1. Introduction
The international trade of spicy peppers (
Capsicum species) constitutes a vibrant and economically significant sector within global agriculture and commerce [
1]. Worldwide, the demand for spice peppers continues to rise, fueled by their role in ethnic cuisines, food preservation, and the growing recognition of their health-promoting properties, such as capsaicin content [
1,
2,
3]. Major producing countries, including Brazil, India, China, and Mexico, utilize pepper cultivation as a vital agricultural activity that supports rural livelihoods, exports, and local economies [
1,
4]. The stability of the pepper production chain ensures a constant market supply. The Food and Agriculture Organization (FAO) reported that global pepper production in 2022 reached 812,673 tons, with Brazil producing approximately 128,331 tons [
4]. Peppers are essential spices and widely used horticultural crops with global cultivation origins in South America [
1]. Peppers, commonly used in the culinary, pharmaceutical, and cosmetic industries, vary in color, heat, size, and shape. In Brazil, varieties such as Malagueta (
Capsicum frutescens), Dedo-de-Moça (
Capsicum baccatum), and Bode (
Capsicum chinense) exhibit distinct traits, with seed variation influencing their characteristics [
5].
Consumer satisfaction with spicy peppers is a multifaceted concept that significantly influences market demand and product differentiation. This satisfaction is not solely derived from heat level but also encompasses flavor profiles, aroma, freshness, and perceived health benefits [
6,
7]. Accurate identification of spicy varieties is crucial for optimizing production, enhancing quality, and minimizing errors in post-harvest management and market. Traditional post-harvest and market management screening methods are manual, time-consuming, and prone to errors in peppers (
Capsicum spp.), which are widely cultivated and valued for their diverse flavors, shapes, and heat levels. These limitations underscore the need to adopt advanced technologies, such as computer vision, to streamline post-harvest practices [
8,
9].
The accurate identification of pepper (
Capsicum spp.) varieties is a critical concern in agricultural production, as misclassification can result in substantial economic losses for producers, diminished product quality, and compromised supply chain efficiency. Given the increasing demand for specific pepper varieties in both domestic and international markets, failure to correctly identify and classify peppers can result in reduced market value, increased post-harvest losses, and a loss of consumer trust [
1,
4,
5]. The complexity of distinguishing between morphologically similar varieties, particularly in large-scale operations, further worsens the inherent risks of errors associated with manual sorting and screening processes. Consequently, there is a need for advanced, automated identification methods to improve both the accuracy and efficiency of varietal discrimination in pepper production systems [
6]. Recent developments in image processing have sparked significant interest in agricultural research [
7]. The development and implementation of robust computer vision-based detection systems hold considerable potential for transforming post-harvest handling, quality control, and overall agricultural productivity by reducing human error, lowering operational costs, and ensuring consistent product standards [
10,
11].
Adopting computer vision methods provides greater accuracy and speed in the identification process. Recent advances in object detection methods, particularly those based on deep learning, have shown remarkable progress in agriculture, with several models producing positive results in identification tasks [
12]. These technologies automate processes, reduce errors, enhance agricultural operations, and facilitate research advancements, as well as the integration of monitoring systems, contributing to more precise and sustainable agriculture. With the advancement of AI, deep learning has shown promise in addressing complex computer vision tasks in agriculture, with several deep learning algorithms, such as convolutional neural networks (CNNs), being successfully applied to recognition activities [
13].
Integrating computer vision and artificial intelligence (AI), particularly with deep learning techniques, has revolutionized agricultural practices. Object detection models, such as convolutional neural networks (CNNs), have revealed substantial progress in automating tasks previously performed manually, enhancing speed and accuracy [
12]. The YOLO (you only look once) model family stands out due to its real-time detection capabilities. However, image segmentation accuracy remains a critical factor for computer vision applications, as it directly impacts the performance of identification models. Recent studies emphasize the importance of striking a balance between computational efficiency and segmentation fidelity, thereby ensuring robust results without compromising system performance [
14].
Current research indicates that YOLO-based models are highly effective for detecting and classifying Capsicum (pepper) fruits, including tasks such as growth stage classification, segmentation, and real-time identification [
10,
15]. While YOLO and data augmentation are well established for general
Capsicum detection and classification tasks [
15,
16], their application to efficiently and accurately identify pepper varieties remains underexplored.
The YOLOv8m (medium) model offers a favorable trade-off between detection accuracy and computational efficiency. It outperforms the smaller variants (nano and small) in precision while requiring significantly fewer resources than the larger models (large and extra-large), as previously verified in the current literature [
16]. This outcome makes YOLOv8m a robust and efficient choice for deployment on hardware-constrained devices. The authors emphasize that the YOLO architecture was explicitly designed to be scalable, allowing researchers and practitioners to adjust model complexity according to the specific requirements of both the application and the available hardware. Moreover, YOLO-based models have been increasingly applied in the agriculture sector for tasks such as crop and pest detection, contributing to advancements in precision agriculture and process automation.
