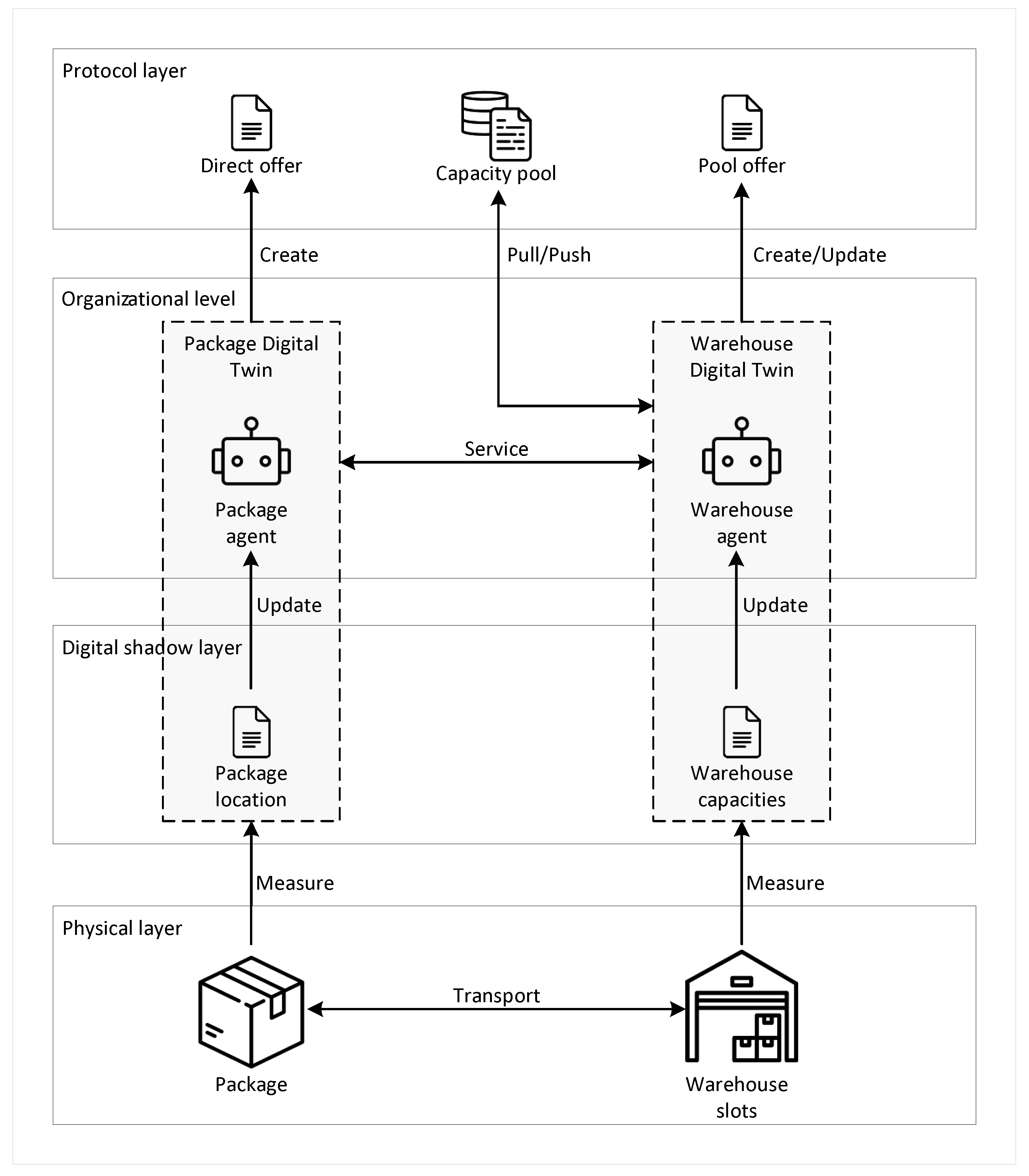
The decentralized warehousing system is built upon a multi-layered architecture, with each of the following first four layers playing a specific role in system operation: the physical layer, the digital shadow layer, the organizational layer, and the protocol layer. In combination, these layers provide the infrastructure and data flows that enable the system to function seamlessly, as illustrated in
Figure 1. In this layered structure, package agents and warehouse agents play the central role, autonomously managing storage services by interacting with and leveraging information from the four layers. The subsequent sections provide a detailed description of each layer’s role and functionality, followed by an in-depth look at the agent design, which covers the states, decision-making processes, and interactions of the package and warehouse agents within this system.
3.1. Physical Layer
The physical layer in the decentralized warehousing system represents the real-world, tangible components that form the foundation of the system’s operations. This includes packages, warehouse slots, and transport processes. The physical layer manages the movement, storage, and spatial arrangement of goods, ensuring that every entity is properly accounted for in terms of its physical position and availability.
In this layer, each package is characterized by its location, as shown in Equation (
12):
where
represents the location of the
i-th package,
denotes the 3D coordinates of the package within the system, and
is the total number of packages.
