

Semantic-Aware Low-Light Image Enhancement by Learning from Multiple Color Spaces



Abstract
1. Introduction
2. Related Work
2.1. Low-Light Image Enhancement
2.1.1. Traditional Methods
2.1.2. Deep Learning-Based Methods
2.2. Semantic-Guided Methods
2.2.1. Loss-Level Semantic Guidance
2.2.2. Feature-Level Semantic Guidance
2.3. Section Summary
3. Overall Architecture
3.1. Original Network: LLFlow
3.2. SKF Framework
3.3. Overall Architecture of the LLIE Method
4. Model Details
4.1. Segmentation Network
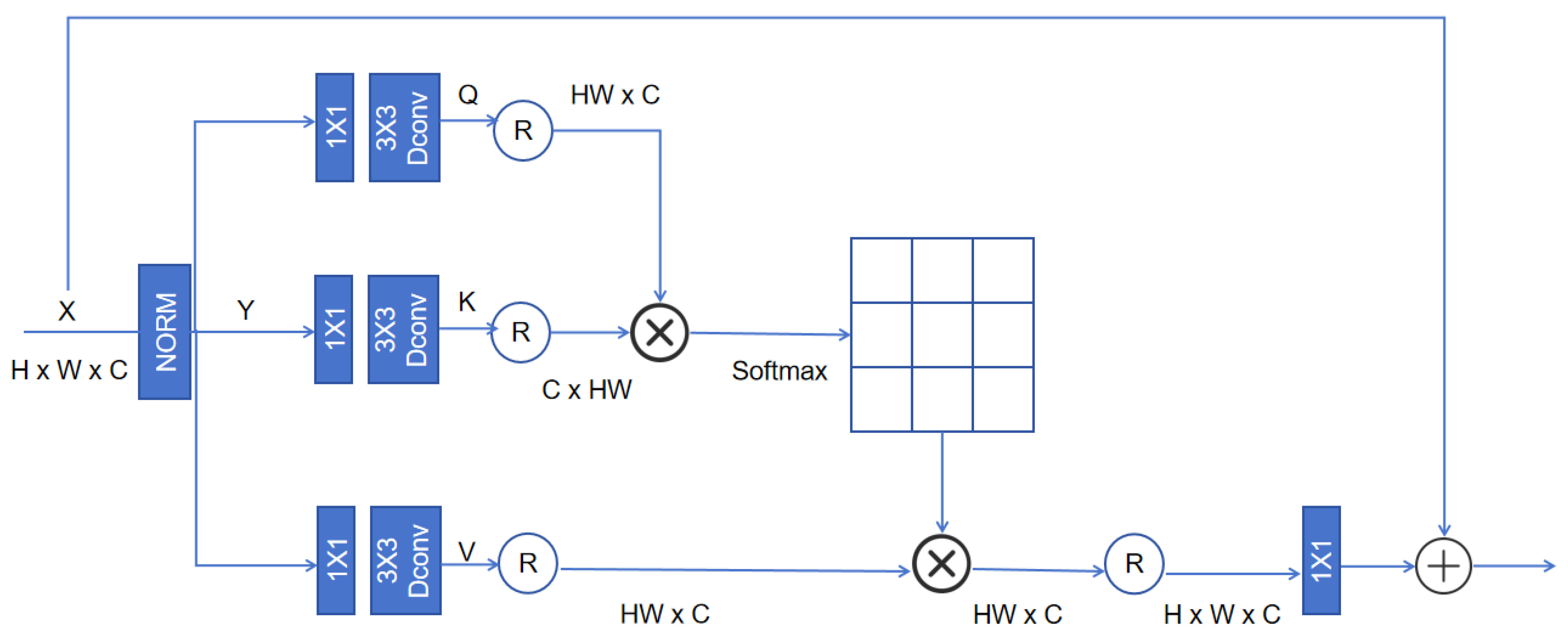
4.2. Semantic Feature Enhancement (SE) Module
4.2.1. Feature Alignment and Fusion
4.2.2. Semantic-Aware Attention Map
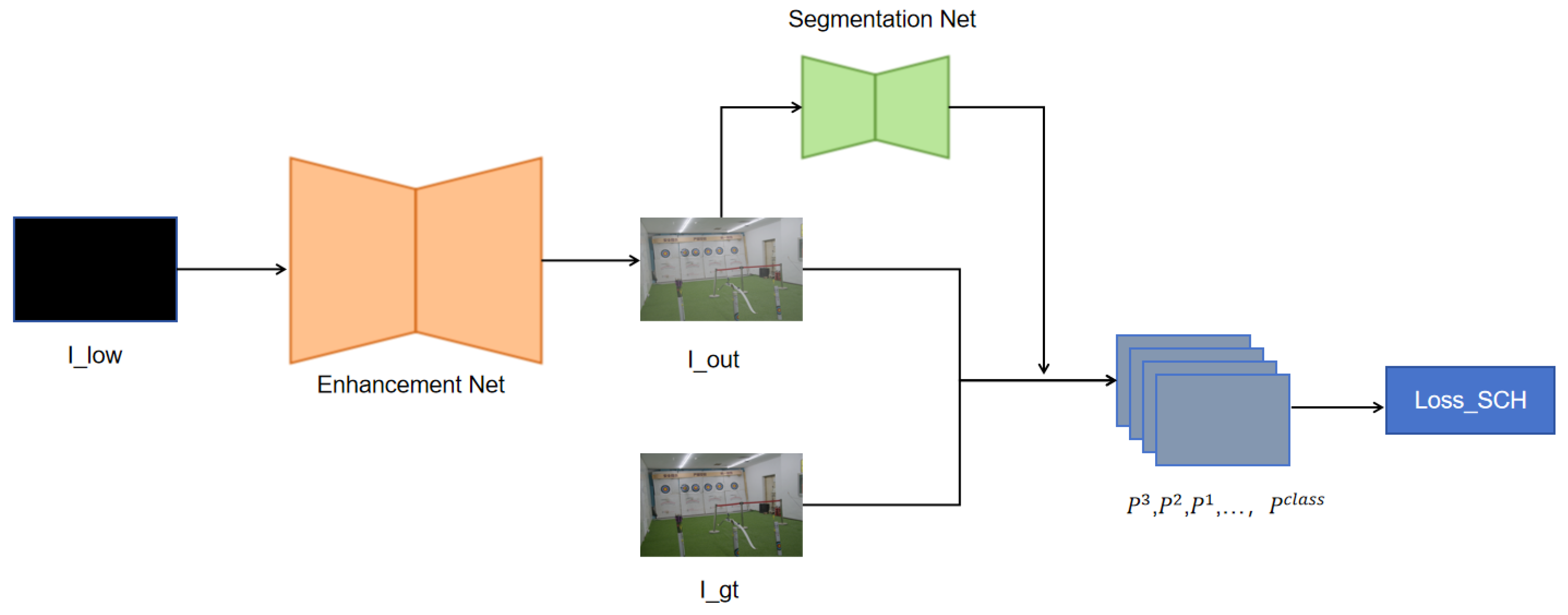
4.3. Semantic-Guided Color Histogram (SCH) Loss
4.3.1. Instance-Level Color Histogram Calculation
4.3.2. Differentiable Color Histogram Estimation
4.3.3. Semantic-Guided Color Histogram Loss
4.4. Semantically Guided Adversarial (SA) Loss
4.4.1. Semantically Guided Local Adversarial Loss
4.4.2. Semantically Guided Global Adversarial Loss
4.4.3. Overall Loss Function
4.5. Semantically Guided Multi-Color Space Loss
4.5.1. Selection and Analysis of Color Spaces
4.5.2. Semantically Guided Color Histogram Loss
4.6. Module Interactions Within the Framework
5. Experiments
5.1. Experimental Settings
- Peak Signal-to-Noise Ratio (PSNR): Measures pixel-level reconstruction accuracy. Higher values indicate better fidelity.
- Structural Similarity Index (SSIM): Assesses structural preservation in luminance, contrast, and texture. Values range [0, 1], with higher scores denoting superior structural consistency.
- Learned Perceptual Image Patch Similarity (LPIPS): Quantifies perceptual similarity using deep features. Lower values reflect better perceptual quality.
- Natural Image Quality Evaluator (NIQE): Blind image quality assessment without reference images. Lower scores indicate more natural outputs.
- Peak Signal-to-Noise Ratio under Low Resolution Conditions, LRC PSNR): PSNR computed under low-resolution conditions to evaluate robustness to resolution degradation.
