

Large Language Model-Powered Automated Assessment: A Systematic Review

Abstract
1. Introduction
2. Materials and Methods
2.1. Search Procedures
2.2. Inclusion and Exclusion Criteria
2.3. Information Sources and Search Strategy
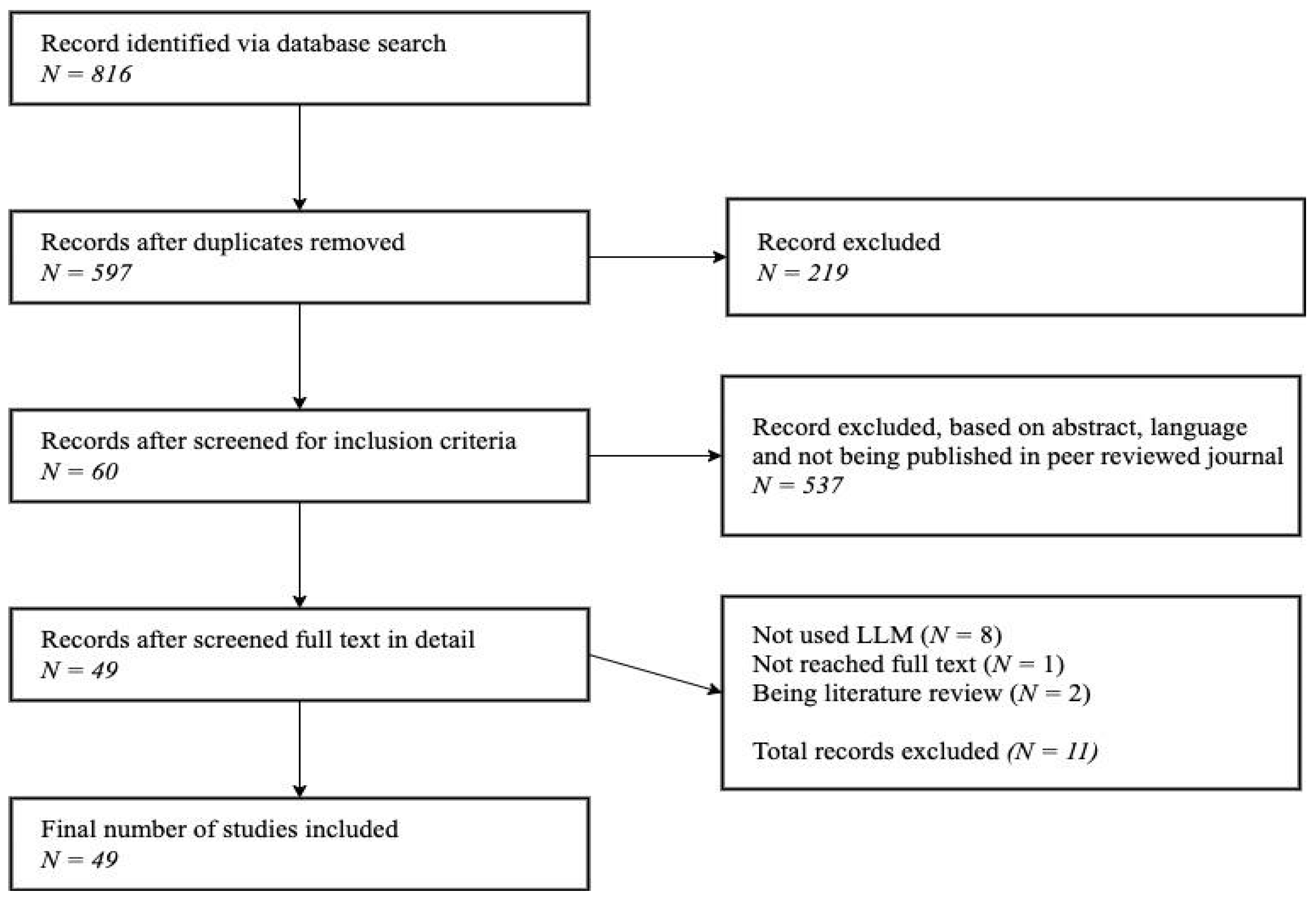
2.4. Screening and Filtering Process
3. Results
3.1. Usage Domains
3.2. Details of LLMPAA Research
3.2.1. Datasets
3.2.2. Languages, Question Types, Sizes, and Additional Info
3.2.3. LLM’s and Evaluation Metrics
- Metrics for determining model performance (accuracy, F1-score, precision, and recall).
- Metrics based on measuring the agreement of LLMs with human (Cohen’s kappa—CK, linear weighted kappa—LWK, quadratic weighted kappa—QWK, correlation coefficient—r).
- Metrics based on measuring the reliability and consistency between different evaluators (human or LLM) (intraclass correlation coefficient—ICC).
- While LLMPAA have frequently demonstrated good or excellent agreement with human raters, some studies have reported moderate or low alignment, suggesting that their effectiveness may vary depending on the context and application.
- BERT and its variants have generally provided a strong foundation for assessment tasks, although performance can differ based on task type and fine-tuning strategies.
- GPT-4 has shown promising results for human-like assessment in many studies, but findings also highlight variability in accuracy and consistency across different scenarios.
- The effectiveness of each model depends on the specific requirements of the task, dataset characteristics, and implementation context.
- Fine-tuning has been shown to significantly improve model performance in several cases, though its impact may depend on the quality and diversity of training data.
