1. Introduction
The sequential and temporal nature of time-series data makes them an essential part of many fields, such as manufacturing, healthcare, finance, and environmental monitoring. To ensure system security, dependability, and efficiency, it is essential to be able to analyze and identify anomalies in time-series data. Data points that substantially deviate from expected patterns are called anomalies, sometimes known as outliers or deviants. These deviations frequently point to important events that could have serious operational or financial repercussions, such as sensor malfunctions, equipment failures, cyberattacks, fraudulent transactions, or other anomalous behaviors [
1,
2].
Industrial environments, especially vital infrastructures such as manufacturing facilities, energy grids, and water management systems, are among the most important places for anomaly detection to be used. These systems are made up of several linked devices that frequently function in intricate and changing environments. To guarantee seamless operations, avoid system failures, and reduce the risks associated with natural or human-made disruptions, these infrastructures must be continuously monitored and managed. However, conventional threshold-based monitoring methods, which depend on static limits or pre-established rules, frequently cannot keep up with the complexity and unpredictability of actual industrial processes. Adoption of more sophisticated, data-driven anomaly detection techniques is required due to the unpredictability of operational environments, the existence of noise in sensor readings, and the changing behavior of interconnected components.
The creation of a baseline that reflects typical operational behavior is a crucial first step in the detection of industrial anomalies. It is possible to identify deviations that might point to possible threats or failures by comprehending and simulating typical system behavior. Predictive maintenance techniques can be created by utilizing past trends and patterns to identify and fix anomalies before they become serious issues. This method increases the resilience of vital infrastructures, reduces downtime, and allocates resources optimally. However, the lack of labeled anomalous data is a fundamental problem in these systems. Industrial anomaly detection frequently suffers from a severe imbalance between normal and abnormal instances, in contrast to traditional machine learning tasks, where labeled datasets are plentiful.
It is challenging to build supervised learning models that rely on substantial amounts of labeled training data because anomalies in these systems are uncommon, unpredictable, and highly context-dependent. Researchers have been concentrating more on unsupervised and semi-supervised techniques that do not require explicit labels for anomalies because of the shortcomings of supervised learning in industrial anomaly detection.
Clustering [
3] and density estimation [
4] are two examples of unsupervised techniques that look for anomalies based on statistical characteristics or departures from learned distributions. In a similar vein, semi-supervised methods concentrate on simulating typical behavior and identifying departures from the learned models. Reconstruction and forecasting methods based on deep neural networks are a commonly used class of models for this purpose. Reconstruction-based models [
5] identify anomalies based on their inability to be accurately reconstructed, while autoencoders or generative models are used to encode normal patterns. Conversely, forecasting-based approaches [
6] identify deviations as possible anomalies and forecast future values based on past observations.
The ability to detect anomalies in time-series data has been further improved by recent developments in deep learning and representation learning. Contrastive representation learning is one promising method that has recently been used for time-series anomaly detection [
7] and has gained popularity in computer vision tasks [
8,
9]. The goal of contrastive learning is to improve the robustness of anomaly detection models by developing feature embeddings that optimize the difference between similar and dissimilar instances. Furthermore, to improve accuracy and adaptability, hybrid models that combine several detection methods, such as forecasting and reconstruction, have been introduced [
10,
11].
Even with great advancements in this area, there are still a number of difficulties, especially when anomalies are not evenly distributed throughout a dataset. Instead of being frequent and widespread, anomalies are sparse and localized in many industrial applications. The efficacy of current models may be diminished by this non-uniformity, which may result in irregular anomaly scores and reconstruction errors. More adaptive and context-aware thresholding mechanisms must be developed because traditional thresholding techniques for anomaly detection frequently do not generalize across various operational conditions.
To address these limitations, this study introduces an MSE-based feedback mechanism within an architecture that integrates both channel and temporal processing layers. Our approach leverages convolutional operations to effectively capture temporal dependencies while employing a dynamic thresholding method to enhance anomaly detection performance across different methodologies. Unlike static thresholding approaches that apply fixed anomaly detection criteria, our proposed dynamic thresholding method adjusts to variations in data distributions, reducing false positives and improving detection accuracy. Furthermore, we evaluate our method against existing techniques to assess its effectiveness in mitigating false alarms and improving anomaly detection robustness.
The main contribution of this work is the introduction of an MSE-based feedback mechanism within an architecture that integrates both channel and temporal processing layers. In this design, convolution is utilized to capture temporal correlations effectively. The proposed dynamic thresholding method is not only applied within our architecture but also tested on existing methods from the literature to evaluate its effectiveness across different anomaly detection approaches. Additionally, we adapt the previously designed WaterLog dataset—originally developed for industrial control system security research—to the anomaly detection domain. The adapted dataset, WaterLog*, is now publicly available for academic use and serves as a valuable benchmark. Unlike many public datasets with frequent and densely packed anomalies, WaterLog* features sparse and isolated anomaly regions, closely reflecting real-world scenarios where anomalies are rare and localized. This makes it a more challenging and realistic benchmark for evaluating anomaly detection methods.
2. Literature Review
The field of time-series anomaly detection has seen significant advancements, with classical methods evolving to address diverse data characteristics. Traditional techniques such as time-series decomposition, clustering, and density estimation have provided robust solutions for identifying anomalies, particularly in data with distinct patterns or significant deviations from normal distributions. Notable examples include the Local Outlier Factor (LOF) [
4], which identifies anomalies based on local density deviations, and the Deep Autoencoding Gaussian Mixture Model (DAGMM) [
12], which leverages density estimation principles. These methods are particularly effective in scenarios where the underlying data distribution is good, allowing for the identification of deviant outliers.
Clustering-based methods often use the distance to the cluster center as an anomaly score. For instance, ITAD (Integrative Tensor-based Anomaly Detection) [
13] employs tensor-based decomposition to model normal behavior patterns and utilizes clustering to group similar patterns. This approach not only enhances the detection of anomalies but also facilitates the understanding of the underlying structure of the data, which can be crucial for operational insights. Deep-SVDD [
3] trains a neural network to map normal data instances close to a central point in the latent space, while IForest [
14] isolates anomalies through a recursive partitioning process, randomly selecting features and split values. The iterative nature of IForest enables the efficient processing of high-dimensional data, making it suitable for complex time-series datasets.
