4.5.1. Comparative Experiments
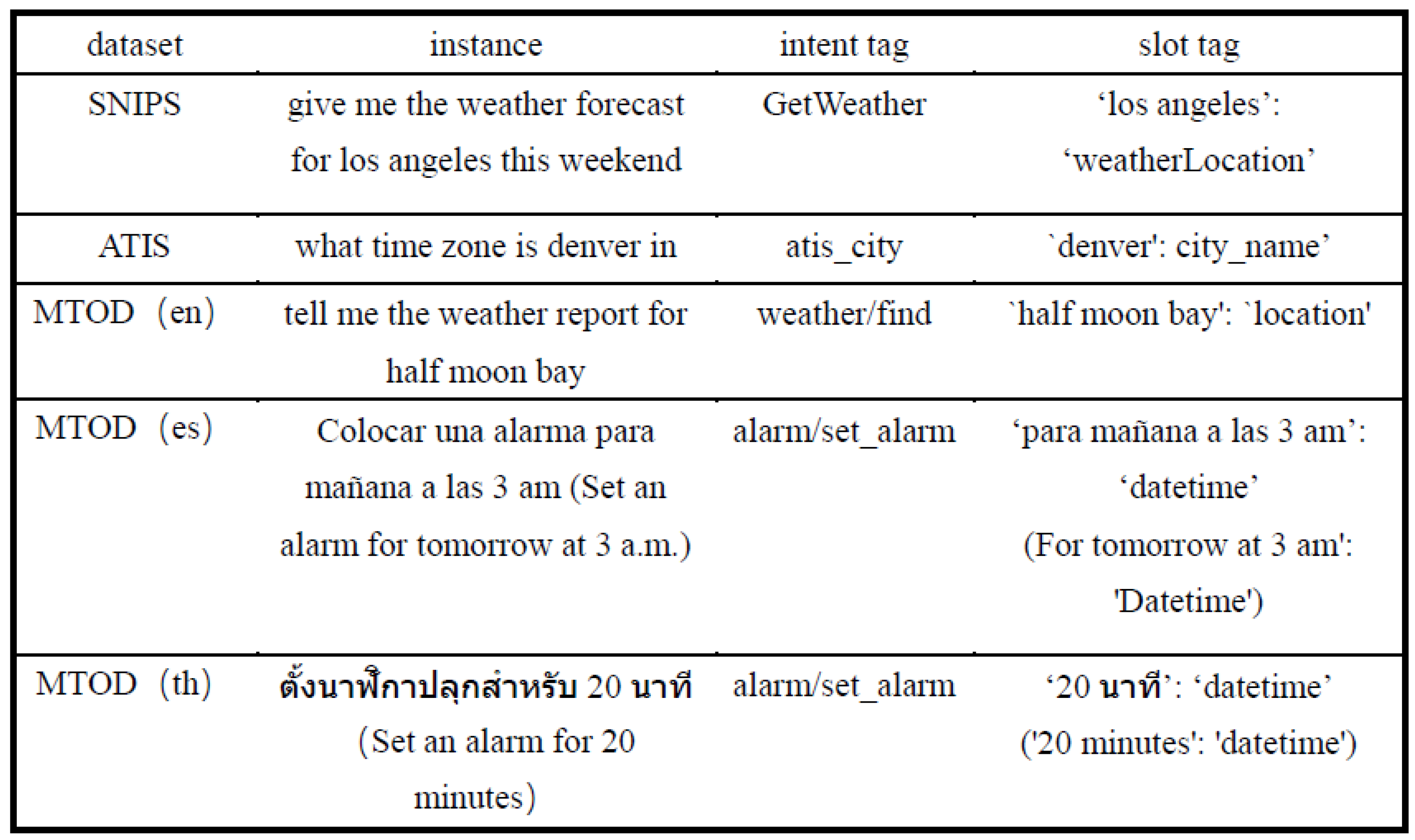
To comprehensively compare the cross-lingual transfer ability of the Bi-XTM model, this experiment uses three different training methods, including the following: (1) Zero-shot training: Only the source language is used during the training process and the model is not exposed to the target language. (2) Single-language training: The model is trained and evaluated separately on different language corpora without distinguishing between the source and target languages. (3) Mixed-language training: The source language is used during the training process, and the model is exposed to the target language. In the zero-shot training method, the main focus is on the model’s cross-lingual transfer ability to Kazakh. Since the source languages are Chinese and English, the evaluation results for the Chinese and English corpora are the same as those for single-language training. The comparison results of the MTOD zero-shot training experiment are shown in
Table 2.