To address these challenges, the present study develops an automated method for identifying pepper varieties post-harvest using the YOLOv8m architecture and data augmentation. The main contributions include the construction of an annotated image dataset, the application of advanced deep-learning techniques, and a comprehensive evaluation of detection performance. The paper is structured as follows: the subsequent sections present the theoretical background, describe the materials and methods, report the results, and discuss the findings and implications for automated quality control in the post-harvest scenario.
2. Related Work
Computer vision is a branch of artificial intelligence that enables machines to interpret and analyze images to make decisions. This process utilizes cameras and computers to identify, track, and measure targets, followed by image processing [
17]. This technology has increased automation and efficiency in various agricultural fields. Critical applications include crop growth monitoring, disease control, product identification and classification, automated harvesting, quality testing, and modern farm management automation. Unmanned aerial vehicles (UAVs) equipped with computer vision technology are used for aerial surveillance of agricultural lands, providing valuable data for decision-making. Automating identification processes through computer vision offers significant benefits, including increased efficiency and productivity, enhanced accuracy and consistency, early problem detection, cost reduction, and continuous monitoring [
17].
Deep learning (DL), a subfield of machine learning (ML) and artificial intelligence (AI), is considered a core technology of the Fourth Industrial Revolution, also known as Industry 4.0 [
18,
19]. The word “deep” refers to the multiple layers through which data is processed to build a hierarchical data-driven model. DL models can automatically extract features from data, enabling them to handle complex tasks accurately. These models are widely applied in healthcare, cybersecurity, business intelligence, and especially agricultural visual recognition tasks.
According to Li et al. [
20], convolutional neural networks (CNNs) represent a fundamental class of deep learning models, particularly significant in the field of computer vision. The architecture of CNNs is designed to process grid-structured data, such as images. This process is achieved through convolutional layers, which apply convolution operations to extract local features from images, followed by pooling layers that reduce the dimensionality of the features while retaining essential representations. These networks have shown remarkable capabilities in learning complex hierarchical representations directly from data, making them highly effective in pattern recognition tasks such as image classification, object detection, and semantic segmentation. The capacity of CNNs to capture detailed and abstract visual patterns makes them ideal for identifying various visual characteristics of agricultural products, such as shape, color, and texture, which are critical for distinguishing between different pepper varieties [
21].
Recent studies show that deep learning methods substantially enhance the detection and classification of agricultural diseases and renewable energy sites. Ioannou and Myronidis [
22] used convolutional neural networks (CNNs) with high-resolution satellite imagery to automatically and accurately detect photovoltaic farms, offering a scalable tool for energy monitoring. In agriculture, Arnob et al. [
23] found that ResNet50 outperformed other deep-learning models in classifying cauliflower diseases, achieving an accuracy of 90.85%. Roy and Kukreja [
24] applied vision transformers (ViTs) for rice leaf disease detection and severity estimation, surpassing some limitations of traditional CNNs and achieving strong performance in both classification and severity assessment. Together, these findings highlight the value of advanced AI models in both environmental monitoring and precision agriculture.
Hussain [
25] explains that the YOLO (you only look once) model represents an innovative approach to real-time object detection, using a single convolutional neural network that simultaneously predicts bounding boxes and class probabilities from an image divided into a grid. This architecture enables the model to process the entire image simultaneously, resulting in high frame-per-second rates suitable for critical applications such as surveillance, autonomous driving, and industrial automation. In post-harvest agricultural contexts, YOLO’s efficiency is emphasized by its ability to perform accurate real-time detections, supporting real-time monitoring and identification essential for dynamic agricultural environments, such as fields or conveyor systems sorting produce [
26].
The YOLO architecture has evolved substantially since its inception, with each version introducing significant enhancements to improve object detection accuracy, speed, and computational efficiency. YOLOv1 marked the initial step toward real-time detection using a grid-based approach to predict bounding boxes. Building on this, YOLOv2 incorporated anchor boxes, significantly improving localization accuracy. YOLOv3 further refined the model by adopting the Darknet-53 architecture and integrating feature pyramid networks (FPNs), enabling better generalization across object scales. In YOLOv4, additional architectural innovations were introduced, including the Bag of Specials (BoS), which improved accuracy without sacrificing speed. A significant shift occurred with YOLOv5, implemented in PyTorch, where optimizations in training processes and the integration of Cross Stage Partial Network (CSPNet) and Path Aggregation Network (PANet) enhanced performance and modularity. YOLOv6 introduced reparameterization techniques and novel backbone designs for greater efficiency. Continuing the trend of architectural improvements, YOLOv7 employed Efficient Layer Aggregation Network (ELAN) blocks to improve feature learning. With YOLOv8m, the focus turned to computational optimization and more refined training strategies, making it suitable for resource-constrained environments. YOLOv9 introduced programmed gradient information (PGI) to further enhance detection precision and efficiency. Most recently, YOLOv10 eliminated the traditional non-maximum suppression (NMS) step, streamlining the detection of multiple overlapping objects and enhancing throughput for dense scenes. This progression reflects a continuous drive to balance speed, accuracy, and model simplicity, particularly in real-time agricultural applications such as pepper variety identification [
11].
