4.1. Deep Reinforcement Learning Architecture
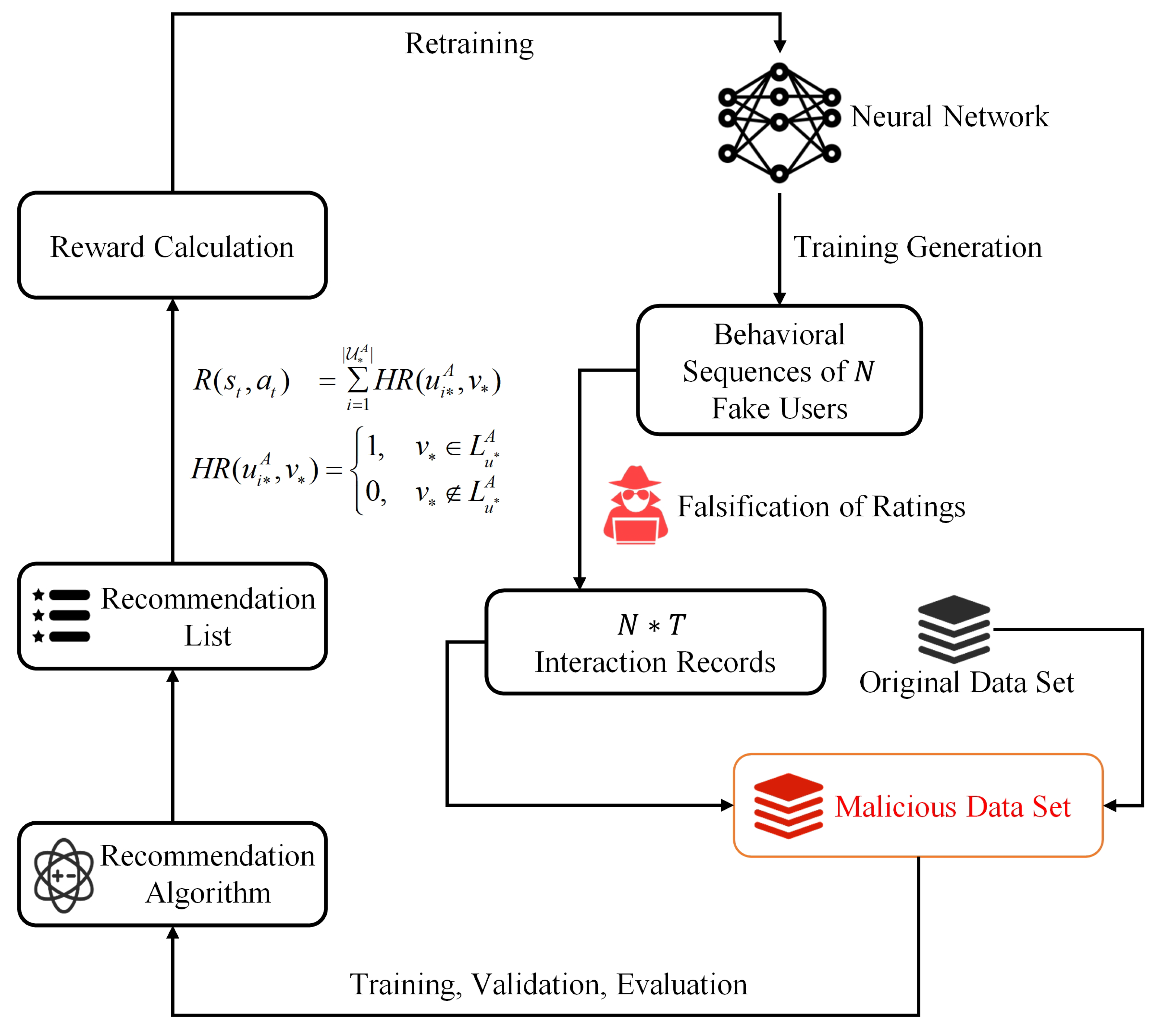
When constructing the DRLAttack, the core concept is to model the attack process as a framework compatible with reinforcement learning. In this framework, the attacker acts as an agent interacting with the environment. To achieve this, it is essential to define new types of state spaces, action spaces, and reward functions and ensure that the entire process complies with the requirements of the Markov Decision Process (MDP). This includes the state space S, action space A, conditional transition probabilities P, reward function R, and discount factor (i.e., ). Here is a detailed introduction to the model architecture:
Environmental modeling: In the DRLAttack framework, the environment comprises the structure and algorithmic parameters of the target recommendation system. This environment is capable of capturing user preferences and behavior patterns through data on interactions between users and items, and it uses this information to generate recommendation lists.
