
Using Graph-Based Maximum Independent Sets with Large Language Models for Extractive Text Summarization


Abstract
1. Introduction
Motivation and Objective
- Does the proposed MIS-based framework improve the summarization accuracy compared to existing popular LLMs?
- Can the framework reduce computational costs and increase efficiency in extractive summarization tasks?
- Does integrating structured information into LLMs enable a more precise modeling of cause–effect relationships within texts?
- Can the use of structured information storage mitigate the context loss inherent in transformer architectures?
- Does structured and canonical data storage reduce the energy consumption of LLMs by optimizing data loads, and does this integration strengthen their performance?
- Can the proposed method achieve a high summarization accuracy at a low cost across different LLMs and datasets?
2. Related Works
3. Datasets
3.1. Description of the DUC Dataset
3.2. Description of the CNN/DailyMail Dataset
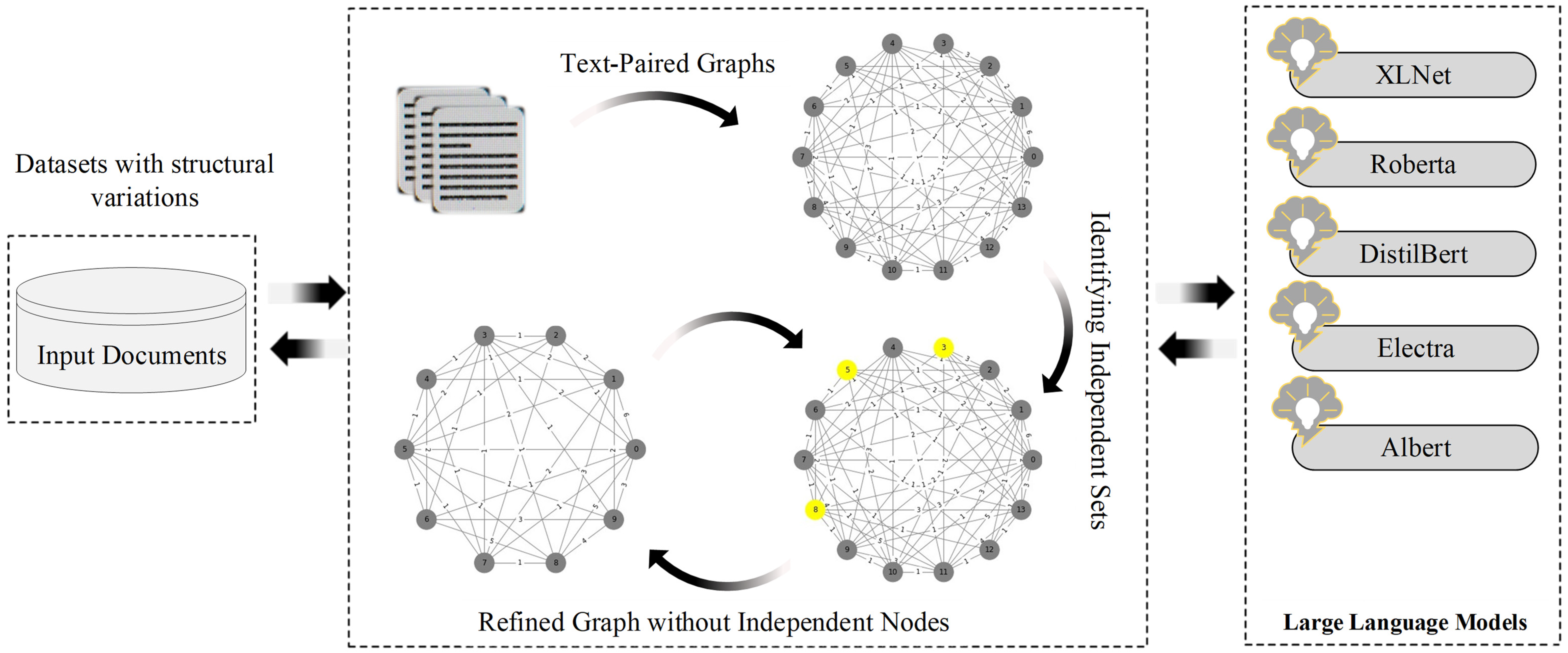
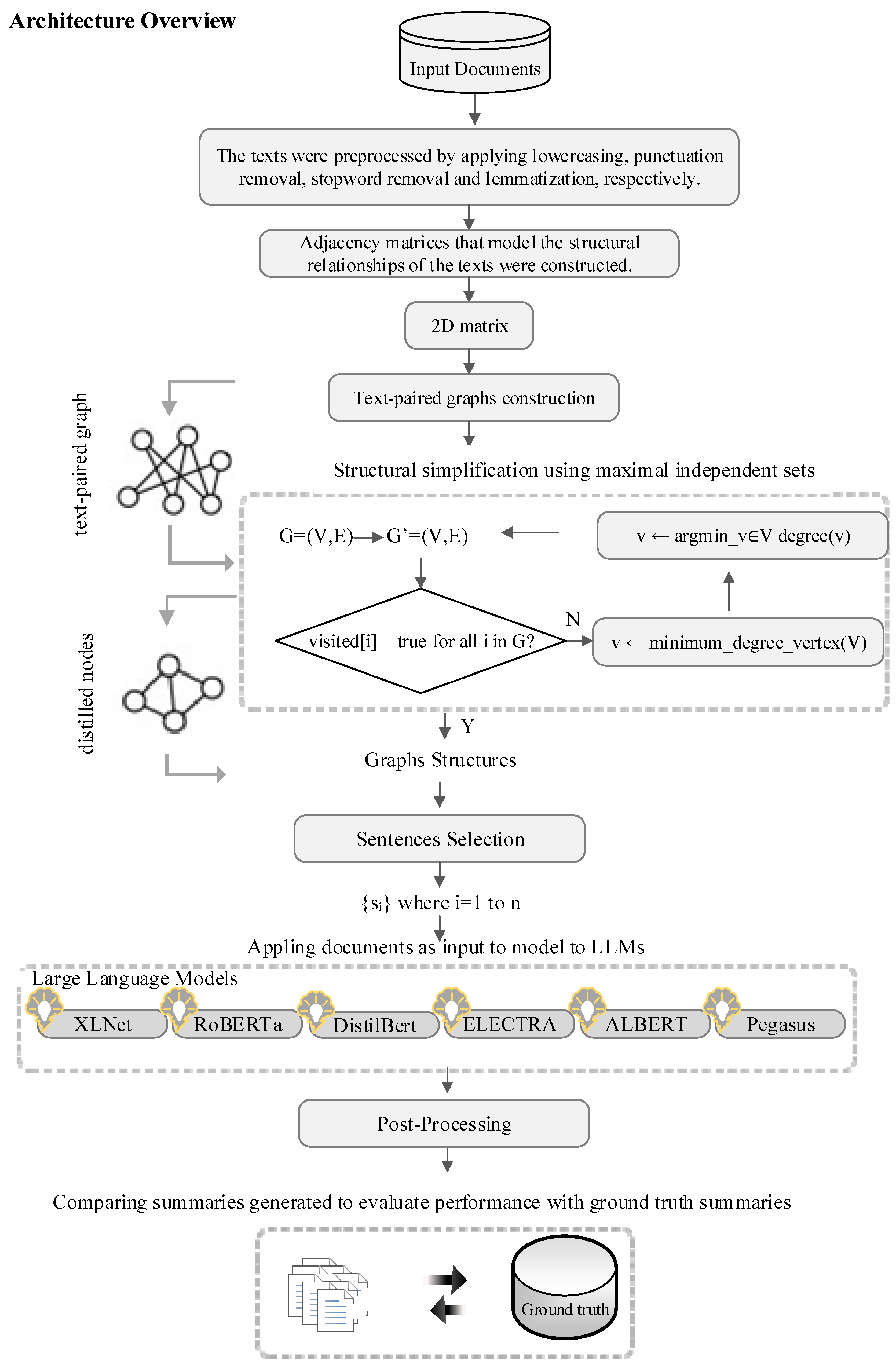
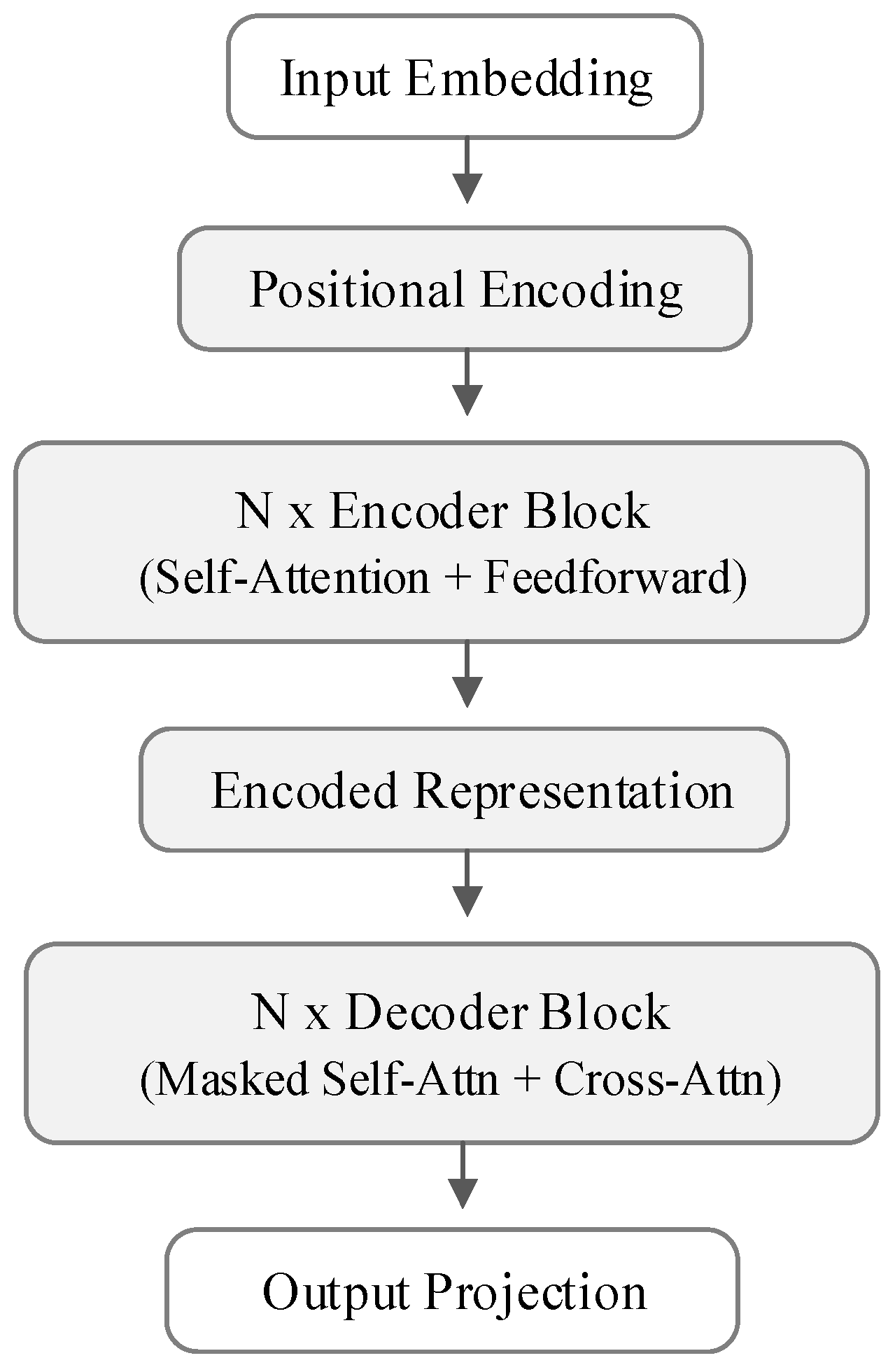
4. Materials and Methods
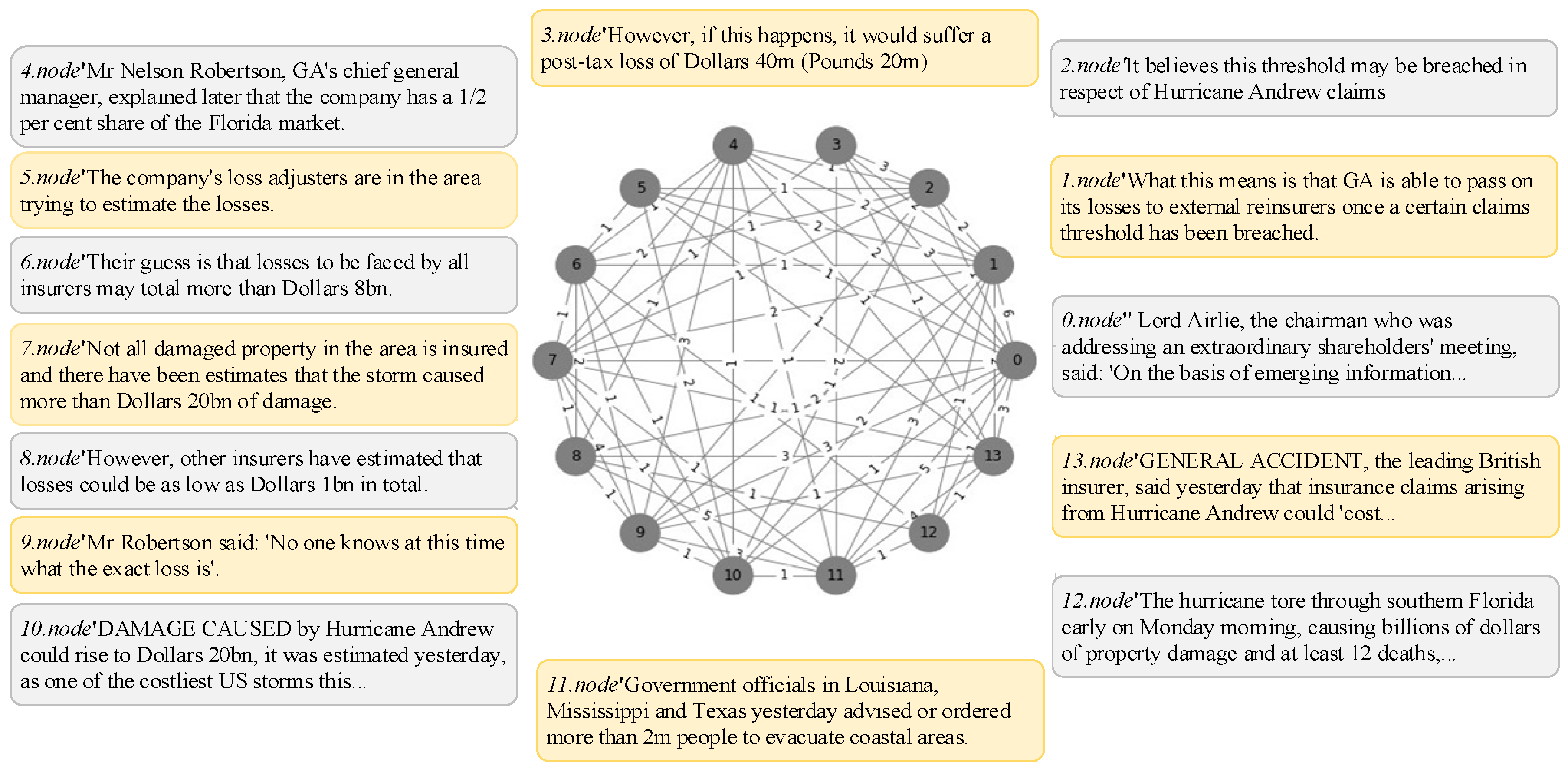
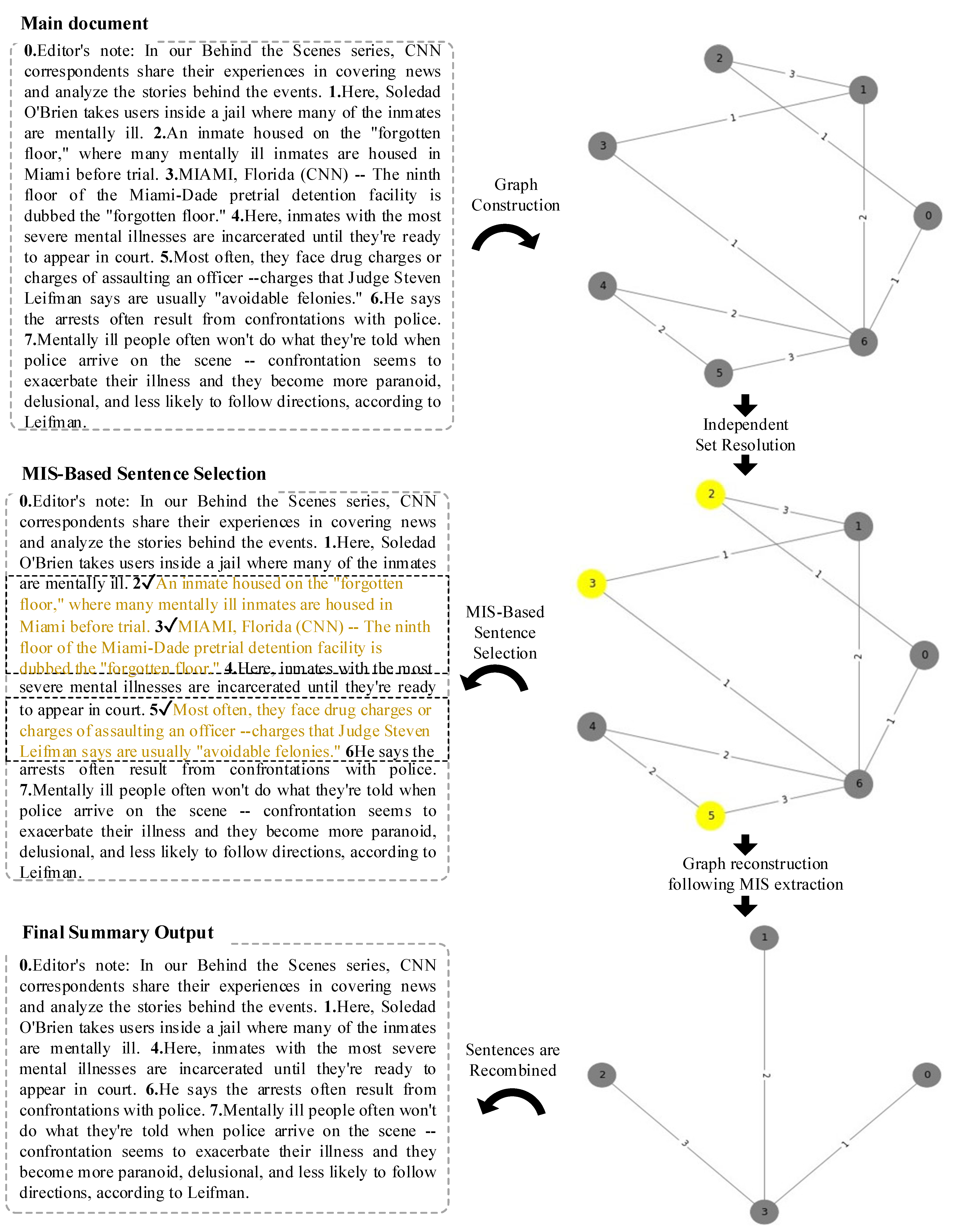
4.1. Integrating Natural Language and Graph-Based Representations
4.2. Independent Set
| Algorithm 1. MIS Algorithm: Maximum_Independent_Set (G). | ||
| 1 | function Maximum_Independent_Set | |
| 2 | if all vertices in have degree 0: | |
| 3 | return | |
| 4 | if is empty: | |
| 5 | return empty set | |
| 6 | select vertex with minimum degree | |
| 7 | if then //(if u is not included in the set) | |
| 8 | ||
| 9 | = Maximum_Independent_Set | |
| 10 | else //(if u is included in the set) | |
| 11 | neigbors | |
| 12 | Maximum_Independent_Set | |
| 13 | if> then | |
| 14 | return | |
| 15 | else | |
| 16 | return | |
| 17 | end function | |
4.3. Formatting of Mathematical Components
4.4. Performance Metrics
5. Experiment Setup and Results
5.1. Experiment Setup
5.2. Experimental Results
6. Discussion
7. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LLM | Large Language Model |
| NLP | Natural Language Process |
| MIS | Maximum Independent Set |
| DUC | Document Understanding Conference |
| CNN | Cable News Network |
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation |
| GAT | Graph Attention Network |
| GNN | Graph Neural Networks |
| OOV | Out-of-Vocabulary |
References
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Floridi, L.; Chiriatti, M. GPT-3: Its Nature, Scope, Limits, and Consequences. Minds Mach. 2020, 30, 681–694. [Google Scholar] [CrossRef]
