1. Introduction
Effective communication is essential to bridging social divides, yet for many in the deaf and hard-of-hearing community, sign language is the primary medium for expression. Unlike spoken languages that rely on auditory signals, sign language presents unique challenges to automated recognition due to its reliance on rapid hand movements, subtle gestures, and intricate facial expressions. These visual cues require systems that not only detect static features but also understand complex motion dynamics over time.
Early efforts in sign language recognition depended on handcrafted features and conventional machine learning techniques, which often struggled to account for the variability inherent in natural signing [
1]. The emergence of deep learning, however, has significantly shifted this paradigm by enabling models to learn rich representations directly from raw data [
2]. Techniques leveraging convolutional neural networks (CNNs) [
3] and recurrent neural networks (RNNs) [
4] have shown promise, yet many such methods tend to overlook the detailed dynamics necessary for capturing fast, fluid gestures.
In addressing these challenges, our work proposes an integrated deep learning framework specifically tailored for Kazakh Sign Language—a language that remains underrepresented in current research, unlike the commonly studied American Sign Language and, recently, Arabic Sign Language [
5,
6].
2. Literature Review
2.1. Proposed Methods
Recent advances in computer vision and deep learning have led to a surge in sign language recognition research, particularly for widely used languages such as American Sign Language (ASL), Indian Sign Language (ISL), and British Sign Language (BSL). However, relatively few studies have addressed less common languages such as Kazakh Sign Language (KSL). Notable efforts include the K-SLARS system for real-time KSL recognition using machine learning [
7], the development of a parallel corpus for KSL and Kazakh [
8], and ensemble models based on ResNet-50 and VGG-19 [
9].
Sign language recognition methods generally fall into two categories: firstly, object-detection-based, using models like YOLO and SSD for spatial gesture detection, and secondly, sequential models, such as LSTM or BiLSTM, which capture temporal dependencies for continuous recognition.
Previous research has successfully combined spatial detection models like YOLO with temporal models such as LSTM to improve recognition in challenging environments. Reference [
9] proposed a multimodal approach integrating visual and sensor data for improved dynamic gesture recognition. These results highlight the potential of applying similar multimodal strategies to the context of KSL recognition.
However, due to the lack of annotated data and gesture templates, most existing methods cannot be directly transferred to KSL without adaptation.
2.2. Dataset
The success of sign language recognition models mostly depends on the quality and diversity of training data [
10,
11]. Some of the most commonly used datasets in the literature are the ASL alphabet dataset, Roboflow ASL Dataset, and ASLYset. However, there is currently no publicly available large-scale dataset for Kazakh Sign Language. This gap is a major obstacle to the application and adaptation of modern deep learning methods to gestures specific to the Kazakh language. Creating a labeled Kazakh Sign Language dataset with both static and dynamic gestures is critical to advancing research in this field and providing inclusive communication tools for the Kazakh-speaking deaf community [
8].
3. Importance of Components
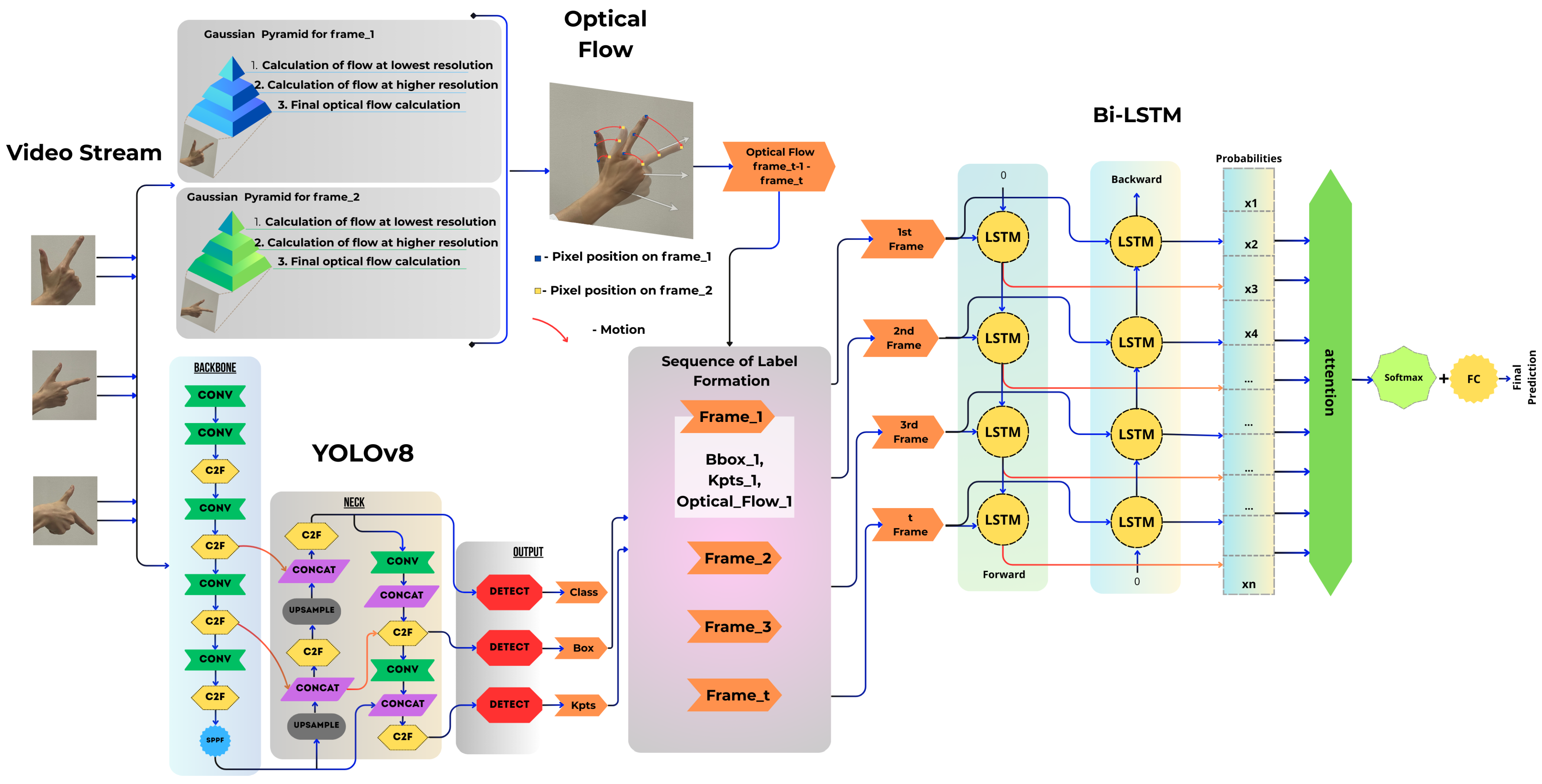
This section describes our integrated approach for recognizing dynamic gestures in Kazakh Sign Language. Our model combines three key components: YOLOv8 for spatial detection of hand keypoints, optical flow analysis for capturing motion details, and a BiLSTM for modeling temporal dynamics.
