Abstract
Despite advances in image captioning, existing models struggle to generate captions that include accurate numerical information, especially the number of objects. One reason for this issue is that the dataset used for training has a limited number of samples with numerical information about the image. To address this issue, we propose a new framework, the Numerically Aware Captioning (NuCap) model, to enhance numerical reasoning in caption generation. We extract dual features by combining a region-attended object encoder for finer-grained object features and a spatially attended grid encoder for encoding spatially distributed global features. We also propose a number-focused cross-entropy loss component to increase sensitivity to numerical tokens, and introduce CountCOCO, a dataset for structured understanding of numerical information. Experiments show that our method achieves statistically significant counting performance improvements over state-of-the-art image captioning models while maintaining similar captioning performance. Despite the significant improvement in numerical reasoning power, our proposed approach has significantly fewer parameters and lower inference latency than large-scale vision language models, demonstrating both computational efficiency and stability. NuCap is an image captioning model that can represent specific numerical information in a given image, making it more suitable for applications that require precise object enumeration, such as automated surveillance, store monitoring, and scientific documentation.
1. Introduction
Image captioning is a core task in vision–language research that involves generating natural language descriptions for a given image. It plays a crucial role in multi-modal learning, as it requires the integration of visual understanding and linguistic expression. A widely adopted framework is the encoder–decoder architecture, in which an image encoder extracts visual features and a language decoder produces the corresponding caption [1]. Initially, convolutional neural networks (CNNs) [2] were commonly used as feature extractors, but the introduction of attention mechanisms [3] led to a shift toward self-attention-based models [4,5,6,7,8]. More recently, large-scale vision–language models (VLMs) have demonstrated strong performance by leveraging extensive pretraining on diverse datasets.
However, despite these advances, current captioning models struggle to accurately represent numerical information, particularly object counts. Captions often omit count information or resort to vague expressions such as “a group of” or “several”, even when the number of objects is visually clear. For example, rather than stating “Five planes flying in the sky”, many models generate the less informative caption “A group of planes flying in the sky”. This limitation becomes more pronounced as the number of objects increases, reducing model effectiveness in applications that require numerical precision. This issue is illustrated in Figure 1, which compares caption outputs from existing models and NuCap on images with countable objects.

Figure 1.
Comparison of captions generated by different models on images containing countable objects. Vague quantifiers such as “a group of” or “several” are marked in red, while correct numerical expressions are highlighted in yellow. NuCap produces captions with precise numerical values, demonstrating improved numerical reasoning in comparison to existing models.
This issue stems primarily from the limitations of existing training datasets, which lack emphasis on numerical reasoning. Models trained on datasets such as COCO [9] or Visual Genome [10] learn to describe scenes generally but fail to incorporate explicit count information. As a result, they rely on ambiguous quantifiers or plural nouns, which may suffice in casual contexts but fall short in domains such as scientific analysis, data annotation, and surveillance systems. Although VLMs show relatively improved numerical awareness due to large-scale pretraining, their computational demands hinder deployment in real-time or resource-constrained environments.
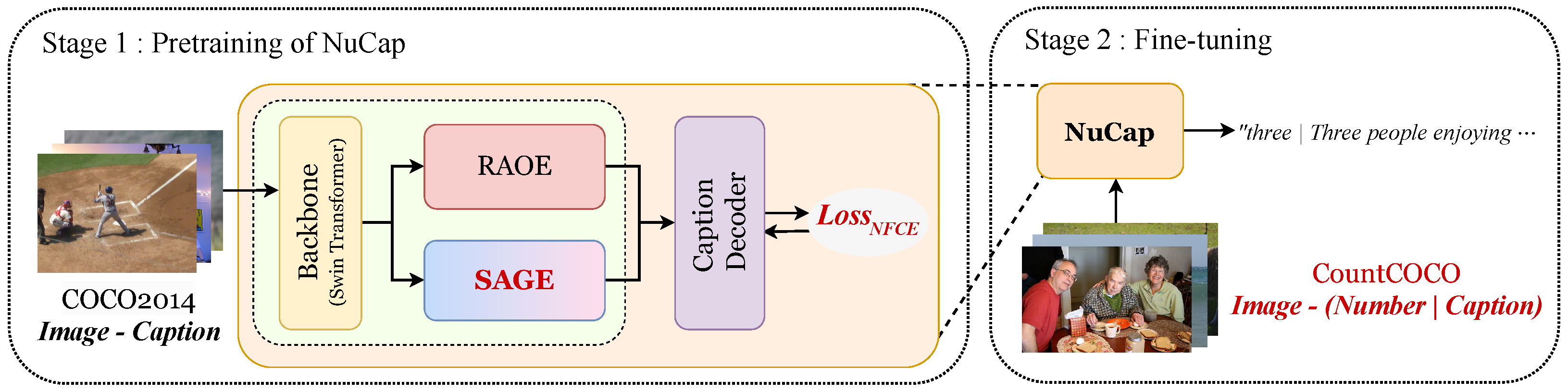
To address these limitations, we propose NuCap—a numerically aware captioning framework that enhances object counting in caption generation. NuCap integrates both local and global visual representations through two key modules: a Region-Attended Object Encoder (RAOE) and a Spatially Attended Grid Encoder (SAGE). We further introduce a Number-Focused Cross-Entropy (NFCE) loss, which emphasizes numeric tokens during training to strengthen numerical reasoning. To support fine-tuning, we construct CountCOCO, a numerically enriched version of the COCO dataset that provides structured captions containing explicit count values. This setup allows the model to learn both semantic fluency and numerical grounding. The overall training process of NuCap, including both pretraining and fine-tuning, is summarized in Figure 2.
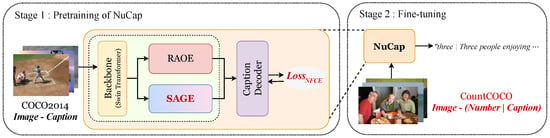
Figure 2.
Overview of the training process of NuCap. The model is first pretrained on the COCO2014 dataset using NFCE loss, and subsequently fine-tuned on CountCOCO with structured captions to enhance its numerical reasoning capabilities.
Our key contributions are summarized as follows:
- We propose NuCap, a unified captioning framework for enhancing numerical reasoning. NuCap integrates SAGE, the NFCE loss function, and a count-enriched dataset (CountCOCO) to improve the model’s ability to represent and reason about quantities in image captions.
