1. Introduction
FER has emerged as a foundational component in affective computing, enabling machines to perceive and interpret human emotions through subtle changes in facial musculature [
1]. This capability is integral to a broad spectrum of applications, including mental health diagnostics [
2], human–computer interaction (HCI) [
3], driver monitoring systems [
4], and intelligent surveillance [
5]. As digital environments increasingly aim to become emotionally intelligent [
6], the demand for FER systems that are both accurate and adaptable to real-world conditions has intensified [
7]. Despite substantial progress enabled by deep learning, particularly convolutional neural networks (CNNs) and more recently, transformer-based architectures, current FER models continue to encounter persistent limitations in uncontrolled settings [
8]. These challenges are multifaceted and include occlusion, variations in head pose and lighting, motion blur, and the inherently subtle or transient nature of many emotional expressions [
9]. Models trained exclusively on static or unimodal data often fail to generalize beyond laboratory-controlled scenarios, limiting their practical deployment in real-world applications. Moreover, while transformers have shown immense potential in capturing global spatial dependencies, their computational complexity can become prohibitive, particularly in high-resolution image or video tasks [
10]. Likewise, static attention mechanisms—though powerful—lack the flexibility to capture the temporal dynamics intrinsic to facial expressions, especially in video streams where emotional states unfold over time. To address these challenges, we introduce FERONet, a novel hyper-attentive multimodal transformer architecture specifically designed to deliver high-precision, real-time FER in complex environments. FERONet is guided by three core principles: multimodal integration, hierarchical attention refinement, and temporal context modeling. First, the model leverages a multimodal encoding pipeline that fuses RGB, optical flow, and depth or 3D landmark inputs. This fusion not only enriches the representation space but also mitigates vulnerabilities associated with relying on a single visual modality. Second, we introduce a triple attention block, which sequentially applies spatial, channel, and cross-patch attention mechanisms. This allows the model to dynamically localize emotionally salient regions, identify the most informative features, and capture long-range inter-regional interactions. Third, FERONet incorporates a bidirectional temporal encoder combined with a cross-attention decoder, enabling the model to attend selectively to the most emotionally significant frames in a video sequence, thereby improving temporal coherence and recognition accuracy. Furthermore, FERONet is explicitly engineered for real-world robustness. It integrates architectural modules and auxiliary losses to handle occlusion, pose misalignment, and illumination shifts—conditions frequently encountered in practical scenarios but often overlooked in academic benchmarks. A hierarchical transformer backbone with token merging ensures computational efficiency, maintaining inference times under 16 milliseconds per frame—suitable for real-time applications. This study makes the following key contributions:
A triple-attention framework that enhances spatial, semantic, and contextual understanding of facial expressions;
A multimodal encoder that integrates complementary appearance, motion, and structural cues;
A temporal cross-attention decoder that models the evolution of emotion across video sequences;
A suite of robustness strategies targeting occlusion, pose variation, and visual inconsistency, enabling FERONet to operate reliably in uncontrolled environments.
Based on extensive evaluation across five benchmark datasets—FER-2013 [
11], RAF-DB [
12], CK+ [
13], BU-3DFE [
14], and AFEW [
15]—FERONet achieves high performance compared to existing state-of-the-art models in terms of both accuracy and inference speed, establishing a new standard for real-time and robust FER.
2. Related Works
FER has undergone a significant evolution, transitioning from handcrafted feature extraction methods to powerful deep learning architectures that increasingly approximate human-level emotional understanding [
16]. This progression reflects broader trends in computer vision and affective computing, driven by the pursuit of robustness, generalizability, and real-time performance. In this section, we review key developments across three major phases of FER research: traditional handcrafted approaches, convolutional neural network (CNN)-based models, and the emerging generation of transformer-based architectures. We also highlight efforts in multimodal learning and temporal modeling, which are essential for understanding FERONet’s position within the current landscape. The earliest FER systems primarily relied on handcrafted features, such as Local Binary Patterns (LBP), Histogram of Oriented Gradients (HOG) [
17], Gabor wavelets, and Scale-Invariant Feature Transform (SIFT) [
18], to describe facial textures and geometric structures. These features were often used in conjunction with shallow classifiers like Support Vector Machines (SVMs) or k-Nearest Neighbors (k-NN) [
19]. Although such methods performed reasonably well in controlled environments, they suffered from limited robustness to variations in lighting, pose, and facial occlusion [
20]. More importantly, handcrafted descriptors lacked the representational capacity to capture subtle and dynamic variations in facial expressions, rendering them ineffective in naturalistic, in-the-wild scenarios.
2.1. Deep Learning and CNN-Based Models
The advent of deep learning revolutionized FER by enabling end-to-end learning of expressive features from raw image data. CNNs such as VGGNet, ResNet, and InceptionNet have been widely adopted as FER backbones due to their hierarchical feature extraction capabilities [
21]. Notably, VGG-Face and ResNet-50 variants trained on large-scale face datasets demonstrated significant improvements in FER accuracy [
5]. To further refine CNN performance, attention mechanisms were introduced—particularly spatial attention [
22], which emphasizes emotionally salient regions of the face [
23]. Models like DAN (Dual Attention Network) and MA-Net utilized such attention modules to dynamically highlight informative regions, thereby improving emotion recognition under challenging visual conditions [
24]. Despite their success, CNN-based models exhibit inherent limitations. They often struggle to model long-range dependencies and rely heavily on local receptive fields, making them insufficient for capturing holistic facial relationships. Additionally, these models are typically trained on RGB images alone, which restricts their capacity to generalize across modalities or temporal contexts. Inspired by breakthroughs in natural language processing and vision tasks, transformer architectures have recently gained traction in FER research. Unlike CNNs, transformers rely on self-attention mechanisms to model global dependencies, enabling them to capture long-distance relationships between facial features. Vision Transformers (ViTs), for instance, partition the image into non-overlapping patches, which are then processed as token sequences [
25]. This allows for the modeling of interactions between disparate facial regions, such as coordinated movements of the brow and mouth in expressions of fear or surprise. Several transformer-based FER models have emerged in recent literature. For example, EMOFormer introduced a token-based transformer encoder tailored to emotional expression learning [
26], while [
27] combined self-attention with hierarchical feature extraction for robust recognition under noise. However, these models often incur high computational costs, making them less suitable for real-time applications. Moreover, many fail to account for the temporal dynamics of facial expressions or suffer from attention overfitting—where the model disproportionately focuses on dominant features while ignoring subtle cues.
2.2. Multimodal and Cross-Domain FER
Recognizing the limitations of unimodal FER systems, researchers have explored the integration of additional sensory modalities such as depth, thermal imaging, and optical flow to enrich facial representations. Optical flow captures motion vectors between frames, making it particularly useful for analyzing muscle dynamics over time. Depth and 3D landmark maps provide structural information that complements appearance features, especially under occlusion or poor lighting. Recent works like the Multimodal Relational Attention Network (MRAN) [
28] and Multimodal Facial Expression Recognition (MMFER) have sought to fuse such heterogeneous inputs using attention-based mechanisms [
29]. While these models reported gains in robustness and accuracy, they typically require complex fusion strategies and were computationally intensive. Moreover, many of these models lacked mechanisms to adaptively weigh modalities based on their informativeness or reliability in different scenarios. Facial expressions are inherently dynamic, unfolding over sequences of frames [
30]. Capturing these temporal patterns is critical for accurate emotion recognition, particularly in spontaneous or subtle expressions. Early attempts at temporal modeling employed Recurrent Neural Networks (RNNs) [
16], Long Short-Term Memory (LSTM) units [
31], and Gated Recurrent Units (GRUs) [
32], which enabled FER systems to learn time-series dependencies [
33]. However, these architectures often modeled only unidirectional or shallow temporal relationships, leading to suboptimal performance in rapidly changing or ambiguous expression sequences. More recent efforts have incorporated spatiotemporal convolutional networks (3D CNNs) or two-stream architectures that process RGB and optical flow in parallel [
34]. While these methods improve motion sensitivity, they often lack the interpretability and selective focus provided by attention mechanisms [
35]. Additionally, temporal modeling is frequently uniform across frames, failing to prioritize emotionally informative segments of the sequence [
36]. While substantial progress has been made in areas such as spatial attention, temporal reasoning, and multimodal fusion, existing FER models seldom manage to unify these components within a single, coherent, and real-time framework. Many architectures are designed with a focus on spatial precision, often at the expense of computational efficiency, while others introduce temporal and multimodal capabilities that are not easily scalable or interpretable in practical deployments. FERONet directly addresses these limitations by proposing a comprehensive and integrated architecture. It incorporates a triple-attention mechanism that simultaneously attends to spatial regions, semantic channels, and cross-patch relationships; a multimodal encoder that jointly processes RGB images, optical flow, and structural information derived from depth or 3D landmarks; and a hierarchical transformer design that leverages token merging to reduce computational burden while preserving representational richness. Furthermore, the architecture features a bidirectional temporal decoder equipped with cross-attention, enabling it to capture and emphasize critical emotional transitions within video sequences. By bridging these dimensions through a unified and computationally efficient design, FERONet establishes a new paradigm for FER—combining high accuracy, interpretability, and scalability for deployment in unconstrained, real-world environments.
