1. Introduction
A pseudoword is constructed with proper linguistic structure but lacks meaning [
1]. Pseudowords adhere to a language’s phonotactic and orthographic rules and are typically characterized by the absence of frequency statistics since they are not part of the language’s lexicon [
2]. Pseudowords are used in linguistic research by being integrated into lexical decision tasks, production and perception experiments, vocabulary evaluations, etc. For instance, in morphology experiments, the renowned pseudoword ‘wug’ is often used to assess the productivity of plural rules [
3], revealing the implicit knowledge children have acquired about the morphology of their language, i.e., English. In a broader context, pseudowords have been extensively used in phonetic decoding [
4] and visual word recognition, including lexical decision and naming tasks [
5]. Furthermore, pseudowords help assess the credibility of learners’ responses in non-native vocabulary tests [
6,
7,
8,
9]. They can also function as stimuli to examine the mechanisms within cognitive models of reading [
10,
11,
12,
13]. Pseudowords are also employed in standardized tests (e.g.,
PAT—Phonological Awareness Test,
TOWRE—Test of Word Reading Efficiency) to assess a speaker’s skills in phonological processing, decoding ability, and overall literacy [
14,
15].
Several methods have been proposed for the construction of pseudowords, many of which are accompanied by databases and software applications designed to streamline pseudoword generation on a large scale. However, most of the methods applied for pseudoword construction, whether conducted manually or with the help of specific applications or software, come with certain limitations. For instance, they often require a high level of proficiency in the language and/or an in-depth understanding of its phonotactics, syllable structure, and orthographic conventions that researchers may not have.
In the context of such experimental applications, achieving reliable results depends on the careful development of appropriate pseudowords. The pseudowords must conform to the phonotactic rules of the language in the sense that they could potentially be real words while also meeting the researchers’ experiment-specific criteria. Depending on the nature of the experiment, these pseudowords may need, for example, to closely resemble high or low-frequency words or, conversely, avoid bearing too strong a resemblance to existing words.
After first reviewing some existing approaches for generating pseudowords and the challenges they face at the empirical level, we introduce our proposal for constructing and evaluating pseudowords in Greek, a language lacking a concrete methodology for pseudoword construction. Specifically, we present SyBig-r-Morph, a tool we developed for pseudoword construction that uses syllables, bigrams, orthographic conventions, and morphological information to construct pseudowords. This application can serve as a valuable resource for experimental tasks aimed at studying the phonological characteristics of the language.
In Greek, stress assignment is heavily determined by lexical factors, with any of the last three syllables of a phonological word potentially serving as a stress location, as exemplified by words like [ˈθo.ɾi.vos] ‘noise’, [zo.ˈɣra.fos] ‘painter’, [po.ta.ˈmos] ‘river’ [
16,
17,
18]. For illustrative purposes in this article, we focus on constructing pseudonouns for experimental tasks that explore how young and adult Greek speakers apply stress rules. As suggested by relevant research [
19,
20,
21], we anticipate that the distribution of the three grammatical stress patterns will be affected by the size and morphological class of the noun. Therefore, the following criteria are essential when constructing pseudonouns. Firstly, they must strictly adhere to the phonotactic rules of the specific language to prevent any resemblance to foreign words. Secondly, the constructed nouns should avoid significant similarity to real words, which could influence young and adult participants when choosing stress patterns.
The remainder of the article is organized as follows:
Section 2 provides an overview of current methods and applications for creating pseudowords in various languages, including Greek.
Section 3 introduces SyBig-r-Morph, highlighting its important innovations and distinct features.
Section 4 presents the outcomes of an additional evaluation process that we applied to words generated by SyBig-r-Morph to assess its suitability for the hypothesized experimental task.
Section 5 provides a discussion and concludes this article.
3. Methods
Our research focuses on constructing pseudonouns due to their diverse accentual patterns, which set them apart from other grammatical categories. We aim to build pseudonouns from various inflectional classes to be used in experimental tasks that explore how young and adult Greek speakers apply stress rules. Specifically, we strive to generate pseudowords from a specific lexicon, ensuring they are morphophonologically correct and distinct from existing words.
Currently, specialized software tools for the large-scale generation of Greek pseudowords are lacking, and, as discussed above, existing tools present significant challenges when applied to Greek. To address this gap, we introduce SyBig-r-Morph. The Flask-based web application (v2.3.3) requires Python 3.7+ for implementation and integrates two primary lexical resources: ILSP’s
Clean Corpus [
41,
44] and
GreekLex2.1 [
45,
46].
GreekLex2.1 offers detailed insights into Greek word forms and linguistic patterns by providing part-of-speech information, syllabification, phonetic and orthographic details for each entry, and metrics for word similarity. It was developed using entries from the
Dictionary of Standard Modern Greek [
47]. The database is also enhanced with a set of statistical metrics for these entries from the
Hellenic National Corpus(HNC), an extensive compilation (over 97 million words) of written materials, including newspapers, books, periodicals, and other textual sources, developed by the
Institute for Language and Speech Processing/R.C. Athena (ILSP) [
48,
49]. GreekLex2.1 encompasses around 35,000 lemmas found in both the dictionary and the HNC.
The Clean Corpus is an extensive collection of 217,664 word types and 29.6 million tokens from the HNC journalistic, legal, and literary texts. It provides essential information for each word, including syllabic structure, word length, stress pattern, and frequency. Moreover, it offers useful statistical information on metrics like average letters, phonemes, syllable frequencies, and counts of orthographic and phonological neighbors. Unfortunately, Clean lacks data on the morphological characteristics of words, which is particularly significant for studies focused on specific grammatical categories like nouns. In SyBig-r-Morph, we use the “Ignoring Stress” version, which provides the relevant data, including complete tables of syllables and their associated type and token frequencies, without taking stress diacritics into account.
To ensure optimal performance and access to the necessary linguistic data, both lexical resources are loaded during application startup. This initialization process, illustrated in
Figure 1, involves loading the lexical data and accompanying information from GreekLex2.1, along with the Clean Corpus. Due to the substantial size of the Clean Corpus (217,664 word types), the loading process typically completes in under a minute, after which users can begin pseudoword generation with full access to the capabilities of both databases (
Figure 1).
