates an adaptive upsampling kernel based on the content of the input feature map [
22], facilitating more sophisticated feature map reconstruction. This approach enhances the representation of small objects and minimizes information loss during upsampling. CARAFE incorporates global contextual information by utilizing a larger receptive field, significantly improving small object detection performance, particularly in complex background scenarios. The YOLO architecture with the CARAFE module builds on the backbone, neck, and head structure of the existing YOLOv8n model, with the CARAFE module integrated explicitly into the neck component. The structure is illustrated in
Figure 2.
The backbone processes the input image to generate a multi-scale feature map. YOLOv8’s backbone is based on the cross-stage partial network (CSPNet) structure, which ensures efficient feature extraction while reducing the computational cost [
26]. This design is essential for preserving global and regional information and detecting small objects.
The neck component further strengthens the multi-scale features by combining feature maps generated in the backbone and propagating semantic information from the higher to lower layers. In the YOLOv8 architecture, the CARAFE module replaces the Path Aggregation Network (PANet)-based upsampling module used in previous YOLO models [
27]. This replacement enables the integration of broader contextual information and maximizes the expressive power of the feature map during the upsampling process.
CARAFE generates a dynamically adapted upsampling kernel based on the content of the input feature map, enabling more detailed and accurate feature restoration compared to traditional upsampling methods [
28,
29,
30]. The head component then predicts the location and class of objects based on the multi-scale features provided by the neck. The Decoupled head structure separates detection and classification tasks, optimizing the performance of each task independently and ensuring high accuracy for both small and large objects. The CARAFE module is a lightweight upsampling operator, as depicted in
Figure 3, consisting of two main components: a kernel prediction module and a content-aware reassembly module.
As shown in
Figure 3, given a feature map
of size
and an upsampling ratio
, CARAFE generates a new feature map
of size
. For each target position
in the output,
corresponds to an input position
, where
. Here,
represents a neighborhood region of size
centered at position
. The kernel prediction module predicts the reassembly kernel
for each position
, based on the neighborhood of
. This process can be expressed using the following Equations (1) and (2):
Each position in the input feature map corresponds to target positions in the output feature map . Each target position requires a reassembly kernel of size . The Content Encoder encodes the content by taking the compressed feature map as input and generates reassembly kernels. Subsequently, the Kernel Normalization Module normalizes each reassembly kernel using a softmax function. The generated reassembly kernel is used in the Content-Aware Reassembly Module to reassemble the features within the corresponding region, achieved through a simple weighted sum function .
The reassembly process for target position
and its corresponding square region
in the input can be represented by Equation (3):
In the reassembly kernel , each pixel in the region contributes differently to the upsampled pixel , depending on the content of the corresponding feature rather than merely the spatial distance. This allows the model to focus more on relevant regions, thereby enhancing the semantic representation capability of the reassembled feature map.
The incorporation of the CARAFE module is crucial in enhancing the overall detection performance of the YOLO architecture. Specifically, it improves the detection of small objects and provides stability in complex background environments, demonstrating high applicability across various use cases [
31,
32].
3.2. Additional Image Processing Steps
In this study, a CR process-based detection algorithm was developed to enhance the detection performance of small objects, utilizing the YOLOv8n model. The algorithm workflow, illustrated in
Figure 4, involves the following main steps (refer to Algorithm 1):
| Algorithm 1: Pseudo code for CR process |
INPUT: Image I, YOLO model M, thresholds T1 = 0.1, T2 = 0.5
OUTPUT: Final detections D_final
Begin
1. Initialize:
High confidence list: D_high = []
Low confidence list: D_low = []
Processed crops: C_processed = []
2. Initial detection:
D_all = M.detect(I, T1)
3. Split detections:
FOR d in D_all:
IF d.confidence ≥ T2:
D_high.append(d)
ELSE IF d.area ≤ 5% of I.area:
D_low.append(d)
4. Process low confidence detections:
FOR d in D_low:
Expand d to Crop_box by 8x.
IF Crop_box overlaps with any c in C_processed:
SKIP
ELSE:
C_processed.append(Crop_box)W
Crop_region = I[Crop_box]
D_crop = M.detect(Crop_region, T2)
Adjust D_crop to original coordinates
D_high.extend(D_crop)
5. Output results:
D_final = D_high
Annotate I with D_final
Save I
END |
The algorithm begins by performing object detection on the input image am using the YOLO model M. During the initial detection phase, the confidence threshold is set at 0.1 or higher to maximize object detection coverage. All detected results are stored in and divided based on confidence levels and area conditions.