Similarly, each warehouse slot
is characterized by both its location and its occupancy status, as shown in Equation (
13):
where
are the 3D coordinates of the
j-th warehouse slot,
is the occupancy status, where
if the slot is occupied and
if it is vacant, and
represents the total number of warehouse slots.
Transport processes are responsible for changing the states of packages and warehouse slots. They facilitate the movement of packages from one location to another, changing their location. The process operates between two points in time: the initial time
t, when transport begins, and the final time
, when transport is completed. Let
represent the location of package
i at the starting time
t, and
represent its location after the transport process is completed. Initially, the package’s location is defined by Equation (
14):
And, after the transport process (Equation (
15), the new location is
The transition can be represented as shown in Equation (
16):
where
represents the change in the position of the coordinates of the package caused by the transport process. The changes in coordinates
,
,
are defined as
.
The state of the warehouse slots also changes during the transport process, reflecting the movement of packages between locations. As a package is transported from one warehouse to another, the origin slot becomes vacant, and the destination slot becomes occupied. Let
(Equation (
17)) represent the state of the origin warehouse slot at time
t:
And let
represent the state of the destination warehouse slot at time
t (Equation (
18)):
indicates that the origin slot is occupied, and
indicates that the destination slot is vacant. After the transport process, the occupancy of the slots changes as shown in Equation (
19):
This means that, after the transport process, the origin slot becomes vacant (), and the destination slot becomes occupied ().
The transport time
consists of three phases, as shown in Equation (
20):
The loading time () represents the period during which the package is prepared and placed onto the transport system. During the transit time (), the package physically moves between the origin and destination, where its coordinates change as a function of time. Finally, the unloading time () accounts for the removal of the package from the transport system and its placement into the destination storage.
3.2. Digital Shadow Layer
The digital shadow layer is a part of the system’s digital twin, providing a real-time, synchronized reflection of the physical layer. This layer mirrors the current states of packages and warehouse slots, allowing other system layers to access up-to-date information without directly interacting with the physical components. The state of the system in the digital shadow is updated continuously by measuring the real-world physical processes, ensuring accurate and timely representation of the system.
The package state in the digital shadow mirrors the physical layer. The location of each package at time
t is reflected in the digital shadow, as shown in Equation (
21):
where
represents the digital shadow state of the
i-th package and
are the 3D coordinates of the package at time
t, mirroring the real-world location.
represents the total number of packages.
Similarly, the warehouse slot state in the digital shadow reflects the physical state of the slot, including both its location and occupancy status, as shown in Equation (
22):
where
represents the digital shadow state of the
j-th warehouse slot,
is the occupancy status of the warehouse slot at time
t, with
if it is occupied and
if it is vacant, and
represents the total number of warehouse slots.
The digital shadow layer can also perform a higher level of data abstraction. The spatial part of each slot’s location can be simplified by using slot IDs instead of precise 3D coordinates, as shown in Equation (
23):
where
is the ID that abstracts the warehouse slot’s spatial position and
represents the occupancy status, indicating whether the slot is occupied (1) or vacant (0).
Similarly, an abstraction of the spatial location of packages to the warehouse slot IDs can be performed. This means that, instead of tracking the exact 3D coordinates of packages throughout their journey, the system simplifies the process by associating each package with the ID of the warehouse slot where it is stored. This abstraction helps streamline the management of packages, focusing on the start and end points of the package’s journey rather than continuously monitoring every movement.
When a package arrives at a specific warehouse slot, it adopts the ID of that slot as its location. Thus, the final state of the package is represented by the slot ID, as shown in Equation (
24):
where
represents the digital shadow state of the
i-th package and
is the ID of the warehouse slot where the package is stored.
The digital shadow layer includes both detailed physical data and abstracted information. While the exact 3D coordinates of packages and warehouse slots are continuously tracked for precise monitoring, spatial abstraction simplifies management by mapping package locations to slot IDs. This duality ensures both real-time accuracy and simplified data which can be utilized by other layers.
