

A Lightweight Framework for Audio-Visual Segmentation with an Audio-Guided Space–Time Memory Network

Abstract
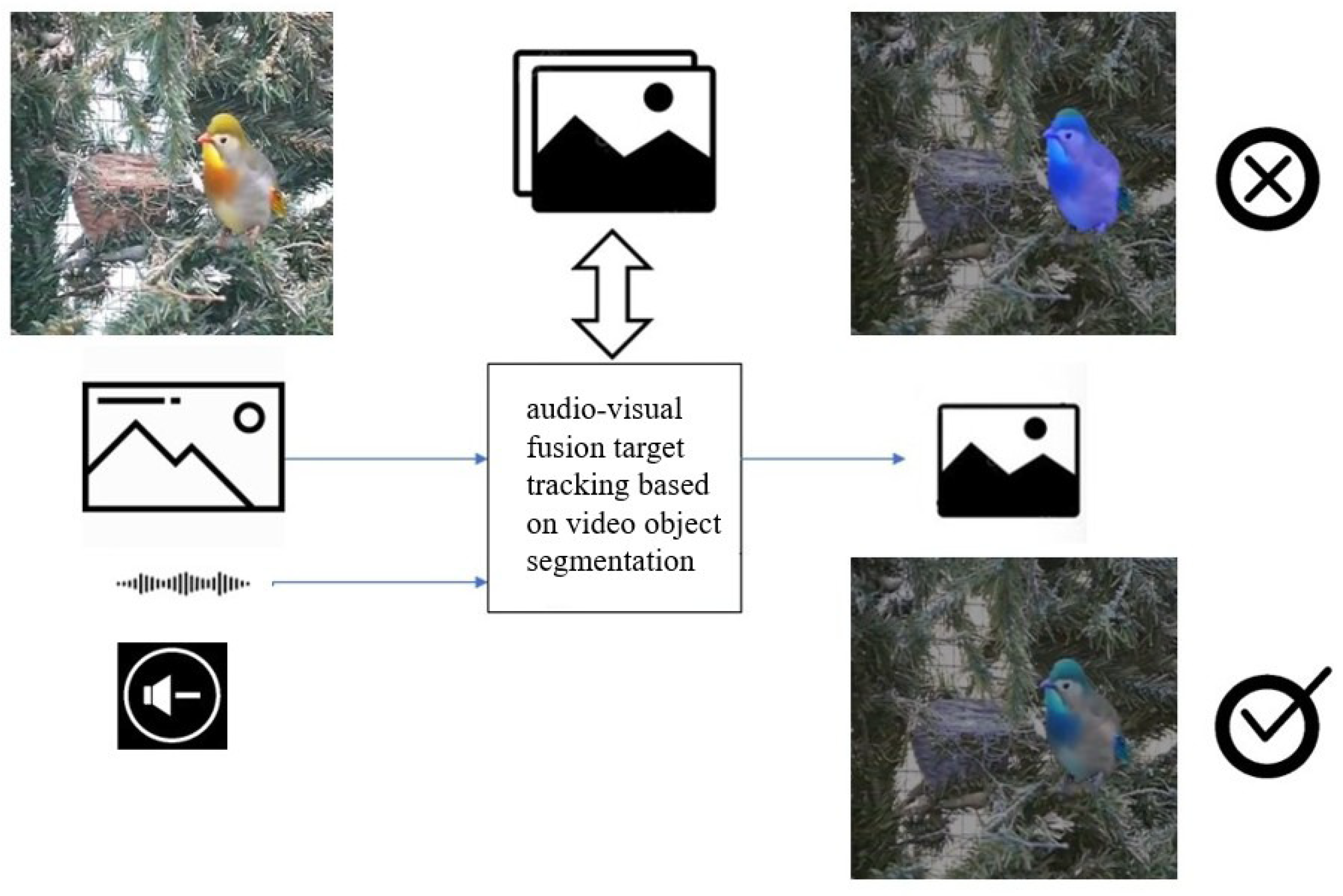
1. Introduction
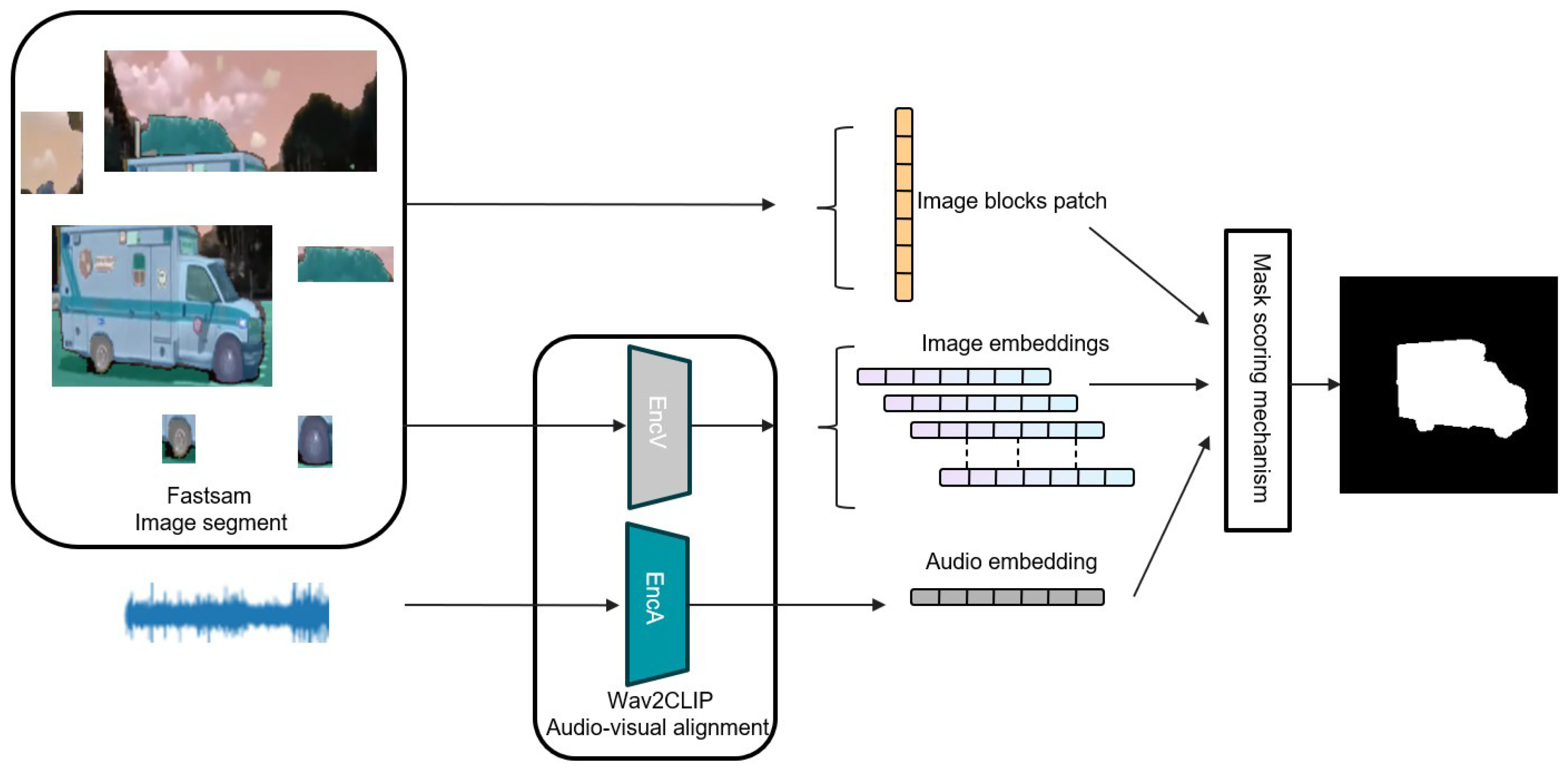
- To achieve lightweight audio-visual segmentation, this research proposes an efficient audio-visual mask generator leveraging pre-trained lightweight