1. Introduction
In recent years, the rapid advancement in Internet of Things (IoT) and Artificial Intelligence (AI) technologies has given rise to a wide range of cross-disciplinary innovations. The IoT enables interconnectivity among physical objects via the Internet, allowing devices to sense, collect, and exchange data, as well as to perform context-aware actions. This paradigm shift has accelerated the digital transformation of the physical world, leading to applications across multiple sectors, such as smart manufacturing, smart cities, healthcare, and intelligent transportation systems. Concurrently, AI technologies have been extensively adopted across diverse domains. Among the most prominent applications are cybersecurity and data management, where AI is utilized to detect anomalies, reinforce security architectures, and facilitate intelligent risk assessment. In the medical field, AI-powered image analysis and diagnostic tools have significantly improved both diagnostic accuracy and operational efficiency. Furthermore, AI continues to demonstrate substantial value in sectors such as digital marketing, fraud detection, autonomous driving, and governmental surveillance.
According to IoT Analytics [
1], the global number of connected IoT devices reached 16.6 billion by the end of 2023, marking a 15% increase compared to 2022, with projections estimating growth to 40 billion devices by 2030. Despite these technological advancements, road safety remains a significant concern, particularly in Taiwan, where traffic accidents have dramatically increased by 130%, from 170,127 cases in 2008 to 393,918 cases in 2024 [
2]. This surge is largely due to human factors, including driver negligence and delayed responses to road indicators. While traffic signs and road markings are designed for optimal visibility, their effectiveness can be compromised in low-visibility conditions, emphasizing the urgent need for advanced assistive systems. Addressing these challenges, rapid developments in IoT and image recognition technologies have significantly enhanced intelligent transportation systems (ITSs) in smart cities worldwide, substantially improving road safety, traffic efficiency, and sustainability [
3]. For instance, Wang et al. developed the CGADNet model [
4], a lightweight YOLOv8-based deep learning network specifically tailored for efficient real-time detection of pedestrian crosswalks and guide arrows in complex urban environments. Similarly, Zhang et al. proposed the CDNet model [
5], which is based on YOLOv5, while Lu et al. introduced X-CDNet [
6], an improved model based on YOLOX. Both models were designed to provide robust real-time object detection capabilities, thereby contributing to the advancement of intelligent transportation systems. Additionally, Dadashev and Török introduced the SmartDENM system [
7], integrating YOLO-based object detection with Vehicle-to-Everything (V2X) communications through Roadside Units (RSUs), enabling real-time decentralized environmental notification messages (DENMs) to prompt immediate safety actions like speed reduction or lane changes. Furthermore, technologies such as vehicular ad hoc networks (VANETs), Intelligent Traffic Lights (ITLs), Virtual Traffic Lights (VTLs), and Mobility Prediction methods further highlight the trajectory toward optimized traffic management, urban sustainability, and significant environmental impact reduction.
In contrast, road surface markings—such as lane lines and pedestrian crossings—are inherently more prone to occlusion by vehicles or degradation due to adverse environmental conditions, including poor lighting, nighttime driving, and inclement weather. These limitations can impair driver perception and increase the risk of traffic incidents. In scenarios where intersections lack traffic signs or signals, road markings often serve as the primary means of traffic control. Among these, pedestrian crossings are especially vital for safeguarding pedestrian rights-of-way. However, their effectiveness depends heavily on clear visibility and prompt recognition. To enhance the accuracy of pedestrian-crossing detection, this study proposes an integrated system combining YOLO-based automatic labeling with a CycleGAN [
8] loop-learning framework. This approach not only improves detection precision but also increases the overall system efficiency, enabling faster scalable pedestrian-crossing identification and streamlined model retraining. Our system design offers two advantages:
The improved pedestrian-crossing detection system enhances the capabilities of driving assistance technologies by providing more accurate and timely warnings to drivers when approaching pedestrian crossings. This contributes to increased road safety by reducing the risk of pedestrian-related accidents.
The integration of an automatic labeling system significantly reduces the time and manpower required for manual verification, thereby streamlining the annotation process.
This study begins with the collection of image and video data capturing pedestrian crossings under diverse conditions. The data were gathered from urban roads surrounding Feng Chia University in Taichung, Taiwan, which represent typical local traffic environments. In addition to varying times of day (e.g., daytime and nighttime), we focused on five specific environmental scenarios: night, rainy day, rainy night, sun glare, and high-beam glare. These five conditions were chosen based on their relevance to real-world driving hazards, particularly those that impair pedestrian-crossing visibility and increase the risk of driver oversight. Due to the limited availability of annotated data under such challenging conditions, daytime scenes—which are easier to capture—were used to train a Cycle-Consistent Generative Adversarial Network (CycleGAN) to generate synthetic images corresponding to these five scenarios. This augmentation technique expands the dataset and improves the model’s generalizability. The pedestrian-crossing detection model was trained using YOLO [
9,
10,
11] on a combination of real and synthetic datasets. To manage and scale the storage of both raw and annotated images, we utilized a cloud-based infrastructure provided by Amazon Web Services (AWS).
A dedicated automated labeling module was developed to leverage the YOLO detection model for large volumes of new images, significantly reducing the need for manual annotation. While limited human verification remains necessary to eliminate false positives, the system is designed to support continuous improvement. Through this iterative loop of data collection, model training, and system deployment, the pedestrian-crossing detection framework is continuously optimized, leading to progressively higher accuracy and reliability in real-world applications. The remainder of this paper is organized as follows:
Section 2 provides an overview of the existing research and relevant technologies.
Section 3 outlines the system architecture and methodologies adopted in this study.
Section 4 details the data collection process and implementation methods used for pedestrian-crossing detection.
Section 5 presents the experimental results, including an evaluation of different situational datasets and the impact of incorporating generated images into the training process.
Section 6 concludes the study and highlights potential directions for future research.
2. Related Work
Traditional pedestrian-crossing detection methods primarily rely on the characteristic black-and-white-striped patterns of zebra crossings. The early studies often adopted these visual cues as the foundation for algorithm selection and system design [
12]. Uddin et al. [
13] proposed a method based on bipolarity-based segmentation and projective-invariant-based recognition. Their approach verified the bipolarity of each image block and used a voting mechanism grounded in projective invariants to guide image binarization. Wu et al. [
14] employed the Hough Transform to extract pedestrian-crossing lines from surveillance footage, enabling both location and directional analyses. Additionally, their method assessed the degradation of pedestrian crossings, providing valuable insights for road safety management. Herumurti et al. [
15] applied Speeded-Up Robust Features (SURFs) to extract distinct striped patterns for pedestrian-crossing detection. Despite its high computational cost at increased resolutions, SURFs demonstrated strong accuracy in feature extraction.
With the advent of deep learning and object detection technologies, traffic information retrieval has significantly improved, surpassing traditional hand-crafted feature-based techniques. Sommer et al. [
16] applied Fast R-CNN for vehicle detection in aerial imagery, using VGG-16 as the backbone network. Their approach divided input images into multiple regions and predicted object presence with confidence scores, effectively eliminating irrelevant background regions such as rural landscapes, thereby reducing computational overhead. Xiong et al. [
17] developed a traffic sign detection algorithm based on a deep convolutional neural network (CNN) utilizing a region proposal network (RPN). Their system, capable of real-time performance and achieving over 99% detection accuracy, could identify Chinese traffic signs from onboard cameras and dashcams, contributing to comprehensive traffic sign datasets. In the domain of pedestrian-crossing detection, Dow et al. [
18] integrated environmental feature vectors with YOLO-based pedestrian detection to identify both crossings and waiting areas. Their hybrid system combined deep learning for pedestrian identification with traditional image processing techniques for crossing recognition. Lin et al. [
19] adopted the YOLO architecture, fine-tuning it on the COCO dataset to enhance pedestrian-crossing detection. These studies collectively highlight the shift from classical vision-based techniques to deep-learning-based approaches, offering improvements in detection accuracy, robustness, and real-time performance across various traffic monitoring tasks.
In recent years, the YOLO architecture has been extensively applied to pedestrian-crossing image-detection tasks [
4,
5,
6]. Data collection efforts have typically focused on acquiring images from real-world road scenes or publicly available online image repositories. Data augmentation methods frequently involve synthetic scene simulations, such as foggy conditions; however, these approaches often overlook whether the simulated scenarios adequately resemble real-world conditions. The method proposed in this study leverages a limited set of real-world images captured under specific challenging conditions to generate synthetic images from standard daytime images, thereby enriching the training dataset and balancing class distributions. This approach ultimately enhances the model’s F1-scores across various scenarios.
Table 1 presents a comparison of the data collection and augmentation methods between our proposed approach and those in [
4,
5,
6].
While deep learning methods are powerful, their effectiveness largely depends on the availability of well-annotated large-scale datasets. Manual data labeling, however, remains time-consuming, repetitive, and labor-intensive. To address this bottleneck, several researchers have focused on automatic labeling techniques. Liu et al. [
20] introduced a mobile-compatible system for incremental labeling, which annotates non-stationary data using evolving unknown labels. Lin et al. [
21] proposed a multi-task learning framework for multi-source image labeling, demonstrating that combining datasets from different sources outperforms traditional single-task learning. Ji et al. [
22] combined generative and discriminative modeling by leveraging local discriminant topics around unlabeled images to minimize misclassification, particularly for visually ambiguous data. Zhang et al. [
23] explored similarity-based labeling in telemetry imagery by analyzing spectral, shape, and hybrid features to match unlabeled regions with the most similar labeled samples, thereby reducing manual annotation. Yu et al. [
24] used multimodal unsupervised image-to-image translation (MUNIT) to synthesize training images from labeled data, expanding the training corpus without requiring additional human input. Similarly, Chen et al. [
25] proposed an automated video labeling method in which user-defined sample patterns are extracted, analyzed, and iteratively used to refine the recognition model, resulting in progressively improved accuracy.