3.3. Challenges in LLMPAA
3.3.1. Bias and Fairness
3.3.2. Consistency
3.3.3. Dataset Quality
3.3.4. Explainability and Transparency
3.3.5. Hallucinations
3.3.6. Language and Human Characteristics
3.3.7. Privacy and Security
4. Discussion
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AES | Automated essay scoring |
| ASAG | Automated short answer grading |
| BERT | Bidirectional encoder representations from transformers |
| ICC | Intraclass correlation coefficient |
| LLMPAA | Large Language Model-Powered Automated Assessment |
| LWK | Linear weighted kappa |
| ML | Machine learning |
| NLP | Natural language processing |
| PRISMA | Preferred Reporting Items for Systematic Reviews and Meta-Analyses |
| RLHF | Reinforcement learning with human feedback |
| QWK | Quadratic weighted kappa |
References
- Ikiss, S.; Daoudi, N.; Abourezq, M.; Bellafkih, M. Improving Automatic Short Answer Scoring Task Through a Hybrid Deep Learning Framework. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 1066–1073. [Google Scholar] [CrossRef]
- Urrutia, F.; Araya, R. Who’s the Best Detective? Large Language Models vs. Traditional Machine Learning in Detecting Incoherent Fourth Grade Math Answers. J. Educ. Comput. Res. 2024, 61, 187–218. [Google Scholar] [CrossRef]
- Süzen, N.; Gorban, A.N.; Levesley, J.; Mirkes, E.M. Automatic Short Answer Grading and Feedback Using Text Mining Methods. Procedia Comput. Sci. 2020, 169, 726–743. [Google Scholar] [CrossRef]
- Yan, Y.; Liu, H. Ethical Framework for AI Education Based on Large Language Models. Educ. Inf. Technol. 2024, 1–19. [Google Scholar] [CrossRef]
- Dikli, S.; Russell, M. An Overview of Automated Scoring of Essays. J. Technol. Learn. Assess. 2006, 5, 1–35. [Google Scholar]
- Firoozi, T.; Mohammadi, H.; Gierl, M.J. Using Active Learning Methods to Strategically Select Essays for Automated Scoring. Educ. Meas. Issues Pract. 2023, 42, 34–43. [Google Scholar] [CrossRef]
- Burrows, S.; Gurevych, I.; Stein, B. The Eras and Trends of Automatic Short Answer Grading. Int. J. Artif. Intell. Educ. 2015, 25, 60–117. [Google Scholar] [CrossRef]
- Henkel, O.; Hills, L.; Roberts, B.; Mcgrane, J. Can LLMs Grade Open Response Reading Comprehension Questions? An Empirical Study Using the ROARs Dataset. Int. J. Artif. Intell. Educ. 2024, 1–26. [Google Scholar] [CrossRef]
- Moher, D.; Shamseer, L.; Clarke, M.; Ghersi, D.; Liberati, A.; Petticrew, M.; Shekelle, P.; Stewart, L.A.; Estarli, M.; Barrera, E.S.A.; et al. Preferred Reporting Items for Systematic Review and Meta-Analysis Protocols (PRISMA-P) 2015 Statement. Rev. Esp. Nutr. Humana Diet. 2016, 20, 148–160. [Google Scholar] [CrossRef]
- Mendonça, P.C.; Quintal, F.; Mendonça, F. Evaluating LLMs for Automated Scoring in Formative Assessments. Appl. Sci. 2025, 15, 2787. [Google Scholar] [CrossRef]
- Thurzo, A. Provable AI Ethics and Explainability in Medical and Educational AI Agents: Trustworthy Ethical Firewall. Electronics 2025, 14, 1294. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL HLT 2019—2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies—Proceedings of the Conference, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Arici, N.; Gerevini, A.E.; Olivato, M.; Putelli, L.; Sigalini, L.; Serina, I. Real-World Implementation and Integration of an Automatic Scoring System for Workplace Safety Courses in Italian. Future Internet 2023, 15, 268. [Google Scholar] [CrossRef]
- Azhari, A.; Santoso, A.; Agung, A.; Ratna, P.; Prestiliano, J. Optimization of AES Using BERT and BiLSTM for Grading the Online Exams. Int. J. Intell. Eng. Syst. 2024, 17, 395–411. [Google Scholar] [CrossRef]
- Beseiso, M.; Alzahrani, S. An Empirical Analysis of BERT Embedding for Automated Essay Scoring. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 204–210. [Google Scholar] [CrossRef]
- Bonthu, S.; Sree, S.R.; Prasad, M.H.M.K. SPRAG: Building and Benchmarking a Short Programming-Related Answer Grading Dataset. Int. J. Data Sci. Anal. 2024, 1–13. [Google Scholar] [CrossRef]
- Bui, N.M.; Barrot, J.S. ChatGPT as an Automated Essay Scoring Tool in the Writing Classrooms: How It Compares with Human Scoring. Educ. Inf. Technol. 2024, 30, 2041–2058. [Google Scholar] [CrossRef]
- Chassab, R.H.; Zakaria, L.Q.; Tiun, S. An Optimized BERT Fine-Tuned Model Using an Artificial Bee Colony Algorithm for Automatic Essay Score Prediction. PeerJ Comput. Sci. 2024, 10, e2191. [Google Scholar] [CrossRef]
- Cho, M.; Huang, J.X.; Kwon, O.W. Dual-Scale BERT Using Multi-Trait Representations for Holistic and Trait-Specific Essay Grading. ETRI J. 2024, 46, 82–95. [Google Scholar] [CrossRef]