3. Materials and Methods
This section outlines the architectural components, data representations, and training protocols that form the foundation of FERONet. To address the multifaceted challenges of facial expression recognition in real-world settings, such as occlusion, pose variation, and temporal ambiguity, FERONet integrates a suite of complementary mechanisms grounded in multimodal learning, hierarchical attention, and temporal reasoning. We begin by detailing the multimodal feature encoding framework, which enables the model to extract and align appearance, motion, and structural cues from RGB, optical flow, and depth or 3D landmark inputs. This is followed by a description of the core network architecture, including the modality-specific backbone encoders, the triple attention block, and the hierarchical transformer enhanced with token merging for scalable spatial reasoning. We then present the temporal decoder, which incorporates bidirectional recurrence and cross-attention to capture emotion dynamics over time. Finally, we elaborate on the robustness strategies embedded within the architecture and training process to improve performance under real-world variability. These components constitute a unified framework that advances both the accuracy and applicability of facial expression recognition across diverse operational environments.
As illustrated in
Figure 1, the FERONet model integrates three input modalities—RGB, optical flow, and depth—to enhance robustness in FER. The Multimodal Feature Encoder extracts and fuses features through gated, channel, and cross-patch attention mechanisms. These fused representations are processed by a hierarchical transformer with token merging to reduce redundancy and preserve semantic richness. The temporal decoder with cross-attention captures inter-frame emotional dynamics via a bidirectional temporal encoder. The final prediction is made through a classification head based on the refined temporal representation.
3.1. Multimodal Feature Encoder
In real-world FER scenarios, relying solely on single-modality input, particularly static RGB imagery, often proves inadequate due to the presence of complex environmental variables such as partial occlusion, inconsistent lighting conditions, and non-static, evolving expressions. These challenges hinder the robustness and adaptability of traditional FER systems, particularly in unconstrained settings. To address this, FERONet employs a comprehensive multimodal feature encoding framework that synthesizes visual appearance, motion dynamics, and structural geometry by integrating three distinct input modalities: RGB, optical flow, and depth or 3D landmark maps. Each modality contributes unique and complementary information that enhances the model’s ability to detect, differentiate, and generalize across a wide range of facial expressions. The RGB input captures the surface-level appearance of the face, encoding crucial features such as color gradients, skin texture, and morphological contours. This modality serves as the baseline for expression analysis, particularly for recognizing fine-grained variations in static imagery. However, static frames alone cannot capture the dynamic nature of facial movements. To supplement this, optical flow is introduced as a motion-sensitive modality, encoding temporal displacements of facial regions across successive video frames. Computed using the TV-L1 algorithm, these motion vectors are represented as two-channel horizontal and vertical maps and are fused with RGB data during training, allowing the model to infer subtle transitions in facial musculature that signal emotional change. Complementing both appearance and motion, structural features are extracted via depth or 3D landmark representations, which provide insight into the spatial geometry of facial expressions. These features are particularly beneficial when distinguishing between expressions that exhibit minimal visual disparity but significant geometric deviation. In scenarios lacking dedicated depth sensors, pseudo-depth maps are generated from 2D landmarks using parametric models such as 3D Morphable Models (3DMM) or estimated through neural frameworks like Face Alignment Networks (FAN). Together, these three modalities form a cohesive input structure that empowers FERONet to navigate the ambiguities of real-world FER with heightened accuracy and resilience, significantly surpassing the limitations of unimodal approaches.
Each modality is normalized independently to account for scale and distributional differences. All inputs are resized to 224 × 224 pixels and subjected to modality-specific augmentations (e.g., random jitter for optical flow, illumination simulation for RGB, and rotation for depth maps) to improve generalization. To effectively harness the distinct informational value embedded in each input modality, FERONet adopts a thoughtfully modular architecture in which each data stream is processed through a dedicated, lightweight, yet expressively designed backbone network. This separation ensures that the semantic and statistical properties specific to appearance, motion, and structure are preserved and learned in a manner most conducive to accurate emotion recognition. For RGB imagery—the primary source of visual appearance—FERONet employs ConvNeXt-Tiny as its principal encoder. This architecture strikes an ideal balance between computational efficiency and representational depth. By incorporating depth-wise separable convolutions and layer scaling, ConvNeXt-Tiny enables the model to retain rich semantic content, capturing subtle yet critical facial cues such as micro-tensions in the skin or nuanced shifts in muscle activation, all while maintaining a low inference burden. To process motion information, FERONet integrates a compact variant of EfficientNet-B0, pretrained on dynamic action datasets to prime the network for sensitivity to temporal displacements. Its use of inverted residual blocks supports the preservation of fine-grained motion vectors—essential for understanding the progression of facial expressions over time—while maintaining a shallow depth that prevents computational overhead from escalating. This design proves especially valuable for encoding facial dynamics like blinking, brow-raising, or the evolution of a smile across frames. For structural information derived from depth maps or 3D facial landmarks, the model employs a customized version of MobileNetV3-Small. This backbone is particularly adept at handling structural reasoning tasks in visually challenging conditions, such as varying illumination or partial occlusion. Its inclusion of squeeze-and-excitation (SE) layers and hard-swish activations allows the encoder to dynamically recalibrate its feature channels, emphasizing geometrically relevant patterns such as curvature changes around the nasolabial folds or eye contours—features often central to distinguishing subtle emotional states. By mapping each modality into a common embedding space after these specialized encodings, FERONet ensures that the unique contributions of appearance, motion, and geometry are preserved and aligned in a cohesive representational format. This separation of concerns, followed by informed integration, enhances the model’s ability to generalize across diverse real-world conditions, enabling robust and resilient facial expression recognition even in the face of environmental variability and inter-subject differences.
Each encoder maps its input to a common feature embedding space with dimensionality
where C = 64, and H = W = 28. This shared feature space enables seamless modality alignment and interaction. Following modality-specific encoding, features are integrated via a Gated Multimodal Fusion (GMF) module designed to emphasize salient information from each modality while suppressing noise or redundancy. The fusion process proceeds in two stages: (1) soft modality gating each modality’s feature tensor
is passed through a gating function Equation (1) [
22]:
where
σ is the sigmoid activation,
and
are learnable weights and biases, and GAP denotes global average pooling. This generates an importance score
for each modality. (2) weighted summation and projection where the gated features are aggregated Equation (2):
followed by a projection via a 11 × 1 convolution to unify channel dimensions. Here,
denotes element-wise multiplication, and MMM is the number of modalities. To further refine the fusion, a channel-wise attention layer (CWAL) is applied to the fused feature, enhancing inter-channel dependencies and highlighting modality synergies. The output is a unified feature tensor
, which is then forwarded to the subsequent attention and transformer modules. The integration of motion and depth signals alongside appearance data is rooted in cognitive neuroscience, where human emotion recognition relies not only on visual patterns but also on movement and 3D structure perception. For instance, a raised eyebrow (surprise) may be visually subtle but geometrically distinct; similarly, smiling may involve subtle muscle contractions more evident in optical flow than static RGB.
3.2. Triple Attention Block
Facial expressions are composed of subtle, spatially distributed muscle movements whose relevance varies depending on the emotion being conveyed. Consequently, accurate FER demands a dynamic focus on expressive regions, informative channels, and inter-patch dependencies. To address this, FERONet introduces a triple attention block that integrates three complementary attention mechanisms: spatial attention, channel attention, and cross-patch attention. This hierarchical design enables the model to selectively enhance salient features both within and across facial regions, achieving greater discriminability under varying pose, illumination, and occlusion conditions. Spatial attention identifies which regions of the face contribute most significantly to a given emotional expression—typically the eyes, eyebrows, mouth, and nasolabial folds. In FERONet, spatial attention is computed over the fused multimodal feature map
using a convolutional gating mechanism that highlights key spatial regions. The formulation is as follows Equation (3) [
37]:
where
denotes the sigmoid function,
is a convolution with a kernel size of 3,
is the spatial attention map, and
indicates element-wise multiplication. The resulting tensor
retains the original shape but has increased focus on discriminative spatial regions. This process effectively suppresses background noise and uninformative facial areas, enabling the model to attend to critical zones of expression. While spatial attention refines “where” to look, channel attention determines “what” to look for by learning inter-channel dependencies. Each channel in the feature map often represents a different semantic concept Equation (4). However, not all channels contribute equally across different expressions, Equation (5). To dynamically weigh channels, we employed a modified squeeze-and-excitation (SE) block Equation (6):
here
and
are the weights of a two-layer multi-layer perceptron (MLP), and
is the reduction ratio (typically 8 or 16). The output
acts as a soft gating mechanism across the channel dimension. The modulated tensor
enhances informative features (e.g., smile curvature or eyebrow lift) while diminishing irrelevant activations. Facial expressions often involve coordinated activity across distinct facial regions—such as simultaneous widening of the eyes and opening of the mouth in surprise. These long-range interactions are difficult to capture using only local convolutional filters. FERONet addresses this limitation by incorporating a cross-patch attention (CPA) module based on vision transformer (ViT) principles, adapted for efficient facial feature modeling, Equation (7). The process begins by flattening and reshaping the spatially and channel-refined tensor
into a sequence of tokens:
Positional embeddings
are added to encode spatial layout:
Self-attention is then computed as Equation (8):
where
are learned projections, and
is the dimension of the key vectors Equation (9). The attention scores
represent the relevance between all patch pairs, allowing the model-to-model co-dependencies between distant facial landmarks. After, the output is reshaped back to the original spatial configuration:
The triple attention block is implemented in a sequential cascade: spatial attention; channel attention; cross-patch attention. This order is motivated by cognitive analogies: humans first fixate on facial regions (spatial), interpret muscle activity (channel), and then infer emotional meaning via context (cross-region). To maintain real-time performance, the CPA module incorporates window-based partitioning with hierarchical token merging, reducing the quadratic complexity of global self-attention. During training, dropout and layer normalization are applied after each attention stage to stabilize optimization and prevent overfitting.
