


Phenology-Based Maize and Soybean Yield Potential Prediction Using Machine Learning and Sentinel-2 Imagery Time-Series




Abstract
Featured Application
Abstract
1. Introduction
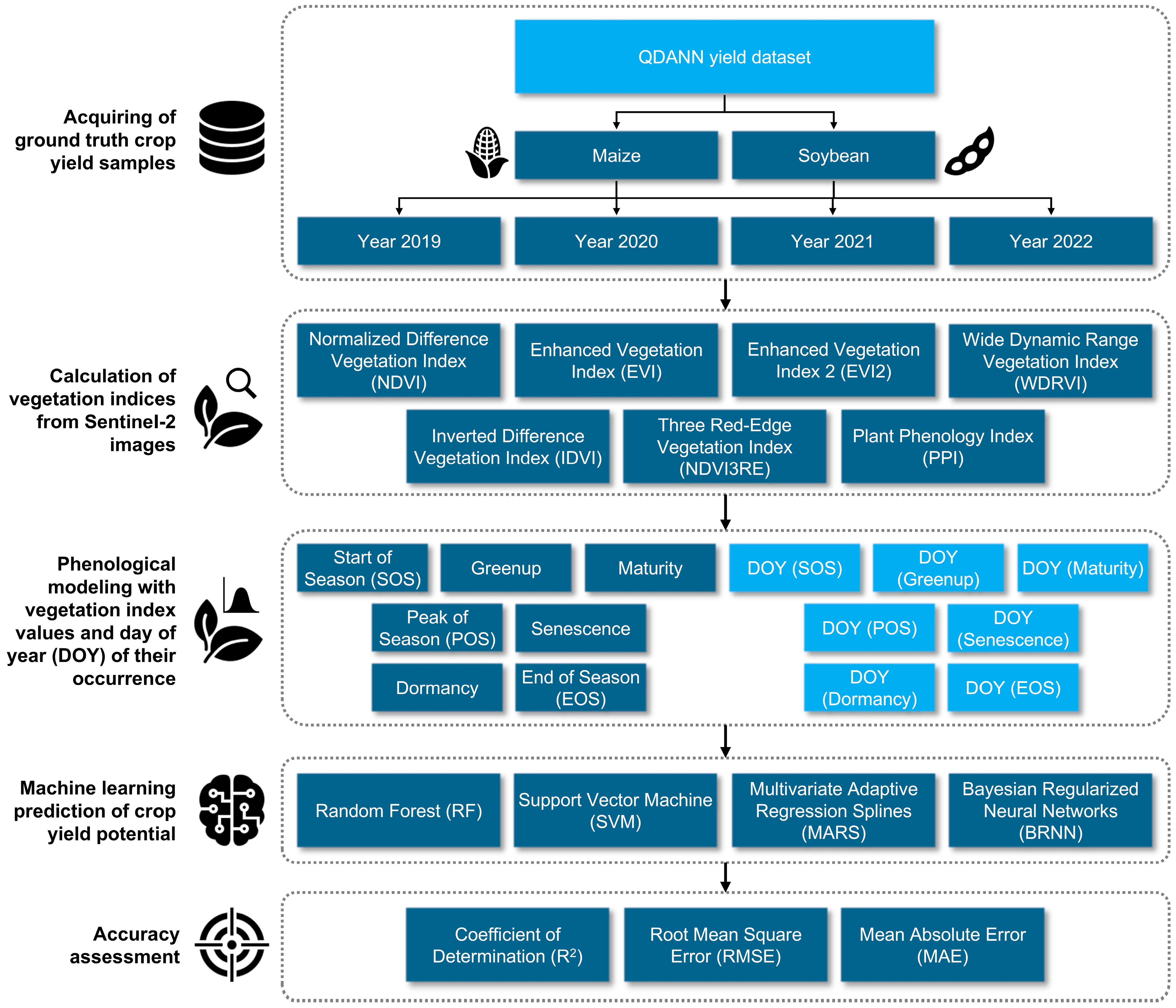
2. Materials and Methods
2.1. Study Area and Crop Yield Data
2.2. Calculation of Vegetation Indices from Sentinel-2 Images
2.3. Phenological Modeling Based on Vegetation Indices from Sentinel-2 Images
2.4. Machine Learning Prediction of Crop Yield Potential
2.5. Accuracy Assessment of Predicted Crop Yield Potential
3. Results and Discussion
4. Conclusions
- RF consistently outperformed the SVM, MARS, and BRNNs in both the cross-validation and final model fit accuracy assessment metrics, indicating its superior ability to capture nonlinear relationships in derived phenological indicators for yield prediction.
- While RF’s cross-validation R2 was moderately high (up to 0.409 in 2019), its final fit R2 of 0.898 suggests that the full training set provided a substantial benefit to model learning but this observation leaves an ambiguity in the discrepancy between cross-validation and final model fit metrics, with no definite knowledge on expected prediction accuracy when using new, unseen datasets.