- Clauser, B.E.; Yaneva, V.; Baldwin, P.; An Ha, L.; Mee, J. Automated Scoring of Short-Answer Questions: A Progress Report. Appl. Meas. Educ. 2024, 37, 209–224. [Google Scholar] [CrossRef]
- Fernández, A.A.; López-Torres, M.; Fernández, J.J.; Vázquez-García, D. ChatGPT as an Instructor’s Assistant for Generating and Scoring Exams. J. Chem. Educ. 2024, 101, 3788. [Google Scholar] [CrossRef]
- Firoozi, T.; Mohammadi, H.; Gierl, M.J. Using Automated Procedures to Score Educational Essays Written in Three Languages. J. Educ. Meas. 2025, 62, 33–56. [Google Scholar] [CrossRef]
- Grévisse, C. LLM-Based Automatic Short Answer Grading in Undergraduate Medical Education. BMC Med. Educ. 2024, 24, 1060. [Google Scholar] [CrossRef]
- Huang, F.; Sun, X.; Mei, A.; Wang, Y.; Ding, H.; Zhu, T. LLM Plus Machine Learning Outperform Expert Rating to Predict Life Satisfaction from Self-Statement Text. IEEE Trans. Comput. Soc. Syst. 2024. [Google Scholar] [CrossRef]
- Ivanovic, I. Can AI-Assisted Essay Assessment Support Teachers? A Cross-Sectional Mixed-Methods Research Conducted at the University of Montenegro. Ann. Istrian Mediterr. Stud. 2023, 33, 571–590. [Google Scholar]
- Jackaria, P.M.; Hajan, B.H.; Mastul, A.R.H. A Comparative Analysis of the Rating of College Students’ Essays by ChatGPT versus Human Raters. Int. J. Learn. Teach. Educ. Res. 2024, 23, 478–492. [Google Scholar] [CrossRef]
- Kaya, M.; Cicekli, I. A Hybrid Approach for Automated Short Answer Grading. IEEE Access 2024, 12, 96332–96341. [Google Scholar] [CrossRef]
- Kortemeyer, G. Toward AI Grading of Student Problem Solutions in Introductory Physics: A Feasibility Study. Phys. Rev. Phys. Educ. Res. 2023, 19, 020163. [Google Scholar] [CrossRef]
- Kortemeyer, G. Performance of the Pre-Trained Large Language Model GPT-4 on Automated Short Answer Grading. Discov. Artif. Intell. 2024, 4, 47. [Google Scholar] [CrossRef]
- Kusumaningrum, R.; Kadarisman, K.; Endah, S.N.; Sasongko, P.S.; Khadijah, K.; Sutikno, S.; Rismiyati, R.; Afriani, A. Automated Essay Scoring Using Convolutional Neural Network Long Short-Term Memory with Mean of Question-Answer Encoding. ICIC Express Lett. 2024, 18, 785–792. [Google Scholar] [CrossRef]
- Lee, J.H.; Park, J.S.; Shon, J.G. A BERT-Based Automatic Scoring Model of Korean Language Learners’ Essay. J. Inf. Process. Syst. 2022, 18, 282–291. [Google Scholar] [CrossRef]
- Li, F.; Xi, X.; Cui, Z.; Li, D.; Zeng, W. Automatic Essay Scoring Method Based on Multi-Scale Features. Appl. Sci. 2023, 13, 6775. [Google Scholar] [CrossRef]
- Li, W.; Liu, H. Applying Large Language Models for Automated Essay Scoring for Non-Native Japanese. Humanit. Soc. Sci. Commun. 2024, 11, 1–15. [Google Scholar] [CrossRef]
- Li, Z.; Huang, Q.; Liu, J. ChatGPT Analysis of Strengths and Weaknesses in English Writing and Their Implications. Appl. Math. Nonlinear Sci. 2024, 9, 1–15. [Google Scholar] [CrossRef]
- Machhout, R.A.; Ben Othmane Zribi, C. Enhanced BERT Approach to Score Arabic Essay’s Relevance to the Prompt. Commun. IBIMA 2024, 2024, 176992. [Google Scholar] [CrossRef]
- Mardini, G.I.D.; Quintero, M.C.G.; Viloria, N.C.A.; Percybrooks, B.W.S.; Robles, N.H.S.; Villalba, R.K. A Deep-Learning-Based Grading System (ASAG) for Reading Comprehension Assessment by Using Aphorisms as Open-Answer-Questions. Educ. Inf. Technol. 2024, 29, 4565–4590. [Google Scholar] [CrossRef]
- Meccawy, M.; Bayazed, A.A.; Al-Abdullah, B.; Algamdi, H. Automatic Essay Scoring for Arabic Short Answer Questions Using Text Mining Techniques. Int. J. Adv. Comput. Sci. Appl. 2023, 14, 768–775. [Google Scholar] [CrossRef]
- Mizumoto, A.; Eguchi, M. Exploring the Potential of Using an AI Language Model for Automated Essay Scoring. Res. Methods Appl. Linguist. 2023, 2, 100050. [Google Scholar] [CrossRef]
- Organisciak, P.; Acar, S.; Dumas, D.; Berthiaume, K. Beyond Semantic Distance: Automated Scoring of Divergent Thinking Greatly Improves with Large Language Models. Think. Ski. Creat. 2023, 49, 101356. [Google Scholar] [CrossRef]
- Pack, A.; Barrett, A.; Escalante, J. Large Language Models and Automated Essay Scoring of English Language Learner Writing: Insights into Validity and Reliability. Comput. Educ. Artif. Intell. 2024, 6, 100234. [Google Scholar] [CrossRef]
- Quah, B.; Zheng, L.; Sng, T.J.H.; Yong, C.W.; Islam, I. Reliability of ChatGPT in Automated Essay Scoring for Dental Undergraduate Examinations. BMC Med. Educ. 2024, 24, 962. [Google Scholar] [CrossRef]
