An Adaptive Variance Adjustment Strategy for a Static Background Error Covariance Matrix—Part I: Verification in the Lorenz-96 Model

 , , ,
, , ,
Abstract
1. Introduction
- Proposing a spatio-temporally adaptive variance rescaling strategy based on deep reinforcement learning: this study develops the DRL-AST method, which enables the spatio-temporal adaptation of the variance of the static B-matrix without incurring additional computational costs. This approach improves the adaptability of data assimilation, thereby enhancing analysis quality and forecast skill.
- Improving performance over long-term assimilation periods: by adaptively rescaling the variance of the B-matrix through spatio-temporal optimization, DRL-AST demonstrates competitive robustness and accuracy in long-term assimilation cycles by consistently reducing analysis errors under varying observational noise levels, while maintaining high computational efficiency.
- Improving forecast skill and stability (validated in the Lorenz-96 model): leveraging a gated recurrent unit (GRU) module to learn historical assimilation states, DRL-AST ensures that the analysis state better aligns with the forecast model’s dynamical evolution. In the Lorenz-96 model, the experimental results demonstrate that DRL-AST effectively delays error growth compared to other methods, thereby improving the accuracy and stability of forecasts.
2. Related Studies
2.1. Traditional Methods for Variance Adjustment in VarDA Systems
2.1.1. Empirical Variance Rescaling
2.1.2. Adaptive Variance Updating
2.2. Deep Learning and Reinforcement Learning in Earth Science and Data Assimilation
2.2.1. Deep Learning for Feature Extraction in Earth System Science
2.2.2. Reinforcement Learning for Data Assimilation and Forecasting
3. Preliminaries
3.1. Variational Formulation
3.2. Background Error Covariance Matrix
3.3. Deep Reinforcement Learning
4. Approach
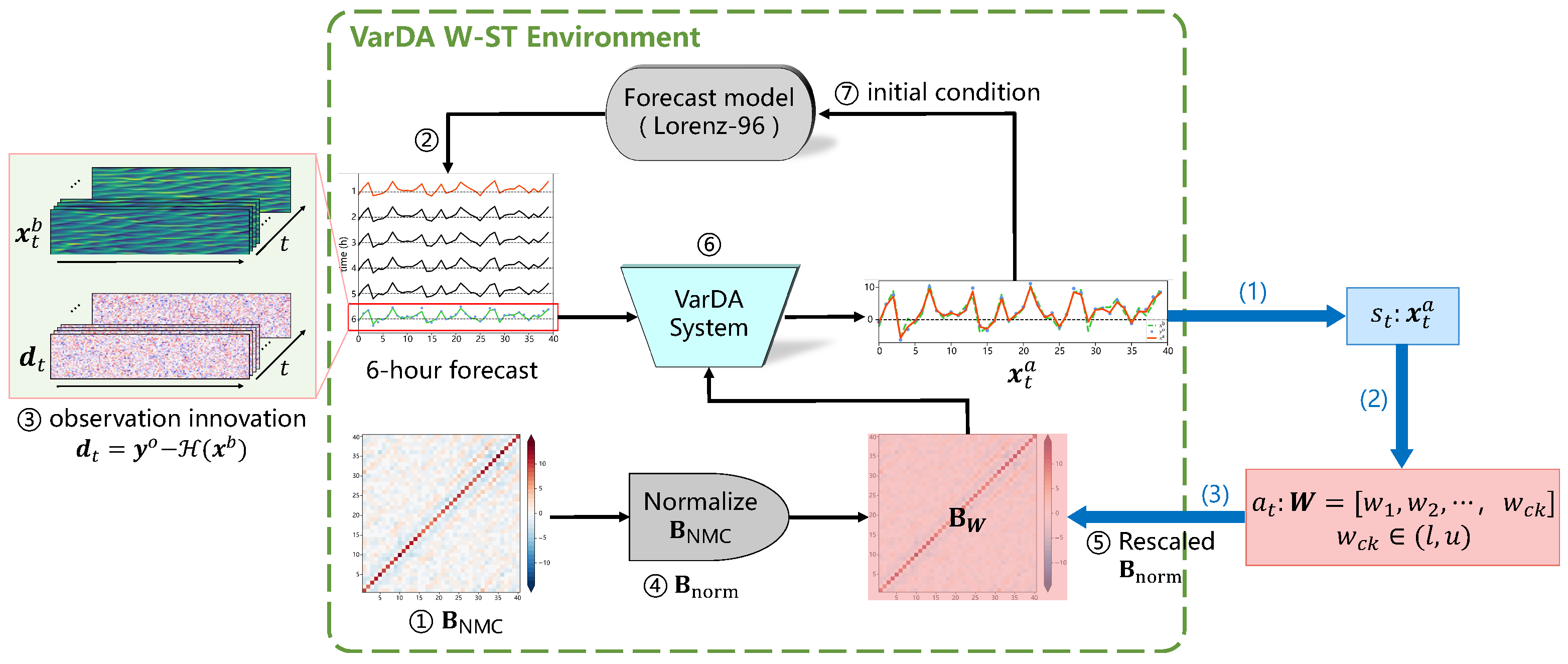
4.1. Benchmark for VarDA System
4.2. DRL-Based Formulation for the VarDA System
- State represents the analysis state produced by the VarDA system at time step t.
- Action is a spatially adaptive scaling vector (), where each element corresponds to a rescaling factor applied within a specific spatial domain. These factors are selected from a bounded interval to ensure computational efficiency. Here, l and u denote the shared lower and upper bounds of the scaling vector, where each corresponds to a spatial chunk and modulates the background error variances within that region.
- Transition is obtained as the numerical solution that minimizes the cost function given in Equation (1) in our formulation (see Algorithm 1):where denotes the outcomes of the Lorenz-96 model when it runs from t to .
- Reward quantifies the immediate benefit of applying action at state , resulting in the new state . This study aims to learn an adaptive variance rescaling policy that improves the quality of assimilation, thereby providing initial conditions that enhance the subsequent forecast performance. Since the effectiveness of data assimilation depends on multiple factor, the detailed formulation of r is provided in subsequent content.
- Discount factor is set close to 1, as our task requires long-term planning over sequential assimilation cycles.
