1. Introduction
Sarcasm is a distinctive form of emotional expression, often characterized by a discrepancy between linguistic content and true intent. With the rapid development of social networks, people increasingly enjoy sharing their daily lives and engaging in discussions on various social platforms. These discussions generate a vast amount of multimodal data. Compared to unimodal data, multimodal data provide a more comprehensive set of information [
1,
2,
3].
The current research developments indicate that a significant challenge in multimodal sarcasm detection lies in identifying the similarities between modalities and effectively extracting and merging information from different modalities during the processing of cross-modal data [
4].
The previous research on multimodal detection has primarily concentrated on image and text modalities [
5], with limited exploration of audio and text detection. Thus, understanding how to semantically align audio and text and effectively utilize their latent sarcastic features remains a key issue [
6].
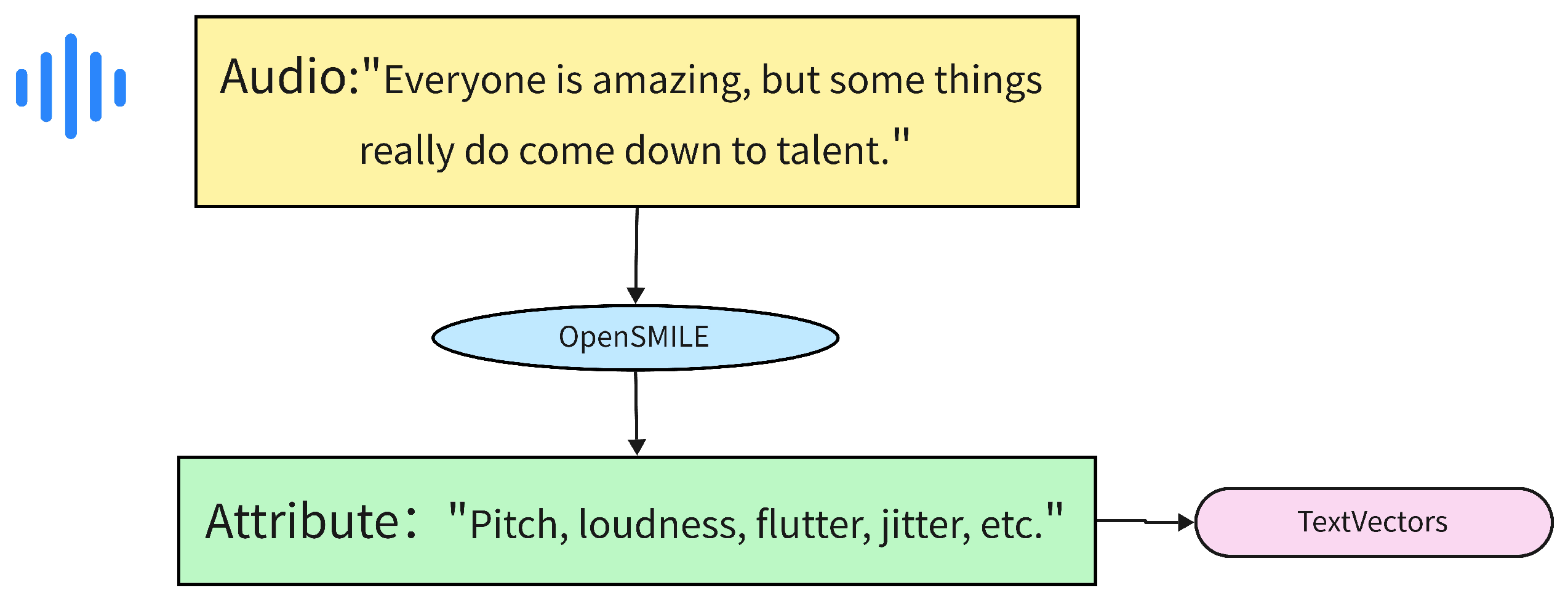
To address these challenges, this paper presents a solution that utilizes critical audio information as attributes for text, enhancing the continuity between text and audio through effective text feature extraction methods, as illustrated in
Figure 1. In this framework, OpenSMILE, an open-source toolkit for extracting acoustic features such as pitch, loudness, and jitter, is utilized to process raw audio signals into structured attribute representations.
This paper introduces a Multimodal Multi-Scale Convolutional Sarcasm Neural Network (MMCSNN) designed to tackle the sarcasm detection task. It processes data across different modalities and their dependencies, effectively integrating text and audio features, and captures multi-scale information to improve sarcasm detection performance.