- We design a Structured Caption Format that explicitly encourages early number generation. By placing numeric tokens at the beginning of captions, this format aligns with the autoregressive nature of decoding, guiding the model to prioritize quantity information during generation.
- We achieve superior numerical accuracy with a compact architecture. Despite having only 180 M parameters, NuCap delivers approximately 3× higher counting accuracy than previous models, including large-scale VLMs such as BLIP and mPLUG-Owl3, while maintaining faster inference and strong captioning fluency.
This framework demonstrates that numerical reasoning can be effectively incorporated into image captioning without sacrificing fluency or computational efficiency. NuCap offers a practical solution for real-world applications that demand numerically grounded descriptions, such as automated surveillance, scientific reporting, and assistive AI systems.
2. Related Work
Image Captioning. Image captioning is a vision–language task that generates natural language descriptions for a given image. It typically follows an encoder–decoder framework, where the visual encoder extracts semantic features from the image, and the decoder generates a sentence based on these features [1]. Early models relied primarily on CNN-based encoders. However, with the introduction of Transformer architectures, it became possible to effectively model long-range dependencies across visual and linguistic modalities, resulting in significant improvements in caption quality. Since then, various extensions to Transformer-based architectures have been proposed. For instance, ExpansionNet v2 [11] alleviates the fixed-sequence-length constraint by dynamically adjusting decoding length, enabling more flexible and accurate caption generation. Recent efforts have aimed to improve the expressiveness and factuality of captions. These include approaches such as external knowledge integration, retrieval-based captioning, and diffusion-based generation. For example, MeaCap [12] leverages external memory to extract image-relevant concepts and incorporate them into the generation process, thereby reducing hallucinations and producing factually grounded descriptions. Retrieval-Augmented Captioning [13] retrieves semantically similar images to complement a single-image input, improving consistency in expressions involving quantities and relationships. Prefix-diffusion [14] injects prefix tokens into the denoising process of diffusion models, allowing efficient and diverse caption generation with fewer parameters. Despite these advancements, most existing models still struggle to generate accurate numerical expressions, such as object counts, distances, or temporal attributes. This limitation largely stems from the characteristics of widely used datasets such as COCO [9] and Visual Genome [10], which prioritize general scene descriptions rather than numerical precision. The gap becomes especially apparent in applications that explicitly require quantitative information.
Object Counting. Object counting is a core task in computer vision, typically approached through detection-based or density map-based methods [15]. In recent years, various approaches have been proposed to improve generalization and enable open-vocabulary counting. CLIP-Count [16] leverages image–text alignment in CLIP to build a text-guided zero-shot counting framework. It employs patch-text contrastive learning and hierarchical interactions to generate high-quality density maps for open-vocabulary object categories. CountGD [17] introduces a multi-modal counting framework that flexibly uses prompts in the form of text, visual exemplars, or both. PseCo [18] integrates the Segment Anything Model (SAM) with CLIP to enable effective few-shot and zero-shot counting, demonstrating strong performance particularly in dense scenes and with small objects. Additionally, diffusion-based data augmentation [19] generates synthetic data from location-conditioned dot maps using a diffusion model, mitigating data scarcity and improving numerical prediction accuracy in crowd counting tasks. Despite their strong numerical estimation capabilities, these models differ fundamentally from captioning systems in both objective and output. Counting models aim for precise quantitative prediction, whereas captioning models prioritize linguistic fluency, often at the expense of numeric accuracy. This gap is particularly evident in applications where accurate quantity descriptions are essential, highlighting the need for captioning approaches that can reliably incorporate numerical information.
Numerical Reasoning in Vision–Language Tasks. Numerical reasoning in vision–language tasks remains a significant challenge despite the progress of large-scale VLMs. Models such as BLIP [20], mPLUG-Owl3 [21], and Idefics2 [22] have demonstrated strong language understanding and effective multi-modal alignment. However, most existing vision–language datasets lack explicit numerical annotations, which restricts the ability of these models to reason accurately about quantities. To diagnose this limitation, the GECKO-NUM benchmark [23] was introduced to evaluate how well text-to-image models reflect numerical information. The study found that while models perform reasonably well for small object counts, their accuracy deteriorates significantly as the number of objects increases. To address this issue, various approaches have been proposed. CountCLIP [24], for example, improves counting performance in CLIP-based models through contrastive learning using numerically annotated data. LVLM-COUNT [25] adopts a divide-and-conquer strategy that partitions the input image into multiple subregions and aggregates the results, achieving strong zero-shot performance across diverse datasets without fine-tuning. While these efforts have contributed to improving numerical perception in VLMs, the problem of generating natural language captions that include accurate quantity descriptions has received relatively little attention. Captioning tasks that require both numerical reasoning and linguistic fluency remain an open challenge in the current vision–language landscape.