3.1. YOLOv8 for Keypoint Detection
YOLOv8 is a well-established and stable model in the YOLO family of object detectors and is designed to process entire images in real time. In our framework, YOLOv8 is trained using annotated gesture data collected with MediaPipe. This enables the model to accurately detect hand keypoints and extract bounding boxes from each frame of the video [
12]. The use of YOLOv8 allows efficient processing of full images without the need for generating region proposals first, ensuring that spatial information is captured reliably [
13].
Keypoint loss is computed by comparing predicted keypoints (
pred) with ground truth keypoints (
truth). First, the Euclidean distance loss measures the difference between predicted and ground truth keypoints in Euclidean space. The formula computes the squared Euclidean distance between the predicted and ground truth keypoints.
Then, the keypoint loss factor is adjusted using a formula that incorporates the area of the object and a scaling factor
representing the uncertainty of the prediction. This equation normalizes the keypoint loss based on the object’s size and prediction confidence.
The formula adjusts the loss for each keypoint depending on the object’s area and the uncertainty of the keypoint prediction. A small constant is used to avoid division by zero and maintain numerical stability.
Next, the final loss is calculated by applying a weight based on the two main components—the object’s area and keypoint uncertainty. The sensitivity factor
e is computed using the following equation:
This term e determines how strongly the penalty is applied to each keypoint, with larger e values corresponding to smaller areas or higher uncertainty, increasing the penalty for inaccuracies in those keypoints.
Finally, the keypoint loss is weighted by a binary mask
, which indicates whether the keypoint is visible (1) or occluded (0). This is defined as follows:
where
B is the batch size and
N is the number of keypoints per sample. Only visible keypoints contribute to the loss. The final loss formula, incorporating all of these components, is as follows:
This equation applies the loss factor and penalty based on visibility and uncertainty, ensuring that only relevant keypoints are considered during training.
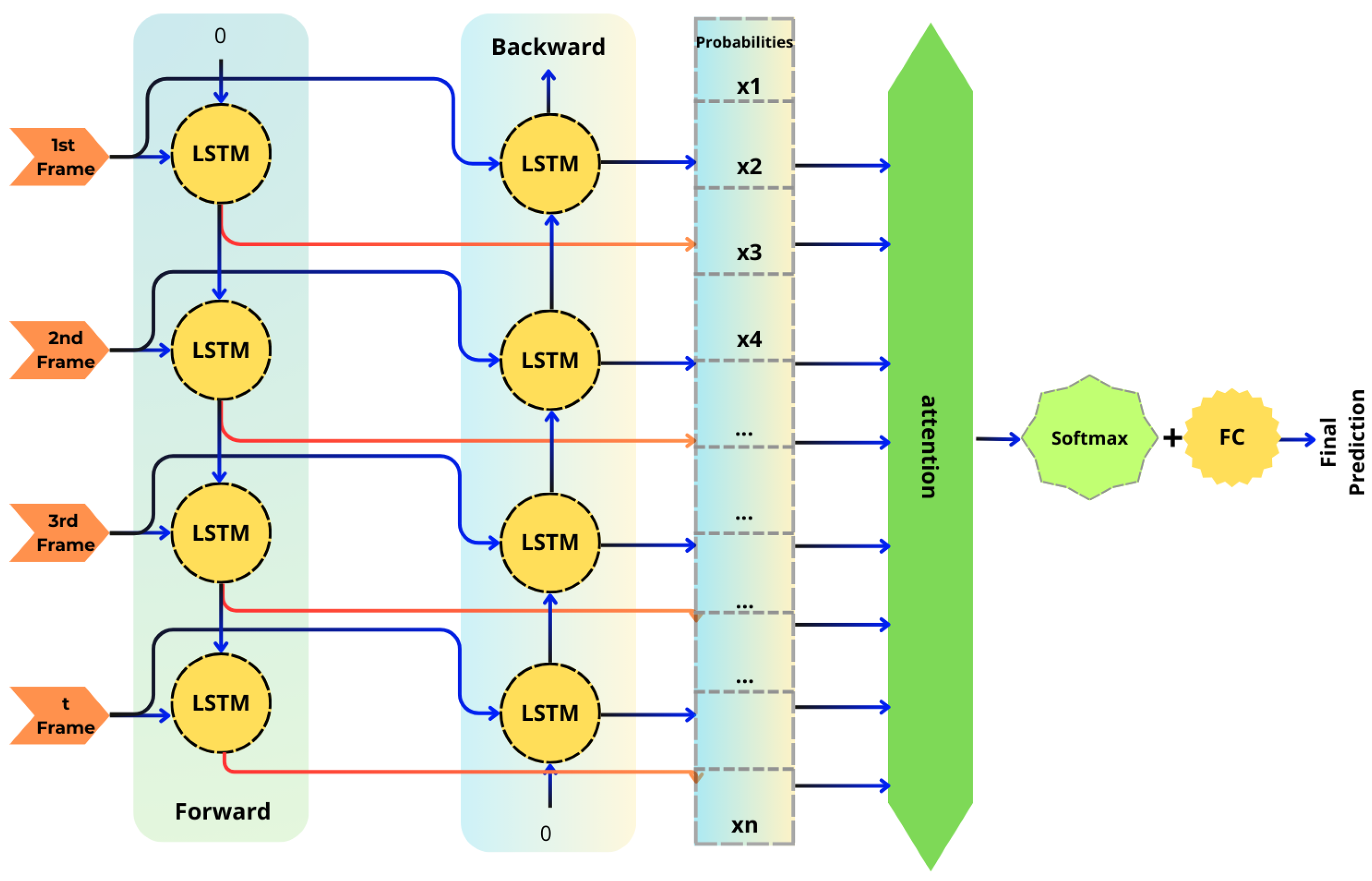
3.2. BiLSTM-Based Temporal Modeling
Sign language recognition requires a model that can effectively process sequential data since gestures are dynamic and change over time. Traditional recurrent neural networks often struggle with long-term dependencies due to the vanishing gradient problem. To address this, long short-term memory networks were introduced, which are capable of learning longer sequences by using gated mechanisms to retain important information while forgetting irrelevant details [
14].
However, standard LSTMs process sequences in a single direction (forward), meaning they may not leverage future context while interpreting a sequence. This limitation is particularly critical for sign language recognition, where understanding a gesture often depends on both previous and upcoming movements [
15]. To improve temporal modeling, we employ a Bidirectional LSTM, which processes sequences in both forward and backward directions (
Figure 1). This architecture provides a richer representation by considering the entire temporal context.
The LSTM updates its states at each time step
t using the following equations:
These equations define the standard architecture of the long short-term memory (LSTM) network, originally proposed by Hochreiter and Schmidhuber [
16]. The model’s ability to control the forgetting and retention of information over time makes it particularly well-suited for learning temporal dependencies in sequential data. Further studies such as Greff et al. [
17] have analyzed and validated the effectiveness of LSTM variants across various tasks.
The BiLSTM network in our project is trained on NumPy arrays containing three types of input features: keypoints extracted by YOLOv8, representing the spatial locations of hands in each frame; bounding boxes, which define the regions surrounding the detected hands and assist in gesture localization; and optical flow features, capturing motion dynamics around the keypoints to distinguish between static and dynamic gestures.
Input Layer.
The input sequence is a time-series representation of the hand gestures. At each timestep t, the input vector consists of the concatenated values of keypoints, bounding box coordinates, and optical flow features.
