
Driver Intention Recognition for Mine Transport Vehicle Based on Cross-Modal Knowledge Distillation



Abstract
1. Introduction
- (1)
- An experimental framework was designed to collect driving intention signals from mine transport vehicles. Driving videos were recorded from two coal mine transport vehicles, processed into video data for intention analysis, and used as stimuli to gather EEG signals related to driving intentions. Additionally, a simulation environment for mine transport vehicle operation was created, allowing multiple subjects to view the videos and generate corresponding EEG data.
- (2)
- A driving intention recognition model for mine transport vehicles was developed using CMKD. An EEG-based intention recognition model was first created to decode driver intentions. This model served as a teacher, providing intention information to train a video-based student model. Guided by the teacher model, the student model achieved effective intention recognition even in the absence of direct EEG data.
2. Materials and Methods
2.1. Experimental Personnel and Stimulus Materials
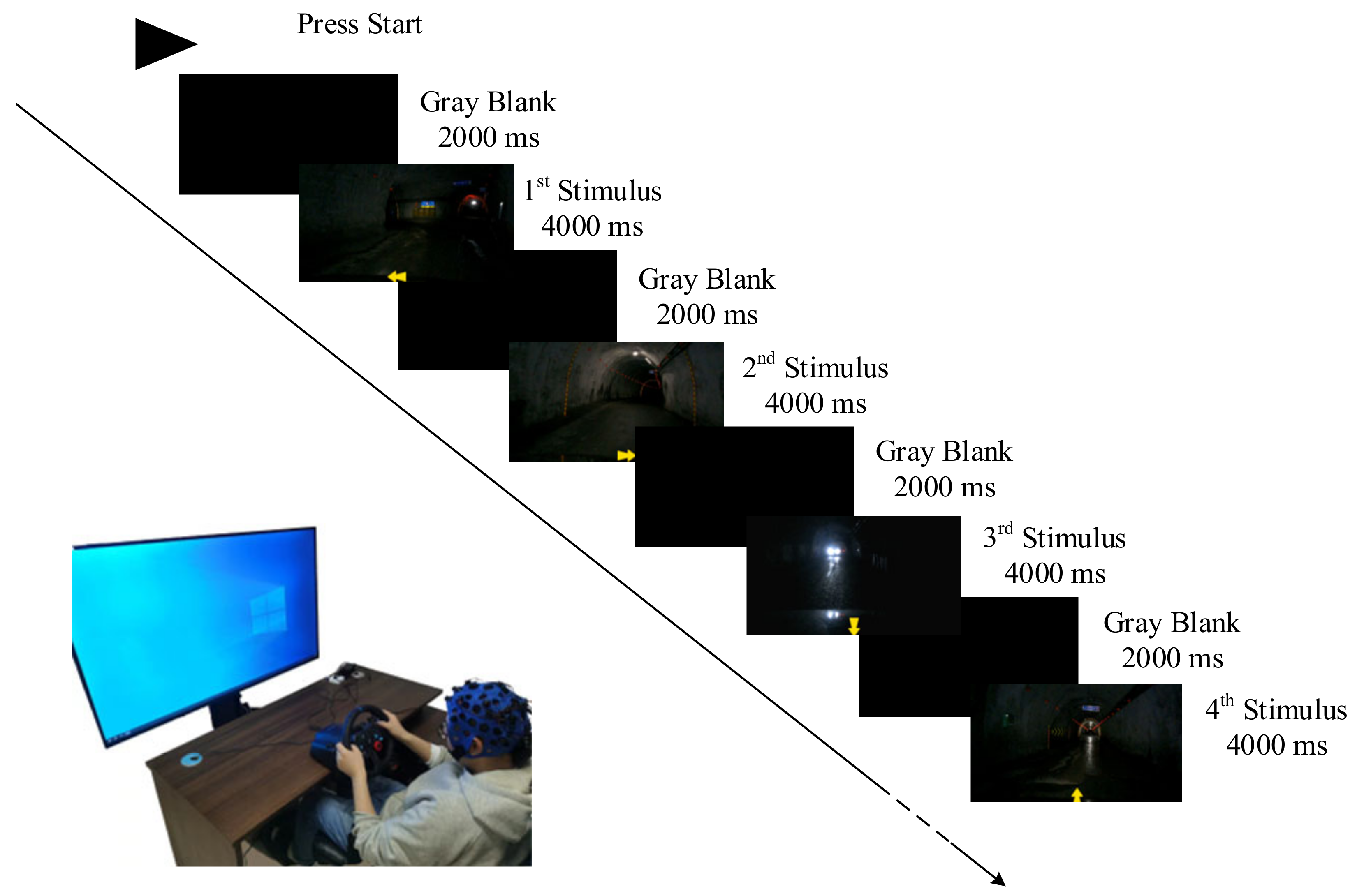
2.2. Experimental Platform and Procedure
2.3. Data Preprocessing
2.4. Driving Intention Characteristics Analysis
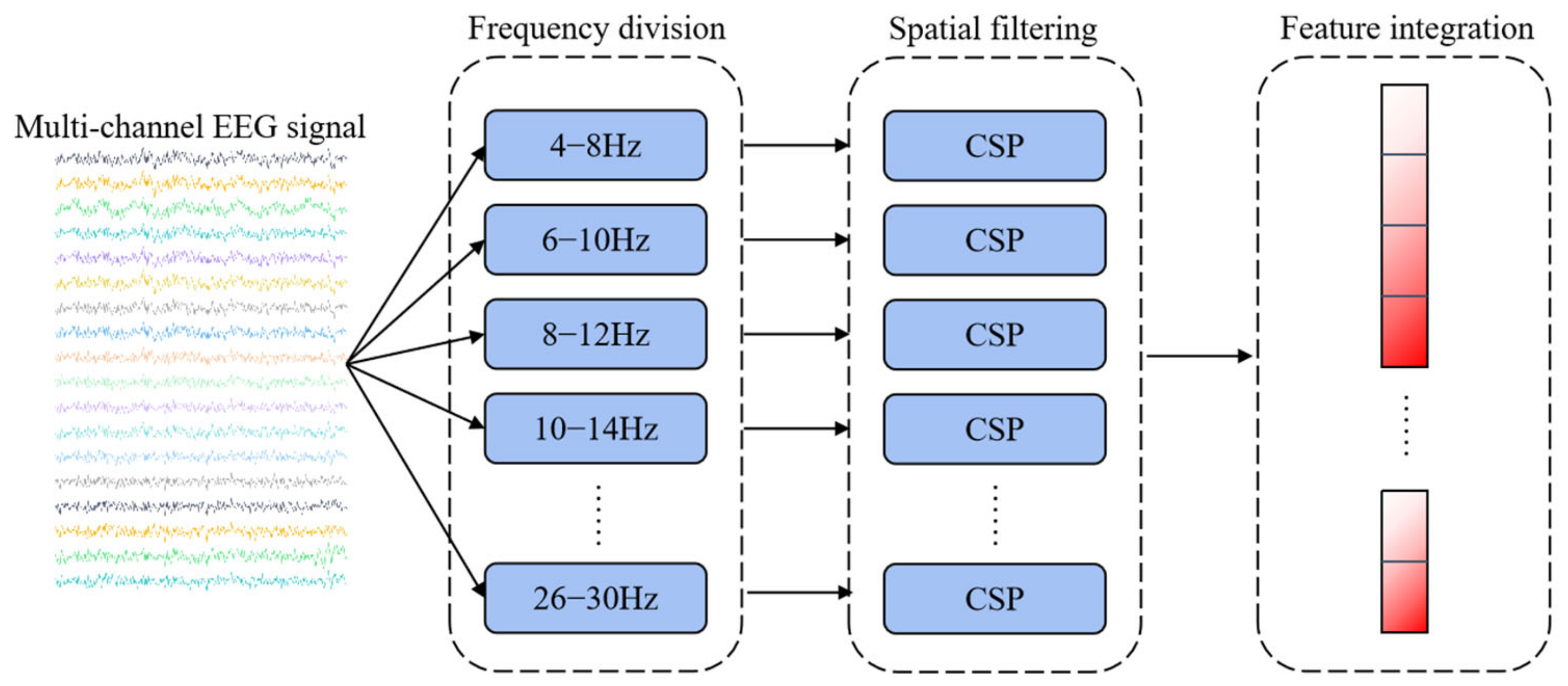
2.5. EEG Feature Extraction
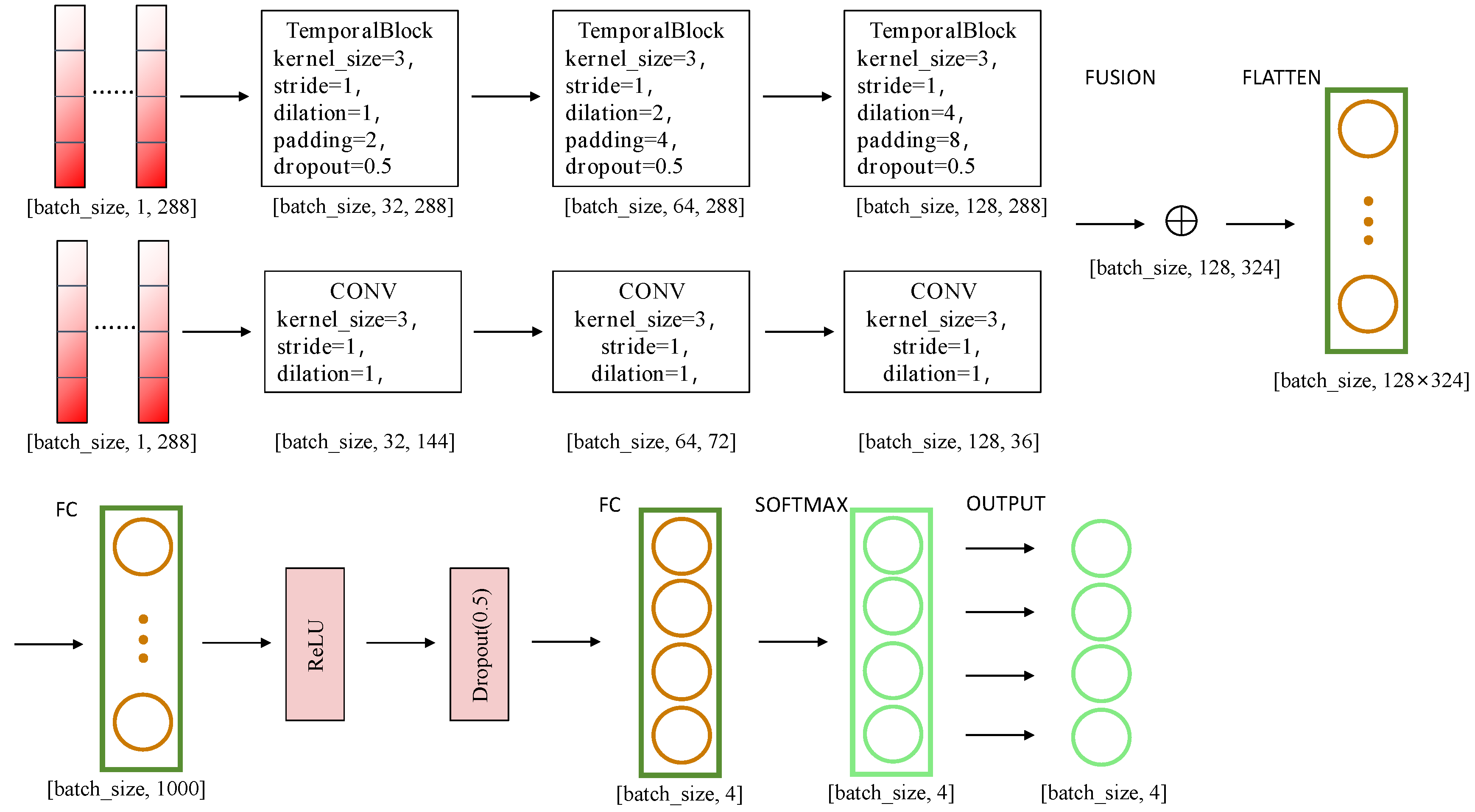
2.6. Construction of a Driving Intention Model Based on Cross-Modal Knowledge Distillation
3. Result and Discussion
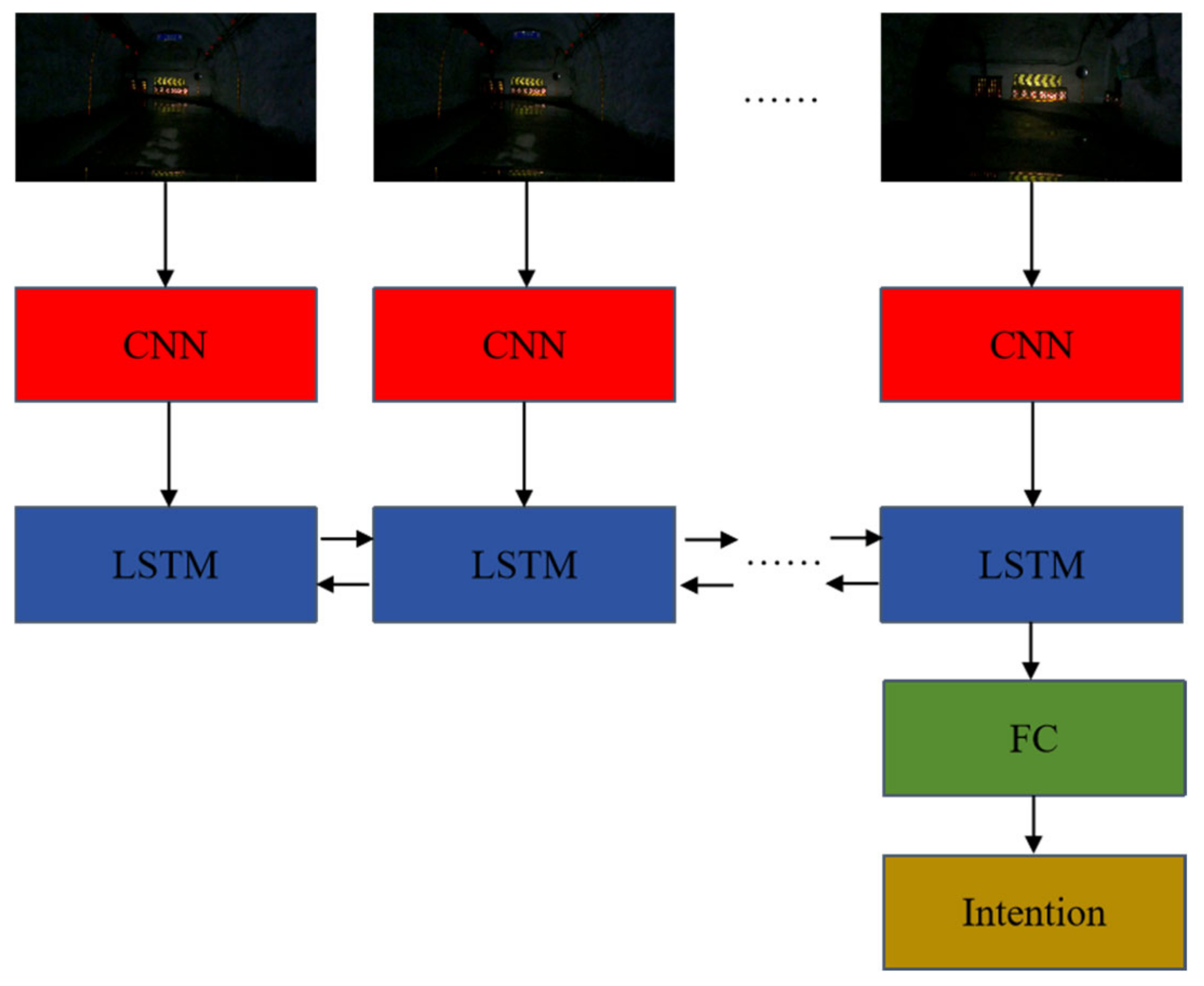
3.1. Driving Intention Recognition Analysis Based on Video Data
3.2. Driving Intention Recognition Analysis Based on EEG Features
3.3. Driving Intention Recognition Analysis Based on Cross-Modal Knowledge Distillation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, Y.; Huang, Y.; Ge, S.; Zhang, Y.; Jiang, E.; Cheng, B.; Yang, S. Low-Carbon Routing Based on Improved Artificial Bee Colony Algorithm for Electric Trackless Rubber-Tyred Vehicles. Complex Syst. Model. Simul. 2023, 3, 169–190. [Google Scholar] [CrossRef]
- Trivedi, M.; Gandhi, T.; McCall, J. Looking-in and looking-out of a vehicle: Selected investigations in computer vision based enhanced vehicle safety. In Proceedings of the IEEE International Conference on Vehicular Electronics and Safety, Xi’an, China, 14–16 October 2005; pp. 29–64. [Google Scholar]
