Structure-Enhanced Prompt Learning for Graph-Based Code Vulnerability Detection


Abstract
1. Introduction
2. Related Work
2.1. Learning-Based Vulnerability Detection
2.2. Pretrained Models for Source Code Analysis
2.3. Prompt Learning
3. Methodology
3.1. Solution Overview
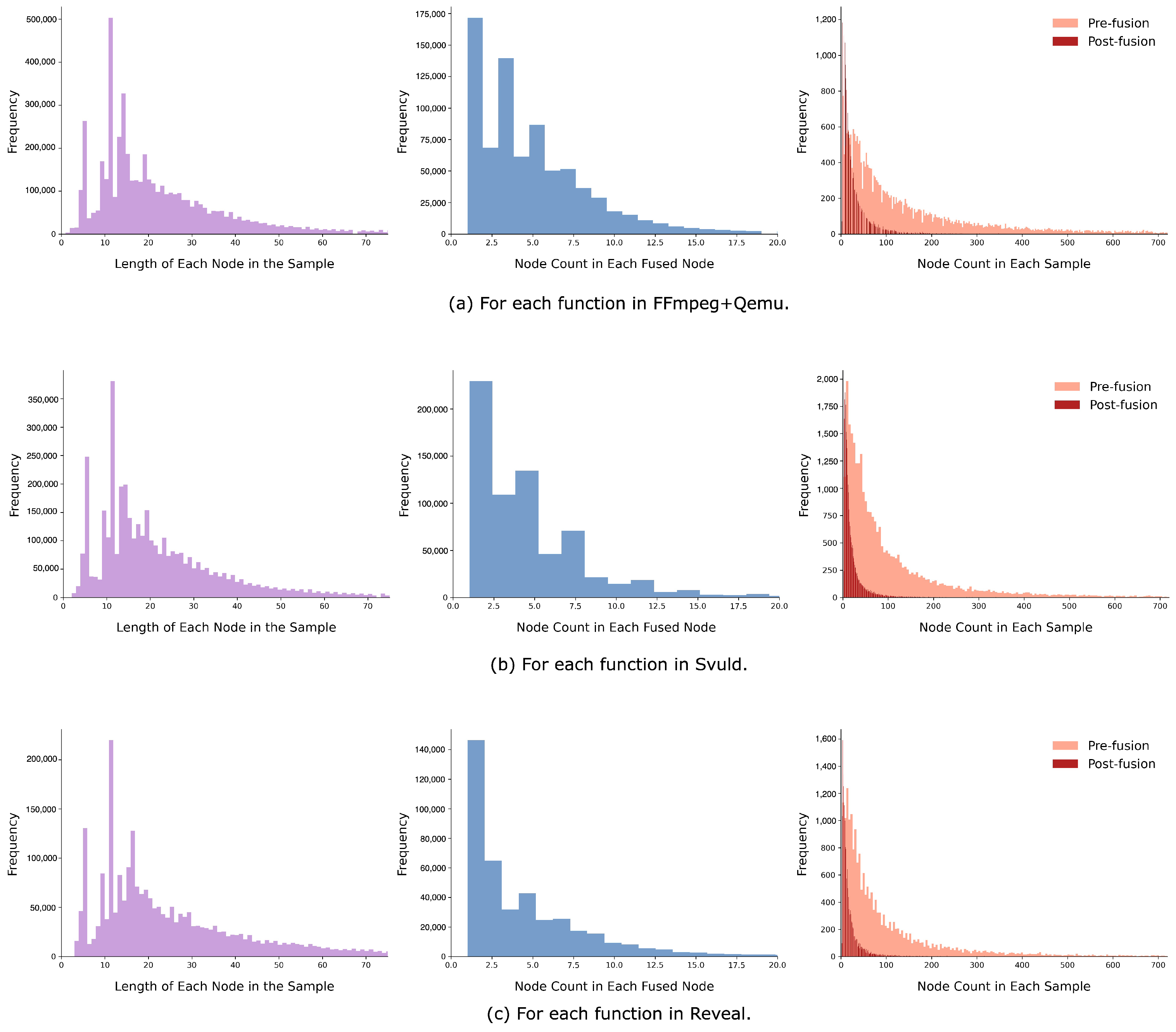
3.2. Code Feature Construction
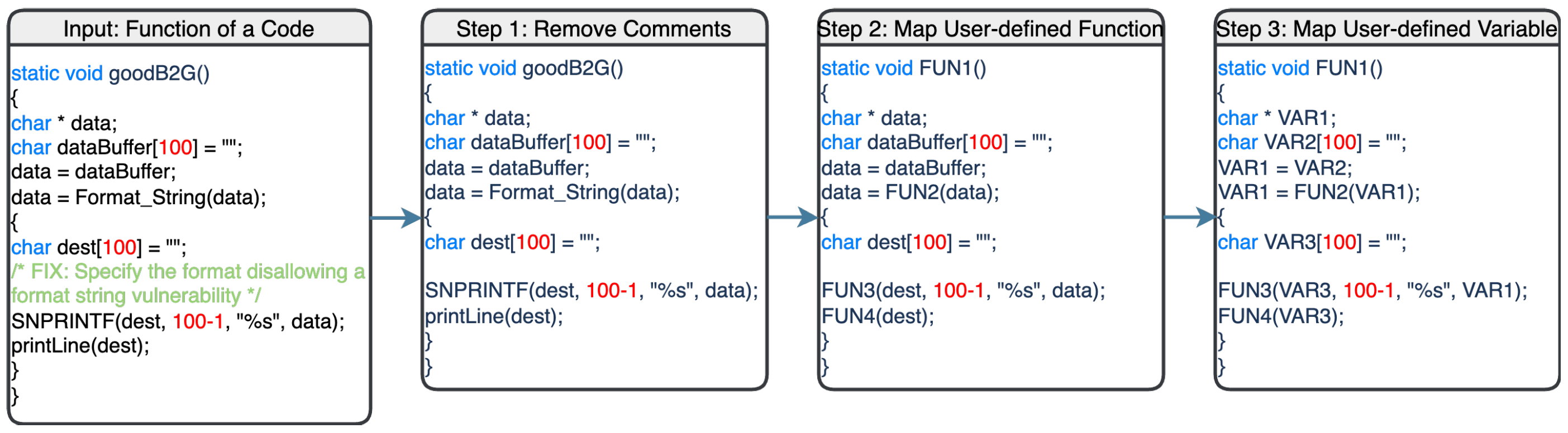
3.2.1. Normalization
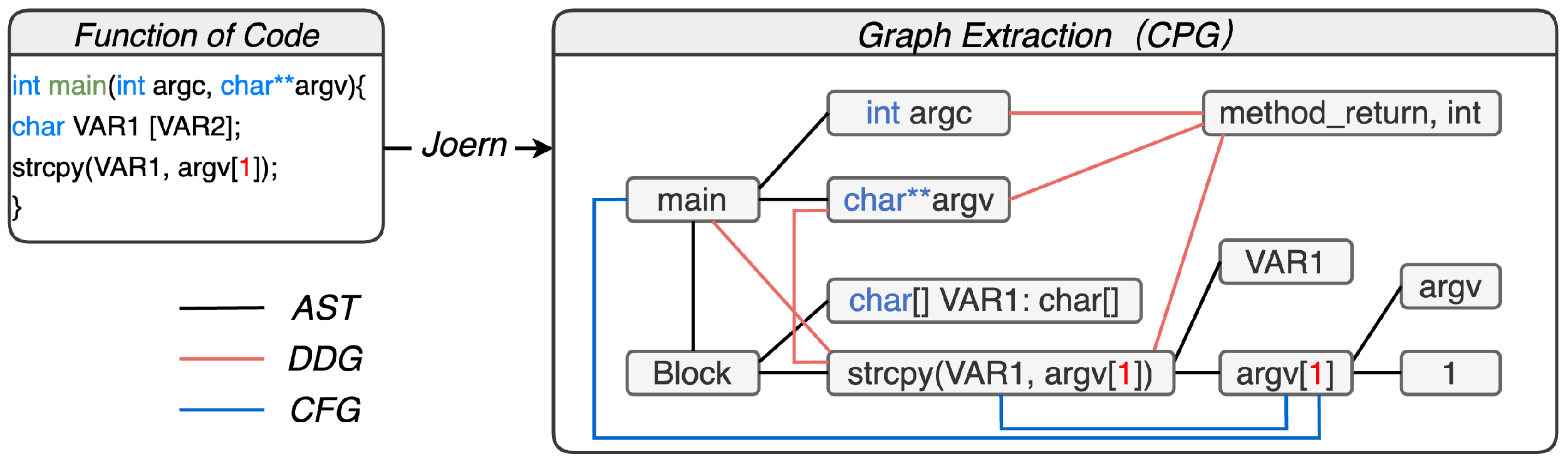
3.2.2. Extracting the Code Property Graph
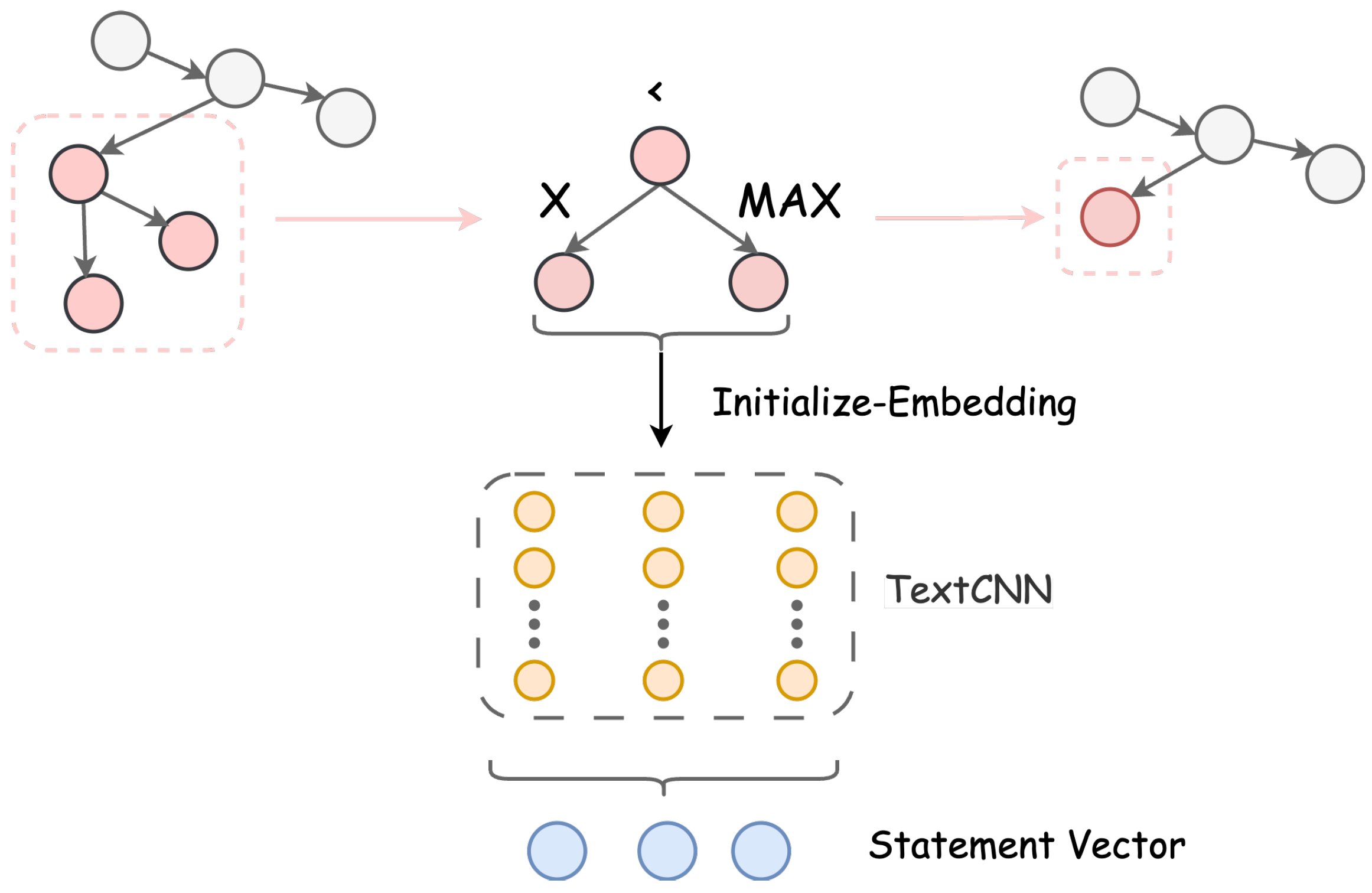