These developments position YOLO as a leading architecture for real-time visual classification systems in the agricultural sector. In parallel, other deep learning approaches, such as convolutional neural networks (CNNs) combined with transfer learning, have also indicated strong practical potential in the agricultural sector. Previous studies have shown their effectiveness, particularly in the pepper production chain. Ren et al. [
27] developed a model to classify bell peppers (
Capsicum annuum) based on external quality, utilizing pre-trained neural networks and image capture tools. Their approach achieved high accuracy (98.14%) and low loss (0.0669), showing excellent performance and generalization without requiring manual feature extraction.
Kurtulmuş et al. [
28] investigated the classification of pepper seeds using computer vision and neural networks. Their study involved extracting color, shape, and texture features from the seeds and using a multilayer perceptron (MLP) for classification, achieving an accuracy of 84.94%. This advancement underscores the feasibility of applying CNNs at various stages of the pepper production chain, from seed to final product. Furthermore, a deep learning model utilizing convolutional neural networks (CNNs) for disease detection in pepper leaves was developed based on a dataset of 2478 images.
Previous research [
29] has emphasized the use of transfer learning to enhance diagnostic accuracy under cultivation conditions. Their results presented an accuracy of 99.55% in distinguishing between healthy and diseased leaves, highlighting the model’s practical applicability for early disease detection in agriculture.
Presenting additional application lines, Mohi-Alden et al. [
30] developed an intelligent classification system for bell peppers using deep convolutional neural networks (DCNN). By employing a modified ResNet50 architecture, the system achieved an accuracy of 96.89% in classifying bell peppers based on maturity stage and size. The system was integrated into a computer vision-based sorting machine, showing significant potential to improve classification processes in the food industry, with an overall sorting rate of approximately 3000 samples per hour.
Research on applying CNNs and transfer learning to classify and detect quality, types, and diseases in bell peppers reveals significant potential to transform food quality assessment practices. Previous studies have proven that integrating these technologies can enhance the accuracy, reduce costs, and increase the efficiency of agricultural processes [
31].
3. Materials and Methods
3.1. Data Recording
Figure 1 presents a schematic overview of the five-step methodology employed for automated pepper variety identification using the YOLOv8m model. Step 1 involved image collection, where photographic images of eight
Capsicum fruit varieties were acquired to establish the initial dataset. Step 2 involved image annotation, where the collected images were standardized to a 640 × 640 pixel resolution and annotated with bounding boxes to identify
Capsicum fruit instances using the Roboflow platform. In Step 3, we performed the initial model training using the YOLOv8m model. Step 4 involved data augmentation, where we enhanced the model’s generalization and expanded the dataset to include larger images through data augmentation techniques. In Step 5, the YOLOv8m model underwent final training using the full and augmented dataset.
The first step involved training the YOLOv8m model using a dataset comprising 1476 images representing eight distinct pepper varieties. Initially, the dataset consisted of approximately 300 images, collected exclusively through in-person visits to the Company of Warehouses and General Stores of São Paulo (CEAGESP (a major public enterprise in Brazil and one of the largest wholesale food centers in the world and the largest in Latin America). Located in São Paulo, Brazil, CEAGESP plays a crucial role in the supply chain of horticultural products, fish, flowers, and other food items. The main unit in São Paulo is the largest such center in South America and handles a significant volume of food products annually, where photographs of the eight pepper types were captured under real market conditions using various devices, including the Samsung Galaxy Tab A8 tablet, which features an 8 MP rear camera; the Samsung Nikon Coolpix L120, a compact camera with a 14.1 MP CCD sensor and a 21 × optical zoom lens; and the iPhone 11 smartphone, which has a dual 12 MP camera and 4 K video recording capability. These devices ensured high-quality, versatile image capture in diverse market settings. However, as the research progressed, it became evident that expanding the number of pepper varieties was essential to enhance the model’s generalization capacity and practical applicability [
32].
Another critical factor was the need to incorporate greater product variability. Observations at CEAGESP indicated that the peppers available for commercial sale exhibited high-quality standards, resulting in limited variation in size, coloration, and overall product condition. This high level of visual uniformity could potentially restrict the model’s ability to accurately identify peppers in more diverse real-market conditions, where variations in texture, ripeness, lighting, and shape are more common. An alternative approach was adopted to expand the dataset to address this limitation: sourcing images from online platforms, including open-access databases such as Google Images under the Creative Commons license. Image selection was based on quality criteria, prioritizing high resolution (≥300 dpi) and a diversity of angles to ensure a dataset that is more representative of the commercial reality of peppers across different contexts.
In the second step, the images were normalized to 640 px × 640 px and annotated with bounding box annotations using the Roboflow platform [
33]. As Matuck et al. [
34] described, Roboflow is a computer vision tool that streamlines the training and deployment of real-time object detection models.