- Ramesh, D.; Sanampudi, S.K. A Multitask Learning System for Trait-Based Automated Short Answer Scoring. Int. J. Adv. Comput. Sci. Appl. 2023, 14, 454–460. [Google Scholar] [CrossRef]
- Ramesh, D.; Sanampudi, S.K. Coherence-Based Automatic Short Answer Scoring Using Sentence Embedding. Eur. J. Educ. 2024, 59, e12684. [Google Scholar] [CrossRef]
- Salim, H.R.; De, C.; Pratamaputra, N.D.; Suhartono, D. Indonesian Automatic Short Answer Grading System. Bull. Electr. Eng. Inform. 2022, 11, 1586–1603. [Google Scholar] [CrossRef]
- Shamim, M.S.; Zaidi, S.J.A.; Rehman, A. The Revival of Essay-Type Questions in Medical Education: Harnessing Artificial Intelligence and Machine Learning. J. Coll. Physicians Surg. Pak. 2024, 34, 595–599. [Google Scholar] [CrossRef] [PubMed]
- Sharma, A.; Jayagopi, D.B. Modeling Essay Grading with Pre-Trained BERT Features. Appl. Intell. 2024, 54, 4979–4993. [Google Scholar] [CrossRef]
- Song, Y.; Zhu, Q.; Wang, H.; Zheng, Q. Automated Essay Scoring and Revising Based on Open-Source Large Language Models. IEEE Trans. Learn. Technol. 2024, 17, 1920–1930. [Google Scholar] [CrossRef]
- Tang, X.; Chen, H.; Lin, D.; Li, K. Harnessing LLMs for Multi-Dimensional Writing Assessment: Reliability and Alignment with Human Judgments. Heliyon 2024, 10, e34262. [Google Scholar] [CrossRef]
- Tate, T.P.; Steiss, J.; Bailey, D.; Graham, S.; Moon, Y.; Ritchie, D.; Tseng, W.; Warschauer, M. Can AI Provide Useful Holistic Essay Scoring? Comput. Educ. Artif. Intell. 2024, 7, 100255. [Google Scholar] [CrossRef]
- Wang, Q.; Gayed, J.M. Effectiveness of Large Language Models in Automated Evaluation of Argumentative Essays: Finetuning vs. Zero-Shot Prompting. Comput. Assist. Lang. Learn. 2024. [Google Scholar] [CrossRef]
- Wijanto, M.C.; Yong, H.S. Combining Balancing Dataset and SentenceTransformers to Improve Short Answer Grading Performance. Appl. Sci. 2024, 14, 4532. [Google Scholar] [CrossRef]
- Wijaya, M.C. Automatic Short Answer Grading System in Indonesian Language Using BERT Machine Learning. Rev. D’intelligence Artif. 2021, 35, 503–509. [Google Scholar] [CrossRef]
- Wu, Y.; Henriksson, A.; Nouri, J.; Duneld, M.; Li, X. Beyond Benchmarks: Spotting Key Topical Sentences While Improving Automated Essay Scoring Performance with Topic-Aware BERT. Electronics 2022, 12, 150. [Google Scholar] [CrossRef]
- Zhu, X.; Wu, H.; Zhang, L. Automatic Short-Answer Grading via BERT-Based Deep Neural Networks. IEEE Trans. Learn. Technol. 2022, 15, 364–375. [Google Scholar] [CrossRef]
- Xue, J.; Tang, X.; Zheng, L. A Hierarchical BERT-Based Transfer Learning Approach for Multi-Dimensional Essay Scoring. IEEE Access 2021, 9, 125403–125415. [Google Scholar] [CrossRef]
- Yamashita, T. An Application of Many-Facet Rasch Measurement to Evaluate Automated Essay Scoring: A Case of ChatGPT-4.0. Res. Methods Appl. Linguist. 2024, 3, 100133. [Google Scholar] [CrossRef]
- Yavuz, F.; Çelik, Ö.; Yavaş Çelik, G. Utilizing Large Language Models for EFL Essay Grading: An Examination of Reliability and Validity in Rubric-Based Assessments. Br. J. Educ. Technol. 2024, 56, 150–166. [Google Scholar] [CrossRef]
- Liang, W.; Yuksekgonul, M.; Mao, Y.; Wu, E.; Zou, J. GPT Detectors Are Biased against Non-Native English Writers. Patterns 2023, 4, 100799. [Google Scholar] [CrossRef]
- Lin, H.; Chen, Q. Artificial Intelligence (AI) -Integrated Educational Applications and College Students’ Creativity and Academic Emotions: Students and Teachers’ Perceptions and Attitudes. BMC Psychol. 2024, 12, 487. [Google Scholar] [CrossRef]
- Hackl, V.; Müller, A.E.; Granitzer, M.; Sailer, M. Is GPT-4 a Reliable Rater? Evaluating Consistency in GPT-4’s Text Ratings. Front. Educ. 2023, 8, 1272229. [Google Scholar] [CrossRef]
- Kosinski, M. Evaluating Large Language Models in Theory of Mind Tasks. Proc. Natl. Acad. Sci. USA 2023, 121, e2405460121. [Google Scholar] [CrossRef]
- Binz, M.; Schulz, E. Using Cognitive Psychology to Understand GPT-3. Proc. Natl. Acad. Sci. USA 2023, 120, e2218523120. [Google Scholar] [CrossRef]
- Masters, K. Medical Teacher’s First ChatGPT’s Referencing Hallucinations: Lessons for Editors, Reviewers, and Teachers. Med. Teach. 2023, 45, 673–675. [Google Scholar] [CrossRef] [PubMed]
- Sallam, M.; Salim, N.A.; Barakat, M.; Al-Tammemi, A.B. ChatGPT Applications in Medical, Dental, Pharmacy, and Public Health Education: A Descriptive Study Highlighting the Advantages and Limitations. Narra J. 2023, 3, e103. [Google Scholar] [CrossRef] [PubMed]
