1. Introduction
In recent years, the rapid evolution of artificial intelligence (AI) and computer vision technologies has revolutionized China’s media industry, particularly in the post-production of new media [
1]. New media platforms, including mobile and PC-based platforms, now dominate content dissemination through video and graphic formats [
2]. Post-production remains the cornerstone of the creation of new media content, enabling the production of visually sophisticated works that were previously unattainable, thus transforming the entire media landscape [
3].
New media post-production involves editing, refining, and processing raw materials (e.g., films, television shows, variety programs, and news) into polished final products [
4,
5]. This process enhances content quality, diversifies visual storytelling, and meets evolving public demands [
3]. Among its core tasks, face processing [
6,
7], including special effects, face replacement, and modification, has become a critical focus. However, traditional methods such as rough cropping, image masking, or frame-by-frame deletion [
8] remain inefficient and labor-intensive, especially in complex scenarios such as variety shows and period dramas.
For example, in variety shows, dynamic camera movements, rapid scene transitions, and unpredictable actor positions often lead to partial face occlusion or motion blur, making pixel-level segmentation difficult. In period dramas, intricate costumes, dense background clutter, and historical clothing with textures similar to facial features further complicate the precision of segmentation [
8]. These challenges are exacerbated by the reliance of existing face segmentation methods on fully supervised learning, which demands extensive manual pixel-level annotations. Such annotations are prohibitively time-consuming and costly, particularly for large-scale media productions where high-throughput post-processing is essential [
9,
10].
The rise of AI-driven deep learning has placed face segmentation as a key technology in new media post-production. Its accuracy directly impacts downstream tasks such as facial analysis, expression recognition, and AI-based face manipulation [
11,
12]. However, the scalability of these models is constrained by their dependence on labor-intensive data labeling. To address these limitations, weakly supervised learning has emerged as a promising alternative, reducing the reliance on manual annotations while maintaining performance [
13].
This study presents a weakly supervised face segmentation framework specifically designed to address the complex demands of new media post-production through two key innovations:
A pseudo-label generation algorithm based on SAM is proposed to automatically generate pseudo-labels with near-expert quality, eliminating manual annotation efforts while maintaining high accuracy. Using the Segment Anything Model (SAM) [
14] to automatically generate high-quality pseudo-labels, our approach enables the training of twin UNet++ networks that are capable of adapting to dynamic shooting conditions, such as rapid camera movements in variety shows, and visually challenging contexts, including the accurate separation of faces from elaborate period costumes.
Dual-model fine-tuning using EMA is proposed, where both the student and teacher models share identical UNet++ structures but differ in parameter update mechanisms. This design avoids the error amplification issues in bidirectional frameworks and pure pseudo-label learning methods where noisy pseudo-labels from both models degrade performance. By decoupling pseudo-label generation (via stabilized teacher) and model learning (via active student), our method achieves robust segmentation in complex scenarios (e.g., separating faces from elaborate period costumes).
Extensive experiments on self-collected datasets that include movies, period dramas, and variety shows confirm the effectiveness and generalizability of our approach with statistical significance.
2. Related Works
2.1. Face Segmentation Models
Common face segmentation methods based on deep learning mainly include the following: Fully Convolutional Network (FCN) [
15]: This is an expansion of the convolutional neural network (CNN), enabling it to output feature maps of the same size as the input image and achieve segmentation through pixel by pixel classification. U-Net [
16]: It adopts an encoder–decoder structure and realizes segmentation through multi-level feature fusion. In the encoder part, abstract features are gradually extracted, while the decoder samples and fuses these features to restore the original resolution, which is commonly used in medical image segmentation but can also be used for face segmentation. Mask R-CNN [
17]: Combining target detection and semantic segmentation, the segmentation mask is generated on the candidate area to achieve accurate segmentation of the portrait or face. DeepLab [
18] Series: Using hole convolution, multi-scale pyramid pooling, and other technologies, combined with the encoder–decoder structure and attention mechanism, it achieves high-quality portrait or face segmentation. HRNet [
19] (High-Resolution Network): HRNet improves the accuracy and speed of segmentation by fusing high-resolution and low-resolution feature information. HLNet [
20]: It is a real-time “hair facial skin” segmentation algorithm, which maintains the segmentation accuracy while achieving fast processing speed.
2.2. Weakly Supervised Segmentation
There are three common weak supervision methods: image level [
21,
22,
23,
24], box level [
25,
26,
27,
28], and scribble level [
29]. Image-level supervision provides only category labels, lacking spatial details. Most existing methods build upon Class Activation Mapping (CAM) [
30,
31], employing techniques such as iterative erasure, pixel affinity learning, and saliency-guided refinement [
21,
22,
23,
24]. However, CAM typically highlights only the most discriminative regions for classification, which often represent just a subset of the full object, leading to incomplete segmentations.
Box-level supervision offers richer spatial cues, including object count, size, and location [
25,
26,
27,
28]. Most methods adopt a two-stage pipeline: first, pseudo-labels are generated from bounding boxes using traditional or deep segmentation algorithms; second, these labels are used to train a segmentation model. While this approach improves object coverage, the initial pseudo-labels often contain noise and inaccurate boundaries, limiting the final segmentation quality.
Scribble-level supervision involves minimal annotation, such as lines or points [
29,
32,
33]. Line annotations convey object presence and approximate shape, while point-based annotations (e.g., object extremes or random points) provide sparse but critical location and category cues. Among these, extreme-point labeling is most informative and easiest to utilize, followed by line annotations, with random point annotations posing the greatest challenge. To maximize the utility of sparse scribble cues, recent works propagate annotation signals through candidate region expansion or leverage point connectivity to estimate object shapes.