- The phenological metric related to the vegetation index values at POS was the most important for the prediction of yield potential in both maize and soybean, closely followed by maturity and senescence. However, temporal components of phenological modeling, quantified as DOYs of occurrence of evaluated phenological metrics, produced the most influential covariates, with DOY (EOS) and DOY (SOS) being crucial for the yield potential prediction in particular years for maize and soybean, respectively.
- NDVI was consistently the most important predictor for the maize yield potential prediction across all years, while NDVI3RE, which is characterized by an increased resistance to the saturation effect due to the increased leaf area index, was the dominant vegetation index for the soybean yield potential prediction.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Crop | Year | Method | Optimal Hyperparameters |
| Maize | 2019 | RF | mtry = 7, splitrule = “extratrees”, min.node.size = 5 |
| SVM | σ = 0.173, C = 2 | ||
| MARS | nprune = 21, degree = 1 | ||
| BRNNs | neurons = 9 | ||
| 2020 | RF | mtry = 10, splitrule = “extratrees”, min.node.size = 5 | |
| SVM | σ = 0.160, C = 2 | ||
| MARS | nprune = 21, degree = 1 | ||
| BRNNs | neurons = 10 | ||
| 2021 | RF | mtry = 14, splitrule = “extratrees”, min.node.size = 5 | |
| SVM | σ = 0.183, C = 2 | ||
| MARS | nprune = 21, degree = 1 | ||
| BRNNs | neurons = 9 | ||
| 2022 | RF | mtry = 10, splitrule = “extratrees”, min.node.size = 5 | |
| SVM | σ = 0.156, C = 2 | ||
| MARS | nprune = 21, degree = 1 | ||
| BRNNs | neurons = 9 | ||
| Soybean | 2019 | RF | mtry = 12, splitrule = “extratrees”, min.node.size = 5 |
| SVM | σ = 0.190, C = 1 | ||
| MARS | nprune = 20, degree = 1 | ||
| BRNNs | neurons = 10 | ||
| 2020 | RF | mtry = 10, splitrule = “extratrees”, min.node.size = 5 | |
| SVM | σ = 0.192, C = 4 | ||
| MARS | nprune = 19, degree = 1 | ||
| BRNNs | neurons = 10 | ||
| 2021 | RF | mtry = 14, splitrule = “extratrees”, min.node.size = 5 | |
| SVM | σ = 0.182, C = 2 | ||
| MARS | nprune = 19, degree = 1 | ||
| BRNNs | neurons = 10 | ||
| 2022 | RF | mtry = 14, splitrule = “extratrees”, min.node.size = 5 | |
| SVM | σ = 0.194, C = 2 | ||
| MARS | nprune = 19, degree = 1 | ||
| BRNNs | neurons = 10 |
References
- Debalke, D.B.; Abebe, J.T. Maize Yield Forecast Using GIS and Remote Sensing in Kaffa Zone, South West Ethiopia. Environ. Syst. Res. 2022, 11, 1. [Google Scholar] [CrossRef]
- Victorino, G.; Braga, R.P.; Santos-Victor, J.; Lopes, C.M. Comparing a New Non-Invasive Vineyard Yield Estimation Approach Based on Image Analysis with Manual Sample-Based Methods. Agronomy 2022, 12, 1464. [Google Scholar] [CrossRef]
- Hu, T.; Zhang, X.; Khanal, S.; Wilson, R.; Leng, G.; Toman, E.M.; Wang, X.; Li, Y.; Zhao, K. Climate Change Impacts on Crop Yields: A Review of Empirical Findings, Statistical Crop Models, and Machine Learning Methods. Environ. Model. Softw. 2024, 179, 106119. [Google Scholar] [CrossRef]
- Gerber, J.S.; Ray, D.K.; Makowski, D.; Butler, E.E.; Mueller, N.D.; West, P.C.; Johnson, J.A.; Polasky, S.; Samberg, L.H.; Siebert, S.; et al. Global Spatially Explicit Yield Gap Time Trends Reveal Regions at Risk of Future Crop Yield Stagnation. Nat. Food 2024, 5, 125–135. [Google Scholar] [CrossRef]
- Piekutowska, M.; Niedbała, G. Review of Methods and Models for Potato Yield Prediction. Agriculture 2025, 15, 367. [Google Scholar] [CrossRef]
- Radočaj, D.; Gašparović, M.; Jurišić, M. Cropland Suitability Prediction Method Based on Biophysical Variables from Copernicus Data and Machine Learning. Appl. Sci. 2025, 15, 372. [Google Scholar] [CrossRef]
- Mishra, H.; Mishra, D. AI for Data-Driven Decision-Making in Smart Agriculture: From Field to Farm Management. In Artificial Intelligence Techniques in Smart Agriculture; Chouhan, S.S., Saxena, A., Singh, U.P., Jain, S., Eds.; Springer Nature: Singapore, 2024; pp. 173–193. ISBN 978-981-97-5878-4. [Google Scholar]