3.2.3. Syntax-Aware Encoder
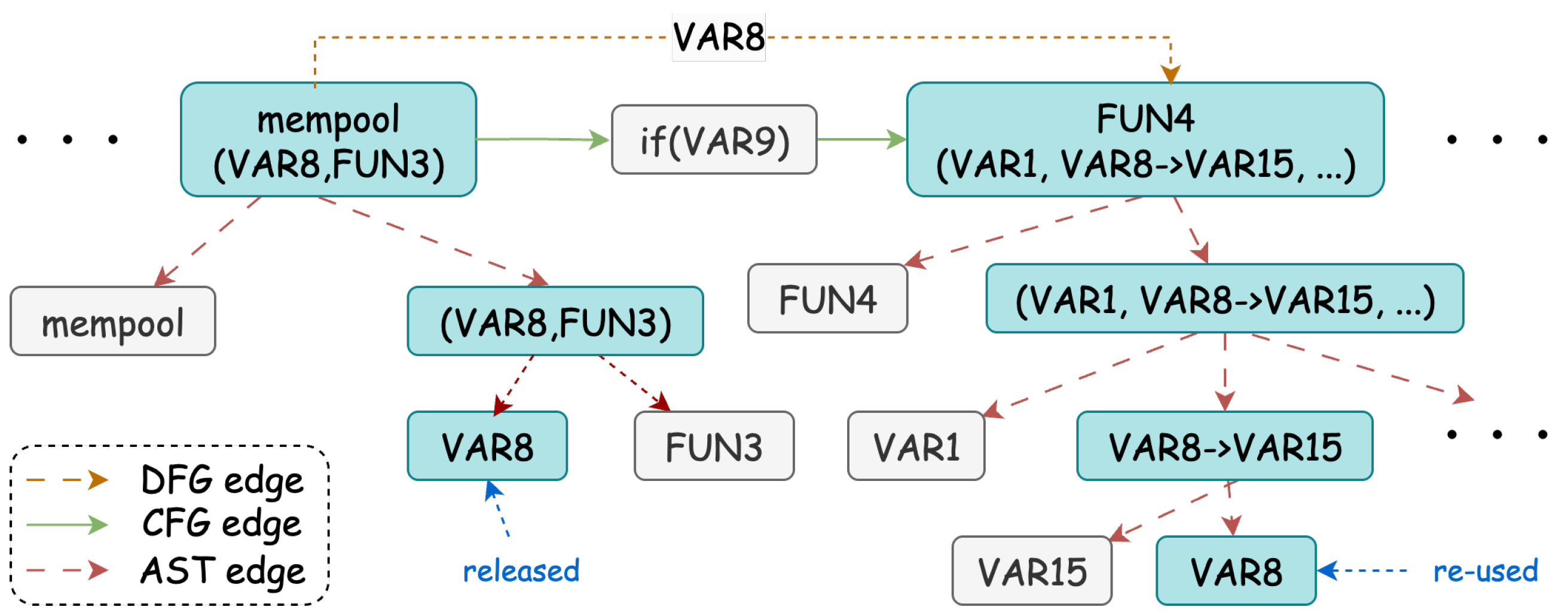
3.2.4. Graph Feature Encoder
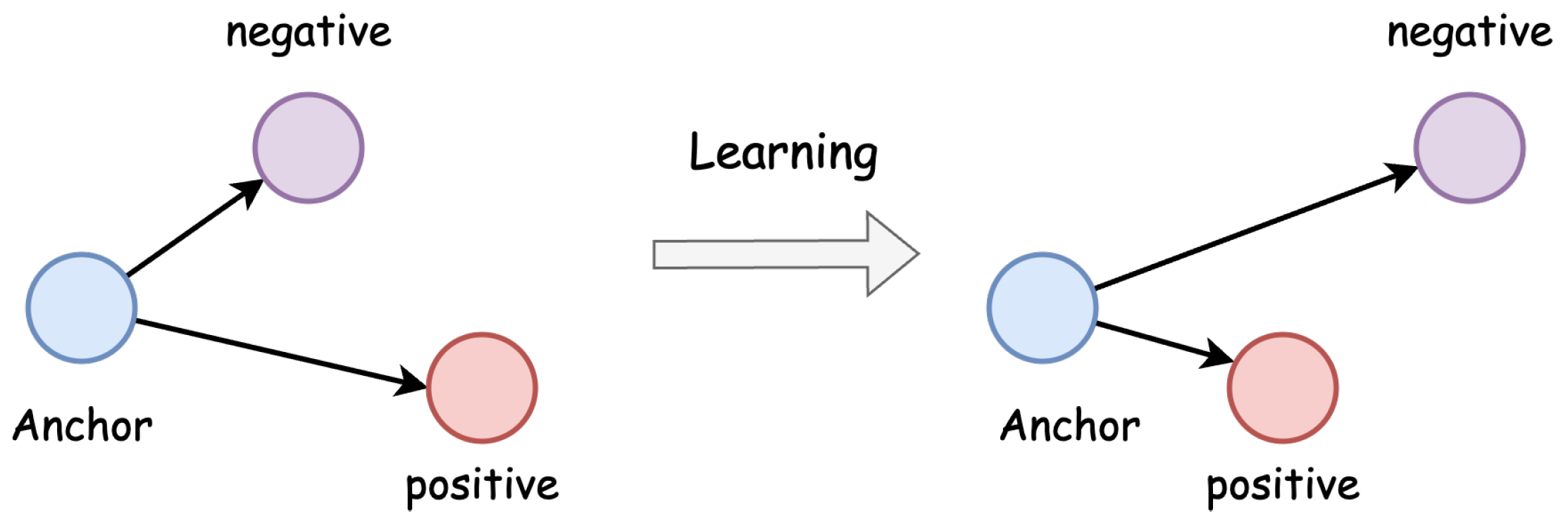
3.3. Structure-Enhanced Prompt
| Algorithm 1 Structure-enhanced prompt generation. |
|
3.3.1. Generation of Structured Prompt
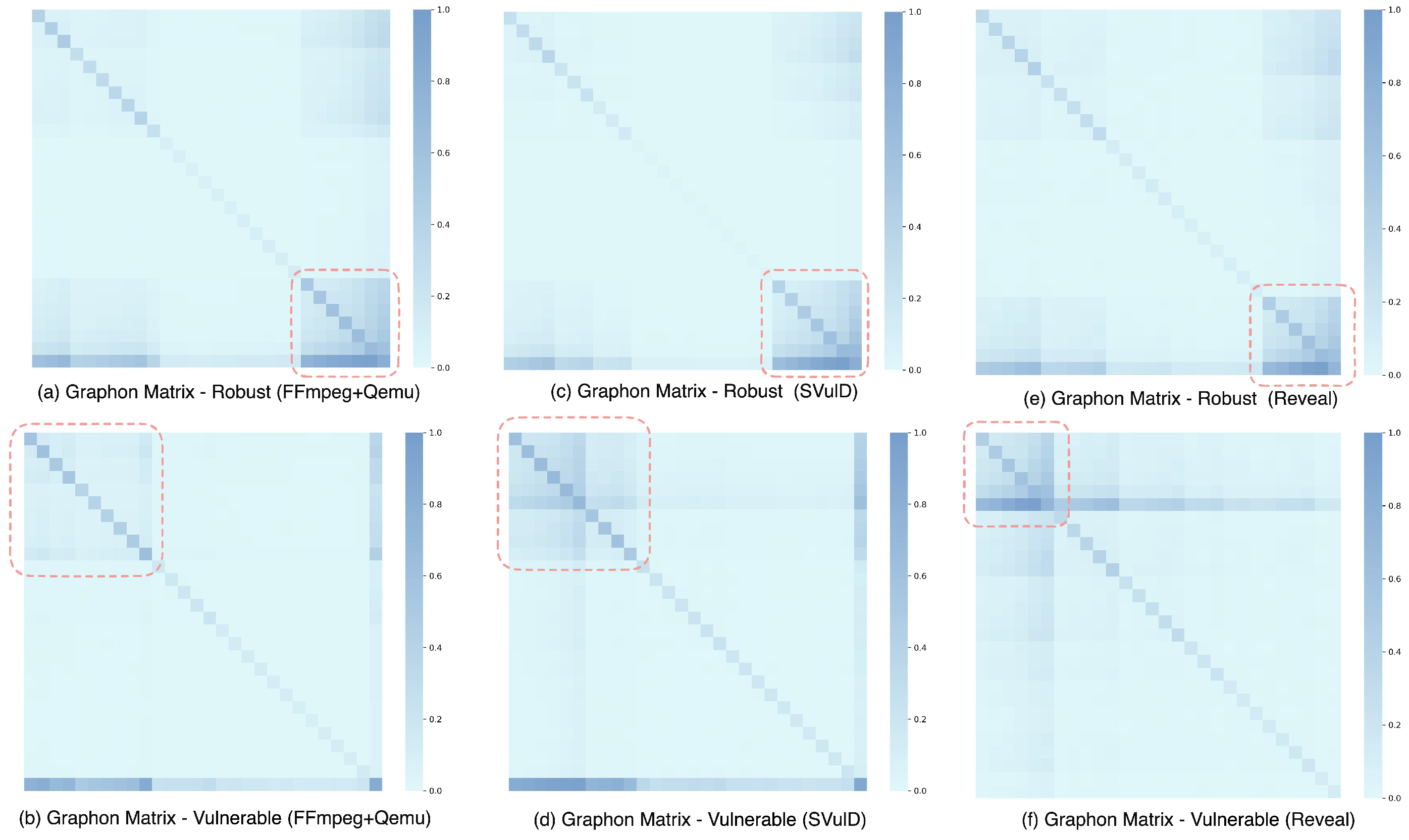
- Given a dataset with two types of graphs, we divide the training set by class to obtain two types of graph sets , representing robust and vulnerable.