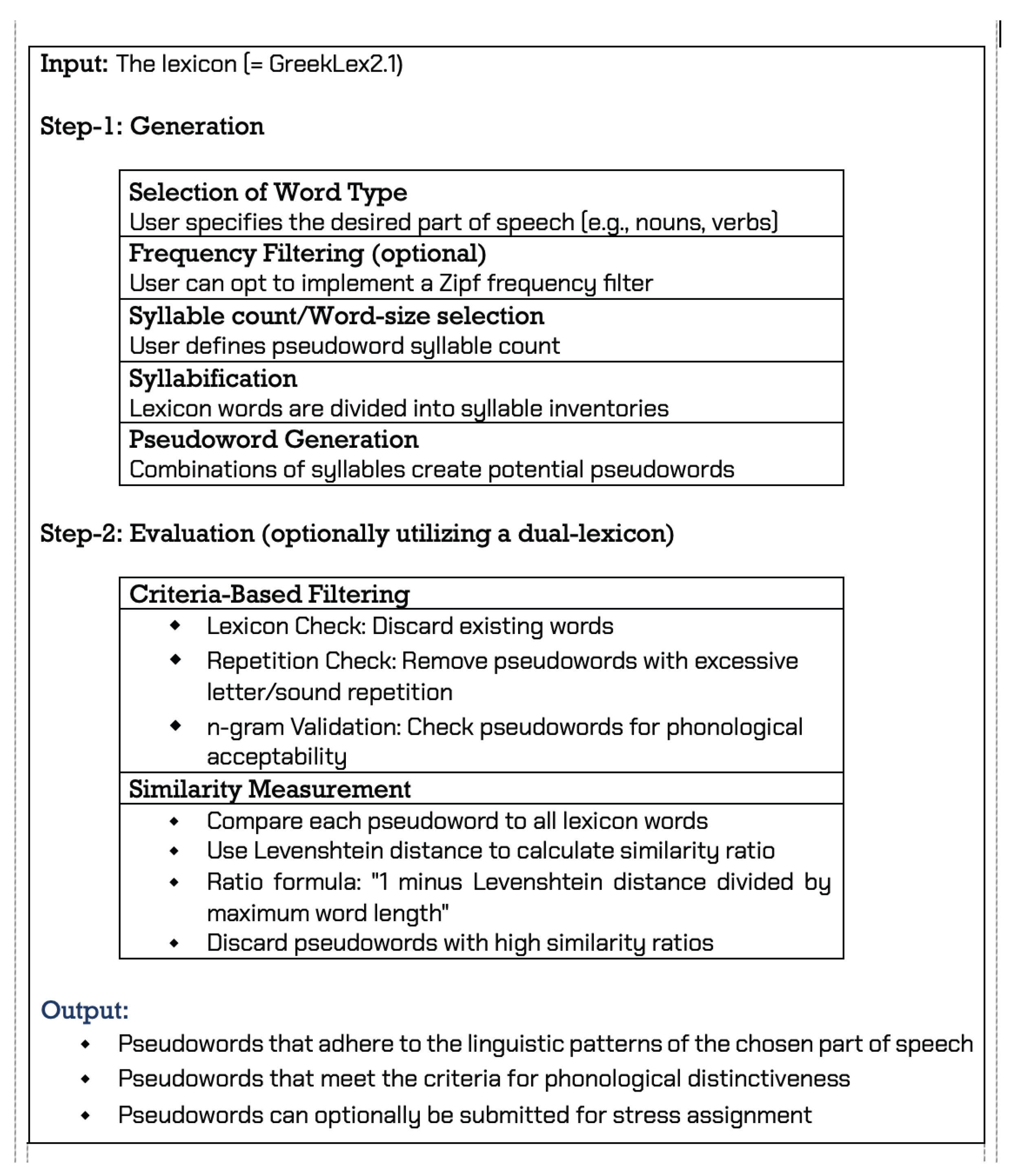
Building on these lexical resources, the application’s technical workflow consists of two main components, that is, a generation component and an evaluation component. The generation component includes lexicon analysis, syllable segmentation, and the strategic reassembly of syllables based on their original positions within words. On the other hand, the evaluation component applies similarity filtering to ensure that the generated pseudowords are sufficiently distinct from existing Greek lexical items.
At the core of our application lies GreekLex2.1, which provides the words upon which the syllable decomposition mechanism will apply to create the syllable arrays for the pseudoword generation, along with essential morphosyntactic information and metrics for word frequency. However, any corpus, lexical database, or wordlist containing information on syllabic structure, word length, part of speech, and frequency can serve for this purpose.
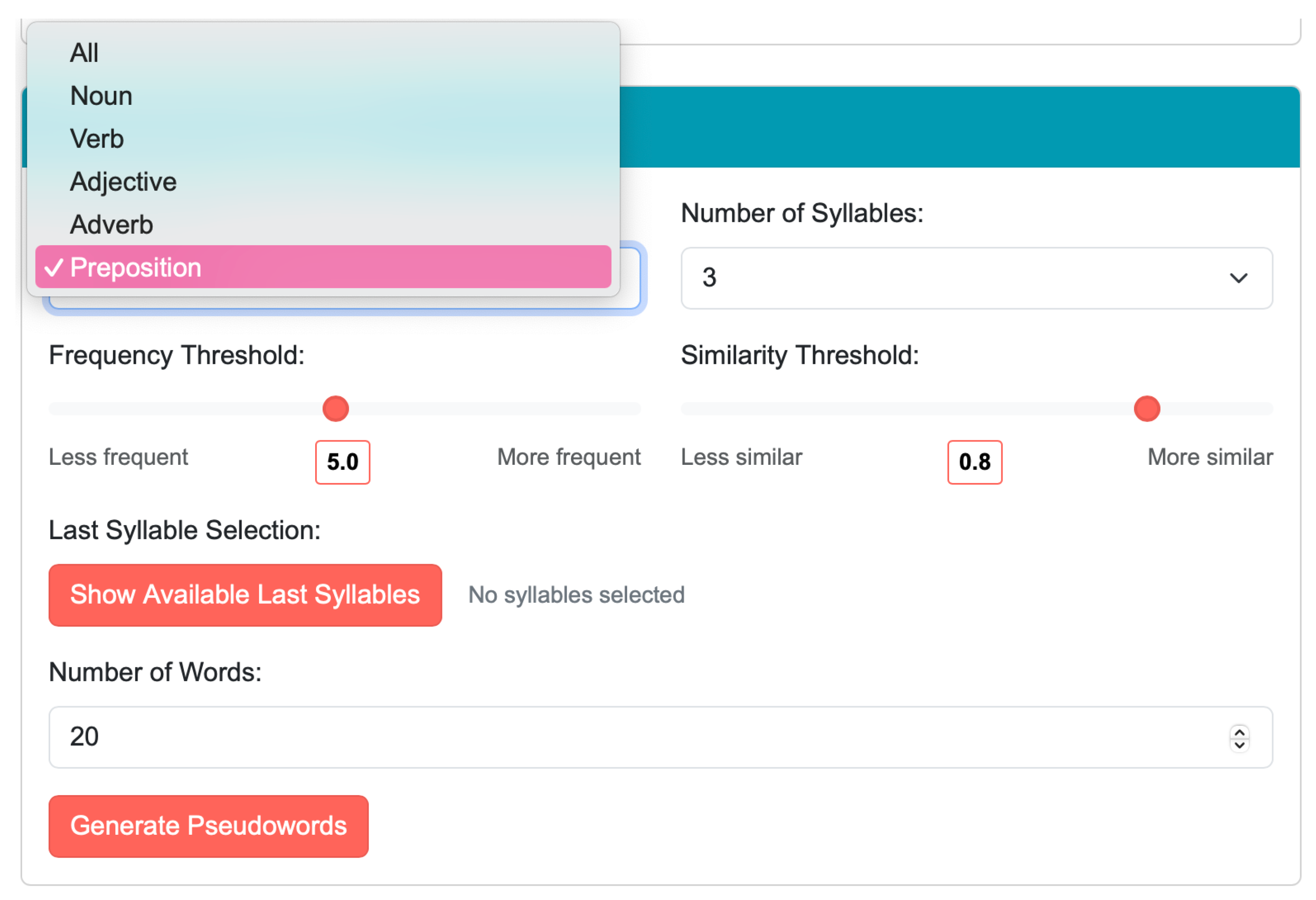
SyBig-r-Morph’s pseudoword generation process begins by letting users specify the morphosyntactic category of the pseudowords they want, such as nouns, verbs, adjectives, adverbs, or prepositions, as shown in
Figure 2. Users can even select all categories if they wish.
