
Dual Attention Equivariant Network for Weakly Supervised Semantic Segmentation


Abstract
1. Introduction
- We propose a dual attention equivariant network model that combines the channel–spatial attention module, equivariance regularization, and pixel-correlation module to effectively improve the accuracy of CAM by considering both channel and spatial information of different feature maps.
- We design a channel–spatial attention module for DAEN to extract accurately features of target objects by considering the correlation among feature maps in different channels.
- Extensive experiments on PASCAL VOC 2012 and LUAD-HistoSeg datasets demonstrate that our proposed model outperforms existing state-of-the-art models for image-level weakly supervised semantic segmentation.
2. Related Work
2.1. Weakly Supervised Semantic Segmentation Based on Image-Level Classification Labels
2.2. Attention Mechanism
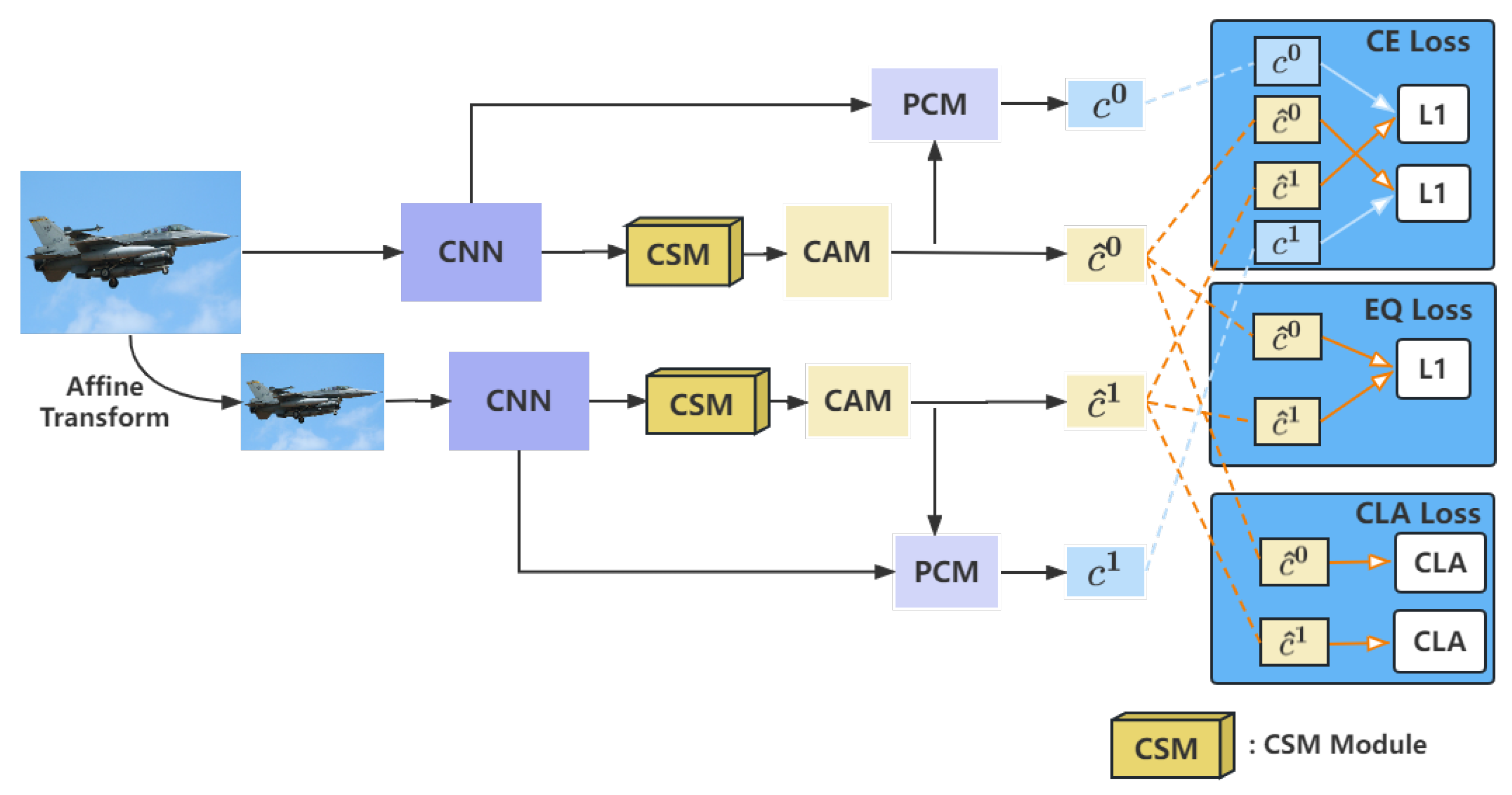
3. Model
3.1. Motivation
3.2. CSM Module
3.2.1. Channel Attention Module
3.2.2. Spatial Attention Module
3.3. Equivariant Regularization
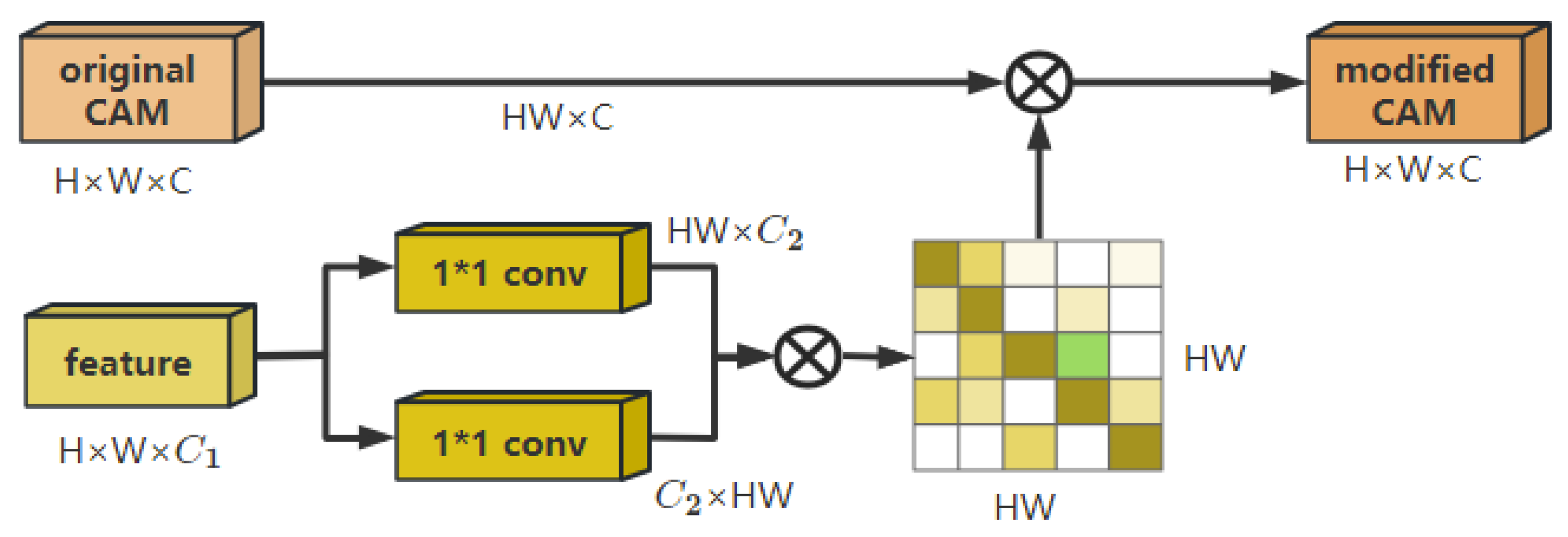
3.4. Pixel Correlation Module
3.5. Loss Function
4. Experiment
4.1. Experiment Setup
4.2. Evaluation of Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI 2015: 18th International Conference), Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhu, L.; Ji, D.; Zhu, S.; Gan, W.; Wu, W.; Yan, J. Learning statistical texture for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 12537–12546. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1635–1643. [Google Scholar]
- Zhu, Y.; Zhou, Y.; Xu, H.; Ye, Q.; Doermann, D.; Jiao, J. Learning instance activation maps for weakly supervised instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3116–3125. [Google Scholar]
- Khoreva, A.; Benenson, R.; Hosang, J.; Hein, M.; Schiele, B. Simple does it: Weakly supervised instance and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 876–885. [Google Scholar]
- Vernaza, P.; Chandraker, M. Learning random-walk label propagation for weakly-supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7158–7166. [Google Scholar]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. Scribblesup: Scribble-supervised convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3159–3167. [Google Scholar]
- Wei, Y.; Feng, J.; Liang, X.; Cheng, M.-M.; Zhao, Y.; Yan, S. Object region mining with adversarial erasing: A simple classification to semantic segmentation approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1568–1576. [Google Scholar]