Table 2,
Table 3 and
Table 4 show the comparative experimental results of the Bi-XTM model on the MTOD dataset. From the experimental results, it can be seen that since mBERT did not include Spanish and Thai training data during the pre-training phase, the model performed poorly on the target language data. The XLM-R model, compared to the mBERT model, used more parallel corpora and monolingual data during the pre-training phase, but this does not mean that it can be directly applied to all languages.
The coverage of Thai data in the training dataset is relatively low, so the XLM-R model may not fully learn and capture the linguistic features of Thai, leading to poor performance on Thai data. The CINO model introduced more low-resource corpora for secondary pre-training, addressing the issue of insufficient data in low-resource languages and improving the model’s adaptability to these languages, thus achieving a significant performance improvement on target language data. The Co-Transformer model, using CINO as the shared encoder, incorporated an explicit bidirectional interaction module, which not only shares lower-level representations but also more finely controls the interaction and information transfer between subtasks. The Co-Transformer model effectively improved intent accuracy on target language data; however, due to the error propagation problem in sentence-level intent vector representations during the transfer to slot vector representations, the model negatively impacted the evaluation of slot scores, with a slight decline in performance on Thai data.
Compared to the baseline models, the Bi-XTM model achieved significant improvements in intent classification accuracy across all languages (English, Spanish, and Thai). Furthermore, on English and Spanish corpora, the Bi-XTM model effectively alleviated the error propagation issues caused by bidirectional information transfer, resulting in notable improvements in slot scores. However, the model’s slot filling performance on Thai data did not reach optimal levels, as the shared encoder introduced minority language semantic vector representations, and shared information between different language families may have been interfered with, leading to data bias. Future research could address this issue by expanding the training samples and labels, including more low-resource languages, such as Thai, to improve the model’s generalization capability in low-resource scenarios. For English corpora, although the Bi-XTM model showed a slight decrease in sentence-level accuracy, its advantage lies in more precisely controlling the bidirectional relationships and information transfer between subtasks in cross-lingual scenarios, resulting in overall good generalization. Therefore, the slight accuracy drop on certain languages is a trade-off to achieve better model generalization.
The comparative experimental results of the Bi-XTM model on the MTOD dataset demonstrate that introducing the subtask interaction module in cross-lingual pre-training models helps alleviate the error propagation issues caused by bidirectional information transfer, positively impacting the joint tasks of intent recognition and slot filling. However, the Bi-XTM model shows performance gaps of 17.8%, 36.6%, and 37.8% in Acc, F1, and Sent.Acc scores between Spanish and Thai, respectively, indicating that cross-lingual transfer between languages from different language families remains challenging.
Specifically, the model’s recognition accuracy on Thai is low. This is primarily because Spanish and English, as widely spoken global languages, have abundant publicly available data resources, allowing the model to fully learn their grammatical and semantic features from large-scale corpora and thus form more accurate representations. In contrast, Thai and minority languages suffer from a lack of data, making it difficult for the model to capture their unique linguistic patterns, which limits classification performance. Spanish and English both belong to the Indo-European language family and share high similarity in grammatical structures and vocabulary composition, enabling the model to transfer and share linguistic knowledge through transfer learning. However, Thai belongs to the Kra–Dai language family, and minority languages such as Tibetan and Mongolian have unique writing systems and grammatical rules that differ significantly from mainstream languages. As a result, it is difficult for the model to directly reuse existing knowledge. These languages require additional adaptation to their specific linguistic characteristics, but due to limited data availability, the model is unable to effectively learn these features, which negatively affects classification performance.