The platform supports image importation, labeling, data preprocessing, model training, and deployment, making the development of computer vision models more accessible and efficient. Through this platform, the images were annotated, and distinct classes were created for each pepper variety: Biquinho Pepper, Bode Pepper, Cambuci Pepper, Chilli Pepper, Fidalga Pepper, Habanero Pepper, Jalapeno Pepper, and Scotch Bonnet Pepper.
Table 1 presents a photographic reference and concise morphological description for the eight pepper cultivars contained in the study (Biquinho, Bode, Cambuci, Chilli, Fidalga, Habanero, Jalapeno, and Scotch Bonnet). Each cultivar is provided with its common name, scientific designation, and key visual traits (shape, color, color variation, and size). These descriptors justify the class labels employed during image annotation and highlight the fine-grained features the YOLOv8m network must learn to distinguish during automated detection.
3.2. Dataset Partitioning and Preprocessing Strategies
In the third step, the dataset was then divided into three distinct subsets to increase the volume and diversity of training samples, considering the limitations of the initial dataset:
Training Set: 1245 images (84% of the total)
Validation Set: 201 images (14% of the total)
Test Set: 30 images (2% of the total)
Although the final test set comprised only 30 images (1% of the total dataset), this decision prioritized maximizing the volume and diversity of training data, which is critical for enhancing deep learning performance in object detection tasks. Although the test set was relatively small (30 images), it was carefully constructed to ensure visual diversity, encompassing variations in lighting, angles, and fruit morphology, thereby reflecting real-world application scenarios. To reduce the risk of overfitting, data augmentation techniques such as rotation and Gaussian blur were employed to introduce controlled variability and improve the model’s generalization capacity. The stabilization of performance metrics after 100 epochs, along with consistent improvements observed with the use of augmented data, indicates a well-adjusted model. Approximately 900 instances were generated for each pepper variety at the end of the process. Subsequently, a second round of model training was conducted using an augmented dataset.
This methodological approach is consistent with the findings of Frizzi et al. [
35], who verified that in data-scarce scenarios, a larger training partition combined with data augmentation effectively mitigates overfitting, provided the validation and test sets retain representative variability. While this principle guides our methodology, we acknowledge that the limited size of the current test set constrains a definitive evaluation of the risk of overfitting. Future research should incorporate strategies such as cross-validation and an expanded test dataset to enhance the robustness and reliability of the findings.
3.3. Data Augmentation
In the fourth step, we employed data augmentation. This process enlarges a training dataset through techniques such as rotation, flipping, cropping, and contrast adjustment, thereby enhancing the model’s generalization and performance [
35]. Data augmentation techniques were applied to the training set to improve the generalization capacity of the YOLOv8m model and optimize its accuracy in pepper identification. This strategy aimed to simulate natural variations in real-world image capture conditions, making the model more robust to changes in lighting, angles, and image sharpness. The augmentation methods, such as rotation and blurring, were selected based on prior studies indicating their positive impact on YOLOv8m accuracy. In contrast, cropping was excluded due to its tendency to eliminate critical features in small objects [
36].
In this study, data augmentation techniques were applied strategically in two distinct phases. Initially, the YOLOv8m model was trained on the original dataset to establish a baseline for performance. Subsequently, data augmentation methods such as rotation and Gaussian blur were introduced during a second training cycle, allowing for a more controlled assessment of their specific impact on the model’s generalization capabilities. Although it is common practice to apply data augmentation before the initial training phase, as noted by Ioannou and Myronidis [
22], the adopted approach offered clearer insights into how augmentation influenced convergence behavior and class-level detection performance. The observed improvements in metrics such as box precision and mAP during the second phase demonstrated that post-baseline augmentation not only enhanced generalization but also contributed to the model’s robustness in recognizing subtle morphological differences among pepper varieties. Additionally, this phased methodology enabled more efficient use of computational resources by avoiding unnecessary dataset expansion before validating the model’s initial learning performance.
Based on these indications, the following procedures were applied to the training dataset:
Rotation: Images were randomly rotated at angles between −30° and +30°, increasing perspective variability and reducing the model’s dependence on fixed angles.
Blurring: A soft Gaussian blur filter (3 × 3 kernel) was applied to simulate focus variations that may arise due to camera movement or differences in image quality.
Following data augmentation, the dataset increased to a total of 3964 images, with the final data split structured as follows:
Training Set: 3733 images (94% of the total)
Validation Set: 201 images (5% of the total)
Test Set 30 images (1% of the total)
The dataset was divided into training (94%), validation (5%), and test (1%) subsets to increase the volume and diversity of training samples, considering the limitations of the initial dataset.
Table 2 and
Table 3 provide the specifications necessary for reproducibility of the training process. This configuration represents a standard cloud-based training setup, ensuring that the model can be reproduced under similar computational conditions.