- Shetty, A.M.; DH., M.; Aljunid, M.F. Fine-tuning XLNet for Amazon review sentiment analysis: A comparative evaluation of transformer models. ETRI J. 2025, 1–18. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, Y.; Saleh, M.; Liu, P. Pegasus: Pre-training with extracted gap-sentences for abstractive summarization. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 13–18 July 2020; pp. 11328–11339. [Google Scholar]
- Pourkeyvan, A.; Safa, R.; Sorourkhah, A. Harnessing the Power of Hugging Face Transformers for Predicting Mental Health Disorders in Social Networks. IEEE Access 2024, 12, 28025–28035. [Google Scholar] [CrossRef]
- Tsai, Y.-H.; Chang, C.-M.; Chen, K.-H.; Hwang, S.-Y. An Integration of TextGCN and Autoencoder into Aspect-Based Sentiment Analysis; Springer: Berlin/Heidelberg, Germany, 2022; pp. 3–16. [Google Scholar]
- Yang, S.; Duan, X.; Xiao, Z.; Li, Z.; Liu, Y.; Jie, Z.; Tang, D.; Du, H. Sentiment Classification of Chinese Tourism Reviews Based on ERNIE-Gram+GCN. Int. J. Environ. Res. Public Health 2022, 19, 13520. [Google Scholar] [CrossRef]
- Zeng, D.; Zha, E.; Kuang, J.; Shen, Y. Multi-label text classification based on semantic-sensitive graph convolutional network. Knowl. -Based Syst. 2024, 284, 111303. [Google Scholar] [CrossRef]
- Zuo, Y.; Wu, J.; Zhang, H.; Lin, H.; Wang, F.; Xu, K.; Xiong, H. Topic Modeling of Short Texts. In Proceedings of the Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 2105–2114. [Google Scholar]
- Zhao, K.; Huang, L.; Song, R.; Shen, Q.; Xu, H. A Sequential Graph Neural Network for Short Text Classification. Algorithms 2021, 14, 352. [Google Scholar] [CrossRef]
- Mouratidis, D.; Kermanidis, K.L. Ensemble and Deep Learning for Language-Independent Automatic Selection of Parallel Data. Algorithms 2019, 12, 26. [Google Scholar] [CrossRef]
- Chai, Z.; Zhang, T.; Wu, L.; Han, K.; Hu, X.; Huang, X.; Yang, Y. GraphLLM: Boosting Graph Reasoning Ability of Large Language Model. arXiv 2023, arXiv:2310.05845. Available online: https://arxiv.org/abs/2310.05845 (accessed on 1 March 2025).
- Chen, Z.; Mao, H.; Li, H.; Jin, W.; Wen, H.; Wei, X.; Wang, S.; Yin, D.; Fan, W.; Liu, H.; et al. Exploring the Potential of Large Language Models (LLMs) in Learning on Graphs. arXiv 2024, arXiv:2307.03393. Available online: https://arxiv.org/abs/2307.03393 (accessed on 1 March 2025). [CrossRef]
- Fatemi, B.; Halcrow, J.; Perozzi, B. Talk like a Graph: Encoding Graphs for Large Language Models. arXiv 2023, arXiv:2310.04560. Available online: https://arxiv.org/abs/2310.04560 (accessed on 1 March 2025).
- Guo, J.; Du, L.; Liu, H.; Zhou, M.; He, X.; Han, S. GPT4Graph: Can Large Language Models Understand Graph Structured Data ? An Empirical Evaluation and Benchmarking. arXiv 2023, arXiv:2305.15066. Available online: https://arxiv.org/abs/2305.15066 (accessed on 2 March 2025).
