1. Introduction
The Internet of Medical Things (IoMT)—a subset of the Internet of Things (IoT)—comprises interconnected smart medical devices, wearable health gadgets, and other medical hardware [
1,
2]. The widespread adoption of IoMT enables the continuous transfer and exchange of patient medical data among medical institutions, healthcare professionals, devices, and applications. However, due to competitive pressures, medical institutions are often reluctant to share their medical data with others. The transmission of patient health information, which includes sensitive personal and institutional details, poses risks to individual privacy, institutional security, and potentially national security. To overcome these challenges and harness the full potential of IoMT data, secure and trusted data sharing approaches are urgently needed.
Federated learning (FL) represents an innovative approach to machine learning that enables joint model development across decentralized datasets owned by multiple devices, while ensuring that the data are still stored on local devices [
3]. This framework achieves knowledge exchange through the periodic aggregation of updated model parameters from participating devices. However, existing federated learning frameworks still face security vulnerabilities, particularly due to the centralized server architecture’s susceptibility to targeted attacks on critical nodes, which may result in unauthorized access to sensitive training datasets [
4]. Blockchain’s decentralization, immutability, and traceability [
5] have been leveraged for integration with FL frameworks for model parameter aggregation, replacing the traditional central server [
6,
7]. Blockchain-based federated learning (BFL) enhances the reliability and scalability of FL by mitigating single points of failure (SPFs) and improving communication efficiency [
8,
9]. Warnat-Herresthal et al. [
10] introduced a BFL approach called Swarm Learning (SL), which combines blockchain and FL to collaboratively train models for the diagnosis of multiple diseases while safeguarding patient data privacy and security. However, maintaining gradient data as transactional entries within BFL systems can create security vulnerabilities. Studies have revealed that malicious actors infiltrating blockchain records could launch inference-based assaults to reconstruct sensitive training datasets from exposed gradients [
11].
To mitigate these risks, privacy-preserving federated learning (PPFL) frameworks have gained substantial attention across research and industrial domains [
12]. The PPFL framework predominantly employs three core methodologies: differential privacy (DP) mechanisms, homomorphic encryption (HE) protocols, and secure multi-party computation (MPC) techniques. Biscotti [
13] combines DP with secure aggregation protocols [
14] to fortify BFL architectures against both data poisoning attempts and gradient-based inference breaches. Chen et al. [
15] illustrated how swarm learning updates can implement partial HE to safeguard BFL systems from inference threats, although this method suffers from operational inefficiencies due to computational complexities in cipher-text processing. MPC-based privacy preservation [
16] achieves data indistinguishability through secret sharing mechanisms, but requires significant communication resources due to intensive client–server coordination demands. However, existing PPFL methods primarily ensure the indistinguishability of private information while often neglecting the threat of adversarially manipulated gradients. Attackers can craft malicious gradients to undermine aggregation results and disrupt the training process. Several aggregation rules have been developed to counteract poisoning attacks [
17,
18,
19], which filter out malicious gradients by distinguishing them from legitimate ones. For example, Krum [
17] identifies and excludes poisonous gradients by measuring their Euclidean distance from benign gradients. However, these poisoning defense strategies inherently conflict with privacy-preserving FL, which seeks to maintain the indistinguishability of private gradients.
To simultaneously address both poisoning attacks and privacy protection in FL, we propose a novel BFL framework specifically designed for secure medical data exchange within smart healthcare ecosystems. Our contributions are as follows:
A robust global model is maintained through rigorous cosine similarity analysis to filter out harmful gradients, effectively mitigating the risks of data poisoning attacks. This approach enhances model integrity by systematically identifying and removing manipulated parameter updates during distributed training processes.
We propose an actively secure MPC framework that maintains data confidentiality throughout FL processes, effectively addressing the inherent tension between data privacy preservation and robust defense against poisoning attacks.
We establish a hierarchical framework to mitigate poisoning attacks and protect the data privacy of devices while using blockchain, in order to facilitate transparent processes and the enforcement of regulations. This innovative framework facilitates the formation of an autonomously coordinated learning alliance, eliminating the need for a central coordinating authority during model training processes.
Through conducting rigorous evaluations across two widely-accepted benchmark datasets, our proposed framework exhibits superior performance compared to existing cutting-edge methodologies, in terms of operational stability and computational effectiveness.
The remainder of this paper is organized as follows:
Section 2 introduces foundational concepts.
Section 3 surveys the existing literature.
Section 4 describes the proposed framework and its objectives.
Section 5 elaborates on the developed approach.
Section 6 and
Section 7 examine security evaluation and efficiency assessment, respectively. Finally,
Section 8 summarizes the key findings and conclusions of the study.
2. Background
Our work is closely related to data sharing in the IoMT, federated learning (FL), blockchain-based federated learning (BFL), and Actively Secure Evaluation Protocol, and we provide relevant background knowledge in this section.
2.1. Data Sharing in IoMT
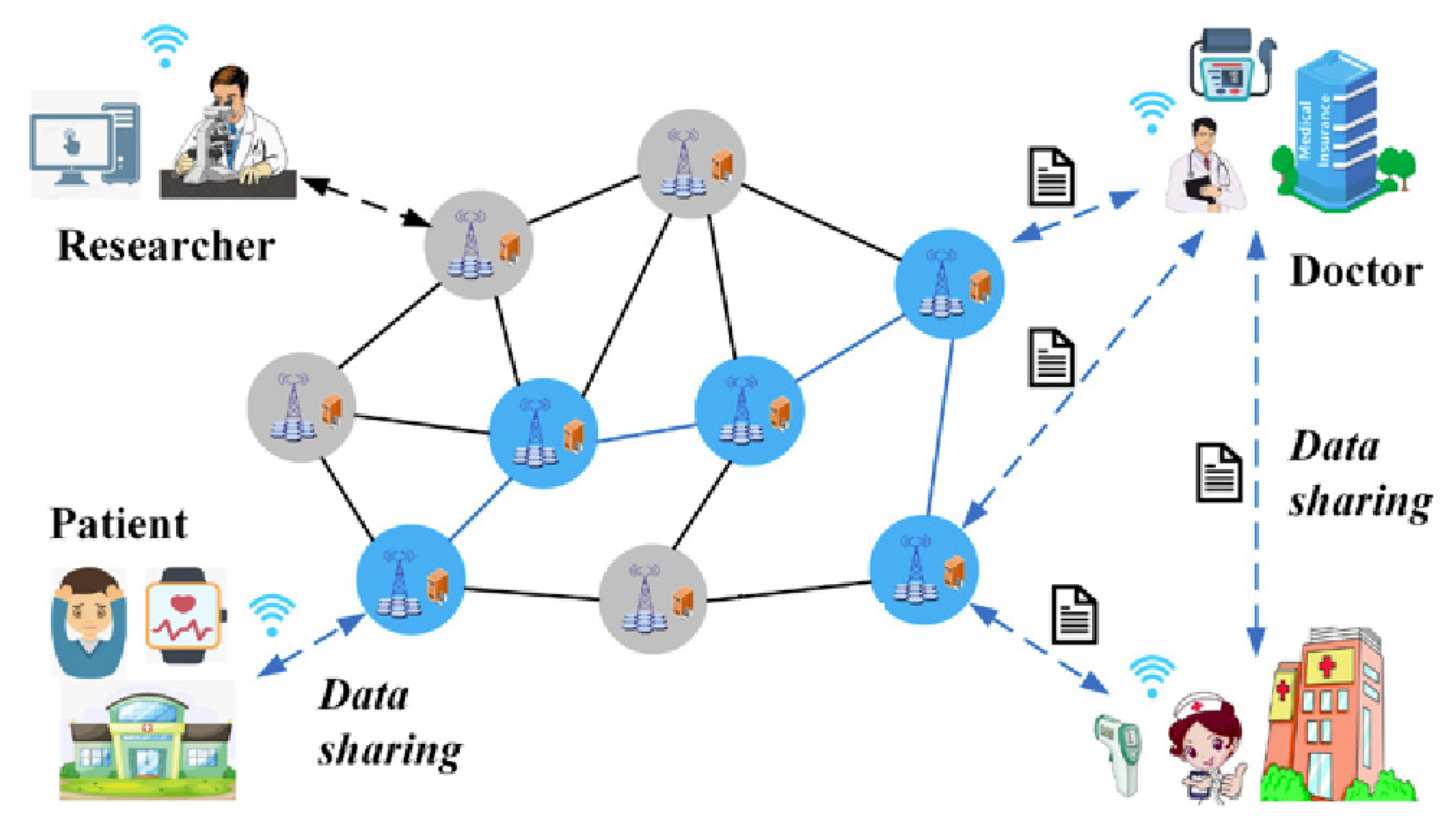
The Internet of Medical Things (IoMT) facilitates the interconnection of communication-enabled medical-grade devices and their integration into wider-scale health networks in order to improve patients’ health. As shown in
Figure 1, patient health data are continually transferred and exchanged between medical institutions, medical workers, medical devices, and medical applications in the IoMT context.