- Abd-Alrazaq, A.; AlSaad, R.; Alhuwail, D.; Ahmed, A.; Healy, P.M.; Latifi, S.; Aziz, S.; Damseh, R.; Alrazak, S.A.; Sheikh, J. Large Language Models in Medical Education: Opportunities, Challenges, and Future Directions. JMIR Med. Educ. 2023, 9, e48291. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Lin, Y. The Benefits and Challenges of ChatGPT: An Overview. Front. Comput. Intell. Syst. 2022, 2, 81–83. [Google Scholar] [CrossRef]
- Kasneci, E.; Sessler, K.; Küchemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; Günnemann, S.; Hüllermeier, E.; et al. ChatGPT for Good? On Opportunities and Challenges of Large Language Models for Education. Learn. Individ. Differ. 2023, 103, 102274. [Google Scholar] [CrossRef]
- Yao, Y.; Duan, J.; Xu, K.; Cai, Y.; Sun, Z.; Zhang, Y. A Survey on Large Language Model (LLM) Security and Privacy: The Good, The Bad, and The Ugly. High-Confid. Comput. 2024, 4, 100211. [Google Scholar] [CrossRef]
- Gao, R.; Merzdorf, H.E.; Anwar, S.; Hipwell, M.C.; Srinivasa, A.R. Automatic Assessment of Text-Based Responses in Post-Secondary Education: A Systematic Review. Comput. Educ. Artif. Intell. 2024, 6, 100206. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. Adv. Neural Inf. Process Syst. 2020, 33, 1877–1901. [Google Scholar]
- Polverini, G.; Gregorcic, B. Performance of ChatGPT on the Test of Understanding Graphs in Kinematics. Phys. Rev. Phys. Educ. Res. 2024, 20, 010109. [Google Scholar] [CrossRef]
- Kaufmann, T.; Weng, P.; Kunshan, D.; Bengs, V.; Hüllermeier, E. A Survey of Reinforcement Learning from Human Feedback. arXiv 2023, arXiv:2312.14925. [Google Scholar]
- Atkinson, J.; Palma, D. An LLM-Based Hybrid Approach for Enhanced Automated Essay Scoring. Sci. Rep. 2025, 15, 14551. [Google Scholar] [CrossRef] [PubMed]
- Introducing Claude 3.5 Sonnet\Anthropic. Available online: https://www.anthropic.com/news/claude-3-5-sonnet (accessed on 8 May 2025).
- Giray, L. Prompt Engineering with ChatGPT: A Guide for Academic Writers. Ann. Biomed. Eng. 2023, 51, 2629–2633. [Google Scholar] [CrossRef] [PubMed]
- Nazir, A.; Wang, Z. A Comprehensive Survey of ChatGPT: Advancements, Applications, Prospects, and Challenges. Meta Radiol. 2023, 1, 100022. [Google Scholar] [CrossRef]
- Provost, F.; Fawcett, T. Data Science and Its Relationship to Big Data and Data-Driven Decision Making. Big Data 2013, 1, 51–59. [Google Scholar] [CrossRef]
- Powers, D.M.W. Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness and Correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Cohen, J. Weighted Kappa: Nominal Scale Agreement Provision for Scaled Disagreement or Partial Credit. Psychol. Bull. 1968, 70, 213–220. [Google Scholar] [CrossRef]
- Mohammad, A.F.; Clark, B.; Agarwal, R.; Summers, S. LLM/GPT Generative AI and Artificial General Intelligence (AGI): The Next Frontier. In Proceedings of the 2023 Congress in Computer Science, Computer Engineering, and Applied Computing, CSCE 2023, Las Vegas, NV, USA,, 24–27 July 2023; pp. 413–417. [Google Scholar] [CrossRef]
- AI Principles|OECD. Available online: https://www.oecd.org/en/topics/ai-principles.html (accessed on 7 May 2025).
- Shahriari, K.; Shahriari, M. IEEE Standard Review—Ethically Aligned Design: A Vision for Prioritizing Human Wellbeing with Artificial Intelligence and Autonomous Systems. In Proceedings of the IHTC 2017—IEEE Canada International Humanitarian Technology Conference 2017, Toronto, ON, Canada, 21–22 July 2017; pp. 197–201. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Howard, J.; Ruder, S. Universal Language Model Fine-Tuning for Text Classification. In Proceedings of the ACL 2018—56th Annual Meeting of the Association for Computational Linguistics, Proceedings of the Conference (Long Papers), Melbourne, Australia, 15–20 July 2018; Volume 1, pp. 328–339. [Google Scholar] [CrossRef]
- Christiano, P.F.; Leike, J.; Brown, T.B.; Martic, M.; Legg, S.; Amodei, D. Deep Reinforcement Learning from Human Preferences. Adv. Neural Inf. Process Syst. 2017, 2017, 4300–4308. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the 33rd International Conference on Machine Learning, ICML 2016, New York, NY, USA, 19–24 June 2016; Volume 3, pp. 1651–1660. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2019, 21, 1–67. [Google Scholar]
- Goslen, A.; Kim, Y.J.; Rowe, J.; Lester, J. LLM-Based Student Plan Generation for Adaptive Scaffolding in Game-Based Learning Environments. Int. J. Artif. Intell. Educ. 2024, 1–26. [Google Scholar] [CrossRef]
- Grok 3 Beta—The Age of Reasoning Agents|XAI. Available online: https://x.ai/news/grok-3 (accessed on 8 May 2025).