- Liang, Y.; Zheng, P.; Xia, L. A visual reasoning-based approach for driving experience improvement in the AR-assisted head-up displays. Adv. Eng. Inform. 2023, 55, 101888. [Google Scholar] [CrossRef]
- Hanel, A.; Stilla, U. STRUCTURE-FROM-MOTION FOR CALIBRATION OF A VEHICLE CAMERA SYSTEM WITH NON-OVERLAPPING FIELDS-OF-VIEW IN AN URBAN ENVIRONMENT. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2017, 42, 181–188. [Google Scholar] [CrossRef]
- Jamonnak, S.; Zhao, Y.; Huang, X.; Amiruzzaman, M. Geo-Context Aware Study of Vision-Based Autonomous Driving Models and Spatial Video Data. IEEE Trans. Vis. Comput. Graph. 2022, 28, 1019–1029. [Google Scholar] [CrossRef]
- Xu, H.; Gao, Y.; Yu, F.; Darrell, T. End-to-End Learning of Driving Models from Large-Scale Video Datasets. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3530–3538. [Google Scholar]
- Ma, H.; Wang, Y.; Xiong, R.; Kodagoda, S.; Tang, L. DeepGoal: Learning to Drive with driving intention from Human Control Demonstration. arXiv 2019, arXiv:1911.12610. [Google Scholar] [CrossRef]
- Frossard, D.; Kee, E.; Urtasun, R. DeepSignals: Predicting Intent of Drivers Through Visual Signals. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9697–9703. [Google Scholar]
- Bonyani, M.; Rahmanian, M.; Jahangard, S.; Rezaei, M. DIPNet: Driver intention prediction for a safe takeover transition in autonomous vehicles. IET Intell. Transp. Syst. 2023, 17, 1769–1783. [Google Scholar] [CrossRef]
- Guo, X.; Zhang, B. The Research of Coal Mine Underground Rubber Tyred Vehicle Wireless Video Aided Scheduling System. In Information Technology and Intelligent Transportation Systems: Volume 1, Proceedings of the 2015 International Conference on Information Technology and Intelligent Transportation Systems ITITS 2015, Xi’an, China, 12–13 December 2015; Springer International Publishing: Cham, Switzerland, 2017; Volume 454, pp. 365–371. [Google Scholar]
- Xue, G.; Li, R.; Liu, S.; Wei, J. Research on Underground Coal Mine Map Construction Method Based on LeGO-LOAM Improved Algorithm. Energies 2022, 15, 6256. [Google Scholar] [CrossRef]
- Hanif, M.; Yu, Z.; Bashir, R.; Li, Z.; Farooq, S.; Sana, M. A new network model for multiple object detection forautonomous vehicle detection in mining environment. IET Image Process. 2024, 18, 3277–3287. [Google Scholar] [CrossRef]
- Yang, W.; Wang, S.; Wu, J.; Chen, W.; Tian, Z. A low-light image enhancement method for personnel safety monitoring in underground coal mines. Complex Intell. Syst. 2024, 10, 4019–4032. [Google Scholar] [CrossRef]
