
An Improved YOLOv8-Based Dense Pedestrian Detection Method with Multi-Scale Fusion and Linear Spatial Attention


Abstract
1. Introduction
- (a)
- Occluded pedestrians exhibit sparse or blurred features, hindering effective feature extraction by neural networks.
- (b)
- Overcrowding leads to reduced individual target resolution, increasing missed-detection rates.
- (c)
- Complex background features in dense scenes impair accurate classification and localization, causing false positives.
- (1)
- We designed a C2f_D2CN module to address the challenge of extracting small-scale pedestrian features in dense scenarios. This module enhances feature extraction capability by incorporating a backbone network improved with deformable convolution and dynamic convolution. Additionally, a multi-scale linear spatial attention module was designed to enhance the visible features of occluded pedestrians while suppressing interference from complex backgrounds.
- (2)
- We integrated a small-scale pedestrian detection head into the neck of the YOLOv8 network, effectively improving the detection accuracy of small-scale pedestrians in dense scenarios. Additionally, to improve training efficiency, we designed a novel loss function named DFL-SIoU, which enhances model convergence and achieves better bounding box regression performance.
- (3)
- We conducted experiments on two challenging dense pedestrian datasets, CrowdHuman and WiderPerson, and the detection accuracy showed significant improvement compared to most existing methods.
2. Related Work
2.1. Pedestrian Detection
2.2. Dense Pedestrian Detection
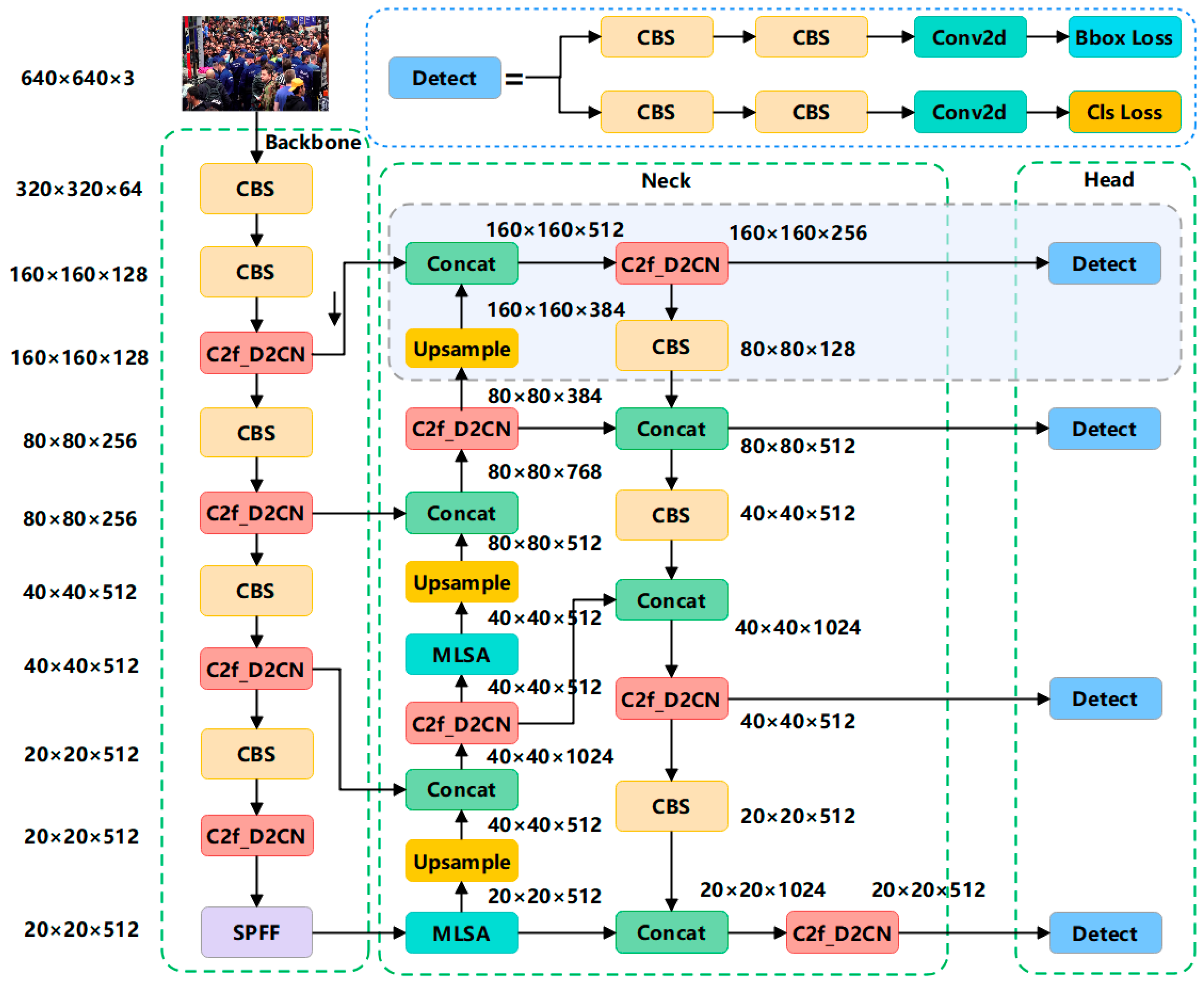
3. Methodology
3.1. C2f-D2CN Module
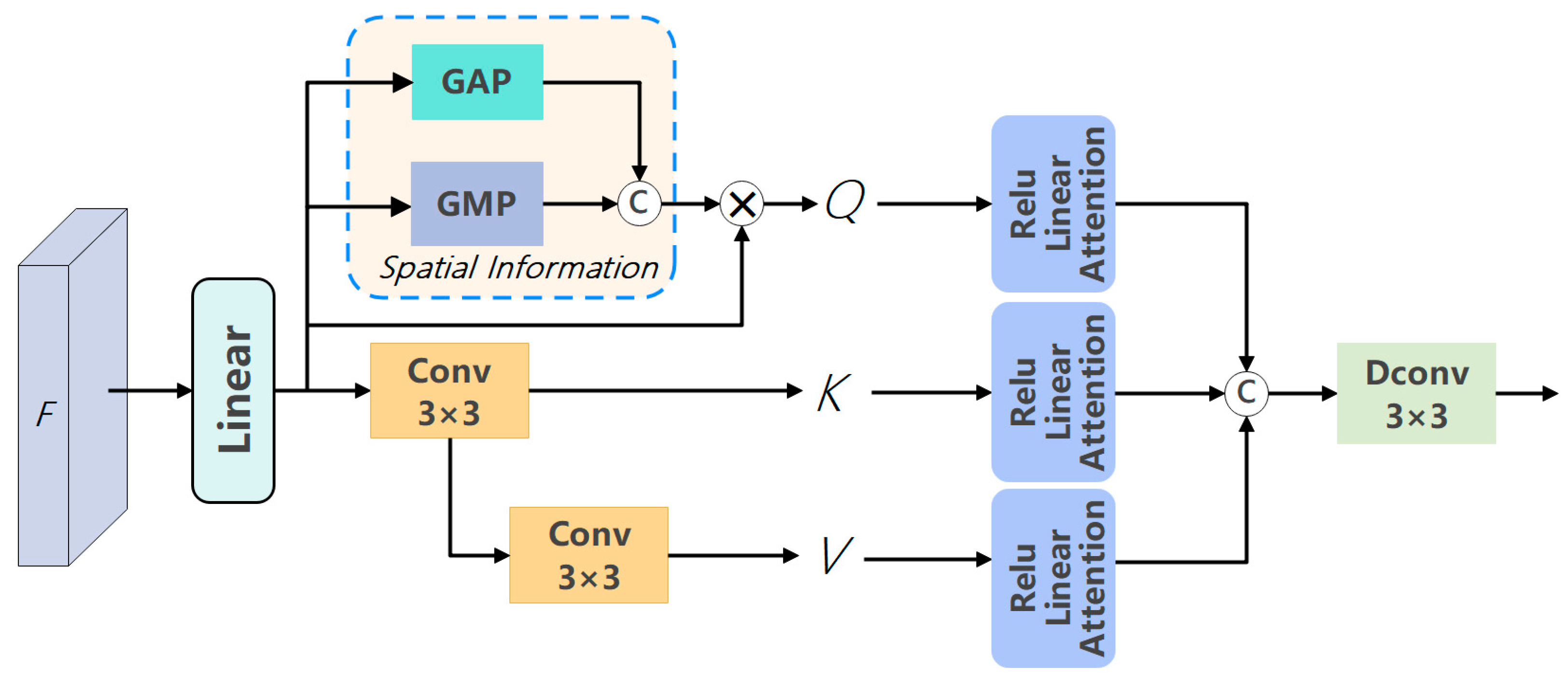
3.2. Multi-Scale Linear Spatial Attention Module
3.3. Add Small-Target Detection Head
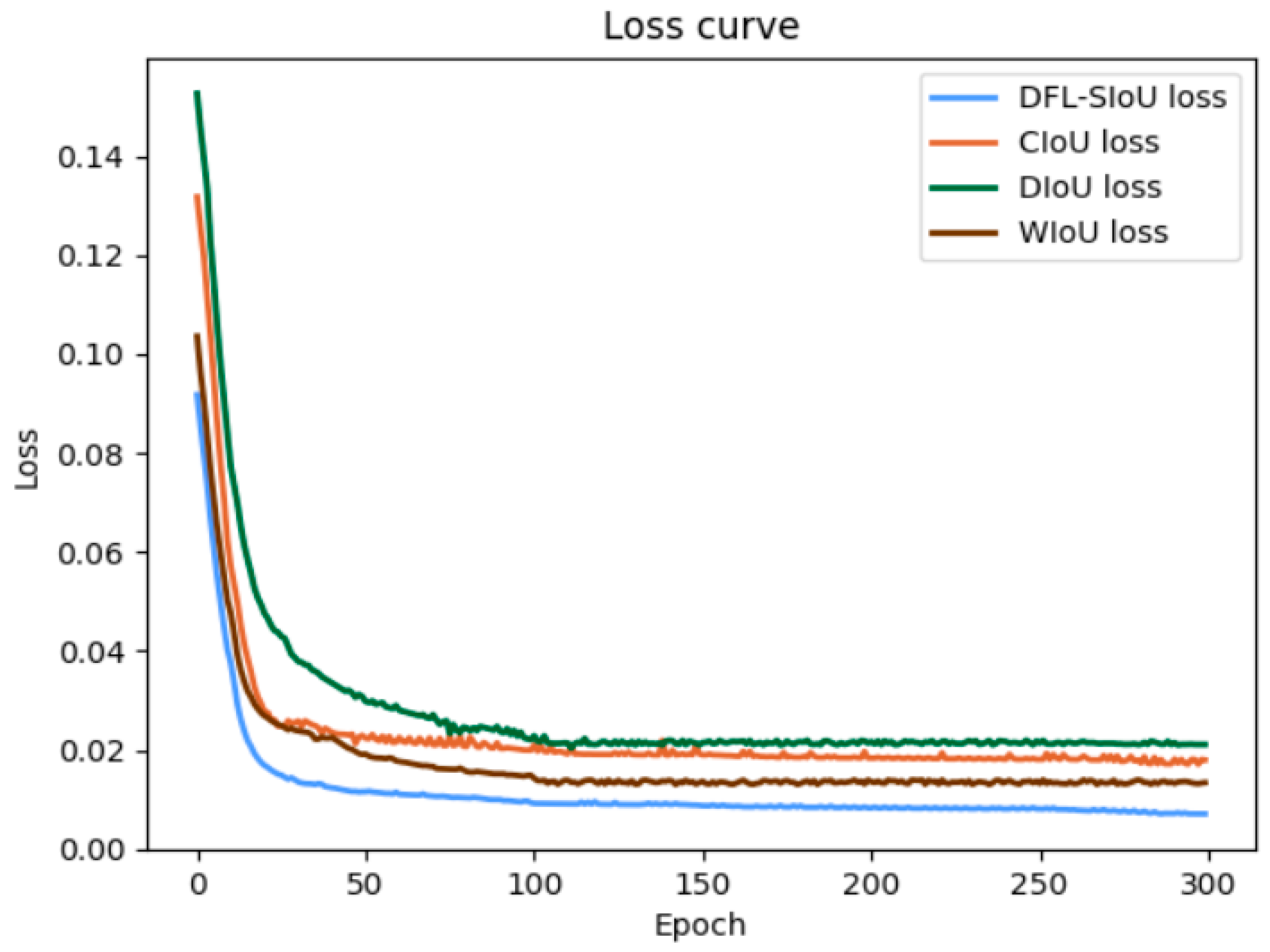
3.4. DFL-SIoU Loss Function
4. Experiments and Results
4.1. Datasets
4.2. Experimental Environment and Implementation Details
4.3. Evaluation Metrics
4.4. Ablation Experiment
4.4.1. Module Ablation Experiment
4.4.2. Ablation Experiment on C2f_D2CN
4.4.3. Ablation Experiment on Attention Mechanisms
4.4.4. Ablation Experiment on Loss Function
4.4.5. Ablation Experiment on Parameters
4.5. Comparison with State-of-the-Art Methods
