4.2. Evaluating GPT-Generated Text as a Data Augmentation Tool
The first experiment examines whether GPT-generated text can serve as an effective data augmentation tool for addressing class imbalance in text classification. Although the experimental structure was framed around an imbalanced dataset, the underlying goal was to assess the utility of synthetic data in improving model performance for underrepresented classes. This corresponds to the first of our two research questions: can GPT-generated text function as a meaningful supplement to real data?
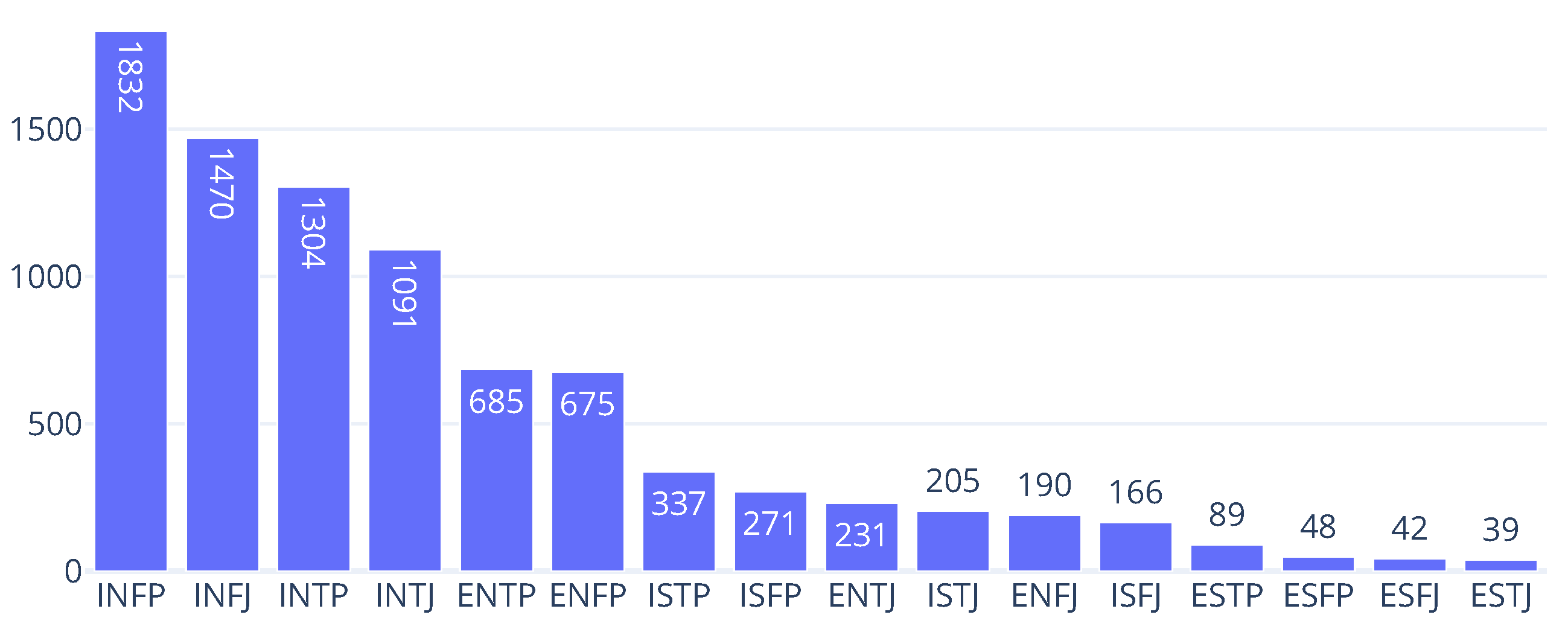
The experiment was conducted under two settings: the Base Dataset and the Extended Dataset. In the Base Dataset setting, we used the original MBTI dataset from Kaggle [
14] and split each MBTI type equally into 50% training and 50% test sets. Although a 1:1 train–test split is not standard in typical machine learning practice, we deliberately adopted this ratio to ensure that even low-resource classes would have enough test samples to allow stable and interpretable evaluation. This decision aligned with the core objective of the study—not to build the most optimized model, but to assess the contribution of GPT-generated text under controlled and comparable conditions.
