
BrushGaussian: Brushstroke-Based Stylization for 3D Gaussian Splatting


Abstract
1. Introduction
- 1.
- An efficient Gaussian pruning algorithm that reduces the density of 3D Gaussian scenes while maintaining structural consistency.
- 2.
- A texture mapping technique that enables the projection of arbitrary style textures onto 3D Gaussian primitives, preserving local geometric style elements such as brushstroke effects.
2. Related Works
2.1. Two-Dimensional Image Style Transfer
2.2. Three-Dimensional Representation and Style Transfer
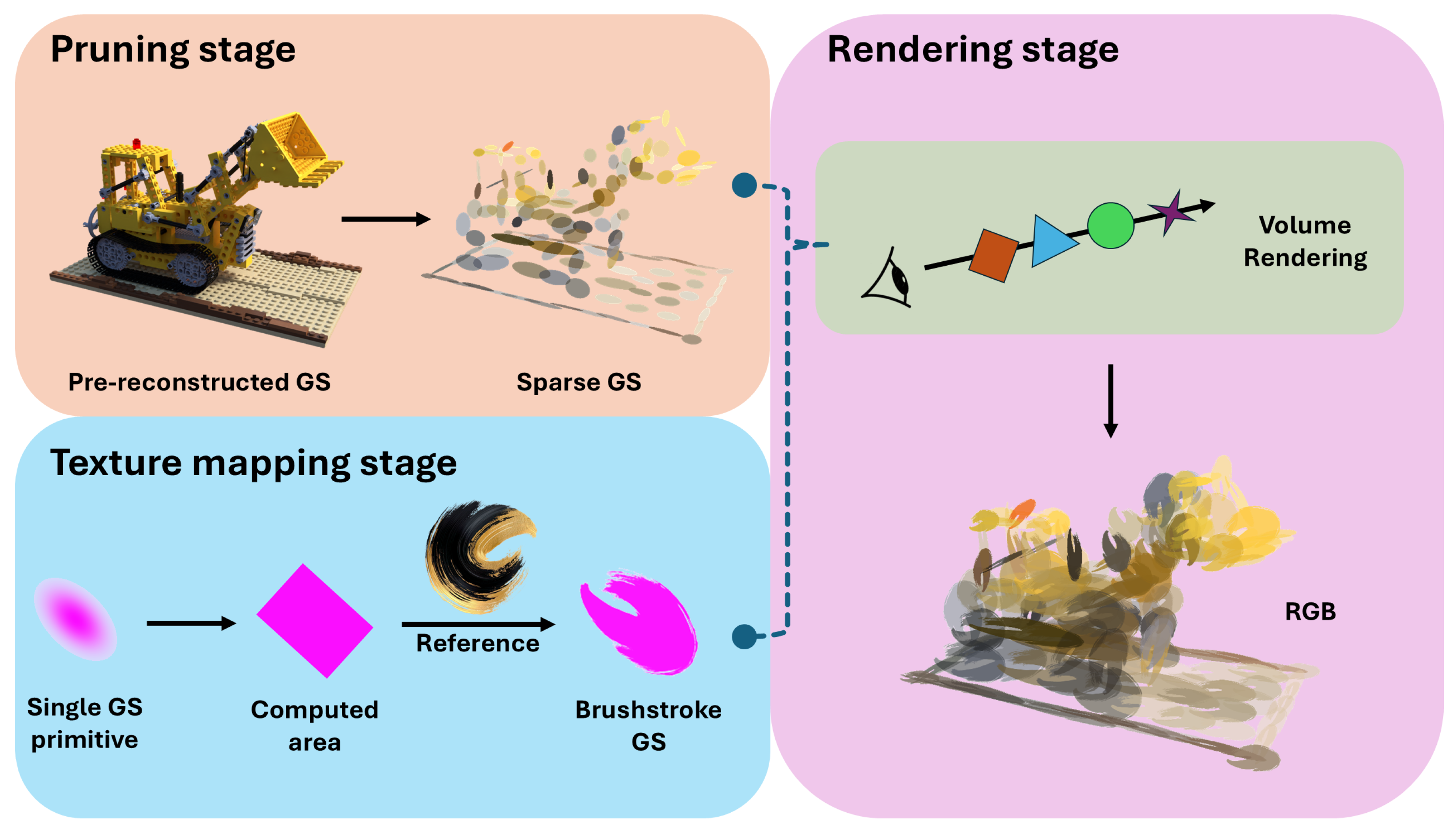
3. Methods
3.1. Three-Dimensional Gaussian Splatting
3.2. Gaussian Pruning and Expansion
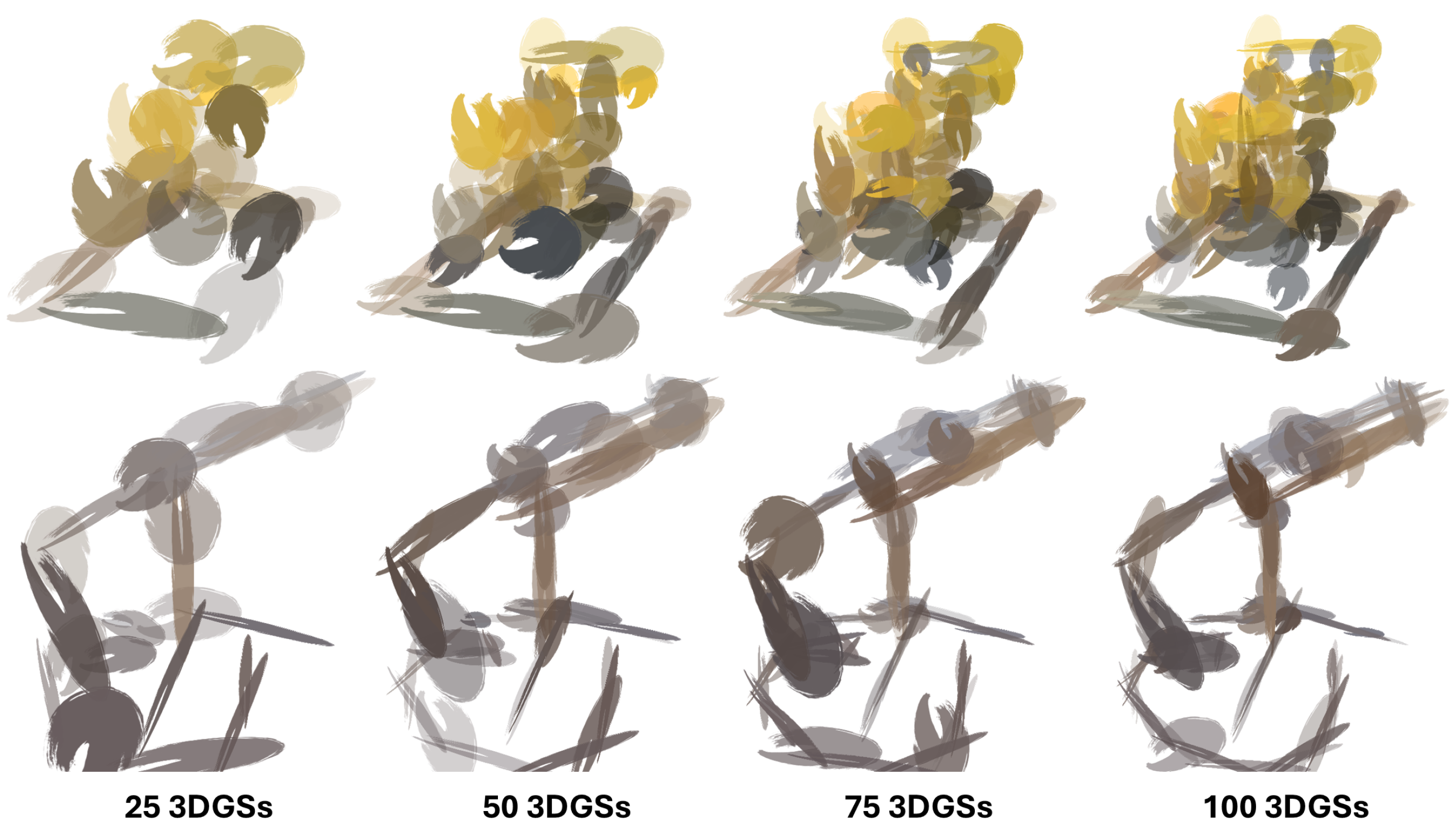
3.2.1. Clustering for 3DGS Reduction
3.2.2. Adaptive Scaling of Gaussian Primitives
3.3. Computing the 2D Projection Area
3.4. Texture Mapping
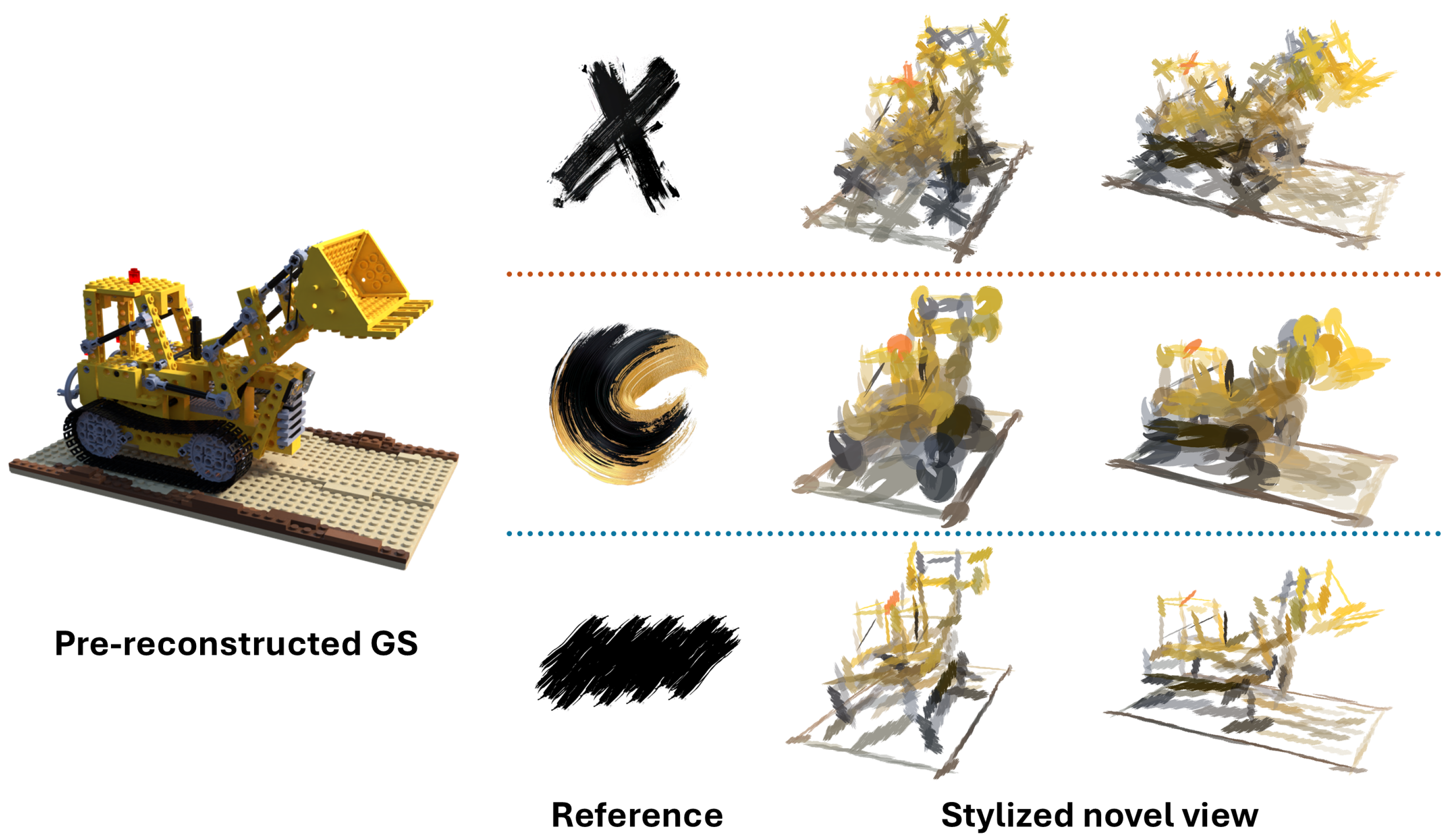
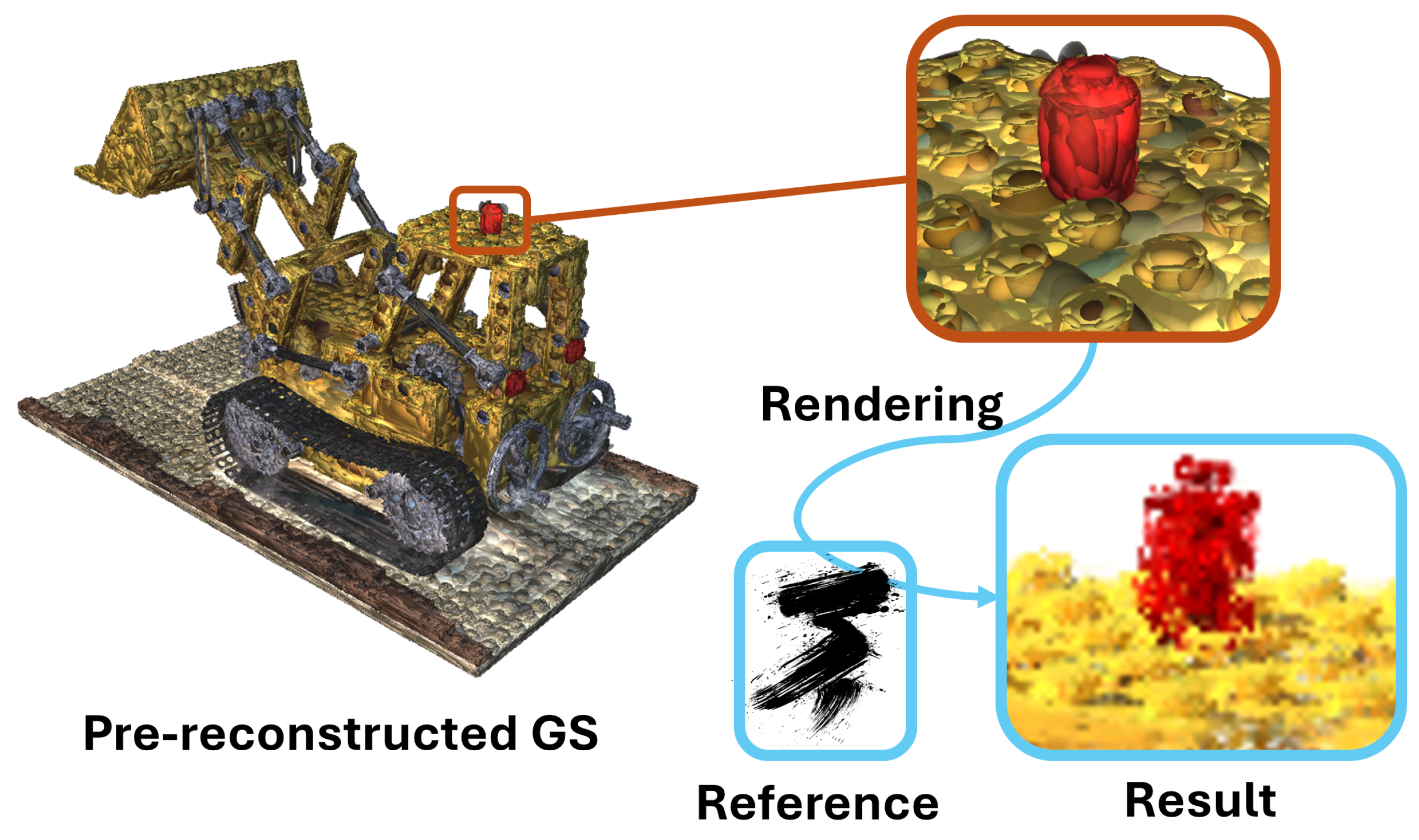
4. Experiments
4.1. Stroke-Based Rendering
4.2. Comparison with Other Methods
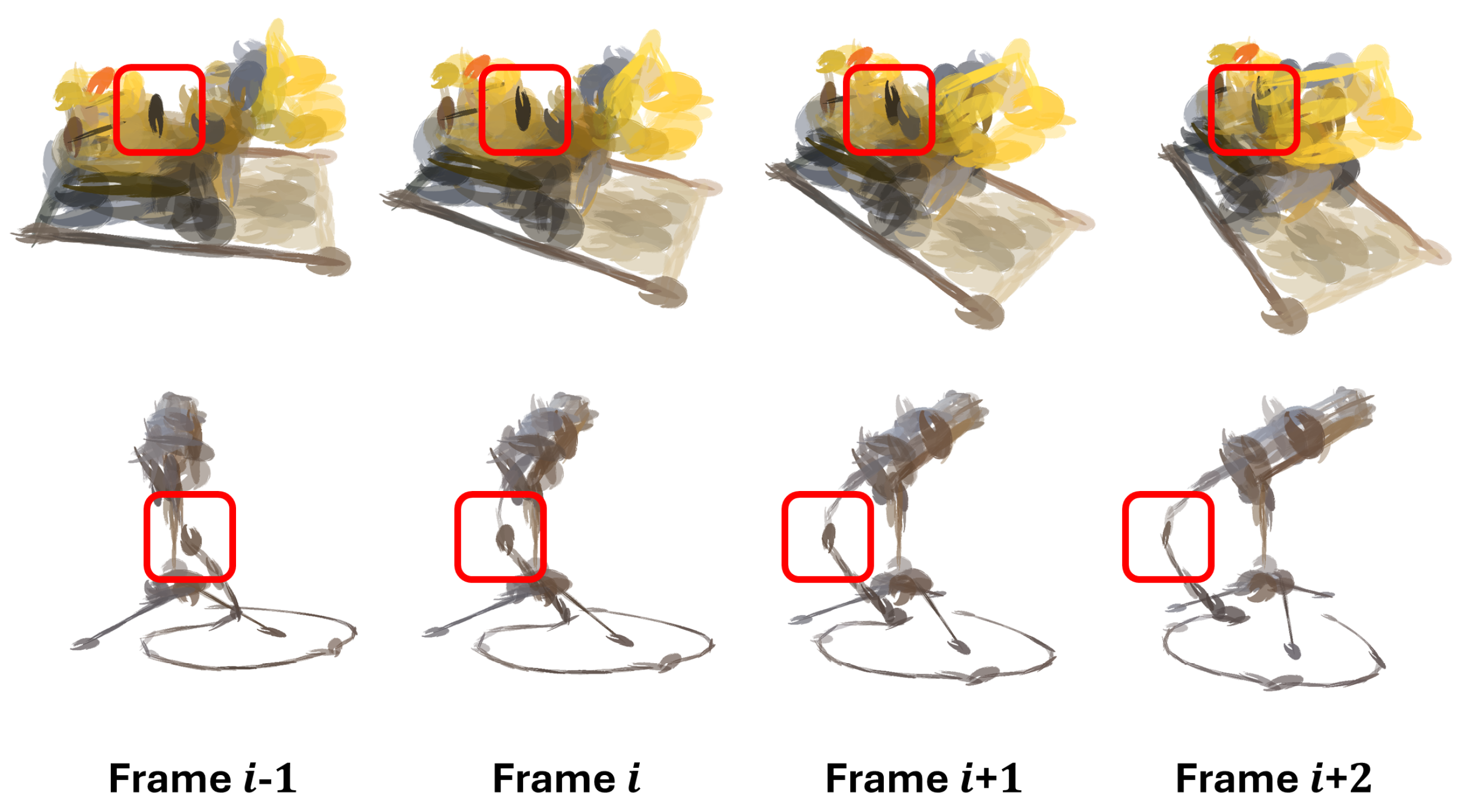
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| The mean value of a 3D Gaussian Splatting (3DGS) primitive; | |
| The covariance matrix of a 3DGS primitive; | |
| Variance of a 3DGS primitive projected onto the image plane; | |
| Covariance of a 3DGS primitive projected onto the image plane; | |
| o | The opacity of a 3DGS primitive; |
| c | The color of a 3DGS primitive. |
Appendix A
| Algorithm A1: Densification and Clustering |
 |
| Algorithm A2: Texture Mapping Algorithm for 3DGS |
 |
References
- Kato, H.; Ushiku, Y.; Harada, T. Neural 3d mesh renderer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3907–3916. [Google Scholar]
- Gomes Haetinger, G.; Tang, J.; Ortiz, R.; Kanyuk, P.; Azevedo, V. Controllable Neural Style Transfer for Dynamic Meshes. In Proceedings of the ACM SIGGRAPH 2024 Conference Papers, Denver, CO, USA, 27 July–1 August 2024; pp. 1–11. [Google Scholar]
