
Analytic Continual Learning-Based Non-Intrusive Load Monitoring Adaptive to Diverse New Appliances


Abstract
1. Introduction
- (1)
- An analytic, continual learning-based framework adaptive to diverse new appliances is proposed. This framework establishes a closed-loop iteration between novelty detection and continual learning for streaming appliance data. It eliminates original data storage requirements and learns new appliances through a single forward propagation.
- (2)
- A unified model is designed featuring a depthwise separable convolutional feature extractor and dual output branches for load identification and novelty detection. Crucially, the novelty detection branch represents the original data via a hypersphere center and radius in feature space, avoiding the need for data storage.
- (3)
- A supervised contrastive learning-based pretraining strategy is proposed to enhance intra-type clustering and inter-type separation in feature space. This strategy provides a strong foundation for analytic, continual learning, enhancing both learning efficiency and task performance of load identification and novelty detection.
- (4)
- Extensive experiments are conducted on four public datasets covering 56 appliance types. The results demonstrate that the proposed method significantly outperforms existing continual learning-based NILM methods. Additionally, deployment testing on an STM32F407-based smart socket confirms the viability of the proposed method in real-world settings.
2. Problem Statement
2.1. Event-Based NILM
2.2. The Continual Learning Setting of NILM
3. Methodology
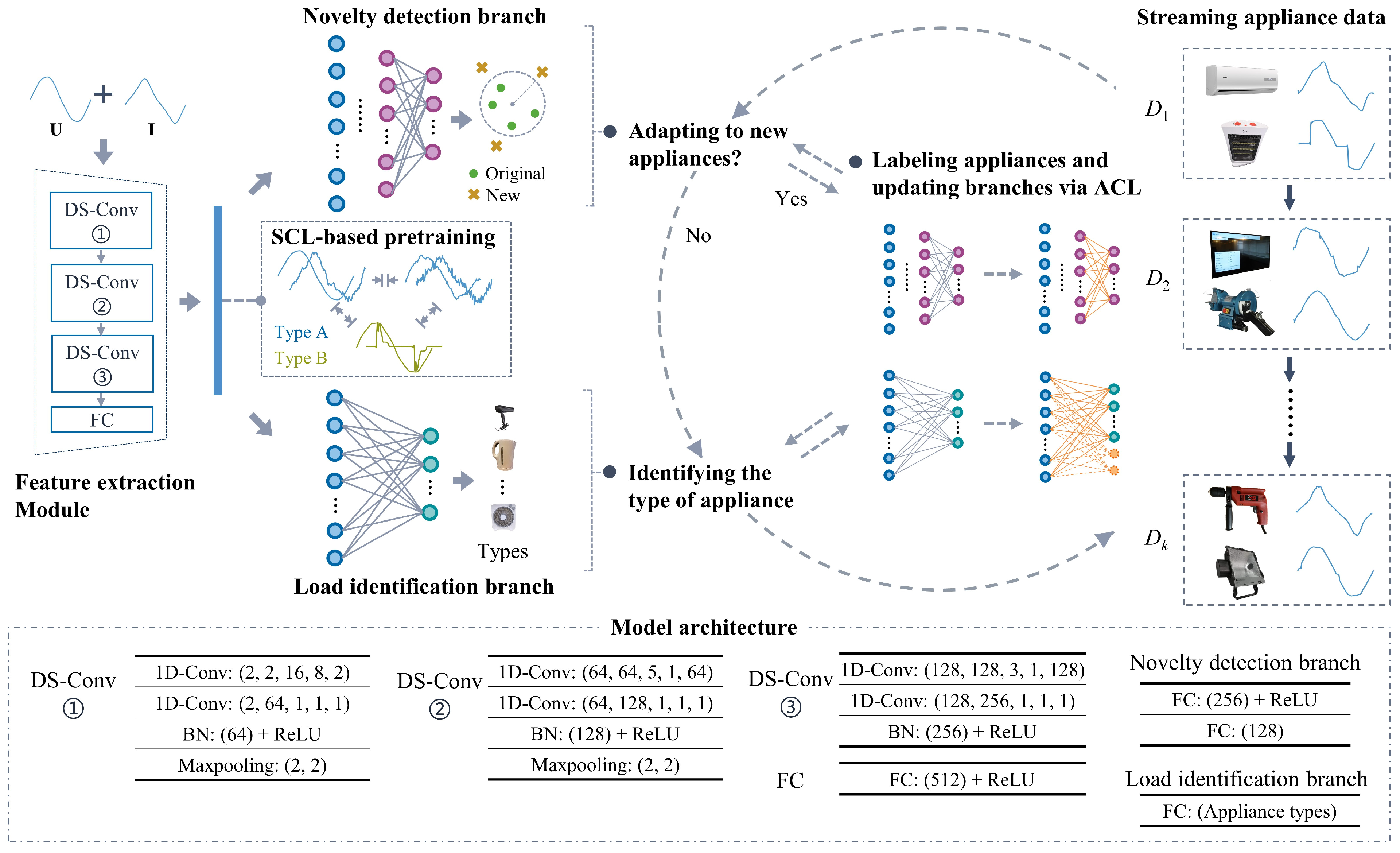
3.1. NILM Framework for Adapting to Diverse New Appliances
