1. Introduction
Electrocardiogram (ECG) analysis for arrhythmia classification is crucial for the early detection and timely intervention of cardiac abnormalities, significantly reducing morbidity and mortality risks [
1]. Recent advances in deep learning have substantially improved arrhythmia detection performance; however, the practical applicability of these models remains limited due to their inability to generalize well across heterogeneous datasets [
2,
3]. Variations among ECG datasets, including differences in patient demographics, recording devices, clinical environments, and annotation granularities, significantly degrade the generalization capability of conventional ECG classification models [
4,
5,
6].
Traditional ECG arrhythmia classification methods typically rely on fully supervised learning paradigms, necessitating extensive datasets with fine-grained, beat-level annotations [
7,
8,
9,
10]. While these methods achieve strong performance in well-controlled scenarios, their dependency on precise annotations restricts scalability and applicability to new, coarsely annotated databases. Consequently, domain adaptation (DA) techniques have emerged to address these challenges by aligning data distributions across different domains [
11,
12,
13]. Although these approaches, including adversarial learning and explicit feature alignment, can mitigate cross-database discrepancies, they often require complex procedures and detailed labels from target databases [
14,
15].
Recent deep learning approaches, including CNN-based [
16], attention-based [
17], and transformer-based models [
18], have shown promising results in arrhythmia classification tasks. With advances in deep learning-based ECG classification, some works have also explored on-device arrhythmia monitoring using ultra-low-power, single-chip integrated circuits [
19,
20]. These systems integrate ECG acquisition, arrhythmia detection, and cardiovascular signal analysis into compact and energy-efficient platforms, underscoring the growing interest in mobile and wearable deployment scenarios. However, most studies still rely on single-database evaluation settings, and their generalizability across heterogeneous ECG datasets remains underexplored.
Lately, weakly supervised learning (WSL) has been proposed to reduce reliance on fine-grained annotations by utilizing coarse-grained, record-level labels [
21,
22]. Despite the success of WSL in other fields, the existing WSL-based ECG classification approaches have not explicitly addressed cross-database generalization challenges. They have primarily focused on single-database scenarios without adequately accounting for dataset variability, limiting their applicability to broader clinical practice [
23].
To address these limitations, we propose a novel two-stage cross-database learning framework for ECG arrhythmia classification that simultaneously utilizes both fine-grained and coarse-grained annotations. Our framework initially pretrains a beat-level classifier using fine-grained labels from a well-annotated dataset and then adapts the classifier to new datasets via weakly supervised learning with coarse-grained, record-level annotations. In contrast to traditional domain adaptation methods—such as adversarial learning or explicit feature alignment—which often require intricate procedures and detailed annotations, our approach effectively handles domain variability through weak supervision. This method is designed to improve the model’s robustness and generalization performance across a variety of ECG databases.
The objective of this study is to improve cross-database arrhythmia classification by utilizing both fine-grained and coarse-grained annotations together within a unified framework, while developing ECG classification models that are more adaptable to real-world clinical data conditions.
The main contributions of our work can be summarized as follows:
We introduce a cross-database generalization framework for ECG arrhythmia classification that utilizes a 2D beat-score-map (BSM) representation, derived from ECG signals, as the input to an ECG rhythm classifier. This 2D BSM representation effectively captures the beat-level features of the ECG signal, enhancing the classifier’s ability to differentiate arrhythmia rhythms.
We propose a two-stage learning approach that utilizes both fine-grained and coarse-grained labels from multiple datasets, thereby inherently addressing dataset discrepancies without the need for explicit alignment procedures. Our framework achieves domain adaptation implicitly through weakly supervised learning, ensuring robust generalization across diverse ECG databases.
Through cross-database experiments on publicly available benchmark datasets, we demonstrate that our method effectively captures class-specific ECG patterns across heterogeneous databases, consistently improving classification performance. Specifically, by supplementing the base model pretrained with fine-grained annotations from one database with coarse-grained annotations from other databases, we enhance the model’s ability to differentiate between various ECG rhythm types.
The remainder of this paper is organized as follows:
Section 2 discusses recent approaches to cross-database ECG classification, emphasizing domain adaptation techniques and weakly supervised learning.