- Affanni, A.; Najafi, T. Drivers’ Attention Assessment by Blink Rate Measurement from EEG Signals. In 2022 IEEE International Workshop on Metrology for Automotive (MetroAutomotive); IEEE: Piscataway, NJ, USA, 2022; pp. 128–132. [Google Scholar]
- Zhang, X.; Xiao, X.; Yang, Y.; Hao, Z.; Li, J.; Huang, H. EEG Signal Analysis for Early Detection of Critical Road Events and Emergency Response in Autonomous Driving. In Proceedings of the 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC), Bilbao, Spain, 24–28 September 2023; pp. 1706–1712. [Google Scholar]
- Jang, M.; Oh, K. Development of an Integrated Longitudinal Control Algorithm for Autonomous Mobility with EEG-Based Driver Status Classification and Safety Index. Electronics 2024, 13, 1374. [Google Scholar] [CrossRef]
- Li, M.; Wang, W.; Liu, Z.; Qiu, M.; Qu, D. Driver Behavior and Intention Recognition Based on Wavelet Denoising and Bayesian Theory. Sustainability 2022, 14, 6901. [Google Scholar] [CrossRef]
- Martínez, E.; Hernández, L.; Antelis, J. Discrimination Between Normal Driving and Braking Intention from Driver’s Brain Signals. Bioinform. Biomed. Eng. 2018, 10813, 129–138. [Google Scholar]
- Kadrolkar, A.; Sup, F.C. Intent recognition of torso motion using wavelet transform feature extraction and linear discriminant analysis ensemble classification. Biomed. Signal Process. Control 2017, 38, 250–264. [Google Scholar] [CrossRef]
- Zhao, M.; Gao, H.; Wang, W.; Qu, J. Research on Human-Computer Interaction Intention Recognition Based on EEG and Eye Movement. IEEE Access 2020, 8, 145824–145832. [Google Scholar] [CrossRef]
- Fu, R.; Wang, Z.; Wang, S.; Xu, X.; Chen, J.; Wen, G. EEGNet-MSD: A Sparse Convolutional Neural Network for Efficient EEG-Based Intent Decoding. IEEE Sens. J. 2023, 23, 19684–19691. [Google Scholar] [CrossRef]
- Sun, J.; Liu, Y.; Ye, Z.; Hu, D. A Novel Multiscale Dilated Convolution Neural Network with Gating Mechanism for Decoding Driving Intentions Based on EEG. IEEE Trans. Cogn. Dev. Syst. 2023, 15, 1712–1721. [Google Scholar] [CrossRef]
- Ju, J.; Bi, L.; Feleke, A.G. Noninvasive neural signal-based detection of soft and emergency braking intentions of drivers. Biomed. Signal Process. Control 2022, 72, 103330. [Google Scholar] [CrossRef]
- Liang, X.; Yang, Y.; Liu, Y.; Liu, K.; Liu, Y.; Zhou, Z. EEG-based emergency braking intention detection during simulated driving. BioMed. Eng. OnLine 2023, 22, 65. [Google Scholar] [CrossRef]