The experimental results on a publicly available dataset [
7] suggest that our model makes more effective use of multimodal signals, leading to a clear boost in sarcasm detection accuracy.
In summary, this work introduces a multimodal sarcasm detection framework that emphasizes the integration of audio attributes into text feature space, supported by a multi-scale convolutional architecture. The proposed model aims to enhance the cross-modal interaction and achieve more robust and accurate sarcasm detection. Extensive experiments validate its effectiveness across various benchmarks.
The main contributions of this work are as follows:
We incorporate audio-based cues as a central element in the sarcasm detection process, enhancing the interaction between audio and textual features. By embedding these audio attributes into the model, we enable closer alignment between spoken tone and linguistic content, which helps to capture sarcastic expressions more reliably.
The application of multi-scale convolutional neural networks to multimodal global features: The paper proposes the use of multi-scale convolutional neural networks to extract global features from both text and audio at different scales. Multi-scale convolution effectively captures both local and global information, improving feature robustness [
8]. This method not only enhances the representation ability of audio features but also boosts the overall model performance through multi-scale feature fusion.
Extensive experimental analysis: The paper conducts a thorough experimental analysis, with the results demonstrating that the proposed method significantly outperforms the existing baseline methods across multiple evaluation metrics. The experiments validate the effectiveness and advantages of the Multimodal Multi-Scale Convolutional Sarcasm Neural Network in sarcasm detection.
4. Experiment Settings
4.1. Dataset and Evaluation Metrics
We evaluate our model on the publicly available MCSh dataset (Multimodal Chinese Sarcasm and Humor), which contains sarcastic and humorous content collected primarily from stand-up comedy performances. Each sample includes textual transcriptions and the corresponding video clips. Additionally, the speaking style of the MCSH dataset predominantly carries a humorous and sarcastic tone, typical of stand-up comedy performances. The topics mainly revolve around entertainment and social commentary, aligning with the general themes of stand-up comedy. The textual transcriptions are provided along with the original dataset and are assumed to be manually annotated, ensuring the alignment between audio and text.
For this study, we further process the original data by segmenting the video content and extracting audio tracks for each instance. The resulting dataset is split into training, validation, and test subsets, with 4,899 samples used for training, 612 for validation, and 613 for testing.
Each sample is annotated with a binary label, where 0 denotes non-sarcastic content and 1 indicates sarcasm. A detailed breakdown of the dataset statistics is presented in
Table 2.
Based on previous work, accuracy (Acc), precision (Pre), recall (Rec), and F1-score (F1) are used as evaluation metrics. Additionally, due to the imbalanced distribution of the MCSh dataset, macro-average precision (Macro Pre) is also used as an evaluation metric to comprehensively assess the experimental results.
4.2. Hyperparameter Settings
We adopt bert-base-chinese as the text encoder to extract semantic representations from the input text. For the audio modality, VGGish is employed to capture acoustic features, while handcrafted audio attributes are derived using OpenSMILE (version 3.0).
A summary of the remaining training hyperparameters is provided in
Table 3.
4.3. Baseline Comparison
We compare the proposed method against several representative baseline models commonly used in sarcasm detection tasks. The core characteristics of each model are briefly summarized as follows:
TextCNN [
35]: Applies convolutional neural networks to textual data for sentence-level classification, leveraging n-gram patterns to capture semantic cues.
TextCNN-LSTM: Integrates CNNs with long short-term memory units. CNNs handle local feature extraction, while LSTMs model long-range dependencies to improve overall classification performance.
BERT: A bidirectional-transformer-based model pre-trained on large-scale corpora, known for its effectiveness in semantic representation and downstream language understanding tasks.
VGGish: An audio feature extraction model based on Convolutional Neural Networks (CNNs), which extracts high-dimensional spatiotemporal features from raw audio waveforms through hierarchical convolution operations.
MFCC [
36]: A classical acoustic feature extraction method with strong interpretability, widely used in tasks such as speech recognition and speaker identification.
OPENL3: A self-supervised learning-based audio representation model, suitable for open-domain multimodal scenarios.
BERT+VGGish: A dual-stream architecture that integrates textual and acoustic information. The textual branch uses the BERT pre-trained language model to extract word-level or sentence-level semantic features, while the acoustic branch uses VGGish to capture prosodic features.