3. Methodology
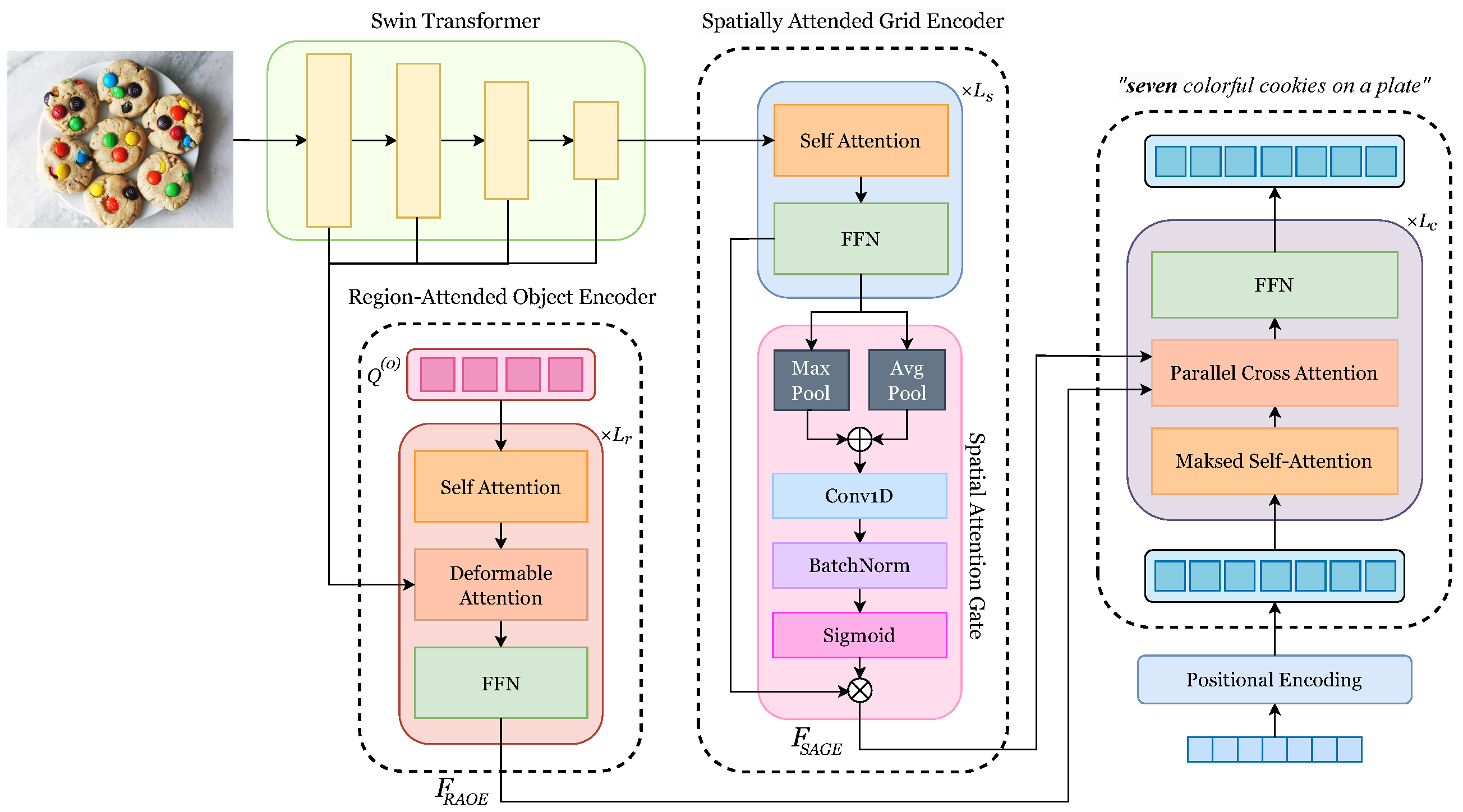
In this section, we propose NuCap, a numerically aware captioning framework that explicitly incorporates numerical reasoning while preserving natural language fluency. Our model builds upon the GRIT architecture [26], extending it with a structured numerical learning pipeline. NuCap consists of an image encoder and a caption decoder (Figure 3).
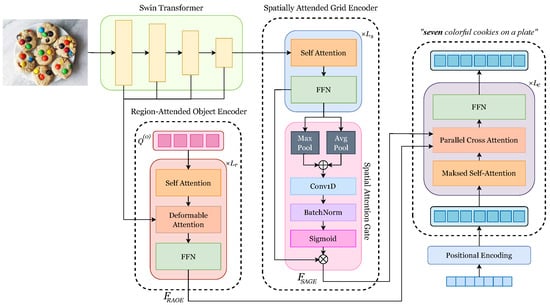
Figure 3.
Overview of NuCap architecture.
3.1. Image Encoder
The image encoder is designed to extract a rich representation that combines fine-grained object details and global scene-level context. It consists of a Swin Transformer [27] backbone and two feature extraction modules: RAOE, which extracts object-centric features, and SAGE, which refines globally distributed spatial features.
3.1.1. Backbone Network
The input image is first fed into a Swin Transformer backbone, which extracts multi-scale hierarchical features. It is partitioned into non-overlapping patches, which are projected into an embedding space via a convolutional layer:
where and are the learnable weight and bias parameters of a convolutional layer with a kernel size. P represents the patch size and D is the embedding dimension.
The backbone architecture employs two key attention mechanisms: Window-based Multi-Head Self-Attention (W-MSA), which models local dependencies within each window, and Shifted Window Multi-Head Self-Attention (SW-MSA), which enables interactions across neighboring windows by shifting the window partitioning. The output at each layer is computed as follows:
Here, X denotes the input embedding at each stage. After each attention operation, the intermediate features are passed through a multilayer perceptron (MLP), which improves feature expressiveness while preserving spatial structure. Layer normalization (LN) is applied before each module to stabilize training and improve convergence. The final refined representation at each stage is denoted by Y.
Through this hierarchical process, the Swin Transformer backbone generates a set of multi-scale feature maps , where each corresponds to a different resolution level. These feature maps are passed to the RAOE and SAGE modules, which independently extract object-centric and globally distributed visual features, respectively.
3.1.2. Region-Attended Object Encoder
NuCap adopts RAOE to extract object-centric features based on a Transformer-based object detection architecture. Following the GRIT framework [26], RAOE leverages Deformable DETR [28], which enhances multi-scale feature learning while maintaining low computational overhead.
The input to RAOE consists of the multi-scale feature maps where each represents a different spatial resolution, ranging from fine to coarse. To unify their dimensions, each feature map is processed through a shared 1 × 1 convolution followed by group normalization (GN):
A set of learnable object queries is initialized as where is the number of object queries. Each query serves as an object-centric representation and is refined through iterative attention-based interactions with the multi-scale features . These object queries first undergo self-attention to model inter-query relationships:
This is followed by deformable cross-attention, in which the object queries attend to multi-scale visual features at sampled reference points:
Here, denotes the reference points propagated from the previous layer. The initial reference points are computed from the object queries via a linear projection followed by a sigmoid activation:
These reference points guide the attention mechanism across multiple feature levels, enabling the model to dynamically focus on spatially relevant regions. The attended features are then passed through a feedforward network (FFN) to update the object query representations:
The decoder iterates over layers, progressively refining the object-centric features. The final output, denoted as , obtained from the last decoder layer, encodes both spatial and semantic information and serves as a key visual input for the caption decoder.
3.1.3. Spatially Attended Grid Encoder
While RAOE focuses on object-centric regions, SAGE captures globally distributed spatial features. This module enhances grid-wise representations and employs a spatial attention mechanism to emphasize salient regions.
SAGE takes as input the highest-resolution feature map from the backbone network. This feature map is linearly projected into an embedding space to ensure dimensional consistency, resulting in G. The projected features are then refined through stacked layers, each comprising Multi-Head Self-Attention (MHSA) followed by an FFN:
where , ensuring that the initial grid features are enhanced iteratively before applying spatial attention.