- Assimakopoulos, F.; Vassilakis, C.; Margaris, D.; Kotis, K.; Spiliotopoulos, D. Artificial Intelligence Tools for the Agriculture Value Chain: Status and Prospects. Electronics 2024, 13, 4362. [Google Scholar] [CrossRef]
- Rodrigues, D.M.; Coradi, P.C.; Timm, N.d.S.; Fornari, M.; Grellmann, P.; Amado, T.J.C.; Teodoro, P.E.; Teodoro, L.P.R.; Baio, F.H.R.; Chiomento, J.L.T. Applying Remote Sensing, Sensors, and Computational Techniques to Sustainable Agriculture: From Grain Production to Post-Harvest. Agriculture 2024, 14, 161. [Google Scholar] [CrossRef]
- Karunathilake, E.M.B.M.; Le, A.T.; Heo, S.; Chung, Y.S.; Mansoor, S. The Path to Smart Farming: Innovations and Opportunities in Precision Agriculture. Agriculture 2023, 13, 1593. [Google Scholar] [CrossRef]
- Rezaei, E.E.; Webber, H.; Asseng, S.; Boote, K.; Durand, J.L.; Ewert, F.; Martre, P.; MacCarthy, D.S. Climate Change Impacts on Crop Yields. Nat. Rev. Earth Environ. 2023, 4, 831–846. [Google Scholar] [CrossRef]
- Eze, V.H.U.; Eze, E.C.; Alaneme, G.U.; BUBU, P.E.; Nnadi, E.O.E.; Okon, M.B. Integrating IoT Sensors and Machine Learning for Sustainable Precision Agroecology: Enhancing Crop Resilience and Resource Efficiency through Data-Driven Strategies, Challenges, and Future Prospects. Discov. Agric. 2025, 3, 83. [Google Scholar] [CrossRef]
- Wijerathna-Yapa, A.; Pathirana, R. Sustainable Agro-Food Systems for Addressing Climate Change and Food Security. Agriculture 2022, 12, 1554. [Google Scholar] [CrossRef]
- Pospišil, A.; Pospišil, M. Soybean Yield and Yield Components Depending on Sowing Rate and Sowing Date. Poljoprivreda 2024, 30, 10–16. [Google Scholar] [CrossRef]
- Banaj, A.; Banaj, Đ.; Stipešević, B.; Horvat, D. The Impact of Planting Technology on the Maize Yield. Poljoprivreda 2024, 30, 100–107. [Google Scholar] [CrossRef]
- Darra, N.; Anastasiou, E.; Kriezi, O.; Lazarou, E.; Kalivas, D.; Fountas, S. Can Yield Prediction Be Fully Digitilized? A Systematic Review. Agronomy 2023, 13, 2441. [Google Scholar] [CrossRef]
- Jumaah, H.J.; Rashid, A.A.; Saleh, S.A.R.; Jumaah, S.J. Deep Neural Remote Sensing and Sentinel-2 Satellite Image Processing of Kirkuk City, Iraq for Sustainable Prospective. J. Opt. Photonics Res. 2024. [Google Scholar] [CrossRef]
- Phiri, D.; Simwanda, M.; Salekin, S.; Nyirenda, V.R.; Murayama, Y.; Ranagalage, M. Sentinel-2 Data for Land Cover/Use Mapping: A Review. Remote Sens. 2020, 12, 2291. [Google Scholar] [CrossRef]
- Parida, P.K.; Somasundaram, E.; Krishnan, R.; Radhamani, S.; Sivakumar, U.; Parameswari, E.; Raja, R.; Shri Rangasami, S.R.; Sangeetha, S.P.; Gangai Selvi, R. Unmanned Aerial Vehicle-Measured Multispectral Vegetation Indices for Predicting LAI, SPAD Chlorophyll, and Yield of Maize. Agriculture 2024, 14, 1110. [Google Scholar] [CrossRef]
- Radočaj, D.; Plaščak, I.; Jurišić, M.; Majić, I.; Ozimec, S.; Sarajlić, A.; Rožac, V. Phenology Analysis for Detection of Vegetation Changes Based on Landsat 8 Images in Nature Park Kopački Rit, Croatia. Geogr. Pannonica 2024, 28, 238–249. [Google Scholar] [CrossRef]
- Eisfelder, C.; Asam, S.; Hirner, A.; Reiners, P.; Holzwarth, S.; Bachmann, M.; Gessner, U.; Dietz, A.; Huth, J.; Bachofer, F.; et al. Seasonal Vegetation Trends for Europe over 30 Years from a Novel Normalised Difference Vegetation Index (NDVI) Time-Series—The TIMELINE NDVI Product. Remote Sens. 2023, 15, 3616. [Google Scholar] [CrossRef]
- Garcia-Perez, M.A.; Rodriguez-Galiano, V.; Sanchez-Rodriguez, E.; Egea-Cobrero, V. Yield Estimation of Wheat Using Cropland Masks from European Common Agrarian Policy: Comparing the Performance of EVI2, NDVI, and MTCI in Spanish NUTS-2 Regions. Remote Sens. 2023, 15, 5423. [Google Scholar] [CrossRef]
- Zhou, L.; Nie, C.; Su, T.; Xu, X.; Song, Y.; Yin, D.; Liu, S.; Liu, Y.; Bai, Y.; Jia, X.; et al. Evaluating the Canopy Chlorophyll Density of Maize at the Whole Growth Stage Based on Multi-Scale UAV Image Feature Fusion and Machine Learning Methods. Agriculture 2023, 13, 895. [Google Scholar] [CrossRef]
- Sentinel-2 L2A—Documentation. Available online: https://documentation.dataspace.copernicus.eu/APIs/SentinelHub/Data/S2L2A.html (accessed on 3 June 2025).
