1. Introduction
Large Language Models (LLMs), a class of artificial intelligence (AI) systems designed for complex language processing tasks, are increasingly being applied in healthcare and medical education [
1,
2]. These models can retrieve domain-specific knowledge, generate clinical reasoning pathways, and simulate decision-making processes, which position them as promising tools for diagnostic assistance and medical training. Their performance on English-language assessments, such as the United States Medical Licensing Examination (USMLE), has approached or exceeded that of human examinees in recent studies [
3,
4].
Despite these advances, there is a limited understanding of how LLMs perform in high-stakes, non-English medical certification settings. This gap is especially relevant given the linguistic, cultural, and curricular variability in the global medical education systems. Evaluating model performance in such contexts is essential to determine whether LLMs generalize beyond English-dominant datasets and standardized examinations.
The Chilean National Certification Examination in Anesthesiology (CONACEM), a rigorous Spanish-language board exam, provides an ideal setting for benchmarking AI performance in a specialized clinical field. Anesthesiology requires not only factual knowledge of pharmacology, physiology, and critical care but also situational decision-making and clinical reasoning. These multifaceted cognitive requirements are likely to challenge current LLMs, which tend to excel in recall-based tasks but may falter on items that require inference, synthesis, or contextual nuance.
While previous studies evaluating AI on multiple-choice questions have primarily relied on Classical Test Theory (CTT) [
5,
6], which captures surface-level accuracy, this study integrates Item Response Theory (IRT)—specifically the one-parameter logistic Rasch model—to provide deeper insight into latent ability and item difficulty. To further enhance interpretability, we classified all test items according to Bloom’s revised taxonomy [
7,
8] (Recall, Understand, Apply, Analyze), which enabled a stratified analysis across cognitive domains.
In addition, we conducted a qualitative error analysis of incorrect LLM responses using a classification framework adapted from Roy et al. (2024) [
9]. Each justification was reviewed and coded into one of four error types: reasoning-based, knowledge-based, reading comprehension error, or plausible non-error. This allowed us to probe the underlying mechanisms of failure, moving beyond simple correctness to assess the cognitive and interpretive limitations of LLMs in clinical decision-making.
We hypothesized that closed-source models (e.g., GPT-4o and GPT-o1) would outperform their open-source counterparts (e.g., LLaMA 3 and Deepseek-R1) due to their extensive training datasets and architectural refinements. Nonetheless, we anticipated that all models would underperform on high-difficulty and high-discrimination items, especially those requiring deep reasoning. Human examinees are expected to maintain an advantage in tasks involving contextual judgment and clinical nuances.
The primary aim of this study was to benchmark the performance of nine state-of-the-art LLMs against human anesthesiology candidates using psychometrically calibrated exam data. By incorporating cognitive complexity analysis and error taxonomy, we offer a multidimensional evaluation framework that enhances the understanding of LLM behavior in educational and clinical assessment contexts.
2. Methods
2.1. Study Design and Ethical Approval
This study employed a cross-sectional experimental design to benchmark the performance of nine large language models against historical responses from human examinees on a Spanish-language board examination in anesthesiology. The dataset comprised anonymized responses from 134 Chilean anesthesiology candidates who had previously completed the National Certification Examination in Anesthesiology under standard conditions. Given the retrospective nature of the analysis and complete de-identification of human data, a formal ethical review was not required under local research governance protocols. The CONACEM board previously approved data used for educational and benchmarking purposes.
2.2. Exam Dataset Preparation
A total of 68 multiple-choice questions (MCQs) were selected from recent versions of the CONACEM exam. These questions represent the core domains of anesthesiology, including pharmacology, physiology, airway management, pediatric and obstetric anesthesia, critical care, and perioperative monitoring.
Exclusion Criteria and Item Refinement
To ensure compatibility across all evaluated LLMs, items involving multimodal inputs (e.g., imaging or waveform interpretation) were excluded, as several models (e.g., Deepseek-R1) lack vision capabilities. The remaining items were then subjected to psychometric refinement. An exploratory factor analysis (EFA) was attempted to examine dimensionality; however, given the limited sample size (n = 153), the results were considered unstable, with factor loadings below 0.5. Consequently, EFA findings were not used in the final calibration, and unidimensionality was instead assessed using Rasch-based methods.
To minimize item bias, we conducted Differential Item Functioning (DIF) analysis using both Hansel’s method and binary logistic regression, following established psychometric practices for detecting subgroup-based variance in item functioning [
10,
11]. Five items flagged for significant DIF were excluded from the analysis. The final dataset consisted of 63 MCQs, representing a refined and psychometrically sound unidimensional instrument appropriate for Rasch modeling and model-human comparisons.
2.3. Response Generation and Model Evaluation
Nine state-of-the-art LLMs were tested, including GPT-4o [
12] and GPT-o1 [
13] (OpenAI), Claude and Sonnet (Anthropic) [
14], Deepseek-R1 [
15] (Deepseek), Qwen 2.5 [
16] (Alibaba), Gemini 1.5 Pro [
17] (Google), and two versions of Meta’s LLaMA-3 [
18] (70B and 405B). Each model was accessed via its official API and tested using a standardized zero-shot prompting [
19] approach, meaning that no in-context learning or chain-of-thought strategies were applied. All the MCQs were presented verbatim in Spanish to preserve clinical and linguistic fidelity. To assess the impact of sampling randomness, responses were generated at two temperature settings: T = 0 for the deterministic output and T = 1 to allow for variability. The exact prompts used for all models are provided in the
Supplementary Materials.