Autoregressive models, which predict future values based on past observations, have also been widely used. With the rise of deep learning, recurrent neural networks (RNNs) and their variants, such as LSTM networks, have gained prominence for their ability to capture long-term dependencies and temporal patterns. CL-MPPCA [
15], an extension of ARIMA, combines LSTM-based neural networks with probabilistic PCA (Principal Component Analysis) models to detect deviations between predicted and actual values. This hybrid approach provides a more detailed understanding of the data as it combines both temporal dynamics and probabilistic modeling.
Autoencoders, a class of neural networks designed for dimensionality reduction and feature learning, have also been extensively applied in anomaly detection. They consist of an encoder that maps input data to a lower-dimensional latent space and a decoder that reconstructs the data from this representation. Variational Autoencoders (VAEs) extend this framework by encoding inputs into distributions, typically Gaussian, and reconstructing data from these distributions. For example, LSTM-VAE [
16] and its improved variants [
17,
18] have been applied to anomaly detection. The ability of VAEs to model uncertainty in the data representation makes them particularly suitable for scenarios where anomalies may not conform to a single distribution.
Rao [
19] presents a comprehensive examination of dimension reduction techniques in time-series data through a novel framework called the Bi-Functional Autoencoder (BFAE) in their work. The paper identifies the limitations of existing methods, such as Functional Principal Component Analysis (FPCA) and standard Autoencoders, which typically rely on linear approximations and scalar representations, thus inadequately addressing the complex and nonlinear nature of real-world time-series data. The authors propose an innovative methodology that utilizes a nonlinear function-on-function approach by integrating a functional encoder and decoder to effectively capture dynamic temporal relationships. This is achieved through the deployment of continuous neurons that facilitate the transformation of functional inputs into a lower-dimensional latent space, preserving the functional nature of the data throughout the encoding and decoding processes. Furthermore, the optimization of BFAE relies on traditional gradient descent techniques combined with Fréchet derivatives, allowing for computations of functional gradients that are essential for training the model. In contrast to conventional sequential models such as Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs) that operate with fixed parameters, the BFAE provides a more nuanced framework that accommodates feature effects that dynamically change over time intervals. Overall, this advancement in functional data analysis presents promising applications across various domains, enabling improved efficiency and accuracy in the analysis of temporal data.
The article by Delibasoglu [
20] presents LMS-AutoTSF, which distinguishes itself from traditional forecasting models by employing dual encoders that operate at multiple scales and is specifically designed to handle the nuanced variations in time-series data. These encoders utilize learnable filters to separate trend and seasonal components dynamically, employing both low-pass filters to capture long-term trends and high-pass filters for seasonal variations. This effectively allows the model to isolate and analyze the intricacies of the data in the frequency domain, a feature that is particularly beneficial for multivariate time-series forecasting, where different variables may interact and influence their temporal behaviors. The architecture integrates autocorrelation to enhance temporal modeling by computing lagged differences, thus capturing dependencies across time steps more efficiently than prior methodologies. Furthermore, the article elaborates on the challenges inherent in time-series forecasting, including the presence of linear and nonlinear trends, seasonal fluctuations, and the dynamic nature of the datasets, including those used for traffic forecasting (PEMS datasets) mentioned in the analysis. Traditional algorithms often struggle with these complexities; however, the LMS-AutoTSF framework combines frequency-domain filtering with temporal and channel-wise transformations, granting it an edge in discerning and processing detailed temporal patterns across multiple features and data dimensions. Consequently, this makes the model not only more effective in capturing long-term dependencies but also more efficient in processing, ensuring high precision while maintaining a lightweight design conducive to faster prediction times. The authors of [
21] introduce an approach within the context of forecasting. Transformers have demonstrated significant capability in sequence modeling; however, they face scalability issues and performance degradation when dealing with multivariate series that include large lookback windows. The authors contend that standard Transformer architectures tend to merge multiple variables into single temporal tokens, impairing the model’s ability to learn meaningful representations and resulting in ineffective attention maps that fail to capture nuanced correlations. The proposed iTransformer architecture adopts an inverted approach, meaning that it separates the temporal and variable dimensions to enhance representation learning. The normalization process transforms individual variable representations into a Gaussian distribution, helping to mitigate inconsistencies caused by measurement discrepancies. This adjustment improves the model’s ability to effectively tackle non-stationary problems commonly found in time-series data. The authors utilize feed-forward networks (FFNs) customized for individual variable tokens, leveraging the universal approximation theorem to uncover complex relationships within the data. By doing so, the architecture efficiently encodes observed time-series data and decodes them for future predictions, demonstrating superior performance across seven real-world datasets compared with existing models such as Autoformer and LSTNet.
The authors of [
22] introduce TimeMixer, a novel model designed for time-series forecasting that fundamentally utilizes a multiscale mixing approach. TimeMixer incorporates two primary architectural components: Past-Decomposable-Mixing (PDM) blocks and Future-Multipredictor-Mixing (FMM) blocks. The PDM blocks facilitate the decomposition of complex time series into distinct components such as seasonal and trend elements, allowing for fine-to-coarse and coarse-to-fine information mixing and effectively capturing both microscopic and macroscopic variations within the series. The FMM blocks, conversely, leverage multiple predictor models to enhance forecasting accuracy by exploiting complementary insights derived from varied temporal patterns across multiple scales. This method addresses the inherent challenges posed by the non-stationary nature of real-world data, which often exhibits intricate variations due to various influences, including trends and seasonal fluctuations common in applications ranging from economics to traffic planning. The empirical results demonstrate that TimeMixer achieves state-of-the-art performance across multiple benchmark datasets, thereby validating the efficacy of its proposed multiscale strategy in forecasting tasks.
