1. Introduction
Brain–computer interface (BCI) technology is a rapidly evolving interdisciplinary field that enables direct communication between the central nervous system (CNS) and external devices, bypassing traditional neuromuscular pathways [
1,
2]. By decoding brain signals into interpretable control commands, BCI systems have been widely applied in human–machine interaction, neurorehabilitation, and communication support for individuals with severe motor impairments [
3,
4,
5].
Among various BCI paradigms, steady-state visual evoked potentials (SSVEPs) have been widely adopted due to their high signal-to-noise ratio (SNR), low training requirements, and strong cross-subject consistency [
6,
7,
8]. In SSVEP-based systems, users focus on flickering visual stimuli to evoke frequency-specific EEG responses for multi-target selection. However, prolonged exposure to high-frequency flickering stimuli can induce visual fatigue, reducing user comfort and long-term usability [
9]. To improve user experience, researchers have proposed the steady-state motion visual evoked potential (SSMVEP) paradigm. This approach uses periodic motion stimuli—such as expanding or contracting rings—instead of flashing lights, preserving the frequency-specific response while improving visual comfort [
10]. Previous studies have shown that SSMVEPs are more suitable for long-term use, offering better user acceptance and greater signal stability in practical environments [
11].
In terms of operational mode, BCI systems can be categorized into synchronous and asynchronous types [
12]. Synchronous BCIs require users to issue commands within predefined temporal windows, which simplifies signal processing but limits user autonomy and interaction flexibility [
13]. In contrast, asynchronous BCIs allow users to initiate commands at any arbitrary time, aligning more closely with natural interaction. However, such systems must continuously monitor EEG signals to distinguish between intentional control (IC) and non-control (NC) states in real time—a technically demanding task in real-world scenarios [
14,
15,
16].
State detection methods for asynchronous BCIs can be broadly divided into threshold-based and classifier-based approaches [
17]. Threshold-based methods, such as canonical correlation analysis (CCA), are efficient but sensitive to individual variability and environmental noise, which may degrade performance [
18,
19]. Recently, more studies have introduced supervised learning classifiers to enhance system adaptability and robustness. Existing methods have explored convolutional neural networks [
20], complex network analysis [
21], and multimodal feature fusion techniques [
22]. For example, Zhang X et al. [
20] proposed an FFT-CNN architecture that achieved improved accuracy in asynchronous SSVEP classification, but the model was prone to overfitting due to its high complexity. Zhang W et al. [
21] employed filter banks and an optimized complex network (OCN) to extract attention-related features from multiband EEG data, followed by classification using a support vector machine (SVM). However, this approach focused primarily on attention state representation and did not fully leverage frequency-specific evoked responses inherent to SSVEP/SSMVEP paradigms. Du et al. [
22] introduced a feature fusion technique combining task-related component analysis (TRCA) coefficients and power spectral density (PSD) features into a composite TRPSD descriptor, achieving enhanced performance with a stepwise linear discriminant analysis (SWLDA) classifier. Despite the progress in feature fusion techniques, many existing methods still rely on either spatial or frequency domain features alone, overlooking the benefits of their integration. Furthermore, the lack of consideration for the compatibility between specific feature types and classifier architectures often leads to suboptimal model performance.
In the context of SSMVEP-based asynchronous state detection, the core assumption is that NC-state EEG lacks pronounced frequency components corresponding to stimulus frequencies, whereas IC-state EEG exhibits clear responses at stimulus frequencies and their harmonics [
23]. Therefore, a hybrid feature extraction strategy that integrates frequency domain correlation and spatial energy distribution is desirable. Canonical correlation analysis is particularly effective for quantifying the similarity between EEG signals and reference templates across multiple frequencies, requiring no training and offering high efficiency for real-time applications [
24]. In parallel, the common spatial pattern (CSP) algorithm can identify spatial filters that maximize the variance difference between IC and NC states, enabling the extraction of discriminative spatial features [
25]. Motivated by these insights, this study proposes a dual-feature fusion framework combining CCA and CSP-derived features, designed to capture both frequency and spatial domain information.
Moreover, different classifiers exhibit varying degrees of compatibility with different types of features [
26]. SVMs have been widely applied to motor-related EEG classification tasks, showing robust performance in high-dimensional, sparse, and linearly separable data contexts [
27]. In contrast, extreme gradient boosting (XGBoost) has demonstrated strong capability in modeling nonlinear relationships and handling redundant features, making it well suited for complex EEG tasks such as seizure detection and emotion recognition [
28,
29]. The features extracted by FBCSPs and FBCCA differ substantially in their statistical characteristics, representational structures, and dimensional profiles. FBCSPs extract channel-wise variance through linear spatial filtering, producing relatively low-dimensional features with a linear structure. These properties make FBCSP features well suited for boundary-based classifiers such as SVMs [
30]. In contrast, FBCCA generates high-dimensional features by measuring frequency domain correlation with reference templates. These features are inherently nonlinear and more complex in structure, aligning well with XGBoost, which excels in nonlinear modeling and embedded feature selection [
31]. The direct concatenation of these heterogeneous feature sets into a single classifier could introduce issues such as dimensionality mismatch, overfitting, and compromised generalization. To address this, the proposed framework adopts a structured feature–classifier pairing approach: the SVM is paired with FBCSP features, and XGBoost is paired with FBCCA features. This strategy leverages the strengths of each classifier in handling its respective feature type. A weighted probabilistic fusion mechanism is then employed to integrate the outputs from the two classifiers. This fusion enables the system to exploit the complementary strengths of both classifiers without diminishing discriminative capability. By employing this dual-branch classifier fusion scheme—an SVM for FBCSPs and XGBoost for FBCCA—the framework achieves both classifier-specific adaptability and coordinated optimization of feature–model compatibility, thereby enhancing robustness and generalization in asynchronous BCI state detection.
In summary, this study proposes a dual-level fusion framework for asynchronous SSMVEP-based BCI systems, incorporating a three-tier collaborative structure that integrates heterogeneous features, heterogeneous classifiers, and decision-level fusion. At the feature level, spatial–domain and frequency domain features are extracted using FBCSP and FBCCA, enabling joint modeling of spatial distributions and frequency-locked responses in EEG signals. At the classifier level, SVM and XGBoost are respectively employed to process the FBCSP and FBCCA features, and their outputs are combined using a weighted probabilistic fusion strategy to achieve structured feature–classifier alignment and collaborative optimization.
This study systematically introduces a novel dual-feature fusion mechanism based on FBCSPs and FBCCA into the asynchronous SSMVEP framework, achieving joint modeling of spatial and frequency information. Furthermore, a classifier ensemble is constructed based on feature–classifier compatibility, where an SVM and XGBoost are paired with their respective feature types, enhancing the model’s adaptability to heterogeneous features and improving generalization performance. The proposed method offers a novel and practical approach for developing high-performance, scalable asynchronous BCI systems.
2. Materials and Methods
2.1. Subjects
A total of 10 participants aged between 23 and 26 years were recruited for this study. All participants had normal or corrected-to-normal vision and no history of psychiatric disorders. Written informed consent was obtained from all participants after a full explanation of the experimental procedures.