Pseudo-labeling has emerged as a crucial strategy in computer vision [
26], enabling the automatic annotation of unlabeled or sparsely labeled datasets and significantly reducing the reliance on costly and time-consuming human labeling. This technique has proven particularly beneficial in complex road environments, where acquiring high-quality labeled data is often challenging. Recent studies have leveraged pseudo-labeling to enhance model performance by iteratively training on both manually labeled and automatically pseudo-labeled data. For instance, Riaz et al. [
27] proposed the S2R-UDA-CP framework, which utilizes synthetic videos with crossing/non-crossing (C/NC) labels to automatically assign pseudo-labels to real-world pedestrian intention videos, effectively bridging the domain gap and improving model accuracy. Similarly, Sun et al. [
28] introduced a refined soft pseudo-labeling approach guided by centroid similarity ranking, which enhances label reliability in domain-adaptive vehicle re-identification. Additionally, Zhao et al. [
29] incorporated generative adversarial networks (GANs) into semantic segmentation tasks, demonstrating that adversarial learning can capture subtle visual features and improve model generalization in challenging road scenes. Collectively, these advancements underscore the transformative impact of pseudo-labeling in automating the annotation process, accelerating model development, and enhancing performance in intelligent transportation systems.
These advancements in AI-assisted data annotation significantly improve the scalability, efficiency, and accuracy of deep learning systems. Future directions may further explore human–AI collaboration for annotation refinement and enhanced adaptability across domains. In addition to data labeling, cyclic learning has emerged as a powerful training strategy in machine learning, emphasizing iterative and feedback-driven processes. Unlike static training protocols, cyclic learning frameworks adjust parameters or data representations in repeated loops to promote better convergence and generalization. The key examples include the following:
Cyclical Learning Rate Schedules: Introduced by Smith [
30], this approach oscillates the learning rate within a predefined range during training to prevent convergence to suboptimal local minima, reducing the need for extensive manual tuning while enhancing classification performance.
General Cyclical Training: Also proposed by Smith, this broader concept involves cyclically modifying parameters such as weight decay, batch size, data augmentation strategies, or loss functions during the training phase to prevent overfitting and encourage learning of more robust features.
Iterative Reinforcement Learning Loops: Common in reinforcement learning (RL) [
8,
31,
32,
33], agents interact with the environment through repeated cycles of action, observation, and policy updates. This self-improving loop enables agents to discover superior strategies over time, often outperforming manually designed policies in complex tasks.
Across various disciplines—including engineering design, control systems, and organizational learning—cyclic learning offers adaptive refinement through feedback, enhancing both the robustness and efficiency of systems. In the context of pedestrian-crossing detection, such iterative training strategies can be harnessed to continuously improve model performance via recurring data collection, retraining, and system deployment cycles. Compared with the prior work, our proposed system differs in three key aspects. First, unlike traditional vision-based approaches and deep learning models that rely heavily on large-scale annotated datasets, we introduce a CycleGAN-based loop-learning framework to address data scarcity under visually challenging conditions. Second, while the existing pedestrian-crossing detection systems often focus solely on model performance, we integrate a dual-loop system that includes automated labeling and iterative retraining, enabling continual model refinement with minimal manual intervention. Third, rather than assuming ideal training environments, our method targets five safety-critical environmental conditions—such as glare and rainy night scenes—that are typically underrepresented in prior datasets. These design choices allow our approach to maintain robustness in real-world applications and lay the foundation for future deployment in driver-assistance systems.
3. System Architecture
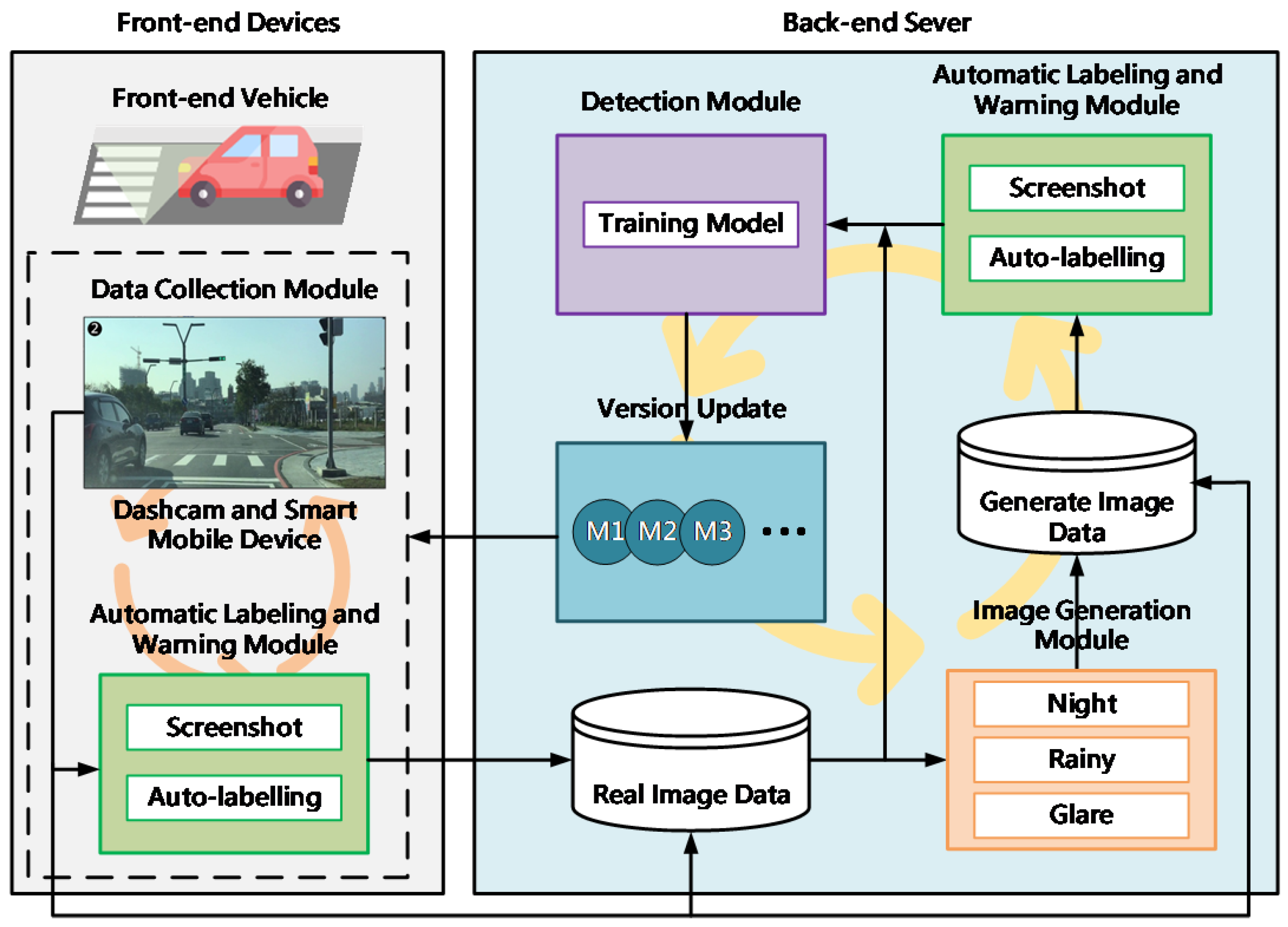
This section introduces the detailed architecture of our pedestrian-crossing detection system, outlining the essential components and their interactions. Initially, we describe the overall system overview, highlighting the methods for collecting and augmenting pedestrian-crossing data to address data scarcity under challenging conditions. We employ CycleGAN to generate synthetic images simulating scenarios like nighttime, rain, and glare, complementing real-world data. YOLO technology serves as the central detection mechanism, enabling rapid and accurate pedestrian-crossing recognition. An automated labeling module integrates initial model predictions with manual annotations, greatly reducing manual annotation efforts while maintaining accuracy through minimal human verification. The collected data are systematically stored using AWS cloud storage, enhancing scalability and cost-effectiveness. Subsequent iterations of the model leverage expanded datasets, forming a self-improving, feedback-driven learning cycle aimed at the continuous enhancement of pedestrian-crossing detection capabilities.
3.1. System Overview
We begin by collecting pedestrian-crossing data, including images and videos captured at various times of the day and night. Video data are converted into individual frames to facilitate subsequent deep learning training. These images are then manually annotated with pedestrian-crossing features and supplemented with additional contextual information. To address the imbalance of training data under specific conditions, a CycleGAN-based image generation module is employed to synthesize a limited number of images representing scenarios such as nighttime, rain, and glare. Both real and synthetic images are used to train the first version of the pedestrian-crossing detection model using YOLO technology.
Next, the initial detection model is integrated with previous manual annotation functions to develop an automatic labeling module capable of detecting and labeling pedestrian crossings at scale. While the system substantially reduces manual effort, a small degree of human verification is still required to eliminate incorrectly labeled instances. Additionally, this automatic labeling module is used to filter out low-quality synthetic images produced by CycleGAN as inconsistencies in generated image quality may otherwise degrade the clarity of crossing features during training. To further enhance model generalization, the dataset is gradually expanded by continuously collecting new pedestrian-crossing images from a variety of environments. Beginning with the area surrounding Feng Chia University, data collection efforts are extended to diverse backgrounds, such as urban centers, school zones, commercial districts, and suburban areas.
A large volume of raw and labeled image data are stored using Amazon Web Services (AWS) cloud storage solutions. This approach offers greater flexibility for subsequent analysis and significantly reduces storage costs compared to traditional local data warehousing methods. As the training dataset grows, second and third iterations of the pedestrian-crossing detection model will be developed. Each updated model is fed back into both the automatic labeling module and the front-end vehicle assistance system, forming a feedback-driven learning loop. Ultimately, the goal is to realize a pedestrian-crossing detection system capable of continuous self-improvement through both external and internal cyclic learning processes. The overall system architecture is illustrated in
Figure 1.
The data collection module comprises dashcams and smart mobile devices. The image generation module, based on CycleGAN, is used to synthesize pedestrian-crossing scenes under various environmental conditions. YOLO serves as the core detection module for training pedestrian-crossing recognition. The trained detection model is then integrated with rule-based logic to construct the automatic labeling module, which facilitates large-scale annotation of pedestrian-crossing features.