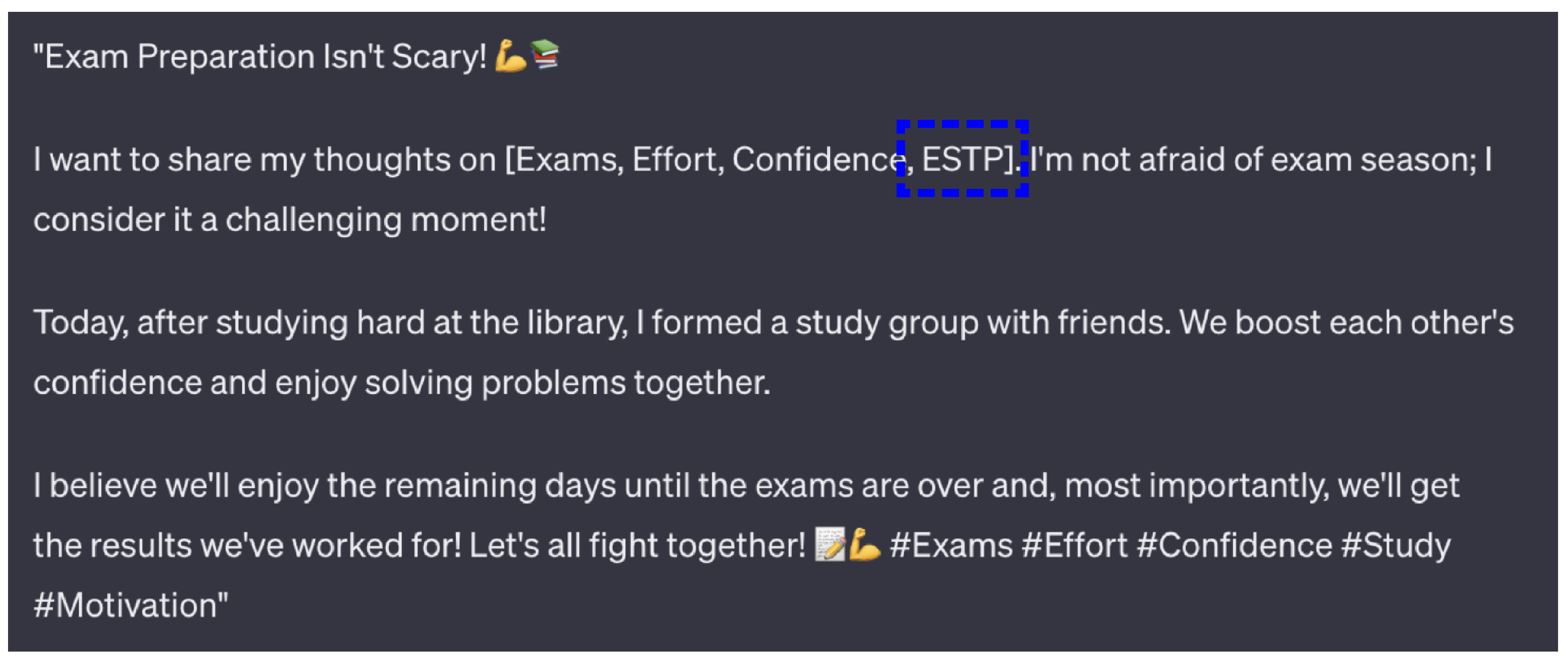
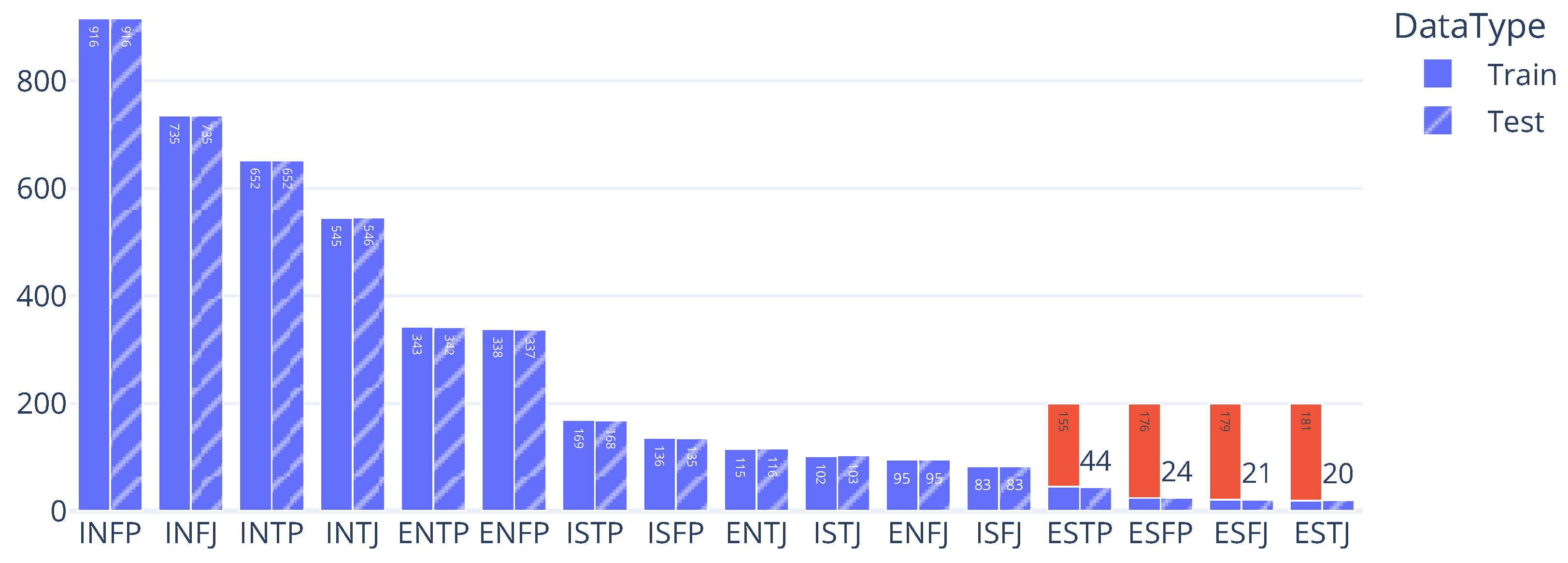
The Extended Dataset setting built on the Base Dataset by supplementing the training data for four low-resource MBTI types—ESTP, ESFP, ESFJ, and ESTJ—with synthetic samples generated by GPT. For each of these types, we increased the number of training examples to a total of 200 by combining the original Kaggle data with GPT-generated posts, while keeping the test sets unchanged. In this setup, the Base Dataset consisted of a straightforward 50:50 split of the original data, whereas the Extended Dataset added synthetic text to reach 200 training examples per class for the selected types. The resulting sample distribution is visualized in
Figure 2.
This design allowed us to directly assess whether GPT-generated text contributed to model improvement. If performance improved, we could infer that synthetic text was useful in supplementing scarce data. Conversely, if no improvement was observed, the setup still offered clear evidence that the synthetic data may have lacked sufficient informativeness or compatibility with the learning model.
Our analysis followed a conventional approach to text classification, combining traditional feature-based methods with machine learning models. We began by cleaning and tokenizing the text data, removing stop words and special characters, and applying basic normalization. From the preprocessed text, we generated 3-g features—sequences of three consecutive tokens. Each document was then represented as a frequency vector based on these N-grams and used as input to the classification models. For classification, we experimented with a variety of models, including gradient boosting methods such as LightGBM [
15,
16], CatBoost [
17], and XGBoost [
18]; ensemble-based methods such as Random Forest and Extra Trees; a distance-based method (K-Nearest Neighbors); a simple feedforward neural network; and a weighted ensemble meta-model [
19] that combined the outputs of individual classifiers. Model performance was evaluated on the test set using precision, recall, F1 score, and Area Under the Curve (AUC).
The experimental results for this study are available at
https://seoyeonc.github.io/MBTI_dashboard (accessed on 10 May 2025), with the results for the experiment in the current section presented under Experiment 1 on the dashboard. The dashboard was built using the Quarto publishing system [
20]. Simulations were conducted using
Autogluon [
21,
22], which enabled automated model selection and evaluation. Due to the large volume of results, the main text presents only a selected subset of findings that are most relevant for discussion. We limited our analysis to the top six models based on overall classification performance. Among various evaluation metrics, we report only the AUC, as it offers a threshold-independent and stable measure of classification performance—particularly suitable for comparing models in imbalanced data settings.