2.2. Paradigm Design
This study employed a ring-shaped contraction–expansion SSMVEP paradigm. The SSMVEP paradigm consisted of a high-contrast background and a low-contrast annular stimulus. The primary parameters of the low-contrast ring included its inner and outer diameters. The high-contrast background determined the maximum diameter of the entire visual paradigm. The area ratio (
C) between the ring and the background was defined as follows:
In this equation, represents the total area of the annular stimulus, and denotes the total area of the background.
At the onset of the paradigm, the outer diameters of the concentric rings were arranged in an arithmetic sequence. Given the maximum diameter of the visual field (
), the outer diameter (
) and inner diameter (
) of each ring were related to the area as follows:
In this equation, denotes the index of the -th ring counted from the center outward, and represents the total number of rings. indicates the area enclosed between the outer diameter of the -th ring and that of the ( − 1)-th ring, while refers to the area of the -th annular ring.
To ensure that the overall luminance of the paradigm remains constant during motion, the area ratio
between the annular rings and the background must be maintained at a fixed value. Therefore, the inner diameter of each ring needs to be determined through calculation. Based on Equations (1)–(4), the inner diameter
of the
-th ring can be computed as follows:
Let the variation range of the outer diameter of each annular ring be defined as
. The outer diameter follows a sinusoidal motion trajectory. Accordingly, the time-dependent change in the outer diameter
of the
-th ring can be expressed as:
In this equation, represents the stimulation frequency, and denotes the stimulation time.
In this study, eight types of ring-shaped stimulation paradigms with distinct flickering frequencies (i.e., 3.00 Hz, 3.25 Hz, 3.50 Hz, 3.75 Hz, 4.00 Hz, 4.25 Hz, 4.50 Hz, and 4.75 Hz) were employed, as illustrated in
Figure 1. In addition, to evaluate the proposed algorithm’s ability to distinguish between idle and control states, a designated idle region was included to collect EEG data corresponding to the idle state. Participants were instructed to fixate within a dashed rectangular frame during idle trials to ensure that no control commands were generated. As a result, a total of nine target classes were collected in this study, including eight stimulation conditions and one idle condition.
2.3. Data Acquisition
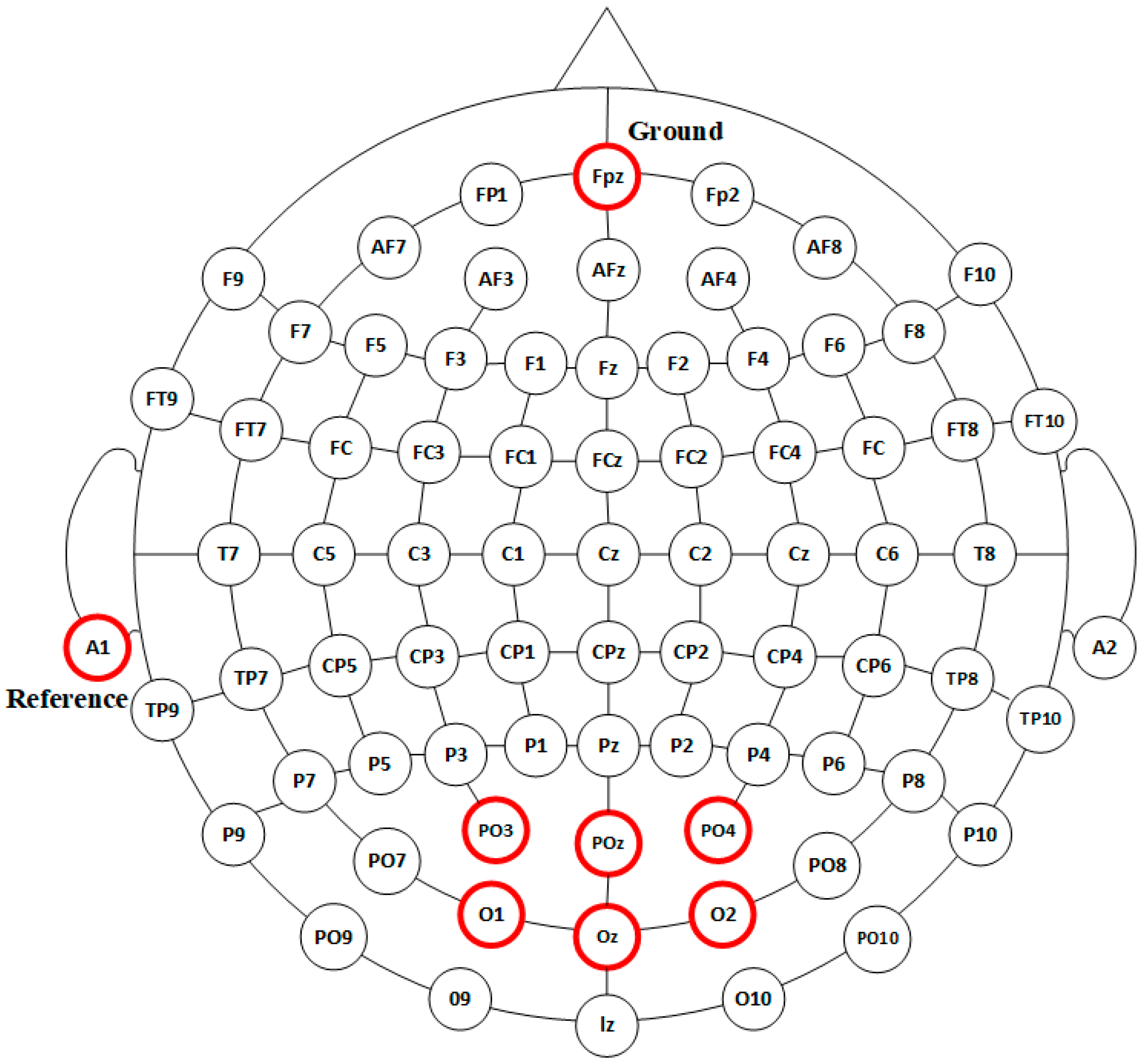
EEG signals were recorded using the g.USBamp system (The manufacturer of this device is g.tec medical engineering GmbH, Schiedlberg, Austria). EEG electrodes were positioned in accordance with the international 10–20 system. The reference electrode (A1) was placed on the unilateral earlobe of the subject, while the ground electrode was located at Fpz, on the prefrontal cortex. Since SSMVEPs elicit the strongest responses in the occipital region of the brain, six electrodes—O1, Oz, O2, PO3, POz, and PO4—were selected for data acquisition in this area, as illustrated in
Figure 2. EEG signals were sampled at 1200 Hz, followed by preprocessing steps that included a 4th-order Butterworth notch filter (48–52 Hz) to eliminate powerline interference and an 8th-order Butterworth band-pass filter (2–100 Hz) to suppress low- and high-frequency noise. The filtered signals were subsequently downsampled to 240 Hz. Throughout the recording session, electrode impedance was maintained below 10 kΩ.
