1. Introduction
The use and application of unmanned aerial vehicles (UAVs) have gained significant attention in recent years, driven by rapid advancements in UAV technology. Currently, UAVs are widely adopted in the consumer industry for purposes such as videography, content creation, and event-based filmmaking. Several companies are also promoting the use of UAVs for logistics and transportation, although such services are still limited to specific regions [
1,
2,
3]. The evolution of UAVs into more compact, affordable, and easily controllable devices has facilitated their adoption among end-users [
4,
5]. However, this ease of access presents security and privacy concerns, as UAVs may violate public or personal safety [
6,
7,
8]. This is primarily due to the difficulty in regulating and controlling individual users. Moreover, the trend toward smaller UAVs exacerbates the problem, as such drones are more difficult to detect and localize. Consequently, it is critical to develop systems capable of reliably detecting and tracking nearby UAVs to safeguard against unauthorized intrusions.
Currently, the technologies for detecting illegally operating UAVs remain incomplete and unreliable [
9]. Several methods have been proposed, most of which utilize radar [
10], radio frequency (RF) signals [
11,
12,
13], acoustic sensors [
14], or image-based techniques [
15,
16,
17]. Radar-based methods suffer from limitations related to radar cross-section (RCS), which defines the minimum detectable size of an object. As such, these systems are often ineffective for detecting small UAVs and are more suited to larger aerial targets. RF- and acoustic-based methods, on the other hand, are highly sensitive to environmental noise, often resulting in poor performance when detecting smaller UAVs.
With the rapid advancement of deep learning in image processing, image-based object detection has become significantly more feasible and accurate. Using this technology, it is now possible to detect UAVs from image inputs with high precision. Generic object detection models such as YOLO [
18], SSD [
19], and Faster-RCNN [
20] can be trained on UAV datasets to identify and localize drones within images. Compared to other detection methods, image-based approaches are simpler and more cost-effective, as they require only basic camera hardware. This makes them especially advantageous for detecting small- to large-sized UAVs. The primary limitation of image-based detection lies in its range, as it can only identify UAVs within the visible field of view of the camera.
To develop deep learning models for UAV detection, appropriate datasets are essential for training, evaluation, and testing. Several datasets have been introduced for UAV object detection tasks [
21,
22,
23,
24]. These datasets are typically designed for object detection and provide UAV locations in the form of bounding boxes. Models trained on these datasets consume RGB or infrared (IR) images and attempt to localize UAVs by predicting bounding boxes around them. Consequently, all existing UAV datasets and associated models are designed solely for object detection tasks.
While many datasets and detection models exist, they often struggle with small object detection. Some methods have been proposed to improve performance on small objects, but they typically result in increased model size and reduced real-time performance. Furthermore, recent anti-UAV challenges [
22] have expanded the focus beyond detection to include UAV tracking to neutralize threats posed by unauthorized UAVs.
In this study, we propose a new direction for the anti-UAV task by utilizing semantic segmentation instead of traditional object detection. Semantic segmentation assigns a class label to each pixel in the image, providing superior accuracy for UAV localization. Compared to bounding box methods, semantic segmentation is better suited for detecting small UAVs due to its pixel-level precision. However, to the best of our knowledge, no UAV-specific dataset for semantic segmentation currently exists. Therefore, we introduce a novel semantic segmentation dataset for UAV localization, capable of handling small to large UAVs. We hope this dataset will benefit the research community and aid in reducing threats posed by illegal UAV activity.
Due to the high-speed nature of UAV movement, detection accuracy alone is not sufficient. Real-time performance is also critical to ensure the system can track and respond to UAVs effectively without excessive computational load. To address this, we also propose a lightweight semantic segmentation model, ThinDyUNet, capable of real-time UAV localization using our VL and IR dataset. We compare ThinDyUNet with several baseline semantic segmentation models retrained on the proposed dataset. The main contributions of this study are summarized as follows:
We introduce a new semantic segmentation dataset for UAV detection. The dataset includes a wide range of UAV types, sizes, and distances, with paired RGB and IR images and corresponding segmentation masks. The dataset is publicly available for unrestricted research use.
We propose ThinDyUNet, a lightweight model designed for semantic segmentation-based UAV detection. ThinDyUNet achieves real-time performance with significantly reduced model size, enabling fast inference compared to existing baseline models.
Based on the main contributions, this paper mainly proposes a new semantic segmentation dataset for recognizing a small rotary-wing UAV that flies in various environments and consists of two image types: VL and IR images. Since there is no available dataset for anti-UAV using semantic segmentation tasks, this paper becomes the first one to propose it. To initiate the model for the semantic segmentation task using this dataset, we propose a model called ThinDyUNet. By having a proposed model, we hope that it can help to create a benchmark model that can be compared for future research that uses the proposed dataset. Furthermore, we hope that the proposed model can be used as a guide to improve the field of semantic segmentation into a lightweight model and capability for real-time implementation, especially for anti-UAV tasks.
This paper is organized as follows.
Section 2 reviews existing datasets and models for anti-UAV detection.
Section 3 introduces the proposed UAV semantic segmentation dataset.
Section 4 details the ThinDyUNet model architecture.
Section 5 presents a performance comparison between ThinDyUNet and baseline semantic segmentation models using the proposed dataset.
Section 6 concludes the paper.
2. Related Work
This section reviews recent advances in anti-UAV datasets and novel models for anti-UAV tasks.
2.1. Anti-UAV Dataset
We focus exclusively on datasets that use UAVs as the primary class for detection. Multi-class datasets containing UAVs alongside other objects are omitted to maintain relevance to the specific task. Several datasets dedicated solely to UAV detection have been developed. MAV-VID [
25] is a public dataset consisting of 64 videos of flying UAVs, totaling 40,323 images extracted from video frames. Among the 64 videos, 53 are designated for training and 11 for validation. In this dataset, UAV movements are predominantly horizontal, and UAVs are mainly centered in the images. MAV-VID contains only RGB images and is publicly accessible on the Kaggle platform.
The Anti-UAV dataset [
22] initiated the first Anti-UAV Challenge & Workshop. It comprises 318 annotated videos for object detection and tracking tasks, including both RGB and IR images with corresponding labels. UAV positions in this dataset are mostly concentrated near the center of the images. The dataset features varying UAV object sizes, promoting more reliable detection performance.
Isaac-Medina et al. [
21] proposed a dataset that integrates images from three UAV datasets: MAV-VID [
25], Drone-vs-Bird [
26], and Anti-UAV [
22]. This combined dataset serves as a benchmark for UAV detection and tracking, evaluated using various state-of-the-art models such as Faster R-CNN [
20], YOLOv3 [
27], SSD [
19], DETR [
28], SORT [
29], Deep-SORT [
30], and Tracktor [
31].
The DUT-Anti-UAV dataset [
23] is another large-scale resource designed for UAV detection and tracking. It improves upon the Anti-UAV and MAV-VID datasets by providing a more diverse UAV distribution with scattered positions throughout the images. The dataset exhibits a more uniform horizontal and vertical distribution of UAVs. It also includes 35 different UAV types, increasing object variety. Most images feature small-sized UAVs, which pose challenges for model performance due to the increased difficulty of detection and higher likelihood of failure.
To date, no publicly available dataset focuses specifically on the semantic segmentation of UAVs. In this paper, we propose and release a UAV semantic segmentation dataset. This enables more precise UAV localization in images, particularly for small-sized UAVs, by leveraging pixel-level classification rather than bounding boxes.
2.2. Anti-UAV Detection
Numerous methods have been proposed for image-based UAV detection. For example, several state-of-the-art object detection models have been applied to UAV detection datasets [
17,
32,
33,
34,
35]. Faster R-CNN [
20], combined with feature extraction backbones such as ResNet50, ResNet18, or VGG16, achieves a mean average precision (mAP) greater than 0.6. Its inference speed, measured in frames per second (FPS), can reach up to 19.4 [
23]. These results demonstrate that Faster R-CNN can effectively perform UAV detection. However, its FPS is relatively low for real-time applications. To address this, faster models such as YOLOX [
36] and SSD [
19] have been utilized. Although these models achieve lower mAP scores ranging from approximately 0.4 to 0.63, they offer significantly higher inference speeds, with FPS values reaching up to 53.7 [
23].