- Liu, A.; Feng, B.; Xue, B.; Wang, B.; Wu, B.; Lu, C.; Zhao, C.; Deng, C.; Zhang, C.; Ruan, C.; et al. Deepseek-v3 technical report. arXiv 2024, arXiv:2412.19437. [Google Scholar]

{kind=link}
| Include | Exclude |
|---|---|
| between 2018 and 30 October 2024 | duplicates |
| peer-reviewed journals | not using LLM in the abstract section |
| written in English | not written in English |
| grading or scoring using LLM | not using LLM |
| literature reviews | |
| no accessible full text |
| Topic | Search Terms (Boolean Operator: AND) |
|---|---|
| application | scoring OR grading OR evaluation |
| question types | short answer OR essay OR open-ended |
| language models | large language model OR llm OR chatgpt OR gemini OR gpt OR claude OR llama OR bert |
| date range | 2018–2024 (30 October) |
| Databases | Number |
|---|---|
| Web of Science | 287 |
| Scopus | 142 |
| IEEE | 49 |
| ACM Digital Library | 161 |
| PubMed | 177 |
| Total | 816 |
| References | Domains | Datasets | Languages | Question Types | Sizes | Additional Info |
|---|---|---|---|---|---|---|
| [13] | Workplace Safety | ASAG-IT | Italian | Open-ended | 10,560 | Collected from final-year dental students. |
| [14] | Writing Skill | SELF | English | Essay | 10,000 | Essays collected from ESL learners during a university admissions test. |
| [15] | RC, CT, AT | ASAP-AES | English | Essay | 12,978 | Essays collected from students in grades 7–10 in the USA. |
| [16] | Computer Science | SPRAG | English | Short-answer | 4039 | Essays collected from students in grades 7–10 in the USA. |
| [17] | Computer Science, Language Education | ICNALE | English | Essay | 200 | Collected from college students across ten Asian countries/territories. |
| [18] | RC, CT, AT | ASAP-AES, ETS | English | Essay | 25,078 | Essays collected from students in grades 7–10 in the USA. |
| [19] | RC, CT, AT, Language Education | ASAP-AES, TOEFL iBT | English | Essay | 28,989 | Essays collected from students in grade 7 in the USA. |
| [20] | Medical Education | SELF | English | Short-answer | 37,346 | Examined university entrance exams from 2020 to 2023. |
| [21] | Chemistry Education | SELF | English | Short answer | 128 | Collected from 199 undergraduate students at Universidad del Norte. |
| [6] | RC, CT, AT | ASAP-AES | English | Essay | 12,978 | Collected from final-year dental undergraduate students at the National University of Singapore. |
| [22] | Language Education | MERLIN | German, Italian, Czech | Essay | 2267 | Collected from students at the University of Montenegro. |
| [23] | Medical Education | SELF | English, French, German | Short-answer | 2288 | Collected from undergraduate medical education courses at the University of Luxembourg. |
| [8] | Reading Comprehension | ROARS | English | Short-answer | 1068 | Collected from 130 students aged 9–18 in Ghana. |
| [24] | Psychology | SELF | English | Essay | 378 | Collected from non-native English speakers who took the TOEFL test in 2006 and 2007. |
| [1] | Computer Science | MOHLER, SELF | English | Short-answer | 2273 | Collected from the University of North Texas. |
| [25] | Language Education | SELF | English | Essay | 78 | Collected from Mega Italia Media’s e-learning platform. |
| [26] | Writing Skill | SELF | English | Essay | 20 | Collected from national exam essays by the Indonesian Ministry of Education and Culture. |
| [27] | Computer Science | MOHLER, SemEval-2013 | English | Short-answer | 6214 | Collected from 15 diverse science domains and the University of North Texas. |
| [28] | Physics | SELF | English | Essay | 25 | Collected from multilingual learners. |
| [29] | Computer Science | SciEntsBank | English | Short-answer | 14,186 | Collected from college students at Mindanao State University. |
| [30] | Writing Skill | UKARA | Indonesian | Short-answer | 638 | Collected from 5th- and 6th-grade primary school students in Tunisia. |
| [31] | Language Education | SELF | English | Essay | 586 | Collected from undergraduate computer science students and IT division employees. |
| [32] | RC, CT, AT | ASAP-AES, ELLIPSE | English | Essay | 12,978 | Collected from undergraduate students. |
| [33] | Language Education | I-JAS | Japanese | Short-answer | 1400 | Collected from non-native Japanese learners with 12 different first languages. |
| [34] | Medical Education | SELF | English | Essay | 500 | Collected from grade 3–6 students. |
| [35] | RC, CT, AT, Writing Skill | SELF | Arabic | Essay | 380 | Generated by GPT-4 for grading physics proE30. |
| [36] | RC, CT, AT | SELF | Spanish | Short-answer | 3772 | Collected from students in grades 7–10 in the USA, EFL learners (ETS dataset: 12,100). |
| [37] | Cybercrime, History | AR-ASAG, SELF | Arabic | Short-answer | 2183 | Collected from a cybercrime and history course exam. |