2.4. Experimental Procedure
During the experiment, participants were instructed to sequentially gaze at eight target stimuli, each corresponding to a different stimulation frequency (3.00 Hz, 3.25 Hz, 3.50 Hz, 3.75 Hz, 4.00 Hz, 4.25 Hz, and 4.75 Hz). Each frequency-specific target was presented 20 times, with idle fixation trials randomly interspersed among the eight stimulation conditions to simulate the non-control state. Each trial lasted 5 s, consisting of a 1 s cue period, a 3 s stimulation period, and a 1 s rest period. The entire experiment comprised 10 blocks, with each block containing 16 trials. After the completion of each block, participants were given a 2 min break to minimize fatigue.
2.5. Feature Extraction and Classification Algorithms
2.5.1. Common Spatial Patterns
The CSP is a spatial filtering algorithm specifically designed for binary classification tasks, and it is widely used in the field of brain signal processing. This algorithm effectively extracts spatial distribution features from multichannel EEG data. CSPs have been extensively applied in brain–computer interface systems and other neural signal analysis tasks, demonstrating particularly strong performance in decoding motor imagery, such as hand movement intentions. The core principle of CSPs involves the use of matrix diagonalization techniques to identify an optimal set of spatial filters. These filters are then used to project the EEG data in a way that maximizes the variance difference between two classes. This approach enables the extraction of feature vectors with enhanced class separability.
Assume two classes of EEG data,
and
, with each trial having dimensions of N × T (number of channels × number of time points). By applying Equations (7) and (8) to
and
, the average sample covariance matrices for the two classes,
and
, can be obtained.
In these equations, and represent the total number of samples in and , respectively. and denote the transpose of the -th sample in and , respectively. refers to the sum of the elements along the main diagonal of matrix .
Next, the composite spatial covariance matrix is calculated using Equation (9), and eigenvalue decomposition is performed on the resulting composite covariance matrix
using Equation (10):
In this equation, denotes the diagonal matrix of eigenvalues of the covariance matrix , represents the matrix of corresponding eigenvectors, and is the transpose of .
After obtaining the eigenvalue matrix
and eigenvector matrix
through decomposition, the whitening transformation matrix
is computed as follows:
The whitening matrix
is then applied to transform the average covariance matrix
and
, as follows:
Subsequently, principal component decomposition is performed on
and
.
Using Equations (14) and (15), it can be demonstrated that the eigenvector matrices of
and
are identical. Under this condition, the eigenvalue matrices of
and
satisfy the following relationship:
According to Equation (16), the eigenvalue matrices of
and
are complementary and sum to the identity matrix. This implies that when an eigenvalue of
reaches its maximum, the corresponding eigenvalue of
attains its minimum. Therefore, the eigenvalues of
are sorted in descending order, while those of
are sorted in ascending order. The eigenvectors corresponding to the top mmm largest eigenvalues of
and the top mmm smallest eigenvalues of
are selected and combined to form
. Consequently, the final spatial filter projection matrix
is obtained as:
Let
denote the input EEG signal. By applying the spatial filter, the filtered signal
can be obtained as follows:
Subsequently, the variance of the filtered signal is calculated, normalized, and then log-transformed to obtain the corresponding feature vector
for the input signal
, as shown below:
In this equation, denotes the variance of the filtered signal .
2.5.2. Canonical Correlation Analysis
CCA is an unsupervised machine learning algorithm used to explore the relationship between two sets of variables, and . The fundamental idea of CCA is to find two sets of non-zero vectors, and , which are used to linearly combine the variables in each set into new variables, and . Specifically, the linear combinations are defined as and . By applying the coefficient vectors and , the analysis shifts from examining the relationship between the original variable sets, and , to investigating the correlation between the derived variables, and .
In the process of using CCA to identify SSMVEP signals, a set of sine and cosine functions must be constructed as reference signals, as defined by the following equation:
In this equation, denotes the number of harmonics, represents the number of sampling points, and is the sampling frequency.
The recorded evoked EEG signal is denoted as
, where
is the number of electrode channels. By solving Equation (21), a set of canonical correlation coefficients between the EEG signal
and the reference signal
can be obtained, represented as
.
After computing each set of data, four correlation coefficient vectors,
, are obtained, each corresponding to a specific flickering frequency,
, as shown in Equation (22). The frequency associated with the maximum correlation coefficient
in the vector
is selected as the final identified target frequency, denoted as
.
Since the CCA algorithm employs the correlation coefficient corresponding to each stimulus frequency as the basis for classification, its accuracy can to some extent reflect the quality of the evoked signals induced by the paradigm.
2.5.3. Filter Bank Combination Characteristics
Filter banks (FBs) are a commonly used signal processing technique that decomposes the input signal into multiple frequency sub-bands. It has been widely applied in EEG signal analysis and has given rise to algorithms such as filter bank common spatial patterns (FBCSPs) and filter bank canonical correlation analysis (FBCCA). In this approach, the EEG signal is first filtered into different frequency bands using a filter bank. The filter bank analysis decomposes the original EEG signal into five sub-band signals using a set of predefined band-pass filters. Each sub-band covers a specific frequency range and facilitates the effective extraction of frequency-specific neural activity features, while preserving the phase information of the signal. The selected five sub-bands span the frequency range of 2–40 Hz and are defined as follows: [2–8] Hz, [8–14] Hz, [14–20] Hz, [20–30] Hz, and [30–40] Hz. This configuration encompasses commonly observed EEG rhythms, including delta, theta, alpha, beta, and low-gamma bands, thereby providing a comprehensive frequency representation for subsequent feature extraction and classification tasks.
Features are then extracted from the filtered signals using CSP and CCA methods. Finally, the CSP and CCA features are combined through a cross-feature fusion strategy. The detailed procedure is as follows:
First, the input data
are processed using a set of predefined filters, resulting in a filter bank denoted as
.
In this equation, denotes the -th filter, and represents the total number of filters in the filter bank.
The input data are then transformed using the filter bank
, resulting in the filtered data
, as expressed by the following equation:
Feature extraction is performed on the filter bank outputs using the CCA algorithm (Equation (21)) and the CSP algorithm (Equation (19)), resulting in the following expression:
The combined feature
is obtained by cross-fusing the features extracted using the CSP and CCA algorithms.
