1. Introduction
The rapid advancement of next-generation sequencing (NGS) technologies has led to an exponential increase in the volume of genomic data, creating significant challenges for genomic analysis systems [
1].
The collection and analysis of genomic data require the cooperation between multiple computation nodes [
2,
3,
4,
5,
6]. Genomic data are transmitted between these nodes through a network. Recent research has been focused on the acceleration of genomic analysis [
2,
3,
4,
7,
8,
9,
10,
11]. However, the performance of data transmission and storage has not kept up pace with the increase in the genomic data volume in recent years [
12,
13,
14,
15]. As a result, storage and transmission have become bottlenecks in genomic analysis systems.
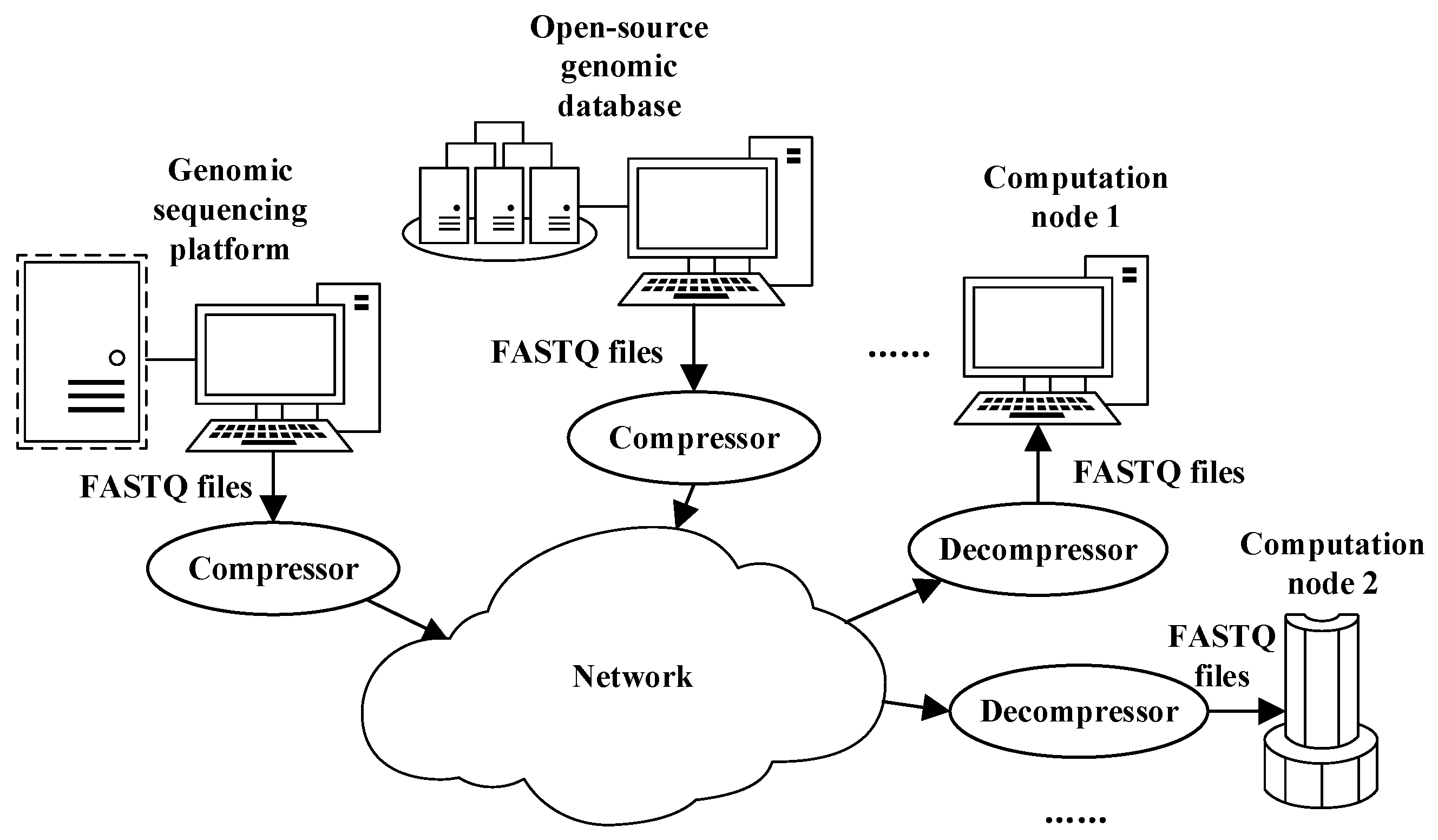
Compression algorithms can address these challenges by reducing the volume of genomic data (an example is shown in
Figure 1). The compression result is transmitted by the network, while decompression is used to recover the files when genomic data analysis is requested by computation nodes. Currently, the volume of genomic data generated by high-throughput sequencing platforms or those downloaded from open-source genomic databases has reached GB or even TB level [
16,
17,
18]. Furthermore, a NovaSeq X NGS platform can generate 8Tbase output in about 17–48 h [
18]. It takes minutes, even hours [
19,
20,
21], for the current available CPU-based compression algorithms to compress and decompress. For example, the algorithm in [
20] used 10 min to compress a 7708 MB genomic file. The long processing time reduces the overall analysis system performance. Therefore, the acceleration of compression and decompression would be beneficial.
Online compression and decompression [
22,
23,
24] can process data streams simultaneously with their input. FPGA (field-programmable gate array) is known for its support of high parallelism, flexible programming, and excellent real-time processing. These features make FPGA an ideal platform for implementing online compression algorithms. High parallelism helps increase the processing speed. Flexible programming enables special designs for genomic data to process input data faster and consume fewer power and hardware resources, which can help FPGA-based implementations easily embed in edge devices with limited resources and collaborate with existing FPGA-based data analysis algorithms [
7,
8,
9,
10,
25,
26,
27].
FASTQ is a commonly used file format [
17,
19,
20,
21,
28,
29], with ‘.fastq’ as its suffix, for genomic data. Compression algorithms for FASTQ files can be categorized as either lossless or lossy. Although lossy compression can achieve higher compression ratios, it loses information after compression. This paper focuses on lossless compression for FASTQ files to maintain all the valid information.
LZ4 [
30] and Zstd [
31] are general lossless compression algorithms designed for fast compression, and they can be used to compress FASTQ files. The basic idea of such algorithms is to use contextual redundancy in a sliding window to achieve compression. However, the size of the sliding window is limited. The structural characteristics of FASTQ files determine that sliding windows often fail to capture much of the contextual redundancy.
Several lossless compression methods specifically designed for FASTQ files have been proposed. A reference probabilistic de Bruijn Graph, built de novo from a set of reads and stored in a Bloom filter, was used to compress sequencing data in [
19]. Faraz Hach designed SCALCE, a ‘boosting’ scheme based on the Locally Consistent Parsing technique, to achieve FASTQ compression in [
20]. Shubham Chandak developed a FASTQ compressor with multiple compression modes called SPRING in [
21]. These algorithms are performed by CPU and can achieve a good compression ratio. However, their compression processes suffer from low throughput rates and high CPU occupation. It usually takes minutes (even hours), large memory, and multiple CPU cores for them to compress GB-level FASTQ files. Therefore, these algorithms can not achieve online compression.
J. Arram proposed a reference-based genomic alignment (REBA) method to perform genomic compression on FPGA in [
16]. This method can achieve a better compression ratio than reference-free compression algorithms. ‘Reference-based’ algorithms require a genome sequence reference used as a dictionary to compress, while ‘reference-free’ algorithms do not need a genomic reference. However, storing the reference sequence and frequent memory access consume a great deal of power and hardware resources. In addition, looking up in the reference introduces unpredictable latency, which limits its throughput rate. The high resource and power consumption decrease the flexibility and reusability of the algorithm, which makes further parallel implementation difficult. Moreover, the decompression method was not proposed in [
16].
In summary, when facing the challenge of online compression for genomic data, current genomic compression algorithms present several limitations:
The CPU-based general and genomic-specific compression algorithms typically occupy multiple CPU cores while delivering limited processing speed. Therefore, these algorithms cannot achieve online compression and decompression.
The FPGA-based general and reference-based compression algorithms tend to consume significant memory resources and require frequent memory access. Furthermore, our evaluations reveal that FPGA-based general-purpose compression algorithms yield suboptimal compression ratios when applied to FASTQ files.
Existing studies primarily emphasize the acceleration of compression algorithms, with little attention given to the optimization or acceleration of decompression algorithms.
To address these issues, we propose PLORC, a novel Pipelined Lossless Reference-free Compression architecture, comprising both a compressor and a decompressor, specially designed for streaming genomic data in a FASTQ format. The main contributions of our work are as follows:
We designed a fully pipelined architecture of the compressor and decompressor for streaming genomic data in a FASTQ format. All the modules were specially designed and built according to the structure of FASTQ files and the features of FPGA. As far as we know, PLORC is the first FPGA-based pipelined reference-free FASTQ compression architecture.
The PLORC compressor achieved the best throughput rate among the representative algorithms we tested, while the decompressor matched the high throughput rate, maintaining balanced performance.
PLORC demonstrated superior resource utilization and power efficiency compared to the FPGA-based algorithms evaluated in this study.
The PLORC compressor surpassed some common general-purpose algorithms in terms of the compression ratio.
This paper is organized as follows:
Section 2 provides a detailed explanation of the PLORC compressor and its hardware implementation.
Section 3 discusses the PLORC decompressor and its corresponding hardware architecture.
Section 4 presents the experimental results and discusses the findings. Finally,
Section 5 concludes the paper and outlines directions for future work.