However, IoMT entities often lack sufficient trust, and there is some skepticism regarding IoMT data-sharing platforms. This mistrust creates huge obstacles for IoMT-based data sharing. Therefore, there is an urgent need for IoMT data sharing approaches to fully utilize the potential value of IoMT data.
2.2. Federated Learning (FL) for Data Sharing in the IoMT
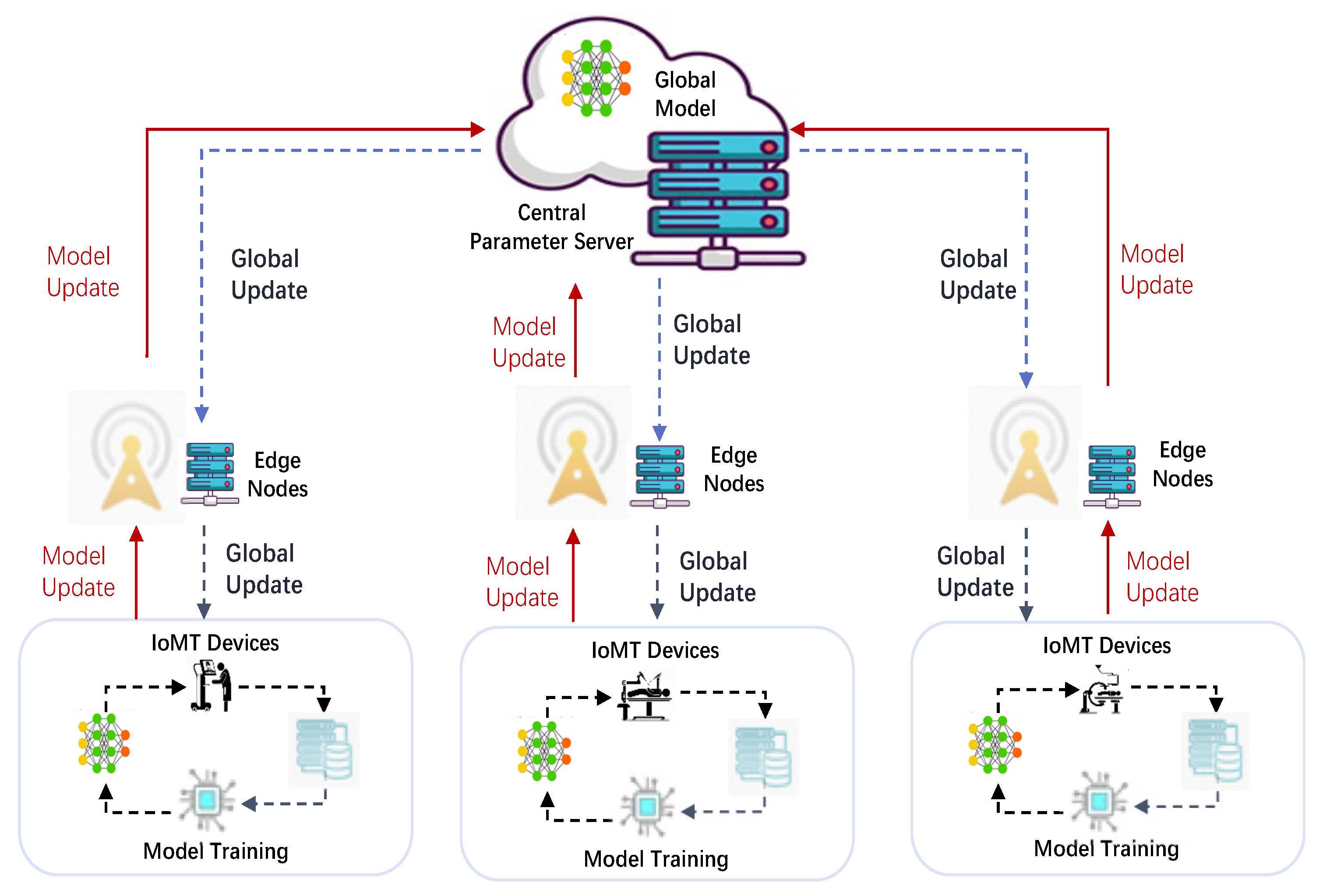
As depicted in
Figure 2, federated learning (FL) operates as a collaborative machine learning framework in which multiple edge devices jointly develop shared predictive models without having to exchange their private datasets.
Consider a network of N distributed nodes represented by , each possessing a distinct local training dataset , . These participants aim to collaboratively optimize a shared global model w while maintaining strict data confidentiality for their respective information sources. During the training cycle, the FL process unfolds through three sequential stages:
- Step I:
The central server distributes the updated global model to all participating devices through network transmission.
- Step II:
Every participating device develops an individual model through training on its own dataset. In particular, the device solves an optimization problem to update the local model using stochastic gradient descent, where is the loss function. These edge devices subsequently transmit their local model updates to the central server.
- Step III:
The server synthesizes these distributed parameters through aggregation algorithms to formulate an enhanced global model
, where
is the size of the
device’s local training dataset, and
S is the total number of training examples. Next, the server updates the global model via
where
is the global learning rate. This global model is then redistributed to all connected devices for subsequent optimization cycles.
2.3. Blockchain-Based Federated Learning (BFL) for Data Sharing in IoMT
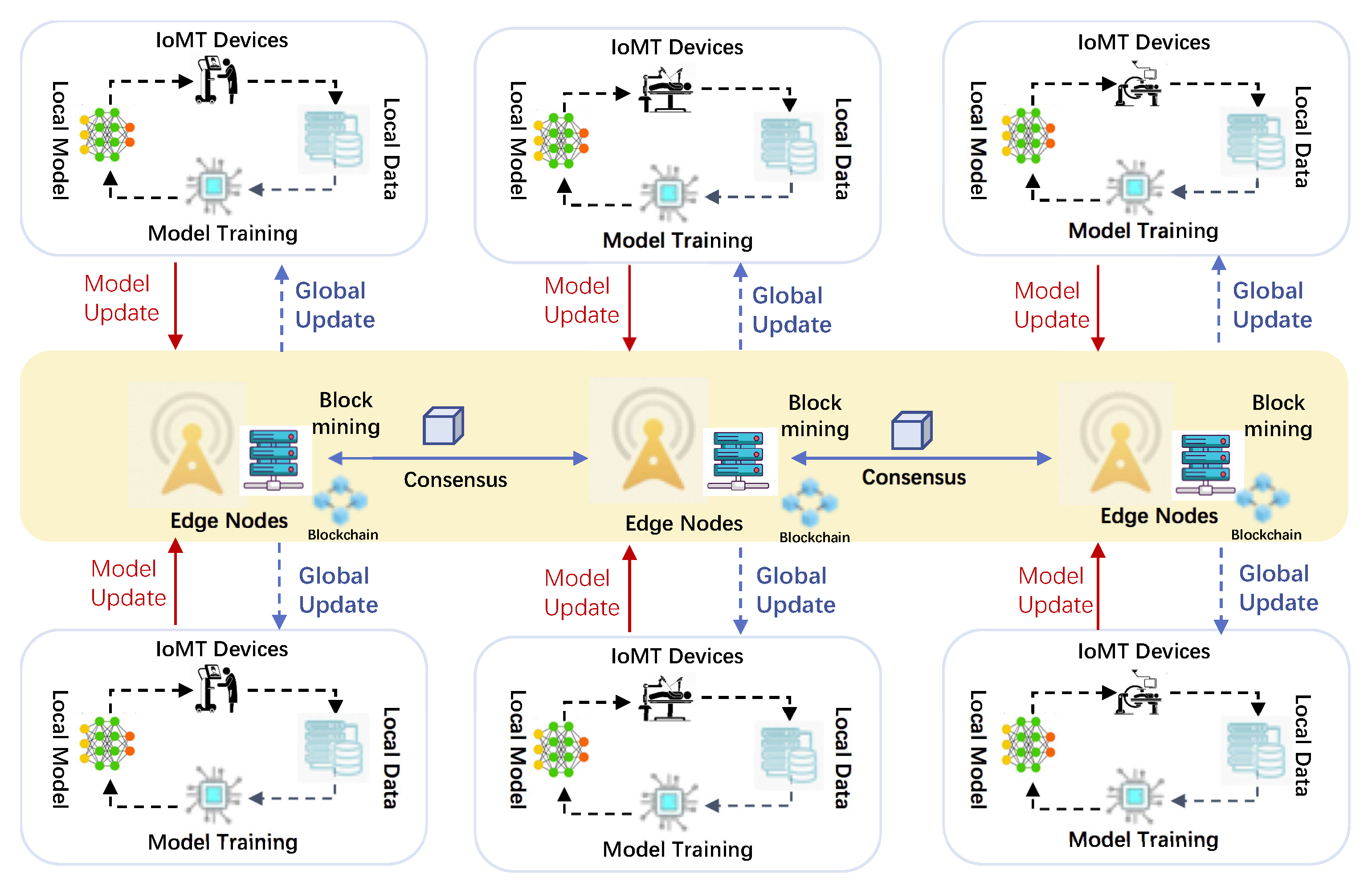
A key limitation of federated learning (FL) lies in its reliance on a central server, which significantly impacts the privacy and performance of all devices within the system. In order to address this issue by reducing the network’s dependence on a singular node and improving communication efficiency, blockchain-based federated learning (BFL) leverages blockchain technology to eliminate the necessity of a central server.
