
Named Entity Recognition Based on Multi-Class Label Prompt Selection and Core Entity Replacement


Abstract
1. Introduction
- A model is designed to address the NER task in few-shot scenarios. A multi-class label prompt selection strategy is designed to select an annotated instance with a clear sentence structure for demonstration. The entity context information between the sentence and the multi-class label prompts is enhanced to improve the accuracy of core entity recognition. The optimization effect of multi-class label prompt demonstrations on word vector representations for entities in target sentences is empirically validated. The low-density core entity demonstrations empirically prove that prompts with clearer sentence structures can effectively enhance the accuracy of core entity recognition.
- A core entity replacement strategy is designed to increase the diversity of input word vectors during training. A weighted random algorithm is employed to retrieve the core entities that are to be replaced in the prompt. The core entities selected in the multi-class label prompt are updated during each the training epoch. The vector of each token in the training data is updated. The core entity replacement method dynamically updates word vector labels in demonstration prompts. A novel approach to enrich input data in few-shot learning scenarios is proposed.
- Experiments on the CoNLL-2003, OntoNotes 5.0, OntoNotes 4.0, and BC5CDR datsets showed the superiority of our model in few-shot NER.
2. Related Work
2.1. Prompt Learning
2.2. Data Augmentation
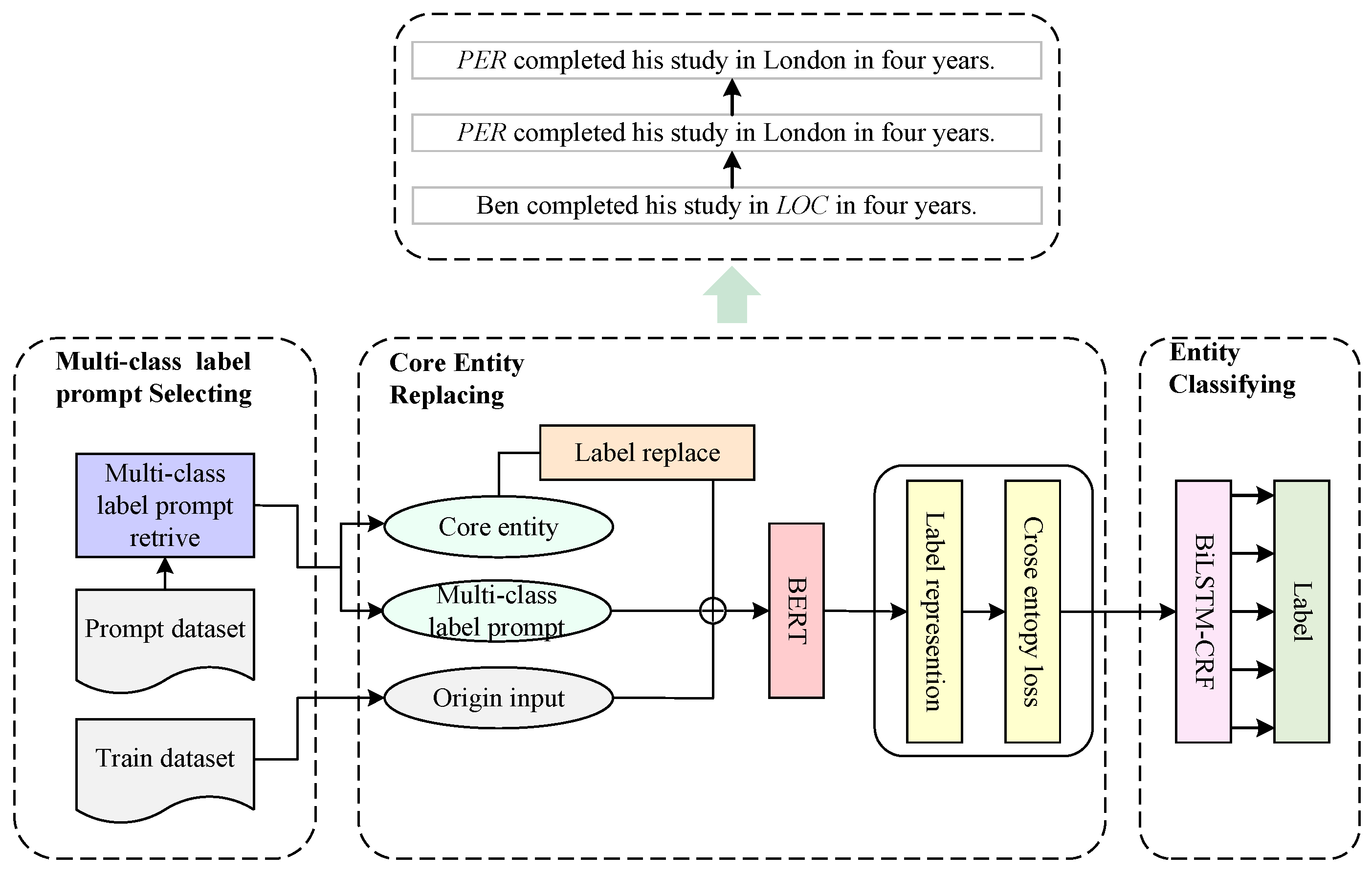
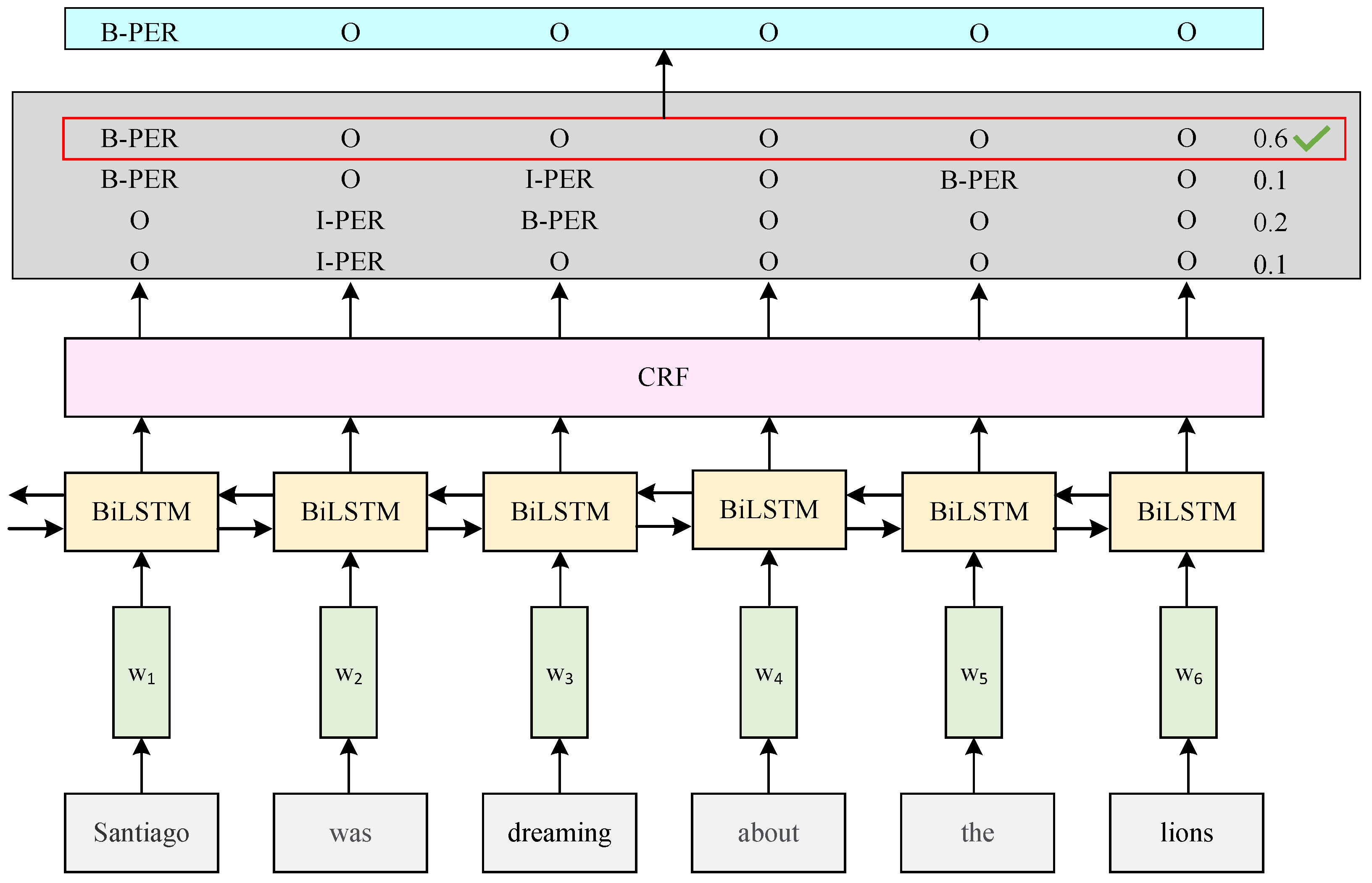
3. The MPSCER-NER Model
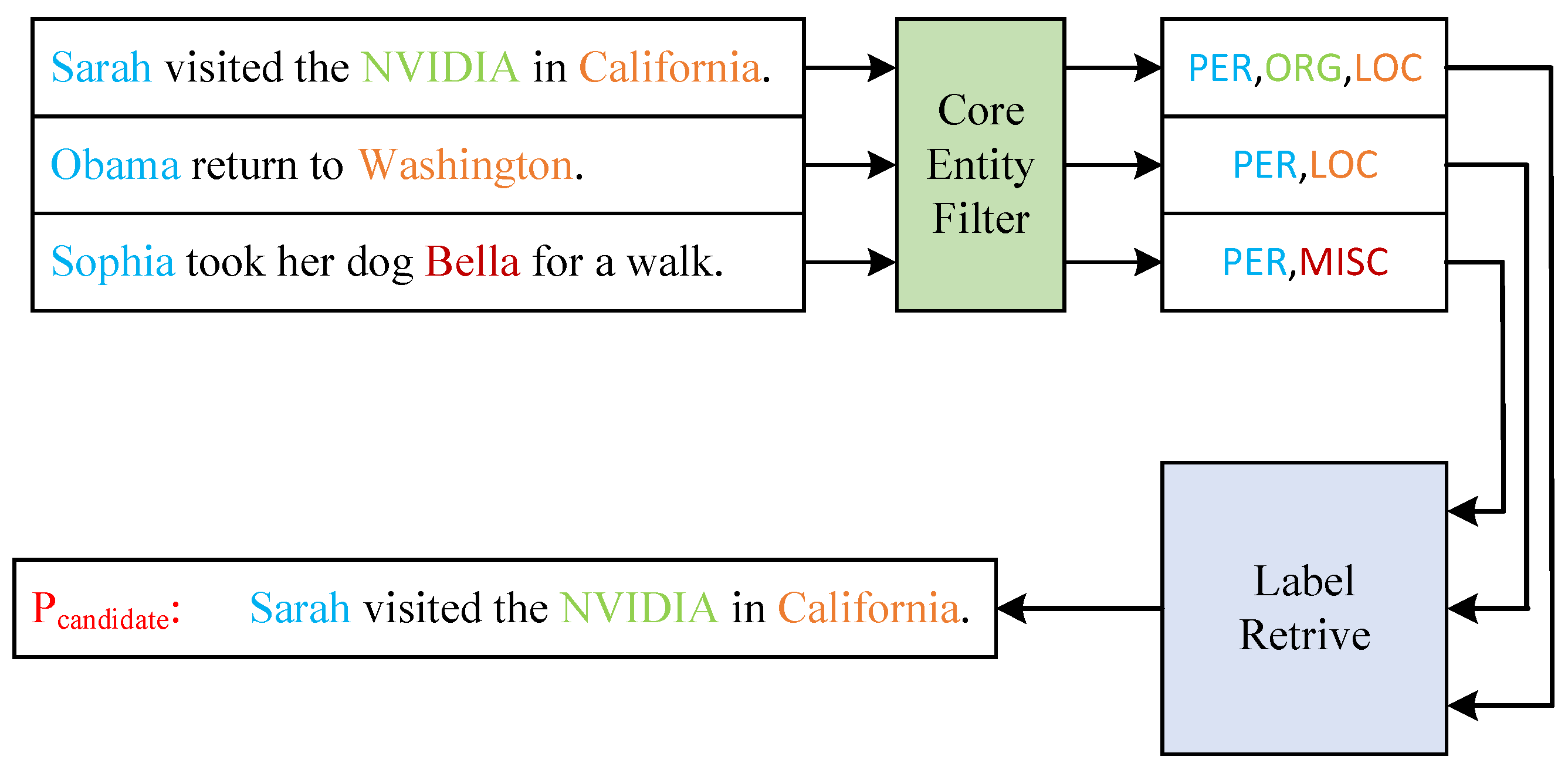
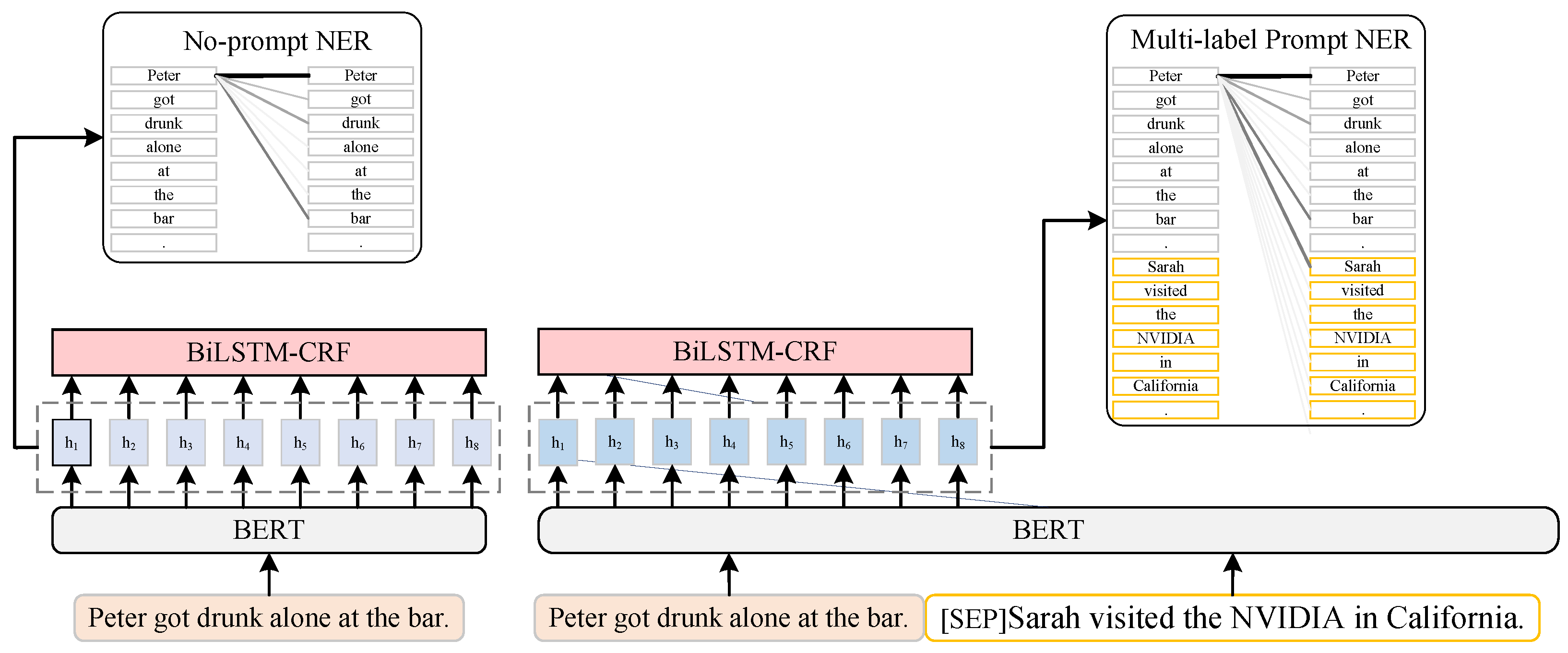
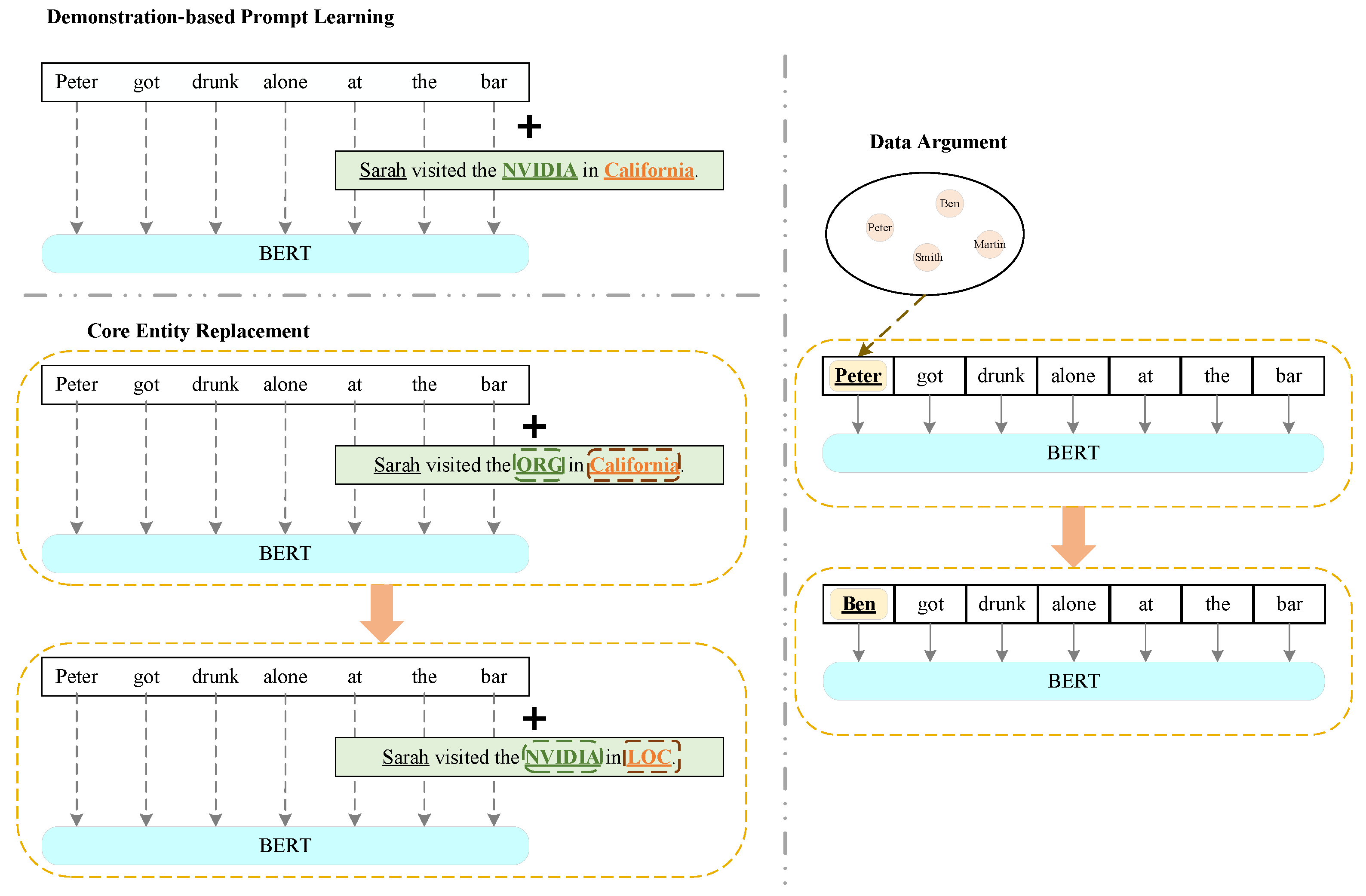
3.1. Multi-Class Label Prompt Selecting
3.2. Core Entity Replacement
3.3. BiLSTM-CRF Classification
| Algorithm 1 MPSCER-NER model training |
| Require: Training dataset—D; prompt dataset—P; batch size—; epoch—; learning rate—; dropout—; —the initial MPSCER-NER model parameters. |
Ensure:
The MPSCER-NER model().