2.4. Rasch Modeling and Item Characterization
Item Response Theory (IRT) modeling was conducted using a one-parameter logistic (1PL) Rasch model, implemented in the eRm package in R (v4.3.2). The Rasch model was selected for its desirable psychometric properties, including sample-independent item calibration, interval-scale measurement, and robustness under small-to-moderate sample sizes [
20,
21]. The Rasch framework assumes that all items measure the same latent trait—in this case, theoretical competence in anesthesiology—and that they do so with equal discrimination [
6]. Item difficulty parameters (β) were estimated from human response data and then fixed, enabling the maximum likelihood estimation (MLE) of latent ability scores (θ) for each LLM on the same psychometric scale.
In addition to the Rasch difficulty estimates, each item was further characterized using the Discrimination Index (DI), defined as the difference in correct response rates between the top and bottom quartiles of human performers. Although a Classical Test Theory (CTT) measure, DI remains widely used for its interpretability and complementary value in assessing item quality [
7]. Items were categorized into three difficulty groups (easy: β < 0.3; moderate: 0.3 ≤ β < 0.8; hard: β ≥ 0.8) and four discrimination groups (poor: DI < 0; marginal: 0 ≤ DI < 0.2; good: 0.2 ≤ DI < 0.4; excellent: DI ≥ 0.4), enabling a stratified analysis of model behavior across psychometric categories [
21,
22].
To evaluate the psychometric validity and Rasch model assumptions, we conducted three core fit diagnostics. Andersen’s Likelihood Ratio Test assessed item parameter invariance across examinee subgroups [
23], the Martin-Löf Test confirmed the unidimensionality of the item set [
24,
25], and the Wald Test [
26,
27] verified the item-level model fit. These tests provided rigorous statistical confirmation that the dataset satisfied the Rasch modeling assumptions, allowing for defensible ability estimation and model comparison.
2.5. Statistical Analysis
Two main performance metrics were used to evaluate the LLM outputs: (1) accuracy, defined as the proportion of correctly answered items, and (2) response time, measured as the average number of seconds taken per item. To explore the impact of item features on model performance, a series of inferential statistical tests was conducted. Logistic regression models were used to assess whether item difficulty (β) and DI significantly predicted the likelihood of a correct model response [
20]. Additionally, Pearson’s correlation coefficients were computed to quantify the linear relationship between item difficulty and model accuracy. Group-level comparisons of correct versus incorrect model responses were analyzed using the Mann–Whitney U test, while chi-square tests assessed associations between categorical levels of item difficulty/discrimination and accuracy, with Cramer’s V reported as a measure of effect size. To examine the influence of sampling variability, the accuracy rates at T = 0 and T = 1 were compared using Mann–Whitney U tests.
To assess the cognitive alignment between human and artificial intelligence systems, Pearson’s correlation analysis was conducted on the accuracy rates of humans and LLMs across the 15 anesthesiology knowledge domains. This analysis aimed to determine whether humans and LLMs show similar difficulty patterns across clinical domains or reveal fundamentally different cognitive architectures in medical reasoning.
For all statistical tests, a two-tailed p-value < 0.05 was considered significant, and the False Discovery Rate (FDR) correction was applied to control for multiple comparisons. Where appropriate, Cohen’s d and other effect size estimates were reported to aid in interpretation.
The sample size of 134 human participants was considered appropriate for Rasch modeling and item calibration. Prior psychometric literature indicates that sample sizes between 100 and 200 are adequate for 1PL models when working with instruments containing 30–100 items, particularly under unidimensional assumptions and when sufficient item variability is present. Moreover, Rasch models are known for their statistical stability and low bias in small-to-moderate samples due to their strong model constraints [
20,
21,
28]. While larger samples would enable finer subgroup analysis or exploration of multidimensional constructs, the present study—designed as a benchmarking analysis—offers robust estimates for the intended comparisons.
All statistical analyses were conducted using Python (v3.9) and R (v4.3.2), with Rasch-specific modeling performed in eRm, and general statistical analyses conducted using base R and the stats models and scipy libraries in Python.
2.6. Cognitive Complexity Categorization and Error Taxonomy
To further analyze the qualitative performance of the language models, we categorized all 63 refined multiple-choice questions according to Bloom’s revised taxonomy [
7,
8] into four cognitive domains: Recall, Understand, Apply, and Analyze. This categorization was performed independently by two medical educators with content expertise in anesthesiology. Discrepancies were resolved by consensus. This classification enabled stratified performance comparisons across varying cognitive demands, providing deeper insights into the strengths and limitations of knowledge processing and clinical reasoning.