| Algorithm 1 State transition process in the VarDA W-ST environment |
|
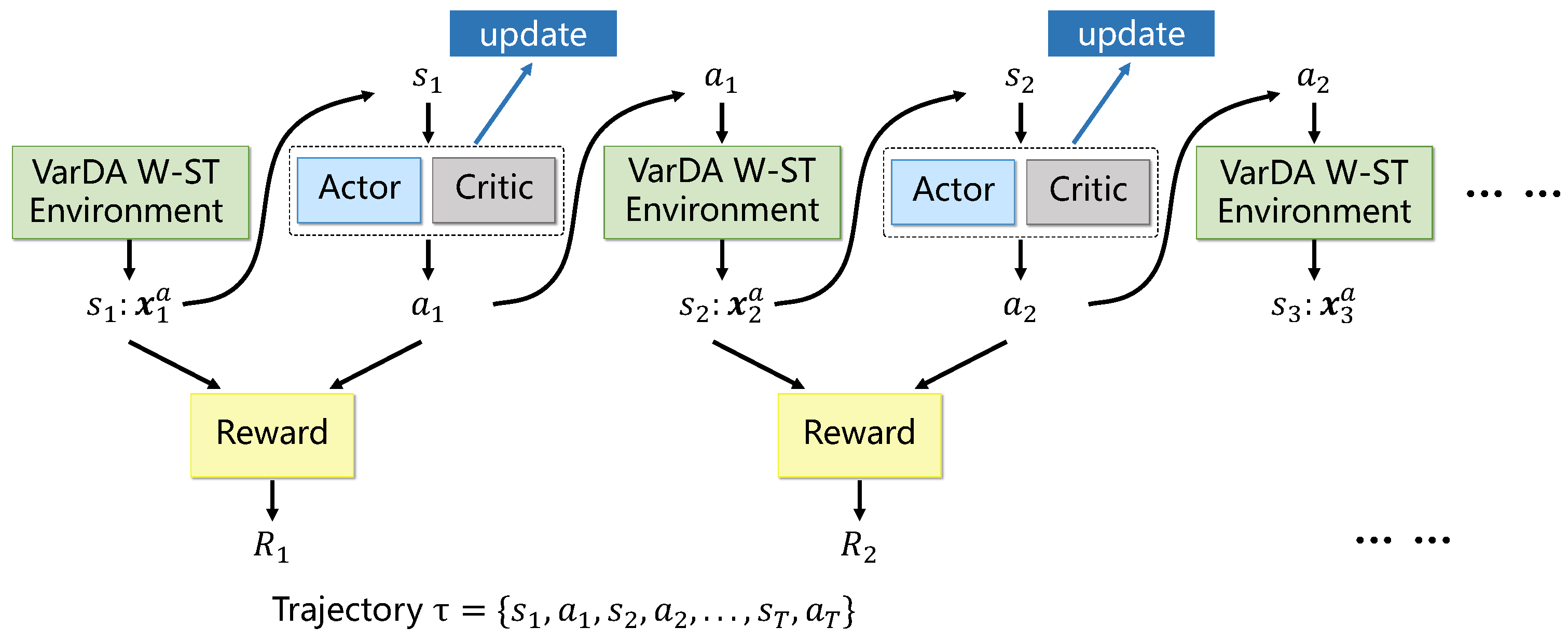
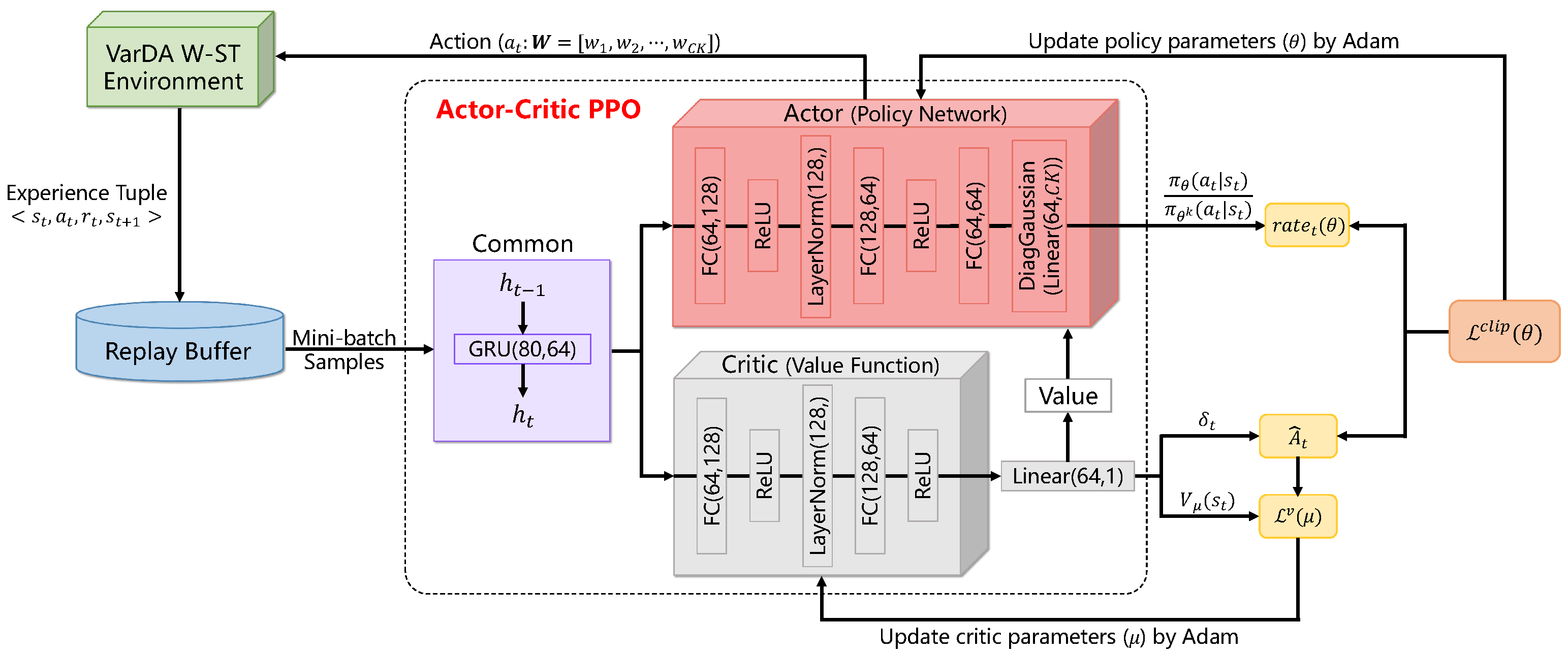
4.3. Actor–Critic Framework and Proximal Policy Optimization (PPO) Algorithm
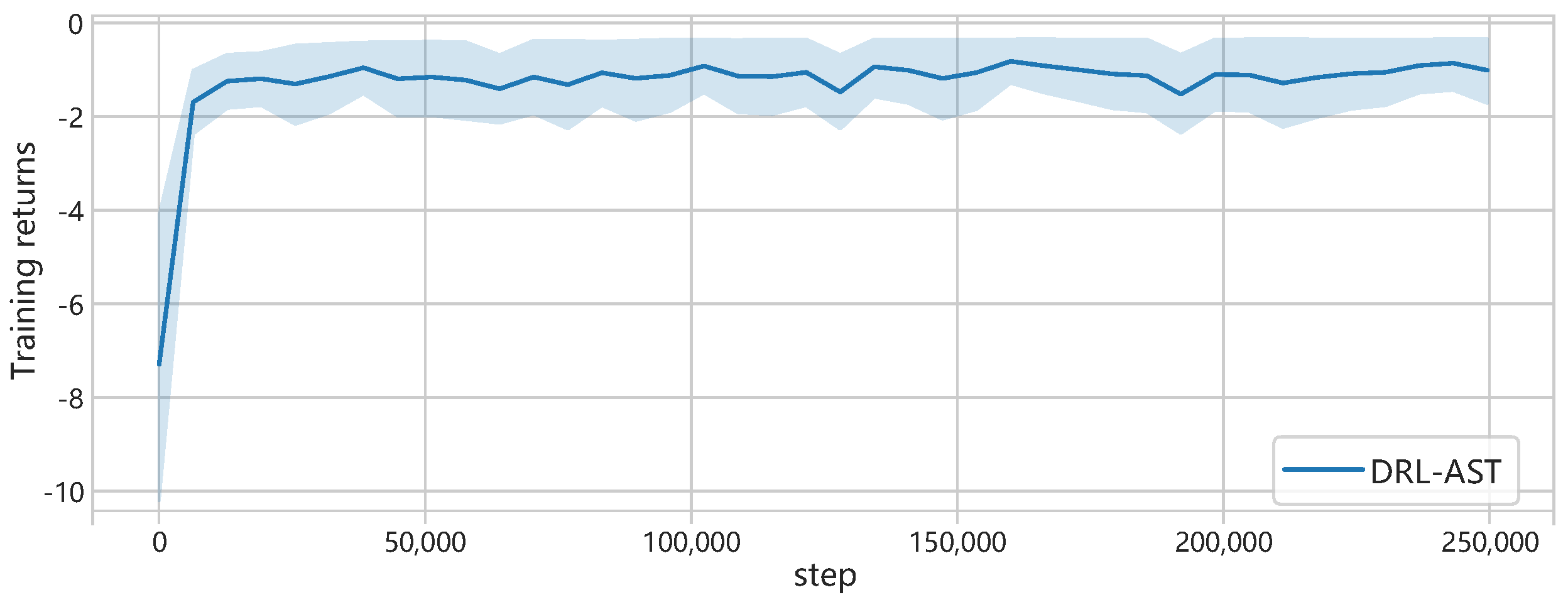
4.4. Implementation Details in the DRL-AST Method
- GRU-Based Encoder (Common Module): a shared gated recurrent unit (GRU) encoder [57] is used to capture temporal dependencies in the input state sequence. At each timestep t, it updates the hidden state based on the previous hidden state . The resulting representation is fed into both the actor and critic networks. This shared structure helps extract temporal features and improves training stability.
- Actor (Policy Network): the actor network receives the encoded state and passes it through fully connected layers with ReLU activation [58] and LayerNorm normalization [59]. The fully connected layers perform linear mappings from state features to the action space. ReLU introduces nonlinearity, and LayerNorm stabilizes training. The final layer outputs the mean and log standard deviation of a diagonal Gaussian distribution with dimension . An action is then sampled from this distribution to produce the adaptive scaling vector.