3.3. Organizational Layer
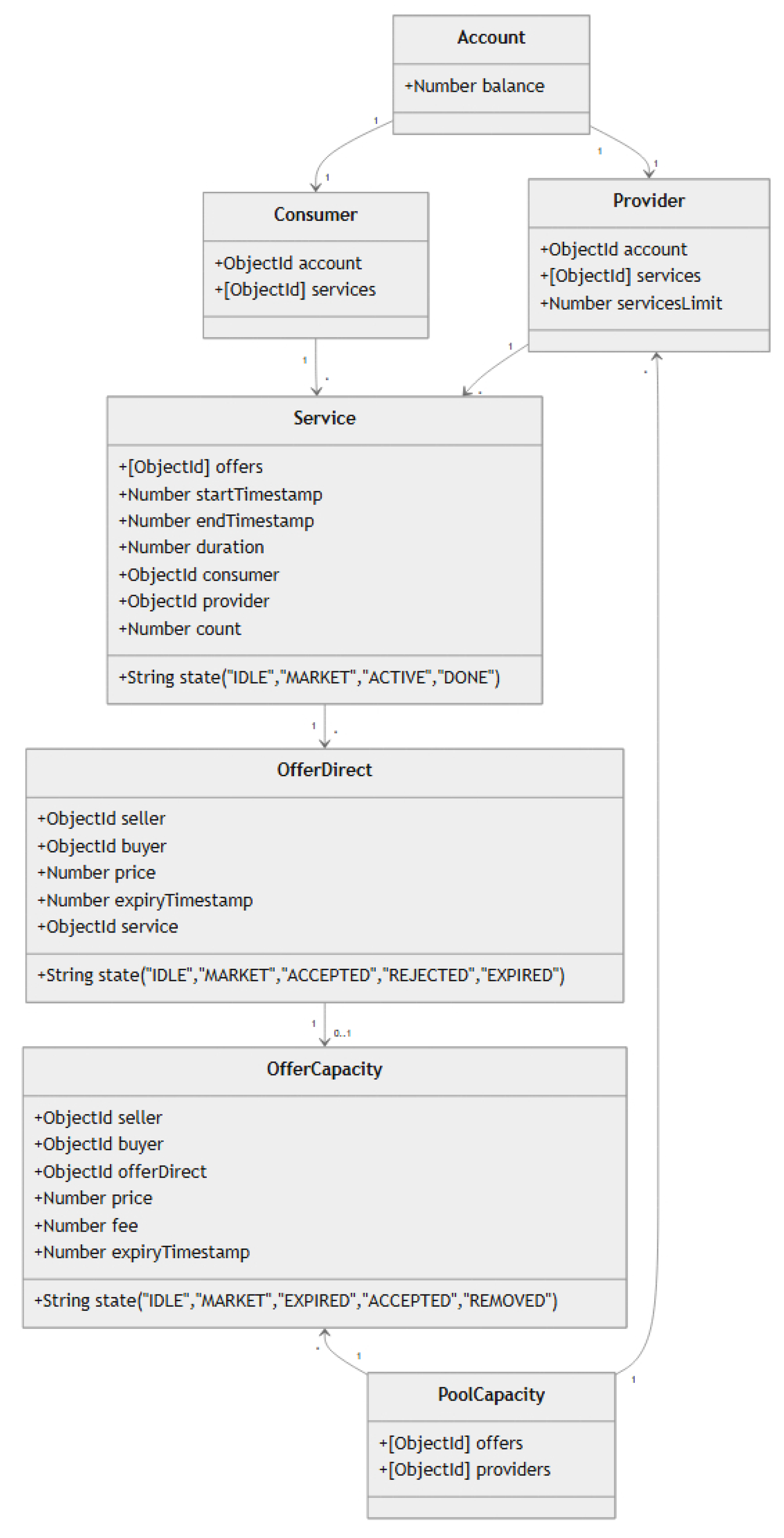
The organizational layer is where the decision-making processes and interactions between agents take place. This layer hosts the package and warehouse agents, autonomously negotiating and executing services. A service represents the actions or resources requested by a package agent and provided by a warehouse agent. Two types of services are defined within this system: a storage service
, which is responsible for storing a package in a warehouse slot, and a transport service
, which involves transporting a package between warehouse slots, as shown in Equation (
25):
where
and
are the times that define the start and the end of the service execution,
identifies the specific warehouse slot,
and
represent the source and target warehouse slots, and
is the ID of the package being transported.
In our current system, transport services are ignored under the assumption that the time required to execute storage services is significantly greater than the time required for the execution of transport services. As a result, transport times are considered negligible in comparison to storage times. Therefore, the transport service component does not have a major impact on the system’s overall timing and execution of processes.
A storage service transitions through multiple states during its lifecycle, as shown in Equation (
26):
Initially, the service enters the Negotiation state (before ), where the parameters, such as the start time , end time , and warehouse slot, are agreed upon by the agents. After the negotiation is completed, the service transitions to the Scheduled state, which occurs before the start time, indicating that the service is planned but not yet active. Once the start time is reached, the service moves into the Active state, meaning the package is being stored in the designated warehouse slot between and . During this time, the warehouse slot is fully occupied by the package. Finally, when the end time is reached, the service transitions to the Completed state, at which point the package is removed from the slot, and the slot becomes available for future use.
3.4. Protocol Layer
The protocol layer plays a crucial role in facilitating the negotiation of services between agents in the organizational layer. While the agents are responsible for making autonomous decisions, the protocol layer provides the standardized frameworks and data structures that allow these agents to effectively communicate and negotiate service agreements, ensuring consistency across the system.
A direct offer is a data structure which is initiated by the package agent and sent to the warehouse agent as a formal proposal for service. The direct offer
defines the terms under which the package agent requests a service and includes several essential parameters, as shown in Equation (
27):
where
is the proposed start time for the service,
is the proposed end time of the service,
is the price proposed by the package agent for the service, and
represents the expiry time or deadline until which the offer is valid. Direct offers ensure that both the package and warehouse agents have a clear, standardized structure for negotiating the service terms.