3.2. Data Collection from Real-World Driving
This study aims to enhance the development of the pedestrian-crossing detection system that assists drivers in rapidly identifying pedestrian crossings in real-world driving scenarios. To ensure the training data accurately reflect the driver’s visual experience, image collection is conducted during actual driving rather than relying on secondary sources such as Google Street View. Images obtained from online sources often differ in angle, perspective, and context and thus fail to represent the visual conditions encountered by drivers on the road. Moreover, real-world driving across different regions exposes the vehicle to a variety of road designs and local traffic scenarios—such as white-and-green-striped crossings or diagonally painted crossings near school zones—which are rarely represented in publicly available datasets. These rare but critical cases are essential for improving the robustness and adaptability of the detection model. Consequently, our data collection strategy emphasizes capturing authentic road images during on-road driving, supplemented by synthetic images generated through CycleGAN under varying environmental conditions.
To replicate the driver’s perspective, data acquisition devices are mounted with consideration of the average adult driver’s eye level, which is approximately 130 cm above the ground. A dashcam is installed behind the rearview mirror of the vehicle, slightly offset to the right and positioned at the standard eye level of the driver. In addition, a smartphone is mounted on the front windshield by a passenger, aligned straight forward at a height of approximately 116 cm from the ground. These two recording devices are selected to approximate the driver’s field of view from both central and slightly offset perspectives. During data collection, the vehicle travels at a consistent speed of 40 km/h, maintaining a minimum following distance of 20 m to ensure safety and clear visibility. This setup is designed to maximize the number of pedestrian-crossing instances captured in a single driving session. Together, the vehicle, dashcam, and mobile device constitute the data collection module within the overall system architecture.
3.3. Data Augmentation via CycleGAN
In supervised deep learning, training an effective detection model typically requires large volumes of labeled data. Data engineers must manually annotate tens of thousands of images to enable the neural network to learn to recognize specific objects. This process is both time-consuming and labor-intensive. The challenge becomes more pronounced when the target objects are rare or appear only under specific environmental conditions, such as adverse weather or nighttime. In such cases, acquiring a sufficiently diverse and representative dataset during the initial stages of development poses significant difficulties. To address the issue of limited data availability, Goodfellow et al. [
34] introduced generative adversarial networks (GANs) in 2014. A GAN consists of two components: a generator and a discriminator. The generator attempts to create synthetic images that are indistinguishable from real ones, while the discriminator tries to differentiate between real and generated images. Through this adversarial learning process, the generator progressively learns to produce increasingly realistic images. This technique offers a powerful solution to data scarcity by enabling the generation of synthetic training data that mimic real-world samples.
In 2017, Zhu et al. [
8] proposed Cycle-Consistent Adversarial Network (CycleGAN), a specialized form of GAN designed for unpaired image-to-image translation. Unlike conventional GANs that require paired training data (e.g., the same scene captured in two different conditions), CycleGAN only requires sets of images from two different domains. This significantly lowers the barrier to training data preparation as paired samples—such as summer and winter views of the same scene, or visually similar zebras and horses—are often difficult to obtain. CycleGAN extends the GAN architecture by introducing cycle consistency, training two generators and two discriminators simultaneously. The first generator learns to map images from domain A to domain B, while the second generator maps from domain B back to domain A. Cycle consistency ensures that, when an image is translated to the other domain and then translated back, the final output remains consistent with the original input. This bidirectional mapping enforces structural fidelity and enhances the quality of the translated images.
CycleGAN has been widely adopted in various domains for its ability to generate realistic images under constrained-data conditions. For instance, Wang et al. [
31] applied CycleGAN to convert between visible-light and near-infrared facial images, achieving a facial recognition accuracy of 96.5%. Zhang et al. [
32] used CycleGAN to generate synthetic foggy images from clear remote sensing imagery in order to train a defogging model based on visual features rather than physical simulations. Xu et al. [
33] introduced an environment-aware CycleGAN for synthesizing rare or missing typhoon-intensity features using unpaired satellite image sequences. Their results demonstrated that the model could effectively generate samples from previously unseen categories, improving predictive performance.
These studies highlight the effectiveness of CycleGAN in augmenting datasets under limited or specialized conditions. Building on this foundation, we adopt CycleGAN as the image generation module in our proposed system. Specifically, it is used to generate pedestrian-crossing images under visually challenging scenarios—such as nighttime, rain, and direct glare from sunlight or artificial high beams—that are critical for enhancing the robustness and accuracy of the pedestrian-crossing detection model.
3.4. Pedestrian-Crossing Detection
YOLO (You Only Look Once) employs a deep neural network to detect and classify objects in a single forward pass, offering both high speed and accuracy. Unlike traditional two-stage object detection methods that separately generate candidate regions and classify objects, YOLO directly predicts bounding boxes and class probabilities in a unified framework. This end-to-end architecture significantly improves detection efficiency and has become a widely adopted approach in real-time object detection tasks. Numerous researchers have leveraged and optimized the YOLO architecture for various applications. For instance, Chen et al. [
35] proposed a real-time vehicle detection system based on the YOLO architecture for deployment on embedded devices. By quantizing the network parameters, their model achieved a mean Average Precision (mAP) of 69.79% and a detection speed of 28 frames per second (FPSs), making it suitable for resource-constrained environments. Kim et al. [
36] integrated YOLO with a Support Vector Machine (SVM) to develop a high-resolution automotive radar system capable of classifying pedestrians and vehicles. Their hybrid model demonstrated classification accuracy exceeding 90% in experimental evaluations.
Strbac et al. [
37] explored the feasibility of replacing LIDAR with a stereo-vision system for distance estimation. By capturing two slightly offset images from a pair of cameras and applying a YOLO-based deep neural network, their system estimated the distance to detected objects using principles of stereo imaging. Furthermore, Kim et al. [
38] conducted a comparative study on real-time vehicle detection performance across several object detection models and obtained the result that YOLO outperformed the other models in terms of F1-score, precision, recall, and mAP while achieving near-optimal processing speed—second only to SSD. Given its superior balance between accuracy and inference speed, YOLO is particularly well-suited for real-time applications such as advanced driver-assistance systems (ADASs) and Internet of Vehicles (IoV) platforms. Therefore, in this research, YOLO is adopted as the core object detection module for identifying pedestrian crossings under diverse environmental conditions.
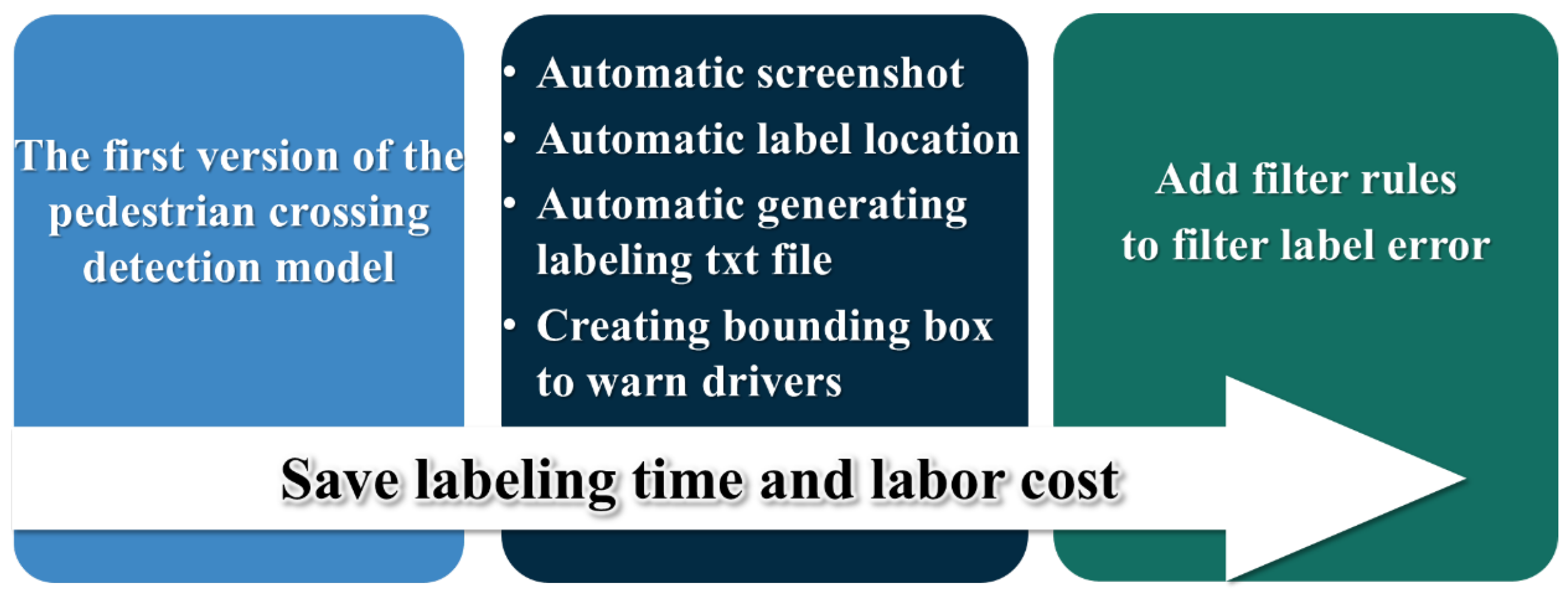
3.5. Pedestrian-Crossing Automatic Labeling
The first version of the trained pedestrian-crossing detection model is utilized as the foundation for the automatic labeling module. As illustrated in
Figure 2, this module is capable of performing automatic screenshot capture, object detection, and label-file generation in a unified workflow. Once a video is provided as input, the system automatically extracts frames, detects pedestrian crossings, and generates corresponding annotation files in .txt format, eliminating the need for manual frame extraction and individual labeling.