Section 3 describes the proposed cross-database learning method based on BSMs in detail.
Section 4 presents extensive experimental results validating our approach on multiple ECG databases. Finally, in
Section 5, we conclude our work with some discussion.
3. Materials and Methods
The proposed Domain-Adapted Beat-Score-Map (DA-BSM) framework is designed to address the cross-database challenges in ECG analysis, including label scarcity and domain variability. This section describes the three core components of the framework: pretraining on fine-grained databases, weakly supervised domain adaptation for coarse-grained databases, and the final arrhythmia classification step. An overview of the entire process is provided in
Figure 1.
3.1. Datasets
We employed three arrhythmia datasets: MITDB, SPH, and PTB-XL. These datasets were chosen to encompass a range of annotation granularities and diverse patient populations.
Table 1 provides a structured overview of these datasets.
MIT-BIH Arrhythmia Database (MITDB) [
32]: This database contains 48 half-hour ECG recordings, each sampled at 360 Hz, using leads MLII and V5. For this study, only the MLII recordings were used. Each recording is annotated with 15 beat types at the R-peak positions, along with rhythm labels that include specific onset times. These detailed annotations provide the granularity required for training the beat-type classifier and evaluating its effectiveness on fine-grained data.
Shaoxing People’s Hospital (SPH) Arrhythmia Database [
33]: This database includes 10-s ECG recordings from 10,696 patients, sampled at 500 Hz using a 12-lead setup. This dataset was resampled to 360 Hz for consistency with the MITDB and PTB-XL dataset. For this study, only Lead II was used to ensure consistency in analysis while retaining sufficient information for classification. The annotations consist of 11 rhythm classes and nine specific beat types at the record level, making it ideal for testing the DA-BSM’s adaptability to coarse-grained annotations. The rhythms were grouped into four primary categories: SB, AFIB, the SR, and GSVT. These categories were selected for their clinical relevance and representation of diverse arrhythmia rhythm types.
Table 2 provides the sample distribution across these categories.
Physikalisch-Technische Bundesanstalt-XL (PTB-XL) [
35]: This database provides over 21,000 ECG recordings from approximately 18,000 patients, each 10 s long and recorded at 500 Hz. Record-level annotations include diagnostic labels for rhythm types and beat types. For consistency in analysis, only Lead II recordings were utilized in this study. Among the annotated rhythm types, we specifically focused on the sinus rhythm (SR) and atrial fibrillation (AFIB), as they are the most prevalent clinically significant arrhythmias and are widely studied in ECG arrhythmia research, and their reliable discrimination serves as an essential baseline for evaluating classification performance and clinical applicability.
Table 3 presents the sample distribution for these rhythm types. This setup is designed to assess the effectiveness of ECG signal classification, even when coarse-grained annotations are used.
3.2. Pretraining the Beat-Type Classifier on Fine-Grained Database
To start the proposed framework, we use the MIT-BIH Arrhythmia Database (MITDB), which provides fine-grained annotations, including beat-level labels for each R peak and rhythm annotations with the corresponding onset and offset [
32]. To reduce the impact of signal noise, we applied discrete wavelet transform using the Daubechies-4 wavelet, while preserving key morphological features. Unlike conventional bandpass filtering (e.g., 0.5–40 Hz), the wavelet transform attenuates noise through multiresolution decomposition, without requiring a fixed pass-band. A convolutional neural network (CNN) is then pretrained on the denoised dataset to learn the primitive features of multiple beat types, such as waveform morphology, from ECG beat segments. This model follows a 1D convolutional neural network architecture adapted from the VGG16 structure [
36]. While the rhythm classification model in our framework is based on a modified VGG16 architecture for its proven performance in hierarchical feature extraction, the framework itself is compatible with alternative CNN structures. In our implementation, we employed all five convolutional blocks of VGG16, followed by a global average pooling layer and two fully connected layers. All layers were trained from scratch. The total number of parameters is approximately 14.7 million, all of which are trainable. The remaining parameters are batch normalization statistics and model buffers.