Additionally, for the top-performing models—GPT-o1 and Deepseek-R1—we conducted an in-depth qualitative error analysis of incorrect responses. For each incorrect answer, the associated model-generated justification was examined and annotated into one of four categories adapted from the error taxonomy proposed by Roy et al. (2024) [
9] for GPT-4’s performance in the USMLE:
- -
Class 1 Reasoning-based errors: Incorrect due to flawed clinical logic or premature conclusions.
- -
Class 2 Knowledge-based errors: Resulting from factual inaccuracies or misapplication of domain knowledge.
- -
Class 3 Reading comprehension errors: Due to misinterpretation or neglect of critical information in the prompt.
- -
Class 4: Non-errors, such as plausible alternative justifications.
This categorization was carried out by two medical experts following refined guidelines adapted from Roy et al.’s [
9] multi-label span annotation framework. The taxonomy enabled the identification of systematic patterns in model reasoning and highlighted areas where even correct medical logic could still lead to incorrect answers, a phenomenon also observed in GPT-4’s performance on the USMLE questions.
3. Results
3.1. Psychometric Evaluation of the Instrument
Model fit was assessed using three psychometric tests following the refinement of the item pool. Prior to Rasch calibration, a Differential Item Functioning (DIF) analysis identified five biased items (44, 63, 68, 23, and 11), which were excluded to ensure fairness and parameter invariance in subsequent modeling.
With the bias-free item set, three psychometric tests were conducted:
First, Andersen’s Likelihood Ratio Test (LR = 76.125, df = 61, p = 0.092) did not reject the null hypothesis of parameter invariance, indicating item stability across the ability levels.
Second, the Martin-Löf Test confirmed unidimensionality (p = 1.0), supporting the interpretation that the test assessed a single latent trait—namely, theoretical competence in anesthesiology.
Third, the Wald Test (
Supplementary Table S1) showed no significant item-level deviations for most items, further validating the Rasch model assumptions.
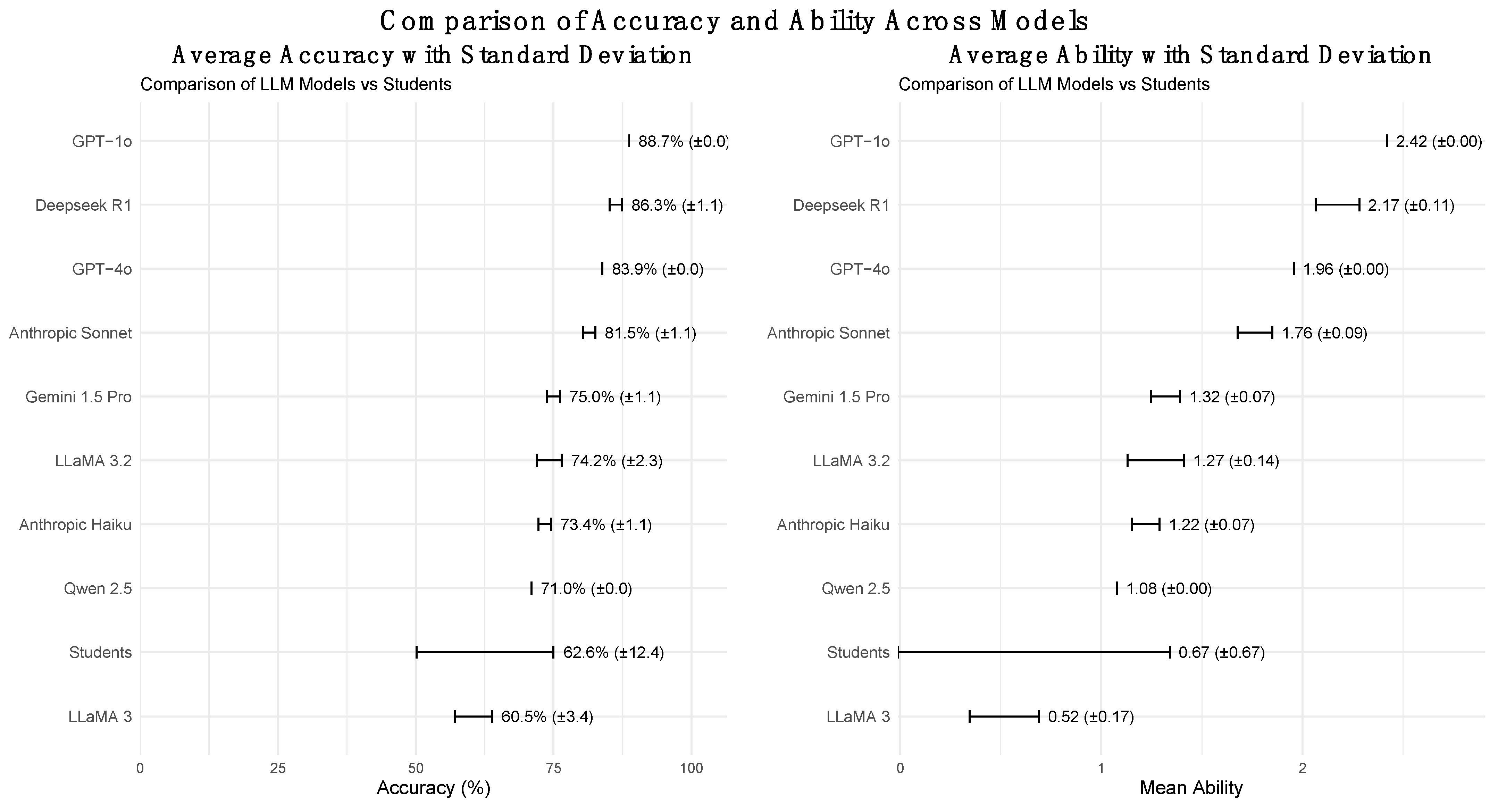
Rasch-based ability estimates (θ) were then computed for each model anchored to human performance. GPT-o1 achieved the highest ability (θ = 2.42), followed by Deepseek-R1 (θ = 2.17), and GPT-4o (θ = 1.96). LLaMA 3 70B had the lowest (θ = 0.52), indicating a weaker alignment with human-level performance under the IRT framework.
