1. Introduction
Recent studies have observed that deep models are sensitive to adversarial examples, which have been shown to be threatening in various domains, such as computer vision [
1,
2], natural language processing [
3], and speech recognition [
4]. Research efforts aim to mitigate the impact of adversarial examples, such as adversarial training [
5], input denoising [
6], and attack detection [
7].
Adversarial training is one of the most effective defense mechanisms, which generates adversarial examples and incorporates them into the training set [
5]. This strengthens the decision boundaries [
8] of the model subjected to such training. These new boundaries are harder to breach because they usually do not overfit the training distribution too closely. However, these boundaries can still be overcome with a larger perturbation or a new attack algorithm [
9]. In brief, a model trained with these techniques will keep the reinforced weights and be static. A consequence of this is that an attacker finding a successful perturbation will be able to use it and replay it to consistently fool the model. We qualify defense strategies that exhibit this pattern as static.
Another way to defend against it would be to completely prevent the generation of attacks by stopping the correct flow of the gradient, for instance. This kind of defense, called gradient obfuscation [
10], is often criticized and overlooked because of its intrinsic tendency to hide potential new vulnerabilities introduced in the defense method itself. For this reason, it is not desirable to prevent the generation of the attack according to the definition of gradient obfuscation [
11], but rather to rely on a dynamic aspect that introduces discrepancies between the generation of the attack and the inference stages.
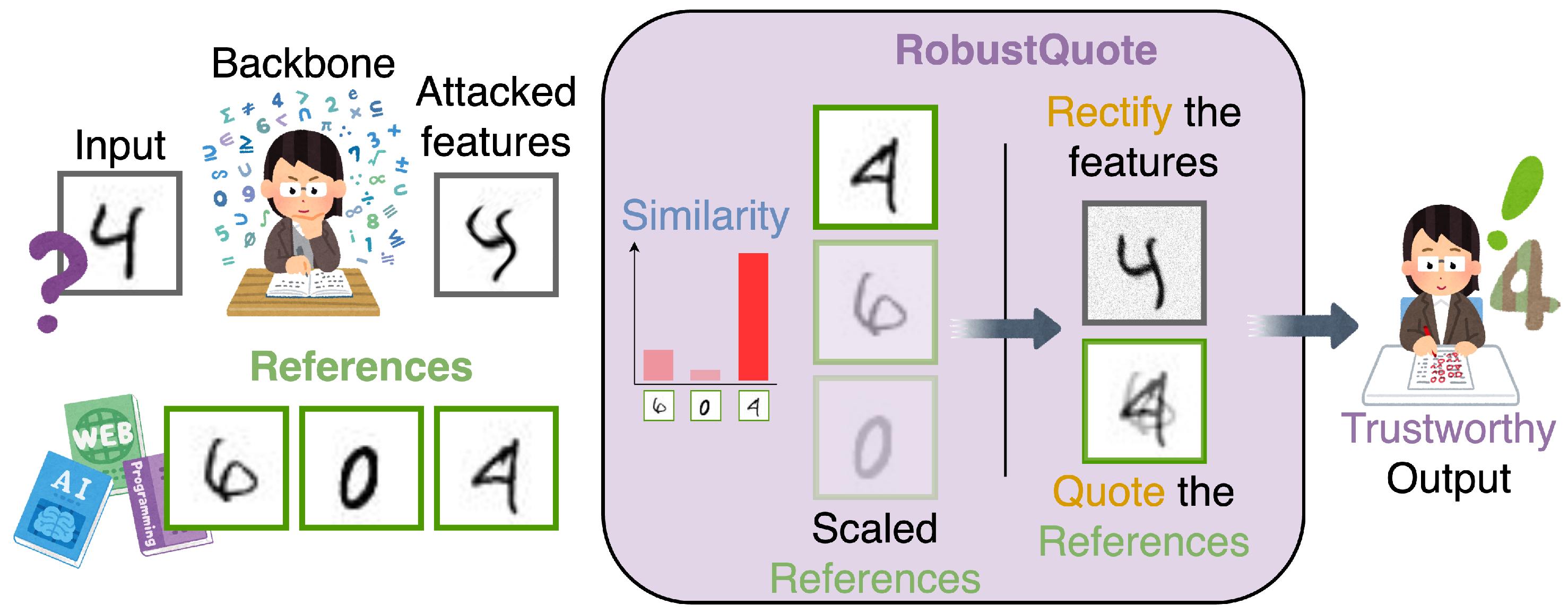
We propose making the adversarial perturbation less relevant to the final inference task by leveraging the generalization capabilities of the model to find citations and self-corrections from reference images. Following
Figure 1, we compare the classification task to the process of testing a student’s knowledge. The input image is the question, the internal features are the student’s thinking process, and the predicted result is the student’s answer. So, adversarial examples can be considered as a deformed representation of the question, affecting the student’s thinking process, and in turn the answer. The attacker, or the evil examiner, may design a question that seems ambiguous, and even confuse the model/student in a given context, but can hardly generalize to all possible contexts. But how can a context interact with the input image? We follow our inspiration from the student’s test and argue that the quotation relies on generalized features that can be compared with a context, in a trackable way, but also in a way that varies with a different context. Specifically, we can request the student to retrieve information from reference documents to answer the question and to substantiate their reasoning using the same documents. This information retrieval and valorization, performed at inference time and generalizable on an arbitrary set of references, is the core of this work, putting the attacker in an asymmetric situation between attack generation and inference time.