Bidirectional Processing.
The sequence is simultaneously passed through two separate LSTM layers. The forward LSTM processes the sequence from to , while the backward LSTM processes it from to .
The hidden states are computed as follows:
Fully Connected Layer and Classification:
The concatenated hidden state is passed through a fully connected layer that maps it to class probabilities.
A softmax activation function is applied to generate the final classification of the gesture [
18]:
Training and Loss Function:
The model is trained using cross-entropy loss, which is optimized via backpropagation through time (BPTT) [
19].
The Adam optimizer is used to adjust weights for better performance.
By combining YOLO-based keypoint detection, optical flow computation, and BiLSTM-based sequence modeling, our method achieves accurate and robust recognition of dynamic gestures in Kazakh Sign Language.
3.3. Optical Flow Analysis
To capture the dynamic aspects of hand gestures, we compute the optical flow around each detected keypoint. Optical flow measures the visible motion of objects between successive video frames and is calculated under the assumption that pixel intensity remains constant over a short time interval. This can be mathematically expressed as follows:
Using a Taylor series expansion and dividing by
, we obtain the motion components:
where
u and
v represent the horizontal and vertical components of motion, respectively. We define a square region around each keypoint with a size determined by the following:
To ensure that optical flow is computed in a localized region around each keypoint, a 10% area of the image height is used to define square regions of interest (ROIs) centered on each point. As previously described, each video frame is processed using YOLOv8-Pose to extract 21 keypoints per hand. These keypoints are normalized and used to define ROIs, whose size is determined by the parameter scale (scale = 0.1 in case of 10% of the frame height), which controls the proportion of the image height, and h (h = 480 in case of 640 × 480 resolution), the height of the frame. The scale value determines how large each ROI will be. Dense optical flow is then computed for each ROI using the Farneback algorithm. The final input to the algorithm is a pair of grayscale patches, extracted from corresponding ROIs in two consecutive frames. At each step, the algorithm computes the average magnitude and angle of motion within each ROI, producing a motion feature vector of shape (84), per frame—42 motion values per hand.
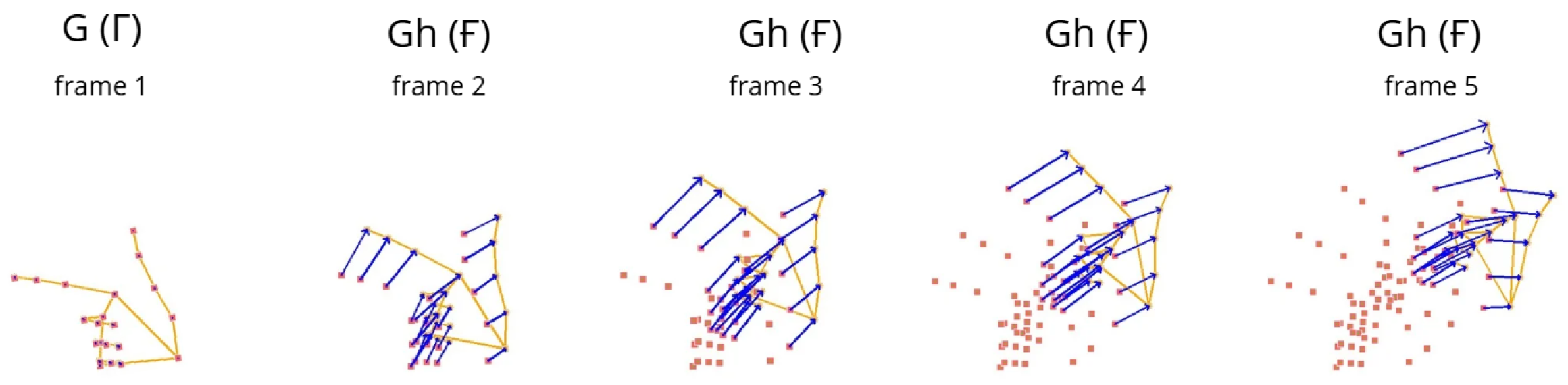
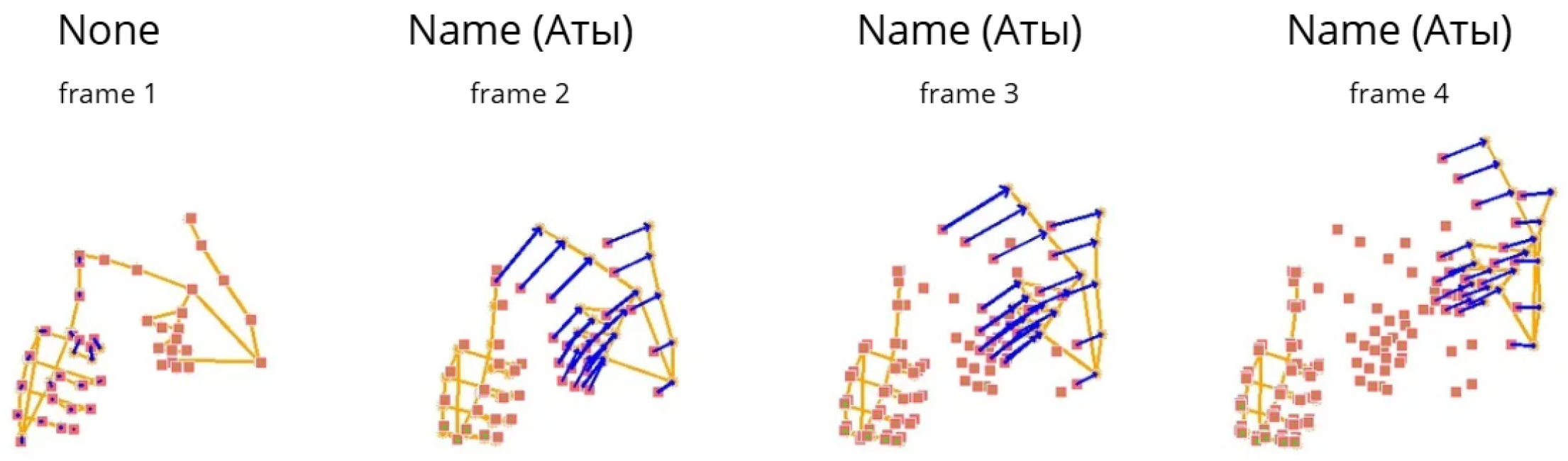
This localized optical flow calculation provides critical information about movement, which is essential for accurately recognizing rapid and subtle gestures. As shown (
Figure 2 and
Figure 3), the red squares denote the initial positions from which the optical flow vectors are computed, while the blue arrows illustrate the direction and magnitude of the motion between consecutive frames, thereby effectively capturing the temporal dynamics of hand movement.
These figures also demonstrate that static gestures form one category characterized by minimal or no motion, whereas dynamic gestures constitute a separate category distinguished by significant temporal changes. This distinction underscores the necessity of incorporating temporal features when analyzing dynamic gestures, as these cannot be fully captured through spatial information alone. Optical flow thus provides a vital temporal dimension that enhances the discriminative power of gesture recognition systems.
3.4. Data Processing Pipeline
The overall data processing pipeline consists of several key stages. First, video data are organized into folders according to gesture class. Annotations are initially generated using MediaPipe, providing ground-truth keypoint positions.