Supporting psychometric visuals—including the Item Characteristic Curve (ICC) plots, Item Fit Map, and Person-Item Map—are presented in
Supplementary Figures S1–S3.
Figure 1 illustrates the distribution of the scores of the LLMs and human examinees.
3.2. Overall Performance Metrics
The model performance varied notably in terms of accuracy, IRT score, and response time (
Table 1). GPT-o1 reached the highest mean accuracy (88.7 ± 0.0%), while LLaMA 3 70B had the lowest (60.5 ± 3.4%). Regarding efficiency, Deepseek-R1 had the slowest response (60.0 ± 29.3 s), whereas LLaMA 3.2 450B had the fastest (2.1 ± 0.5 s).
Figure 2 provides a side-by-side comparison of the model accuracies and Rasch-based abilities, reinforcing the observed performance disparities.
3.3. Effect of Item Difficulty and Discrimination on Model Performance
The impact of item difficulty (β) and discrimination index (DI) on model performance was analyzed using logistic regression, correlation analysis, non-parametric comparisons, and categorical testing.
Logistic regression (
Supplementary Table S2) revealed that item difficulty was a consistent and significant negative predictor of the model accuracy. For instance, GPT-4o at T = 1 had an odds ratio of 0.07 (95% CI: [0.01, 0.44];
p = 0.005), indicating a marked decline in correct responses for harder items. In contrast, DI was not a reliable predictor; although some models, like Deepseek-R1, showed high odds ratios (e.g., OR = 40.5), these lacked statistical significance.
Pearson’s correlation analysis (
Supplementary Tables S3 and S4) further confirmed these findings. Models such as LLaMA 3.2 450B, Anthropic Haiku, Qwen 2.5, and Gemini 1.5 demonstrated strong correlations between item difficulty and accuracy (r = 0.48–0.60;
p < 0.001), while GPT-o1 and GPT-4o showed moderate but significant correlations (r ≈ 0.33–0.40). Other models, including Deepseek-R1, LLaMA 3 70B, and Anthropic Sonnet, showed negligible associations, indicating a lower sensitivity to difficulty.
These results were mirrored by the Mann−Whitney U tests, which identified significant differences in item difficulty between correct and incorrect responses for models with high correlations (p < 0.01; Cohen’s d > 1.0). Models with weak correlations, such as GPT-4o (T = 1) and Deepseek-R1, showed no significant differences and small effect sizes, confirming the variability in difficulty sensitivity across models.
Chi-square tests (
Supplementary Table S5) using categorical groupings of item difficulty (easy, moderate, hard) showed significant associations with accuracy in most models (e.g., GPT-4o: χ
2 = 16.97,
p < 0.001; Cramer’s V = 0.52), indicating that harder items were more likely to be answered incorrectly. In contrast, the discrimination category had no significant effect on model performance (all
p > 0.5), with consistently low Cramer’s V values (<0.25), suggesting that LLMs are generally insensitive to item discrimination.
3.4. Influence of Temperature Settings
To assess the role of randomness, the model performance was compared across two temperature settings (T = 0 vs. T = 1) using Mann-Whitney U tests. No significant differences were found in the accuracy of any model (
p range: 0.609–1.000), suggesting that the model outputs were robust to variations in temperature (
Table 2).