To this end, our novel defense mechanism, called RobustQuote, is a newly designed network block that can be plugged into most
vision
transformer (
ViT) [
12] architectures. This block aims to use the classification token of reference images to create a new classification token free of perturbations from the input image. We achieve this by replacing the classification token of the query image with a mixture of equivalent tokens from reliable and unattacked references. We propose to rely on the generalization of class embedding to create a dynamic defense method. In practice, this means utilizing a new set of references during each inference, thereby breaking the attacker’s guarantee that the perturbation computed for a given batch of references will transfer to another batch. It also appears obvious that the technique’s weakness is in relying on dynamic references to prevent the attacker from generating relevant attacks, rather than preventing him from generating the attack altogether. Yet, even in this case of the attacker gaining complete knowledge of the inference context, we argue that this scenario is as good as the traditional transformer inference, with no context to perform correction.
Inspired by the works in cross-attention mechanism [
13,
14,
15] and feature correction [
16,
17], we use the class embedding of references as the new values for the output class embedding (i.e., value vector in the terminology of attention mechanism), which constitutes the quoting module. At the same time, while we replace the classification token, we present a complementary rectification module, intervening over the rest of the image patches. Using previously selected supporting references, we generate a correction to all the patches of the input image, specifically trained to exclusively mitigate adversarial perturbations. Therefore, RobustQuote is a block composed of two modules that fulfill the above-mentioned functions and is a plug-and-play module that can be integrated into recent vision transformer architectures [
12,
18].
We empirically demonstrate the robustness of our method and its competitiveness against state-of-the-art (SotA) defense methods. On the CIFAR-10 [
19] and ImageNette benchmarks [
20], ref. [
5], we achieve gains up to 9.6% under the PGD-100 attack, and up to 0.5% under stronger AutoAttack [
21]. We evaluate our method against the common weaknesses of gradient obfuscation, confirming the extent of the obfuscation but also showing that we still maintain the backbone’s robust scores in the case of an adaptive attack. We record interesting effects of the placement of the block along the structure of ViT, connected to the learned representation of ViTs. We uncover a tension between early block and robust rectifications and later blocks and accurate predictions.
3. Method
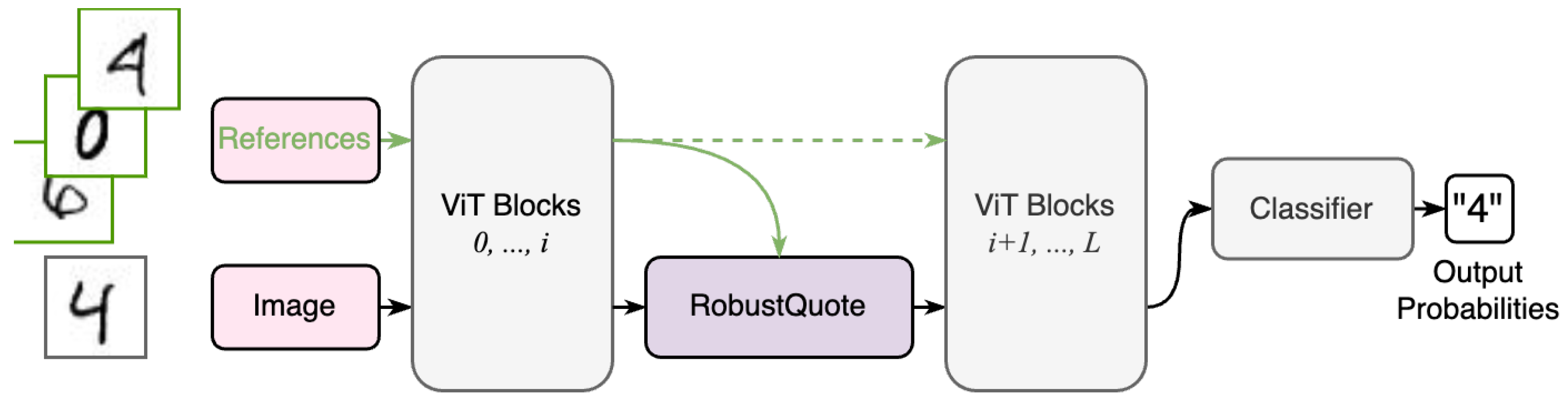
RobustQuote is designed for vision transformer models such as ViT [
12] and DeiT [
18]. See
Figure 2. RobustQuote is a modular block that can be inserted into arbitrary positions between a consecutive pair of transformer blocks. A RobustQuote block limits the
snowball effect of adversarial attack [
32] by (i) reconstructing the input image’s
[cls] token from those of the reference images so as to cut off the direct path from the input image to the prediction, and (ii) contextualizing input image’s patch features with other patch features so as to dilute the impact of the perturbations. In detail, the proposed RobustQuote consists of a quotation module (responsible for (i)) and a rectification module (responsible for (ii)), each of which is shown in
Figure 3.