Next, the annotated dataset is used to train the YOLOv8 model. Once trained, YOLOv8 is capable of detecting hand keypoints and extracting bounding boxes from each video frame.
Following detection, spatial features are extracted from the video frames using YOLOv8. In parallel, optical flow is computed within a region covering 10% of the area around each detected keypoint. This step captures the motion dynamics necessary for distinguishing between static and dynamic gestures.
The extracted spatial and motion features are then compiled into NumPy arrays, forming a sequential representation of each gesture. These sequences are subsequently used to train the BiLSTM network, which learns temporal dependencies across frames and performs gesture classification.
This model integrates advanced object detection, motion analysis, and sequence modeling to effectively recognize complex and dynamic gestures in Kazakh Sign Language. The combination of YOLOv8, optical flow, and BiLSTM ensures that both spatial details and temporal dynamics are accurately captured.
4. Proposed Method
In this project, a system for recognizing Kazakh Sign Language was developed that combines YOLOv8-Pose, Bi-LSTM, and the optical flow algorithm—Farneback. The main goal of the system is accurate and reliable gesture recognition using keypoints and dynamic characteristics of movements. Recent studies, such as [
20], have demonstrated the effectiveness of deep learning approaches for sign language recognition. Their work focuses on translating Saudi Sign Language using neural networks, confirming the relevance of keypoint-based and sequence-processing methods. Inspired by such approaches, our system integrates YOLO-based keypoint detection with temporal modeling using Bi-LSTM to enhance dynamic gesture recognition.
The method is based on a combination of keypoint detection and optical flow analysis, followed by processing of sequences using a recurrent neural network. At the first stage, a video stream with gestures is fed to a detector (YOLO) based on a convolutional neural network, which extracts bounding boxes and keypoints of hands. Then, the optical flow around the keypoints is calculated, which allows the pixel shift between frames to be fixed. After that, the obtained features, including the coordinates of the keypoints and their dynamics, are transferred to bidirectional long short-term memory, which processes temporal dependencies and forms the final gesture prediction.
Thus, the method combines spatial and temporal features for more accurate gesture recognition (
Figure 4).
4.1. Dataset
To streamline dataset generation, MediaPipe was used as an automated annotation tool for the YOLO-based dataset. The dataset was structured with image files and annotation text files, each containing bounding box coordinates and 21 hand keypoints per hand in the format [21, 2], where each keypoint is defined by its (x, y) coordinates (
Figure 5b).
A separate dataset was created using video sequences to train the Bi-LSTM model, with a two-minute video recorded for each gesture class. Frame-by-frame annotations were extracted using the YOLOv8-Pose model, collecting hand keypoints, bounding box coordinates, and optical flow vectors. Optical flow was computed with the Farneback algorithm, and all features were stored in structured NumPy arrays for sequence modeling.
To evaluate the feasibility of the proposed method, a small pilot dataset was collected with two visually similar dynamic gesture classes: “Aty” and “Tegi” (“Name” and “Surname”), each consisting of 900 images and corresponding YOLO label files. The dataset was then expanded to 13 gesture classes, including 4 static and 9 dynamic signs, totaling 45,851 samples, or around 3527 samples per class.
Finally, a comprehensive dataset was compiled for full-scale training and evaluation, including the entire Kazakh Sign Language alphabet and 7 common words, with 27 static and 20 dynamic gesture classes.
Figure 5a demonstrates the visual difference between dynamic and static signs. Samples from the original, gathered dataset are shown in
Figure 5b. The dataset grew to 166,010 samples, or about 3532 samples per class, enabling performance evaluation across a diverse set of gesture types and complexities.
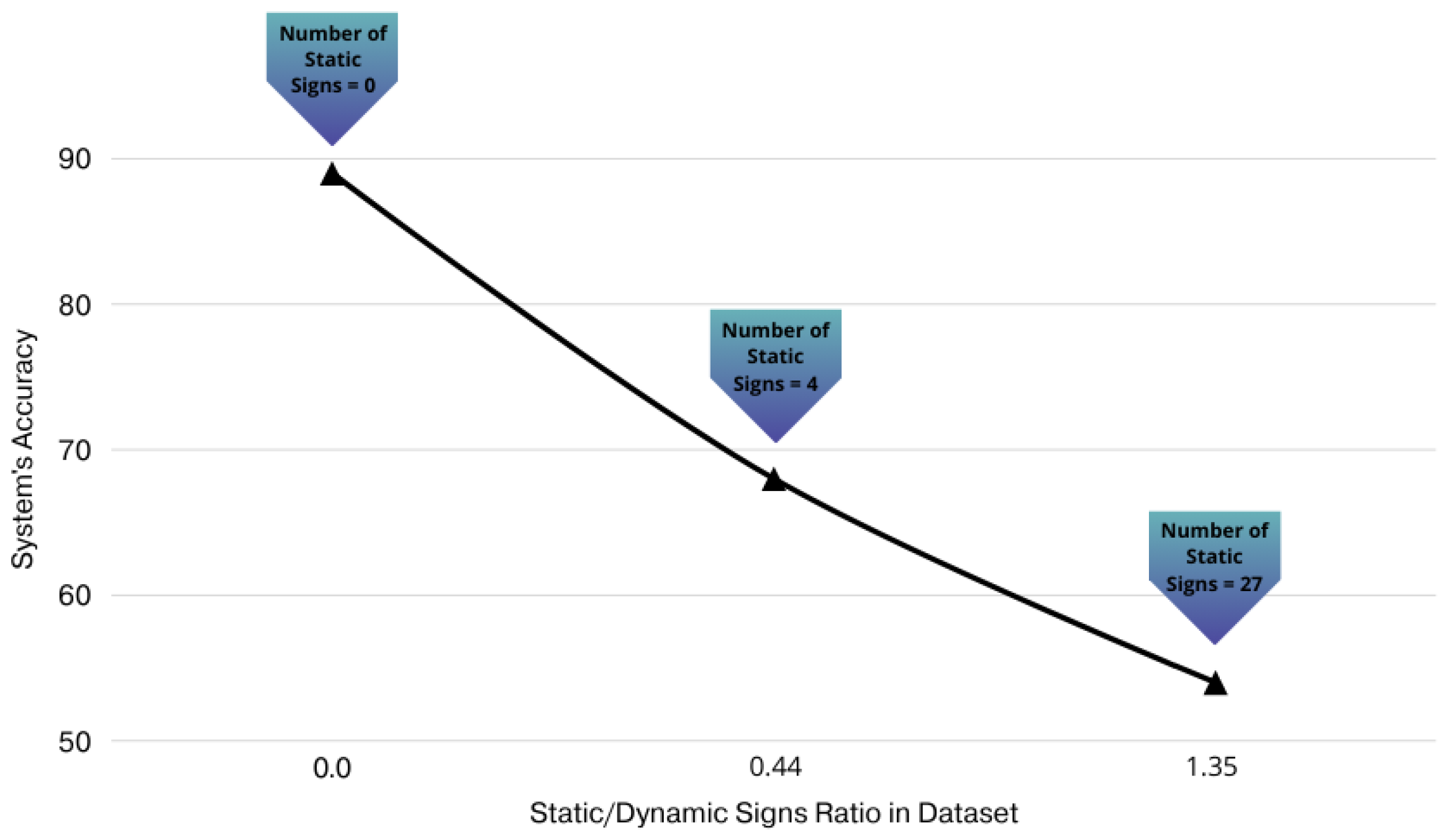
Figure 6 illustrates how the the static and dynamic sign ratio in the dataset affects the system’s classification accuracy. As the proportion of static signs increases, there is a consistent decline in model performance.