Table 5,
Table 6 and
Table 7 show the comparative experimental results of the Bi-XTM model on the JISD dataset. During the pre-training phase, both the mBERT and XLM-R models used a large amount of multi-lingual data; however, these datasets lacked sufficient Kazakh data, preventing the models from fully learning the linguistic features and semantic information of Kazakh, leading to poor performance in cross-lingual scenarios.
The CINO model uses a large amount of data from Chinese minority languages, including a significant amount of Kazakh data, enabling the CINO model to better understand and learn Kazakh’s grammatical structures and semantic rules. The rich data volume and diversity provide the model with a more comprehensive linguistic background and knowledge, significantly improving its recognition performance in Kazakh. The Co-Transformer model still faces the issue of error propagation caused by sentence-level intent information transfer. Compared to CINO, this model shows a slight improvement in intent accuracy but reduces slot recognition performance. The Bi-XTM model outperforms the baseline model on all three metrics, demonstrating its excellent cross-lingual transfer ability. However, its overall accuracy has not yet reached a stage where it is fully applicable, so a further comparison experiment using the mixed-language training method is considered.
To compare with the mixed-language training method, this experiment also included single-language training, using Chinese and Kazakh corpora as the model’s training data to observe the model’s performance on different language corpora. Compared to the zero-shot training method, the mBERT and XLM-R models show significant performance improvements on the Kazakh corpus. However, due to the lack of specialized training and optimization for low-resource languages, these two models still exhibit a significant performance gap when compared to the CINO and Co-Transformer models. Although the Bi-XTM model achieves optimal performance on the Kazakh corpus across all three metrics, the model struggles to reach system-level application effectiveness due to data scarcity when trained solely on low-resource single-language corpora.
Mixed-language training allows the model to share knowledge between the source and target languages. There may be certain linguistic similarities and shared features between different languages, and mixed-language training enables the model to encounter multiple languages during the training phase, allowing it to learn these shared features. From the results of the mixed-language training experiment, it can be seen that the Bi-XTM model achieves optimal performance on the Kazakh corpus across all three metrics. However, the model shows an overall decrease in performance on the Chinese corpus compared to the other two training methods. This is because factors such as linguistic differences between languages, domain-specific differences, and lexical ambiguity affect the model’s performance on the source language. Therefore, in practical applications, it is important to consider the proportion of mixed-language training samples based on the specific situation to achieve a performance balance across languages and enhance the model’s generalization ability.
Zero-shot, monolingual, and mixed-language comparative experiments conducted on the JISD dataset show that introducing semantic vector representations of Chinese minority languages in cross-lingual pre-trained models, combined with the use of the subtask interaction module, can effectively alleviate the error propagation caused by sentence-level intention information transmission and significantly enhance the model’s cross-lingual transfer ability from Chinese to Kazakh.
