1. Introduction
With the advancement in cloud computing, virtualization has become ubiquitous and, simultaneously, has emerged as a significant target for attackers. One of the essential principles of software security is the premise that an application can be modified or configured exclusively by authorized entities [
1]. This makes the use of solutions that ensure this principle indispensable. In this context, assessing the integrity of virtual machines becomes a pressing issue as it is crucial to ensure that these VMs operate as expected and have not been tampered with by malicious actors. The ability to continuously verify the integrity of virtual machines is essential for users to establish and maintain trust in the computing resources used in the cloud, protecting both sensitive data and the underlying infrastructure [
2].
Some existing methods for measuring integrity in computing systems incorporate Trusted Computing technology, following a chain of trust established by the TPM (Trusted Platform Module) [
3]. The TPM is a cryptographic coprocessor integrated into most modern servers, recognized for its combination of affordability and security.
The use of the TPM as a root of trust is enabled by the presence of the Endorsement Key (EK). The EK is an asymmetric key whose private part cannot be extracted from the TPM. During manufacturing, each chip is assigned a unique EK, signed by a trusted certification authority. The EK is used to verify the authenticity of the TPM. In this way, the TPM can serve as a root of trust, allowing remote attestation through digital signatures of cryptographic hashes of software components [
4]. In this context, remote attestation guarantees that a software, firmware, or hardware component is genuine or correct.
However, hardware TPMs are known to have limited resources, such as reduced amounts of persistent and non-persistent storage, as well as low input and output performance [
3]. Therefore, in cloud computing environments, where multiple virtual machines (VMs) are often run on a single physical machine and can be migrated between these machines, using a single hardware TPM to provide security services to all the VMs becomes inefficient and complex [
5,
6].
To address this issue, the vTPM was proposed—a virtual TPM designed to provide a root of trust for virtual machines by emulating the functionality of a physical TPM. Instead of relying on physical persistent memory, the vTPM uses a memory abstraction in the form of a file to store secret keys. This enables, similarly to a physical TPM, the storage of credentials, execution of cryptographic operations, and integrity measurement [
5].
Solutions based on virtualized TPMs (vTPMs) have widespread applications in commercial cloud platforms, such as VMware Cloud [
7], Google Cloud [
8], Microsoft Azure Cloud [
9], and Amazon AWS [
10]. They play a crucial role by enabling the construction of elements that adhere to the same principles and characteristics as a physical TPM chip, such as cryptographic operations, integrity registers, and secure cryptographic key generation. This allows for the establishment of roots of trust and security solutions for virtual machines [
11]. However, since it is a software-based solution, a vTPM does not offer the same security guarantees as a hardware TPM. For example, using a vTPM presents significant challenges in protecting persistent memory, which is typically stored in a disk file, in contrast to a conventional TPM, which utilizes memory embedded directly into the chip.
Over time, various challenges and vulnerabilities have been identified that could compromise the integrity and reliability of vTPMs [
11,
12]. One example illustrating these issues is the discovery of critical vulnerabilities in SWTPMs (Software Trusted Platform Modules) [
13], a widely used open-source vTPM emulator [
14,
15], as reported by the CVE (Common Vulnerabilities and Exposures) [
16]. More recently, a vulnerability was also identified in the TCG (Trusted Computing Group) reference implementation of TPM 2.0 [
17]. This flaw likely affected all the commercial platforms using this implementation, including Google, Microsoft, and AWS [
8,
18,
19].
In this regard, the scientific community has been actively working on proposing solutions to enhance the security of virtual TPMs. Most of these studies focus on integrating the vTPM with the platform’s physical TPM [
5,
6], implementing hardware-independent certification authorities (CAs) [
5,
15], and exploring Trusted Execution Environments (TEEs) [
11,
20]. These proposals generally prioritize confidentiality, suggesting approaches to specifically protect TPM keys.
Approaches that anchor the vTPM to the physical TPM have the advantage of establishing a hardware-based root of trust. However, these approaches require the presence of a TPM chip. In the event of a host machine failure or during the migration of the vTPM instance to another host, the recovery or re-establishment of the anchoring process can be complex since the vTPM is directly linked to a physical TPM.
Another relevant aspect in cloud computing environments is the migration of virtual machines, a widely adopted practice due to various benefits, such as the dynamic reallocation of VMs, optimization of physical resource usage, cost reduction, and maximization of performance and profit. However, during migration, it is necessary to ensure that vTPM data are transferred securely and consistently, as well as to re-establish the chain of trust in the new environment. According to Perez et al. (2006) [
5], the migration of the virtual TPM must ensure that any state of the vTPM instance in transit is not subject to modification, deduplication, or any other form of compromise. Such guarantees are challenging to achieve.
Additionally, the requirement for a TPM chip limits its applicability in scenarios where not all the nodes have this component. Virtual machines utilizing vTPMs are often found in large-scale infrastructures, such as those in data centers. These environments are typically distributed and heterogeneous. In this context, standardizing hardware requirements can present a significant challenge. Moreover, in certain situations, this diversity can be advantageous as it eliminates the need to equip all the devices with every available technology, which can be costly. Instead, more expensive resources can be selectively implemented, reserved for specific demands that truly require such advanced capabilities.
Moreover, over time, data centers have evolved to adopt hyperconverged infrastructure (HCI), which integrates computing, storage, and networking resources into a single solution. While traditional data centers rely on separate components for each function—leading to increased complexity and management costs—HCI simplifies the infrastructure by consolidating everything into a unified platform. The adoption of technologies such as server virtualization, software-defined storage (SDS), and software-defined networking (SDN) within hyperconverged architectures has further accelerated this transition.
However, in emerging technologies, the initial focus is often on automation, deployment, and performance rather than on designing robust security mechanisms. In this context, it becomes more convenient to rely on traditional tools for system protection. Nevertheless, many security products were not designed with HCI in mind, lacking the flexibility and capability to extend and prevent malicious activities across all the levels and types of resources within the infrastructure.
Therefore, security in the realm of hyperconvergence still requires significant exploration [
21]. While HCI aims to integrate resources into a cohesive infrastructure, its security must also be integrated and comprehensive to effectively protect the platform. Thus, security in HCI is just as vital as the unified and comprehensive nature of the platform itself. In this context, there is a need for investigations that enable the development of security approaches tailored to the inherent characteristics of hyperconvergence—both integrating with and leveraging its benefits.
In this paper, we propose an approach to hyperconverged TPMs. In the proposed solution, the resources of all the physical TPMs are combined and managed jointly by a single software layer. In this way, all the services in the data center are provided with the hardware TPM resource, even if the chip is not physically available in the host where the service is allocated. In other words, although the machine hosting a vTPM does not have a TPM, it can be anchored on another machine with a TPM in a way that is transparent to the user.
The anchoring of vTPMs in the hyperconverged TPM is performed by mapping the changes in the volatile and non-volatile states of the vTPMs. This process is implemented through kernel modules responsible for receiving measurements of the internal states of the vTPMs and anchoring them into the hyperconverged TPM. Additionally, these modules expose, in a protected area of the sysfs-based file system, files containing the necessary information for generating integrity evidence. As a result, the proposed approach enables remote attestation of vTPM instances, allowing their integrity to be verified in a manner analogous to IMA (integrity measurement architecture)-based mechanisms used for attesting execution environments.
The remainder of this paper is organized as follows:
Section 2 reviews the related work.
Section 3 presents the technologies that underpin the proposed solution.
Section 4 provides a detailed description of the proposed mechanism.
Section 5 discusses the methodology employed to evaluate the approach. The main experimental results are presented and analyzed in
Section 6. Finally,
Section 7 concludes the paper with a summary of the contributions and directions for future work.
4. Hyperconverged TPM
In the solutions found in the literature to provide security for vTPMs, the anchoring of the vTPM to the TPM is managed and performed individually and locally on the node hosting the VM, which brings two main limitations. First, there is the prerequisite that the node hosting the VMs must have a physical TPM. Although the adoption of TPM chips is growing, establishing such a requirement limits the use of this approach to contexts where all nodes in the system have a TPM. In different data centers, hybrid scenarios are common, where some hosts have the chip and others do not.