These findings indicate that state-of-the-art object detection models can be successfully applied to UAV detection after training on relevant datasets. Nonetheless, these models still struggle with accurately detecting small UAVs. To address this challenge, Tong et al. [
37] proposed a transformer-based model called ST-Trans, which improves small object detection performance in UAV detection tasks. Despite its improved accuracy, ST-Trans still faces limitations in achieving real-time inference speeds.
Currently, there are no publicly available datasets for UAV semantic segmentation, and consequently, no existing models specifically designed for this task. However, state-of-the-art semantic segmentation models from related detection tasks can be adapted for UAV semantic segmentation. In this paper, we propose a novel lightweight model tailored for UAV semantic segmentation, optimized for both higher mean intersection over union (mIoU) and real-time performance. The proposed model is evaluated against existing state-of-the-art segmentation models retrained on our newly proposed dataset.
3. Anti-UAV Semantic Segmentation Dataset
This section describes the creation of the UAV semantic segmentation dataset, detailing the preparation of input images, label generation, and dataset statistics.
3.1. Dataset Source
Collecting real UAV semantic segmentation images in our research environment is challenging. Therefore, we compiled our dataset by integrating images from multiple existing sources. Specifically, we combined UAV images and their corresponding bounding boxes from three different datasets:
From these sources, image and label pairs were randomly selected to form our proposed dataset. For folder organization, we adopted the folder structure used in the Anti-UAV dataset. Each image sequence contains RGB and infrared (IR) image pairs when available, primarily from the Anti-UAV dataset. If an IR image is not available for a given sequence, only the RGB image is included.
Since the original datasets focus on object detection and tracking tasks, only the images and their corresponding UAV bounding boxes were utilized. Each image and bounding box pair was used to generate semantic segmentation masks in the next step.
Figure 1 shows example images sampled from the various dataset sources.
3.2. Labels Generation
The sampled image-label pairs are originally in object detection format, where labels are bounding boxes defined by (). Here, x and y represent the coordinates of the bounding box’s top-left corner, while w and h denote the width and height of the object, respectively. However, semantic segmentation requires pixel-level masks as labels for model training. Therefore, converting bounding boxes into segmentation masks is necessary.
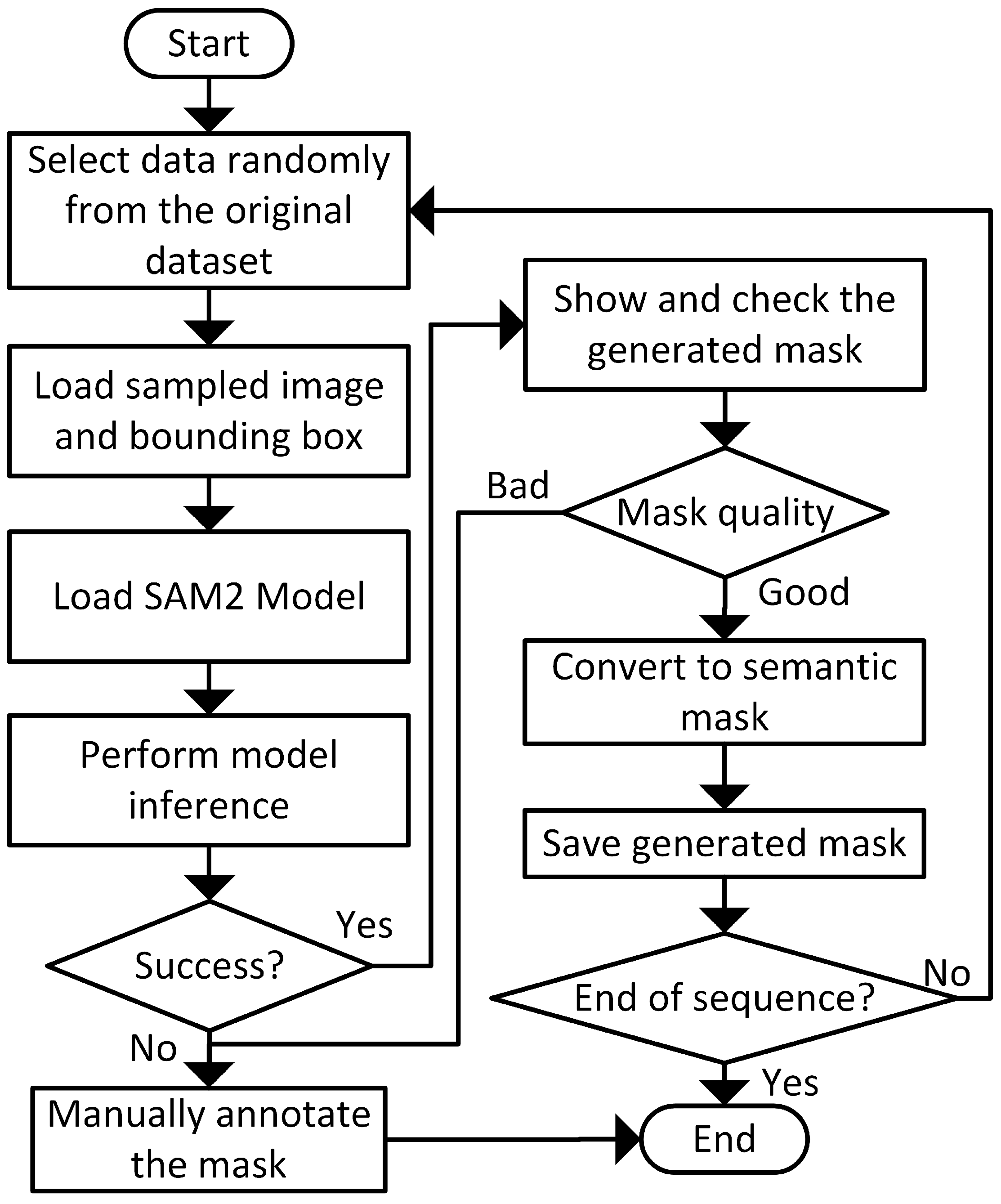
In this work, we utilize the segment anything model (SAM) [
38] provided by Ultralytics [
39] to generate the segmentation masks for the UAV. The workflow of the mask generation process is shown in
Figure 2 to generate segmentation masks for the UAVs.
Figure 2 illustrates the workflow of this mask generation process. It begins by loading each sampled image and its corresponding bounding box. Next, the SAM2 model [
40] is loaded via the Ultralytics library and used to predict masks.
The loaded SAM2 model performs inference using the RGB image and bounding box as inputs. The model outputs an instance segmentation mask that identifies objects within the bounding box as the object of interest, while treating regions outside the box as background. Since SAM2 produces instance segmentation masks, we convert these into semantic segmentation masks by mapping all pixels to either 0 or 1, reflecting our binary classification task: UAV versus background. Specifically, pixels labeled 0 represent the background, and pixels labeled 1 represent the UAV.
In the final semantic masks, pixel values are exclusively 0 or 1 to represent background and UAV classes, respectively. In images containing multiple UAVs, all UAV pixels are labeled 1, maintaining the binary mask format.