- Hou, Q.; Jiang, P.; Wei, Y.; Cheng, M.-M. Self-erasing network for integral object attention. In Proceedings of the Advances in Neural Information Processing Systems 31 (NeurIPS 2018), Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Huang, Z.; Wang, X.; Wang, J.; Liu, W.; Wang, J. Weakly-supervised semantic segmentation network with deep seeded region growing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7014–7023. [Google Scholar]
- Wu, T.; Tang, S.; Zhang, R.; Cao, J.; Zhang, Y. CGNet: A light-weight context guided network for semantic segmentation. IEEE Trans. Image Process. 2020, 30, 1169–1179. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Lin, G.; Cai, J.; Shen, T.; Shen, C.; Kot, A.C. Decoupled spatial neural attention for weakly supervised semantic segmentation. IEEE Trans. Multimed. 2019, 21, 2930–2941. [Google Scholar] [CrossRef]
- Chaudhry, A.; Dokania, P.K.; Torr, P.H.S. Discovering class-specific pixels for weakly-supervised semantic segmentation. arXiv 2017, arXiv:1707.05821. [Google Scholar]
- Sun, K.; Shi, H.; Zhang, Z.; Huang, Y. ECS-net: Improving weakly supervised semantic segmentation by using connections between class activation maps. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 7283–7292. [Google Scholar]
- Wang, X.; You, S.; Li, X.; Ma, H. Weakly-supervised semantic segmentation by iteratively mining common object features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1354–1362. [Google Scholar]
- Wang, Y.; Zhang, J.; Kan, M.; Shan, S.; Chen, X. Self-supervised scale equivariant network for weakly supervised semantic segmentation. arXiv 2019, arXiv:1909.03714. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Fan, J.; Zhang, Z.; Tan, T.; Song, C.; Xiao, J. CIAN: Cross-image affinity net for weakly supervised semantic segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10762–10769. [Google Scholar]
- Wang, Y.; Zhang, J.; Kan, M.; Shan, S.; Chen, X. Self-supervised equivariant attention mechanism for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12275–12284. [Google Scholar]
- Kolesnikov, A.; Lampert, C.H. Seed, expand and constrain: Three principles for weakly-supervised image segmentation. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, 223 Part IV 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 695–711. [Google Scholar]
- Lee, J.; Kim, E.; Lee, S.; Lee, J.; Yoon, S. Ficklenet: Weakly and semi-supervised semantic image segmentation using stochastic inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5267–5276. [Google Scholar]
- Araslanov, N.; Roth, S. Single-stage semantic segmentation from image labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4253–4262. [Google Scholar]