- Chang, W.; Meng, W.; Yan, G.; Zhang, B.; Luo, H.; Gao, R.; Yang, Z. Driving EEG based multilayer dynamic brain network analysis for steering process. Expert Syst. Appl. 2022, 207, 118121. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. Comput. Sci. 2015, 14, 38–39. [Google Scholar]
- Chen, Z.; Li, Z.; Zhang, S.; Fang, J.; Jiang, Q.; Zhao, F. BEVDistill: Cross-Modal BEV Distillation for Multi-View 3D Object Detection. In Proceedings of the International Conference on Learning Representations (ICLR), Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Thoker, F.M.; Gall, J. Cross-Modal Knowledge Distillation for Action Recognition. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 6–10. [Google Scholar]
- Li, Y.; Wang, Y.; Cui, Z. Decoupled Multimodal Distilling for Emotion Recognition. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 6631–6640. [Google Scholar]
- Bano, S.; Tonellotto, N.; Gotta, A. Drivers Stress Identification in Real-World Driving Tasks. In Proceedings of the 2022 IEEE International Conference on Pervasive Computing and Communications Workshops and other Affiliated Events (PerCom Workshops), Pisa, Italy, 21–25 March 2022; pp. 140–141. [Google Scholar]
- Zhang, S.; Tang, C.; Guan, C. Visual-to-EEG cross-modal knowledge distillation for continuous emotion recognition. Pattern Recognit. 2022, 130, 108833. [Google Scholar] [CrossRef]
- Liang, J. EEG Analysis and BCI Research Based on Motor Imagery Under Driving Behavior. Ph.D. Thesis, Hebei University of Technology, Tianjin, China, 2012. [Google Scholar]
- Lopez-Paz, D.; Bottou, L.; Bernhard, S.; Vapnik, V. Unifying distillation and privileged information. arXiv 2015, arXiv:1511.03643. [Google Scholar]
- Cavazza, J.; Ahmed, W.; Volpi, R.; Morerio, P.; Bossi, F.; Willemse, C.; Wykowska, A.; Murino, V. Understanding action concepts from videos and brain activity through subjects’ consensus. Sci. Rep. 2022, 12, 19073. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Chintala, S. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regulation. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Hara, K.; Kataoka, H.; Satoh, Y. Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 3154–3160. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A Closer Look at Spatiotemporal Convolutions for Action Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6450–6459. [Google Scholar]