Figure 3 illustrates how BFL handles model updates by treating them as data within a block, which is shared through a consensus mechanism.
The blockchain is initiated with a single block that includes the initial global model. On the device side, the local model is initialized with the global model and trained on the data from the device. Subsequently, the device uploads data to the blockchain by constructing a block comprising a header, the trained model, and the uploader’s identifier (ID). Devices engage directly with a group of miners to acquire the Merkle root of the data before transmitting the block. A smart contract (SC) on the blockchain enforces specific rules to decide when to update the global model. The aggregation mechanisms of BCFL employ an averaging function akin to federated averaging (FedAVG).
2.4. Cosine Similarity
To distinguish between truthful and deceitful gradient vectors, we employ cosine similarity—a widely used metric for quantifying the alignment between two vectors—to assess the directional consistency between a local model gradient (denoted as
) and the aggregated sum gradient vector
. Namely,
where
guides the global decent to an appropriate direction,
denotes the
-norm, and
signifies the dot product between vectors. The cosine similarity metric for
and the gradient
calculates the ratio of their inner product to the product of their respective magnitudes, mathematically expressed as
.
2.5. Actively Secure Evaluation Protocol
An MPC-based protocol can ensure the privacy of devices against Byzantine devices by utilizing the concepts of verifiable secret sharing [
20] and Lagrange interpolation. Each device
i divides the secret
into
N committed shares locally and transmits each
to all other devices
j (
). Collaboration among devices enables secure computation of addition, multiplication by a constant, and multiplication. Addition and multiplication by a constant can be performed easily by each device through direct local operations. For the multiplication of two secrets, complex multiplication is transformed into local addition operations using multiplication triples, thereby reducing online overhead. Further elaboration on this protocol is provided below.
- 1.
Secret Sharing: Each participant
i possesses a secret
, allowing them to construct a polynomial
where the coefficients
are selected at random within the field
, with the constructed polynomial maintaining a maximum degree of
. In particular, the polynomial’s degree remains within
while its coefficients are randomly sampled from the finite field. Through the evaluation of
across multiple distinct points, participating entities can obtain
Subsequently, participant
i allocates the share
across all other devices
j. To maintain the integrity of these distributed shares, participant
i also broadcasts verifiable commitments regarding the polynomial coefficients of
, specifically defined as
Here, denotes a generator within the finite field , with all arithmetic operations being executed under the modulus . The prime must be appropriately chosen such that is divisible by p, ensuring the required algebraic structure for implementation.
Upon receiving the commitments in (2), each device
can verify the secret share
by checking the equation:
where all mathematical operations within this framework are executed using modulo
calculations. The cryptographic commitment protocol guarantees the accurate generation of confidential shares derived from Equation (
2)’s polynomial expression, consequently establishing proof of their authenticity through verification processes.
- 2.
Computation: Three types of calculations are permitted in the protocol, as follows:
Addition: Given two confidential parameters
and
, represented by their respective shares
and
, participating devices collectively perform computations on these shared values:
Multiply-by-constant: When provided with a constant
and the shared secret
corresponding to element
, all participating devices perform the multiplication operation to scale the threshold-shared value by the given scalar within the prime field:
Multiplication: For confidential parameters
and
, represented as shared values
and
, combined with precomputed randomized triples
,
,
(satisfying
), the process is initiated by calculating
. Participants then employ a reconstruction protocol to publicly reveal masked values
and
, which maintain their statistical randomness. Through algebraic expansion, the product
equates to
. This formulation enables distributed computation, where each device independently calculates the combined result using the pre-shared triple components and revealed values.
- 3.
Reconstruction: During the secret reconstruction phase, each participant
i acquires a secret share of
, denoted as
. These shares are subsequently transmitted to the smart contract by all devices, enabling the recovery of
through Lagrange interpolation. More precisely, given a polynomial
of degree
, the reconstruction employs the Lagrange basis expression
. Here,
satisfies
, where
represents a polynomial of degree
, defined as
. The recombination vector may then be straightforwardly determined through the calculation of
, defined by
. Subsequently, the secret
is recovered as follows:
3. Related Work
This study investigates critical obstacles present in existing FL frameworks, with a concentrated analysis of three distinct research domains.
3.1. Blockchain-Based Federated Learning
Conventional federated learning architectures predominantly rely on centralized servers, introducing vulnerabilities such as single points of failure and possible server misconduct. The integrity of federated learning ecosystems becomes jeopardized when the central servers experience security breaches [
21]. Emerging blockchain technology has attracted significant interest, due to its decentralized nature and robust security features. Blockchain-enhanced federated learning (BFL) systems utilize distributed ledger technology to eliminate central server dependencies and associated risks. The BAFFLE framework [
22] implements smart contracts (SCs) to orchestrate model storage and monitor participant statuses, executing both model updates and aggregation processes through automated contractual agreements. This approach enhances system resilience against centralized failures while ensuring equitable client participation. Parallel innovations such as BlockFL [
23] leverage blockchain-based smart contracts for secure model update exchanges and validation processes, simultaneously resolving single-point vulnerability issues and incentivizing broader device participation through sample-size proportional rewards. Within medical applications, Swarm Learning integrates FL with blockchain technology to enable collaborative disease diagnosis models while preserving patient data confidentiality [
10]. Existing implementations nevertheless face challenges, as smart contract-mediated model aggregation generates considerable computational demands and network congestion for blockchain nodes, while lacking mechanisms to detect adversarial gradient contributions. To mitigate these limitations, researchers have proposed committee-consensus BFL frameworks [
24] that streamline computational requirements and enhance security against malicious actors, although the determination of optimal committee formation criteria remains an open research question.
3.2. Privacy-Preserving Federated Learning
While existing research has explored various strategies for protecting privacy in federated learning and blockchain systems, the proposed solutions can be primarily grouped into three distinct approaches: 1. Differential Privacy (DP); 2. Homomorphic Encryption (HE); and 3. Secure Multi-Party Computation (MPC).
- 1.
Differential Privacy (DP): DP mechanisms safeguard blockchain-powered federated learning (BFL) systems through randomized data modification during information exchange. Learning Chain [
25] implements such a mechanism by distorting local gradients through probabilistic noise injection based on exponential mechanisms prior to blockchain integration, disseminating these adjusted parameters throughout the BCFL framework. Blade-FL [
26] adopts a dual-role architecture where participants simultaneously engage in computational validation and model refinement via decentralized peer-to-peer training, incorporating Gaussian-distributed perturbations during gradient preparation before cryptographic encapsulation. Biscotti [
11] enhances BCFL security through a hybrid approach combining DP with multi-party computation techniques, effectively countering both adversarial manipulation and privacy inference attempts.
- 2.