The warehouse agent can respond to a direct offer in three distinct ways: by accepting, rejecting, or forwarding the offer. If the warehouse agent agrees to the terms set forth in the offer, the service is scheduled, and the package agent is informed that the service will proceed as requested. No formal contract is signed, but the scheduling of the service solidifies the agreement between the two agents. If the warehouse agent cannot fulfill the offer or disagrees with the proposed terms, the offer is rejected, and no further action is taken. Alternatively, the warehouse agent may choose to forward the offer to the capacity pool, where other warehouses can review and potentially fulfill the request.
The capacity pool is a shared resource where warehouse agents can place unfulfilled direct offers for other warehouses to pick up. This system enables capacity pooling concepts, enabling warehouses to balance resources across the network. When a direct offer is forwarded to the pool, it becomes a pool offer
, which retains the original offer’s start time and end time but allows the warehouse agent to modify the price and expiry time. The price in the pool offer can be expressed as the original price from the direct offer plus a fee charged by the forwarding warehouse agent, as shown in Equation (
28):
where
and
are the start and end times inherited from the original direct offer,
is the price proposed in the original direct offer,
represents the fee added by the forwarding warehouse agent, which can reflect their desired gain or added cost, and
is the new expiry time set by the forwarding warehouse agent. The capacity pool
functions as an aggregator of pool offers, centralizing unfulfilled service requests from individual warehouses into a shared resource, as shown in Equation (
29):
Figure 2 shows a sequence diagram of the service negotiation process.
(Package Agent 1) initiates the process by sending
(directOffer1) to
(Warehouse Agent 1). The offer includes the proposed start and end times, price, and expiry time, as shown in Equation (
30):
Upon receiving the offer,
has three possible responses: to accept, reject, or forward the offer. If
accepts, it sends an acceptance response back to
, finalizing the scheduling of the service
. If the offer is rejected,
informs
of the rejection
. Alternatively,
can forward the offer to the capacity pool
as
(
), modifying the price and expiry time while retaining the original start and end times, as shown in Equation (
31):
This allows other warehouse agents, such as (Warehouse Agent 2), to review and accept the offer from the pool. If accepts the offer , informs that the service has been scheduled: . This formalizes the negotiation process, showing how agents exchange and process offers, with the capacity pool acting as a passive repository for unfulfilled offers.
In the negotiation protocol, the following inputs are gathered: the direct offer from the package agent (P1), which includes the start time, end time, price, and expiry time; and the internal state of the warehouse agent (W1), which comprises its current capacity and scheduled services. If the offer is forwarded, additional inputs emerge: the pool offer in the capacity pool (C1), which includes modified terms like the adjusted price and expiry time; and the internal state of another warehouse agent (W2), also consisting of its current capacity and scheduled services. Following these inputs, the outputs are produced, including W1’s initial decision on the direct offer, which can be to accept, reject, or forward it (if forwarded, the pool offer is sent to C1), W2’s decision on the pool offer, which can be to accept or ignore it (if W2 accepts, an acceptance message is sent from W2 to W1), and, finally, W1’s ultimate response to P1, indicating whether the service is accepted or rejected.
3.4.1. Agent Design
In the decentralized warehousing system, package and warehouse agents make autonomous decisions based on a combination of perceptual data, derived insights, a decision process, and a defined action space. Perceptual data include real-time information such as storage availability and pricing, while derived insights are based on historical trends and performance metrics, offering a broader context for decision-making. Each agent uses a decision process to evaluate these data types and optimize its objective function. The action space outlines the available actions—such as sending, accepting, or forwarding offers—that agents execute to achieve their goals within the system. The agents balance real-time operations with strategic objectives through these components, ensuring efficient and optimized performance.
Package Agent Design
A package agent operates autonomously to ensure continuous storage for its package while minimizing the total cost associated with storage services. The agent relies on perceptual data (inputs) to make informed decisions and has a set of actions (outputs) available to achieve its objectives.
Perceptual data
The perceptual data
for package agent
i include both the current occupied slot ID and the list of scheduled services, as shown in Equation (
32):
where
represents the abstracted identifier of the warehouse slot occupied by package agent
i (see Equation (
23)), and
is the list of scheduled services
. Each service
in
is defined as per Equation (
25) and includes details such as the start time
, end time
, and price
.
Action space
The package agent’s action space
encompasses all possible actions that the agent can perform to achieve its objectives within the decentralized warehousing system. In our system, the action space is defined by a single action, as shown in Equation (
33):
where SendDirectOffer represents the action of formulating and sending a direct offer
to warehouse agents.
Decision Process
The primary objective of the package agent is to ensure continuous storage for its package while minimizing the total cost of storage. A penalty is applied for any gaps in storage, which can disrupt service continuity. The objective function for the package agent
is defined as follows:
where
n is the total number of scheduled services,
is the price per unit time for the
k-th storage service,
is the duration of the
k-th service,
G represents the total duration of gaps in storage, penalizing any breaks in service continuity, and
w is the penalty weight for gaps, reflecting their impact on the package agent’s operations.