Let
be a natural image that is potentially attacked and classified into the category
. RobustQuote aims to utilize a trusted set
of reference images
, sampled from the training set (detailed in
Section 3.5). Then, we denote a learned transformer model as
parameterized by
, which uses a patch representation of
and
, as well as a vector corresponding to the
[cls] token. Let
denote the set of feature vectors for every image patch in
, and
the feature vector corresponding to the
[cls] token (while
and
X are processed together in the ViT backbone, we represent them here separately). All reference images
also go through the same backbone, and we denote their feature vectors as
and
for them (we assume the same number of patches in input and reference images for simplicity).
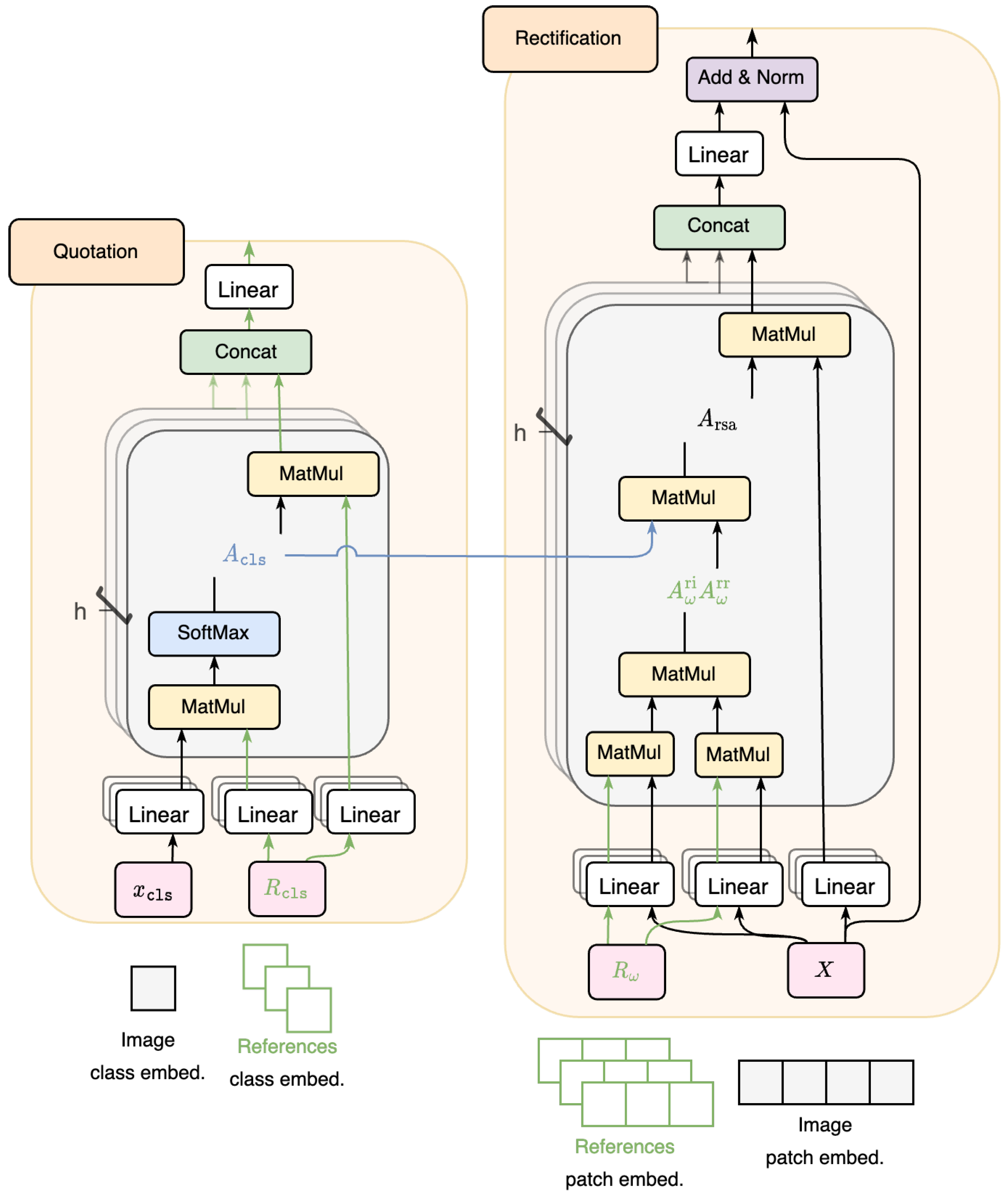
3.1. Quotation Module
We design the quotation module to substitute
, which can be the primary carrier of adversarial perturbations, with unaltered (i.e., trustworthy)
’s. Let
denote the set of all
’s. The quotation module calculates the scaled dot-product attention
as follows:
where
and
are linear projections, and
with
Q and
K being arbitrary matrices whose number of rows is
D. The quotation module then reconstructs
with
’s weighted by
, according to the following definition of cross-attention:
where
and
are linear projections. We replace
with
to sever the propagation of adversarial perturbations through
.