|
4. Experimental Results and Analysis
4.1. Datasets and Experimental Settings
4.2. Evaluation Indicators
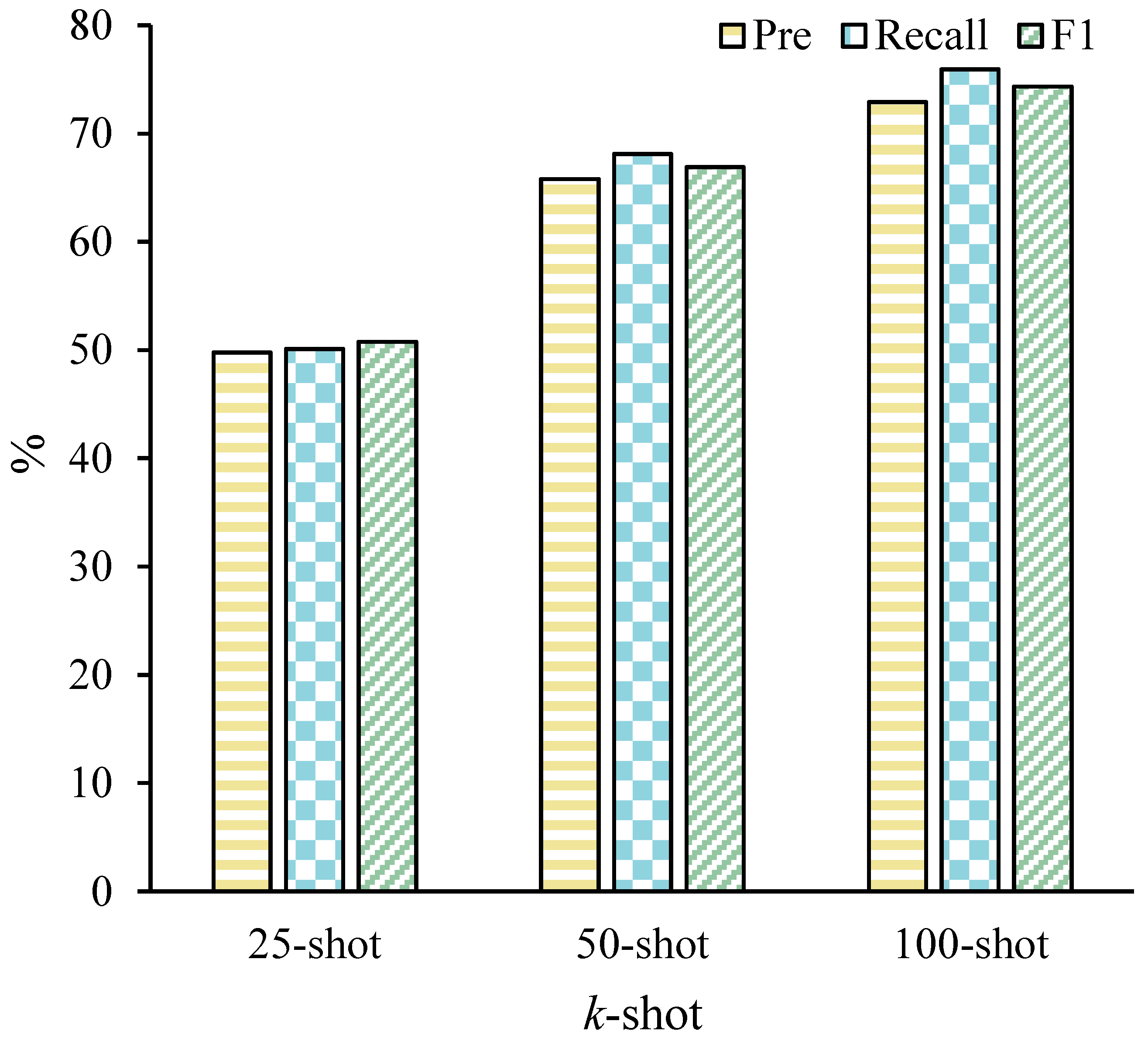
4.3. Effectiveness on K-Shot
4.4. Confusion Matrices
4.5. Ablation Studies
4.6. Baselines
- NNshot and StructShot [27] comprise a simple NER based on nearest neighbor learning and structured reasoning. This is a supervised NER model trained on the source domain, which is used for feature extraction; a nearest neighbor classifier is used to learn in the feature space, capturing label dependencies between entity labels.