- Donahue, J.; Hendricks, L.A.; Guadarrama, S.; Rohrbach, M. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6201–6210. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Bkassiny, M. A Deep Learning-based Signal Classification Approach for Spectrum Sensing using Long Short-Term Memory (LSTM) Networks. In Proceedings of the 2022 6th International Conference on Information Technology, Information Systems and Electrical Engineering (ICITISEE), Yogyakarta, Indonesia, 13 December 2022; pp. 667–672. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Thakkar, B. Continuous variable analyses: Student’s t-test, Mann–Whitney U test, Wilcoxon signed-rank test. In Translational Cardiology; Academic Press: Cambridge, MA, USA, 2025; pp. 165–167. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject/Driver Intention | Left | Right | Normal | Avoidance | Scale (μV) |
|---|---|---|---|---|---|
| Subject 1 |  | 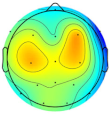 | 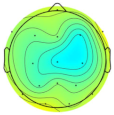 |  |  |
| Subject 2 | 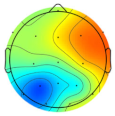 |  | 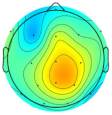 | 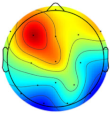 | |
| Subject 3 | 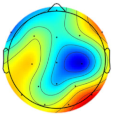 | 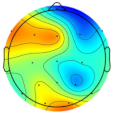 | 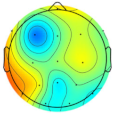 | 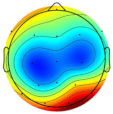 |
| Algorithm | Classes | Avg. Precision (%) | Avg. Recall (%) | Avg. F1 (%) | Avg. Accuracy (%) | Model File Size (MB) |
|---|---|---|---|---|---|---|
| R3D | left | 74.29 | 25.00 | 33.13 | 45.63 ± 5.23 | 129.753 |
| right | 76.91 | 35.00 | 40.22 | |||
| normal | 39.65 | 95.00 | 54.40 | |||
| avoidance | 78.57 | 27.50 | 38.67 | |||
| R(2+1)D | left | 79.33 | 27.50 | 38.93 | 53.13 ± 4.94 | 129.862 |
| right | 63.79 | 52.50 | 56.18 | |||
| normal | 70.70 | 57.50 | 57.71 | |||
| avoidance | 45.92 | 75.00 | 51.71 | |||
| LRCN_18 | left | 61.24 | 40.00 | 45.70 | 59.38 ± 3.83 | 57.097 |
| right | 59.09 | 45.00 | 47.34 | |||
| normal | 56.25 | 95.00 | 68.26 | |||
| avoidance | 94.00 | 57.50 | 66.99 | |||
| LRCN_34 | left | 23.33 | 20.00 | 21.43 | 47.50 ± 5.13 | 96.646 |
| right | 45.67 | 47.50 | 44.17 | |||
| normal | 55.12 | 75.00 | 59.83 | |||
| avoidance | 74.17 | 47.50 | 46.52 | |||
| SlowFast_32 | left | 45.33 | 25.00 | 31.74 | 57.50 ± 5.23 | 84.450 |
| right | 50.16 | 47.50 | 47.14 | |||
| normal | 66.62 | 77.50 | 68.97 | |||
| avoidance | 73.33 | 80.00 | 70.95 | |||