This integrated three-in-one module significantly streamlines the data annotation process. Moreover, if the detection model inadvertently identifies objects unrelated to pedestrian crossings, user-defined filtering rules can be applied to exclude such false positives. This additional layer of filtering helps to reduce labeling errors, saving both time and labor costs during the dataset preparation stage.
4. System Implementation
This section further details the practical implementation aspects of the pedestrian-crossing detection system. It outlines the planning and execution of data collection, emphasizing real-world driving scenarios along carefully chosen routes to ensure initial model efficacy. Data preprocessing steps, including frame extraction and class balancing through synthetic image generation, are described to illustrate dataset preparation. Additionally, the implementation specifics of the CycleGAN-based image generation module are provided, highlighting architectural decisions and training parameters designed to enhance dataset diversity. Finally, the operational details of the YOLO-based detection module and automatic labeling mechanism are explained, demonstrating how these elements collaboratively support efficient, accurate pedestrian-crossing annotation and detection.
4.1. Planning of Data Collection
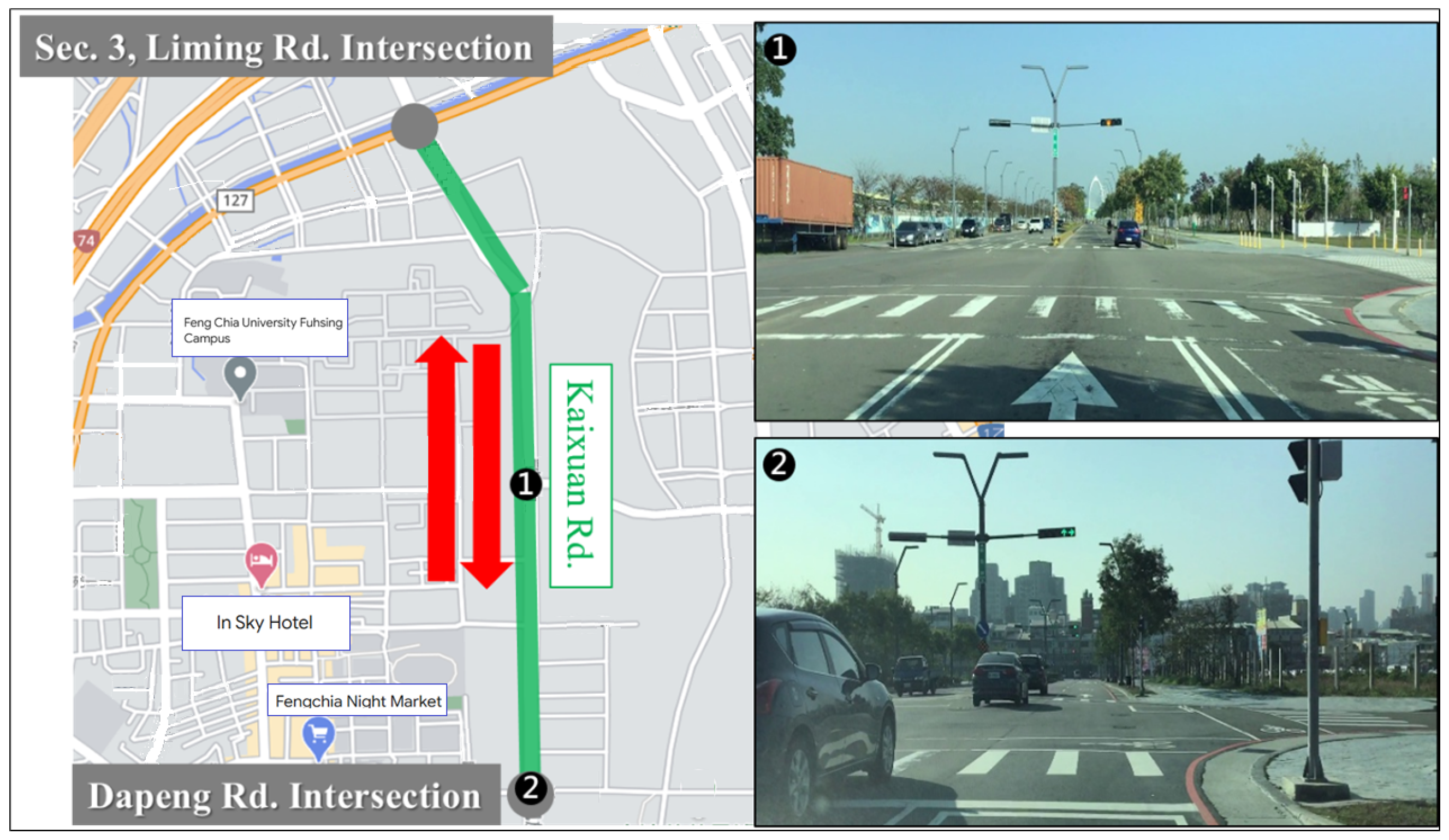
To ensure that the collected pedestrian-crossing data accurately reflect real-world driving conditions, we focused on acquiring images captured from actual vehicle operation. The initial dataset was collected along Kaixuan Road, located near Feng Chia University in Xitun District, Taichung City, Taiwan. This roadway, as shown in
Figure 3, is a relatively new urban development and features consistently marked pedestrian crossings, all equipped with standardized signage and a regular layout. The digital map background used in
Figure 3 is adapted from Google Maps and is included for illustrative and academic purposes. The data collection route began at the Dapeng intersection, proceeded along Kaixuan Road, and turned at the Liming intersection before returning along the same route to the original starting point. Along this segment, a total of ten intersections with designated pedestrian crossings were recorded. This well-structured and visually consistent environment was selected as the training dataset for the first version of the pedestrian-crossing detection model and the automatic labeling module. The clarity and regularity of the markings in this area facilitated initial model development and annotation efficiency, laying the groundwork for subsequent system iterations and performance optimization.
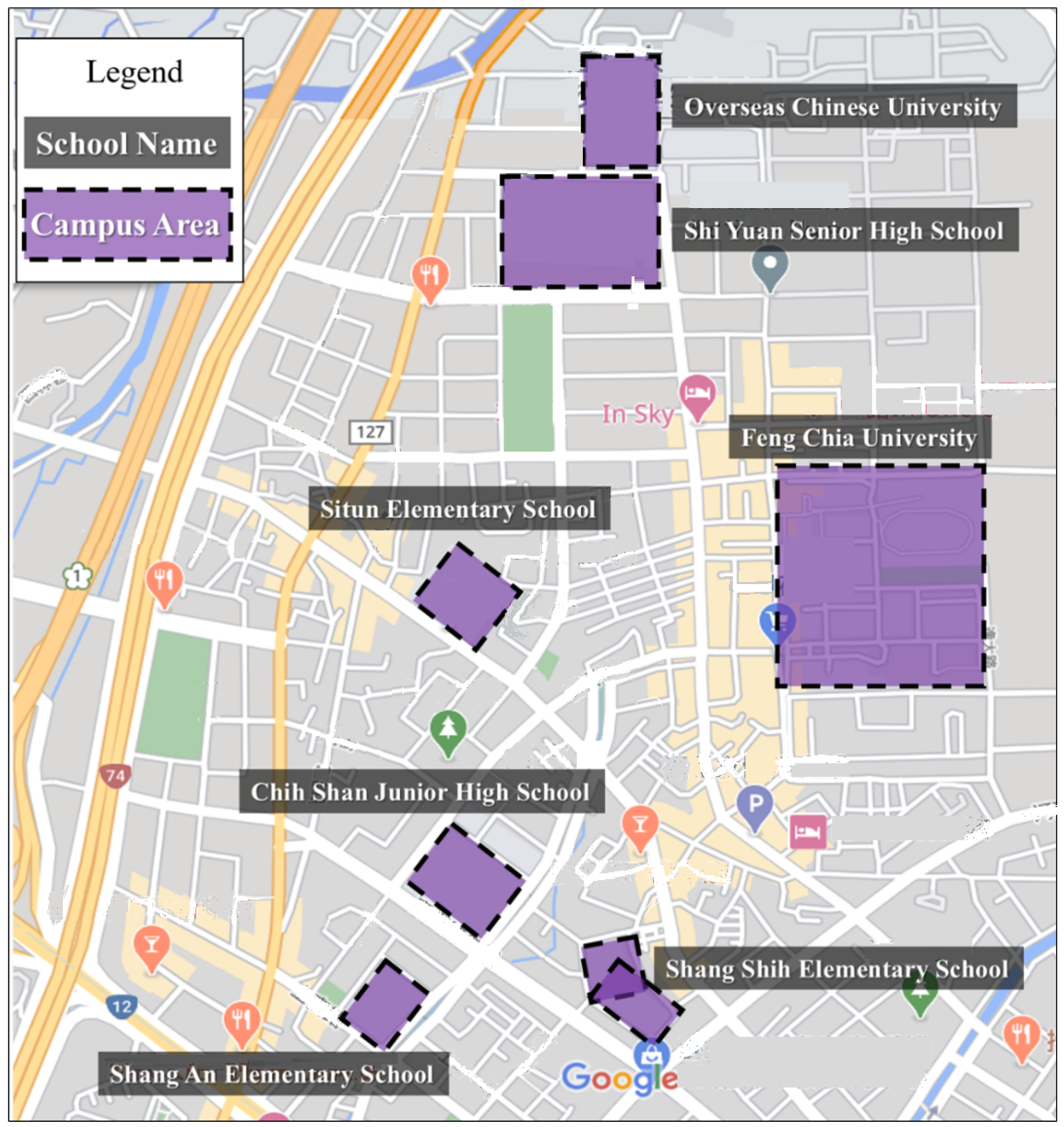
After acquiring initial data collection experience, training insights, and conducting observations of real-world road conditions, we extended our data collection to include pedestrian crossings at intersections without signage, particularly in areas near school zones. These locations often feature irregular or non-standard crossing markings, making them valuable for enhancing the model’s generalization capabilities. To this end, we selected seven schools, including Feng Chia University and other institutions in its vicinity, as target areas for data collection. The pedestrian crossings around these schools were documented to capture a diverse range of crossing styles and environmental conditions. The geographic locations of the selected schools are illustrated in
Figure 4, with the map background also based on Google Maps.