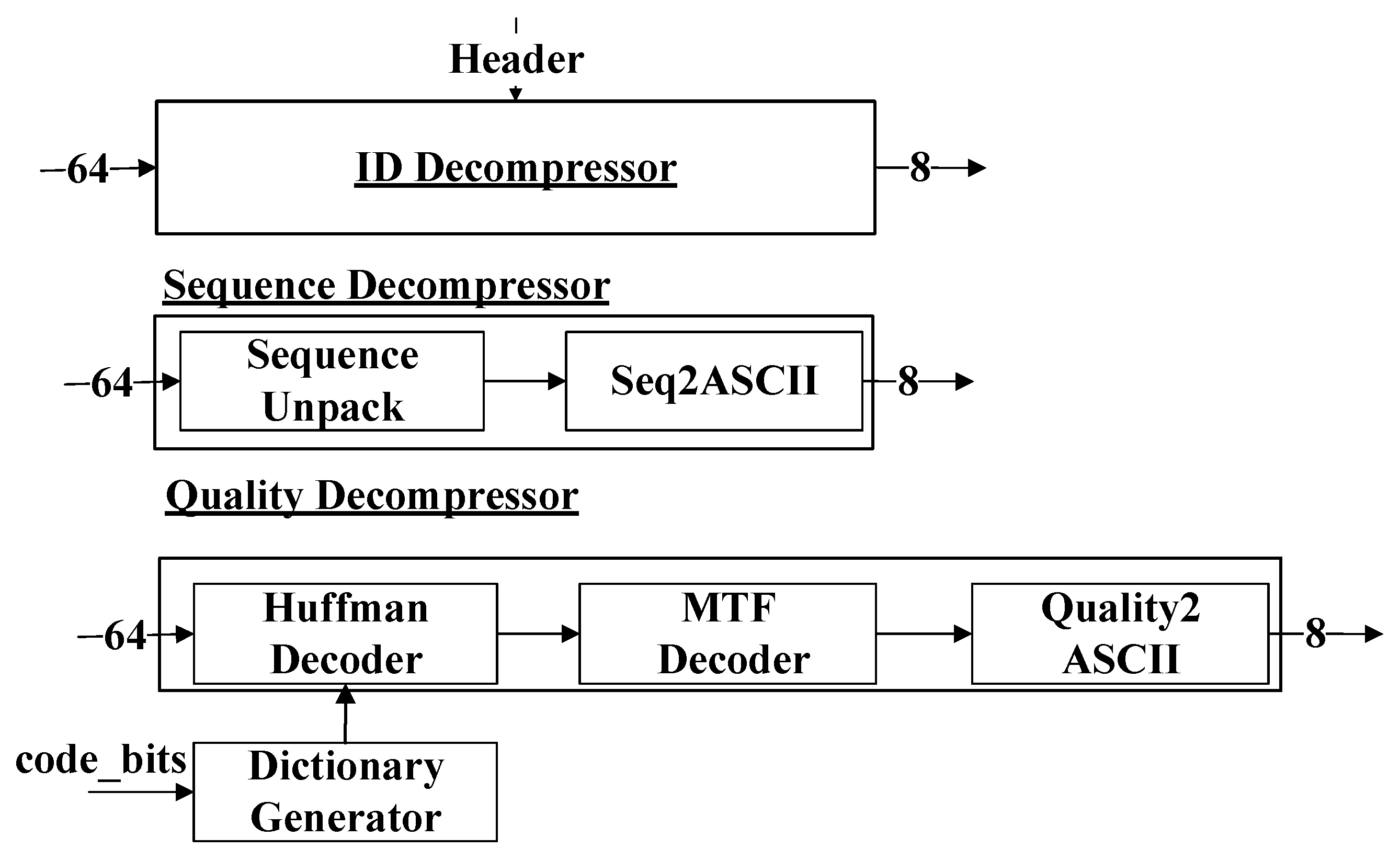
2. Proposed Compressor
FASTQ files consist of fundamental data units called reads. Each read includes four parts [
32] (as depicted in
Figure 2): ID, sequence, plus, and quality. The sequence part represents the nucleotide bases. The quality part indicates the error probability of the bases. The plus part serves as a delimiter.
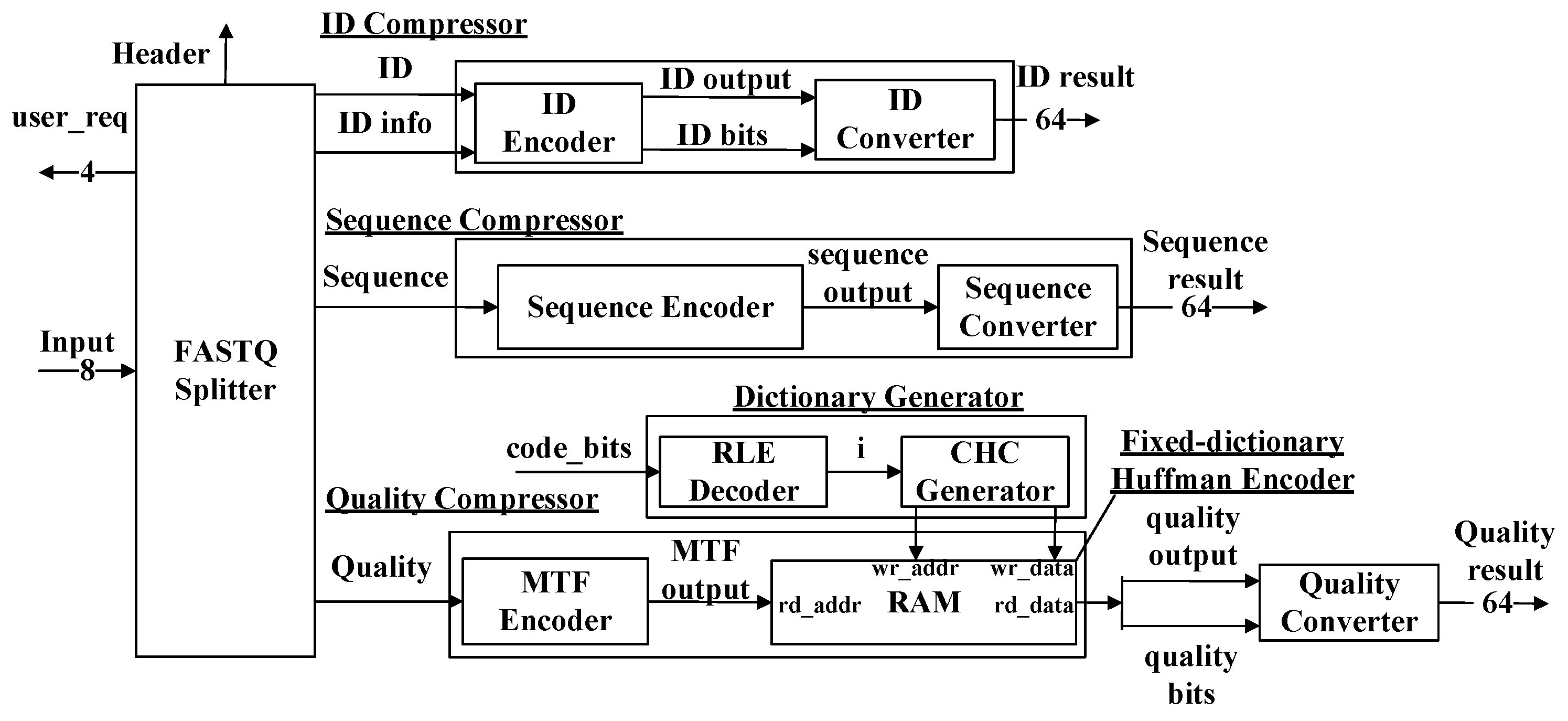
The block diagram of our proposed compressor is shown in
Figure 3. The input of our compressor is in the format of an 8-bit ASCII (American Standard Code for Information Interchange) code stream. The compressor consists of seven modules: the FASTQ Splitter, the ID Compressor, the Sequence Compressor, the Quality Compressor, the ID Converter, the Sequence Converter, and the Quality Converter. ‘
ID output’, ‘
sequence output’, and ‘
quality output’ stand for the compression results. ‘
ID bits’ and ‘
quality bits’ represent the number of valid bits in ‘
ID output’ and ‘
quality output’. The ‘
code_bits’ signal represents a stream of the length of Huffman code words. The output is then processed by the three converter modules, respectively, to extract the valid information and form 64-bit output streams.
2.1. The FASTQ Splitter Module
The FASTQ Splitter module is responsible for the following:
Dividing the input data stream into three output streams. The three compressors receive the streams and perform compression processes, respectively.
Generating the header and ‘
ID_info’ signal, as shown in
Figure 3. The FASTQ Splitter extracts (1) the length of the first ID, (2) the content of the first ID, and (3) the positions, type, and amount of the special characters other than the numbers and English letters in the first ID. The information is transformed into the header and ‘
ID_info’.
Handling some exceptional situations and requesting user intervention. The module detects the exceptional situations and sets the corresponding bit as one in ‘user_req’ to call for user intervention. The information about ‘user_req’ is listed below:
- –
The ‘user_req[0]’ notation represents the occurrence of ambiguous bases other than ‘A’, ‘C’, ‘G’, ‘T’, and ‘N’.
- –
The ‘user_req[1]’ notation determines that the number of quality scores is different from the bases in the current read.
- –
The ‘user_req[2]’ notation means a mismatch between the type or amount of special characters in the first read and the current read.
- –
The ‘user_req[3]’ notation means some of the four parts are missing in the current read.
2.2. The ID Encoder Module
Figure 4 shows an example of IDs randomly selected from a FASTQ file. The characters in an ID can be divided into two categories:
Numbers and English letters.
Special characters other than numbers and English letters, such as ‘@’, ‘:’, and space.
The IDs from a FASTQ file are of a identical format [
33]. Each ID is divided into several areas by special characters. The areas contain different information about this read. The differences between these IDs are merely a few symbols. Therefore, the IDs from the same FASTQ file show high structural similarity.