3.2. Lightweight Dual-Branch NILM Model
3.3. Supervised Contrastive Learning-Based Pretraining Strategy
3.4. Analytic Continual Learning-Based NILM Model Updating Strategy
4. Experiments and Analysis
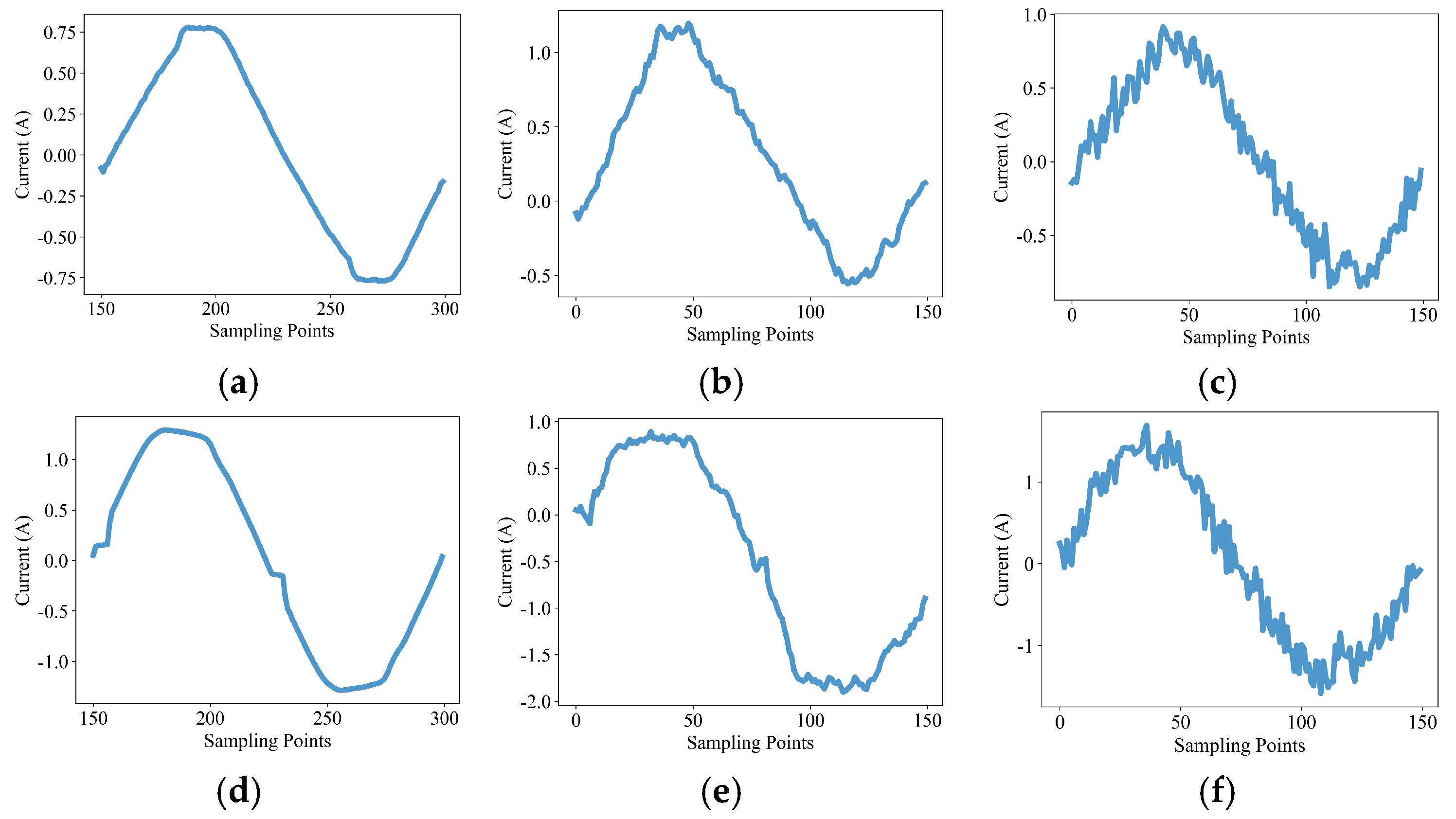
4.1. Introduction of Public Datasets
4.2. Validation Metrics
4.3. Experiments for Validating the Basic Abilities of the Pretrained NILM Model
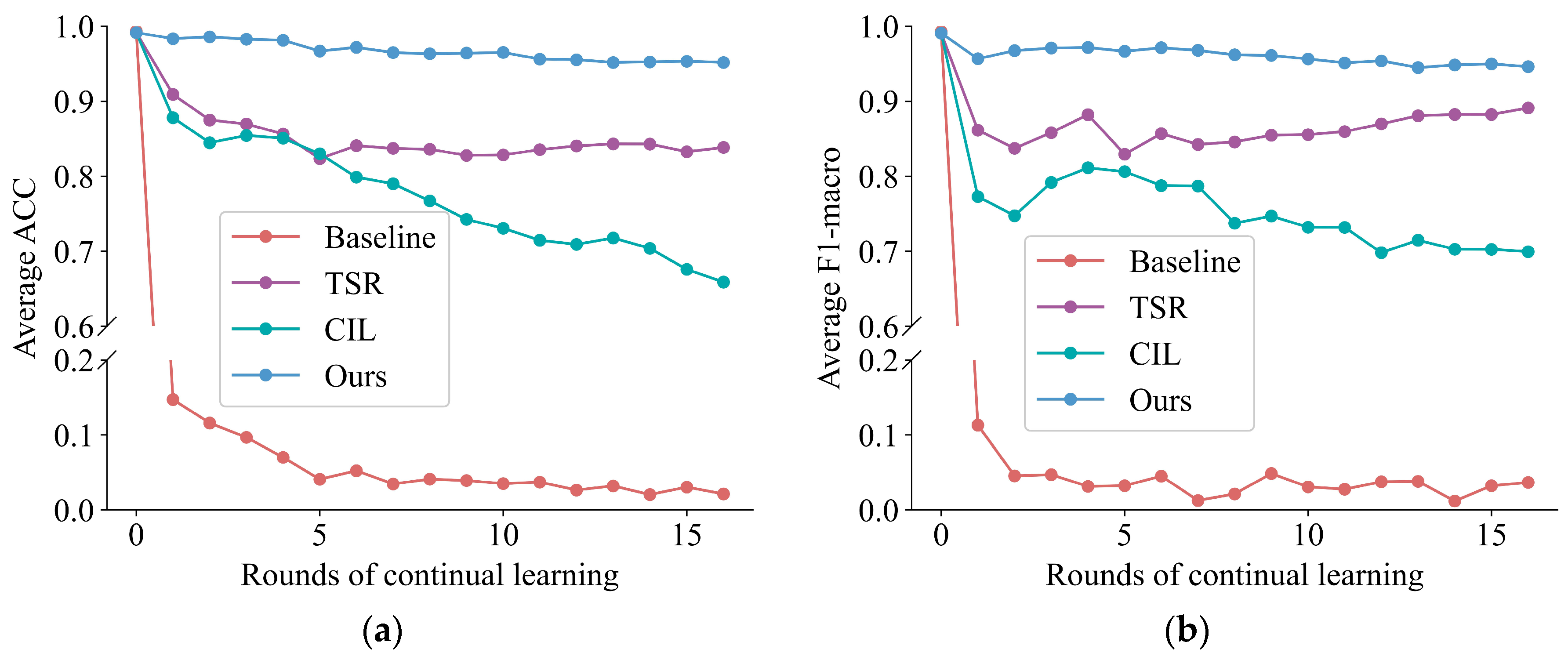
4.4. Experiment for Validating Analytic Continual Learning-Based Method in Load Identification
4.5. Experiment for Validating Analytic Continual Learning-Based Method in Novelty Detection
4.6. Experiment for Validating the Proposed SCL-Based Pretraining Strategy
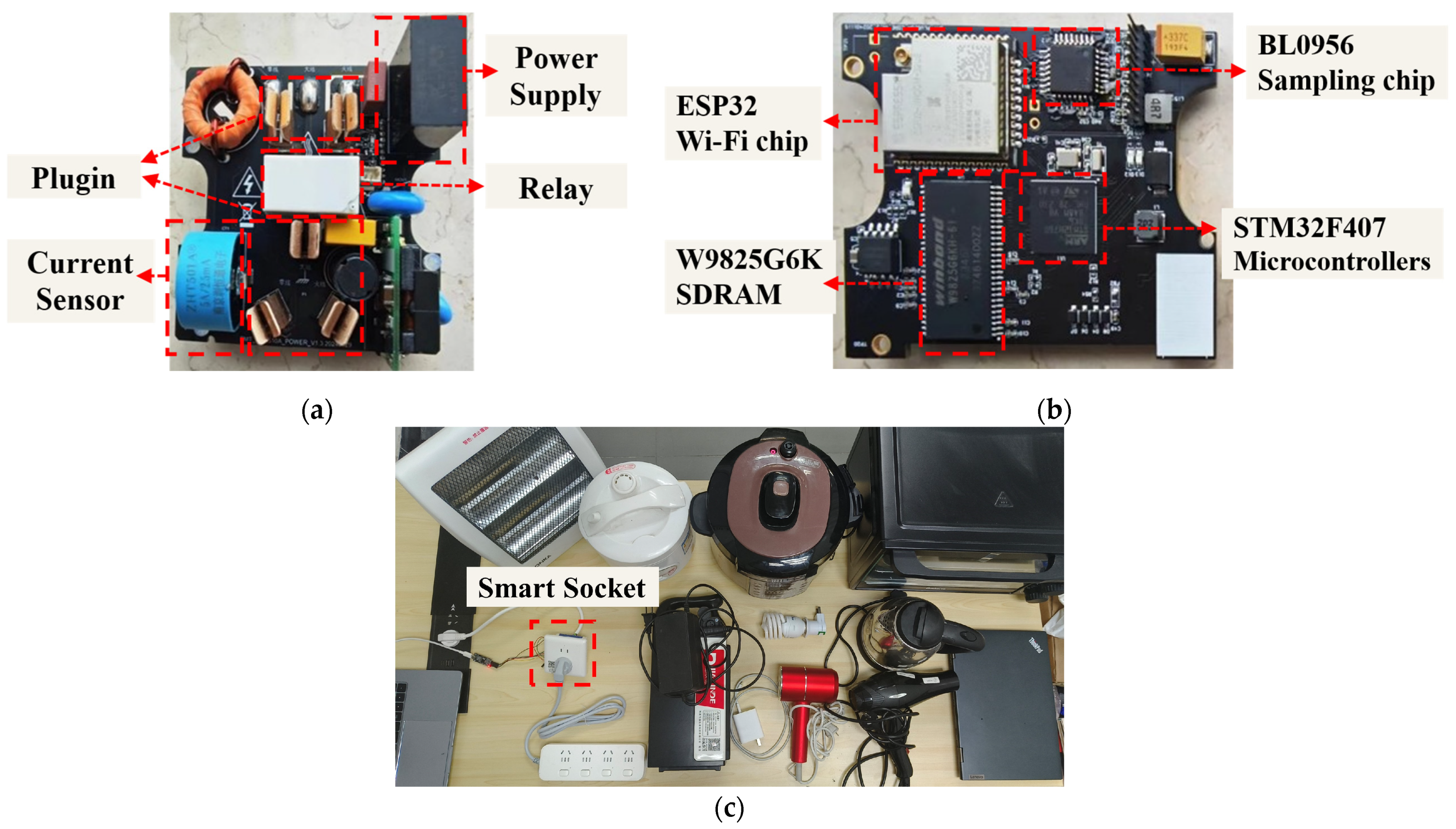
4.7. Validation of Hardware Deployment in Real-World Settings
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Wang, Y.; Ma, J. Non-Intrusive Load Monitoring in Smart Grids: A Comprehensive Review. arXiv 2024, arXiv:2403.06474. [Google Scholar]
- Mari, S.; Bucci, G.; Ciancetta, F.; Fiorucci, E.; Fioravanti, A. A review of non-intrusive load monitoring applications in industrial and residential contexts. Energies 2022, 15, 9011. [Google Scholar] [CrossRef]
- Ji, T.; Chen, J.; Zhang, L.; Lai, H.; Wang, J.; Wu, Q. Low frequency residential load monitoring via feature fusion and deep learning. Electr. Power Syst. Res. 2025, 238, 111092. [Google Scholar] [CrossRef]
- Luo, Q.; Yu, T.; Lan, C.; Huang, Y.; Wang, Z.; Pan, Z. A Generalizable Method for Practical Non-Intrusive Load Monitoring via Metric-Based Meta-Learning. IEEE Trans. Smart Grid 2024, 15, 1103–1115. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, X.; You, W. Non-Intrusive Load Monitoring by Voltage–Current Trajectory Enabled Transfer Learning. IEEE Trans. Smart Grid 2019, 10, 5609–5619. [Google Scholar] [CrossRef]