2.5.4. Classifier Design and Fusion Strategy
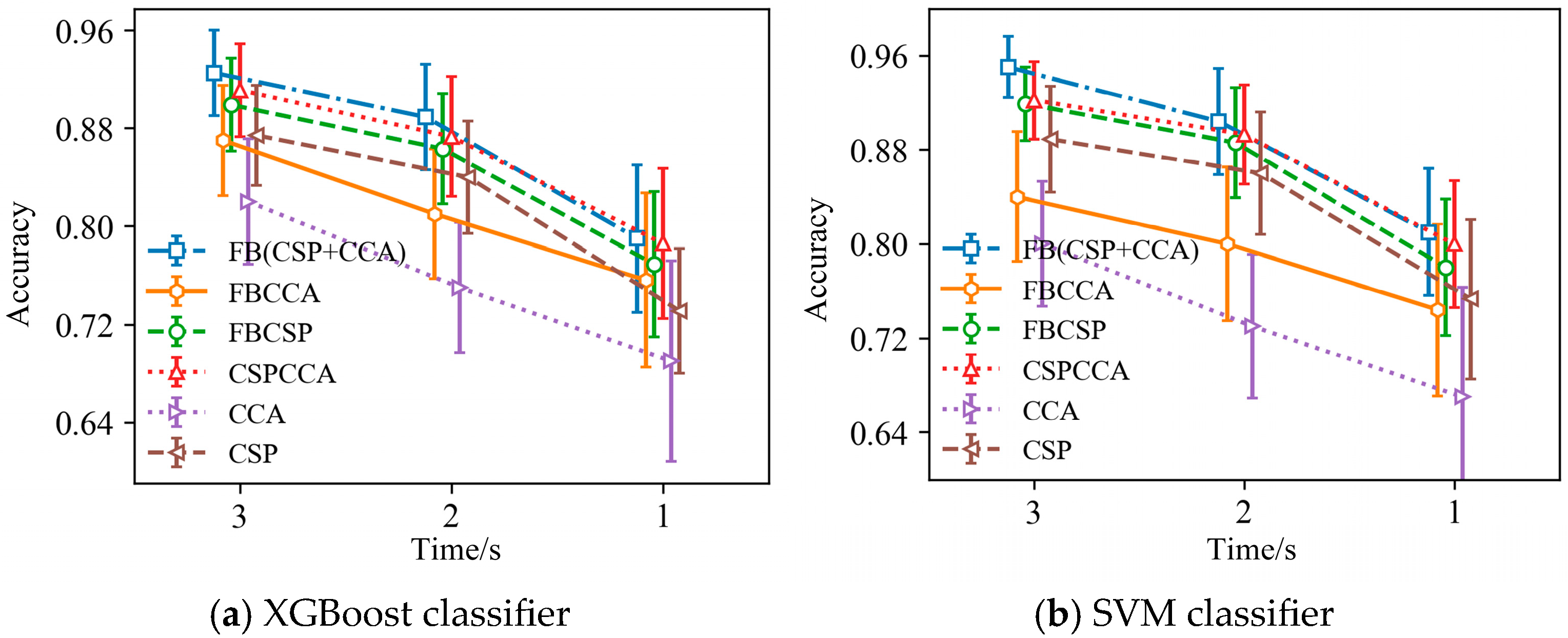
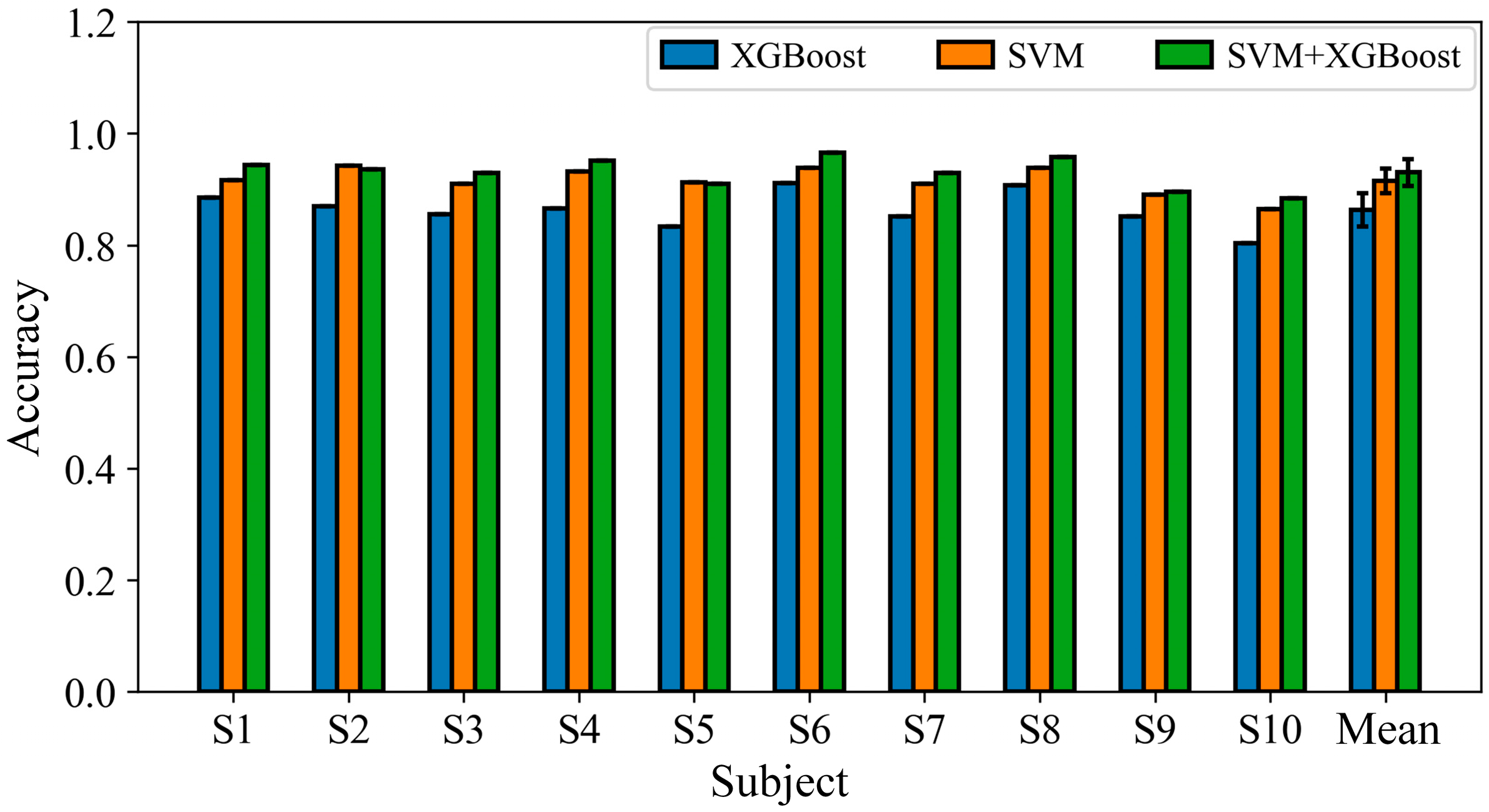
Considering that the extracted features require classification, two classifiers were selected based on the characteristics of the respective features. For features extracted using the CSP algorithm, SVM was adopted, as the CSP aims to maximize variance between two classes, making an SVM a suitable choice for binary classification. In contrast, the features derived from the CCA algorithm tend to have higher dimensionality due to the presence of multiple stimulation frequencies; therefore, the XGBoost algorithm, an ensemble learning method, was chosen to better handle this complexity. Accordingly, in this study, an SVM and XGBoost were used to classify features extracted by the CSP and CCA algorithms, respectively.