Additionally, users can opt to apply a frequency filter, using metrics such as Zipf frequency, which is included in GreekLex2.1. Operating within a range of 1.327 to 7.533 (based on GreekLex2.1 items), this parameter regulates the proximity of generated words to low- and high-frequency words. Lower values indicate low Zipf frequency, while higher values indicate high Zipf frequency.
In the present version of SyBig-r-Morph, we have set the default Zipf frequency value to 5 because we would like our hypothetical experimental materials to have an equal distance between existing low and high-frequency words. Raising this threshold entails fewer words passing the filter, resulting in a smaller pool of syllables available for word generation. Our testing showed that a high Zipf frequency setting resulted in a smaller set of word-final syllables. This led to the exclusion of some less productive inflectional classes. This feature is optional; users who do not wish to control the pseudoword frequency of existing words can choose not to apply the frequency filter. Once frequency parameters are established (or bypassed), users can then define the structural characteristics of their pseudowords by specifying the desired word size and number for the generated pseudowords. In its current settings, the application can create up to 1000 pseudowords.
Our application carefully filters the input lexicon and creates a dictionary by keeping only those words that match the specified syllable count. An innovation of SyBig-r-Morph is that it includes a syllabification component that breaks words into their respective syllables (sequences of onset(s) – nucleus – coda(s)). The syllabification stage is crucial because each word from the filtered list is deconstructed into constituent syllables. These syllables are then categorized based on their position in the word, such as first, second, third, etc., thus creating a foundation for constructing plausible pseudowords.
Table 1 illustrates a compilation of syllables per position for trisyllabic words:
The syllable compilation shown in
Table 1 reveals an important design feature of SyBig-r-Morph: all syllables are delivered without stress diacritics. This reflects the application’s systematic approach to stress handling. As a direct result, all words generated by SyBig-r-Morph are stressless. While this feature works well for studies like our hypothetical scenario that investigates speakers’ stress assignment patterns, it may pose challenges for other research that requires stressed outputs. To address this need, we have incorporated an option for assigning stress to the generated pseudowords. This feature will be discussed in more detail below.
Following the creation of the syllable inventory, SyBig-r-Morph systematically explores all potential syllable combinations to generate pseudoword candidates. However, not all theoretically possible combinations yield linguistically valid or experimentally useful pseudowords. To ensure the quality and appropriateness of generated items, all candidates must undergo rigorous evaluation through the application’s second major component: the evaluation system.
The first evaluation phase is
criteria-based filtering, which is carried out in several steps. This evaluation is designed to work with any available database, wordlist, or corpus. The current version of SyBig-r-Morph uses both GreekLex2.1 and the Clean Corpus [
41]. They are collectively called the “Lexicon” in the remainder of the article.
The filtering process begins with a “Lexicon check” that removes any pseudoword that may already exist in the lexicon/lexica it checks with. Next, the “Repetition check” applies to discard those pseudowords that contain sequences of repeating letters or sounds exceeding a threshold of two or more consecutive identical letters: this way, words like ααα [aaa], ααγη [aaʝi], αριθθον [aɾiθθon] are eliminated. As a side effect, this process excludes words with two consecutive letters, even those permitted in Greek orthography, such as ρρ. That is, words like απουρρα [apuɾa] will be excluded. The same filtering mechanism operates on segments, disallowing words with phonetically identical vowels, but different spelling, e.g., εαιγη [eeʝi], παωο [paoo].
Following pseudoword generation, the process continues with n-gram validation, during which the application assesses the generated pseudowords for phonotactic acceptability. More precisely, it constructs bigrams and trigrams for each pseudoword. If any of these generated n-grams fail to match words in the lexicon, the pseudoword is marked as phonologically unacceptable and is thus excluded from further analysis. This filter will rule out pseudowords like αριθδρος [aɾiθðɾos], παιχπουρστο [pexpuɾsto].
Subsequently, the process continues with a comparative analysis stage that measures the similarity between each pseudoword and all words in the reference databases, i.e., GreekLex2.1 and Clean, or any other specified lexical resource. Employing a similarity ratio grounded in the Levenshtein distance [
50], SyBig-r-Morph proceeds to this evaluation as follows: “1 minus the Levenshtein distance divided by the maximum length of the compared words.” In this formula, the Levenshtein distance is normalized by dividing it by the maximum length of the two words being compared. Then the resulting ratio is subtracted from 1 to generate a similarity score so that a smaller distance yields a higher similarity score between the two words. This step ensures that the final score will range from 0, with no similarity, to 1, a perfect match. Pseudowords exhibiting a high similarity ratio to actual words will be excluded as being too similar to existing ones, e.g.,
αυρειο [avrio] (cf.