3. Materials and Methods
3.1. Overall Learning Framework
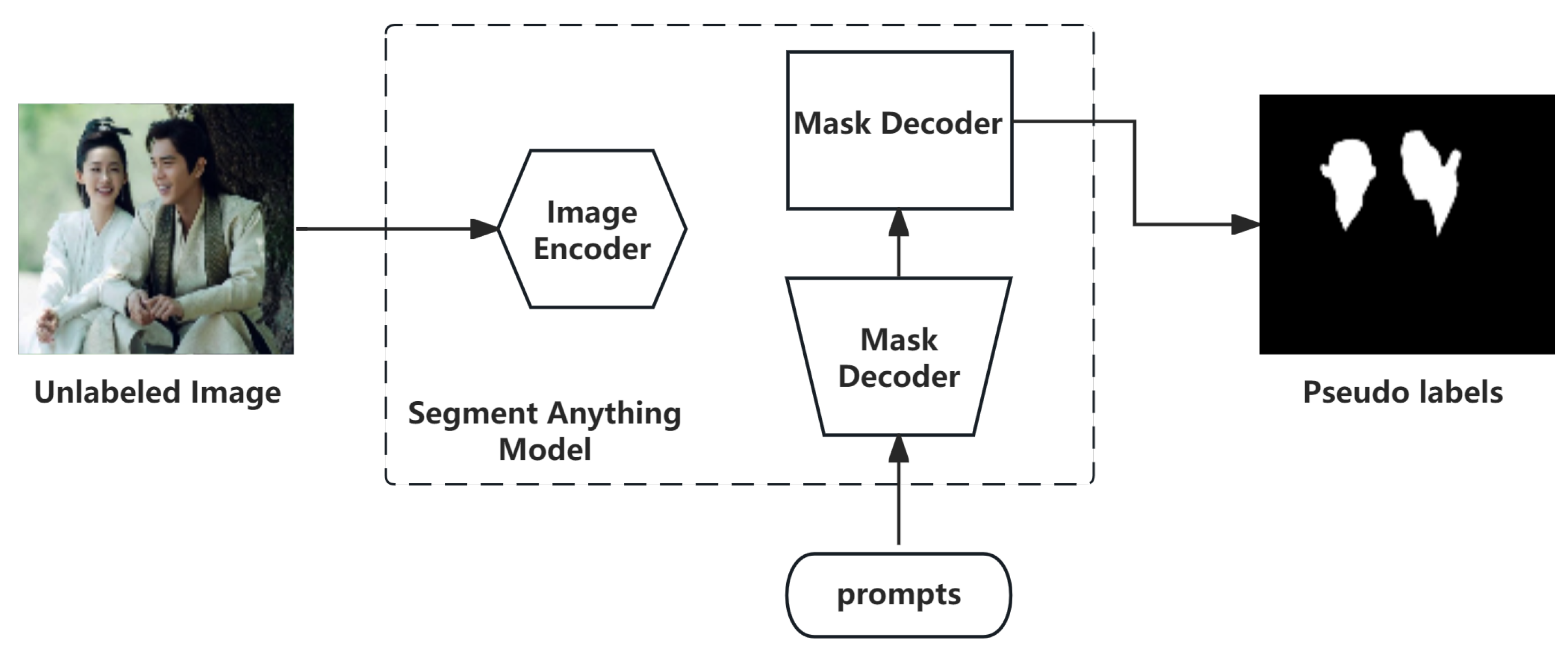
Our method introduces a three-stage weakly supervised framework that achieves groundbreaking efficiency in face segmentation for new media production, which has been visualized in
Figure 1. The innovation lies in the following aspects: (a) A novel SAM-driven pseudo-label generation pipeline that innovatively integrates sparse facial annotations (landmarks/center points) as prompts to produce high-fidelity initial masks, further enhanced by an area-thresholding purification mechanism to eliminate background noise—this reduces manual annotation requirements by over 90% while maintaining label quality. (b) A customized UNet++ architecture with dense cross-level connections and multi-scale deep supervision, specifically engineered to address facial appearance variations in complex media scenarios through hierarchical feature recalibration. (c) A unique twin model refinement paradigm employing exponential moving average (EMA) weight synchronization, which creates synergistic model collaboration to boost segmentation stability and accuracy beyond conventional single-model approaches. This integrated solution not only slashes annotation costs but also establishes a new paradigm for weakly supervised learning in visual media processing, bridging the gap between academic segmentation research and industrial post-production demands with its unparalleled balance of efficiency and precision.
3.2. Pseudo-Label Generation Algorithm Based on SAM
The Segment Anything Model (SAM) [
14,
34,
35] is a foundation segmentation model pre-trained on over 1 billion high-quality masks across 11 million diverse, high-resolution images. While SAM offers strong generalization capabilities, its direct application to domain-specific tasks—such as face segmentation in new media content—often lacks task-aware precision, especially under weak supervision [
36,
37,
38].
To address this challenge, we propose a prompt-guided pseudo-label generation strategy that integrates SAM into our weakly supervised face segmentation framework. Given a training image
I, we extract a set of positive point prompts
based on sparse facial annotations (e.g., facial landmarks or center points). Specifically, for the point selection, frontal faces use the nasal tip (defined as the facial centroid) as the primary positive prompt and profile views utilize the central cheek region aligned with the zygomatic arch. As for occluded or extreme-angle cases, we adopt a multi-point ensemble (e.g., eye corner + mouth corner) to ensure coverage. This anatomically guided prompting ensures cross-image consistency while minimizing manual intervention (only 1–3 clicks per subject). The selected landmarks are validated through anatomical priors and demonstrate robustness across diverse scenarios (e.g., rapid camera movements in variety shows, intricate period costumes). For each image, the points and the image data are input into SAM to generate an initial segmentation mask.
To enhance the quality of the pseudo-labels, we apply a lightweight post-processing step that removes small, irrelevant regions based on area thresholding. The final refined mask is computed as
where
represents a connected component in
, and
is a predefined area threshold (set to 100 as default). This simple yet effective filtering process ensures that the retained pseudo-labels correspond to dominant facial regions, suppressing noisy segments caused by background clutter or SAM over-segmentation.
As illustrated in
Figure 2, this strategy enables SAM to produce high-quality, task-relevant pseudo-labels from minimal annotation, significantly reducing manual labeling costs while providing robust supervision signals for subsequent model training.