- Shimoda, W.; Yanai, K. Self-supervised difference detection for weakly-supervised semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5208–5217. [Google Scholar]
- Zhang, Z.; Peng, Q.; Fu, S.; Wang, W.; Cheung, Y.-M.; Zhao, Y.; Yu, S.; You, X. A Componentwise Approach to Weakly Supervised Semantic Segmentation Using Dual-Feedback Network. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 7541–7554. [Google Scholar] [CrossRef] [PubMed]
- Jiang, P.-T.; Zhang, C.-B.; Hou, Q.; Cheng, M.-M.; Wei, Y. LayerCAM: Exploring Hierarchical Class Activation Maps for Localization. IEEE Trans. Image Process. 2021, 30, 5875–5888. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.; Xiao, J.; Wei, Y.; Huang, K.; Luo, S.; Zhao, Y. End-to-end weakly supervised semantic segmentation with reliable region mining. Pattern Recognit. 2022, 128, 108663. [Google Scholar] [CrossRef]
- Li, Y.; Sun, J.; Li, Y. Weakly-Supervised Semantic Segmentation Network With Iterative dCRF. IEEE Trans. Intell. Transp. Syst. 2022, 23, 25419–25426. [Google Scholar] [CrossRef]
- Zeng, X.; Wang, T.; Dong, Z.; Zhang, X.; Gu, Y. Superpixel Consistency Saliency Map Generation for Weakly Supervised Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, D.; Zhang, L.; Tang, J. Coupling Global Context and Local Contents for Weakly-Supervised Semantic Segmentation. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 13483–13495. [Google Scholar] [CrossRef] [PubMed]
- Ahn, J.; Kwak, S. Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4981–4990. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. FcaNet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 783–792. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Stammes, E.; Runia, T.F.H.; Hofmann, M.; Ghafoorian, M. Find it if you can: End-to-end adversarial erasing for weakly-supervised semantic segmentation. In Proceedings of the Thirteen International Conference on Digital Image Processing (ICDIP 2021), SPIE, Singapore, 20–23 May 2021; Volume 11878, pp. 610–619. [Google Scholar]
- Zhang, B.; Xiao, J.; Wei, Y.; Sun, M.; Huang, K. Reliability does matter: An end-to-end weakly supervised semantic segmentation approach. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12765–12772. [Google Scholar]
- Chan, L.; Hosseini, M.S.; Rowsell, C.; Plataniotis, K.N.; Damaskinos, S. HistoSegNet: Semantic segmentation of histological tissue type in whole slide images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10662–10671. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1 | 2 | 3 | 4 | 5 | Average Result | |
|---|---|---|---|---|---|---|
| SEAM | 54.362 | 54.726 | 54.563 | 54.607 | 54.598 | 54.57 |
| SM | 55.086 | 54.933 | 54.949 | 55.018 | 54.963 | 54.98 |