αύριο [ˈavrio] ‘tomorrow’),
αδεικα [aðika] (cf.
άδικα [ˈaðika] ‘unfairly’),
αγογος [aɣoɣos] (cf.
άγονος [ˈaɣonos] ‘infertile’),
οναδα [onaða] (cf.
ομάδα [oˈmaða] ‘team’). This way, the application guarantees that the final output consists of pseudowords distinct from actual words in the Lexicon.
In the current version, the cut-off point is set at 0.8. During testing, we observed that lowering this threshold for nouns resulted in pseudonouns significantly dissimilar to existing nouns, while increasing it resulted in pseudowords that closely resembled existing ones. We arrived at this conclusion during a manual evaluation phase discussed in
Section 4.
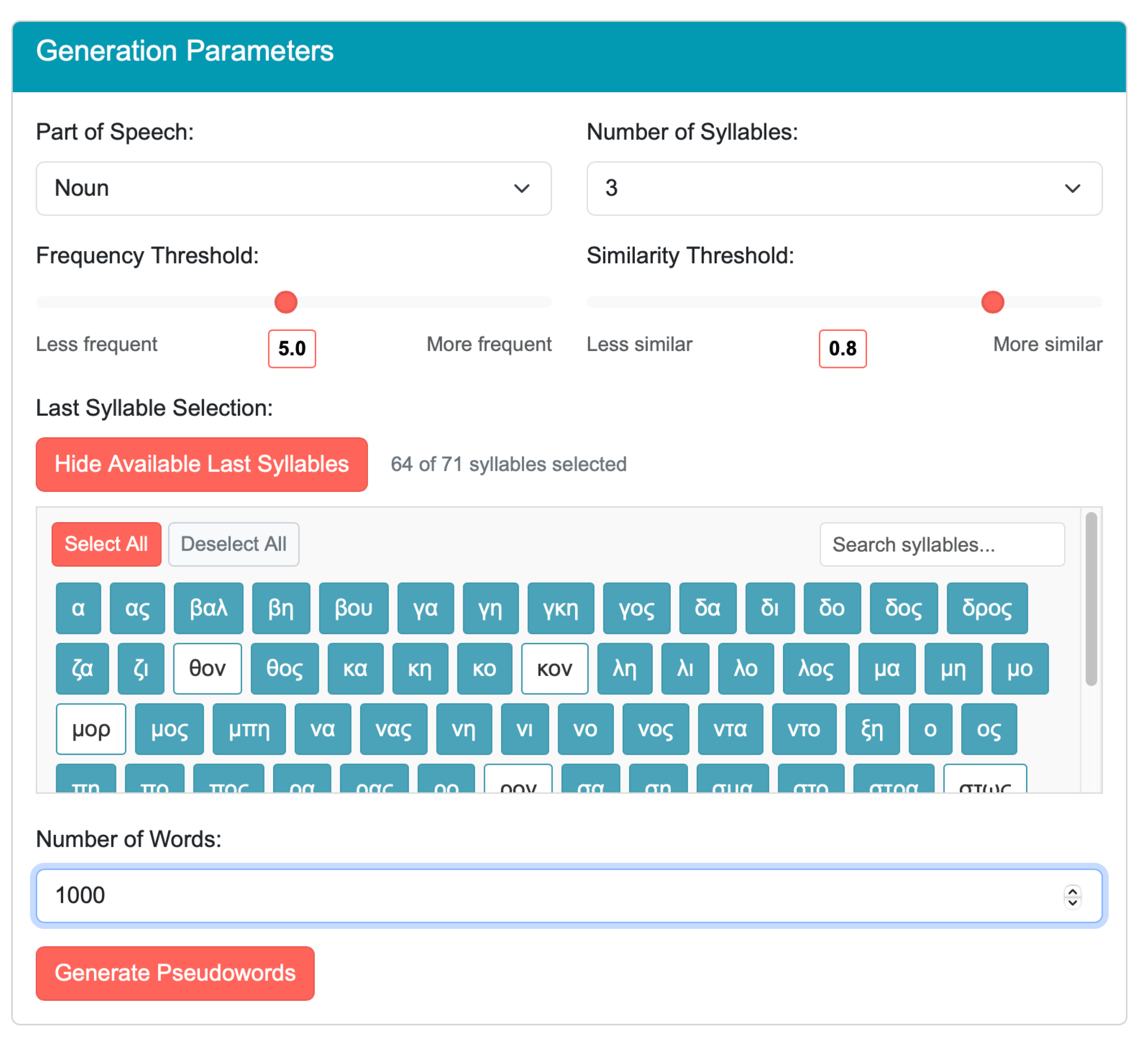
Figure 3 illustrates the application’s selection dashboard, which includes user-friendly predetermined threshold values for frequency and familiarity, as explained above. It also includes several user-defined parameters, such as the selection of part of speech, the number of syllables, and the number of words. The latter value is set to 1000, the maximum number of words allowed in the application’s current settings. Importantly, users can view and select either all syllables or only those appearing in the word-final position, allowing them to determine specific noun classes or verb voice based on word endings. This is a crucial feature because it allows users to precisely control the grammatical properties of generated pseudowords. Furthermore, users can also decide to either include or exclude words with marginal word-final phonotactics, such as those ending in consonants other than /n/ and /s/, which are the only word-final consonants phonotactically permitted in Greek.