In our model implementation, we use 2.4-s-long beat-centered ECG segments as the input and classify them into 15 beat types annotated in the MITDB, including normal (N), premature ventricular contraction (V), and atrial premature (A) beats. A complete list of beat types used in this study is provided in
Appendix A Table A1. The CNN architecture consists of multiple convolutional and pooling layers followed by fully connected layers, optimized with categorical cross-entropy loss. The beat-type classifier learned through this process becomes a kind of feature extractor that captures the intrinsic characteristics of the ECG signal for several predefined beat types. This 15-class beat-label configuration follows the standard MITDB annotations, which we also used in our previous work [
34]. The weights of the pretrained classifier serve as initialization for the subsequent domain adaptation process and are later further refined to adapt to coarse-grained databases.
3.3. Weakly Supervised Domain Adaptation on Coarse-Grained Database
Unlike the MITDB, which provides fine-grained annotations, coarse-grained databases such as the SPH and PTB-XL ones only provide record-level labels indicating the presence or absence of specific beat or rhythm types for each record and do not provide detailed beat-level annotations. Hence, we bridge the gap between the two databases by applying WSL to tune the pretrained beat-type classifier on the MITDB against the coarse-grained database.
Specifically, the input ECG record is segmented into smaller time intervals, called ECG beat segments, and each segment is applied to a pretrained beat-type classifier. This produces a beat-type score vector for each segment, where each component of the vector represents a prediction score for a different beat type. The beat-type score vectors of all segments are aggregated using a global max pooling operation to produce a single prediction score vector for the entire record, called the global prediction score vector. The global predictions are compared to the record-level labels, and the weights of the pretrained beat-type classifier are optimized to minimize the discrepancy between the aggregated global predictions and the actual record-level labels. This optimization ensures that the beat-type classifier adapts effectively to coarse-grained annotations while retaining its ability to classify individual beat segments into multiple predefined beat types.
Figure 2 illustrates the weakly supervised learning (WSL)-based domain adaptation process for the pretrained beat-type classifier. In this approach, domain adaptation is achieved implicitly during the WSL process, eliminating the need for explicit domain alignment. By this process, the weak-beat-type labels provided in the coarse-grained database guide the beat-type classifier to extract beat-level features that are invariant across domains, enhancing the classifier’s robustness and adaptability.