- MatchingCNN [28] is a network that maps a small labeled support set; an unlabeled example for its label was proposed. It calculates the similarity between query instances and support instances, adapting to the recognition of new class types.
- ProtoBERT [29] uses a token-level prototypical network that represents each class by averaging token representations with the same label; then, the label of each token in the query set is decided by its nearest class prototype.
- DemonstrationNER [11] is a prompt learning NER method based on demonstration. The sentences marked in the dataset are selected as prompts to be input into the BERT model. The authors presented a demonstration of the relationship between the entities and the labels after the example sentences were constructed. This process helps the model to learn the contextual information from the task demonstration, contextualizing the task before the input, and enabling the model to recognize more entities through a good demonstration.
- SR-Demonstration [30] is an NER method that was proposed for marking the relevance of demonstrations; it removes useless information from demonstration prompts, creates a relevance vocabulary consisting of tokens that appear in the annotated datasets, samples the tokens from the relevance vocabulary to replace the tokens in the demonstration, and calculates the most suitable demonstration sentence length required to achieve a demonstration of NER.
5. Conclusions
6. Limitations
7. Future Work
7.1. Domain Transfer
7.2. Zero-Shot Data Generation
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jiang, M.; Chen, H. Label-Guided Data Augmentation for Chinese Named Entity Recognition. Appl. Sci. 2025, 15, 2521. [Google Scholar] [CrossRef]
- Jehangir, B.; Radhakrishnan, S.; Agarwal, R. A survey on Named Entity Recognition—datasets, tools, and methodologies. Nat. Lang. Process. J. 2023, 3, 100017. [Google Scholar] [CrossRef]
- Gong, F.; Tong, S.; Du, C.; Wan, Z.; Qiu, S. Named Entity Recognition in the Field of Small Sample Electric Submersible Pump Based on FLAT. Appl. Sci. 2025, 15, 2359. [Google Scholar] [CrossRef]
- Hu, Y.; Chen, Q.; Du, J.; Peng, X.; Keloth, V.K.; Zuo, X.; Zhou, Y.; Li, Z.; Jiang, X.; Lu, Z.; et al. Improving large language models for clinical named entity recognition via prompt engineering. J. Am. Med. Inform. Assoc. 2024, 31, 1812–1820. [Google Scholar] [CrossRef]
- Chen, Y.; Zheng, Y.; Yang, Z. Prompt-Based Metric Learning for Few-Shot NER. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; pp. 7199–7212. [Google Scholar]
- Petroni, F.; Rocktäschel, T.; Riedel, S.; Lewis, P.; Bakhtin, A.; Wu, Y.; Miller, A. Language Models as Knowledge Bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 2463–2473. [Google Scholar]
- Ding, N.; Chen, Y.; Han, X.; Xu, G.; Wang, X.; Xie, P.; Zheng, H.; Liu, Z.; Li, J.; Kim, H.G. Prompt-learning for Fine-grained Entity Typing. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 6888–6901. [Google Scholar]
- He, K.; Mao, R.; Huang, Y.; Gong, T.; Li, C.; Cambria, E. Template-free prompting for few-shot named entity recognition via semantic-enhanced contrastive learning. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 18357–18369. [Google Scholar] [CrossRef] [PubMed]
- Hu, S.; Ding, N.; Wang, H.; Liu, Z.; Wang, J.; Li, J.; Wu, W.; Sun, M. Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Volume 1, pp. 2225–2240. [Google Scholar]
- Gao, T.; Fisch, A.; Chen, D. Making Pre-trained Language Models Better Few-shot Learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual, 5–6 August 2021; Volume 1, pp. 3816–3830. [Google Scholar]
- Lee, D.H.; Kadakia, A.; Tan, K.; Agarwal, M.; Feng, X.; Shibuya, T.; Mitani, R.; Sekiya, T.; Pujara, J.; Ren, X. Good Examples Make A Faster Learner: Simple Demonstration-based Learning for Low-resource NER. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Volume 1, pp. 2687–2700. [Google Scholar]