- Bian, J.; Huang, X.; Zhou, H.; Huang, T.; Zhu, S. GoSum: Extractive summarization of long documents by reinforcement learning and graph-organized discourse state. Knowl. Inf. Syst. 2024, 66, 7557–7580. [Google Scholar] [CrossRef]
- Chen, T.; Wang, X.; Yue, T.; Bai, X.; Le, C.X.; Wang, W. Enhancing Abstractive Summarization with Extracted Knowledge Graphs and Multi-Source Transformers. Appl. Sci. 2023, 13, 7753. [Google Scholar] [CrossRef]
- Zeng, G.-H.; Liu, Y.-Q.; Zhang, C.-Y.; Cai, H.-C.; Chen, C.L.P. Adaptive Multi-Document Summarization Via Graph Representation Learning. IEEE Trans. Cogn. Dev. Syst. 2024, 1–12. [Google Scholar] [CrossRef]
- Ivanisenko, T.V.; Demenkov, P.S.; Ivanisenko, V.A. An Accurate and Efficient Approach to Knowledge Extraction from Scientific Publications Using Structured Ontology Models, Graph Neural Networks, and Large Language Models. Int. J. Mol. Sci. 2024, 25, 11811. [Google Scholar] [CrossRef]
- Chen, J.; Yang, D. Structure-Aware Abstractive Conversation Summarization via Discourse and Action Graphs. arXiv 2021, arXiv:2104.08400. Available online: https://arxiv.org/abs/2104.08400 (accessed on 2 March 2025).
- Cui, P.; Hu, L.; Liu, Y. Enhancing Extractive Text Summarization with Topic-Aware Graph Neural Networks. arXiv 2020, arXiv:2010.06253. Available online: https://arxiv.org/abs/2010.06253 (accessed on 4 March 2025).
- Yasunaga, M.; Zhang, R.; Meelu, K.; Pareek, A.; Srinivasan, K.; Radev, D. Graph-based Neural Multi-Document Summarization. arXiv 2017, arXiv:1706.06681. Available online: https://arxiv.org/abs/1706.06681 (accessed on 3 March 2025).
- Sun, G.; Wang, Y.; Niyato, D.; Wang, J.; Wang, X.; Poor, H.V.; Letaief, K.B. Large Language Model (LLM)-enabled Graphs in Dynamic Networking. IEEE Netw. 2024, 1. [Google Scholar] [CrossRef]
- Plaza, L.; Díaz, A.; Gervás, P. A semantic graph-based approach to biomedical summarisation. Artif. Intell. Med. 2011, 53, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Givchi, A.; Ramezani, R.; Baraani-Dastjerdi, A. Graph-based abstractive biomedical text summarization. J. Biomed. Inform. 2022, 132, 104099. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Xue, H.; Zhao, Z.; Xu, W.; Huang, J.; Guo, M.; Wang, Q.; Zhou, K.; Zhang, Y. LLM as GNN: Graph Vocabulary Learning for Text-Attributed Graph Foundation Models. arXiv 2025, arXiv:2503.03313. Available online: https://arxiv.org/abs/2503.03313 (accessed on 3 March 2025).
- Document Understanding Conferences. Available online: http://duc.nist.gov (accessed on 14 July 2021).