Secondly, even in environments where all the nodes have physical TPMs, it may be appropriate to create replicas of the anchoring. Replicating an anchoring refers to anchoring the vTPM in more than one TPM chip. This is especially important for critical systems that require guarantees of availability, integrity, and security. In this way, if one of the anchorings becomes inaccessible, the replicas ensure that the vTPM remains attested and verified. Furthermore, in cases of VM migration to another host, the replica of the anchoring allows for easier migration of the vTPM.
Both situations presented can be solved by removing the requirement for the vTPM to be anchored only to the TPM chip of the host where it is physically allocated. Therefore, in this work, we propose an approach for hyperconverged TPMs. In the proposed solution, the resources of all the physical TPMs are combined and managed jointly by a single software layer. In this way, all the services in the data center can make use of the hardware TPM resource, even if the chip is not physically available in the host where the service is allocated. In other words, although the machine hosting the vTPM does not have a physical TPM, its anchoring can be performed on another machine with a TPM in a way that is transparent to the user. In this approach for a hyperconverged TPM, each node provides its individual TPM to create a distributed TPM across the nodes of the data center.
4.1. Anchoring Architecture
Among the architectures that propose the anchoring of the vTPM to the physical TPM, the approach presented in this paper is an evolution of the architecture introduced in Tassyany et al. (2024) [
51]. This architecture considers the protection of the vTPM’s integrity through the monitoring of both the persistent and volatile states. The relationship between the main components of the solution can be visualized in
Figure 3, where we can identify the following elements:
Hosts: Machines that comprise the hyperconverged system. There are two types of hosts: hosts with TPMs and hosts without TPMs.
User VMs: Virtual machines used by system users to run their applications and store data.
u-vTPM: vTPM instances allocated to user VMs.
Management VM (m-VM): Individually, the m-VM is the virtual machine responsible for coordinating the anchoring of the u-vTPMs to their own vTPM. Together, the m-VMs form a logically centralized but physically distributed management system (MS). Each m-VM that makes up the management system is responsible for consuming the TPM resources and managing access to its resources by other m-VMs. To do so, the m-VMs exchange information among themselves to make the most appropriate decision about where to perform the anchoring of the vTPM, whether when the local node does not have a hardware TPM or when anchoring replicas are required.
m-vTPM: vTPM instance allocated to m-VM.
Software TPM Emulator: Software component responsible for providing the instances of u-vTPM and m-vTPM. Furthermore, it is the element that reports legitimate modifications made to the states of the vTPMs.
vTPM Anchoring Module (vTPM-AM): Kernel module running on the m-VM, responsible for anchoring the u-vTPMs to the m-vTPM. It also anchors remote m-vTPMs, located on machines that either lack a local TPM chip or require information replication.
m-vTPM Anchoring Module (m-vTPM-AM): Kernel module running on hosts with TPM, responsible for anchoring the m-vTPM to the TPM chip.
Agent–Host: Component responsible for receiving the measurements from the software emulator, identifying whether they belong to the m-vTPM or u-vTPM, and forwarding them to the appropriate element for anchoring. On a Host with TPM, the Agent–Host sends the anchoring data to the vTPM-AM when the measurement refers to the u-vTPM and to the m-vTPM-AM when it refers to the m-vTPM. On a host without a TPM, the Agent–Host forwards the anchoring data for both the u-vTPM and m-vTPM to the vTPM-AM.
TPM: A chip present in some hosts, responsible for providing hardware-based root of trust by anchoring the m-vTPM.
In the proposed hyperconverged anchoring system, there are two types of hosts: hosts with TPMs and hosts without TPMs. Each of these hosts can host multiple user VMs, each with its own u-vTPM. The hosts must also have a management VM (m-VM), enabling the integration of the solution with one of the main architectures used in hyperconverged infrastructures [
32].
When using this architecture to build hyperconverged environments, the m-VM takes on the responsibility of allocating resources and managing access to these resources by other VMs. The main benefit of this model is flexibility as it tends to support multiple hypervisors and operate on different platforms. Furthermore, this architecture enables the implementation of mechanisms to manage the load on the TPM, resulting from the anchoring of vTPMs and the intrinsic limitations of the chip’s hardware [
52].
In this context, we consider that the anchoring of vTPMs can occur either locally or remotely. Local anchoring occurs when the trust chain is established with the local TPM chip on the same machine hosting the vTPM as the root of trust. This means that local anchoring of a vTPM applies to hosts that have a TPM chip. Remote anchoring occurs when the trust chain is based on the hyperconverged TPM as the root of trust. In this case, anchoring is performed on a TPM that is not on the same host as the vTPMs. The following sections will describe how each type of anchoring occurs.
4.1.1. Local Anchoring
In local anchoring, it is assumed that the states of the u-vTPMs are anchored in the m-vTPM and that, in turn, the m-vTPM is anchored in the host’s TPM chip to consolidate the trust chain. Therefore, to verify the integrity of a u-vTPM, it is necessary, first, to prove the presence of a genuine TPM. This enables the establishment of trust in the m-vTPM, which then allows the verification of trust in the u-vTPM.
In other words, by relying on the host’s TPM, it is possible to verify the integrity of the management VM’s vTPM (m-vTPM) and, ultimately, the integrity of the user VMs’ vTPMs (u-vTPMs). This framework establishes a trust relationship in which the TPM only handles the anchoring of the m-vTPM, avoiding the storage of all the individual actions performed on each of the existing vTPMs. This enables the implementation of auxiliary mechanisms to reduce the overhead in the root of trust.
In both the cases of m-vTPMs and u-vTPMs, all the anchors are related to the measurement and mapping of changes in the states of the vTPMs, which are reported directly by the TPM software emulator. Functionally, every legitimate request must pass through the TPM emulator. Therefore, the emulator is the only component authorized to make changes to the states of the vTPMs.
Therefore, the approach assigns the emulator the responsibility of identifying changes in the states and performing the necessary measurements. With this information, it is possible to anchor the measurements of the vTPM states whenever changes occur, following the same concept as solutions like IMA [
53], which verifies the integrity of the critical files in the system. Additionally, it is important to emphasize that the solution assumes the prior execution of the remote attestation process of the host that hosts the VMs (and, consequently, the vTPMs). This ensures the maintenance of the integrity of the applications running on it.
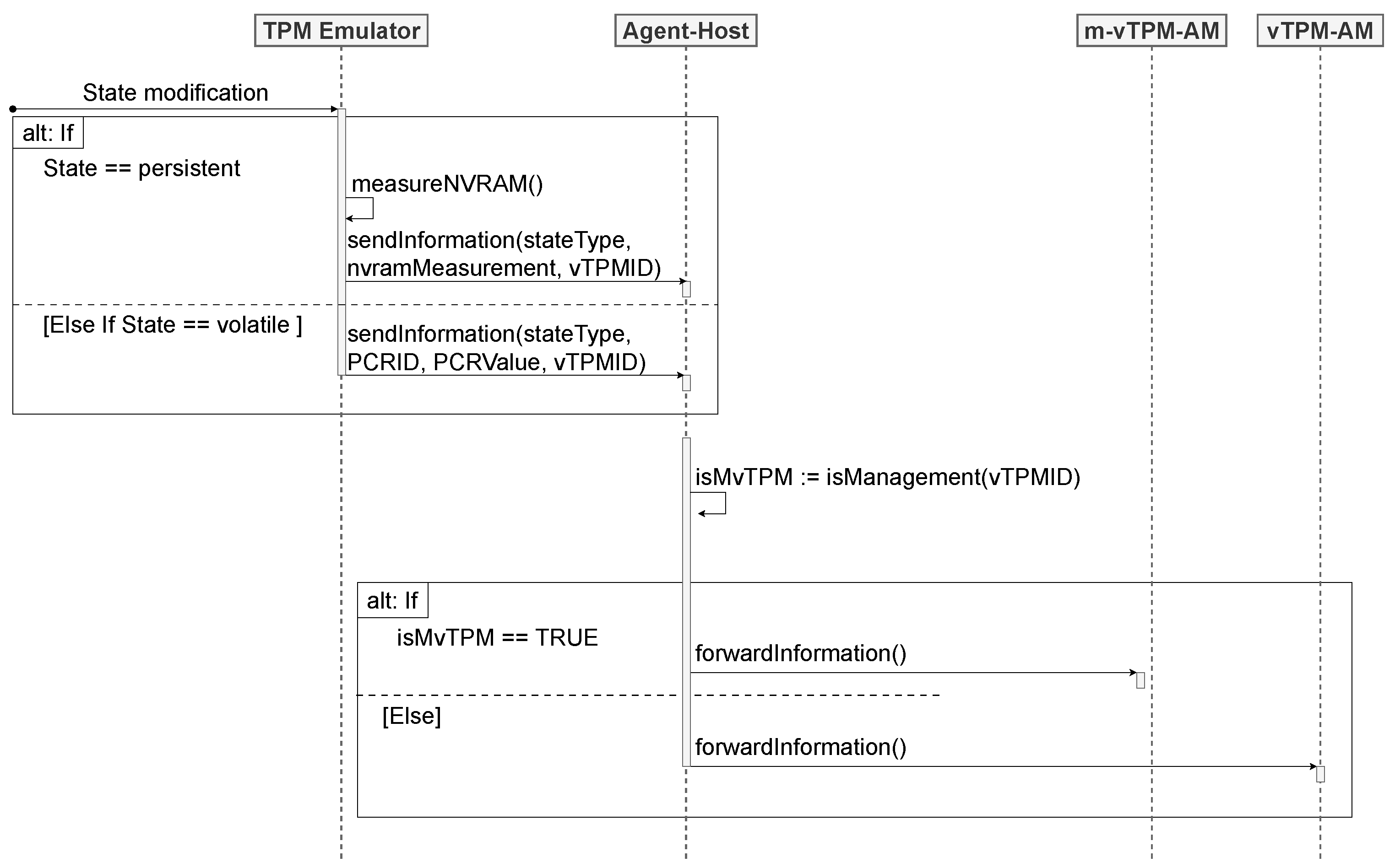
Whenever the emulator detects a state change, the Agent–Host is triggered. The Agent–Host is responsible for processing the changes reported by the emulator, discerning whether they originate from a u-vTPM or m-vTPM. The approach assumes that the persistent state is altered when there is a modification in the vTPM’s NVRAM and that the volatile state is altered when one or more PCRs are modified.