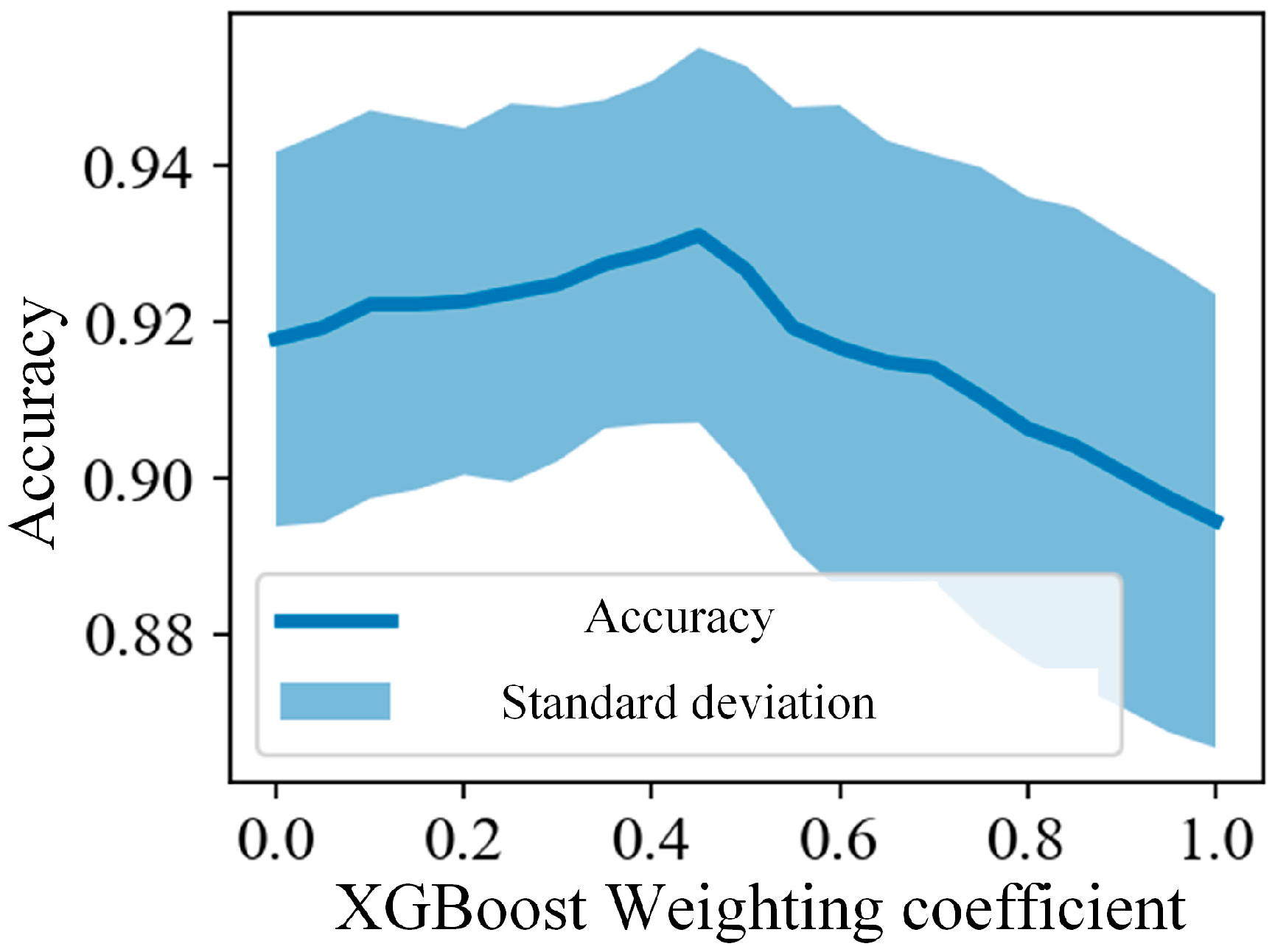
XGBoost is well suited for handling a large number of features and can automatically learn nonlinear relationships among them, making it particularly effective for complex and high-dimensional datasets. In contrast, SVMs excel at identifying optimal decision boundaries, especially in binary classification tasks. Given the nature of the combined features—CCA-derived features represent multi-class frequency information, while CSP-derived features capture binary spatial energy differences—XGBoost may outperform an SVM when classifying CCA features, whereas an SVM may be more effective than XGBoost for CSP features. Therefore, a weighted (SVM + XGBoost) classifier is proposed to predict the combined FB(CSP + CCA) features. This hybrid approach enables the classifier to learn the relative importance of different feature types, potentially enhancing the model’s ability to recognize asynchronous states. The detailed design is as follows:
In this equation, represents the final predicted probability for the combined feature ; denotes the weighting coefficient. is the fused feature vector constructed from both CSP and CCA features. and correspond to the predicted probabilities generated by the SVM and XGBoost classifiers, respectively, based on the input feature .
2.6. Statistical Analyses
For the classification accuracy of different methods under each subject condition, we adopted the paired t-test to evaluate the statistical significance of the differences between the methods. And Bonferroni correction was adopted to adjust the p value. A corrected p value of less than 0.05 was taken as the criterion for judging that the difference was statistically significant.
4. Discussion
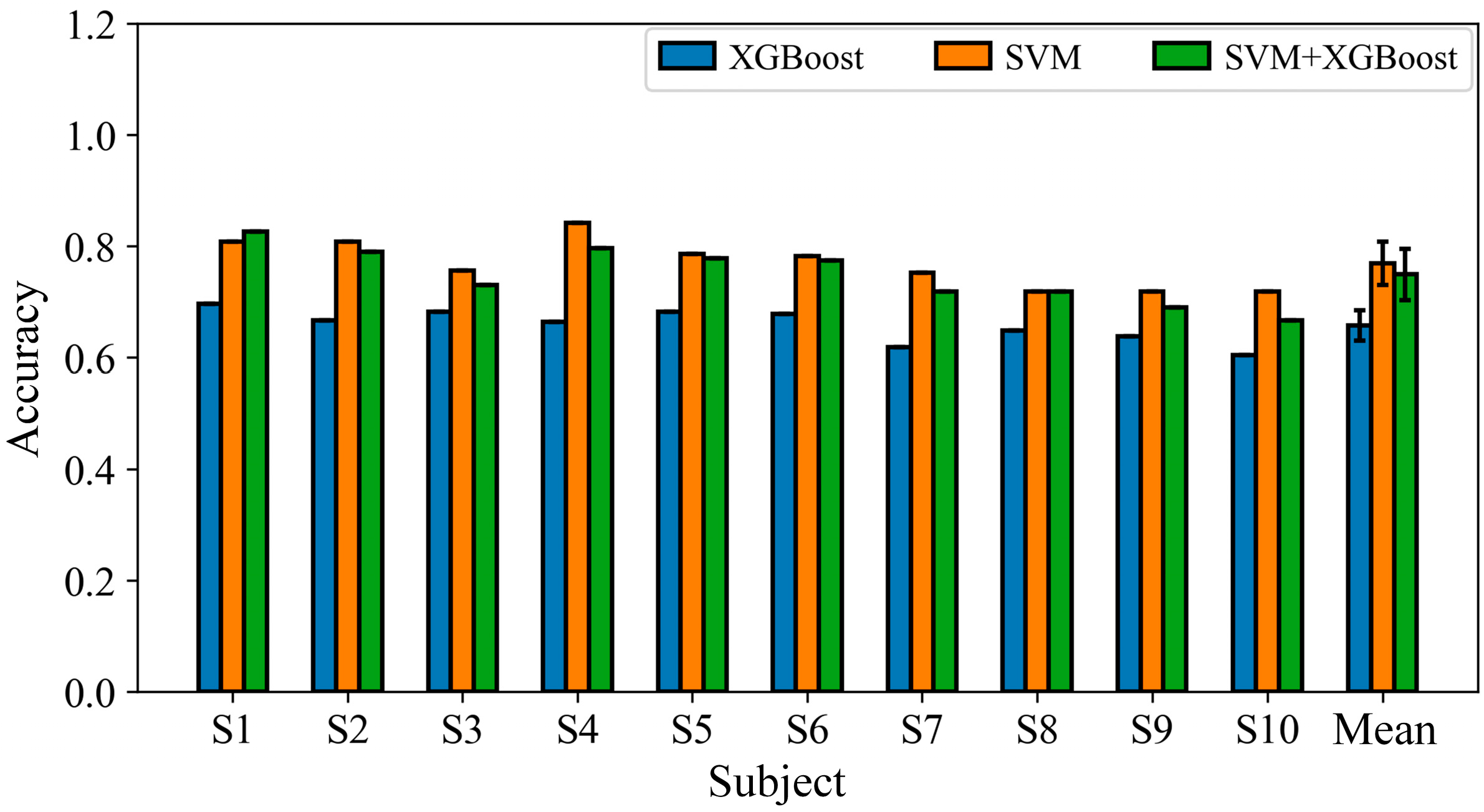
This study addresses the challenge of reliably distinguishing between IC and NC states in asynchronous BCIs. It proposes a hybrid SSMVEP-BCI system that integrates multidimensional features with a structurally complementary classification strategy. The system combines FBCSPs and FBCCA to jointly extract spatial and frequency information from EEG signals, effectively enhancing inter-class separability during the feature modeling phase. For classification, the SVM and XGBoost are fused with weighted integration to improve both the discriminative power and stability of the model. Experimental results demonstrate that under asynchronous conditions, the proposed system significantly outperforms methods based on single-feature extraction or traditional classification architectures, validating its effectiveness and practicality.