- Höllein, L.; Johnson, J.; Nießner, M. Stylemesh: Style transfer for indoor 3d scene reconstructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6198–6208. [Google Scholar]
- Ma, Y.; Zhang, X.; Sun, X.; Ji, J.; Wang, H.; Jiang, G.; Zhuang, W.; Ji, R. X-mesh: Towards fast and accurate text-driven 3d stylization via dynamic textual guidance. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 2749–2760. [Google Scholar]
- Michel, O.; Bar-On, R.; Liu, R.; Benaim, S.; Hanocka, R. Text2mesh: Text-driven neural stylization for meshes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13492–13502. [Google Scholar]
- Huang, H.P.; Tseng, H.Y.; Saini, S.; Singh, M.; Yang, M.H. Learning to stylize novel views. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 13869–13878. [Google Scholar]
- Mu, F.; Wang, J.; Wu, Y.; Li, Y. 3d photo stylization: Learning to generate stylized novel views from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16273–16282. [Google Scholar]
- Zhang, Y.; Wang, H.; Lin, G.; Nicholas, V.C.H.; Shen, Z.; Miao, C. StarNet: Style-Aware 3D Point Cloud Generation. arXiv 2023, arXiv:2303.15805. [Google Scholar]
- Cao, X.; Wang, W.; Nagao, K.; Nakamura, R. Psnet: A style transfer network for point cloud stylization on geometry and color. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 3337–3345. [Google Scholar]
- Bae, E.; Kim, J.; Lee, S. Point Cloud-Based Free Viewpoint Artistic Style Transfer. In Proceedings of the 2023 IEEE International Conference on Multimedia and Expo Workshops (ICMEW). IEEE, Brisbane, Australia, 10–14 July 2023; pp. 302–307. [Google Scholar]
- Zhou, Y.; Xu, C.; Lin, Z.; He, X.; Huang, H. Point-StyleGAN: Multi-scale point cloud synthesis with style modulation. Comput. Aided Geom. Des. 2024, 111, 102309. [Google Scholar] [CrossRef]
- Chiang, P.Z.; Tsai, M.S.; Tseng, H.Y.; Lai, W.S.; Chiu, W.C. Stylizing 3d scene via implicit representation and hypernetwork. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, New Orleans, LA, USA, 18–24 June 2022; pp. 1475–1484. [Google Scholar]