Homomorphic Encryption (HE): Homomorphic encryption (HE) serves as a cryptographic method to enhance secure learning by allowing computations on cipher-texts without requiring prior decryption. For example, SL+HE [
15] implements partial HE to encrypt swarm learning updates, thereby enhancing security against inference attacks in blockchain-based federated learning (BCFL). Similarly, additive HE can be applied in distributed learning systems to protect model updates and maintain gradient confidentiality, as detailed in [
12]. Meanwhile, PBFL [
27] leverages cosine similarity metrics to detect malicious gradients while employing fully HE for secure aggregation processes.
- 3.
Secure Multiparty Computation (SMC): This cryptographic technique safeguards the data of participants by producing randomized data points divergent from source information, which are then allocated across participating entities for decentralized processing. Within SMC frameworks, participant-held datasets remain indecipherable until aggregated computational outputs are synthesized through collaborative analysis. Illustrating this paradigm, the MPC-driven PPML framework [
16] caters to single-server architectures, while SecureML [
28] (alongside Securenn [
29]) target distributed multi-server ecosystems requiring coordinated computation protocols.
3.3. Federated Learning Against Poisoning Attacks
Federated learning systems remain vulnerable to multiple poisoning attack variants, which researchers typically classify into two primary dimensions. From an objective perspective, attacks can be divided into non-targeted and targeted attacks. The former seeks to degrade model performance across all test data, while the latter selectively impairs recognition capabilities for specific inputs while maintaining normal prediction accuracy for other data. From another perspective (i.e., examining adversarial capabilities), attacks manifest as either data corruption or parameter manipulation. Malicious actors conducting data poisoning attacks tamper with local training datasets to indirectly influence parameter updates through contaminated samples. In contrast, model poisoning attacks involve direct manipulation of parameter updates on compromised devices through gradient alteration.
To address poisoning threats from malicious participants, various Byzantine-resilient aggregation techniques have been developed for federated learning systems. For example, Krum [
17] counters these attacks by identifying gradient vectors with minimal Euclidean distance to their majority neighbors. Trim-mean [
19] adopts a ranking approach, excluding extreme model updates before calculating the trimmed average of remaining gradients. RLR [
30] offers an efficient defense against back door attempts by dynamically adjusting the server’s learning rate based on sign pattern analysis of client contributions. FLTrust [
31] utilizes a curated reference set to generate baseline model updates, effectively neutralizing malicious inputs without relying on client majority assumptions. PEFL [
32] achieves dual protection against data poisoning and privacy breaches through homomorphic encryption-based malicious behavior identification in encrypted gradient space. While traditional FL security solutions focus on centralized architectures, blockchain-integrated federated learning (BCFL) enhances security during aggregation through the use of consensus-aligned update validation mechanisms [
33].
4. Problem Formulation
In this section, we formalize the problem definition and design goals.
4.1. Problem Definition
In this study, we consider a typical IoMT setting consisting of two types of participants—namely, edge nodes and IoMT devices—which cooperate to achieve the FL training task. The knowledge and capabilities of k malicious IoMT devices in a total of N devices are defined as follows:
Malicious devices can hold their own toxic data, but cannot access the local data of other honest IoMT devices.
Malicious devices can obtain the global model. However, local model updates uploaded by a single honest devices cannot be observed.
Malicious devices can collude and share a common goal to amplify the impact of their malicious attacks.
Malicious devices can launch either targeted or non-targeted attacks.
Based on the assumptions regarding the knowledge and behavior of the malicious devices, it is obvious that malicious IoMT devices can direct the global model in the wrong direction. Due to the poisoning attack of one or more malicious IoMT devices, the accuracy and reliability of the global model may be greatly reduced, thereby leading to the global model’s distrust of honest IoMT devices.
4.2. Design Goals
Our primary aim is to design a blockchain-driven federated learning system (PP-BFL) that integrates data privacy safeguards and robust defense mechanisms against adversarial interference. This architecture seeks to mitigate data poisoning threats while simultaneously optimizing computational efficiency and ensuring model integrity. Key objectives encompass: developing attack-resistant algorithms, implementing lightweight cryptographic protocols, and establishing decentralized verification processes that maintain confidentiality while reducing resource consumption.
Privacy: The primary goal involves securing IoMT device data against breaches while maintaining the privacy of their gradient information. This framework prevents unauthorized entities—whether malicious devices or external actors—from gaining entry to or deducing sensitive details contained within these gradients.
Robustness: The proposed framework should be robust against malicious attacks, which means that the accuracy of the global model should not be affected by malicious IoMT devices.
Efficiency: The proposed framework must prioritize operational efficiency by minimizing both computational demands and data transmission costs while maintaining system performance.
Accuracy: The proposed framework maintains high accuracy levels while ensuring data confidentiality and mitigating adversarial data manipulation. This balance is achieved through cryptographic privacy preservation techniques combined with anomaly detection mechanisms that identify and neutralize malicious input patterns without degrading model performance.
Reliability: All operations must be comprehensively documented to safeguard against potential denial attempts by malicious devices, ensuring accountability throughout system interactions.
5. Proposed Approach and System
This section presents our proposed privacy-preserving, poisoning-defending, blockchain-based federated learning (PPBFL) scheme. First, we present an overview of the system architecture. Next, we discuss the various components of our proposed framework in detail.
Table 1 systematically organizes key terms and symbolic representations for reference.
5.1. System Architecture
Figure 4 depicts our proposed framework, which consists of four primary components: 1. Task Publisher; 2. Trusted Authority; 3. IoMT Edge Nodes; and 4. IoMT Devices, supported by 5. blockchain Infrastructure. The roles and interactions of these components are elaborated below.
- 1.
Task Publisher: To address IoMT application needs, the task publisher (TP) designs the FL model training task, implements it through a blockchain smart contract (SC), and pays a fee as a bonus pool. IoMT devices that meet the requirements can apply to participate in the task. Then, the TP will initialize the model parameters and upload them to the blockchain by way of transactions.
- 2.
Trusted Authority: The trusted authority (TA) initializes the system by generating and distributing public/private key pairs for IoMT edge nodes.
- 3.
IoMT Edge Nodes: Edge nodes, functioning as blockchain clients, possess public/private key pairs issued by the Trusted Authority (TA). Their responsibilities encompass: (a) registering with the Smart Contract (SC), (b) downloading the global model from the blockchain, (c) collecting secret shares of all gradients and computing partial similarities between these secret shares, and (d) partially aggregating the secret shares of gradients from the selected models.
- 4.
IoMT Devices: Devices are responsible for: (a) locally training the model, quantizing, and securely sharing gradients each round; (b) broadcasting gradient secret shares to all edge nodes; and (c) downloading the global model from an edge node to update local model parameters.
- 5.
Blockchain: In the Internet of Medical Things (IoMT), blockchain technology substitutes the traditional federated learning (FL) parameter server. Its responsibilities are: (a) verifying the public keys of registered nodes; (b) gathering secret shares of similarities from these nodes and reconstructing the similarities between local model updates; (c) collecting secret shares of aggregated gradients from all nodes and reconstructing the aggregated gradients.
5.2. Threat Model
Within our security framework, we acknowledge potential scenarios in which medical IoT devices could engage in adversarial behaviors by transmitting manipulated parameter updates to undermine the integrity of the aggregated model. Our analysis distinguishes between two critical vulnerabilities—namely, data exposure risks and model corruption attempts—which are thoroughly examined in subsequent sections.
- 1.
Privacy leakage: In federated learning processes, compromised IoMT equipment may be able to deduce confidential data from legitimate participants. These adversarial actors could access gradient data submitted by compliant devices through blockchain records to reverse-engineer sensitive parameters. Contrary to protocol-following passive devices, maliciously active participants might alter intermediate computations within secure multiparty protocols. Furthermore, coordinated groups of IoMT devices could cooperate maliciously, amplifying their capacity to compromise the confidentiality of data.
- 2.
Poisoning attacks: In the training phase, external adversaries might exploit compromised IoMT devices to initiate poisoning attacks. Attackers could potentially intercept sensitive details regarding localized training datasets and parameter adjustments from hijacked nodes. Simultaneously, they might intentionally distort the devices’ optimization gradients to impede the collaborative learning model’s stabilization process and degrade its predictive performance.
We outline the workflow of the proposed protocol in Algorithm 1.
| Algorithm 1: Privacy-Preserving Poisoning-Defending BCFL |
![Applsci 15 05472 i001]() |
5.3. Initialization
The blockchain-based federated learning (FL) system is established by initializing system parameters and publishing public parameters on the blockchain. Each device must register as a legitimate participant before engaging in training. The specific processes are executed as follows:
- 1.