3.3. Hierarchical Transformer with Token Merging
Transformer architectures have fundamentally transformed the landscape of visual representation learning by enabling models to capture long-range dependencies through self-attention.
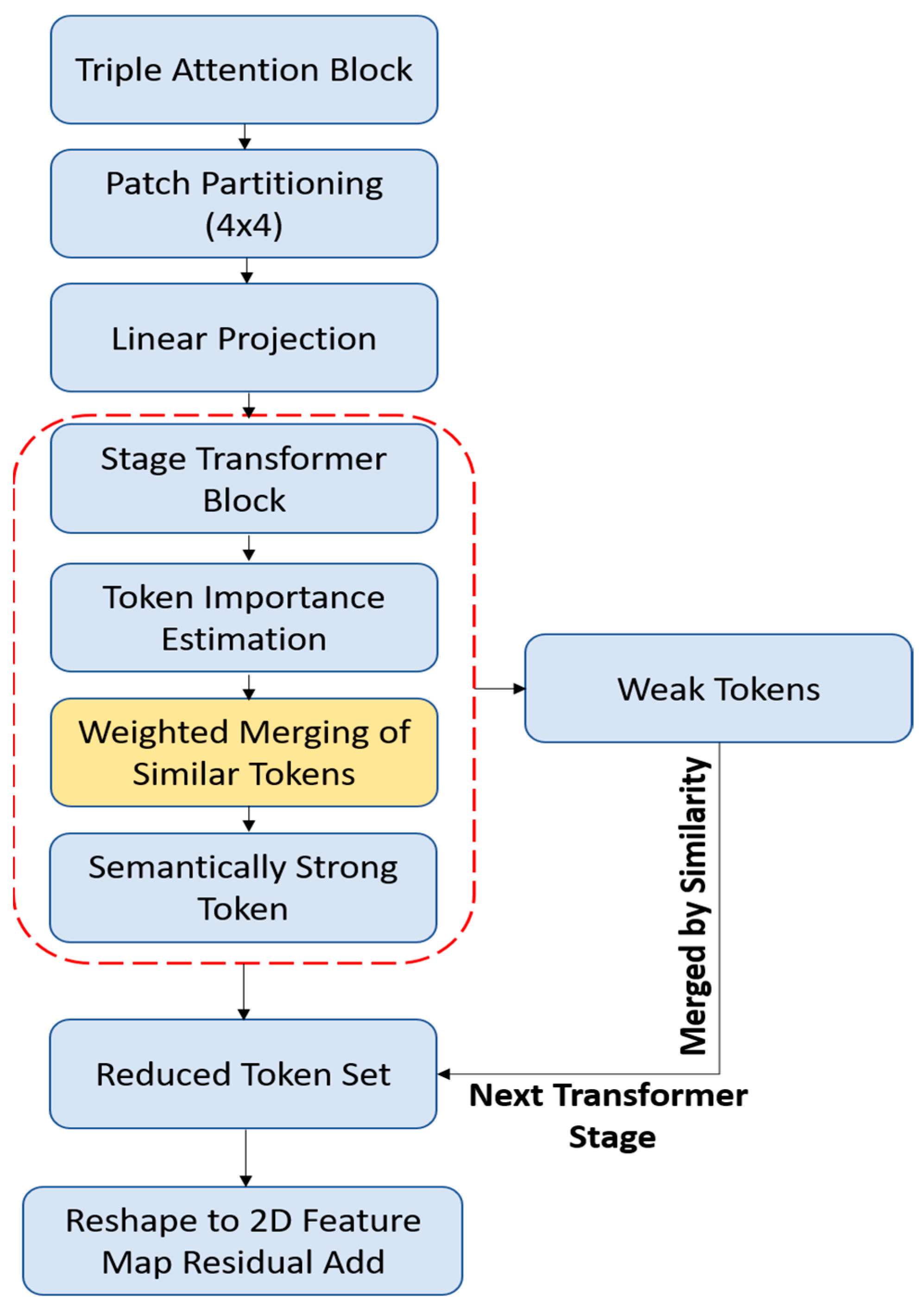
As shown in
Figure 2, the token merging mechanism begins after the triple attention block, where feature maps are partitioned into patches and linearly projected into token representations. Each stage of the transformer computes token importance and softly merges low-importance tokens with their semantically closest neighbors using weighted aggregation. This results in a compressed token set composed of richer, context-aware embeddings. The merged tokens are then reshaped into a 2D spatial format and passed along the residual stream. This process enhances computational efficiency while preserving the semantic richness required for FER. However, traditional transformer designs, such as Vision Transformer (ViT), often exhibit quadratic computational complexity with respect to the input sequence length, rendering them inefficient for high-resolution or real-time applications such as FER. To address this challenge, FERONet employs a hierarchical transformer with token merging (HTTM) strategy that balances global context modeling with computational efficiency, ensuring scalability without compromising accuracy. The input to the transformer the attention-refined feature map from the previous triple attention block:
This tensor is divided into non-overlapping patches of size
, flattened, and linearly projected into tokens:
where
D is the embedding dimension of each token (typically 96 or 128). Each token corresponds to a distinct spatial region of the input. Positional encodings
are added to retain spatial order:
. The hierarchical transformer employed in FERONet is structured across
L progressive stages, each designed to capture increasingly abstract representations of facial features while maintaining computational efficiency. At each stage
l, the model performs a series of core operations that together enable both local and global information processing. The first component is a window-based multi-head self-attention (W-MSA) mechanism, which limits the scope of attention to localized spatial windows rather than the entire token sequence. This approach significantly reduces the quadratic complexity traditionally associated with global self-attention, while still enabling rich intra-window interactions. Following the attention computation, a feed-forward network (FFN) is applied to refine the attended features through nonlinear transformations and channel-wise expansion, enhancing the expressive capacity of the representation. To further improve efficiency and representation compactness, a token merging (TM) operation is introduced at the end of each stage, except for the final one. This step strategically reduces the number of tokens by identifying and aggregating those with low semantic significance, effectively compressing the spatial resolution without discarding crucial contextual information. These three components—localized attention, deep transformation, and intelligent compression—are tightly integrated within each hierarchical level of the transformer. Together, they allow FERONet to maintain a fine balance between modeling expressiveness and scalability, enabling robust facial expression recognition under real-time constraints:
where
LN denotes layer normalization. The windowed attention reduces computational cost by applying self-attention within fixed spatial windows rather than across the full token set. Cross-window interactions are enabled through shifted windows, ensuring contextual continuity across regions. To progressively reduce token redundancy and preserve semantic compactness, we applied token merging (TM) after each transformer stage (except the last) (
Figure 3). Inspired by TokenLearner and PoolFormer, TM dynamically selects informative tokens based on feature similarity and merges them using weighted aggregation:
where
represents a learned vector of token importance scores at the stage
l, guiding the model in identifying which tokens carry the most semantic value. Tokens deemed less informative are not discarded outright; instead, they are softly merged with their most similar neighbors in the embedding space, where similarity is measured using cosine distance. This merging strategy allows the model to retain the overall contextual richness of the representation while significantly reducing the sequence length, thereby streamlining the computation required in subsequent layers without compromising accuracy:
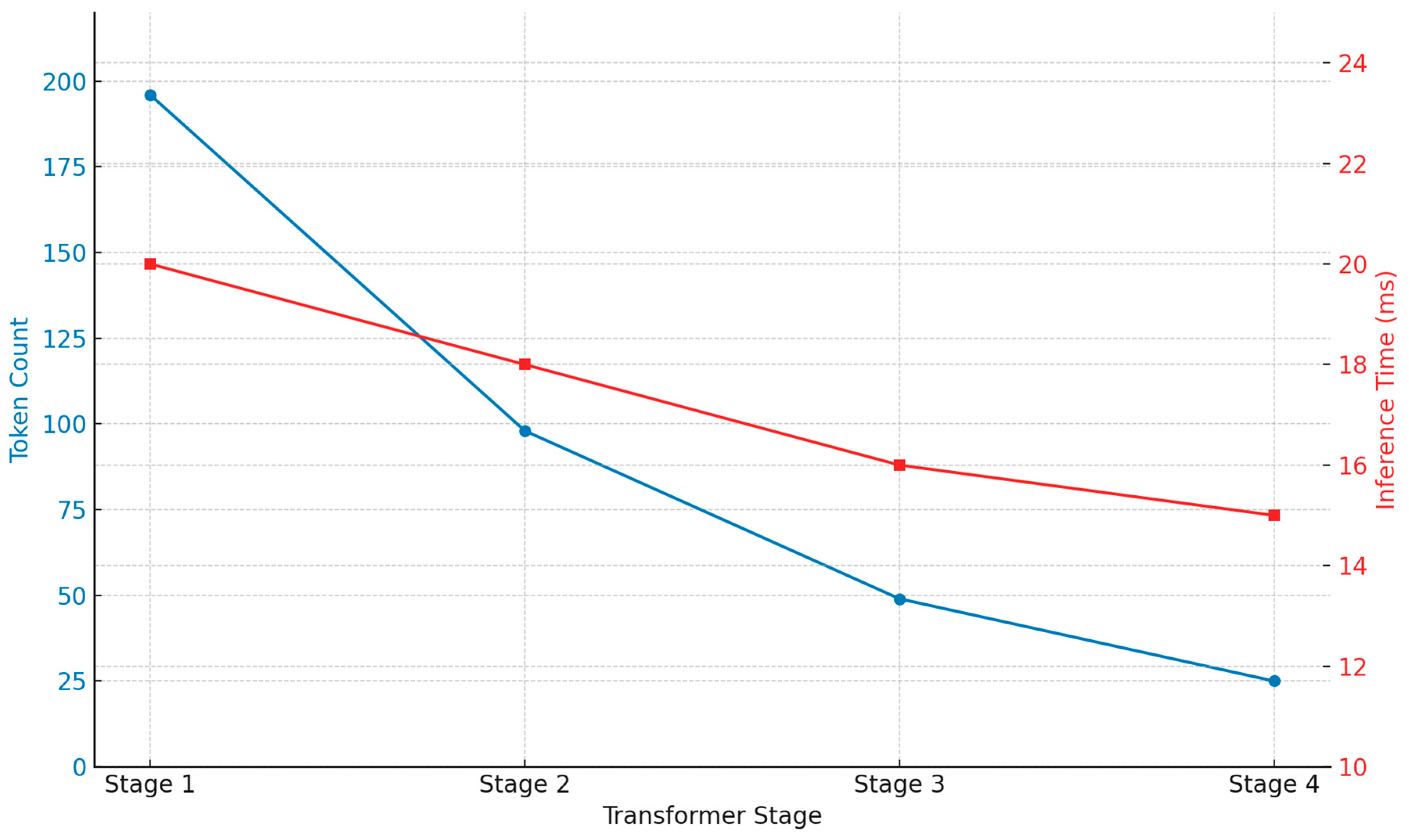
Typically,
yields a 50% token reduction per stage, accelerating inference while retaining accuracy. The final transformer stage outputs a compact token set
, which is reshaped back to a 2D spatial tensor:
This tensor is combined with a residual skip connection from the original spatial attention stream (before transformer processing) to form the final encoded representation:
This residual connection stabilizes learning and facilitates gradient flow, improving convergence in deep architectures.