The paper by Nie [
23] investigates the efficacy of Transformer models for long-term forecasting within time-series data, particularly emphasizing advancements made possible through self-supervised learning techniques. The author gives details about the architecture of the proposed model, PatchTST, which leverages the capabilities of Transformers. Transformers are highlighted as suitable candidates for modeling sequential data due to their effective attention mechanisms, which facilitate learning relationships across broader contexts in data, unlike previous models. Additionally, the paper evaluates existing models, including state-of-the-art frameworks such as Informer, Autoformer, and FEDformer, establishing them as baselines to benchmark performance improvements achieved through the PatchTST architecture. The authors of [
5] present a novel approach to unsupervised anomaly detection in time-series data by leveraging a Transformer-based architecture, which is referred to as the Anomaly Transformer. The central methodology involves adapting Transformer models that utilize self-attention mechanisms to capture intricate temporal dynamics and relationships within the time series. Key innovations include the introduction of an association-based criterion for anomaly identification, which is co-designed with temporal models to enhance the learning of informative associations across time points, thereby addressing limitations found in prior methodologies that primarily focused on pointwise or pairwise representations. The Anomaly Transformer demonstrates superior performance when benchmarked against various existing anomaly detection methods, including local outlier factors and clustering techniques, underscoring the importance of temporal information in accurately identifying anomalies in complex datasets. The comprehensive evaluation across multiple datasets further emphasizes the model’s robustness and generalizability, revealing a consistent state-of-the-art performance across benchmarks.
OmniAnomaly [
17] integrates VAEs with a stochastic RNN (Recurrent Neural Network) framework using GRUs to model temporal dependencies, while InterFusion [
24] employs a hierarchical VAE to capture inter-metric and temporal relationships. These developments highlight the importance of being able to identify both temporal and cross-metric relationships that can significantly increase the accuracy of anomaly detection in complex datasets. GAN-based methods, such as MAD-GAN [
18] (Multivariate Anomaly Detection for time-series data with a Generative Adversarial Network), use LSTM networks in both the generator and discriminator to detect anomalies. The GANs training framework allows for the creation of realistic data distributions that can be used to effectively identify deviations.
DGHL [
25] (Deep Generative model with Hierarchical Latent) introduces a hierarchical latent space representation using convolutional networks, enhancing the model’s ability to capture complex patterns in time-series data. This hierarchical approach allows for the modeling of both global and local patterns, which is essential for effective anomaly detection in multi-dimensional time series. BEATGAN [
26] is another GAN-based reconstruction method. MTAD-GAT [
10] combines forecasting and reconstruction-based networks, leveraging both outputs for anomaly detection. This dual approach not only enhances the robustness of the detection mechanism but also provides a comprehensive view of the data’s temporal dynamics.
Recent advancements have also introduced attention mechanisms into anomaly detection frameworks. AnomalyTransformer [
5] introduces an Anomaly-Attention mechanism to compute association discrepancies, focusing on differences between normal and anomalous patterns. This attention mechanism allows the model to dynamically focus on the most relevant features of the data, improving the detection of subtle anomalies that may be overlooked by traditional methods. DCDetector [
7] employs contrastive learning with a multi-scale dual attention model to enhance anomaly detection capabilities, demonstrating the effectiveness of attention-based approaches in this context. By leveraging contrastive learning, DCDetector can better differentiate between normal and anomalous patterns, leading to improved detection performance.
AE-FAR [
27] (Autoencoder with Feedback Attention Reconstruction) integrates the capabilities of autoencoders and Recurrent Neural Networks (RNNs) with a feedback mechanism driven by reconstruction error. The method leverages autoencoders to learn compact representations of normal data and employs RNNs to capture temporal dependencies within time-series data. A key innovation of AE-FAR is its feedback mechanism, which utilizes the Mean Squared Error (MSE) to iteratively refine the reconstruction process. This iterative refinement process allows AE-FAR to adaptively improve its anomaly detection capabilities over time, making it particularly effective in dynamic environments where data characteristics may change.
As a result, advances in time-series anomaly detection reflect the rich interplay between classical methods and modern deep learning techniques. The integration of various methodologies, including clustering, density estimation, and advanced neural network architectures, has led to more robust and effective systems for identifying anomalies. As the field continues to evolve, ongoing research will likely focus on improving these methodologies and exploring new approaches to improve anomaly detection in complex time-series data. Future directions may include exploring hybrid models that combine the strengths of various techniques and applying transfer learning to improve performance in low-data scenarios.
3. Methodology
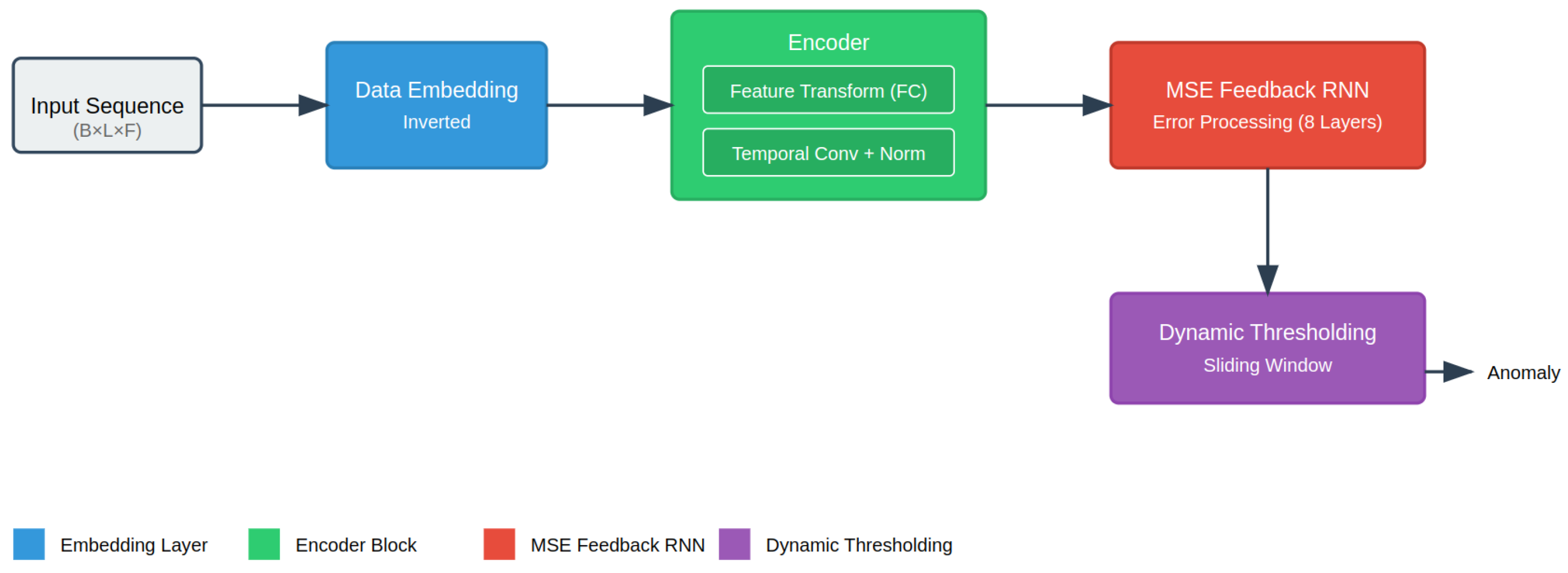
The anomaly detection process in our proposed ChaMTeC framework follows a systematic and modular pipeline that is designed to capture both temporal and feature-wise dependencies in multivariate time-series data. The process begins with input sequences , where B is the batch size, L is the sequence length, and F is the number of features (16 in our WaterLog dataset). The input is normalized and passed through the embedding layer called "DataEmbeddingInverted", which not only transforms feature dimensions but also prepares the data for temporal processing by transposing the sequence layout for improved temporal correlation learning. The core of the architecture consists of a multi-stage encoder composed of the following: feature-wise transformations using fully connected layers; a temporal self-attention module (optional) to capture long-range dependencies; a temporal convolutional module to extract localized temporal patterns; residual connections and layer normalization to stabilize training and enhance feature reuse. Once the embedding is encoded, a reconstruction of the original input is produced. The reconstruction error is computed as the Mean Squared Error (MSE), which serves as the basis for anomaly scoring. This error is then fed back into a Recurrent Neural Network (RNN), specifically, a GRU-based feedback mechanism, which adjusts the reconstruction iteratively by modeling the evolution of error patterns over time. The final corrected reconstruction is obtained by learning a residual correction from the RNN’s hidden states. To decide whether a sample is anomalous, we apply a sliding-window-based dynamic thresholding technique. This method calculates a moving average and standard deviation of error within a local window and computes a threshold. This allows the system to adapt to local variations and avoid false positives in high-variance but non-anomalous regions.