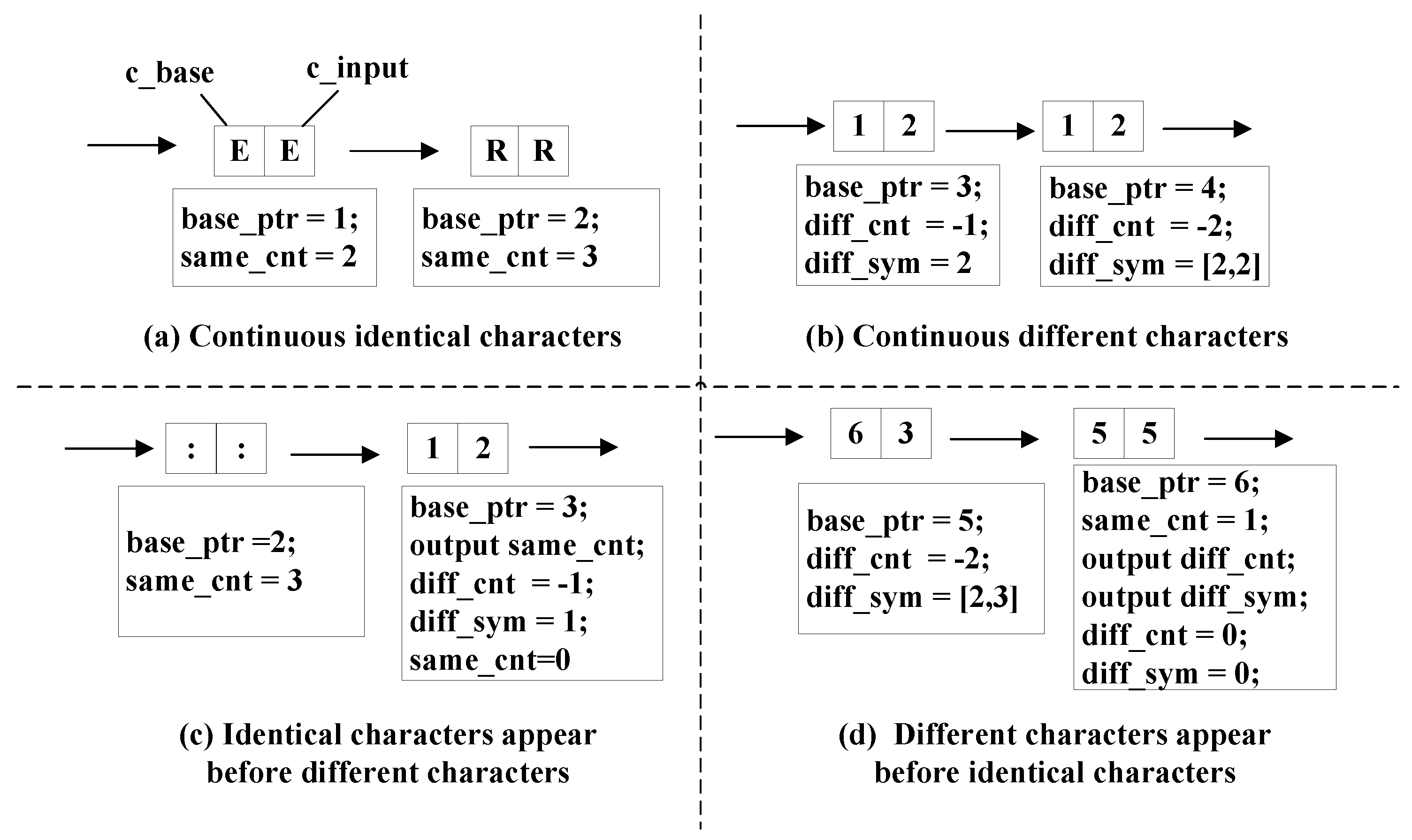
We designed an encoding method based on character comparison utilizing structural similarity. The method divides the character comparison process into eight different input patterns and employs different strategies. We used segments in the comparison to illustrate the strategies. The segments are shown in
Figure 5 and
Figure 6. The patterns in
Figure 6 are the special cases of those in
Figure 5. They are defined as ‘special patterns’ because they require special treatments compared with common patterns.
The ‘base_ID’ stores the ID from the previous read to participate in the comparison. For the first read, the ‘base_ID’ is itself extracted by the FASTQ Splitter module. The length of the ‘base_ID’ in bytes is also stored. The ‘input_ID’ represents the streaming ID input. The ‘base_ptr represents which symbol in the ‘base_ID’ is participating in the comparison, which is named ‘c_base’. The character from the ‘input_ID’ is referred to as the ‘c_input’. The first 4 bits of the result are the difference between the length of the current input ID and the previous ID in bytes, which is called the ‘len_diff’.
The encoding process decides which pattern the current comparison between the ‘c_base’ and ‘c_input’ belongs to and then applies the corresponding strategy.
The strategies for common patterns shown in
Figure 5 are listed below.
In
Figure 5a, there are continuous identical characters. A 1-byte register named ‘
same_cnt’ is used to store the number of identical characters.
In
Figure 5b, there are continuous different characters. Another 1-byte register ‘
diff_cnt’ calculates the number of different characters. Its value is negative to separate itself from the ‘
same_cnt’ register. The ‘
diff_sym’ register stores the input character. The number of characters contained in ‘
diff_sym’ is recorded for future output.
In
Figure 5c, a pair of identical characters appear before different characters. The comparison status is changed. Therefore, the value of ‘
same_cnt’ becomes the output signal ‘
ID output’ in
Figure 3 and is then set as zero. The ‘
ID bits’ is 8 because ‘
same_cnt’ is a 1-byte register.
In
Figure 5d, a pair of different characters appear before identical characters. The output is generated from ‘
diff_sym’ nad ‘
diff_cnt’.
The strategies for special patterns shown in
Figure 6 are listed below.
In
Figure 6a, the ‘
c_base’ becomes a special character before ‘
c_input’. It is a special case of
Figure 5d, and it means the same special character will appear after some characters in
input_ID because of the high structural similarity. The
base_ptr should remain unchanged. The ‘
diff_sym’ and ‘
diff_cnt’ are required to update continuously until the special character in ‘
input_ID’ arrives. The following operations are the same as in
Figure 5d.
In
Figure 6b, the ‘
c_input’ becomes a special character before ‘c_base’. This pattern is also a special case of
Figure 5d. The difference between the situations shown in
Figure 6a,b is are the same as that in
Figure 6b, and the ‘
c_input’ can not remain unchanged when waiting for the special character from ‘
base_ID’ because it introduces stream interruption. Therefore, the ‘
base_ptr’ should jump to the position of the next special character in ‘
base_ID’. The position is provided by the FASTQ Splitter module. The other operations are the same as in
Figure 5d.
In
Figure 6c, the ‘
c_input’ reaches the end of ‘
input_ID’ first. The encoder should generate the output immediately and set the ‘
base_ptr’ to zero to wait for new inputs. If the comparison status before the end is a pair of identical characters, the output should be generated from ‘
same_cnt’. Otherwise, the output should be generated from ‘
diff_sym’ and ‘
diff_cnt.
In
Figure 6d, the ‘
c_base’ reaches the end of ‘
base_ID’ first. Under this situation, the following characters from ‘
input_ID’ should be treated as pairs of different characters because there is no character from ‘
base_ID’ to participate in the comparison. The encoder is supposed to wait until the ‘
input_ID’ reaches its end and then generate outputs from ‘
diff_sym’ and ‘
diff_cnt’.
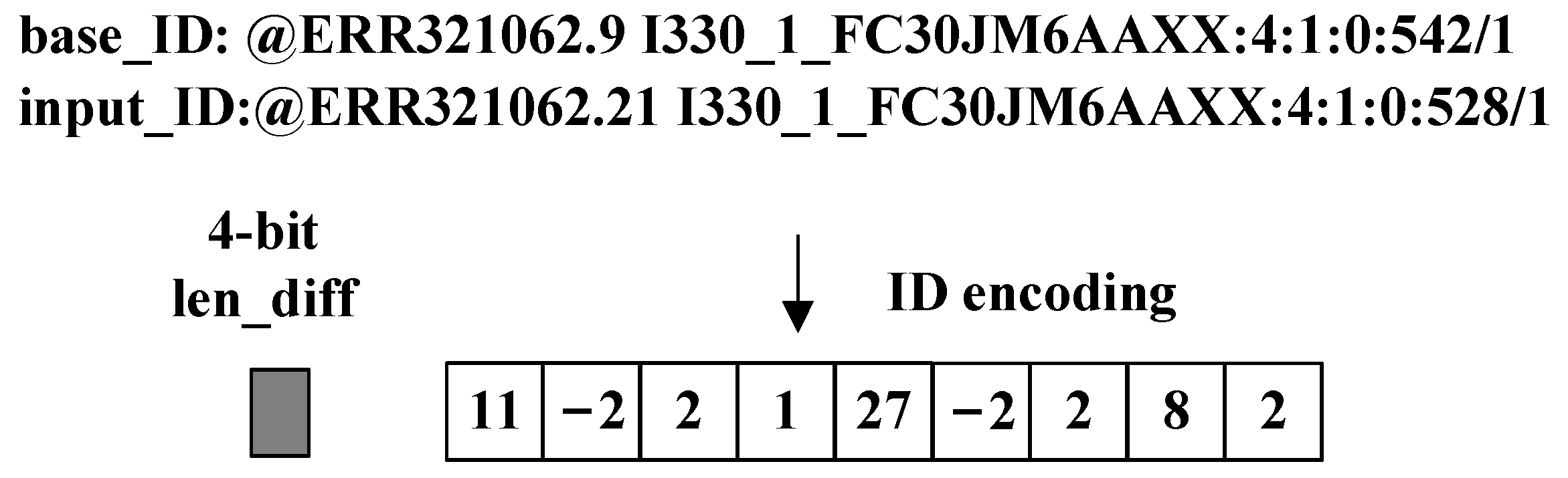
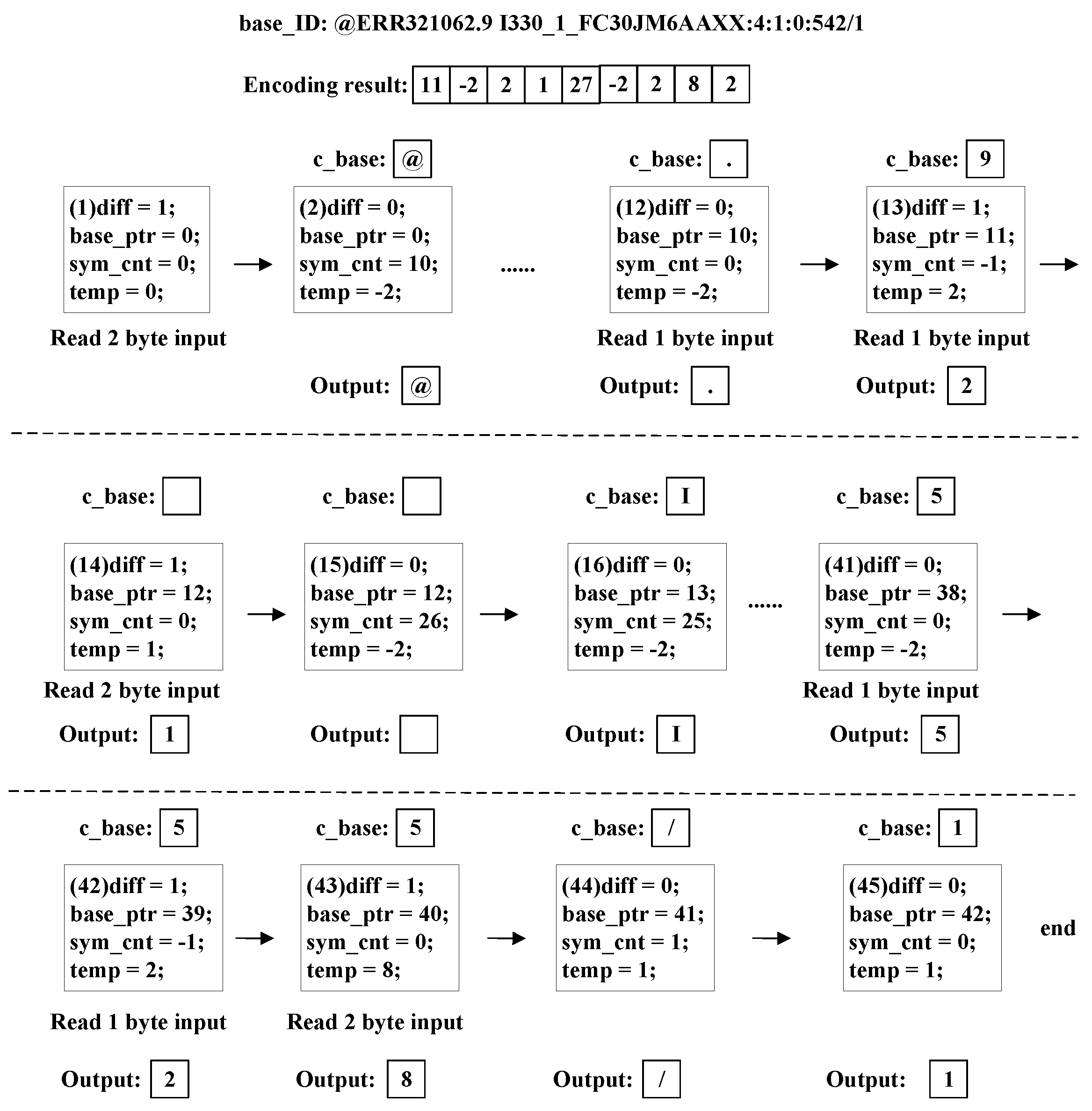
An example is shown below to illustrate the encoding process on a real ID.