4.6. Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, Q.; Wang, J.; Deng, Y.H. Pedestrian detection and tracking algorithm based on occlusion-aware. Transducer Microsyst. Technol. 2023, 42, 126–130. [Google Scholar]
- Zhang, T.; Ye, Q.; Zhang, B.; Liu, J.; Zhang, X.; Tian, Q. Feature calibration network for occluded pedestrian detection. IEEE Trans. Intell. Transp. Syst. 2020, 23, 4151–4163. [Google Scholar] [CrossRef]
- Liu, Y.; Yu, C.Y.; Li, G.Y.; Pan, Y.H. UAST-RCNN: Object detection algorithm for blocking pedestrians. J. Electron. Meas. Instrum. 2022, 36, 168–175. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; He, H.; Li, J.; Li, Y.; See, J.; Lin, W. Variational pedestrian detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 11622–11631. [Google Scholar] [CrossRef]
- Chu, X.; Zheng, A.; Zhang, X.; Sun, J. Detection in crowded scenes: One proposal, multiple predictions. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 12214–12223. [Google Scholar] [CrossRef]
- Hong, M.; Li, S.; Yang, Y.; Zhu, F.; Zhao, Q.; Lu, L. SSPNet: Scale selection pyramid network for tiny person detection from UAV images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Huang, S.; Lu, Z.; Cheng, R.; He, C. FaPN: Feature-aligned pyramid network for dense image prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 864–873. [Google Scholar] [CrossRef]
- Terven, J.; Cordova-Esparza, D.M.; Romero-Gonzalez, J.A. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLOv8, 2023. Available online: https://github.com/ultralytics/ultralytics/tree/v8.0.6 (accessed on 6 January 2025).
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Li, J.; Liang, X.; Shen, S.; Xu, T.; Feng, J.; Yan, S. Scale-aware fast R-CNN for pedestrian detection. IEEE Trans. Multimed. 2017, 20, 985–996. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. pp. 21–37. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Dong, C.; Luo, X. Research on a Pedestrian Detection Algorithm Based on Improved SSD Network. J. Phys. Conf. Ser. 2021, 1802, 032073. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Mark Liao, H.-Y. Yolov9: Learning what you want to learn using programmable gradient information. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2024; pp. 1–21. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar] [CrossRef]
- Jocher, G.; Qiu, J. Ultralytics YOLO11, 2024. Available online: https://github.com/ultralytics/ultralytics (accessed on 1 March 2025).