To improve spatial awareness, we apply a spatial attention gate (SAG) [29], which selectively highlights informative regions within the grid representation. The attention map is computed by concatenating average-pooled and max-pooled features along the channel axis, passing them through a 1D convolution followed by batch normalization and a sigmoid activation:
The final grid feature is computed by applying the attention map element-wise to the refined features:
By dynamically emphasizing spatially relevant regions, SAGE enables the model to capture both global context and fine-grained spatial details. Combined with RAOE, it contributes to a more comprehensive visual understanding, ultimately supporting the generation of numerically grounded and contextually coherent captions.
3.2. Caption Decoder
The caption decoder generates a caption from extracted from RAOE and extracted from SAGE. To effectively integrate the two complementary visual features, the decoder uses a parallel attention mechanism to generate the output caption. Each input word is first embedded into a continuous vector space and combined with sinusoidal positional encodings, yielding the initial embedding .
Each transformer decoder layer consists of three sub-modules: masked self-attention, parallel cross-attention, and FFN. At the l-th layer, masked self-attention captures intra-sequence dependencies among the previously generated tokens:
The output then serves as a query to two separate multi-head attention modules, attending independently to the features from SAGE and RAOE:
At each stage, adaptive attention weighting is introduced to dynamically adjust the contributions of the two visual features. Instead of directly fusing the attended features, the decoder learns separate importance scores for each feature type:
where and are learnable weight matrices and denotes the sigmoid activation. The final fused representation is computed by applying adaptive attention weights to the two features, followed by normalization and an FFN:
This process is repeated for layers. Finally, the output from the last layer is projected into the vocabulary space and normalized with a log-softmax to generate the probability distribution over the next word:
where W is a learnable projection matrix, and is the probability of generating token at time t.
Training Objective. To optimize the model for numerically aware image captioning, we adopt a two-stage training strategy. In the first stage, the model is trained on the COCO dataset using a combination of Number-Focused Cross-Entropy (NFCE) loss and CIDEr-D optimization. NFCE loss encourages the model to pay greater attention to numerical tokens, while CIDEr-D optimization improves the overall fluency of the generated captions. Unlike standard cross-entropy used in conventional captioning models, our NFCE loss dynamically assigns higher weights to numerical tokens during training. The model predicts the next token in the sequence while minimizing the negative log-likelihood, defined as follows:
Here, is set to 1 for non-numerical tokens, and to a hyperparameter () for numerical tokens. is the ground-truth token at timestep t, and is the predicted probability of the token given the previous tokens and the image representation I. This formulation enhances numeric sensitivity while maintaining training stability through normalization.
To further improve fluency, we apply CIDEr-D optimization using Self-Critical Sequence Training (SCST) [30]. Instead of token-level supervision, this approach evaluates the entire generated caption against reference captions and assigns a reward based on the CIDEr-D score. The objective function is defined as follows:
Here, is the i-th sampled caption, is the CIDEr-D reward assigned to the generated caption, and b is the baseline reward used for stabilizing training.
In the second stage, the model was further fine-tuned using the CountCOCO dataset, which contains structured captions with explicit object counts designed to improve the model’s numerical reasoning. Further details about CountCOCO and structured captioning are discussed in Section 3.3.
3.3. CountCOCO: Fine-Tuning for Numerically Aware Captioning
To enable the model to generate captions that explicitly reflect object counts, we introduce CountCOCO, a numerically grounded captioning dataset designed to reinforce numerical reasoning during fine-tuning. This additional stage teaches the model to generate fluent descriptions while incorporating accurate count information.
CountCOCO was constructed using the COCO 2014 [9] training set. For each image, captions were generated using Qwen2-VL [31], a large-scale VLM. The numbers were set between 2 and 10 to balance the diversity of the numbers while avoiding extreme values. The exact prompts used in this process are as follows: “Find objects in the given image with a count between two and ten. Create a caption with one of those numbers that must include that number”.
The initial caption generated by the VLM was post-processed and filtered using the following procedure:
- 1.
- Extracted only the caption sentence for the image, removing all unnecessary text such as quotes or formatting artifacts (such as the phrase “Caption:”).
- 2.
- Only captions that explicitly contain numeric values were retained, and captions that did not contain numeric information were discarded.
- 3.
- Because the dataset focused on numbers between 2 and 10, captions containing numbers outside of this range were removed.
To assess the reliability of the generated numeric annotations, we conducted a sanity check on a randomly sampled subset of 500 image–caption pairs. Each pair was manually inspected to verify whether the number mentioned in the caption corresponded to the actual number of objects in the image. Although some noise was observed, most samples were consistent with the visual content, and severely inaccurate cases were rare. We consider this level of imperfection acceptable within the weak supervision paradigm widely adopted in vision–language tasks.
Additionally, we analyzed the overall distribution of numeric values and found an overrepresentation of the number “2”. To mitigate potential bias, we removed a portion of those samples to maintain a balanced distribution. These verification and filtering steps support the use of CountCOCO as a reliable dataset for fine-tuning numerically aware captioning models.
Structured caption format. To further reinforce numeric grounding, we reorganize each caption into a structured format: Number|Caption. This format leverages the autoregressive nature of language models, encouraging the decoder to generate the count token first. By providing a clear and standardized input, this approach prevents the model from defaulting to vague quantifiers like “many” or “several” and encourages the model to generate captions that include counts. Fine-tuning on CountCOCO enables the model to align semantic descriptions with grounded count information, improving its numerical fluency without sacrificing language quality.
4. Experiments
Unlike conventional image captioning tasks, our approach introduces a fine-tuning strategy that explicitly targets numerical representation, aiming to enhance number comprehension while maintaining caption fluency. In this section, we evaluate the effectiveness of NuCap by assessing both its captioning performance and its ability to accurately represent object counts in images. We compare NuCap to state-of-the-art image captioning models, including BLIP [20], ExpansionNet v2 [11], GRIT [26], and VLMs such as mPLUG-Owl3 [21].
4.1. Datasets
We evaluated our model on two datasets: COCO 2014, to assess general captioning performance, and CountBench, to evaluate numerical reasoning in generated captions.
The Microsoft COCO 2014 dataset [9] serves as the primary training and evaluation dataset. Following the Karpathy split [32], we use 113,287 images for training, 5000 for validation, and 5000 for testing. Each image is annotated with five captions, offering diverse textual descriptions.
To evaluate the model’s ability to generate numerically informative captions, we use CountBench [24], a benchmark specifically designed for object counting in captioning tasks. CountBench consists of 540 images, each featuring between two and ten instances of specific objects, accompanied by descriptive captions. We used a filtered subset of 509 images, excluding samples with broken URLs.