4.2. Data Preprocessing and Quantity Inventory
After multiple rounds of driving, we accumulated a substantial number of videos containing pedestrian crossings. However, these raw video files require preprocessing before they can be used for model training. As an initial step, each video is converted into still images at a frame rate of 30 frames per second as image-based input is required for deep learning. To minimize dataset noise, frames lacking visible pedestrian crossings are manually excluded prior to annotation. During manual labeling, only unobstructed regions of pedestrian crossings—those not occluded by vehicles or pedestrians—are annotated to avoid introducing ambiguity. These annotations are created using the LabelImg tool, with each visible segment labeled with a bounding box and assigned the class ‘pedestrian crossing’. In the subsequent detection phase, fragmented bounding boxes corresponding to the same crossing are merged to form complete representations of pedestrian crossings.
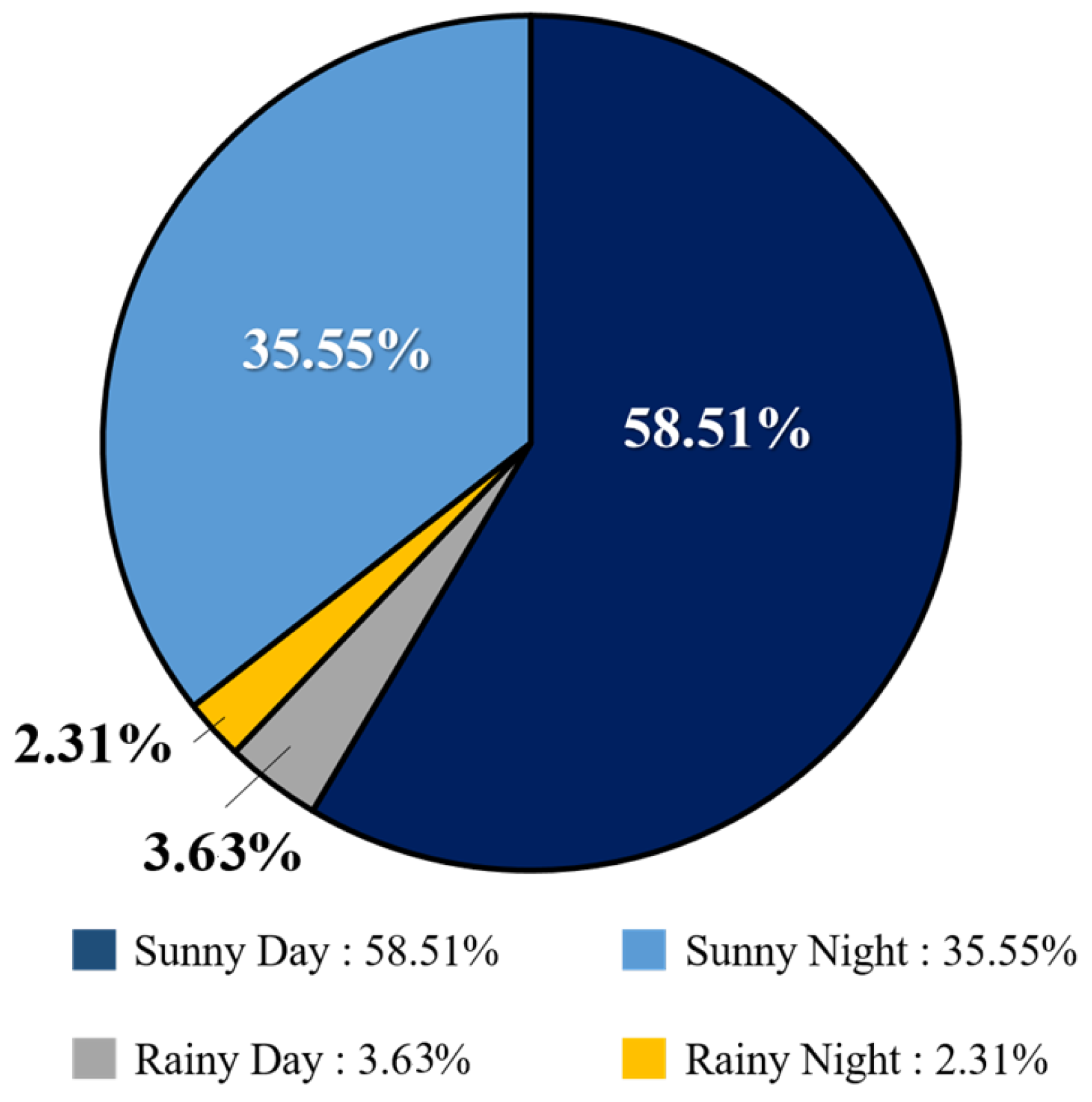
An analysis of the collected dataset reveals a significant class imbalance in terms of weather conditions. As shown in
Figure 5, images captured on sunny days total 41,912, representing 94.06% of the dataset, while only 2648 images (5.94%) were recorded on rainy days. This severe imbalance is attributed to the practical challenges of collecting data under adverse weather conditions, such as safety concerns and limited visibility during driving. To address this imbalance and ensure the model performs reliably across diverse scenarios, we employ CycleGAN to generate synthetic images representing rare conditions—such as rain, nighttime, and glare. These generated samples serve to augment the training dataset, increasing its diversity and improving the model’s generalization capabilities. Balancing the dataset is essential for achieving consistent detection accuracy across varying real-world environments.
4.3. Image Generation Module
After data collection and preprocessing, we employ CycleGAN to generate synthetic pedestrian-crossing images under various environmental conditions. These generated images retain visual similarity to the original input while allowing feature-level transformations—such as converting daytime scenes into night, rain, or glare conditions. The purpose of this augmentation process is to enhance dataset diversity and improve the robustness of the YOLO-based pedestrian-crossing detection module trained in the subsequent stages. This image generation module is implemented using the open-source CycleGAN repository available on
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix (Jun-Yan Zhu and Taesung Park) (accessed on 5 June 2025) [
39], leveraging the PyTorch 1.4.0 deep-learning framework and executed within the Google Colab environment.
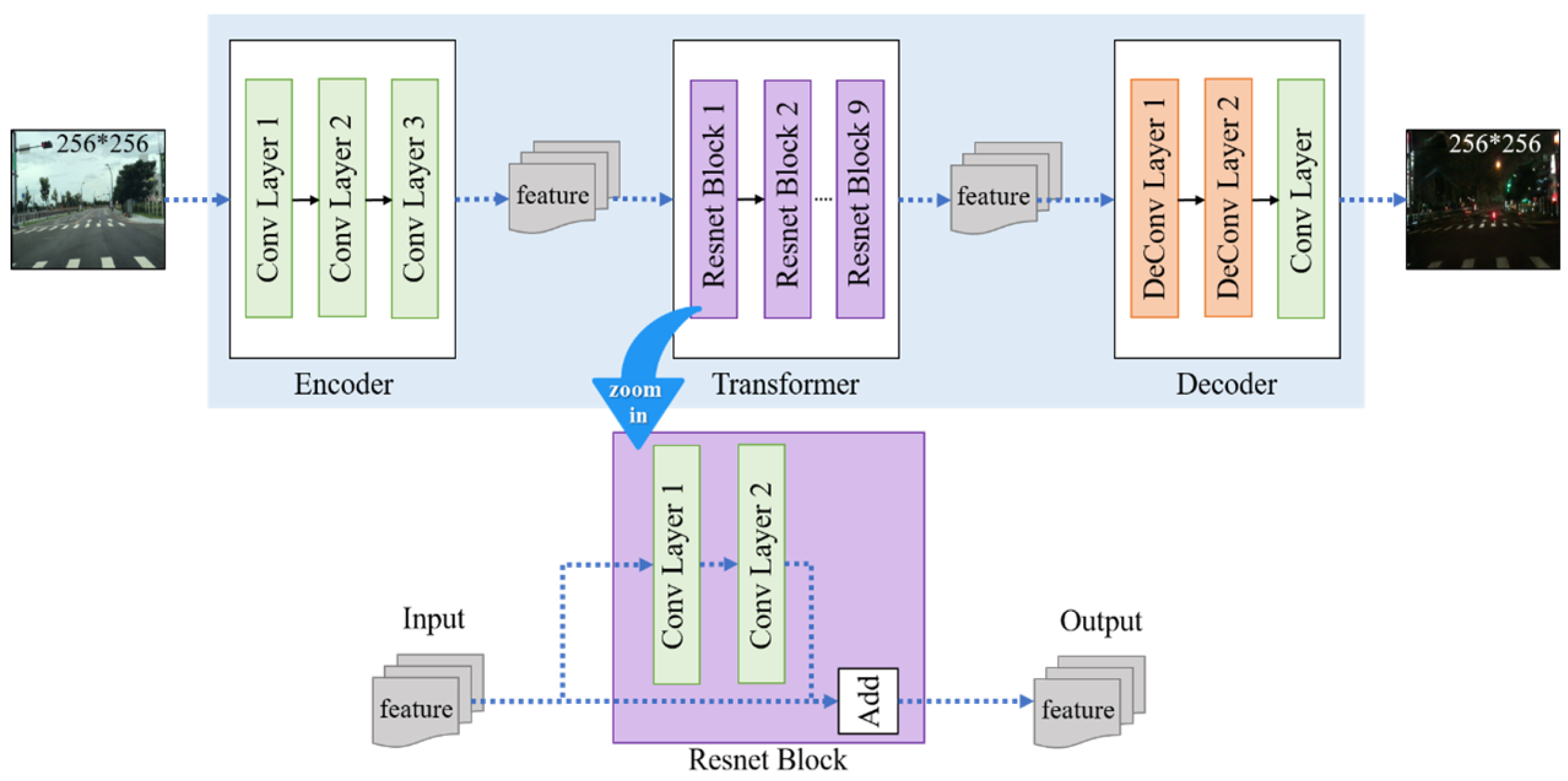
The CycleGAN architecture comprises two main components: the generator and the discriminator. The generator itself consists of three submodules: the encoder, transformer, and decoder. In the encoder stage, input images from domain A are first resized to 256 × 256 pixels and passed through a series of convolutional neural network (CNN) layers for feature extraction. We configure the number of output features in the convolutional layers to 32. This decision is based on the observation that simpler detection tasks do not require a large number of extracted features. Setting the feature count to 64, for example, may lead to excessive memory usage and overemphasis on high-frequency features (such as sharp edges), which are not essential for this task. Instead, we prioritize low-frequency features—such as smooth color transitions—that are more representative of the pedestrian crossing as a whole. The encoder depth is fixed at three layers, corresponding to the RGB color channels. The batch size for training is set to 32, a standard setting commonly used in CycleGAN training to balance performance and resource efficiency.