3.5. Comparison of LLM and Human Performance by Topic
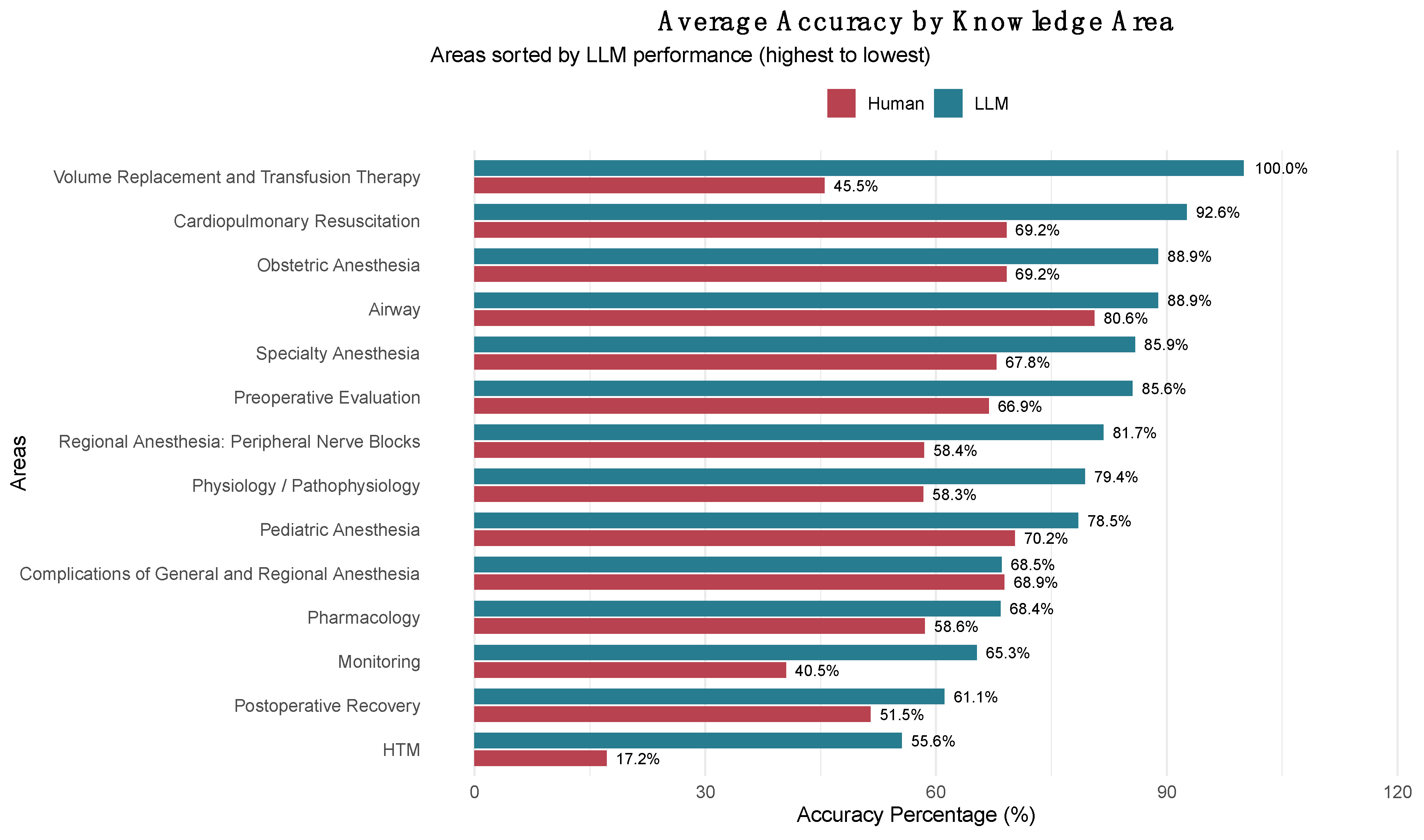
A comparison at the domain level between the LLMs and human examinees revealed significant performance differences (see
Supplementary Table S6). The LLMs exhibited better results in areas such as Volume Replacement and Transfusion Therapy (100% vs. 45.5%), Cardiopulmonary Resuscitation (92.6% vs. 69.2%), and Obstetric Anesthesia (88.9% vs. 69.2%). Conversely, domains like Complications of General and Regional Anesthesia showed nearly identical performances (68.5% vs. 68.9%).
Pearson’s correlation analysis between human and LLM accuracy across the 15 anesthesiology domains revealed a moderate positive correlation (r = 0.567, p = 0.0346, 95% CI: 0.052–0.844). The most significant performance differences favoring LLMs were noted in Volume Replacement and Transfusion Therapy (+54.5 percentage points), HTM (+38.4 percentage points), and Monitoring (+24.8 percentage points). The smallest differences were observed in Complications of General and Regional Anesthesia (‒0.4 percentage points), Pediatric Anesthesia (+8.2 percentage points), and Airway (+8.3 percentage points).
Figure 3 illustrates these domain-specific comparisons, ranking content areas by LLM performance and highlighting the performance differences between the two groups across all anesthesiology knowledge domains.
3.6. Cognitive and Error-Type Analysis
To deepen our understanding of the model performance beyond surface-level accuracy, we conducted a detailed analysis of the errors made by the two highest-performing language models (GPT-o1 and Deepseek-R1). This analysis considered both the cognitive demands of the exam items, classified using Bloom’s taxonomy, and the nature of the errors, based on qualitative evaluation of the models’ answer justifications.