- Critic (Value Network): the critic receives the encoded state and a similar architecture with the actor. It outputs a scalar value , representing the expected cumulative reward from state . This value is used as a baseline to estimate the advantage , which is essential for guiding policy improvement during training.
- Replay Buffer: following each interaction, the agent receives the next state and a scalar reward , which reflects the improvement in assimilation quality resulting from taking action in state . The experience tuple is temporarily stored in a replay buffer. During training, the agent samples mini-batches of these collected experiences to update the policy and value networks. This strategy improves sample efficiency and reduces the effects of temporal correlation in sequential data, thereby enhancing training stability.
5. Experimental Results
5.1. Baselines
- 1.
- Empirical variance rescaling by a constant factor (named CON for short): this method is the most widely used in operational VarDA systems, recognized for its high assimilation performance and straightforward implementation. Despite its lack of a rigorous theoretical foundation, extensive validation in operational environments has established it a practical and reliable benchmark.
- 2.
- An observation-dependent spatio-temporal update vector named CUTE reported by the authors of [31] (named CUTE-ST for short): CUTE-ST has been shown to outperform traditional adaptive techniques in both theoretical and practical evaluations. By leveraging background-observation error covariance within the existing VarDA cycle, it realizes spatio-temporal adaptivity in the B-matrix without introducing additional computation, rendering it an efficient and suitable baseline for comparison.
- 1.
- CON: this baseline meticulously selects a specified constant factor within the range of 0.05 to 3.16 through an extensive series of empirical experiments. It is imperative to underscore that in instances where the observational error attains a conspicuous magnitude indicative of its unreliability, the initial value should be set to 0. However, given that the weight is contingent upon the inverse of the variance, the utilization of 0 as the denominator is precluded. Consequently, our study employs a suitably diminutive value of 0.05. The upper limit is derived from the paradigm presented by the authors of [60], wherein the forgetting factor (, following the original notation therein) spans the interval of 0.1 to 1, thereby resulting in a variance inflation factor () that ranges from 1 to 3.16. To balance computational cost and resolution, the incremental step size for value traversal was set to 0.05.
- 2.
- CUTE-ST: under the assumption of perfect knowledge of the -matrix and , this baseline reutilizes observations and takes the error covariance of and —that is, Cov(, )—into account within the iterative process of the covariance refinement. This algorithm enhances the posterior state estimation while simultaneously improving the structure of the comprehensive -matrix. Although Cheng et al. [39] also introduced the PUB method, CUTE is adopted as the control experiment in this study due to its superior assimilation performance when the initial -matrix is arbitrarily specified under sufficient observational conditions.
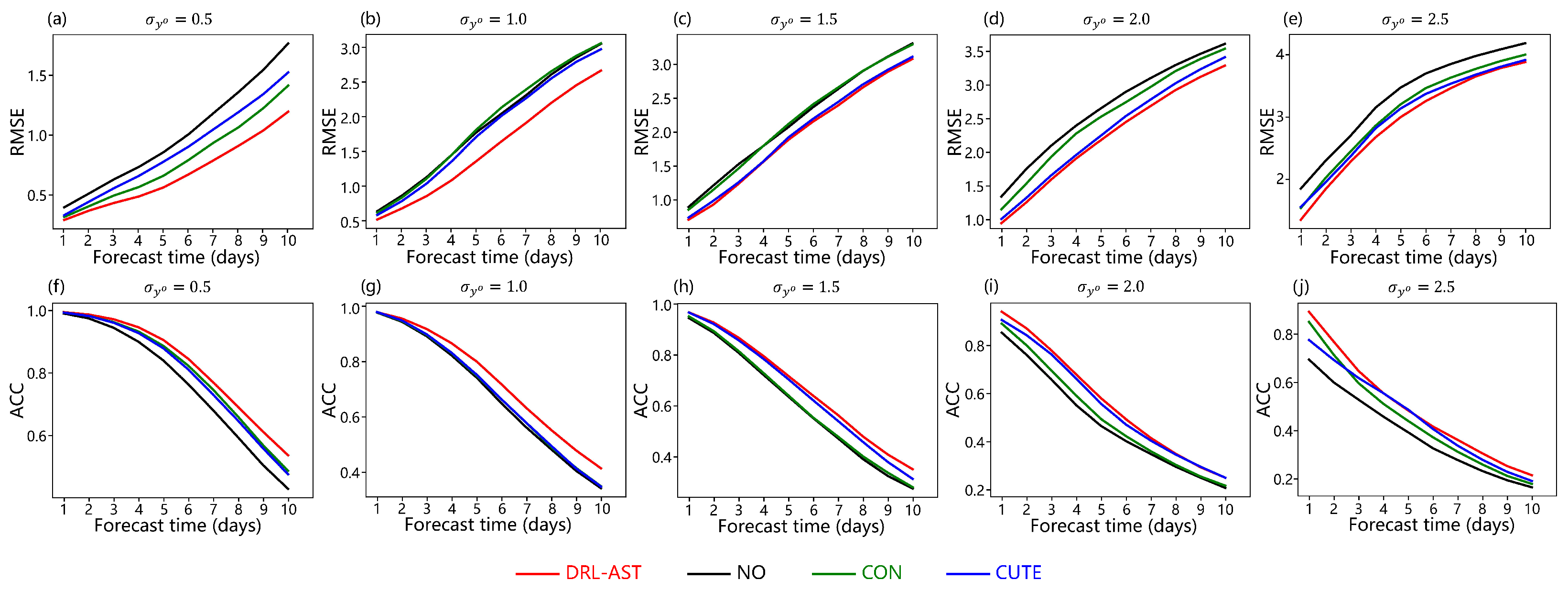
5.2. Evaluation Metrics
- : a standard metric for directly assessing the accuracy of the analysis state generated by the DA system.
- : continuous predictions initialized from the analysis state are performed over 72 h, 7 days, and 15 days without additional data assimilation. The resulting forecast performance is used to directly evaluate the dynamical consistency and adaptability of the initial conditions provided by the DA system.