Hyperparameters were defined based on the default configurations provided in the defaults.yaml file of the official Ultralytics YOLOv8 implementation. These values reflect established best practices for training object detection models [
37]. The use of standardized configurations ensures methodological consistency with the YOLOv8 framework and facilitates the comparability of results across related studies.
3.4. YOLO Usage
The selection of the YOLOv8m model is justified by its superior performance in agricultural contexts, particularly in terms of accuracy, inference speed, and model compactness, compared to alternatives such as EfficientDet and CenterNet. YOLO’s architecture, which frames object detection as a single-pass regression problem, provides a significant velocity advantage crucial for real-time applications [
12].
This claim is substantiated by a systematic review of 30 studies by Badgujar et al. [
26], which concluded that YOLO models consistently outperform frameworks such as SSD, Faster R-CNN, and EfficientDet in agricultural tasks. Given its verified efficiency and accuracy, YOLOv8m is well suited for the present study on varietal pepper classification in uncontrolled environments.
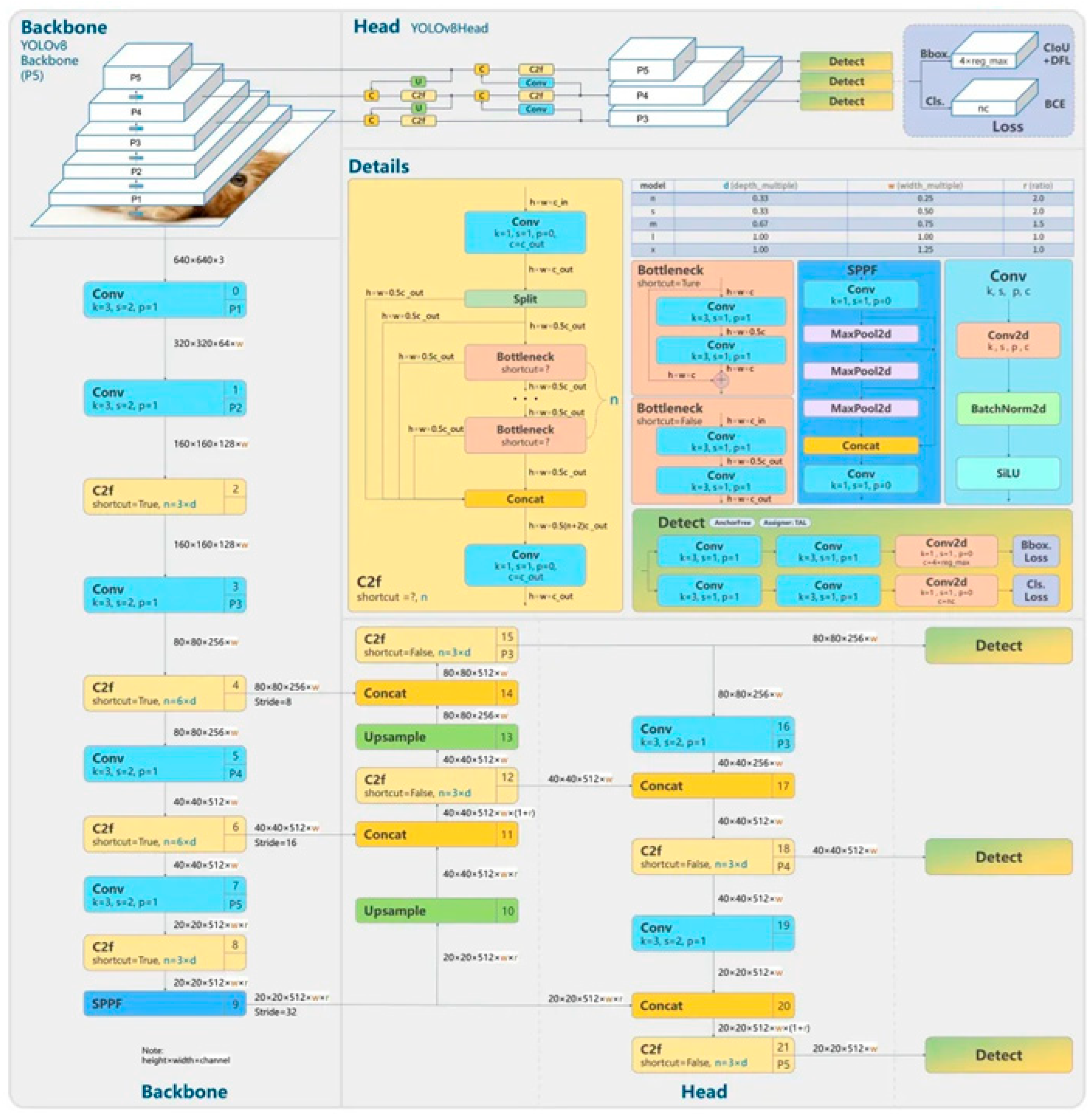
Figure 2 illustrates the flow of features through convolutional layers, C2f modules, and the anchor-free detection head.