We propose a novel time-series anomaly detection framework that combines an inverted embedding strategy, channel (feature) fusion, multi-layer temporal encoding, and an MSE-based feedback mechanism with dynamic thresholding, as illustrated in
Figure 1. The framework consists of four main components: (1) data embedding and input transformation (
Section 3.1), which invert temporal and feature dimensions for temporal processing; (2) an encoder layer for temporal and feature processing (
Section 3.2), which leverages both feature-wise transformations and convolutional temporal dependencies; (3) an MSE-based feedback recurrent neural network (
Section 3.3), which iteratively refines reconstructions using squared error feedback; (4) sliding-window-based dynamic thresholding (
Section 3.4.2), which adapts anomaly detection sensitivity to local data distributions.
3.1. Data Embedding and Input Transformation
The input sequence , where B is the batch size, L is the sequence length, and F is the feature dimension, is first processed using an embedding layer.
Let x denote the multivariate feature vector representing the operational state of the water management system. Each vector includes continuous measurements and indicators of all physical devices serving as data sources across five stations (tank, refilling1, refilling2, purification, and dam) working in the drinking water process. These features include variables such as the Dam Level, Purification Level, Elevator Level, Consumer Level, and Tank Level, as well as the pump status and flow level of these stations. The full feature vector spans n = 16 dimensions, and the data are collected at fixed intervals (e.g., 10 min), forming a multivariate time series used for anomaly detection.
DataEmbeddingInverted refers to the inverse transformation of input features with the aim of dimensionality transformation for temporal encoding. In our case, it denotes the reconstruction of the original input vector from its compressed representation, which is essential for reconstruction-based anomaly detection. This step typically involves a linear projection layer that maps low-dimensional latent vectors back to the input feature space.
where
represents the transformed embedding. This transformation ensures that the model captures temporal dependencies before further processing in the encoder.
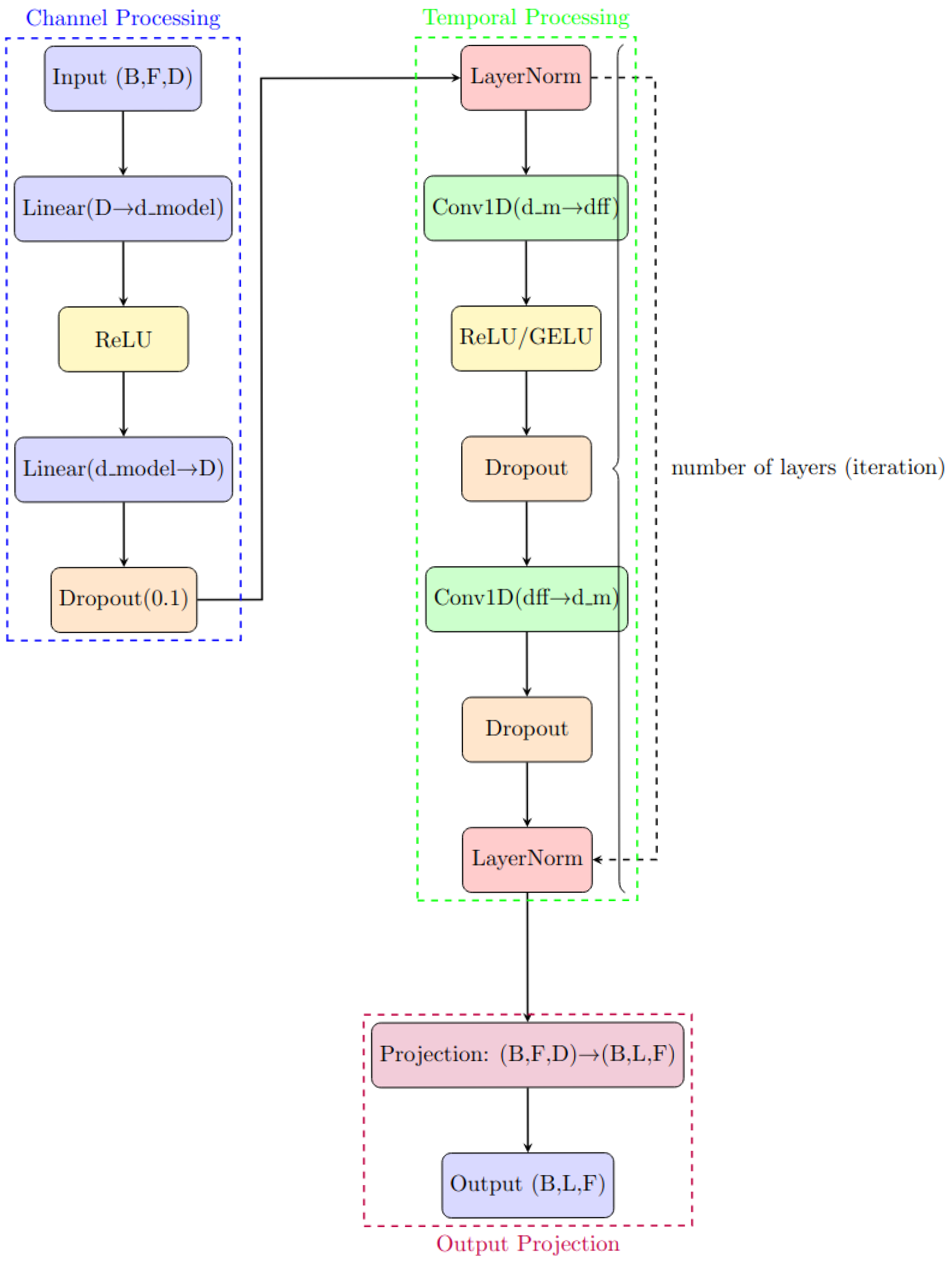
3.2. Encoder Layer for Channel and Temporal Processing
The encoder consists of multiple layers, each leveraging fully connected (FC) layers for feature-wise transformations and convolutional layers for temporal dependencies, as represented in
Figure 2. This design enables the encoder to perform channel and temporal processing in a unified manner. Channel processing focuses on capturing the interactions between features (or sensor channels) at a given time step through fully connected layers, allowing the model to learn complex relationships such as correlations between pump flow, tank levels, and operational statuses. In parallel, temporal processing aims to model the evolution of each feature across time. To achieve this, the encoder integrates multi-head self-attention for learning long-range dependencies and dilated convolutional layers for capturing localized short-term trends. While attention enables the model to dynamically focus on relevant past time steps, convolutions ensure the efficient extraction of patterns across fixed-length receptive fields. Together, these mechanisms allow the encoder to simultaneously learn spatial (channel-wise) and temporal representations, making the framework robust against both point anomalies and context-dependent deviations in multivariate time-series data.
Multivariate time-series data in industrial systems exhibit dependencies both across features (channels) at each time step and along the temporal axis across sequences. Capturing these dependencies is essential for accurate anomaly detection. Therefore, the encoder is designed to jointly process. To achieve this, we implement a hybrid encoder that consists of two main stages:
This combination of global (attention) and local (convolutional) processing, together with residual connections and normalization, enables robust sequence encoding. It equips the model to detect both point anomalies (e.g., abrupt state changes) and contextual anomalies (e.g., gradual divergence from operational norms) within multivariate industrial data.