The initially detected objects are categorized into two groups based on a secondary confidence threshold (set at 0.5) and the area conditions of the detected object:
High Confidence Group (): includes objects with confidence scores greater than or equal to (0.5), a typical threshold for object detection models.
Low Confidence Group (): comprises objects with confidence scores below (0.5) and bounding box areas less than 5% of the total image area.
This separation process identifies small objects with low confidence as additional targets for detection.
For each object in the low confidence group (), a crop area is created by expanding its bounding box by a factor of 8. If the extended crop area overlaps with a previously processed region (), the redetection of the corresponding box is skipped to avoid redundant processing. Non-overlapping crop areas are subjected to redetection using the YOLO model . The resulting redetected objects () are then added to the high confidence group () after transforming their coordinates to the original image scale.
Through this, low reliability appeared due to the blur or low IoU of a small object in the image, so the detection rate could be increased by detecting the dropped part from the original image once more through the CR process
4. Experimental Configuration
The COCO (Common Objects in Context) 2017 image dataset was used for training. This dataset is widely used for training the YOLOv8n model, making it an appropriate benchmark for comparison [
33]. The COCO 2017 image dataset comprises 80 classes, with 118,287 training images, 40,670 testing images, and 5000 validation images. The training was performed on a system equipped with an NVIDIA GeForce RTX 4070 Super GPU and running Windows 11. The implementation was done in Python 3.12 with CUDA 12.1.
5. Experimental Results
Precision, Recall, AP (Average Precision), and mean Average Precision (mAP) are key evaluation metrics for assessing the performance of object detection algorithms. These metrics quantitatively measure the detection accuracy and reliability of a model, offering insights into its effectiveness under various conditions [
34].
Precision refers to the proportion of correctly detected objects among all detected objects. In other words, it evaluates the model’s ability to minimize false positives. Mathematically, precision is defined as follows:
Higher precision indicates that the model effectively minimizes false positives, ensuring that only relevant objects are detected. This is a crucial evaluation metric, particularly in applications where false positives present significant challenges.
Recall, in contrast, measures the proportion of actual objects correctly detected by the model among all real objects. In other words, it assesses the model’s ability to minimize false negatives. Recall is calculated as follows:
A higher Recall means that the model can detect more objects, especially in critical object detection that should not be missed.
AP represents the area under curve (AUC) of the Precision-Recall Curve, which represents the relationship between Precision and Recall, and is used as a single indicator of the performance of the model for a particular class. AP is defined as follows:
Here, represents Recall. In practice, AP is computed discretely by sampling Precision and Recall values at various confidence thresholds. AP is used to assess the trade-off between precision and recall for each class.
mAP is obtained by averaging AP values across all classes, providing a measure of the model’s overall performance. It is defined as follows:
Here, N denotes the total number of classes. Specifically, mAP@0.5 refers to the average AP computed with a fixed Intersection over Union (IoU) threshold of 0.5. In contrast, mAP@0.5:0.95 varies the IoU threshold from 0.5 to 0.95 in increments of 0.05 and averages the resulting AP values. mAP@0.5:0.95 provides a more comprehensive performance evaluation by assessing the model’s detection capability under varying IoU thresholds.
In this study, these metrics were used for an objective evaluation of detection accuracy, and the results are presented in
Table 1. The evaluation was conducted using a subset of the COCO 2017 test dataset. By leveraging the annotation information provided in the dataset, the detection results of the proposed model were compared with those of similar models, and the corresponding evaluation metrics were computed.
In safety-critical tasks such as fire or defect detection, Recall and the more stringent mAP@0.5:0.95 are the primary yardsticks, because missing a true alarm is costlier than raising a few false ones. Conversely, real-time monitoring systems that must minimize nuisance alerts tend to value Precision and the widely adopted mAP@0.5 threshold. Reporting all four metrics, therefore, provides a balanced view tailored to both risk-averse and precision-oriented scenarios.
Figure 5 shows the detection results and shows the detection results of YOLOv8n, YOLOv8n-CARAFE, YOLOv8m, and YOLOv8n-CARAFE+CR, the model proposed in this study. It can be seen that the detection rate gradually increases from YOLOv8n to YOLOv8m, where the calculation cost is low. Finally, the model proposed in this study was based on YOLOv8n, but it can be confirmed that the highest detection rate appears through the additional technique proposed.
