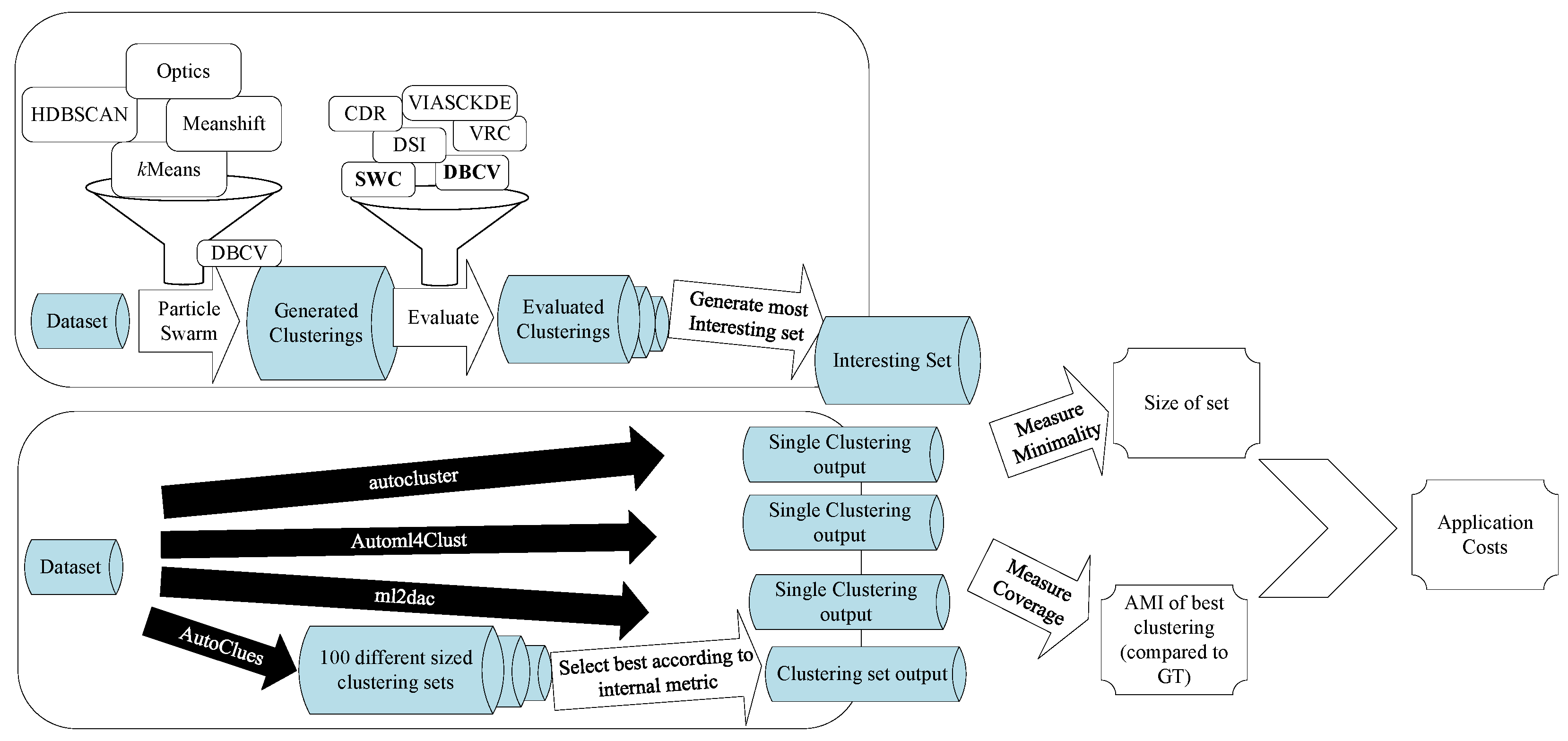
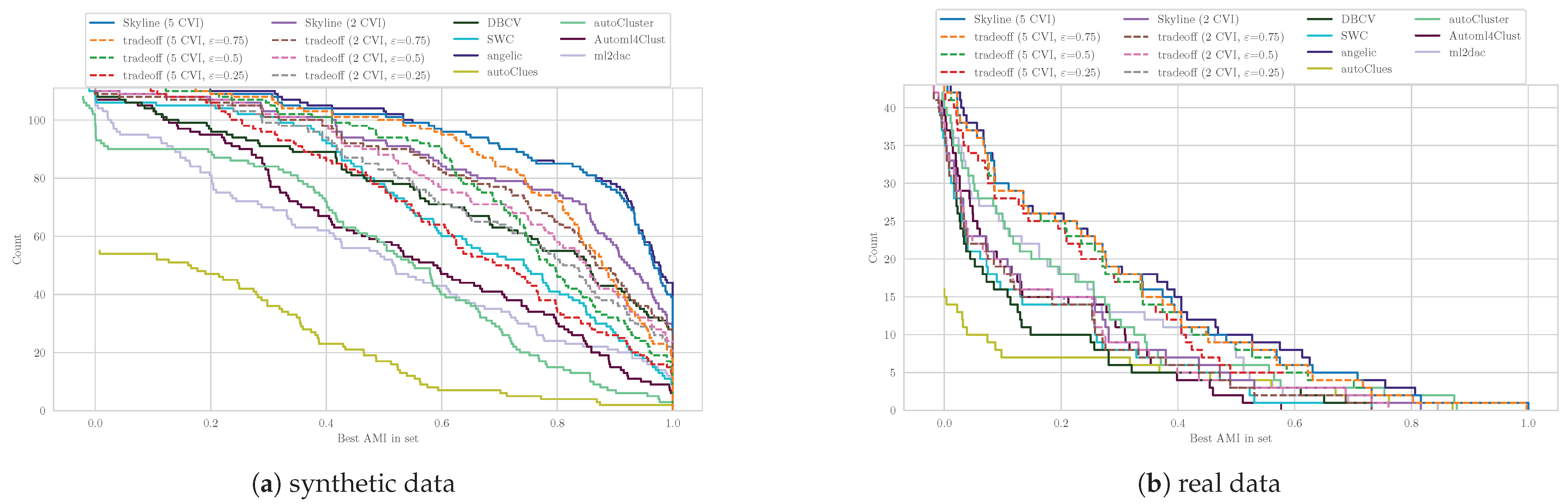
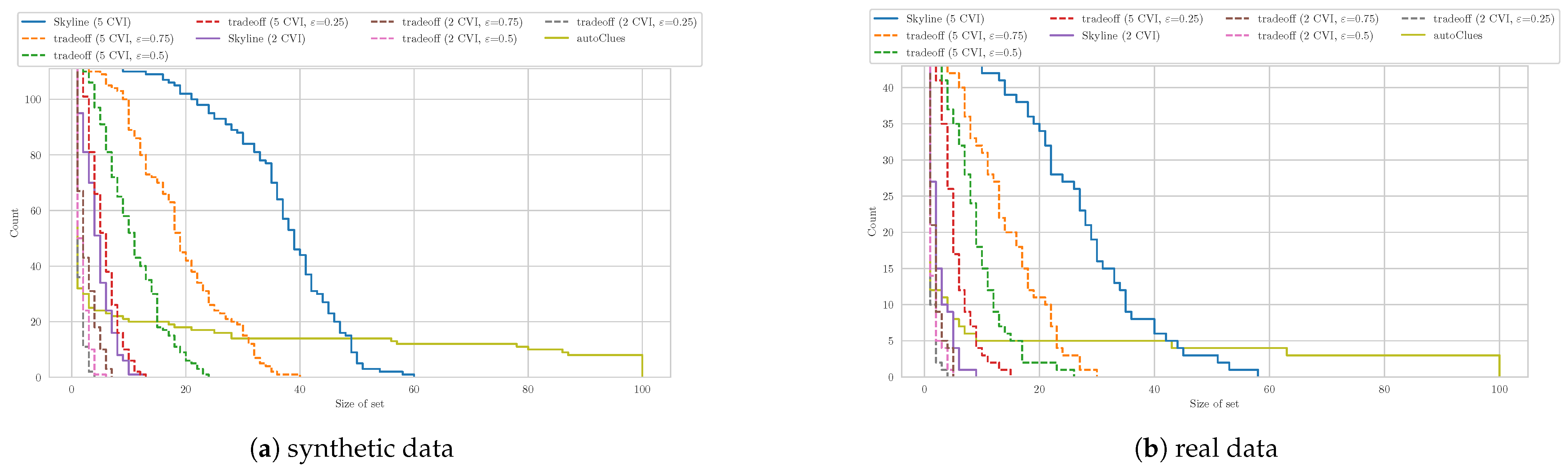
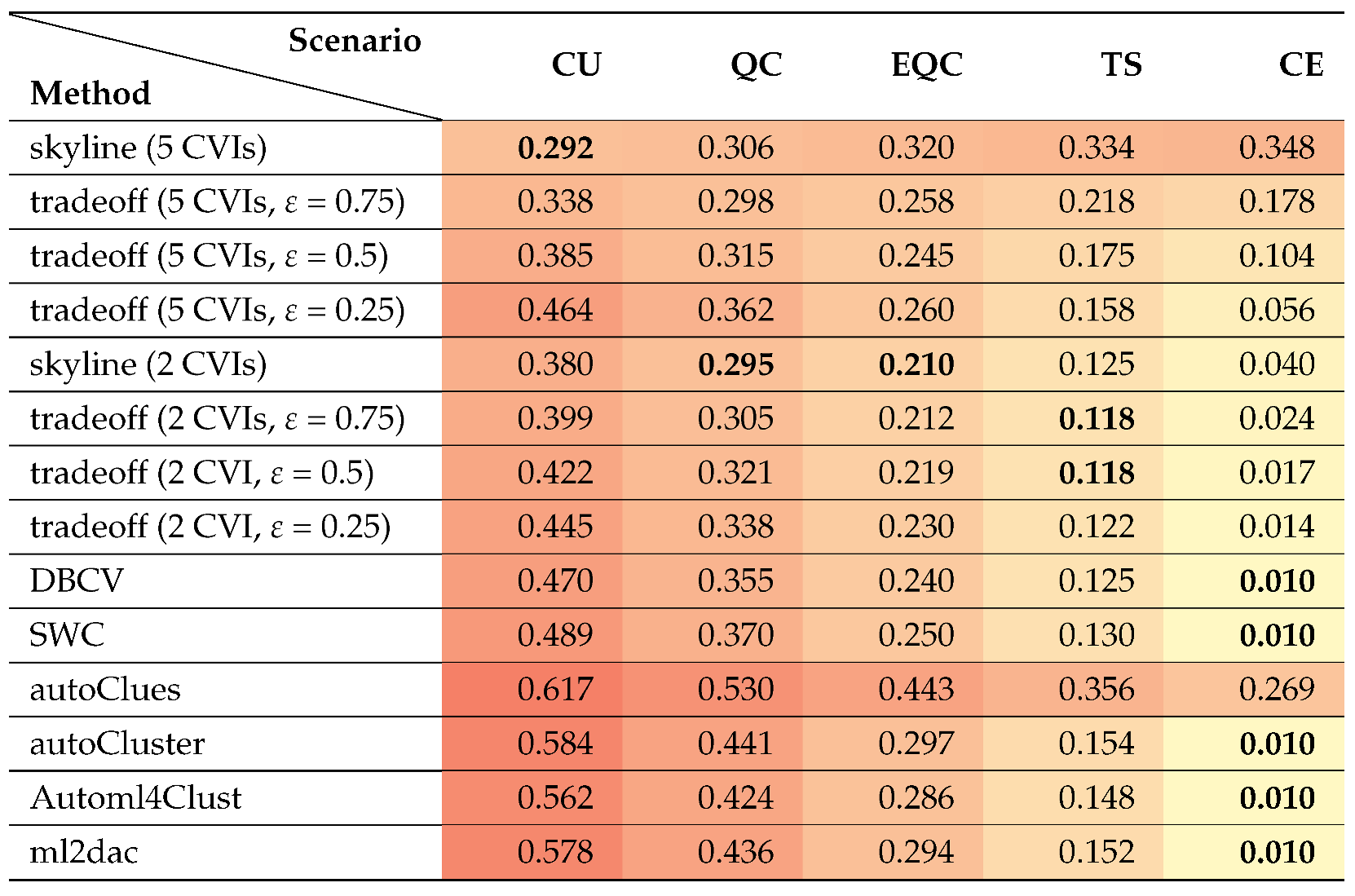
We will start this section by outlining the usual lifecycle of Automated Clustering before we describe the problems associated with this approach and by following up with the concrete problem definition. Whilst we know that there exist multiple areas of clustering with different goals like fuzzy [
26] or hierarchical clustering [
54], we will solely focus on the field of partitioning a dataset, meaning every single object will be assigned exactly one label assigning the object to exactly one cluster or identifying it as noise. This is not due to a limitation of our approach, but to keep the focus of this paper on our novel approach without the deviations of properties used in different situations. In fact, our methodology is agnostic to the actual used clustering algorithms, as long as a similarity between clusterings can be modelled and some quality metrics can compare them fairly. In this paper, we want to focus on the problem of AEC and specifically on the selection of an interesting set of clusters instead of describing a possible framework as a solution in detail. For this reason, we will consider some practical context-important parts like clustering generation, usage of different distance functions, and preprocessing steps, as black boxes for this paper, and we will provide an overview of the utilized algorithms together with the description of our experiments.
3.1. AutoML Lifecycle
The general goal of AutoML can be considered to be solving the
Combined Algorithm Selection and Hyperparameter Optimization (CASH) [
4] problem, i.e., finding both the perfect algorithm and hyperparameters for a user’s problem. This takes the cumbersome activity of fitting a good machine learning model from a data scientist to a computer and hence enables more inexperienced users to find good solutions.