Task Publish: During initialization, system participants (e.g., IoMT devices and edge nodes) establish connections to create a peer-to-peer network. A TP initiates a FL task by implementing an SC on the blockchain network, and pays a fee as a bonus pool. Within the deployed SC, the TP sets the initial public parameter , where , , and b represent the initial weights, learning rate, and training batch size, respectively. Subsequently, other authenticated devices can synchronize with it.
- 2.
System Initialization: The Trusted Authority (TA) initially selects a security parameter and two large safe prime numbers, p and q, where . Subsequently, the TA computes and . A generator h of order is then chosen by TA; for example, , where a is a random number in . Following this, the TA picks N unique elements from . Each device requests the TA for and N distinct elements .
- 3.
Edge Node Register: Let there be
m nodes in the system. Each node
i randomly chooses a private key
and calculates their public key as
. In order to demonstrate the validity of
, a common non-interactive zero-knowledge (NIZK) proof,
, is generated [
34]. The NIZK proving and verification processes are represented by
and
, respectively, as outlined in Algorithms 2 and 3. Subsequently, each node publishes their public key
along with the corresponding
on the blockchain.
| Algorithm 2: NIZK Prove Function |
- Input:
, - Output:
- 1:
function prove(,) - 2:
- 3:
- 4:
- 5:
- 6:
- 7:
return - 8:
end function
|
| Algorithm 3: NIZK Verify Function |
![Applsci 15 05472 i002]() |
5.4. Local Computation
Local computation comprises model updating, local training, normalization, and secret sharing. The processes of LocalComputation are outlined in Algorithm 1. Below, we elaborate on these components.
- 1.
Model update: Device
retrieves the most recent global model
from an edge node. Subsequently, the local model
is updated using Equation (
7), where
represents the local learning rate. If the devices’ objective function converges, the training process concludes; otherwise,
proceeds to the next iteration.
The specifics of updating the local models are elucidated by invoking ModelUpdate, as defined in Algorithm 4.
| Algorithm 4: ModelUpdate |
![Applsci 15 05472 i003]() |
- 2.
Local training: During the
iteration of training, each device
involved in FL leverages its local dataset
(
) and local model
to compute the local gradient
, as defined in Equation (
12).
where
denotes the empirical loss function, with ∇ representing the derivative operation.
- 3.
Normalization and quantization: For device
, we employ Equation (
13) to normalize the local gradients as follows:
where
represents the unit vector. For any integer
, we introduce a stochastic rounding function, defined as:
where
denotes the largest integer less than or equal to
x. It is important to note that this function is unbiased; that is,
. The parameter
q serves as a tuning parameter corresponding to the quantization level. The variance of
diminishes with increasing
q. Subsequently, we define the quantized gradient as:
where the function
from Equation (
9) is applied element-wise and a mapping function
is specified to represent a negative integer in the finite field using the two’s complement representation.
- 4.
Secret sharing: Each device
within the range of
produces secret shares of the quantized gradient
by creating a random polynomial
of degree
T:
where the vectors
are randomly generated from
by device
i. Subsequently, device
i transmits the secret shares:
to edge node
m within the range of
. In order to ensure the verifiability of these shares, device
i also publicly discloses the commitments
to the coefficients of
to all edge nodes. These commitments are defined as:
where
represents a generator of
, and all computations are performed modulo
, with
defined as a large prime such that
p divides
.
5.5. Secure Similarity Computation
Algorithm 1 outlines the similarity computation processes as follows:
- 1.
Partial similarity computation: In our privacy-preserving similarity computation method, each edge node calculates partial similarities using the secret shares of gradients provided by all devices. Specifically, edge node
m computes the partial similarities as
where
represents the normalized gradient of each device
, and
denotes the sum of all gradients.
- 2.
Publication: Each edge node m publicly discloses the partial similarities on the blockchain.
- 3.
Similarity reconstruction: Upon receiving adequate partial similarities from multiple edge nodes, the smart contract is activated to reconstruct the quantized similarities
using Lagrange interpretation. Subsequently, the smart contract converts
from the finite field to the real domain.
for
, where
q is the integer parameter in Equation (17) and the de-mapping function
is defined as follows:
The variable
quantifies the alignment between the normalized gradient
of each device
i and the total gradient sum
. A negative value of
indicates an opposite direction between
and
, which can detrimentally impact the global model. To filter out adversarial gradients during aggregation, the rectified linear unit (ReLU) function is employed:
This allows us to compute the score for each device j. Subsequently, the smart contract broadcasts to all edge nodes.
5.6. Secure Model Aggregation
- 1.
Local gradient aggregation: Each edge node
m locally aggregates the secret shares, weighted by their corresponding scores.
where
. The entity then publishes
to the blockchain for public verification.
- 2.
Reconstruction of the global gradients: Upon receiving computation results from a sufficient number of devices, the smart contract is activated to reconstruct the quantized global gradients
through Lagrange interpretation. Subsequently, the smart contract converts
from the finite field to the real domain as follows:
6. Security Analysis
As outlined in
Section 3.2, our threat model encompasses two types of security threats: privacy leakage and poisoning attacks. In this section, we concentrate solely on privacy protection, specifically ensuring the confidentiality of IoMT device gradients originating from edge nodes and blockchain systems. Indeed, the security of our PPBFL is based on our actively secure evaluation protocol, which not only ensures privacy protection in an information-theoretic sense, but also resists malicious attacks carried out by the participants (i.e., it provides active security). First, each IoMT device uploads only committed shares of its local gradients to edge nodes throughout the entire training process. Based on the security provided by verifiable Shamir’s secret sharing, even if at most
nodes collude with one another, neither the edge nodes nor blockchain can infer any useful information about the devices from these committed shares or forge them. All operations conducted on edge nodes and within the blockchain are executed under a secure multiparty computation (MPC) framework, thus ensuring the confidentiality of device gradients. Next, we present a proof for our scheme using a hybrid approach [
35].
Theorem 1. Assuming there exists a set of malicious edge nodes, denoted as holding , it is always possible to identify a simulator with adequate computational power such that, given parameters p, T, and M, indistinguishability between simulator and real protocol can be assured in an information-theoretic sense—even when edge nodes belonging to collaborate with one another. Proof. Considering REAL’s input of and SIM’s input of with identical distributions, we demonstrate the indistinguishability between and as well as the unforgeability against active edge nodes throughout the entire execution process of our scheme, as follows.
In this step, each edge node receives the committed shares of device gradients. Each node in the real protocol takes the shares denoted by , while each node in the simulator utilizes . Consequently, indistinguishability between and is assured.
In this step, each edge node computes . Each node in the real protocol calculates while simultaneously calculating in the simulator. Given that and share an identical distribution due to properties inherent to Shamir’s secret sharing and Lagrange interpolation techniques, we can guarantee their indistinguishability.
In this step, each edge node transmits the to the smart contract for reconstruction of . In the real protocol, each node sends to the smart contract, while in the simulator it sends to reconstruct . Leveraging the properties of Lagrange interpolation, it can be ensured that only the final reconstructed result is disclosed. Consequently, indistinguishability between and is guaranteed.
In this step, each edge node computes . Each node performs this calculation as follows: in the real protocol, it calculates while, in the simulator, it computes . Given that both and share identical distributions due to Shamir’s secret sharing and Lagrange interpolation properties, their indistinguishability can be assured.
In this step, each edge node submits to the smart contract for the reconstruction of . Specifically, in the real protocol context, every node sends its respective to facilitate reconstruction of while, during simulation, they send instead for reconstructing . Based on the principles of Lagrange interpolation, only information pertaining to the final reconstructed results may be revealed. Thus, we ensure indistinguishability between and .
□
7. Experimental Setup
We implemented our scheme on a private Ethereum blockchain setup. The smart contract (SC) layer was developed using the Solidity programming language and deployed on the private blockchain utilizing Truffle. Our experiments were conducted using PyTorch version 2.6.0 running on a workstation equipped with Ubuntu 20.04 OS, an AMD Ryzen Threadripper 3970X (32 cores, 64 threads, 3.7 GHz), an RTX 3090 Ti GPU, and 256 GB of RAM. Simultaneously, we simulated edge nodes using independent threads, with each thread implementing a real-world PyTorch classifier. Additionally, mobile phones (Huawei nova 7, 2.6 GHz, 8 cores, and 8 GB RAM) were employed as model Internet of Medical Things (IoMT) devices. Furthermore, our scheme operated within a finite field , with the secure framework based on a -threshold multi-party computation (MPC)-based protocol. The protocol utilized threshold multi-party computation (MPC), with the parameter p configured as to avoid data overflow. Standard threshold parameters were predefined as and in this framework.