- Fu, P.; Zhang, X.; Yang, H. Answer sheet layout analysis based on YOLOv5s-DC and MSER. Vis. Comput. 2024, 40, 6111–6122. [Google Scholar] [CrossRef]
- Xu, Z.; Li, B.; Yuan, Y.; Dang, A. Beta r-cnn: Looking into pedestrian detection from another perspective. Adv. Neural Inf. Process. Syst. 2022, 33, 19953–19963. [Google Scholar] [CrossRef]
- Wang, J.; Song, L.; Li, Z.; Sun, H.; Sun, J.; Zheng, N. End-to-end object detection with fully convolutional network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 15849–15858. [Google Scholar] [CrossRef]
- Li, N.; Bai, X.; Shen, X.; Xin, P.; Tian, J.; Chai, T.; Wang, Z. Dense pedestrian detection based on GR-YOLO. Sensors 2024, 24, 4747. [Google Scholar] [CrossRef]
- Dong, C.; Tang, Y.; Zhu, H.; Zhang, L. HCA-YOLO: A non-salient object detection method based on hierarchical attention mechanism. Clust. Comput. 2024, 27, 9663–9678. [Google Scholar] [CrossRef]
- Li, H.; Zhang, S.; Hu, L. Towards real-time accurate dense pedestrian detection via large-kernel perception module and multi-level feature fusion. J. Real-Time Image Process. 2025, 22, 16. [Google Scholar] [CrossRef]
- An, R.; Zhang, X.; Sun, M.; Wang, G. GC-YOLOv9: Innovative smart city traffic monitoring solution. Alex. Eng. J. 2024, 106, 277–287. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11030–11039. [Google Scholar]
- Katharopoulos, A.; Vyas, A.; Pappas, N.; Fleuret, F. Transformers are rnns: Fast autoregressive transformers with linear attention. In Proceedings of the International Conference on Machine Learning, Online, 13–18 July 2020. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inform. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inform. Process. Syst. 2020, 33, 21002–21012. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar] [CrossRef]
- Shao, S.; Zhao, Z.; Li, B.; Xiao, T.; Yu, G.; Zhang, X.; Sun, J. CrowdHuman: A Benchmark for Detecting Human in a Crowd. arXiv 2018, arXiv:1805.00123. [Google Scholar] [CrossRef]
- Zhang, S.; Xie, Y.; Wan, J.; Xia, H.; Li, S.Z.; Guo, G. Widerperson: A diverse dataset for dense pedestrian detection in the wild. IEEE Trans. Multimedia 2019, 22, 380–393. [Google Scholar] [CrossRef]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 743–761. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11534–11542. [Google Scholar] [CrossRef]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023. [Google Scholar] [CrossRef]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Zanjia, T.; Yuhang, C.; Zewei, X.; Rong, Y. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS--improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Adaptive nms: Refining pedestrian detection in a crowd. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6459–6468. [Google Scholar] [CrossRef]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation networks for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 3588–3597. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar] [CrossRef]