models, Fastsam and Wav2CLIP. Additionally, a mask-scoring mechanism is designed to optimize the mask, thereby enhancing the accuracy and precision of target segmentation;
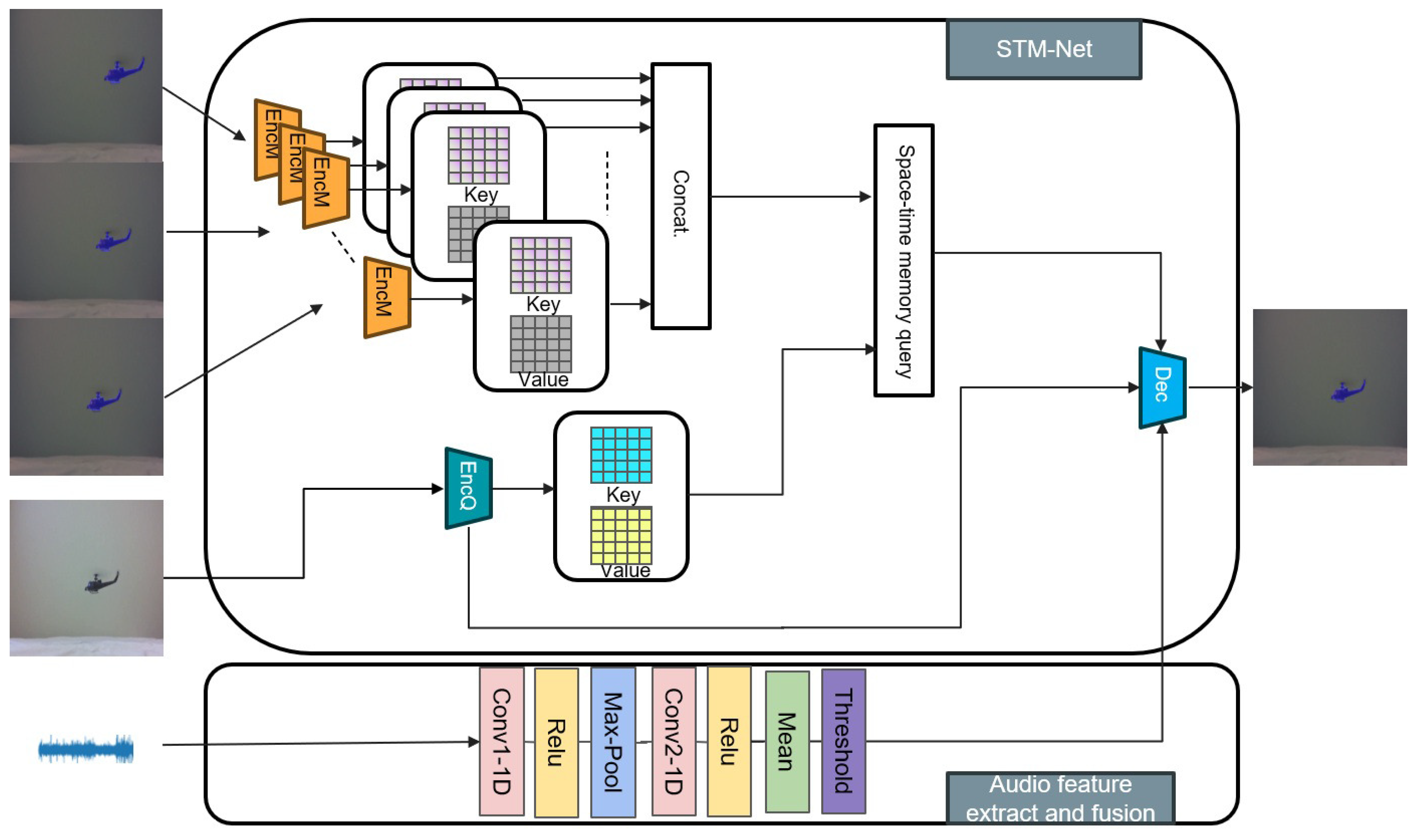
- In addition to the audio-visual fusion mask, to enable continuous tracking of the vocal target guided by the fusion mask, this research proposes a video object tracking network based on a space–time memory network (STM-Net). The audio feature extraction and fusion module within the network detects changes in the audio signal and transmits the output information to the upsampling module of the mask decoder to guide the generation of the final segmentation mask, thereby suppressing the interference of environmental noise.