3.3. MSE-Based Feedback Recurrent Neural Network
To refine time-series reconstruction, we propose an MSE-based feedback recurrent neural network (MSEFeedbackRNN) that leverages squared reconstruction errors to iteratively improve predictions. This approach enables the model to dynamically adjust future predictions by learning error dependencies over time, as briefly represented in
Figure 3.
RNN stands for Recurrent Neural Network, a type of deep learning model designed to process sequential data by maintaining a hidden state across time steps. In this study, we use RNNs to model the temporal dependencies in multivariate time-series data. Specifically, the RNN layer captures how the operational states of pumps, switches, and volume levels evolve over time. The MSEFeedbackRNN module is configured with an input size of the feature dimension, a hidden size of half the input size (8 for WaterLog), and an output size equal to the input size (16 for WaterLog). The model uses a multi-layer RNN architecture with 8 stacked recurrent layers, allowing it to capture hierarchical temporal dependencies. The recurrent layer is followed by a linear projection layer that maps the hidden-state outputs back to the original input dimensionality. All RNN computations are performed in batch-first mode to align with the input tensor format (batch, sequence, features).
3.3.1. Error Computation and Injection
Given an input sequence
, the reconstructed output
is obtained from the output of the encoder module and the projection layer. The reconstruction error is computed as the following element-wise squared difference:
To propagate error information into future steps, the error sequence is injected into the reconstruction output as follows:
This formulation ensures that regions with higher reconstruction errors have a greater influence on the feedback process, enabling the model to focus on correcting large deviations.
3.3.2. Temporal Error Processing with RNNs
The error-augmented sequence
is processed by a recurrent neural network (RNN) with
H hidden units and
D layers to capture temporal dependencies in the error dynamics as follows:
where
represents the hidden state at time step
t, and
is the recurrent function, such as an RNN. The output of the RNN is then projected back to the original feature space as follows:
where
and
are learnable parameters.
3.3.3. Final Correction and Reconstruction
The final reconstructed sequence is obtained by adding the learned correction
to the original reconstruction output as follows:
This iterative feedback mechanism allows the model to refine predictions over multiple time steps, adapting to recurring error patterns and improving reconstruction quality. To ensure numerical stability, input sequences are first normalized using their mean and standard deviation as follows:
where
and
are the mean and standard deviation computed along the sequence dimension. After reconstruction, denormalization is applied to restore the original scale as follows:
This step ensures that error adjustments remain meaningful in the original data domain.
4. Datasets
We conduct experiments using six publicly available datasets and one newly prepared dataset. The publicly available datasets are the Mars Science Laboratory (MSL) rover dataset [
28], the Soil Moisture Active Passive (SMAP) dataset [
28], the Server Machine Dataset (SMD) [
17], the Secure Water Treatment (SWAT) dataset [
29], the Pooled Server Metrics (PSM) dataset [
30], and a dataset from the pulp-and-paper manufacturing industry [
31]. The MSL dataset, collected by NASA, captures the operational status and environmental conditions of the Mars rover. Similarly, the SMAP dataset, also provided by NASA, includes soil moisture measurements and telemetry data used for monitoring the Mars rover. The SMD dataset comprises metrics such as CPU usage, memory usage, and network traffic collected from server machines in a data center, with the goal of identifying anomalies that may indicate hardware failures or network issues. The SWAT dataset contains sensor data from critical infrastructure systems, while the PSM dataset consists of IT system monitoring data from eBay server machines. Lastly, the pulp-and-paper manufacturing dataset provides insights into industrial processes within the manufacturing sector.