5.2. Qualitative Analysis
5.3. Quantitative Analysis
5.4. Albation Studies
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Raji, A.; Thaibaoui, A.; Petit, E.; Bunel, P.; Mimoun, G. A gray-level transformation-based method for image enhancement. Pattern Recognit. Lett. 1998, 19, 1207–1212. [Google Scholar] [CrossRef]
- Yuan, Z.; Zeng, J.; Wei, Z.; Jin, L.; Zhao, S.; Liu, X. Clahe-based low-light image enhancement for robust object detection in overhead power transmission system. Procedia Eng. 2023, 38, 2240–2243. [Google Scholar] [CrossRef]
- Hao, W.; He, M.; Ge, H.; Wang, C.; Gao, Q. Retinex-like Method for Image Enhancement in Poor Visibility Conditions. Procedia Eng. 2023, 15, 2798–2803. [Google Scholar] [CrossRef]
- Lamba, M.; Mitra, K. Restoring extremely dark images in real time. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3487–3497. [Google Scholar]
- Maharjan, P.; Li, L.; Li, Z.; Xu, N.; Ma, C.; Li, Y. Improving extreme low-light image denoising via residual learning. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 916–921. [Google Scholar]
- Chen, C.; Chen, Q.; Xu, J.; Koltun, V. Learning to see in the dark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3291–3300. [Google Scholar]
- Liang, D.; Li, L.; Wei, M.; Yang, S.; Zhang, L.; Yang, W.; Du, Y.; Zhou, H. Semantically contrastive learning for low-light image enhancement. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 1555–1563. [Google Scholar]
- Reza, A.M. Realization of the contrast limited adaptive histogram equalization (CLAHE) for real-time image enhancement. J. VLSI Signal Process. Syst. Signal Image Video Technol. 2004, 38, 35–44. [Google Scholar] [CrossRef]
- Ibrahim, H.; Kong, N.S.P. Brightness preserving dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 2007, 53, 1752–1758. [Google Scholar] [CrossRef]
- Abdullah-Al-Wadud, M.; Kabir, M.H.; Dewan, M.A.A.; Chae, O. A dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 2007, 53, 593–600. [Google Scholar] [CrossRef]
- Veluchamy, M.; Subramani, B. Image contrast and color enhancement using adaptive gamma correction and histogram equalization. Optik 2019, 183, 329–337. [Google Scholar] [CrossRef]
- Chiu, Y.S.; Cheng, F.C.; Huang, S.C. Efficient contrast enhancement using adaptive gamma correction and cumulative intensity distribution. In Proceedings of the 2011 IEEE International Conference on Systems, Man, and Cybernetics, Anchorage, AK, USA, 9–12 October 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2946–2950. [Google Scholar]
- Ng, M.K.; Wang, W. A total variation model for retinex. SIAM J. Imaging Sci. 2011, 4, 345–365. [Google Scholar] [CrossRef]
- Kimmel, R.; Elad, M.; Shaked, D.; Keshet, R.; Sobel, I. A variational framework for retinex. Int. J. Comput. Vis. 2003, 52, 7–23. [Google Scholar] [CrossRef]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-Light Image/Video Enhancement Using CNNs. In Proceedings of the BMVC, Newcastle upon Tyne, UK, 3–6 September 2018; Northumbria University: Newcastle upon Tyne, UK, 2018; Volume 220, p. 4. [Google Scholar]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1632–1640. [Google Scholar]
- Zhang, Y.; Guo, X.; Ma, J.; Liu, W.; Zhang, J. Beyond brightening low-light images. Int. J. Comput. Vis. 2021, 129, 1013–1037. [Google Scholar] [CrossRef]
- Zhu, M.; Pan, P.; Chen, W.; Yang, Y. Eemefn: Low-light image enhancement via edge-enhanced multi-exposure fusion network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13106–13113. [Google Scholar]
- Li, J.; Li, J.; Fang, F.; Li, F.; Zhang, G. Luminance-aware pyramid network for low-light image enhancement. IEEE Trans. Multimed. 2020, 23, 3153–3165. [Google Scholar] [CrossRef]
- Wang, L.W.; Liu, Z.S.; Siu, W.C.; Lun, D.P. Lightening network for low-light image enhancement. IEEE Trans. Image Process. 2020, 29, 7984–7996. [Google Scholar] [CrossRef]
- Lim, S.; Kim, W. DSLR: Deep stacked Laplacian restorer for low-light image enhancement. IEEE Trans. Multimed. 2020, 23, 4272–4284. [Google Scholar] [CrossRef]
- Wang, C.; Wu, H.; Jin, Z. Fourllie: Boosting low-light image enhancement by fourier frequency information. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 7459–7469. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef]
- Yang, W.; Wang, S.; Fang, Y.; Wang, Y.; Liu, J. From fidelity to perceptual quality: A semi-supervised approach for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3063–3072. [Google Scholar]