Agent design: DRLAttack employs a Deep Q-Network (DQN) deep reinforcement learning algorithm as its agent. This agent improves its strategy by observing the current state, selecting appropriate actions, and receiving rewards provided by the environment. The goal of the agent is to maximize the cumulative reward.
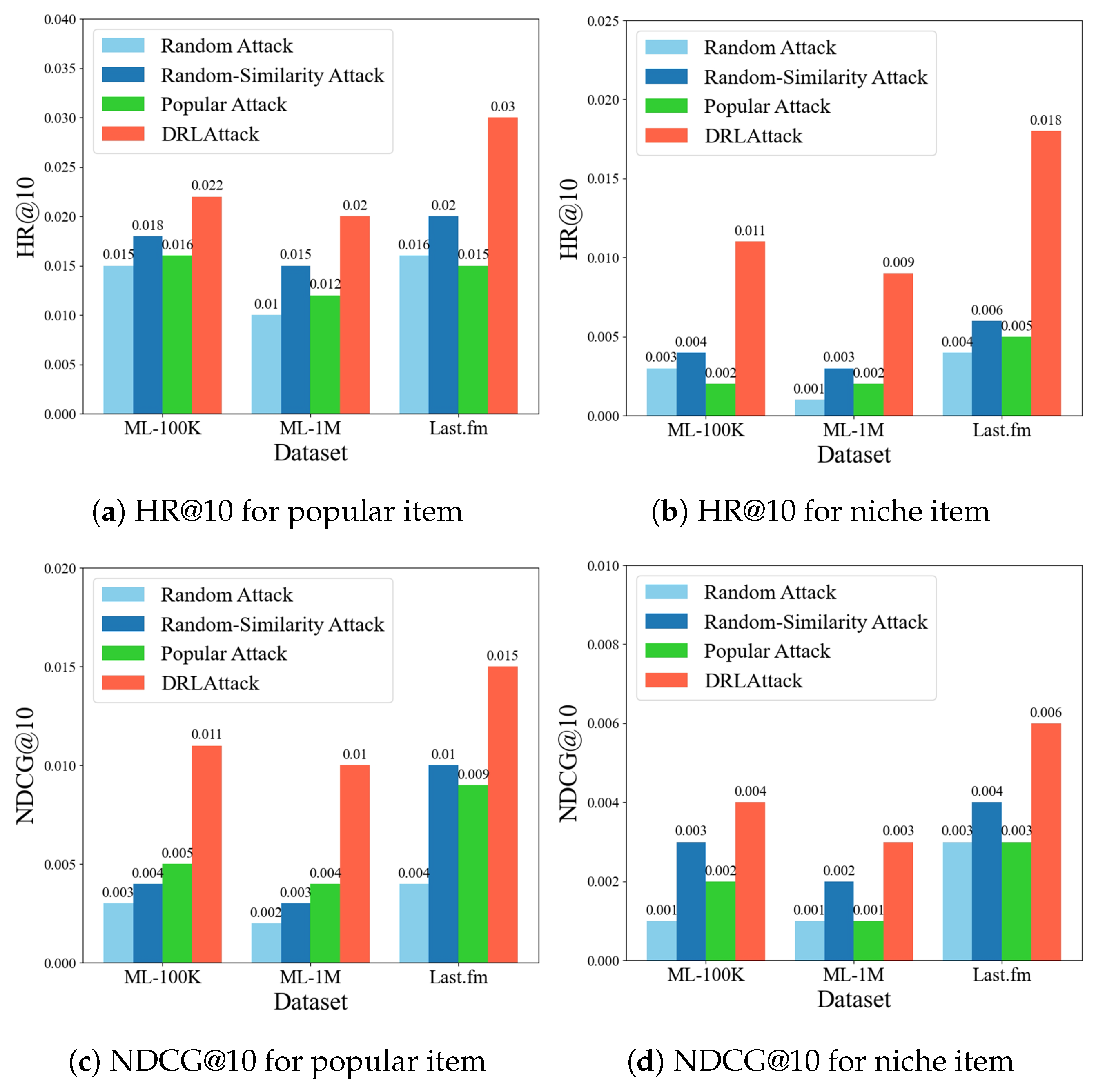
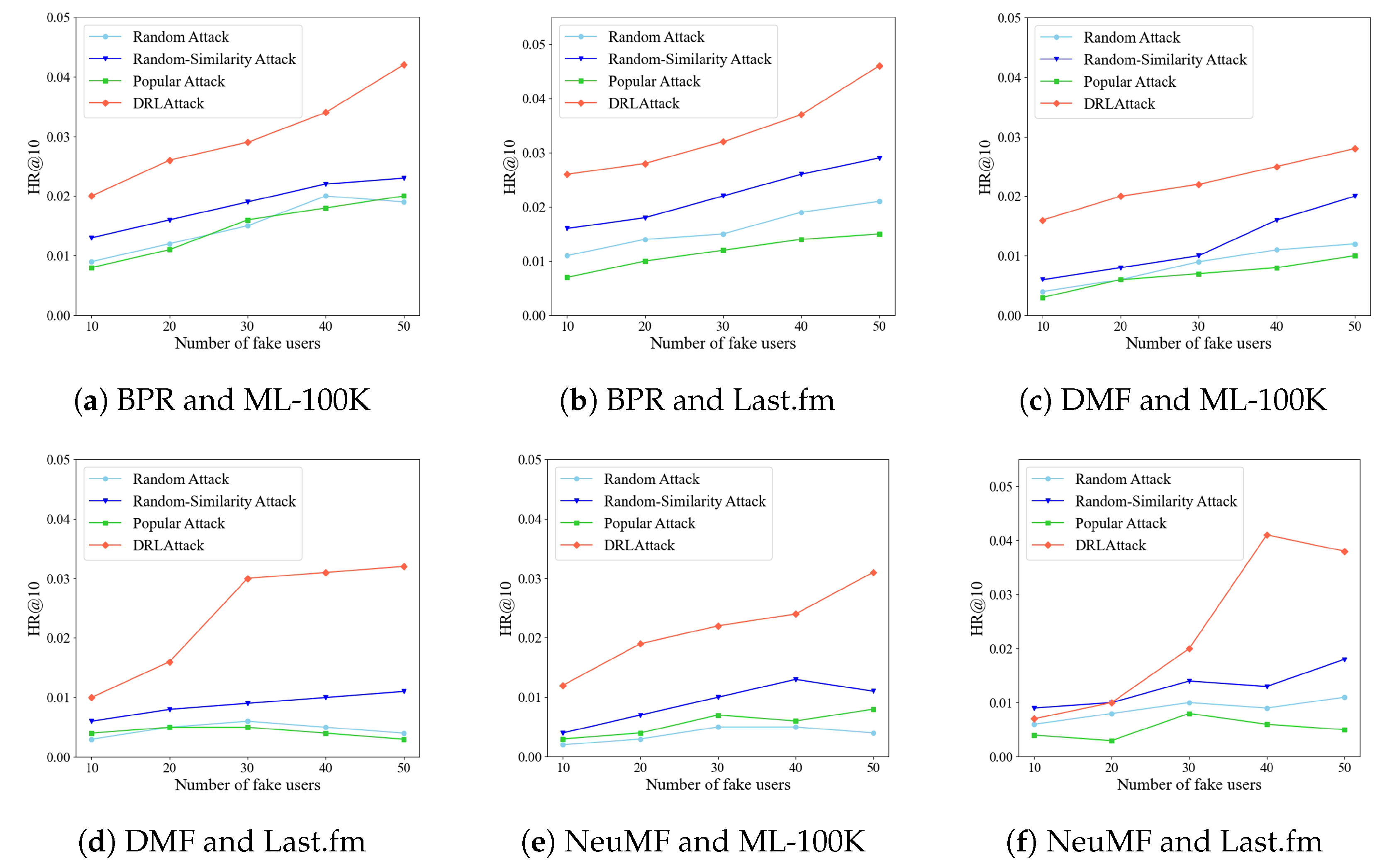
Design of action space A: The action space defines all the possible actions that an attacker can perform, typically including the set of all items in the recommendation system. However, designing it this way often has a negative impact on the learning of the agent’s attack strategies, as the number of items in a real recommendation system’s training dataset is usually very large. It is challenging for the agent to identify correlations between users and items within a vast action space using limited attack resources, leading to a low success rate for attacks. To improve the design of the action space, we first analyze the training dataset before preparing the attack. Using similarity measurement methods, we identify other items similar to the target item
to form a candidate item set
. For implicit datasets, we use the Jaccard coefficient to find candidate items. The Jaccard similarity [
26] between any two items
and
is calculated as follows:
where
represents the number of times two items are interacted with by the same user (i.e., the count of simultaneous interactions with both items by users), and
represents the total number of interactions where at least one of the items is interacted with by users (i.e., the count of interactions with at least one of the two items). The process of finding
n similar items first involves constructing a matrix