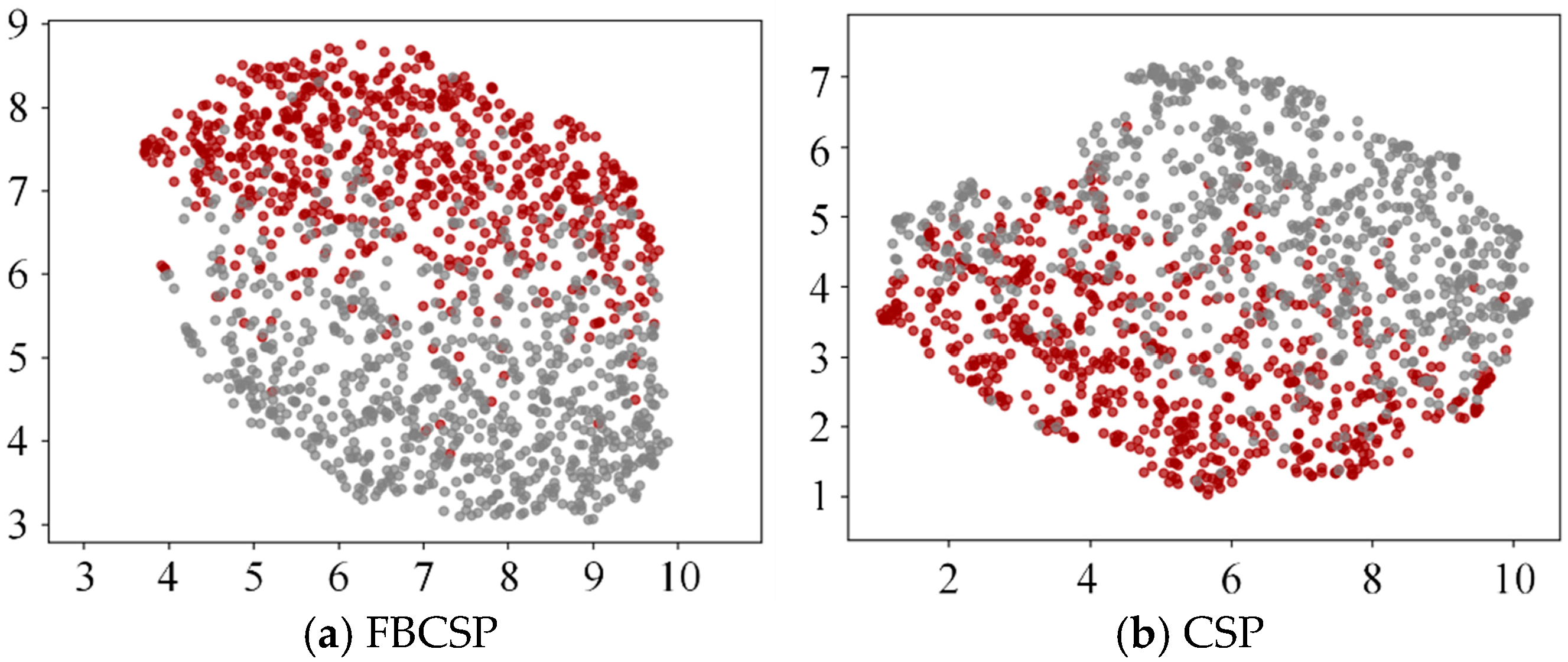
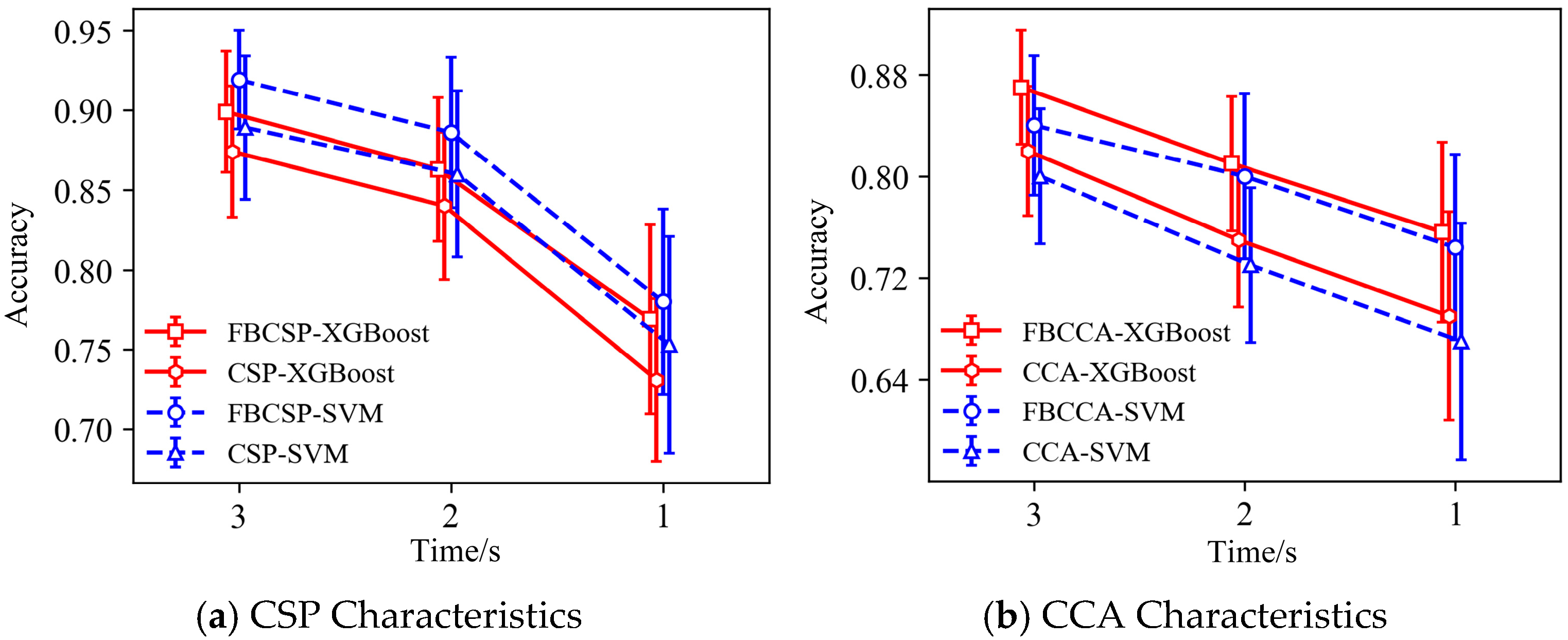
FBCSPs and FBCCA represent two fundamental processing pathways for extracting information from EEG signals: spatial patterns and frequency features, respectively. FBCSPs, which are derived from the CSP method, apply spatial filtering to maximize the covariance difference between two classes. This reflects category-specific differences in the spatial distribution of cortical activity and is particularly effective for capturing cooperative patterns across multiple channels in tasks such as attentional shifts or motor imagery [
32,
33]. FBCCA, on the other hand, is based on CCA, which assumes that the brain exhibits phase-locked responses at specific frequencies to periodic external stimuli (e.g., SSVEPs/SSMVEPs). It extracts neural coherence features by maximizing the correlation between EEG signals and reference sinusoidal sequences [
34,
35]. These two feature types model distinct neural mechanisms: FBCSPs focus on spatial distribution patterns, while FBCCA emphasizes frequency-locked coupling. They are not redundant but rather represent highly complementary neural encoding pathways.
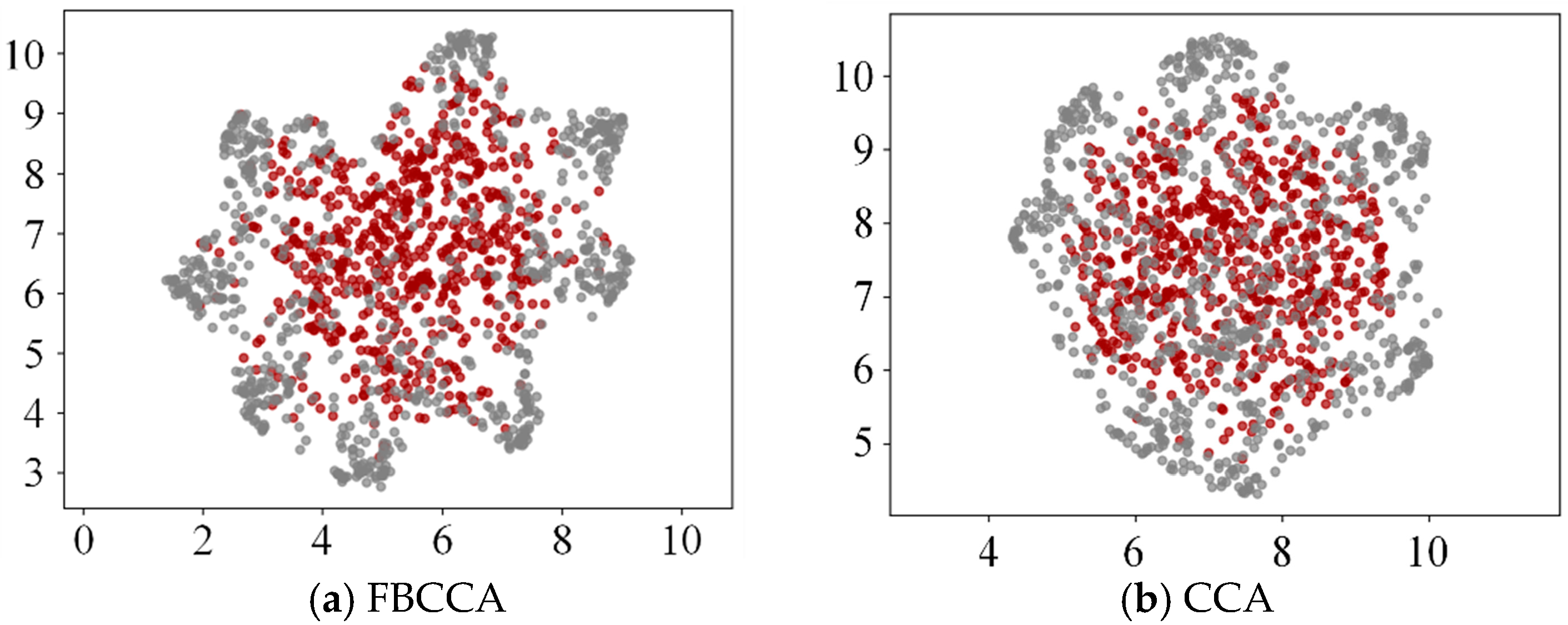
Moreover, both FBCSPs and FBCCA employ a filter bank strategy to decompose and reconstruct signals across multiple frequency sub-bands. This approach helps mitigate the distribution instability caused by individual frequency drift and channel jitter, and it has become a key trend in recent steady-state visual evoked potential (SSVEP) research [
36,
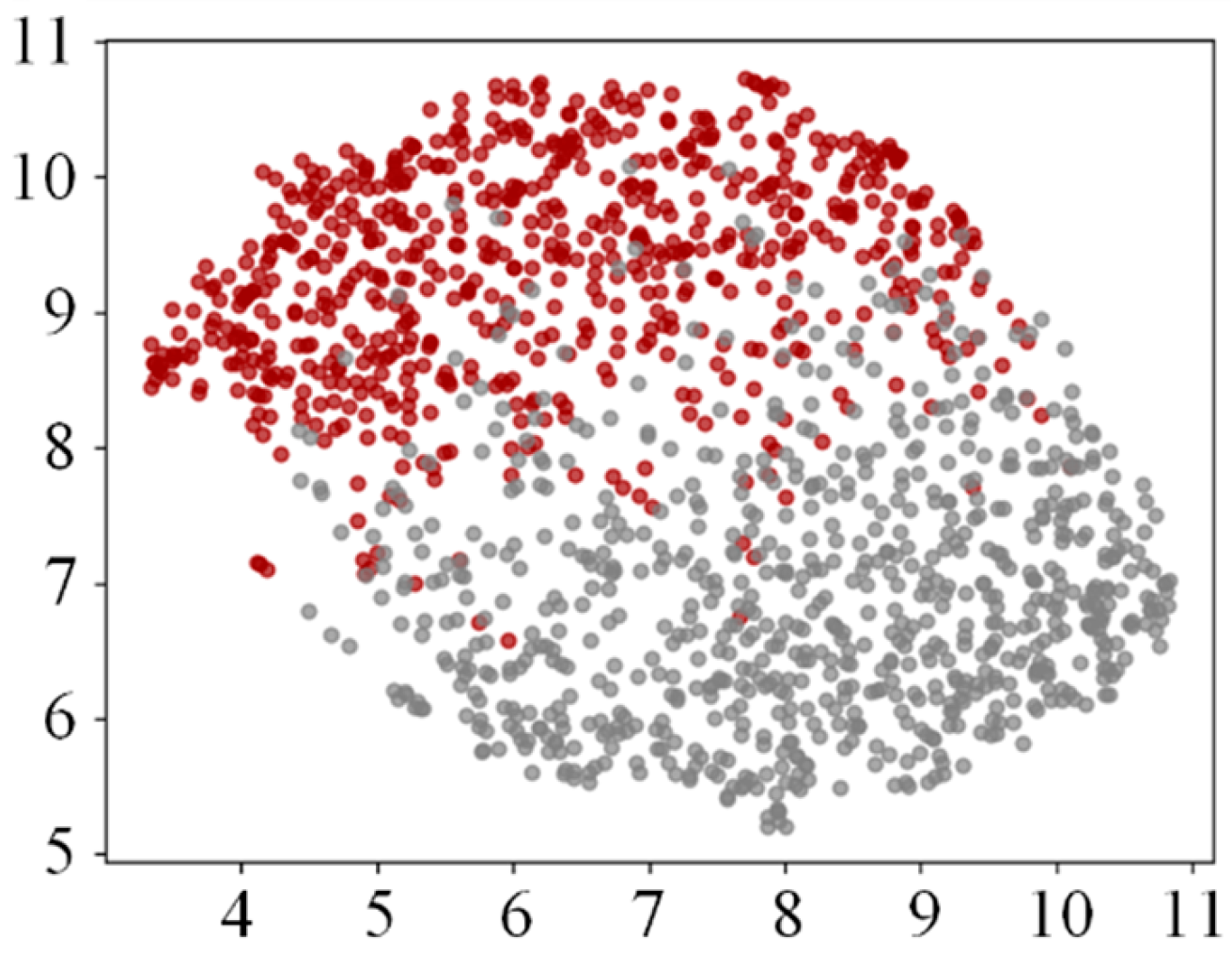
37]. By integrating features from different frequency bands and decoding pathways, this study achieves a robust and biologically grounded feature representation. This enriched signal foundation enhances the discrimination of complex IC/NC states in asynchronous tasks and improves resistance to noise. The fusion of FBCSPs and FBCCA enables synergistic modeling of the multichannel encoding characteristics in SSMVEP signals, enhancing the structural representation of neural information. Visualization results demonstrate superior inter-class separability for the fused features, supporting our modeling hypothesis regarding the spatial–frequency coupling mechanism. This study, based on the fusion idea of the complementarity of neural processing paths, has advantages in terms of physiological rationality and model interpretability.