In the transformer stage, the extracted features are interpreted as combinations of image characteristics, and the network learns to map them to a different domain distribution. We adopt a ResNet-9 block structure for this purpose. By adding residual connections, the network ensures that information from earlier layers is preserved in deeper layers. This residual learning technique helps to maintain the spatial and structural integrity of the original input, ensuring that key features such as object shape and size are not lost during transformation.
Finally, in the decoder stage, a series of deconvolutional layers are used to reconstruct the image from the transformed feature vector. The decoder outputs a 256 × 256 image corresponding to domain B. Like the encoder, the decoder uses 32 convolutional features to maintain consistency and avoid introducing unnecessary complexity. The full architecture and training process of the generator are illustrated in
Figure 6.
To complete the adversarial training process of CycleGAN, it is essential to construct a discriminator network alongside the generator. The discriminator extracts visual features from the input image to distinguish between real and synthetic data. As in the generator, we set the number of output features extracted from the convolutional layers to 32. A final convolutional layer with a one-dimensional output is appended to produce the final prediction score. The discriminator then classifies the input image as either a real (original) image or a fake (generated) image produced by the generator.
In selecting the environmental conditions for this study, practical considerations and real-world driving scenarios in Taiwan’s urban areas played a central role. Five specific conditions—night, rainy day, rainy night, sun glare, and high-beam glare—were identified due to their frequent occurrence and impact on driver visibility. Although other scenarios such as fog or snow were not included due to their rarity in the region, the proposed framework remains adaptable and may be extended to additional environmental contexts in future research to enhance model generalizability. As part of addressing data imbalance across different environmental scenarios, the collected real images were categorized into five condition-specific groups: (1) day to night, (2) day to rainy day, (3) day to rainy night, (4) day to sun glare, and (5) day to high-beam glare. For each condition, the available real images were proportionally divided into five training subsets (datasets 1–5), as detailed in
Table 2, to examine how dataset size affects the quality of image generation. Each subset was used to train a CycleGAN model over two-hundred epochs, with model checkpoints saved every five epochs. The evolution of image translation quality is illustrated in
Figure 7, where representative results from the 100th and 200th epochs are compared across all five conditions.
These qualitative evaluations informed our selection of the most suitable training configuration for each scenario. A quantitative evaluation of the generation quality—based on Fréchet Inception Distance (FID) scores computed from 1,000 generated images per condition—is presented in
Section 5.2. This analysis aims to determine under which data volume and epoch configuration the CycleGAN model is able to produce synthetic images that most closely resemble realistic environmental conditions. A quantitative comparison of detection performance under different data augmentation strategies is presented in
Section 5.3. Specifically, three configurations were evaluated for each environmental condition: (1) 500 real images, (2) 500 real + 500 synthetic images, and (3) 1000 real images.
Throughout the training process, no evident failure cases, such as mode collapse or severe visual artifacts, were observed. On the contrary, as training epochs increased, the quality of the generated images consistently improved, as reflected by a downward trend in FID scores. Notably, for scenarios involving challenging lighting conditions—such as sun glare or high-beam glare—the synthetic images generated at later epochs (e.g., epoch 200) not only preserved structural fidelity but also captured contextual features more effectively than earlier-stage outputs. These findings suggest that the proposed framework remains stable over extended training and is particularly effective in simulating complex illumination scenarios.
4.4. Detection and Automatic Labeling Module
After collecting and preprocessing the pedestrian-crossing images—inclusive of augmenting rare-condition samples using CycleGAN—the dataset was partitioned into training and testing sets to facilitate model training and performance evaluation. The pedestrian-crossing detection module in this study was trained using the pretrained yolov4.conv.137 [
9], which performs object prediction through grid-based feature localization and generates bounding boxes that identify pedestrian-crossing regions in the input images. Although YOLO has evolved into its twelfth generation, each version possesses distinct advantages [
11]. Notably, YOLOv4 achieved substantial improvements in detection accuracy, while subsequent versions have primarily focused on model compression and computational efficiency. The training environment was configured as a virtual machine with 4 GB RAM and a Tesla P100 PCIe 16 GB GPU. For the YOLOv4 training parameters, the number of classes was set to 1, and the number of filters was adjusted to 18. The maximum number of batches was set to 6000, with step sizes at 4800 and 5400. The batch size and subdivisions were both set to 64. According to the detection speed evaluations conducted by Bochkovskiy et al. [
9], the YOLOv4 model consistently achieved a detection speed exceeding 30 FPS, meeting the benchmark for real-time detection.
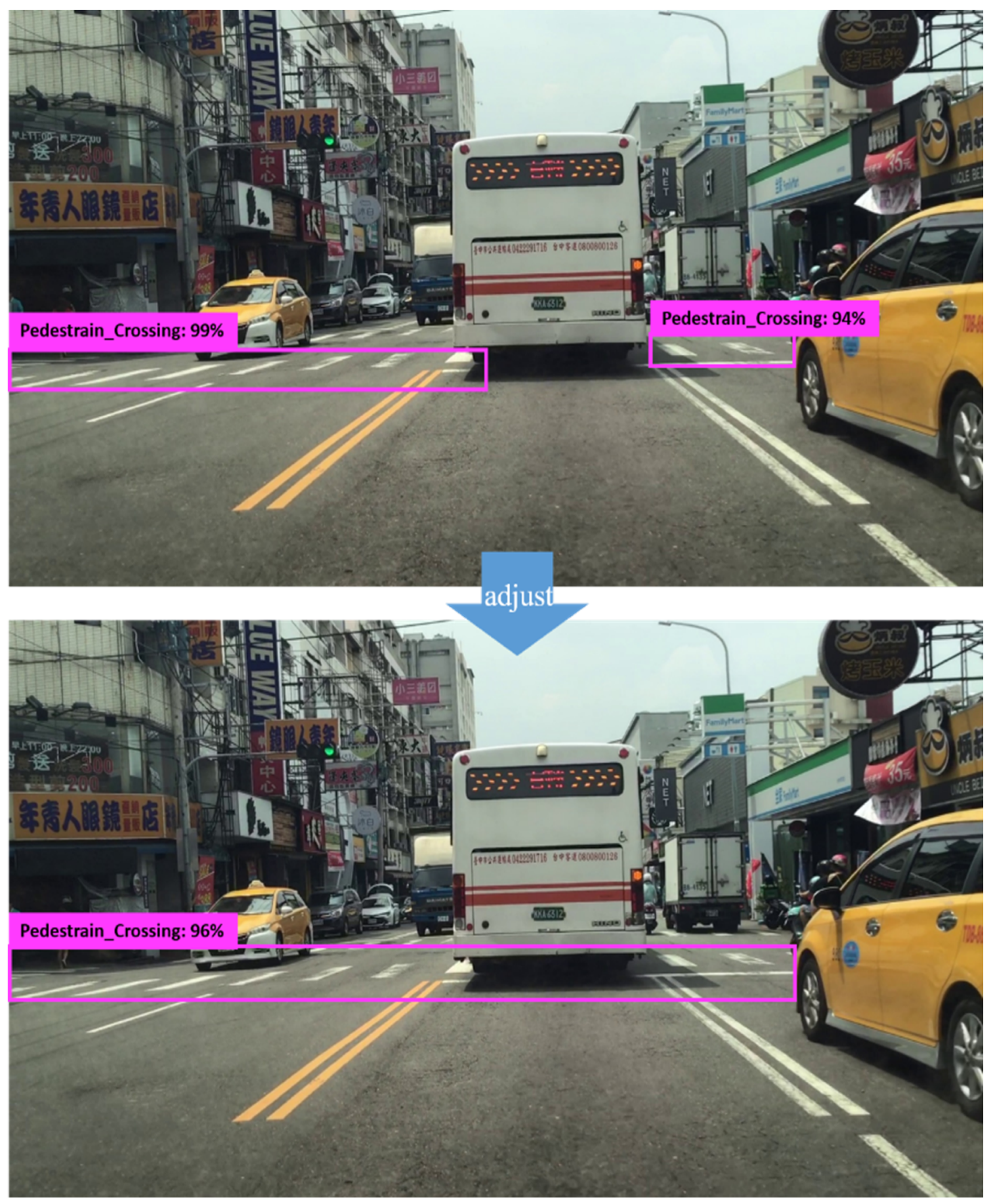
The pedestrian-crossing automatic labeling module was developed using Python 3.7 and comprises several core functions. For video processing, frames are sampled at a rate of six frames per second to prevent redundant captures of the same intersection. Given that the original video resolution is 1080p at 60 frames per second, selecting one frame every ten frames ensures appropriate temporal spacing. At a driving speed of approximately 50 km/h through green-lit intersections, the pedestrian crossing typically remains visible for 1.5 to 2 s, allowing the system to capture approximately ten unique frames per intersection. Since pedestrian crossings usually appear near the lower portion of the frame where the Y-coordinate is larger (given the image origin is at the top-left corner), while the upper portion of the frame often contains background objects, such as the sky, traffic lights, or distant buildings that could be incorrectly detected as pedestrian crossings, a vertical threshold is applied to filter out such false positives. Specifically, detections with bounding-box centers below this Y-axis threshold (i.e., with smaller Y values) are flagged as potential misclassifications and excluded from the labeling process, while detections with bounding-box centers above this threshold (i.e., with larger Y values) are retained as likely valid detections. As illustrated in
Figure 8, the module also includes mechanisms to identify repeated detections of the same pedestrian crossing or splits caused by occlusions (e.g., parked vehicles). These are post-processed and consolidated to ensure consistent labeling of single pedestrian crossings.
