1. Introduction
Natural Language Processing (NLP) plays a key role in developing speech and text processing systems, wherein the analysis of words and their formation is an essential component. Morphology is the systematic study of word formation, where details of a language are required in the process of constructing a meaningful sentence. Morphological analysis is an essential phase in NLP where a morphological analyzer decodes a given word into its constituent components: stem and affixes [
1]. Given a word, its morphological analysis can be generated by humans who might have learned the language formally or informally or by machines trained to use a morphological analyzer. A morphological analyzer can serve as a necessary component in developing Stemmer, Named Entity Recognition (NER), and Machine Translation (MT) systems, to name a few NLP applications [
2].
The morphological analyzer generates morphemes for a given word, where a morpheme is a minimal meaningful unit, which can be either a stem or an affix, causing inflections based on number, gender, tense, or case [
1]. The inflections are based on morphological rules that vary from one language to another and are often associated with parts of speech that contribute differently during inflections. For instance, verbs in English have inflections with the
-ing or -ed suffix being added to the stem [
3]. The various parts of speech contribute differently in inflections. Nouns undergo inflection based on the eight cases: nominative, accusative, instrumental, dative, ablative, genitive, locative, and vocative, whereas verbs inflect based on tenses: past, present, and future. Indeclinables do not generate inflections when gender, tense, number, or case are altered [
4].
Automated morphological analysis can assist in downstream NLP applications, especially for low-resource languages and assist language documentation efforts for endangered languages [
5]. Many low-resource languages lack large, annotated corpora or linguistic resources, making it difficult to analyze or process them computationally. By developing morphological analyzers, it becomes possible to create linguistic resources for such languages. This supports machine translation and contributes to the documentation and preservation of endangered languages. The purpose of the study is to encourage the development of morphological analyzer for low-resource languages, whose development can help build more NLP tools. In machine translation, especially for morphologically rich languages, morphological analyzers play a crucial role in enhancing translation accuracy by breaking down complex words into constituent morphemes. This approach addresses challenges such as data sparsity and vocabulary explosion, which are prevalent in languages with intricate morphological structures [
6]. Morphological analysis is particularly beneficial for low-resource languages, where large parallel corpora are scarce. By segmenting words into meaningful units, translation systems can better handle rare and out-of-vocabulary words, improving translation quality [
7].
In recent decades, morphological analyzers have been built for English and other European languages. The Stanford CoreNLP [
8] toolkit processes mainly the English language but also supports languages like French, German, Arabic and Italian. Morphological analyzers have been built for Indian languages [
9] by creating the necessary corpus or dictionary. Indian languages are broadly classified as belonging to the following families: Indo-European (Hindi, Marathi, Urdu, Gujarati, and Sanskrit), Dravidian (Kannada, Tulu, Tamil, Telugu, Malayalam), Austroasiatic (Munda in particular), and Sino-Tibetan (Tibeto-Burman in particular) [
10]. Kannada is one of the Dravidian languages spoken widely in the state of Karnataka. It is included in the eighth schedule of the Indian Constitution [
11] and has approximately 40 million speakers in India. In this paper, the WX notation is used throughout to represent Kannada words [
12].
Kannada is highly agglutinative in nature, meaning two or more words can be combined into a single word, resulting in a complex word structure. It is morphologically rich in nature by having a greater number of inflections for a given word. The agglutinative nature of the language makes it difficult to split the words conjoined as a feature of euphonic change (
Sandhi), in which case it is even more difficult to perform morphological analysis [
13]. In English, a verb
learn undergoes inflection based on person/number and tense as
learnt, learning, learns, learned, whereas in Kannada, the equivalent word for
learn is
kali, and inflections based on gender, number and tense are shown in
Table 1.
From
Table 1, it is clear that there are multiple suffixes added based on gender, person, number, and tense for a verb in Kannada, whereas it is simplified in English as the inflections are unaffected for gender, but change only for person/number and tense. English still undergoes the
-s inflection in the third-person singular form. These inflections show the complex structure and morphological richness of the Kannada language, which makes it challenging to develop a morphological analyzer in Kannada. The complex structure of morphemes makes it difficult to build an automated morphological analyzer, as linguistic features such as the case markers, gender, tense, number, and honorifics affect the morpheme, leading to more inflected forms.