- McCloskey, M.; Cohen, N.J. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of Learning and Motivation; Elsevier: Amsterdam, The Netherlands, 1989; Volume 24, pp. 109–165. [Google Scholar]
- D’Incecco, M.; Squartini, S.; Zhong, M. Transfer Learning for Non-Intrusive Load Monitoring. IEEE Trans. Smart Grid 2020, 11, 1419–1429. [Google Scholar] [CrossRef]
- Wang, L.; Mao, S.; Wilamowski, B.M.; Nelms, R.M. Pre-Trained Models for Non-Intrusive Appliance Load Monitoring. IEEE Trans. Green Commun. Netw. 2022, 6, 56–68. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, X.; Su, H.; Zhu, J. A comprehensive survey of continual learning: Theory, method and application. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5362–5383. [Google Scholar] [CrossRef]
- Sykiotis, S.; Kaselimi, M.; Doulamis, A.; Doulamis, N. Continilm: A Continual Learning Scheme for Non-Intrusive Load Monitoring. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Zhang, J.; Tan, Z.; Gao, J.; Liu, B.; Zeng, P. A Generalizability-Enhancing Method for Load Identification Based on Typical Sample Replay. In Proceedings of the 2023 3rd International Conference on Computer Science, Electronic Information Engineering and Intelligent Control Technology (CEI), Wuhan, China, 13–15 December 2023; pp. 683–687. [Google Scholar]
- Yin, L.; Ma, C. Interpretable Incremental Voltage–Current Representation Attention Convolution Neural Network for Nonintrusive Load Monitoring. IEEE Trans. Ind. Inf. 2023, 19, 11776–11787. [Google Scholar] [CrossRef]