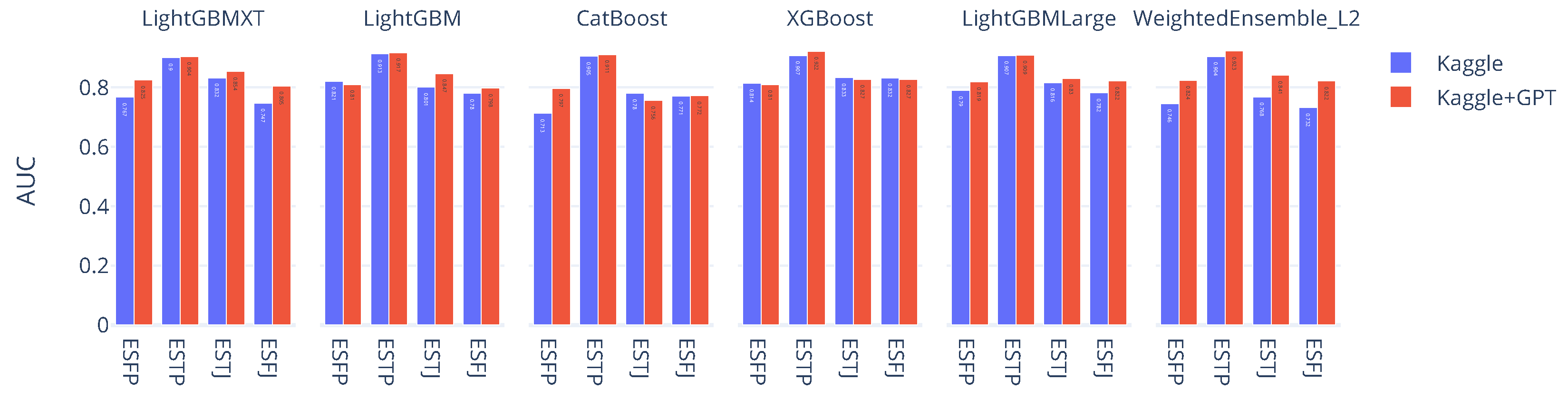
Figure 3 compares the AUC scores of six top-performing models across four underrepresented MBTI types (ESFP, ESTP, ESTJ, ESFJ). The blue bars represent performance using only the original Kaggle dataset, while the red bars reflect results from the Extended Dataset, which included GPT-augmented samples. Across most combinations of model and personality type, the inclusion of GPT-generated text led to performance improvements. For instance, models such as LightGBM and CatBoost showed notable gains for ESTP and ESFP when augmented data were added. Although the magnitude of improvement varied by model, the overall trend remained consistent: synthetic data contributed positively to classification performance. In no case did performance significantly deteriorate due to augmentation, and in several cases, it helped close the gap caused by data scarcity. Taken together, the results suggest that although the degree of improvement varied across models and MBTI types, GPT-based augmentation consistently led to performance gains. While there were a few exceptions where augmentation did not yield clear improvements (as shown for XGBoost and some other models in the dashboard, possibly due to differences in how the model processes textual features or responds to synthetic inputs), the majority of cases showed that models trained on augmented datasets performed better than those trained on the original data alone. In fact, for every MBTI class examined, the highest AUC score was always achieved using the augmented dataset—a strong indication that synthetic data are not only helpful but at times critical in overcoming data scarcity. These results provide empirical support for our first research question—whether large language model outputs can be leveraged as an effective data augmentation strategy. Having established the utility of GPT-augmented data as a supplemental resource, we now turn to a deeper question: can synthetic text also function as a substitute for real-world data? In other words, if we had replaced the GPT-generated samples with actual human-written text, would the performance have improved even more? To address this, we designed a second experiment under a few-shot learning setup, which provided a more extreme and controlled scenario for testing such substitution. We describe this next.
4.3. Assessing the Substitutive Value of GPT-Generated Text
This section investigates the extent to which GPT-generated text can serve as a substitute for real data. In particular, we ask whether such text goes beyond mere surface-level fluency and stylistic plausibility to contain information that is genuinely useful for a classification task. The central question is whether GPT-generated text can function not just as a supplemental augmentation resource but as a training signal of equivalent value to human-written data. This distinction can be illustrated with an analogy from image processing. Augmented images—created via transformations such as rotation, cropping, or color adjustment—are ultimately derivatives of existing data. In contrast, a new real-world image captures independent information from a novel viewpoint. As such, the latter typically provides more diverse and informative content, which can contribute more significantly to model learning. The aim of this section is to determine whether GPT-generated text belongs in the former or the latter category—whether it can match the informational value of truly independent samples.