| CM | 55.129 | 55.236 | 55.100 | 55.160 | 55.040 | 55.13 |
| DAEN | 55.360 | 55.302 | 55.351 | 55.244 | 55.211 | 55.29 |
| CLA | EQ | CE | mIoU |
|---|---|---|---|
| ✓ | 50.44% | ||
| ✓ | 13.04% | ||
| ✓ | 50.58% | ||
| ✓ | ✓ | 51.43% | |
| ✓ | ✓ | 18.35% | |
| ✓ | ✓ | 54.38% | |
| ✓ | ✓ | ✓ | 55.36% |
| 1 | 2 | 3 | 4 | 5 | Average Result | |
|---|---|---|---|---|---|---|
| SEAM + AffinityNet | 62.434 | 62.914 | 62.578 | 62.694 | 62.605 | 62.65 |
| DAEN + AffinityNet | 64.461 | 64.373 | 64.390 | 64.298 | 64.288 | 64.36 |
| Category | SEAM | DAEN | Category | SEAM | DAEN |
|---|---|---|---|---|---|
| backgroud | 87.3 | 87.7 | diningtable | 51.6 | 54.6 |
| aeroplant | 67.6 | 63.8 | dog | 68.9 | 76.4 |
| bicycle | 40.2 | 39.1 | horse | 75.7 | 77.4 |
| bird | 81.8 | 83.3 | motorbike | 79.1 | 77.5 |
| boat | 42.5 | 36.3 | person | 52.1 | 60.8 |
| bottle | 56.2 | 65.6 | pottedplant | 44.0 | 48.1 |
| bus | 72.9 | 75.3 | sheep | 89.9 | 90.5 |
| car | 75.9 | 77.6 | sofa | 51.9 | 57.3 |
| cat | 60.5 | 71.4 | train | 67.0 | 64.0 |
| chair | 33.5 | 33.7 | tv | 55.2 | 55.2 |
| cow | 78.8 | 79.5 | mIoU | 63.5 | 65.5 |
| Methods | Backbone | val | Test |
|---|---|---|---|
| AffinityNet [33] | Resnet38 | 61.7 | 63.7 |
| SSDD [26] | Resnet38 | 64.9 | 65.5 |
| Araslanov [25] | Resnet38 | 62.7 | 64.3 |
| PSA [40] | Resnet38 | 62.8 | 63.8 |
| RRM [41] | Resnet38 | 62.6 | 62.9 |
| SEAM [22] | Resnet38 | 64.5 | 65.7 |
| WS-FCN [32] | Resnet38 | 65.0 | 64.2 |
| SEAM * [22] | Resnet38 | 63.5 | 64.7 |
| Our DAEN * | Resnet38 | 65.5 | 66.8 |
| Methods | TE | NEC | LYM | TAS | Average Result |
|---|---|---|---|---|---|
| HistoSegNet [42] | 45.6 | 36.3 | 58.3 | 50.8 | 47.7 |
| SEAM | 47.6 | 49.5 | 48.3 | 56.9 | 50.6 |
| Our DAEN | 48.2 | 51.1 | 49.4 | 58.7 | 51.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, G.; Zheng, Z.; Li, J.; Zhang, M.; Liu, J.; Zhang, L. Dual Attention Equivariant Network for Weakly Supervised Semantic Segmentation. Appl. Sci. 2025, 15, 6474. https://doi.org/10.3390/app15126474
Huang G, Zheng Z, Li J, Zhang M, Liu J, Zhang L. Dual Attention Equivariant Network for Weakly Supervised Semantic Segmentation. Applied Sciences. 2025; 15(12):6474. https://doi.org/10.3390/app15126474
Chicago/Turabian StyleHuang, Guanglun, Zhaohao Zheng, Jun Li, Minghe Zhang, Jianming Liu, and Li Zhang. 2025. "Dual Attention Equivariant Network for Weakly Supervised Semantic Segmentation" Applied Sciences 15, no. 12: 6474. https://doi.org/10.3390/app15126474
APA StyleHuang, G., Zheng, Z., Li, J., Zhang, M., Liu, J., & Zhang, L. (2025). Dual Attention Equivariant Network for Weakly Supervised Semantic Segmentation. Applied Sciences, 15(12), 6474. https://doi.org/10.3390/app15126474