Figure 7 shows an example of a real ID encoding result. Its encoding process is shown in
Figure 8. The white blocks in
Figure 7 and
Figure 8 represent 1-byte data. Our encoding method turns 44 bytes ‘
input_ID’ into a 9.5-byte encoding result, including a 4-bit ‘
len_diff’.
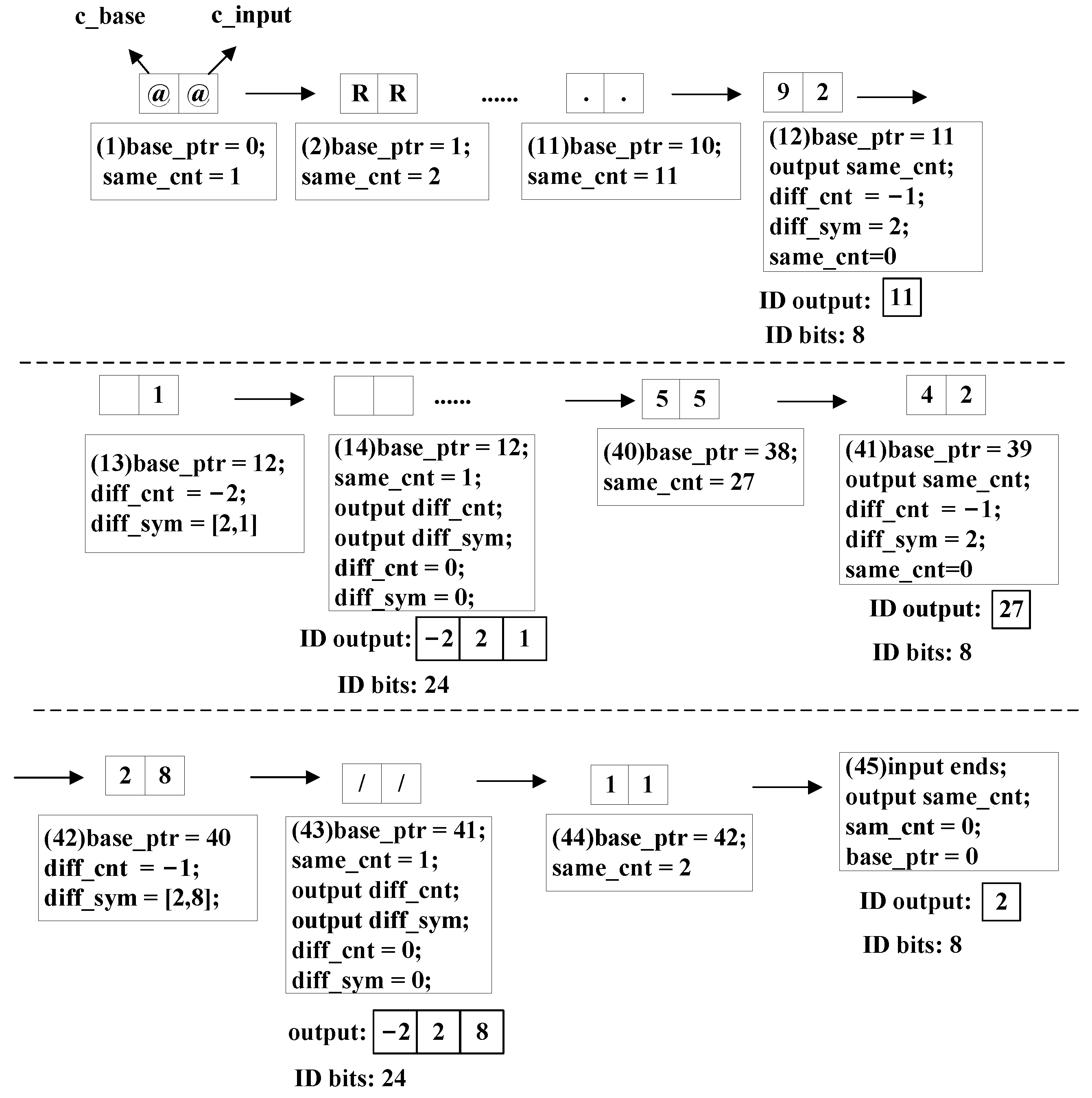
In
Figure 8, ‘
c_base’ means a character from ‘
base_id’, and ‘
c_input’ means a character from ‘
input_id’. The value of ‘
c_base’ changes with ‘
base_ptr’ and the ‘
c_input’ changes with the input stream.
The encoder first generates the ‘len_diff’ from the difference between the length of the current input ID and the previous ID in bytes. The ‘c_input’ character in each step is stored, and the number of ‘c_input’ characters is recorded by registers to update the ‘base_id’ at the end of the current comparison.
From Step (1) to Step (11) in
Figure 8, the encoder encounters continuous identical characters, as shown in
Figure 5a. The ‘
same_cnt’ and ‘
base_ptr’ registers the increase by one in each step.
The encoder encounters a pair of identical characters in Step (11) and then different characters in Step (12), as shown in
Figure 5c. Therefore, the ‘
ID output’ signal is generated from ‘
same_cnt’. Meanwhile, ‘
diff_sym’ and ‘
diff_cnt’ begin to update.
In Step (12) and Step (13), the encoder encounters continuous different characters, as shown in
Figure 5b. Then, ‘
diff_sym’ and ‘
diff_cnt’ resisters continue to update.
The value of register ‘
c_base’ becomes a special character in Step (13) first, as shown in
Figure 6a. The ‘
c_base’ register remains unchanged until the special character from ‘
input_id’ arrives in Step (14). The ‘
ID output’ signal is generated from ‘
diff_sym’ and ‘
diff_cnt’.
From Step (14) to Step (40), the encoder encounters continuous identical characters again. Then, ‘same_cnt’ and ‘base_ptr’ register the increase by one in each step.
The encoder encounters a pair of identical characters in Step (40) and a pair of different characters in Step (41). The pattern is the same as Step (11)–(12).
In Step (41) and Step (42), the encoder encounters continuous different characters. The pattern is the same as Steps (12)–(13).
The encoder encounters a pair of different characters in Step (42) and identical characters in Step (43), as shown in
Figure 5d. The ‘
ID output’ signal is generated from ‘
diff_sym’ and ‘
diff_cnt’. Meanwhile, ‘same_cnt’ begins to update.
In Steps (43) and (44), the encoder encounters continuous identical characters the third time. The operations are the same as Steps (1)–(11).
In Step (45), ‘
c_input’ reaches the end first, as shown in
Figure 6c. The outputs are generated, and all the registers are set to zero. Then, ‘
base_ID’ and its size are updated by the ‘
input_ID’ in the finished comparison and its length in bytes.