| SlowFast_50 | left | 13.33 | 7.50 | 9.52 | 46.25 ± 8.67 | 131.569 |
| right | 43.89 | 35.00 | 37.75 | |||
| normal | 54.71 | 80.00 | 61.80 | |||
| avoidance | 57.06 | 62.50 | 54.85 |
| Algorithm | Classes | Avg. Precision (%) | Avg. Recall (%) | Avg. F1 (%) | Avg. Accuracy (%) |
|---|---|---|---|---|---|
| CNN | left | 66.97 | 69.84 | 68.34 | 69.28 ± 0.62 |
| right | 72.22 | 64.57 | 68.17 | ||
| normal | 74.24 | 69.18 | 71.60 | ||
| avoidance | 64.91 | 73.73 | 69.02 | ||
| LSTM | left | 63.17 | 68.80 | 65.81 | 67.86 ± 0.53 |
| right | 71.23 | 64.10 | 67.42 | ||
| normal | 70.78 | 71.79 | 71.27 | ||
| avoidance | 66.73 | 66.87 | 66.79 | ||
| CNN_LSTM | left | 56.87 | 60.73 | 58.73 | 59.38 ± 1.55 |
| right | 60.12 | 52.86 | 56.48 | ||
| normal | 63.21 | 61.74 | 62.43 | ||
| avoidance | 57.21 | 62.45 | 59.75 | ||
| CNN_BiGRU | left | 58.34 | 58.95 | 58.62 | 60.08 ± 1.68 |
| right | 59.65 | 59.14 | 59.37 | ||
| normal | 63.10 | 60.58 | 61.81 | ||
| avoidance | 59.40 | 61.57 | 60.45 | ||
| Transformer | left | 63.51 | 67.44 | 65.39 | 67.83 ± 1.01 |
| right | 67.34 | 66.10 | 66.66 | ||
| normal | 72.43 | 69.56 | 70.87 | ||
| avoidance | 68.55 | 68.24 | 68.33 | ||
| CNN_Attention | left | 53.01 | 55.39 | 54.16 | 56.75 ± 1.36 |
| right | 58.56 | 54.86 | 56.63 | ||
| normal | 59.62 | 59.23 | 59.40 | ||
| avoidance | 55.83 | 57.45 | 56.60 | ||
| CNN_Transformer | left | 56.20 | 58.32 | 57.11 | 59.09 ± 2.28 |
| right | 60.66 | 55.53 | 57.95 | ||
| normal | 63.46 | 58.36 | 60.63 | ||
| avoidance | 57.04 | 64.22 | 60.39 | ||
| LSTM_Attention | left | 61.95 | 66.39 | 64.09 | 67.49 ± 0.68 |
| right | 72.46 | 64.29 | 68.12 | ||
| normal | 70.37 | 70.12 | 70.54 | ||
| avoidance | 65.66 | 68.53 | 67.06 | ||
| CNN_TCN | left | 63.05 | 63.35 | 63.09 | 65.71 ± 0.67 |
| right | 67.69 | 65.53 | 66.42 | ||
| normal | 67.92 | 68.79 | 68.23 | ||
| avoidance | 64.81 | 65.00 | 64.86 | ||
| TCN_CNN | left | 69.86 | 70.37 | 70.11 | 71.55 ± 0.51 |
| right | 72.55 | 68.95 | 70.68 | ||
| normal | 73.18 | 76.91 | 74.94 | ||
| avoidance | 70.75 | 69.90 | 70.29 | ||
| TCN_Attention | left | 61.51 | 63.87 | 62.66 | 64.78 ± 1.02 |
| right | 67.03 | 63.43 | 65.05 | ||
| normal | 68.40 | 68.50 | 68.44 | ||
| avoidance | 62.71 | 63.24 | 62.81 | ||
| TCN_LSTM | left | 57.38 | 59.68 | 58.46 | 59.61 ± 0.57 |
| right | 61.23 | 57.52 | 59.25 | ||
| normal | 62.03 | 61.74 | 61.84 | ||
| avoidance | 58.05 | 59.51 | 58.76 |