The quotation module is trained so that is still useful for classification. Our expectation is that it learns to reconstruct the features corresponding to the cls token from semantically similar reference images.
3.2. Rectification Module
The rectification module (right module in
Figure 3) aims to correct the adversarial features in
, referring to the unattacked information in
’s as follows:
where
G calculates vectors to mitigate the effect of adversarial perturbation. Here, we propose to use the self-attention mechanism [
33] and two derived strategies involving
to a greater and greater degree to generate the term
G.
Self-attention block: We use the traditional self-attention module without intervention of
as a baseline, formulated as follows:
where
,
,
, and
are all linear projections. These projections allow us to find robust features in the original image’s patch and combine them to create an efficient rectification, guided by a secondary loss described in
Section 3.4.
Reference-aware self-attention:
patches are used as a comparison ground to decide the natural/corrupted state of
X. This approach selects patch features in
X that are similar to those in
to correct patch features in
X that most diverge from
. Specifically, we use a slightly modified version of the scaled dot-product attention to find the attention weight for the correcting patches from
X:
where
and
are linear projections. We use the element-wise max function instead of softmax as we wish to use only positively relevant patch features in
X, expecting that the similarity to a natural feature works as a proxy to the relevance for robust correction. Likewise, the attention for the correction’s targets in
X is provided by the following:
where
and
are linear projections. This time, we negate the similarity as we wish to target only patch features in the original
X that are most different from natural features (this negation is used to emphasize our expectation and is unnecessary as it can be learned in
and
).
The final attention map is the weighted average of these attention maps, provided by the following:
where
is the attention weight in
in Equation (
2), corresponding to the category
, which provides the semantic relevance between the input and the reference for
. Eventually, we compute
G with this attention map as follows:
where
and
are linear projections.
Reconstruction: Similarly to the quotation module, we can reconstruct
X directly from
’s. The attention weight can be provided by the following:
and
G is calculated as follows:
where
,
,
, and
are linear projections, respectively.
3.3. RobustQuote Block
We feed the outputs of the quotation and rectification modules into a residual architecture as follows:
with
as a multi-layer perceptron following the same dimensions as the ones in ViT blocks, shared for two types of tokens. After these operations, the representations of
and
X are recombined and forwarded to the next transformer block of the network.
3.4. Training Loss
An output of the model with RobustQuote blocks (after softmax) can be denoted by
as it takes both the input image and the reference images. Let
denote the input image and the corresponding ground-truth category. We train the model with a RobustQuote block using TRADES-based adversarial training [
24], which minimizes the KL divergence between the natural and adversarial logits:
where
is the cross-entropy loss,
the KL divergence loss, and
is the trade-off term used to balance classification loss and adversarial robustness. In this equation,
is the adversarial perturbation crafted by the PGD attack [
5] (as in
Section 2.1).
In addition, we introduce a loss term for our rectification given by
G (i.e., one of
,
, and
). When the input image
is attacked,
G should produce patch features that cancel it; otherwise,
G should be closer to 0, as there is nothing to cancel. Formally, let
and
be patch features for patch
p in the set of all patches
in natural and attacked sets
X and
of patch features after applying
G (that is,
and
) for the same image
. We penalize the model when the length of
is long compared to that of
; that is, the loss term
is provided by the following:
where
specifies the upper bound of the length of
relative to
.
Overall training loss is defined as follows:
where
is a hyperparameter to balance the two terms,
l identifies the index of the layer where the RobustQuote block is installed, and
L is the set of indices of all layers at which a RobustQuote block is inserted.
3.5. Reference Set Selection
The reference set
is a pivotal aspect of RobustQuote, and how this set is collected is crucial. The images in
should be natural images as they are used to provide supporting features from the categories and to define the unattacked distribution of patch features. Thus, we isolate a subset from the training dataset
. In practice,
is divided into
subsets
for each class according to the labels of each image. At each new inference (training, test, or evaluation), we draw a new
with a random sample from each class in
. Doing so ensures that the training is not catered to a given set of references but instead is guided by its interpretation of each class. This methodology of reference set construction is independent of the dataset properties, as no training is performed based on the features extracted from these images. The only property that this set must satisfy is the representation of each class in a sufficiently large quantity to ensure robustness to expectation-based attacks (see
Section 3.6). In practice, the same references
will be shared with all
in a batch to accelerate computation.
3.6. Source of the Robustness
RobustQuote tightly entangles the input image’s patch features with reference images in the inference process. The [cls] token is completely replaced with one created from the reference images in the RobustQuote block, and all patch features are also adjusted by the reference images (for and ) so that the original adversarial perturbation is mitigated. Thus, the prediction is highly dependent on the choice of the reference images. As a consequence, a different set of reference images will have drastically different results in the results of RobustQuote.