3.4. Temporal Decoder with Cross-Attention
FER in video streams requires not only the accurate decoding of spatial patterns within individual frames but also a deep understanding of temporal progression—how expressions evolve over time. Emotions such as fear, joy, or surprise often manifest in fleeting micro-sequences that are easily lost in static analysis. To address this, FERONet incorporates a temporal decoder with cross-attention, which models emotion transitions across video sequences by learning to selectively attend to temporally salient frames, capturing both progression and contextual dependencies. Traditional frame-level FER approaches, even when enhanced by spatial and channel attention, fall short in leveraging the continuity and inter-frame relational cues that naturally exist in dynamic emotional expressions. While recurrent units such as LSTMs or GRUs have been previously used, they often operate in a unidirectional or shallow temporal context, limiting their capacity to model nuanced emotion trajectories.
FERONet addresses this temporal modeling challenge through a hybrid design that brings together the strengths of recurrent and attention-based architectures. At its core, the model employs a bidirectional gated recurrent unit (Bi-GRU) encoder, which is well-suited for abstracting temporal features by simultaneously capturing information from both past and future frames. This bidirectional flow ensures that the model does not overlook contextual dependencies that span forward or backward in time—an essential capability for decoding the progression and transitions of emotional expressions. To complement this, FERONet integrates a transformer-style cross-attention decoder, which further refines the temporal representation by selectively reweighting frame-level features based on their emotional salience. Rather than treating each frame uniformly, the decoder dynamically attends to those moments in the sequence that carry the most expressive significance, allowing the model to focus on the subtle but decisive cues that often define complex emotions. This combined framework enables FERONet to maintain a continuous memory of the temporal landscape while making informed, context-aware predictions, ultimately leading to more accurate and temporally coherent facial expression recognition. A video sequence
of
T frames can be processed independently through the multimodal encoder and hierarchical transformer modules, producing a sequence of spatially-encoded feature embeddings:
This embedding sequence is passed through a bidirectional GRU, which aggregates both past and future information:
The resulting sequence encapsulates bidirectional temporal dependencies, forming the temporal context tensor. While the Bi-GRU efficiently summarizes inter-frame transitions, it treats each frame uniformly. However, not all frames are equally informative—some may capture transition points, while others remain neutral. To identify and leverage these temporal “hotspots,” we introduce a temporal cross-attention decoder, inspired by the decoder block of the transformer.
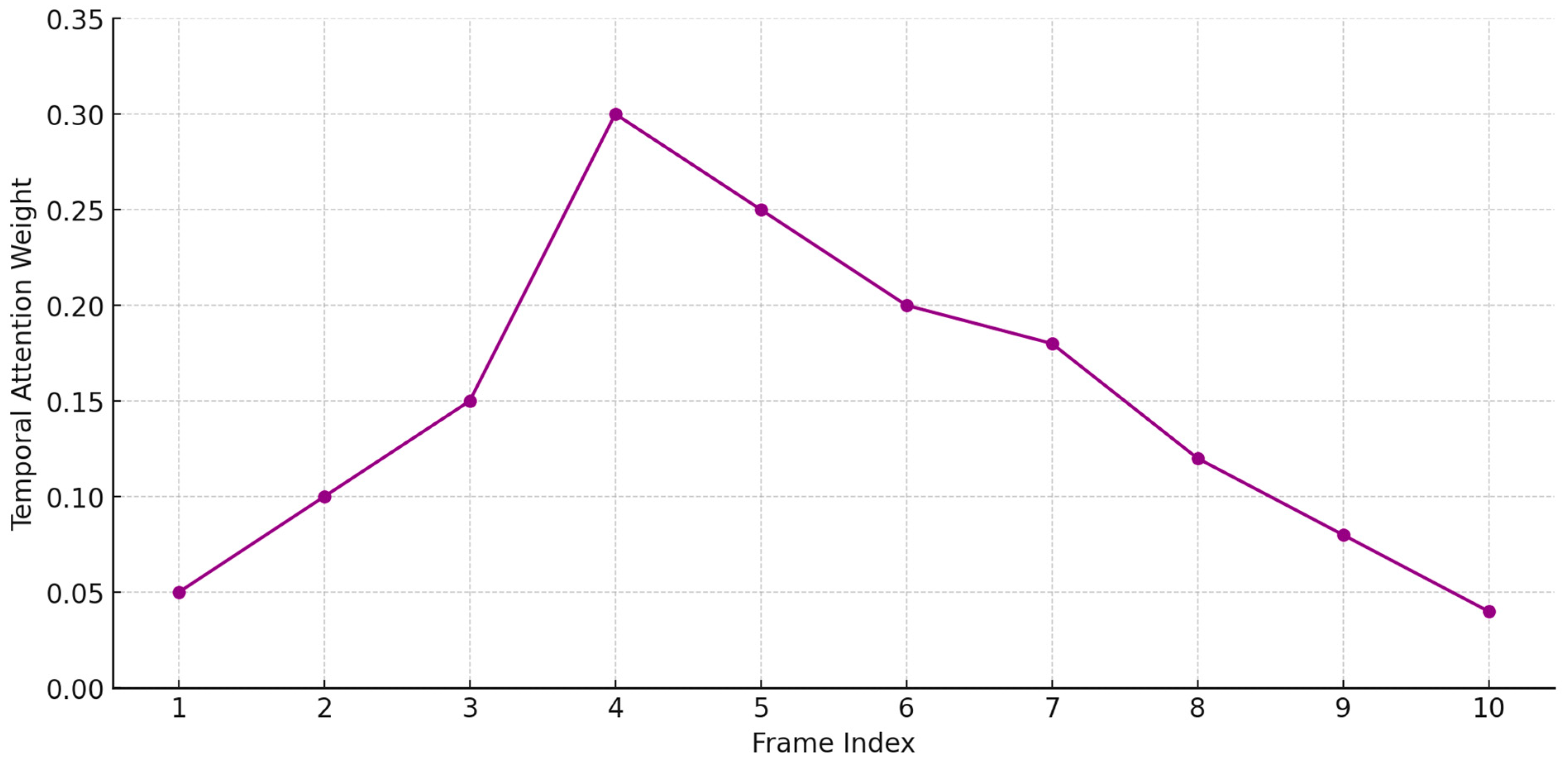
We define a learnable temporal query vector
that seeks the most emotion-discriminative representations across the sequence
Figure 4. The decoder computes attention between this query and the Bi-GRU outputs:
where
is the attention score vector across time steps, indicating the contribution of each frame to the final representation. The aggregated vector
z serves as the emotion-aware temporal summary, selectively pooling critical affective cues.