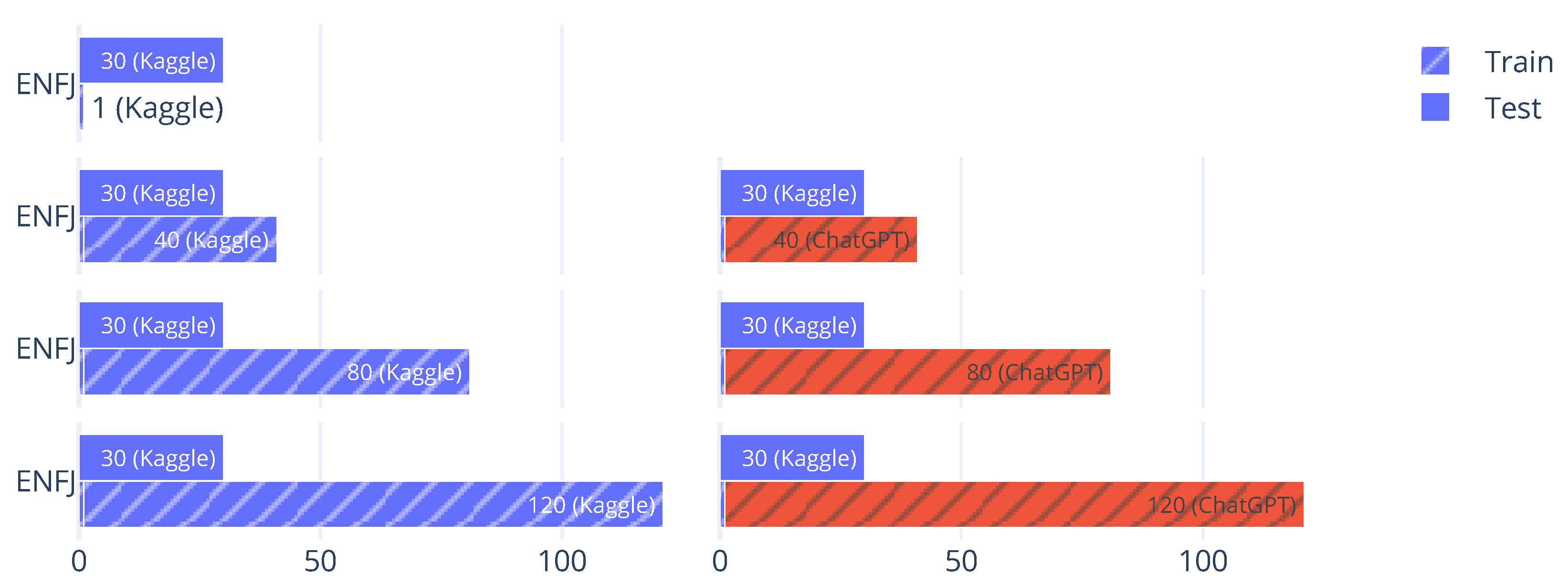
To test this, we constructed a few-shot learning scenario. By limiting the amount of data available for all classes, we were able to observe how heavily the model relied on the training samples and thereby assess the informational depth of GPT text. The experiment centered on ENFJ, a relatively underrepresented MBTI type in the Kaggle dataset. The training set included only a single real ENFJ example, while the test set contained 30 fixed ENFJ examples. Under this setup, we compared two data addition conditions: one in which the training set was augmented with GPT-generated ENFJ text and the other in which it was augmented with the same number of real ENFJ samples from the remaining Kaggle data. The structure and distribution of the training and test sets are illustrated in
Figure 4. In this figure, hatched bars indicate test samples, and red bars represent additional GPT-generated samples added to the training set. Blue bars denote real data from the original Kaggle corpus.
The experimental scenario was designed based on the following ideas. First, we artificially reduced the number of training samples for a specific class to simulate an extreme few-shot learning condition. Under such circumstances, the model’s performance was inevitably limited, and it was reasonable to expect that adding more training samples would lead to improved performance. Second, we established two experimental conditions: one in which only GPT-generated synthetic data were added for the target class and another in which the same number of real samples were added instead. As a result, one experiment involved a training set for the target class composed almost entirely of synthetic data, while the other used only real data. If the performance improvement achieved by adding synthetic data was substantially lower than that achieved by adding real data, it would be difficult to consider synthetic data equivalent to real data in providing an effective learning signal. This experiment differed significantly from the previous experiment. In the earlier setting, both synthetic and real data were included across all classes, and the role of synthetic data was evaluated primarily as a supplemental augmentation resource. In contrast, the current experiment isolated the effect by including only synthetic or only real data for a specific class, thereby directly assessing whether synthetic data can function as an equivalent training signal to real data.