| [38] | Language Education | TOEFL11 | English | Essay | 12,100 | Collected from high school students in Bandung, Indonesia. |
| [39] | Divergent Thinking | SELF | English | Open-ended | 27,217 | Responses from 2039 participants across nine datasets. |
| [40] | Language Education | SELF | English | Essay | 119 | Collected from essays on ‘Healthy Diet’. |
| [41] | Medical Education | SELF | English | Essay | 69 | Essays collected from students in grades 7–10 in the USA and EFL learners. |
| [42] | RC, CT, AT, Computer Science | ASAP-AES, SELF | English | Essay | 15,368 | Essays collected from students in grades 8 and 10 in the USA. |
| [43] | RC, CT, AT, Computer Science | ASAP-AES, SELF | English | Essay | 15,959 | Collected from 8th- to 10th-grade students in the USA. |
| [44] | Computer Science | SELF | Indonesian | Short-answer | 3977 | Collected from Asian learners of English, rated by 80 human raters and ChatGPT-4.0. |
| [45] | Medical Education | SELF | English | Essay | 10 | Responses collected from medical students in a high-stakes test context. |
| [46] | RC, CT, AT | ASAP-AES | English | Essay | 12,978 | Essays collected from students in grades 7–10 in the USA. |
| [47] | Writing Skill | SELF | Chinese | Essay | 600 | Collected from 2870 Chinese primary school students in grade 3. |
| [48] | RC, CT, AT | ASAP-AES | English | Essay | 1730 | Essays collected from students in grades 7–10 in the USA and collected from Chinese EFL learners. |
| [49] | Language Education, History | PATHWAY 2.0, Crossley, WRITE CFT, SELF | English | Essay | 1786 | Collected from students at Universitas Terbuka, Indonesia. |
| [2] | Mathematics Education | SELF | Spanish | Open-ended | 677 | Responses from fourth-grade students. |
| [50] | Language Education | ELLIPSE | English | Essay | 480 | Collected from TOEFL test takers. |
| [51] | Computer Science | MOHLER | English | Short-answer | 2273 | Collected from the University of North Texas. |
| [52] | Computer Science | SELF | Indonesian | Short-answer | 480 | Collected from foreign learners at the Intermediate 1 level. |
| [53] | RC, CT, AT | ASAP-AES | English | Essay | 5152 | Essays collected from students in grades 7–10 in the USA. |
| [54] | Computer Science | MOHLER, SemEval-2013 | English | Short-answer | 13,077 | Collected from 15 diverse science domains and the University of North Texas. |
| [55] | RC, CT, AT, Language Education | ASAP-AES, CELA | Chinese | Essay | 13,122 | Collected engineering faculty students. |
| [56] | Language Education | ICNALE-GRA | English | Essay | 136 | Collected from language, history, and writing courses. |
| [57] | Language Education | SELF | English | Essay | 3 | Rated by 15 human raters. |
| References | LLMs | Evaluation Metrics | Results |
|---|---|---|---|
| [13] | BERT, ELECTRA, Multilingual BERT, RoBERTa | F1: 0.72 | BERT model performed the highest F1 score. |
| [14] | BERT-XLNET, CNN-BiLSTM, BERT-BiLSTM, R2BERT, ATT-CNN-LSTM | CK: 0.91 | BERT-BiLSTM achieved better agreement compared to other models. |
| [15] | 30-manually extracted features + 300-word2vec + 768-BERT, 300-word2vec + 768-BERT, 768-BERT, 30-manually extracted features + 768-BERT, 300-word2vec | ACC: 0.75, QWK: 0.77 | The best agreement was achieved with the 30-manually extracted features + 300-word2vec + 768-BERT model. |
| [16] | all-MiniLM-L6-v2, paraphrase-MiniLM-L6-v2, paraphrase-albert-small-v2, quora-distilbert-base, stsb-roberta-large, multi-qa-MiniLM-L6-cos-v1, multi-qa-distilbert-cos-v1, stsb-distilbert-base | ACC: 82.56, ρ: 0.64, r: 0.69/ACC: 56.11, ρ: 0.76, r: 0.73 | Different models showed accuracy up to 82.56% in binary classification and up to 56.11% in multi-class classification. |
| [17] | GPT-4 | r: 0.382; ICC: 0.447 | GPT-4 showed weak correlation with human and low consistency. |
| [18] | ABC-BERT-FTM, BERT | QWK: 0.9804 | The ABC-BERT-FTM model achieved the highest agreement. |
| [19] | BigBird, BERT, DualBERT-Trans-CNN, Considering-Content-XLNet, MTL-CNN-BiLSTM, Trans-BERT-MS-ML-R | QWK: 0.791 | The highest performance was achieved with the Trans-BERT-MS-ML-R model. |
| [20] | ACTA, BERT | QWK: 0.99 | The ACTA model achieved the highest agreement with human. |
| [21] | GPT-4 | r: 0.85 | GPT-4 showed successful results with high correlation and low error rate. |
| [6] | BERT | QWK: 0.78 | BERT achieved high agreement after fine-tuning. |
| [22] | LaBSE, mBERT | ACC: 0.88, CK: 0.83, QWK: 0.85 | LaBSE performed better in all languages, showing superior performance in QWK and accuracy. |
| [23] | Gemini 1.0 Pro, GPT-4 | ACC: 0.68 (binary), 0.59 (multi) | Gemini performed better in binary classification, while GPT-4 showed better performance in multi-class classification. |