| Algorithm | Classes | Avg. Precision (%) | Avg. Recall (%) | Avg. F1 (%) | Avg. Accuracy (%) |
|---|---|---|---|---|---|
| CNN | left | 72.37 | 64.04 | 67.84 | 64.76 ± 0.66 |
| right | 65.01 | 60.58 | 62.68 | ||
| normal | 63.40 | 71.15 | 66.97 | ||
| avoidance | 60.11 | 63.27 | 61.60 | ||
| LSTM | left | 69.94 | 66.73 | 68.17 | 66.08 ± 0.60 |
| right | 69.65 | 63.08 | 65.66 | ||
| normal | 67.49 | 69.04 | 68.07 | ||
| avoidance | 59.95 | 65.48 | 62.54 | ||
| CNN_LSTM | left | 46.72 | 49.90 | 48.25 | 49.06 ± 2.24 |
| right | 44.59 | 43.17 | 43.87 | ||
| normal | 56.08 | 52.60 | 54.24 | ||
| avoidance | 49.41 | 50.30 | 49.95 | ||
| CNN_BiGRU | left | 52.84 | 54.14 | 53.39 | 51.75 ± 1.72 |
| right | 48.14 | 49.13 | 48.59 | ||
| normal | 55.58 | 55.96 | 55.73 | ||
| avoidance | 50.63 | 47.79 | 49.01 | ||
| Transformer | left | 68.55 | 68.46 | 68.48 | 66.64 ± 1.12 |
| right | 71.57 | 59.71 | 64.79 | ||
| normal | 66.27 | 70.96 | 68.51 | ||
| avoidance | 62.39 | 67.40 | 64.56 | ||
| CNN_Attention | left | 46.76 | 52.02 | 49.22 | 49.11 ± 2.27 |
| right | 44.49 | 46.06 | 45.24 | ||
| normal | 56.33 | 52.79 | 54.47 | ||
| avoidance | 50.27 | 45.58 | 47.68 | ||
| CNN_Transformer | left | 50.20 | 55.48 | 52.56 | 51.28 ± 3.06 |
| right | 48.60 | 47.40 | 47.92 | ||
| normal | 54.36 | 54.23 | 54.25 | ||
| avoidance | 52.41 | 47.98 | 50.01 | ||
| LSTM_Attention | left | 61.66 | 63.37 | 62.47 | 61.59 ± 0.97 |
| right | 57.78 | 58.56 | 58.16 | ||
| normal | 64.93 | 67.60 | 66.22 | ||
| avoidance | 61.96 | 56.83 | 59.28 | ||
| CNN_TCN | left | 59.15 | 61.44 | 60.19 | 58.70 ± 0.72 |
| right | 54.96 | 54.04 | 54.47 | ||
| normal | 63.88 | 63.17 | 63.43 | ||
| avoidance | 56.98 | 56.16 | 56.51 | ||
| TCN_CNN | left | 72.62 | 69.71 | 71.10 | 67.31 ± 0.93 |
| right | 73.53 | 60.00 | 66.02 | ||
| normal | 65.03 | 69.52 | 67.04 | ||
| avoidance | 60.97 | 70.00 | 65.08 | ||
| TCN_Attention | left | 56.96 | 59.52 | 58.12 | 55.87 ± 1.53 |
| right | 51.59 | 52.69 | 52.04 | ||
| normal | 58.30 | 59.62 | 58.94 | ||
| avoidance | 56.89 | 51.63 | 54.08 | ||
| TCN_LSTM | left | 49.52 | 54.42 | 51.85 | 52.86 ± 1.06 |
| right | 48.66 | 50.67 | 49.62 | ||
| normal | 61.91 | 54.71 | 58.07 | ||
| avoidance | 53.05 | 51.63 | 52.32 |
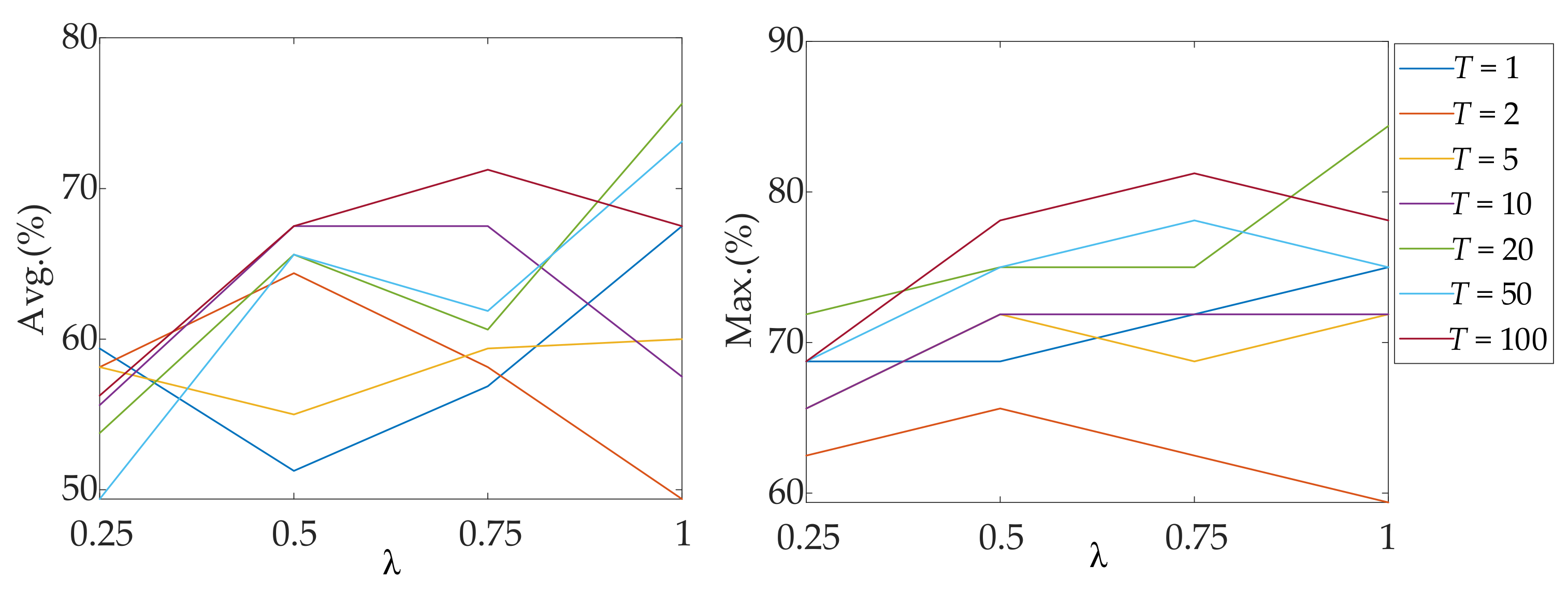
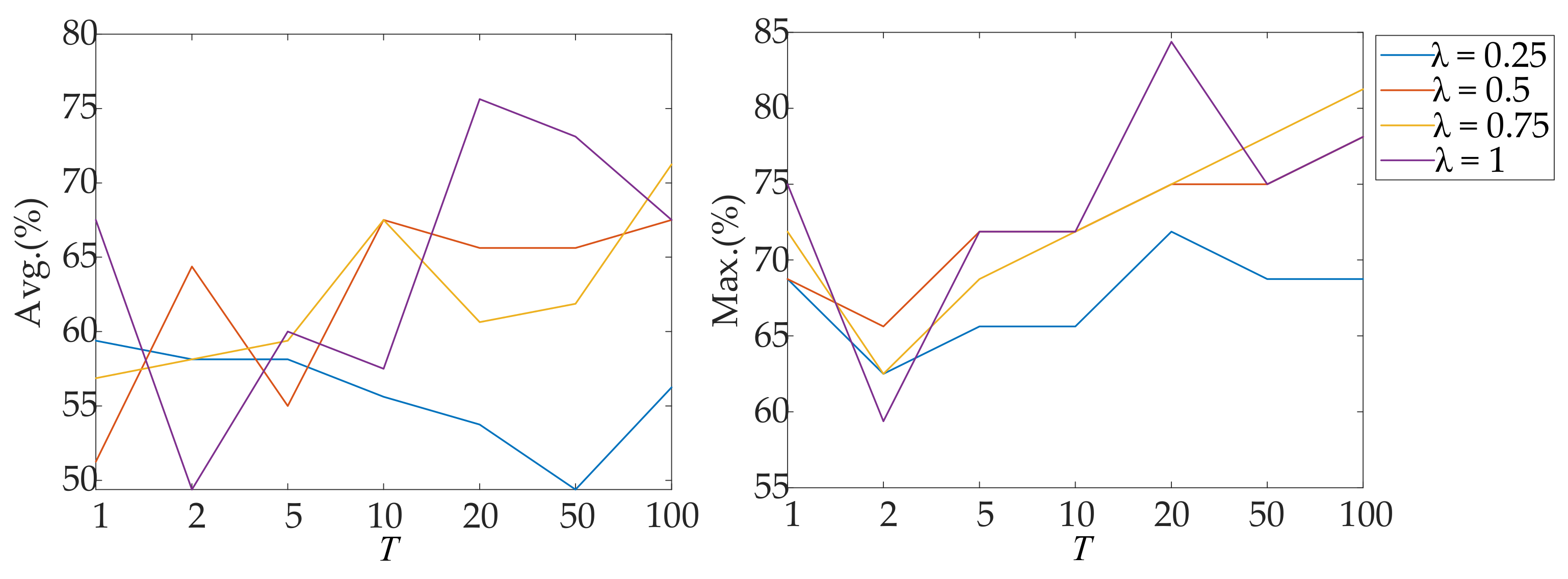
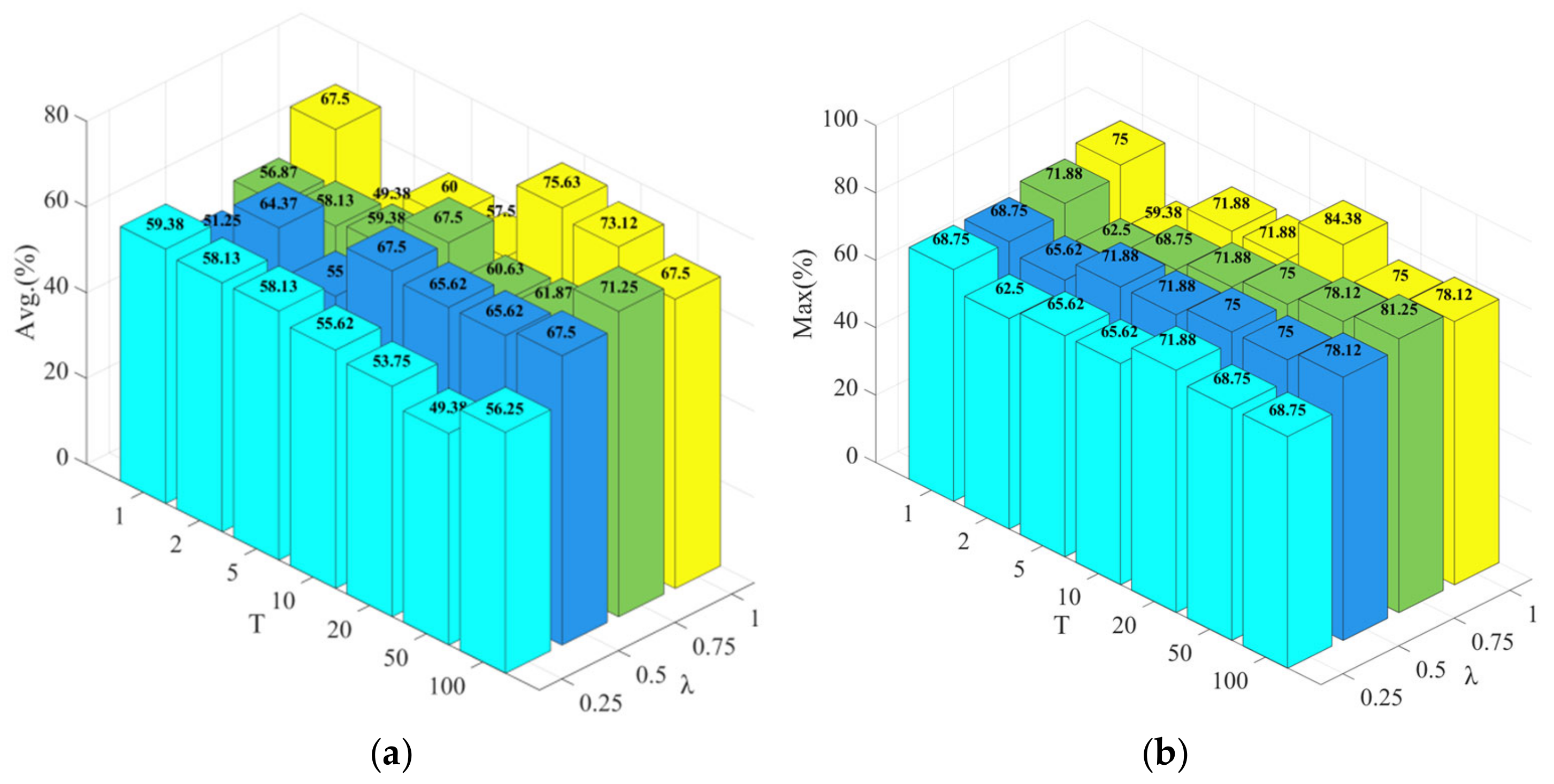
| Parameter | λ = 0.25 | λ = 0.5 | λ = 0.75 | λ = 1 | ||||
|---|---|---|---|---|---|---|---|---|