Definition 1 (CASH-Problem)
. Given a clustering , a Quality function on a solution , an algorithm , and , the set of possible hyperparameters for , the CASH-Problem can be formulated as follows:where is the optimal algorithm with the optimal parametrization ,
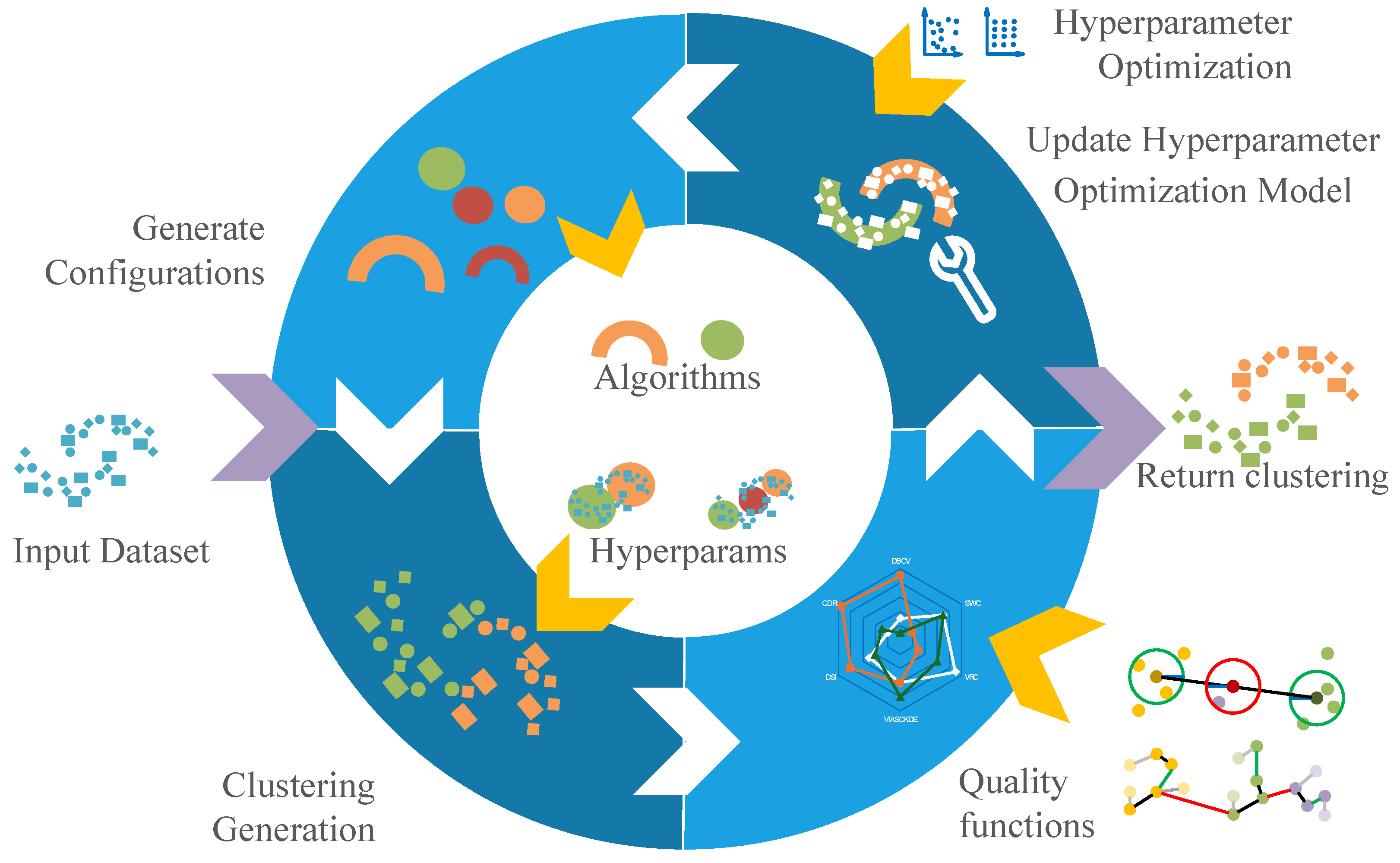
and is the set of all investigated solutions. In practice, many approaches try to solve this problem using an optimization cycle like the one illustrated in
Figure 2. When using the framework, a user inputs a dataset and a time budget. The hyperparameter optimizer, Quality function, used algorithms, and their hyperparameter ranges are generally determined by the framework, although some frameworks also enable the user to make decisions on these. The optimizer will select promising combinations of algorithm and hyperparameters and use these to cluster the dataset. The goodness of these clusterings is measured by the Quality function. If the time budget is not exceeded, the optimizer will be updated based on the goodness of the previous clusterings. New algorithm and hyperparameter combinations are then chosen by the optimizer, where the values of the Quality function on the previous combinations are used to improve the quality. When no time is left, the best solution according to the Quality function is returned. In the current Automated Clustering literature, a solution is a single clustering of a dataset, whilst the Quality function is often either a single CVI [
19,
20], a consensus, or another combination of multiple CVIs [
18].