- Zhou, R.; Fang, X. Non-intrusive Load Monitoring Based Data-Free Incremental Electrical Appliance Identification. In Proceedings of the International Conference on Energy and Environmental Science, Chongqing, China, 5–7 January 2024; pp. 869–879. [Google Scholar]
- Qiu, L.; Yu, T.; Lan, C. A semi-supervised load identification method with class incremental learning. Eng. Appl. Artif. Intell. 2024, 131, 107768. [Google Scholar] [CrossRef]
- Tanoni, G.; Principi, E.; Mandolini, L.; Squartini, S. Appliance-Incremental Learning for Non-Intrusive Load Monitoring. In Proceedings of the 2023 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm), Glasgow, UK, 31 October–3 November 2023; pp. 1–6. [Google Scholar]
- Guo, X.; Wang, C.; Wu, T.; Li, R.; Zhu, H.; Zhang, H. Detecting the novel appliance in non-intrusive load monitoring. Appl. Energy 2023, 343, 121193. [Google Scholar] [CrossRef]
- Kang, J.-S.; Yu, M.; Lu, L.; Wang, B.; Bao, Z. Adaptive Non-Intrusive Load Monitoring Based on Feature Fusion. IEEE Sens. J. 2022, 22, 6985–6994. [Google Scholar] [CrossRef]
- Zhao, Q.; Liu, W.; Li, K.; Wei, Y.; Han, Y. Unknown appliances detection for non-intrusive load monitoring based on vision transformer with an additional detection head. Heliyon 2024, 10, e30666. [Google Scholar] [CrossRef] [PubMed]
- Gao, A.; Zheng, J.; Mei, F.; Sha, H.; Xie, Y.; Li, K.; Liu, Y. Non-intrusive multi-label load monitoring via transfer and contrastive learning architecture. Int. J. Electr. Power Energy Syst. 2023, 154, 109443. [Google Scholar] [CrossRef]
- Lu, L.; Kang, J.-S.; Meng, F.; Yu, M. Non-intrusive load identification based on retrainable siamese network. Sensors 2024, 24, 2562. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Faustine, A.; Pereira, L.; Klemenjak, C. Adaptive Weighted Recurrence Graphs for Appliance Recognition in Non-Intrusive Load Monitoring. IEEE Trans. Smart Grid 2021, 12, 398–406. [Google Scholar] [CrossRef]