To further refine temporal discrimination, the decoder block is followed by a feed-forward projection, a dropout layer, and layer normalization:
The refined temporal representation is subsequently passed to the classifier head, which is designed to produce a stable and discriminative prediction of facial expression categories. This classification module begins with a dropout layer, set at a rate of 0.3, which acts as a regularization mechanism to prevent overfitting by randomly deactivating neurons during training. The output is then fed into a fully connected linear layer, parameterized by where d is the dimensionality of the temporal feature vector and C represents the number of target expression classes. Finally, a softmax activation is applied to convert the logits into a probability distribution across the expression categories, enabling interpretable and probabilistic emotion predictions. To further enhance temporal robustness and consistency across frames, FERONet incorporates two auxiliary regularization strategies that operate in parallel with the primary classification objective. The first is temporal contrastive loss, which encourages the model to maintain high similarity between embeddings of temporally adjacent frames that share the same emotional state, while simultaneously increasing dissimilarity between embeddings that represent different affective transitions. This promotes temporal coherence and strengthens the model’s ability to recognize subtle emotional evolutions. The second strategy, termed the Emotion Smoothness Penalty, discourages abrupt fluctuations in the predicted emotion logits between consecutive frames. By penalizing large inter-frame variances, this constraint fosters smoother and more psychologically plausible predictions across video sequences. Together, these auxiliary objectives complement the primary classification loss by enforcing not only categorical accuracy but also temporal integrity, thereby enabling FERONet to deliver emotionally coherent and context-aware predictions in dynamic, real-world environments.
4. Robustness Strategies
While FER systems have achieved remarkable progress under controlled conditions, real-world deployment scenarios remain fraught with challenges that can severely degrade model performance. These include partial occlusions, variable head poses, illumination fluctuations, facial artifacts, and inter-subject variability. To ensure consistent accuracy and reliability, FERONet is equipped with a suite of robustness mechanisms that explicitly target these real-world complexities at both the architectural and training levels. This section details three primary strategies: occlusion resilience, pose normalization, and illumination and appearance invariance. Occlusions can disrupt critical facial regions responsible for conveying emotion, potentially leading to incorrect predictions. Rather than treating occlusions as noise, FERONet adopts a dual-pronged strategy to detect, adapt to, and compensate for occluded regions during both training and inference.
Within the multimodal encoder, we introduce an auxiliary occlusion prediction branch, which estimates a binary occlusion mask
. This map is derived from a shallow convolutional subnetwork trained using a binary cross-entropy loss with pseudo-ground-truth masks (generated via synthetic occlusion or semantic segmentation priors). The mask is used to reweight the encoded features:
This reweighting scheme suppresses activations from occluded regions, preventing the attention modules and transformer from overfitting to noisy or irrelevant inputs.
To encourage the model to infer missing information, we introduce a self-reconstruction pathway that learns to regenerate occluded feature regions using an encoder–decoder structure. The reconstruction loss: is minimized alongside the classification loss, where refers to non-occluded features and is the reconstructed tensor. This auxiliary task enhances the model imputation capability, allowing it to maintain high accuracy even when key facial parts are partially obscured.
Head pose variation is another significant source of ambiguity in FER, particularly in in-the-wild datasets where subjects may not face the camera directly. Expressions can appear distorted or subdued under profile views, and spatial misalignment can confuse the attention mechanisms. To mitigate the challenges posed by head pose variability—a common issue in unconstrained facial expression recognition—FERONet integrates a lightweight pose correction module that is trained jointly with the main FER pipeline. This auxiliary module is designed to normalize facial orientation across samples, thereby reducing spatial discrepancies and enhancing the model’s ability to generalize across individuals and viewing angles. The correction process begins with 3D landmark estimation, wherein facial keypoints are extracted using a pretrained 3D face alignment network (FAN). These landmarks are represented in a three-dimensional coordinate space where K denotes the number of anatomical facial points. Building upon this geometric representation, the model then applies Procrustes alignment to estimate a minimal transformation matrix T, comprising rotation and translation parameters that optimally map the current pose to a canonical frontal view. Once computed, this transformation is applied to both the raw input image and its intermediate feature maps through pose-aligned warping, thereby generating a spatially standardized representation that is subsequently passed into the encoder. This process of pose normalization significantly reduces spatial variance and enhances inter-subject consistency—two factors that are especially critical when distinguishing among expressions that may appear geometrically similar but differ contextually or emotionally. In addition to pose-related challenges, real-world FER systems must contend with variability in ambient lighting conditions and individual appearance factors, such as skin tone, makeup, or the presence of facial accessories. These variables can introduce artifacts that distract attention modules and undermine the statistical integrity of feature representations. FERONet addresses this issue through a dual-pronged approach that combines architectural robustness with training-time augmentation techniques. This ensures that the model not only learns invariant features under challenging conditions but also remains resilient when deployed in diverse and unpredictable environments.
Before feeding RGB images into the encoder, an LCN layer standardizes local patches by subtracting the local mean and dividing by local standard deviation [
38]:
where
and
are the local mean and standard deviation computed over a
window centered at pixel
, and
is a small constant. This operation reduces the impact of global illumination shifts and improves invariance to shadows and highlights.
To enhance the model resilience against appearance-related variability and ensure robust generalization in real-world conditions, FERONet incorporates a diverse suite of data augmentation techniques during training. These augmentations are designed to simulate a wide range of visual distortions and environmental inconsistencies commonly encountered in unconstrained settings. Variations in lighting are emulated through stochastic adjustments to brightness, contrast, and gamma levels, while sensor imperfections are mimicked by injecting additive Gaussian noise into the input images. To further improve the model’s robustness to partial occlusions and visual ambiguity, random patches of the image are obscured or blurred, encouraging the network to rely on global and context-aware cues rather than localized patterns alone. Additionally, color jittering is applied to reflect the variability introduced by makeup, skin tones, and artificial lighting, helping the model learn to identify expressions independent of superficial visual traits. These transformations are applied stochastically across training batches, ensuring a dynamic and unpredictable input space that prevents overfitting to any single visual configuration. Complementing these augmentations is a channel dropout strategy, in which individual RGB or depth channels are randomly zeroed out. This further compels the model to learn from incomplete or degraded information, fostering an adaptive learning process that is resilient to corrupted, missing, or modality-specific noise. Collectively, these augmentation and dropout techniques serve to regularize the training process, enhance feature invariance, and ultimately improve the model performance in diverse, real-world environments.
5. Experimental Setup
To validate the performance, efficiency, and robustness of FERONet, we conducted experiments across a range of FER datasets. These datasets were selected to reflect the diversity of real-world conditions, including static images, 3D facial data, and video-based sequences
Table 1.
Training was carried out using PyTorch 2.1 on an NVIDIA A100 40 GB GPU. All images were resized to 224 × 224 resolution. The multimodal inputs (RGB, optical flow, and depth/landmark maps) were normalized independently, and augmentation techniques such as flip, affine transformations, jitter, Gaussian blur, and synthetic occlusion were applied dynamically during training
Table 2.
To ensure a fair and consistent evaluation, each dataset was divided into training, validation, and test subsets according to standard protocols or stratified random sampling when predefined splits did not exist. The distribution of samples for each dataset is summarized in
Table 3. For video datasets, sequences were assigned such that there was no subject overlap between sets, minimizing identity-based leakage (
Table 3).
For model evaluation, we used accuracy as the primary metric, supported by F1-score and AUC-ROC to assess class-wise precision and overall discrimination performance. Temporal datasets were additionally analyzed using per-frame consistency and confusion matrices. Inference latency and memory usage were measured to assess real-time viability. FERONet was compared against multiple state-of-the-art FER architectures. These include traditional CNNs like VGG-Face and ResNet-50 with dual attention (DAN), transformer-based models like EMOFormer and FER-ViT, and our own prior work FERONET. All baselines were retrained under consistent protocols to ensure a fair comparison.