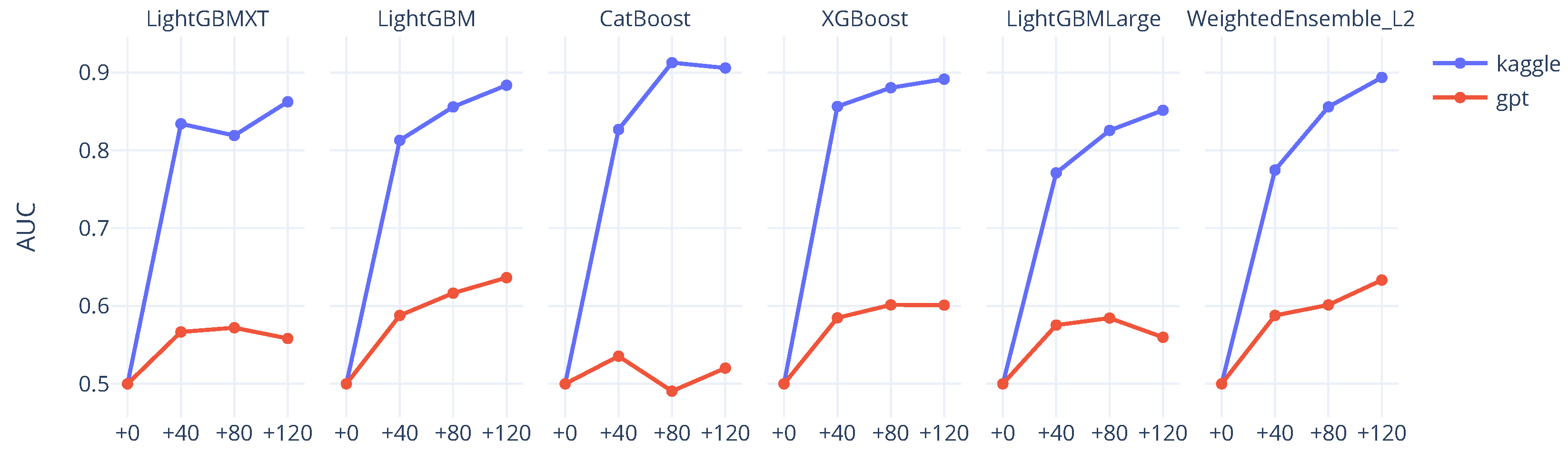
The experimental results are summarized in the Experiment 2 tab at
https://seoyeonc.github.io/MBTI_dashboard (accessed on 10 May 2025), with only a subset visualized in
Figure 5. Overall, we found that GPT-generated text could improve performance relative to the one-shot baseline. However, its effectiveness remained consistently below that of real data, even when the quantity of synthetic samples increased. This suggests that while GPT outputs may appear fluent and coherent on the surface, they often lack the subtle, class-discriminative signals necessary for fine-grained classification.
In conclusion, GPT-generated text appears to be a useful supplement to training data, especially under conditions of scarcity. However, it falls short of functioning as a true substitute for real-world samples in terms of informational richness and diversity. This finding highlights a key limitation and provides an important cautionary insight into the role of synthetic text in supervised learning tasks.
The previous experiment demonstrated a consistent performance gap between GPT-generated text and real-world data in fine-grained classification. However, while this result was clear, it also raised a new question: does such a difference imply a binary distinction between usefulness and uselessness, or might synthetic data still retain partial informativeness? Rather than concluding that GPT-generated text is entirely lacking in value, we sought to explore whether it might preserve some—but not all—of the characteristics necessary for accurate classification.
For instance, consider the ENFJ personality type. To convincingly replicate an ENFJ-written post, a model must reflect all four dimensions—E, N, F, and J. If GPT-generated text reflects only some traits (e.g., E and N), it may not resemble a complete ENFP profile, but rather a partial form like EN−− or E−−J (in this notation, the “−” symbol indicates an MBTI trait that is unclear or not strongly represented in the text). In such cases, the synthetic text may enable coarse-grained differentiation (e.g., extroverted vs. introverted) but fail in more nuanced distinctions between similar personality types. This motivated a refined hypothesis: while GPT-generated content may underperform in subtle classifications, it could still be effective when distinguishing between types that are more linguistically and conceptually distant.