- Ruff, L.; Vandermeulen, R.; Goernitz, N.; Deecke, L.; Siddiqui, S.A.; Binder, A.; Müller, E.; Kloft, M. Deep one-class classification. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4393–4402. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Zhao, R.; Lu, J.; Liu, B.; Yu, Z.; Ren, Y.; Zheng, W. Non-Intrusive Load Identification Method Based on Self-Supervised Regularization. IEEE Access 2023, 11, 144696–144704. [Google Scholar] [CrossRef]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Zhuang, H.; Weng, Z.; Wei, H.; Xie, R.; Toh, K.-A.; Lin, Z. ACIL: Analytic class-incremental learning with absolute memorization and privacy protection. Adv. Neural Inf. Process. Syst. 2022, 35, 11602–11614. [Google Scholar]
- Zhuang, H.; Fang, D.; Tong, K.; Liu, Y.; Zeng, Z.; Zhou, X.; Chen, C. Online Analytic Exemplar-Free Continual Learning with Large Models for Imbalanced Autonomous Driving Task. IEEE Trans. Veh. Technol. 2024, 74, 1949–1958. [Google Scholar] [CrossRef]
- Zhuang, H.; Yan, Y.; He, R.; Zeng, Z. Class incremental learning with analytic learning for hyperspectral image classification. J. Franklin Inst. 2024, 361, 107285. [Google Scholar] [CrossRef]
- Woodbury, M.A. Inverting Modified Matrices; Department of Statistics, Princeton University: Princeton, NJ, USA, 1950. [Google Scholar]
- Medico, R.; De Baets, L.; Gao, J.; Giri, S.; Kara, E.; Dhaene, T.; Develder, C.; Berges, M.; Deschrijver, D. A voltage and current measurement dataset for plug load appliance identification in households. Sci. Data 2020, 7, 49. [Google Scholar] [CrossRef] [PubMed]
