
A Lightweight Detection Method for Meretrix Based on an Improved YOLOv8 Algorithm


Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset Preparation
2.2. Experimental Environment and Parameter Settings
2.3. Improved YOLOv8 Network
3. Improved Lightweight Method for Clam Detection
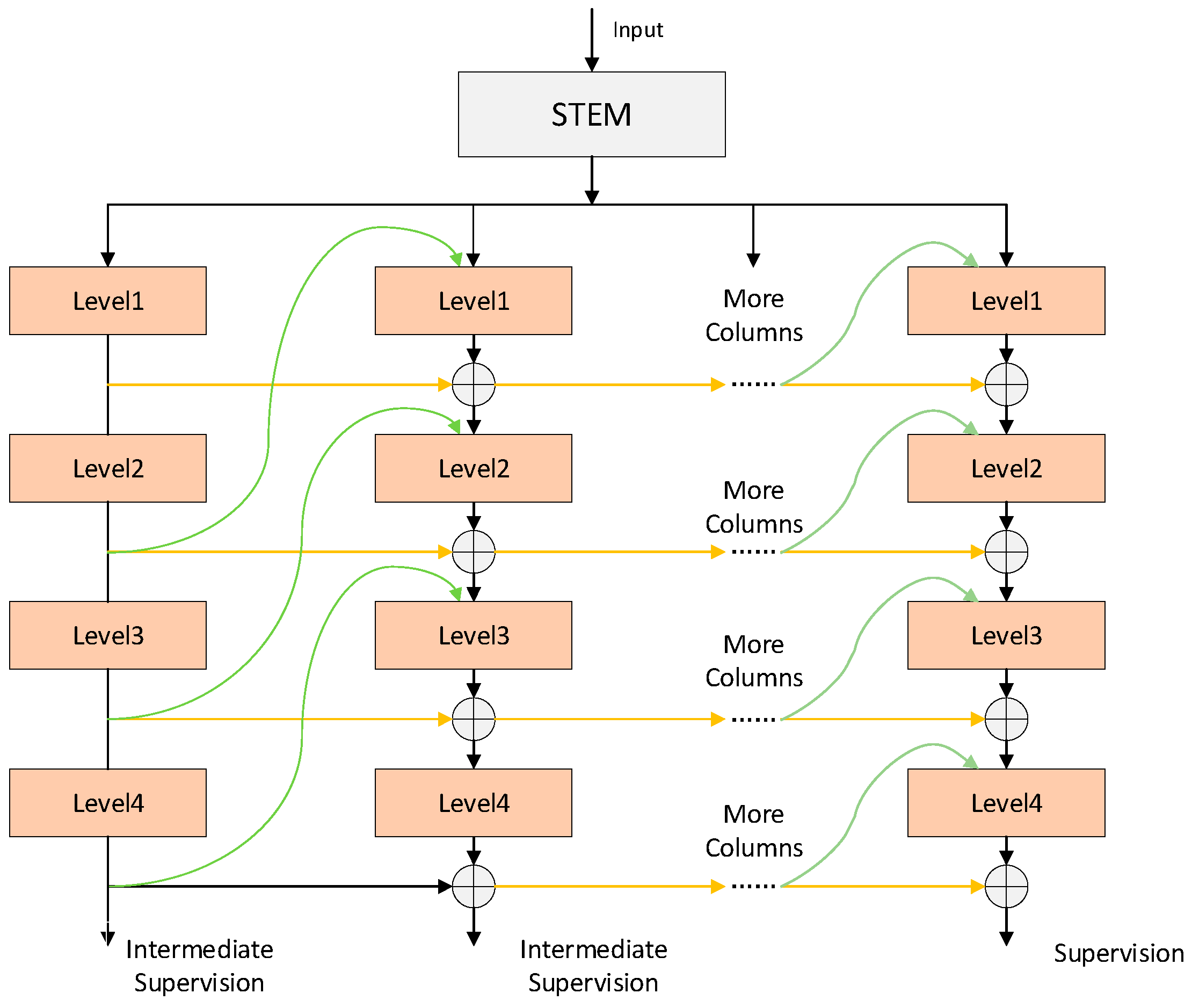