- The degree of the nodes serves as the metric for each graph set . The alignment procedure begins by sorting the nodes in descending order of degree, then reorganizing the adjacency matrix accordingly.
- The graphon is estimated from the aligned graphs in usingwhere denotes the graphon estimation operator and represents aligned graph sets. K is the number of nodes that account for 80% of the total nodes in the graph set . We adopt Universal Singular Value Thresholding (USVT) [47] for graphon estimation. This method stacks adjacency matrices of aligned graphs and applies Singular Value Decomposition (SVD) to extract dominant structural features. The resulting graphon captures the generalized structural characteristics of the graphs in , providing a distribution that can generate topological structures.
3.3.2. Prompt Ensembling
3.4. Vulnerability Detection
3.4.1. Model Training
3.4.2. Detecting Vulnerability
3.5. Computational Complexity and Scalability Analysis
4. Experiments
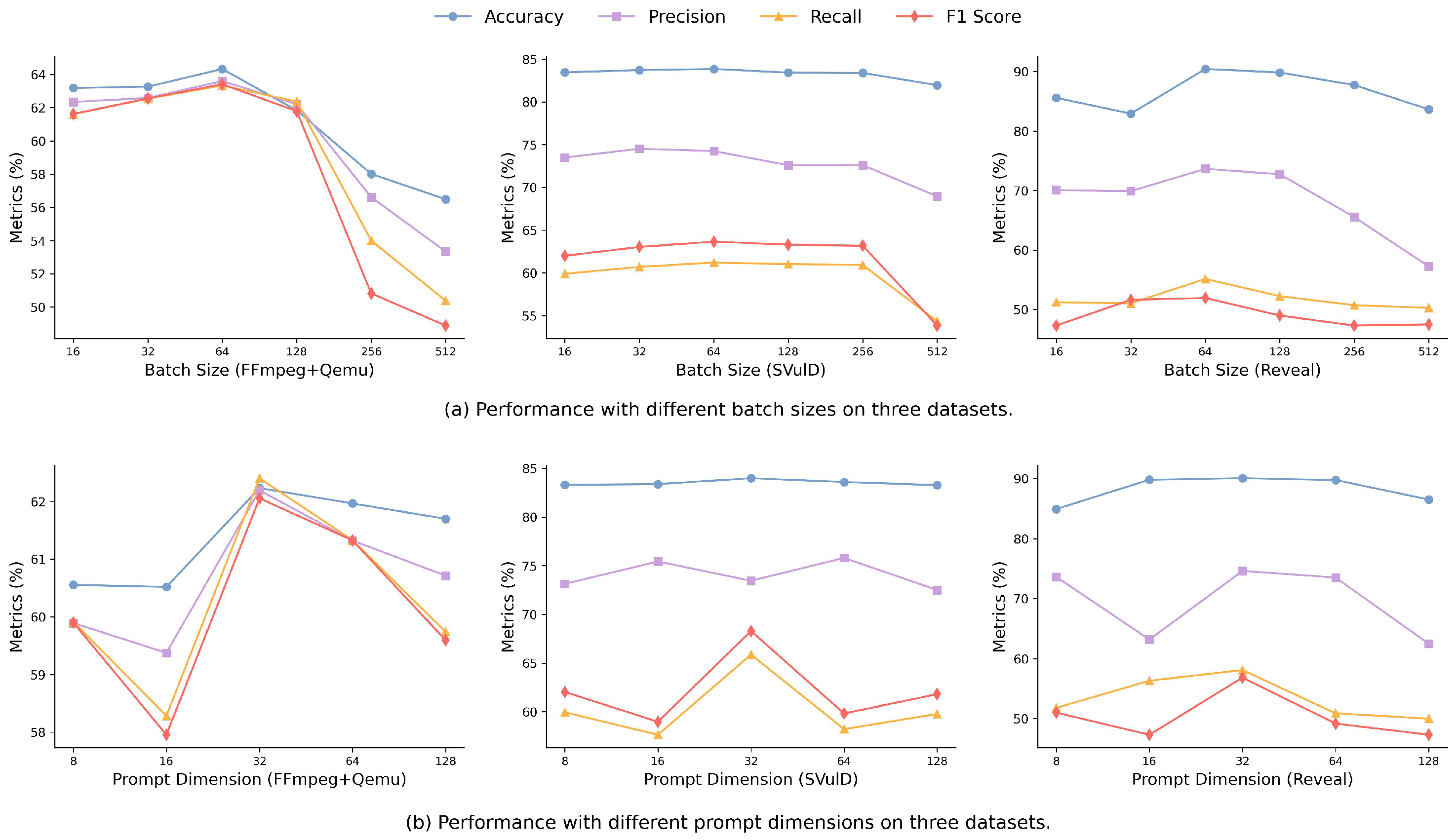
- RQ1: How does our method perform with varying model parameters?