7.1. Datasets and Settings
To evaluate the performance of our privacy-preserving blockchain federated learning (PP-BFL), we conducted experiments on two widely used datasets: PathMNIST [
36] and OCTMNIST [
37]. Details regarding these datasets are presented in
Table 2. The PathMNIST dataset comprises
non-overlapping image patches from hematoxylin and eosin-stained histological images, including a test dataset of
image patches from a different clinical center. The dataset is comprised of 9 types of tissues, and each image has dimensions of
pixels. The OCTMNIST dataset comprises
valid optical coherence tomography (OCT) images for retinal diseases. The dataset is comprised of four diagnosis categories, and each image is resized to
pixels.
7.2. Poisoning Attacks
In this experiment, we considered both targeted and non-targeted attacks. For non-targeted attacks, our analysis presumed that adversarial devices transmit randomized parameter updates, designed to undermine the global model’s reliability. Conversely, for targeted attacks—specifically assessing two prominent variants: class-redirection and covert-channel—we emulated class-redirection tactics by reassigning the original training labels and produced covert-channel instances through the deliberate insertion of activation patterns into unprocessed training data. Expanded methodological particulars are presented in the subsequent sections.
Label-flipping: We conducted a label-flipping attack on the PathMNIST dataset, where compromised devices relabeled the training dataset’s labels from 2 to 4 to simulate this type of attack.
Backdoor: To construct backdoor examples, we reassigned labels for DRUSEN exhibiting white horizontal stripes as diabetic macular edema (DME) on the OCTMNIST dataset.
7.3. Evaluation Metrics
We utilized test accuracy and test error rate as indicators for models trained on various datasets. The primary objective of our approach was to enhance the accuracy of the global model. Swarm Learning (SL) [
10] serves as a widely recognized method in non-adversarial settings within Blockchain Federated Learning (BFL). Consequently, we evaluated the SL scheme without attacks as a baseline comparison against Krum [
17], while also presenting results from our proposed scheme under varying numbers of malicious devices.
7.4. FL Settings
In our evaluation setup, we configured the number of devices at
, selecting all devices during each iteration throughout training. Our training model was based on a Convolutional Neural Network (CNN) with the following architecture:
. The weight and bias parameters for each layer were defined as follows: for the Conv layer,
and
; Fully Connected layer,
and
; and the Output layer,
and
. Additional training parameters are summarized in
Table 3.
Data allocation per device was performed equally, with each device containing 8000 uniformly distributed data points from the PathMNIST dataset and 9000 from the OCTMNIST dataset. We examined different scenarios regarding the proportion of malicious devices ranging from to . Our scheme was compared against both the SL and Krum methodologies. The batch size was set at . Furthermore, we observed that the loss function generally converged after approximately 50 rounds; thus, we established the number of training epochs at .
8. Experimental Results
In this section, based on extensive experimental results, we analyze the performance of our scheme from two perspectives: (1) Defensive effectiveness against both targeted and non-target attacks; and (2) computational and communication overheads.
8.1. Defense Effectiveness
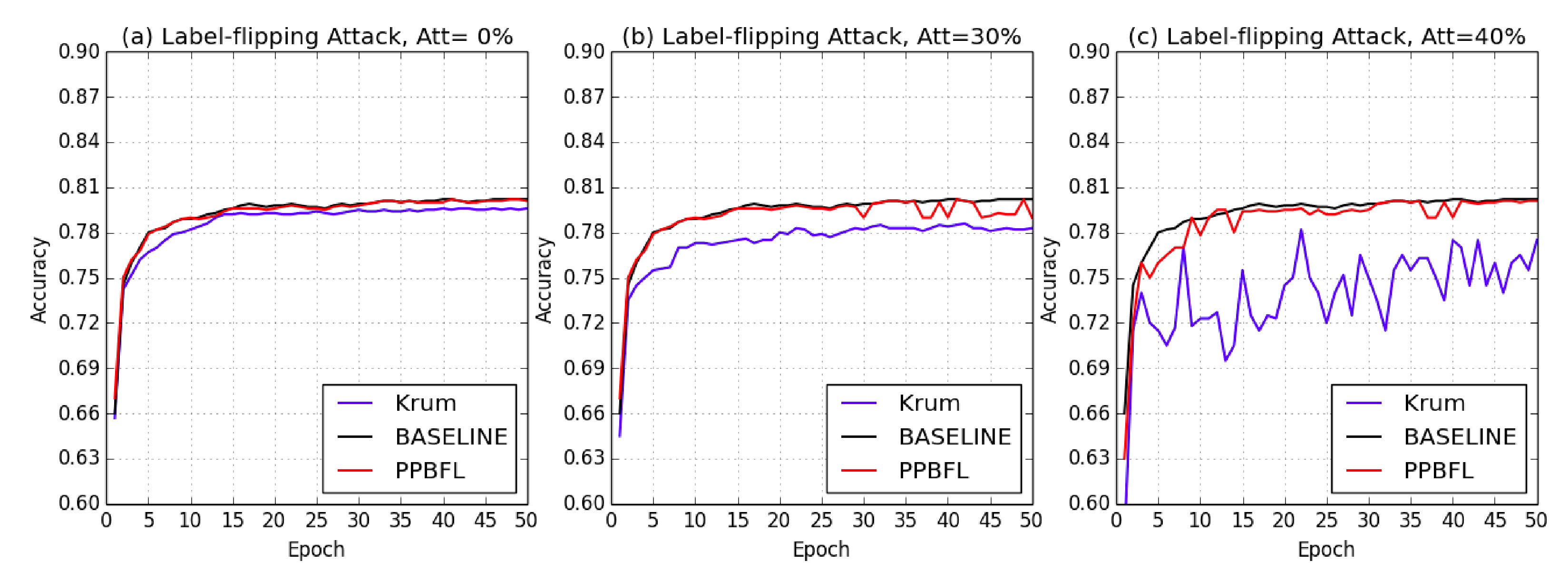
To assess the defensive effectiveness of our PPBFL, we conducted simulations of both non-targeted and targeted attacks on the PathMNIST and OCTMNIST datasets. The experiments were analyzed from the perspective of varying attack proportions and different iterations. Additionally, we provide an accuracy comparison with the baseline scheme (SL) [
10], as well as state-of-the-art methods such as Krum [
17].
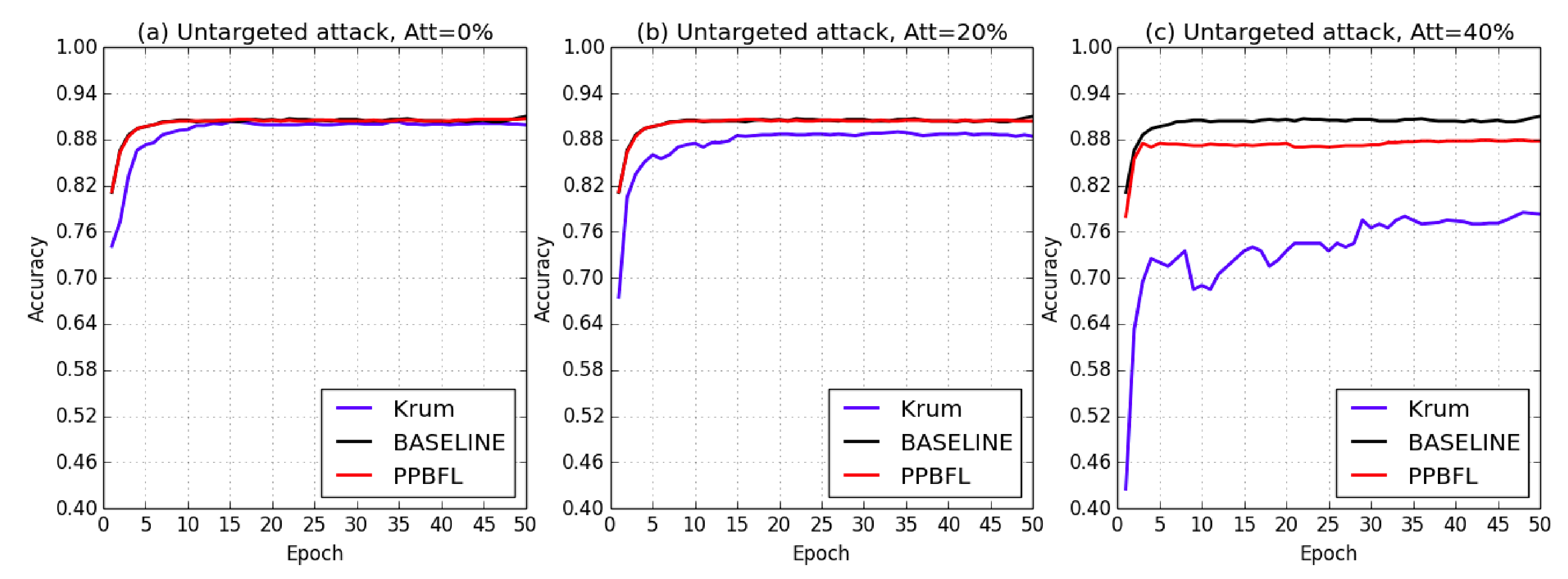
Figure 5 and
Figure 6 illustrate the training processes over 50 iterations for the PathMNIST and OCTMNIST datasets, respectively. Specifically, despite varying numbers of attackers, our PP-BFL maintained an accuracy rate consistent with that of the baseline under both non-targeted and targeted attacks, thereby achieving robustness alongside high accuracy.