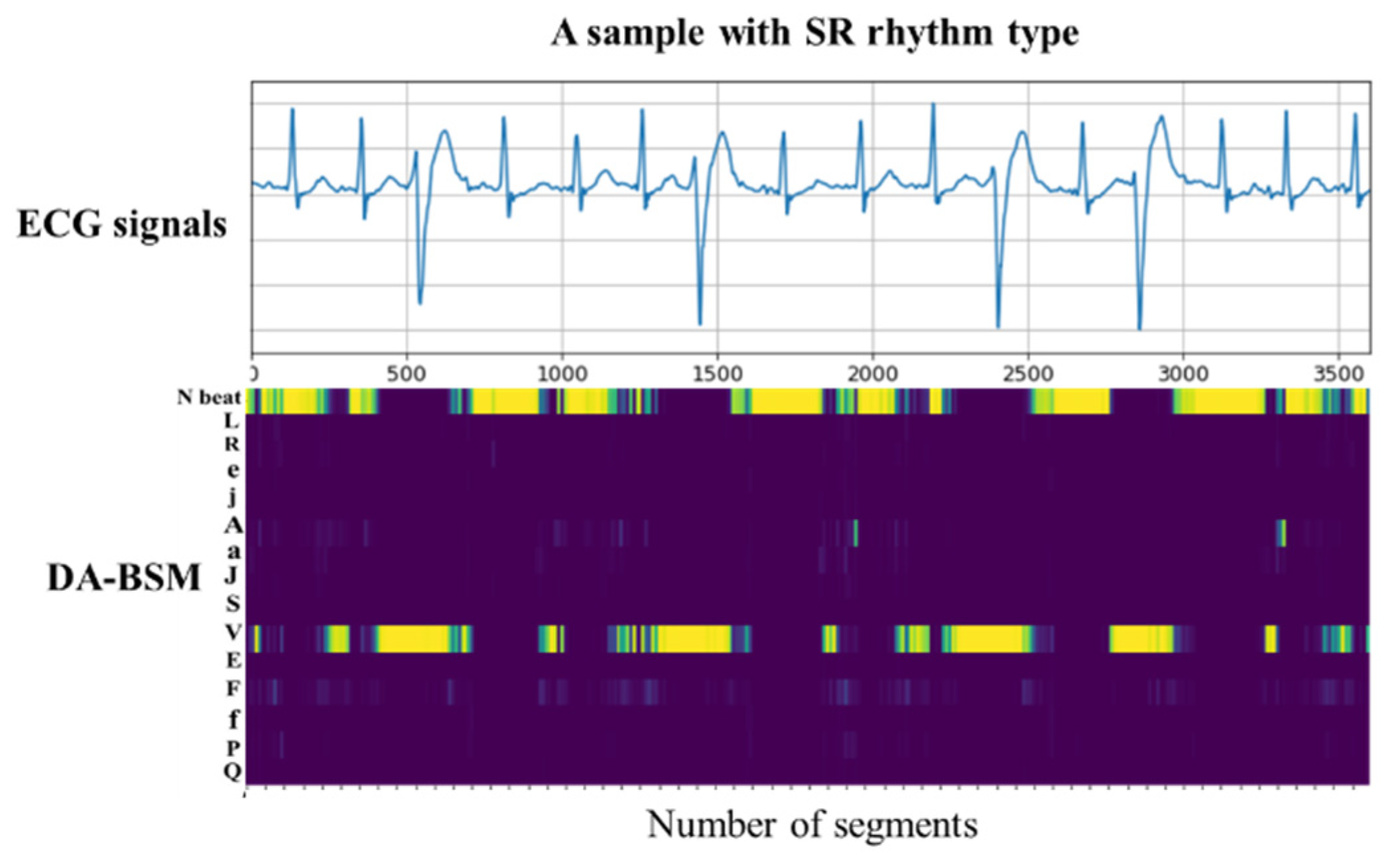
3.4. Generating Domain-Adapted Beat-Score Maps (DA-BSMs)
After the WSL-based adaptation process, the adapted beat-type classifier is employed to generate a Domain-Adapted Beat-Score Map (DA-BSM) for the input ECG signal. The input signal is first segmented into a sequence of beat-centered segments, each of which is passed through the adapted classifier to produce a beat-type score vector. These vectors are temporally aligned and stacked in the order of occurrence, forming a two-dimensional We checked and added explanation matrix in which each column corresponds to a beat-type score vector and each row corresponds to the prediction scores for a specific beat type over all beat-centered segments. This DA-BSM encodes the time-varying distribution of the beat-type predictions, effectively representing the dynamic rhythm structure of the input signal. An example of this transformation from the ECG signal to the DA-BSM is illustrated in
Figure 3.
Since the beat-type classifier is adapted using weakly supervised learning with record-level labels, the resulting score maps contain features that are both robust to domain differences and sensitive to label information. The DA-BSM representation acts as an intrinsic feature map, capturing the underlying characteristics of the input ECG signals, thereby improving the generalizability of our method across diverse databases.
The proposed method ensures that the beat-type classifier is optimized for each new database. For instance, in the SPH dataset with nine beat types, the DA-BSM method focuses on refining the features of the nine beat types present in the coarsely annotated SPH dataset. In contrast, for the remaining beat types learned from the MITDB but not present in the SPH dataset, the features undergo only minimal adjustments due to the preceding refinement process. This adaptation helps mitigate domain discrepancies arising from differences in measurement environments, sensors, and patient demographics, thereby enhancing the method’s generalization ability across diverse databases.
3.5. ECG Arrhythmia Classification with DA-BSMs
The DA-BSM generated in the preceding step is fed into a rhythm classification model trained to identify a set of rhythm types, depending on the datasets. In our experiments, these include rhythm categories such as a normal sinus rhythm (SR), atrial fibrillation (AFIB), grouped supraventricular tachycardia (GSVT), and sinus bradycardia (SB). This process utilizes the spatially structured features encoded in the DA-BSM to enhance rhythm-level classification performance.