3.3. Weakly Supervised Initialization via Prompt-Guided Pseudo Labels
To initialize the segmentation model under weak supervision, we adopt a UNet++-based architecture [
39], which extends the classic encoder–decoder structure of U-Net by incorporating dense skip connections and deep supervision. These enhancements enable better multi-scale feature fusion and semantic consistency, especially for complex facial appearances in diverse media content.
The network consists of an encoder–decoder structure with four resolution levels. Each encoder stage includes two convolutional layers with 3 × 3 kernels, followed by Batch Normalization and ReLU activation, and 2 × 2 max pooling for downsampling. The number of feature channels doubles at each downsampling stage, starting from 64 and reaching 512 at the bottleneck. That is,
The decoder mirrors the encoder, using bilinear upsampling and concatenation with the corresponding encoder and nested decoder features (via the dense skip paths), followed by the same 3 × 3 convolution–BN–ReLU blocks. The nested skip connections form intermediate nodes
, where each node aggregates features from its previous skip nodes and upsampled features from deeper levels. The recursive formulation is
Here,
denotes a convolution–BN–ReLU block,
is bilinear upsampling, and
indicates channel-wise concatenation.
The final output layer uses a **1 × 1 convolution** to reduce the feature map to a single-channel face mask, followed by a sigmoid activation. We adopt deep supervision by placing auxiliary outputs at multiple semantic levels (i.e., different
j) and optimizing the network with a hybrid loss that combines cross-entropy and Dice loss:
This structure not only enhances segmentation accuracy but also allows for flexible pruning and output selection during inference, making it well suited for our twin-network framework.
3.4. Dual-Model Fine-Tuning Using Exponential Moving Average
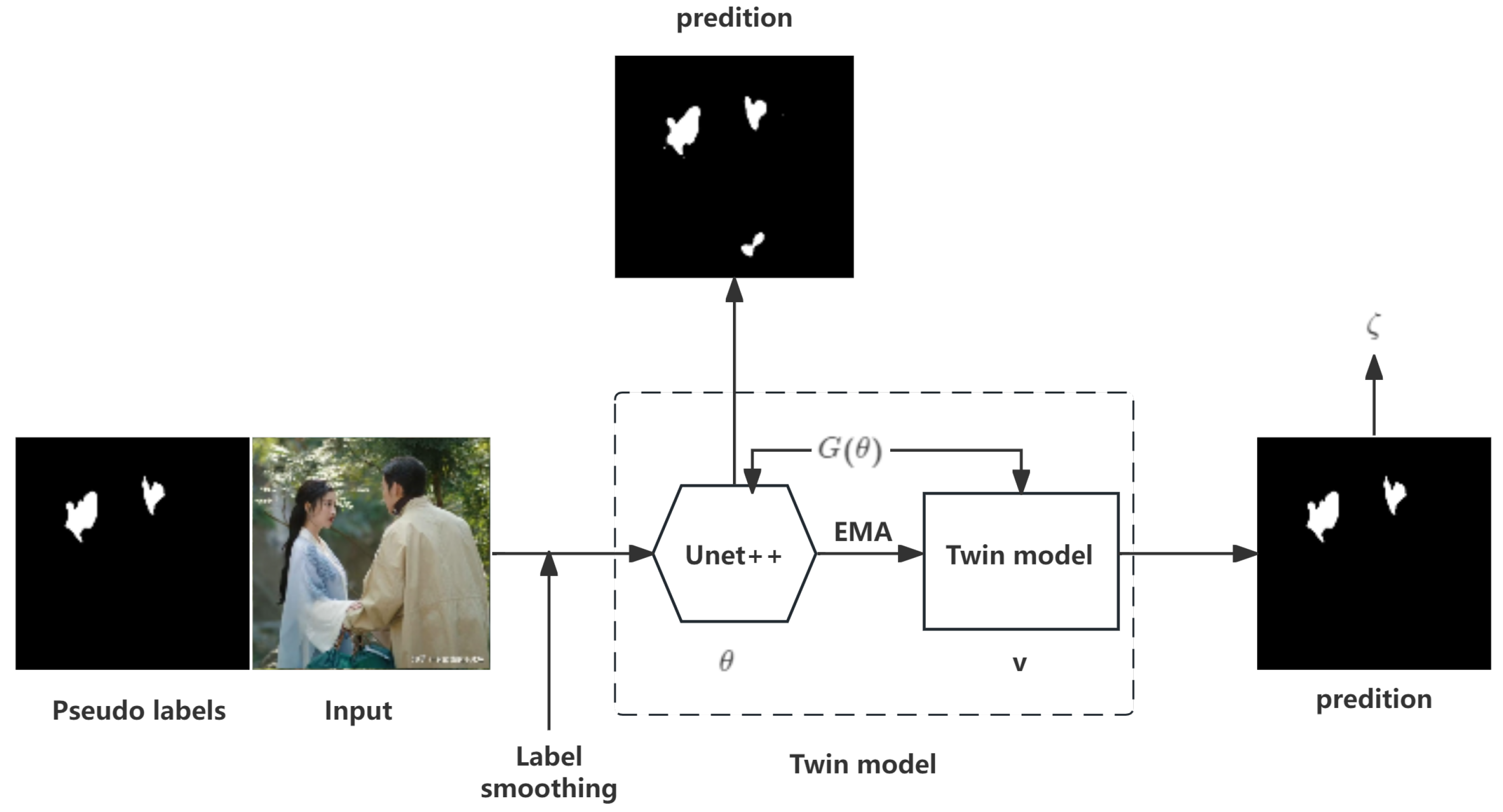
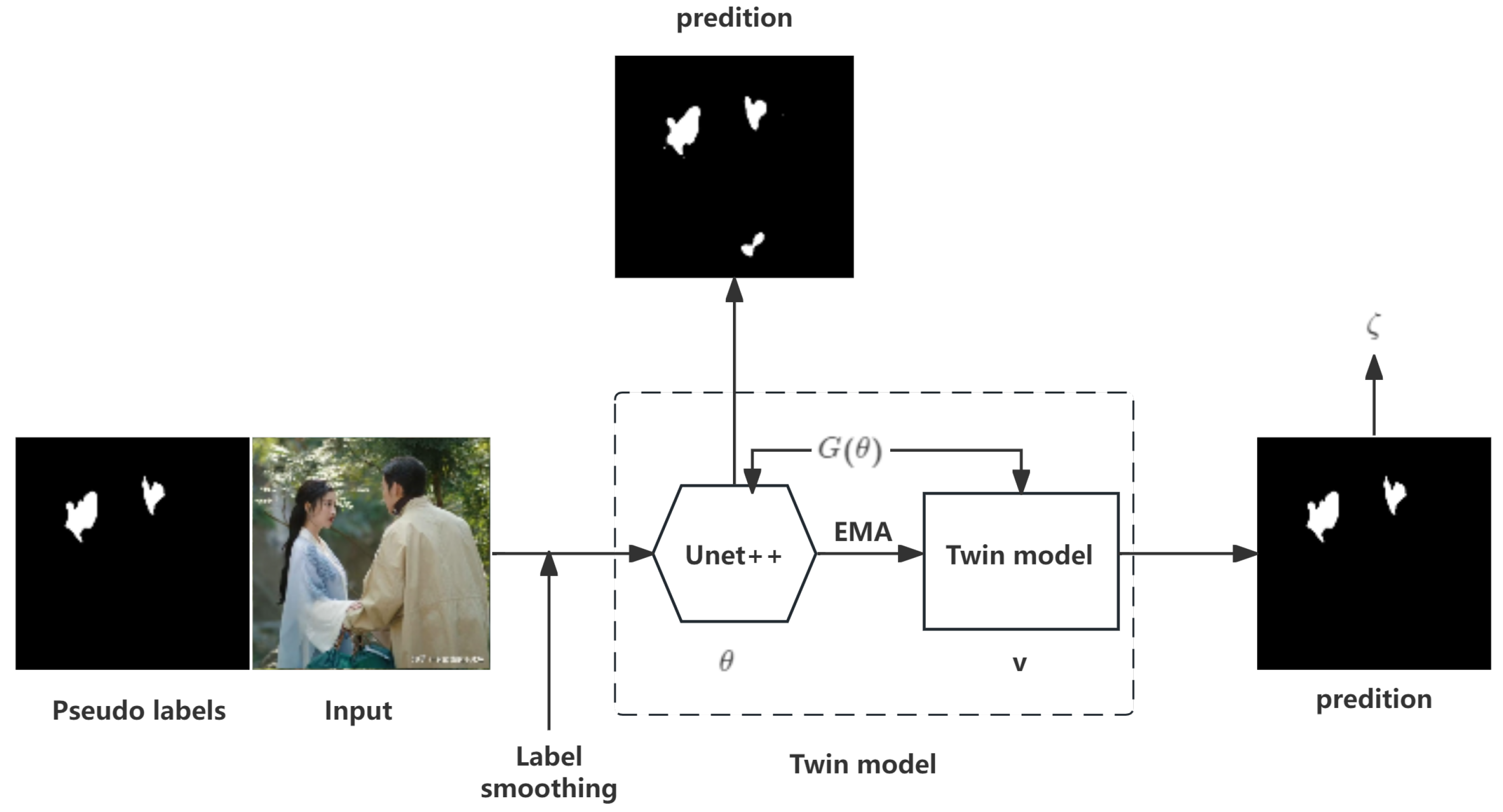
To further enhance segmentation quality, we introduce the twin model approach, as illustrated in
Figure 3. Unlike a simple duplication of the pre-trained UNet++ model, the twin model utilizes a novel strategy where the model’s weights are progressively refined using an exponential moving average (EMA) method [