R from the user–item implicit interaction data, where rows represent users and columns represent items. An element value of 1 indicates an interaction between a user and an item, while 0 indicates no interaction. Then, calculate the similarity: for target item
, iterate through all other items in the matrix to compute the Jaccard similarity between each item and target item
. Finally, rank all items based on the calculated Jaccard similarities and select the top
n items with the highest similarity as the candidate set for target item
.
For explicit datasets (where users provide ratings for items), cosine similarity is used to identify other items most similar to the target item to form a candidate item set. For any two items
a and
, their cosine similarity [
26] is calculated as follows:
where
and
represent the ratings given by user
i to items
a and
b, respectively, and
n represents the total number of users who rated the items.
Additionally, if the action space only includes items similar to the target item, this may make the attack actions more conspicuous and easily recognizable by the recommendation system’s anomaly detection mechanisms. On the other hand, an action space purely based on similar items might limit the agent’s exploration range, affecting learning efficiency and the ultimate effectiveness of the attack. Therefore, we opt to combine n ordinary item and n candidate items to form the action space. The redesign of action space A can make the behavior of fake users more akin to that of real users, reducing the risk of detection. The mix of candidate and ordinary items also enhances the diversity of the action space.
Design of state space S: The core of the state space is the sequence of items that the agent has chosen in the steps leading up to the current step t. Existing data poisoning attack methods often fix the target item’s identifier at the beginning of the state space and then base subsequent actions on the agent’s learning. While this approach is straightforward, it generates a highly correlated sequence of fake user behaviors that can be easily detected and mitigated by the recommendation system’s defensive mechanisms. Practical scenarios also require the consideration of limited attack resources, as each fake user can interact with only a limited number of items. Therefore, we define state space S as a sequence , where represents the sequence of items a fake user chooses to interact with at timestep t. The length of the sequence is determined by the maximum number of items T that a fake user can manipulate.
In the DRLAttack framework, the goal is to generate N independent fake user behavior sequences, each reaching the predetermined maximum length of T. Therefore, the process is set up to proceed in parallel, where each fake user independently selects actions from action space A without interfering with others, until their respective sequences are complete. For each fake user and at each timestep t, the update rule for the behavior sequence is , continuing until . This design facilitates the parallel generation of multiple independent fake user behavior sequences under limited attack resources, enhancing the stealth and efficiency of the attack.
Design of conditional transition probability: The transition probability defines the likelihood that, following an action taken by the attacker at timestep t, the state transitions from the current state to the next state .