Obviously, modern Automated Clustering approaches are more sophisticated and employ different techniques such as meta-learning or constraints given by the user, but for this paper, this abstraction will suffice to display our criticism on this model and to define the differences to our AEC problem. Clustering can be used for different tasks [
15]. On the one hand, in sophisticated machine learning pipelines, clustering is often used as a preprocessing step and the quality (or usefulness) of a clustering can be evaluated by evaluating the effect of the clustering on the performance of the complete pipeline (if it can be measured). On the other hand, clustering is often used as an exploratory technique to find new insights in the structures of the data. Here, it is not possible to objectively evaluate the usefulness of a clustering, since the same insight might be very useful for one practitioner but trivial or even completely meaningless for another. Some consider that a “natural” clustering exists on any dataset [
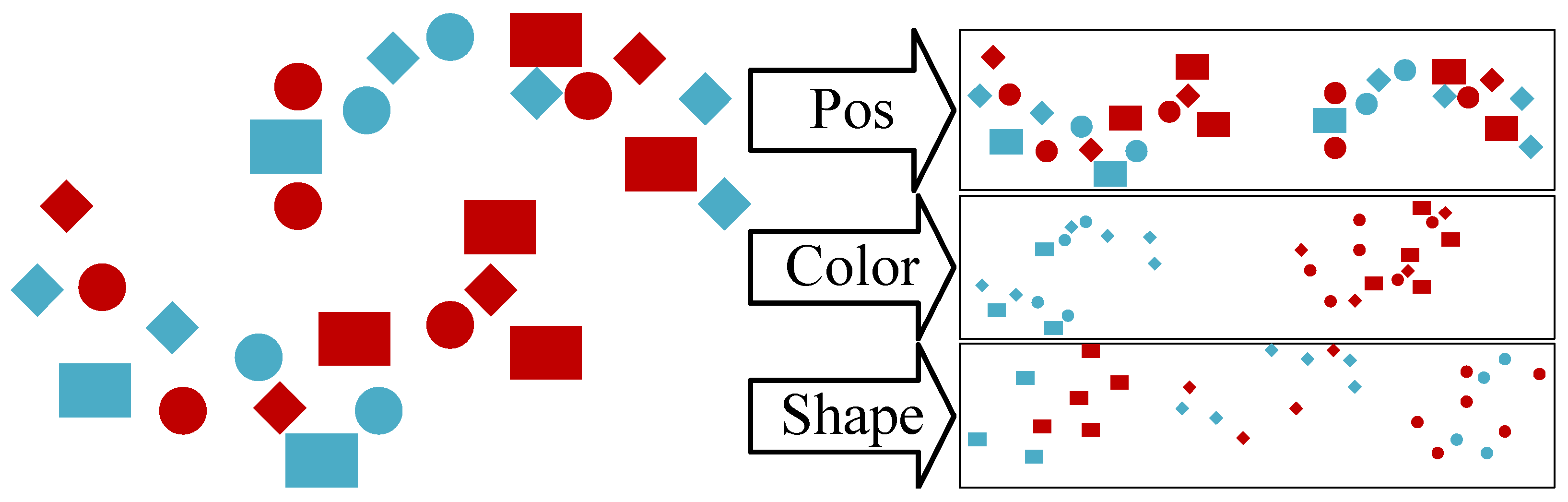
55]. However, this is, even if true, very dependent on the used distance and the notion of similarity, which are both non-trivial choices even for experienced data scientists. Consider for example the dataset in
Figure 3, where every object has three properties as follows: position, shape, and colour. Without any further information, we can see three clear “natural” clusterings, where one is based on the position, one on the colour, and one on the shape. These clusterings all can be viewed as “correct”, but they are three completely different clusterings with not even the same number of clusters. One could even argue that all combinations of these clusters, resulting in 12 different clusters, would be the “natural” clustering. Without any specification by the data scientist, it cannot be known which of these clusterings is the most interesting for them.
Following this, we conclude that an Automated Clustering for exploratory data analysis has to provide a set of clusterings rather than a single clustering.
3.2. Theoretical Definition
The goal of AEC should be, to generate a set of multiple unique clusterings, each of which has the potential to be useful. However, on the other hand, this set should be as small as possible, since every cluster has to be investigated by a domain expert. As opposed to classical Automated Clustering, we will not search for a single clustering but a set of clusterings as the result of an AEC search. To find the “best” set of clusterings, we will define an
interestingness measure, which needs to be optimized. This interestingness could also be used as a Quality function in our abstract AutoML lifecycle. However, in the scope of this paper, we generate the clusterings in a traditional Automated Clustering fashion (optimizing a single CVI) and select the resulting sets based on all clusterings generated during the training phase. For this reason, the methods in this paper might also be thematically close to the field of diversification (see, e.g., [
50]). However, as our focus lies on the problem of finding a good interestingness to directly optimize the clustering sets, future research should divert from the field focused on a posteriori analysis. In contrast to our previous conference paper [
25], we streamlined the necessary functions and omit the previously used usefulness function. While this leads to many definitions being different, it does not change any significant content.
The following notation is summarized in
Table 1 for a quicker overview. We will denote
as the set of all (investigated) clusterings and
as a single clustering. The power set of all clusterings will be denoted as
and a set of all investigated clusterings as
.
Definition 2 (Quality Function)
. The Quality function
is defined as the vector of evaluation results of a single clustering: The Quality function outputs a vector of scalars, and in our example, this will be a number of different CVI evaluations for the clustering. The Quality function can be arbitrarily complex, so a measure combining multiple CVI can also be a single component of the quality vector.