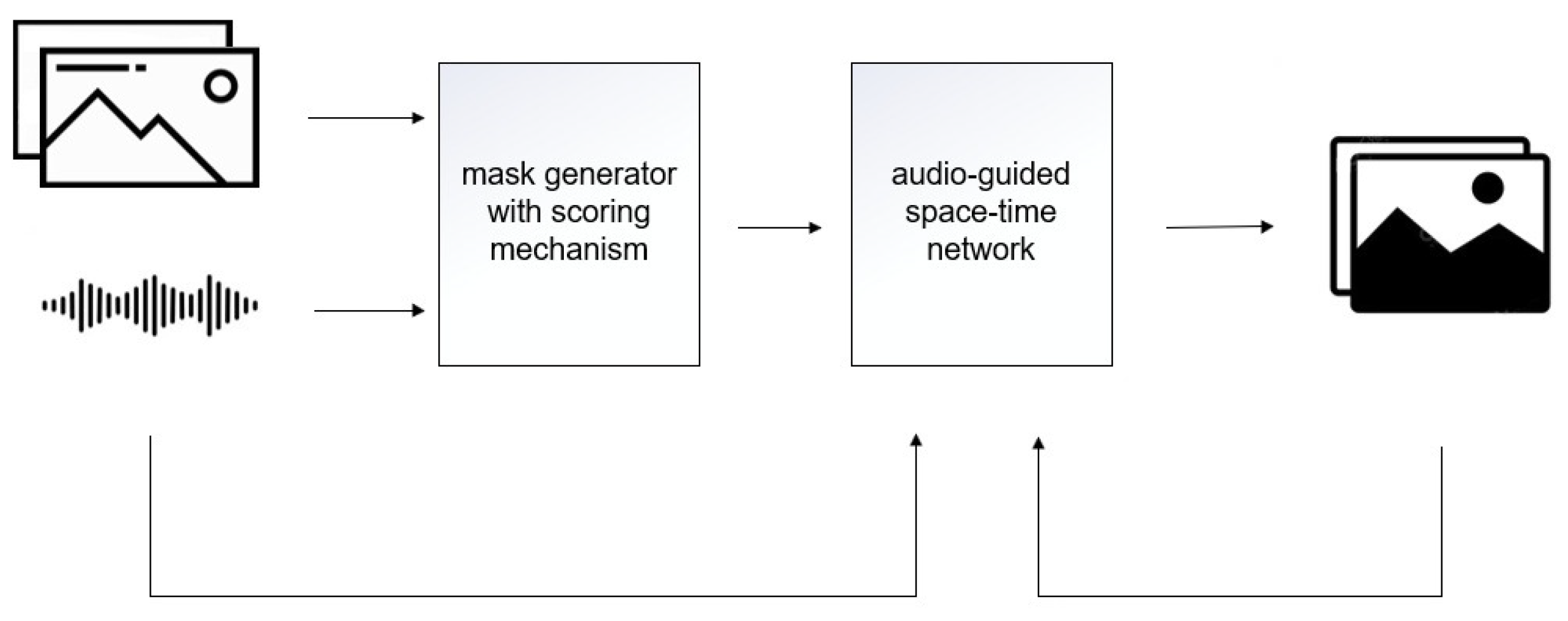
2. Methodology
2.1. Mask Generator
2.2. Audio-Guided Space–Time Memory Network
3. Experiments and Results
3.1. Mask Generator
3.1.1. Dataset, Evaluation Metrics, and Hardware
3.1.2. Experiments
- (1)
- Parameter determination
- (2)
- Comparison experiments
- (3)
- Visualization and case study
3.2. Audio-Guided Space–Time Memory Network
3.2.1. Dataset, Evaluation Metrics, and Hardware
3.2.2. Experiments
- (1)
- Training
- (2)
- Testing and Evaluation
- (3)
- Visualization and case study
4. Conclusions and Discussion
- (1)
- To achieve lightweight audio-visual fusion object segmentation, a mask generator based on a pre-trained audio-visual modal alignment model is proposed. The pre-trained lightweight image segmentation model, Fastsam, is employed to generate initial masks. A mask-scoring mechanism is then designed to guide the refinement of the final mask output, thereby realizing audio-visual target mask generation. On the AVSbench test dataset, the proposed mask generator achieves an mIoU score of 54.5.