4.2. Implementation Details
We trained our model using the Adam optimizer with a learning rate of 0.001 and a weight decay of 0.01. The batch size is set to 8, and the model uses a hidden dimension of 512. We used eight attention heads in multi-head attention layers and applied a dropout rate of 0.2. NFCE loss applies a numerical token weight of 1.6. All input images are resized to a resolution of . The model was trained for 10 epochs with NFCE loss, followed by 10 epochs with CIDEr-D optimization. During fine-tuning on CountCOCO, we trained for eight epochs using the same hyperparameter settings and hardware environment. All experiments were conducted on four NVIDIA A5000 GPUs (NVIDIA Corporation, Santa Clara, CA, USA).
4.3. Ablation Study
Model Components. To assess the individual contribution of each proposed component, we conducted an ablation study by selectively removing SAGE, NFCE loss, and the structured caption format (Number|Caption) from the model. A detailed description of the evaluation metrics is provided in Section 4.5.1, and results are summarized in Table 1.

Table 1.
Ablation study on the impact of SAGE, NFCE loss, and structured caption format Number|Caption. Each row corresponds to a different model variant, where ✓ indicates the inclusion of a component and denotes its removal.
Introducing NFCE loss alone yields a counting accuracy of 26.92%, demonstrating that emphasizing numerical tokens during training improves numerical focus. Applying only SAGE results in a slightly higher accuracy of 28.29%, validating the importance of spatially distributed visual features. Notably, using the structured caption format alone achieves the highest individual performance at 29.67%, suggesting that positioning the numeric token at the beginning of the caption imposes a strong inductive bias that encourages the model to prioritize count information during generation.
This finding aligns with the autoregressive nature of the decoder: by generating the numeric token first, the model is naturally prompted to attend to quantity-relevant features before composing the rest of the caption. Combining the Structured Format with NFCE loss yields an accuracy of 28.29%, and with SAGE, 29.08%, both outperforming NFCE loss and SAGE in isolation. These results indicate that the Structured Format enhances the effectiveness of other components by reinforcing the model’s early focus on numerical reasoning.
The highest performance of 34.18% is achieved when all three components—SAGE, NFCE loss, and Structured Format—are integrated. This highlights the synergistic effect among the modules when used in combination. While SAGE improves spatial awareness and NFCE loss sharpens token-level sensitivity to numbers, the Structured Format directly influences the decoding pathway by steering the model to prioritize count information from the outset. Together, these elements significantly improve count-aware caption generation through the combination of structured input design and visually grounded learning.
Numeric Token Weight. We also conducted an ablation study to examine the effect of the numeric token weight used in NFCE loss. As shown in Table 2, increasing leads to higher counting accuracy but slightly lowers the captioning quality (e.g., CIDEr). We found that offers the best trade-off between numerical precision and overall fluency, and therefore adopted it as our default setting in all experiments.
Table 2.
Impact of numeric token weight () on captioning quality and counting accuracy.
4.4. Captioning Performance
4.4.1. Metrics
We evaluate captioning performance using standard metrics: BLEU [33], METEOR [34], ROUGE [35], and CIDEr [36]. BLEU measures n-gram precision using a geometric mean, capturing lexical overlap between generated and reference captions. METEOR accounts for semantic similarity by incorporating stemming and synonym matching. ROUGE calculates the degree of overlap by comparing overlapping n-grams with the reference sentence. CIDEr, specifically designed for image captioning, evaluates similarity based on the term frequency–inverse document frequency.
4.4.2. Results
Table 3 presents the captioning results across different models. Despite the integration of numerically focused modules—SAGE and NFCE loss—NuCap maintains high scores across all evaluation metrics. Notably, NuCap achieves a CIDEr score of 143.5, which is highly competitive with GRIT and ExpansionNet v2. It also demonstrates strong performance in lexical metrics such as BLEU-1 and in semantic metrics including METEOR and ROUGE, confirming that its structured learning strategy effectively supports both numerical and linguistic expressiveness.
Table 3.
Captioning performance of different models.
These findings demonstrate that incorporating numerical reasoning mechanisms does not compromise linguistic quality. NuCap not only supports numerically grounded captioning, but also retains competitive expressiveness and fluency, validating its applicability in real-world vision–language tasks.
4.5. Counting Performance
4.5.1. Metrics
To evaluate the model’s ability to generate numerically accurate captions, we employ accuracy and F1 score as the primary evaluation metrics. Given our focus on explicit numerical reasoning, we refine standard metrics to more appropriately reflect counting performance.
We define counting accuracy to reflect both successful number predictions and failure cases where no number is generated. Specifically, we assign a score of to captions lacking any numeric content, unlike conventional metrics that ignore such failures. This adjustment yields a more faithful evaluation of the model’s capacity for numeric understanding.
To assess the precision–recall trade-off, we use an adjusted F1 score. The traditional F1 computation evaluates only correctly predicted numbers and excludes captions without numbers, leading to overly optimistic results. To address this, we treat failure cases as false negatives during recall computation. This adjusted F1 score penalizes models that frequently omit numeric outputs, ensuring a more rigorous and fair assessment of numerical reasoning ability.
All evaluations are performed on CountBench [24], a benchmark designed to test object-count grounding in VLMs. For quantitative evaluation of the counting performance, we also include confusion matrix analysis.
4.5.2. Comparative Performance Analysis
As shown in Table 4, NuCap achieves the highest counting accuracy of 34.18%, outperforming all baseline models. This represents a roughly 3× improvement over competitive captioning models such as GRIT and ExpansionNet v2, and a significant margin over large-scale VLMs, including mPLUG-Owl3 (2B: 11.39%, 7B: 13.36%). Among VLMs, BLIP (large) achieves the next-best accuracy at 28.29%, but still lags behind NuCap. Notably, NuCap also attains the highest F1 score (0.342), confirming its ability to both generate numeric tokens more frequently and reduce severe miscounts.
Table 4.
Counting performance across different models.
These results highlight NuCap’s core advantage: it bridges the gap between caption fluency and accurate numerical grounding. By combining visually grounded features with count-aware supervision, NuCap addresses a key limitation in existing models. This positions NuCap as a reliable framework for real-world applications requiring numerically informative vision–language generation.