- Zhang, K.; Kolkin, N.; Bi, S.; Luan, F.; Xu, Z.; Shechtman, E.; Snavely, N. Arf: Artistic radiance fields. In Computer Vision—ECCV 2022, Proceedings of the 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 717–733. [Google Scholar]
- Liu, K.; Zhan, F.; Chen, Y.; Zhang, J.; Yu, Y.; El Saddik, A.; Lu, S.; Xing, E.P. Stylerf: Zero-shot 3d style transfer of neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 8338–8348. [Google Scholar]
- Zhang, Y.; He, Z.; Xing, J.; Yao, X.; Jia, J. Ref-npr: Reference-based non-photorealistic radiance fields for controllable scene stylization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 4242–4251. [Google Scholar]
- Haque, A.; Tancik, M.; Efros, A.A.; Holynski, A.; Kanazawa, A. Instruct-nerf2nerf: Editing 3d scenes with instructions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 19740–19750. [Google Scholar]
- Men, Y.; Liu, H.; Yao, Y.; Cui, M.; Xie, X.; Lian, Z. 3DToonify: Creating Your High-Fidelity 3D Stylized Avatar Easily from 2D Portrait Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 10127–10137. [Google Scholar]
- Haeberli, P. Paint by numbers: Abstract image representations. In Proceedings of the 17th Annual Conference on Computer Graphics and Interactive Techniques, Dallas, TX, USA, 6–10 August 1990; pp. 207–214. [Google Scholar]
- Hertzmann, A. Painterly rendering with curved brush strokes of multiple sizes. In Proceedings of the 25th Annual Conference on Computer Graphics and Interactive Techniques, Orlando, CA, USA, 19–24 July 1998; pp. 453–460. [Google Scholar]
- Hertzmann, A.; Jacobs, C.E.; Oliver, N.; Curless, B.; Salesin, D.H. Image analogies. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, Association for Computing Machinery, 2001, SIGGRAPH ’01. Los Angeles, CA, USA, 12–17 August 2001; pp. 327–340. [Google Scholar] [CrossRef]
- Winnemöller, H.; Olsen, S.C.; Gooch, B. Real-time video abstraction. ACM Trans. Graph. 2006, 25, 1221–1226. [Google Scholar] [CrossRef]