- See, A.; Liu Google Brain, P.J.; Manning, C.D. Get To The Point: Summarization with Pointer-Generator Networks. arXiv 2017, arXiv:1704.04368. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Text Summarization Branches Out (WAS 2004); Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 25–26. [Google Scholar]
- Hermann, K.M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching machines to read and comprehend. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Moscibroda, T.; Wattenhofer, R. Maximal independent sets in radio networks. In Proceedings of the Twenty-Fourth Annual ACM Symposium on Principles of Distributed Computing, Las Vegas, NV, USA, 17–20 July 2005; ACM: New York, NY, USA, 2005; pp. 148–157. [Google Scholar]
- McIlroy, D. The UNIX Time-Sharing System: Foreword. In Proceedings of the First ACM SIGPLAN Conference on History of Programming Languages (HOPL-I), Los Angeles, CA, USA, 1–3 June 1978; ACM: New York, NY, USA, 2005; pp. 207–212. [Google Scholar]
- Mrzic, A.; Meysman, P.; Bittremieux, W.; Moris, P.; Cule, B.; Goethals, B.; Laukens, K. Grasping frequent subgraph mining for bioinformatics applications. BioData Min. 2018, 11, 20. [Google Scholar] [CrossRef]
- Uçkan, T.; Karcı, A. Extractive multi-document text summarization based on graph independent sets. Egypt. Inform. J. 2020, 21, 145–157. [Google Scholar] [CrossRef]
- Öztemiz, F. A greedy approach to solve maximum independent set problem: Differential Malatya independent set algorithm. Eng. Sci. Technol. Int. J. 2025, 63, 101995. [Google Scholar] [CrossRef]
- YAKUT, S.; ÖZTEMİZ, F.; KARCİ, A. A New Approach Based on Centrality Value in Solving the Maximum Independent Set Problem: Malatya Centrality Algorithm. Comput. Sci. 2023, 8, 16–23. [Google Scholar] [CrossRef]
- Jou, M.-J.; Chang, G.J. The Number Of Maximum Independent Sets In Graphs. Taiwan J. Math. 2000, 4, 685–695. [Google Scholar] [CrossRef]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A Survey of Large Language Models. arXiv 2025, arXiv:2303.18223. Available online: https://arxiv.org/abs/2303.18223 (accessed on 5 March 2025).
- Feng, S.Y.; Gangal, V.; Wei, J.; Chandar, S.; Vosoughi, S.; Mitamura, T.; Hovy, E. A Survey of Data Augmentation Approaches for NLP. arXiv 2021, arXiv:2105.03075. Available online: https://arxiv.org/abs/2105.03075 (accessed on 5 March 2025).
- Novelli, C.; Casolari, F.; Rotolo, A.; Taddeo, M.; Floridi, L. Taking AI risks seriously: A new assessment model for the AI Act. AI Soc. 2024, 39, 2493–2497. [Google Scholar] [CrossRef]
- Cai, Y.; Mao, S.; Wu, W.; Wang, Z.; Liang, Y.; Ge, T.; Wu, C.; You, W.; Song, T.; Xia, Y.; et al. Low-code LLM: Graphical User Interface over Large Language Models. arXiv 2024, arXiv:2304.08103. Available online: https://arxiv.org/abs/2304.08103 (accessed on 2 March 2025).
- Yao, Y.; Duan, J.; Xu, K.; Cai, Y.; Sun, Z.; Zhang, Y. A survey on large language model (LLM) security and privacy: The Good, The Bad, and The Ugly. High-Confid. Comput. 2024, 4, 100211. [Google Scholar] [CrossRef]
- Zhongyu, S.; Zhou, W.; Ding, C.; Xia, M. Multi-Resolution Transformer Network for Building and Road Segmentation of Remote Sensing Image. ISPRS Int. J. Geo-Inf. 2022, 11, 165. [Google Scholar] [CrossRef]
- Kalyan, K.S. A survey of GPT-3 family large language models including ChatGPT and GPT-4. Nat. Lang. Process. J. 2024, 6, 100048. [Google Scholar] [CrossRef]
- Liu, Z.; Roberts, R.A.; Lal-Nag, M.; Chen, X.; Huang, R.; Tong, W. AI-based language models powering drug discovery and development. Drug Discov. Today 2021, 26, 2593–2607. [Google Scholar] [CrossRef]
- Kour, H.; Gupta, M.K. AI Assisted Attention Mechanism for Hybrid Neural Model to Assess Online Attitudes About COVID-19. Neural Process. Lett. 2023, 55, 2265–2304. [Google Scholar] [CrossRef]
- Marrone, S.; Sansone, C. On the transferability of adversarial perturbation attacks against fingerprint based authentication systems. Pattern Recognit. Lett. 2021, 152, 253–259. [Google Scholar] [CrossRef]
- Potamias, R.A.; Siolas, G.; Stafylopatis, A.-G. A transformer-based approach to irony and sarcasm detection. Neural Comput. Appl. 2020, 32, 17309–17320. [Google Scholar] [CrossRef]
- Yang, T.; Li, F.; Ji, D.; Liang, X.; Xie, T.; Tian, S.; Li, B.; Liang, P. Fine-grained depression analysis based on Chinese micro-blog reviews. Inf. Process. Manag. 2021, 58, 102681. [Google Scholar] [CrossRef]