- (2)
- In order to achieve target tracking with audio-visual fusion mask prompts and address the issue of model mis-segmentation caused by environmental noise, a lightweight sound-controlled target tracking network is proposed. A space–time memory network is employed for target tracking and segmentation, while an audio feature extraction and fusion module is introduced to suppress environmental noise and interference sound sources. The experimental results demonstrate that the proposed method can effectively track targets under audio-visual fusion mask guidance, dynamically adjust the mask output in response to audio changes, and successfully suppress environmental noise. This network achieved an mIoU score of 53.2 on the Ref-AVSbench (S4) test dataset.
- (3)
- To evaluate the complete model, the mask generator was integrated with the audio-guided space–time memory network. The experimental results on the Ref-AVSbench (S4) test dataset demonstrate that the complete model is capable of recognizing and tracking vocal objects, providing a viable solution for audio-visual fusion target tracking. The mIoU score is 41.5.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, J.; Wang, J.; Zhang, J.; Sun, W.; Zhang, J.; Birchfield, S.; Guo, D.; Kong, L.; Wang, M.; Zhong, Y. Audio–visual segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 386–403. [Google Scholar]
- Zhang, S.; Zhang, Y.; Liao, Y.; Pang, K.; Wan, Z.; Zhou, S. Polyphonic sound event localization and detection based on Multiple Attention Fusion ResNet. Math. Biosci. Eng. 2024, 21, 2004–2023. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Liu, Y.; Zhang, F.; Ju, C.; Zhang, Y.; Wang, Y. Audio-visual segmentation via unlabeled frame exploitation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 26328–26339. [Google Scholar]
- Chen, T.; Tan, Z.; Gong, T.; Chu, Q.; Wu, Y.; Liu, B.; Lu, L.; Ye, J.; Yu, N. Bootstrapping audio-visual segmentation by strengthening audio cues. arXiv 2024, arXiv:2402.02327. [Google Scholar] [CrossRef]
- Guo, C.; Huang, H.; Zhou, Y. Enhance audio-visual segmentation with hierarchical encoder and audio guidance. Neurocomputing 2024, 594, 127885. [Google Scholar] [CrossRef]
- Hao, D.; Mao, Y.; He, B.; Han, X.; Dai, Y.; Zhong, Y. Improving audio-visual segmentation with bidirectional generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 2067–2075. [Google Scholar]
- Yang, Q.; Nie, X.; Li, T.; Gao, P.; Guo, Y.; Zhen, C.; Yan, P.; Xiang, S. Cooperation does matter: Exploring multi-order bilateral relations for audio-visual segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 27134–27143. [Google Scholar]
- Mao, Y.; Zhang, J.; Xiang, M.; Zhong, Y.; Dai, Y. Multimodal variational auto-encoder based audio-visual segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 954–965. [Google Scholar]
- Liu, C.; Li, P.P.; Qi, X.; Zhang, H.; Li, L.; Wang, D.; Yu, X. Audio-visual segmentation by exploring cross-modal mutual semantics. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 7590–7598. [Google Scholar]
- Wang, Y.; Sun, P.; Li, Y.; Zhang, H.; Hu, D. Can Textual Semantics Mitigate Sounding Object Segmentation Preference? In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2024; pp. 340–356. [Google Scholar]
- Wang, Y.; Zhu, J.; Dong, F.; Zhu, S. Progressive Confident Masking Attention Network for Audio-Visual Segmentation. arXiv 2024, arXiv:2406.02345. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 4015–4026. [Google Scholar]
- Mo, S.; Tian, Y. AV-SAM: Segment anything model meets audio-visual localization and segmentation. arXiv 2023, arXiv:2305.01836. [Google Scholar]