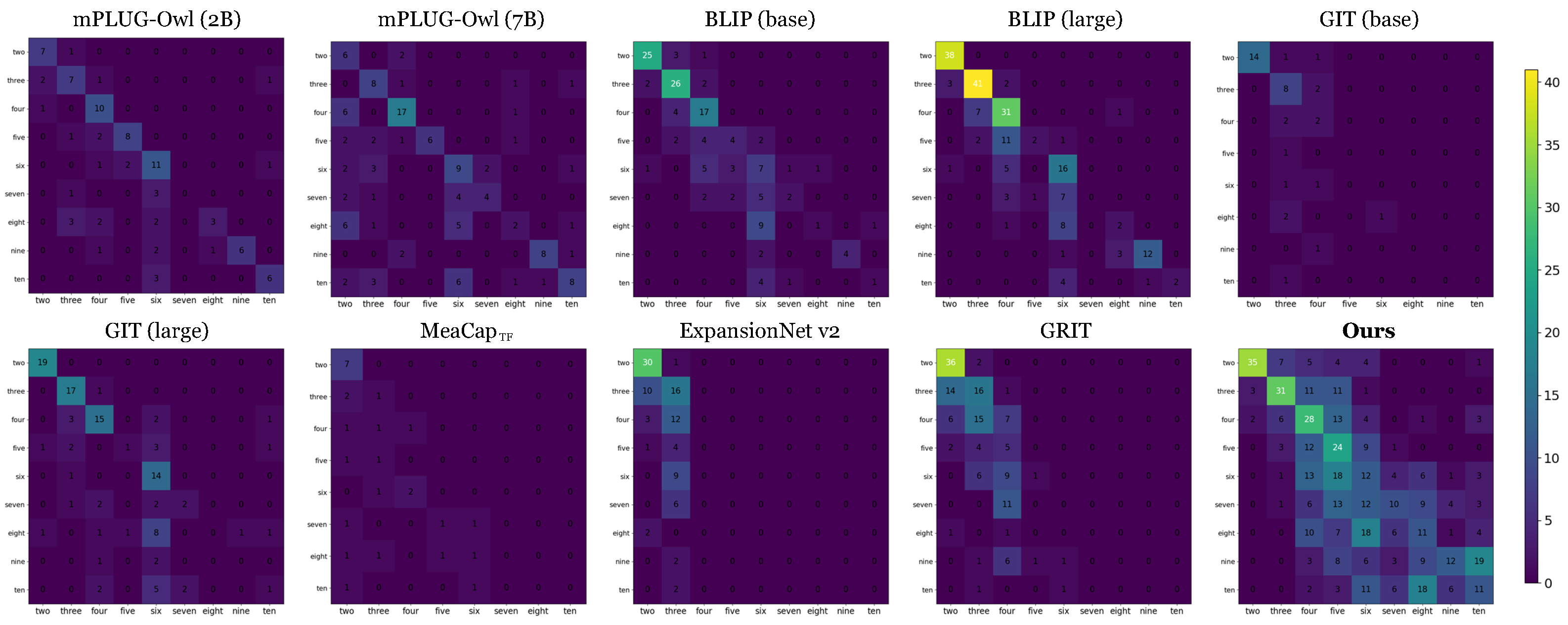
4.5.3. Confusion Matrix Analysis
Figure 4 provides a comparative view of counting predictions via confusion matrix visualization. Traditional captioning models such as BLIP, GIT, and ExpansionNet v2 exhibit a clear tendency to omit numeric tokens as object counts increase. This behavior suggests a limited ability to generalize beyond low-count scenarios, often defaulting to generic descriptions that lack explicit numerical information.
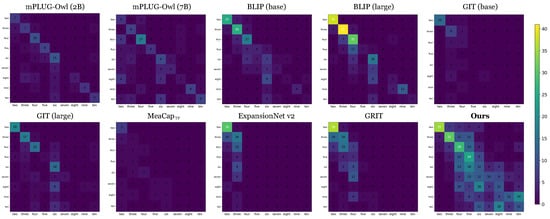
Figure 4.
Confusion matrix of different models evaluating quantitative counting performance. The horizontal axis denotes the predicted object count, and the vertical axis shows the ground-truth count. Diagonal concentration indicates higher accuracy.
VLMs like mPLUG-Owl3 and BLIP (large) demonstrate relatively better numerical reasoning; however, their predictions remain concentrated around smaller numbers, and they frequently fail to generate captions with counts greater than five. This indicates a persistent limitation in modeling structured numerical relationships.
In contrast, NuCap demonstrates improved numerical consistency across a wider count range. The confusion matrix reveals that NuCap’s predictions are more closely aligned with ground-truth counts, particularly in the mid-range (4–8), where existing models struggle the most. Furthermore, NuCap minimizes large-count errors, with predictions densely concentrated along the diagonal. These findings highlight NuCap’s effectiveness in mitigating number generation failures and in incorporating numerical information into captions.
4.6. Cost Efficiency
A key consideration in real-world captioning systems is balancing model complexity, inference latency, and performance. As summarized in Table 5, NuCap adopts a compact architecture with 180 million parameters—significantly smaller than large-scale VLMs such as mPLUG-Owl3 and BLIP, while remaining comparable in size to typical image captioning models.
Table 5.
Comparison of model size and inference time across different image captioning and VLMs. Inference time is measured on the CountBench dataset.
Despite its smaller size, NuCap delivers the highest counting accuracy and competitive captioning performance, while also achieving the fastest inference time among comparable models. In contrast, large-scale VLMs demand substantial computational resources and incur high inference latency, whereas lightweight models such as ExpansionNet v2 lack the capacity for robust numerical reasoning.
NuCap effectively balances computational efficiency and numerical precision. Its ability to outperform larger models in count-aware tasks demonstrates that numerical reasoning can be integrated into captioning systems without incurring excessive computational cost.