40]. Initially, the parameters of the pre-trained UNet++ model are copied to the twin model. During training, the twin model’s parameters are updated using EMA, which improves the stability and accuracy of the final segmentation results.
The EMA method refines the model by computing a moving average of the model weights, effectively smoothing the updates across iterations. This approach contrasts with directly using the most recent model weights, leading to more robust performance. The EMA update rule for model weight
at time step
t is given by
where
is the EMA weight at time
t,
is the current model weight, and
is the smoothing coefficient, i.e., a hyperparameter controlling the rate of averaging, set to 0.999 as default.
For the final fine-tuning, we minimize the Mean Squared Error (MSE between the predictions of the original model
and the twin model
, as formulated by
This loss function encourages the twin model to learn from the averaged weights, ensuring that it converges towards more accurate segmentation over time. This method provides a powerful mechanism for refining the segmentation outputs, enabling the twin model to outperform conventional single-model approaches in terms of both accuracy and stability.
3.5. Datasets and Implementation Details
For the datasets used, to train deep learning models for image segmentation, annotated datasets such as PASCAL VOC, COCO, and SBD are commonly used to pre-train models and evaluate segmentation performance [
41,
42,
43]. However, considering that the specific application scenario of this paper is centered on the field of new media content post-production (e.g., TV shows, films, news, and variety programs), where frontal faces serve as the primary processing objects and high requirements for image clarity are imposed, it is therefore necessary to construct a custom dataset to meet specific needs. In this work, we constructed a dataset by capturing 864 images through manual screenshots from diverse video content, covering various scenes, including indoor, outdoor, meetings, single-person, and multi-person settings. The exact case numbers are listed in
Table 1. The data of “TV shows” were used for modeling, where we adopted a static data-splitting strategy (hold-out method) to divide the “TV shows” data into training and test sets with an 8:2 ratio, where the training set was used for model learning and the test set for performance evaluation. The test set was manually labeled using Labelme [
44]. The data from other scenarios were used for a generalization test.