In Kannada, several researchers have proposed methods for word categorization into declinables and indeclinables [
14]. Declinables are nouns, verbs, adjectives, and pronouns, and indeclinables are conjunctions, interjections, and adverbs. Verbs undergo inflection based on gender, number, and tense. Pronouns and adjectives generate inflection similar to that of nouns. Compared to nouns, verbs have more inflections. Indeclinables like conjunctions, interjection, and adverbs do not show any inflection based on gender, number, tense, or case. Using these declinables and by building a dictionary of stems and affixes, it is possible to generate morphological analyses in Kannada.
Considering the above-mentioned challenges, a Kannada morphological analyzer can be approached in two ways: the first is a rule-based approach, which utilizes a dictionary and applies predefined morphological rules to the words in the dictionary. This approach involves manually defining the rules, which are subsequently integrated into the system. The second approach is corpus-based, where a corpus is created, and machine learning algorithms are applied to generate the morphological analysis [
15]. A paradigm refers to a set of rules that can be recognized in the process of word formation [
16]. A morphological analyzer can be built by creating paradigms for various word categories in a dictionary.
The rule-based approach is the most suitable approach among analysis techniques for morphologically rich languages, as there can be more inflections generated with multiple suffixes being added to the stem [
17]. Deep learning methods have also been popular among NLP researchers for morphological analysis due to the availability of open-source architectures [
18]. The researchers have implemented morphological analyzers using sequence-to-sequence, Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), and Transformer architectures.
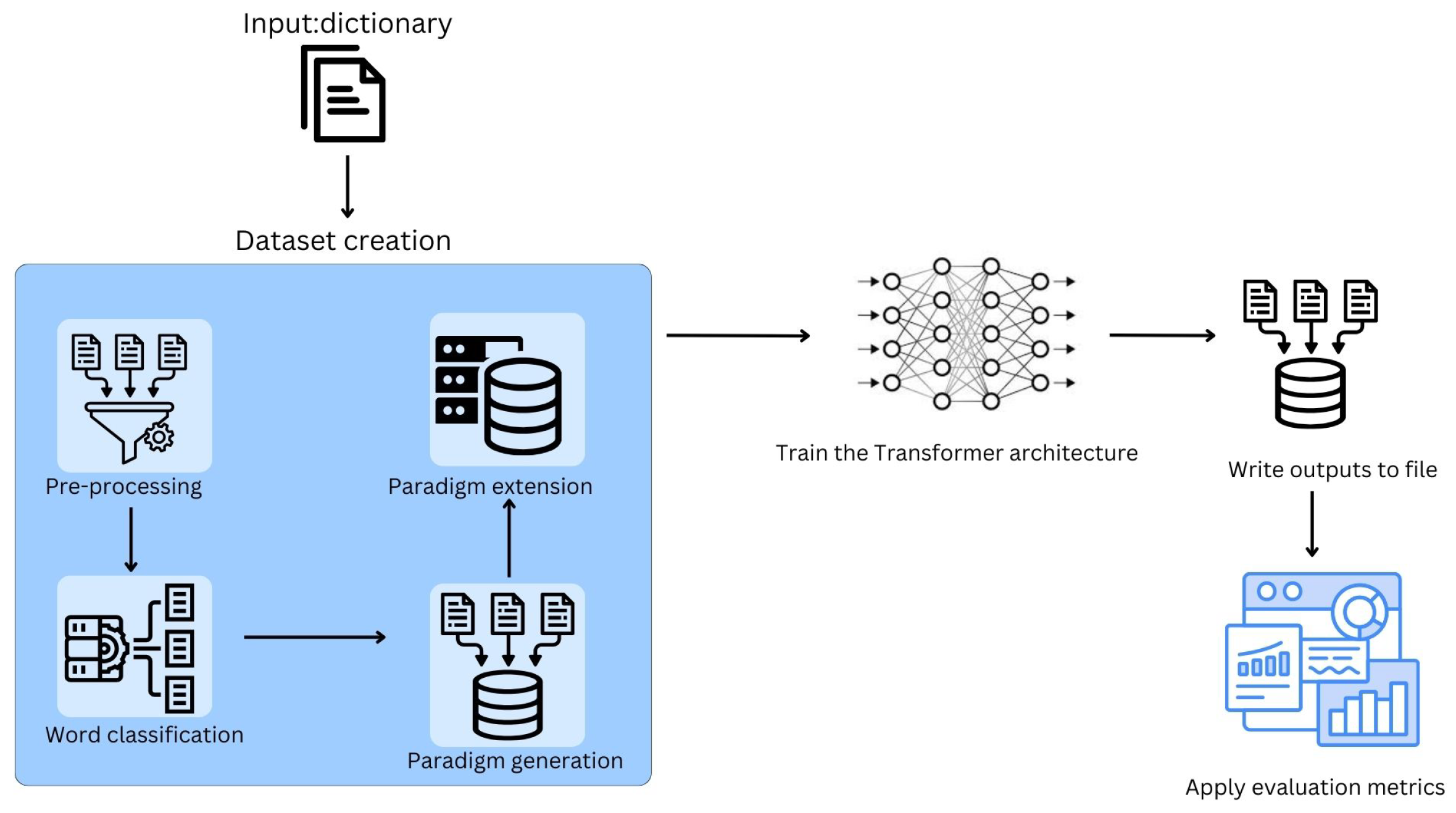
Based on the significance of deep learning techniques in NLP, this paper focuses on developing rule-based paradigms for morphological analysis and building a unique corpus on which a Transformer architecture is trained [
19]. The significant outcome here is to generate the morphological analysis of new words that are not present in the dictionary. The following are the contributions in developing a morphological analyzer for the Kannada language:
- 1.
A set of paradigms is designed for the words in a standard dictionary using morphological rules based on gender, number, tense, person, and case applicable to individual word categories.
- 2.
A unique morphological analysis dataset is developed using the generated paradigms on the standard dictionary.
- 3.
A hybrid model is trained on a unique dataset that is capable of analyzing any new inflection.
The remainder of the paper is organized as follows: a literature survey on morphological analyzers specific to Kannada is discussed in
Section 2, followed by a detailed methodology on the creation of paradigms to generate morphological analysis in Kannada presented
Section 3. Based on these discussions, the implementation details are explained in