In
Figure 4, a sequence diagram is shown that represents the interaction between the emulator and the Agent–Host. If the modification results from the persistent state, the emulator measures the NVRAM file of the vTPM and sends these data to the Agent–Host. In case of changes in the volatile state, indicating modifications in the PCRs of the vTPM, the emulator informs the Agent–Host of the details regarding the number and current value of the affected PCR. Furthermore, each set of information sent to the Agent–Host includes the specification of the state type (volatile or persistent) and the identification of the VM that had its vTPM modified (VMID). Thus, the Agent–Host evaluates the origin of the measurement, determining whether it comes from a u-vTPM or m-vTPM.
When the measurement is associated with a u-vTPM, the Agent–Host forwards it to a u-vTPM Anchoring Module (u-vTPM-AM). The u-vTPM-AM is a kernel module running on the management VM. In local anchoring, the module is responsible for receiving the measurement information through a netlink socket and anchoring the u-vTPM states to the m-vTPM. Similarly, when the Agent–Host determines that the measurement comes from an m-vTPM, it forwards it to an m-vTPM Anchoring Module (m-vTPM-AM). The m-vTPM-AM is a kernel module operating on the host machine, responsible for the local anchoring of the m-vTPM states to the TPM. In the subsequent sections, the anchoring process performed by each of these modules in the context of local anchoring will be detailed.
Anchoring of the Persistent State
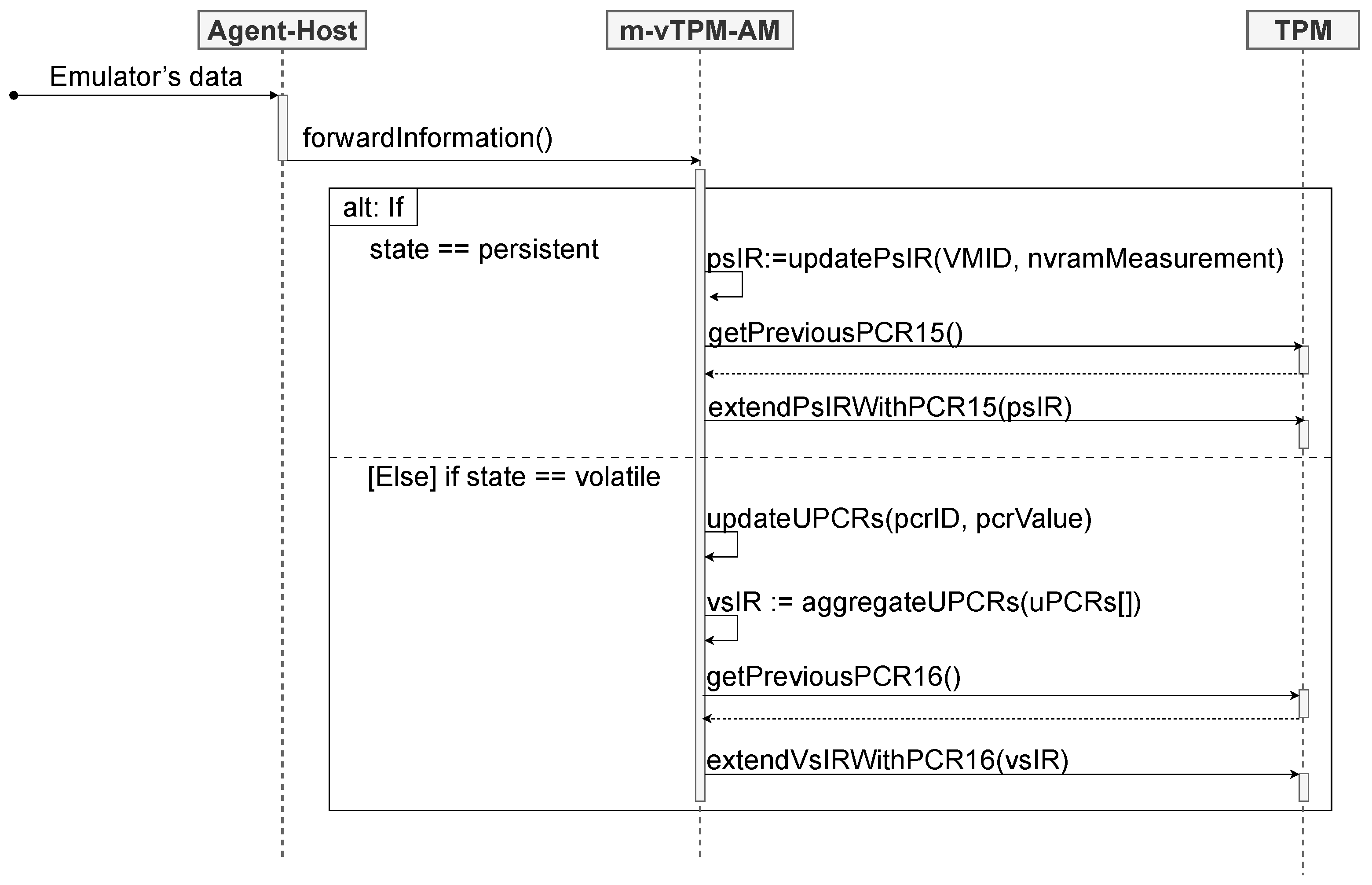
Upon receiving a measurement originating from the persistent state, the vTPM-AM stores the information in its corresponding ps-IR. In this scenario, the module always keeps the most recent measurement value of the persistent state of a u-vTPM stored in its respective ps-IR. When a new ps-IR is created (in the case of a new u-vTPM instance) or any of the ps-IRs are modified, all the ps-IRs are aggregated and extended into mPCR 15. The aggregation should be understood as an operation analogous to the extended hash executed by the TPM on a PCR, with the difference that the aggregation is performed by the vTPM-AM, before triggering the extended hash operation of the m-vTPM.
Furthermore, to enable the recomputation of the current value of mPCR 15, the vTPM-AM also retains its previous value. In this way, if the previous value of mPCR 15 extended with the aggregated value of all the ps-IRs matches the current value of mPCR 15, the ps-IRs can be trusted. The sequence diagram shown in
Figure 5 illustrates the operations performed by the vTPM-AM. To exemplify the interaction between components, a scenario was considered in which a modification is made to the value of an existing ps-IR.