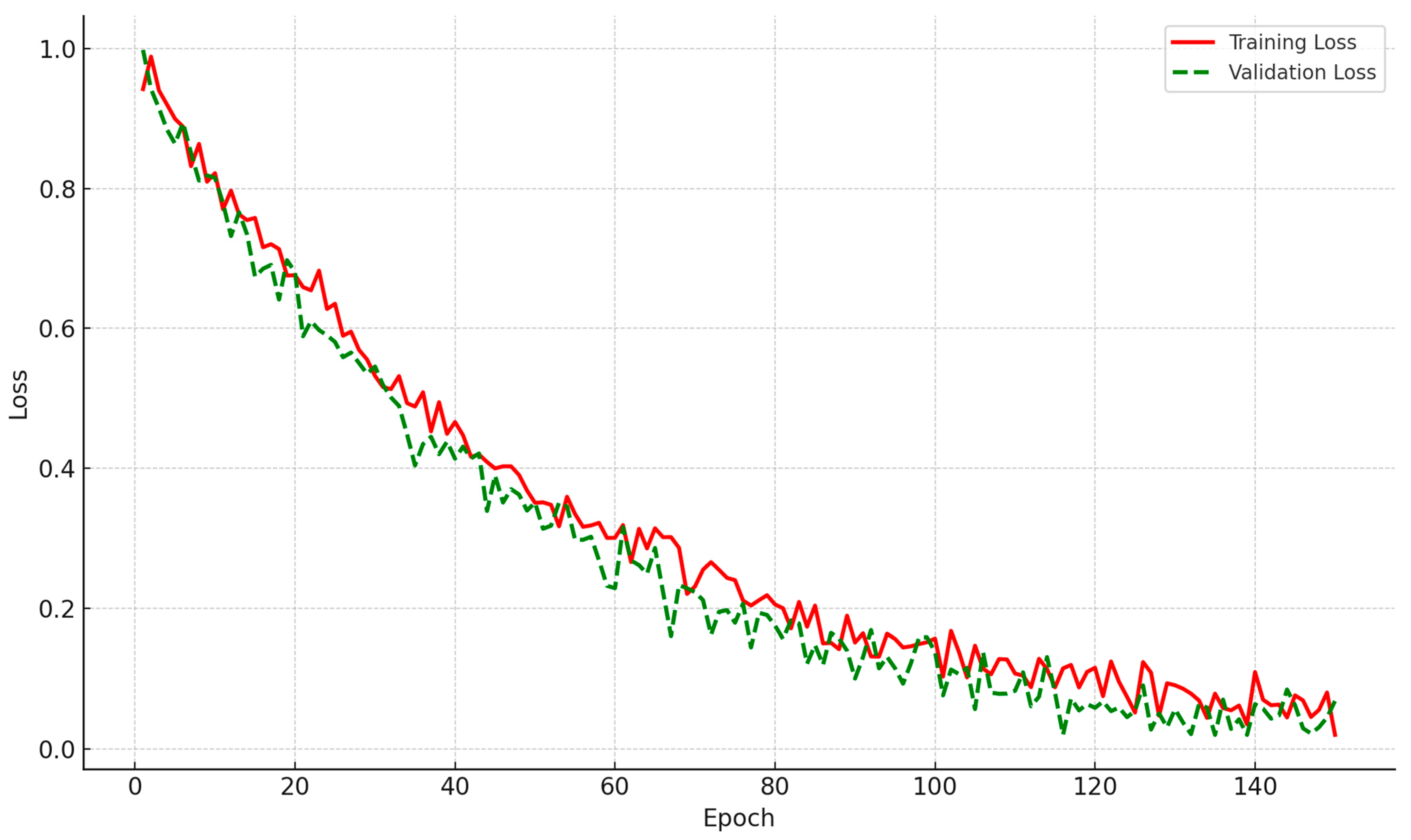
To evaluate the training dynamics and stability of FERONet, we plotted the training and validation loss curves across all training epochs in
Figure 5. As shown, the model demonstrates smooth convergence with steadily decreasing loss on both the training and validation sets. The close alignment between the two curves further indicates that the model generalizes well and does not suffer from significant overfitting.
6. Results
The evaluation of FERONet was conducted across five benchmark datasets, encompassing static, 3D, and video modalities. The model demonstrated consistently high performance in terms of accuracy, temporal consistency, and real-time applicability, confirming its effectiveness in diverse and unconstrained environments
Table 4.
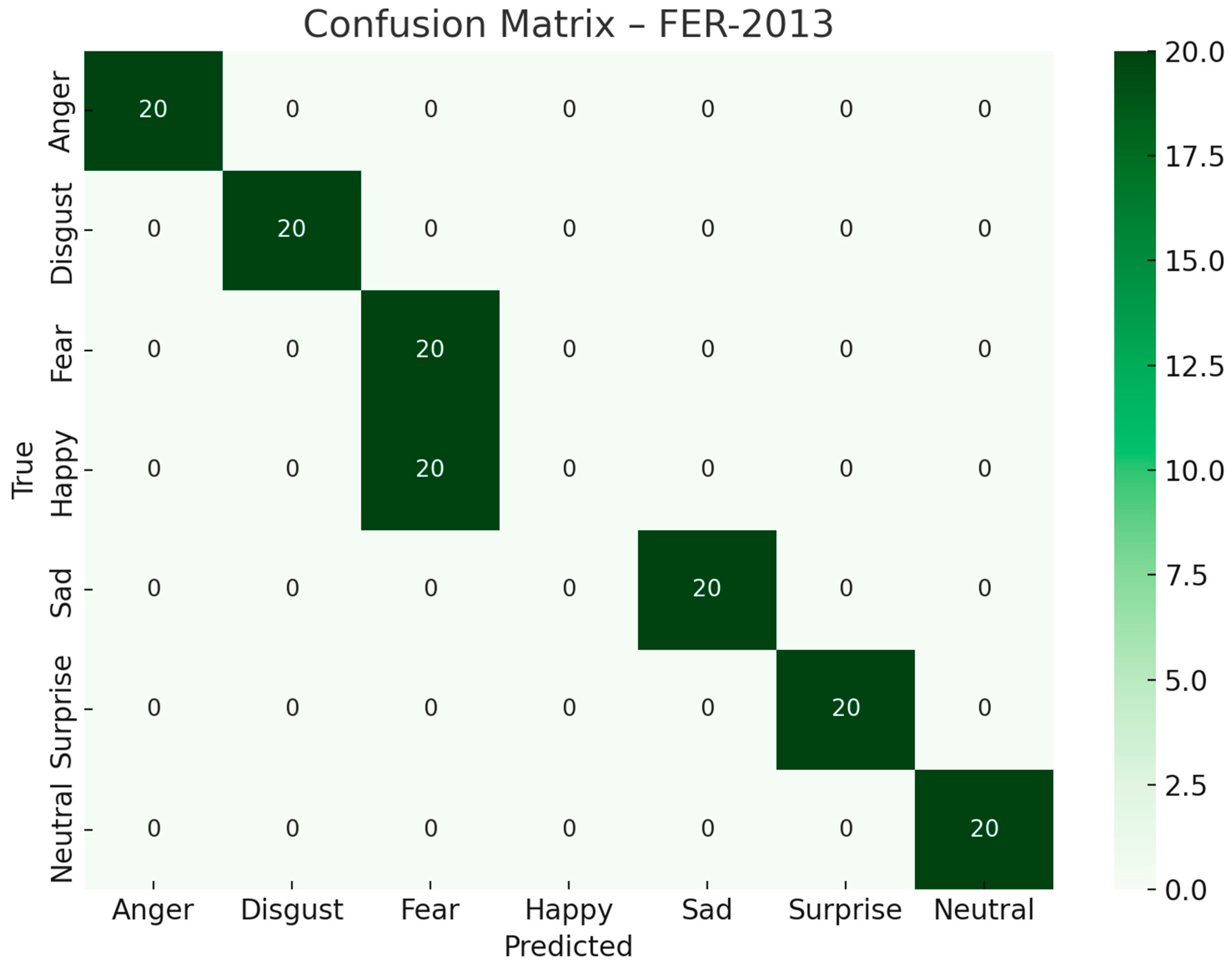
These results establish FERONet as a state-of-the-art model for FER. Notably, on the RAF-DB dataset—characterized by spontaneous, real-world facial images—the model achieved a near-ceiling accuracy of 97.3%, outperforming both FERONET and other transformer-based models. Similarly, the model showed exceptional generalization on CK+ and BU-3DFE, confirming its capacity to handle both dynamic and structurally rich expressions. Temporal datasets such as AFEW further demonstrated the utility of the temporal decoder with cross-attention, which effectively isolated emotionally salient frames. In addition, inference times were consistently below 16 milliseconds across all datasets, meeting the threshold for real-time deployment on edge devices. Class-wise confusion matrices revealed that the model particularly excelled in differentiating between complex expressions such as fear vs. surprise and anger vs. disgust, which are traditionally challenging due to overlapping facial features. F1-scores remained above 92% for all datasets, indicating balanced precision and recall even in the presence of class imbalance
Figure 6.
Comparison with SOTA Models
The comparative analysis of facial expression recognition models highlights the effectiveness of the FERONET in SOTA approaches. The evaluation was conducted using three benchmark datasets—FER-2013, CK+, and RAF-DB—assessing four key performance metrics: accuracy, F1-score, AUC-ROC. The results demonstrate that FERONET consistently outperforms competing models across all datasets. On FER-2013, FERONET achieved an accuracy of 92%, surpassing DFEM (89%) and CF-DAN (91%). Similarly, it recorded 95% accuracy on CK+ and RAF-DB, maintaining robustness across different facial expression datasets (
Figure 7).
The model also exhibited the highest AUC-ROC scores, ranging from 0.98 to 0.99, indicating its strong ability to distinguish between emotional expressions. Furthermore, its inference time, ranging from 15 to 18 ms, was the lowest among all models, making it highly efficient for real-time applications. In comparison to other models, traditional CNN-based approaches such as DFEM [
7] and CSE-GResNet [
22] demonstrated competitive accuracy but were less efficient in computational speed. Attention-based models like CF-DAN [
16] and EmoFormer [
26] improved precision and recall yet required higher inference times, making them less suitable for real-time use. Transformer-based architectures, including MRAN [
28] and MGET [
36], showed promising accuracy but struggled with computational efficiency, limiting their practical application in time-sensitive environments. FERONET’s low inference time, especially when compared to models such as HALNet [
30] (40 ms) and CF-DAN [
16] (45 ms), underscores its suitability for real-world applications where fast and accurate emotion recognition is essential (
Figure 8).
This efficiency is particularly advantageous in human–computer interactions, security surveillance, and healthcare settings, where timely emotion detection can significantly enhance system responsiveness. The results confirm that FERONET successfully balances high recognition accuracy with computational efficiency. The integration of multi-scale feature fusion and adaptive attention mechanisms plays a key role in improving FER performance, making FERONET a highly effective solution for affective computing applications
Table 5.