To prevent missing any pedestrian crossings, frames that were not automatically assigned pseudo-labels undergo manual frame-by-frame inspection and annotation. During video processing, detection results are displayed sequentially for each frame. For every frame in which a pedestrian crossing is successfully detected, the system saves both a .jpg image and a corresponding .txt file sharing the same filename. The .txt file contains five fields: the class ID, followed by the x and y coordinates of the bounding-box center (expressed as ratios relative to the image width and height), and the width and height of the bounding box (also as relative ratios). If no pedestrian crossing is detected in a given frame, the system outputs a message indicating “not found.” Upon completion of automated labeling, a manual quality check is conducted to rapidly review and remove incorrectly labeled images. Although some human oversight remains necessary, the proposed system significantly reduces time, labor, and costs compared to fully manual annotation processes.
5. Experimental Results
In this section, we present the experimental results evaluating the effectiveness of our pedestrian-crossing detection system under diverse environmental conditions. We first assess the baseline performance using real images, identifying significant performance variations across different scenarios. Subsequently, we evaluate the realism of the CycleGAN-generated images via the Fréchet Inception Distance (FID) metric, confirming their suitability for dataset augmentation. Lastly, we demonstrate the improvement in detection accuracy achieved by augmenting the training dataset with CycleGAN-generated images, highlighting the model’s enhanced generalization and robustness.
5.1. The Performance in Different Testing-Set Situations
Before incorporating the generated pedestrian-crossing images into the training process, we first evaluated the performance of a model trained solely on real pedestrian-crossing images under various real-world testing conditions. The goal of this preliminary experiment is to assess whether incorporating images from different environmental scenarios is necessary to improve dataset diversity and detection accuracy. Since daytime images are the most readily available and abundant in our dataset, we selected them as the fixed training set for this experiment. The model is trained exclusively on real daytime images, and its performance is benchmarked against a testing set also composed of real daytime images. To evaluate the model’s generalization ability, additional testing is conducted on real pedestrian-crossing images captured under five distinct conditions: night, rainy day, rainy night, sun glare, and high-beam glare. To ensure a fair comparison across all the scenarios, we controlled the dataset size by maintaining a consistent 8:2 ratio between the training and testing subsets.
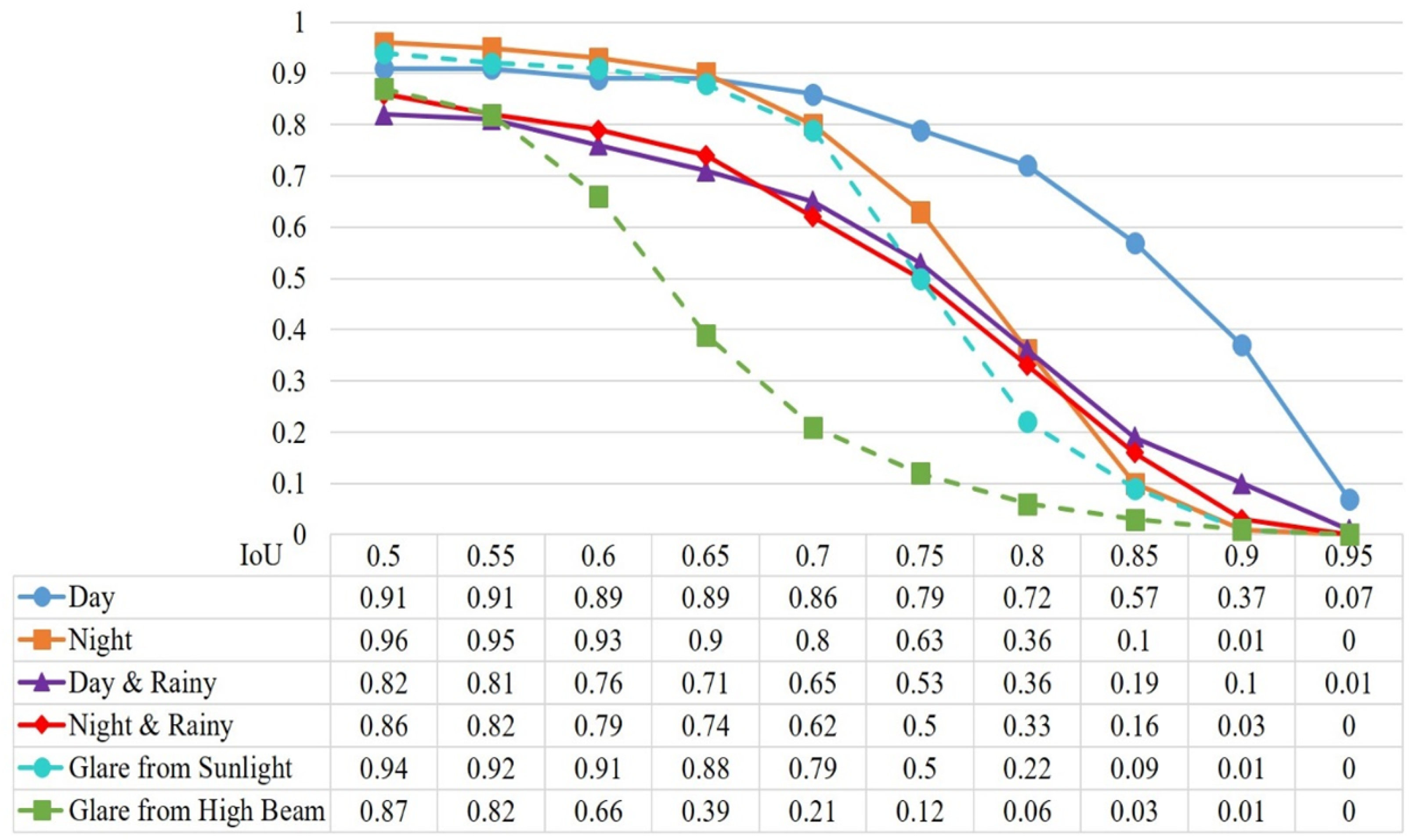
Accordingly, the real daytime dataset and the datasets from each of the five environmental conditions were proportionally partitioned to match this ratio. We then conducted a series of evaluations by adjusting the Intersection over Union (IoU) threshold to analyze the F1-score variations. In object detection tasks, performance is typically assessed starting from an IoU threshold of 0.5, incremented by 0.05 up to 0.95. As shown in
Figure 9, the F1-score exhibits a consistent downward trend as the IoU threshold increases across all six environmental conditions, which is expected due to the stricter overlap requirement. At IoU = 0.5, high F1-scores were observed in most scenarios (e.g., 0.96 for night, 0.94 for sunlight glare, and 0.91 for day). However, as the threshold rises to 0.8 and above, the decline becomes more pronounced—particularly under challenging lighting conditions. For instance, in the glare from high-beam scenarios, the F1-score drops from 0.87 (IoU = 0.5) to just 0.06 at IoU = 0.8, eventually approaching zero at IoU = 0.9. This indicates reduced boundary precision and highlights the vulnerability of detection performance under intense artificial lighting.
In contrast, scenarios such as day, night, and rainy night demonstrate more gradual declines in F1-score, suggesting relatively stable spatial prediction performance. Nevertheless, all the non-daytime conditions—including rainy day, rainy night, and sunlight glare—consistently underperform the daytime baseline, even at lower thresholds. These results quantitatively confirm that detection performance is highly sensitive to environmental variability. Overall, the findings underscore that training exclusively on daytime images is insufficient for achieving robust detection. It is essential to include diverse real-world conditions—such as low light, rain, and glare—during training to enhance generalization and reliability across different environments.
5.2. Comparison of FID Scores of Generated Images
The Fréchet Inception Distance (FID) score is a widely adopted metric for evaluating the quality of images generated by GANs. Proposed by Heusel et al. in 2017 [
40], FID quantifies the similarity between two sets of images based on the statistical distance between their feature representations, which is extracted using the Inception v3 image classification network. Specifically, it compares the mean and covariance of real and generated image feature distributions. A lower FID score indicates higher similarity between the generated and real images, with an ideal score of 0.0, signifying perfect alignment—although this is rarely achievable in practice when working with synthetic image generation.
In our experiment, FID scores were computed using the output from the final pooling layer of Inception v3, with a feature dimension of 2048. We trained multiple CycleGAN models using varying amounts of real images and training epochs to simulate five environmental conditions: night, rainy day, rainy night, sun glare, and high-beam glare. Each trained model was then used to generate 1000 images per condition, which were compared against corresponding real-image sets from the same condition using FID. The goal of this evaluation is to quantify the visual closeness of the synthetic images to real-world counterparts under different training configurations.
The FID scores obtained across different data volumes and epoch counts are summarized in
Table 3. The results demonstrate that increasing both the number of training images and the number of training epochs generally leads to improved FID scores. For example, in the day to night scenario, the FID decreases from 133.55 (with 1000 training images) to 98.79 when trained with 4000 images for 200 epochs—representing the best-performing configuration overall. Similar downward trends are observed in the other conditions, particularly those involving glare or low-light settings. Nevertheless, the improvements tend to plateau beyond 200 epochs, and, in a few cases, excessive training data or longer training durations result in slightly increased FID scores, likely due to model instability or overfitting. These findings suggest the need for careful tuning of training volume and duration to achieve optimal generative performance.