Once the ps-IRs are considered trustworthy, they can be used to assess the integrity of the persistent state. If the result matches the current value of mPCR 15, it indicates that the ps-IR values are reliable. Thus, it becomes possible to validate the integrity of the persistent state of a specific u-vTPM by comparing the hash of its NVRAM with the value of the corresponding ps-IR. If these values match, it can be concluded that the persistent state is intact.
Anchoring of the Volatile State
When the measurement originates from the volatile state, the vTPM-AM establishes a structure that records the most recent value of each of the 24 PCRs of each u-vTPM (uPCR). For example, if the vTPM-AM stores the value
Z for uPCR 10 and receives an indication from the Agent–Host that uPCR 10 has been updated to value
H, then value
Z will be replaced with
H. In this way, the vTPM-AM maintains a record of the expected values for the uPCRs of each user VM. Accordingly, by anchoring this information, whenever there is a new change in the values of the uPCRs, the vTPM-AM performs an extended hash of the aggregated uPCR values into its corresponding vs-IR. This means that the vs-IR of each vTPM will store the aggregated value of its respective 24 uPCRs. The sequence diagram shown in
Figure 5 illustrates the operations carried out by the vTPM-AM to anchor the volatile state when a new measurement is received. As previously mentioned, in the use case considered for this diagram, the received measurement does not originate from a new vTPM instance.
Similar to the persistent state, when one of the vs-IRs is created or modified, all vs-IRs are aggregated and extended in mPCR 16. Additionally, as with the ps-IRs, the previous value of mPCR 16 is also stored to allow the recomputation of mPCR 16 during the vs-IR integrity verification process.
Therefore, after verifying the integrity of the vs-IRs, it is possible to check the volatile state of the u-vTPM of a specific VM. To achieve this, an aggregation of the 24 uPCR values recorded by the module is performed. If the resulting value matches the vs-IR of that u-vTPM, it indicates that the values recorded by the module can be trusted. In this scenario, when requesting a quote from the corresponding u-vTPM, the values of each of its uPCRs are expected to match those recorded by the vTPM-AM in order for the volatile state to be considered intact.
Anchoring Process of the m-vTPM to the TPM Carried Out by the m-vTPM-AM
The m-vTPM-AM operates analogously to the vTPM-AM; however, it relies exclusively on a vs-IR and a ps-IR. This is because we are considering the anchoring of only one vTPM: the m-vTPM. The sequence diagram shown in
Figure 6 illustrates the operations performed by the m-vTPM-AM to anchor the volatile state when a new measurement is received.
Anchoring of the Persistent State
Upon receiving a measurement from the persistent state, the m-vTPM-AM stores the information in the ps-IR and performs an extended hash operation of this information into PCR 15 of the TPM. In this scenario, the module always retains the most recent value of the persistent state measurement in the ps-IR.
Additionally, as in vTPM-AM, to enable the recomputation of the current value of PCR 15, the m-vTPM-AM also retains its previous value. During a persistent state integrity verification process, the previous value of PCR 15 is extended with the ps-IR value. If the result matches the current value of PCR 15, it indicates that the ps-IR—i.e., the measurement recorded by the m-vTPM-AM—can be trusted. Finally, the ps-IR must be compared with the hash of the NVRAM file. If the values match, the persistent state of the m-vTPM is considered to be intact.
Anchoring of the Volatile State
Similarly to vTPM-AM, for the volatile state, m-vTPM-AM establishes a structure that records the most recent value of each of the 24 mPCRs of the m-vTPM. Thus, upon every update to the mPCR values, the m-vTPM-AM aggregates these values into the vs-IR and performs an extended hash of the aggregated value into physical TPM PCR 16. Analogous to the persistent state, it is also necessary to store the previous value of PCR 16. During integrity verification, the previous value of PCR 16 is extended with the vs-IR value. If the result matches the current value of PCR 16, this indicates that the vs-IR value can be trusted.
If the vs-IR is considered trustworthy, it can be used to validate the integrity of the mPCR records generated by the m-vTPM-AM. If the extended hash across all 24 mPCR values stored by the m-vTPM-AM matches the value of the vs-IR, it indicates that the mPCR records can be trusted. Consequently, during an integrity attestation process, it is possible to request a quote from the m-vTPM and compare it with the reference values stored by the m-vTPM-AM. If the values match, this indicates that the integrity of the volatile state can be trusted.
Given this, if the physical TPM is validated as legitimate during the authenticity verification process and the states of the m-vTPM anchored to it are confirmed to be intact, it is safe to trust the m-vTPM. Accordingly, if a u-vTPM anchored to the m-vTPM has its states considered intact, it follows that the u-vTPM can also be trusted.
Measurement Files
The vTPM-AM and m-vTPM-AM store measurement values for both the persistent and volatile states in files that share the same characteristics and security properties as those generated by IMA in traditional Linux systems. In the management VM, for the persistent state, vTPM-AM generates a file containing the ps-IR of each u-vTPM and the ID of the VM to which each u-vTPM belongs, as well as the previous value of PCR 15. For the volatile state, vTPM-AM generates a file containing the previous value of PCR 16, the vs-IR of each u-vTPM, and the corresponding VM identifier. Additionally, for each u-vTPM, a file is created to store the uPCR values, which are used during the verification process of the volatile state. The m-vTPM-AM also generates the same set of files, with the difference that the information pertains exclusively to the m-vTPM. All the files are stored in a protected area using
sysfs [
54] as the file system. This enables integrity checks, including remote attestation.
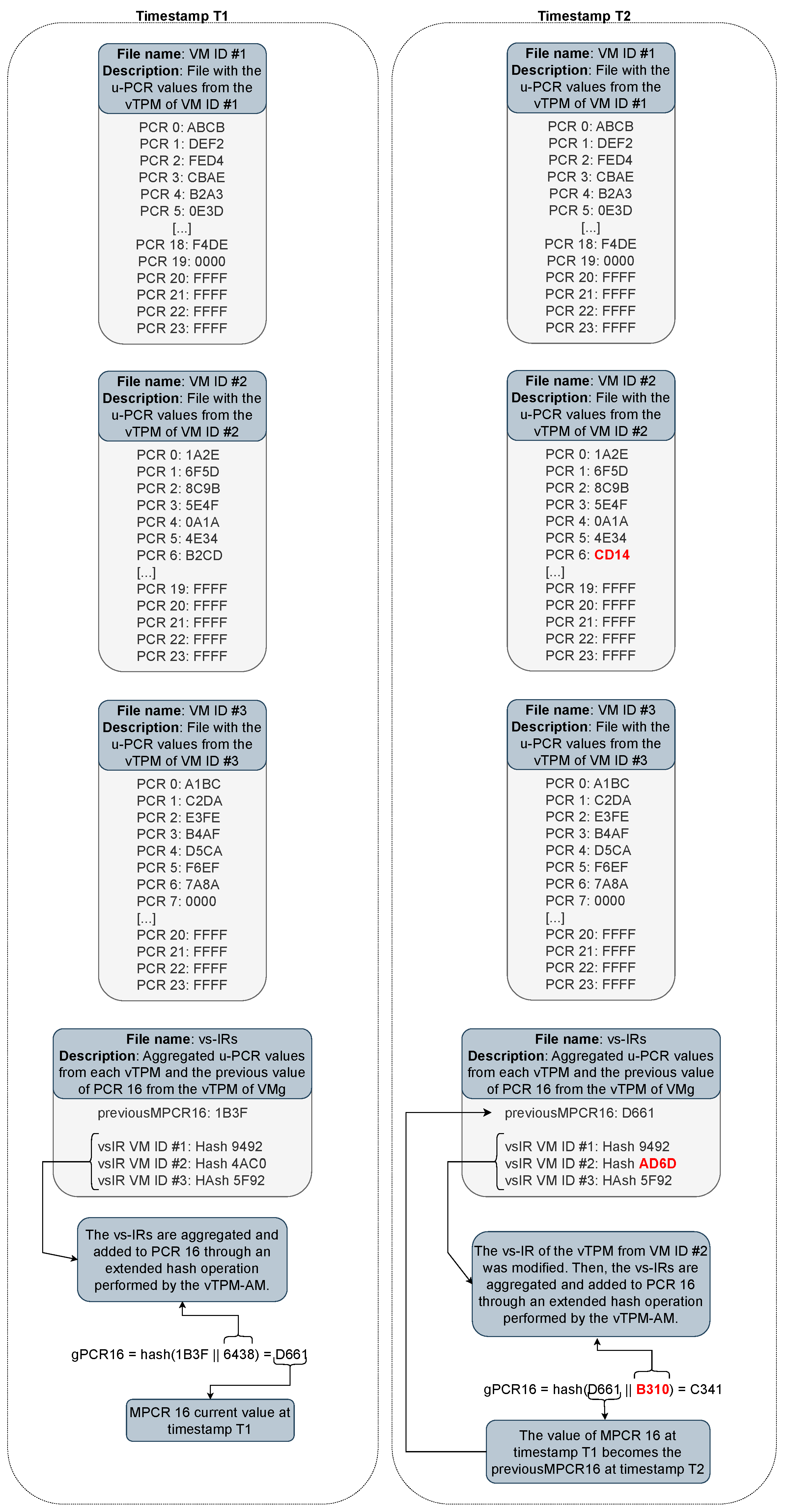
Figure 7 presents an example of the content of the files stored in the management VM, which are required for validating the integrity of the volatile state of the u-vTPMs. The example illustrates a scenario involving three user VMs. In this context, there are four files: three containing the uPCR values of each VM and one containing the vs-IR of each u-vTPM along with the previous value of mPCR 16 (previous-mPCR16). For simplicity, hypothetical values and the CRC-16 (Cyclic Redundancy Check, 16-bit) algorithm were used. In the actual implementation, however, more robust algorithms, such as SHA-256 (Secure Hash Algorithm, 256-bit) and SHA-512 (Secure Hash Algorithm, 512-bit), are employed.