The fifth step involved model training conducted using the Google Colab Pro infrastructure [
38], which ensured access to hardware acceleration for deep learning tasks. The computational configuration comprised an NVIDIA Tesla T4 GPU with 15 GB of VRAM, driver version 550.54.15, and CUDA version 12.4. Available memory was 15.36 GB, with GPU power consumption ranging from 9 W (minimum usage) to 70 W (maximum capacity).
The frameworks used were Python 3.10.12 [
39], PyTorch 2.5.1 [
40], and Ultralytics YOLOv8m [
37], along with OpenCV [
41] and Roboflow [
33]. Google Colab Pro was selected due to its access to high-performance GPUs, which enables the efficient training of the YOLOv8m model within a reduced time frame. The programming language used was Python [
39], in combination with several specialized libraries, including:
After training, the model’s performance was evaluated using the following metrics provided by the YOLOv8m CNN (Equations (1)–(3)):
where TP = true positive, and FP = false positive. The TP is a predicted bounding box that correctly matches a ground truth bounding box of the same class. FP is a predicted bounding box that does not correspond to a real object.
where TP = true positive, and FN = false negative. The FN is a ground truth bounding box that the model failed to detect.
Mean Average Precision at 50% IoU (mAP50): Calculates the average precision across different intersection-over-union (IoU) thresholds, focusing on a 50% threshold (Equation (3)). The mAP50 is a standard metric for evaluating object detection models. It represents the average of the average precision (AP) calculated for each object class. For this metric, a predicted bounding box is considered a true positive only if its intersection over union (IoU) with a ground truth box of the same class is 0.50 or greater. The AP for each class is the area under its corresponding precision–recall curve, reflecting the trade-off between precision and recall at varying detection confidence thresholds under the 0.50 IoU criterion.
where N = total number of object classes, and AP_c, 0.50 = average precision for class c, calculated using an IoU threshold of 0.50. This metric refers to the area under the precision–recall curve for class c, where predictions are counted as true positives if their IoU with ground truth is greater than 0.50.
where N = total number of object classes, and AP_c, 0.95 = average precision for class c, calculated using a fixed IoU threshold of 0.95. This metric is the area under the precision–recall curve for class c, where predictions are counted as true positives if their IoU with ground truth is greater than 0.95.
The YOLOv8m model was chosen for the present study due to its proven efficiency in real-time object detection tasks, aligning with the precision and speed requirements for identifying pepper varieties. This version represents a significant advancement within the YOLO family, combining architectural enhancements and advanced training techniques, making it particularly suited for agricultural applications. According to Terven and Cordova-Esparza [
11], YOLOv8m achieved superior performance in metrics such as mean average precision (mAP) compared to earlier models, including YOLOv5, and even competing approaches like Faster R-CNN. The results were compared between datasets with and without augmentation, highlighting the impact of data augmentation on the YOLOv8m model’s performance in pepper detection.
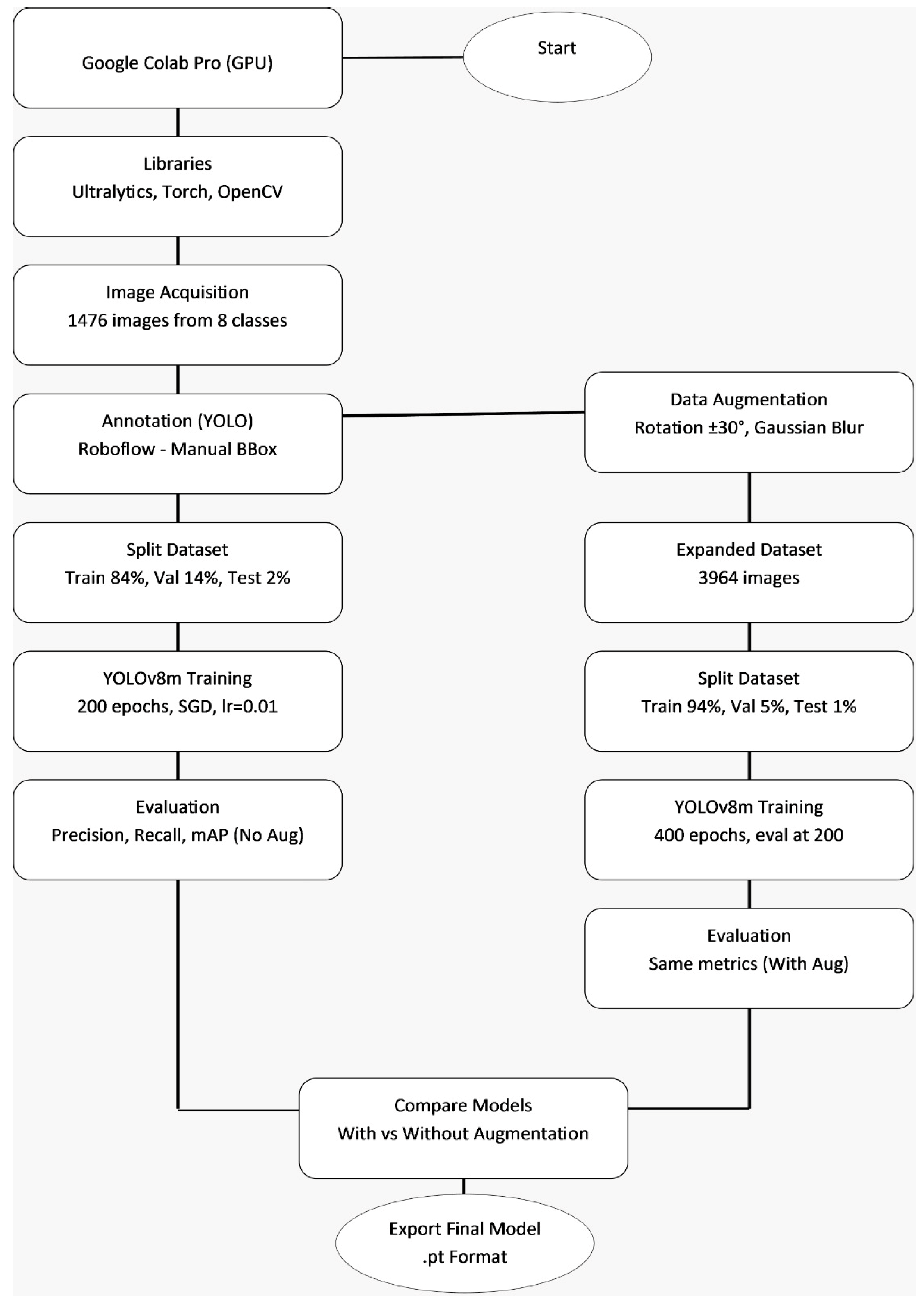
Figure 3 shows the workflow of the methodology.
4. Results