TextCNN+VGGish: A multimodal framework that combines local text patterns with global acoustic features.
Wav2Vec2.0 + BERT + CMA [
37]: A multimodal fusion model that combines audio and text embeddings extracted from pre-trained Wav2Vec2.0 and BERT encoders. The two modality-specific representations are then aligned via a cross-modal attention (CMA) mechanism to capture interaction patterns for sarcasm detection.
5. Experimental Results and Analysis
5.1. Main Experimental Results
Table 4 presents the performance comparison between our proposed Multimodal Multi-Scale Convolutional Sarcasm Neural Network (MMCSNN) and several competitive baselines on the MCSh dataset. The baselines include models based on single modalities (text or audio) and multimodal fusion strategies.
In the single-text modality, BERT achieves the best performance due to its strong contextual understanding.
For the audio-only modality, the combination of OPENL3 and SVM achieves excellent results, indicating that audio cues such as pitch and tonal variation play a crucial role in sarcasm detection.
After fusing the two modalities, a significant performance improvement can be observed, which demonstrates that combining textual and audio features indeed enhances sarcasm detection capabilities. Among them, our proposed MMCSNN model outperforms all the baseline methods across all the metrics, achieving an accuracy of 86.88%, an F1-score of 88.20%, and a Macro F1 of 86.17%.
These results directly reflect the advantages of our model from a quantitative perspective. Further analysis of its structural improvements is provided in
Section 5.2.
To further strengthen the comparison, we additionally incorporate a recent multimodal baseline: Wav2Vec2.0+BERT with cross-modal attention (CMA). This model leverages pre-trained encoders for both audio and text, followed by attention-based cross-modal fusion. As shown in
Table 4, this method achieves strong performance (F1 = 83.20) but still lags behind our proposed MMCSNN across all the key metrics.
5.2. Multimodal Results Analysis
As shown in
Table 4, multimodal models that integrate both textual and audio features show a clear performance improvement over traditional unimodal methods.
This is because traditional unimodal models, such as text-based approaches like TextCNN and BERT, although capable of capturing syntactic and semantic structures effectively, often struggle to identify the hidden sarcastic cues embedded in audio signals.
On the other hand, audio-only models like VGGISH can perceive tonal variations, but the lack of contextual information limits their ability to achieve strong results.
In contrast, the excellent performance of our proposed MMCSNN model across all the evaluation metrics demonstrates that the key to sarcasm detection lies in cross-modal reasoning—specifically the analysis of semantic and acoustic shifts across modalities.
To address this, we introduce the concept of audio attributes, improving the model’s ability to detect tonal changes related to sarcasm and further enhancing the integration of multimodal features.
In addition, the use of a dynamic multi-scale convolutional layer allows the model to perform deeper analysis under varying receptive fields, enabling it to detect more complex and globally distributed hidden cues.
To further verify the model’s performance, a confusion matrix is plotted based on the results on the test set, as shown in
Figure 6. The model achieves balanced classification across both the sarcastic and non-sarcastic categories, with relatively low false positive and false negative rates. This result highlights the model’s ability to handle subtle sarcasm cues while maintaining robustness against misclassifications.
5.3. Robustness and Significance Verification
To further evaluate the robustness and statistical reliability of our proposed MMCSNN model, we conducted five independent training runs using different random seeds.
Table 5 reports the mean and standard deviation (mean ± std) for the accuracy, F1, and Macro F1-scores of both the MMCSNN and the strong baseline BERT+VGGish.
As shown in the results, the MMCSNN consistently achieves superior performance with relatively low variance across runs, demonstrating the model’s stability under stochastic training conditions, including dropout and data augmentation. In addition, we performed paired two-tailed t-tests on the five results between the MMCSNN and BERT+VGGish. The performance improvements achieved by the MMCSNN are statistically significant across all the metrics, with .
5.4. Ablation Study
To better demonstrate the contribution of each module, this paper conducts an ablation study by removing each module individually using a controlled variable approach. The experimental results are summarized in
Table 6 and illustrated in
Figure 7.
To further investigate the impact of different audio attribute subsets, we conducted an ablation study by isolating low-level and high-level descriptor groups, and by removing individual key features. As shown in
Table 7, the high-level features (HNR, F1, and F2) yielded slightly better performance compared to the low-level ones (F0, shimmer, and jitter), indicating their superior ability to capture vocal tract characteristics essential for sarcasm recognition. However, removing F0 caused the most significant drop in accuracy, suggesting its crucial role as a tonal anchor. These results validate the complementary nature of prosodic and spectral features in our attribute design.