- Houidi, S.; Fourer, D.; Auger, F.; Sethom, H.B.A.; Miegeville, L. Home electrical appliances recordings for NILM. IEEE DataPort 2020. [Google Scholar] [CrossRef]
- Kahl, M.; Haq, A.U.; Kriechbaumer, T.; Jacobsen, H.-A. Whited-a worldwide household and industry transient energy data set. In Proceedings of the 3rd International Workshop on Non-Intrusive Load Monitoring, Vancouver, BC, Canada, 14–15 May 2016; pp. 1–4. [Google Scholar]
- Picon, T.; Meziane, M.N.; Ravier, P.; Lamarque, G.; Novello, C.; Bunetel, J.-C.L.; Raingeaud, Y. COOLL: Controlled on/off loads library, a public dataset of high-sampled electrical signals for appliance identification. arXiv 2016, arXiv:1611.05803. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, H.; Ma, Q.; Yang, Q.; Wang, Y. A Learnable Image-Based Load Signature Construction Approach in NILM for Appliances Identification. IEEE Trans. Smart Grid 2023, 14, 3841–3849. [Google Scholar] [CrossRef]
- Liu, Y.; Xu, Q.; Yang, Y.; Zhang, W. Detection of Electric Bicycle Indoor Charging for Electrical Safety: A NILM Approach. IEEE Trans. Smart Grid 2023, 14, 3862–3875. [Google Scholar] [CrossRef]
- Fu, Y.; Zhu, X.; Li, B. A survey on instance selection for active learning. Knowl. Inf. Syst. 2013, 35, 249–283. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PLAID | WHITED | HOUIDI | COOLL | ||||
|---|---|---|---|---|---|---|---|---|
| ACC | F1-Macro | ACC | F1-Macro | ACC | F1-Macro | ACC | F1-Macro | |
| LRG | 0.989 | 0.968 | 0.987 | 0.981 | 0.965 | 0.912 | 0.999 | 0.998 |
| AWRG | 0.978 | 0.955 | 0.979 | 0.975 | 0.998 | 0.993 | 0.999 | 0.998 |
| 2DCNN | 0.947 | 0.936 | 0.986 | 0.982 | 0.902 | 0.833 | 0.973 | 0.964 |
| Ours | 0.968 | 0.970 | 0.996 | 0.993 | 0.996 | 0.992 | 0.999 | 0.998 |