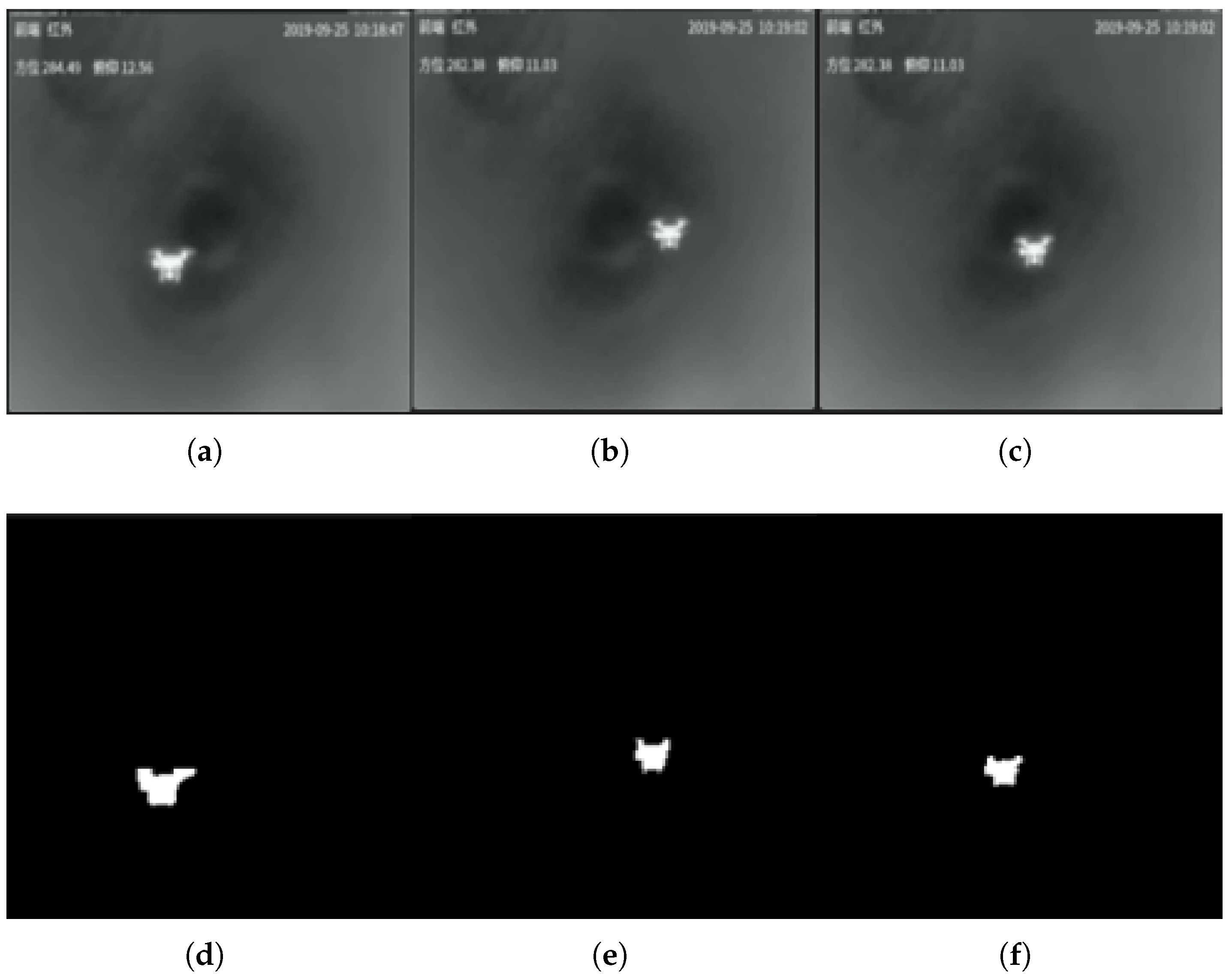
Figure 3 shows examples of original images and their corresponding generated semantic segmentation masks.
3.3. Dataset Characteristics
The dataset is divided into three splits: training, validation, and testing. It contains both RGB and IR images.
Table 1 summarizes the dataset statistics. In total, the dataset includes 605,045 images, comprising a mix of RGB and IR images. Specifically, there are 308,144 RGB images and 296,901 infrared images. All images and their corresponding labels have been resized to a resolution of
pixels to maintain consistency across the dataset.
In this dataset, we combine the images from the images scraping process and several datasets. Hence, the dataset contains multiple types of UAVs with various sizes. There are more than 40 types of UAVs that are contained in our dataset. All of the UAVs are in the form of small- to medium-sized UAVs with a maximum dimension of 1 m. The major types of UAVs that consist of our dataset are shown in
Table 2.
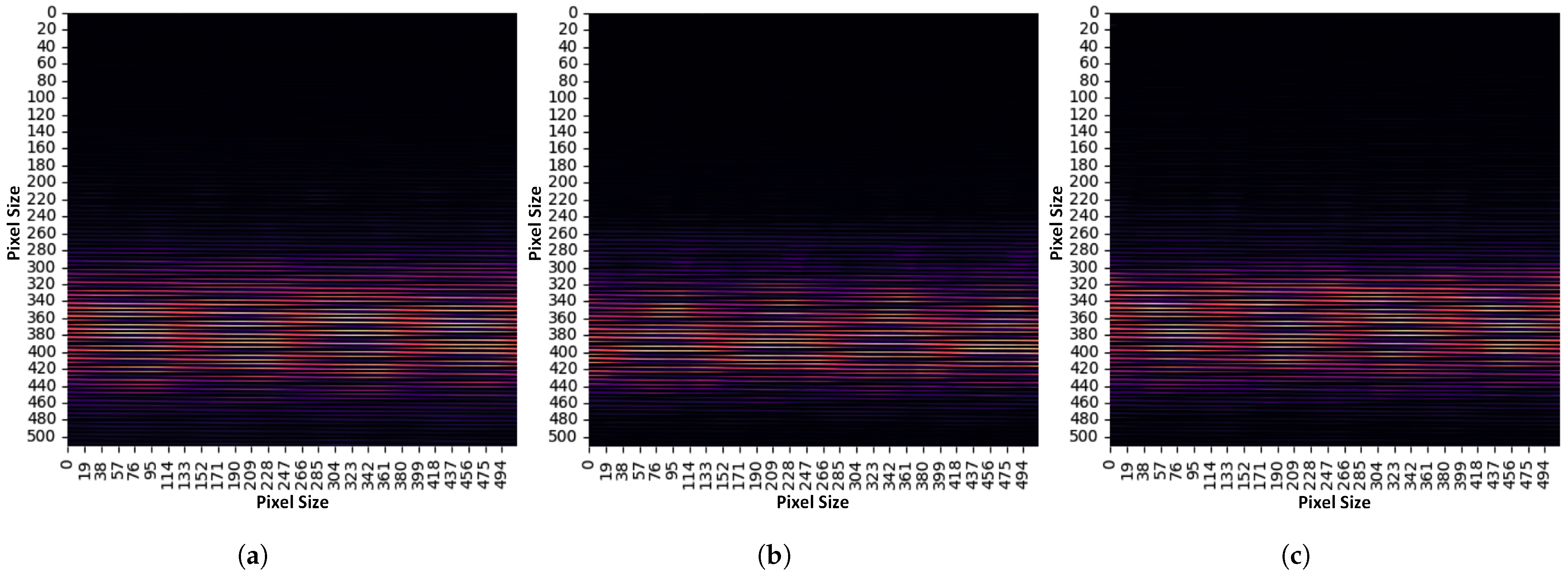
The position of the UAV object in the dataset also varies. In this dataset, the UAV position is distributed from left to right. Compared to the existing dataset, in which the UAV is only positioned in the center images, the proposed dataset provides a more varying UAV position on the horizontal axis. The position distribution of the UAV object is shown in
Figure 4.