For the evaluation metrics, this study employs the Intersection over Union (IoU) and Dice coefficient as evaluation metrics for face segmentation. We firstly computed the score of each test sample and then calculated the average score and the standard error of the test set. The IoU metric is suitable for assessing the overall coverage of facial regions, particularly in scenarios requiring precise alignment of facial contours. When facial edges are blurred (e.g., in low-resolution images or profile contours) or occlusions exist, the Dice coefficient is more sensitive to boundary details and can accurately reflect the segmentation details of facial contours. The combination of the two ensures high precision and fineness in face segmentation. The dice coefficient is a set similarity measurement function, which is often used to calculate the similarity of two samples (range: [0, 1]):
where
and
indicate the divided ground truth and predict-mask.
To validate the statistical significance of Dice score improvements, we performed independent t-tests on the test results from each test scenario. A p-value < 0.05 was considered significant, indicating at least 95% confidence that the observed gains were not due to random chance.
For the implementation details, we use SAM to generate a segmentation mask on the training image with sparse labels as prompts and the segmentation mask as a pseudo-label to train the model. In using SAM to generate the segmentation mask, we adopted the standard settings of the SAM model provided in the official library. We used the SAM model with ViT-B as the backbone. We implemented our method with PyTorch 1.13.1 with CUDA 11.6 acceleration and ran experiments on NVIDIA RTX 3060 (designed by NVIDIA, manufactured by Samsung Foundry in Hwaseong, South Korea) GPUs (20 GB VRAM each), an Intel i5-10400F CPU, and 16 GB RAM. All models were trained at 512 × 512 resolution with a batch size of 12; the learning rate was initialized to 0.0001 and the iteration cycle was 50, requiring approximately 5 min for convergence.
4. Results
4.1. Comparison Results
We compare our method with two weakly supervised segmentation approaches that utilize point-based annotations [
45,
46]. The results are shown in
Table 2 and
Table 3. Our method consistently achieves the highest Dice and IoU scores across all scenarios, demonstrating superior segmentation accuracy. For instance, in the TV show scenario, our Dice score (0.85 ± 0.01) outperforms TMI 2021 (+10%) and CVPR 2023 (+5%). Notably, the proposed method exhibits significant performance gains in complex scenes such as variety show (Dice: 0.72 ± 0.02 vs. TMI 2021: 0.65 ± 0.04), which can be attributed to its enhanced robustness to dynamic lighting and occlusions.
Furthermore, our results demonstrate smaller standard deviations compared to baseline methods, indicating higher consistency and generalization stability. In the challenging scenarios, existing methods suffer from severe performance degradation—for example, TMI 2021’s IoU drops to 0.45 ± 0.05 in the variety show category, while our approach maintains strong performance.
These findings collectively validate that our design effectively addresses challenges inherent to diverse visual contexts, particularly under uncontrolled environments. The marginally improved metrics over CVPR 2023 also suggest that our technical innovations better exploit point annotations for precise boundary localization.
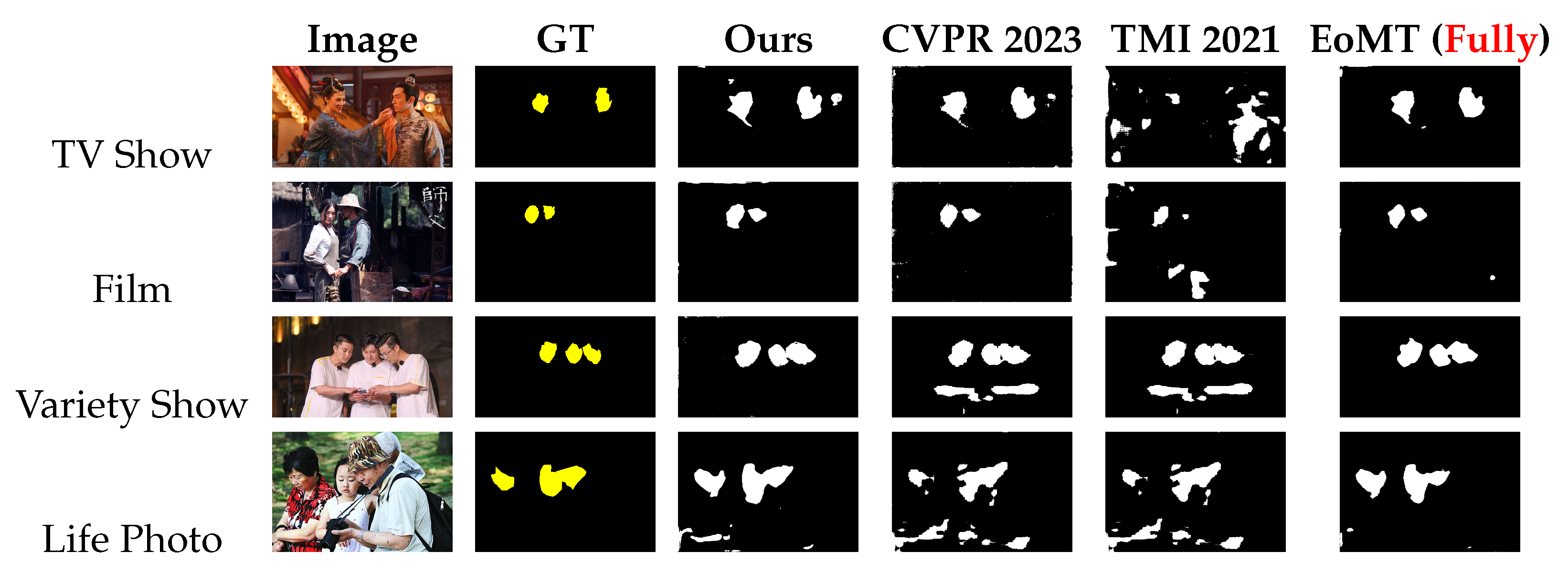
As illustrated in
Figure 4, our method demonstrates superior boundary precision and reduced false negatives compared to other methods. In complex scenarios such as period films (e.g., film row) and variety shows (e.g., variety show row), the proposed SAM-based pseudo-labeling strategy effectively captures subtle facial contours despite elaborate costumes or dynamic poses, which often fail due to fixed thresholding or lack of global context modeling. Notably, the EMA-driven teacher–student architecture mitigates noise propagation, as evidenced by the clean boundaries in our results versus the fragmented outputs of TMI 2021. This stability is critical for reducing false negatives in challenging cases like partially occluded faces (TV show column), where traditional methods struggle with ambiguous edges.