4.2. Training
The dual nature of sign language, combining static and dynamic gestures and poses, is challenging for recognition systems, particularly in capturing motion over time. Indeed, YOLOv8 effectively detects hand regions and extracts keypoints from individual frames. However, it lacks temporal modeling. To address this, we integrated a bidirectional long short-term memory network to learn temporal dependencies from gesture sequences [
21].
Some gestures, such as Name and Surname, are visually and dynamically similar, increasing the risk of misclassification. To improve sensitivity to motion, optical flow computed via the Farneback algorithm was added as an input feature [
22], providing information about motion direction and magnitude between consecutive frames.
For training, we applied stratified sampling [
23] to maintain class balance. Annotation files provided class labels and keypoint coordinates in the format [21, 2] (for 21 hand keypoints). These were defined in a custom configuration file, specifying class names and metadata.
The YOLOv8-Pose model was trained for 100 epochs with a batch size of 16 on two GPUs to simultaneously perform hand detection and keypoint regression [
24]. During training, loss metrics and checkpoints were recorded. After convergence, the model was used to extract features for the Bi-LSTM sequence recognition pipeline.
For each video, three types of features were extracted. First, hand keypoints were obtained and reshaped from a [21, 2] format into an 84-dimensional vector to serve as spatial descriptors. Second, optical flow vectors were computed using the Farneback algorithm to capture motion dynamics. Third, bounding box coordinates were extracted using the YOLOv8 model to localize hand regions within each frame.
These were concatenated into a single 176-dimensional feature vector per frame. Sequences of 30 frames formed one input sample. A total of 30 sequences per class were collected for dynamic gestures Aty and Tegi. Missing frames were zero-padded. The final dataset had the shape , where N is the number of sequences. Labels were integer-encoded using a predefined map.
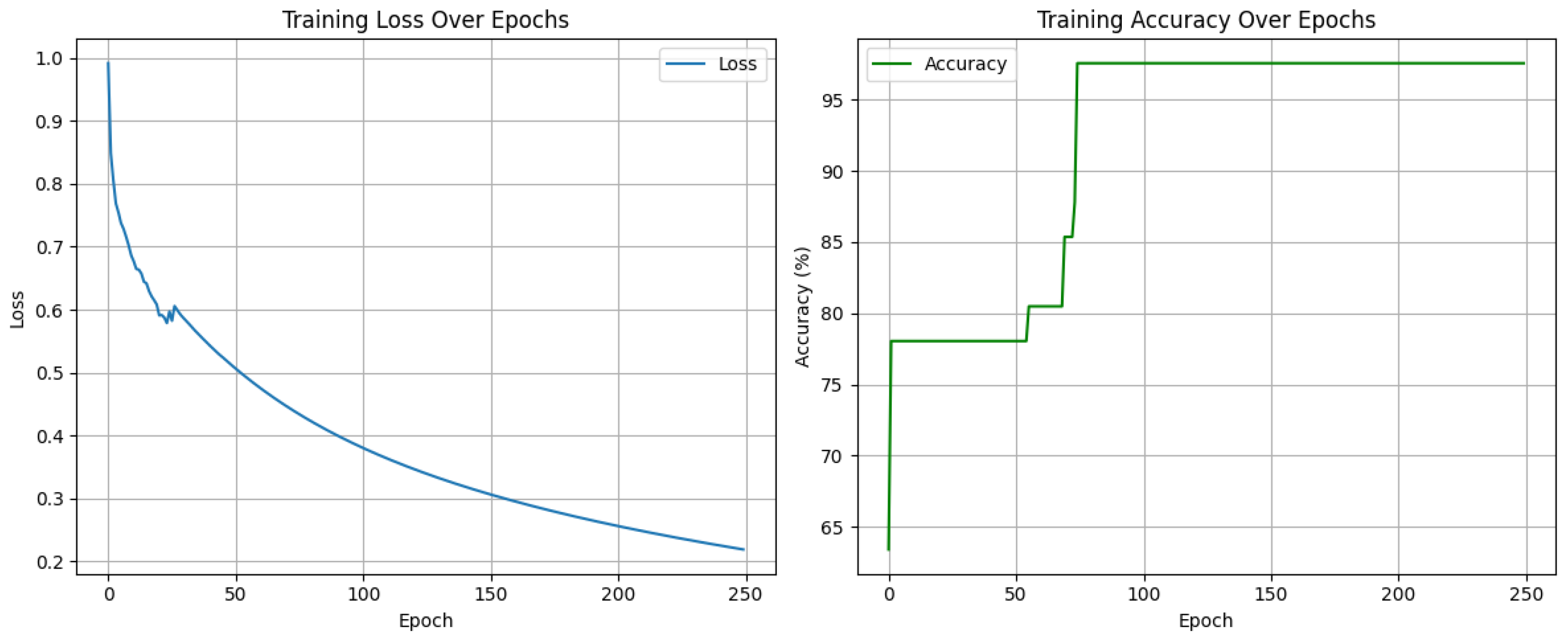
For the binary classification task involving the dynamic gestures
Aty and
Tegi, we employed a standard bidirectional long short-term memory (Bi-LSTM) network. The model consisted of a single bidirectional LSTM layer with 128 hidden units, followed by a fully connected softmax layer. It was trained for 250 epochs using the Adam optimizer (learning rate
, weight decay = 5 × 10
−4), a batch size of 32, with the
ReduceLROnPlateau scheduler and gradient clipping to ensure stable convergence (
Figure 7).