| [8] | GPT-3.5 Turbo (Few-Shot, Zero-Shot), GPT-4 (Few-Shot, Zero-Shot) | LWK: 0.94 (2-class), QWK: 0.91 (3-class) | GPT-4 (Few-Shot) achieved the highest agreement. |
| [24] | Qwen-max-0428 | r: 0.491 | Qwen-max-0428 achieved low agreement with humans. |
| [1] | BERT (fine-tuned), LSTM | r: 0.761 | BERT + LSTM showed the highest correlation. |
| [25] | GPT-3.5 | ICC: 0.81 | GPT-3.5 achieved high consistency with human. |
| [26] | GPT-3.5 | ICC: 0.56 | GPT-3.5 achieved medium consistency in language criteria. |
| [27] | BERT, RoBERTa, XLNet, SBERT | ACC: 0.76 (3-class), 0.82 (2-class) | BERT showed the most consistent and highest performance as the recommended model across all datasets; other models were competitive in specific tasks but generally performed lower. |
| [28] | GPT-4 | r: 0.84 | GPT-4 showed high correlation. |
| [29] | GPT-4 | P: 0.788 | GPT-4 showed high precision in the SciEntsBank dataset. |
| [30] | CNN-LSTM, IndoBERT | QWK: 0.465 | IndoBERT achieved a 14.47% increase in agreement compared to CNN-LSTM. |
| [31] | BERT | ACC: 0.958 | BERT performed with high accuracy. |
| [32] | CNN-LSTM-ATT, LSTM-MoT, SkipFlow LSTM, TSLF, Sentence-BERT, CNN-LSTM-ATT, Tran-BERT-MS-ML-R | QWK: 0.852 | TSLF model achieved the highest agreement. |
| [33] | BERT, GPT-4, OCLL | QWK: 0.819 | GPT-4 achieved the highest agreement. |
| [34] | GPT-4 | ACC: 0.75 | GPT-4 performed with high accuracy with humans. |
| [35] | AraBERT | r: 0.88 | AraBERT showed high correlation with humans. |
| [36] | BERT-1-EN, BERT-1-ES, BERT-2-EN, BERT-1-MU, BERT-2-MU, Skip-Thought, BERT-2-ES | r: 0.83 | BERT-1-ES showed the best results. |
| [37] | BERT, Word2vec, WordNet | r: 0.841 | BERT showed the highest result across all datasets. |
| [38] | GPT-3 text-davinci-003 | CK: 0.682 | GPT-3 achieved agreement with humans. |
| [39] | BERT, GPT-3 (ada, babbage, curie, davinci), GPT-4 | r: 0.813 | Davinci showed the highest correlation. |
| [40] | GPT-3.5, GPT-4, Claude 2, PaLM 2 | ICC: 0.927, r: 0.731 | GPT-4 showed the highest consistency. |
| [41] | GPT-4 | ICC: 0.858 | GPT-4 showed excellent consistency with humans. |
| [42] | BERT, sentence embedding-LSTM | QWK: 0.766 | The best agreement was achieved with the BERT model. |
| [43] | Bi-LSTM, Sentence-BERT | QWK: 0.76 | The best agreement was achieved with the Sentence-BERT model. |
| [44] | ALBERT, BERT | r: 0.950 | ALBERT showed the highest performance. |
| [45] | GPT-3.5 | - | It showed high agreement with humans. |
| [46] | Aggregated-BERT + handcrafted + SVR, BERT-64 + LSTM, HISK + BOSWE(SVR), Skipflow, TSLF-all | QWK: 0.81 | The highest agreement was achieved by Aggregated-BERT + Handcrafted + SVR. |
| [47] | ChatGLM2-6B, Baichuan-13B, InternLM-7B | QWK: 0.571 | ChatGLM2-6B achieved the highest agreement. |
| [48] | Claude 2, GPT-3.5, GPT-4 | QWK: 0.567 | The highest agreement was achieved with GPT-4. |
| [49] | GPT-4 | CK: 0.88 | GPT-4 achieved the best agreement. |
| [2] | BLOOM, GPT-3, YouChat | P: 0.488, R: 0.912 | GPT-3 showed high recall and low precision. |
| [50] | GPT-3.5 (Base), GPT-3.5 (fine-tuned: FTP1, FTP2, FTPB), GPT-4 (Base) | QWK: 0.78 | Fine-tuned models FT-P1 achieved the highest QWK value. |
| [51] | all-distilroberta-v1, all-MiniLM-L6-v2, paraphrase-albert-small-v2, paraphrase-MiniLM-L6-v2, multi-qa-distilbert-cos-v1, multi-qa-mpnet-base-dot-v1, stsb-distilbert-base, stsb-roberta-large | r: 0.9586 | All-distilroberta-v1 showed the highest correlation. |
| [52] | BERT | CK: 0.75 | BERT achieved agreement with humans. |
| [53] | BERT, Bi-LSTM, CNN-T BERT, fine-tuned BERT, Xsum-T BERT, YAKE-T BERT | QWK: 0.789 | Xsum-T BERT and YAKE-T BERT achieved the highest agreement. |
| [54] | BERT, Bi-LSTM, Capsule Network, fine-tuned BERT | r: 0.897 | BERT showed high correlation with the extended dataset. |
| [55] | BERT-MTL-fine-tune, BERT-MTL-fine-tune (CELA dataset), BERT-fine-tune | QWK: 0.83 | BERT-MTL-fine-tune achieved the highest agreement. |
| [56] | GPT-4 | r: 0.67–0.82 | GPT-4 showed medium correlation with humans. |
| [57] | Bard, GPT-3.5 (default, fine-tuned) | ICC: 0.972 | Fine-tuned GPT-3.5 performed with the highest consistency. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Emirtekin, E. Large Language Model-Powered Automated Assessment: A Systematic Review. Appl. Sci. 2025, 15, 5683. https://doi.org/10.3390/app15105683
Emirtekin E. Large Language Model-Powered Automated Assessment: A Systematic Review. Applied Sciences. 2025; 15(10):5683. https://doi.org/10.3390/app15105683
Chicago/Turabian StyleEmirtekin, Emrah. 2025. "Large Language Model-Powered Automated Assessment: A Systematic Review" Applied Sciences 15, no. 10: 5683. https://doi.org/10.3390/app15105683
APA StyleEmirtekin, E. (2025). Large Language Model-Powered Automated Assessment: A Systematic Review. Applied Sciences, 15(10), 5683. https://doi.org/10.3390/app15105683