The package agent aims to minimize by negotiating for the lowest possible storage prices and by ensuring there are no gaps () between consecutive storage services in . This objective function balances cost and service continuity, guiding the package agent’s decision-making process.
Each package agent follows a specific decision-making process, leveraging the actions available in its action space to achieve its objectives. By continuously monitoring its perceptual data and scheduled services, the package agent proactively identifies when additional storage services are needed and initiates negotiations with warehouse agents to secure favorable terms.
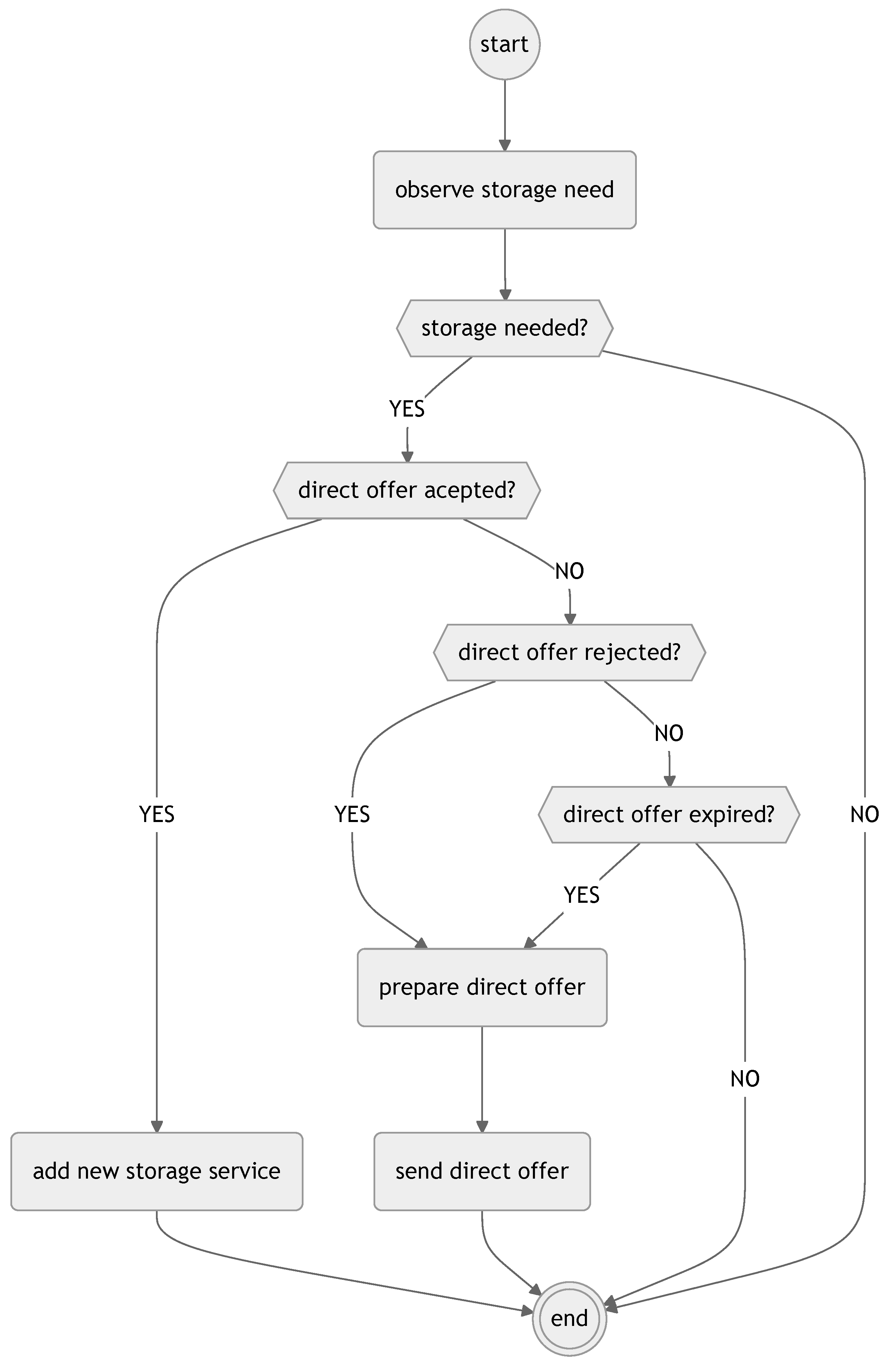
The package agent’s decision process is illustrated in
Figure 3.
The process begins with the agent observing its storage needs. If no additional storage is required, the process terminates. If storage is required, the agent first checks if a direct offer has already been accepted. If the offer has been accepted, the agent adds a new storage service to its schedule and completes the process.
If the offer has not been accepted, the agent checks whether the offer has been rejected. If the offer has been rejected, the agent prepares a new direct offer and sends it to the warehouse agents. If the offer has not been rejected, the agent checks whether the direct offer has expired. If the offer has expired without being accepted or rejected, the agent prepares and sends a new direct offer.
Once a direct offer is accepted and the storage service is added to the schedule or a new offer is sent, the process is completed. This decision-making process allows the package agent to handle its storage requirements proactively, securing storage services as needed.