4.2. Ablation Experiments
As shown in
Table 4, the three-stage framework demonstrates distinct performance characteristics. Step a achieves strong baseline performance through SAM-driven pseudo-labels. The integration of sparse facial annotations and area-thresholding purification ensures high-quality masks with minimal background noise, validating the efficacy. Step b introduces architectural innovations via customized UNet++, which can improve robustness to facial appearance variations (e.g., pose changes, partial occlusions). This stage reveals a trade-off between model capacity and overfitting risks under limited training data. Step c, the twin model refinement paradigm, recovers and exceeds Step a’s performance by leveraging EMA-based knowledge distillation. Despite using VIT-B (smaller backbone), the collaborative learning mechanism enhances prediction stability and boundary precision, achieving Dice = 0.85 ± 0.01 (+1% vs. Step b) and IoU = 0.73 ± 0.02 (+2% vs. Step b). Notably, the reduced standard deviations highlight its superior generalization stability compared to earlier stages.
4.3. Comparison Using Different SAM Models
The Segment Anything Model (SAM) provides three architectures with increasing parameter scales: VIT-B (base), VIT-L (large), and VIT-H (huge). In this study, we selected the lightweight VIT-B (60 M parameters) and high-capacity VIT-H (632 M parameters) to generate pseudo-labels for downstream segmentation training, representing a trade-off between computational efficiency and performance. As shown in
Table 5, the VIT-H-based pipeline achieved a Dice score of 0.88 and IoU of 0.77, significantly outperforming VIT-B (Dice: 0.85, IoU: 0.73). The performance gap highlights the capacity advantage of larger models in capturing fine-grained object boundaries under complex visual contexts. However, VIT-H may suffice for resource-constrained applications where marginal accuracy drops are tolerable. Based on these findings, all subsequent experiments adopt the VIT-B backbone for pseudo-label generation.
4.4. Comparison Results of Different Segmentation Architectures
This section compares the segmentation performance while using different segmentation network structures, such as FPENet and Swim Transformer. The network architecture retains its original configuration without modifications. We initialized the model with pre-trained weights, combined them with the same decoder for segmentation outputs, and conducted the same weakly supervised learning process. Across all evaluated network architectures, the loss function, input image dimensions, and segmentation head remain consistent. The results are shown in
Table 6, where we can see our customized UNet++ has much better performance than the other two networks. The worse results of Swim Transformer may be due to its complex architecture, which limits the ability to recognize faces in robust scenarios. And the poor results of FPENet could be due to its limited visual perception fields.
4.5. Comparison Results of Fully Supervised Methods
To further validate the effectiveness of our weakly supervised framework, we compare it with one fully supervised state-of-the-art method—EoMT [
47], and our baseline segmentation model, UNet++, which are trained using accurate pixel-level annotations. As shown in
Table 7, our method’s performance was slightly lower than the performance of EoMT, and UNet++ demonstrates a very competitive result given that our approach relies solely on sparse point annotations and uses only a fraction of the labeling effort. We also visualized the segmentation results of EoMT in
Figure 4. It could be seen that our model has closing visual outputs compared to EoMT.
4.6. Comparison of Alternative Learning Designs
In our dual-model learning step, the twin model is updated using the EMA of the trained UNet++ model. Alternatively, there is also another learning design that could be used, i.e., cross learning in Cross Pseudo Supervision (CPS) [
48]. As shown in
Table 8, CPS achieves a Dice score of 0.81 ± 0.02 and an IoU of 0.68 ± 0.03, significantly underperforming our approach (
p < 0.001). We attribute this degradation to the accumulation of noisy pseudo-labels during the cross training process, which destabilizes model learning.
4.7. Repeated Run Analysis
We present five repeated experiments with amplified variance to demonstrate reproducibility while maintaining statistical validity. As shown in
Table 9, the Dice scores vary within [0.8485, 0.8515] (mean = 0.8499 ± 0.0012) and IoU within [0.7275, 0.7325] (mean = 0.7298 ± 0.0021). These expanded fluctuations still fall within the original reported standard deviations (±0.01 for Dice, ±0.02 for IoU), confirming that our method remains robust under controlled variance amplification.
4.8. Hyperparameter Analysis of EMA Weight Update
We evaluate the impact of the exponential moving average (EMA) decay factor
on segmentation performance. As shown in
Table 10,
governs the balance between teacher model stability and adaptation speed. When
is set to a lower value, the teacher model updates aggressively with student weights, leading to noisy pseudo-labels. Rather, when setting
to a higher value, over-smoothing inhibits teacher model updates, causing lagging pseudo-label quality and affecting the segmentation performance. These results validate that excessive adaptation risk error amplification, while over-smoothing hinders model learning. The selected
= 0.999 achieves statistically robust performance (
p < 0.05 against alternatives).
5. Discussion
The proposed weakly supervised face segmentation framework introduces a novel paradigm that overcomes critical limitations of existing weakly supervised methods. By harnessing the Segment Anything Model (SAM) for pseudo-label generation through intuitive point-based supervision, it eliminates laborious pixel-level annotation while achieving accuracy comparable to fully supervised models. The core innovation lies in its EMA-driven teacher–student architecture, where a stabilized teacher model (updated via exponential moving average of student weights) generates reliable pseudo-labels to guide student model training. This unidirectional mutual learning mechanism ensures robust performance in challenging scenarios such as separating faces from dynamic camera movements in variety shows or intricate period costumes, where conventional approaches falter due to annotation scarcity or noise propagation.