5.3. Quantitative Results
5.3.1. Basic Settings of VarDA System
5.3.2. Sensitivity to Hyperparameters
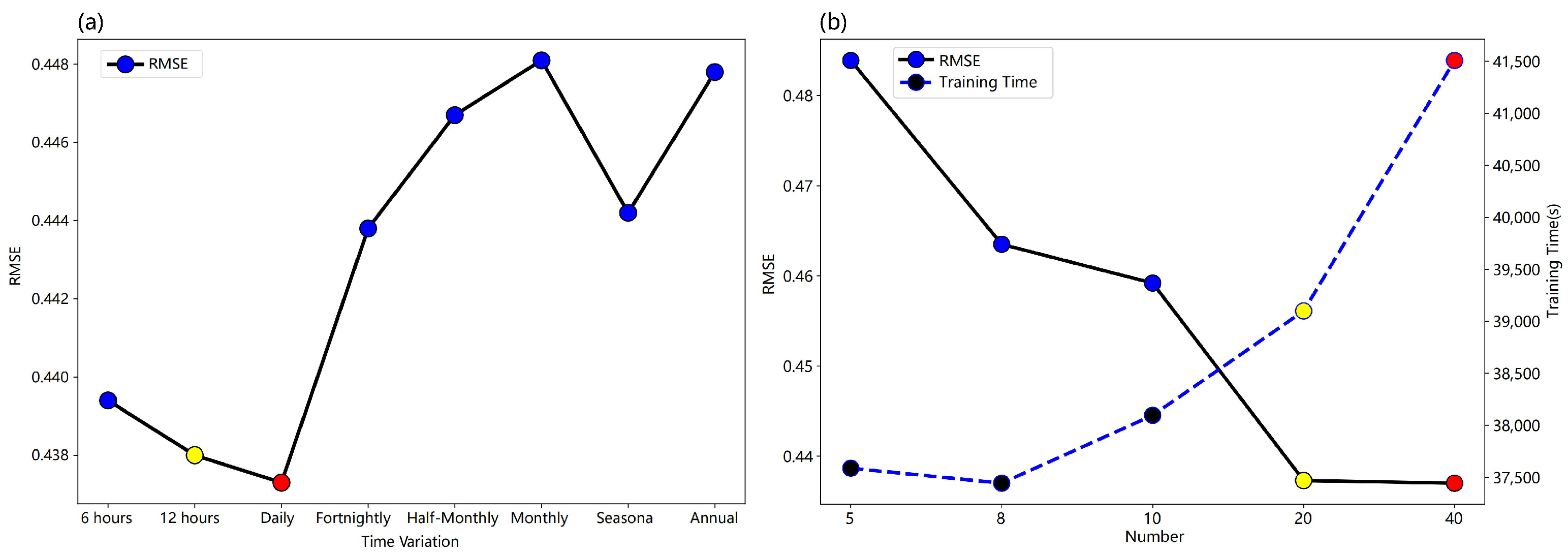
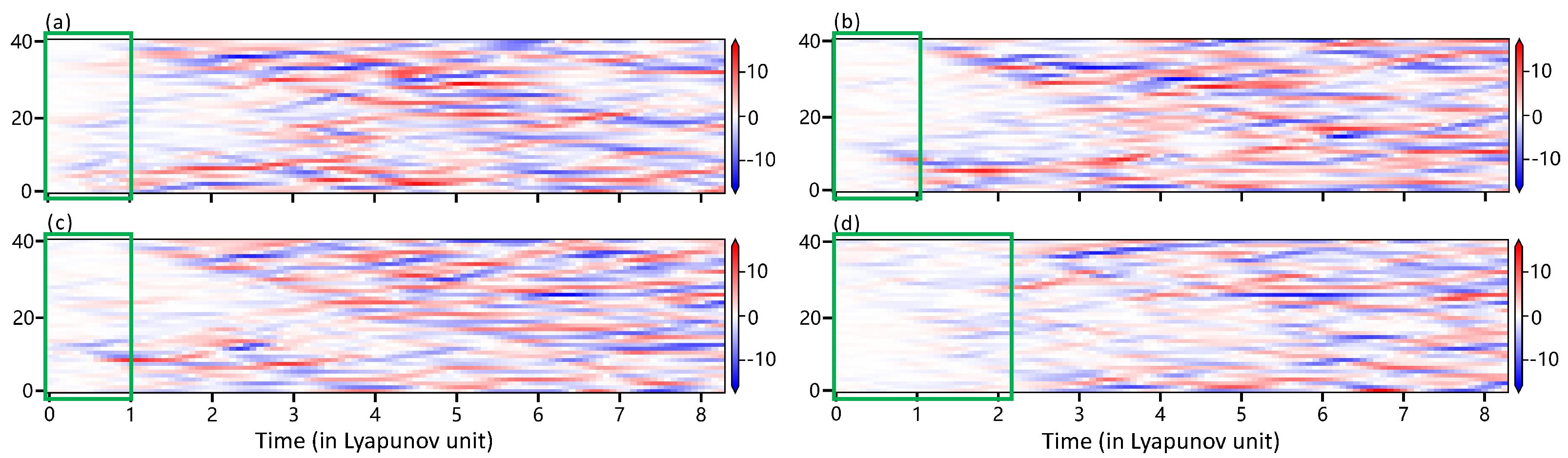
- Time variation: seven controlled experiments were conducted to compare and evaluate the effect of time variations on assimilation performance and the training cost of neural network models, including 6 h, 12 h, daily, semi-monthly, monthly, seasonal, and annual intervals. The experimental results are shown in Figure 4a, revealing that assimilation performance is optimal when the variance is rescaled daily (as indicated by the value in the solid red dot). There is no notable change in assimilation performance with higher rescaled frequency, which may be related to the inherent stability of the Lorenz-96 model itself. Thus, the daily change is deemed sufficient to reflect the flow-dependent characteristics of the model. Then, our study opts for daily variation in follow-up experiments.
- The number of rescaling factors: guided by the inherent characteristics of the Lorenz-96 model variables, where 40 variables are equidistant around the equator, we explore a concept called ‘chunking’, in which a block corresponds to a rescaling factor and adjacent variables share the same factor. Our experimentation encompasses block sizes of 5, 8, 10, 20, and 40 because there are 40 variables in our study for even distribution. Remarkably, as shown in Figure 4b, an escalation in the number of blocks positively correlates with improved assimilation performances. Nevertheless, transitioning from 20 to 40 blocks yields only marginal gains in assimilation performance, while increasing model training costs. Consequently, this study adopts a balanced approach, opting for 20 blocks ().
5.3.3. Performance of DA System and Model Forecasting
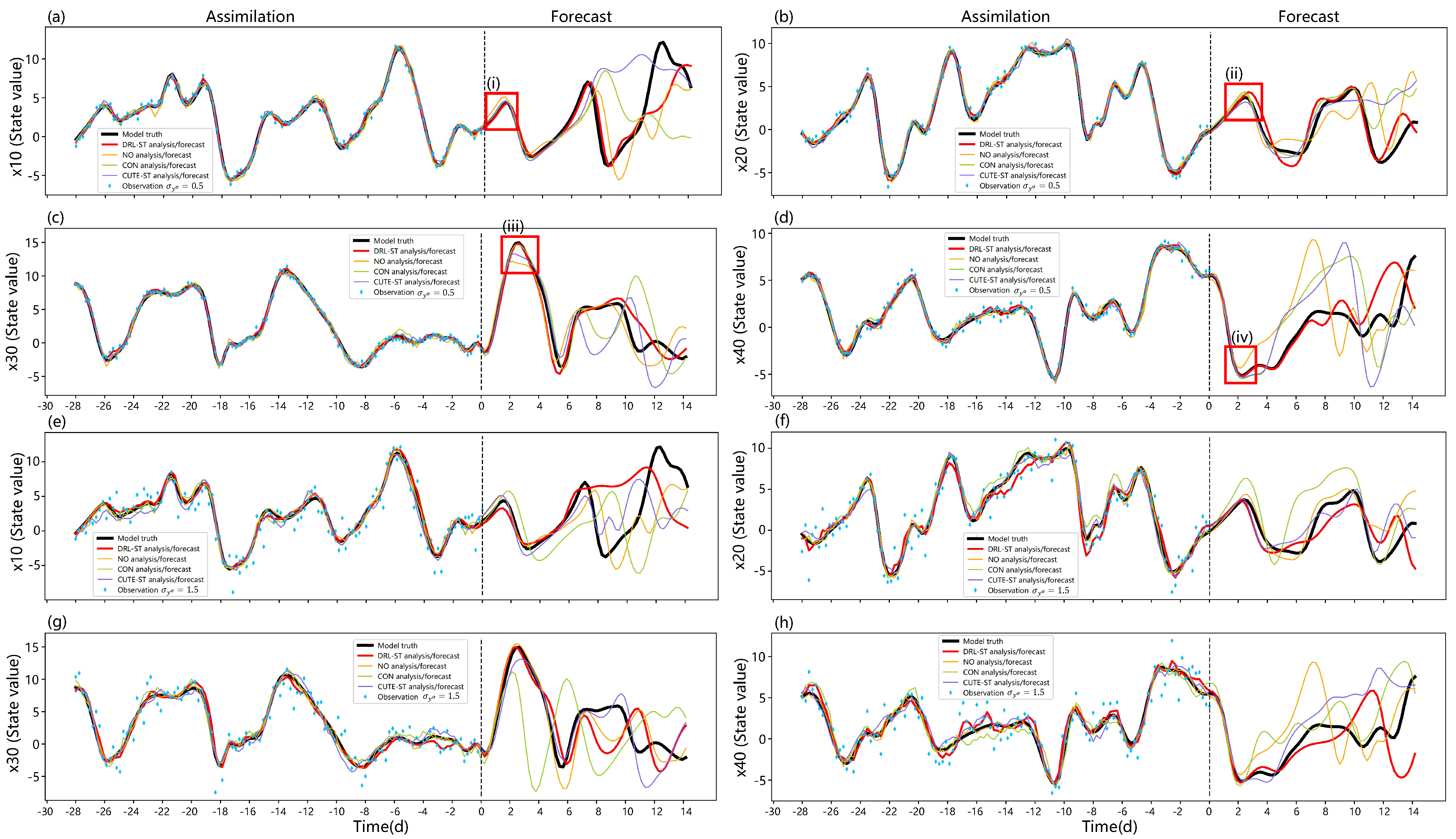
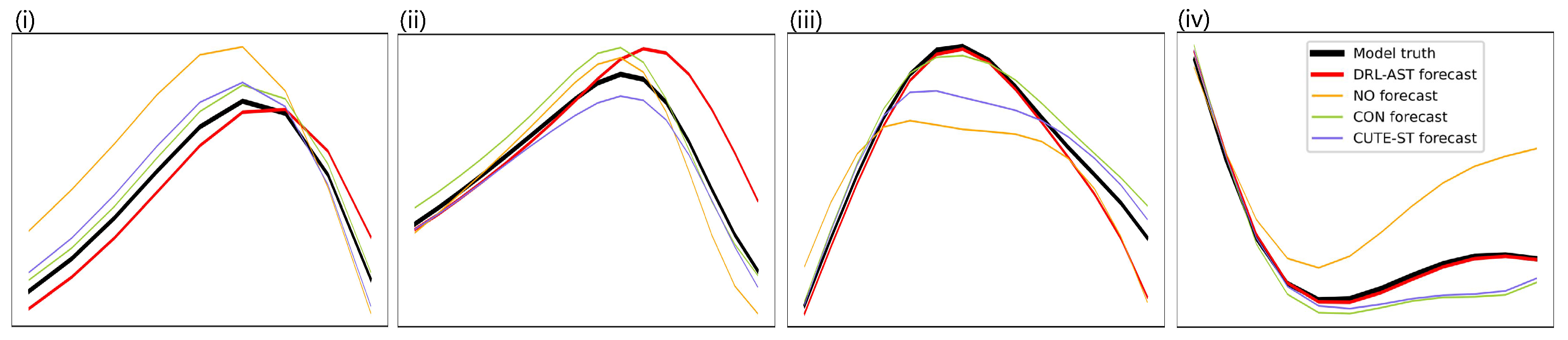
5.4. Qualitative Results
6. Discussion
6.1. The Rationality of the Full Observation
6.2. Feasibility and Applicability of DRL-AST in High-Dimensional NWP Systems
- 1.