- RQ2: Does the introduction of the syntax-aware embedding module provide better detection capability and stability?
- RQ3: Does introducing code structure information in text prompts have better detection ability and stability?
- RQ4: How does our method perform compared to state-of-the-art vulnerability detection methods?
4.1. Datasets
4.2. Experimental Setup
4.3. Result Analysis
4.3.1. RQ1: Parameter Analysis
4.3.2. RQ2: Syntax-Aware Embedding Effectiveness
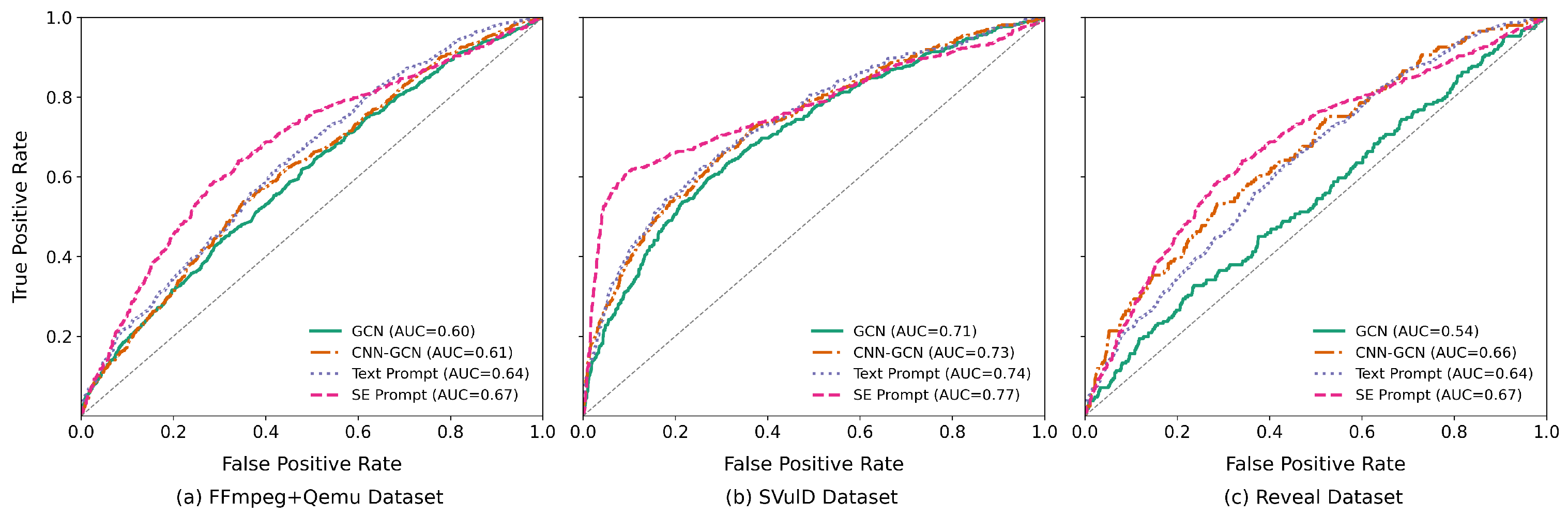
4.3.3. RQ3: Structure-Enhanced Prompt Effectiveness
4.3.4. RQ4: Comparison with State of the Art
4.4. Feature Visualization
4.4.1. Graphon Visualization
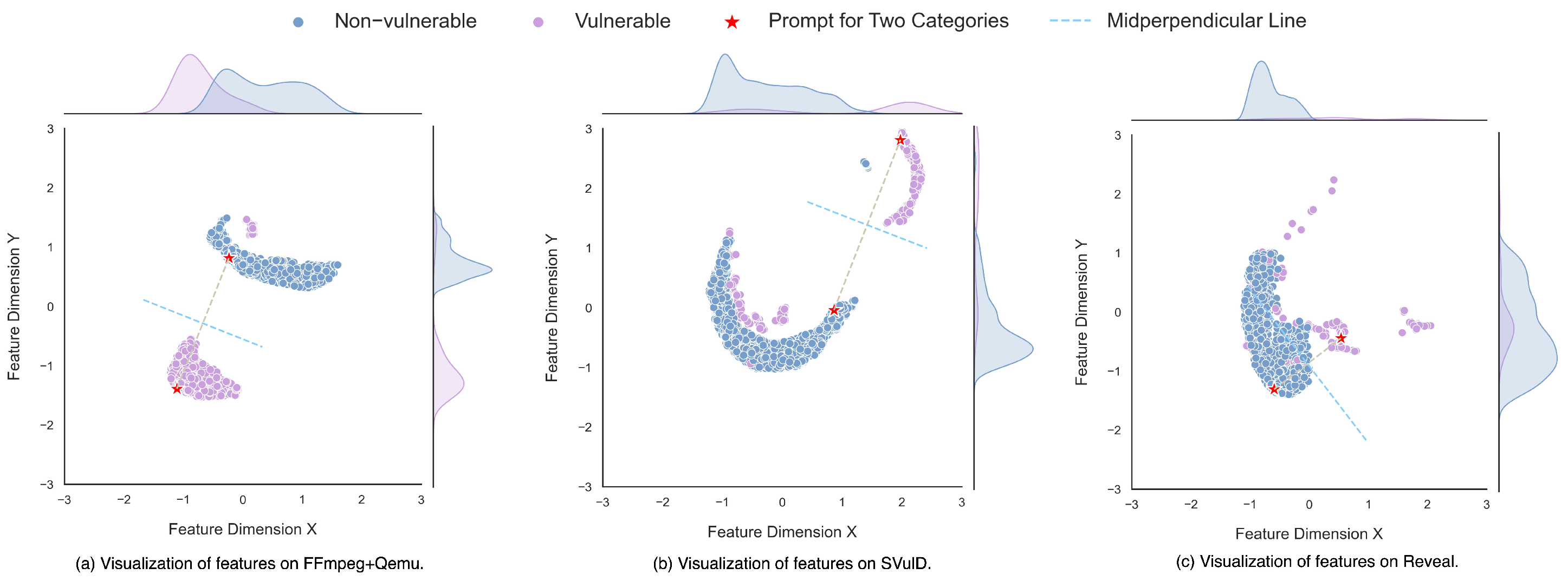
4.4.2. Code Feature Visualization
4.5. Threats to Validity
4.5.1. Internal Validity
4.5.2. External Validity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- MITRE. Common Vulnerabilities and Exposures. Available online: https://www.cve.org/ (accessed on 15 January 2025).