The package agent’s decision-making process, shown in
Figure 3, uses inputs including perceptual data on storage needs, current scheduled services, and the status of direct offers (accepted, rejected, or expired). The outputs include a decision to terminate if no action is needed, a new direct offer with parameters like start time, end time, price, and expiry time if the prior offer was rejected or expired, or a new storage service added to the schedule if an offer is accepted.
To delve deeper into the package agent’s decision-making process, we focus on two main processes: observing storage needs and preparing direct offers. In the observing storage needs process, the package agent continuously monitors its perceptual data , particularly the list of scheduled services . The agent checks for potential gaps in storage by examining the end times and start times of consecutive services. A gap exists if , contributing to the total gap duration G. Additionally, the agent assesses if the time until the end of the last scheduled service is shorter than a predefined threshold by checking if . If either condition is met, the agent determines that additional storage is needed to prevent service disruptions.
Once the need for storage is identified, the agent proceeds to prepare a direct offer. The direct offer is formulated with the aim of minimizing costs and ensuring continuity. The start time is set to the end time of the last scheduled service or the end time of the service before a detected gap. The end time is determined based on the desired storage duration or set to the start time of the next scheduled service to fill a gap. The proposed price p is set to minimize costs while being acceptable to warehouse agents, considering budget constraints and market rates. The offer expiry time is set to encourage timely responses from warehouse agents.
By following these steps, the package agent proactively manages its storage needs, ensuring continuous storage and minimizing costs in alignment with its objective function.
Warehouse Agent Design
A warehouse agent operates autonomously to maximize revenue from storage services while efficiently managing its available capacity. The agent relies on perceptual data (inputs) to make informed decisions and has a set of actions (outputs) available to achieve its objectives.
Perceptual Data
The perceptual data
for warehouse agent
j are defined as shown in Equation (
35):
where (
) is a set of scheduled services that contains all the storage services already scheduled by the warehouse agent, (
) is a set of direct offers that contains the offers received directly from package agents, and (
) is a set of pool offers that contains the offers in the capacity pool, including those forwarded by other warehouse agents and by warehouse agent
j itself.
These perceptual data are fundamental for the warehouse agent’s decision-making, enabling it to evaluate incoming offers, manage its existing storage services, and potentially forward offers to other agents in the network.
Action space
The warehouse agent’s action space
encompasses all possible actions that the agent can perform, as shown in Equation (
36):
The AcceptDirectOffer action is used when the agent agrees to provide the storage service as requested in the direct offer, signaling acceptance to the package or other warehouse agents. The AcceptPoolOffer signals the acceptance of a direct offer forwarded through the capacity pool. The RejectDirectOffer action communicates that the agent is not able or willing to accept the direct offer, without altering its current schedule or capacity. The ForwardDirectOffer action is used when the warehouse agent decides to forward the direct offer to the capacity pool, potentially with an added fee, allowing other warehouse agents to consider it. These actions serve as the outputs of the agent’s decision process, facilitating interaction with the network while keeping the internal decision-making separate, which will be discussed in the next section.
Decision processes
The warehouse agent operates autonomously to maximize revenue from storage services and efficiently manage its available capacity. The agent fulfills two primary roles within the decentralized warehousing system: one as a provider of storage services and the other as a trader of offers in the capacity pool. In its provider role, the agent evaluates direct offers from package agents and decides whether to accept or reject them based on available capacity and potential revenue. In its trader role, the agent forwards unaccepted offers to the capacity pool, allowing other warehouse agents to accept the offers and earn a forwarding fee in return.
These two roles are reflected in the warehouse agent’s objective function, which aims to maximize both the revenue from accepted storage services and the additional income from trading offers in the capacity pool. The objective function is defined as shown in Equation (
37):
where
is the price accepted for the
i-th service,
is the duration of the
i-th service,
represents the profit per unit time for each service, emphasizing high price and short duration, and
is the fee added to the
k-th forwarded pool offer. The agent’s objective function reflects its goal of maximizing profit by accepting a large number of profitable offers while also minimizing the impact on capacity. Therefore, the objective function prioritizes offers with high prices and short durations. Additionally, by offloading offers to other warehouses via the capacity pool, the warehouse can reduce its occupancy burden while generating additional income through fees.