- Rosin, P.; Collomosse, J. Image and Video-Based Artistic Stylisation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 42. [Google Scholar]
- Hertzmann, A. A survey of stroke-based rendering. IEEE Comput. Graph. Appl. 2003, 23, 70–81. [Google Scholar] [CrossRef]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Simonyan, K. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14; Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Ulyanov, D. Instance normalization: The missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Ulyanov, D.; Lebedev, V.; Vedaldi, A.; Lempitsky, V. Texture networks: Feed-forward synthesis of textures and stylized images. arXiv 2016, arXiv:1603.03417. [Google Scholar]
- Chen, D.; Yuan, L.; Liao, J.; Yu, N.; Hua, G. Stylebank: An explicit representation for neural image style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1897–1906. [Google Scholar]
- Li, Y.; Fang, C.; Yang, J.; Wang, Z.; Lu, X.; Yang, M.H. Universal style transfer via feature transforms. Adv. Neural Inf. Process. Syst. 2017, 30, 385–395. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Risser, E.; Wilmot, P.; Barnes, C. Stable and controllable neural texture synthesis and style transfer using histogram losses. arXiv 2017, arXiv:1701.08893. [Google Scholar]
- Wang, X.; Oxholm, G.; Zhang, D.; Wang, Y.F. Multimodal transfer: A hierarchical deep convolutional neural network for fast artistic style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5239–5247. [Google Scholar]
- Kolkin, N.; Kucera, M.; Paris, S.; Sykora, D.; Shechtman, E.; Shakhnarovich, G. Neural neighbor style transfer. arXiv 2022, arXiv:2203.13215. [Google Scholar]
- Gupta, A.; Johnson, J.; Alahi, A.; Fei-Fei, L. Characterizing and improving stability in neural style transfer. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4067–4076. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Liu, G.; Tao, A.; Kautz, J.; Catanzaro, B. Video-to-video synthesis. arXiv 2018, arXiv:1808.06601. [Google Scholar]