4.3. Evaluation Metrics
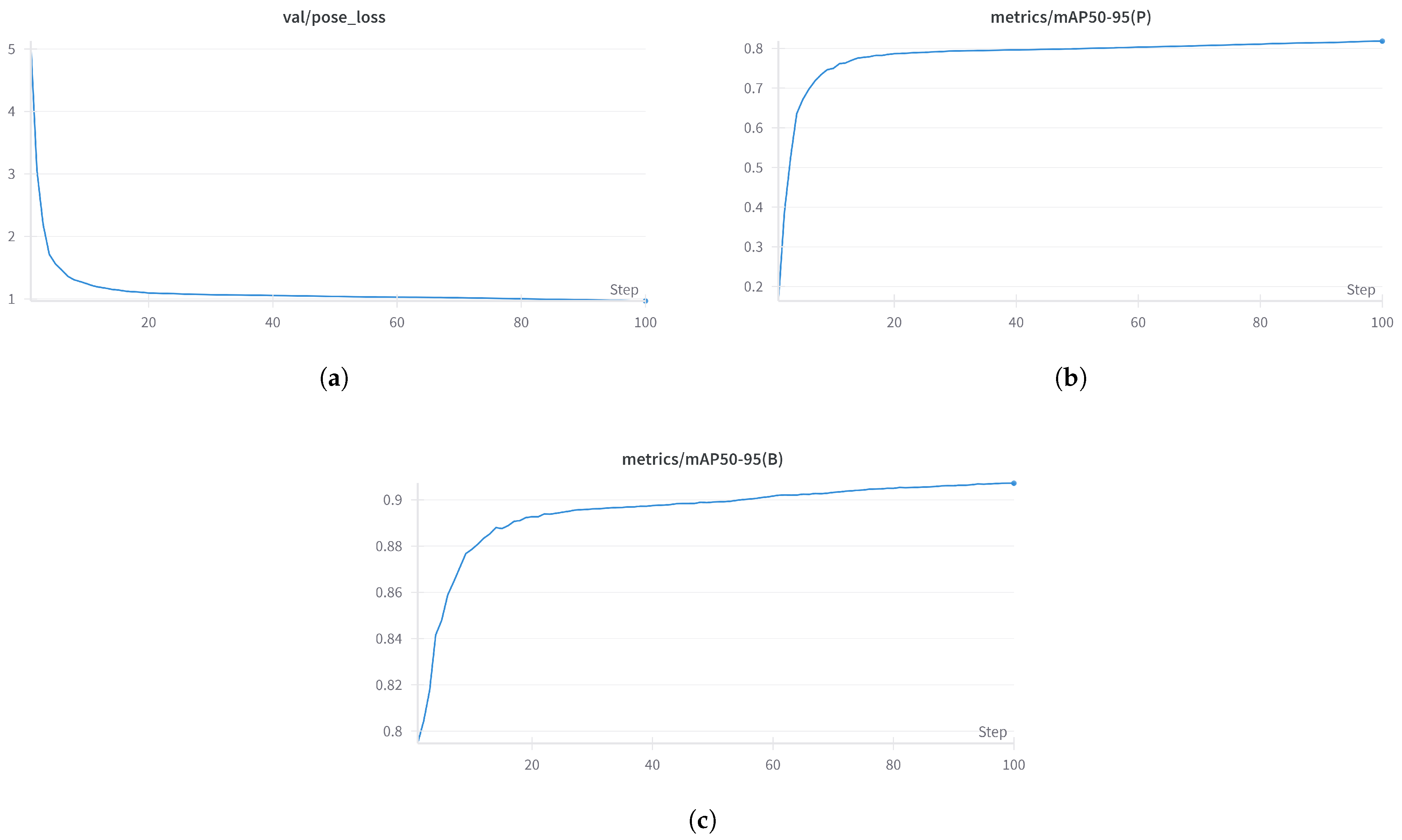
To evaluate the performance of the proposed sign language recognition system, we used standard metrics for object detection and sequence classification. The evaluation occurred in two steps: first, we assessed the YOLOv8-Pose model for hand detection and keypoint extraction, and second, we evaluated the Bi-LSTM model for classifying gesture sequences using keypoints and motion data. The YOLOv8-Pose model’s pose loss measures keypoint prediction accuracy, with lower values indicating better localization. As shown in the training loss and metric plots, key loss components (box, pose and classification loss) gradually decreased. The validation pose loss (
Figure 8a) decreased from 2.5 to about 1.0, indicating strong hand keypoint detection.
The precision and recall metrics were consistently high, with keypoint (P) and bounding box (B) (
Figure 8b,c) scores exceeding 0.8 and 0.9, respectively. The mAP metric, which summarizes the precision–recall curve at different IoU thresholds, showed excellent results, which show the YOLOv8-Pose model’s effectiveness in detecting hand regions and key points.
For sequence classification, we used a standard classification report, including precision, recall, F1-score, and accuracy, similar to prior studies evaluating LSTM-based sign language recognition [
25]. These metrics provide a thorough assessment of the system’s ability to recognize both static and dynamic signs, including those with high visual similarity.
5. Results and Discussion
To evaluate the effectiveness of the proposed method, a series of experiments were conducted using three datasets of varying complexity, containing 2, 13, and 47 gesture classes, respectively. The objective was to assess the influence of optical flow integration on the performance of the BiLSTM model across various metrics, including accuracy, precision, recall, F1-score, and inference time. The results provide a comprehensive overview of how the inclusion of motion information affects classification performance, especially in the context of dynamic gestures.
In addition to internal benchmarking, our method was compared with recent state-of-the-art approaches in sign language recognition, particularly those utilizing YOLO-based frameworks. Tyagi et al. [
26] developed a system based on YOLOv5 and YOLOv8 for the detection of American Sign Language (ASL) letters. Their custom-trained model achieved a precision of 95%, recall of 97%, and mean average precision (mAP@0.5) of 96% on their ASL alphabet dataset, demonstrating strong real-time detection performance. In another study, Rahman et al. [
27] introduced a bilingual recognition system using YOLOv11 to simultaneously detect letters from both Bangla Sign Language (BdSL) and ASL. Their model was trained on a dataset comprising 9556 annotated images across 64 different signs. Evaluation of the system yielded a precision of 99.12%, an average recall of 99.63%, and high mAP values over 30 training epochs, making the approach suitable for real-time communication technologies.
Compared to these object detection approaches, our BiLSTM-based model emphasizes temporal dynamics by integrating keypoint sequences and optical flow. The experimental results indicate that this method provides competitive performance in binary classification tasks and meaningful accuracy in larger multi-class setups, though with some decline in precision due to inter-class similarity. Nevertheless, the integration of motion features proves valuable, offering a distinct advantage in capturing gesture transitions over time. These findings highlight the complementary strengths of temporal sequence modeling compared to spatial object detection in the domain of sign language recognition.
5.1. Results on Two-Class Dataset
The first dataset consists of two gesture classes. The results (
Table 1) indicate that incorporating optical flow with an optimal parameter (Bi-LSTMOF-10) greatly improves all performance metrics. Specifically, accuracy increases from 78.95% (without optical flow) to 89.47%. However, increasing the optical flow region size (Bi-LSTMOF-20 and Bi-LSTMOF-30) leads to a decline in generalization ability, as evidenced by a drop in accuracy and F1-score. Bi-LSTMOF-30, as the least effective option, achieves accuracy of (57.89%).
5.2. Results on 13-Class Dataset
For the 13-class dataset (
Table 2), the usage of optical flow results in a decline in accuracy from 77% (without optical flow) to 68%. Some gesture classes, such as “Kim” and “Bar”, exhibit a notable decrease in recall, while the “Tegi” class is not recognized at all when optical flow is used. However, in certain cases, such as the “G” and “Gh” classes, the optical flow version of a system achieves more balanced results. These findings suggest that motion processing may introduce noise, reducing overall classification quality.
5.3. Results on 47-Class Dataset
For the 47-class dataset (
Table 3), the model without optical flow significantly outperforms the model with optical flow in terms of accuracy (92% vs. 54%). This suggests that the additional motion information introduces excessive noise or complicates model training, damaging classification accuracy. The high complexity of a 47-class dataset may require more refined motion processing techniques to prevent the loss of essential gesture features.