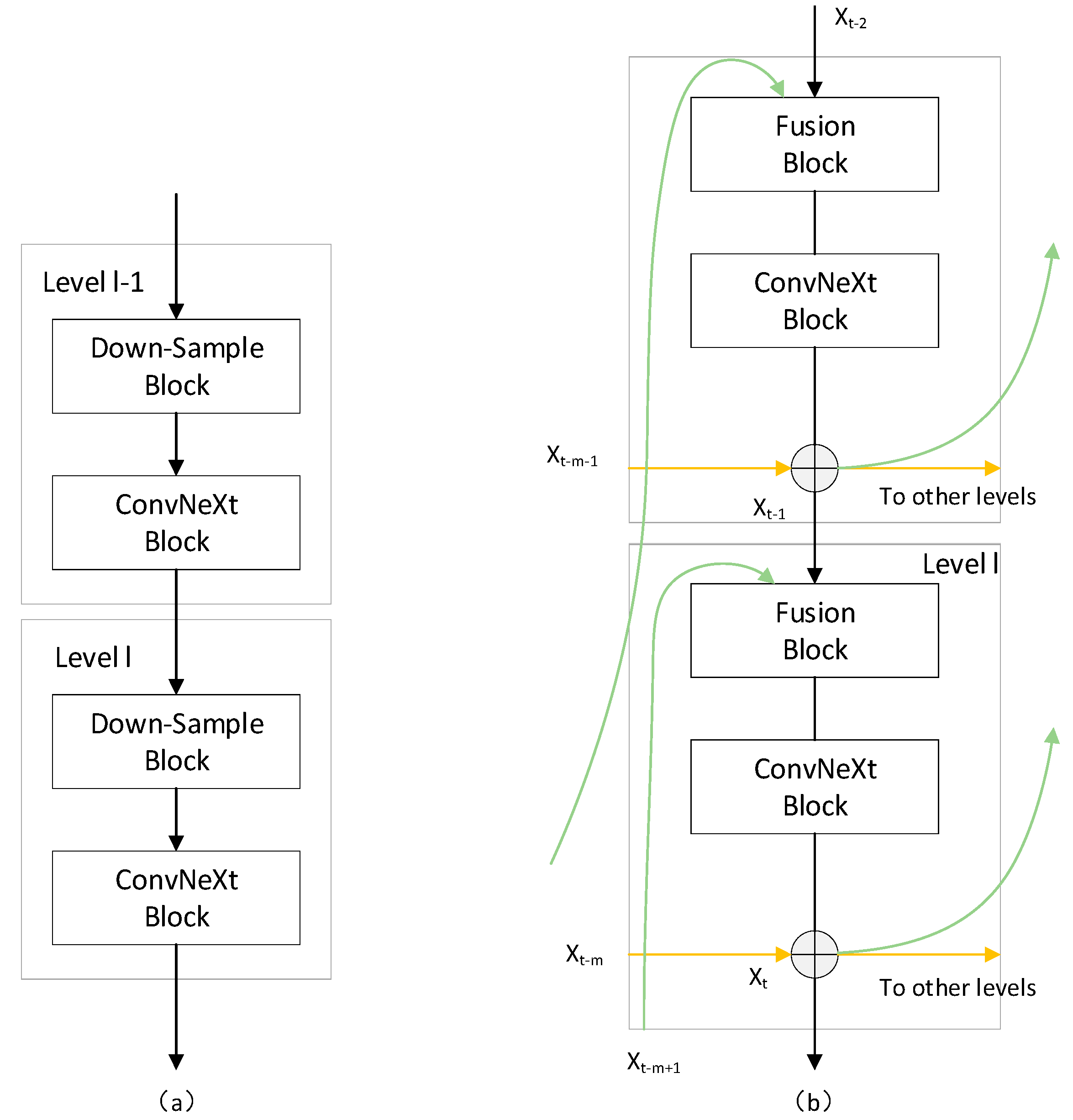
3.1. RevColNet
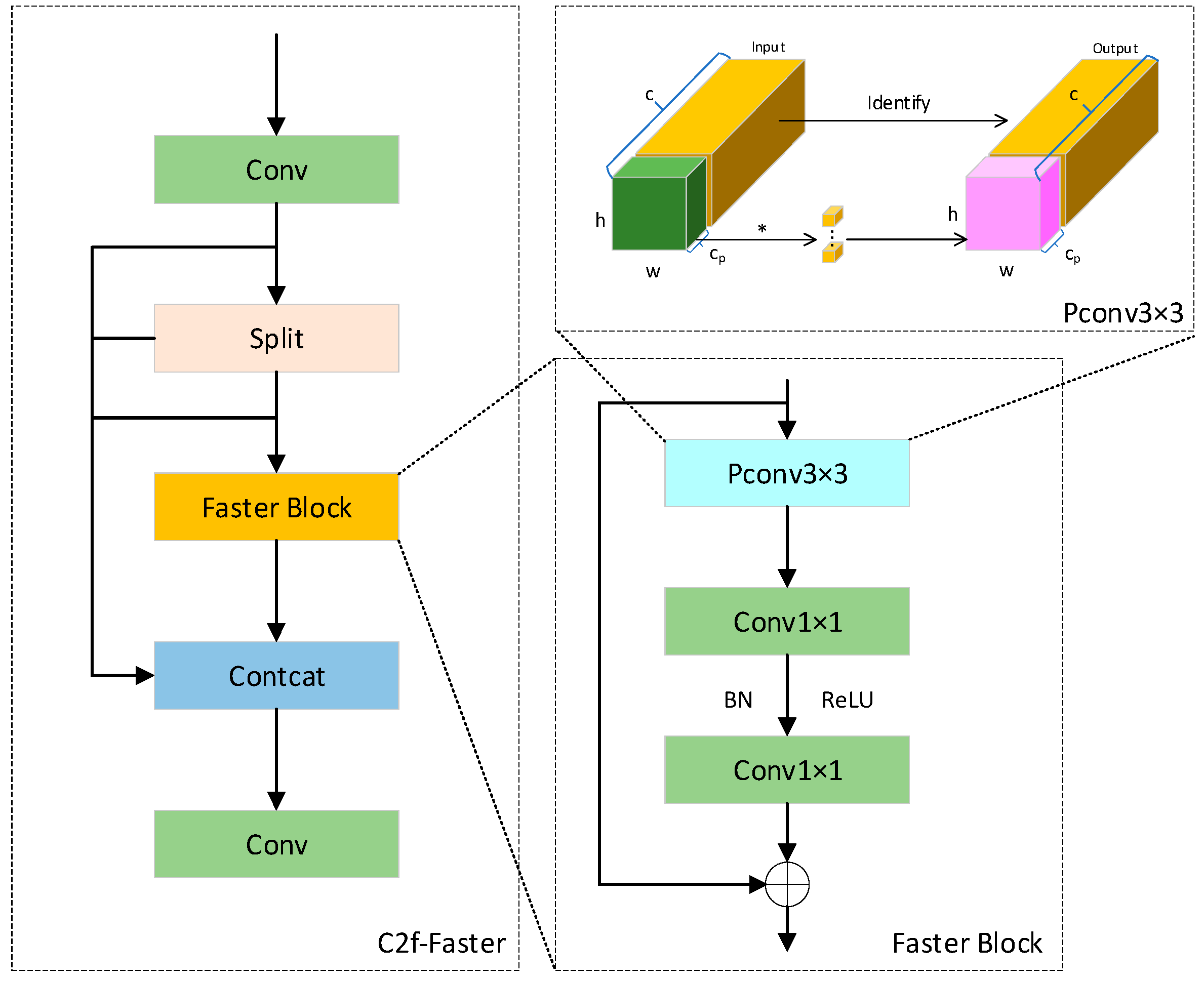
3.2. C2f-Faster
3.3. DyHead
4. Experiment and Analysis
4.1. Evaluation Metrics
4.2. Experimental Results and Analysis
4.2.1. Comparison of Different Algorithms
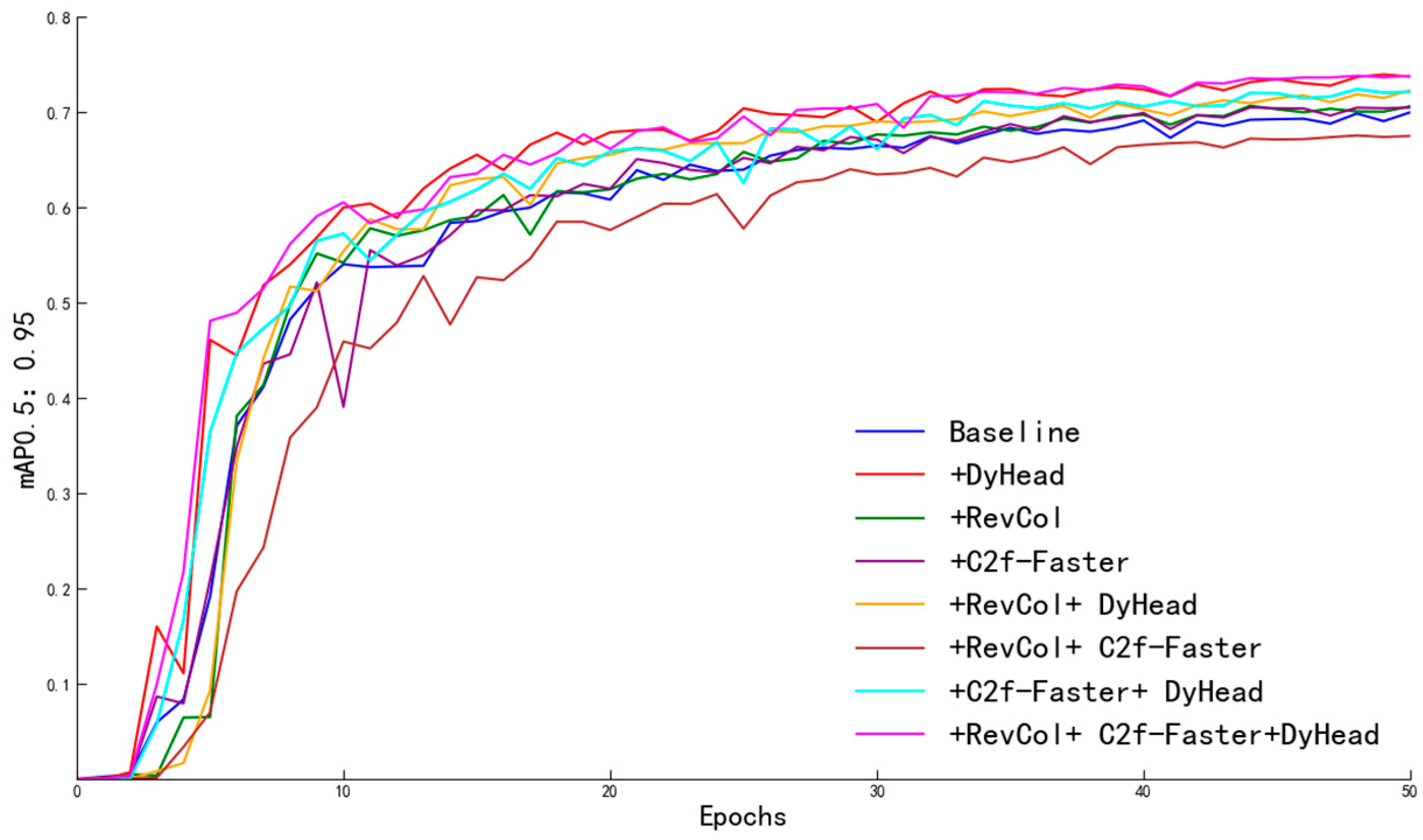
4.2.2. Ablation Study
4.2.3. Visualization Experiments
5. Conclusions
- (1)
- In the feature extraction stage, RevColNet is introduced as the backbone network, replacing the original deep convolutional structure. This network enhances the representation ability for clam targets through its efficient feature aggregation mechanism. It exhibits stronger feature learning ability when handling complex background interference and multi-scale targets, while significantly reducing redundant computation. The introduction of RevCol alone reduces the number of parameters from 3.16 M to 2.28 M, while maintaining the mAP@50:95 without any degradation. It is suitable for target detection tasks in complex background conditions.