Section 4, followed by an evaluation of the results in
Section 5. Finally, the conclusion and future scope of the proposed work are dealt with in
Section 6.
2. Related Work
Indian languages can be classified into the following language families in particular: Indo-European (Hindi, Marathi, Urdu, Gujarati, Sanskrit), Dravidian (Kannada, Tulu, Tamil, Telugu, Malayalam), Austroasiatic (Munda in particular), and Sino-Tibetan (Tibeto-Burman) [
10]. Indo-Aryan languages are a subgroup of the Indo-Iranian branch of the Indo-European language family, which are morphologically rich and share some commonalities. As a result, this literature survey examines languages from both the Indo-Aryan and Dravidian language families as source languages for morphological analysis.
2.1. Morphological Analyzer for Indo-Aryan Languages
Goyal and Lehal proposed a morphological analyzer and generator for Hindi based on a dictionary-reliant approach [
20]. In the database, all possible word forms for every root word are stored. The main focus was on words like nouns and other word classes but excludes proper nouns to some extent. This approach prefers time and accuracy to memory space, which is a drawback.
Malladi et al. developed a statistical morphological analyzer trained on the Hindi tree bank (HTB) [
21]. The analyzer identifies the lemma, gender, number, person (GNP), and case marker for every word in a given sentence by training separate models on the Hindi tree bank for each of them. Other grammatical features such as TAM (tense, aspect, and modality) and case are analyzed using heuristics on fine-grained POS tags of the input sentence. This analyzer achieved an accuracy of 82.03% compared with the Paradigm-Based Analyzer (PBA) for lemma, gender, number, person, case and TAM. As a a statistical model, it analyzed out-of-vocabulary words. The prediction of gender, number, and person of words in their sentential context could have been better if dependency relations were given as inputs. However, the standard natural language analysis pipeline forbids using parsing information during morphological analysis.
Bapat et al. presented a morphological analyzer for Marathi using a paradigm-based approach considering only inflections [
22]. The classification of postpositions and the development of morphotactic FSA was one of the important contributions, as Marathi has complex morphotactics. Though improvement was shown in shallow parsing, the morphological analyzer does not handle the derivation morphology and compound words.
Jena et al. developed a morphological analyzer using Apertium for Oriya [
17]. The analyzer data conformed to Apertium’s
dix format, and the dictionary showed correspondences between surface and lexical forms for any given word.The paper lacks a detailed analysis of the inflections for nouns and verbs. In the case of verbs, a few verbs did not fall into any of the existing verb paradigms, which can be ascribed to the lower robustness of the paradigms or to the need for separate paradigms for these verbs, which is a shortcoming. Causative verbs and verbal complexes were not handled, and these remain unanalyzed.