This study investigated the training of the YOLOv8m convolutional neural network (CNN) to identify eight distinct varieties of peppers. The model’s performance was evaluated both with and without the application of data augmentation techniques, considering key metrics such as bounding box precision (BoxP), recall, and mean average precision across different intersection over union (IoU) thresholds (mAP50-95).
Table 4 summarizes the evolution of global detection metrics—bounding-box precision (BoxP), recall, mAP<sub>50</sub>, and mAP<sub>50–95</sub>—at four representative training epochs (10, 50, 100, 170) for models trained with and without augmentation. The results indicate that rotation and Gaussian-blur augmentation accelerated convergence and yielded substantial gains.
The results presented in
Table 4 indicate the model’s performance progression throughout the training process, highlighting the positive effects of data augmentation. The application of these techniques led to improvements across all evaluated metrics.
Continuing training beyond 100 epochs revealed the stabilization of performance metrics, indicating that the model had reached an appropriate point of convergence for the dataset. This behavior suggests that increasing the number of epochs beyond this threshold would not yield significant improvements in the model’s learning performance.
Figure 4 shows that the results display consistent improvements in box precision, recall, and mean average precision (mAP) when augmentation techniques were applied, indicating enhanced generalization capabilities of the model.
The comparative analysis between models trained with and without data augmentation techniques revealed consistent improvements in the average values of precision, F1-score, and AP@0.5:0.95. These results underscore the importance of incorporating data augmentation methods to enhance the robustness and generalization capacity of object detection models. As emphasized by Abdulkareem et al. [
42], applying geometric transformations such as rotation, flipping, and scaling increases the visual diversity of the training dataset. This broader variability enables convolutional neural networks, particularly those based on the YOLO architecture, to detect objects more accurately across different orientations, scales, and visual perspectives.
Table 5 provides the class performance values (BoxP, recall, mAP<sub>50</sub>, and mAP<sub>50–95</sub>) for the best non-augmented and augmented models after 170 epochs. The table highlights how varietal morphology affects detector sensitivity and where further targeted data enrichment may be necessary.
The data show that the impact of data augmentation varied across classes, with some varieties benefiting more from the technique than others (
Supplementary material). Peppers that showed improvement with data augmentation:
Cambuci-Pepper achieved the highest gains through data augmentation, reaching 0.852 in BoxP (+14%) and 0.827 in mAP50 (+1.1%).
Chilli-Pepper also identified significant improvements, particularly in recall (+22%) and mAP50-95 (+31%).
The peppers with more stable or decreased performance with data augmentation were the Fidalga Pepper, which showed a reduction in precision (BoxP dropped from 0.768 to 0.652), suggesting that the model may have been affected by noise in the newly generated samples, and Habanero-Pepper, which also showed a decline in BoxP (from 0.636 to 0.577); however, it showed an improvement in recall (+8.8%), indicating that more objects were detected, even though with lower precision.
The peppers that consistently performed well under both conditions were the Jalapeno pepper and Scotch Bonnet pepper, which exhibited minimal variation between tests. This result suggests that the model effectively captures their visual characteristics, regardless of the training strategy.