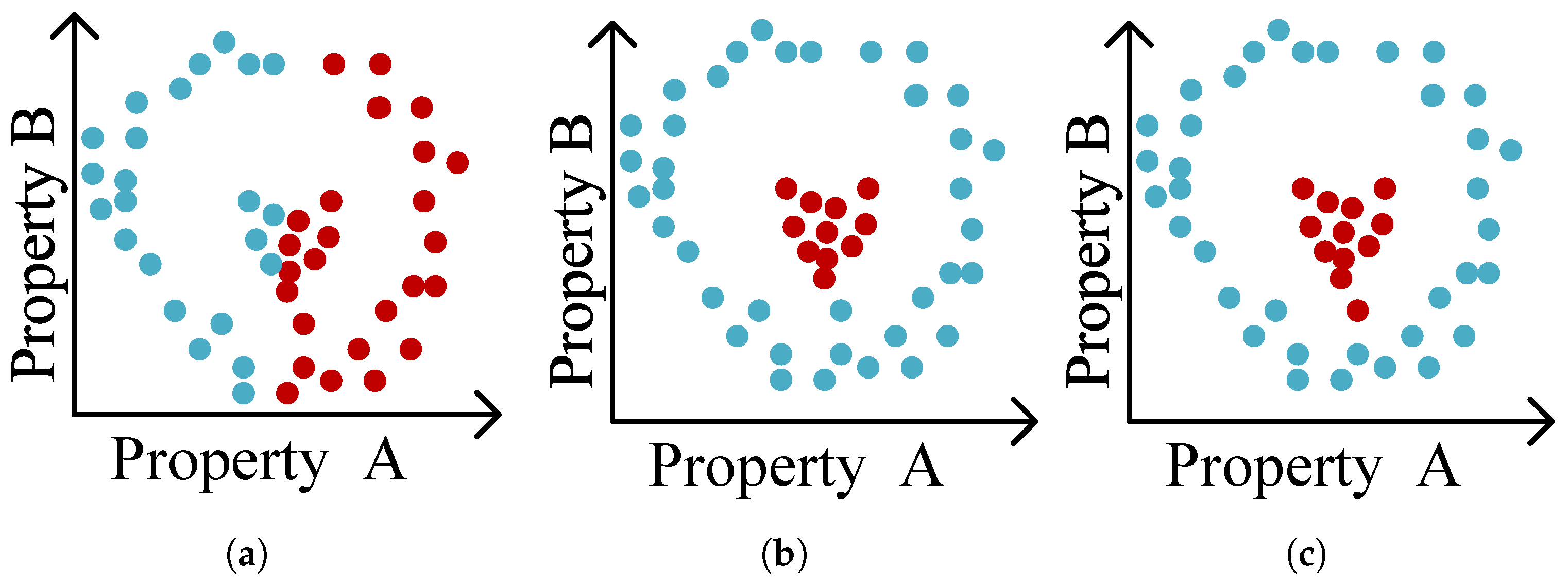
To be interesting in a set of clusters, a cluster must not only be “good” to some extent (most likely measured by a Quality function) but also unique in some kind of way. If we consider the three clusterings in
Figure 4, we can see that two of these three (
Figure 4b,c) clusterings have a very strong similarity and only differ in the labelling of one object, whilst the other clustering (
Figure 4a) is vastly different. If we need to select two clusters from this set, it would grant little to no extra value for a practitioner if these clusters are as shown in
Figure 4b,c, since it is highly unlikely that the single changed object will lead to many new insights. The other clustering, however, even while intuitively “worse” than the other two, would grant more insight as an addition to the other clustering (furthermore, it might even be the better fitting clustering, if Property B turns out to be irrelevant.). For this reason, the Interestingness function will need to weight the novelty and the quality of a clustering.
Definition 3 (Interestingness function)
. The Interestingness function
defines the likely interestingness of a set of clusterings to a practitioner as follows: In the end, the Interestingness function defines which sets of clusterings will be selected. For this reason, finding a good Interestingness function, most likely employing Q, will be a main goal in the field of AEC. Before we propose and investigate different Interestingness functions, we will first provide a formal definition of the AEC problem.
Definition 4 (AEC Problem)
. The Automated Exploratory Clustering
problem is to find an Interestingness function such that the set of clusterings, which is defined assatisfies minimality,
i.e.,
is minimal, and coverage,
i.e.,
contains all relevant clusterings. As can be seen in the definition above, the problem of Automated Exploratory Clustering is to find an appropriate Interestingness function that minimizes the set of relevant clusterings. While this problem definition is not tied to any specific application domain, it can accommodate various notions of interestingness and thus it is generally difficult to identify suitable characteristics. The following Corollary summarizes the characteristics for a well-chosen Interestingness function.
Corollary 1. A well-chosen Interestingness function epitomizes the following properties:
- 1.
All clusterings in are different.
- 2.
The set is much smaller than the set of all clusterings, i.e., .
- 3.
Any two clusterings in exhibit a sufficient degree of dissimilarity.
- 4.
The set is the smallest set containing all relevant clusterings.
Based on the definition of the AEC problem, we propose three different Interestingness functions which aim for (i) minimality, (ii) coverage, and (iii) tradeoff between both. The first Interestingness function, introduced in
Section 3.3, optimizes minimality by returning a single clustering like in traditional Automated Clustering approaches, while the second function, presented in
Section 3.4, optimizes coverage by returning all clusterings regarded important by several CVIs, regardless of their similarity among each other. Finally, the Interestingness function proposed in
Section 3.5 balances the tradeoff between minimality and coverage by taking a skyline and pruning similar clusterings.