Design of reward function R: In reinforcement learning, the reward provided by the environment offers immediate feedback to the agent. This paper focuses on push attacks in a targeted attack scenario, where the attacker aims to recommend the target item to as many users as possible. DRLAttack employs a rank-based reward function, where a positive reward is calculated whenever the target item
appears on user
’s recommendation
-k list. Here,
represents the set of all users, and
is a subset of target users selected by the attacker for calculating the reward, considering that the general logic of recommendation systems is to not recommend items a user has already interacted with. Therefore,
essentially represents the subset of users who have not interacted with the target item. The hit rate (HR@K) is used as the ranking metric in the reward function
for a given state
and action
. After all
N fake user behavior sequences are generated and injected into the target recommendation system to obtain the recommendation lists
for the target users, the reward value
is calculated as the sum of all HR@K values for the user set
as follows:
where
s and
a, respectively, represent the current state and the action taken in that state. The calculation of the reward is not directly related to the specific action but is based on the overall effect of the attack.
returns the hit rate of the target item
in the recommendation
-k list of the target user
. The reward value
is the sum of all hit rates for all target users in
.
When an attacker aims to promote a group of target items to as many users as possible, the design of the reward function needs to consider the overall recommendation success of all target items. It can be defined as the sum of successful recommendations for each target item across a set of target users as follows:
By calculating the hit rate for each target item in the recommendation list and summing these rates, the agent is encouraged to recommend the items from the target item set to as many users as possible. Such a reward mechanism makes the attack strategy more explicit and goal-oriented.
4.2. Optimization Process of Attack Strategies
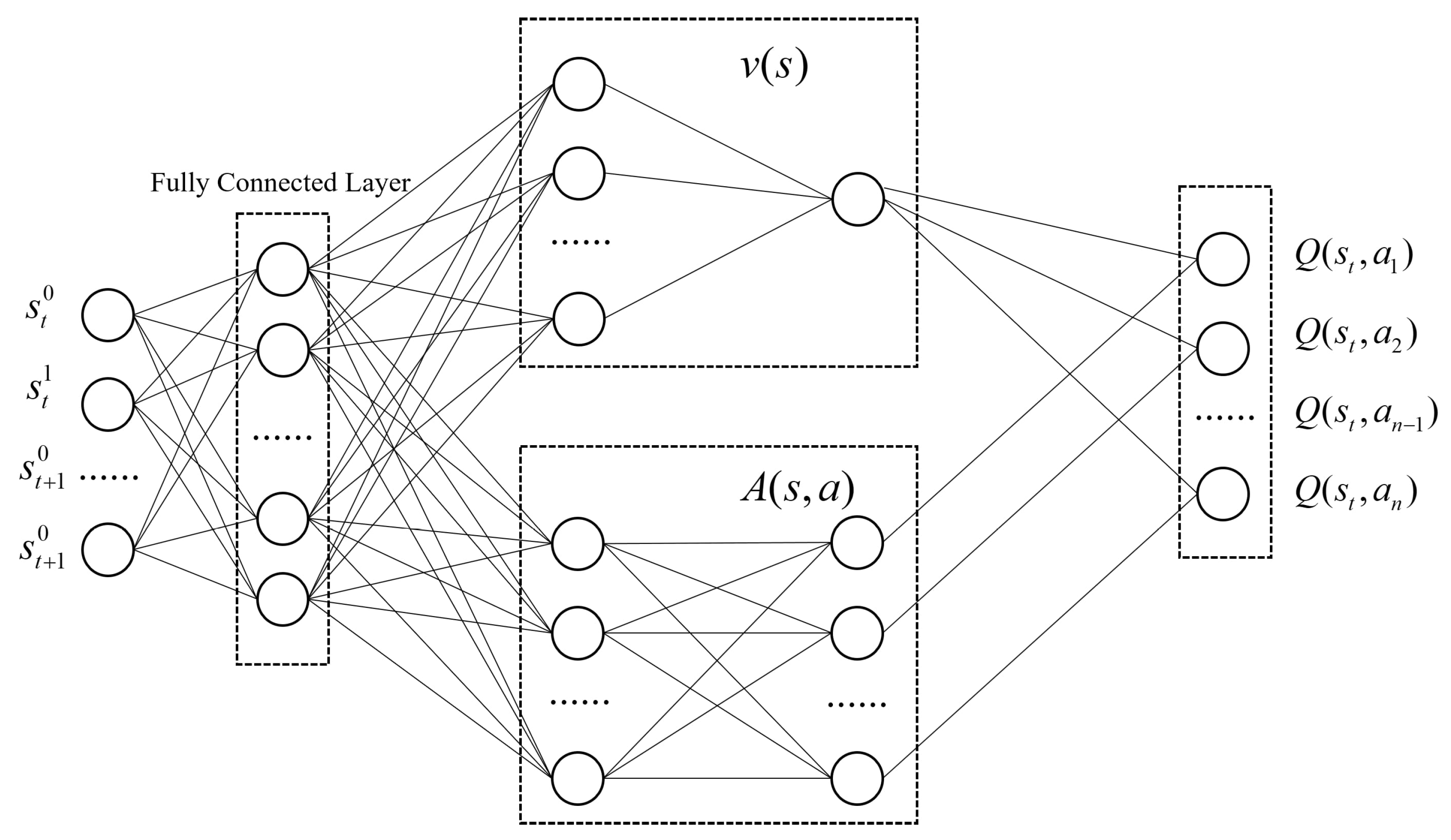
In the previous section, the Markov Decision Process (MDP) was used to simulate the interaction between attackers and the recommendation system. To address the challenges posed by high-dimensional state and action spaces, we utilize a Deep Q-Network (DQN) in the DRLAttack framework, enhanced with a Dueling Network architecture to further optimize network performance. A Dueling Network is a neural network design that decomposes the Q-function into two separate components [
27]: the value function
and the advantage function
. The purpose of this design is to better learn the relative advantage of choosing each action in a given state, while maintaining an overall estimate of the state value. In the Dueling Network, the calculation of the Q-function is accomplished by combining the value function and the advantage function as follows:
where
represents the average of the advantage functions across all actions, which ensures that the contribution of the advantage function to the Q-value is zero when summed over all possible actions. This arrangement allows the value function
to remain independent of the chosen action, while the advantage function