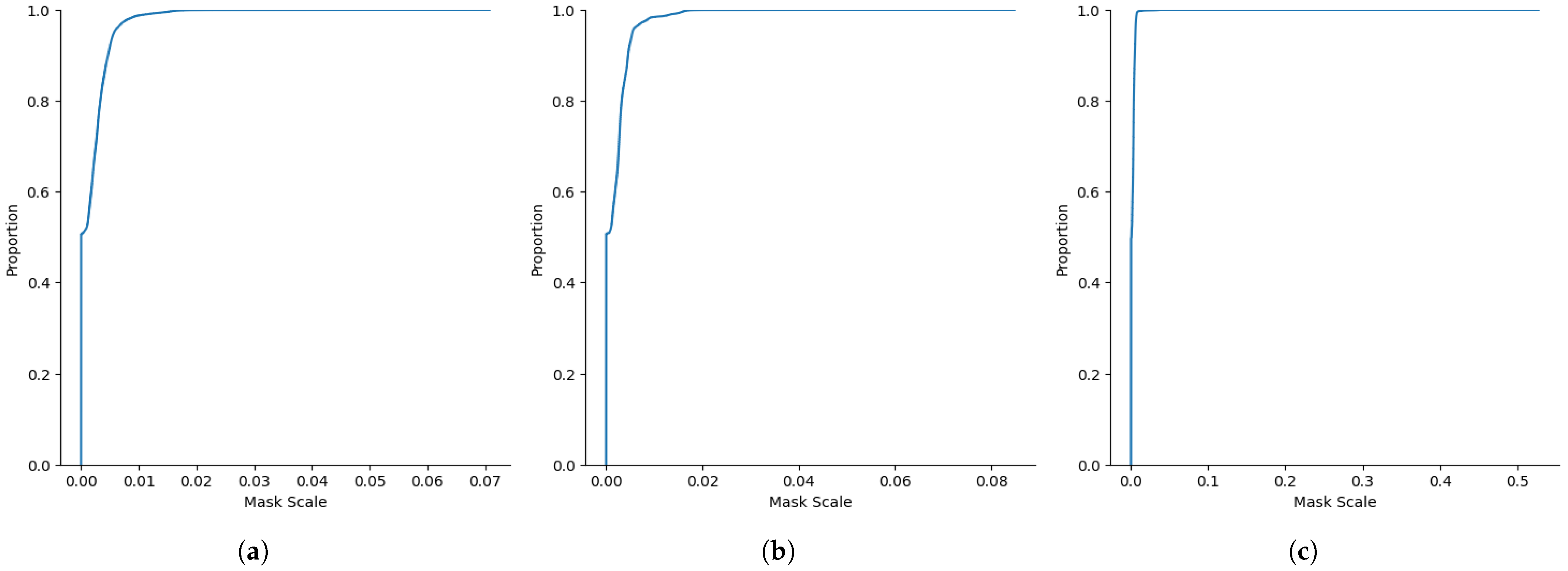
Figure 5 shows the distribution of the mask scale in the dataset. The mask scale is calculated by comparing the area of the segmentation mask with the size of the image. Larger values expressed larger object sizes in the image and vice versa. The distribution plot clearly shows that there are more smaller UAV object sizes compared to the large object. This suggests that the proposed UAV semantic segmentation dataset is focused on solving issues with smaller-size UAV recognition and is fit for researchers who are having issues with small-size UAV recognition. In the training and validation set, the dataset contains a wider variance of object size. Meanwhile, for the test set, there are many more small UAV object sizes, and the maximum object size is almost half of the maximum object size in the training and validation set. This situation verifies the model generalization performance for recognizing a smaller UAV object size.
4. ThinDyUNet Realtime Segmentation Model
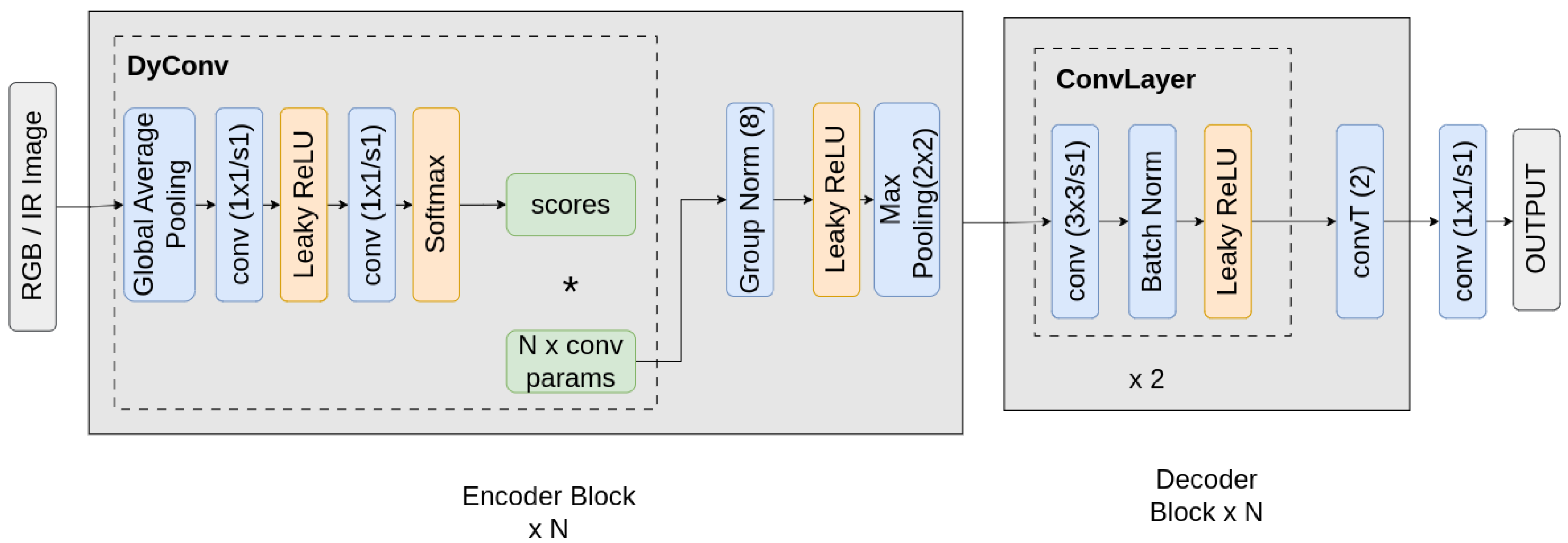
The architecture of the proposed model retains the general structure of the U-Net framework but incorporates significant modifications to reduce the model size and improve its ability to effectively process VL and IR images. In the original U-Net, the encoder’s shallowest layer has 64 channels, and the number of channels doubles after each convolutional block in the encoder’s downsampling path. That method is designed for complex data such as multi-label segmentation tasks that trained on datasets like ImageNet or COCO; it relies on a large number of parameters and diverse channel combinations to capture a wide range of semantic information. However, such a level of complexity is not required for simpler, single-class tasks. In our case, the task mainly focuses on segmenting a single UAV, which inherently requires less representational power. Therefore, our proposed model adopts a more efficient architecture by using fixed 64 channels across all convolutional blocks in both the encoder and decoder. This design significantly reduces the number of parameters to approximately 1.3 million, making it computationally efficient and well-suited for real-time inference.
In the encoder, the conventional double convolutional layers are replaced by attention-based dynamic convolution layers. This mechanism enables the network to adapt its feature extraction dynamically based on the input modality. The attention mechanism is based on the squeeze-and-excitation (SE) method, which consists of two main steps. The squeeze step performs global average pooling (GAP) over the spatial contextual information. Followed by the excitation step, where the descriptor is passed through a fully connected layer or 1 × 1 convolutions and then activated by a non-linear function (e.g., sigmoid) to generate attention weights. These weights are used to recalibrate the input channels by scaling them accordingly.
In dynamic convolution, the SE method of attention applied not to channel-wise features but to a set of convolution kernel parameters. The input feature map first undergoes global pooling to generate the descriptor and is then processed through two convolutions and a SoftMax function to produce a set of attention scores, as shown in
Figure 6. These scores represent the importance of each in a predefined set of N kernels. A dynamic kernel is computed as the weighted sum of these kernels, using the attention scores as weights. This kernel then applied to the features with standard convolution followed by normalization and activation to allow the network to converge more efficiently with better gradient flow.
The dynamic convolution mechanism enables the model to adaptively generate task-relevant kernels conditioned on the input, making it particularly effective for processing data with more than one modality. Given an input feature map , the process begins by extracting a global representation through global average pooling (GAP), followed by pointwise convolution. Those layers act as a fully connected network to produce a latent vector z, where N corresponds to the number of predefined candidate convolution kernels. This vector captures high-level information from the input feature map and is modality-aware, as the global pooling summarizes the global context across the entire feature map from different input types.
Subsequently, the SoftMax operation is applied to z to generate an attention score , where the value represents the relevance of each kernel in the context of the given input. The score is used to compute the dynamic convolution kernel by linearly combining the predefined kernels . The dynamic kernel assembly allows the model to adjust its convolutional behavior depending on the modality and content of the input, enhancing adaptability to the feature characteristics.