- Dong, G.; Wang, Z.; Zhao, J.; Zhao, G.; Guo, D.; Fu, D.; Hui, T.; Zeng, C.; He, K.; Li, X.; et al. A multi-task semantic decomposition framework with task-specific pre-training for few-shot ner. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, Birmingham, UK, 21–25 October 2023; pp. 430–440. [Google Scholar]
- Huang, Y.; He, K.; Wang, Y.; Zhang, X.; Gong, T.; Mao, R.; Li, C. Copner: Contrastive learning with prompt guiding for few-shot named entity recognition. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 2515–2527. [Google Scholar]
- Su, L.; Chen, J.; Peng, Y.; Sun, C. Based Learning for Few-Shot Biomedical Named Entity Recognition Under Machine Reading Comprehension. J. Biomed. Inform. 2024, 159, 104739. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Chen, J.; Ma, L. Chinese Named Entity Recognition by Fusing Dictionary Information and Sentence Semantics. Comput. Mod. 2024, 3, 24–28. [Google Scholar]
- Lu, X.; Sun, L.; Ling, C.; Tong, Z.; Liu, J.; Tang, Q. Named entity recognition of Chinese electronic medical records incorporating pinyin and lexical features. J. Chin. Mini-Micro Comput. Syst. 2025. [Google Scholar] [CrossRef]
- Mengge, X.; Yu, B.; Zhang, Z.; Liu, T.; Zhang, Y.; Wang, B. Coarse-to-Fine Pre-training for Named Entity Recognition. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual, 16–20 November 2020; pp. 6345–6354. [Google Scholar]
- Chen, J.; Liu, Q.; Lin, H.; Han, X.; Sun, L. Few-shot Named Entity Recognition with Self-describing Networks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Volume 1, pp. 5711–5722. [Google Scholar]
- Bartolini, I.; Moscato, V.; Postiglione, M.; Sperlì, G.; Vignali, A. Data augmentation via context similarity: An application to biomedical Named Entity Recognition. Inf. Syst. 2023, 119, 102291. [Google Scholar] [CrossRef]
- Liu, W.; Cui, X. Improving named entity recognition for social media with data augmentation. Appl. Sci. 2023, 13, 5360. [Google Scholar] [CrossRef]
- Zhou, R.; Li, X.; He, R.; Bing, L.; Cambria, E.; Si, L.; Miao, C. MELM: Data Augmentation with Masked Entity Language Modeling for Low-Resource NER. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Volume 1, pp. 2251–2262. [Google Scholar]
- Ghosh, S.; Tyagi, U.; Kumar, S.; Manocha, D. Bioaug: Conditional generation based data augmentation for low-resource biomedical ner. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, Taipei, Taiwan, 23–27 July 2023; pp. 1853–1858. [Google Scholar]
- Chang, J.; Han, X. Character-to-word representation and global contextual representation for named entity recognition. Neural Process. Lett. 2023, 55, 8551–8567. [Google Scholar] [CrossRef]
- Fang, J.; Wang, X.; Meng, Z.; Xie, P.; Huang, F.; Jiang, Y. MANNER: A variational memory-augmented model for cross domain few-shot named entity recognition. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; Volume 1, pp. 4261–4276. [Google Scholar]
- Sajun, A.R.; Zualkernan, I.; Sankalpa, D. A Historical Survey of Advances in Transformer Architectures. Appl. Sci. 2024, 14, 4316. [Google Scholar] [CrossRef]
- Li, J.; Sun, Y.; Johnson, R.J.; Sciaky, D.; Wei, C.H.; Leaman, R.; Davis, A.P.; Mattingly, C.J.; Wiegers, T.C.; Lu, Z. BioCreative V CDR task corpus: A resource for chemical disease relation extraction. Database 2016, 2016, baw068. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Katiyar, A. Simple and Effective Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual, 16–20 November 2020; pp. 6365–6375. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching Networks for One Shot Learning. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3630–3638. [Google Scholar]
- Fritzler, A.; Logacheva, V.; Kretov, M. Few-shot classification in named entity recognition task. In Proceedings of the ACM Symposium on Applied Computing, Limassol, Cyprus, 8–12 April 2019; pp. 993–1000. [Google Scholar]
- Zhang, H.; Zhang, Y.; Zhang, R.; Yang, D. Robustness of Demonstration-based Learning Under Limited Data Scenario. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 1769–1782. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Dataset | Named Entity Type | Dataset Size |