This consequence secures the robustness of RobustQuote. Suppose that we deploy a model with RobustQuote blocks in a real-world application. In this scenario, the attacker can only upload the input image while the model obtains a randomized set from . Even in the white-box setting, where the attacker obtains the architecture along with the model’s parameters, the selection of the new reference set is uncontrollable for the attacker, as the selection is carried out server-side after the attacked image is submitted. Images used in the reference set can be publicly available, but one could choose to further refine the generation of this set or even use new images. We set our minimal robustness requirement so that the selection of from is unpredictable to the attacker.
Even if the attackers have access to all possible reference images, they then require finding the ones that will actually be used in inference, which is improbable. For example, in the case of CIFAR10, there are approximately 5000 images of each of the 10 classes. By picking one image per class, you can generate combinations of the references, which is beyond reasonable for a blind search, such as brute force.
We argue that this robustness comes at the cost of accuracy in the prediction or difficulty in training. Equation (
2) implies that the features corresponding to the
[cls] token are reconstructed from relevant reference images, which should be the image of the correct category. This means that RobustQuote requires a significant level of understanding of images, even to make correct classifications at the position where it is installed in the transformer model. Therefore, the position of the RobustQuote block may be limited to the latter part of the original network.
4. Experiments
As stated, the purpose of RobustQuote is to improve the robustness to attacks based on asymmetric (outdated) information between the attacker and the defender. To demonstrate our claims, we will evaluate our novel method against other state-of-the-art methods striving to normalize adversarial inputs, as well as submit our method to an attacker with symmetrical knowledge, demonstrating that our method’s major lever is the creation of that asymmetrical scenario. We also wish to study our connection with gradient obfuscation techniques, underlining comparable measurements from different causes. Finally, we will demonstrate the impact of the parameter values and design variations presented in
Section 3.
4.1. Experimental Setups
We conducted experiments on the CIFAR10 [
19] and ImageNette [
20] datasets. We utilized DeiT3-T as our backbone model, as it is one of the best-performing ViT pre-trained models. RobustQuote was compared with several state-of-the-art techniques, such as ARD and PRM [
34]. SACNet [
35] is a two-layer regularization method, like DH-AT [
36]. We also included feature regularization, as presented by Kim et al. [
17], with the FSR model. Our evaluation was performed over PGD-20 [
5], PGD-100, C&W-20 [
37], and AutoAttack (AA) [
21] with a perturbation budget of
(“PGD-
k” refers to the projected gradient descent-based attack with
k-step iterations, while “C&W-
k” is the PGD attack with
k-step iterations using C&W loss [
37]).
We used pre-trained models from the open source Hugging-Face and Pytorch Image models project (the implementations of baseline models together with weights are from
https://huggingface.co/models?pipeline_tag=image-classification&search=timm/deit3 accessed and up to date as of 22 January 2025). For each method, we update the ViT architecture with the most up-to-date DeiT3-T weights pre-trained with the ImageNet dataset [
38]. All of our models and the SotA methods start with the same pre-trained parameters and are finetuned with the loss functions found in their respective publications. The training parameters, such as optimizer, learning rate, and epochs, however, are shared. We then proceeded to fine-tune the model for 40 epochs on the TRADES training pipeline. We used the SGD optimizer with a momentum of
and a weight decay of
. The initial learning rate was set to
, reduced by a factor of 10 at the fifth and second-to-last epochs. We empirically set
and
for our RobustQuote method and
for the TRADES parameter. In our experiments, we used a single RobustQuote block, placed after the 7-th block of ViT (among 12 blocks), with the
RSA rectification module. We used different sets of reference images, which were randomly sampled from the training dataset, in attack generation and inference, which is most likely to happen as it is rather easy to find a publicly shared dataset, but it is much harder to predict the content of a randomly sampled batch during inference for the previous attack generation as we discussed in
Section 3.6.
4.2. Robustness Evaluation
We first evaluated the effectiveness of RobustQuote in improving robustness against adversarial attacks on DeiT3 backbones. The accuracy scores are summarized in
Table 1. RobustQuote consistently improved accuracy under adversarial perturbation of DeiT3 backbones. We also observed a good natural accuracy, unlike defense methods such as FSR or SACNet, which degraded it by up to 4.5%. RobustQuote’s performance remained within 2.5% of the best-performing ARD+PRM at 78.54% on CIFAR10 and 82.73% on ImageNette. More interestingly, we observed a drastic increase in adversarial robustness of +7.7% on average on CIFAR10 and +4.3% on ImageNette compared to the best-performing ARD+PRM.