The WaterLog dataset [
32] is designed to facilitate research in both normal and attack scenarios within industrial control systems (ICSs), specifically focusing on the integration of OPC and big data technologies. The dataset includes process data collected from a drinking water management testbed featuring five stations: tank, refilling1, refilling2, purification, and dam. These stations serve as data sources to monitor the drinking water process. Attack scenarios were crafted based on real-world ICS attacks and well-documented tactics and techniques from the literature. Scenarios were adapted to the SAU CENTER Water Management Systems, incorporating examples of ICS attacks drawn from academic studies [
33]. The dataset comprises 16 feature columns and one target column indicating attack status. Data were recorded over six days: four days of normal operation and two days under abnormal conditions induced by executing specified attack scenarios. Throughout the process, it was observed that transitions between normal and attack states were no shorter than 1 s. As a result, data were collected at one-second intervals. Attacks were carried out for various purposes and over different durations. After each attack, the system was allowed to return to normal operation. The dataset captures both normal and abnormal process behaviors, offering a comprehensive resource for analyzing ICS functionality and resilience under attack.
The WaterLog dataset was previously designed to support research on industrial control system security by collecting data under both normal and attack scenarios in the drinking water management testbed [
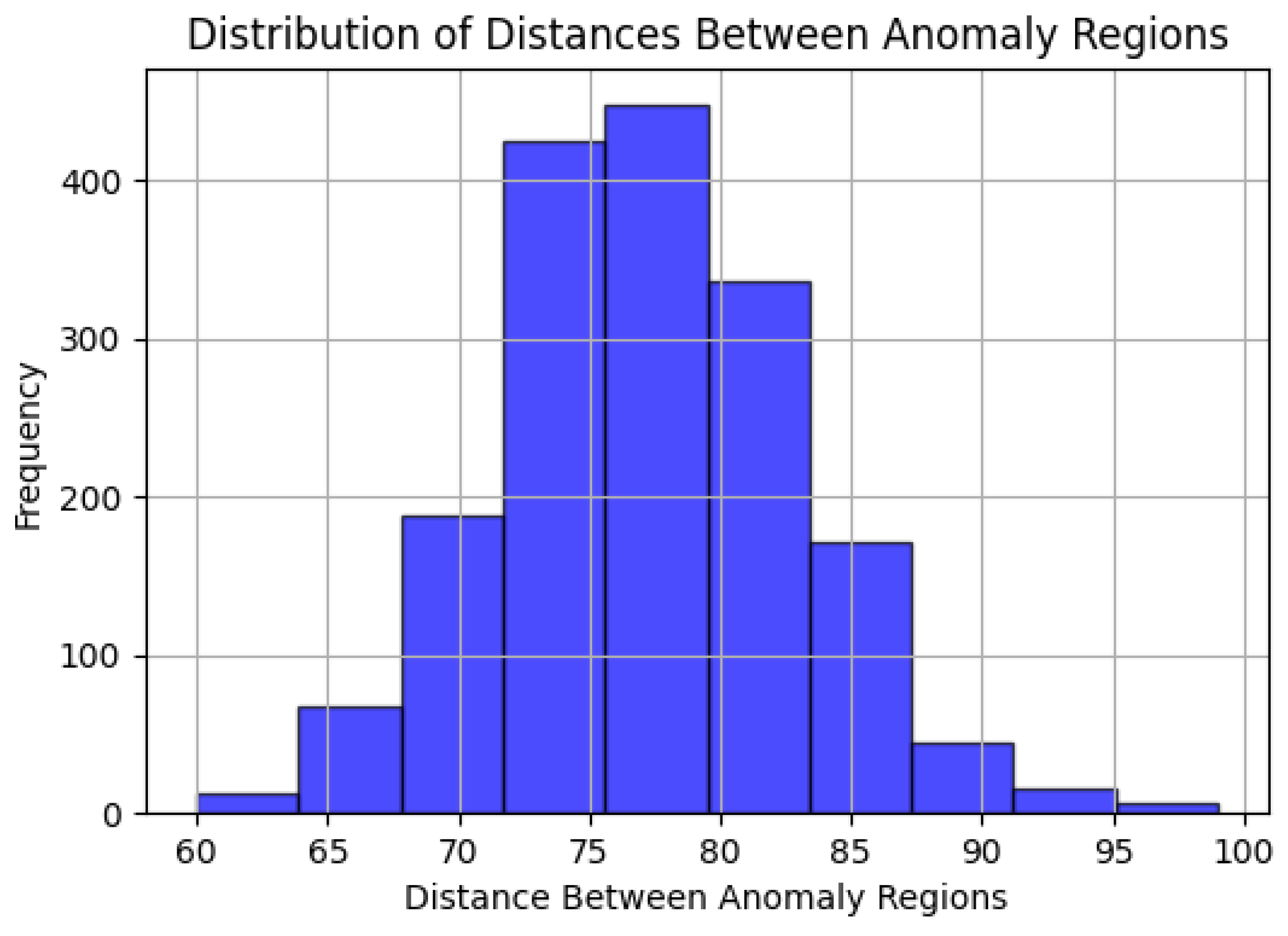
32]. The original WaterLog dataset contained a high frequency of attack instances (∼130,000 Normal, ∼50,000 Attack), which could have led to unrealistic anomaly detections. However, in real-world industrial control systems (ICSs), anomalies are rare, making anomaly detection inherently challenging. To better reflect real operational environments, a diluted version of the dataset, denoted as WaterLog*, was prepared. This version reduces the anomaly rate and provides a more natural distribution by minimizing excessively anomalous regions and ensuring a realistic balance between normal and anomalous instances.
Figure 4 presents a histogram of point distances between anomaly regions, while
Figure 5 visualizes how many anomalies exist in each anomaly region. Our proposed model was tested and evaluated under conditions similar to the real-time anomaly detection challenges in industrial environments while considering the reduced anomaly rate and structured temporal patterns. In the diluted dataset, which was named WaterLog* dataset, the total number of samples is 132,319, consisting of 129,890 normal samples and 2429 attack samples. The dataset is divided into training and testing sets as follows: the training set includes 90,941 samples (1682 attack), while test set contains 39,696 samples (747 attack), ensuring a realistic evaluation scenario with a balanced representation of normal and anomalous instances.
Table 1 shows examples from WaterLog* dataset. A comparative summary table of all datasets mentioned in this section is presented in
Table 2.