- State space expands from low to high dimensions: a key challenge in transitioning DRL-AST from the Lorenz-96 model to more complex NWP models like SPEEDY and WRF is the dramatic increase in the dimensionality of the state space. Unlike the low-dimensional structure of Lorenz-96, both the SPEEDY and WRF models simulate multivariate atmospheric states, such as temperature, wind velocity, and humidity. This substantial expansion in state dimensionality introduces computational complexity, impeding efficient RL training by exacerbating convergence difficulties, increasing computational cost, and limiting policy generalization. To mitigate these challenges, future research should explore using DL for feature extraction, enabling dimensionality reduction while retaining the key physical characteristics of the atmospheric state. Possible approaches include convolutional neural networks (CNNs) for local feature extraction, variational autoencoders (VAEs) for compact latent representations, and Transformer-based attention mechanisms to enhance long-range dependencies between atmospheric variables. These methods collectively facilitate efficient state encoding, reducing computational costs and improving the RL model’s trainability. Furthermore, to enhance training stability and computational efficiency in high-dimensional NWP models, manifold-learning-based dimensionality reduction strategies, such as principal component analysis (PCA) and locally linear embedding (LLE), may be investigated. These approaches help ensure that reduced state representations retain essential physical information while minimizing redundant computations. Additionally, incorporating multi-scale feature fusion networks could further improve DRL-AST’s adaptability to diverse dynamical regimes, ensuring robust policy generalization across varying meteorological conditions. After policy inference, an inverse mapping technique may be employed to reconstruct the full atmospheric state from the reduced feature space, allowing RL-driven optimization to be effectively applied to SPEEDY and WRF models. This approach avoids direct RL applications in high-dimensional spaces, alleviating computational bottlenecks and enhancing training stability.
- 2.
- Selecting a collaborative data assimilation system: to validate DRL-AST beyond idealized testing, we plan to first implement it within the SPEEDY model and subsequently extend it to the WRF model. The Parallel Data Assimilation Framework (PDAF) supports 3D-Var, EnKF, and hybrid methods, and its modular design facilitates efficient coupling with SPEEDY for DA experiments [72]. The WRF Data Assimilation (WRFDA) system offers a comprehensive suite of DA techniques and is tightly integrated with WRF, supporting the assimilation of diverse real-world observations to improve initial conditions [73]. For this study, we consider 3D-Var as the baseline assimilation framework due to its computational efficiency and suitability for frequent RL-environment interactions. Unlike four-dimensional variational assimilation (4D-Var) and EnKF, which involve high computational costs, 3D-Var employs a static B, allowing for rapid gradient-based optimization. However, static B cannot dynamically adapt to evolving weather regimes, potentially resulting in assimilation errors, particularly in rapidly changing systems such as deep convection and tropical cyclones. By leveraging DRL-AST to adaptively optimize the variance component of B, we anticipate improving 3D-Var’s performance across different meteorological conditions.
- 3.
- Design and optimization of the action space: the DRL-AST action space must align with the formulation of B in the intermediate-to-complex DA system, such as those employed for SPEEDY and WRF models. Instead of storing B explicitly as a full-rank matrix, DA frameworks like PDAF and WRFDA utilize a control variable transform (CVT) approach to model B [18]. This approach decomposes B into key statistical components, including variances (), eigenvectors, eigenvalues, and horizontal/vertical length scales. These elements provide a compact yet accurate approximation of B, preserving its essential statistical characteristics while substantially reducing storage demands and computational costs. Therefore, in experiments involving these DA systems, the action space of DRL-AST is formulated as a vector comprising spatially adaptive variance scaling factors at time step . These factors govern the variance of different control variables across distinct regions and are dynamically adjusted by the RL agent to optimize assimilation performance. At each subsequent time step, this vector evolves, enabling a temporally adaptive adjustment mechanism. The spatial distribution of variance in B is influenced by multiple factors, including topography, large-scale circulation patterns, observational network density, and model errors. For instance, complex terrain (e.g., mountainous regions) often amplifies local dynamical processes, resulting in increased variance estimates, while observation-sparse regions such as oceans may suffer from underestimated or overestimated background errors. To identify an appropriate spatial partitioning scheme—whether based on latitude, topography, or meteorological considerations—we will draw upon literature reviews, sensitivity experiments, and data-driven statistical analyses. Furthermore, since these DA systems represent B through CVT, future extensions could refine horizontal and vertical length scales and other key components by expanding the action space. This would enable the more precise spatio-temporal tuning of B, improving variational assimilation accuracy.
- 4.
- Bridging idealized and operational reward functions: a key challenge in extending DRL-AST from idealized environments to intermediate-to-complex NWP systems lies in constructing reward functions that remain valid when the true state of the atmosphere is not observable, as is typical in operational settings. A widely adopted solution in AI for Earth system science is to use reanalysis datasets, such as the fifth-generation ECMWF reanalysis dataset (ERA5), as proxies for the true state during training and evaluation [37]. Although ERA5 has limitations—including coarse spatial resolution and assimilation-induced biases—it provides a physically consistent and globally accessible benchmark. For high-resolution applications, such as extreme precipitation nowcasting, more localized observational datasets, including in-situ station data, radar reflectivity, and radar-derived precipitation estimates, are commonly used to approximate the true state at fine spatial and temporal scales [74,75]. These data sources serve as high-quality reference signals for constructing reward functions in DRL settings, enabling training under realistic observability constraints. By leveraging such datasets, DRL-AST can be trained in a way that respects the observational constraints of real-world NWP systems while maintaining physical realism, thereby improving its transferability from idealized testbeds (e.g., Lorenz-96) to more complex models such as SPEEDY and WRFDA.
- 5.