- Xu, H.-h.; Wang, X.-q.; Wang, D.; Duan, B.-g.; Rui, T. Object detection in crowded scenes via joint prediction. Def. Technol. 2023, 21, 103–115. [Google Scholar] [CrossRef]
- Wu, J.; Zhou, C.; Zhang, Q.; Yang, M.; Yuan, J. Self-mimic learning for small-scale pedestrian detection. In Proceedings of the ACM International Conference on Multimedia, Online, 12–16 October 2020. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar] [CrossRef]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Luo, P. Sparse R-CNN: An End-to-End Framework for Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 15650–15664. [Google Scholar] [CrossRef]
- Zheng, A.; Zhang, Y.; Zhang, X.; Qi, X.; Sun, J. Progressive end-to-end object detection in crowded scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 857–866. [Google Scholar] [CrossRef]
- Ci, Y.; Wang, Y.; Chen, M.; Tang, S.; Bai, L.; Zhu, F.; Zhao, R.; Yu, F.; Qi, D.; Ouyang, W. Unihcp: A unified model for human-centric perceptions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 17840–17852. [Google Scholar] [CrossRef]
- Tang, Y.; Liu, M.; Li, B.; Wang, Y.; Ouyang, W. OTP-NMS: Toward Optimal Threshold Prediction of NMS for Crowded Pedestrian Detection. IEEE Trans. Image Process. 2023, 32, 3176–3187. [Google Scholar] [CrossRef]
- Tang, W.; Liu, K.; Shakeel, M.S.; Wang, H.; Kang, W. DDAD: Detachable Crowd Density Estimation Assisted Pedestrian Detection. IEEE Trans. Intell. Transp. Syst. 2023, 24, 1867–1878. [Google Scholar] [CrossRef]
- Liu, Q.; Wei, M.; Wang, W.; Zhang, L.; Zhao, X. An Anchor-Free Dual-Branch Approach for Real-Time Metro Passenger Detection. IEEE Trans. Instrum. Meas. 2024, 73, 3428635. [Google Scholar] [CrossRef]
- Yuan, Q.; Huang, G.; Zhong, G.; Yuan, X.; Tan, Z.; Lu, Z.; Pun, C. Triangular Chain Closed-Loop Detection Network for Dense Pedestrian Detection. IEEE Trans. Instrum. Meas. 2024, 73, 5003714. [Google Scholar] [CrossRef]
- Ali, A.; Gaikov, G.; Rybalchenko, D.; Chigorin, A.; Laptev, I.; Zagoruyko, S. PairDETR: Joint Detection and Association of Human Bodies and Faces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024. [Google Scholar] [CrossRef]
- Jiang, H.; Zhang, X.; Xiang, S. Non-Maximum Suppression Guided Label Assignment for Object Detection in Crowd Scenes. IEEE Trans. Multimed. 2024, 26, 2207–2218. [Google Scholar] [CrossRef]
- Wang, A.; Liu, L.; Chen, H.; Lin, Z.; Han, J.; Ding, G. Yoloe: Real-time seeing anything. arXiv 2025, arXiv:2503.07465. [Google Scholar]
- Ge, Z.; Jie, Z.; Huang, X.; Xu, R.; Yoshie, O. Ps-rcnn: Detecting secondary human instances in a crowd via primary object suppression. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020. [Google Scholar] [CrossRef]
- Rukhovich, D.; Sofiiuk, K.; Galeev, D.; Barinova, O.; Konushin, A. Iterdet: Iterative scheme for object detection in crowded environments. In Proceedings of the Structural, syntactic, and statistical pattern recognition: Joint IAPR international workshops, s+ SSPR 2020, Padua, Italy,, 21–22 January 2021. [Google Scholar] [CrossRef]