6. Conclusions
This study proposed a novel algorithm to enhance small object detection performance by integrating the lightweight YOLOv8n model with the CARAFE module. This combination leveraged the strengths of both components: the YOLOv8 model for its efficient object detection capabilities and the CARAFE module for its content-aware upsampling technique. By adopting this approach, the algorithm improved the basic detection capabilities of the YOLOv8 model. It effectively captured surrounding contextual information, mitigating information loss during upsampling and preserving detailed features of small objects. The study introduced reliability-based filtering and bounding box expansion techniques to strengthen small object detection further. These methods facilitated the additional detection of small objects with low confidence scores. Expanding the bounding box allowed the algorithm to capture contextual information around the object, enhancing detection accuracy by re-detecting objects within the expanded area. A mechanic was implemented to check for duplicate processing to optimize the process, thereby minimizing unnecessary operations and increasing algorithm efficiency. These enhancements made the proposed algorithm more practical for applications where accurate small object detection is critical. Experimental results demonstrated that the proposed algorithm significantly outperformed the existing YOLOv8n model on various object detection datasets. Notably, detection accuracy improved markedly when identifying small objects with low reliability and performing re-detection. This validated the effectiveness of the contextual information obtained through the bounding box expansion and the content-aware upsampling technique of the CARAFE module.
However, using bounding box expansion, the crop-based re-detection approach incurs additional computational cost. Optimization is necessary to improve efficiency in real-time processing environments. Nevertheless, the proposed method is advantageous compared to traditional slicing techniques, as the computational cost does not increase linearly. Additional operations are only performed when the model encounters objects with uncertain classifications. In high-risk scenarios, such as fire detection, early and accurate identification is crucial despite the added computational expense. Therefore, the algorithm ensures timely and reliable detection, potentially preventing severe consequences. Moreover, the area management technique designed to prevent duplicate processing is expected to enable more refined improvements in complex scenes. Future research could explore integrating attention mechanisms to allocate computational resources more effectively to critical areas or adopting multi-resolution approaches to capture detailed information about small objects precisely.
This study demonstrated the potential to significantly improve small object detection by combining the YOLOv8n model with the CARAFE module. The proposed algorithm holds promise for applications requiring accurate small-object detection—such as drone imagery, medical imaging, and unstructured big-data fusion analysis that integrates visual streams with other heterogeneous data sources. This study is expected to guide future research and applications in object detection by providing a foundation for practical performance improvements.
Author Contributions
Conceptualization, J.R.; Methodology, J.R. and D.K.; Software, J.R. and S.C.; Visualization, J.R. and S.C.; Supervision, D.K.; Validation, D.K. and S.C.; Writing—original draft preparation, J.R.; Writing—review and editing, D.K. and S.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the specialized university program for confluence analysis of Weather and Climate Data of the Korea Meteorological Institute (KMI), funded by the Korean government (KMA).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author(s).
Acknowledgments
This work was supported by the Starting Growth Technological R&D Program [RS-2024-00468241], funded by the Ministry of SMEs and Startups (MSS, Korea).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Rekavandi, A.M.; Rashidi, S.; Boussaid, F.; Hoefs, S.; Akbas, E.; Bennamoun, M. Transformers in Small Object Detection: A Benchmark and Survey of State-of-the-Art. arXiv 2023, arXiv:2309.04902. [Google Scholar]
- Shah, S.; Tembhurne, J. Object detection using convolutional neural networks and transformer-based models: A Review. J. Electr. Syst. Inf. Technol. 2023, 10, 54. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in Vision: A Survey. ACM Comput. Surv. 2023, 55, 174. [Google Scholar] [CrossRef]