- (2)
- In terms of model lightweighting, the C2f-Faster lightweight convolution module is adopted to replace the traditional feature fusion unit. This module optimizes the computation path and parameter reuse strategy, reducing the GFLOPs to 6.3 with minimal loss in accuracy.
- (3)
- In the design of the detection head, the DyHead dynamic detection head is introduced. Through the dynamic allocation mechanism of cross-layer feature weights, the model’s adaptability to multi-scale targets is enhanced. Compared with the traditional fixed weight allocation method, this approach captures target edge information more accurately, further reducing false detection rates and enabling small target detection in dense scenes.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, F.; Huang, Z.; Shen, Q.; Deng, C. Application of edge computing power in intelligent aquaculture. Fish. Mod. 2024, 51, 53–60. [Google Scholar]
- Liu, W.; Hu, Q.; Mei, J.; Feng, J.; Ma, M.; Li, X. Differences in Morphology and Carbon and Nitrogen Contents of Venus Clam Meretrix meretrix from Different Geographical Populations. Fish. Sci. 2024, 43, 737–745. [Google Scholar]
- Qian, C.; Zhang, J.; Tu, X.; Liu, H.; Qiao, G.; Liu, S. Turbot fish egg recognition and counting method based on CBAM-UNet. S. China Fish. Sci. 2024, 20, 132–144. [Google Scholar]
- Wei, J.; Peng, J.; Xu, B.; Tong, Z. Real-time detection of underwater river crab based on multi-scale pyramid fusion image enhancement and MobileCenterNet model. Comput. Electron. Agric. 2023, 204, 107522. [Google Scholar]
- Wang, Z.; Zhang, X.; Li, J.; Luan, K. A YOLO-Based Target Detection Model for Offshore Unmanned Aerial Vehicle Data. Sustainability 2021, 13, 12980. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, C.; Wang, R.; Wang, K.; Qiao, Q. Freshness recognition of small yellow croaker based on image processing and improved DenseNet network. South China Fish. Sci. 2024, 20, 133–142. [Google Scholar]
- Li, Y.; Fan, Q.; Huang, H.; Han, Z.; Gu, Q. A Modified YOLOv8 Detection Network for UAV Aerial Image Recognition. Drones 2023, 7, 304. [Google Scholar] [CrossRef]
- Hao, J.; Yan, G.; Wang, L.; Pei, H.; Xiao, X.; Zhang, B. Lightweight Transmission Line Outbreak Target Obstacle Detection Incorporating ACmix. Processes 2025, 13, 271. [Google Scholar] [CrossRef]
- Mao, Y.; Yang, Y.; Ma, Z.; Li, M. Efficient Low-Cost ship detection for SAR imagery based on simplified U-Net. IEEE Access 2020, 8, 69742–69753. [Google Scholar] [CrossRef]
- Ma, N.; Su, Y.; Yang, L.; Li, Z.; Yan, H. Wheat Seed Detection and Counting Method Based on Improved YOLOv8 Model. Sensors 2024, 24, 1654. [Google Scholar] [CrossRef]
- Sun, L.; Hu, G.; Chen, C.; Cai, H.; Li, C.; Zhang, S.; Chen, J. Lightweight Apple Detection in Complex Orchards Using YOLOV5-PRE. Horticulturae 2022, 8, 1169. [Google Scholar] [CrossRef]
- Xin, S.; Ge, H.; Yuan, H.; Yang, Y.; Yao, Y. Improved lightweight underwater target detection algorithm of YOLOv7. Comput. Eng. Appl. 2024, 60, 88–99. [Google Scholar]
- Hao, Y.; Zhang, C.; Li, X. Research on defect detection method of bearing dust cover based on machine vision and multifeature fusion algorithm. Meas. Sci. Technol. 2023, 34, 105016. [Google Scholar] [CrossRef]