Each DA-BSM is constructed as a 2D matrix of shape (T, C), where T denotes the number of beat-type score vectors and C represents the number of beat types. For example, with 360 segments and 15 beat types, the input matrix has a shape of 360 × 15. This shape may vary across datasets depending on segmentation and beat types.
For this purpose, we employ a 2D CNN model based on the VGG16 architecture, chosen for its effectiveness in capturing spatial patterns in image-like representations such as DA-BSMs. While our current implementation uses VGG16 for consistency across stages, the framework itself is compatible with other standard CNN architectures.
Figure 4 provides an overview of the model architecture.
The rhythm classification model architecture remained the same across all experiments. Only the output layer size was adjusted depending on the number of rhythm classes in each dataset (e.g., four classes for the SPH dataset, two classes for the PTB-XL dataset).
4. Results
4.1. Experimental Setup
To match the input signal characteristics, we used 360 Hz resampled signals from Lead II across all datasets, as described in the respective dataset subsections. Based on the preprocessing and dataset setup described in
Section 3, we conducted a series of experiments to evaluate the robustness and generalizability of the proposed DA-BSM framework.
The evaluation process was designed to assess the robustness and generalizability of the proposed DA-BSM framework across heterogeneous ECG datasets with varying annotation granularities. Specifically, the framework first involved pretraining a beat-level classifier using all labeled beat segments contained within the 48 ECG recordings of the MITDB. These fine-grained labels enabled the model to effectively learn detailed beat-level characteristics essential for accurate arrhythmia classification.
In contrast, the SPH and PTB-XL datasets, which contain only coarse-grained annotations at the record level, were partitioned into training (80%), validation (10%), and test (10%) subsets. This strategic partitioning allowed us to rigorously evaluate the model’s capability to adapt the fine-grained knowledge acquired from MITDB pretraining to datasets characterized by limited labeling granularity.
During training, the Adam optimizer with a learning rate of 0.0001 was employed, and early stopping criteria were applied to mitigate overfitting. Training was conducted for a maximum of 50 epochs. Categorical cross-entropy loss was utilized for the arrhythmia classification task, while binary cross-entropy loss was applied during the WSL-based domain adaptation phase. This training procedure ensured that the model effectively transferred learned beat-level patterns to new, coarsely annotated datasets, thus demonstrating enhanced robustness and generalization performance.
We provided training and validation curves for the rhythm classifier in
Figure 5. While minor fluctuations are observed, the validation accuracy exhibits convergence in both datasets. Early stopping based on validation loss was applied to prevent overfitting and ensure stable model training. All models were implemented in Python 3.10, While Python’s development started in the Netherlands, the Python Software Foundation, which now maintains the language, is based in the United States, using TensorFlow 2.10 and Keras and trained on a desktop PC equipped with an NVIDIA RTX 3070 GPU.
Several performance metrics—including accuracy, sensitivity, specificity, and F1 score—were computed on the test subsets of the SPH and PTB-XL datasets to quantitatively evaluate the effectiveness of the proposed framework. This comprehensive experimental setup ensured that the models were thoroughly validated on unseen data, providing reliable results.
4.2. Arrhythmia Classification Using DA-BSMs for Coarse-Grained Databases
The proposed DA-BSM-based ECG classification framework was evaluated using multiple ECG databases to address domain discrepancies caused by inter-individual differences, varying measurement conditions, and annotation granularities. Specifically, two heterogeneous datasets, the SPH and PTB-XL ones, which contain recordings from diverse patient populations and exhibit coarse-grained annotation, were used to rigorously assess the framework’s domain adaptability. Additionally, we compared the classification performance of our proposed approach against state-of-the-art methods to validate its effectiveness and generalizability.
4.2.1. Evaluation with SPH Database
Table 4 summarizes the classification performance for four arrhythmia rhythm types on the SPH database. The proposed DA-BSM approach achieved a precision, recall, F1-score, and accuracy of 0.9306, 0.9299, 0.9301, and 0.9380, respectively, clearly outperforming the baseline BSM method (denoted as “Pretraining-only” in
Table 4). These results demonstrate the effectiveness of our weakly supervised domain adaptation in improving classification performance, particularly in scenarios with limited annotations. When trained exclusively on the coarsely annotated SPH dataset (denoted as “Coarse-only” in
Table 4), the accuracy was 0.8628. Pretraining solely on the finely annotated MITDB dataset increased the accuracy to 0.9243, while incorporating weakly supervised adaptation after pretraining further improved the accuracy to 0.9380. This performance progression underscores the advantage of the DA-BSM framework in effectively utilizing both fine-grained and coarse-grained annotations, thus ensuring strong adaptability and generalization across diverse ECG database environments.