| Metric | Siamese Network | DBSCAN | OC-SVM | Ours |
|---|---|---|---|---|
| ACC | 0.875 | 0.649 | 0.595 | 0.823 |
| F1-macro | 0.871 | 0.579 | 0.532 | 0.816 |
| Without original data | × | × | × | √ |
| Appliance Types in the Dataset | Role |
|---|---|
| D0: Hair dryer, induction cooker, fan, rice cooker, kettle, charger | Pretraining |
| D1: Disinfection cabinet, fridge, LED lamp | Continual learning |
| D2: Humidifier, iron, network switch | Continual learning |
| D3: Stove, TV, dehumidifier | Continual learning |
| D4: Electric bicycle, microwave, juice maker | Continual learning |
| D5: Electric blanket, incandescent light bulb, heater | Continual learning |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lan, C.; Luo, Q.; Yu, T.; Liang, M.; Guo, W.; Pan, Z. Analytic Continual Learning-Based Non-Intrusive Load Monitoring Adaptive to Diverse New Appliances. Appl. Sci. 2025, 15, 6571. https://doi.org/10.3390/app15126571
Lan C, Luo Q, Yu T, Liang M, Guo W, Pan Z. Analytic Continual Learning-Based Non-Intrusive Load Monitoring Adaptive to Diverse New Appliances. Applied Sciences. 2025; 15(12):6571. https://doi.org/10.3390/app15126571
Chicago/Turabian StyleLan, Chaofan, Qingquan Luo, Tao Yu, Minhang Liang, Wenlong Guo, and Zhenning Pan. 2025. "Analytic Continual Learning-Based Non-Intrusive Load Monitoring Adaptive to Diverse New Appliances" Applied Sciences 15, no. 12: 6571. https://doi.org/10.3390/app15126571
APA StyleLan, C., Luo, Q., Yu, T., Liang, M., Guo, W., & Pan, Z. (2025). Analytic Continual Learning-Based Non-Intrusive Load Monitoring Adaptive to Diverse New Appliances. Applied Sciences, 15(12), 6571. https://doi.org/10.3390/app15126571