- Kotovenko, D.; Wright, M.; Heimbrecht, A.; Ommer, B. Rethinking style transfer: From pixels to parameterized brushstrokes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12196–12205. [Google Scholar]
- Zou, Z.; Shi, T.; Qiu, S.; Yuan, Y.; Shi, Z. Stylized neural painting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15689–15698. [Google Scholar]
- Liu, S.; Lin, T.; He, D.; Li, F.; Deng, R.; Li, X.; Ding, E.; Wang, H. Paint transformer: Feed forward neural painting with stroke prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6598–6607. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Patashnik, O.; Wu, Z.; Shechtman, E.; Cohen-Or, D.; Lischinski, D. Styleclip: Text-driven manipulation of stylegan imagery. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2085–2094. [Google Scholar]
- Crowson, K.; Biderman, S.; Kornis, D.; Stander, D.; Hallahan, E.; Castricato, L.; Raff, E. Vqgan-clip: Open domain image generation and editing with natural language guidance. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 88–105. [Google Scholar]
- Karras, T. Progressive Growing of GANs for Improved Quality, Stability, and Variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Karras, T. A Style-Based Generator Architecture for Generative Adversarial Networks. arXiv 2019, arXiv:1812.04948. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Karras, T.; Aittala, M.; Hellsten, J.; Laine, S.; Lehtinen, J.; Aila, T. Training generative adversarial networks with limited data. Adv. Neural Inf. Process. Syst. 2020, 33, 12104–12114. [Google Scholar]
- Karras, T.; Aittala, M.; Laine, S.; Härkönen, E.; Hellsten, J.; Lehtinen, J.; Aila, T. Alias-free generative adversarial networks. Adv. Neural Inf. Process. Syst. 2021, 34, 852–863. [Google Scholar]