From the literature survey, it is observed that the morphological analyzers developed for Indo-Aryan languages are limited to inflectional morphology and do not handle derivational morphology and compound words. Most of the methods use the dictionary-based approach and consume more memory as all the affixes and stems are stored.
2.2. Morphological Analyzer for Dravidian Languages
Kumar et al. developed a morphological analyzer for the Tamil language using a sequence labeling approach of machine learning [
23]. Support Vector Machine was used in morphological analysis for classification. Their work employs machine learning techniques in data preparation without a morpheme dictionary, but the system is trained on morpheme boundaries. Jayan et al. surveyed three major methods for developing a morphological analyzer in Malayalam, viz. paradigm-based and suffix-stripping hybrid [
24] methods. The availability of morphological paradigms and classification was a major issue in developing a morphological analyzer.
Prathibha and Padma proposed an analyzer only for Kannada verbs [
25]. They created verb, suffix, and root databases and used a hybrid approach with suffix-stripping for the paradigms. Although they used transliterated text, there was no proper standardized notation mentioned in their model. Padma et al. proposed a rule-based stemmer, an analyzer, and a generator for nouns in the Kannada language [
26]. Their model made use of noun–suffix- and noun–noun-based dictionaries, which were implemented using suffix stripping. Their work was restricted to only nouns, whereas other parts of speech (POSs) present in the Kannada language were ignored. Veerappan et al. proposed a rule-based morphological analyzer and generator using Finite State Transducer (FST) [
15]. The system was implemented using the AT&T Finite State Machine. The lexicon data and the analyzer are not openly available, and the testing was performed on random samples.
Prathibha et al. proposed a morphological analyzer for Kannada using a hybrid approach [
27]. The affixes are stripped, followed by the use of a paradigm-based approach. A rule-based method is employed in the creation of the lexicon. A questionnaire-based approach was used to make new entries into the lexicon. Kannada’s derivational words and foreign words were not considered for nouns, and for verbs, multiple suffixes were not considered. Shambhavi et al. proposed a morphological analyzer and generator for Kannada using the
Trie data structure in a paradigm-based approach [
28]. They constructed individual
tries for handling suffixes corresponding to each paradigm class and linked them to the roots that could be mapped to the same paradigm. A limitation of their work was the high memory consumption.
Murthy proposed a network and process model for a morphological analyzer and generator [
29]. In this approach, the Sandhi (euphonic change) between the root and affixes was treated as a process, while the formation of morphemes was treated as a network modeled using a finite automaton, following a rule-based approach. Limitations of rule-based approaches lie in their inability to span the rules on new words that were not seen as part of the lexicon. Anitha et al. proposed a Morph-analyzer for the Kannada dialect [
30] by employing machine learning techniques like Support Vector Machine on printed Kannada text. They extracted the words by OCR and performed morphological analysis. A custom dataset was developed using a Romanized Kannada text, without any standard format, which is not publicly available. There was no explicit algorithm provided for handling grammatical features or for performing morphological analysis.
Most of the methods employed for Dravidian languages were rule-based in nature by making use of a dictionary. The creation of paradigms poses a challenging task for this kind of morphological analysis. As language evolves and new words are added to the dictionary, rule-based methods may struggle to generate accurate analysis, subsequently leading to failures in adapting to these changes.
2.3. Morphological Analyzer Developed Using Neural Networks
Karahan et al. proposed TransMorpher [
31], a two-level analyzer for the Turkish language that consists of a rule-based phonological normalization module and a sequence-to-sequence character translation module developed using the Transformer architecture. The model was extended to other languages, but the results did not match those of state-of-the-art models. Premjith et al. proposed a deep learning approach for Malayalam morphological analysis [
18] at the character level. Recurrent Neural Network (RNN), Long Short-Term Memory (LSTM), and Gated Recurrent Units (GRUs) were used to learn the rules for identifying the morphemes automatically and segmenting them from the original word. Further, each of the morphemes was analyzed to identify the grammatical structure of the word. They made use of Romanized scripts and generated inflections based on paradigms prior to analysis, where the development of the paradigms was the challenging task. Dasari et al. proposed
Transformer-based Context Aware Morphological Analyzer for Telugu [
32]. They experimented with available Telugu Transformer models and existing multi-lingual Transformer models, out of which Bert-Te outperformed other multilingual models.