It can be observed that, at time instant T1, the aggregation of the vs-IRs is added to mPCR 16 through an extended hash operation. At time instant T2, the value of one of the uPCRs of VM ID #2 was modified. This modification triggers an update to the vs-IR of VM ID #2 in the vs-IR file. When a vs-IR is modified, the previous value of mPCR 16 is stored as the previous-mPCR16, and mPCR 16 is updated using an extended hash operation with the aggregated value of the vs-IRs. It can be seen that the value of mPCR 16 at time instant T1 becomes the previous-mPCR16 at time instant T2.
As an example, during an integrity verification process of the u-vTPM of VM ID #3, after verifying the m-vTPM and receiving the mPCR report, it becomes possible to check the integrity of the vs-IR file. To do so, the value of mPCR 16, obtained from the mPCR report, is compared with the result of the extended hash operation between the previous-mPCR16 and the aggregated value of the vs-IRs. If the values match, the integrity of the vs-IR file is validated, allowing its use in the validation of the volatile state of the u-vTPMs.
Subsequently, the vs-IR file is used to validate the integrity of the VM ID #3 file. To this end, the values of the uPCRs reported in the VM ID #3 file are aggregated and compared with the corresponding vs-IR of that VM in the vs-IR file. If the values match, the VM ID #3 file is considered intact and can be used to verify whether each PCR reported by the u-vTPM is as expected.
It is important to highlight that, in the persistent state, the logic of the presented example remains the same, with the exception that there is only a file containing the ps-IRs, where each ps-IR represents the expected measurement of the NVRAM file of each u-vTPM. Furthermore, up to this point, we have discussed the files used for attesting the u-vTPM. However, as previously mentioned, to verify the integrity of the m-vTPM, the structure of the files is the same, except that it contains information related to a single vTPM—specifically the m-vTPM.
Additionally, another important aspect to highlight is that we do not assume the measurement files stored in sysfs to be inherently secure. Although sysfs is an in-memory file system with restricted access and characteristics similar to those used by IMA (integrity measurement architecture), it remains susceptible to potential integrity breaches. For this reason, our approach does not consider these files to be suitable as reference values for the vTPM states until their integrity has been previously verified.
In the proposed architecture, the values reported in sysfs are validated based on the trust chain anchored in the physical TPM. This means that the verification process consists of comparing the current state of the vTPM with the values stored in sysfs, after the integrity attestation has been performed following a trust chain rooted in the hardware TPM. Since the physical TPM cannot be modified, it is considered a secure root of trust. This approach follows the same principle adopted by established remote attestation mechanisms based on IMA (integrity measurement architecture), which assume that the recorded measurements reflect hardware-protected states that can be externally verified.
Therefore, in scenarios involving, for example, replay attacks, it is possible to detect the violation of the integrity of measurement files. In such cases, the presence of redundant anchoring ensures the continuity of the vTPM attestation process by leveraging measurement files obtained from other trusted anchoring. This resilience is enabled by the use of the hyperconverged TPM, which incorporates the remote anchoring mechanism, described in detail in
Section 4.1.2.
4.1.2. Remote Anchoring
The components and processes involved in remote anchoring are similar to those used in local anchoring. In local anchoring, two kernel modules are employed. The first one runs on the host machine and is responsible for anchoring the m-vTPM to the physical TPM (m-vTPM-AM). The second module runs on the m-VM and anchors the u-vTPMs to the m-vTPM (vTPM-AM). Both modules receive information from the Agent–Host. The Agent–Host determines whether the measurement originates from a u-vTPM or an m-vTPM and forwards the measurements to the appropriate module.
In the case of remote anchoring, the local host’s m-vTPM-AM is not used. In this scenario, when the Agent–Host receives a measurement belonging to the m-vTPM, it forwards it to the management VM (m-VM). At this point, two processes are carried out by the m-VM. The first process involves executing an anchoring selection algorithm to decide which remote m-VM the m-vTPM will be anchored to. The second process concerns sending the respective m-vTPM measurements to the selected remote m-VM.
The remote m-VM anchors the received measurements in its own m-vTPM using the same anchoring process as the u-vTPM described in
Section 4.1.1. The only difference is that the integrity records of the persistent and volatile states (ps-IR and vs-IR) are anchored in different PCRs. This allows the attestation of the m-vTPMs to occur independently of the u-vTPM. For example, while the IRs of the u-vTPMs are anchored in mPCRs 15 and 16, those of the m-vTPM are anchored in mPCRs 17 and 18. This remote anchoring process is illustrated in
Figure 8.
The verification process of the hyperconverged TPM is carried out in three phases. The first phase involves the verification of the TPM-enabled machines. For a host with a TPM to be considered part of the pool that constitutes the hyperconverged TPM, it must be attested. Therefore, this phase consists of the attestation process of all the TPM-enabled machines in the system, aiming to ensure that the TPM chip is genuine and that the execution environment is trustworthy. If any of the machines are found to be in an untrusted state, they will be excluded from the hyperconverged TPM pool.
The second phase refers to the integrity verification of m-vTPMs that are anchored to the TPM chip, i.e., those belonging to hosts with a TPM. This verification is performed as described in the Section Measurement Files. If an m-vTPM is deemed untrustworthy, the host to which it belongs, as well as all the hosts hosting m-vTPMs anchored to it, will be excluded from the hyperconverged TPM.
The third phase refers to the integrity verification of m-vTPMs anchored in a remote m-vTPM. This verification is performed analogously to the verification of the u-vTPM, as described in the solution presented in
Section 4.1.1. Similarly, if the m-vTPM anchored to the remote m-vTPM is found to be compromised, the machine hosting it will be removed from the hyperconverged TPM.
4.1.3. Management System
In order for the management VMs to make appropriate decisions regarding where to perform remote anchoring, they must share the same state. This state includes information about all the nodes equipped with TPM chips, along with the metrics that enable each m-VM to compute the anchoring cost.
Possible metrics include the number of m-vTPMs anchored by the m-VM, the transmission time of the anchoring data, the resource utilization rate, the nature of the services hosted on the users’ VMs, and the criticality of these services in terms of security, among other factors.
To enable state sharing among virtual machines (VMs), we consider the adoption of a consensus algorithm. Consensus algorithms are fundamental mechanisms in distributed systems, ensuring that multiple nodes reach agreement on a given value or state, even in the presence of failures or communication delays [
55]. In the analyzed context, one or more VMs that are part of the management system propose a state value to be accepted. Then, the VMs exchange messages to verify and validate the proposal. Finally, after gathering sufficient information, the VMs converge on a single value, which is subsequently recorded as definitive.