The constructed kernel is applied to the input feature map X, and the result is passed through Group Normalization followed by the LeakyReLU activation function. This step is used to maintain stable training and introduces non-linearity to enhance the model learning. This approach effectively merges the strength of attention mechanisms with efficient convolution operations, providing flexibility and robustness in multiple modalities tasks such as UAV-based segmentation.
Overall, the attention mechanism prioritizes the most relevant convolution kernels based on the input data, while the dynamic convolution allows adaptive feature extraction tailored to varying input conditions. This makes the proposed ThinDyUNet model highly effective for VL and IR segmentation tasks with real-time performance.
5. Experiments
5.1. Baseline Models
In our experiments, we compare the proposed ThinDyUNet model with four state-of-the-art semantic segmentation models: UNet [
41], pyramid attention network (PAN) [
42], pyramid scene parsing network (PSPNet) [
43], and TransUNet model [
44]. Each model is re-implemented and retrained using the UAV semantic segmentation dataset. Details of each model are shown in the next subsections.
5.1.1. UNet
The UNet [
41] model is widely used for semantic segmentation. It employs an encoder–decoder architecture designed to output segmentation masks of the same size as the input image, making it suitable for pixel-wise prediction tasks. We re-implemented UNet using the segmentation models library [
45], with ResNet-34 as the feature extractor. The feature extractor weights were initialized with ImageNet pretrained parameters.
5.1.2. PAN
PAN [
42] is a state-of-the-art model for semantic segmentation that incorporates Feature Pyramid Attention and Global Attention Upsample modules to enhance feature representation and localization accuracy. We re-implemented PAN using the semantic models library [
45], employing ResNet-34 as the backbone with ImageNet pretrained weights for fair comparison.
5.1.3. PSPNet
PSPNet [
43] leverages a pyramid parsing module to extract global contextual information through multi-region context aggregation. This approach optimizes both local and global feature extraction, improving segmentation accuracy. We re-implemented PSPNet with the Semantic Models library using ResNet-34 as the backbone and ImageNet pretrained weights.
5.1.4. TransUNet
TransUNet [
44] was originally proposed for medical image segmentation and combines the UNet architecture with a Vision Transformer [
46] integrated into the encoder. This model addresses some limitations of traditional UNet architectures and aims to improve segmentation performance. We re-implemented the TransUNet model by following the original author’s implementation. During the model training, ImageNet pretrained weights are utilized.
5.2. Implementation Details
All models presented herein are trained using the same hardware and dataset sequence to ensure a fair comparison. Each model receives input images of size , which may be either RGB or IR images. The models are implemented in Python 3.12.3 using the PyTorch 2.4.1 library. Training is performed using the Adam optimizer with a learning rate of , while all other hyperparameters remain at their PyTorch defaults. A batch size of 24 is used, and training is conducted for up to 50 iterations. An early stopping mechanism is employed to halt training if the loss fails to improve over ten consecutive iterations. All experiments are executed on a single NVIDIA RTX 3090 GPU purchased from the NVIDIA, Seoul, South Korea.
For real-world implementations, we performed the test on an embedded computer environment. The trained weights from the training process are copied into the embedded computer. The test set images are also put in the embedded computer. Then, the models are inferred on the embedded computer using the trained weights. In this work, the embedded computer is using LattePanda Sigma, which is equipped with an RTX A500 external GPU from the Pocket AI.
5.3. Model Performance Comparison
To demonstrate the effectiveness of the proposed semantic segmentation dataset and the ThinDyUNet model, we provide both quantitative and qualitative comparison results.
5.3.1. Quantitative Results
Table 3 presents the performance of each model trained on the proposed UAV semantic segmentation dataset. All models were able to produce meaningful mIoU values, confirming that they successfully learned to generate semantic segmentation masks. This result validates the suitability of the dataset for training models on the UAV semantic segmentation task. For comparison, we use four metrics of precision, recall, Dice coefficient, and mIoU. The Dice coefficient and mIoU are metrics to measure the quality of the generated segmentation mask. To calculate those metrics, the metrics of precision and recall are required. Therefore, the final value of the Dice coefficient and mIoU is linear with the value of precision and recall.
Among all models, the PAN model achieved the highest validation mIoU, indicating superior accuracy in UAV mask prediction. The UNet model ranked second, with a validation mIoU only (or %) lower than PAN, showing comparable effectiveness.
The proposed ThinDyUNet model achieved a validation mIoU of , placing it third overall. Although it did not surpass the top-performing models, the performance gap is relatively small, just (or %) lower than PAN. The lowest performance was observed in the PSPNet model, which produced a validation mIoU of only . Overall, the spread of mIoU performance between the models is quite small, indicating that during the training, all models are learning properly.
Dice coefficient parameters are also considered as metrics to compare the model performance. The Dice coefficient measures the shape similarities of the generated object mask with the ground truth mask. Based on
Table 3, the results are not much different than the mIoU metrics, where all models are able to perform a decent value on Dice coefficient metrics. However, the PSPNet consistently has the lowest performance compared to other models. In this metric, the UNet, PAN, and TransUNet perform better than the ThinDyUNet model, where the proposed model achieves only
. However, the highest Dice coefficient is
, which shows only a
or
spread difference compared to the ThinDyUNet, which explains the slight performance difference between the aforementioned models.
Despite not leveraging any pretrained weights, the ThinDyUNet model demonstrated competitive performance, closely approaching that of models initialized with pretrained weights and a much larger number of parameters. This effectiveness is largely due to the use of the dynamic convolution mechanism, which allows the model to adaptively extract features and the configuration of the model’s layer for more efficient learning.
In
Table 4, the model performance in the test set is compared. Compared with results in the validation set, several models undergo a drastic reduction in performance for all metrics. Mainly, the PAN model, which is the first-rank performance and validation set, become the worst performance in the test set. Meanwhile, the TransUNet model, which got moderate performance in the validation set, also endured the same situation as the PAN model. The situation where the model achieves decent metrics in the validation set but decreases significantly in the test set is usually caused by overfitting during the model training. Meanwhile, the UNet and PSPNet models achieve a higher metrics performance on the test set compared to the validation set.
The ThinDyUNet model achieves a stable performance in both the validation and test sets. It proved that the model can converge well during the model training. The ThinDyUNet achieved the value of 0.744 for Dice coefficient metrics and 0.646 for mIoU metrics in the test set. These metric values showed small differences when compared to the best models that achieved the best metric values, indicating that the proposed model exhibits similar performance to the best models.
Moreover, the ThinDyUNet model offers a significant advantage in terms of model size. As shown in
Table 5, ThinDyUNet has the smallest number of parameters, approximately four times fewer than TransUNet and about twenty times fewer than UNet, PAN, and PSPNet. This reduction is achieved by efficiently utilizing a fixed number of channels in each convolutional layer, making the model highly lightweight and efficient. Despite its compact size, ThinDyUNet remains competitive with larger models. To evaluate inference performance, we measured the average inference time per image using the validation dataset. ThinDyUNet recorded the fastest inference time among all models, thanks to its smaller size and lower computational complexity.
In contrast, UNet, PAN, PSPNet, and TransUNet recorded inference times of more than four milliseconds per image due to their significantly higher parameter counts. The PAN model has the slowest performance among all models, with a 6.01-millisecond inference time. Meanwhile, for other models, such as UNet, PSPNet, and TransUNet, it has around 4 ms of inference time. For the proposed ThinDyUNet model, it showed the fastest inference time of 2.45 ms. Due to the smallest number of model parameters, the amount of computation in the ThinDyUNet model is far less than other models, resulting in faster processing time for inference of one image frame.
5.3.2. Qualitative Results
In this section, we present the predicted segmentation masks generated by each model and compare them with the original input images and the corresponding ground truth masks.
Figure 7 illustrates the qualitative comparison results on an RGB image sampled from the test dataset—images that were not seen by the models during training. From
Figure 7, it can be observed that the proposed ThinDyUNet, as well as UNet, PAN, TransUNet, and PSPNet, can generate reasonable segmentation masks. Although the shapes of the predicted masks do not perfectly align with the ground truth, the general position and size of the masks are similar and correctly located.