Decision Process for Direct Offer
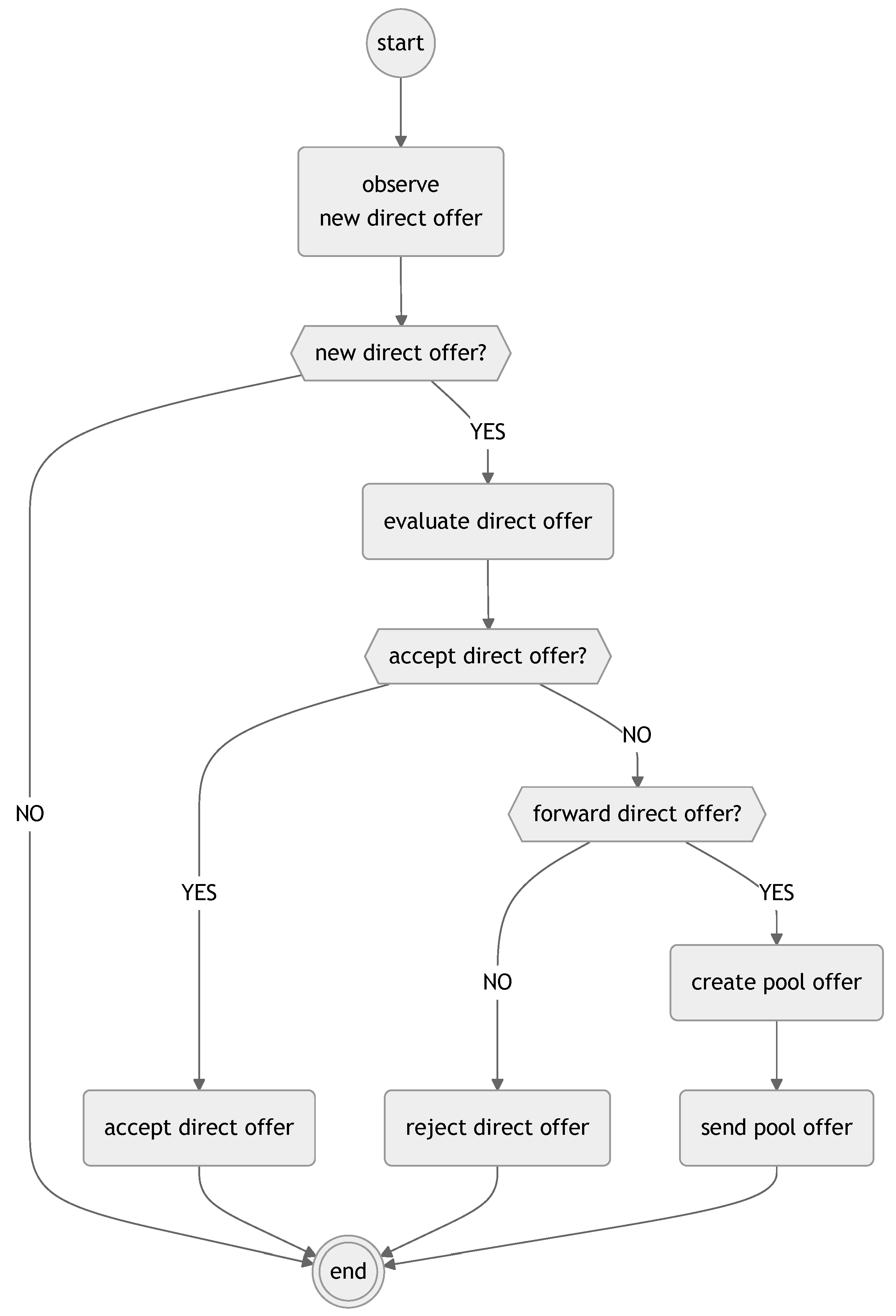
The warehouse agent’s direct offer decision process is illustrated in
Figure 4.
The process begins with the agent observing new direct offers from package agents. If no new direct offer is available, the process terminates. However, if a new direct offer is detected, the agent proceeds to evaluate the offer based on its internal criteria, such as available capacity and the revenue potential of the offer.
After evaluating the offer, the agent checks whether the direct offer is to be accepted or not. If the offer is acceptable, the agent accepts the offer, schedules the service, and the process completes. If the offer is not accepted, the agent checks whether the direct offer is to be forwarded to the capacity pool. If forwarding is chosen, the agent creates a pool offer by adding a fee and forwards it to the capacity pool, then completes the process. If the offer is neither accepted nor forwarded, the agent rejects the direct offer and the process terminates.
The warehouse agent’s direct offer decision process, depicted in
Figure 4, relies on inputs including new direct offers from package agents with parameters such as start time, end time, price, and expiry time, and the agent’s internal state, encompassing available capacity and revenue goals. The outputs consist of a decision to terminate if no new offer exists, acceptance of the direct offer with a scheduled service if it is deemed acceptable, a pool offer with an added fee sent to the capacity pool if it is forwarded, or rejection of the direct offer if it is neither accepted nor forwarded.
This decision process allows the warehouse agent to make decisions regarding direct offers in a structured manner, balancing its storage capacity and revenue goals.