While these FID scores exceed the high-quality thresholds typically reported in natural image benchmarks, our visual inspection and the detection performance results presented in
Section 5.3 suggest that synthetic images with FID values below 200 still retain sufficient structural and contextual realism to support effective model training. These findings indicate that, for task-specific synthetic image generation—particularly under challenging lighting conditions—a higher FID threshold may still be acceptable for practical use. In our case, images with FID scores below 200 were deemed realistic enough to be incorporated into the pedestrian-crossing detection training pipeline. Among the evaluated cases, the best-performing model achieved an FID score of 98.79, indicating high visual fidelity to real images—albeit requiring substantial training resources.
In this study, FID was used as a theoretical basis for selecting the most visually realistic CycleGAN models under each environmental condition. The models yielding the lowest FID scores were chosen to generate synthetic images, which were then incorporated into the detection model training in
Section 5.3. However, we note that no direct experimental comparison was conducted to evaluate how different FID levels affect F1-score outcomes. Therefore, while the selection of lower-FID models is consistent with the common practice in generative model evaluation, the impact of FID on downstream detection performance remains a potential direction for future investigation.
5.3. F1-Score Enhancement via CycleGAN-Augmented Training Sets
As previously established, environmental variations significantly impact the performance of pedestrian-crossing detection. To achieve reliable detection across diverse scenarios, it is necessary to increase the quantity and diversity of training data corresponding to these conditions. However, acquiring such data is inherently challenging as it requires capturing images during specific weather events or lighting conditions that are infrequent or difficult to replicate. To address this limitation, we employ CycleGAN to generate synthetic images that simulate these rare or hard-to-capture scenarios for the purpose of data augmentation.
This experiment aims to evaluate the effect of different quantities of generated images on the model’s detection performance, measured using the F1-score. For each of the five scenarios (night, rainy day, rainy night, sun glare, and high-beam glare), we select the generator models that achieved the lowest FID scores in the previous experiment, ensuring the highest image quality. The baseline training set consists of 500 real images per condition. We then incrementally add 250, 500, 750, and 1000 generated images to train new detection models. For comparison, an additional model is trained using 1000 real images.
Each trained model is evaluated using 100 real independent testing images from the corresponding condition, using an IoU threshold of 0.5. Additionally, we construct dependent testing sets that share some distributional similarity with the training data, also evaluated at IoU = 0.5. The F1-score is chosen as the primary evaluation metric as it provides a balanced view of both precision and recall, making it particularly suitable for comparative analysis in this context.
The detailed results are summarized in
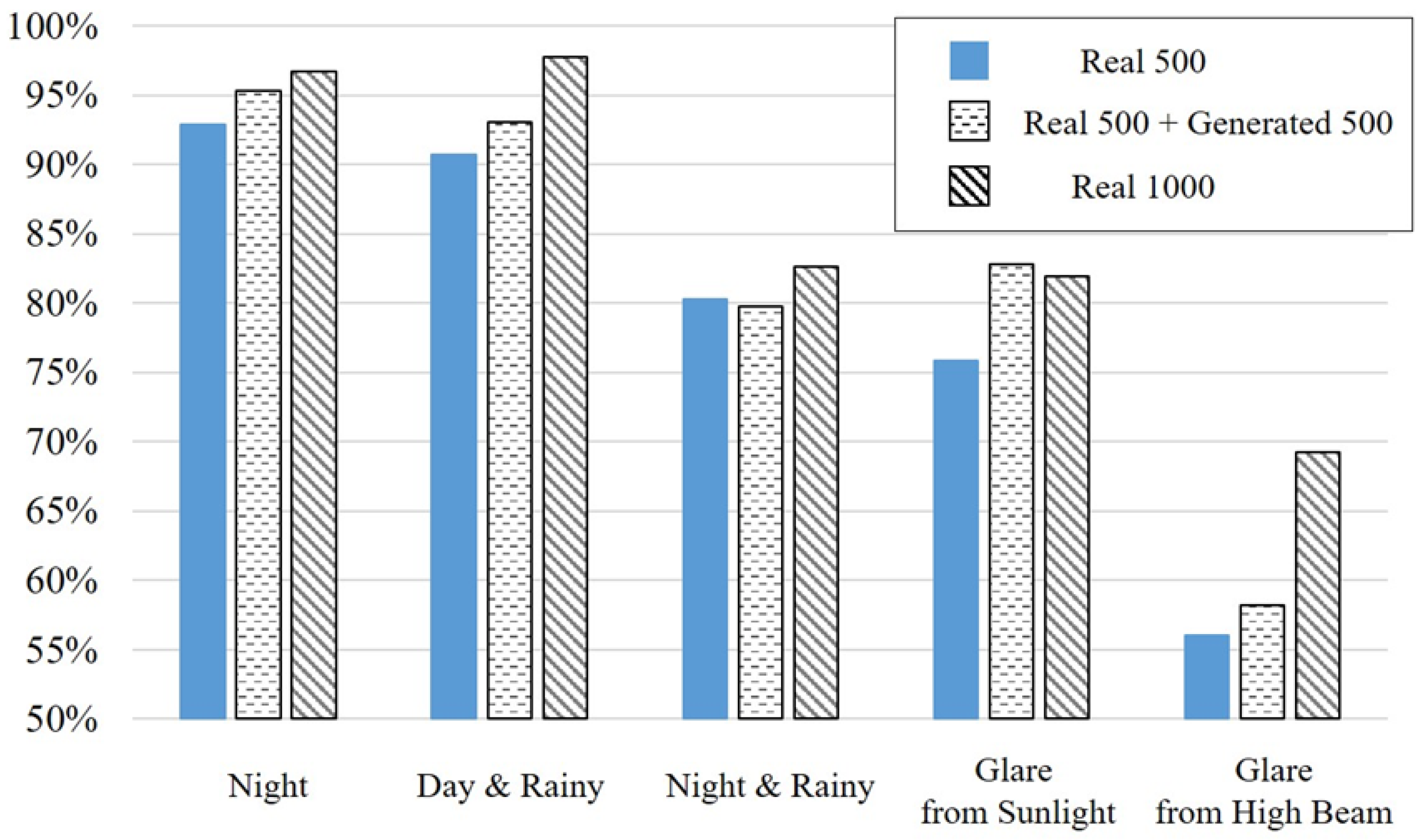
Table 4, which reports F1-scores across five environmental conditions under varying training configurations. Each scenario includes two rows: the first corresponds to the independent testing set, while the second represents the dependent testing set. Across all the scenarios, the models trained with a combination of real and generated images consistently outperform those trained on 500 real images alone. Notably, the configuration of 500 real + 500 generated images yields a significant performance gain and, in many cases, approaches the F1-score of the 1000 real-only configuration.
For instance, in the rainy-day condition, the F1-score improves from 91.74% (Real 500) to 95.79% (Real 500 + Gen 500) in the independent set, and from 94.32% to 97.17% in the dependent set—closely matching the 97.88% and 98.42% achieved with 1000 real images. Similar trends are observed in the other scenarios, including rainy night, sun glare, and high-beam glare, where the inclusion of high-quality synthetic images notably boosts detection performance. These results reinforce the effectiveness of CycleGAN-generated images in augmenting training data under conditions where real-world image acquisition is limited. They also suggest that a balanced augmentation ratio—specifically 1:1 between real and synthetic samples—can yield near-optimal detection performance, providing a practical trade-off between data availability and model accuracy.
To further illustrate these findings,
Figure 10 visualizes the dependent-testing-set F1-scores across different training configurations. The bar chart clearly shows that the Real 500 + Gen 500 configuration consistently outperforms the Real 500 baseline and approaches the performance of the Real 1000 model across all the scenarios. This visual evidence complements the tabulated data and emphasizes the practical value of synthetic augmentation in challenging environments.
In this experiment, the F1-score was evaluated using an IoU threshold of 0.5, which is commonly adopted as a baseline in object detection benchmarks. As demonstrated in
Section 5.1 (
Figure 9), increasing the IoU threshold generally results in lower F1-scores due to stricter localization requirements. Therefore, for the purpose of analyzing performance variation with different quantities of synthetic images, we selected IoU = 0.5 to ensure clearer differentiation and consistent comparison across configurations. Extending this analysis to higher IoU thresholds is a valuable direction for future work to further evaluate model robustness under stricter evaluation criteria.
6. Conclusions
This study presented a pedestrian-crossing detection system that integrates cyclic learning, CycleGAN-based data augmentation, and cloud-based automation to improve detection accuracy under varying environmental conditions. Real-world images were collected and annotated across diverse scenarios—including day, night, rain, and glare—and augmented with synthetic images to expand the dataset coverage. A YOLO-based detection model trained on this enriched dataset exhibited improved performance, particularly under visually challenging or underrepresented conditions. To reduce manual effort and streamline data preparation, an automated labeling module was incorporated into the loop-learning framework. While not quantitatively assessed, the module significantly reduced the need for manual annotations during iterative training, enabling synthetic images to be automatically labeled and reused in successive rounds. The experimental results revealed considerable variation in model performance across different environmental conditions. As expected, daytime scenes yielded the highest F1-scores, while rain, glare, and nighttime conditions posed greater challenges. Notably, adding 500 CycleGAN-generated images to 500 real samples improved the average F1-score by 5.7%, with gains exceeding 10% in the most difficult scenarios, such as rainy nights and high-beam glare. These findings validate the effectiveness of combining generative augmentation with automated labeling to address data scarcity and enhance detection robustness.
Future work will focus on real-time integration between vehicle front-end and cloud-based back-end systems to deliver immediate pedestrian-crossing alerts. While the current evaluation was conducted in an offline environment, the system architecture is designed with real-time deployment in mind. This work demonstrates how the integration of generative models and automated annotation can improve the generalization of detection systems in complex environments. The proposed system lays a foundation for scalable real-time safety applications in intelligent transportation. By improving the visibility and timely recognition of pedestrian crossings, it also supports broader goals in sustainable urban mobility, particularly in enhancing pedestrian safety and reducing traffic-related risks in walkable cities. The intended end users are drivers operating in urban areas with complex or low-visibility conditions. Future extensions may explore integration with smart city infrastructure to further promote pedestrian- and cyclist-friendly mobility strategies.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}