|---|---|---|---|
| 1 | CoNLL-2003 | 4 | 22k |
| 2 | Ontonotes 5.0 | 18 | 625k |
| 3 | Ontonotes 4.0 | 4 | 100k |
| 4 | BC5CDR | 2 | 70k |
| Number | Hyper-Parameter | Value |
|---|---|---|
| 1 | Learning rate | 2 × 10−5 |
| 2 | Batch size | 64 |
| 3 | Epoch | 50 |
| 4 | Dropout | 0.5 |
| 5 | Maxnoincre | 15 |
| Models | 5-Shot | 10-Shot | ||||||
|---|---|---|---|---|---|---|---|---|
| TP | TN | FN | FP | TP | TN | FN | FP | |
| PER | 2427 | 36,632 | 339 | 65 | 2627 | 36,568 | 139 | 129 |
| LOC | 1223 | 36,994 | 700 | 546 | 1561 | 36,789 | 362 | 751 |
| ORG | 1906 | 35,609 | 589 | 1359 | 1833 | 36,153 | 662 | 815 |
| MISC | 270 | 37,946 | 648 | 599 | 527 | 37,914 | 391 | 631 |
| Models | 5-Shot | 10-Shot | ||||||
|---|---|---|---|---|---|---|---|---|
| TP | TN | FN | FP | TP | TN | FN | FP | |
| PER | 2389 | 36,628 | 317 | 129 | 2563 | 36,602 | 203 | 95 |
| LOC | 1185 | 37,059 | 738 | 481 | 1467 | 36,902 | 456 | 638 |
| ORG | 1935 | 35,502 | 560 | 1466 | 1874 | 36,267 | 621 | 701 |
| MISC | 247 | 38,017 | 671 | 528 | 546 | 37,919 | 372 | 626 |
| Models | 5-Shot | 10-Shot | ||||||
|---|---|---|---|---|---|---|---|---|
| TP | TN | FN | FP | TP | TN | FN | FP | |
| PER | 2479 | 36,638 | 287 | 59 | 2654 | 36,625 | 112 | 72 |
| LOC | 1255 | 37,059 | 668 | 481 | 1581 | 36,858 | 342 | 682 |
| ORG | 1975 | 35,502 | 520 | 1466 | 1979 | 36,230 | 516 | 738 |
| MISC | 263 | 38,017 | 655 | 528 | 557 | 37,909 | 361 | 636 |
| Module Number | Module | Multi-Class Label Prompt Demonstration | Core Entity Replacing | Low Core Entity Density Selecting |
|---|---|---|---|---|
| 1 | MPD | √ | ||
| 2 | MPD + CEDS | √ | √ | |
| 3 | CER | √ | ||
| 4 | MPD + CER | √ | √ | |
| 5 | MPSCER-NER | √ | √ | √ |
| k-Shot | Module Number | F1 | ||
|---|---|---|---|---|
| 25-shot | 1 | 51.22 | 46.64 | 48.75 |
| 2 | 66.51 | 47.92 | 48.98 | |
| 3 | 47.11 | 49.13 | 48.28 | |
| 4 | 51.75 | 50.11 | 50.75 | |
| 5 | 52.61 | 50.44 | 51.50 | |
| 50-shot | 1 | 65.92 | 62.51 | 63.61 |
| 2 | 66.11 | 63.91 | 64.36 | |
| 3 | 65.36 | 64.92 | 65.18 | |
| 4 | 66.11 | 68.13 | 66.96 | |
| 5 | 66.89 | 68.85 | 67.55 | |
| 100-shot | 1 | 71.95 | 73.53 | 72.44 |
| 2 | 72.11 | 73.82 | 72.91 | |
| 3 | 73.31 | 74.66 | 73.92 | |
| 4 | 73.53 | 75.94 | 74.63 | |
| 5 | 73.92 | 76.15 | 74.95 |
| Models | CoNLL-2003 | Ontonotes 5.0 | Ontonotes 4.0 | BC5CDR | ||||
|---|---|---|---|---|---|---|---|---|
| 5-Shot | 10-Shot | 5-Shot | 10-Shot | 5-Shot | 10-Shot | 25-Shot | 50-Shot | |
| NNshot | 51.43 | 62.45 | 40.11 | 56.17 | 41.23 | 55.18 | 48.71 | 50.13 |
| StructShot | 50.23 | 63.67 | 41.49 | 58.09 | 42.34 | 58.46 | 49.33 | 51.94 |
| MacthingCNN | 50.23 | 63.67 | 41.49 | 58.09 | 42.34 | 58.46 | 49.87 | 51.28 |
| ProtoBERT | 50.23 | 63.67 | 41.49 | 58.09 | 42.34 | 58.46 | 50.14 | 54.61 |
| DemonstrationNER | 57.23 | 65.11 | 46.11 | 58.37 | 46.67 | 59.78 | 52.20 | 56.22 |
| SR-Demonstration | 57.19 | 65.01 | 46.57 | 59.41 | 47.37 | 60.71 | 52.50 | 56.43 |
| MPSCER-NER | 58.55 | 67.25 | 47.62 | 60.73 | 48.21 | 62.17 | 53.93 | 57.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, D.; Chen, Y.; Yan, M. Named Entity Recognition Based on Multi-Class Label Prompt Selection and Core Entity Replacement. Appl. Sci. 2025, 15, 6171. https://doi.org/10.3390/app15116171
Wu D, Chen Y, Yan M. Named Entity Recognition Based on Multi-Class Label Prompt Selection and Core Entity Replacement. Applied Sciences. 2025; 15(11):6171. https://doi.org/10.3390/app15116171
Chicago/Turabian StyleWu, Di, Yao Chen, and Mingyue Yan. 2025. "Named Entity Recognition Based on Multi-Class Label Prompt Selection and Core Entity Replacement" Applied Sciences 15, no. 11: 6171. https://doi.org/10.3390/app15116171
APA StyleWu, D., Chen, Y., & Yan, M. (2025). Named Entity Recognition Based on Multi-Class Label Prompt Selection and Core Entity Replacement. Applied Sciences, 15(11), 6171. https://doi.org/10.3390/app15116171