Further analysis of the SPH database revealed that the DA-BSM method achieved performance improvements, especially for complex arrhythmias such as GSVT and AFIB, which involve prominent morphological variations and interval irregularities.
Table 5 summarizes the detailed F1-scores for these complex rhythms, clearly demonstrating the enhanced adaptability of the DA-BSM method compared to the baseline methods. These improvements confirm that the weakly supervised domain adaptation strategy effectively captures subtle morphological differences and dynamic signal characteristics across patient populations and varying measurement conditions, thereby addressing the inherent variability of ECG signals.
To validate the effectiveness of our DA-BSM approach,
Table 6 presents a performance comparison with state-of-the-art ECG arrhythmia classification methods. While the existing methods typically require multiple leads or extensive preprocessing steps, the DA-BSM method demonstrates significant performance improvement using only a single lead, highlighting its practicality and computational efficiency. For instance, Yoon et al. [
37] reported a high accuracy of 0.952, but their method requires all 12 leads and generates large-scale, high-resolution image representations (e.g., two 299×299 images per sample), resulting in a more complex and resource-intensive processing pipeline. Aziz et al. [
38] achieved an accuracy of 0.907, but their approach depends on additional demographic information (e.g., age and gender), limiting practicality under resource-constrained conditions. Jang et al. [
39] simplified the input requirement to a single lead; however, their reported F1-score of 0.86 indicates limitations in accurately classifying complex arrhythmias and achieving robust generalizability. In contrast, our proposed DA-BSM method effectively achieves a superior classification performance with an F1-score of 0.9301, requiring minimal preprocessing and utilizing a single ECG lead, thereby emphasizing its potential advantage in real-world clinical applications.
To visually demonstrate the advantages of the DA-BSM framework,
Figure 6 presents the t-distributed stochastic neighbor embedding (t-SNE) [
41] visualizations of the ECG data distributions at different stages of the proposed method. In this figure, panel (A) depicts the raw data distribution without any preprocessing or adaptation, where significant overlap among rhythm classes (AFIB, SB, SR, GSVT) in the ECG signals is evident. Panel (B) illustrates the limited class separation achieved by training exclusively with weakly supervised learning (WSL) on coarse-grained annotations, without pretraining. Panel (C) highlights the improved separability obtained from pretraining alone on the fine-grained MITDB dataset. Panel (D) shows significantly enhanced and clearly distinguishable rhythm clusters by the combination of pretraining and weakly supervised adaptation. These results visually underscore the effectiveness of our proposed approach in enhancing class distinction, robustness, and adaptability across heterogeneous ECG datasets.
4.2.2. Evaluation with PTB-XL Database
Table 7 provides a classification performance comparison for the PTB-XL database, revealing consistent trends with the previous results; the DA-BSM approach significantly outperformed the baseline methods. The DA-BSM effectively mitigated domain differences, demonstrating strong robustness and adaptability across datasets. An ablation study further assessed the individual contributions of pretraining (fine-grained annotations from the MITDB) and WSL-based adaptation. The results indicate that combining pretraining with WSL-based adaptation yielded the best classification performance, emphasizing the complementary role of these components in handling coarse-grained annotations.
In particular, our results on the PTB-XL database showed superior performance in classifying AFIB, where the quasi-periodic rhythm characteristics were effectively captured and adapted.
Table 8 specifically highlights the improvements achieved by the DA-BSM method in classifying the SR and AFIB rhythm types.
To further validate the efficacy of the DA-BSM framework, a comparative analysis was conducted with existing state-of-the-art ECG arrhythmia classification methods on the PTB-XL database.
Table 9 presents the key performance metrics, highlighting the advantages of the DA-BSM method in terms of accuracy and generalization performance compared to recent approaches.