Observations of the results on test images also raise several considerations.
Figure 5 presents eight subfigures (a to h) showing the YOLOv8m model’s detection of each pepper class on test images. The eight pepper varieties evaluated in the study are (a) Biquinho, (b) Bode, (c) Cambuci, (d) Chilli, (e) Fidalga, (f) Habanero, (g) Jalapeno, and (h) Scotch Bonnet. The bounding boxes inside the images highlight the detections made by the model, along with the confidence scores assigned to each prediction.
The confidence values vary from image to image, as they depend on the specific conditions of each sample evaluated by the model. This variation in confidence arises from multiple factors, including lighting and contrast, the position and angle of the peppers, instance overlap, image quality, and resolution. Such fluctuations in confidence values are expected and reflect the model’s robustness when dealing with diverse capture conditions. However, the variability in prediction confidence suggests that the model can still be optimized to reduce fluctuations in values across different images. Strategies such as adjusting the detection threshold, refining class balance, and implementing post-processing techniques could help improve the consistency of predictions.
5. Discussion
The reduction in precision observed for the Fidalga-Pepper and Habanero-Pepper classes may be attributed to the introduction of variations that do not accurately represent the actual distribution of the training images. The reduced performance observed in certain pepper varieties, such as Fidalga, is likely attributable to their visual similarity to other yellow, rounded types like Habanero and Scotch Bonnet, combined with the possible introduction of unrealistic variations during data augmentation, which may have impaired the model’s ability to distinguish subtle inter-class differences. This effect has already been documented in the literature, as noted by Yilmaz and Kutbay [
36], who indicate that data augmentation techniques can, in some cases, generate unrealistic instances, hindering the model’s generalization capacity. The variation in performance across classes suggests that some pepper varieties possess visual characteristics that facilitate detection, while others require further refinement of the model to improve detection.
The application of data augmentation also impacted the total training time of the model. Without augmentation, training was completed in 200 epochs, totaling 3 h and 43 min. Using the augmentation technique, there was a reduction in epochs (170), but the processing time more than doubled, reaching 6 h and 54 min. This increase in processing time, from 3 h and 43 min without augmentation to 6 h and 54 min with augmentation, can be attributed to the larger volume of images and the increased computational complexity introduced by greater sample diversity. This impact on training time aligns with the findings of Yilmaz and Kutbay [
36], who report that applying data augmentation techniques can significantly increase model execution time, especially when implemented on large datasets. The increase in training time needs to be weighed against the gains in model accuracy. Although data augmentation yielded better performance for some pepper classes, the computational cost remains a critical factor for deploying the model in real-world applications.
The present study’s findings confirm previous research [
43], indicating the effectiveness of computer vision in agricultural product identification while highlighting the challenges associated with automated pepper detection. An earlier study [
17] highlights the increasing application of computer vision in agricultural automation, noting that CNN-based models can replace traditional screening methods, thereby reducing time and minimizing human error. Similarly, Li et al. [
10] show that the performance of CNNs is highly dependent on the quantity and diversity of the dataset, which explains the positive impact of data augmentation observed in the present study.
The choice of YOLOv8m for this study aligns with research by Hussain [
25] and Terven and Cordova-Esparza [
11], who highlight the YOLO architecture’s advances in efficiency and speed in agricultural object detection. This study reinforces these findings, demonstrating that YOLOv8m can accurately identify pepper varieties, especially when trained on a diverse dataset.
We observed a clear trend based on the experimental results: model performance, as indicated by metrics such as mAP50 and AP50-95, generally improves with increased training from 10 to 200 epochs without data augmentation. However, further training to 400 epochs yields diminishing returns and introduces the risk of overfitting. In contrast, data augmentation, particularly evident after 50 epochs, substantially enhances the model’s generalization capabilities across the eight distinct pepper varieties. This result points out the crucial role of data augmentation in enabling extended training durations to achieve robust and accurate fine-grained classification.
The YOLOv8m model indicated a notable improvement in performance after applying data augmentation techniques. Key metrics such as box precision (BoxP) and recall showed significant gains after 50 epochs, with further stabilization observed after 100 epochs. For instance, the mAP50 for Chilli-Pepper increased from 0.648 to 0.790 with augmentation, while the recall for Bode peppers improved from 0.436 to 0.564. The precision and recall values across the eight pepper varieties indicate the model’s capacity to differentiate effectively between them. These results underscore the crucial role of data augmentation in enhancing the performance of CNN models in agricultural contexts, laying a solid foundation for future advancements in automated crop identification and management systems.
Future research should explore advanced architectural enhancements, such as integrating attention mechanisms (e.g., SE-Net, CBAM), to improve spatial and channel feature refinement. Alternatively, employing ensemble approaches that combine predictions from multiple models could increase robustness across heterogeneous field conditions. Investigating lightweight architectures (e.g., MobileNet, YOLO-NAS) may also support deployment in edge devices used in precision agriculture.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