The state of an m-VM is modified when, for example, it receives the anchoring of an additional m-vTPM. When the leader receives an indication of a state change, it reports this update to the other m-VMs, ensuring that all the VMs maintain the same set of information.
When a new node is added, its m-VM must also communicate with the leader to indicate whether it has a TPM and to receive the leader’s updated state. All the communication between m-VMs is carried out via the management API. This API receives requests, authenticates them, and validates the received state information. For this purpose, we use mTLS (Mutual Transport Layer Security), a security protocol that ensures mutual authentication between two parties in a communication [
56].
Each m-VM makes its own decision regarding where to anchor its m-vTPM. To do so, based on the metrics available in its state, the m-VM calculates the anchoring cost. This cost is computed as the sum of the normalized values for each considered metric. The TPM that results in the lowest cost is selected for anchoring. If multiple TPMs yield the same cost, the decision is made randomly among the candidates with equivalent costs.
5. Materials and Methods
In this section, we detail the methodology used to evaluate the performance of the proposed approach. The initial experiments were conducted with the aim of analyzing the overhead introduced by the solution in the anchoring time, as well as assessing the impact of the approach on the system’s computational resources.
5.1. Implementation
The solution was implemented in SWTPM [
13], an open-source and widely used software emulator [
14,
15]. In parallel, the anchoring components of the solution (vTPM-AM and m-vTPM-AM) were integrated into kernel modules. Moreover, as mentioned in Section Measurement Files, these modules are also responsible for maintaining the files that contain the state measurement values, which are essential for vTPM attestation. These files are stored in a secure area, in a manner similar to the measurement files produced by IMA.
To build the management system, we implemented a Golang-based API that enables communication between the m-VMs. All communication between m-VMs is encapsulated using the mTLS protocol, ensuring security and authenticity in the interactions. State sharing among the VMs was based on an approach similar to that used in Kubernetes [
57]. Kubernetes employs etcd as a distributed key–value store to retain all cluster-related information. In this context, we adopted etcd [
58] to store and share the states of the m-VMs. Etcd is a distributed key–value database that implements the Raft consensus algorithm [
59].
In this scenario, when using etcd, the sharing of states among the VMs follows the specifications defined by the Raft consensus algorithm. In this context, one of the VMs is elected as the leader, and, if the leader fails, another VM is elected to take its place. Each VM can be in one of three states: leader, responsible for managing the transaction log and replicating entries to the followers; candidate, a server competing to become the leader; and follower, passive servers that receive log entries from the leader.
All VMsgs start in the follower state. An m-VM remains a follower as long as it regularly receives valid communications from the leader (a “heartbeat”). If the follower does not receive messages from the leader within a certain period (“election timeout”), it assumes that the leader has failed and initiates a new election.
To initiate an election, the m-VM transitions from the follower state to the candidate state, votes for itself, and sends a vote request (RequestVote) to all other m-VMs. A follower is willing to vote for another node to become the leader if it is no longer receiving messages from the current leader, has not itself become a candidate, and has not yet voted in the term specified in the received vote request.
The candidate m-VM must obtain a majority of votes to become the leader. If it receives votes from the majority of VMs, it becomes the leader and starts sending periodic “heartbeat” messages to the followers, maintaining its leadership and preventing new elections. If the candidate m-VM fails to obtain a majority—due to a tie, for example—it reverts to the follower state, and a new election term is initiated after a random timeout, reducing the likelihood of subsequent ties.
If the leader m-VM fails, the election process restarts, ensuring that there is always a leader in the cluster. The timeout before a follower becomes a candidate is randomly chosen within a given interval, helping to avoid simultaneous election collisions. Once elected, the leader m-VM is responsible for receiving state modification reports from the other m-VMs.
Initially, we consider that the state information stored in etcd refers to data about all nodes equipped with a TPM chip, as well as the number of m-vTPMs anchored to each m-VM. The number of m-vTPMs anchored to a given m-VM is important for enabling better load balancing in VM resource usage and for avoiding overload scenarios that could compromise its performance.
In this case, the cost is defined by the number of m-vTPMs anchored to an m-VM. Therefore, when a new m-vTPM is detected on a host without a TPM, the local m-VM queries the database to retrieve information about which hosts have a TPM and runs an algorithm to select the host with the m-VM that has the fewest anchored m-vTPMs. If multiple hosts meet this criterion, one of them is selected at random.
It is worth noting that, although etcd supports communication via mTLS, we chose not to enable this feature during the experiments in order to simplify the test environment. This decision was driven by the observation that, from the perspective of the proposed solution, the adoption of mTLS would not introduce a significant impact on performance. This is due to the limited role of etcd within the system: it is used solely to store information about which VMs have a physical TPM chip and how many vTPMs are anchored to each of them.
Moreover, etcd is accessed only at specific moments, such as during the selection of the remote host to which a new vTPM will be anchored, or when changes occur in the state of cluster nodes (e.g., when a vTPM is added). In these cases, the use of mTLS could lead to (1) a slight increase in the decision time regarding the remote host on which a vTPM should be anchored—an operation that typically occurs only during the vTPM’s initialization; and (2) a minor delay in state propagation among cluster nodes, which could occasionally result in decisions based on slightly outdated information, without compromising the overall functioning of the solution. Furthermore, etcd is not a mandatory component of the proposed architecture and could be replaced by any other distributed storage system that relies on consensus algorithms.
5.2. Experimental Environment
The test environment was set up on two hosts, both equipped with an Intel i9-12900 processor, 32 GB of RAM, 1 TB of SSD storage, and a network interface card with 1 Gbit/s capacity. We used the NPCT75x TPM 2.0 as our hardware TPM model. All hosts ran Ubuntu 20.04 as the operating system, using QEMU version 4.2.1. For the experiments, we configured the management VM to run Ubuntu 22.04, with 4 vCPUs and 4 GB of main memory. The user VMs ran OpenSUSE 5.14, with 1 vCPU and 1.5 GB of main memory. Each VM was equipped with a vTPM instance emulated by SWTPM version 0.8.1, using the libtpms library version 0.9.6.
To evaluate the proposed solution, we aim to analyze the overhead introduced by remote anchoring in comparison to local anchoring. For this purpose, we consider that each of the two hosts (Host 1 and Host 2) hosts ten user VMs and one management VM (m-VM1 and m-VM2). In the local anchoring scenario, we assume that each management VM is anchored locally; that is, m-VM1 is anchored to the TPM of Host 1 and m-VM2 is anchored to the TPM of Host 2. In the remote anchoring scenario, we assume that m-VM1 is remotely anchored to the TPM of Host 2.
To modify the volatile state, 10, 100, 1000, 10,000, and 100,000 extends were performed for each scenario on each of the m-VMs. Each extend triggers an anchoring operation; therefore, the time of each anchoring on m-VM1 was measured. The goal is to evaluate the anchoring time when m-VM1 is anchored locally and remotely. Additionally, the remote anchoring scenario was executed both with and without mTLS in order to assess the overhead introduced by the protocol on anchoring time.
Additionally, during the execution of the scenarios, we monitored CPU and memory usage to evaluate the load imposed by our solution on these resources. Furthermore, to establish a baseline for the system’s standard resource consumption, we measured the resource usage of the environment without the proposed solution.
During the experimental process, in order to mitigate threats to conclusion validity, preliminary experiments were conducted to estimate the required sample size. Furthermore, the bootstrap resampling method [
60] was employed, with estimates reported along with 95% confidence intervals.
6. Results and Discussion
Regarding anchoring time, the results indicate that the increased system load resulting from a higher number of extends does not have a significant impact.
Figure 9 presents the average anchoring times estimated with 95% confidence. In all the analyzed scenarios, an increase in anchoring time is observed when anchoring is performed remotely. For instance, in the scenario with 100,000 extends, an increase in anchoring time between 7.62 ms and 8.48 ms was observed when compared to local anchoring. Additionally, the use of remote anchoring with mTLS resulted in an increase between 24.22 ms and 25.00 ms relative to local anchoring.
Table 1 and
Table 2 summarize the results concerning the impact of remote anchoring and the use of mTLS, highlighting the observed increases compared to local anchoring, with a 95% confidence estimate.