In terms of classifier design, this study adopts the principle of feature structure–classifier preference matching to construct a dual-classifier framework integrating an SVM and XGBoost. The SVM, which is grounded in the theory of margin maximization, demonstrates a strong generalization ability when dealing with structured, low-dimensional, and boundary-concentrated data. It is particularly suited for spatially projected features that are linearly or nearly linearly separable [
38]. In EEG signal processing, SVMs are widely used for classification tasks, such as motor imagery and SSVEP, due to their robustness and resistance to overfitting in high-dimensional spaces [
39,
40]. In contrast, XGBoost, as a representative of ensemble tree models, excels in handling nonlinear, high-dimensional data with strong feature interdependencies [
41]. It is especially effective for modeling complex frequency domain features [
42], such as the high-dimensional sub-band response features produced by FBCCA.
The weighted fusion mechanism we designed goes beyond traditional majority voting. Instead, it establishes a structurally synergistic decision-making process by analyzing the performance weights of each classifier across different feature types. This approach balances discriminative power and resistance to interference, avoiding the interpretability challenges often associated with deep learning models. Compared to recent “black-box” deep learning-based EEG decoding methods [
43], our dual-classifier structure maintains high interpretability and flexible parameter tuning, making it particularly well suited for high-reliability, asynchronous systems where minimizing false activations is critical. SVMs excel at learning geometric boundaries in the low-dimensional space shaped by FBCSPs, while XGBoost effectively handles the high-dimensional, nonlinear feature distributions derived from FBCCA. By fusing the outputs of both classifiers with learned weights, the system achieves enhanced discriminative stability in high-dimensional feature space and avoids overfitting to specific feature sets that can occur with single models. This classifier fusion represents not only an improvement in model accuracy but also an architectural optimization of the fusion strategy, highlighting the system’s innovation in information integration mechanisms.