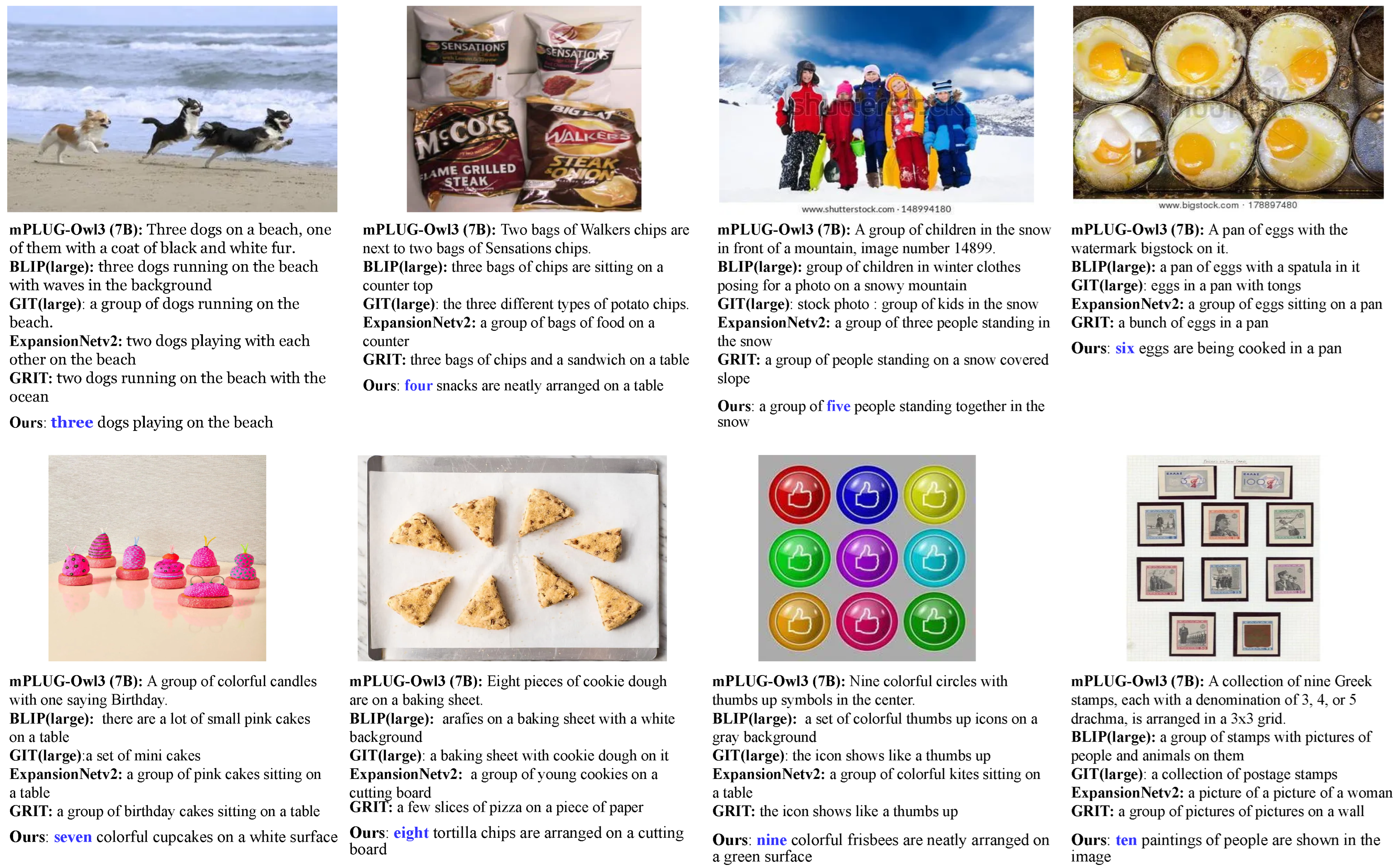
4.7. Qualitative Evaluation
To further assess NuCap’s ability to generate count-aware captions, we conduct a qualitative analysis using a subset of images from the CountBench dataset, each containing 3 to 10 instances of a specific object. Figure 5 shows the results of captions generated by different captioning models, including NuCap and traditional baseline tools.
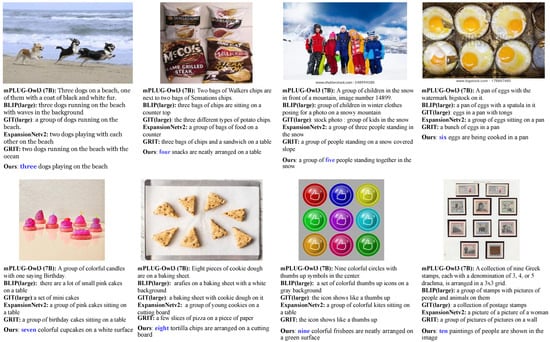
Figure 5.
Sample images from the CountBench dataset, each containing 3 to 10 objects.
The examples reveal clear differences in numerical reasoning ability. Conventional captioning models such as GRIT and GIT frequently omit explicit count information or rely on vague quantifiers such as “a group of” or “a set of”, particularly in images with higher object counts (6–10). While VLMs like mPLUG-Owl3 exhibit relatively better numeric awareness, they still struggle to consistently generate accurate object counts.
In contrast, NuCap consistently produces captions that explicitly and correctly reflect the number of objects in the scene. Its performance is especially strong in mid-range object counts (4–8), where baseline models tend to falter. These qualitative findings align with the quantitative results reported in Table 4 and Figure 4, reinforcing NuCap’s ability to integrate numeric reasoning into fluent caption generation. These findings suggest that NuCap can serve as a practical solution in vision–language tasks requiring precise numerical grounding.
5. Conclusions
This paper presents NuCap, a numerically aware image captioning framework that enhances numerical reasoning while preserving caption fluency. NuCap integrates two complementary modules—RAOE for object-centric features and SAGE for globally distributed spatial context—to provide a dual-perspective visual representation. We further introduce the Number-Focused Cross-Entropy (NFCE) loss and construct CountCOCO, a dataset consisting of captions with explicit object counts. It incorporates a structured format that places numeric tokens at the beginning, guiding the decoder to attend to count information and enhancing numerical accuracy.
Extensive experiments show that NuCap significantly outperforms existing captioning models in numerical reasoning tasks while maintaining competitive performance on standard captioning benchmarks. Confusion matrix analysis further confirms its numerical robustness across a wide range of object counts, particularly in mid-range values where traditional models tend to struggle. Moreover, NuCap achieves this with a comparatively compact model and low inference latency, making it suitable for deployment in resource-constrained or real-time environments.
Directions for Future Work
A key challenge moving forward is to incorporate numerical representations into captions for broader and more complex scenarios. To address this, we identify two key directions. First, we plan to extend NuCap to handle larger object counts beyond the current range of 2–10, which are common in real-world applications such as crowd monitoring and dense scene understanding. While NuCap does not impose an explicit upper bound on count values, scaling to higher numbers will benefit from dataset augmentation and architectural refinements—such as density-aware encoders or range-adaptive counting modules.
Second, we aim to explore more flexible caption formats that support multiple numeric references in a single sentence (e.g., “3 people and 2 dogs”). This will involve training the model to associate each numeric token with the correct object type. Approaches such as placeholder tokens, count-object templates, or position-aware decoding strategies may help guide this alignment. These extensions would further enhance NuCap’s ability to generate structured, context-rich captions in complex visual scenarios.