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20, Red Hook, NY, USA, 6–12 December 2020. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; Volume 139, pp. 8748–8763. [Google Scholar]
- Hu, S.; Ding, N.; Wang, H.; Liu, Z.; Wang, J.; Li, J.; Wu, W.; Sun, M. Knowledgeable prompt-tuning: Incorporating knowledge into prompt verbalizer for text classification. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 2225–2240. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, N.; Xie, X.; Deng, S.; Yao, Y.; Tan, C.; Huang, F.; Si, L.; Chen, H. Knowprompt: Knowledge-aware prompt-tuning with synergistic optimization for relation extraction. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 2778–2788. [Google Scholar] [CrossRef]
- Alon, U.; Yahav, E. On the Bottleneck of Graph Neural Networks and its Practical Implications. arXiv 2021, arXiv:2006.05205. [Google Scholar]
- Wen, X.C.; Chen, Y.; Gao, C.; Zhang, H.; Zhang, J.M.; Liao, Q. Vulnerability Detection with Graph Simplification and Enhanced Graph Representation Learning. In Proceedings of the 45th International Conference on Software Engineering, ICSE’23, Melbourne, Australia, 14–20 May 2023; IEEE Press: Piscataway, NJ, USA, 2023; pp. 2275–2286. [Google Scholar] [CrossRef]
- Cheng, X.; Wang, H.; Hua, J.; Xu, G.; Sui, Y. Deepwukong: Statically detecting software vulnerabilities using deep graph neural network. ACM Trans. Softw. Eng. Methodol. (TOSEM) 2021, 30, 1–33. [Google Scholar] [CrossRef]
- Hin, D.; Kan, A.; Chen, H.; Babar, M.A. LineVD: Statement-level Vulnerability Detection using Graph Neural Networks. In Proceedings of the 2022 IEEE/ACM 19th International Conference on Mining Software Repositories (MSR), Pittsburgh, PA, USA, 23–24 May 2022; pp. 596–607. [Google Scholar] [CrossRef]
- Diaconis, P.; Janson, S. Graph limits and exchangeable random graphs. arXiv 2007, arXiv:0712.2749. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 1746–1751. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, S.; Siow, J.; Du, X.; Liu, Y. Devign: Effective Vulnerability Identification by Learning Comprehensive Program Semantics via Graph Neural Networks. arXiv 2019, arXiv:1909.03496. [Google Scholar]
- Ni, C.; Yin, X.; Yang, K.; Zhao, D.; Xing, Z.; Xia, X. Distinguishing Look-Alike Innocent and Vulnerable Code by Subtle Semantic Representation Learning and Explanation. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2023, San Francisco, CA, USA, 5–7 December 2023; pp. 1611–1622. [Google Scholar] [CrossRef]
- Chakraborty, S.; Krishna, R.; Ding, Y.; Ray, B. Deep learning based vulnerability detection: Are we there yet? IEEE Trans. Softw. Eng. 2021, 48, 3280–3296. [Google Scholar] [CrossRef]
- Russell, R.; Kim, L.; Hamilton, L.; Lazovich, T.; Harer, J.; Ozdemir, O.; Ellingwood, P.; McConley, M. Automated Vulnerability Detection in Source Code Using Deep Representation Learning. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 757–762. [Google Scholar] [CrossRef]
- Li, Z.; Zou, D.; Xu, S.; Ou, X.; Jin, H.; Wang, S.; Deng, Z.; Zhong, Y. VulDeePecker: A Deep Learning-Based System for Vulnerability Detection. In Proceedings of the 2018 Network and Distributed System Security Symposium, San Diego, CA, USA, 18–21 February 2018; Internet Society: Reston, VA, USA, 2018. [Google Scholar] [CrossRef]
- Li, Z.; Zou, D.; Xu, S.; Jin, H.; Zhu, Y.; Chen, Z. SySeVR: A framework for using deep learning to detect software vulnerabilities. IEEE Trans. Dependable Secur. Comput. 2022, 19, 2244–2258. [Google Scholar] [CrossRef]
- Peng, B.; Liu, Z.; Zhang, J.; Su, P. CEVulDet: A Code Edge Representation Learnable Vulnerability Detector. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; pp. 1–8. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, B.; Xin, Y.; Yao, L. CPVD: Cross project vulnerability detection based on graph attention network and domain adaptation. IEEE Trans. Softw. Eng. 2023, 49, 4152–4168. [Google Scholar] [CrossRef]
- Wen, X.C.; Gao, C.; Ye, J.; Li, Y.; Tian, Z.; Jia, Y.; Wang, X. Meta-path based attentional graph learning model for vulnerability detection. IEEE Trans. Softw. Eng. 2024, 50, 360–375. [Google Scholar] [CrossRef]
- Wang, Q.; Li, Z.; Liang, H.; Pan, X.; Li, H.; Li, T.; Li, X.; Li, C.; Guo, S. Graph Confident Learning for Software Vulnerability Detection. Eng. Appl. Artif. Intell. 2024, 133, 108296. [Google Scholar] [CrossRef]
- Tian, Z.; Tian, B.; Lv, J.; Chen, Y.; Chen, L. Enhancing vulnerability detection via AST decomposition and neural sub-tree encoding. Expert Syst. Appl. 2024, 238, 121865. [Google Scholar] [CrossRef]
- Wen, X.C.; Gao, C.; Gao, S.; Xiao, Y.; Lyu, M.R. SCALE: Constructing Structured Natural Language Comment Trees for Software Vulnerability Detection. In Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2024, Vienna, Austria, 16–20 September 2024; pp. 235–247. [Google Scholar] [CrossRef]
- Wu, Y.; Zou, D.; Dou, S.; Yang, W.; Xu, D.; Jin, H. VulCNN: An image-inspired scalable vulnerability detection system. In Proceedings of the 44th International Conference on Software Engineering, Pittsburgh, PA, USA, 22–24 May 2022; pp. 2365–2376. [Google Scholar] [CrossRef]