- Pham, H.T.; Awange, J.; Kuhn, M.; Nguyen, B.V.; Bui, L.K. Enhancing Crop Yield Prediction Utilizing Machine Learning on Satellite-Based Vegetation Health Indices. Sensors 2022, 22, 719. [Google Scholar] [CrossRef]
- Radočaj, D.; Plaščak, I.; Jurišić, M. Fusion of Sentinel-2 Phenology Metrics and Saturation-Resistant Vegetation Indices for Improved Correlation with Maize Yield Maps. Agronomy 2025, 15, 1329. [Google Scholar] [CrossRef]
- Irawan, A.N.R.; Komori, D. Beyond Fixed Dates and Coarse Resolution: Developing a Dynamic Dry Season Crop Calendar for Paddy in Indonesia from 2001 to 2021. Agronomy 2024, 14, 564. [Google Scholar] [CrossRef]
- Li, T.; Zhong, S. Advances in Optical and Thermal Remote Sensing of Vegetative Drought and Phenology. Remote Sens. 2024, 16, 4209. [Google Scholar] [CrossRef]
- Amankulova, K.; Farmonov, N.; Mukhtorov, U.; Mucsi, L. Sunflower Crop Yield Prediction by Advanced Statistical Modeling Using Satellite-Derived Vegetation Indices and Crop Phenology. Geocarto Int. 2023, 38, 2197509. [Google Scholar] [CrossRef]
- Sharifi, A. Yield Prediction with Machine Learning Algorithms and Satellite Images. J. Sci. Food Agric. 2021, 101, 891–896. [Google Scholar] [CrossRef]
- Desloires, J.; Ienco, D.; Botrel, A. Out-of-Year Corn Yield Prediction at Field-Scale Using Sentinel-2 Satellite Imagery and Machine Learning Methods. Comput. Electron. Agric. 2023, 209, 107807. [Google Scholar] [CrossRef]
- Joshi, A.; Pradhan, B.; Gite, S.; Chakraborty, S. Remote-Sensing Data and Deep-Learning Techniques in Crop Mapping and Yield Prediction: A Systematic Review. Remote Sens. 2023, 15, 2014. [Google Scholar] [CrossRef]
- Shuai, G.; Fowler, A.; Basso, B. Within-Season Vegetation Indices and Yield Stability as a Predictor of Spatial Patterns of Maize (Zea mays L) Yields. Precis. Agric. 2024, 25, 963–982. [Google Scholar] [CrossRef]
- Radočaj, D.; Plaščak, I.; Jurišić, M. A Machine-Learning Approach for the Assessment of Quantitative Changes in the Tractor Diesel-Engine Oil During Exploitation. Poljoprivreda 2024, 30, 108–114. [Google Scholar] [CrossRef]
- Kaya, F.; Keshavarzi, A.; Francaviglia, R.; Kaplan, G.; Başayiğit, L.; Dedeoğlu, M. Assessing Machine Learning-Based Prediction under Different Agricultural Practices for Digital Mapping of Soil Organic Carbon and Available Phosphorus. Agriculture 2022, 12, 1062. [Google Scholar] [CrossRef]
- Schwalbert, R.A.; Amado, T.; Corassa, G.; Pott, L.P.; Prasad, P.V.V.; Ciampitti, I.A. Satellite-Based Soybean Yield Forecast: Integrating Machine Learning and Weather Data for Improving Crop Yield Prediction in Southern Brazil. Agric. For. Meteorol. 2020, 284, 107886. [Google Scholar] [CrossRef]
- Patil, Y.; Ramachandran, H.; Sundararajan, S.; Srideviponmalar, P. Comparative Analysis of Machine Learning Models for Crop Yield Prediction Across Multiple Crop Types. SN Comput. Sci. 2025, 6, 64. [Google Scholar] [CrossRef]
- Chen, C.; Wang, J.; Li, D.; Sun, X.; Zhang, J.; Yang, C.; Zhang, B. Unraveling Nonlinear Effects of Environment Features on Green View Index Using Multiple Data Sources and Explainable Machine Learning. Sci. Rep. 2024, 14, 30189. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Y.; Li, G.; Qi, Z. Integration of Remote Sensing and Machine Learning for Precision Agriculture: A Comprehensive Perspective on Applications. Agronomy 2024, 14, 1975. [Google Scholar] [CrossRef]