For the RGB images in the test set, all models seem to be able to generate a proper segmentation mask. Although the metrics for metrics vary for each model, all models are still able to produce segmentation masks that are similar to the ground truth. Notably, the proposed ThinDyUNet, despite having a smaller number of parameters, was still able to learn effectively and produce accurate segmentation results.
Figure 8 shows the prediction results on an IR image randomly sampled from the test dataset. In this case, the overall model performance degraded when applied to IR images. Although the metrics are quite decent in the test set and able to generate masks correctly for RGB input, the UNet model generates a wrong mask for the IR input. The UNet model generate two mask objects as shown in
Figure 8d and a mask with a hole as shown in
Figure 8k,r. This suggests that the model may have overfitted to the RGB images and failed to generalize to IR inputs. The TransUNet model fails to generate a proper segmentation image by generating a largely different object mask compared to the ground truth. This also suggests the metrics reduce between the validation and test set of the TransUNet model. The PAN model is also facing a similar issue where the metrics are decreasing in the test set, causing the model to not be able to generate a proper segmentation mask for IR images. The PSPNet model, on the other hand, successfully predicted a single object in the mask, accurately identifying its position. However, the size and shape of the predicted mask did not precisely match the ground truth. The proposed ThinDyUNet outperformed the other models in IR segmentation. It successfully generated a mask that closely matched the position of the ground truth. While the shape and size of the predicted mask were slightly different from the ground truth, the proportions were more accurate than those produced by PSPNet.
The presented mask comparison in
Figure 7 and
Figure 8 is small, and readers might not be able to see clearly and find distinction between them. Hence, in
Figure 9 and
Figure 10, we show only the original images, ground truth segmentation mask, generated mask by ThinDyUNet, and UNet model, which have the best performance metrics in the test set. By selecting fewer images, the generated mask size can be larger and the difference between masks is clearer. We select only the images from the middle row from
Figure 7 and
Figure 8.
In both
Figure 9 and
Figure 10, the ThinDyUNet and UNet are able to generate a mask properly. For the RGB images, the mask generated by the ThinDyUNet model is more similar to the ground truth mask in terms of size and shape. Compared with the mask from the UNet model, it is smaller in size, and the shape is not as similar to the ground truth mask.
Meanwhile, for the IR images, the mask shape of the UNet model is more similar in size and shape compared to the mask generated by the ThinDyUNet model. Although it has a hole in the center of the mask, overall, the mask generated by the UNet is more similar to the ground truth. The mask generated by the ThinDyUNet model is able to generate a proper mask, although the shape is different than the ground truth and the overall size of the mask is a little bit smaller than the ground truth.
Based on both quantitative and qualitative results, the proposed ThinDyUNet model demonstrates effective learning and generalization capabilities when trained on the UAV semantic segmentation dataset. Although the ThinDyUNet does not achieve the best performance metrics, it shows a reliable and stable performance on RGB and IR image inputs compared to other models, which are mostly only good for RGB image inputs and fail for IR image inputs. Despite its compact architecture and low parameter count, ThinDyUNet performs well on both RGB and IR input images, producing segmentation masks with satisfactory accuracy. These results confirm the efficiency and robustness of the proposed model in handling VL and IR inputs.
5.3.3. Ablation Study
To prove the impact of the proposed dynamic convolution on the model performance, we perform an ablation study to compare the model performance when using dynamic convolution and only regular convolution. In this ablation study, only the dynamic convolution part is omitted and replaced with regular convolution blocks. The rest of the model is untouched and kept the same for both the model with dynamic convolution and the model with regular convolution. The ablation study is performed by measuring the model metrics, such as the precision, recall, Dice, and mIoU, on the validation and test sets.
Both models are trained using the same set of training, validation, and test sets. During training, both models’ performances are compared using the validation set. Results from the validation set are shown in
Table 6, where it shows the model parameters, precision, recall, Dice, and mIoU metrics. From the table, it shows that both models have a significant difference in the number of model parameters. In the model with dynamic convolution, the model parameters are only 1.3 million, while the model parameters in the model with regular convolution reach up to 15.3 million. Although both models are using a similar channel size, the number of parameters is larger in a regular convolution.
Table 6 also shows the metrics performance of both models. It is clearly shown that the models can learn the data properly during training, which is shown by the decent metrics value. Both models can achieve an mIoU of more than 0.64, with the model with dynamic convolution achieving lower performance than the model with a regular convolution. The Dice metrics of the models also show that the models are able to generate a similar mask compared with the ground truth mask. Again, the model with regular convolution can show a better Dice coefficient value compared to the model with dynamic convolution. Due to the large number of parameters, which means that the model has a greater number of receptors to learn the characteristics of the data, the model with regular convolution is able to overcome the model with dynamic convolution performance.
However, in the test set results, which are shown in
Table 7, the metrics performance of the model with regular convolution is degraded. Both the Dice and mIoU values of the model with regular convolution are decreased by almost half. Meanwhile, the performance of the model with dynamic convolution remains stable without much difference from the training phase. The model with regular convolution might face an overfitting case, where the model performance degrades significantly in the test phase. Therefore, the model with dynamic convolution performs better in this case because it can perform a similar result during the training and testing phase.
6. Conclusions
In this study, we proposed a UAV semantic segmentation dataset specifically designed for UAV segmentation tasks. The dataset is constructed by integrating three publicly available UAV detection and tracking datasets. We presented an automated method to convert object detection bounding box annotations into semantic segmentation masks. This method effectively generates accurate masks and significantly reduces the time required compared to manual annotation. The resulting dataset is large-scale, consisting of up to 605,045 images across training, validation, and testing splits. In addition, we introduced a novel lightweight model, named ThinDyUNet, designed for real-time semantic segmentation. Experimental results show that the proposed model has a significantly smaller size compared to state-of-the-art models, yet achieves competitive mIoU performance. Qualitative analysis further demonstrates that the proposed model is capable of accurately generating segmentation masks for both RGB and IR image inputs. Despite its compact architecture, ThinDyUNet outperforms or matches the performance of larger, more complex models, highlighting its efficiency and effectiveness. For future work, we aim to extend the dataset to support instance and panoptic segmentation tasks to further advance research in UAV localization. Moreover, we plan to conduct additional experiments by deploying the proposed model on an embedded system mounted on a drone to evaluate its real-world performance and real-time processing capabilities.