- Buratti, L.; Pujar, S.; Bornea, M.; McCarley, S.; Zheng, Y.; Rossiello, G.; Morari, A.; Laredo, J.; Thost, V.; Zhuang, Y.; et al. Exploring Software Naturalness through Neural Language Models. arXiv 2020, arXiv:2006.12641. [Google Scholar]
- Feng, Z.; Guo, D.; Tang, D.; Duan, N.; Feng, X.; Gong, M.; Shou, L.; Qin, B.; Liu, T.; Jiang, D.; et al. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 1536–1547. [Google Scholar] [CrossRef]
- Guo, D.; Ren, S.; Lu, S.; Feng, Z.; Tang, D.; Liu, S.; Zhou, L.; Duan, N.; Svyatkovskiy, A.; Fu, S.; et al. GraphCodeBERT: Pre-training Code Representations with Data Flow. arXiv 2021, arXiv:2009.08366. [Google Scholar]
- Zhou, S.; Alon, U.; Agarwal, S.; Neubig, G. CodeBERTScore: Evaluating Code Generation with Pretrained Models of Code. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 13921–13937. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; de Oliveira Pinto, H.P.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating Large Language Models Trained on Code. arXiv 2021, arXiv:2107.03374. [Google Scholar]
- Petroni, F.; Rocktäschel, T.; Lewis, P.; Bakhtin, A.; Wu, Y.; Miller, A.H.; Riedel, S. Language models as knowledge bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 2463–2473. [Google Scholar] [CrossRef]
- Jiang, Z.; Xu, F.F.; Araki, J.; Neubig, G. How can we know what language models know? Trans. Assoc. Comput. Linguist. 2020, 8, 423–438. [Google Scholar] [CrossRef]
- Shin, T.; Razeghi, Y.; Logan IV, R.L.; Wallace, E.; Singh, S. Autoprompt: Eliciting knowledge from language models with automatically generated prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 4222–4235. [Google Scholar] [CrossRef]
- Lester, B.; Al-Rfou, R.; Constant, N. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 3045–3059. [Google Scholar] [CrossRef]
- Zhong, Z.; Friedman, D.; Chen, D. Factual probing is [mask]: Learning vs. learning to recall. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 5017–5033. [Google Scholar] [CrossRef]
- Li, Y.; Liang, F.; Zhao, L.; Cui, Y.; Ouyang, W.; Shao, J.; Yu, F.; Yan, J. Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm. arXiv 2022, arXiv:2110.05208. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Wang, C.; Yang, Y.; Gao, C.; Peng, Y.; Zhang, H.; Lyu, M.R. Prompt Tuning in Code Intelligence: An Experimental Evaluation. IEEE Trans. Softw. Eng. 2023, 49, 4869–4885. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, H.; Zeng, J.; Yang, K.; Li, Y.; Li, H. Prompt-Enhanced Software Vulnerability Detection Using ChatGPT. In Proceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings, Lisbon, Portugal, 14–20 April 2024; pp. 276–277. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Learning to prompt for vision-language models. Int. J. Comput. Vis. 2022, 130, 2337–2348. [Google Scholar] [CrossRef]
- Yamaguchi, F.; Golde, N.; Arp, D.; Rieck, K. Modeling and discovering vulnerabilities with code property graphs. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 18–21 May 2014; pp. 590–604. [Google Scholar] [CrossRef]
- Wang, H.; Ye, G.; Tang, Z.; Tan, S.H.; Huang, S.; Fang, D.; Feng, Y.; Bian, L.; Wang, Z. Combining graph-based learning with automated data collection for code vulnerability detection. IEEE Trans. Inf. Forensics Secur. 2021, 16, 1943–1958. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Conditional prompt learning for vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16816–16825. [Google Scholar] [CrossRef]
- Goldenberg, A.; Zheng, A.X.; Fienberg, S.E.; Airoldi, E.M. A survey of statistical network models. Found. Trends® Mach. Learn. 2010, 2, 129–233. [Google Scholar] [CrossRef]
- Lovász, L. Large Networks and Graph Limits; American Mathematical Society: Providence, RI, USA, 2012; Volume 60. [Google Scholar]
- Frieze, A.; Kannan, R. Quick approximation to matrices and applications. Combinatorica 1999, 19, 175–220. [Google Scholar] [CrossRef]
- Chatterjee, S. Matrix estimation by universal singular value thresholding. Ann. Stat. 2015, 43, 177–214. [Google Scholar] [CrossRef]
- Fan, J.; Li, Y.; Wang, S.; Nguyen, T.N. A C/C++ Code Vulnerability Dataset with Code Changes and CVE Summaries. In Proceedings of the 2020 IEEE/ACM 17th International Conference on Mining Software Repositories (MSR), Seoul, Republic of Korea, 29–30 June 2020; pp. 508–512. [Google Scholar] [CrossRef]
- Lu, S.; Guo, D.; Ren, S.; Huang, J.; Svyatkovskiy, A.; Blanco, A.; Clement, C.; Drain, D.; Jiang, D.; Tang, D.; et al. Codexglue: A machine learning benchmark dataset for code understanding and generation. CoRR 2021, arXiv:2102.04664. [Google Scholar]
- Wen, X.C.; Wang, X.; Gao, C.; Wang, S.; Liu, Y.; Gu, Z. When Less is Enough: Positive and Unlabeled Learning Model for Vulnerability Detection. In Proceedings of the 2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE), Luxembourg, 11–15 September 2023; pp. 345–357. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, W.; Joty, S.; Hoi, S.C. CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 8696–8708. [Google Scholar] [CrossRef]