Despite the encouraging results achieved in this study, several issues remain that warrant further investigation. First, the current fusion weights are empirically set and cannot dynamically adapt to real-world interaction conditions such as user state fluctuations and signal variability. Future research could explore adaptive weighting mechanisms based on reinforcement learning, Bayesian optimization, or neural architecture search, aiming to enhance the system’s long-term applicability and robustness. Second, the system has not yet been deployed in a real-time asynchronous interaction environment, lacking comprehensive evaluation in terms of response latency, computational resource consumption, and user feedback. Asynchronous BCI systems are highly sensitive to response time [
44]. Therefore, future efforts should focus on embedding the model into real-time systems and conducting system-level online testing.
The current experimental validation was conducted only with healthy subjects, and there is a lack of application evaluation in clinical populations such as individuals with motor disorders or cognitive impairments. Given the known differences in neural response timing and activation patterns among these groups [
45,
46], it is important to develop personalized EEG feature extraction strategies to improve the model’s generalizability across diverse populations. Additionally, this study has not yet conducted a direct quantitative comparison of classification performance with other mainstream methods, such as TRCA or CNN-based classifiers. Therefore, in future work, we plan to integrate our fusion strategy into more advanced models to evaluate its generalizability, robustness, and applicability across different classification frameworks. These insights would provide a theoretical foundation for developing highly trustworthy, interpretable, and auditable BCI systems.
In conclusion, this study demonstrates that combining multi-band EEG features (FBCSP and FBCCA) with dual classifier ensembles (SVM and XGBoost) provides a promising solution for improving asynchronous state detection in SSMVEP-BCI systems. The proposed methodology enhances feature separability and classification reliability, which is a key step in the development of practical, user-friendly, and high-performance asynchronous BCIs.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}