Most of the neural methods employed for the above languages were based on a prior dataset that used rules/paradigms and trained the neural architectures to generate the morphological analysis. Similar approaches can be extended to low and extremely low-resource languages.
Among the state-of-the-art models on morphological analyzers in Kannada, a lack of standardization in transliteration has been observed. Rule-based methods have not been evaluated on benchmark datasets, and open-source platforms were not used. Despite several efforts in the morphological analysis of Kannada, the evaluations tend to be ad hoc without adherence to standard metrics or validation against benchmark datasets. The following points serve as motivation to carry out the task of creating a morphological analyzer in the Kannada language:
- 1.
It is observed from the literature that there is a lack of a morphological analysis dataset based on a standard dictionary.
- 2.
The existing rule-based methods do not tend to generate analysis for words outside the dictionary, so the morphological analysis of for new words is not generated at all.
- 3.
The current dataset creation strategies struggle to produce valid input datasets for deep learning models and hence demand additional efforts.
5. Discussion and Analysis of Results
The Kannada dictionary dataset with 11,005 words is considered in this study. After pre-processing, a total of 9879 stems are extracted [
37]. The stems are classified into nouns, verbs, indeclinables, adjectives, numeric words, and pronouns. Nouns are segregated by genders—masculine, feminine, and neuter. The gender details are assigned manually to nouns, and the description for the same is shown in
Table 10. A total of 29 paradigms are formed for nouns and 42 for verbs.
In addition to the nouns and verbs, 12 pronoun stems and their paradigms for cases are coded manually. The details describing the stems and their genders are shown in
Table 11.
The generated sample output from the developed model is as follows:
The sample outputs generated from the rule-based part of the morphological analyzer, with details of their analysis, are shown in
Table 12. The noun
xeviyalli is correctly categorized as a noun that is singular, locative, and feminine. Similarly, words in the other POS categories are also correctly analyzed.
Some nouns do not follow the paradigm rules, and the inflections generated are not the actual words in usage; hence, we have written separate paradigms as exceptions. The semantic correctness of a word is based on the language in the context used, as given in
Table 13.
The word
aNNa can follow the paradigm for
huduga following an ending letter that is the same. But the proper paradigm is to create a new exception paradigm for
aNNa. The incorrect usage is shown in
Table 13 for the plural forms corresponding to the paradigm
huduga, and the correct usages are the ones mentioned under the column of the exception paradigm. There are a total of 35 words that are exceptions to the paradigms defined manually and added to the exceptions list with a separate paradigm. The proposed work covers all the vowel (
svara) ending nouns, verbs, numbers, adjectives (
guNavAcaka), and indeclinables (
avyaya) in the Kannada dictionary by Subbanna and Madhava [
37], along with manually identified pronouns. The generated analysis can be used in machine translation to enhance the quality of translated text, which is a possibility that needs to be explored.
Using the Transformer architecture, the generated morphological analysis was evaluated for 1000 inflected nouns, and the results are shown in
Table 14. The test set was independent of the inflectional words present in the training or validation set. Hence, the test was performed on new data that the model had not seen. The Precision, Recall, and F1 scores for steps 500, 5000 and 10,000 were calculated by varying the number of sentences, as shown in
Table 15. The graphical representation of the overall scores is shown in
Figure 11.
It is observed from
Table 14 that the best values for Precision, Recall, and F1 Scores are 0.924, 0.925, and 0.925, respectively. These values are obtained by testing the generated morphological analysis of 1000 inflections.
The model is trained for 10,000 steps, and the evaluation measures such as the Precision, Recall and F1 score are analyzed at 500, 5000 and 10,000 steps and incrementing the dataset by 100 sentences. It is observed from
Table 15 that the scores are 0.011 higher at the initial step with the test data with 1000 inflections, but at the 10,000th step the actual training is complete and Precision, Recall and F1 score values of 0.924, 0.925 and 0.925 are obtained.