Without loss of generality, we assume for all subsequent Interestingness functions that the Quality function of a single clustering is to be maximized in all components, and all resulting values are non-negative (as a minimized value can be multiplied by −1 in order to be maximized and normalization can ensure that all values are greater than 0 by an addition with a constant c).
3.3. Conventional Automated Clustering
Considering the minimality in Definition 4, the easiest way to optimize in this regard (apart from returning an empty set) is to always only return a single element. This is carried out by many conventional Automated Clustering methods like autoCluster [
18], Automl4Clust [
19], or ml2dac [
20]. The idea of returning a single clustering is formally defined in terms of an Interestingness function as shown in the definition below. For this purpose, me make use of a reduction function
R that reduces multiple CVIs into a scalar value.
Definition 5 (Single-Return Interestingness)
. Let be any reduction function, the Single-Return Interestingness function
is defined as follows: It can be seen that the function is negative for all sets of clusterings with and only singleton sets consisting of one clustering have positive values of , where is the sole clustering in the set. With this interestingness, a single clustering, which is regarded “best” by means of the Quality function Q, will be returned. This scenario is just a reformulation of the conventional Automated Clustering case, where arbitrary complex (combinations of) CVIs are used to select a single best clustering. For example, can just be a simple reduction like the average, maximum, or minimum of a number of CVIs. However, it can also be an arbitrary complex combination of those.
3.4. Skyline Operator
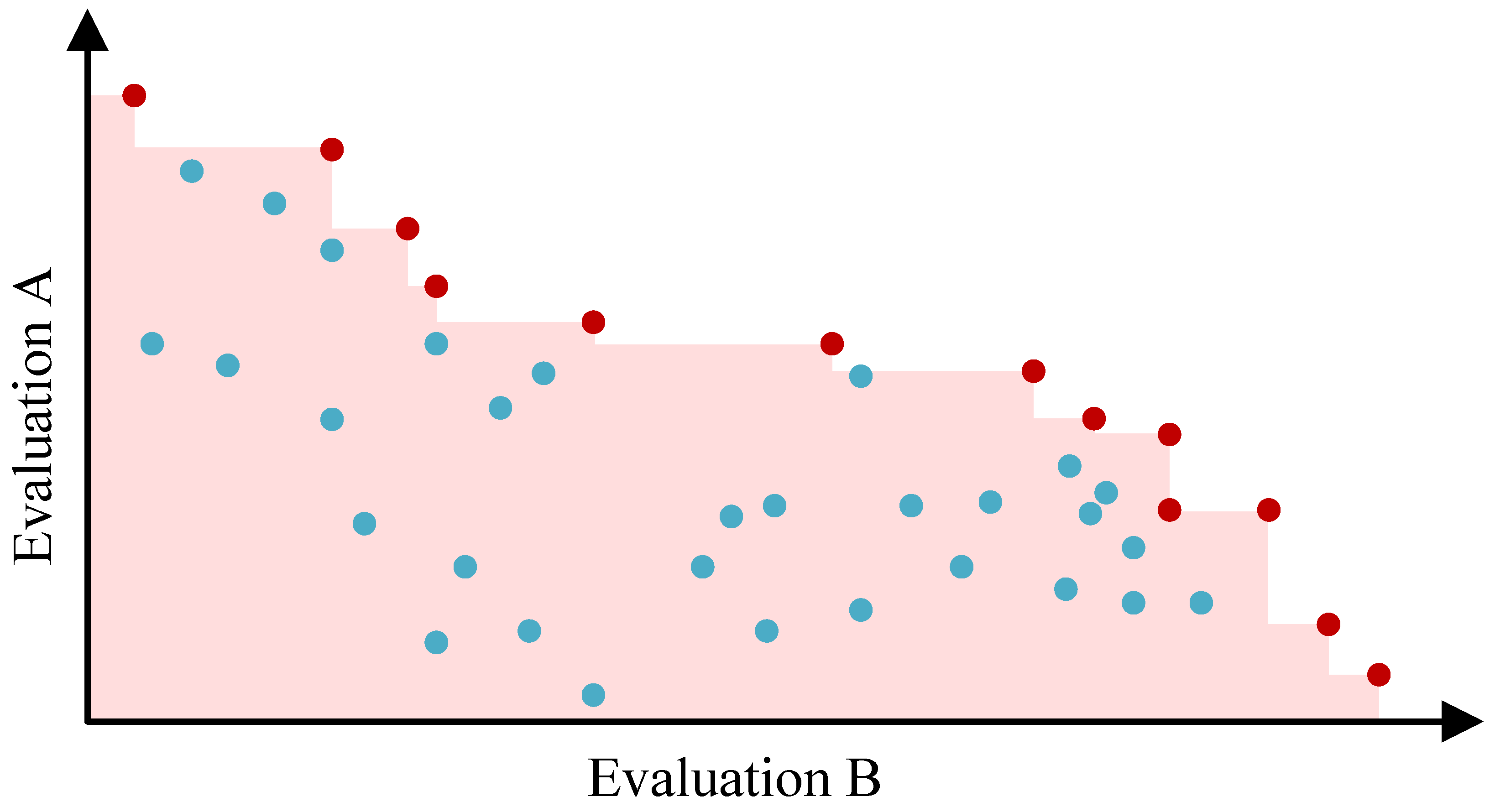
If we want to optimize the coverage, we need to include all clusterings that are somewhat interesting. A common approach for this is to determine the
skyline or
Pareto set of all clusterings, which comprises every clustering that is not dominated in every CVI by another clustering [
56]. The resulting clusterings are considered to be interesting, as also visualized by means of an example of a skyline, indicated by red objects, in
Figure 5. The underlying concept of domination is formalized in the following definition.