- Chen, X.; Xu, C.; Yang, X.; Song, L.; Tao, D. Gated-gan: Adversarial gated networks for multi-collection style transfer. IEEE Trans. Image Process. 2018, 28, 546–560. [Google Scholar] [CrossRef]
- Kazemi, H.; Iranmanesh, S.M.; Nasrabadi, N. Style and content disentanglement in generative adversarial networks. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, Waikoloa Village, HI, USA, 7–11 January 2019; pp. 848–856. [Google Scholar]
- Park, T.; Zhu, J.Y.; Wang, O.; Lu, J.; Shechtman, E.; Efros, A.; Zhang, R. Swapping Autoencoder for Deep Image Manipulation. In Proceedings of the Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 7198–7211. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Zhang, L.; Rao, A.; Agrawala, M. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 3836–3847. [Google Scholar]
- Zhang, Y.; Huang, N.; Tang, F.; Huang, H.; Ma, C.; Dong, W.; Xu, C. Inversion-based style transfer with diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10146–10156. [Google Scholar]
- Brooks, T.; Holynski, A.; Efros, A.A. Instructpix2pix: Learning to follow image editing instructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18392–18402. [Google Scholar]
- Ruiz, N.; Li, Y.; Jampani, V.; Pritch, Y.; Rubinstein, M.; Aberman, K. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22500–22510. [Google Scholar]
- Kawar, B.; Zada, S.; Lang, O.; Tov, O.; Chang, H.; Dekel, T.; Mosseri, I.; Irani, M. Imagic: Text-based real image editing with diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6007–6017. [Google Scholar]
- Shi, M.; Seo, J.; Cha, S.H.; Xiao, B.; Chi, H.L. Generative AI-powered architectural exterior conceptual design based on the design intent. J. Comput. Des. Eng. 2024, 11, 125–142. [Google Scholar] [CrossRef]
- Meng, C.; He, Y.; Song, Y.; Song, J.; Wu, J.; Zhu, J.Y.; Ermon, S. Sdedit: Guided image synthesis and editing with stochastic differential equations. arXiv 2021, arXiv:2108.01073. [Google Scholar]
- Zhang, Z.; Han, L.; Ghosh, A.; Metaxas, D.N.; Ren, J. Sine: Single image editing with text-to-image diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6027–6037. [Google Scholar]