Decision Process for Pool Offer
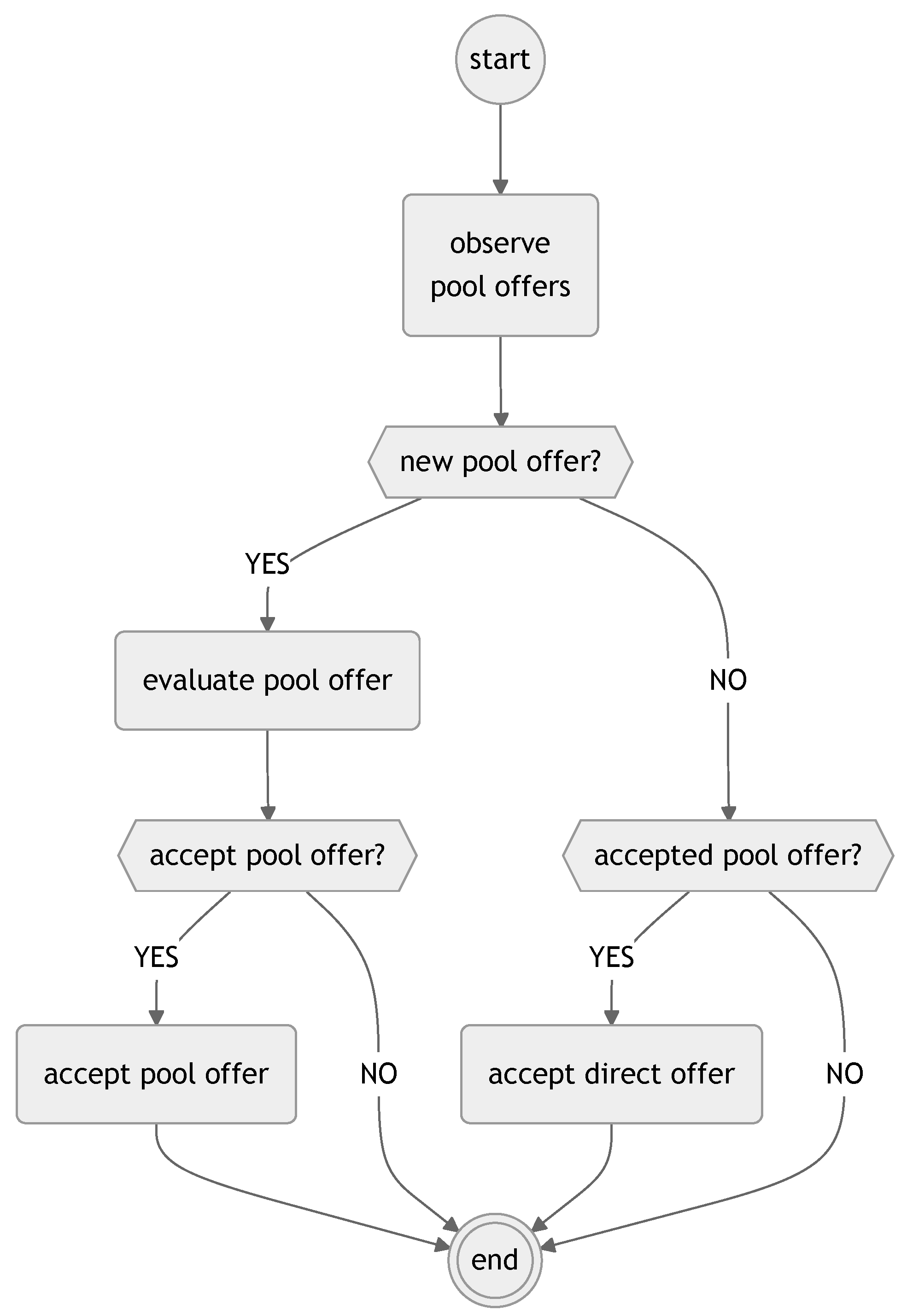
The warehouse agent’s pool offer decision process is illustrated in
Figure 5.
The process begins with the agent observing the pool of offers forwarded by other warehouse agents or their own previously forwarded offers. If no new pool offer is available, the agent checks if any of the previously forwarded direct offers have been accepted from the pool. If a pool offer has been accepted, the agent processes the acceptance and completes the process. If no new pool offer has been observed or accepted, the process terminates.
The warehouse agent’s pool offer decision process, shown in
Figure 5, uses inputs including new pool offers from the capacity pool with parameters such as start time, end time, modified price, and expiry time, the status of previously forwarded direct offers (accepted or pending), and the agent’s internal state, encompassing current capacity and financial objectives. The outputs include a decision to terminate if no new or accepted pool offer exists, acceptance of a pool offer with a scheduled storage service if it is deemed profitable, or processing of an accepted direct offer from the pool, finalizing the service schedule.
If a new pool offer is detected, the agent evaluates the offer, considering whether it is in line with its current capacity and financial objectives. After evaluation, the agent checks whether to accept the pool offer. If the agent accepts the pool offer, the storage service is scheduled and the process is completed. If the pool offer is not accepted, the process terminates without making any changes to the agent’s schedule.
This decision process allows the warehouse agent to handle offers in the capacity pool, enabling the agent to maximize its revenue by selectively accepting profitable offers or processing their own forwarded offers.
The warehouse agent’s objective is to maximize revenue from storage services while managing available capacity. The warehouse agent can earn revenue through direct storage services and by forwarding offers with added fees to the capacity pool. The objective function for the warehouse agent is defined as shown in Equation (
37).
Each agent follows a specific decision-making process, leveraging the actions available to them in their action space.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}