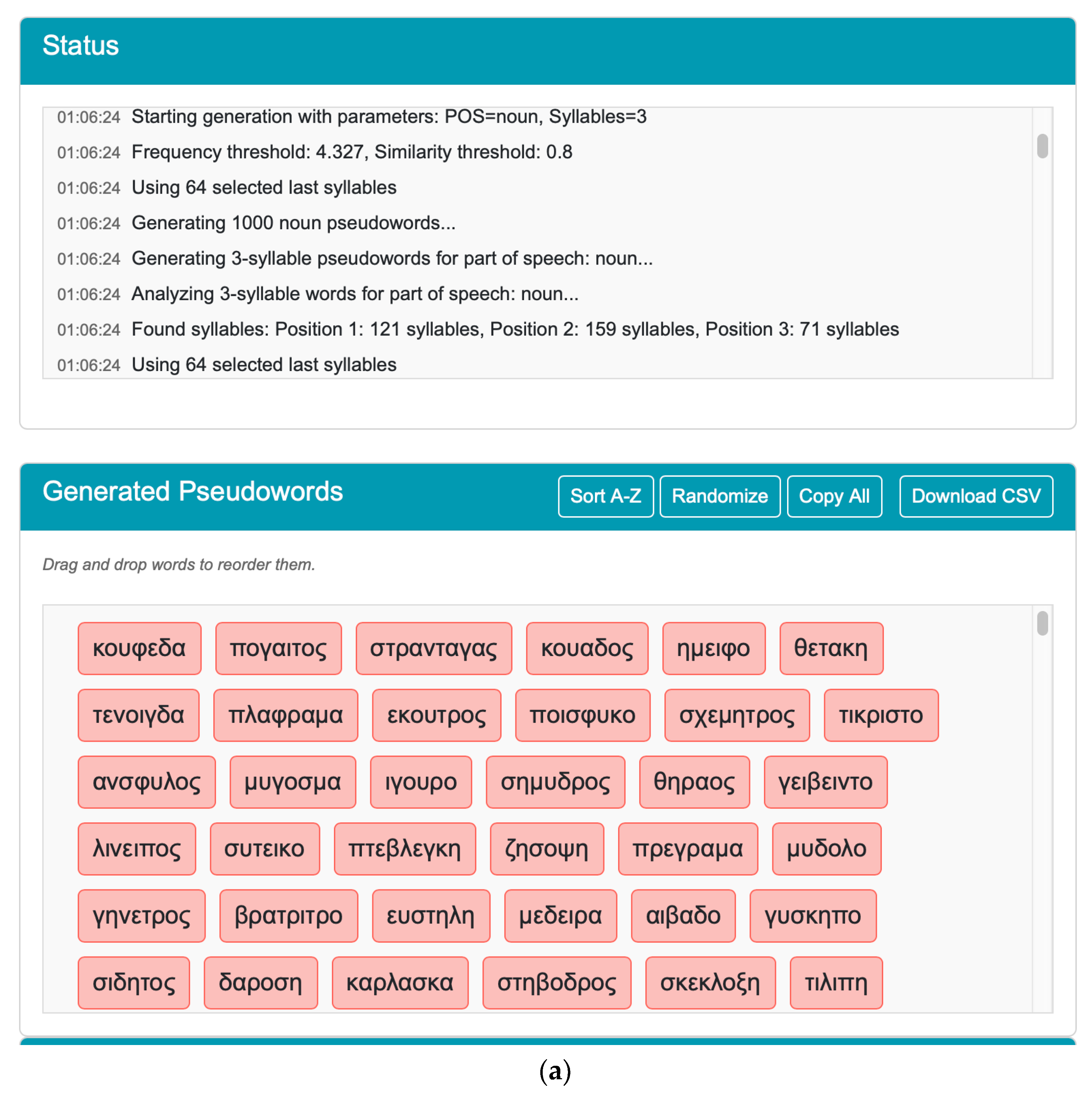
As shown in
Figure 4, the “Status” panel below the pseudoword generation button provides users with comprehensive information about their selections and the pseudoword generation process. During initialization, it displays the lexicon loading process and parameters, including part-of-speech specification (noun), syllable count (3), and threshold settings (frequency: 4.327, similarity: 0.8). Once processing begins, the system reports the distribution of syllables across three positions, identifying 121 initial, 159 medial, and 71 final syllables. Following Greek phonotactic constraints, the panel indicates that 64 of the 71 final syllables were selected, with endings from loanwords and archaic forms being systematically excluded.
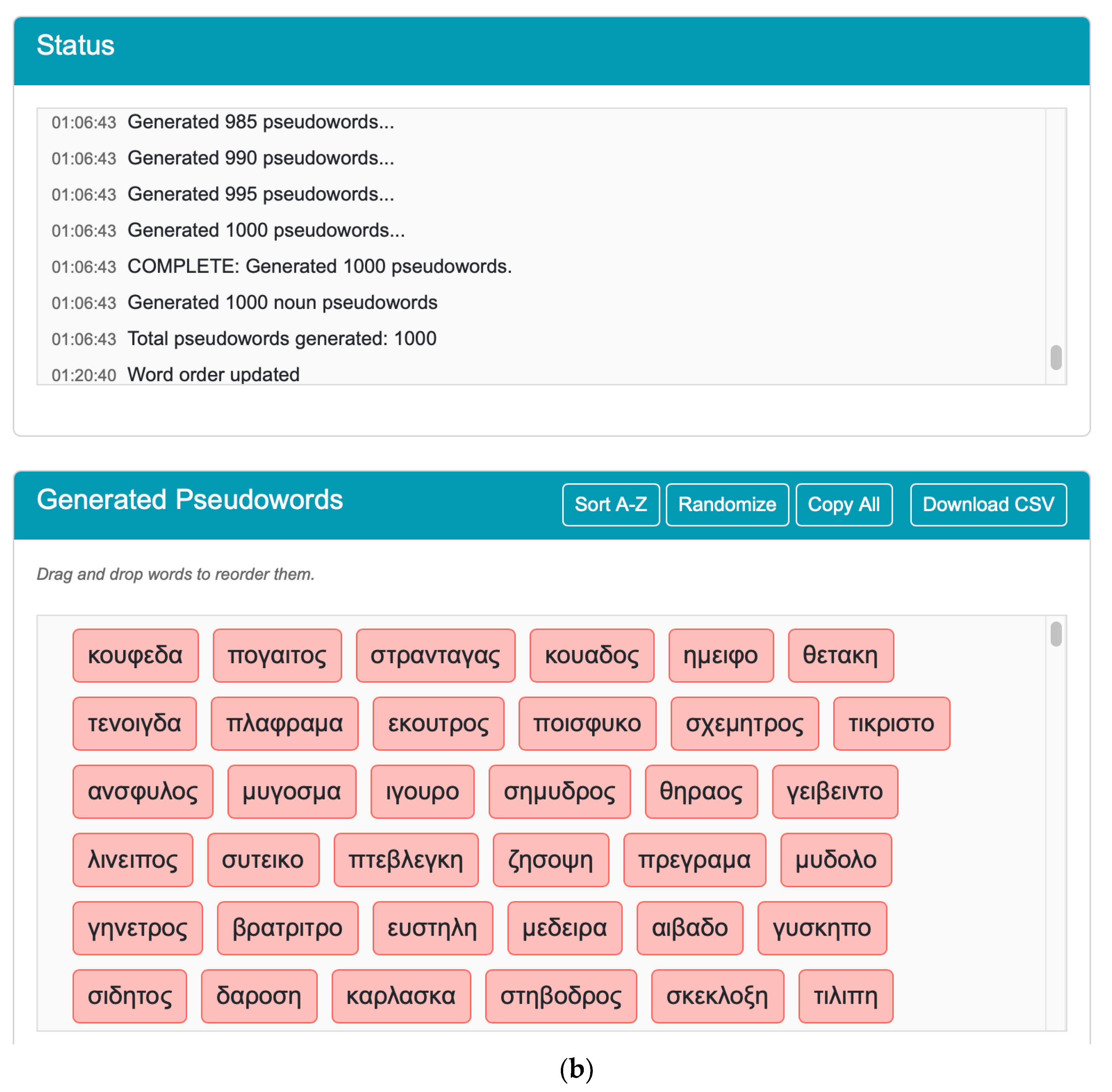
Throughout the generation phase, the interface provides real-time progress updates, tracking incremental production in sets of 5 pseudowords from the initial batch to the final target of 1000. In this demonstration, the entire process was completed in approximately 19 s (01:06:24 to 01:06:43), achieving an average generation rate of 53 words per second. The panel concludes with a completion message confirming the successful generation of all requested pseudowords.