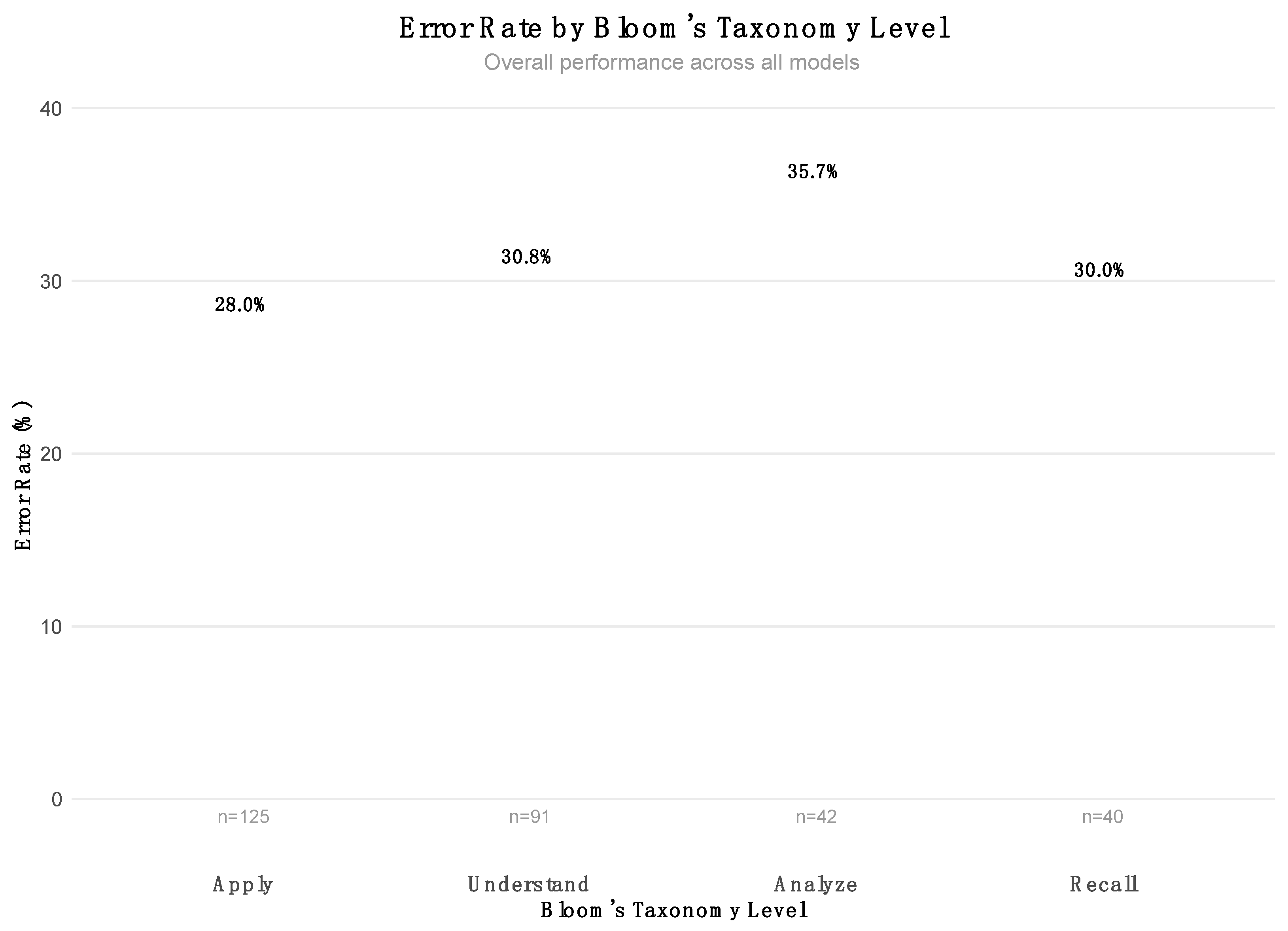
Among the 298 total items administered across the nine models, the distribution across Bloom’s cognitive levels was as follows: Apply (125 items, 41.9%), Understand (91 items, 30.5%), Analyze (42 items, 14.1%), and Recall (40 items, 13.4%). This distribution indicates a deliberate emphasis on higher-order cognitive processes, particularly the application and comprehension of clinical knowledge, which aligns with the CONACEM exam’s focus on critical thinking and reasoning in anesthesiology. The associated error rates for these categories are shown in
Figure 4.
To assess the qualitative nature of the model errors, we conducted a focused review of 36 incorrect responses generated by GPT-o1 and Deepseek-R1. Each response was manually classified into one of three dominant error categories: (1) Reasoning-Based Errors, which reflected flawed clinical logic or unjustified conclusions; (2) Knowledge-Based Errors, stemming from factual inaccuracies or misapplications of medical knowledge; and (3) Reading Comprehension Errors, which arose from misinterpretation or omission of key information in the question prompt.
The distribution of these error types across cognitive domains revealed several important trends. The Apply category contained the largest number of reasoning (n = 5) and knowledge (n = 10) errors, underscoring the challenge faced by these models in integrating knowledge into clinically relevant scenarios. The Understand and Recall categories exhibited a mixture of all three error types, highlighting limitations not only in inferential reasoning but also in basic information retrieval and comprehension. In contrast, Analyze tasks were exclusively associated with knowledge-based errors, likely reflecting the small sample size and inherent complexity of such high-level tasks. The detailed breakdown is summarized in
Table 3.
4. Discussion
The results of our study provide a comprehensive evaluation of LLMs in the Chilean National Anesthesiology Certification Exam, offering critical insights into their strengths and limitations and future applications in medical education. Our findings align with prior research that underscores the potential of LLMs in medical reasoning while also revealing key gaps in their performance, particularly in specialized non-English contexts [
17,
29].