8.2. Overhead of Our Scheme
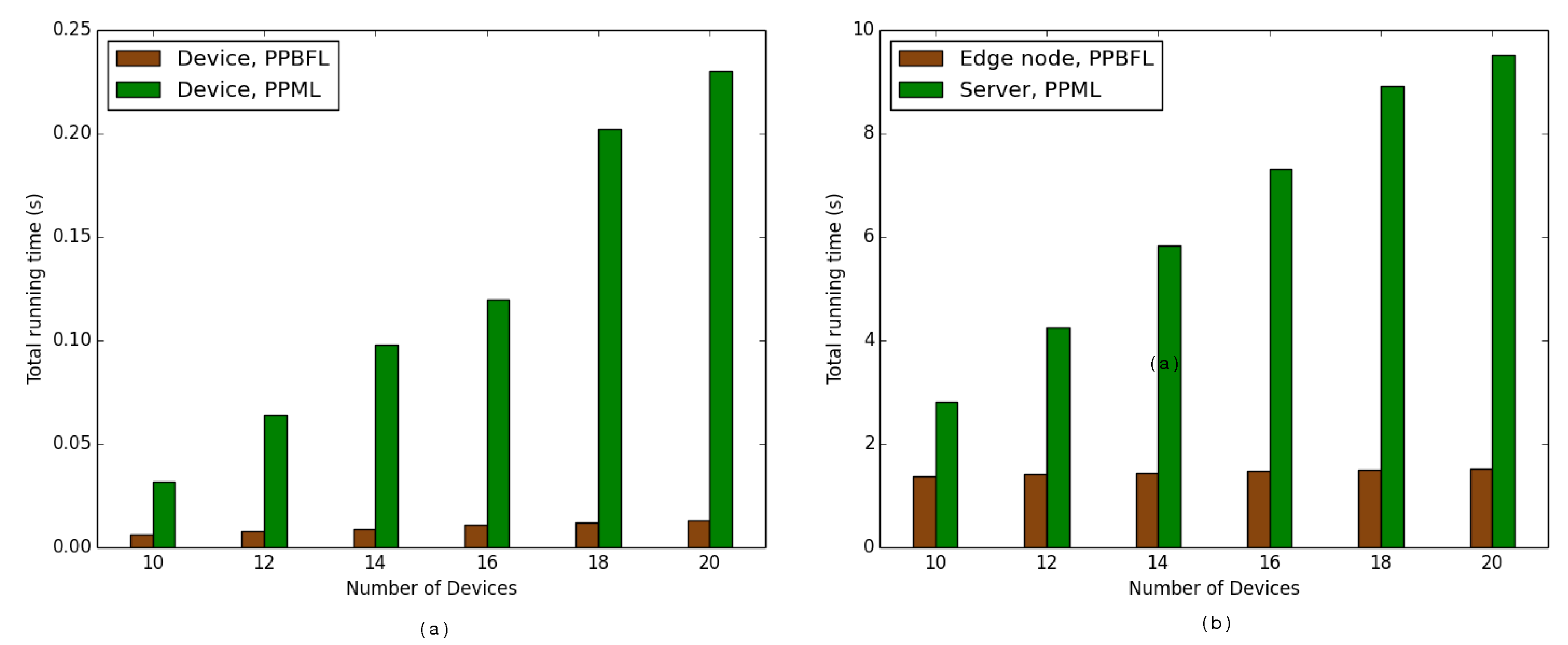
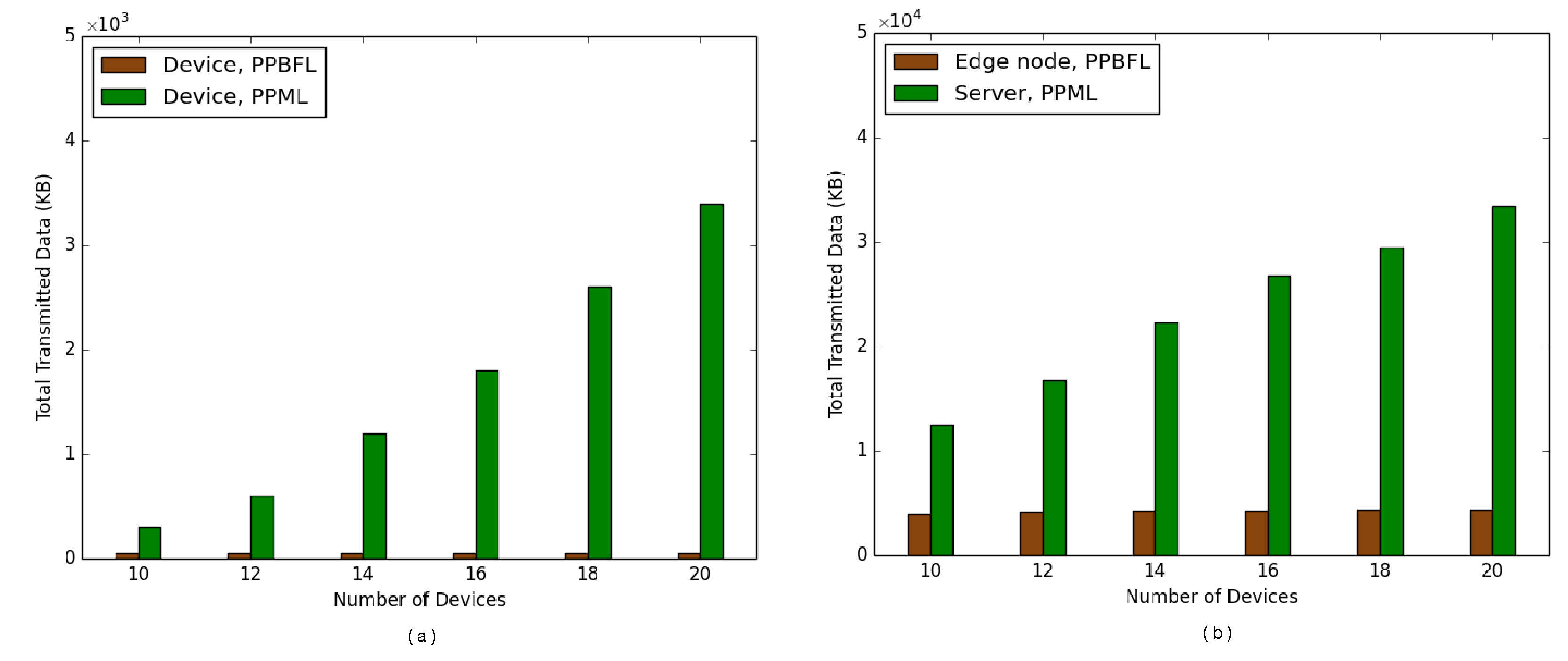
The computational efficiency of PPBFL is closely tied to its operational performance. We evaluated its resource consumption by measuring computational and communication demands, tracking how these metrics evolve as more devices join the network.