- Yaseen, M. What is YOLOv8: An In-Depth Exploration of the Internal Features of the Next-Generation Object Detector. arXiv 2024, arXiv:2408.15857. [Google Scholar]
- Nikouei, M.; Baroutian, B.; Nabavi, S.; Taraghi, F.; Aghaei, A.; Sajedi, A.; Moghaddam, M.E. Small Object Detection: A Comprehensive Survey on Challenges, Techniques and Real-World Applications. arXiv 2025, arXiv:2503.20516. [Google Scholar]
- Wei, W.; Cheng, Y.; He, J.; Zhu, X. A Review of Small Object Detection Based on Deep Learning. Neural Comput. Appl. 2024, 36, 6283–6303. [Google Scholar] [CrossRef]
- Cheng, G.; Yuan, X.; Yao, X.; Yan, K.; Zeng, Q.; Xie, X.; Han, J. Towards large-scale small object detection: Survey and benchmarks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13467–13488. [Google Scholar] [CrossRef]
- Saleh, K.; Szenasi, S.; Vamossy, Z. Occlusion handling in generic object detection: A Review. In Proceedings of the 2021 IEEE 19th World Symposium on Applied Machine Intelligence and Informatics (SAMI), Herl’any, Slovakia, 21–23 January 2021; pp. 477–484. [Google Scholar]
- Liu, Z.; Gan, M.; Xiong, L.; Mao, X.; Que, Y. Small Object Detection Methods in Complex Background: An Overview. Int. J. Pattern Recognit. Artif. Intell. 2023, 37, 2350002. [Google Scholar] [CrossRef]
- Liu, Z.; Gan, M.; Xiong, L.; Mao, X.; Que, Y. Multilevel receptive field expansion network for small object detection. IET Image Process. 2023, 17, 2385–2398. [Google Scholar] [CrossRef]
- Ke, L.; Tai, Y.-W.; Tang, C.-K. Deep Occlusion-Aware Instance Segmentation with Overlapping BiLayers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 4019–4028. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Liu, K.; Fu, Z.; Jin, S.; Chen, Z.; Zhou, F.; Jiang, R.; Chen, Y.; Ye, J. ESOD: Efficient Small Object Detection on High-Resolution Images. IEEE Trans. Image Process. 2025, 34, 183–195. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Gao, G.; Sun, L.; Fang, Z. HRDNet: High-Resolution Detection Network for Small Objects. arXiv 2020, arXiv:2006.07607. [Google Scholar]
- Wu, S.; Lu, X.; Guo, C.; Guo, H. Accurate UAV Small Object Detection Based on HRFPN and EfficentVMamba. Sensors 2024, 24, 4966. [Google Scholar] [CrossRef]
- Telçeken, M.; Akgun, D.; Kacar, S.; Bingol, B. A New Approach for Super Resolution Object Detection Using an Image Slicing Algorithm and the Segment Anything Model. Sensors 2024, 24, 4526. [Google Scholar] [CrossRef]
- Akyon, F.C.; Altinuc, S.O.; Temizel, A. Slicing Aided Hyper Inference and Fine-Tuning for Small Object Detection. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 966–970. [Google Scholar]
- Sun, H.; Zhang, B.; Li, Y.; Cao, X. Confidence-Driven Bounding Box Localization for Small Object Detection (C-BBL). arXiv 2023, arXiv:2303.01803. [Google Scholar]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. CARAFE: Content-Aware ReAssembly of Features. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3007–3016. [Google Scholar]
- Wang, J.; Gao, J.; Zhang, B. A Small Object Detection Model in Aerial Images Based on CPDD-YOLOv8. Sci. Rep. 2025, 15, 770. [Google Scholar] [CrossRef]
- Jing, R.; Zhang, W.; Liu, Y.; Li, W.; Li, Y.; Liu, C. An Effective Method for Small Object Detection in Low-Resolution Images. Eng. Appl. Artif. Intell. 2024, 127, 107206. [Google Scholar] [CrossRef]
- Chen, Y.; Zhu, X.; Li, Y.; Wei, Y.; Ye, L. Enhanced Semantic Feature Pyramid Network for Small Object Detection. Signal Process. Image Commun. 2023, 113, 116919. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Jiang, T.; Li, Y.; Feng, H.; Wu, J.; Sun, W.; Ruan, Y. Research on a Trellis Grape Stem Recognition Method Based on YOLOv8n-GP. Agriculture 2024, 14, 1449. [Google Scholar] [CrossRef]
- Qu, S.; Cui, C.; Duan, J.; Lu, Y.; Pang, Z. Underwater Small Target Detection under YOLOv8-LA Model. Sci. Rep. 2024, 14, 16108. [Google Scholar] [CrossRef] [PubMed]
- Gong, C.; Jiang, W.; Zou, D.; Weng, W.; Li, H. An Insulator Fault Diagnosis Method Based on Multi-Mechanism Optimization YOLOv8. Appl. Sci. 2024, 14, 8770. [Google Scholar] [CrossRef]
- Lv, K.; Wu, R.; Chen, S.; Lan, P. CCi-YOLOv8n: Enhanced Fire Detection with CARAFE and Context-Guided Modules. arXiv 2024, arXiv:2411.11011. [Google Scholar]
- Zhao, K.; Xie, B.; Miao, X.; Xia, J. LPO-YOLOv5s: A Lightweight Pouring Robot Object Detection Algorithm. Sensors 2023, 23, 6399. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; Volume 8693, pp. 740–755. [Google Scholar]
- He, Z.; Wang, K.; Fang, T.; Su, L.; Chen, R.; Fei, X. Comprehensive Performance Evaluation of YOLOv11, YOLOv10, YOLOv9, YOLOv8 and YOLOv5 on Object Detection of Power Equipment. arXiv 2024, arXiv:2411.18871. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}