4.5.2. Ablation Experiments
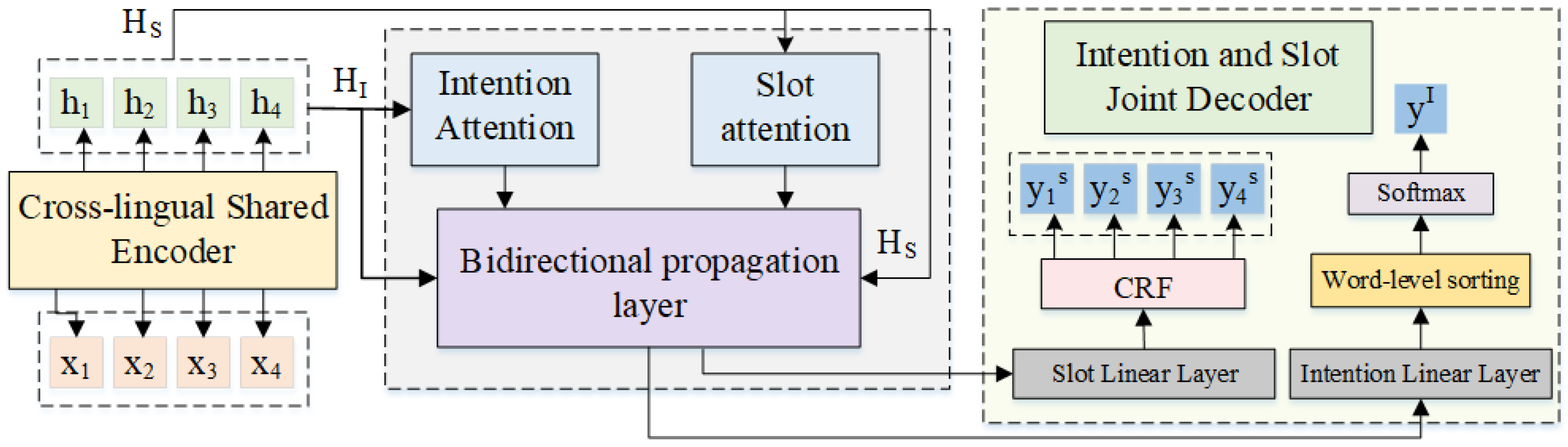
The comparative experiment analyzed the cross-lingual transfer performance of the Bi-XTM model on the joint task of question understanding. To further investigate the positive impact of the subtask interaction module on the model, the following ablation experiments were conducted: (1) Encoder: The probability outputs generated by the cross-lingual shared encoder are directly fed into the intent and slot decoders without adding any explicit interaction layers. (2) w/o BP: The subtask interaction layer is removed to explore the effect of collaborative interaction attention on the model’s performance. (3) w/o CA: The collaborative interaction attention layer is removed, keeping the subtask interaction layer, and the word-level encoding method is used to understand the positive impact brought by the subtask interaction layer. (4) Intent: Information transmission from intent vectors to slot vectors in the interaction layer is canceled. (5) Slot: Information transmission from slot vectors to intent vectors in the interaction layer is canceled.
Table 8 and
Table 9 show the ablation experiment results of the Bi-XTM model on the target language data of the MTOD and JISD datasets, respectively. After removing the subtask interaction module, the model degrades into an implicit joint model (Encoder), exhibiting the worst cross-lingual transfer performance across the three target language corpora. This is because relying solely on shared low-level representations does not enable the model to learn the direct correlation between intent vectors and slot vectors.
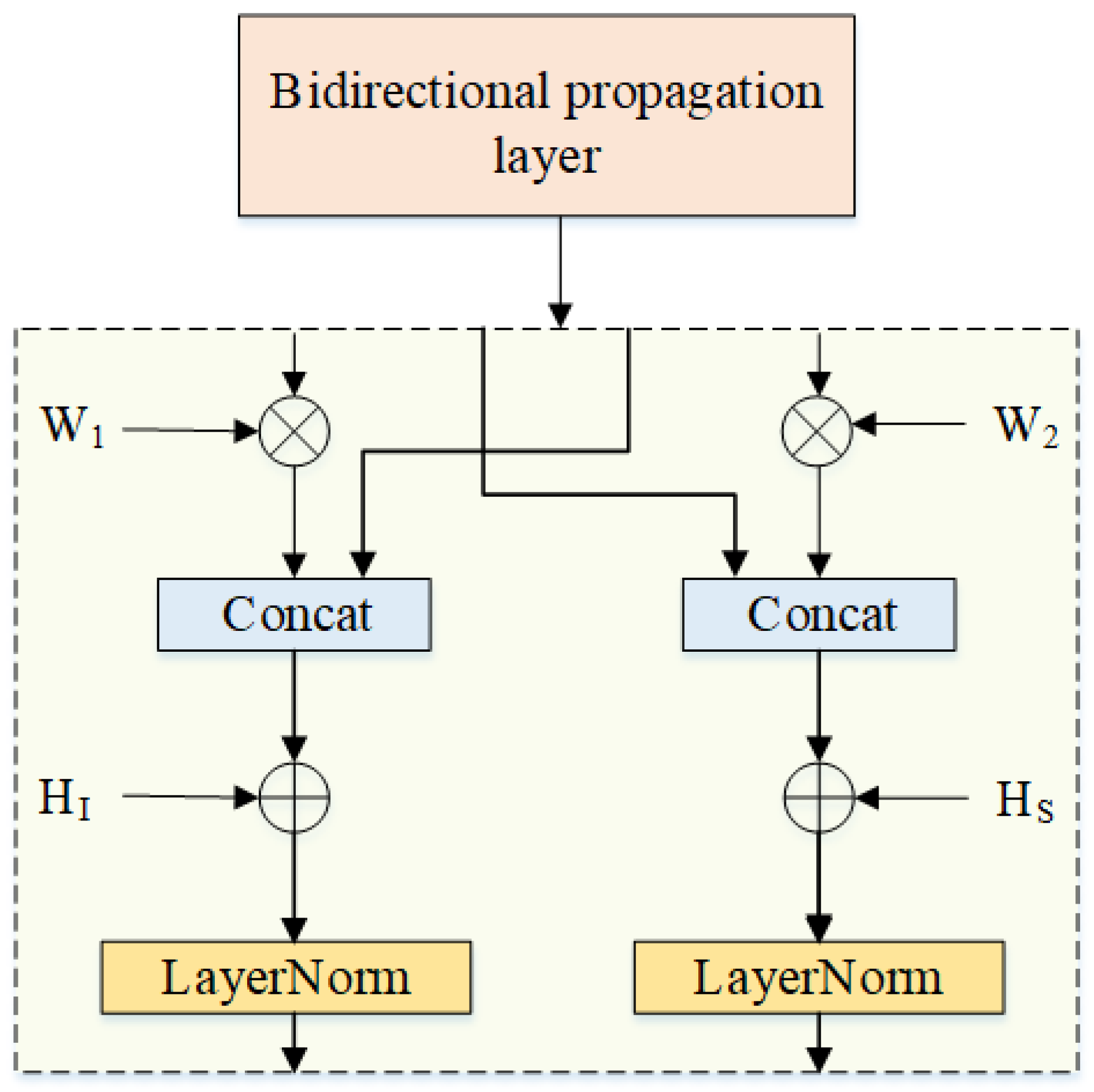