In addition to the ablation studies conducted, we further examined the architectural variations suggested by the reviewer. Specifically, for the multi-scale convolution module, we explored different kernel size combinations (e.g., 1–3–5, 3–5–7, and 5–7–9) during the model development. The experimental results showed that, while varying the kernel sizes slightly affected performance, the default setting of 3 × 3, 5 × 5, and 7 × 7 achieved the best trade-off between capturing local fine-grained cues and broader contextual information. Therefore, we adopted 3 × 3, 5 × 5, and 7 × 7 as the default setting for our multi-scale convolutional structure. Additionally, regarding the feature fusion strategy, we employed a late fusion approach rather than early fusion. Early fusion, which directly concatenates raw features from different modalities, often leads to scale mismatches and noisy interactions that obscure subtle sarcastic signals. In contrast, late fusion allows each modality to be deeply encoded before integration, resulting in a more semantically aligned and robust multimodal representation for sarcasm detection.
5.5. Robustness Under Noisy Conditions
To evaluate the performance of the MMCSNN in complex acoustic environments, we conducted a noise augmentation experiment. By simulating real-world usage scenarios, various types of background noise were introduced, including white noise, café background chatter, and electrical interference—common disturbances in audio inputs. Each type of noise was tested under three different signal-to-noise ratio (SNR) levels: 20 dB, 10 dB, and 5 dB.
As shown in
Figure 8, the MMCSNN still performs well under all the noise conditions. Even at 5 dB, the Macro F1-score remains above 77%. It is worth noting that, starting from 10 dB, white noise caused a significant performance drop. This may be due to its broad spectral coverage, which can interfere with the extraction of audio attribute features.
5.6. Training Convergence Analysis
To further examine the learning dynamics and ensure that the MMCSNN model is not prone to overfitting, we visualize the training and validation loss across 5-fold cross-validation in
Figure 9. The results show consistent downward trends with minimal divergence between the curves, indicating stable convergence behavior and good generalization. This further verifies the model’s robustness under stochastic optimization.
5.7. Generalization Across Datasets
To assess whether the MMCSNN can generalize beyond its original training distribution, we evaluate its performance on the CMU-MOSEI dataset. While CMU-MOSEI includes visual signals, only the text and audio modalities are used here to stay consistent with our model’s design, which excludes visual input in favor of streamlined bimodal processing.
We compare the MMCSNN with two commonly used bimodal baselines: BERT+OpenL3, which pairs contextual text embeddings with audio features from a pre-trained encoder, and LSTM+Acoustic, which combines sequential modeling of text with handcrafted prosodic descriptors. These baselines are chosen to match our two-modality setup and are widely adopted in related tasks involving sentiment and sarcasm analysis.
As reported in
Figure 10, the MMCSNN reaches an F1-score of 86.1% and a Macro F1 of 84.3%, outperforming both baselines. This suggests that the model is capable of adapting to different data distributions and linguistic styles while maintaining effective cross-modal alignment.
Overall, compared with the traditional methods, the MMCSNN model still shows certain improvement and can be effectively transferred to different domains without relying on visual information. This further verifies the generalization ability of the MMCSNN model.
5.8. Computational Complexity Analysis
To evaluate the practical feasibility of deploying the MMCSNN in real-world scenarios, we conducted an empirical analysis of its computational complexity.
Table 8 reports the average inference time per sample and the total model size for the MMCSNN and several strong baselines. All the experiments were executed on a dual NVIDIA RTX 3090 GPU setup with a batch size of 32.
Despite integrating multi-scale convolution and audio attribute modules, the MMCSNN exhibits a comparable inference time and significantly lower memory footprint than the existing transformer-based multimodal models. Notably, the model size of the MMCSNN is only 30.2 MB, substantially smaller than models such as BERT+VGGish (104.6 MB) and Wav2Vec2.0+BERT+CMA (837.6 MB). This is because pre-trained encoders like BERT and VGGish are used in frozen feature extraction mode and not embedded into the saved model architecture, making the final deployable model lightweight and highly portable.
These results confirm that the MMCSNN achieves a favorable balance between performance and computational cost, making it more suitable for deployment in latency-sensitive or resource-constrained environments.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}