- Scalability of DRL-AST in the 4D-Var framework: following the validation of DRL-AST within the WRF model, its scalability to the 4D-Var framework warrants further investigation. In 4D-Var, while B is implicitly adjusted through the assimilation window, B remains static at the initial time of each assimilation window. Thus, the adaptive variance scaling strategy learned in 3D-Var could be applied to optimize the specification of B at the beginning of each assimilation window in 4D-Var. Moreover, future studies may involve fine-tuning the RL policy within the 4D-Var context, leveraging the properties of error propagation to achieve optimal assimilation performance across extended assimilation windows. However, to fully adapt to the unique characteristics of 4D-Var, the further fine-tuning of the RL policy may be required to enhance assimilation performance.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bauer, P.; Thorpe, A.; Brunet, G. The quiet revolution of numerical weather prediction. Nature 2015, 525, 47–55. [Google Scholar] [CrossRef] [PubMed]
- Abbe, C. The physical basis of long-range weather forecasts. Mon. Weather Rev. 1901, 29, 551–561. [Google Scholar] [CrossRef]
- Verhulst, F. Nonlinear Differential Equations and Dynamical Systems; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Richardson, L.F. Weather Prediction by Numerical Process; Cambridge University Press: Cambridge, UK, 1922. [Google Scholar]
- Wolf, A.; Swift, J.B.; Swinney, H.L.; Vastano, J.A. Determining Lyapunov exponents from a time series. Phys. D Nonlinear Phenom. 1985, 16, 285–317. [Google Scholar] [CrossRef]
- Arnol’d, V.I. Small denominators and problems of stability of motion in classical and celestial mechanics. Russ. Math. Surv. 1963, 18, 85. [Google Scholar] [CrossRef]
- Arnold, V.I. Geometrical Methods in the Theory of Ordinary Differential Equations; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Pecora, L.M.; Carroll, T.L. Synchronization in chaotic systems. Phys. Rev. Lett. 1990, 64, 821. [Google Scholar] [CrossRef]
- Wang, B.; Zou, X.; Zhu, J. Data assimilation and its applications. Proc. Natl. Acad. Sci. USA 2000, 97, 11143–11144. [Google Scholar] [CrossRef]
- Talagrand, O. Assimilation of observations, an introduction. J. Meteorol. Soc. Jpn. Ser. 1997, 75, 191–209. [Google Scholar] [CrossRef]
- Daley, R. Atmospheric Data Analysis; Cambridge University Press: Cambridge, UK, 1993. [Google Scholar]
- Asch, M.; Bocquet, M.; Nodet, M. Data Assimilation: Methods, Algorithms, and Applications; SIAM: Philadelphia, PA, USA, 2016. [Google Scholar]
- Gettelman, A.; Geer, A.J.; Forbes, R.M.; Carmichael, G.R.; Feingold, G.; Posselt, D.J.; Stephens, G.L.; Van den Heever, S.C.; Varble, A.C.; Zuidema, P. The future of Earth system prediction: Advances in model-data fusion. Sci. Adv. 2022, 8, eabn3488. [Google Scholar] [CrossRef]
- Carrassi, A.; Bocquet, M.; Bertino, L.; Evensen, G. Data assimilation in the geosciences: An overview of methods, issues, and perspectives. Wiley Interdiscip. Rev. Clim. Change 2018, 9, e535. [Google Scholar] [CrossRef]
- Benjamin, S.G.; Weygandt, S.S.; Brown, J.M.; Hu, M.; Alexander, C.R.; Smirnova, T.G.; Olson, J.B.; James, E.P.; Dowell, D.C.; Grell, G.A.; et al. A North American hourly assimilation and model forecast cycle: The Rapid Refresh. Mon. Weather Rev. 2016, 144, 1669–1694. [Google Scholar] [CrossRef]
- Dowell, D.C.; Alexander, C.R.; James, E.P.; Weygandt, S.S.; Benjamin, S.G.; Manikin, G.S.; Blake, B.T.; Brown, J.M.; Olson, J.B.; Hu, M.; et al. The High-Resolution Rapid Refresh (HRRR): An hourly updating convection-allowing forecast model. Part I: Motivation and system description. Weather Forecast. 2022, 37, 1371–1395. [Google Scholar] [CrossRef]
- Bannister, R.N. A review of operational methods of variational and ensemble-variational data assimilation. Q. J. R. Meteorol. Soc. 2017, 143, 607–633. [Google Scholar] [CrossRef]
- Bannister, R.N. A review of forecast error covariance statistics in atmospheric variational data assimilation. II: Modelling the forecast error covariance statistics. Q. J. R. Meteorol. Soc. A J. Atmos. Sci. Appl. Meteorol. Phys. Oceanogr. 2008, 134, 1971–1996. [Google Scholar] [CrossRef]
- Bannister, R.N. A review of forecast error covariance statistics in atmospheric variational data assimilation. I: Characteristics and measurements of forecast error covariances. Q. J. R. Meteorol. Soc. A J. Atmos. Sci. Appl. Meteorol. Phys. Oceanogr. 2008, 134, 1951–1970. [Google Scholar] [CrossRef]
- Gustafsson, N.; Bojarova, J.; Vignes, O. A hybrid variational ensemble data assimilation for the HIgh Resolution Limited Area Model (HIRLAM). Nonlinear Process. Geophys. 2014, 21, 303–323. [Google Scholar] [CrossRef]
- Tandeo, P.; Ailliot, P.; Bocquet, M.; Carrassi, A.; Miyoshi, T.; Pulido, M.; Zhen, Y. A review of innovation-based methods to jointly estimate model and observation error covariance matrices in ensemble data assimilation. Mon. Weather Rev. 2020, 148, 3973–3994. [Google Scholar] [CrossRef]
- Parrish, D.F.; Derber, J.C. The National Meteorological Center’s spectral statistical-interpolation analysis system. J. Abbr. 1992, 120, 1747–1763. [Google Scholar] [CrossRef]
- Bonavita, M.; Isaksen, L.; Hólm, E. On the use of EDA background error variances in the ECMWF 4D-Var. Q. J. R. Meteorol. Soc. 2012, 138, 1540–1559. [Google Scholar] [CrossRef]
- Bormann, N.; Bonavita, M.; Dragani, R.; Eresmaa, R.; Matricardi, M.; McNally, A. Enhancing the impact of IASI observations through an updated observation-error covariance matrix. Q. J. R. Meteorol. Soc. 2016, 142, 1767–1780. [Google Scholar] [CrossRef]
- Jung, B.-J.; Ménétrier, B.; Snyder, C.; Liu, Z.; Guerrette, J.J.; Ban, J.; Baños, I.H.; Yu, Y.G.; Skamarock, W.C. Three-dimensional variational assimilation with a multivariate background error covariance for the Model for Prediction Across Scales—Atmosphere with the Joint Effort for Data assimilation Integration (JEDI-MPAS 2.0. 0-beta). Geosci. Model Dev. 2024, 17, 3879–3895. [Google Scholar] [CrossRef]
- Wiering, M.A.; Van Otterlo, M. Reinforcement learning. Adapt. Learn. Optim. 2012, 12, 729. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Bellman, R. A Markovian decision process. Indiana Univ. Math. J. 1957, 6, 679–684. [Google Scholar] [CrossRef]
- Derber, J.; Bouttier, F. A reformulation of the background error covariance in the ECMWF global data assimilation system. Tellus A Dyn. Meteorol. Oceanogr. 1999, 51, 195–221. [Google Scholar] [CrossRef]
- Desroziers, G.; Berre, L.; Chapnik, B.; Poli, P. Diagnosis of observation, background and analysis-error statistics in observation space. Q. J. R. Meteorol. Soc. A J. Atmos. Sci. Appl. Meteorol. Phys. Oceanogr. 2005, 131, 3385–3396. [Google Scholar] [CrossRef]
- Cheng, S.; Argaud, J.-P.; Iooss, B.; Lucor, D.; Ponçot, A. Background error covariance iterative updating with invariant observation measures for data assimilation. Stoch. Environ. Res. Risk Assess. 2019, 33, 2033–2051. [Google Scholar] [CrossRef]