- Rajakumaran, M.; Arulselvan, G.; Subashree, S.; Sindhuja, R. Crop Yield Prediction Using Multi-Attribute Weighted Tree-Based Support Vector Machine. Meas. Sens. 2024, 31, 101002. [Google Scholar] [CrossRef]
- Sarkar, S.; Osorio Leyton, J.M.; Noa-Yarasca, E.; Adhikari, K.; Hajda, C.B.; Smith, D.R. Integrating Remote Sensing and Soil Features for Enhanced Machine Learning-Based Corn Yield Prediction in the Southern US. Sensors 2025, 25, 543. [Google Scholar] [CrossRef]
- Delfani, P.; Thuraga, V.; Banerjee, B.; Chawade, A. Integrative Approaches in Modern Agriculture: IoT, ML and AI for Disease Forecasting amidst Climate Change. Precis. Agric. 2024, 25, 2589–2613. [Google Scholar] [CrossRef]
- Pinakana, S.D.; Raysoni, A.U.; Sayeed, A.; Gonzalez, J.L.; Temby, O.; Wladyka, D.; Sepielak, K.; Gupta, P. Review of Agricultural Biomass Burning and Its Impact on Air Quality in the Continental United States of America. Environ. Adv. 2024, 16, 100546. [Google Scholar] [CrossRef]
- Preza Fontes, G.; Greer, K.D.; Pittelkow, C.M. Does Biochar Improve Nitrogen Use Efficiency in Maize? GCB Bioenergy 2024, 16, e13122. [Google Scholar] [CrossRef]
- Cui, D.; Liang, S.; Wang, D. Observed and Projected Changes in Global Climate Zones Based on Köppen Climate Classification. WIREs Clim. Change 2021, 12, e701. [Google Scholar] [CrossRef]
- Ma, Y.; Liang, S.-Z.; Myers, D.B.; Swatantran, A.; Lobell, D.B. Subfield-Level Crop Yield Mapping without Ground Truth Data: A Scale Transfer Framework. Remote Sens. Environ. 2024, 315, 114427. [Google Scholar] [CrossRef]
- Zhao, Q.; Yu, L.; Li, X.; Peng, D.; Zhang, Y.; Gong, P. Progress and Trends in the Application of Google Earth and Google Earth Engine. Remote Sens. 2021, 13, 3778. [Google Scholar] [CrossRef]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring Vegetation Systems in the Great Plains with ERTS; NASA: Washington, DC, USA, 1974. [Google Scholar]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the Radiometric and Biophysical Performance of the MODIS Vegetation Indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Jiang, Z.; Huete, A.R.; Didan, K.; Miura, T. Development of a Two-Band Enhanced Vegetation Index without a Blue Band. Remote Sens. Environ. 2008, 112, 3833–3845. [Google Scholar] [CrossRef]
- Gitelson, A.A. Wide Dynamic Range Vegetation Index for Remote Quantification of Biophysical Characteristics of Vegetation. J. Plant Physiol. 2004, 161, 165–173. [Google Scholar] [CrossRef]
- Sun, Y.; Ren, H.; Zhang, T.; Zhang, C.; Qin, Q. Crop Leaf Area Index Retrieval Based on Inverted Difference Vegetation Index and NDVI. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1662–1666. [Google Scholar] [CrossRef]
- Qiao, K.; Zhu, W.; Xie, Z.; Wu, S.; Li, S. New Three Red-Edge Vegetation Index (VI3RE) for Crop Seasonal LAI Prediction Using Sentinel-2 Data. Int. J. Appl. Earth Obs. Geoinf. 2024, 130, 103894. [Google Scholar] [CrossRef]
- Jin, H.; Eklundh, L. A Physically Based Vegetation Index for Improved Monitoring of Plant Phenology. Remote Sens. Environ. 2014, 152, 512–525. [Google Scholar] [CrossRef]
- Kong, D.; Xiao, M.; Zhang, Y.; Gu, X.; Cui, J. Phenofit: Extract Remote Sensing Vegetation Phenology. Available online: https://cran.r-project.org/web/packages/phenofit/index.html (accessed on 4 June 2025).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing, Vienna, Austria. Available online: https://www.r-project.org/ (accessed on 4 June 2025).