We also evaluated the evolution of adversarial robustness as the attack budget increases. Although the attack budget increased from PGD-20 to PGD-100 to C&W, which are increasingly more efficient at reducing accuracy on the other models, we observed almost identical accuracy (within 0.8%) with RobustQuote. Only AutoAttack produced a substantial accuracy drop of 12.9% on CIFAR10 and 7.5% on ImageNette. This is because the AutoAttack implementation requires multiple attacks on each sample, triggering, by design, a new set of reference images. This leads AutoAttack to look for the best attack on the weakest set of references. We explain the behavior of the previous PGDs and C&W attacks by arguing that the better an attack is at optimizing a perturbation for a given input, the worse this perturbation will perform in a new setting with the same input but with different references. In this paradigm, attacks that come closer to the definition of a universal perturbation will perform better than specific attacks.
Evaluation for Black-Box and Adaptive Attacks
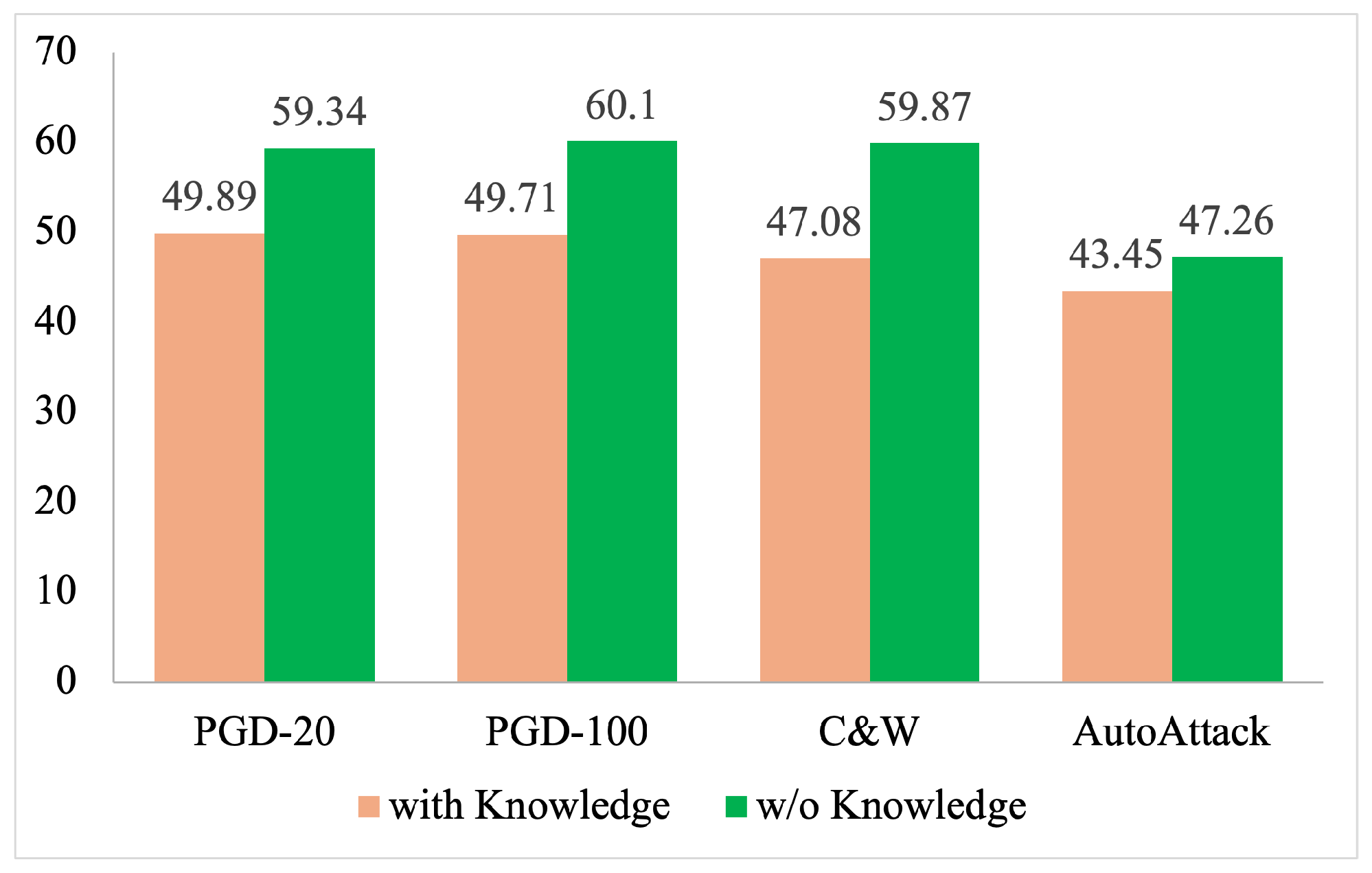
We further investigated various attack scenarios to understand the robustness conditions of our RobustQuote model. First, we report in
Figure 4 the scenario in which the adversary possesses perfect knowledge of the inference time. In this situation, the benefits of using reference images are completely lost, and the attacker knows in advance which reference images will be used during the inference. We observed a notable decrease in accuracy (ranging from 3.8% to 12.8%) under PGD and C&W, where RobustQuote previously exhibited a significant advantage over existing methods. In this context, RobustQuote remained within 0.8% of the original DeiT3, proving that additional evasions are not introduced with references.