- Capris, T.; Takagi, Y.; Figueiredo, D.; Henriques, J.; Pires, I.M. A Convolutional Neural Network-enabled IoT framework to verify COVID-19 hygiene conditions and authorize access to facilities. Procedia Comput. Sci. 2022, 203, 727–732. [Google Scholar] [CrossRef] [PubMed]
- Kinger, S.; Kinger, D.; Thakkar, S.; Bhake, D. Towards smarter hiring: Resume parsing and ranking with YOLOv5 and DistilBERT. Multimed. Tools Appl. 2024, 83, 82069–82087. [Google Scholar] [CrossRef]
- Wang, H.; Kang, X.; Ren, F. Emotion-Sentence-DistilBERT: A Sentence-BERT-Based Distillation Model for Text Emotion Classification; Springer: Berlin/Heidelberg, Germany, 2022; pp. 313–322. [Google Scholar]
- Leteno, T.; Gourru, A.; Laclau, C.; Gravier, C. An Investigation of Structures Responsible for Gender Bias in BERT and DistilBERT; Springer: Berlin/Heidelberg, Germany, 2023; pp. 249–261. [Google Scholar]
- Jojoa, M.; Eftekhar, P.; Nowrouzi-Kia, B.; Garcia-Zapirain, B. Natural language processing analysis applied to COVID-19 open-text opinions using a distilBERT model for sentiment categorization. AI Soc. 2024, 39, 883–890. [Google Scholar] [CrossRef]
- Qiu, K.; Zhang, Y.; Feng, Y.; Chen, F. LogAnomEX: An Unsupervised Log Anomaly Detection Method Based on Electra-DP and Gated Bilinear Neural Networks. J. Netw. Syst. Manag. 2025, 33, 33. [Google Scholar] [CrossRef]
- Yu, J.-L.; Dai, Q.-Q.; Li, G.-B. Deep learning in target prediction and drug repositioning: Recent advances and challenges. Drug Discov. Today 2022, 27, 1796–1814. [Google Scholar] [CrossRef]
- Ding, M. The road from MLE to EM to VAE: A brief tutorial. AI Open 2022, 3, 29–34. [Google Scholar] [CrossRef]
- Ye, Z.; Zuo, T.; Chen, W.; Li, Y.; Lu, Z. Textual emotion recognition method based on ALBERT-BiLSTM model and SVM-NB classification. Soft Comput. 2023, 27, 5063–5075. [Google Scholar] [CrossRef]
- Heim, E.; Ramia, J.A.; Hana, R.A.; Burchert, S.; Carswell, K.; Cornelisz, I.; Cuijpers, P.; El Chammay, R.; Noun, P.; van Klaveren, C.; et al. Step-by-step: Feasibility randomised controlled trial of a mobile-based intervention for depression among populations affected by adversity in Lebanon. Internet Interv. 2021, 24, 100380. [Google Scholar] [CrossRef]
- Hunhevicz, J.J.; Hall, D.M. Do you need a blockchain in construction? Use case categories and decision framework for DLT design options. Adv. Eng. Inform. 2020, 45, 101094. [Google Scholar] [CrossRef]
- Azmi, A.M.; Altmami, N.I. An abstractive Arabic text summarizer with user controlled granularity. Inf. Process. Manag. 2018, 54, 903–921. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Main Contribution | Advantages | Disadvantages |
|---|---|---|---|
| [12] Graph + LLM | Context length reduction | Performance boost | Model heavily dependent on graph and LLM type |
| [14] Graph to Text | Converts graphs to text for LLM | Effective with suitable representation | Large-scale graphs less effective |
| [15] Benchmark for LLM Graph Understanding | Highlights critical factors affecting LLM | Good insight into LLM limits | LLM lags behind graph-specialized models |
| [16] GoSum | High ROUGE on PubMed/arXiv datasets | Effective summarization | Performance depends on document structure |
| [17] MultiBART-GAT | Abstractive summarization and info accuracy | Controls info accuracy | Computationally expensive |
| [18] HeterMDS | Maintains structure and content integrity | High-quality summaries | High integration cost |
| [19] Protein Interaction Pred. | High-accuracy interaction predictions | Meaningful explanations | Domain-specific |
| [20] Discourse, Action Graphs | Improves summary correctness | Success in automatic and human evals | Complexity of graphs |
| [21] Document-Level Graphs | Significant success on scientific datasets | Handles long documents well | Dataset dependency and high cost |
| [22] Multi-Document Summ. | Effective multi-doc summaries | High ROUGE on DUC-2004 | No context integrity, repetitive sentences |
| [24] Biomed. Text Summ. | Uses UMLS semantic types | Meaningful biomedical summaries | Domain-specific |
| [25] Extended Biomed. Graphs | More robust graph creation | Improved node connections | Domain-specific |
| [26] Prompt-Based GNN | Task transferability improvements | Overcomes OOV issue | Ignores semantic similarity across graphs |
| Proposed framework | MIS-based structural filtering with LLM integration | High summarization accuracy, lower cost | Potential information loss in short summaries |