5.4. YOLOv8-Pose Model Inconsistencies
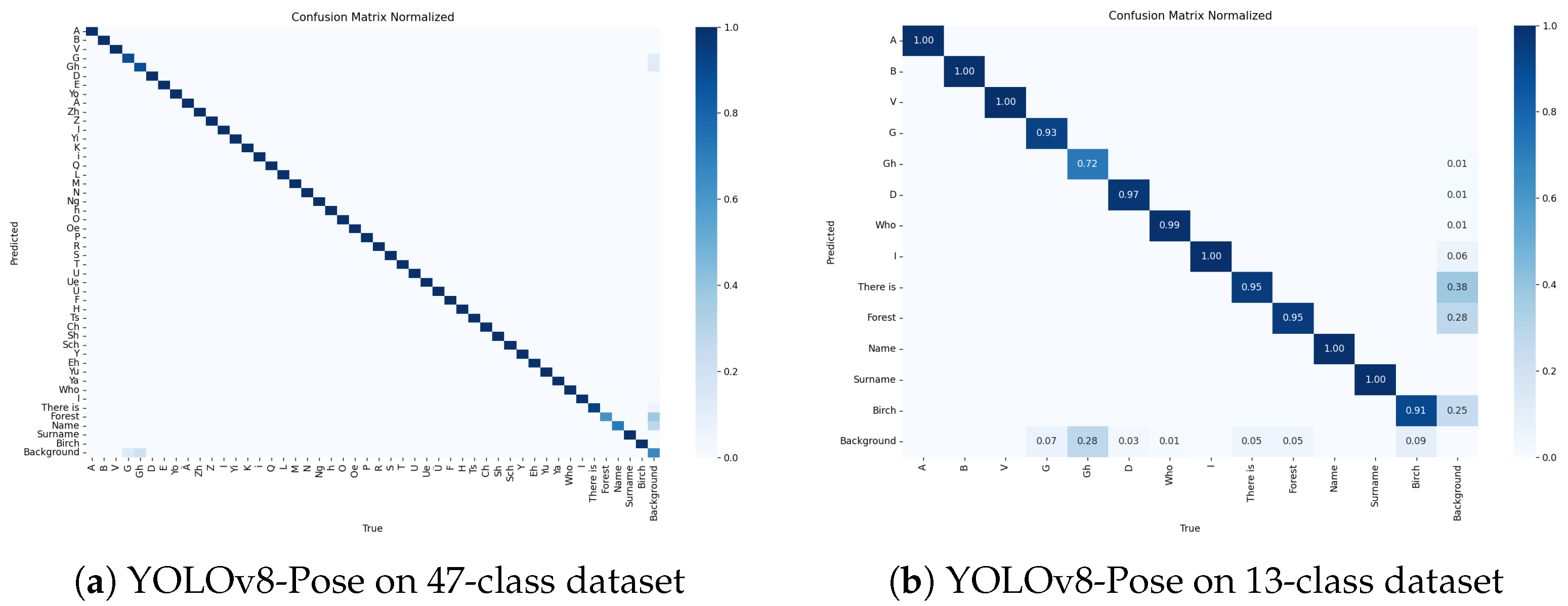
To further analyze the limitations of the proposed approach, we examined the inconsistencies in the YOLOv8-Pose model across different dataset sizes. Specifically, we calculated inconsistency matrices for the dataset of 47 classes (
Figure 9a) and the subset of 13 classes (
Figure 9b). These matrices reveal how frequently the model misclassifies gestures, which provides an understanding of patterns of confusion.
5.4.1. Inconsistency Analysis for the 47-Class Dataset
The full dataset inconsistency matrix highlights several key observations. Firstly, certain gestures exhibit high misclassification rates, particularly those with similar hand positions or overlapping motion patterns. Secondly, the model often confuses gestures that involve minimal hand movement, as static optical flow values may not capture subtle differences. Finally, few dynamic gestures suffer from incorrect temporal associations, where partial hand trajectories are similar to other gestures.
5.4.2. Inconsistency Analysis for the 13-Class Dataset
For the smaller dataset, the inconsistency matrix reveals that specific gesture pairs still show significant confusion, while classification accuracy is generally higher than in the 47-class case. Moreover, motion-based signs such as “Kim” and “Bar” exhibit higher inconsistency scores, suggesting that optical flow introduces noise rather than useful motion cues in these cases. Therefore, the model performs best for gestures with distinct hand shapes, while signs with similar postures but different motion paths are more prone to errors.
5.5. Discussion
The experimental results suggest that optical flow is beneficial for binary classification tasks (e.g., two-class dataset) when appropriately optimized (Bi-LSTMOF-10). It enhances motion understanding and contributes to improved performance. However, excessively increasing the optical flow region leads to performance degradation due to excessive noise.
For datasets with higher class diversity, optical flow does not provide an advantage and can even degrade classification quality. In the 13-class dataset, accuracy drops when optical flow is introduced, indicating the need for careful tuning. In the 47-class dataset, optical flow severely impacts performance due to noise values obtained for static signs, possibly by complicating training and obscuring key gesture features.
These findings suggest that the effectiveness of optical flow depends on the complexity of the dataset. Although it helps in simpler cases, it requires careful optimization to avoid negative impacts on larger and more complex datasets, specifically, containing static classes.
6. Future Research
Although the current system shows promising results in recognizing Kazakh Sign Language using YOLOv8-Pose and Bi-LSTM, several areas remain open for future research.
One key area is expanding the dataset to include more gesture diversity and samples per class. Most KSL research focuses on alphabet datasets [
28,
29], but sign language also includes words and phrases. Although this work covers a comprehensive set of static and dynamic gestures, the dataset could be improved by adding a continuous sign language, covering a wider range of users, and incorporating different handshapes, speeds, and environments to improve generalization.
Another important area is developing real-time systems for recognizing continuous sign language in natural conversation. This includes gesture segmentation, recognition, sign language grammar modeling, and natural language translation for practical applications like gesture-to-text and gesture-to-speech. Recent research shows that transformer-based architectures perform well in Kazakh Sign Language translation [
7]. Building on this, incorporating optical flow into the recognition pipeline could enhance the prediction of dynamic and visually similar classes, improving translation accuracy and robustness in real-world scenarios.
7. Conclusions
This study proposed a two-stage framework for Kazakh Sign Language recognition, combining YOLOv8-Pose for spatial hand detection with a Bi-LSTM model for temporal sequence classification. The system handles both static and dynamic gestures.
YOLOv8-Pose accurately detected hands and extracted 21 keypoints, which, along with bounding-box coordinates and optical flow vectors, formed informative input sequences. The usage of motion features allowed the model to distinguish between similar gestures, improving recognition performance. A structured dataset covering alphabetic and frequently used dynamic gestures was presented as a basis for further research into Kazakh Sign Language.
The results demonstrate the effectiveness of combining real-time detection with temporal modeling, showing a new approach for developing communication tools for the deaf and hard of hearing communities in Kazakhstan.