- Avrahami, O.; Fried, O.; Lischinski, D. Blended latent diffusion. ACM Trans. Graph. 2023, 42, 1–11. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, R.; Lei, J.; Zhang, Y.; Jia, K. Tango: Text-driven photorealistic and robust 3d stylization via lighting decomposition. Adv. Neural Inf. Process. Syst. 2022, 35, 30923–30936. [Google Scholar]
- Richardson, E.; Metzer, G.; Alaluf, Y.; Giryes, R.; Cohen-Or, D. Texture: Text-guided texturing of 3d shapes. In Proceedings of the ACM SIGGRAPH 2023 Conference Proceedings, Los Angeles, CA, USA, 6–10 August 2023; pp. 1–11. [Google Scholar]
- Liu, H.T.D.; Tao, M.; Jacobson, A. Paparazzi: Surface editing by way of multi-view image processing. ACM Trans. Graph. 2018, 37, 221. [Google Scholar] [CrossRef]
- Gao, W.; Aigerman, N.; Groueix, T.; Kim, V.; Hanocka, R. Textdeformer: Geometry manipulation using text guidance. In Proceedings of the ACM SIGGRAPH 2023 Conference Proceedings, Los Angeles, CA, USA, 6–10 August 2023; pp. 1–11. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Duan, H.B.; Wang, M.; Li, Y.X.; Yang, Y.L. Neural 3D Strokes: Creating Stylized 3D Scenes with Vectorized 3D Strokes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 5240–5249. [Google Scholar]
- Kerbl, B.; Kopanas, G.; Leimkühler, T.; Drettakis, G. 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph. 2023, 42, 139. [Google Scholar] [CrossRef]
- Kovács, Á.S.; Hermosilla, P.; Raidou, R.G. G-Style: Stylized Gaussian Splatting. Comput. Graph. Forum 2024, 43, e15259. [Google Scholar] [CrossRef]
- Zhang, D.; Yuan, Y.J.; Chen, Z.; Zhang, F.L.; He, Z.; Shan, S.; Gao, L. Stylizedgs: Controllable stylization for 3d gaussian splatting. arXiv 2024, arXiv:2404.05220. [Google Scholar]
- Liu, K.; Zhan, F.; Xu, M.; Theobalt, C.; Shao, L.; Lu, S. Stylegaussian: Instant 3d style transfer with gaussian splatting. In Proceedings of the SIGGRAPH Asia 2024 Technical Communications, Tokyo, Japan, 3–6 December 2024; pp. 1–4. [Google Scholar]