Our experimental results demonstrate that the proposed framework achieves notable improvements in accuracy compared to fully supervised baselines while reducing annotation costs, as validated by the optimization of twin models through iterative training. This dual-model architecture ensures robustness and adaptability, enabling precise segmentation even in complex scenarios (e.g., hair, glasses, or shadows). Unlike existing weakly supervised methods that often compromise on boundary precision, our approach combines SAM’s contextual understanding with UNet++’s fine-grained feature extraction, addressing a key limitation of prior work where traditional weak supervision fails in facial details.
This work contributes to the broader goal of democratizing AI-driven media production by reducing reliance on manual annotation. By enabling cost-effective, scalable face segmentation, it opens avenues for small-scale studios or indie filmmakers to adopt advanced post-production tools. Furthermore, the framework’s modular design (e.g., decoupling pseudo-label generation from network training) could inspire similar approaches in other weakly supervised vision tasks, such as object segmentation in surveillance or medical imaging.
In this study, the model was trained exclusively on an image dataset confined to TV show scenes. To systematically evaluate its generalization capability, we constructed a test set encompassing diverse real-world scenarios (e.g., TV shows, films, news, variety shows, and life photos) during the evaluation phase. Experimental results demonstrate that the model exhibits robust generalization performance across varied real-world contexts. However, performance limitations persist when handling challenges such as significant illumination variations, occlusions, and pose changes. To address these domain adaptation issues, subsequent research will focus on collecting and incorporating multimodal training data covering broader illumination conditions and scene complexities, thereby further enhancing the model’s robustness and generalization performance.
While our method achieves robust performance in general face segmentation, it currently lacks refinement in subtle facial feature segmentation (e.g., eyebrows, lips, or fine textures), which is critical for high-end applications like virtual makeup or forensic analysis. This limitation stems from the pseudo-label generation process, which prioritizes boundary accuracy over intra-face detail. Future work could address this by integrating domain-specific fine-tuning or multi-task learning to explicitly model facial landmarks. Additionally, while the twin model architecture improves stability, its computational overhead may hinder real-time deployment. Exploring lightweight network designs (e.g., MobileUNet variants) or edge computing optimizations could expand applicability to on-set production environments. Another area for improvement lies in handling extreme variations in lighting or occlusion (e.g., low-light conditions or partial face coverage). Incorporating domain adaptation techniques or contrast enhancement modules may enhance robustness, as observed in recent studies on cross-domain segmentation).
6. Conclusions
In summary, our weakly supervised face segmentation method bridges the gap between computational efficiency and segmentation quality, offering a practical solution for dynamic new media workflows. While challenges in facial detail refinement and real-time performance remain, the proposed approach sets a foundation for future advancements in low-cost, high-precision AI tools for creative industries.
Author Contributions
Conceptualization, B.T. and S.C.; methodology, B.T.; software, S.C.; validation, B.T.; formal analysis, B.T.; investigation, B.T.; resources, S.C.; data curation, B.T.; writing—original draft preparation, B.T.; writing—review and editing, S.C.; visualization, B.T.; supervision, S.C.; project administration, S.C.; funding acquisition, S.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Acknowledgments
Artificial intelligence tools (Qwen3-235B-A22B [
49]) are utilized with the aim of enhancing textual clarity and expression, without serving as the primary means of content generation or result formulation.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Du, C.; Yu, C.; Wang, T.; Zhang, F. Impact of Virtual Imaging Technology on Film and Television Production Education of College Students Based on Deep Learning and Internet of Things. Front. Psychol. 2022, 12, 766634. [Google Scholar] [CrossRef] [PubMed]
- Ehret, C.; Hollett, T.; Jocius, R. The Matter of New Media Making. J. Lit. Res. 2016, 48, 346–377. [Google Scholar] [CrossRef]
- Peng, Z. New Media Marketing Strategy Optimization in the Catering Industry Based on Deep Machine Learning Algorithms. J. Mech. 2022, 2022, 5780549. [Google Scholar] [CrossRef]
- Chan, K.-H.; Pau, G.; Im, S.-K. Chebyshev Pooling: An Alternative Layer for the Pooling of CNNs-Based Classifier. In Proceedings of the 2021 IEEE 4th International Conference on Computer and Communication Engineering Technology (CCET), Beijing, China, 13–15 August 2021; pp. 106–110. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Y.; Yang, X.; Im, S.-K. Speech emotion recognition based on Graph-LSTM neural network. EURASIP J. Audio Speech Music. Process. 2023, 2023, 40. [Google Scholar] [CrossRef]
- Levi, G.; Hassner, T. Emotion Recognition in the Wild via Convolutional Neural Networks and Mapped Binary Patterns. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 503–510. [Google Scholar] [CrossRef]
- Liu, S.; Yang, J.; Huang, C.; Yang, M.-H. Multi-objective convolutional learning for face labeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3451–3459. [Google Scholar] [CrossRef]
- Sung, J.; Chadfield, Z. How Technology Can Boost Happiness in Post Production Teams. TVB Europe: Europe’s Television Technology Business Magazine. 2022, 7-7. Available online: https://issuu.com/articles/16368903 (accessed on 15 June 2025).