| Datasets | SD | MD | Data Size | Human Annotation | Purpose of Use |
|---|---|---|---|---|---|
| Duc-2002 | no | yes | 567 document | yes | Information fusion–Content synthesis |
| CNN/DailyMail | yes | no | 290,000 news | yes | Main idea extraction–Summary of information |
| ROUGE Metrics | ROUGE Performance Values (DUC—400-Word Abstracts) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| XLNet | Roberta | Distilbert | Electra | Albert | Pegasus | ||||||||
| Baseline | Prop. | Baseline | Prop. | Baseline | Prop. | Baseline | Prop. | Baseline | Prop. | Baseline | Prop. | ||
| Rouge 1 | R | 0.48489 | 0.49119▲ (+0.0063) | 0.45074 | 0.50124▲ (+0.0505) | 0.48725 | 0.49911▲ (+0.0118) | 0.44350 | 0.49335▲ (+0.0498) | 0.47411 | 0.53538▲ (+0.0612) | 0.50153 | 0.52736▲ (+0.02583) |
| P | 0.47843 | 0.48946▲ (+0.0110) | 0.45095 | 0.48953▲ (+0.0385) | 0.48447 | 0.49456▲ (+0.0100) | 0.44173 | 0.49230▲ (+0.0505) | 0.47534 | 0.52823▲ (+0.0528) | 0.49371 | 0.52692▲ (+0.03321) | |
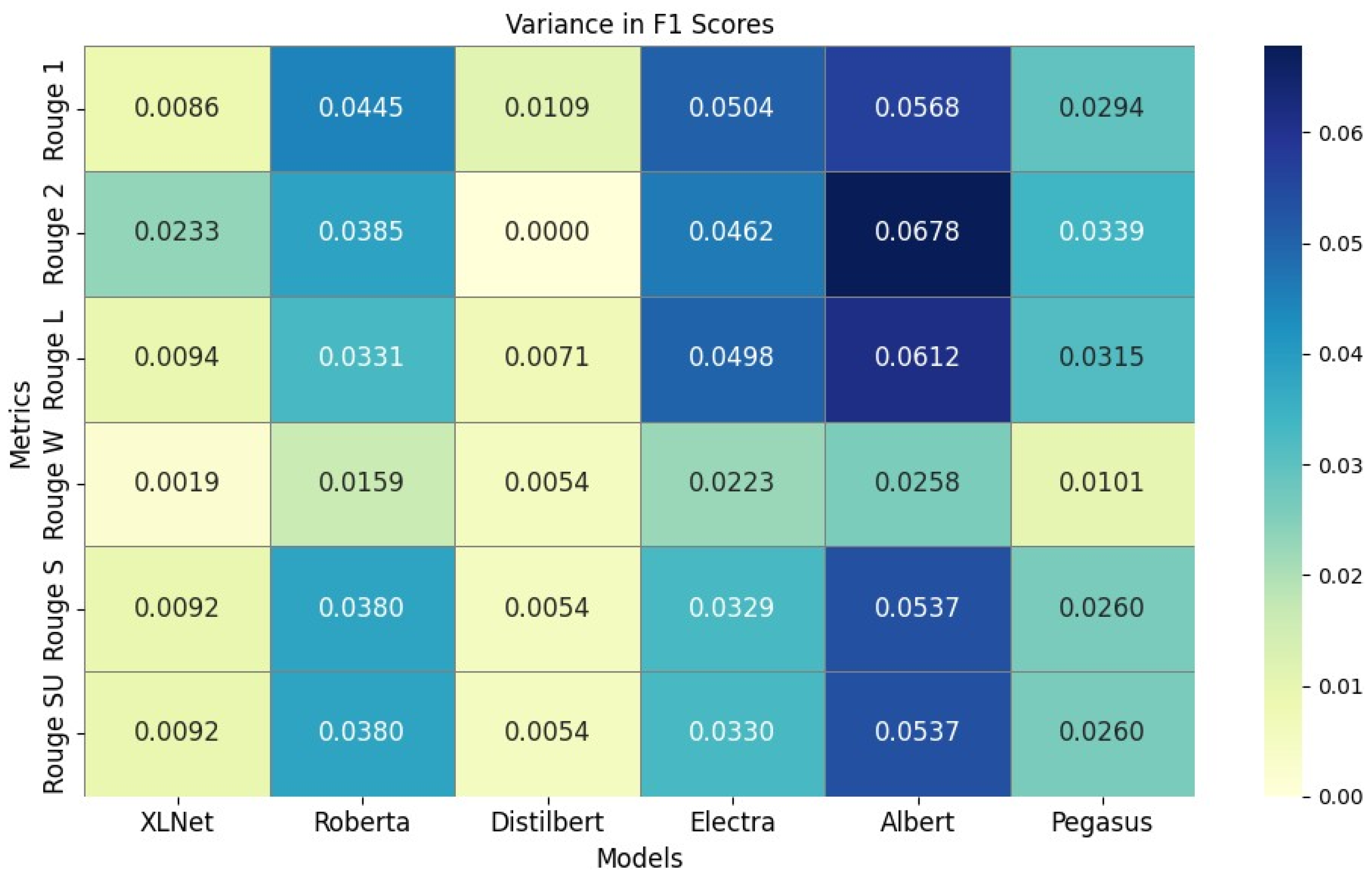
| F1 | 0.48155 | 0.49018▲ (+0.0086) | 0.45067 | 0.49519▲ (+0.0445) | 0.48565 | 0.49659▲ (+0.0109) | 0.44229 | 0.49278▲ (+0.0504) | 0.47468 | 0.53156▲ (+0.0568) | 0.49751 | 0.52693▲ (+0.02942) | |
| Rouge 2 | R | 0.15739 | 0.18030▲ (+0.0229) | 0.14651 | 0.18695▲ (+0.0404) | 0.19473 | 0.19485▲ (+0.0001) | 0.12382 | 0.16971▲ (+0.0458) | 0.16493 | 0.23507▲ (+0.0701) | 0.19069 | 0.22390▲ (+0.03321) |
| P | 0.15564 | 0.17936▲ (+0.0237) | 0.14585 | 0.18261▲ (+0.0367) | 0.19315 | 0.19170 | 0.12259 | 0.16900▲ (+0.0464) | 0.16566 | 0.23143▲ (+0.0657) | 0.18767 | 0.22250▲ (+0.03483) | |
| F1 | 0.15648 | 0.17978▲ (+0.0233) | 0.14612 | 0.18471▲ (+0.0385) | 0.19385 | 0.19317 | 0.12313 | 0.16935▲ (+0.0462) | 0.16528 | 0.23314▲ (+0.0678) | 0.18914 | 0.22313▲ (+0.03399) | |
| Rouge L | R | 0.44662 | 0.45390▲ (+0.0072) | 0.41937 | 0.45791▲ (+0.0385) | 0.44972 | 0.45778▲ (+0.0080) | 0.40410 | 0.45331▲ (+0.0492) | 0.43460 | 0.50005▲ (+0.0654) | 0.46817 | 0.49639▲ (+0.02822) |
| P | 0.44077 | 0.45237▲ (+0.0116) | 0.41951 | 0.44727▲ (+0.0277) | 0.44708 | 0.45336▲ (+0.0062) | 0.40212 | 0.45221▲ (+0.0500) | 0.43577 | 0.49323▲ (+0.0574) | 0.46088 | 0.49587▲ (+0.03499) | |
| F1 | 0.44360 | 0.45300▲ (+0.0094) | 0.41927 | 0.45241▲ (+0.0331) | 0.44821 | 0.45534▲ (+0.0071) | 0.40283 | 0.45272▲ (+0.0498) | 0.43514 | 0.49641▲ (+0.0612) | 0.46442 | 0.49594▲ (+0.03152) | |
| Rouge W | R | 0.13854 | 0.13958▲ (+0.0010) | 0.12577 | 0.14008▲ (+0.0143) | 0.13673 | 0.14140▲ (+0.0046) | 0.12054 | 0.13855▲ (+0.0180) | 0.13356 | 0.15578▲ (+0.0222) | 0.14722 | 0.15464▲ (+0.00742) |
| P | 0.21547 | 0.21928▲ (+0.0038) | 0.19820 | 0.21550▲ (+0.0173) | 0.21439 | 0.22085▲ (+0.0064) | 0.18877 | 0.21788▲ (+0.0291) | 0.21129 | 0.24207▲ (+0.0307) | 0.22846 | 0.24374▲ (+0.01528) | |
| F1 | 0.16860 | 0.17051▲ (+0.0019) | 0.15382 | 0.16972▲ (+0.0159) | 0.16689 | 0.17231▲ (+0.0054) | 0.14701 | 0.16936▲ (+0.0223) | 0.16362 | 0.18944▲ (+0.0258) | 0.17901 | 0.18916▲ (+0.01015) | |
| Rouge S | R | 0.21424 | 0.22180▲ (+0.0075) | 0.18482 | 0.22801▲ (+0.0431) | 0.22186 | 0.22857▲ (+0.0067) | 0.18591 | 0.21787▲ (+0.0319) | 0.20370 | 0.26192▲ (+0.0582) | 0.22906 | 0.25236▲ (+0.0233) |
| P | 0.20871 | 0.21989▲ (+0.0111) | 0.18417 | 0.21726▲ (+0.0330) | 0.21888 | 0.22330▲ (+0.0044) | 0.18348 | 0.21667▲ (+0.0331) | 0.20467 | 0.25468▲ (+0.0500) | 0.22189 | 0.25099▲ (+0.0291) | |
| F1 | 0.21129 | 0.22057▲ (+0.0092) | 0.18420 | 0.22228▲ (+0.0380) | 0.21999 | 0.22544▲ (+0.0054) | 0.18420 | 0.21719▲ (+0.0329) | 0.20411 | 0.25782▲ (+0.0537) | 0.22526 | 0.25130▲ (+0.02604) | |
| Rouge SU | R | 0.21556 | 0.22310▲ (+0.0105) | 0.18611 | 0.22934▲ (+0.0432) | 0.22315 | 0.22988▲ (+0.0067) | 0.18717 | 0.21921▲ (+0.0320) | 0.20501 | 0.26325▲ (+0.0582) | 0.23038 | 0.25369▲ (+0.02331) |
| P | 0.21001 | 0.22120▲ (+0.1119) | 0.18547 | 0.21856▲ (+0.0330) | 0.22017 | 0.22460▲ (+0.0044) | 0.18474 | 0.21800▲ (+0.0332) | 0.20598 | 0.25599▲ (+0.0500) | 0.22319 | 0.25233▲ (+0.02914) | |
| F1 | 0.21259 | 0.22188▲ (+0.0092) | 0.18550 | 0.22359▲ (+0.0380) | 0.22128 | 0.22675▲ (+0.0054) | 0.18546 | 0.21853▲ (+0.0330) | 0.20541 | 0.25914▲ (+0.0537) | 0.22657 | 0.25263▲ (+0.02606) | |
| ROUGE Metrics | ROUGE Performance Values (DUC—200-Word Abstracts) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| XLNet | Roberta | Distilbert | Electra | Albert | Pegasus | ||||||||