Author Contributions
Conceptualization, S.-C.K.; methodology, S.-C.K. and Y.M.J.; software, S.-C.K.; validation, S.-C.K. and Y.M.J.; formal analysis, S.-C.K.; investigation, S.-C.K.; resources, S.-C.K. and Y.M.J.; data curation, S.-C.K.; writing—original draft preparation, S.-C.K.; writing—review and editing, S.-C.K.; visualization, S.-C.K.; supervision, Y.M.J.; project administration, Y.M.J.; funding acquisition, S.-C.K. and Y.M.J. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Korea Research Institute for defense Technology Planning and advancement (KRIT) grant funded by the Korea government (DAPA (Defense Acquisition Program Administration)) (KRIT-CT-23-041, LiDAR/RADAR Supported Edge AI-based Highly Reliable IR/UV FSO/OCC Specialized Research Laboratory, 2024).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| UAV | Unmanned Aerial Vehicle |
| RGB | Red, Green, and Blue |
| IR | Infrared |
| RADAR | Radio Detection and Ranging |
| RF | Radio Frequency |
| RCS | Radar Cross-Section |
| YOLO | You Only Look Once |
| SSD | Single-Shot Multibox Detection |
| RCNN | Region-based Convolutional Neural Network |
| mAP | Mean-Average Precision |
| FPS | Frame Per Second |
| mIoU | Mean Intersection over Union |
| PAN | Pyramid Attention Network |
| PSPNet | Pyramid Scene Parsing Network |
References
- Betti Sorbelli, F. UAV-Based Delivery Systems: A Systematic Review, Current Trends, and Research Challenges. ACM J. Auton. Transport. Syst. 2024, 1, 1–40. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, C.; Huang, Z.; Chang, Y.C.; Liu, L.; Pei, Q. A Low-Cost and Lightweight Real-Time Object-Detection Method Based on UAV Remote Sensing in Transportation Systems. Remote Sens. 2024, 16, 3712. [Google Scholar] [CrossRef]
- Moradi, N.; Wang, C.; Mafakheri, F. Urban Air Mobility for Last-Mile Transportation: A Review. Vehicles 2024, 6, 1383–1414. [Google Scholar] [CrossRef]
- Jayaram, D.K.; Raja, V.; Stanislaus Arputharaj, B.; AL-bonsrulah, H.A.Z. Design, Multiperspective Investigations, and Performance Analysis of Multirotor Unmanned Aerial Vehicle for Precision Farming. Int. J. Aerosp. Eng. 2024, 2024, 8703004. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, Q.; Mao, P.; Bai, Q.; Li, F.; Pavlova, S. Design and Control of an Ultra-Low-Cost Logistic Delivery Fixed-Wing UAV. Appl. Sci. 2024, 14, 4358. [Google Scholar] [CrossRef]
- Aggarwal, V.; Kaushik, A.R.; Jutla, C.; Ratha, N. Enhancing Privacy and Security of Autonomous UAV Navigation. In Proceedings of the 2024 IEEE Conference on Artificial Intelligence (CAI), Singapore, 25–27 June 2024; pp. 518–523. [Google Scholar] [CrossRef]
- Shah, I.A. Privacy and Security Challenges in Unmanned Aerial Vehicles (UAVs). In Cybersecurity in the Transportation Industry; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2024; Chapter 5; pp. 93–115. [Google Scholar] [CrossRef]
- Tu, Y.J.; Piramuthu, S. Security and privacy risks in drone-based last mile delivery. Eur. J. Inf. Syst. 2024, 33, 617–630. [Google Scholar] [CrossRef]
- Wang, B.; Li, Q.; Mao, Q.; Wang, J.; Chen, C.L.P.; Shangguan, A.; Zhang, H. A Survey on Vision-Based Anti Unmanned Aerial Vehicles Methods. Drones 2024, 8, 518. [Google Scholar] [CrossRef]
- Li, Y.; Fu, M.; Sun, H.; Deng, Z.; Zhang, Y. Radar-Based UAV Swarm Surveillance Based on a Two-Stage Wave Path Difference Estimation Method. IEEE Sens. J. 2022, 22, 4268–4280. [Google Scholar] [CrossRef]
- Vasant Ahirrao, Y.; Yadav, R.P.; Kumar, S. RF-Based UAV Detection and Identification Enhanced by Machine Learning Approach. IEEE Access 2024, 12, 177735–177745. [Google Scholar] [CrossRef]
- AlKhonaini, A.; Sheltami, T.; Mahmoud, A.; Imam, M. UAV Detection Using Reinforcement Learning. Sensors 2024, 24, 1870. [Google Scholar] [CrossRef]
- Bisio, I.; Garibotto, C.; Haleem, H.; Lavagetto, F.; Sciarrone, A. RF/WiFi-based UAV surveillance systems: A systematic literature review. Internet Things 2024, 26, 101201. [Google Scholar] [CrossRef]
- Sun, Y.; Li, J.; Wang, L.; Xv, J.; Liu, Y. Deep Learning-based drone acoustic event detection system for microphone arrays. Multimed. Tools Appl. 2024, 83, 47865–47887. [Google Scholar] [CrossRef]
- Dewangan, V.; Saxena, A.; Thakur, R.; Tripathi, S. Application of Image Processing Techniques for UAV Detection Using Deep Learning and Distance-Wise Analysis. Drones 2023, 7, 174. [Google Scholar] [CrossRef]
- Nguyen, D.D.; Nguyen, D.T.; Le, M.T.; Nguyen, Q.C. FPGA-SoC implementation of YOLOv4 for flying-object detection. J. Real-Time Image Process. 2024, 21, 63. [Google Scholar] [CrossRef]
- Yu, Q.; Ma, Y.; He, J.; Yang, D.; Zhang, T. A Unified Transformer Based Tracker for Anti-UAV Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Vancouver, BC, Canada, 17–24 June 2023; pp. 3036–3046. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Isaac-Medina, B.K.S.; Poyser, M.; Organisciak, D.; Willcocks, C.G.; Breckon, T.P.; Shum, H.P.H. Unmanned Aerial Vehicle Visual Detection and Tracking using Deep Neural Networks: A Performance Benchmark. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 1223–1232. [Google Scholar] [CrossRef]
- Jiang, N.; Wang, K.; Peng, X.; Yu, X.; Wang, Q.; Xing, J.; Li, G.; Guo, G.; Ye, Q.; Jiao, J.; et al. Anti-UAV: A Large-Scale Benchmark for Vision-Based UAV Tracking. IEEE Trans. Multimed. 2023, 25, 486–500. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, J.; Li, D.; Wang, D. Vision-Based Anti-UAV Detection and Tracking. IEEE Trans. Intell. Transp. Syst. 2022, 23, 25323–25334. [Google Scholar] [CrossRef]
- Coluccia, A.; Fascista, A.; Schumann, A.; Sommer, L.; Dimou, A.; Zarpalas, D.; Akyon, F.C.; Eryuksel, O.; Ozfuttu, K.A.; Altinuc, S.O.; et al. Drone-vs-Bird Detection Challenge at IEEE AVSS2021. In Proceedings of the 2021 17th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Washington, DC, USA, 16–19 November 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Isaac-Medina, B.K.S.; Poyser, M.; Organisciak, D.; Willcocks, C.G.; Breckon, T.P.; Shum, H.P.H. Unmanned Aerial Vehicle Visual Detection and Tracking using Deep Neural Networks: A Performance Benchmark. arXiv 2021, arXiv:2103.13933. [Google Scholar]
- Coluccia, A.; Fascista, A.; Schumann, A.; Sommer, L.; Dimou, A.; Zarpalas, D.; Méndez, M.; de la Iglesia, D.; González, I.; Mercier, J.P.; et al. Drone vs. Bird Detection: Deep Learning Algorithms and Results from a Grand Challenge. Sensors 2021, 21, 2824. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple Online and Realtime Tracking with a Deep Association Metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar] [CrossRef]
- Bergmann, P.; Meinhardt, T.; Leal-Taixé, L. Tracking Without Bells and Whistles. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 941–951. [Google Scholar] [CrossRef]
- Huang, B.; Chen, J.; Xu, T.; Wang, Y.; Jiang, S.; Wang, Y.; Wang, L.; Li, J. SiamSTA: Spatio-Temporal Attention based Siamese Tracker for Tracking UAVs. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 1204–1212. [Google Scholar] [CrossRef]
- Cheng, F.; Liang, Z.; Peng, G.; Liu, S.; Li, S.; Ji, M. An Anti-UAV Long-Term Tracking Method with Hybrid Attention Mechanism and Hierarchical Discriminator. Sensors 2022, 22, 3701. [Google Scholar] [CrossRef] [PubMed]
- Fang, A.; Feng, S.; Liang, B.; Jiang, J. Real-Time Detection of Unauthorized Unmanned Aerial Vehicles Using SEB-YOLOv8s. Sensors 2024, 24, 3915. [Google Scholar] [CrossRef]
- Dadboud, F.; Patel, V.; Mehta, V.; Bolic, M.; Mantegh, I. Single-Stage UAV Detection and Classification with YOLOV5: Mosaic Data Augmentation and PANet. In Proceedings of the 2021 17th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Washington, DC, USA, 16–19 November 2021; pp. 1–8. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Tong, X.; Zuo, Z.; Su, S.; Wei, J.; Sun, X.; Wu, P.; Zhao, Z. ST-Trans: Spatial-Temporal Transformer for Infrared Small Target Detection in Sequential Images. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 5001819. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Ultralytics. Home. 2025. Available online: https://docs.ultralytics.com/ (accessed on 15 January 2025).