2.3. The Sequence Compressor Module
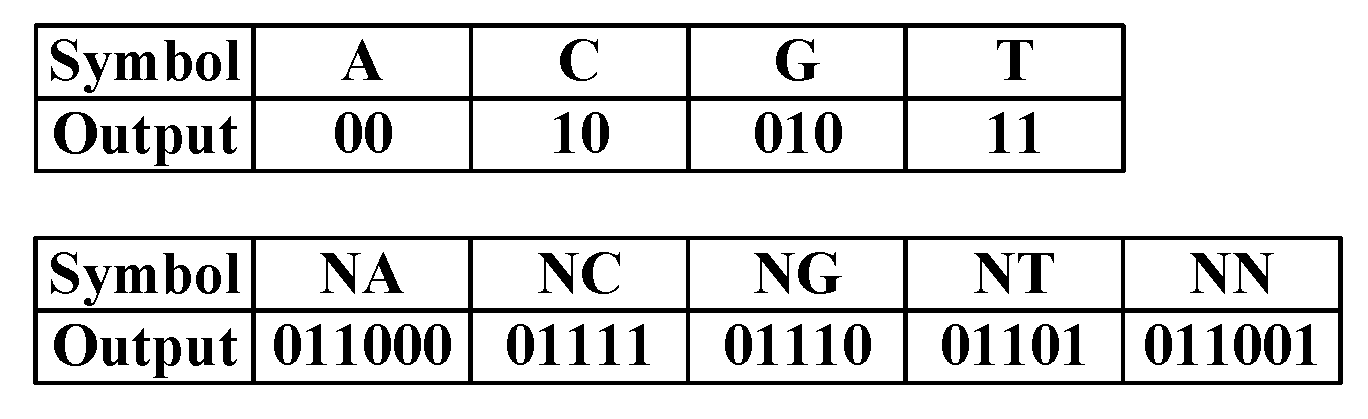
Sequences are composed of four nucleotide bases: ‘A’, ‘C’, ‘G’, and ‘T’. In addition, the character ‘N’ indicates an ambiguous base in the sequence. We used a Huffman code table to encode the sequence part losslessly, as shown in
Figure 9. During the encoding, the code table is unchanging.
The number of bases in the sequence part is calculated and serves as the first 2 bytes of the ‘sequence output’ of each read.
2.4. The Quality Compressor Module
There are merely 41 types of characters in the quality part [
34]. The distribution pattern of the quality part is that characters corresponding to higher sequencing accuracy tend to occur with higher frequency [
35].
Figure 10 shows the frequency distribution of characters based on the first 1000 reads of ERR174310_1.fastq. The x-axis represents the rank of the occurrence frequency of the characters in descending order. The y-axis represents the percentage of the character.
Table 1 shows the percentage of the top five characters in terms of appearance frequency, where
p_error means the probability of error. This distribution pattern can be used to simplify the compression process.
Given the distribution pattern shown in
Figure 10, entropy encoding can achieve appreciable compression performance. Among the entropy encoding methods, Huffman encoding can be easily realized by FPGA devices using RAMs. Therefore, an optimized Huffman encoding process is used in the Quality Compressor module.
The structure of the Quality Compressor is shown in
Figure 3.
The hardware details of the submodules are discussed below.
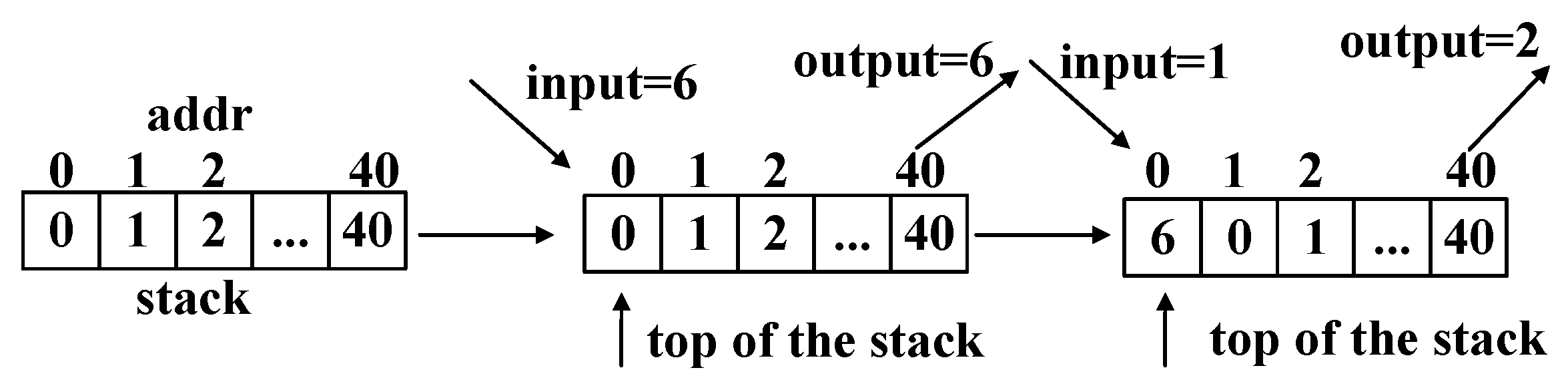
2.4.1. The MTF Encoder Module
We apply the MTF (move-to-front) transform [
36] to turn the characters into numbers. An example of the MTF encoding process is shown in
Table 2. A stack is maintained to achieve the encoding process. The stack is initialized with incremental integers, starting from 0. The first input signal is 1. This input signal is then looked up in the stack, and its address is returned as the output signal. Element 1 is then moved to the top of the stack. The second input signal is 0. According to the above process, the corresponding output signal is 1. An example of the MTF encoding for quality parts is shown in
Figure 11. The basic encoding method is the same as in
Table 2.
The architecture of the MTF Encoder module is shown in
Figure 12. The
signal is the stack in the MTF Encoder module. ‘RR’ means ‘register’ in
Figure 12.
The MTF Encoder transforms those characters that appear more frequently into smaller integers.
Table 3 shows the MTF encoding input and results on ERR174310_1.fastq and SRR554369_2.fastq, where the percentage of the first, second, and third most frequent characters and their sums are listed. As shown in
Table 3, the sum of the percentage of the top 3 characters is increased after MTF encoding. Additionally, the percentages of the top 2 characters are both increased by MTF.
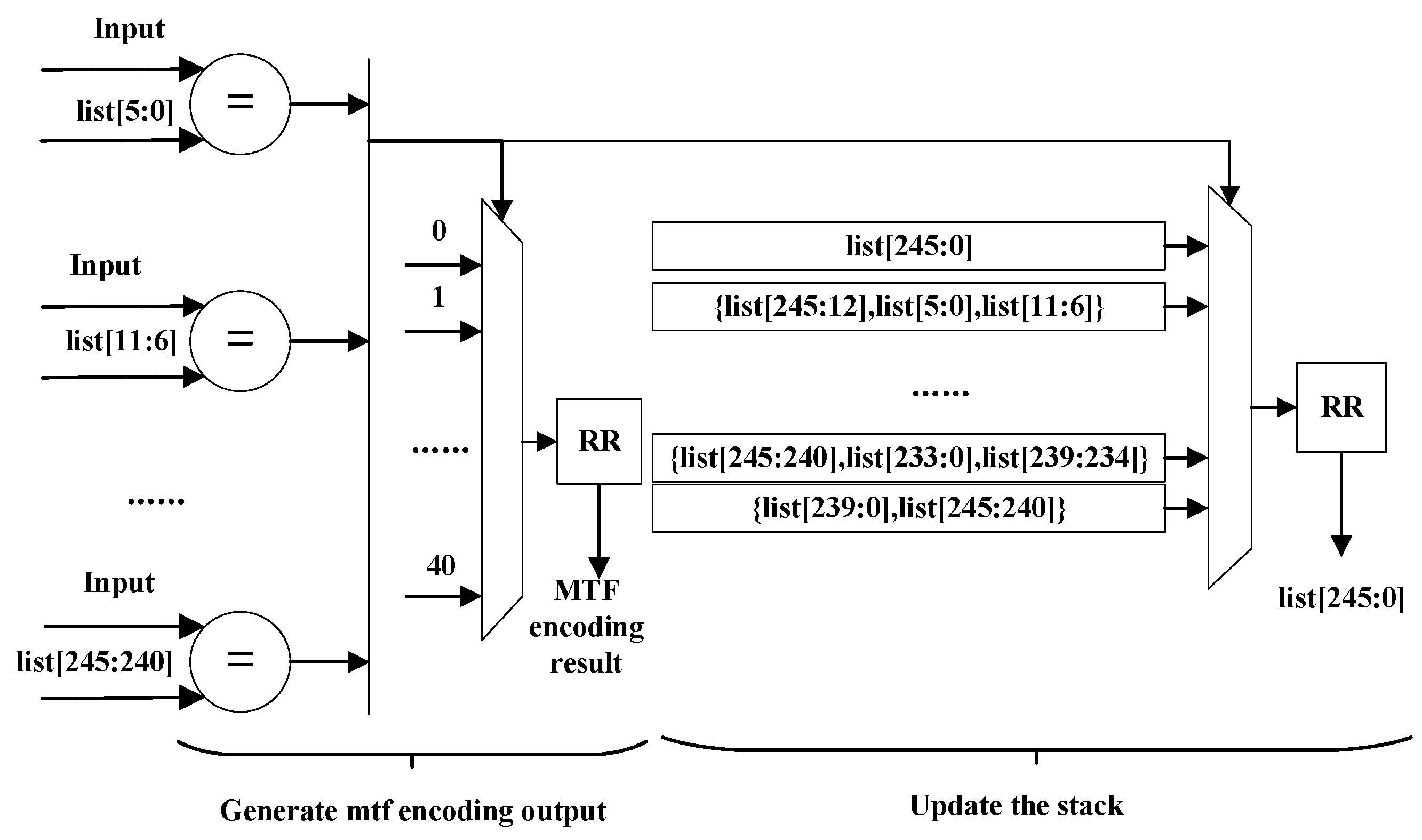
2.4.2. The Dictionary Generator Module
The structure of the Dictionary Generator is shown in
Figure 3. It transforms the Huffman code word length values into the corresponding Huffman code table. The code word length values are set by the users before the compression. The Huffman code table remains unchanged during the compression process.
We introduce Canonical Huffman Coding (CHC) [
37,
38,
39] to simplify the transmission of the Huffman dictionary. CHC allows generating binary Huffman codes
from the Huffman code length
i and several rules. These rules are listed below.
The codes with the same length are consecutive integers in binary format.
The first code of length i can be calculated from the last code of length , which can be expressed as .
The first code with the smallest length starts from 0.
If does not exist after , and the nearest code word is , then .
The Dictionary Generator module consists of two submodules: the RLE Decoder module and the CHC Generator module.