Table 1 quantifies the additional time introduced by remote anchoring, calculated as the difference between the remote and local anchoring times. For instance, under a load of 10,000 extends, an increase ranging from 7.50 ms to 8.34 ms was observed compared to local anchoring.
Table 2, in turn, presents the results obtained when considering remote anchoring with mTLS, using the same calculation methodology. For the same load of 10,000 extends, the additional time observed ranged from 24.43 ms to 24.99 ms relative to local anchoring, demonstrating the communication overhead introduced by the use of mTLS.
This increase in remote anchoring time is an expected behavior, resulting from the time required for data transmission. Additionally, the computational overhead associated with establishing and maintaining secure connections via mTLS also contributes to increased latency. However, in scenarios where the integrity and availability of attestation data are more critical than minimizing response time, the benefits provided by these measures justify the additional costs.
In a scenario without the proposed solution, VMs hosted on nodes without a TPM cannot benefit from any anchoring service. By employing the hyperconverged TPM mechanism, a layer is introduced that abstracts the physical TPM, creating a logical TPM. In this case, it becomes possible to provide anchoring services to all the VMs, even though this process naturally introduces some overhead. Moreover, in more robust hyperconverged infrastructures—characterized by low-latency networks—optimization strategies can be implemented to mitigate the impact and enhance the solution’s efficiency.
Alongside the evaluation of anchoring time, CPU and memory usage measurements were conducted to analyze the computational load imposed by the proposed solution.
Figure 10 and
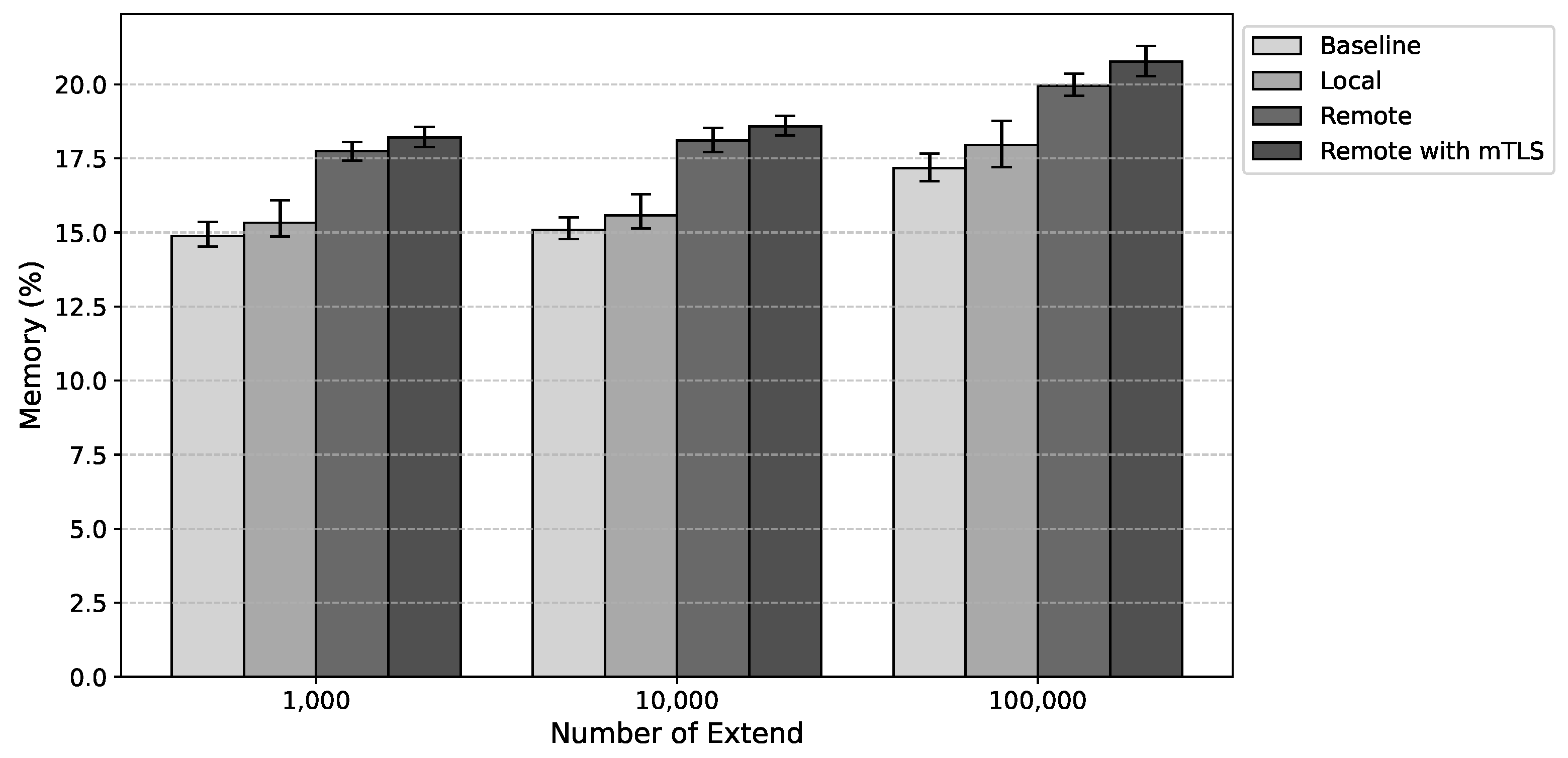
Figure 11 present the estimated values for average CPU usage, corresponding to Host 1 and Host 2, respectively. The results suggest a slight increase in CPU utilization. Compared to local anchoring, under a load of 100,000 extends, there was an average increase of 0.18 percentage points for remote anchoring and 0.56 for remote anchoring with mTLS. These results indicate that the proposed solution has a minimal impact on CPU usage.
In terms of memory usage, remote anchoring led to an average increase of 2.97 percentage points without mTLS and 3.82 percentage points with mTLS compared to local anchoring.
Figure 12 and
Figure 13 present the estimated values for average memory usage, corresponding to Host 1 and Host 2, respectively. This behavior was expected given the overhead associated with running the additional components required for the solution’s operation, such as etcd. In addition to the increased storage resulting from anchoring files—necessary for state validation—there is also an increase in the amount of data stored in etcd, used for sharing the system hosts’ states.
Thus, the results suggest that, although the adopted strategy leads to an increase in resource consumption, this overhead can be considered moderate and potentially acceptable for most application scenarios. Therefore, in environments with high memory and CPU demand, the proposed solution is unlikely to affect performance.
However, the main consideration concerns the observed increase in anchoring time. The introduction of remote communication or the implementation of an additional security layer, such as the use of mTLS, inherently results in increased process latency. In this context, a careful evaluation of the scenarios in which local or remote anchoring will be used becomes essential. For example, in contexts involving critical services, it is possible to adopt a strategy that combines local anchoring with redundant remote anchoring. In such an arrangement, the redundant remote anchoring would function as a backup mechanism, activated only in the event of failures or specific needs, thereby ensuring greater system resilience.
Another relevant point concerns the analysis of the need for an additional security scheme, such as mTLS, in the context of remote anchoring communication. In scenarios involving on-premises data centers, anchoring may be performed without implementing mTLS in order to optimize response time since these infrastructures are locally maintained and managed. In contrast, in situations involving communication with external elements—where the external entity may pose a risk of compromise—the adoption of mTLS becomes crucial to ensure the integrity of the parties involved in the communication. In this context, the costs associated with using mTLS are justified by the benefits it provides, especially in mitigating risks and ensuring the security of interactions.
Theoretical Evaluation of the Solution in the Context of Real Vulnerabilities
In this section, we conduct a theoretical assessment of the proposed solution, focusing on real-world vulnerabilities documented in CVEs and the scientific literature. The analysis emphasizes recent vulnerabilities that compromise the integrity of the vTPM. We begin by describing potential threats to the system that could be exploited by malicious actors. Then, we present three threat scenarios constructed based on actual identified vulnerabilities. Finally, we analyze how the proposed solution can be employed to detect integrity violations.
In this assessment, we consider the possibility of an attacker gaining full control over all the resources in the environment. This implies that the adversary may acquire superuser privileges, granting unrestricted access to the entire stack of services and infrastructure associated with the compromised node. This stack encompasses not only software and operating systems but also hypervisors and the virtualization layer.