- Beck, P.S.A.; Atzberger, C.; Høgda, K.A.; Johansen, B.; Skidmore, A.K. Improved Monitoring of Vegetation Dynamics at Very High Latitudes: A New Method Using MODIS NDVI. Remote Sens. Environ. 2006, 100, 321–334. [Google Scholar] [CrossRef]
- Kong, D.; Zhang, Y.; Wang, D.; Chen, J.; Gu, X. Photoperiod Explains the Asynchronization Between Vegetation Carbon Phenology and Vegetation Greenness Phenology. J. Geophys. Res. Biogeo. 2020, 125, e2020JG005636. [Google Scholar] [CrossRef]
- Kong, D.; McVicar, T.R.; Xiao, M.; Zhang, Y.; Peña-Arancibia, J.L.; Filippa, G.; Xie, Y.; Gu, X. Phenofit: An R Package for Extracting Vegetation Phenology from Time Series Remote Sensing. Methods Ecol. Evol. 2022, 13, 1508–1527. [Google Scholar] [CrossRef]
- Singh, B.; Kumar, S.; Elangovan, A.; Vasht, D.; Arya, S.; Duc, N.T.; Swami, P.; Pawar, G.S.; Raju, D.; Krishna, H.; et al. Phenomics Based Prediction of Plant Biomass and Leaf Area in Wheat Using Machine Learning Approaches. Front. Plant Sci. 2023, 14, 1214801. [Google Scholar] [CrossRef]
- Agyeman, P.C.; Khosravi, V.; Michael Kebonye, N.; John, K.; Borůvka, L.; Vašát, R. Using Spectral Indices and Terrain Attribute Datasets and Their Combination in the Prediction of Cadmium Content in Agricultural Soil. Comput. Electron. Agric. 2022, 198, 107077. [Google Scholar] [CrossRef]
- Radočaj, D.; Jug, D.; Jug, I.; Jurišić, M. A Comprehensive Evaluation of Machine Learning Algorithms for Digital Soil Organic Carbon Mapping on a National Scale. Appl. Sci. 2024, 14, 9990. [Google Scholar] [CrossRef]
- Molnar, C.; König, G.; Bischl, B.; Casalicchio, G. Model-Agnostic Feature Importance and Effects with Dependent Features: A Conditional Subgroup Approach. Data Min. Knowl. Discov. 2024, 38, 2903–2941. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Wright, M.N.; Wager, S.; Probst, P. Ranger: A Fast Implementation of Random Forests. Available online: https://cran.r-project.org/web/packages/ranger/index.html (accessed on 4 June 2025).
- Brereton, R.; Lloyd, G. Support Vector Machines for Classification and Regression. Analyst 2010, 135, 230–267. [Google Scholar] [CrossRef]
- Karatzoglou, A.; Smola, A.; Hornik, K.; Australia (NICTA), N.I.; Maniscalco, M.A.; Teo, C.H. Kernlab: Kernel-Based Machine Learning Lab. Available online: https://cran.r-project.org/web/packages/kernlab/index.html (accessed on 4 June 2025).
- Friedman, J.H.; Roosen, C.B. An Introduction to Multivariate Adaptive Regression Splines. Stat. Methods Med. Res. 1995, 4, 197–217. [Google Scholar] [CrossRef]
- Milborrow, S.; Hastie, T.; Tibshirani, R.; Miller, A.; Lumley, T. Earth: Multivariate Adaptive Regression Splines. Available online: https://cran.r-project.org/web/packages/earth/index.html (accessed on 4 June 2025).
- Burden, F.; Winkler, D. Bayesian Regularization of Neural Networks. In Artificial Neural Networks: Methods and Applications; Livingstone, D.J., Ed.; Humana Press: Totowa, NJ, USA, 2009; pp. 23–42. ISBN 978-1-60327-101-1. [Google Scholar]
- Rodriguez, P.P.; Gianola, D. Brnn: Bayesian Regularization for Feed-Forward Neural Networks. Available online: https://cran.r-project.org/web/packages/brnn/index.html (accessed on 4 June 2025).