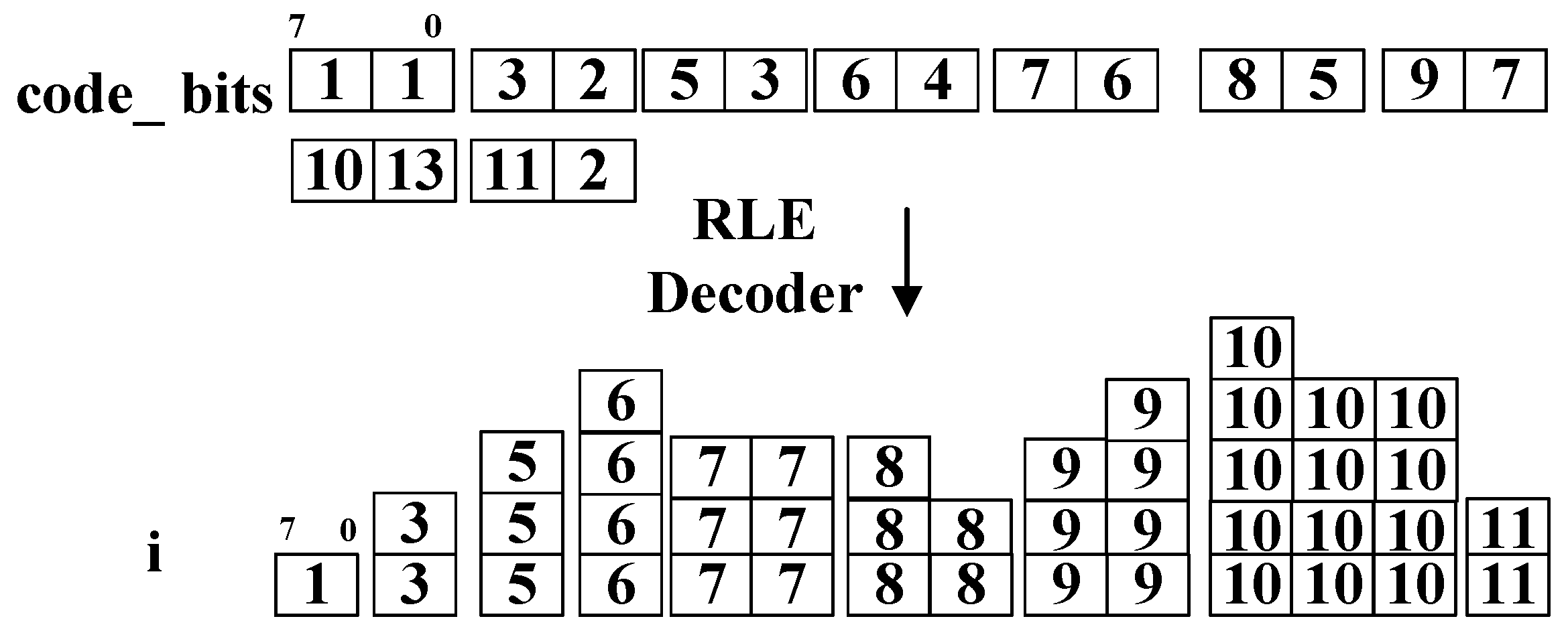
Since consecutive identical code length values occur frequently, the code length values are encoded as the ‘code_bits’ signal with the RLE method.
The RLE Decoder module generates the code length
i from the ‘
code_bits’ signal. An example of the input and output of the RLE Decoder module is shown in
Figure 13, where the total size of ‘
code_bits’ is 9 bytes and the total size of
i is 43 bytes. A smaller volume of the input saves time in configuring the Huffman encoder.
The CHC Generator module transforms the code word length
i into the code table
. Its architecture is shown in
Figure 14. ‘RR’ means ‘register’ in
Figure 14. Its input
i is the output of the RLE Decoder module. Its output
and
are served as the input of the fixed-dictionary Huffman Encoder module. In
Figure 14,
represents the Huffman code table and
means the amount of valid bits in
.
2.4.3. The Fixed-Dictionary Huffman Encoder Module
The traditional Huffman encoding consists of two phases: constructing a Huffman tree, and encoding based on the tree. This scheme requires the nodes on the tree to be scanned twice, which results in a longer encoding time [
39]. The construction of a Huffman tree consumes 38% of the total encoding time [
40]. In addition, the FPGA implementation of the Huffman tree construction process needs extra memory [
41].
To avoid the latency and resource overhead of constructing a Huffman tree, we omitted the Huffman tree construction process and utilized a fixed-dictionary Huffman encoder. Based on the observed character frequency distribution in
Figure 10 and
Table 3, applying fixed-dictionary Huffman encoding will lose little compression ratio. Additionally, this modification enables pipelined and resource-efficient implementation of the Huffman encoding process.
The fixed-dictionary Huffman Encoder module consists of a RAM (Random Access Memory). The Huffman dictionary generated by the Dictionary Generator module is written in RAM. The Huffman encoding process is implemented by reading the RAM with the ‘MTF output’ signal as the reading address.
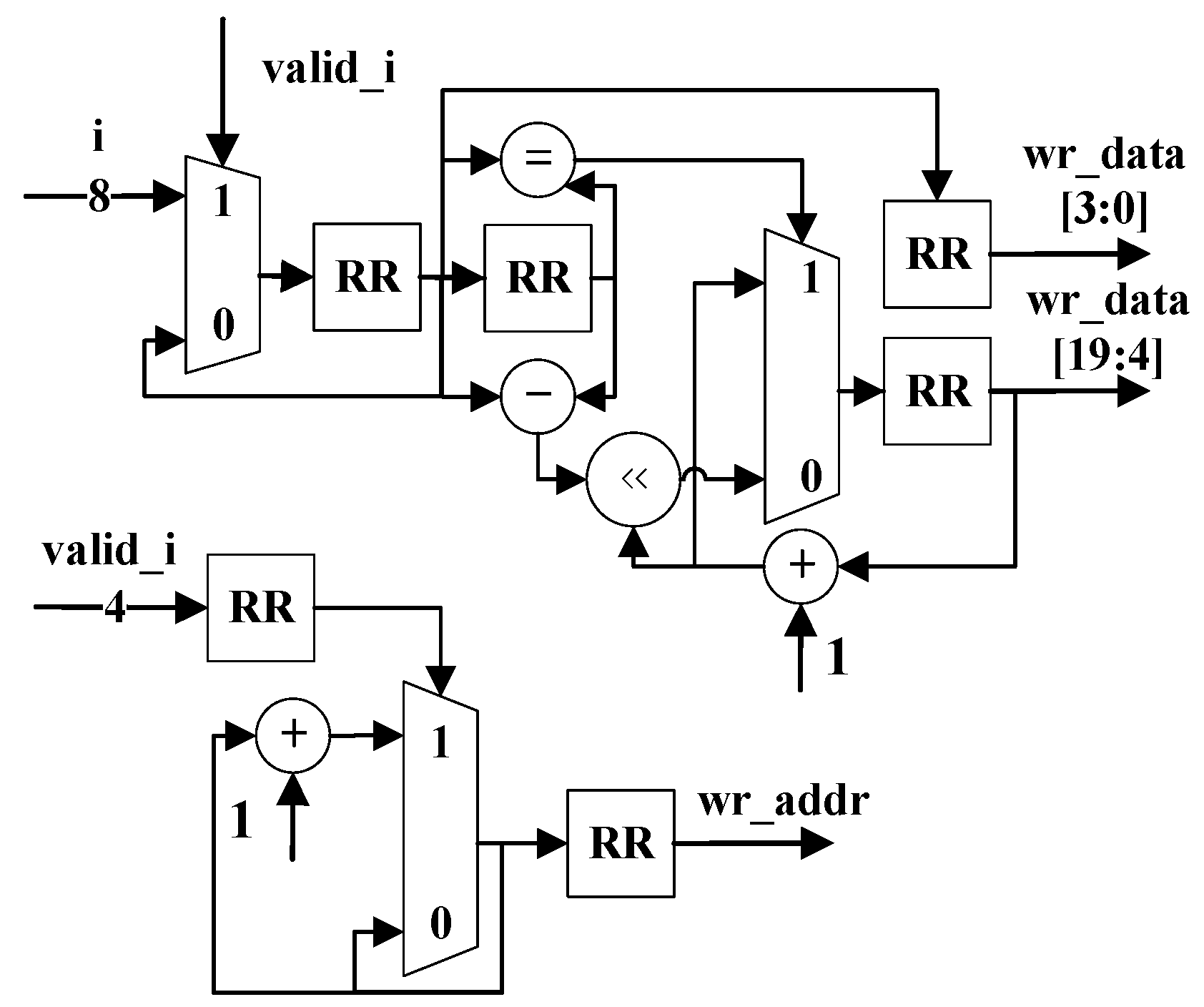
2.5. The ID, Sequence, and Quality Converter Modules
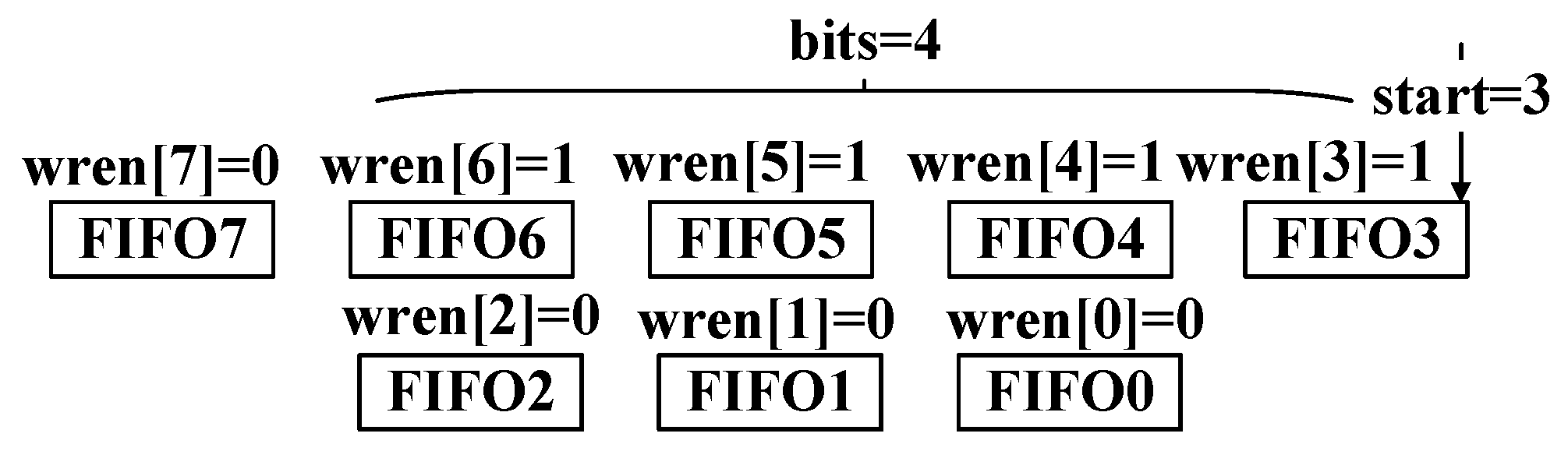
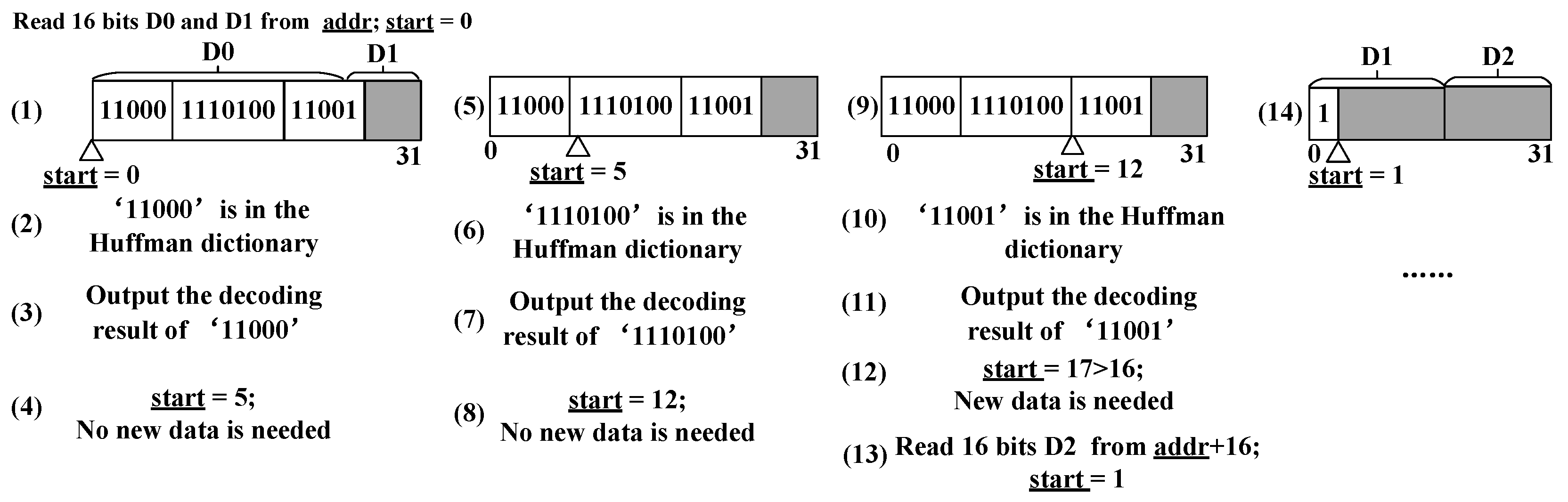
The ID Converter, Sequence Converter, and Quality Converter collect the valid bits in the input and transform these bits into output with a unified bit width. All modules utilize parallel 1-bit width FIFOs to achieve this transformation, as shown in