4.1. Evaluating Model Strengths and Weaknesses
We hypothesized that closed-source models would outperform open-source models due to their access to extensive proprietary datasets and optimized architectures. This was largely confirmed, with models like GPT-o1 and GPT-4o achieving the highest accuracy rates (88% and 83%, respectively), while open-source models such as LLaMA 3 70B struggled with lower accuracy (60.5%). However, Deepseek-R1 proved to be highly competitive, achieving an accuracy of 86% and narrowing the performance gap between the open- and closed-source models.
These results suggest that performance is not solely dependent on access to proprietary data but also on architectural optimization and alignment strategies. The high Rasch-based ability estimates for GPT-o1 and Deepseek-R1 reinforce that well-optimized models, even when open-sourced, can compete with their closed-source counterparts under certain conditions.
4.2. Insights from Comparative Studies
Our findings echo those of previous studies on the performance of LLMs in high-stakes medical assessments. For instance, studies evaluating GPT-4 on the Polish Medical Final Examination (MFE) showed that while the model achieved passing scores, it still lagged behind human performance in complex diagnostic reasoning [
6]. Similarly, GPT-4 achieved top scores on the USMLE but demonstrated difficulties in handling nuanced reasoning tasks compared with clinical experts [
30]. Research in radiology and ultrasound examinations has further shown that model performance drops when dealing with image-based or interpretive questions, with hallucination and overconfidence being noted issues [
31,
32].
Moreover, our work aligns with benchmarking efforts in anesthesiology, such as the Chinese Anesthesiology Benchmark (CAB), which concluded that while LLMs handled factual knowledge adequately, their clinical decision-making capacities remained suboptimal [
5]. These findings reflect a consistent challenge across specialties and languages: while LLMs excel in recall-based tasks, they struggle with synthesis, contextual nuance, and high discrimination tasks.
4.3. Study Limitations and Future Improvements
Despite its valuable insights, this study has several limitations. First, we focused solely on text-based multiple-choice questions, excluding multimodal elements such as patient imaging and waveform analysis. This choice was necessary to ensure a fair evaluation across all models, including those without image capabilities. However, multimodal LLMs, like GPT-4V and Gemini, are gaining traction in medical AI and have shown promise in visual diagnostic tasks [
31,
33]. Future research should include multimodal benchmarks to better simulate real-world clinical conditions.
Second, we evaluated only nine LLMs, and emerging open-source models (e.g., those fine-tuned on biomedical corpora) were not included. All models were tested in zero-shot mode without prompt engineering or domain-specific fine-tuning. While this ensures a standardized baseline comparison, it may underestimate the full potential of LLMs when they are adapted to specific tasks or domains [
23].
4.4. Implications for Medical Training and Certification
The results have important implications for medical education and certification processes. The ability of LLMs to achieve high accuracy on low-difficulty, recall-driven items supports their potential as educational aids for medical education. This aligns with the findings of US-based studies in which LLMs were used to generate clinical vignettes, assist in self-testing, and explain complex topics [
30].
However, the observed drop in performance on higher-difficulty and high-discrimination items underscores the limitations of LLMs as autonomous reasoning agents. In high-stakes clinical environments, especially in specialties like anesthesiology, where decisions are time-sensitive and safety-critical, AI should augment—not replace—human judgment [
34].
4.5. Domain-Specific Performance Patterns: Cognitive Architecture Differences Between Human and Artificial Intelligence
The moderate positive correlation (r = 0.567, p = 0.0346) between human and LLM accuracy across the 14 anesthesiology knowledge domains reveals fundamental differences in cognitive architecture while suggesting partial alignment in difficulty patterns. Domains in which humans struggle moderately (HTM: 17.2%, Monitoring: 40.5%) also challenge LLMs, but to a lesser extent (HTM: 55.6%, Monitoring: 65.3%). This indicates that LLMs maintain baseline competency through systematic knowledge access, even in complex areas that require hemodynamic interpretation and physiological monitoring integration. Conversely, the dramatic LLM advantage in Volume Replacement and Transfusion Therapy (100% vs. 45.5%) reflects LLMs’ superior ability to access and apply algorithmic, protocol-driven knowledge compared with humans’ more variable recall of specific transfusion guidelines and fluid management protocols.
The differential performance profile indicates systematic differences in knowledge processing: LLMs excel in domains that require factual recall and standardized protocol application (Cardiopulmonary Resuscitation, Volume Replacement) but show more modest advantages in areas that demand contextual clinical judgment and experiential reasoning (Complications of Anesthesia, Airway Management). This cognitive complementarity supports the development of hybrid decision-support systems that utilize systematic AI knowledge retrieval for protocol-driven domains while preserving human oversight in complex diagnostic reasoning and complication management. Recent experimental evidence from endoscopic decision-making has shown that effective human-AI collaboration can lead to superior outcomes through the weighted integration of complementary expertise, where clinicians appropriately follow AI advice when it is correct while maintaining independent judgment when AI recommendations are flawed [
35].
4.6. Cognitive Complexity and Error Taxonomy: A Diagnostic Lens into LLM Failures
The stratified analysis of model failures using Bloom’s taxonomy and the error classification schema proposed by Roy et al. offers critical insights into the qualitative nature of LLM shortcomings in clinical assessments. This approach moves beyond simple accuracy metrics to uncover how and why models fail, which is vital for their safe deployment in high-stakes environments.