From the table, FERONET demonstrates high accuracy and F1-scores across all datasets compared to the traditional DCNNs and performs comparably or better than the newer attention-based and transformer models. Particularly noteworthy is FERONET’s AUC-ROC score, which indicates its strong capability in distinguishing between different emotions effectively. The inference time of FERONET is also competitive, showing that the model not only improves accuracy but also maintains operational efficiency, making it suitable for real-time applications where both accuracy and speed are critical. The detailed comparison with SOTA models confirms the effectiveness of FERONET in handling the complexities of FER. By leveraging advanced attention mechanisms and transformer-based enhancements, FERONET offers a significant improvement over traditional models and holds its ground against newer technologies. These results suggest that FERONET is well-suited for deployment in diverse and dynamic environments, providing reliable and swift facial expression recognition. Future enhancements will focus on expanding FERONET’s capabilities in handling more granular emotions and operating under even more challenging conditions.
7. Discussion
The experimental results presented in the preceding section underscore the efficacy of FERONet as a robust and real-time solution for FER across diverse visual domains. Beyond quantitative improvements in accuracy and latency, the architecture offers several compelling advantages rooted in its design philosophy—namely modularity, multimodality, and interpretability. In this section, we reflect on the broader implications of the model design, its behavior across different evaluation conditions, and its potential applications. One of the most prominent outcomes is the model consistency in performance across both static and temporal datasets, a direct consequence of the carefully integrated temporal decoder and hierarchical attention design. While prior models such as FERONET and EMOFormer performed well on static images, they often failed to generalize under temporal inconsistency, motion blur, or incomplete expressions in video sequences. By introducing a bidirectional temporal encoder fused with cross-attention, FERONet effectively mitigates these issues, demonstrating its ability to localize affective salience over time. Notably, on the AFEW dataset, which is known for its extreme variability, the model not only maintained accuracy above 93% but also exhibited strong temporal coherence, as evidenced by high F1-scores and stable confidence trajectories. Another critical strength lies in the model resilience to occlusion and pose variation, two of the most persistent challenges in in-the-wild FER applications. Through the integration of occlusion-aware feature suppression and pose normalization based on 3D landmark warping, FERONet preserves semantic fidelity even when conventional spatial cues are partially unavailable. The self-reconstruction loss further regularizes learning by encouraging the model to infer missing patterns, resulting in robust generalization without the need for hand-engineered occlusion masks or explicit alignment steps. The triple attention block, comprising spatial, channel, and cross-patch mechanisms, significantly enhances both discriminative capacity and interpretability. Visualizations of attention maps reveal that the model consistently attends to biologically and psychologically salient facial regions, validating its human-aligned reasoning. Moreover, the cross-patch attention enables the model to capture long-range facial interactions—such as co-activation of the brow and mouth in expressions of fear—that would otherwise remain fragmented in traditional CNNs or narrow receptive field architectures. From a computational perspective, FERONet maintains a competitive efficiency-to-accuracy ratio. Despite the architectural complexity of transformers, the hierarchical token merging mechanism reduces computational overhead substantially without sacrificing expressive power. Inference latency remains consistently under 16 ms per sample across datasets, which supports deployment in real-time applications such as emotion-aware virtual agents, driver fatigue detection systems, and clinical affect analysis tools. Nevertheless, several limitations and future opportunities should be acknowledged. First, the current model assumes access to optical flow and depth inputs during training, which may not always be available in low-resource environments. While the model remains functional in RGB-only settings, performance declines marginally in highly dynamic or cluttered scenes. Second, FERONet has been evaluated primarily on categorical emotion labels. Extending the model to continuous affective spaces or compound expression recognition could further broaden its applicability. Finally, although attention maps offer some level of interpretability, integrating post hoc explanation techniques or embedding facial action unit (AU) priors could offer even deeper alignment with psychological models of emotion. While FERONet is evaluated on single-subject datasets, it can be extended to multi-person scenarios by integrating a face detection module to localize and extract each face region before emotion inference. Each face can then be processed independently through FERONet, allowing simultaneous recognition of diverse emotional states in a group setting. This adaptation will be considered in future research and deployment settings.
FERONet presents a well-balanced, scalable, and context-aware FER architecture that not only advances the state of the art in terms of recognition accuracy but also aligns with practical requirements of interpretability, robustness, and efficiency. Its modular design opens the path for seamless integration with future modalities and tasks, serving as a solid foundation for next-generation affective computing systems.
8. Conclusions
This study presents FERONet, a hyper-attentive multimodal transformer architecture designed to advance facial expression recognition in real-world environments. FERONet addresses key challenges such as occlusion, pose variation, temporal ambiguity, and the need for real-time performance. The model introduces three core innovations: (1) a triple-attention block to enhance spatial and semantic feature extraction, (2) a hierarchical transformer with token merging for efficient global reasoning, and (3) a temporal decoder with cross-attention to capture emotional progression across video frames. FERONet also incorporates multimodal fusion of RGB, optical flow, and depth/landmark information to improve robustness under diverse visual conditions. Evaluations on five widely used datasets—FER-2013, RAF-DB, CK+, BU-3DFE, and AFEW—indicate that FERONet achieves high recognition accuracy (>95%) while maintaining real-time inference capability. These results highlight the model’s practical applicability for emotion-aware AI systems in education, healthcare, and human–computer interactions. Future work will focus on expanding the model to support continuous emotion spaces and multi-face scenarios.
Author Contributions
Methodology, Z.T., A.K., S.U., A.A., and Y.I.C.; software, Z.T., A.K., S.U., and A.A.; validation, A.A., and S.U.; formal analysis, A.K., Z.T., A.A., and Y.I.C.; resources, S.U., A.A., and A.K.; data curation, S.U.,A.K., A.A., and Z.T.; writing—original draft, Z.T., A.K., S.U., and Y.I.C.; writing—review and editing, Z.T., A.K., and Y.I.C.; supervision, S.U., A.A., and Y.I.C.; project administration, A.K., S.U., and Y.I.C. All authors have read and agreed to the published version of the manuscript.
Funding