Figure 15.
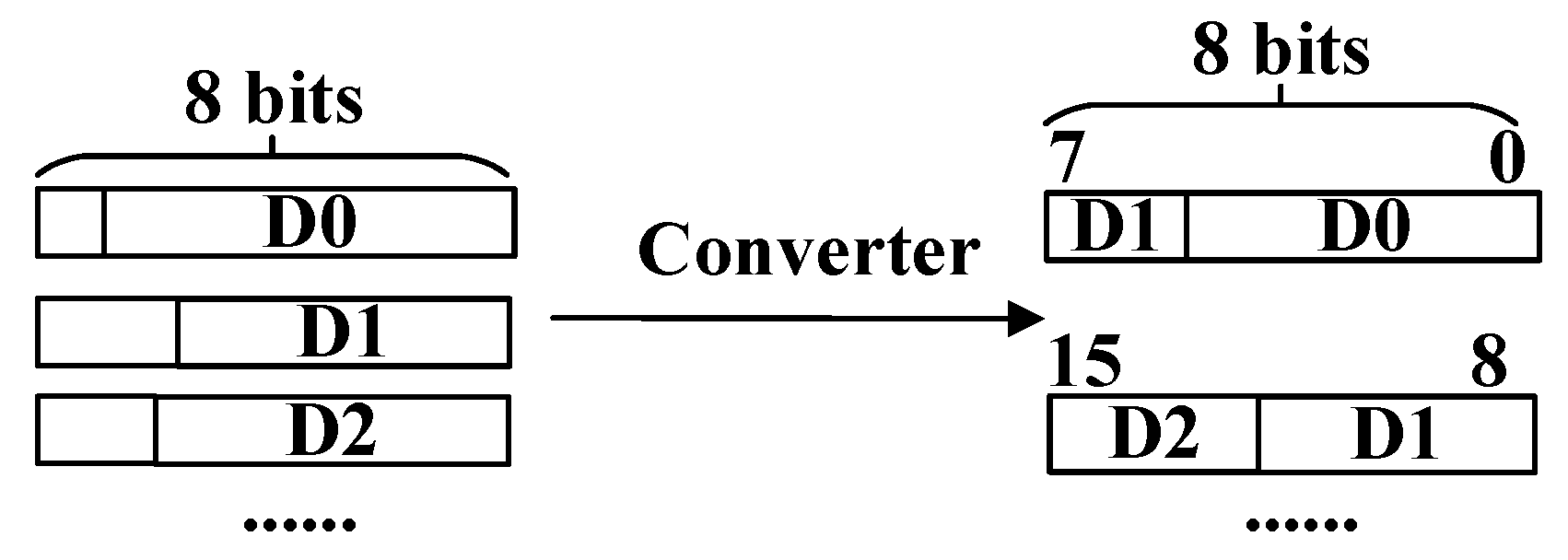
Figure 16 shows the process of transforming the data less than eight bits into eight bits. The input signals are D0, D1, and D2 with a bit width of less than 8 bits. To illustrate their hardware structure, the output bit width of the package module is set as eight bits, as is shown as examples in
Figure 15 and
Figure 16.
Figure 15 shows the hardware architecture of the converter. The input contains 4-bit valid data and should be written starting from FIFO3. Moreover, ‘
bits’ indicates the number of valid bits in the input data. Only these valid bits can be written into FIFOs. Furthermore, ‘
start’ means where this writing process should begin. Reading these FIFOs when they are not empty simultaneously can form an 8-bit signal. The actual output is set to a 64-bit width in the experiments. The 64-bit (8 bytes) width is convenient for further storage and calculation of the compression output. Other output widths can be easily transformed from the 64-bit output.
4. Results and Discussion
4.1. Datasets
The datasets used in this study [
42,
43,
44,
45,
46] comprise publicly available paired-end FASTQ files obtained from EMBL-EBI [
17]. These datasets encompass a wide range of DNA information from species and organisms, with the specific details provided in
Table 7.
4.2. Experiment Information
We executed different compression algorithms on the FASTQ files listed in
Table 7. As discussed in
Section 1, CPU-based genomic-specific compression algorithms [
19,
20,
21] have limited throughput rates. Therefore, these algorithms are not within the comparing scope of this article.
Our PLORC compressor and decompressor are implemented on a Zynq UltraScale+ ZCU102 Evaluation Board by Vivado 2022.2.
We conducted compression experiments on Gzip [
47], LZ4 [
30], and Zstd [
31] to measure their CRs (compression ratios). The definition of CR is shown in Equation (
1). The CRs of the tested compression algorithms are shown in
Table 8. A comparison of the CRs is shown in
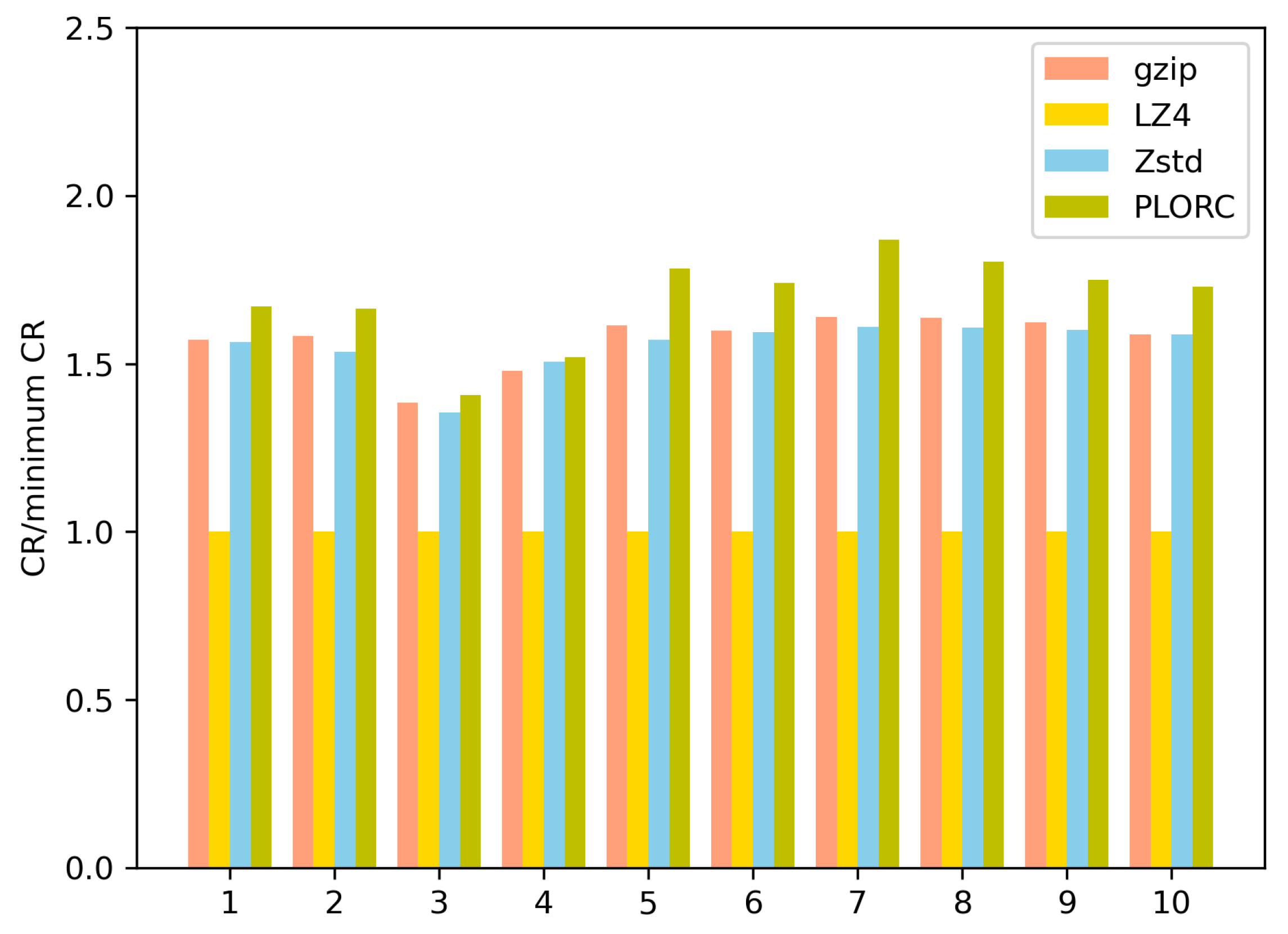
Figure 21. The x-axis of
Figure 21 represents the ‘Dataset Number’ in
Table 7. The y-axis means the ratio between the CR of the tested algorithm and the minimum CR on the same dataset. In addition, we implemented Gzip [
48], LZ4, and Zstd [
49] on a Zynq UltraScale+ ZCU102 Evaluation Board to measure their TPRs (throughput rates) and resource consumption.