| T | Avg. (%) | Max (%) | Avg. (%) | Max (%) | Avg. (%) | Max (%) | Avg. (%) | Max (%) |
| 1 | 59.38 ± 5.41 | 68.75 | 51.25 ± 10.73 | 68.75 | 56.87 ± 8.67 | 71.88 | 67.50 ± 5.68 | 75.00 |
| 2 | 58.13 ± 4.19 | 62.50 | 64.37 ± 1.71 | 65.62 | 58.13 ± 3.57 | 62.50 | 49.38 ± 6.78 | 59.38 |
| 5 | 58.13 ± 4.74 | 65.62 | 55.00 ± 10.03 | 71.88 | 59.38 ± 6.25 | 68.75 | 60.00 ± 8.95 | 71.88 |
| 10 | 55.62 ± 6.01 | 65.62 | 67.50 ± 2.80 | 71.88 | 67.50 ± 4.74 | 71.88 | 57.50 ± 8.73 | 71.88 |
| 20 | 53.75 ± 10.46 | 71.88 | 65.62 ± 5.41 | 75.00 | 60.63 ± 10.74 | 75.00 | 75.63 ± 5.59 | 84.38 |
| 50 | 49.38 ± 11.69 | 68.75 | 65.62 ± 5.85 | 75.00 | 61.87 ± 9.48 | 78.12 | 73.12 ± 1.71 | 75.00 |
| 100 | 56.25 ± 7.97 | 68.75 | 67.50 ± 6.09 | 78.12 | 71.25 ± 6.78 | 81.25 | 67.50 ± 9.27 | 78.12 |
| Parameter Combinations (λ-T) | Classes | Avg. Precision (%) | Avg. Recall (%) | Avg. F1 (%) | Avg. Accuracy (%) |
|---|---|---|---|---|---|
| 0.75–100 | left | 76.29 | 62.50 | 67.95 | 71.25 ± 6.78 |
| right | 73.31 | 65.00 | 64.57 | ||
| normal | 67.28 | 100.00 | 79.49 | ||
| avoidance | 82.79 | 57.50 | 66.48 | ||
| 1–20 | left | 91.56 | 62.50 | 72.21 | 75.63 ± 5.59 |
| right | 76.64 | 77.50 | 72.14 | ||
| normal | 68.27 | 100.00 | 80.44 | ||
| avoidance | 95.00 | 62.50 | 73.82 | ||
| 1–50 | left | 87.79 | 62.50 | 71.19 | 73.12 ± 1.71 |
| right | 79.01 | 62.50 | 68.07 | ||
| normal | 61.64 | 100.00 | 75.68 | ||
| avoidance | 88.81 | 67.50 | 75.76 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Guo, Y.; You, X.; Guo, L.; Miao, B.; Li, H. Driver Intention Recognition for Mine Transport Vehicle Based on Cross-Modal Knowledge Distillation. Appl. Sci. 2025, 15, 6814. https://doi.org/10.3390/app15126814
Zhang Y, Guo Y, You X, Guo L, Miao B, Li H. Driver Intention Recognition for Mine Transport Vehicle Based on Cross-Modal Knowledge Distillation. Applied Sciences. 2025; 15(12):6814. https://doi.org/10.3390/app15126814
Chicago/Turabian StyleZhang, Yizhe, Yinan Guo, Xiusong You, Lunfeng Guo, Bing Miao, and Hao Li. 2025. "Driver Intention Recognition for Mine Transport Vehicle Based on Cross-Modal Knowledge Distillation" Applied Sciences 15, no. 12: 6814. https://doi.org/10.3390/app15126814
APA StyleZhang, Y., Guo, Y., You, X., Guo, L., Miao, B., & Li, H. (2025). Driver Intention Recognition for Mine Transport Vehicle Based on Cross-Modal Knowledge Distillation. Applied Sciences, 15(12), 6814. https://doi.org/10.3390/app15126814