- Bo, G. Research on Two-Way detection of YOLO V5s+Deep sort road vehicles based on attention mechanism. J. Phys. Conf. Ser. 2022, 2303, 012057. [Google Scholar]
- Ding, Y.; Jiang, C.; Song, L.; Liu, F.; Tao, Y. RVDR-YOLOv8: A Weed Target Detection Model Based on Improved YOLOv8. Electronics 2024, 13, 2182. [Google Scholar] [CrossRef]
- Zhang, W.; Li, Y.; Liu, A. RCDAM-Net: A foreign object detection algorithm for transmission tower lines based on RevCol network. Appl. Sci. 2024, 14, 1152. [Google Scholar] [CrossRef]
- Bao, J.; Li, S.; Wang, G.; Xiong, J.; Li, S. Improved YOLOV8 network and application in safety helmet detection. J. Phys. Conf. Ser. 2023, 2632, 012012. [Google Scholar] [CrossRef]
- Yin, B. Lightweight fire detection algorithm based on LSCD-FasterC2f-YOLOv8. In Proceedings of the 2024 5th International Conference on Big Data & Artificial Intelligence & Software Engineering (ICBASE), Wenzhou, China, 20–22 September 2024; IEEE: New York, NY, USA, 2024; pp. 64–67. [Google Scholar]
- Chen, Q.; Dai, Z.; Xu, Y.; Gao, Y. CTM-YOLOv8n: A Lightweight Pedestrian Traffic-Sign Detection and Recognition Model with Advanced Optimization. World Electr. Veh. J. 2024, 15, 285. [Google Scholar] [CrossRef]
- Ding, K.; Ding, Z.; Zhang, Z.; Mao, Y.; Ma, G.; Lv, G. Scd-yolo: A novel object detection method for efficient road crack detection. Multimed. Syst. 2024, 30, 351. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision/% | mAP0.5/% | mAP0.5:0.95/% | Params/M | GFLOPs |
|---|---|---|---|---|---|
| Faster R-CNN | 99.5 | 98.1 | 74.6 | 41.4 | 239.3 |
| YOLOv5s | 85.4 | 84.5 | 62.1 | 7.1 | 16.5 |
| YOLOv8n | 89.8 | 89.3 | 70.4 | 3.2 | 8.9 |
| YOLOv8-RFD | 89.9 | 89.5 | 72.2 | 2.2 | 6.6 |
| Model | Parameter | GFLOPs | mAP50/% | mAP50:95/% |
|---|---|---|---|---|
| YOLOv8n | 3,157,200 | 8.9 | 89.3 | 70.4 |
| YOLOv8n + DyHead | 3,485,263 | 9.6 | 89.6 | 74.0 |
| YOLOv8n + RevCol | 2,276,435 | 6.3 | 89.2 | 70.6 |
| YOLOv8n + C2f-Faster | 2,300,643 | 6.3 | 89.2 | 70.4 |
| YOLOv8n + RevCol + DyHead | 2,755,855 | 7.8 | 89.3 | 71.7 |
| YOLOv8n + RevCol + C2f-Faster | 1,751,835 | 5.0 | 89.1 | 67.2 |
| YOLOv8n + C2f-Faster + DyHead | 2,780,063 | 7.9 | 89.5 | 72.4 |
| YOLOv8n + RevCol + C2f-Faster + DyHead | 2,231,255 | 6.6 | 89.5 | 72.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, Z.; Hou, S.; Yue, X.; Hu, X. A Lightweight Detection Method for Meretrix Based on an Improved YOLOv8 Algorithm. Appl. Sci. 2025, 15, 6647. https://doi.org/10.3390/app15126647
Tian Z, Hou S, Yue X, Hu X. A Lightweight Detection Method for Meretrix Based on an Improved YOLOv8 Algorithm. Applied Sciences. 2025; 15(12):6647. https://doi.org/10.3390/app15126647
Chicago/Turabian StyleTian, Zhongxu, Sifan Hou, Xiaoxue Yue, and Xuewen Hu. 2025. "A Lightweight Detection Method for Meretrix Based on an Improved YOLOv8 Algorithm" Applied Sciences 15, no. 12: 6647. https://doi.org/10.3390/app15126647
APA StyleTian, Z., Hou, S., Yue, X., & Hu, X. (2025). A Lightweight Detection Method for Meretrix Based on an Improved YOLOv8 Algorithm. Applied Sciences, 15(12), 6647. https://doi.org/10.3390/app15126647