When the set of available syllables is particularly limited, however, identical outputs are more likely. For example, generating 15 non-passive verb forms ending in -o/-zo with the same settings resulted in multiple duplicates, as follows: νοστευω, πιβαιω, προμιω, νοκειω, πιμιω, νοκειζω, πιστευζω, πιβαιω, προστευζω, πιμιζω, πικειω, προβαιζω, νοστευω, νοστευζω, προβαιζω. This occurred because the only available final syllables in the syllable set were ζω (/zo/) and ω (/o/). Nevertheless, if users wish to reproduce the same results, they can ensure consistency by adding the following command at the beginning of the sybig-r-morph-gui.py script:
Τhe “Generated Pseudowords” panel of the application displays the pseudowords. This section of the interface includes four control buttons: “Sort A-Z”, which organizes the pseudonounnouns in alphabetical order; “Randomize”, which shuffles their arrangement; “Copy All”, which copies the words to the clipboard; and “Download CSV”, which allows users to export the data. Users can manually reorganize words using a drag-and-drop feature, as indicated by on-screen instructions, to suit experimental needs or categorization schemes. Changes in the order of the constructed words are reported on the “Status” panel.
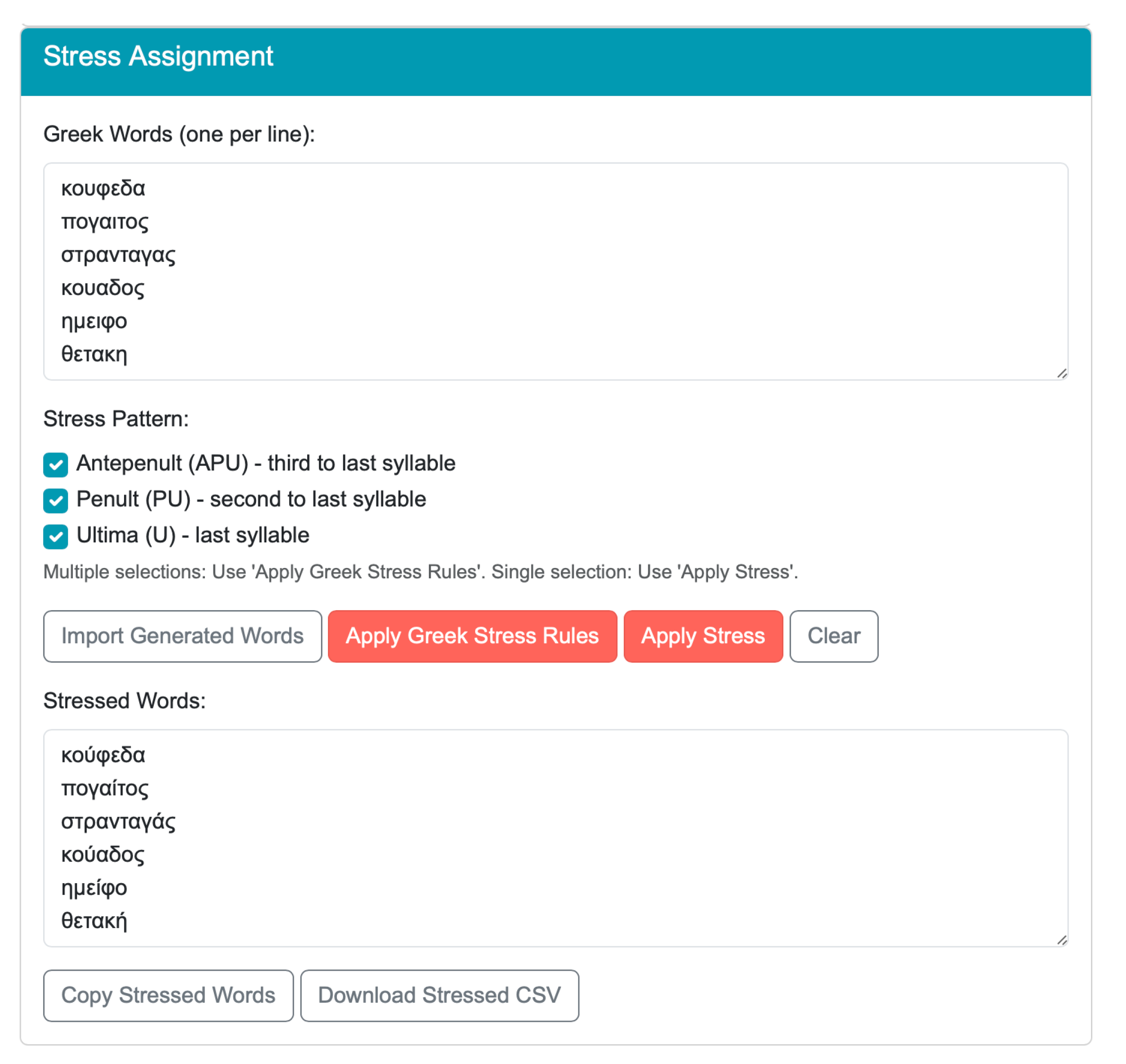
The “Stress Assignment” module allows users to apply systematic stress patterns to generated pseudowords in accordance with Greek stress rules (
Figure 5). The interface is seamlessly integrated with the pseudoword generation process and includes an “Import Generated Words” button that automatically transfers items from the main generation panel into the stress assignment text area.