- Berre, L.; Arbogast, E. Formulation and use of 3D-hybrid and 4D-hybrid ensemble covariances in the Météo-France global data assimilation system. Q. J. R. Meteorol. Soc. 2024, 150, 416–435. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat, F. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef]
- Karniadakis, G.E.; Kevrekidis, I.G.; Lu, L.; Perdikaris, P.; Wang, S.; Yang, L. Physics-informed machine learning. Nat. Rev. Phys. 2021, 3, 422–440. [Google Scholar] [CrossRef]
- Lam, R.; Sanchez-Gonzalez, A.; Willson, M.; Wirnsberger, P.; Fortunato, M.; Alet, F.; Ravuri, S.; Ewalds, T.; Eaton-Rosen, Z.; Hu, W.; et al. Learning skillful medium-range global weather forecasting. Science 2023, 382, 1416–1421. [Google Scholar] [CrossRef]
- Zhang, Y.; Long, M.; Chen, K.; Xing, L.; Jin, R.; Jordan, M.I.; Wang, J. Skilful nowcasting of extreme precipitation with NowcastNet. Nature 2023, 619, 526–532. [Google Scholar] [CrossRef] [PubMed]
- Bi, K.; Xie, L.; Zhang, H.; Chen, X.; Gu, X.; Tian, Q. Accurate medium-range global weather forecasting with 3D neural networks. Nature 2023, 619, 533–538. [Google Scholar] [CrossRef] [PubMed]
- Cheng, S.; Quilodrán-Casas, C.; Ouala, S.; Farchi, A.; Liu, C.; Tandeo, P.; Fablet, R.; Lucor, D.; Iooss, B.; Brajard, J.; et al. Machine learning with data assimilation and uncertainty quantification for dynamical systems: A review. IEEE/CAA J. Autom. Sin. 2023, 10, 1361–1387. [Google Scholar] [CrossRef]
- Cheng, S.; Qiu, M. Observation error covariance specification in dynamical systems for data assimilation using recurrent neural networks. Neural Comput. Appl. 2022, 34, 13149–13167. [Google Scholar] [CrossRef]
- Hammoud, M.A.E.R.; Raboudi, N.; Titi, E.S.; Knio, O.; Hoteit, I. Data assimilation in chaotic systems using deep reinforcement learning. J. Adv. Model. Earth Syst. 2024, 16, e2023MS004178. [Google Scholar] [CrossRef]
- Houtekamer, P.L.; Zhang, F. Review of the ensemble Kalman filter for atmospheric data assimilation. J. Abbr. 2016, 144, 4489–4532. [Google Scholar] [CrossRef]
- Jeung, M.; Jang, J.; Yoon, K.; Baek, S.-S. Data assimilation for urban stormwater and water quality simulations using deep reinforcement learning. J. Hydrol. 2023, 624, 129973. [Google Scholar] [CrossRef]
- Zhao, J.; Guo, Y.; Lin, Y.; Zhao, Z.; Guo, Z. A novel dynamic ensemble of numerical weather prediction for multi-step wind speed forecasting with deep reinforcement learning and error sequence modeling. Energy 2024, 302, 131787. [Google Scholar] [CrossRef]
- Wu, Z.; Fang, G.; Ye, J.; Zhu, D.Z.; Huang, X. A Reinforcement Learning-Based Ensemble Forecasting Framework for Renewable Energy Forecasting. Renew. Energy 2025, 244, 122692. [Google Scholar] [CrossRef]
- Saxena, D.M.; Bae, S.; Nakhaei, A.; Fujimura, K.; Likhachev, M. Driving in dense traffic with model-free reinforcement learning. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 5385–5392. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Deng, Y.; Bao, F.; Kong, Y.; Ren, Z.; Dai, Q. Deep direct reinforcement learning for financial signal representation and trading. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 653–664. [Google Scholar] [CrossRef] [PubMed]
- Lorenz, E.N.; Emanuel, K.A. Optimal sites for supplementary weather observations: Simulation with a small model. J. Atmos. Sci. 1998, 55, 399–414. [Google Scholar] [CrossRef]
- Kurosawa, K.; Poterjoy, J. A statistical hypothesis testing strategy for adaptively blending particle filters and ensemble Kalman filters for data assimilation. Mon. Weather Rev. 2023, 151, 105–125. [Google Scholar] [CrossRef]
- Miyoshi, T. The Gaussian approach to adaptive covariance inflation and its implementation with the local ensemble transform Kalman filter. Mon. Weather Rev. 2011, 139, 1519–1535. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Duan, Y.; Chen, X.; Houthooft, R.; Schulman, J.; Abbeel, P. Benchmarking deep reinforcement learning for continuous control. In Proceedings of the ICML’16: Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1329–1338. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.; Abbeel, P. High-dimensional continuous control using generalized advantage estimation. arXiv 2015, arXiv:1506.02438. [Google Scholar]
- Henderson, P.; Islam, R.; Bachman, P.; Pineau, J.; Precup, D.; Meger, D. Deep reinforcement learning that matters. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 3207–3214. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Nerger, L. On serial observation processing in localized ensemble Kalman filters. Mon. Weather Rev. 2015, 143, 1554–1567. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Wang, W.; Ren, K.; Duan, B.; Zhu, J.; Li, X.; Ni, W.; Lu, J.; Yuan, T. A four-dimensional variational constrained neural network-based data assimilation method. J. Adv. Model. Earth Syst. 2024, 16, e2023MS003687. [Google Scholar] [CrossRef]
- Pegion, K.; DelSole, T.; Becker, E.; Cicerone, T. Assessing the fidelity of predictability estimates. Clim. Dyn. 2019, 53, 7251–7265. [Google Scholar] [CrossRef]
- Brajard, J.; Carrassi, A.; Bocquet, M.; Bertino, L. Combining data assimilation and machine learning to infer unresolved scale parametrization. Philos. Trans. R. Soc. A 2021, 379, 20200086. [Google Scholar] [CrossRef] [PubMed]
- Lange, H.; Craig, G.C. The impact of data assimilation length scales on analysis and prediction of convective storms. Mon. Weather Rev. 2014, 142, 3781–3808. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning, Vancouver, BC, Canada, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Zhou, W.; Li, J.; Yan, Z.; Shen, Z.; Wu, B.; Wang, B.; Zhang, R.; Li, Z. Progress and future prospects of decadal prediction and data assimilation: A review. Atmos. Ocean. Sci. Lett. 2024, 17, 100441. [Google Scholar] [CrossRef]
- Dutta, A.; Harshith, J.; Ramamoorthy, A.; Lakshmanan, K. Attractor inspired deep learning for modelling chaotic systems. Hum.-Centric Intell. Syst. 2023, 3, 461–472. [Google Scholar] [CrossRef]
- Jeswal, S.K.; Chakraverty, S. Recent developments and applications in quantum neural network: A review. Arch. Comput. Methods Eng. 2019, 26, 793–807. [Google Scholar] [CrossRef]
- Molteni, F. Atmospheric simulations using a GCM with simplified physical parametrizations. I: Model climatology and variability in multi-decadal experiments. Clim. Dyn. 2003, 20, 175–191. [Google Scholar] [CrossRef]
- Skamarock, W.C.; Klemp, J.B.; Dudhia, J.; Gill, D.O.; Liu, Z.; Berner, J.; Wang, W.; Powers, J.G.; Duda, M.G.; Barker, D.M.; et al. A description of the advanced research WRF model version 4. Natl. Cent. Atmos. Res. 2019, 145, 550. [Google Scholar]
- Nerger, L.; Hiller, W. Software for ensemble-based data assimilation systems—Implementation strategies and scalability. Comput. Geosci. 2013, 55, 110–118. [Google Scholar] [CrossRef]
- Barker, D.; Huang, X.-Y.; Liu, Z.; Auligné, T.; Zhang, X.; Rugg, S.; Ajjaji, R.; Bourgeois, A.; Bray, J.; Chen, Y.; et al. The weather research and forecasting model’s community variational/ensemble data assimilation system: WRFDA. Bull. Am. Meteorol. Soc. 2012, 93, 831–843. [Google Scholar] [CrossRef]