represents the additional value relative to the average action. This separation facilitates a more focused learning of state values and the specific advantages of each action, improving the efficiency and effectiveness of policy optimization in complex environments. In the DRLAttack framework, the specific details of the network implementation include the input layer, hidden layers, and output layer, as shown in
Figure 1. Input Layer: The input to the network is the representation of state
s, which in the context of recommendation systems is the sequence of behaviors of fake users. Hidden Layers: These consist of multiple fully connected layers (DNN) designed to extract deep features from the state. Output Layer: The value function and advantage function are combined according to Equation (
5) to generate Q-value estimates for each action.
During each iteration of the training phase, there are mainly two stages: the replay memory generation stage and the parameter update stage. In the replay memory generation stage, the agent selects actions from a mixed item set based on the current Q-network and
-strategy. After executing action
, the environment returns a new state
and reward
. In the parameter update stage, the agent randomly samples an experience tuple
from the experience buffer, and then updates parameters by minimizing the defined loss as follows:
where
is the output of the target network, used only for calculating the target value, and
is the output of the current network, used to generate new actions. These two networks have the same architecture but different parameters. Every fixed number of timesteps, the parameters of
and
are synchronized.
Additionally, we introduced the Prioritized Experience Replay (PER) [
28] mechanism into the DRLAttack framework. In PER, each experience tuple
and
is assigned a priority that reflects the importance of learning from that experience. Given that the data poisoning attack on recommendation systems aims to maximize the recommendation of target items to as many users as possible, the priority
p is set based on the reward value
r obtained from each state sequence as follows:
where
is the TD error calculated based on the reward value
r, and
is a small constant used to ensure that every experience has at least a minimal chance of being selected. When using PER, the sampled experiences are assigned importance sampling weights (ISWs)
[
29] to counteract biases from non-uniform sampling as follows:
where
N is the total number of experiences in the replay memory, ensuring proper normalization of weights;
is the probability of an experience tuple being drawn; and
is a hyper-parameter that gradually approaches 1 as training progresses. The updated loss function, incorporating importance sampling weights
, is as follows:
In the aforementioned update rules, the loss function is multiplied by the corresponding importance sampling weight to adjust the impact of each experience update step, offsetting the uneven distribution of updates caused by prioritized sampling. The early stages of training might require more exploration, while the later stages focus more on exploiting the knowledge that has already been learned. Thus, the adjustment of importance sampling weight can help balance between these two aspects.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}