When the subtask interaction layer is removed (w/o BP), the model shares local information of intermediate-layer intent and slot vectors through the collaborative interaction attention mechanism. Under this setting, intent accuracy shows a slight improvement, but the slot score drops significantly. This indicates that the attention layer captures key local information from the characters, allowing the model to predict intents while also capturing the slot information associated with those intents. Such contextual association helps improve the accurate understanding of user input and better semantic modeling. However, when the model uses sentence-level encoding for transmission, if an incorrect intent label is recognized, the slot vector will receive noisy information from the intent, leading to a misunderstanding of slot information and thus causing errors in slot recognition. When the collaborative interaction attention layer is removed (w/o CA), the improvement in intent accuracy is not significant, but the error propagation caused by sentence-level encoding is effectively mitigated. In the one-way transmission methods (Intent and Slot), cutting off either the intent-to-slot or slot-to-intent transmission results in only slight performance differences, and the receiving side of the one-way propagation generally achieves better performance. This is due to the error correction phenomenon induced by cutting the interaction loop in one-way propagation. Although this helps reduce error propagation, it also blocks the positive transmission of intent or slot information. After integrating the collaborative interaction attention layer and the subtask interaction layer (Bi-XTM), the model not only leverages the interdependence between subtasks but also filters out erroneous information during the recognition process through word-level encoding, thus achieving optimal performance.
The ablation experiment results confirm that introducing the subtask interaction method based on the collaborative interaction attention mechanism, along with label-aware word-level intent and slot vector representations, indeed enhances the interaction between the two tasks, leading to better overall performance.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}