- Huang, S.; Ling, R.; Li, H.; Hui, T.; Tang, Z.; Wei, X.; Han, J.; Liu, S. Unleashing the temporal-spatial reasoning capacity of gpt for training-free audio and language referenced video object segmentation. arXiv 2024, arXiv:2408.15876. [Google Scholar] [CrossRef]
- Bhosale, S.; Yang, H.; Kanojia, D.; Deng, J.; Zhu, X. Unsupervised audio-visual segmentation with modality alignment. In Proceedings of the AAAI Conference on Artificial Intelligence, Edmonton, AB, Canada, 10–14 November 2025; Volume 39, pp. 15567–15575. [Google Scholar]
- Liu, J.; Wang, Y.; Ju, C.; Ma, C.; Zhang, Y.; Xie, W. Annotation-free audio-visual segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 5604–5614. [Google Scholar]
- Nguyen, K.B.; Park, C.J. SAVE: Segment Audio-Visual Easy way using Segment Anything Model. arXiv 2024, arXiv:2407.02004. [Google Scholar]
- Lin, Y.B.; Sung, Y.L.; Lei, J.; Bansal, M.; Bertasius, G. Vision transformers are parameter-efficient audio-visual learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2299–2309. [Google Scholar]
- Xu, S.; Wei, S.; Ruan, T.; Liao, L.; Zhao, Y. Each Perform Its Functions: Task Decomposition and Feature Assignment for Audio-Visual Segmentation. IEEE Trans. Multimed. 2024, 26, 9489–9498. [Google Scholar] [CrossRef]
- Zhao, X.; Ding, W.; An, Y.; Du, Y.; Yu, T.; Li, M.; Tang, M.; Wang, J. Fast segment anything. arXiv 2023, arXiv:2306.12156. [Google Scholar]
- Wu, H.H.; Seetharaman, P.; Kumar, K.; Bello, J.P. Wav2clip: Learning robust audio representations from clip. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 7–13 May 2022; pp. 4563–4567. [Google Scholar]
- Oh, S.W.; Lee, J.Y.; Xu, N.; Kim, S.J. Video object segmentation using space-time memory networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Repulic of Korea, 27 October–2 November 2019; pp. 9226–9235. [Google Scholar]
- Yu, J.; Li, H.; Hao, Y.; Wu, J.; Xu, T.; Wang, S.; He, X. How Can Contrastive Pre-training Benefit Audio-Visual Segmentation? A Study from Supervised and Zero-shot Perspectives. In Proceedings of the BMVC, Aberdeen, UK, 20–24 November 2023; pp. 367–374. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Type | Kernel Size | Step Size | Kernel Size | Input Shape | Output Shape |
|---|---|---|---|---|---|
| Conv1-1d | 3 | 1 | 1 | 1 × 22,050 | 64 × 22,050 |
| MaxPool1d | 2 | 2 | - | 64 × 22,050 | 64 × 11,025 |
| Conv2-1d | 3 | 1 | 1 | 64 × 11,025 | 128 × 11,025 |
| n | mIoU | F-Score | ||
|---|---|---|---|---|
| 0.1 | 0.9 | 3 | 54.5 | 0.565 |
| 0.1 | 0.9 | 4 | 42.4 | 0.435 |
| 0.1 | 0.9 | 5 | 41.3 | 0.364 |
| 0.5 | 0.5 | 3 | 32.4 | 0.367 |
| 0.9 | 0.1 | 3 | 19.2 | 0.238 |
| mIoU | F-Score | |
|---|---|---|
| 41.7 | 0.526 | |
| 54.5 | 0.565 | |
| 72.6 | 0.482 | |
| 51.8 | 0.626 | |
| 40.5 | 0.568 | |
| 70.5 | 0.811 |
| STM-Net | Audio-Guided Module | Mask Generator | mIoU | F-Score |
|---|---|---|---|---|
| ✓ | 71.7 | 0.725 | ||
| ✓ | ✓ | 53.2 | 0.551 | |
| ✓ | ✓ | ✓ | 41.5 | 0.535 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zuo, Y.; Zhang, Y. A Lightweight Framework for Audio-Visual Segmentation with an Audio-Guided Space–Time Memory Network. Appl. Sci. 2025, 15, 6585. https://doi.org/10.3390/app15126585
Zuo Y, Zhang Y. A Lightweight Framework for Audio-Visual Segmentation with an Audio-Guided Space–Time Memory Network. Applied Sciences. 2025; 15(12):6585. https://doi.org/10.3390/app15126585
Chicago/Turabian StyleZuo, Yunpeng, and Yunwei Zhang. 2025. "A Lightweight Framework for Audio-Visual Segmentation with an Audio-Guided Space–Time Memory Network" Applied Sciences 15, no. 12: 6585. https://doi.org/10.3390/app15126585
APA StyleZuo, Y., & Zhang, Y. (2025). A Lightweight Framework for Audio-Visual Segmentation with an Audio-Guided Space–Time Memory Network. Applied Sciences, 15(12), 6585. https://doi.org/10.3390/app15126585