| Baseline | Prop. | Baseline | Prop. | Baseline | Prop. | Baseline | Prop. | Baseline | Prop. | Baseline | Prop. | ||
| Rouge 1 | R | 0.38652 | 0.40223▲ (+0.0157) | 0.36219 | 0.37387▲ (+0.0116) | 0.36504 | 0.39377▲ (+0.0287) | 0.39918 | 0.38935 | 0.41210 | 0.42355▲ (+0.0114) | 0.42815 | 0.46058▲ (+0.03243) |
| P | 0.38991 | 0.39357▲ (+0.0036) | 0.35462 | 0.37229▲ (+0.0176) | 0.36654 | 0.38293▲ (+0.0163) | 0.40108 | 0.39035 | 0.40984 | 0.41782▲ (+0.0079) | 0.41472 | 0.45413▲ (+0.03941) | |
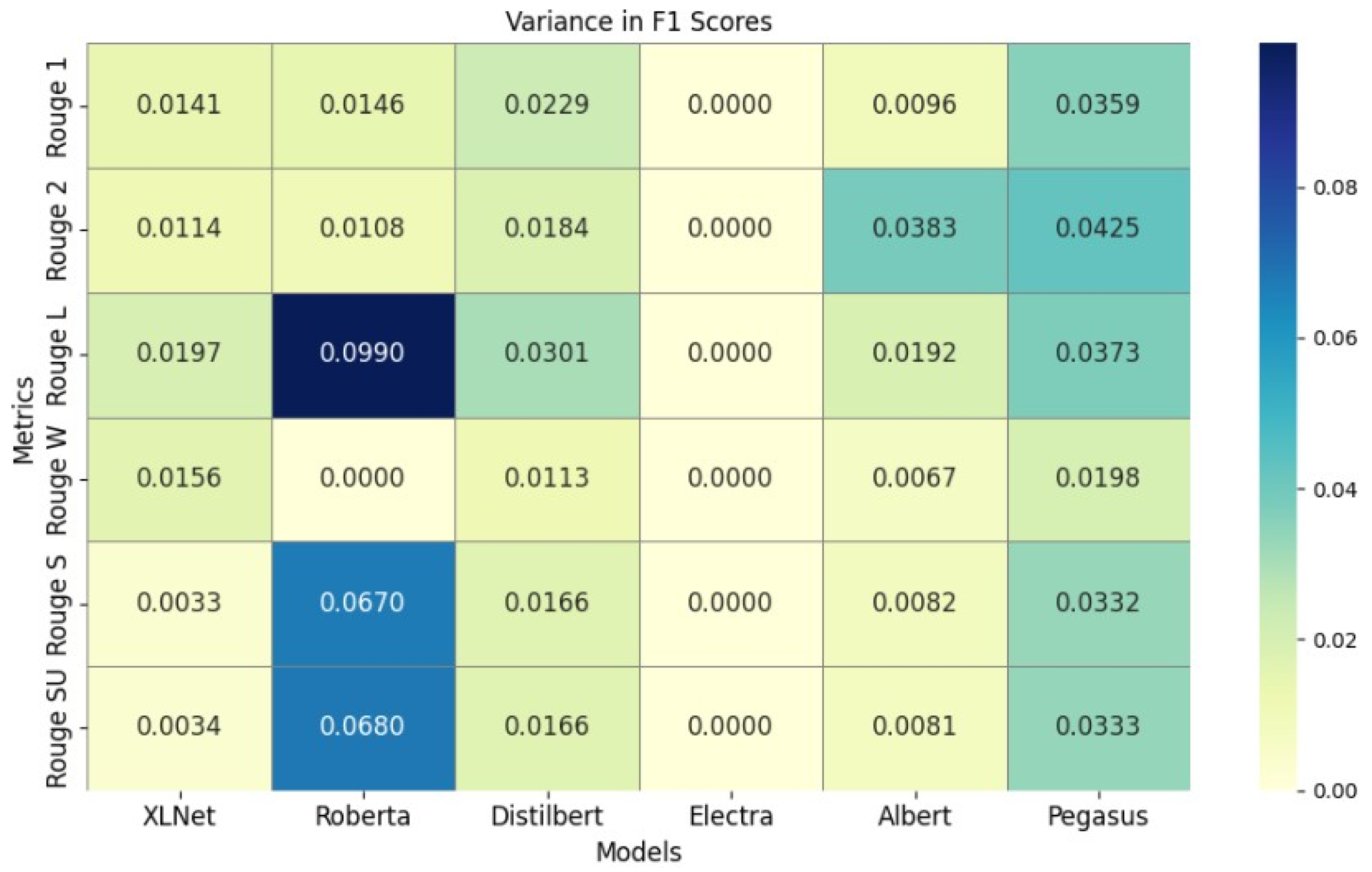
| F1 | 0.38774 | 0.39757▲ (+0.0141) | 0.35814 | 0.37280▲ (+0.0146) | 0.36516 | 0.38811▲ (+0.0229) | 0.39980 | 0.38936 | 0.41066 | 0.42032▲ (+0.0096) | 0.42110 | 0.45704▲ (+0.03594) | |
| Rouge 2 | R | 0.10675 | 0.12093▲ (+0.0141) | 0.08237 | 0.09336▲ (+0.0109) | 0.08405 | 0.10225▲ (+0.0182) | 0.12258 | 0.09785 | 0.13295 | 0.17328▲ (+0.0403) | 0.14364 | 0.18557▲ (+0.04193) |
| P | 0.10868 | 0.11744▲ (+0.0087) | 0.08075 | 0.09154▲ (+0.0107) | 0.08120 | 0.09978▲ (+0.0185) | 0.12155 | 0.09786 | 0.13196 | 0.16860▲ (+0.0366) | 0.13817 | 0.18131▲ (+0.04314) | |
| F1 | 0.10762 | 0.11911▲ (+0.0114) | 0.08151 | 0.09237▲ (+0.0108) | 0.08251 | 0.10097▲ (+0.0184) | 0.12147 | 0.09776 | 0.13240 | 0.17072▲ (+0.0383) | 0.14079 | 0.18332▲ (+0.04253) | |
| Rouge L | R | 0.34285 | 0.36832▲ (+0.0254) | 0.32800 | 0.4235▲ (+0.0955) | 0.32469 | 0.36007▲ (+0.0353) | 0.35715 | 0.35130 | 0.36813 | 0.38939▲ (+0.0212) | 0.38714 | 0.42147▲ (+0.03433) |
| P | 0.34649 | 0.36020▲ (+0.0137) | 0.32139 | 0.4235▲ (+0.0121) | 0.32559 | 0.34981▲ (+0.0242) | 0.35923 | 0.35256 | 0.36599 | 0.38244▲ (+0.0164) | 0.37493 | 0.41512▲ (+0.04019) | |
| F1 | 0.34426 | 0.36397▲ (+0.0197) | 0.32446 | 0.4235▲ (+0.099) | 0.32458 | 0.35472▲ (+0.0301) | 0.35790 | 0.35148 | 0.36678 | 0.38607▲ (+0.0192) | 0.38073 | 0.41801▲ (+0.03728) | |
| Rouge W | R | 0.11470 | 0.12901▲ (+0.0143) | 0.11311 | 0.11237 | 0.11165 | 0.12231▲ (+0.0006) | 0.12332 | 0.12067 | 0.12695 | 0.13287▲ (+0.0059) | 0.13477 | 0.15021▲ (+0.01544) |
| P | 0.18244 | 0.19869▲ (+0.0162) | 0.17439 | 0.17599▲ (+0.0016) | 0.17629 | 0.18719▲ (+0.0109) | 0.19514 | 0.19063 | 0.19868 | 0.20661▲ (+0.0079) | 0.20555 | 0.23306▲ (+0.02751) | |
| F1 | 0.14067 | 0.15635▲ (+0.0156) | 0.13714 | 0.13708 | 0.13653 | 0.14789▲ (+0.0113) | 0.15102 | 0.14762 | 0.15480 | 0.16159▲ (+0.0067) | 0.16274 | 0.18259▲ (+0.01985) | |
| Rouge S | R | 0.13650 | 0.14431▲ (+0.0078) | 0.12181 | 0.12721▲ (+0.0054) | 0.12333 | 0.14294▲ (+0.0196) | 0.15122 | 0.14147 | 0.15531 | 0.16666▲ (+0.0113) | 0.15566 | 0.18696▲ (+0.0313) |
| P | 0.13886 | 0.13740 | 0.11690 | 0.12506▲ (+0.0081) | 0.12242 | 0.13501▲ (+0.0125) | 0.15210 | 0.14193 | 0.15335 | 0.15891▲ (+0.0055) | 0.14543 | 0.18059▲ (+0.03516) | |
| F1 | 0.13706 | 0.14045▲ (+0.0033) | 0.11901 | 0.12573▲ (+0.0067) | 0.12205 | 0.13870▲ (+0.0166) | 0.15114 | 0.14103 | 0.15391 | 0.16211▲ (+0.0082) | 0.15005 | 0.18325▲ (+0.0332) | |
| Rouge SU | R | 0.13887 | 0.14676▲ (+0.0078) | 0.12409 | 0.12956▲ (+0.0054) | 0.12562 | 0.14532▲ (+0.0197) | 0.15358 | 0.14382 | 0.15777 | 0.16910▲ (+0.0113) | 0.15825 | 0.18957▲ (+0.03132) |
| P | 0.14126 | 0.13979 | 0.11910 | 0.12741▲ (+0.0083) | 0.12476 | 0.13742▲ (+0.0126) | 0.15449 | 0.14430 | 0.15580 | 0.16136▲ (+0.0055) | 0.14791 | 0.18317▲ (+0.03526) | |
| F1 | 0.13944 | 0.14287▲ (+0.0034) | 0.12125 | 0.12807▲ (+0.0068) | 0.12436 | 0.14103▲ (+0.0166) | 0.15352 | 0.14338 | 0.15636 | 0.16455▲ (+0.0081) | 0.15258 | 0.18584▲ (+0.03326) | |
| ROUGE Metrics | ROUGE Performance Values (CNN/DailyMail—3-Word Abstracts) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| XLNet | Roberta | Distilbert | Electra | Albert | Pegasus | ||||||||
| Baseline | Prop. | Baseline | Prop. | Baseline | Prop. | Baseline | Prop. | Baseline | Prop. | Baseline | Prop. | ||
| Rouge 1 | R | 0.20274 | 0.33916▲ (+0.1364) | 0.31928 | 0.29687 | 0.34964 | 0.39377▲ (+0.0441) | 0.39918 | 0.38935 | 0.25092 | 0.34894▲ (+0.0980) | 0.34134 | 0.32971 |
| P | 0.17316 | 0.18269▲ (+0.0095) | 0.20929 | 0.17842 | 0.21146 | 0.38293▲ (+0.1714) | 0.40108 | 0.39035 | 0.18516 | 0.18799▲ (+0.0028) | 0.22404 | 0.17474 | |
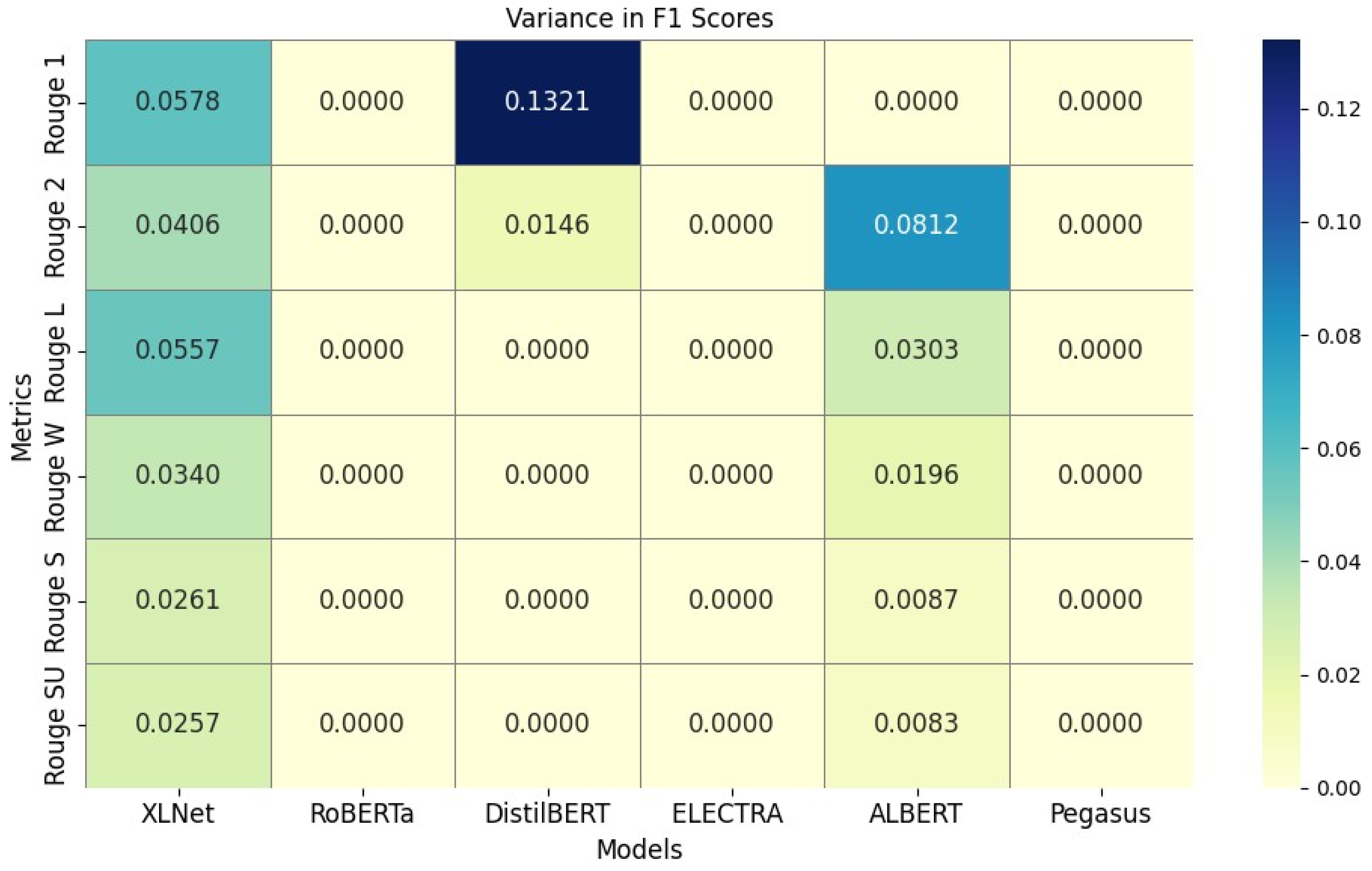
| F1 | 0.17462 | 0.23245▲ (+0.0578) | 0.24024 | 0.21643 | 0.25597 | 0.38811▲ (+0.1321) | 0.39980 | 0.38936 | 0.20367 | 0.23983▲ (+0.0361) | 0.25771 | 0.22518 | |
| Rouge 2 | R | 0.02720 | 0.09733▲ (+0.0701) | 0.10391 | 0.06482 | 0.12666 | 0.10225 | 0.12258 | 0.09785 | 0.04476 | 0.09292▲ (+0.0481) | 0.10747 | 0.08703 |