In the study by Vasconcelos et al. [
42], ECG signals were converted into image representations in both the time and frequency domains separately for each lead. Although this approach achieved a high F1-score of 0.960, the requirement of all 12 ECG leads and the extensive data resampling to handle class imbalances limit its applicability in real-world clinical environments. Choi et al. [
43] utilized an autoencoder-based anomaly detection method designed to distinguish AFIB from the SR by measuring reconstruction errors. Despite achieving a robust F1-score of 0.925 with a single lead, this method’s dependence on significant resampling restricts its scalability. Smigiel et al. [
44] proposed a lightweight CNN utilizing entropy-based features extracted from normalized ECG signals, achieving computational efficiency but a comparatively lower F1-score of 0.8910, highlighting its limitations in classifying complex arrhythmias like AFIB.
In contrast, the proposed DA-BSM framework demonstrated competitive performance (F1-score: 0.9267) while requiring only a single lead and eliminating the need for data resampling. By effectively bridging the gap between fine-grained and coarse-grained annotations, the DA-BSM ensures strong adaptability and consistent generalization performance across heterogeneous ECG databases and diverse clinical environments.
To visually illustrate the benefits of the DA-BSM framework,
Figure 7 presents t-SNE visualizations of the ECG data distributions from the PTB-XL database at different stages of the proposed method. In this figure, panel (A) depicts the raw ECG data distribution without any preprocessing or domain adaptation, showing considerable overlaps between rhythm classes (SR and AFIB). Panel (B) illustrates the limited class separation obtained by training exclusively with WSL using coarse-grained annotations without pretraining. Panel (C) demonstrates the improved separability achieved by pretraining alone on the fine-grained MITDB dataset, though the overlaps between classes remain noticeable. Finally, panel (D) shows distinct and clearly separated rhythm clusters resulting from the combined application of pretraining and weakly supervised adaptation. These visual results further underscore the effectiveness of the proposed approach in enhancing class distinction, robustness, and generalization performance across heterogeneous ECG databases.
5. Conclusions
This study introduces a novel cross-database learning framework for ECG arrhythmia classification based on a 2D BSM representation. By effectively utilizing both fine-grained beat-level annotations and coarse-grained record-level annotations, our approach addresses the limitations of the existing supervised and weakly supervised methods. Unlike other approaches for cross-database applications, we pretrain on fine-grained annotated databases and then implicitly incorporate domain adaptation via weakly supervised learning on coarse-grained annotated databases to improve model generalization on heterogeneous datasets.
Experimental evaluations on the SPH and PTB-XL datasets demonstrate that the proposed framework consistently outperforms the baseline methods that do not use pretraining or weakly supervised adaptation, achieving F1 scores of 0.9301 and 0.9267 for classifying different arrhythmia rhythm types, respectively. Additionally, t-SNE visualizations clearly confirmed the proposed framework’s capability to distinctly separate complex arrhythmia classes, enhancing both classification performance and clinical applicability.
Despite its advantages, our proposed method has several limitations. Firstly, its effectiveness depends on the accuracy and granularity of the available record-level annotations, indicating that incorrect or overly coarse labels could reduce classification accuracy. Integrating additional semi-supervised or self-supervised methods could further enhance the discriminative capability of the learned BSM embeddings, leading to improved overall classification performance. Moreover, computational efficiency remains a challenge; optimizing the framework for efficient real-time processing, especially in wearable and mobile devices, would significantly enhance its practical deployment in clinical settings. While this study conducted experiments on a PC equipped with a GPU, it would be worthwhile to investigate how the framework could be adapted for energy-constrained environments, such as embedded or portable systems.
Future research directions include validating the framework’s generalizability across a broader range of public and clinical ECG databases. Furthermore, extending the DA-BSM beyond ECGs to multimodal biomedical signals such as PPG and EEG could increase its clinical utility. Such extensions would not only demonstrate the versatility of our method but also facilitate the development of scalable multimodal diagnostic solutions. By continuing to enhance the efficiency and adaptability of the DA-BSM framework, we aim to establish a robust foundation for practical, real-time, and clinically meaningful biomedical signal analysis applications.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}