Definition 6 (Domination)
. Let be two clusterings. The clustering dominates according to a Quality function , if it is worse in no single dimension and superior in at least one as follows [57]: Based on the definition of domination among clusterings, we can now define a skyline or Pareto-optimal subset as follows:
Definition 7 (Skyline)
. Let be a set of objects and a Quality function. The Skyline is defined as follows: It is evident that the size of the skyline is only limited by the size of the input dataset and can be independent of the number of CVIs. However, every clustering which seems to be the “best” according to one component of the Quality function Q or a combination of components will be part of the skyline. It is easy to construct an Interestingness function that will directly lead to the skyline set being returned.
Definition 8 (Skyline interestingness)
. Using the skyline defined in Definition 7, we define the skyline Interestingness function
as follows: While this method gives a maximal coverage (according to the Quality function inherently utilized in the skyline ), the resulting skylines can be extensive and exhibit significant redundancy wrt. to similarity of the contained clusterings. This issue is addressed via the subsequent Interestingness function.
3.5. Similarity-Based Tradeoff
As we have now seen two variants, which optimize the two different goals of Definition 4, we will now propose a third Interestingness function that exactly balances the aforementioned tradeoff. While it will still use the skyline to get a high coverage, we will prune similar clusterings to ensure a much smaller resulting set.
Definition 9 (Similarity-pruned interestingness)
. Using the skyline defined in Definition 7 and a similarity function , we can define the following: We will get the biggest possible subset of the skyline, in case there are no two elements which have a higher similarity value than . Using this, we can control the tradeoff between minimality and coverage by adapting , as a value close to zero will eliminate most clusterings and only leave a small subset, while a high value of will retain the complete skyline.
It can be seen that both methods mentioned earlier are in fact only special parametrisations of this approach. Setting the will lead to all clusterings in the skyline being selected, while setting will grant only one clustering (provided an apt method to handle ties is added).
The choice of the similarity function of two clusterings will have a significant impact on this result. Possible choices include the ARI [
58] or the AMI [
51]. However, any external CVI can be used. The creation of this set is similar to the motley algorithm used in the field of diversification [
50,
59]. However, in that field, the size of the resulting set is fixed instead of the threshold parameter.
This set can be approximated more efficiently by a greedy algorithm shown in Algorithm 1. We start to build the set with the skyline element with the minimal highest similarity to any other clustering in the skyline. Following this, we expand the resulting set with the clustering, which has the minimal highest similarity to any selected clustering. We stop this once no clustering is left. In l. 1–3, the skyline set S is built, and for every clustering, the highest similarity to any other clustering is stored. In l.4–7, the starting element is selected and stored in the target set t, while the remaining set is initialized and the current minimal maximal similarity to any object in the rest set is initialized to 0. While this similarity is smaller than (hence there still are clusterings in with a similarity less than to all clusterings to t), an addition of new clusterings to the target set is evaluated (l. 8–16). The array is updated to reflect the maximal similarity to any object in the t set for every object in , and the clustering with the minimal maximum similarity is selected for as the next new element (l. 9–10). If the similarity of this object to any object in t is smaller than , the element is added to set t (l. 11–15); otherwise, the resulting set is returned (l. 17).
The time complexity lies in
. The first part (l.1–7) has a complexity of
, as every similarity between two clusterings must be computed. The following while loop (l. 8–16) can happen up to
n times, as all clusterings can be less similar than the threshold. The time complexity of assigning each element in the remaining set the maximum similarity of a set in the target set (l. 9) is in
. For this reason, the complexity of the for loop is in
The main space requirement for this algorithm are the pairwise similarities. For this reason, the space complexity is in
.
| Algorithm 1 An algorithm to greedy approximate the tradeoff set |
Input: Clusterings , Interestingness Function S, threshold , Clustering similarity function s
Output: most interesting set t- 1:
- 2:
▹ S according to Q - 3:
- 4:
- 5:
- 6:
- 7:
- 8:
while
do - 9:
- 10:
- 11:
- 12:
if then - 13:
- 14:
- 15:
end if - 16:
end while - 17:
return
t
|





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}