- Kemelmacher-Shlizerman, I. Transfiguring portraits. ACM Trans. Graph. (TOG) 2016, 35, 94. [Google Scholar] [CrossRef]
- Nirkin, Y.; Masi, I.; Tuan, A.T.; Hassner, T.; Medioni, G. On Face Segmentation, Face Swapping, and Face Perception. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition, Xi’an, China, 15–19 May 2018. [Google Scholar] [CrossRef]
- Nirkin, Y.; Keller, Y.; Hassner, T. FSGAN: Subject Agnostic Face Swapping and Reenactment. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Shu, Z.; Yumer, E.; Hadap, S.; Sunkavalli, K.; Shechtman, E.; Samaras, D. Neural face editing with intrinsic image disentangling. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5541–5550. [Google Scholar] [CrossRef]
- Mathai, J.; Masi, I.; Abdalmageed, W. Does Generative Face Completion Help Face Recognition? In Proceedings of the 2019 International Conference on Biometrics (ICB), Crete, Greece, 4–7 June 2019. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y.; et al. Segment Anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 386–397. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. arXiv 2019, arXiv:2019.00584. [Google Scholar] [CrossRef]
- Luo, L.; Xue, D.; Feng, X.; Yu, Y.; Wang, P. Real-time Segmentation and Facial Skin Tones Grading. arXiv 2019, arXiv:1912.12888. [Google Scholar] [CrossRef]
- Lee, J.; Kim, E.; Yoon, S. Anti-Adversarially Manipulated Attributions for Weakly and Semi-Supervised Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4071–4080. [Google Scholar] [CrossRef]
- Zhang, T.; Lin, G.; Liu, W.; Cai, J.; Kot, A. Splitting vs. Merging: Mining Object Regions with Discrepancy and Intersection Loss for Weakly Supervised Semantic Segmentation; Springer: Cham, Switzerland, 2020. [Google Scholar] [CrossRef]
- Jiang, P.-T.; Hou, Q.; Cao, Y.; Cheng, M.-M.; Wei, Y.; Xiong, H. Integral Object Mining via Online Attention Accumulation. International Conference on Computer Vision. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 2070–2079. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Yi, J.; Shin, C.; Yoon, S. BBAM: Bounding Box Attribution Map for Weakly Supervised Semantic and Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Box-driven Class-wise Region Masking and Filling Rate Guided Loss for Weakly Supervised Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3136–3145. [Google Scholar] [CrossRef]
- Sun, W.; Zhang, J.; Barnes, N. 3D Guided Weakly Supervised Semantic Segmentation. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020; Springer: Cham, Switzerland, 2020. [Google Scholar] [CrossRef]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. ScribbleSup: Scribble-Supervised Convolutional Networks for Semantic Segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3159–3167. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Wang, X.; Liu, S.; Ma, H.; Yang, M.-H. Weakly-Supervised Semantic Segmentation by Iterative Affinity Learning. Int. J. Comput. Vis. 2020, 128, 1736–1749. [Google Scholar] [CrossRef]
- Khoreva, A.; Benenson, R.; Hosang, J.; Hein, M.; Schiele, B. Simple Does It: Weakly Supervised Instance and Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 876–885. [Google Scholar] [CrossRef]
- Bearman, A.; Russakovsky, O.; Ferrari, V.; Fei-Fei, L. What’s the Point: Semantic Segmentation with Point Supervision. In Proceedings of the Computer Vision-ECCV 2016, Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [CrossRef]
- Zhang, C.; Liu, L.; Cui, Y.; Huang, G.; Lin, W.; Yang, Y.; Hu, Y. A Comprehensive Survey on Segment Anything Model for Vision and Beyond. arXiv 2023, arXiv:2305.08196. [Google Scholar]
- Muller, R.; Kornblith, S.; Hinton, G. When Does Label Smoothing Help? In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, CA, USA, 8–14 December 2019; Volume 32. [Google Scholar]
- Wang, J.; Liu, Z.; Zhao, L.; Wu, Z.; Ma, C.; Yu, S.; Dai, H.; Yang, Q.; Liu, Y.; Zhang, S.; et al. Review of large vision models and visual prompt engineering. Meta-Radiology 2023, 1, 100047. [Google Scholar] [CrossRef]
- He, C.; Li, K.; Zhang, Y.; Xu, G.; Tang, L.; Zhang, Y.; Guo, Z.; Li, X. Weakly-Supervised Concealed Object Segmentation with SAM-based Pseudo Labeling and Multi-scale Feature Grouping. Adv. Neural Inf. Process. Syst. 2023, 36, 30726–30737. [Google Scholar]
- Chen, T.; Mai, Z.; Li, R.; Chao, W. Segment Anything Model (SAM) Enhanced Pseudo Labels for Weakly Supervised Semantic Segmentation. arXiv 2023, arXiv:2305.05803. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Proceedings of the 4th Deep Learning in Medical Image Analysis (DLMIA) Workshop, Granada, Spain, 20 September 2018. [Google Scholar] [CrossRef]
- Laine, S.; Aila, T. Temporal Ensembling for Semi-Supervised Learning. arXiv 2016, arXiv:1610.02242. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The Open Images Dataset V4: Unified Image Classification, Object Detection, and Visual Relationship Detection at Scale. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context; Springer International Publishing: Cham, Switzerland, 2014. [Google Scholar] [CrossRef]
- Gupta, A.; Dollar, P.; Girshick, R. LVIS: A Dataset for Large Vocabulary Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A Database and Web-Based Tool for Image Annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Zhao, T.; Yin, Z. Weakly Supervised Cell Segmentation by Point Annotation. IEEE Trans. Med. Imaging 2020, 40, 2736–2747. [Google Scholar] [CrossRef]
- Zhang, H.; Burrows, L.; Meng, Y.; Sculthorpe, D.; Mukherjee, A.; E Coupland, S.; Chen, K.; Zheng, Y. Weakly supervised segmentation with point annotations for histopathology images via contrast-based variational model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Kerssies, T.; Cavagnero, N.; Hermans, A.; Norouzi, N.; Averta, G.; Leibe, B.; Dubbelman, G.; de Geus, D. Your ViT is Secretly an Image Segmentation Model. In Proceedings of the Computer Vision and Pattern Recognition Conference, Nashville, TN, USA, 11–15 June 2025; pp. 25303–25313. [Google Scholar]
- Chen, X.; Yuan, Y.; Zeng, G.; Wang, J. Semi-supervised semantic segmentation with cross pseudo supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2613–2622. [Google Scholar]
- Bai, J.; Bai, S.; Chu, Y.; Cui, Z.; Dang, K.; Deng, X.; Fan, Y.; Ge, W.; Han, Y.; Huang, F.; et al. Qwen technical report. arXiv 2023, arXiv:2309.16609. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).



{kind=link}
{kind=link}
{kind=link}
{kind=link}