- Fushiki, T. Estimation of Prediction Error by Using K-Fold Cross-Validation. Stat. Comput. 2011, 21, 137–146. [Google Scholar] [CrossRef]
- Knight, C.; Khouakhi, A.; Waine, T.W. The Impact of Weather Patterns on Inter-Annual Crop Yield Variability. Sci. Total Environ. 2024, 955, 177181. [Google Scholar] [CrossRef] [PubMed]
- Song, I.; Kim, D. Three Common Machine Learning Algorithms Neither Enhance Prediction Accuracy Nor Reduce Spatial Autocorrelation in Residuals: An Analysis of Twenty-Five Socioeconomic Data Sets. Geogr. Anal. 2023, 55, 585–620. [Google Scholar] [CrossRef]
- Barreñada, L.; Dhiman, P.; Timmerman, D.; Boulesteix, A.-L.; Van Calster, B. Understanding Overfitting in Random Forest for Probability Estimation: A Visualization and Simulation Study. Diagn. Progn. Res. 2024, 8, 14. [Google Scholar] [CrossRef]
- Li, K.; DeCost, B.; Choudhary, K.; Greenwood, M.; Hattrick-Simpers, J. A Critical Examination of Robustness and Generalizability of Machine Learning Prediction of Materials Properties. NPJ Comput. Mater. 2023, 9, 1–9. [Google Scholar] [CrossRef]
- Montesinos López, O.A.; Montesinos López, A.; Crossa, J. Overfitting, Model Tuning, and Evaluation of Prediction Performance. In Multivariate Statistical Machine Learning Methods for Genomic Prediction; Montesinos López, O.A., Montesinos López, A., Crossa, J., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 109–139. ISBN 978-3-030-89010-0. [Google Scholar]
- Paudel, D.; Boogaard, H.; de Wit, A.; van der Velde, M.; Claverie, M.; Nisini, L.; Janssen, S.; Osinga, S.; Athanasiadis, I.N. Machine Learning for Regional Crop Yield Forecasting in Europe. Field Crops Res. 2022, 276, 108377. [Google Scholar] [CrossRef]
- Galić Subašić, D.; Rapčan, I.; Jurišić, M.; Petrović, D.; Radočaj, D. The Effect of Irrigation on the Yield and Soybean (Glycine max L. Merr.) Seed Germination in the Three Climatically Varying Years. Poljoprivreda 2024, 30, 17–24. [Google Scholar] [CrossRef]
- Guo, Y.; Jiang, S.; Miao, H.; Song, Z.; Yu, J.; Guo, S.; Chang, Q. Ground-Based Hyperspectral Estimation of Maize Leaf Chlorophyll Content Considering Phenological Characteristics. Remote Sens. 2024, 16, 2133. [Google Scholar] [CrossRef]
- van Dijk, D.; Shoaie, S.; van Leeuwen, T.; Veraverbeke, S. Spectral Signature Analysis of False Positive Burned Area Detection from Agricultural Harvests Using Sentinel-2 Data. Int. J. Appl. Earth Obs. Geoinf. 2021, 97, 102296. [Google Scholar] [CrossRef]
- Mahmud, M.S.; Huang, J.Z.; Salloum, S.; Emara, T.Z.; Sadatdiynov, K. A Survey of Data Partitioning and Sampling Methods to Support Big Data Analysis. Big Data Min. Anal. 2020, 3, 85–101. [Google Scholar] [CrossRef]
- Subhashree, S.N.; Marcaida, M.; Sunoj, S.; Kindred, D.R.; Thompson, L.J.; Ketterings, Q.M. Exploring the Use of High-Resolution Satellite Images to Estimate Corn Silage Yield Within Field. Remote Sens. 2024, 16, 4081. [Google Scholar] [CrossRef]
- Radočaj, D.; Jurišić, M. A Phenology-Based Evaluation of the Optimal Proxy for Cropland Suitability Based on Crop Yield Correlations from Sentinel-2 Image Time-Series. Agriculture 2025, 15, 859. [Google Scholar] [CrossRef]
- Pejak, B.; Lugonja, P.; Antić, A.; Panić, M.; Pandžić, M.; Alexakis, E.; Mavrepis, P.; Zhou, N.; Marko, O.; Crnojević, V. Soya Yield Prediction on a Within-Field Scale Using Machine Learning Models Trained on Sentinel-2 and Soil Data. Remote Sens. 2022, 14, 2256. [Google Scholar] [CrossRef]