These future directions aim to broaden NuCap’s applicability to more complex scenarios. They also extend its core philosophy of accurate and structured numerical grounding, paving the way for more advanced and contextually aware vision–language models.
Author Contributions
Conceptualization, Y.J.; methodology, Y.J. and Y.-S.C.; software, Y.J.; validation, Y.J. and Y.-S.C.; formal analysis, Y.J. and Y.-S.C.; investigation, Y.J.; resources, Y.J. and Y.-S.C.; data curation, Y.J.; writing—original draft preparation, Y.J. and Y.-S.C.; writing—review and editing, Y.J. and Y.-S.C.; visualization, Y.J.; supervision, Y.-S.C.; project administration, Y.-S.C.; funding acquisition, Y.-S.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Research Foundation of Korea (NRF) grant (No. RS-2025-00520618) and the Institute of Information and communications Technology Planning and evaluation (IITP) grant (No. RS-2020-II201373), funded by the Korean Government (MSIT: Ministry of Science and Information and Communication Technology).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The COCO 2014 dataset can be downloaded from https://cocodataset.org/ (accessed on 2 May 2024). The CountBench dataset can be downloaded from https://github.com/teaching-clip-to-count/teaching-clip-to-count.github.io (accessed on 10 September 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Stefanini, M.; Cornia, M.; Baraldi, L.; Cascianelli, S.; Fiameni, G.; Cucchiara, R. From show to tell: A survey on deep learning-based image captioning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 539–559. [Google Scholar] [CrossRef] [PubMed]
- O’shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Yang, X.; Liu, Y.; Wang, X. Reformer: The relational transformer for image captioning. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 5398–5406. [Google Scholar]
- Cornia, M.; Stefanini, M.; Baraldi, L.; Cucchiara, R. Meshed-memory transformer for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10578–10587. [Google Scholar]
- Yu, J.; Li, J.; Yu, Z.; Huang, Q. Multimodal transformer with multi-view visual representation for image captioning. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 4467–4480. [Google Scholar] [CrossRef]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6077–6086. [Google Scholar]
- Huang, L.; Wang, W.; Chen, J.; Wei, X.Y. Attention on attention for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4634–4643. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef]
- Hu, J.C.; Cavicchioli, R.; Capotondi, A. Exploiting multiple sequence lengths in fast end to end training for image captioning. In Proceedings of the 2023 IEEE International Conference on Big Data (BigData), Sorrento, Italy, 15–18 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 2173–2182. [Google Scholar]
- Zeng, Z.; Xie, Y.; Zhang, H.; Chen, C.; Chen, B.; Wang, Z. Meacap: Memory-augmented zero-shot image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 14100–14110. [Google Scholar]
- Sarto, S.; Cornia, M.; Baraldi, L.; Nicolosi, A.; Cucchiara, R. Towards retrieval-augmented architectures for image captioning. ACM Trans. Multimed. Comput. Commun. Appl. 2024, 20, 242. [Google Scholar] [CrossRef]
- Liu, G.; Li, Y.; Fei, Z.; Fu, H.; Luo, X.; Guo, Y. Prefix-diffusion: A lightweight diffusion model for diverse image captioning. arXiv 2023, arXiv:2309.04965. [Google Scholar]
- Farjon, G.; Huijun, L.; Edan, Y. Deep-learning-based counting methods, datasets, and applications in agriculture: A review. Precis. Agric. 2023, 24, 1683–1711. [Google Scholar] [CrossRef]
- Jiang, R.; Liu, L.; Chen, C. Clip-count: Towards text-guided zero-shot object counting. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 4535–4545. [Google Scholar]
- Amini-Naieni, N.; Han, T.; Zisserman, A. Countgd: Multi-modal open-world counting. Adv. Neural Inf. Process. Syst. 2024, 37, 48810–48837. [Google Scholar]
- Huang, Z.; Dai, M.; Zhang, Y.; Zhang, J.; Shan, H. Point Segment and Count: A Generalized Framework for Object Counting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 17067–17076. [Google Scholar]
- Wang, Z.; Li, Y.; Wan, J.; Vasconcelos, N. Diffusion-based data augmentation for object counting problems. In Proceedings of the ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025; IEEE: Piscataway, NJ, USA, 2025; pp. 1–5. [Google Scholar]
- Li, J.; Li, D.; Xiong, C.; Hoi, S. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In Proceedings of the International Conference on Machine Learning. PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 12888–12900. [Google Scholar]
- Ye, J.; Xu, H.; Liu, H.; Hu, A.; Yan, M.; Qian, Q.; Zhang, J.; Huang, F.; Zhou, J. mplug-owl3: Towards long image-sequence understanding in multi-modal large language models. In Proceedings of the Thirteenth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Laurençon, H.; Tronchon, L.; Cord, M.; Sanh, V. What matters when building vision-language models? Adv. Neural Inf. Process. Syst. 2024, 37, 87874–87907. [Google Scholar]
- Kajić, I.; Wiles, O.; Albuquerque, I.; Bauer, M.; Wang, S.; Pont-Tuset, J.; Nematzadeh, A. Evaluating numerical reasoning in text-to-image models. Adv. Neural Inf. Process. Syst. 2024, 37, 42211–42224. [Google Scholar]
- Paiss, R.; Ephrat, A.; Tov, O.; Zada, S.; Mosseri, I.; Irani, M.; Dekel, T. Teaching clip to count to ten. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 3170–3180. [Google Scholar]
- Qharabagh, M.F.; Ghofrani, M.; Fountoulakis, K. LVLM-COUNT: Enhancing the Counting Ability of Large Vision-Language Models. arXiv 2024, arXiv:2412.00686. [Google Scholar]
- Nguyen, V.Q.; Suganuma, M.; Okatani, T. Grit: Faster and better image captioning transformer using dual visual features. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 167–184. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Rennie, S.J.; Marcheret, E.; Mroueh, Y.; Ross, J.; Goel, V. Self-critical sequence training for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7008–7024. [Google Scholar]
- Wang, P.; Bai, S.; Tan, S.; Wang, S.; Fan, Z.; Bai, J.; Chen, K.; Liu, X.; Wang, J.; Ge, W.; et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv 2024, arXiv:2409.12191. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3128–3137. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Wang, J.; Yang, Z.; Hu, X.; Li, L.; Lin, K.; Gan, Z.; Liu, Z.; Liu, C.; Wang, L. Git: A generative image-to-text transformer for vision and language. arXiv 2022, arXiv:2205.14100. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).