The throughput rates and power consumption results of the FPGA-based algorithms are shown in
Table 9. The resource consumption is shown in
Table 10. ‘Com’ means ‘compressor’ and ‘Decom’ means ‘decompressor’ in
Table 9 and
Table 10. The throughput rate and resource consumption results of REBA are calculated from the results in [
16,
50].
To provide a comprehensive evaluation, we introduce Power Efficiency (PE), as shown in
Table 9. The definition of PE is shown in Equation (
2).
4.3. Compression Ratios
As illustrated in
Table 8 and
Figure 21, our PLORC compressor achieved a better compression ratio than Gzip, LZ4, and Zstd.
Our compression algorithm was specially designed and implemented according to the structure of FASTQ files. Therefore, the PLORC compressor can better reduce contextual redundancy.
Gzip, LZ4, and Zstd utilize a sliding window and dictionary-based methods to reduce contextual redundancy. When applied to FASTQ files, the size of one read often exceeds the size of the sliding window. Therefore, general compression algorithms, such as Gzip, LZ4, and Zstd, often fail to capture much contextual redundancy.
The reference-based design in [
16] achieved a superior CR 14.1 on a 964 MB FASTQ file from the ERP001652 dataset [
53]. However, this high CR depends on manual selection for reference. Additionally, it consumes a great deal of hardware resources, as illustrated later in
Section 4.5.
4.4. Throughput Rates
Our PLORC compressor and decompressor achieve a better TPR than Gzip, LZ4, and Zstd on FPGA, enabling the online compression of FASTQ files. Moreover, our decompressor achieves a TPR matching that of the compressor, as shown in
Table 9. This means that our compressor and decompressor can work at nearly identical speeds. The development of automated high-speed data processing accelerators calls for fast data recovery [
54,
55]. A decompressor with a high throughput rate is helpful to address the issue [
56].
Our compressor and decompressor are fully pipelined, with no dependencies between the input and output of the same submodule. The PLORC compressor and decompressor can process input streams continuously, significantly improving their TPRs. Our architecture requires no data buffering or string matching. Therefore, there is no unpredictable latency. In addition, the latency between the input and output is small considering the large input data scale and the streaming design.
Gzip, LZ4, and Zstd achieve compression by searching the dictionary for a string that matches the input data. Each search contains an uncertain amount of access to BRAM. Multiple BRAM access before finding a matching string or traversing the dictionary without finding a matching string introduces unpredictable latency, interrupting the input data stream. This interruption forces the following parts of the algorithm to wait.
Large memory must be allocated for the reference-based designs to store the reference sequence. For example, the reference sequence for the human genome is 17 GB according to [
16]. In addition, frequent memory access is also required to find the matched string. The memory access process introduces unpredictable latency, hampering continuous data processing. Moreover, to increase the TPR of the design, a clock domain crossing design between memory devices and FPGA logic is introduced in [
16]. The memory devices in REMA work at a faster clock than the FPGA logic. The clock domain crossing design makes the implementation more complex and consumes more hardware resources. Additionally, it prevents the FPGA logic from achieving a better TPR by increasing the clock frequency.
4.5. Power and Resource Consumption
Table 9 further demonstrates that the PLORC compressor delivers the highest power efficiency, achieving a superior processing speed with equivalent power and hardware resource consumption. In addition, the power efficiency of our decompressor is better than that of the other tested decompressors.
Table 10 indicates the resource consumption of the tested algorithms. Our PLORC compressor and decompressor consume relatively fewer LUTs and FFs. Moreover, our architecture consumes no BRAM. The high power and resource efficiency enable the implementation of multiple PLORC architectures on a single ZCU102 board to compress data from multiple sequencing platforms in the future. Considering LUTs and Flip-Flops, the total logic resource on a ZCU102 FPGA platform can support the implementation of about dozens of PLORC compressors or decompressors.
As analyzed in
Section 4.4, Gzip, LZ4, Zstd, and REBA demand considerable memory resources and frequent memory access. The BRAM usage in LZ4 and Zstd is detailed in
Table 10, and the memory requirement for REBA is in the GB range according to [
16]. Furthermore, applying different clock domains between memory devices and FPGA logic in REBA introduces circuit complexity and increases resource consumption.
5. Conclusions and Future Work
In this paper, we introduce PLORC, a pipelined resource-efficient, power-efficient, lossless, and reference-free FASTQ compression architecture for streaming genomic data in a FASTQ format, along with its FPGA implementation. Experiments demonstrated that our proposed design can achieve a significantly higher throughput rate than other tested compression algorithms. Additionally, PLORC offers superior resource and power efficiency over other FPGA-based implementations, making it particularly suitable for integration into computational nodes and collaboration with other FPGA-based genomic analysis frameworks. Furthermore, the architecture lends itself well to the parallel deployment of several PLORC blocks, which can further enhance the overall throughput rate. In the future, we will improve our architecture to support more comprehensive mechanisms of error handling and recovery from exceptional situations.



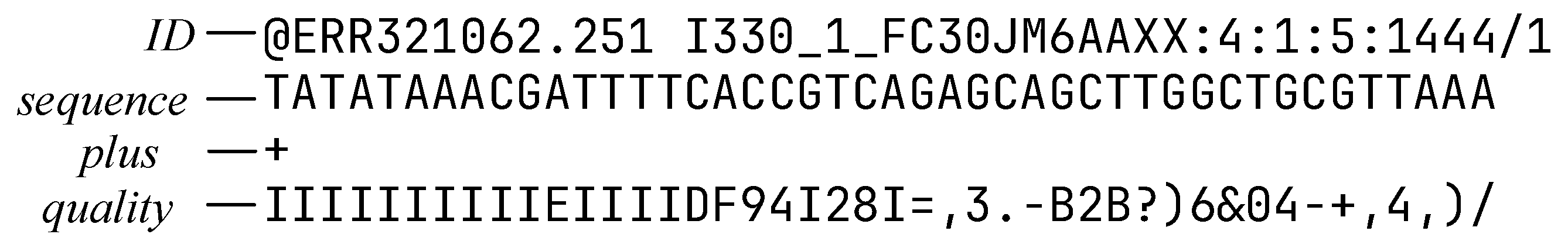
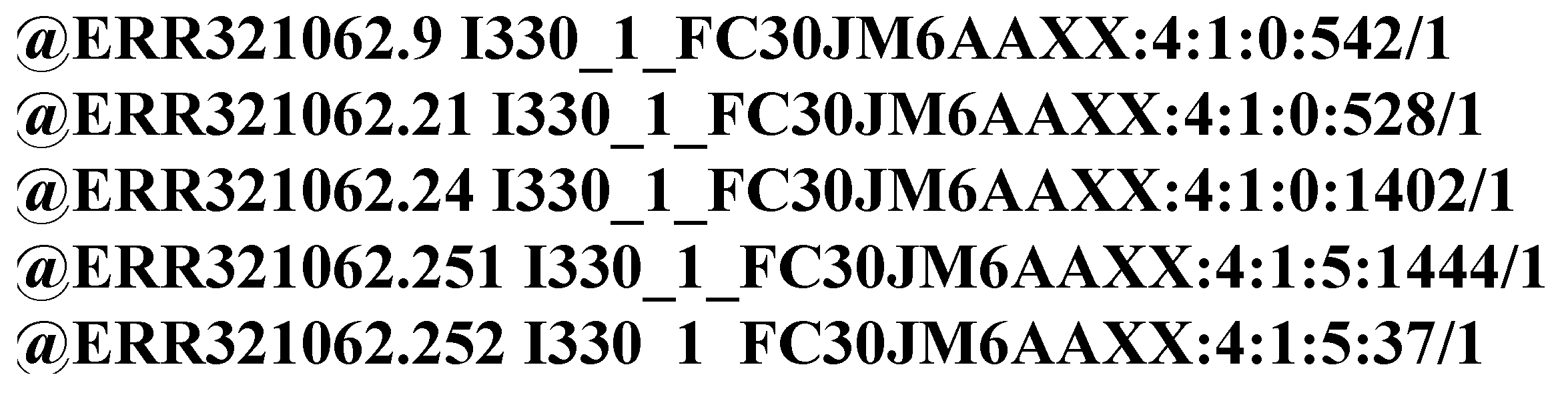




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}