- Guo, D.; Lu, S.; Duan, N.; Wang, Y.; Zhou, M.; Yin, J. Unixcoder: Unified cross-modal pre-training for code representation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 7212–7225. [Google Scholar] [CrossRef]
- Fu, M.; Tantithamthavorn, C. LineVul: A Transformer-based Line-Level Vulnerability Prediction. In Proceedings of the 2022 IEEE/ACM 19th International Conference on Mining Software Repositories (MSR), Pittsburgh, PA, USA, 23–24 May 2022; pp. 608–620. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, Z.; Hu, X.; Xia, X.; Li, S. Vulnerability Detection by Learning From Syntax-Based Execution Paths of Code. IEEE Trans. Softw. Eng. 2023, 49, 4196–4212. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2020, arXiv:1802.03426. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Total | Vul | Non-Vul | Ratio (%) |
|---|---|---|---|---|
| FFmpeg+Qemu | 22,361 | 10,067 | 12,294 | 45.02 |
| SVulD | 28,730 | 5260 | 23,470 | 18.31 |
| Reveal | 18,169 | 1664 | 16,505 | 9.16 |
| Parameter | Setting | Parameter | Setting |
|---|---|---|---|
| Loss function | CE & Triplet Loss | Batch | 64 |
| Activation function | ReLU | Learning rate | 1 × to 1 × |
| Optimizer | AdamW | Epoch number | 300 |
| Dataset | Method | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| FFmpeg+Qemu | GCN | 57.14 ± 0.18 | 55.69 ± 0.18 | 54.60 ± 0.04 | 53.52 ± 0.21 |
| CNN-GCN | 58.05 ± 1.12 | 56.95 ± 1.36 | 58.05 ± 1.12 | 55.47 ± 1.44 | |
| Text Prompt | 61.32 ± 0.34 | 60.41 ± 0.35 | 59.71 ± 0.89 | 59.53 ± 0.67 | |
| SE Prompt | 64.40 ± 0.50 | 63.59 ± 0.47 | 63.33 ± 0.48 | 63.41 ± 0.49 | |
| SVulD | GCN | 82.36 ± 0.89 | 71.96 ± 0.72 | 57.56 ± 0.38 | 59.31 ± 0.68 |
| CNN-GCN | 82.52 ± 0.68 | 74.65 ± 1.45 | 57.66 ± 0.97 | 59.39 ± 0.92 | |
| Text Prompt | 82.69 ± 0.15 | 75.59 ± 0.29 | 65.60 ± 0.96 | 68.37 ± 0.84 | |
| SE Prompt | 83.44 ± 0.18 | 75.89 ± 0.53 | 67.80 ± 0.69 | 70.69 ± 0.60 | |
| Reveal | GCN | 88.90 ± 0.15 | 44.61 ± 0.14 | 50.00 ± 0.15 | 47.15 ± 0.02 |
| CNN-GCN | 89.21 ± 0.35 | 55.35 ± 1.62 | 50.08 ± 0.89 | 50.42 ± 1.69 | |
| Text Prompt | 89.69 ± 0.06 | 61.68 ± 1.16 | 51.76 ± 0.58 | 52.01 ± 1.25 | |
| SE Prompt | 90.69 ± 0.62 | 56.63 ± 0.51 | 55.14 ± 0.55 | 56.11 ± 0.66 |
| Model | Dataset | Accuracy (p/e) | Precision (p/e) | Recall (p/e) | F1 Score (p/e) |
|---|---|---|---|---|---|
| GCN | FFmpeg+Qemu | 5.79 × /1.00 | 6.75 × /1.00 | 6.75 × /1.00 | 6.57 × /1.00 |
| SVulD | 1.37 × /1.00 | 6.78 × /1.00 | 6.78 × /1.00 | 6.73 × /1.00 | |
| Reveal | 5.60 × /1.00 | 5.65 × /1.00 | 3.42 × /1.00 | 5.65 × /1.00 | |
| CNN-GCN | FFmpeg+Qemu | 6.27 × /1.00 | 6.78 × /1.00 | 6.66 × /1.00 | 6.75 × /1.00 |
| SVulD | 1.16 × /1.00 | 1.60 × /1.00 | 6.77 × /1.00 | 6.72 × /1.00 | |
| Reveal | 5.42 × /1.00 | 7.72 × /1.00 | 3.42 × /1.00 | 7.72 × /1.00 | |
| Text Prompt | FFmpeg+Qemu | 6.32 × /1.00 | 6.79 × /1.00 | 6.79 × /1.00 | 6.76 × /1.00 |
| SVulD | 6.96 × /1.00 | 2.21 × /1.00 | 6.79 × /1.00 | 6.79 × /1.00 | |
| Reveal | 4.32 × /1.00 | 6.20 × /1.00 | 3.42 × /1.00 | 6.20 × /1.00 |
| Datasets Metrics | FFmpeg+Qemu | SVulD | Reveal | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | Pre | Rec | F1 | Acc | Pre | Rec | F1 | Acc | Pre | Rec | F1 | |
| Devign | 56.89 | 52.50 | 64.67 | 57.95 | 73.57 | 9.72 | 50.31 | 16.29 | 87.49 | 31.55 | 36.65 | 33.91 |
| Reveal | 61.07 | 55.50 | 70.70 | 62.19 | 82.58 | 12.92 | 40.08 | 19.31 | 81.77 | 31.55 | 61.14 | 41.62 |
| CodeBERT | 62.37 | 61.55 | 48.21 | 54.07 | 80.56 | 14.33 | 55.32 | 22.76 | 87.51 | 43.63 | 56.15 | 49.10 |
| CodeT5 | 63.36 | 58.65 | 68.61 | 63.24 | 78.73 | 14.32 | 62.36 | 23.30 | 89.53 | 51.15 | 54.51 | 52.78 |
| UnixCoder | 65.19 | 59.93 | 59.98 | 59.96 | 77.54 | 15.11 | 72.24 | 24.99 | 88.48 | 47.44 | 68.44 | 56.04 |
| EPVD | 63.03 | 59.32 | 62.15 | 60.70 | 76.75 | 14.26 | 69.58 | 23.67 | 88.87 | 48.60 | 63.93 | 55.22 |
| LineVul | 62.37 | 61.55 | 48.21 | 54.07 | 80.57 | 15.95 | 64.45 | 25.58 | 87.51 | 43.63 | 56.15 | 49.10 |
| Ours | 64.40 | 63.59 | 63.33 | 63.41 | 83.44 | 75.89 | 67.80 | 70.69 | 90.69 | 56.63 | 55.14 | 56.11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, W.; Ye, C.; Zhou, H. Structure-Enhanced Prompt Learning for Graph-Based Code Vulnerability Detection. Appl. Sci. 2025, 15, 6128. https://doi.org/10.3390/app15116128
Chang W, Ye C, Zhou H. Structure-Enhanced Prompt Learning for Graph-Based Code Vulnerability Detection. Applied Sciences. 2025; 15(11):6128. https://doi.org/10.3390/app15116128
Chicago/Turabian StyleChang, Wei, Chunyang Ye, and Hui Zhou. 2025. "Structure-Enhanced Prompt Learning for Graph-Based Code Vulnerability Detection" Applied Sciences 15, no. 11: 6128. https://doi.org/10.3390/app15116128
APA StyleChang, W., Ye, C., & Zhou, H. (2025). Structure-Enhanced Prompt Learning for Graph-Based Code Vulnerability Detection. Applied Sciences, 15(11), 6128. https://doi.org/10.3390/app15116128