5. Experimental Results and Performance Evaluation
To rigorously evaluate the proposed method, we conduct extensive experiments against five recent and widely adopted benchmark models in the field of time-series anomaly detection:
LMSAutoTSF [
20]: A learnable multi-scale architecture based on trend–seasonal decomposition.
iTransformer [
21]: Inverted transformer architecture separating variable and temporal tokens.
TimeMixer [
22]: A decomposable multi-scale mixing architecture.
PatchTST [
23]: A transformer variant optimized for long-term forecasting with patch-based input encoding.
AnomalyTransformer [
5]: A transformer-based model leveraging self-attention and an association discrepancy criterion for anomaly scoring.
All baseline models were retrained on the same datasets using their officially released code and configuration guidelines. The comparison metrics used are the following:
F1-Score: The traditional harmonic mean of precision and recall in pointwise anomaly detection.
() (Point-Adjusted F1): A metric that considers a detection correct if it overlaps with a true anomaly window.
() (Coverage-based F1): A stricter metric that requires a certain level of overlap (coverage) with the ground-truth anomaly duration.
In addition, we apply our sliding window dynamic thresholding technique not only to ChaMTeC but also to the baseline models. This ensures that the performance gains are due to architectural innovation and not simply better thresholding.
5.1. Model Configuration
The model operates on multivariate time series with
F input features and reconstructs input sequences of length 100. A summary of the most relevant hyperparameter settings is shown in
Table 3.
5.2. Evaluation Metrics for Time-Series Anomaly Detection
In the context of time-series data, the direct application of the standard F1-score is challenging due to the inherent dissociation between time points and time events. To address this, anomaly predictions are typically adjusted using heuristic-based methods, commonly referred to as point adjustment (PA), prior to F1-score evaluation (). However, these adjustments are often biased toward true positive detection, leading to an overestimation of detector performance. This limitation underscores the need for a more rigorous evaluation framework that better aligns with the temporal nature of anomalies and provides a fairer assessment of detection capabilities. To ensure a rigorous evaluation of time-series anomaly detection, we use a coverage-based point adjustment technique (), ensuring that predicted anomalies are validated by requiring a minimum overlap ratio with ground-truth anomaly segments. Only predictions with sufficient coverage are deemed correct, ensuring a more rigorous evaluation process.
5.3. Standard F1-Score (F1)
The F1-score is the harmonic mean of
Precision and
Recall, measuring the balance between false positives and false negatives.
where
Here, (True Positive) represents the correctly detected anomalies, (False Positive) denotes normal points incorrectly identified as anomalies, and (False Negative) corresponds to undetected anomalies.
The sequential and temporal nature of anomalies makes it difficult to apply the standard F1-score to time-series anomaly detection, even though it works well for discrete classification problems. Direct comparison between predicted and ground-truth anomalies may lead to unfair penalization or overestimation because anomalies happen over a range of time steps rather than isolated points.
5.4. Point-Adjusted F1-Score (F1PA)
A predicted anomaly is deemed a true positive if it falls within any ground-truth anomaly segment according to the Point-Adjusted F1-Score (F1PA), which introduces a heuristic modification to address the drawbacks of the standard F1-score in time-series settings. The following definitions of true positives, false positives, and false negatives are altered in this method:
(Point-Adjusted True Positive): A predicted anomaly point is counted as a true positive if it overlaps with any ground-truth anomaly segment.
(Point-Adjusted False Positive): A predicted anomaly that does not correspond to any ground-truth anomaly.
(Point-Adjusted False Negative): A ground-truth anomaly with no overlapping predicted anomaly points.
Using these adjusted values, the point-adjusted F1-score is calculated as follows:
where
By taking time-continuous anomalies into account, enhances the standard F1-score; however, it introduces a bias towards true positive detection, which may lead to an overestimation of model performance. This problem occurs because, even in cases where the model is unable to identify the majority of the anomaly duration, a single correctly detected anomaly point within an interval is enough to count the entire interval as correctly detected.
5.5. Coverage-Based Point-Adjusted F1-Score (F1CPA)
We use the
Coverage-Based Point-Adjusted F1-Score (F1CPA) to get around the drawbacks of
. This method refines true positive evaluation by requiring a minimum overlap ratio between predicted and actual anomaly segments. A predicted anomaly is only regarded as a true positive in this method if it satisfies a predetermined coverage threshold.
where
represents the ground-truth anomaly segments.
denotes the predicted anomaly segments.
is the length of the intersection between the predicted and ground-truth anomaly segments.
is the total predicted anomaly duration.
is the total ground-truth anomaly duration.
Using these coverage-based definitions, the final
score is computed as follows:
By penalizing predictions that do not adequately cover the actual anomaly period, this metric guarantees a more realistic evaluation. offers a more stringent evaluation of the model’s capacity to capture anomalies as continuous events, in contrast to F1PA, which has the potential to distort performance by favoring scattered detections.
Our dataset, WaterLog*, is particularly well suited for evaluating anomaly detection methods due to its unique characteristics. Unlike many public benchmarks that contain frequent and densely packed anomalies, WaterLog* features sparse and isolated anomaly regions. This sparsity mirrors real-world scenarios where anomalies are rare and often localized, making it a more challenging and realistic candidate for evaluation. By leveraging this dataset, we can better distinguish between methods that perform well in detecting sparse anomalies and those that rely on frequent anomaly occurrences.
Table 4 demonstrates that
and
give the same results because WaterLog* does not contain large anomaly regions; on the other hand, adjustments in the other datasets have a huge effect on the results, as seen in
Table 5. To evaluate the effectiveness of our proposed anomaly detection approach, we conduct an ablation study on two benchmark datasets: the
MSL dataset and
WaterLog dataset. We compare the performance of five state-of-the-art methods—
LMSAutoTSF [
20],
iTransformer [
21],
TimeMixer [
22],
PatchTST [
23], and
AnomalyTransformer [
5]—under two thresholding approaches:
Fixed Thresholding and
Sliding Window Thresholding (thFactor = 2.0). For a comprehensive evaluation, we utilize three metrics:
,
, and
. Additionally, we evaluate two variants of our proposed architecture with and without an attention (w/o) mechanism to analyze the impact of attention components, as detailed in all tables containing results.