| P | 0.02932 | 0.05161▲ (+0.0222) | 0.05958 | 0.04097 | 0.06796 | 0.09978▲ (+0.0318) | 0.12155 | 0.09786 | 0.03120 | 0.04988▲ (+0.0186) | 0.05933 | 0.04602 | |
| F1 | 0.02525 | 0.06587▲ (+0.0406) | 0.07303 | 0.04920 | 0.08628 | 0.10097▲ (+0.0146) | 0.12147 | 0.09776 | 0.03484 | 0.06367▲ (+0.0812) | 0.07460 | 0.05945 | |
| Rouge L | R | 0.15971 | 0.28513▲ (+0.0125) | 0.26122 | 0.24169 | 0.29066 | 0.27501 | 0.35715 | 0.35130 | 0.19718 | 0.27847▲ (+0.0812) | 0.28569 | 0.26888 |
| P | 0.14087 | 0.15279▲ (+0.0119) | 0.16315 | 0.14827 | 0.17326 | 0.15642 | 0.35923 | 0.35256 | 0.14596 | 0.14947▲ (+0.0035) | 0.18835 | 0.13953 | |
| F1 | 0.13901 | 0.19480▲ (+0.0557) | 0.19073 | 0.17801 | 0.21101 | 0.19464 | 0.35790 | 0.35148 | 0.16037 | 0.19068▲ (+0.0303) | 0.21624 | 0.18105 | |
| Rouge W | R | 0.07475 | 0.12937▲ (+0.0546) | 0.12172 | 0.11413 | 0.13721 | 0.12538 | 0.12332 | 0.12067 | 0.09331 | 0.12843▲ (+0.0351) | 0.13270 | 0.12461 |
| P | 0.11091 | 0.11239▲ (+0.0014) | 0.12616 | 0.11453 | 0.13400 | 0.11726 | 0.19514 | 0.19063 | 0.11145 | 0.11186▲ (+0.0004) | 0.14386 | 0.10589 | |
| F1 | 0.08302 | 0.11708▲ (+0.0340) | 0.11670 | 0.11035 | 0.13165 | 0.11770 | 0.15102 | 0.14762 | 0.09679 | 0.11641▲ (+0.0196) | 0.13138 | 0.11225 | |
| Rouge S | R | 0.03106 | 0.10828▲ (+0.0772) | 0.10053 | 0.07424 | 0.12366 | 0.09124 | 0.15122 | 0.14147 | 0.05610 | 0.10345▲ (+0.0473) | 0.10697 | 0.09945 |
| P | 0.02826 | 0.03471 (+0.0064) | 0.03416 | 0.02551 | 0.04174 | 0.02900 | 0.15210 | 0.14193 | 0.02986 | 0.02772 | 0.03548 | 0.02697 | |
| F1 | 0.02284 | 0.04899▲ (+0.0261) | 0.04408 | 0.03507 | 0.05722 | 0.04094 | 0.15114 | 0.14103 | 0.03285 | 0.04162▲ (+0.0087) | 0.04659 | 0.04090 | |
| Rouge SU | R | 0.03960 | 0.12013▲ (+0.0805) | 0.11230 | 0.08574 | 0.13499 | 0.10416 | 0.15358 | 0.14382 | 0.06701 | 0.11635▲ (+0.0493) | 0.11915 | 0.11093 |
| P | 0.03572 | 0.03878 (+0.0030) | 0.04104 | 0.03059 | 0.04719 | 0.03388 | 0.15449 | 0.14430 | 0.03632 | 0.03239 | 0.04262 | 0.03094 | |
| F1 | 0.02900 | 0.05471▲ (+0.0257) | 0.05165 | 0.04152 | 0.06409 | 0.04754 | 0.15352 | 0.14338 | 0.03987 | 0.04817▲ (+0.0083) | 0.05440 | 0.04657 | |
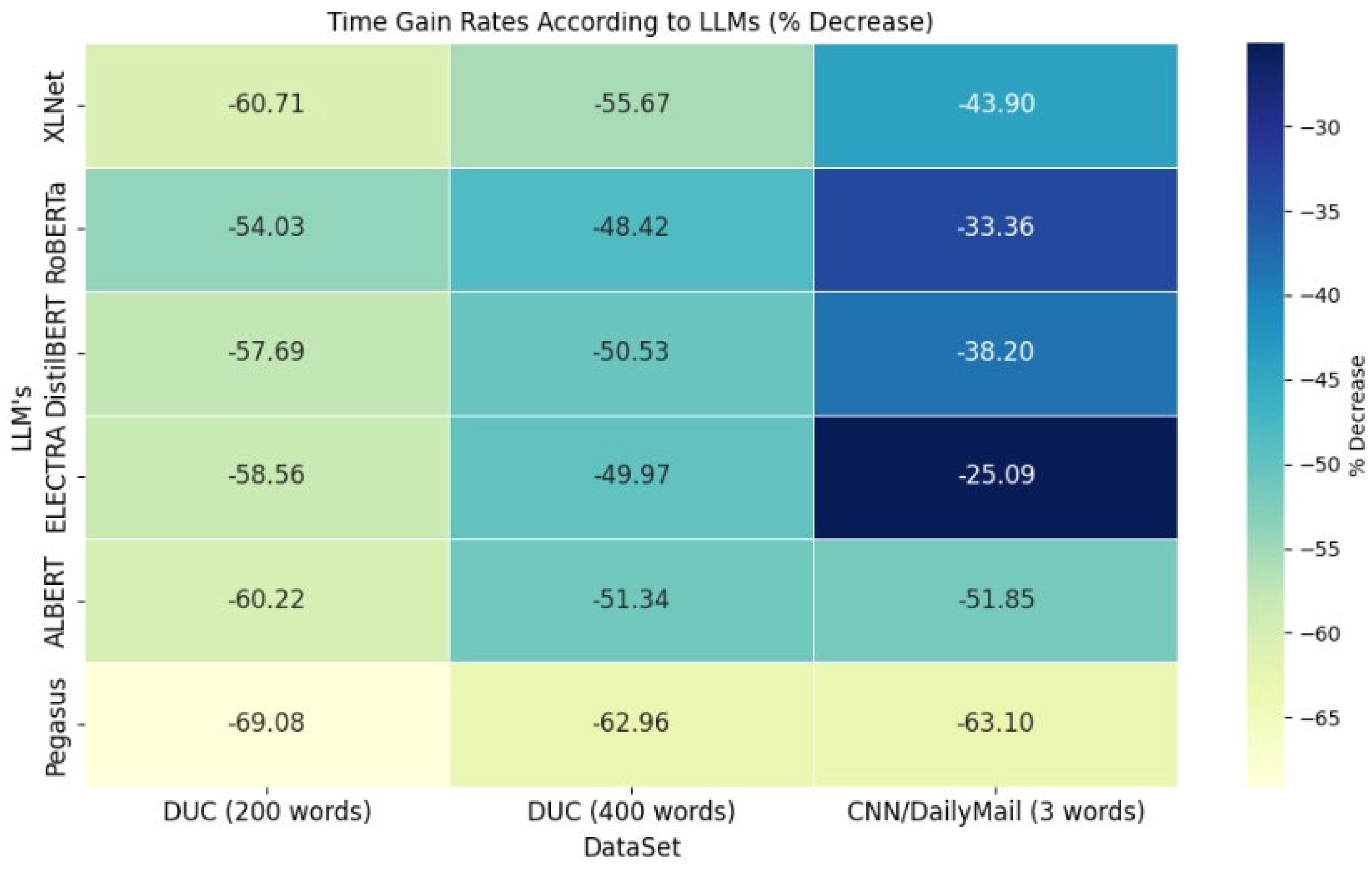
| Models | Effect of the Proposed Framework on Processing Time (sn) | ||
|---|---|---|---|
| DUC | BBC | ||
| 200 Words | 400 Words | 3 Words | |
| XLNet | 196.54→77.23▲ (−60.71%) | 185.35→82.17▲ (−55.67%) | 43.26→24.27▲ (−43.90%) |
| RoBERTa | 122.33→56.24▲ (−54.03%) | 125.03→64.49▲ (−48.42%) | 32.61→21.73▲ (−33.36%) |
| DistilBERT | 64.14→27.14▲ (−57.69%) | 67.58→33.43▲ (−50.53%) | 21.57→13.33▲ (−38.20%) |
| ELECTRA | 37.84→15.68▲ (−58.56%) | 39.62→19.82▲ (−49.97%) | 11.91→8.92▲ (−25.09%) |
| ALBERT | 113.62→45.2▲ (−60.22%) | 114.09→55.52▲ (−51.34%) | 24.32→11.71▲ (−51.85%) |
| Pegasus | 4478.08→1384.51▲ (−69.08%) | 4843.66→1794.01▲ (−62.96%) | 903.73→333.52▲ (−63.10%) |
| Rouge Metrics | t-Statistic | p-Value | |
|---|---|---|---|
| 400-word | Rouge-1 | 5.420 | 0.0056 |
| Rouge-2 | 6.268 | 0.0033 | |
| Rouge-L | 7.407 | 0.0018 | |
| Rouge-W | 6.909 | 0.0023 | |
| Rouge-S | 8.129 | 0.0012 | |
| Rouge-SU | 9.186 | 0.0008 | |
| 200-word | Rouge-1 | 7.301 | 0.0019 |
| Rouge-2 | 6.389 | 0.0031 | |
| Rouge-L | 9.231 | 0.0008 | |
| Rouge-W | 7.714 | 0.0015 | |
| Rouge-S | 10.157 | 0.0005 | |
| Rouge-SU | 8.337 | 0.0011 | |
| 3-word | Rouge-1 | 10.156 | 0.0005 |
| Rouge-2 | 8.500 | 0.0011 | |
| Rouge-L | 12.509 | 0.0002 | |
| Rouge-W | 10.954 | 0.0004 | |
| Rouge-S | 9.436 | 0.0007 | |
| Rouge-SU | 15.922 | 0.0001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hark, C. Using Graph-Based Maximum Independent Sets with Large Language Models for Extractive Text Summarization. Appl. Sci. 2025, 15, 6395. https://doi.org/10.3390/app15126395
Hark C. Using Graph-Based Maximum Independent Sets with Large Language Models for Extractive Text Summarization. Applied Sciences. 2025; 15(12):6395. https://doi.org/10.3390/app15126395
Chicago/Turabian StyleHark, Cengiz. 2025. "Using Graph-Based Maximum Independent Sets with Large Language Models for Extractive Text Summarization" Applied Sciences 15, no. 12: 6395. https://doi.org/10.3390/app15126395
APA StyleHark, C. (2025). Using Graph-Based Maximum Independent Sets with Large Language Models for Extractive Text Summarization. Applied Sciences, 15(12), 6395. https://doi.org/10.3390/app15126395