- Zhang, L.; Zhang, L.; Liu, X.; Shen, Y.; Zhang, S.; Zhao, S. Zero-shot restoration of back-lit images using deep internal learning. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1623–1631. [Google Scholar]
- Zhu, A.; Zhang, L.; Shen, Y.; Ma, Y.; Zhao, S.; Zhou, Y. Zero-shot restoration of underexposed images via robust retinex decomposition. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Liu, R.; Ma, L.; Zhang, J.; Fan, X.; Luo, Z. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10561–10570. [Google Scholar]
- Liu, D.; Wen, B.; Liu, X.; Wang, Z.; Huang, T.S. When image denoising meets high-level vision tasks: A deep learning approach. arXiv 2017, arXiv:1706.04284. [Google Scholar]
- Aakerberg, A.; Johansen, A.S.; Nasrollahi, K.; Moeslund, T.B. Semantic segmentation guided real-world super-resolution. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 449–458. [Google Scholar]
- Wang, X.; Yu, K.; Dong, C.; Loy, C.C. Recovering realistic texture in image super-resolution by deep spatial feature transform. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 606–615. [Google Scholar]
- Fan, M.; Wang, W.; Yang, W.; Liu, J. Integrating semantic segmentation and retinex model for low-light image enhancement. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2317–2325. [Google Scholar]
- Wu, Y.; Pan, C.; Wang, G.; Yang, Y.; Wei, J.; Li, C.; Shen, H.T. Learning semantic-aware knowledge guidance for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1662–1671. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Granada, Spain, 20 September 2018; Proceedings 4. Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Avi-Aharon, M.; Arbelle, A.; Raviv, T.R. Deephist: Differentiable joint and color histogram layers for image-to-image translation. arXiv 2020, arXiv:2005.03995. [Google Scholar]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and locally consistent image completion. ACM Trans. Graph. (ToG) 2017, 36, 1–14. [Google Scholar] [CrossRef]
- Li, Y.; Liu, S.; Yang, J.; Yang, M.H. Generative face completion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3911–3919. [Google Scholar]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep Retinex Decomposition for Low-Light Enhancement. In Proceedingss of the British Machine Vision Conference, Newcastle, UK, 3–6 September 2018; British Machine Vision Association: Durham, UK, 2018. [Google Scholar]
- Yang, W.; Wang, W.; Huang, H.; Wang, S.; Liu, J. Sparse Gradient Regularized Deep Retinex Network for Robust Low-Light Image Enhancement. IEEE Trans. Image Process. 2021, 30, 2072–2086. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | LOL Dataset | LOL-v2 Dataset | ||||||
|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | LRC PSNR | PSNR | SSIM | LPIPS | LRC PSNR | |
| LLFlow | 27.476 | 0.942 | 0.078 | 6.502 | 27.524 | 0.91 | 0.111 | 7.787 |
| LLFlow-SKF | 30.804 | 0.945 | 0.064 | 6.503 | 29.194 | 0.912 | 0.093 | 7.755 |
| KinD++ | 18.970 | 0.804 | 0.175 | 5.605 | 19.087 | 0.817 | 0.180 | 6.372 |
| Zero-DCE | 14.861 | 0.562 | 0.335 | 5.103 | 18.059 | 0.580 | 0.313 | 5.843 |
| EnlightenGAN | 17.483 | 0.652 | 0.322 | 5.406 | 18.640 | 0.677 | 0.309 | 6.193 |
| Models | LOL Dataset | LOL-v2 Dataset | ||||||
|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | LRC PSNR | PSNR | SSIM | LPIPS | LRC PSNR | |
| LLFlow | 27.476 | 0.942 | 0.078 | 6.502 | 27.524 | 0.91 | 0.111 | 7.787 |
| LLFlow + SE | 28.121 | 0.942 | 0.074 | 6.502 | 27.979 | 0.91 | 0.101 | 7.778 |
| LLFlow + SE + SCH | 29.901 | 0.944 | 0.068 | 6.503 | 28.805 | 0.911 | 0.093 | 7.766 |
| LLFlow + SE + SCH + SA (LLFlow-SKF) | 30.804 | 0.945 | 0.064 | 6.503 | 29.194 | 0.912 | 0.093 | 7.755 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, B.; Wang, X.; Yang, N.; Liu, Y.; Chen, X.; Wu, Q. Semantic-Aware Low-Light Image Enhancement by Learning from Multiple Color Spaces. Appl. Sci. 2025, 15, 5556. https://doi.org/10.3390/app15105556
Jiang B, Wang X, Yang N, Liu Y, Chen X, Wu Q. Semantic-Aware Low-Light Image Enhancement by Learning from Multiple Color Spaces. Applied Sciences. 2025; 15(10):5556. https://doi.org/10.3390/app15105556
Chicago/Turabian StyleJiang, Bo, Xuefei Wang, Naidi Yang, Yuhan Liu, Xi Chen, and Qiwen Wu. 2025. "Semantic-Aware Low-Light Image Enhancement by Learning from Multiple Color Spaces" Applied Sciences 15, no. 10: 5556. https://doi.org/10.3390/app15105556
APA StyleJiang, B., Wang, X., Yang, N., Liu, Y., Chen, X., & Wu, Q. (2025). Semantic-Aware Low-Light Image Enhancement by Learning from Multiple Color Spaces. Applied Sciences, 15(10), 5556. https://doi.org/10.3390/app15105556