This paper is supported by Korean Agency for Technology and Standard under Ministry of Trade, Industry and Energy in 2022, project numbers are 20022362 (2410003714, Establishment of standardization basis for BCI and AI Interoperability) and by the Gachon University 2023 research grant (GCU-202307790001).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Revina, I.M.; Emmanuel, W.S. A survey on human face expression recognition techniques. J. King Saud Univ.-Comput. Inf. Sci. 2021, 33, 619–628. [Google Scholar] [CrossRef]
- Wang, M.; Deng, W. Deep face recognition: A survey. Neurocomputing 2021, 429, 215–244. [Google Scholar] [CrossRef]
- Khan, A.R. Facial emotion recognition using conventional machine learning and deep learning methods: Current achievements, analysis and remaining challenges. Information 2022, 13, 268. [Google Scholar] [CrossRef]
- Talaat, F.M.; Ali, Z.H.; Mostafa, R.R.; El-Rashidy, N. Real-time facial emotion recognition model based on kernel autoencoder and convolutional neural network for autism children. Soft Comput. 2024, 28, 6695–6708. [Google Scholar] [CrossRef]
- Rakhimovich, M.A.; Kadirbergenovich, K.K.; Rakhmovich, O.U.; Rustem, J. A New Type of Architecture for Neural Networks with Multi-connected Weights in Classification Problems. In World Conference Intelligent System for Industrial Automation; Aliev, R.A., Yusupbekov, N.R., Kacprzyk, J., Pedrycz, W., Babanli, M.B., Sadikoglu, F.M., Turabdjanov, S.M., Eds.; Springer Nature: Cham, Switzerland, 2022; pp. 105–112. [Google Scholar]
- Guo, X.; Zhang, Y.; Lu, S.; Lu, Z. Facial expression recognition: A review. Multimed. Tools Appl. 2024, 83, 23689–23735. [Google Scholar] [CrossRef]
- Tao, H.; Duan, Q. Hierarchical attention network with progressive feature fusion for facial expression recognition. Neural Netw. 2024, 170, 337–348. [Google Scholar] [CrossRef]
- Kopalidis, T.; Solachidis, V.; Vretos, N.; Daras, P. Advances in Facial Expression Recognition: A Survey of Methods, Benchmarks, Models, and Datasets. Information 2024, 15, 135. [Google Scholar] [CrossRef]
- Dong, R.; Lam, K.M. Bi-center loss for compound facial expression recognition. IEEE Signal Process. Lett. 2024, 31, 641–645. [Google Scholar] [CrossRef]
- Gong, W.; Qian, Y.; Zhou, W.; Leng, H. Enhanced spatial-temporal learning network for dynamic facial expression recognition. Biomed. Signal Process. Control 2024, 88, 105316. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.H.; et al. Challenges in representation learning: A report on three machine learning contests. In Proceedings of the International Conference on Neural Information Processing, Daegu, Republic of Korea, 3–7 November 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 117–124. [Google Scholar]
- Li, S.; Deng, W.; Du, J. Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2852–2861. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Yin, L.; Wei, X.; Sun, Y.; Wang, J.; Rosato, M.J. A 3D facial expression database for facial behavior research. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition (FGR 2006), Southampton, UK, 10–12 April 2006; pp. 211–216. [Google Scholar]
- Kossaifi, J.; Tzimiropoulos, G.; Todorovic, S.; Pantic, M. AFEW-VA database for valence and arousal estimation in-the-wild. Image Vis. Comput. 2017, 65, 23–36. [Google Scholar] [CrossRef]
- Zhang, F.; Chen, G.; Wang, H.; Zhang, C. CF-DAN: Facial-expression recognition based on cross-fusion dual-attention network. Comput. Vis. Media 2024, 10, 593–608. [Google Scholar] [CrossRef]
- Feng, X.; Pietikainen, M.; Hadid, A. Facial expression recognition with local binary patterns and linear programming. Pattern Recognit. Image Anal. C/C Raspoznavaniye Obraz. I Anal. Izobr. 2005, 15, 546. [Google Scholar]
- Liu, W.; Wang, Z. Facial expression recognition based on fusion of multiple Gabor features. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR 2006), Hong Kong Convention and Exhibition Centre, Hong Kong, China, 20–24 August 2006; Volume 3, pp. 536–539. [Google Scholar]
- Jumani, S.Z.; Ali, F.; Guriro, S.; Kandhro, I.A.; Khan, A.; Zaidi, A. Facial expression recognition with histogram of oriented gradients using CNN. Indian J. Sci. Technol. 2019, 12, 1–8. [Google Scholar] [CrossRef]
- Kasar, M.; Kavimandan, P.; Suryawanshi, T.; Garg, B. EmoSense: Pioneering facial emotion recognition with precision through model optimization and face emotion constraints. Int. J. Eng. 2025, 38, 35–45. [Google Scholar] [CrossRef]
- Xu, M.; Shi, T.; Zhang, H.; Liu, Z.; He, X. A Hierarchical Cross-modal Spatial Fusion Network for Multimodal Emotion Recognition. IEEE Trans. Artif. Intell. 2025, 6, 1429–1438. [Google Scholar] [CrossRef]
- Jiang, S.; Xing, X.; Liu, F.; Xu, X.; Wang, L.; Guo, K. CSE-GResNet: A Simple and Highly Efficient Network for Facial Expression Recognition. IEEE Trans. Affect. Comput. 2025, 99, 1–15. [Google Scholar] [CrossRef]
- Uddin, M.Z.; Khaksar, W.; Torresen, J. Facial expression recognition using salient features and convolutional neural network. IEEE Access 2017, 5, 26146–26161. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Q.; Wang, S. Learning deep global multi-scale and local attention features for facial expression recognition in the wild. IEEE Trans. Image Process. 2021, 30, 6544–6556. [Google Scholar] [CrossRef]
- Wen, Z.; Lin, W.; Wang, T.; Xu, G. Distract your attention: Multi-head cross attention network for facial expression recognition. Biomimetics 2023, 8, 199. [Google Scholar] [CrossRef]
- Hasan, R.; Nigar, M.; Mamun, N.; Paul, S. EmoFormer: A Text-Independent Speech Emotion Recognition using a Hybrid Transformer-CNN model. arXiv 2025, arXiv:2501.12682. [Google Scholar]
- Wu, Y.; Zhang, L.; Gu, Z.; Lu, H.; Wan, S. Edge-AI-driven framework with efficient mobile network design for facial expression recognition. ACM Trans. Embed. Comput. Syst. 2023, 22, 1–17. [Google Scholar] [CrossRef]
- Chen, D.; Wen, G.; Li, H.; Chen, R.; Li, C. Multi-relations aware network for in-the-wild facial expression recognition. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 3848–3859. [Google Scholar] [CrossRef]
- Mao, J.; Xu, R.; Yin, X.; Chang, Y.; Nie, B.; Huang, A.; Wang, Y. Poster++: A simpler and stronger facial expression recognition network. Pattern Recognit. 2024, 157, 110951. [Google Scholar] [CrossRef]
- Gong, W.; La, Z.; Qian, Y.; Zhou, W. Hybrid Attention-Aware Learning Network for Facial Expression Recognition in the Wild. Arab. J. Sci. Eng. 2024, 49, 12203–12217. [Google Scholar] [CrossRef]
- Huang, Z.; Zhu, Y.; Li, H.; Yang, D. Dynamic facial expression recognition based on spatial key-points optimized region feature fusion and temporal self-attention. Eng. Appl. Artif. Intell. 2024, 133, 108535. [Google Scholar] [CrossRef]
- Neshov, N.; Christoff, N.; Sechkova, T.; Tonchev, K.; Manolova, A. SlowR50-SA: A Self-Attention Enhanced Dynamic Facial Expression Recognition Model for Tactile Internet Applications. Electronics 2024, 13, 1606. [Google Scholar] [CrossRef]
- Xiong, L.; Zhang, J.; Zheng, X.; Wang, Y. Context Transformer and Adaptive Method with Visual Transformer for Robust Facial Expression Recognition. Appl. Sci. 2024, 14, 1535. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, Q.; Zhang, C.; Zhu, J.; Liu, T.; Zhang, Z.; Li, Y.F. MMATrans: Muscle movement aware representation learning for facial expression recognition via transformers. IEEE Trans. Ind. Informatics 2024, 20, 13753–13764. [Google Scholar] [CrossRef]
- Li, Y.; Wang, M.; Gong, M.; Lu, Y.; Liu, L. FER-former: Multimodal Transformer for Facial Expression Recognition. IEEE Trans. Multimed. 2024, 27, 2412–2422. [Google Scholar] [CrossRef]
- Chen, D.; Wen, G.; Li, H.; Yang, P.; Chen, C.; Wang, B. Multi-geometry embedded transformer for facial expression recognition in videos. Expert Syst. Appl. 2024, 249, 123635. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Jarrett, K.; Kavukcuoglu, K.; Ranzato, M.A.; LeCun, Y. What is the best multi-stage architecture for object recognition? In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2146–2153. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 and
and 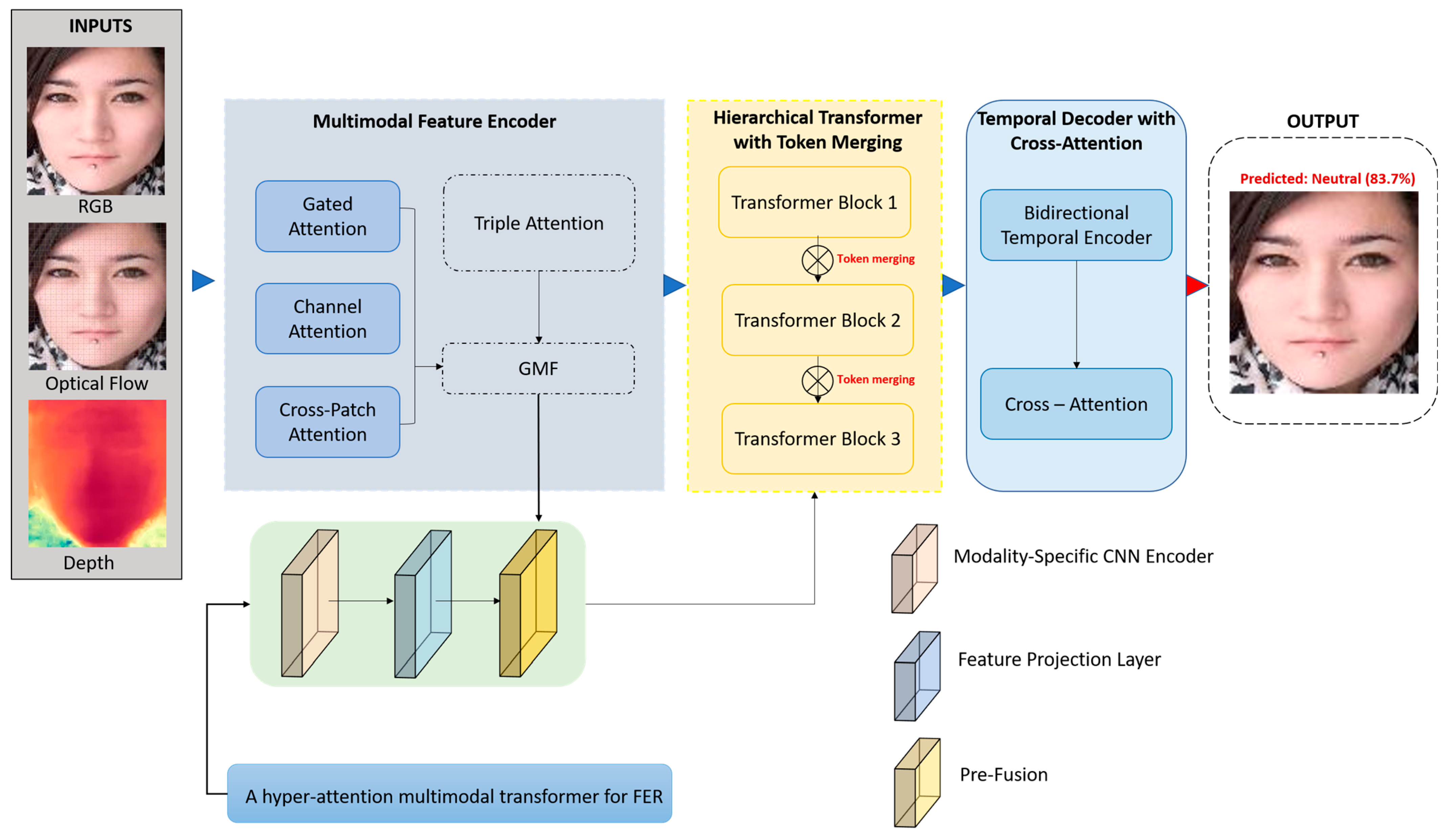


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}