Author Contributions
Conceptualization, Z.B., A.Y. and M.Z.; methodology, Z.B., Z.A. and M.Z.; software, Z.A., Z.Z. and M.Z.; validation, M.A., Z.Z. and M.Z.; formal analysis, M.A., Z.Z. and M.Z.; investigation, M.A., Z.Z. and M.Z.; resources, A.Y., Z.A., Z.B. and M.Z.; data curation, A.Y., M.A. and M.Z.; writing—original draft preparation, M.A., Z.Z. and M.Z.; writing—review and editing, M.A., Z.Z. and M.Z.; visualization, M.A., Z.Z. and M.Z.; supervision, Z.B. and M.Z.; project administration, Z.B. and M.Z.; funding acquisition, Z.B. and M.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research has been funded by the Committee of Science of the Ministry of Science and Higher Education of the Republic of Kazakhstan (Grant No. BR24992875).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available in article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Bhushan, S.; Alshehri, M.; Keshta, I.; Chakraverti, A.K.; Rajpurohit, J.; Abugabah, A. An experimental analysis of various machine learning algorithms for hand gesture recognition. Electronics 2022, 11, 968. [Google Scholar] [CrossRef]
- Adaloglou, N.; Chatzis, T.; Papastratis, I.; Stergioulas, A.; Papadopoulos, G.T.; Zacharopoulou, V.; Xydopoulos, G.J.; Atzakas, K.; Papazachariou, D.; Daras, P. A Comprehensive Study on Deep Learning-Based Methods for Sign Language Recognition. IEEE Trans. Multimed. 2022, 24, 1750–1762. [Google Scholar] [CrossRef]
- Alvin, A.; Shabrina, N.H.; Ryo, A.; Christian, E. Hand gesture detection for sign language using neural network with mediapipe. Ultim. Comput. J. Sist. Komput. 2021, 13, 57–62. [Google Scholar] [CrossRef]
- Lee, C.K.M.; Ng, K.K.H.; Chen, C.-H.; Lau, H.C.W.; Chung, S.Y.; Tsoi, T. American Sign Language Recognition and Training Method with Recurrent Neural Network. Expert Syst. Appl. 2020, 160, 114403. [Google Scholar] [CrossRef]
- Rivera-Acosta, M.; Ruiz-Varela, J.M.; Ortega-Cisneros, S.; Rivera, J.; Parra-Michel, R.; Mejia-Alvarez, P. Spelling Correction Real-Time American Sign Language Alphabet Translation System Based on YOLO Network and LSTM. Electronics 2021, 10, 1035. [Google Scholar] [CrossRef]
- Al Ahmadi, S.; Mohammad, F.; Al Dawsari, H. Efficient YOLO-Based Deep Learning Model for Arabic Sign Language Recognition; King Saud University: Riyadh, Saudi Arabia, 2024. [Google Scholar]
- Sandygulova, A.; Yessenbayev, Z.; Parisi, G.I.; Kimmelman, V.; Aitpayev, K.; Sagatova, N.; Mukushev, M.; Imashev, A.; Nurgabylov, Y. Kazakh Sign Language Automatic Recognition System (K-SLARS); Nazarbayev University: Astana, Kazakhstan, 2022. [Google Scholar]
- Yerimbetova, A.; Sakenov, B.; Sambetbayeva, M.; Daiyrbayeva, E.; Berzhanova, U.; Othman, M. Creating a Parallel Corpus for the Kazakh Sign Language and Learning. Appl. Sci. 2025, 15, 2808. [Google Scholar] [CrossRef]
- Amirgaliyev, Y.; Ataniyazova, A.; Buribayev, Z.; Zhassuzak, M.; Urmashev, B.; Cherikbayeva, L. Application of neural networks ensemble method for the Kazakh sign language recognition. Bull. Electr. Eng. Inform. 2024, 13, 3275–3287. [Google Scholar] [CrossRef]
- Joze, H.R.V.; Koller, O. MS-ASL: A Large-Scale Data Set and Benchmark for Understanding American Sign Language. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Camgoz, N.C.; Hadfield, S.; Koller, O.; Ney, H.; Bowden, R. Neural sign language translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7784–7793. [Google Scholar]
- Maji, D.; Nagori, S.; Mathew, M.; Poddar, D. YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Sohan, M.; Sai Ram, T.; Rami Reddy, C.V. A review on yolov8 and its advancements. In International Conference on Data Intelligence and Cognitive Informatics; Springer: Singapore, 2024; pp. 529–545. [Google Scholar]
- Amin, J.; Anjum, M.A.; Sharif, M.; Kadry, S.; Nam, Y.; Wang, S.H. Convolutional Bi-LSTM Based Human Gait Recognition Using Video Sequences. Comput. Mater. Contin. 2021, 68, 2693–2709. [Google Scholar] [CrossRef]
- Yu, Y.; Yao, Y.; Liu, Z.; An, Z.; Chen, B.; Chen, L.; Chen, R. A Bi-LSTM approach for modelling movement uncertainty of crowdsourced human trajectories under complex urban environments. Int. J. Appl. Earth Obs. Geoinf. 2023, 122, 103412. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space Odyssey’. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed]
- Renjith, R.; Manazhy, S. Sign Language Recognition using BiLSTM model. In Proceedings of the 2024 IEEE 9th International Conference for Convergence in Technology (I2CT), Pune, India, 5–7 August 2024; pp. 1–5. [Google Scholar]
- Subramoney, A.; Nazeer, K.K.; Schöne, M.; Mayr, C.; Kappel, D. Efficient recurrent architectures through activity sparsity and sparse back-propagation through time. arXiv 2022, arXiv:2206.06178. [Google Scholar]
- Al Khuzayem, L.; Shafi, S.; Aljahdali, S.; Alkhamesie, R.; Alzamzami, O. Efhamni: A deep learning-based Saudi sign language recognition application. Sensors 2024, 24, 3112. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Schmidhuber, J. Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Barron, J.L.; Fleet, D.J.; Beauchemin, S.S. Performance of optical flow techniques. Int. J. Comput. Vis. 1994, 12, 43–77. [Google Scholar] [CrossRef]
- Raschka, S. Model Evaluation, Model Selection, and Algorithm Selection in Machine Learning; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Huang, J.; Chouvatut, V. Video-Based Sign Language Recognition via ResNet and LSTM Network. J. Imaging 2024, 10, 149. [Google Scholar] [CrossRef] [PubMed]
- Tyagi, S.; Upadhyay, P.; Fatima, H.; Jain, S.; Sharma, A.K. American Sign Language Detection Using YOLOv5 and YOLOv8. Preprint, 2023. Available online: https://www.researchsquare.com/article/rs-3126918/v1 (accessed on 15 February 2025).
- Navin, N.; Farid, F.A.; Rakin, R.Z.; Tanzim, S.S.; Rahman, M.; Rahman, S.; Karim, H.A. Bilingual Sign Language Recognition: A YOLOv11-Based Model for Bangla and English Alphabets. J. Imaging 2025, 11, 134. [Google Scholar] [CrossRef]
- Yerimbetova, A.; Mukazhanov, N.; Sakenov, B.; Daiyrbayeva, E. Development of A Model of Kazakh Sign Language Recognition Based on Deep Learning Method. In Proceedings of the 20th International Conference on Electronics Computer and Computation (ICECCO), Kaskelen, Kazakhstan, 1–2 June 2023. [Google Scholar]
- Mukhanov, S.; Uskenbayeva, R.; Cho, Y.I.; Dauren, K.; Nurzhan, L.; Amangeldi, M. Gesture Recognition of Machine Learning and Convolutional Neural Network Methods for Kazakh Sign Language. Bull. Astana IT Univ. 2023, 15, 85–100. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}