In view of the aforementioned behaviors, one possible explanation of RobustQuote’s robustness is that it performs some kind of gradient obfuscation [
10]. According to the definition in [
11], we argue that RobustQuote does not prevent the attacker from obtaining useful gradients, as the attack can often be successful when the reference images are the same in attack generation and inference, according to
Figure 4. Nevertheless, we evaluated RobustQuote under the various gradient obfuscation benchmarks to understand its limits.
Firstly, as shown in
Section 3, we employed standard known operations in accordance with [
10], suggesting that all operations should be differentiable and kept in a usable range. The first test consists of gradually increasing the perturbation budget
until the performance approaches zero. We report the results in
Table 2. When
, RobustQuote maintained the performance, while we observed an accuracy drop to 2.84% when
. This reveals that RobusQuote does provide useful gradients for generating stronger perturbations, taking advantage of a larger budget
. This result supports our discussion above that RobustQuote does not obfuscate the gradients.
We performed experiments with a decision-based black-box attack, i.e., square attack [
39]. The number of iterations was set to 1000, with a perturbation budget of
. We observe in
Table 3 that the square attack fails to reduce adversarial performance compared to the white-box attack (i.e., PGD-20 attack). According to the claim in [
10], we again demonstrate that RobustQuote does not obfuscate the gradients.
In
Table 4, we examine the behavior of RobustQuote under a PGD-based transfer attack. We employed both DeiT3-T without adversarial training and DeiT3-T with FSR [
17] as proxy models. We utilized the PGD-20 attack on proxy models with a perturbation budget of
, and then directly applied the crafted adversarial examples to the model with a RobustQuote block. The results in the last row of
Figure 4 show similar behavior to the black-box attack, showing again that gradient-based attacks still outperform transfer-based attacks.
Finally, we evaluated the performance of the targeted adversarial attack, namely APGD-t [
21]. This attack was remarkably more efficient than the default PGD attack, confirming our suspicion that guiding the attack toward a single class can effectively focus on a single reference. In
Table 2, we observe that APGD-t can achieve better results than the PGD-20 attack, but RobustQuote can still defend against this adaptive adversarial attack.
In sum, our results show that RobustQuote exhibits one of the symptoms (PGD-20 attacks perform better than PGD-100) attributed to gradient obfuscation, and we do not strictly adhere to the definition. Based on these results, we believe that RobustQuote offers a brand-new defense strategy that is different from the existing ones.
4.3. Ablation and Parameter Sensitivity Studies
4.3.1. Variants in the Rectification Module
With this first study, we demonstrate that our proposition of rectifying the image features
X is beneficial.
Table 5 shows the scores when the rectification module (and associated loss
) is removed (
None), when a random matrix is used instead of
in Equation (
6) (
Random), when
is used (
Self), when
is used (
RSA), and when
is used (
Rec). We can see that
None performs significantly worse than our full solution by 0.1%.
Random also does not overcome RobustQuote, and still remains 0.05% behind, demonstrating that the robustness is not only because of mixing up the patch features, but also because guiding these permutations boosts the performance.
Self, RSA, and Rec are variants of RobustQuote. Self and Rec are both outperformed by RSA by 0.3% and 0.05%, respectively. This implies that external information is more reliable for finding corrections than the corrupted input, but finding the corrections from within that input is ultimately more stable.
4.3.2. to Determine the Effect of
In the following section, we explore the impact of RobustQuote’s hyperparameters, and , as well as where to place a RobustQuote block and how many to use.
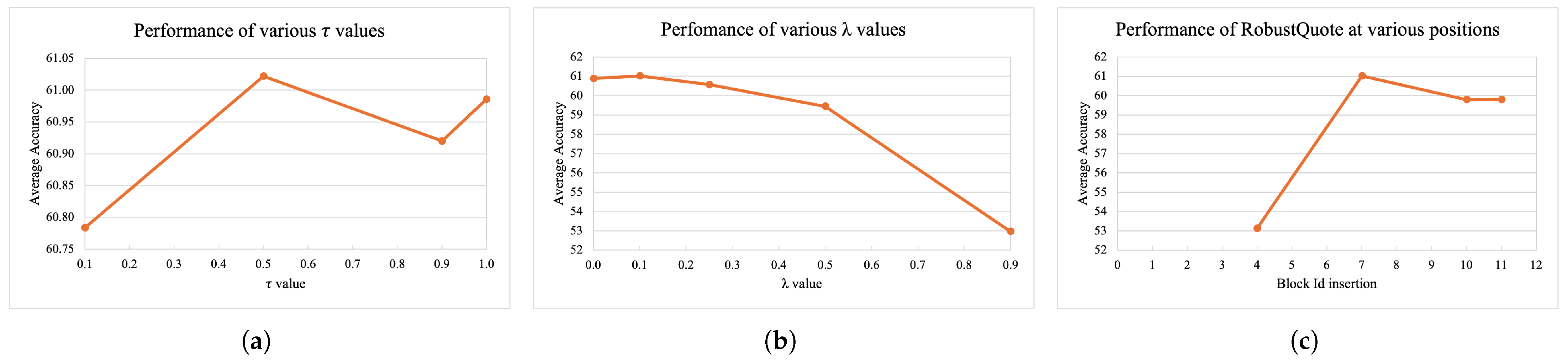
Starting from
, we report the scores for different values in
Table 6 and visualize them in
Figure 5a. We see a clear best value at
, outperforming all other values in adversarial attacks by up to 0.7% in C&W, while lagging by only 0.1 in the worst case in AutoAttack. Overall,
provides a 0.05% average benefit over the second-best choice of
. It seems that values lower than 0.5 (imposing a greater difference of correction) have diminishing returns and it becomes too hard to find large adversarial corrections
relative to
. On the other hand, a larger
, which hardly imposes a constraint on lengths, yields a lower performance than
.