To examine this hypothesis, we designed a binary classification task in which ENFJ is contrasted against five MBTI types presumed to be relatively dissimilar: ISTP, INTP, ISFP, ISTJ, and ESTP. The experimental configuration followed the same few-shot structure as before. The ENFJ class contained only a single real training example, with 30 fixed test samples. GPT-generated ENFJ texts were added to the training set in increments of 20, up to a total of 140 samples. The data distributions for the comparison types were kept consistent with the original Kaggle dataset.
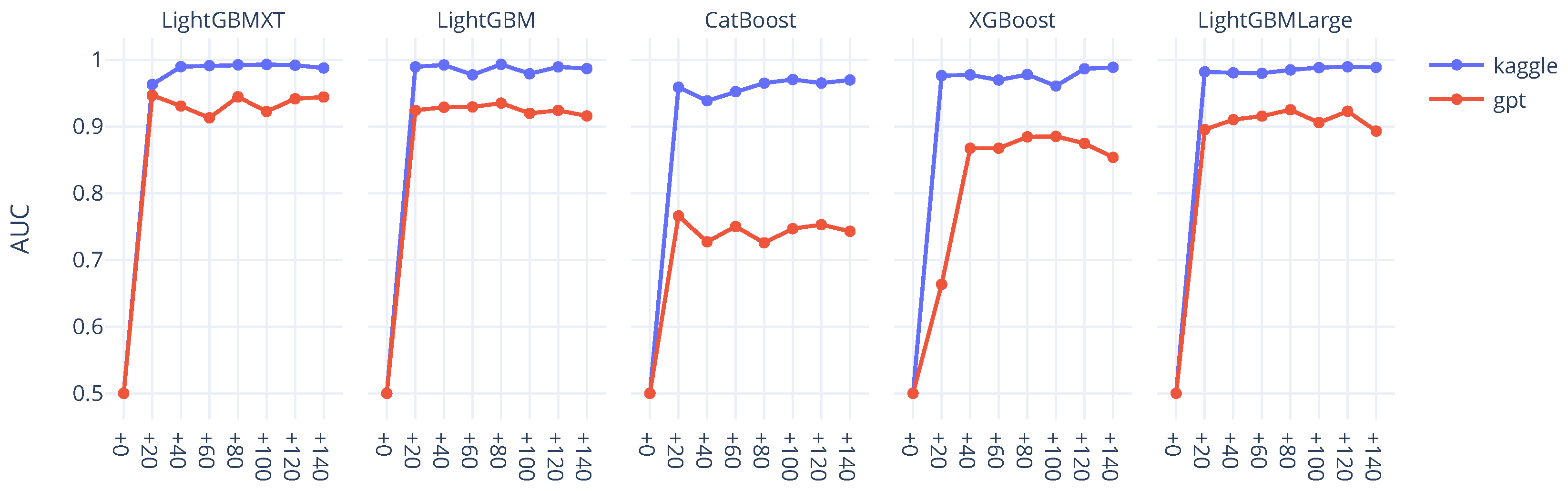
The full results of this experiment are available in the Experiment 3 tab at
https://seoyeonc.github.io/MBTI_dashboard (accessed on 10 May 2025), with key findings visualized in
Figure 6. Interestingly, the results diverged from previous patterns. For several classifiers, performance improved steadily as more GPT-generated data were added, and in some cases, the models approached AUC levels comparable to those of models trained on real data. While overall performance still fell short of the real-data baseline, the synthetic ENFJ text was nevertheless sufficient to distinguish ENFJ from markedly different personality types with reasonable accuracy.
These findings suggest that GPT-generated text is not universally ineffective. In classification settings where the decision boundary is coarse and clearly defined, such as separating ENFJ from conceptually distant types, synthetic data can still serve a functional role. In contrast, more fine-grained tasks—where subtle semantic or stylistic differences are required—appear to exceed the representational capacity of GPT-generated content.
Taken together, this experiment highlights a critical insight: the limitations of synthetic data are not absolute but conditional. GPT-generated samples may behave similarly to real data in broad categories while diverging in finer details. In this sense, the distinction lies not solely in accuracy metrics, but in the grain of information captured. This distinction calls for a more nuanced understanding of generative data—one that accounts for the structure, depth, and specificity of the information being modeled.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}