- Ravi, N.; Gabeur, V.; Hu, Y.T.; Hu, R.; Ryali, C.; Ma, T.; Khedr, H.; Rädle, R.; Rolland, C.; Gustafson, L.; et al. SAM 2: Segment Anything in Images and Videos. arXiv 2024, arXiv:2408.00714. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Mei, Y.; Fan, Y.; Zhang, Y.; Yu, J.; Zhou, Y.; Liu, D.; Fu, Y.; Huang, T.S.; Shi, H. Pyramid Attention Networks for Image Restoration. arXiv 2020, arXiv:2004.13824. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. arXiv 2017, arXiv:1612.01105. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Welcome to Segmentation Models Pytorch Documentation! Available online: https://segmentation-modelspytorch.readthedocs.io/en/latest/ (accessed on 28 May 2025).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
Figure 1.
Example images sampled from various dataset sources. (a) RGB image pair from the Anti-UAV dataset. (b) IR image pair from the Anti-UAV dataset. (c) RGB image from the DUT-Anti-AUV dataset. (d) RGB image from the randomly sourced images.
Figure 1.
Example images sampled from various dataset sources. (a) RGB image pair from the Anti-UAV dataset. (b) IR image pair from the Anti-UAV dataset. (c) RGB image from the DUT-Anti-AUV dataset. (d) RGB image from the randomly sourced images.
Figure 2.
Workflow of semantic segmentation mask generation from object detection labels.
Figure 2.
Workflow of semantic segmentation mask generation from object detection labels.
Figure 3.
Sample original images and generated UAV masks. (a–c) Original images randomly sampled from the dataset. (d–f) Generated semantic segmentation masks from the proposed label conversion process.
Figure 3.
Sample original images and generated UAV masks. (a–c) Original images randomly sampled from the dataset. (d–f) Generated semantic segmentation masks from the proposed label conversion process.
Figure 4.
Heatmap of segmentation mask position distribution in the UAV semantic segmentation dataset. (a) Position distribution in training set. (b) Position distribution in validation set. (c) Position distribution in test set.
Figure 4.
Heatmap of segmentation mask position distribution in the UAV semantic segmentation dataset. (a) Position distribution in training set. (b) Position distribution in validation set. (c) Position distribution in test set.
Figure 5.
Distribution of mask scale in the dataset. (a) Mask scale distribution in training set. (b) Mask scale distribution in validation set. (c) Mask scale distribution in test set.
Figure 5.
Distribution of mask scale in the dataset. (a) Mask scale distribution in training set. (b) Mask scale distribution in validation set. (c) Mask scale distribution in test set.
Figure 6.
Architecture of the proposed ThinDyUNet model.
Figure 6.
Architecture of the proposed ThinDyUNet model.
Figure 7.
Model prediction results on the RGB test image. (a,h,o) Original RGB image. (b,i,p) Ground truth segmentation mask. (c,j,q) Proposed ThinDyUNet prediction results. (d,k,r) UNet prediction results. (e,l,s) TransUNet prediction results. (f,m,t) PAN prediction results. (g,n,u) PSPNet prediction results.
Figure 7.
Model prediction results on the RGB test image. (a,h,o) Original RGB image. (b,i,p) Ground truth segmentation mask. (c,j,q) Proposed ThinDyUNet prediction results. (d,k,r) UNet prediction results. (e,l,s) TransUNet prediction results. (f,m,t) PAN prediction results. (g,n,u) PSPNet prediction results.
Figure 8.
Model prediction results on the IR test image. (a,h,o) Original IR image. (b,i,p) Ground truth segmentation mask. (c,j,q) Proposed ThinDyUNet prediction results. (d,k,r) UNet prediction results. (e,l,s) TransUNet prediction results. (f,m,t) PAN prediction results. (g,n,u) PSPNet prediction results.
Figure 8.
Model prediction results on the IR test image. (a,h,o) Original IR image. (b,i,p) Ground truth segmentation mask. (c,j,q) Proposed ThinDyUNet prediction results. (d,k,r) UNet prediction results. (e,l,s) TransUNet prediction results. (f,m,t) PAN prediction results. (g,n,u) PSPNet prediction results.
Figure 9.
Generated mask by the ThinDyUNet and UNet model on RGB image input (a) Original RGB image. (b) Ground truth segmentation mask. (c) ThinDyUNet prediction masks. (d) UNet prediction mask.
Figure 9.
Generated mask by the ThinDyUNet and UNet model on RGB image input (a) Original RGB image. (b) Ground truth segmentation mask. (c) ThinDyUNet prediction masks. (d) UNet prediction mask.
Figure 10.
Generated mask by the ThinDyUNet and UNet model on IR image input (a) Original RGB image. (b) Ground truth segmentation mask. (c) ThinDyUNet prediction masks. (d) UNet prediction mask.
Figure 10.
Generated mask by the ThinDyUNet and UNet model on IR image input (a) Original RGB image. (b) Ground truth segmentation mask. (c) ThinDyUNet prediction masks. (d) UNet prediction mask.
Table 1.
UAV semantic segmentation data characteristics.
Table 1.
UAV semantic segmentation data characteristics.
| Parameter | Value |
|---|
| Training split | 304,677 |
| Validation split | 126,360 |
| Test split | 174,008 |
| Total RGB images | 308,144 |
| Total IR images | 296,901 |
| Image size | 1920 × 1080 |
Table 2.
Major types of UAVs in the dataset.
Table 2.
Major types of UAVs in the dataset.
| UAV Manufacturer | Types |
|---|
| Tarot | X6 |
| Tarot | X8 |
| DJI | Spark |
| DJI | Mavic family |
| DJI | Phantom 4 |
| Parrot | Parrot |
Table 3.
Model performance comparison on validation set metrics.
Table 3.
Model performance comparison on validation set metrics.
| Model Name | Val Precision | Val Recall | Val Dice | Val mIoU |
|---|
| UNet | 0.98 | 0.696 | 0.757 | 0.672 |
| PAN | 0.985 | 0.687 | 0.756 | 0.673 |
| PSPNet | 0.982 | 0.567 | 0.64 | 0.64 |
| TransUNet | 0.90 | 0.714 | 0.733 | 0.642 |
| ThinDyUNet (proposed) | 0.973 | 0.754 | 0.725 | 0.647 |
Table 4.
Model performance comparison on test set metrics.
Table 4.
Model performance comparison on test set metrics.
| Model Name | Test Precision | Test Recall | Test Dice | Test mIoU |
|---|
| UNet | 0.95 | 0.821 | 0.846 | 0.79 |
| PAN | 0.914 | 0.332 | 0.393 | 0.327 |
| PSPNet | 0.896 | 0.757 | 0.793 | 0.691 |
| TransUNet | 0.74 | 0.493 | 0.487 | 0.404 |
| ThinDyUNet (proposed) | 0.872 | 0.75 | 0.744 | 0.646 |
Table 5.
Model size and inference time comparison.
Table 5.
Model size and inference time comparison.
| Model Name | Model Parameters (M) | Inference Time (ms) |
|---|
| UNet | 24.4 | 4.33 |
| PAN | 21.4 | 6.01 |
| PSPNet | 21.4 | 4.18 |
| TransUNet | 4.2 | 4.41 |
| ThinDyUNet (proposed) | 1.3 | 2.45 |
Table 6.
Model ablation study on validation set.
Table 6.
Model ablation study on validation set.
| Model Name | Model Parameters (M) | Val Precision | Val Recall | Val Dice | Val mIoU |
|---|
| ThinDyUNet (with dynamic convolution) | 1.3 | 0.973 | 0.754 | 0.725 | 0.647 |
| ThinDyUNet (with regular convolution) | 15.3 | 0.953 | 0.786 | 0.819 | 0.755 |
Table 7.
Model ablation study on test set.
Table 7.
Model ablation study on test set.
| Model Name | Model Parameters (M) | Test Precision | Test Recall | Test Dice | Test mIoU |
|---|
| ThinDyUNet (with dynamic convolution) | 1.3 | 0.872 | 0.75 | 0.744 | 0.646 |
| ThinDyUNet (with regular convolution) | 15.3 | 0.953 | 0.444 | 0.475 | 0.42 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}