5.6. Thresholding Approaches and Metrics
Fixed Thresholding: This approach uses a static threshold value for detecting anomalies. While it is straightforward to implement, it lacks the adaptability required for datasets where anomaly magnitudes vary over time.
Sliding Window Thresholding: This dynamic approach computes the threshold as a moving average with a deviation factor. It adapts to variations in anomaly magnitude and enhances the detection of extended anomaly regions.
: In addition to the traditional score and pointwise precision-adjusted score (), we adopt (Coverage-based Precision-Adjusted ) for evaluation. This metric accounts for the temporal continuity of anomalies, rewarding models that detect anomalies consistently across their entire duration. Unlike , which measures pointwise accuracy, ensures that anomalies are treated as coherent regions, making it more suited for real-world applications where anomalies often span multiple time steps.
5.7. Performance Comparison
Table 6 and
Table 7 present comprehensive experimental results comparing ChaMTeC with state-of-the-art models across multiple benchmark datasets. The evaluation metrics include the Point-wise Precision (
), Recall (
), and F1-score (
), which are widely used in anomaly detection tasks. Our proposed ChaMTeC model demonstrates superior overall performance, achieving the highest average F1-CPA score of 0.4053 without attention and 0.3121 with attention across all public benchmark datasets. This significantly outperforms recent state-of-the-art approaches, namely, LMSAutoTSF (0.2244), iTransformer (0.3488), TimeMixer (0.3910), PatchTST (0.2444), and AnomalyTransformer (0.2742). The performance advantage is particularly evident in the precision and recall metrics, where ChaMTeC achieves balanced scores of
and
, indicating its robust detection capability without sacrificing accuracy.
On individual datasets, ChaMTeC shows exceptional performance on the SWAT dataset, achieving an F1-CPA score of 0.7270 and 0.2629 without and with attention, respectively. This is comparable to TimeMixer (0.7497), and it substantially outperforms LMSAutoTSF (0.0845), PatchTST (0.1092), and AnomalyTransformer (0.1006). The strong performance on SWAT, a complex industrial control system dataset, demonstrates our model’s effectiveness in real-world scenarios. Similarly, on our newly introduced WaterLog dataset, ChaMTeC achieves an F1-CPA of 0.3861 and 0.4635, consistently outperforming most baseline models (LMSAutoTSF: 0.1915, iTransformer: 0.3284, TimeMixer: 0.3309, PatchTST: 0.2405). Our experimental results demonstrate that while AnomalyTransformer achieves superior performance on the Waterlog dataset when combined with our proposed dynamic thresholding approach (as detailed in
Table 4), our method consistently outperforms all baseline approaches across the majority of the evaluated datasets. This comprehensive evaluation highlights the robustness and generalizability of our proposed framework. On the other hand, the analysis reveals an important nuance: while temporal attention mechanisms significantly improve detection accuracy for the Waterlog dataset, they prove less effective for the other datasets. This dataset-dependent performance variation suggests that our temporal attention mechanisms require more sophisticated anomaly-specific adaptations, particularly in handling diverse anomaly duration scales, varying temporal dependencies across different sensor types, and complex multi-variate interaction patterns.
These comprehensive results validate that our proposed architecture’s key components—inverted embedding, temporal encoding, and the MSE-based feedback mechanism with dynamic thresholding—work synergistically to enhance anomaly detection performance across diverse datasets. The consistent superior performance, particularly on industrial datasets such as SWAT and WaterLog, demonstrates ChaMTeC’s practical utility in real-world applications.
6. Conclusions
In this paper, we presented ChaMTeC, a novel time-series anomaly detection framework that combines inverted embedding, temporal encoding, and MSE-based feedback mechanisms with dynamic thresholding. Our experimental results demonstrate that ChaMTeC outperforms most of the existing state-of-the-art models across multiple benchmark datasets. In addition, when an ablation study was conducted to evaluate the contribution of each component of the ChaMTeC model to the performance, it was observed that the Inverted embedding component strengthened the model’s ability to detect subtle anomalies in time-series data, and when it was removed, there was a significant decrease in the F1-CPA score. Temporal encoding plays a critical role in understanding time-dependent anomalies, and when it was removed, there was a decrease in the recall rate. Finally, the MSE-based feedback loop and dynamic thresholding increase the accuracy by continuously adjusting the model’s detection thresholds; when this component was removed, there was a significant decrease in precision. These results reveal how each component contributes to the overall performance of ChaMTeC and the model’s anomaly detection ability.
The framework’s effectiveness is particularly evident in its robust performance on complex industrial datasets such as SWAT and our newly introduced WaterLog dataset. Our results suggest that the combination of channel-mixing techniques and temporal convolutional networks, along with our dynamic thresholding approach, is particularly effective for detecting subtle anomalies in industrial control systems. Future work could explore the adaptation of our framework to other domains and the integration of additional context-aware features to further improve detection accuracy. However, we observe that the inclusion of attention mechanisms in our architecture introduces dataset-dependent performance variations. This suggests that standard attention mechanisms may not sufficiently capture anomaly-specific temporal patterns in certain contexts. While ChaMTeC demonstrates strong anomaly detection performance, certain types of anomalies remain challenging, particularly long-duration anomalies, abrupt pattern shifts, and cross-sensor dependencies. Long-duration anomalies spanning multiple sliding windows are harder to detect due to the model’s focus on recent temporal patterns, while abrupt shifts in volatile signals can be mistaken for transient fluctuations. Additionally, complex dependencies between multiple sensor readings in datasets such as WaterLog pose difficulties, as standard feature extraction methods may overlook subtle correlations. Interestingly, while attention mechanisms enhance performance on WaterLog by capturing long-range dependencies, they prove less effective for datasets such as SWAT, where anomalies are more localized. This suggests that standard attention mechanisms may not always align with diverse anomaly types. Future improvements could incorporate sparse attention, dynamic feature gating, and hierarchical temporal modeling to enhance adaptability, ensuring robust detection across various real-world industrial settings.
A significant contribution of this work is the introduction of the WaterLog dataset, which we have made publicly available to the research community. Unlike existing datasets, WaterLog was specifically restructured to reflect real-world industrial control system environments, where anomalies are rare events. By reducing the anomaly rate and restructuring the data distribution, we provide a more realistic benchmark for evaluating anomaly detection systems in industrial settings. This addresses a critical gap in existing benchmarks, which often fail to capture the true challenges of real-time anomaly detection in operational environments.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}