Figure 7 demonstrates substantially reduced processing requirements on devices compared to edge servers—a difference stemming from their distinct operational roles. While devices primarily distribute gradient shares, edge nodes shoulder the majority of secure computational tasks. Communication patterns reveal similar disparities, as illustrated in
Figure 8. Devices maintain leaner communication channels, mainly transmitting gradient shares to edge nodes and receiving aggregated weight updates. Conversely, edge infrastructure manages denser data exchanges to facilitate effective similarity calculations, requiring multiple coordination steps between network components.
In parallel, we conducted comparative analyses between our PPBFL framework and the MPC-based PPML approach [
16], evaluating computational and communication costs across device and edge node operations. The experimental results presented in
Figure 7 reveal that PPBFL demonstrated superior performance in terms of computational efficiency, which was particularly noticeable on devices. Notably, our solution maintained stable computational demand regardless of growth in the quantity of devices, while PPML exhibited a quadratic growth pattern in resource consumption with an increasing number, as can be seen from
Figure 7a. Corresponding server-side analyses, as shown in
Figure 7b, confirmed analogous efficiency advantages. This performance gap stems from PPBFL’s optimized computational architecture, compared to PPML’s more complex operational requirements. The communication metrics illustrated in
Figure 8 further highlight PPBFL’s technical superiority, achieving reduced data transmission requirements through minimized interaction rounds between devices and edge nodes. Unlike PPML’s intensive communication protocols requiring multi-party coordination and cloud server mediation, our framework implements streamlined data exchange mechanisms. Additionally, PPML’s architecture demands supplementary communication resources to handle device disconnections, whereas PPBFL inherently maintains operational stability without requiring such compensatory measures.
Operations executed through the smart contract were processed as Ethereum transactions, prompting us to quantify computational expenses through analyzing the gas units consumed during EVM instruction execution. Therefore, on-chain activities were evaluated through systematic gas utilization assessments, which aligned with transaction processing requirements. Under EIP-1559 specifications, the maximum block gas capacity has been raised from 15 million units to 30 million, although standard operational targets are typically maintained at approximately 15 million units. Moreover, the gas consumption caused by the transactions mined in one block cannot exceed the block gas limit. To avoid reaching the gas limit, we split the submit() and aggregate() functions up and imposed restrictions on the number of gradients published in one transaction to 200. As shown in
Table 4, we measured each operation’s computational consumption in gas.
The deployment of the smart contract necessitates an expenditure of gas units. The framework initially configures authorized addresses within the permissioned blockchain network to restrict unauthorized participation, requiring gas units for this setup phase. Prospective participants must complete blockchain registration by submitting cryptographic public keys, accompanied by Non-Interactive Zero-Knowledge (NIZK) validation credentials, with the blockchain’s verification and storage of these keys demanding gas per registration instance. The subsequent phase involves devices transmitting gradient data to the blockchain network, with transaction processing capacities handling batches of up to 200 gradients at a gas expenditure of per computational transaction. Following complete cipher-text submissions from all participants, the blockchain executes aggregation operations to derive global gradient parameters, with each aggregation transaction consuming gas units.
9. Discussion
In this section, we first assess the functionality of our proposed scheme by comparing it with several related works. Subsequently, we summarize the performance of our PPBFL.
9.1. Functionality
First, the functionality of our PPBFL was evaluated in comparison to several state-of-the-art approaches, including SL [
10], BFLC [
24], Krum [
17], FLTrust [
31], Bift [
33], LearningChain [
25], SL+HE [
15], PPML [
16], and Securenn [
29]. As illustrated in
Table 5, SL [
10] replaces the traditional server with a blockchain framework to mitigate the risks associated with single points of failure (SPFs), as well as potential malicious behaviors exhibited by servers.
Note that the security level includes passive security and active security; here, passive security refers to ensuring the security of the devices when the attackers are honest-but-curious (i.e., the attacker only performs passive attacks such as inference attacks), while active security refers to ensuring the security of devices when the attackers are malicious-and-curious (i.e., the attacker not only carries out passive attacks, but also actively performs malicious behaviors such as poisoning attacks). The DP-based LearningChain [
25], HE-based SL+HE [
15], and MPC-based schemes [
16,
29] consistently safeguard device privacy through their secure frameworks. Obviously, the above schemes can be categorized as passive security, as they do not consider of defending against poisoning attacks. Meanwhile, the Krum [
17], FLTrust [
31], and Bift [
33] frameworks are capable of defending against poisoning attacks but cannot protect device privacy. Therefore, these schemes cannot be categorized as either passive or active security. In contrast to all of the above-mentioned schemes, our PPBFL employs our MPC-based actively secure evaluation protocol to achieve active security, not only protecting the privacy of devices but also preventing poisoning attacks.
Furthermore, as our actively secure evaluation protocol utilizes -threshold MPC to construct our secure framework, our PPBFL can resist collusion between at most edge nodes, as well as supporting edge node dropout up to a level of .
9.2. Performance
As discussed in
Section 8, we conducted a series of experiments to evaluate the efficacy of our PPBFL. Based on the empirical results, the following conclusions can be drawn.
Privacy of Device Data: The PPBFL allows each IoMT device to collaboratively train the FL model locally with their local data. The PPBFL method is unlike the centralized machine learning approach, where the IoMT devices need to send their local data to the cloud for the learning process. Therefore, the proposed FL approach can ensure the privacy of these devices’ sensitive data.
Robustness of Local and Global Model: In our scenario, we consider adversaries that perform poisoning attacks on the IoMT device’s datasets. Such a poisoning attack will lead to a faulty local model and a poisoned global model. Our PPBFL utilizes the cosine similarity to detect and eliminate poisoned local model updates during the aggregation process. Judging from the experimental results, our PPBFL can effectively mitigate the influence of poisoned local model updates. From this result, our PPBFL can guarantee the robustness of both the local and global models.
Privacy of Local Model: In a traditional FL framework, attackers can perform a membership inference attack on the local device models, thus leaking sensitive data from the model. Therefore, we leverage the MPC-based secret sharing protocol, which maintains data confidentiality throughout FL processes, effectively addressing the inherent tension between data privacy preservation and robust defense against poisoning attacks. As the local gradient is protected, model inversion attacks and parameter stealing cannot be performed on the local model by an attacker.
MPC-based Secure Aggregation: In traditional FL approaches, the local models of devices are collected and aggregated into a global model. The aggregation process is the core step of FL to achieve a learning model with higher accuracy. As the aggregation is performed in the blockchain node using MPC-based actively secure evaluation protocol, adversaries cannot tamper with the aggregation process, thus maintaining the model’s accuracy.
Verifiability of the Global Model: As a decentralized technology, blockchain can maintain the integrity of data. In our PPBFL, we leverage blockchain to store the latest global model after the secure aggregation process. The decentralized process makes it impossible for adversaries to tamper with or alter the global model, as this will change the hash value. Later, the global model stored in the blockchain will be sent to the IoMT devices. Moreover, the devices can verify the integrity of the global model by checking the signatures and hashes before they use it.
10. Conclusions
In this study, we proposed a privacy-preserving blockchain-based federated learning (BFL) framework that protects against poisoning attacks, thus promoting safe data sharing in the IoMT context. In particular, the PPBFL was constructed to address the contradictory issues of privacy protection and poisoning defense in BFL. Based on the actively secure evaluation protocol and hierarchical framework, our PPBFL is characterized by its security, utility, robustness, and efficiency, effectively satisfying the demands of practical IoMT.
In the proposed framework, we provide a privacy-preserving training mechanism using a
-threshold MPC-based scheme, which ensures low computation and communication overheads. To resist poisoning attacks, we provide a robust global model by filtering out the harmful gradients using the cosine similarity. Our key insight is that the cosine similarity can be calculated homomorphically, based on our actively secure evaluation protocol, thus making it feasible to simultaneously ensure privacy protection and poisoning defense in FL. Furthermore, the blockchain is used to facilitate transparent processes and the enforcement of regulations, eliminating the need for a central coordinating authority during model training processes. Experiments were carried out on two medical datasets—PathMNIST [
36] and OCTMNIST [
37] —allowing for comparison of the proposed approach with Swarm Learning (SL) [
10] and Krum [
17]. The experimental results demonstrated that the proposed scheme can resist model poisoning attacks and achieve high global model accuracy.
In the future, we plan to develop an efficient consensus mechanism for PPBFL, in order to reduce computational and energy resources, as well as an incentive mechanism for PPBFL, in order to drive participants to actively and honestly take part in FL training tasks. Meanwhile, we plan to broaden the scope of PPBFL in the future in order to better support heterogeneous models in blockchain-based federated learning (BFL) for data sharing in IoMT.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}