Users can also manually insert Greek words and choose from all three permissible stress positions, i.e., antepenult (APU, third-to-last syllable), penult (PU, second-to-last syllable), or ultima (U, last syllable). Multiple stress patterns can be selected using checkboxes, and the selected patterns are then evenly distributed across the input words to ensure a balanced set of stimuli. After clicking “Apply Stress”, the words are processed, and the results are displayed in a designated “Stressed Words” output area, where each word is marked with the appropriate accent diacritic according to the selected stress pattern(s). The “Clean” button removes any selected stress pattern options.
Multiple stress patterns can be selected using checkboxes, and the selected patterns are then evenly distributed across the input words to ensure a balanced set of stimuli by clicking “Apply Greek Stress Rules”. This option applies specific rules of Greek stress; for instance, it will not assign U stress to passive verb forms since such stress positioning is ungrammatical. When a single stress pattern is selected, “Apply Stress” must be clicked. The words are then processed and the results are displayed in the “Stressed Words” output area, where each word is marked with the accent diacritic according to the selected stress pattern(s).
Users can then export their stressed pseudowords using the “Copy Stressed Words” or “Download Stressed CSV” buttons. This workflow enables researchers to regulate the prosodic characteristics of their experimental materials while ensuring phonotactic precision and a systematic distribution of stress.
This careful process produces a refined set of pseudowords that follow the morphophonological patterns of the intended grammatical category while still being distinct from real Greek words.
Appendix B provides sample experimental pseudonouns.
Figure 6 illustrates the main components of SyBig-r-Morph and outlines the specific operations performed within each module.
The main strength of SyBig-r-Morph is its ability to generate natural-sounding pseudowords that conform to the phonotactic rules of Greek, although these words do not exist in real language. By generating words that adhere to specific linguistic patterns without being actual words, this tool provides researchers with valuable resources for linguistic research and related fields.
4. Evaluation of Pseudowords
We added several steps for phonological evaluation to assess further the suitability of the pseudonouns generated by SyBig-r-Morph for our experimental purposes. These steps aim to ensure that our constructed words not only comply with the syllabic and phonotactic rules of Greek but also meet the specific objectives of our experiment. These objectives include creating pseudowords that neither closely resemble native words nor are too distant from them.
To assess the phonological well-formedness of our pseudonouns, we harnessed the power of the online
Num Tool [
41,
51] and a manually annotated subset of the Clean Corpus compiled by Apostolouda [
20], called the
Annotated Clean Corpus (A-Clean), which encompasses 71,105 words.
The Num Tool operates online and provides data equivalent to that found in the Clean Corpus for any word submitted to the platform. It furnishes quantitative metrics for each entered letter string, permitting 20 submissions per session. Users can adapt their preferred metrics by selecting the corresponding checkboxes. The results are presented in a tab-separated format, accessible within the user’s web browser or downloadable with software that manages text columns, such as MS Excel. The range of available metrics encompasses length (letters, phones, syllables), frequency, uniqueness/recognition point, cumulative syllable and bigram frequency, count and frequency of orthographic and phonological neighbors, cohort, stress, and Levenshtein distance neighbors, and indices of orthographic transparency.
Moreover, the Num Tool helps evaluate pseudowords based on statistical measurements of real words documented within the Clean Corpus. Specific lexical and sub-lexical parameters can be pivotal for developing Greek pseudowords within this toolkit. For our study, we selected the following ones:
Log-mean bigram token frequency (phonemes only) (BGtokfreqPho) calculates the logarithmic mean of the frequency of appearance of neighboring phonemes across all samples in the corpus. For example, the combination of the phonemes τ [t] + ο [o] results in το [to] with a log-mean frequency of 3.976 per million samples.
Log-mean bigram type frequency (phonemes only) (BGtypfreqPho) computes the logarithmic mean of neighboring phoneme frequency within the entire set of word types in the corpus. For example, the combination of the phonemes τ [t] + ο [o] = το [to] has a log-mean frequency of 1.709 per million types.
N phonological neighbors (standard: replace only) (nNeiPho) provides the count of words that emerge when a phoneme is substituted within a word. For instance, the word τόνος [ˈtonos] ‘stress’ has phonological neighbors created through substitution: τόνος [ˈtonos] →φόνος [ˈfonos] ‘murder’ (τ /t/ →φ /f/) and τόνος [ˈtonos] →τόκος [ˈtokos] ‘interest’ (ν /n/ → κ /k/).
N phonological neighbors (replace, delete, insert, transpose) (nNeiRDITPho) offers the count of words resulting from phoneme replacement, deletion, insertion, or transposition within a word. For example, the word φόρος [ˈfoɾos] ‘tax’ has phonological neighbors created through various operations: (a) deletion: φόρος [ˈfoɾos] →όρος [ˈoɾos] ‘mountain’ (deletion of initial φ /f/); (b) replacement: φόρος [ˈfoɾos] →χώρος [ˈxoɾos] ‘space’ (replacing φ /f/ with χ /x/); (c) insertion: φόρος [ˈfoɾos] →φόρτος [ˈfoɾtos] ‘burden’ (insertion of τ /t/ before final ος /os/); (d) transposition: φόρος [ˈfoɾos] → ροφόs [ɾoˈfos] ‘dusky grouper’ (change in the position of ρ /ɾ/).
Phonological Levenshtein distance 20 (PLD20; [
50]) calculates phonological similarity by calculating the phonological edits (insertions, deletions, substitutions, or transpositions) required to change one word into the 20 most similar ones [
52].
Having outlined these main parameters, we applied them systematically to evaluate pseudowords generated by SyBig-r-Morph. We selected parameters a and b to measure bigram tokens and type frequency, and parameters c, d, and e to control similiarity to real words. This selection guarantees that our pseudowords align with the Greek phonotactic system without closely resembling actual words, thus preventing any direct connections to existing words that might influence speaker choices.
We conducted comprehensive assessments across different grammatical categories (e.g., nouns, verbs) to demonstrate the practical application of these criteria, with a particular focus on noun evaluation reported here.
Table 2 presents a sample of the pseudonouns and their corresponding parameter values to illustrate the application of our criteria. All pseudonouns were produced from SyBig-r-Morph with the Similarity Threshold set to 0.8. We decided on this value because, with lower values, the pseudonouns were too dissimilar to existing nouns, and with higher values, they were too similar to existing ones.