- Li, D.; Deng, K.; Zhang, D.; Liu, Y.; Leng, H.; Yin, F.; Ren, K.; Song, J. LPT-QPN: A lightweight physics-informed transformer for quantitative precipitation nowcasting. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–19. [Google Scholar] [CrossRef]
- Liu, Q.; Xiao, Y.; Gui, Y.; Dai, G.; Li, H.; Zhou, X.; Ren, A.; Zhou, G.; Shen, J. MMF-RNN: A Multimodal Fusion Model for Precipitation Nowcasting Using Radar and Ground Station Data. IEEE Trans. Geosci. Remote Sens. 2025, 63, 4101416. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description | Definition |
|---|---|---|
| Variational Data Assimilation (VarDA) (notations used in Section 3.1) | ||
| State vector | Model variables (e.g., temperature, winds, pressure) | |
| Background state | Prior estimate of the state | |
| Analysis state | Optimized estimate after data assimilation | |
| True state | Theoretical true state of the atmosphere, unknown in practice | |
| Observations | Atmospheric and multi-modal observational data | |
| Observation operator | Map from model space to observation space | |
| Tangent linear of the observation operator | ||
| Background error covariance matrix | Represents uncertainty in background state | |
| Observation error covariance matrix | Represents uncertainty in observations | |
| Cost function | Minimization objective in variational data assimilation | |
| Background Error Covariance Matrix (notations used in Section 3.2) | ||
| Background error vector | Difference between background and true state | |
| Variance | Diagonal element of , representing the background error variance of the i-th state variable, | |
| Correlation coefficient | ; measures linear dependence between different variables | |
| Correlation matrix | Matrix composed of | |
| Diagonal matrix | Contains the background error standard deviations | |
| Deep Reinforcement Learning (notations used in Section 3.3) | ||
| State space | Set of all possible states in the RL environment | |
| Action space | Set of all possible actions an agent can take | |
| State transition function | Conditional probability density function of transitioning to given and , where t denotes timestep | |
| Reward function | A scalar reward received after taking action in state , quantifying the immediate impact of the action | |
| Discount factor | A scalar ranging between 0 and 1 that discounts long-term rewards | |
| Policy | A stochastic policy parameterized by that maps each state to a distribution over actions | |
| Return at t | Discounted sum of future rewards from time t | |
| Trajectory | A sequence of states and actions: , where T denotes the total time | |
| Parameter | Value | Description |
|---|---|---|
| Scaling factor bounds | Range for the action space in DRL-AST | |
| Learning rate | Adam optimizer learning rate | |
| Batch size | 128 | Number of samples per training batch |
| PPO epochs | 4 | Number of PPO update steps per iteration |
| Total training steps | Total environment steps for training | |
| Discount factor () | 0.998 | Future reward discount factor |
| GAE parameter () | 0.95 | Smoothing factor in GAE |
| PPO clip parameter () | 0.2 | Clipping threshold in PPO |
| Entropy coefficient | 0.01 | Entropy regularization for exploration |
| Value loss coefficient | 0.5 | Weight of value function loss |
| Max gradient norm | 0.5 | Gradient clipping threshold |
| Metrics | Time | Methods | ||||
|---|---|---|---|---|---|---|
| NO | CON | CUTE-ST | DRL-AST (Ours) | |||
| RMSEa | 5 years | 0.5 | 0.36 ± 0.0006 | 0.27 ± 0.0011, 24.46% ± 0.33% | 0.29 ± 0.0006, 18.12% ± 0.21% | 0.25 ± 0.0006, 29.47% ± 0.20% |
| 1.0 | 0.53 ± 0.0017 | 0.51 ± 0.0018, 3.36% ± 0.37% | 0.52 ± 0.0011, 2.07% ± 0.37% | 0.44 ± 0.0016, 17.57% ± 0.42% | ||
| 1.5 | 0.75 ± 0.0057 | 0.74 ± 0.0049, 1.12% ± 1.04% | 0.63 ± 0.0021, 15.82% ± 0.75% | 0.63 ± 0.0021, 15.71% ± 0.70% | ||
| 2.0 | 1.17 ± 0.0188 | 0.97 ± 0.0062, 16.97% ± 1.33% | 0.86 ± 0.0090, 26.18% ± 1.46% | 0.83 ± 0.0037, 29.00% ± 1.18% | ||
| 2.5 | 1.80 ± 0.0252 | 1.20 ± 0.0078, 33.42% ± 1.06% | 1.37 ± 0.0187, 23.69% ± 1.54% | 1.08 ± 0.0035, 39.93% ± 0.86% | ||
| RMSEf | 72 h | 0.5 | 0.72 ± 0.20 | 0.67 ± 0.17, 6.61% ± 5.77% | 0.68 ± 0.19, 6.40% ± 6.51% | 0.58 ± 0.18, 20.10% ± 8.86% |
| 1.0 | 1.21 ± 0.30 | 1.19 ± 0.35, 2.18% ± 6.45% | 1.11 ± 0.29, 8.00% ± 4.39% | 0.94 ± 0.24, 21.80% ± 3.40% | ||
| 1.5 | 1.60 ± 0.45 | 1.54 ± 0.33, 1.74% ± 7.09% | 1.33 ± 0.32, 15.71% ± 6.08% | 1.32 ± 0.29, 15.62% ± 6.06% | ||
| 2.0 | 2.18 ± 0.61 | 2.03 ± 0.49, 5.89% ± 5.03% | 1.74 ± 0.46, 19.84% ± 3.41% | 1.74 ± 0.45, 19.55% ± 4.11% | ||
| 2.5 | 2.61 ± 0.57 | 2.26 ± 0.47, 13.07% ± 3.89% | 2.32 ± 0.54, 11.29% ± 5.31% | 1.96 ± 0.44, 24.62% ± 3.54% | ||
| 7 days | 0.5 | 1.91 ± 0.43 | 1.76 ± 0.44, 8.20% ± 3.50% | 1.87 ± 0.46, 2.62% ± 4.58% | 1.56 ± 0.47, 19.06% ± 7.63% | |
| 1.0 | 2.39 ± 0.43 | 2.46 ± 0.52, −2.42% ± 6.74% | 2.34 ± 0.41, 2.02% ± 3.38% | 2.07 ± 0.42, 13.99% ± 5.43% | ||
| 1.5 | 2.70 ± 0.47 | 2.72 ± 0.47, −0.66% ± 4.33% | 2.51 ± 0.44, 7.02% ± 4.34% | 2.52 ± 0.39, 6.08% ± 6.80% | ||
| 2.0 | 3.15 ± 0.56 | 3.03 ± 0.49, 3.27% ± 5.23% | 2.84 ± 0.45, 9.38% ± 3.01% | 2.83 ± 0.45, 9.53% ± 7.61% | ||
| 2.5 | 3.33 ± 0.41 | 3.29 ± 0.35, 1.04% ± 3.09% | 3.05 ± 0.46, 8.78% ± 6.16% | 3.02 ± 0.46, 9.65% ± 3.88% | ||
| 15 days | 0.5 | 3.34 ± 0.34 | 3.29 ± 0.31, 1.57% ± 2.56% | 3.31 ± 0.37, 1.01% ± 2.73% | 3.06 ± 0.35, 8.51% ± 3.21% | |
| 1.0 | 3.78 ± 0.31 | 3.76 ± 0.36, 0.52% ± 2.01% | 3.63 ± 0.31, 3.88% ± 1.44% | 3.52 ± 0.32, 6.98% ± 1.69% | ||
| 1.5 | 3.94 ± 0.35 | 3.89 ± 0.33, 1.05% ± 2.66% | 3.74 ± 0.34, 4.87% ± 1.79% | 3.79 ± 0.34, 3.59% ± 3.28% | ||
| 2.0 | 4.07 ± 0.31 | 4.05 ± 0.35, 0.47% ± 2.20% | 3.97 ± 0.30, 2.33% ± 1.10% | 3.97 ± 0.30, 2.39% ± 1.06% | ||
| 2.5 | 4.21 ± 0.30 | 4.20 ± 0.23, 0.23% ± 1.97% | 4.08 ± 0.35, 3.24% ± 2.89% | 4.02 ± 0.32, 4.54% ± 2.64% | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, L.; Leng, H.; Song, J.; Wang, D.; Wang, W.; Hu, R.; Cao, H. An Adaptive Variance Adjustment Strategy for a Static Background Error Covariance Matrix—Part I: Verification in the Lorenz-96 Model. Appl. Sci. 2025, 15, 6399. https://doi.org/10.3390/app15126399
Huang L, Leng H, Song J, Wang D, Wang W, Hu R, Cao H. An Adaptive Variance Adjustment Strategy for a Static Background Error Covariance Matrix—Part I: Verification in the Lorenz-96 Model. Applied Sciences. 2025; 15(12):6399. https://doi.org/10.3390/app15126399
Chicago/Turabian StyleHuang, Lilan, Hongze Leng, Junqiang Song, Dongzi Wang, Wuxin Wang, Ruisheng Hu, and Hang Cao. 2025. "An Adaptive Variance Adjustment Strategy for a Static Background Error Covariance Matrix—Part I: Verification in the Lorenz-96 Model" Applied Sciences 15, no. 12: 6399. https://doi.org/10.3390/app15126399
APA StyleHuang, L., Leng, H., Song, J., Wang, D., Wang, W., Hu, R., & Cao, H. (2025). An Adaptive Variance Adjustment Strategy for a Static Background Error Covariance Matrix—Part I: Verification in the Lorenz-96 Model. Applied Sciences, 15(12), 6399. https://doi.org/10.3390/app15126399