Perplexity scores in language models serve as indicators of their language processing efficacy. But in the case of morphological analysis, a model with a low perplexity score indicates higher accuracy and has been trained well on data by understanding the structure of the words present in the language. A model with a higher perplexity score is less reliable than one with a lower score. The perplexity score can be considered a direct measure of the model’s linguistic competence, with lower scores indicating superior language processing capabilities [
41]. A perplexity score of one means that the model perfectly predicts the output given the input, while higher scores indicate worse performance. The perplexity score for the generated morphological analysis of nominal inflections is shown in
Figure 12.
The perplexity score indicates the predictiveness of the next word. In
Figure 12, the perplexity score at every 500th step is plotted, and it can be observed that a stable value of 1.11 is achieved between 2500 and 8000th steps. Later there was a rise to 1.15 before dropping to 1.11 at the 10,000th step. The proposed model is compared with existing Kannada morphological analyzers and summarized in
Table 16.
The existing approaches discussed in the literature show that the majority of methods used in developing a morphological analyzer for Kannada are either rule- or learning-based. Considering a smaller subset of nouns or verbs that were rule-based made the morphological analyzer less useful in practical scenarios, as unknown words could not be categorized. The lack of standard dictionary was a major drawback in the litera, ture which was overcome by the proposed morphological analyzer model. As language evolves, new words continue to be included in the dictionary, but the provision to handle such out-of-vocabulary words is not handled in the literature, whereas the proposed model is capable of handling new nouns and is also based on standard dictionary data that are reliable and can be expanded when new words are added to the dictionary. It can be observed that the proposed hybrid method is suitable for generating an analysis of inflected Kannada words. The proposed method can be easily applied to any low-resource language to create a dataset as well as to generate a morphological analysis.
Limitations and Challenges with Building the Morphological Analyzer
The morphological analyzer developed for Kannada needed a strong open-source Kannada dictionary containing the majority of words used in everyday vocabulary. The creation of paradigms was an uphill task and needed expert supervision prior to the implementation stage. Kannada, a morphologically rich language, poses challenges while generating inflections based on linguistic features like gender, number, tense, and case. Verbs were harder to analyze than nouns, as verbs yielded a greater number of inflections. The exceptional cases required smart handling as they could be mis-categorized. In the neural part, the training would be based on the data curated, so cleaning and transformation were crucial.
6. Conclusions
A hybrid morphological analyzer leveraging the power of rule-based and Transformer-based architectures has been built for a low-resource language, Kannada. The dataset provided by Kannada Vishwa Vidyalaya, Hampi covers major words of the modern Kannada language to which the rule-based morphological analyzer has been built for all POS categories. The morphological analyzer generates inflectional analysis for nouns, pronouns, verbs, indeclinables, and adjectives present in the dictionary based on predefined rules. As most Kannada nouns could be categorized into paradigms defined in the paper, the Transformer training was focused on inflectional morphology for nouns. Further, this work can be expanded onto verbal inflections by curating an extensive dataset capturing the inflectional rule of verbs as carried out for nouns.
The morphological analyzer covers the majority of the common words in Kannada, and the analysis is helpful in developing language-related tools like chunker, POS tagger, stemmer, Named Entity Recognition (NER) and machine translation systems in Kannada. The scope of this work is limited to inflectional morphology, so compound words and derivational morphology are not included. At present, nouns ending with consonants and borrowed foreign words from English, Hindi, Arabic, Oriya, Gujarati, Tamil, Tulu, Telugu, Punjabi, Parsi, Marathi, Malayalam, Sindhi and Sanskrit are not handled. The proposed research is challenging due to the complex structure of the Kannada language. A total of 9879 words have been mapped onto 85 paradigms and 205,659 word inflections have been analyzed. Any new nominal inflection can be analyzed using the proposed model, which contributes additionally in extracting the linguistic information. We observe that the rule-based model retrieves morphological analysis more quickly for words present in the corpus, while the Transformer-based model excels at generating analyses for new words not found in the dictionary. The precision, recall and F1-score obtained are 0.924, 0.925 and 0.925, respectively, on the test set for inflections in Kannada. The inflections tested had no overlap with data seen during the training, and the results are promising. This study can be extended to a wider dictionary for further enhancements. The proposed technique is suitable for low-resource languages to create their own unique dataset, which is beneficial in developing language-specific NLP tools. Better results can be expected with a larger dictionary of root words, and the data/paradigms can be widely extended. It will be interesting to pursue word analysis in derivational morphology and consonant ending nouns of the ancient Kannada language in a future work.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}