4.3.3. to Balance Loss Terms
We looked at the balance of the loss term
. We summarize the results in
Table 7 and
Figure 5c. We again observed a sweet spot around
with diminishing returns as the importance of
. Additionally, we observed that deactivating
completely was also not beneficial and caused a loss of 0.1% accuracy on average. One could argue that this is the result of
, and that this important constraint generates large
loss terms compared to
. We note that
and
must be optimized jointly in order to find the best combination for the task considered. In our experience,
is the most impactful parameter and can be quickly approximated with any
, so fixing
first may be the most efficient strategy.
4.3.4. Positions and Number of RobustQuote Blocks
We studied the impact of the positions and the number of RobustQuote blocks in the ViT backbone, where we tried up to two blocks.
Table 8 and
Figure 5b summarize the scores for various combinations of one or two RobustQuote blocks in a ViT backbone. Inserting a single RobustQuote module in the middle of ViT significantly enhanced performance, with the best average of 56.64% accuracy under the considered attacks. We observed a small loss of 0.5% or 1% of robustness when using RobustQuoute in the later stages of the network and a large loss when it was placed in the earliest blocks. We hypothesize that there is a sweet spot that best leverages the tension between relying on
cls tokens in the quotation and taking advantage of the rectifications made on the image tokens in the following blocks.
This echoes recent observations in [
40], where the
cls tokens form well after the 7-th block and are mainly propagated through the skip connection branch before this block. Based on our empirical observation, inserting a RobustQuote block around the 7-th block is a good choice. As an illustration, when using RobustQuote on the 4-th block, we dropped to 48.32% average robust accuracy due to the lack of relevant information in the
cls token at this stage. We also examined the performance of multiplying the instances of RobustQuote blocks in the backbone, and we tested two variations. We observed that combining two instances resulted in lower robustness than the worst of the two instances used individually, implying that the two blocks may be competing with each other.
Overall, using a single block was preferable, and we added our RobustQuote after the 7-th transformer block.
4.4. Discussion
The experiments in Section Evaluation for Black-Box and Adaptive Attacks showed that the gains of RobustQuote are conditioned on the asymmetric knowledge between the attacker and the defender, regarding the references. As stated in
Section 4.1, the standard robust scenario occurs when the attacker knows everything about the model, the weights
, and the reference dataset
, but ignores the exact images
. We stated in
Section 3.6 the requirements on
to render improbable the random selection of
prior to the inference time. We presented the hypothesis of a model deployed as a backend process, alongside which the defender has their own dataset
to generate
in the backend too. When the user or the attacker uploads their input image
, they will have no control or information on the references used during their inference. Only in the case where the user gains control over the references or when they can predict
used at inference, can they generate the attacks with knowledge presented in
Figure 4. In this case, our method is indeed neutralized and is then equivalent to the static adversarial training methods such as ARD-PRM. We believe that it is a reasonable defense strategy, as obtaining this level of control or information goes beyond the security of AI and now depends on the robustness of the overall design of the AI system deployed.
Finally, we address the computational costs of our method. Our module, added to the original backbone of DeiT3-T, represents an increase of 11% of the model’s weights. The set of references across the transformer block has a negligible impact in the training phase, as no gradient is tracked in the ViT blocks. In the inference stage, they occupy % additional memory alongside what uses. In the RobustQuote block, has a complexity of and has a complexity of . Compared to a standard ViT block with complexity of , this is an increase of %. As such, in the context of CIFAR10 and ImageNette with 10 classes, this represents the memory footprint of 10 standard ViT blocks in parallel. On a system with Nvidia V100-16GB GPU, using a batch size of with DeiT3-T and CIFAR10 images, the standard DeiT3-T computes an inference in 66 ms using 29.3 MB of VRAM, while our RobustQuote requires 170 ms and uses 64.7 MB. This highlights the limitation of datasets with a small number of classes . A possible improvement would be to find a class agnostic quotation and rectification system, with a fixed number of references, providing a natural anchor instead of a class-specific anchor. We consider such improvement as future work.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}