While these initial results demonstrated the tool’s effectiveness, given that all nouns fell within Clean’s phonotactic well-formedness range, we recognized that even more rigorous, noun-specific criteria would better ensure experimental validity. To achieve this precision, we developed enhanced evaluation standards tailored specifically to Greek noun phonotactics. We extracted all di- and trisyllabic nouns from A-Clean. Following the methodology of Revithiadou et al. [
53] and Apostolouda [
20], we calculated the mean (M) and standard deviation (SD) for each of the five parameters for the total number of 5326 trisyllabic nouns across all noun classes present in A-Clean. The lower bound was established using the formula
Mean −
2SD, whereas
Mean + 2SD defined the upper limit. This process allowed us to precisely determine the numerical ranges in which the values of A-Clean nouns naturally fell.
Table 3 shows the admissible ranges of all five parameters.
For trisyllabic nouns, the mean logarithmic bigram token frequency was calculated to be 0.53, with a corresponding standard deviation of 0.365. By applying the formula [M − 2SD to M + 2SD], the acceptable range of values for trisyllabic pseudonouns was determined to be within 0 and 1.260 (M − 2SD = −0.2 and M + 2SD = 1.260). Similar calculations were performed for the remaining parameters. The same process was applied to disyllabic nouns. Having established these refined criteria, we applied them to a focused evaluation of trisyllabic pseudonouns ending in -os.
Table 4 demonstrates how a representative sample of ten pseudowords performed against these stringent parameters, with shaded rows indicating words that fell outside acceptable ranges. Pseudowords exceeding these thresholds were excluded from experimental materials.
To assess the broader applicability of our established thresholds, we repeated the same evaluation process on a larger scale. Specifically, we submitted pseudonouns from various inflectional classes and word lengths (e.g., disyllabic and trisyllabic nouns, such as
-os masculine,
-as masculine,
-a feminine,
-i feminine,
-o neuter,
-i neuter) to the Num Tool platform for evaluation against the pre-defined parameters and subsequently applied our stricter criteria, as depicted in
Table 3. Of these 600 trisyllabic nouns, 521 met and passed our stricter parameter ranges. In a separate evaluation, when we repeated the process with 250 disyllabic nouns (produced using a similarity threshold of 0.8 and a frequency threshold of 5.0), 142 fell within acceptable phonotactic ranges. This outcome is expected, as our strict parameter ranges in
Table 3 evaluate words using metrics designed to avoid direct resemblance to existing words that could influence speaker judgments. Moreover, the lower success rate for disyllabic nouns reflects the higher similarity threshold used in their generation. These results collectively demonstrate SyBig-r-Morph’s high success rate in producing pseudowords suitable for experimental research.
5. Discussion and Conclusions
This article highlighted the importance of pseudowords in (psycho)linguistic studies and addressed the ongoing need for reliable and accessible pseudoword generation tools across various languages. We also presented conventional approaches to pseudoword construction, which often involve modifying real words by changing letters or phonological features. This strategy carries the risk of accidental recognition of base words. In contrast, modern techniques employ high-frequency bigrams or syllable deconstruction, often requiring a good understanding of a language’s grammar.
To address these challenges and the lack of an automatic pseudoword generation tool in Greek, we developed SyBig-r-Morph, an application that introduces several innovations that distinguish it from existing applications and software.
SyBig-r-Morph constructs pseudowords syllable by syllable rather than using n-grams, creating more phonologically natural outputs. It also employs an internal syllabification system that can process wordlists of any size, from databases with hundreds of thousands to millions of entries. Crucially, the system organizes syllables into arrays based on their position within a word, ensuring that generated words display phonotactic patterns consistent with those observed in the selected category. For example, in Greek, the sequence βδ [vð] never appears at the beginning of verbs; it only occurs in nouns. Likewise, σγ [zɣ] is exclusively found in adjectival bases.
Building on this positional sensitivity, additional application features enable users to specify grammatical categories (nouns, verbs, etc.), select specific word endings, and assign stress patterns to their generated pseudowords. This combination of category-specific phonotactics and user customization is particularly valuable for specialized linguistic tests and experimental tasks because it delivers words that adhere to the specific category’s phonotactic restrictions. Moreover, SyBig-r-Morph automatically detects and filters out phonologically invalid letter/sound combinations by recognizing impermissible sequences in Greek, such as κγχ [kɣx], and excluding pseudowords containing such ill-formed combinations.
Further enhancing its versatility, the application employs a dual-lexicon approach, using separate lexicons for input during word formation and validation. In the current implementation, SyBig-r-Morph uses GreekLex2.1 for input and Clean (together with GreekLex2.1) to validate constructed forms, offering greater flexibility and precision in the creation and validation processes.
Another significant advantage of SyBig-r-Morph is that, while it was initially developed for Greek, it can be easily modified to work with any language, provided the user has access to a syllabification tool and a lexicon for the target language.
SyBig-r-Morph has several advantages over similar tools like UniPseudo. For instance, SyBig-r-Morph is more effective at producing words that adhere to proper phonotactic rules and follow Greek orthographic standards. Additionally, unlike UniPseudo, SyBig-r-Morph determines word length based on the number of syllables rather than the number of characters, allowing it to easily generate words that meet the user’s specified length criteria.
Although designed for different languages, both SyBig-r-Morph and Wuggy employ frequency criteria, but they implement these criteria in different ways. Wuggy focuses on transition frequencies between sub-syllabic components; for example, it compares the i to sk transition in the pseudoword misk with the i to lk transition in the word milk. In contrast, SyBig-r-Morph uses Zipf’s frequency to choose either low- or high-frequency words as bases for generating pseudowords and further employs Levenshtein distance to assess phonological similarity. Finally, Wuggy operates on a single-lexicon system, whereas SyBig-r-Morph features a dual (or multiple) lexicon.
The features described above render SyBig-r-Morph useful for linguistic studies, as it produces phonologically well-formed pseudowords that maintain the structural properties of specific Greek grammatical categories. However, the system has two notable limitations, as follows: it cannot produce pseudowords that violate the morphophonological rules of Greek, nor can it deliver stressed words.
In future research, we plan to enhance SyBig-r-Morph with additional features allowing users to construct pseudowords based on more criteria beyond frequency and word similarity considerations. For instance, users can specify the morphosyntactic category and inflectional and derivational affixes for pseudoword beginnings or endings. We also aim to improve the lexicon component by incorporating more comprehensive Greek databases and corpora. These enhancements will increase the tool’s usability and expand its applicability across multiple languages and linguistic contexts.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}