- Wang, J.; Fang, J.; Zhang, X.; Xie, L.; Tian, Q. Gaussianeditor: Editing 3d gaussians delicately with text instructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 20902–20911. [Google Scholar]
- Chao, B.; Tseng, H.Y.; Porzi, L.; Gao, C.; Li, T.; Li, Q.; Saraf, A.; Huang, J.B.; Kopf, J.; Wetzstein, G.; et al. Textured Gaussians for Enhanced 3D Scene Appearance Modeling. arXiv 2024, arXiv:2411.18625. [Google Scholar]
- Zwicker, M.; Pfister, H.; Van Baar, J.; Gross, M. EWA splatting. IEEE Trans. Vis. Comput. Graph. 2002, 8, 223–238. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning. PmLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scene | Chair | Ficus | Hotdog | Lego | Materials | Mic | Mean | |
|---|---|---|---|---|---|---|---|---|
| Style | ||||||||
| Ground truth | 99.95 | 99.61 | 99.07 | 99.32 | 95.46 | 93.51 | 97.82 | |
| StyleRF (swirl) | 69.71 | 2.54 | 2.09 | 60.74 | 34.1 | 15.14 | 30.72 | |
| ARF (swirl) | 99.02 | 98.73 | 23.36 | 99.46 | 32.89 | 99.51 | 75.49 | |
| Ours (swirl) | 99.61 | 96.78 | 96.88 | 68.16 | 60.83 | 64.45 | 81.11 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, Z.-Z.; Xie, C.; Kitahara, I. BrushGaussian: Brushstroke-Based Stylization for 3D Gaussian Splatting. Appl. Sci. 2025, 15, 6881. https://doi.org/10.3390/app15126881
Xiang Z-Z, Xie C, Kitahara I. BrushGaussian: Brushstroke-Based Stylization for 3D Gaussian Splatting. Applied Sciences. 2025; 15(12):6881. https://doi.org/10.3390/app15126881
Chicago/Turabian StyleXiang, Zhi-Zheng, Chun Xie, and Itaru Kitahara. 2025. "BrushGaussian: Brushstroke-Based Stylization for 3D Gaussian Splatting" Applied Sciences 15, no. 12: 6881. https://doi.org/10.3390/app15126881
APA StyleXiang, Z.-Z., Xie, C., & Kitahara, I. (2025). BrushGaussian: Brushstroke-Based Stylization for 3D Gaussian Splatting. Applied Sciences, 15(12), 6881. https://doi.org/10.3390/app15126881