- Karger, D.N.; Nobis, M.P.; Normand, S.; Graham, C.H.; Zimmermann, N.E. CHELSA-TraCE21k—High-Resolution (1 Km) Downscaled Transient Temperature and Precipitation Data since the Last Glacial Maximum. Clim. Past. 2023, 19, 439–456. [Google Scholar] [CrossRef]




| Year | Maize | Soybean | ||
|---|---|---|---|---|
| Moran’s I | p-Value | Moran’s I | p-Value | |
| 2019 | 0.260 | <0.001 | 0.256 | <0.001 |
| 2020 | 0.157 | <0.001 | 0.163 | <0.001 |
| 2021 | 0.132 | <0.001 | 0.160 | <0.001 |
| 2022 | 0.346 | <0.001 | 0.285 | <0.001 |
| Crop | Year | Method | Cross-Validation | Final Model Fit | ||||
|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | R2 | RMSE | MAE | |||
| Maize | 2019 | RF | 0.409 | 1139.7 | 894.4 | 0.898 | 574.8 | 447.1 |
| SVM | 0.367 | 1199.7 | 878.7 | 0.452 | 1111.6 | 788.6 | ||
| MARS | 0.347 | 1195.6 | 938.1 | 0.359 | 1183.4 | 931.2 | ||
| BRNNs | 0.351 | 1193.2 | 927.4 | 0.397 | 1147.7 | 897.2 | ||
| 2020 | RF | 0.319 | 1170.2 | 916.8 | 0.908 | 563.3 | 437.0 | |
| SVM | 0.279 | 1210.2 | 930.1 | 0.365 | 1131.2 | 847.1 | ||
| MARS | 0.257 | 1221.6 | 957.5 | 0.270 | 1209.5 | 949.2 | ||
| BRNNs | 0.271 | 1211.6 | 946.7 | 0.321 | 1166.6 | 917.1 | ||
| 2021 | RF | 0.310 | 981.7 | 767.3 | 0.910 | 464.6 | 358.0 | |
| SVM | 0.268 | 1024.2 | 764.2 | 0.365 | 952.2 | 688.6 | ||
| MARS | 0.262 | 1014.4 | 790.7 | 0.284 | 998.8 | 777.9 | ||
| BRNNs | 0.262 | 1016.1 | 786.5 | 0.311 | 979.3 | 762.2 | ||
| 2022 | RF | 0.371 | 845.3 | 674.1 | 0.914 | 407.4 | 321.3 | |
| SVM | 0.328 | 879.0 | 670.8 | 0.404 | 823.5 | 611.3 | ||
| MARS | 0.316 | 877.4 | 696.0 | 0.331 | 867.0 | 689.8 | ||
| BRNNs | 0.318 | 877.9 | 690.4 | 0.363 | 845.6 | 671.9 | ||
| Soybean | 2019 | RF | 0.398 | 232.1 | 181.4 | 0.913 | 109.9 | 85.0 |
| SVM | 0.336 | 243.5 | 188.2 | 0.419 | 227.7 | 172.5 | ||
| MARS | 0.326 | 245.3 | 191.8 | 0.328 | 244.5 | 192.2 | ||
| BRNNs | 0.296 | 251.1 | 194.8 | 0.349 | 240.7 | 188.9 | ||
| 2020 | RF | 0.393 | 291.3 | 223.9 | 0.904 | 140.9 | 107.0 | |
| SVM | 0.317 | 310.6 | 235.0 | 0.425 | 284.1 | 205.2 | ||
| MARS | 0.306 | 311.3 | 241.9 | 0.317 | 308.4 | 239.9 | ||
| BRNNs | 0.267 | 320.8 | 247.3 | 0.314 | 309.2 | 239.3 | ||
| 2021 | RF | 0.297 | 214.9 | 170.3 | 0.908 | 102.0 | 79.9 | |
| SVM | 0.231 | 231.4 | 166.3 | 0.319 | 216.4 | 149.7 | ||
| MARS | 0.212 | 227.6 | 181.1 | 0.236 | 223.6 | 178.6 | ||
| BRNNs | 0.222 | 226.7 | 178.6 | 0.263 | 219.7 | 174.9 | ||
| 2022 | RF | 0.298 | 214.7 | 170.2 | 0.908 | 101.9 | 79.9 | |
| SVM | 0.230 | 231.7 | 166.6 | 0.324 | 215.6 | 148.9 | ||
| MARS | 0.211 | 227.7 | 181.1 | 0.236 | 223.6 | 178.6 | ||
| BRNNs | 0.221 | 227.0 | 178.8 | 0.285 | 216.4 | 171.6 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Radočaj, D.; Plaščak, I.; Jurišić, M. Phenology-Based Maize and Soybean Yield Potential Prediction Using Machine Learning and Sentinel-2 Imagery Time-Series. Appl. Sci. 2025, 15, 7216. https://doi.org/10.3390/app15137216
Radočaj D, Plaščak I, Jurišić M. Phenology-Based Maize and Soybean Yield Potential Prediction Using Machine Learning and Sentinel-2 Imagery Time-Series. Applied Sciences. 2025; 15(13):7216. https://doi.org/10.3390/app15137216
Chicago/Turabian StyleRadočaj, Dorijan, Ivan Plaščak, and Mladen Jurišić. 2025. "Phenology-Based Maize and Soybean Yield Potential Prediction Using Machine Learning and Sentinel-2 Imagery Time-Series" Applied Sciences 15, no. 13: 7216. https://doi.org/10.3390/app15137216
APA StyleRadočaj, D., Plaščak, I., & Jurišić, M. (2025). Phenology-Based Maize and Soybean Yield Potential Prediction Using Machine Learning and Sentinel-2 Imagery Time-Series. Applied Sciences, 15(13), 7216. https://doi.org/10.3390/app15137216