- He, Y.; He, N.; Zhang, R.; Yan, K.; Yu, H. Multi-scale feature balance enhancement network for pedestrian detection. Multimed. Syst. 2022, 28, 1135–1145. [Google Scholar] [CrossRef]
- Huang, X.; Ge, Z.; Jie, Z.; Yoshie, O. Nms by representative region: Towards crowded pedestrian detection by proposal pairing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 10750–10759. [Google Scholar] [CrossRef]
- Chi, C.; Zhang, S.; Xing, J.; Lei, Z. Pedhunter: Occlusion robust pedestrian detector in crowded scenes. In Proceedings of the 2020 AAAI conference on artificial intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar] [CrossRef]
- Liu, C.; Wang, H.; Liu, C. Double Mask R-CNN for Pedestrian Detection in a Crowd. Mob. Inf. Syst. 2022, 2022, 4012252. [Google Scholar] [CrossRef]
- Ma, C.; Zhuo, L.; Li, J.; Zhang, Y.; Zhang, J. Cascade transformer decoder based occluded pedestrian detection with dynamic deformable convolution and Gaussian projection channel attention mechanism. IEEE Trans. Multimed. 2023, 25, 1529–1537. [Google Scholar] [CrossRef]
- Zhang, S.; Benenson, R.; Schiele, B. Citypersons: A diverse dataset for pedestrian detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3213–3221. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| CPU | Intel® Xeon® Platinum 8373 (36 cores @ 2.6 GHz) |
| RAM | 64 GB |
| Image Resolution | 640 × 640 pixels |
| Batch Size | 32 |
| Training Epochs | 300 |
| Optimizer Method | Adam |
| Learning Rate | 0.01 (initial) |
| Weight Decay | 0.0005 |
| Method | AP | MR−2 | GFLOPS | FPS |
|---|---|---|---|---|
| Baseline | 87.7 | 42.9 | 165.2 | 59.7 |
| Baseline (ResNet50) | 87.2 | 43.6 | 177.9 | 52.7 |
| Baseline + C2f-D2CN | 88.9 | 42.1 | 167.1 | 59.1 |
| Baseline + C2f-D2CN + MLA | 90.2 | 41.3 | 167.6 | 58.7 |
| Baseline + C2f-D2CN + MLSA | 90.7 | 40.7 | 168.2 | 58.5 |
| Baseline + C2f-D2CN + MLSA + SPDH | 92.3 | 39.9 | 168.8 | 58.2 |
| Baseline + C2f-D2CN + MLSA + SPDH + DFL-SIOU(Ours) | 93.3 | 38.7 | 169.3 | 57.9 |
| Method | AP | MR−2 | GFLOPS | FPS |
|---|---|---|---|---|
| C2f + MLSA + SPDH + DFL-SIOU | 91.8 | 39.8 | 166.9 | 62.8 |
| C2f + Deformable Conv +MLSA + SPDH + DFL-SIOU | 92.3 | 39.4 | 168.2 | 59.9 |
| C2f + Dynamic Conv +MLSA+ SPDH + DFL-SIOU | 92.7 | 39.1 | 167.9 | 59.7 |
| C2f_D2CN + MLSA + SPDH + DFL-SIOU (ours) | 93.3 | 38.7 | 169.3 | 57.9 |
| Method | AP | Recall | MR−2 |
|---|---|---|---|
| No attention mechanism | 91.5 | 95.1 | 40.6 |
| Add SENet [41] | 91.7 | 95.5 | 40.2 |
| Add CBAM [42] | 92.0 | 95.8 | 39.9 |
| Add CA [43] | 92.3 | 96.2 | 39.7 |
| Add EMA [44] | 92.6 | 96.5 | 39.3 |
| Add MLSA (Ours) | 93.3 | 97.1 | 38.7 |
| Method | AP | Recall | MR−2 | FPS |
|---|---|---|---|---|
| DIOU [37] | 92.1 | 96.3 | 39.8 | 51.1 |
| CIOU [37] | 92.5 | 96.6 | 39.5 | 41.7 |