However, it is essential that the TPM emulator remains in a state of verified integrity, ensuring the trustworthiness of the information it provides. To achieve this goal, access control and integrity monitoring mechanisms—such as SELinux, IMA, and EVM (Extended Verification Module)—can be employed, along with other approaches that enable the protection, verification, and assurance that the emulator software has not been improperly modified. Therefore, we assume that, if the emulator’s integrity is compromised, the machine will not be included in the hyperconverged TPM pool.
One of the main considerations when using a vTPM concerns the protection of its persistent state, namely the NVRAM. Unlike conventional TPMs, which physically embed NVRAM in the hardware, a vTPM typically uses a disk file to simulate NVRAM [
12]. Protecting the confidential information stored in this file is critically important due to its sensitive nature.
Once inside the environment, the attacker can perform various malicious actions that compromise the integrity of the data within the vTPM instances. The adversary may gain full control over read and write operations, as well as the update and binding of the NVRAM [
11,
12]. These actions can be carried out by exploiting several potential threats in the system, among which the following stand out:
Backdoors and Unpatched Vulnerabilities: Backdoors are software mechanisms or capabilities intentionally inserted by developers for various purposes, often without official documentation and with restricted knowledge, posing a security threat by enabling unauthorized access or manipulation of systems. Unpatched vulnerabilities, on the other hand, are unintentional flaws in software that can be exploited by attackers, presenting significant security risks if not promptly addressed through fixes or patches [
61]. Both issues can compromise the integrity and security of the vTPM, requiring prompt action to mitigate their impact [
17]. These threats become especially critical in environments with high virtual machine density, where there is little or no governance over the software executed by users.
Privilege Escalation: In the context of vTPMs, privilege escalation may allow an attacker to leverage elevated privileges to perform unauthorized modifications to the vTPM’s persistent state, such as a rollback attack [
11,
12].
Hypervisor Vulnerabilities: Vulnerabilities in hypervisor software can be exploited to gain unauthorized access to VM control and the associated NVRAM. Attackers may leverage flaws that allow them to escape the VM’s isolated environment, compromise the hypervisor, and consequently access and modify the NVRAM [
62] belonging to another user, as seen in binding attacks.
Most of the approaches proposed in the literature focus on the confidentiality of the vTPM and NVRAM, utilizing encryption mechanisms and vTPM key anchoring [
5,
6,
15]. However, recently, threat scenarios have emerged that primarily compromise the integrity of the vTPM:
Scenario 01: Rollback Attack: Since NVRAM typically resides in a storage system vulnerable to compromise, an attacker may take control of the NVRAM and make unauthorized modifications, including tampering with the NVRAM files. For example, the attacker could prepare a copy of the persistent state in advance and later replace the stored version with this state. This attack is known as a rollback [
11,
12]. The main consequence of this attack is the lack of a guarantee that the persistent state is always up to date as the attacker has the ability to replace the NVRAM file with an earlier version.
The attacker may have various ways to modify the version of the NVRAM. Recently, CVE (Common Vulnerabilities and Exposures) disclosed a critical vulnerability related to the persistent state of SWTPM, a widely recognized and used open-source vTPM emulator [
14,
15]. In this vulnerability, an attacker is able to overwrite the persistent state file through a symbolic link attack [
16].
Scenario 02: Binding Attack: When attackers gain control over the host platform, they can bind a regular user’s VM to an NVRAM that does not belong to them. For example, an attacker could start a user’s VM with a newly created NVRAM, resulting in the loss of the vTPM data [
11,
12].
Scenario 03: Memory Attacks: The attacker may exploit backdoors and unpatched software vulnerabilities to make modifications in specific areas of memory. This scenario is critical given that the values of the PCRs, which represent the volatile state, are stored in memory [
11].
A relevant example is the vulnerability disclosed in 2023 by CVE in the TCG reference code related to out-of-bounds writes [
17]. This flaw allows an attacker to insert up to 2 extra bytes into a command, enabling unauthorized modifications in specific areas of memory. Therefore, if the security vulnerability impacts the memory area where the PCR data are stored, the integrity of the vTPM’s volatile state is compromised. This is not the first vulnerability associated with the TCG specification. Previously, another vulnerability was reported that allowed local users to replace the static PCRs [
63].
There is limited information available regarding the implementation of vTPMs on commercial platforms, which makes it difficult to assess the security guarantees they provide. However, it is important to note that most of these implementations adhere to the TPM 2.0 specification and reference implementation established by the TCG [
8,
18,
19]. This implies that vulnerabilities identified in the TPM 2.0 specification are likely to affect all the implementations based on it.
All the identified vulnerabilities compromise the integrity of the vTPM. The proposed hyperconverged TPM mechanism is capable of detecting all such integrity violations. In Scenario 01, if an attacker overwrites the NVRAM, this modification will not be recognized by the emulator as it was not performed through legitimate means. As a result, the current hash of the NVRAM will not match the expected hash, indicating a modification in the NVRAM and a compromise of the vTPM’s integrity.
Regarding Scenario 02, the mitigation follows a similar approach: the mechanism binds each vTPM to the identifier of its corresponding VM. If the affected VM has its vTPM linked to a different NVRAM, the expected measurement of the NVRAM, anchored by the mechanism, will differ from the current measurement on disk. Thus, the integrity violation is detected.
In Scenario 03, any memory violation that results in the alteration of a PCR can be detected by the proposed mechanism. The emulator is responsible for reporting all legitimate changes to the volatile state, namely the PCRs. Therefore, if the current value of a PCR differs from the value anchored by the solution, this indicates a compromise of the vTPM.
It is important to emphasize that the proposed solution is not limited to the scenarios and vulnerabilities mentioned but encompasses all cases that could compromise the integrity of the vTPM. Given that the primary purpose of the vTPM is to establish a trusted foundation, our solution ensures the validity of this trust root through integrity checks.
7. Conclusions
The academic community has proposed several approaches to ensure the security of virtual TPMs. One of the most common strategies is hardware-based anchoring, in which the vTPM is bound to a physical TPM. However, approaches that adopt this strategy require the presence of a TPM chip on all nodes. Moreover, these solutions do not take into account the possibility of redundant anchoring across multiple TPM chips.
Moreover, scenarios in which VMs using vTPM instances run on a hyperconverged architecture have become increasingly common. In this context, it is crucial to present proposals that incorporate and leverage the principles of this model, integrating effectively with the existing solutions.
In this work, we address the problem of secure anchoring of virtual TPMs in hyperconverged environments. In this context, we propose a hyperconverged TPM. In this approach, the individual TPMs associated with physical hosts form a pool of TPMs that are shared among all the m-vTPMs through a management system. We consider a vTPM anchoring approach based on evidence of both persistent and volatile state integrity, with the root of trust being the hyperconverged TPM. In this scenario, an m-vTPM hosted on a given physical host can use the TPM associated with a different physical host. This approach is suitable for hybrid scenarios in which not all the hosts are equipped with a TPM chip, and it also enables the distribution of anchoring replicas—particularly useful for critical services that require high availability and reliability guarantees.
The evaluation results indicate that the proposed solution is feasible, presenting a moderate and acceptable overhead without significantly impacting system performance. The analysis demonstrates increased anchoring time, ranging from 7.62 ms to 8.48 ms for remote anchoring without mTLS, and from 24.22 ms to 25.00 ms with mTLS. Additionally, average increases in memory usage of 2.97 percentage points without mTLS and 3.82 percentage points with mTLS were observed, while CPU usage showed a slight increase of 0.18 percentage points without mTLS and 0.56 percentage points with mTLS. These results demonstrate that the proposed approach maintains system performance within acceptable parameters, with the additional costs being justified by the benefits of its implementation.
The experimental scenarios considered demonstrated the feasibility of the proposed solution. As directions for future work, we propose expanding the scope of experimentation to include more representative environments, employing enterprise-grade equipment, as well as investigating other vTPM emulators and hyperconverged solutions. In parallel, we intend to assess the effectiveness of the approach in mitigating potential vulnerabilities, including those already documented by the scientific community. Furthermore, exploring the integration of the solution with confidentiality-based anchoring schemes previously proposed in the literature is considered a promising direction.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}