Among the 298 total question simulations, the cognitive distribution leaned heavily toward higher-order reasoning: Apply (41.9%) and Understand (30.5%) together comprised nearly three-quarters of the total item pool. These domains require not only factual recall but also the capacity to integrate knowledge into dynamic, often ambiguous, clinical contexts. In this setting, the two best-performing models—GPT-o1 and Deepseek-R1—still exhibited systematic vulnerabilities.
A detailed review of 36 incorrect answers showed that knowledge-based errors (n = 23) and reasoning-based errors (n = 9) predominated. Most of these errors occurred in the Apply and Understand level items, highlighting deficiencies in the models’ ability to synthesize and manipulate clinical knowledge, even when they had adequate factual grounding. For instance, models frequently misapply pharmacologic principles or fail to account for contraindications and context-specific factors—mistakes that are critical in anesthesiology, where patient safety depends on nuanced clinical decision-making.
Interestingly, reading comprehension errors (n = 6), though less frequent, were disproportionately present in Recall and Understand tasks, indicating occasional failures to parse essential details or to frame questions. This aligns with the findings of Roy et al., who showed that GPT-4 hallucinated or misattributed clinical features when reasoning paths were not well defined [
9]. Similarly, Herrmann-Werner et al. [
36] found that GPT-4 frequently erred at lower cognitive levels in medical multiple-choice examinations, particularly in tasks requiring basic understanding and recall. These failures suggest that limitations are not confined to higher-order reasoning but may also reflect foundational issues in text comprehension and concept recognition.
Moreover, Roy et al. noted that a significant portion of GPT-4’s errors were judged as “reasonable” by medical annotators, which poses challenges for its use in autonomous settings where plausibility may mask critical inaccuracies [
9]. This reinforces our finding that high performance on knowledge-recall questions may conceal latent weaknesses in inferential reasoning and contextual awareness.
These observations have direct implications for the role of LLMs in formative and summative assessment. While LLMs can serve as effective teaching aids for reinforcing basic knowledge, their deployment in evaluative or autonomous decision-making roles should be approached with caution, particularly in domains that require synthesis, judgment, and patient-specific adaptation.
By explicitly linking cognitive demands to error typologies, this study demonstrates a replicable framework for auditing AI behavior in clinical examinations. Such diagnostic insights are critical for informing future fine-tuning strategies, AI safety protocols, and hybrid human-AI collaboration models in medical education and practice.
4.7. Future Directions for AI in Medical Assessments
To enhance the applicability of LLMs in anesthesiology and other medical domains, several key directions must be pursued.
Fine-Tuning on Medical-Specific Data: Tailoring LLMs using anesthesiology-specific datasets (e.g., case studies, guidelines, perioperative protocols) could boost reasoning capabilities in complex clinical scenarios.
Integration of Multimodal Capabilities: As shown in imaging-based evaluations [
31], incorporating visual interpretation can enhance AI tools for real-world diagnostics.
Cross-Language Optimization: Given the performance variability across languages, particularly Spanish, multilingual alignment must be prioritized to ensure equitable AI in global health systems.
Human-AI Collaboration Models: Rather than aiming for full autonomy, LLMs should be integrated into collaborative workflows in which humans retain clinical oversight, mitigating the risk of error propagation [
32,
34].
Our study highlights both the promise and current limitations of LLMs in complex, non-English clinical certification contexts. While closed-source models outperformed open-source models on average, the strong performance of Deepseek-R1 suggests that optimization, rather than the exclusivity of data, may be the key differentiator. These results support the growing utility of AI in medical education while reinforcing the importance of domain-specific training, multimodal integration, and robust evaluation standards. Moving forward, collaborative efforts among developers, educators, and regulators will be critical to safely and effectively harness the capabilities of LLMs in healthcare.
5. Conclusions
This study provides the first comprehensive evaluation of large language models on a Spanish-language, high-stakes medical certification exam, revealing both the promise and limitations of current AI systems in specialized clinical contexts. Our findings demonstrate that LLMs, particularly closed-source models like GPT-o1 (88.7% accuracy), can achieve impressive performance in factual recall and protocol-driven domains, often surpassing human examinees in areas that require systematic knowledge application, such as volume replacement therapy and cardiopulmonary resuscitation. However, the moderate correlation (r = 0.567) between human and LLM performance patterns across knowledge domains reveals fundamental differences in cognitive architecture, with LLMs maintaining a consistent baseline competency through systematic knowledge access, while humans show greater variability that reflects experiential learning. The predominance of knowledge- and reasoning-based errors in higher-order cognitive tasks (Apply and Understand), combined with LLMs’ sensitivity to item difficulty but not discrimination, underscores persistent limitations in complex clinical reasoning and contextual adaptation. These results support the cautious integration of LLMs as educational aids and decision-support tools in anesthesiology, emphasizing the need for hybrid human-AI collaboration models that leverage AI’s systematic knowledge retrieval capabilities while preserving human oversight for complex diagnostic reasoning and patient-specific clinical judgment.



 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}