| EIOU [45] | 93.0 | 96.8 | 39.2 | 49.5 |
| Wise-IOU [46] | 92.9 | 96.6 | 39.1 | 52.3 |
| DFL-SIOU (ours) | 93.3 | 97.1 | 38.7 | 57.9 |
| AP | MR−2 | |
|---|---|---|
| = 1.0, = 0.0 | 92.9 | 40.7 |
| = 0.8, = 0.2 | 92.1 | 40.1 |
| = 0.6, = 0.4 | 92.3 | 39.7 |
| = 0.5, = 0.5 | 92.5 | 39.6 |
| = 0.4, = 0.6 | 92.8 | 39.2 |
| = 0.2, = 0.8 | 93.3 | 38.7 |
| = 0.0, = 1.0 | 93.0 | 39.1 |
| Method | AP | Recall | MR−2 |
|---|---|---|---|
| FPN [47] | 83.1 | 90.6 | 52.4 |
| Yolov4 [19] | 75.3 | 92.5 | 64.9 |
| FPN + Soft-NMS [48] | 83.9 | 91.7 | 52.0 |
| FPN + Faster RCNN [47] | 84.5 | 90.2 | 50.4 |
| FPN + AdaptiveNMS [49] | 84.7 | 91.3 | 49.7 |
| RelationNet [50] | 81.6 | - | 48.2 |
| RFB-Net [51] | 78.3 | 94.1 | 65.2 |
| RetinaNet [14] | 80.8 | 93.8 | 63.3 |
| FCOS+AEVB [5] | - | - | 47.7 |
| YOLO-CS [52] | 81.9 | 95.3 | 41.9 |
| NOH-NMS [53] | 89.0 | - | 43.9 |
| Deformable-DETR [54] | 91.5 | - | 43.7 |
| Sparse-RCNN [55] | 91.3 | - | 44.8 |
| Iter-Deformable-DETR [56] | 92.1 | - | 41.5 |
| UniHCP [57] | 92.5 | 41.6 | |
| OTP-NMS [58] | 90.9 | - | 41.2 |
| DDAD [59] | 92.5 | - | 39.7 |
| AMPDet [60] | 88.9 | 97.4 | 44.6 |
| ChainDetection [61] | 91.9 | - | 41.7 |
| PairDETR [62] | 87.2 | 42.9 | |
| NGLA [63] | 89.9 | 96.6 | 45.8 |
| Dense-YOLOv8(ours) | 93.3 | 97.1 | 38.7 |
| Method | AP | MR−2 | GFLOPS |
|---|---|---|---|
| YOLOv7 | 86.8 | 43.9 | 104.7 |
| YOLOv9-M | 88.7 | 42.7 | 76.3 |
| YOLOv10-M | 89.5 | 42.1 | 59.1 |
| YOLOv11-M | 90.2 | 41.3 | 68.0 |
| Dense-YOLOv8-M (Ours) | 92.7 | 39.6 | 82.1 |
| RF-DETR-B | 92.8 | 39.9 | 98.6 |
| RF-DETR-L | 93.1 | 39.5 | 435.2 |
| YOLOE-v8-L (no promt) | 91.4 | 39.9 | 165.2 |
| YOLOE-11-L (no promt) | 91.7 | 39.7 | 86.9 |
| YOLOv6-L | 86.3 | 43.7 | 150.7 |
| YOLOv7-X | 87.5 | 42.9 | 189.9 |
| YOLOv9-C | 89.5 | 41.9 | 102.1 |
| YOLOv10-L | 90.1 | 40.8 | 120.3 |
| YOLOv11-L | 91.0 | 39.9 | 86.9 |
| Dense YOLOv8-L (Ours) | 93.3 | 38.7 | 169.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, H.; Li, T.; Wang, L.; Huang, S.; Li, M. An Improved YOLOv8-Based Dense Pedestrian Detection Method with Multi-Scale Fusion and Linear Spatial Attention. Appl. Sci. 2025, 15, 5518. https://doi.org/10.3390/app15105518
Gong H, Li T, Wang L, Huang S, Li M. An Improved YOLOv8-Based Dense Pedestrian Detection Method with Multi-Scale Fusion and Linear Spatial Attention. Applied Sciences. 2025; 15(10):5518. https://doi.org/10.3390/app15105518
Chicago/Turabian StyleGong, Han, Tian Li, Lijuan Wang, Shucheng Huang, and Mingxing Li. 2025. "An Improved YOLOv8-Based Dense Pedestrian Detection Method with Multi-Scale Fusion and Linear Spatial Attention" Applied Sciences 15, no. 10: 5518. https://doi.org/10.3390/app15105518
APA StyleGong, H., Li, T., Wang, L., Huang, S., & Li, M. (2025). An Improved YOLOv8-Based Dense Pedestrian Detection Method with Multi-Scale Fusion and Linear Spatial Attention. Applied Sciences, 15(10), 5518. https://doi.org/10.3390/app15105518